Embed Size (px)
DESCRIPTION
SimAlpha : C++ で記述した もうひとつの Alpha プロセッサシミュレータ. 電気通信大学 大学院情報システム学研究科 吉瀬謙二 本多弘樹 弓場 敏嗣. 2002-08-23 SWoPP 2002 発表資料. はじめに. アーキテクチャの研究、教育のツールとして様々なプロセッサシミュレータが利用されている。 定番の SimpleScalar は、高速なシミュレーションが目的の一つであり、変更が容易なコード記述にはなっていない。 - PowerPoint PPT Presentation
Citation preview

1
SimAlpha : C++ で記述したもうひとつの Alpha プロセッサシミュレータ
電気通信大学 大学院情報システム学研究科吉瀬謙二 本多弘樹 弓場 敏嗣
2002-08-23 SWoPP 2002 発表資料
2
はじめに アーキテクチャの研究、教育のツールとして様々なプロ
セッサシミュレータが利用されている。 定番の SimpleScalar は、高速なシミュレーションが目的
の一つであり、変更が容易なコード記述にはなっていない。 シンプルで理解しやすく、変更が容易なコード記述を第一
の条件として、 Alpha プロセッサシミュレータ SimAlpha Version 1.0 を構築した。
本発表では SimAlpha の高いコード可読性を示すために、変更を加えていない C++ の本物のコードを示しながら、その実装内部の説明を試みる。
利用列として、 SPEC CINT95 と CINT2000 の理想的な命令レベル並列性を測定した結果を報告する。
3
SimAlpha Version 1.0 の設計方針 可読性と拡張性
世の中のコードが可読性を考慮している訳ではない。 シンプルで理解しやすく、変更が容易なコード記述を第一の条件
としてゼロから記述した。 グローバル変数、 goto 文、条件付きコンパイルを利用していない。 インクルードファイルを含むソースは C++ で約 2800 行と少ない。 SPEC CINT95 と CINT2000 のバイナリをシミュレートできる。
もう一つの実装 SimpleScalar の置換えをねらうのではなく、もう一つの実装を示
す。 利用者が多くの選択肢の中から、適切なツールを選べる利点は大
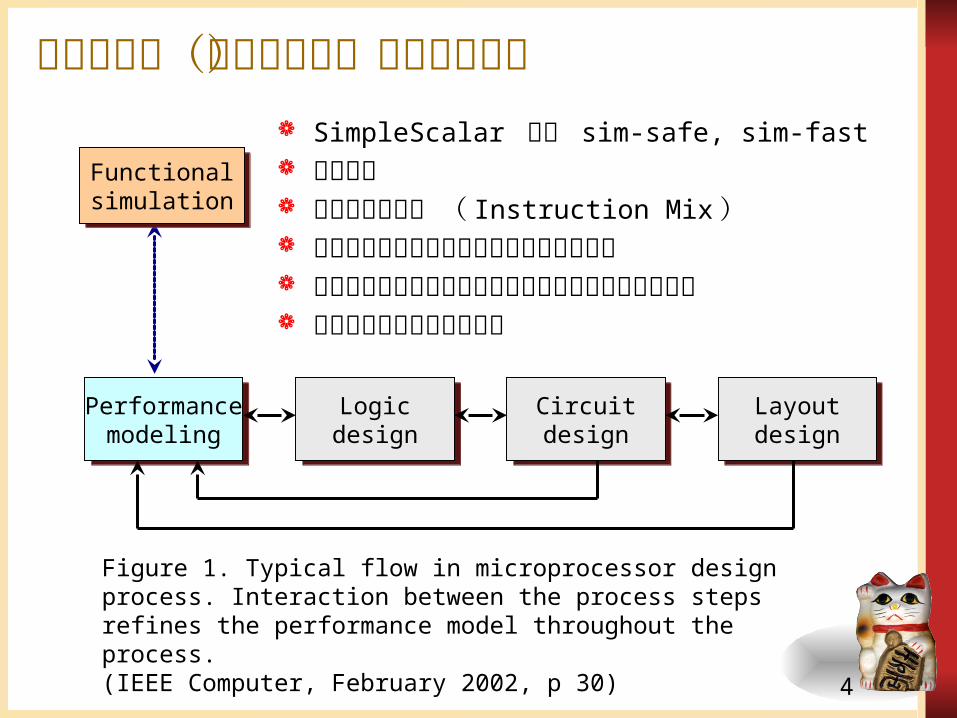
きい。 機能レベルシミュレータ(クロックレベルではない)
アウトオブオーダ実行の性能評価シミュレータを考慮した記述 次の版において、性能評価シミュレータを提供予定
4
機能レベル(命令レベル)シミュレータ
Performancemodeling
Performancemodeling
LogicdesignLogic
designCircuitdesignCircuitdesign
Layoutdesign
Layoutdesign
Figure 1. Typical flow in microprocessor design process. Interaction between the process steps refines the performance model throughout the process.(IEEE Computer, February 2002, p 30)
FunctionalsimulationFunctionalsimulation
SimpleScalar では sim-safe, sim-fast 動作検証 命令の実行頻度 ( Instruction Mix ) 命令レベルで測定した分岐予測のヒット率 命令レベルで測定したキャッシュシステムの
ヒット率 理想的な命令レベル並列性
5
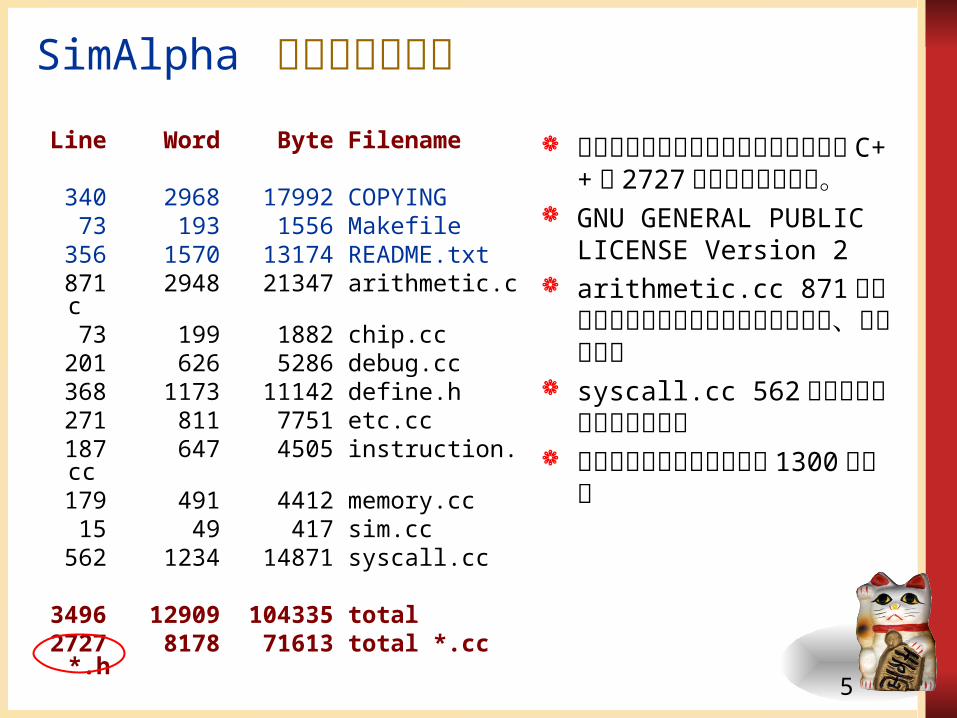
SimAlpha のファイル構成
Line Word Byte Filename
340 2968 17992 COPYING 73 193 1556 Makefile 356 1570 13174 README.txt 871 2948 21347 arithmetic.cc 73 199 1882 chip.cc 201 626 5286 debug.cc 368 1173 11142 define.h 271 811 7751 etc.cc 187 647 4505 instruction.cc 179 491 4412 memory.cc 15 49 417 sim.cc 562 1234 14871 syscall.cc
3496 12909 104335 total 2727 8178 71613 total
*.cc *.h
ソースコードとヘッダファイルの合計 C++ で2727 行と非常に少ない。
GNU GENERAL PUBLIC LICENSE Version 2
arithmetic.cc 871 行は加算や減算などの命令実行の記述で、理解は容易
syscall.cc 562 行はシステムコールの実装
これらを除いた核の部分は 1300 行程度

6
SimAlpha の実行と動作検証
Intel Linux 上で動作 SimpleScalar を用いた動作検証
1命令実行する度に、 SimpleScalar と SimAlpha の全てのアーキテクチャステートを比較し、一致することを確認
SPEC CINT95 と CINT2000 を用いて動作検証
シミュレーション動作速度 sim-safe ( SimpleScalar ) の3倍の時間を必要とする。 シミュレーション開発の時間を短縮できれば、3倍程度の
速度差は問題にならない範囲
独自形式の実行イメージファイルを入力 Alpha バイナリと入力パラメータを用いて構築

7
SimAlpha の実行イメージファイル
/* SimAlpha 1.0 Image File */
/*** Registers ***//@reg 16 0000000000000003/@reg 17 000000011ff97008/@reg 29 0000000140023e90/@reg 30 000000011ff97000/@pc 32 0000000120007d80/*** Memory ***/@11ff97000 00000003@11ff97008 1ff97138@11ff9700c 00000001
独自形式の実行イメージファイルを採用した。
テキストファイルの前半にレジスタの内容を列挙する。
後半でメモリの内容を列挙する。
テキスト形式、容量の大きいもので4MB程度
ELF,COFF といった実行ファイル形式やローダの知識が必要ない。
初心者に優しい。
8
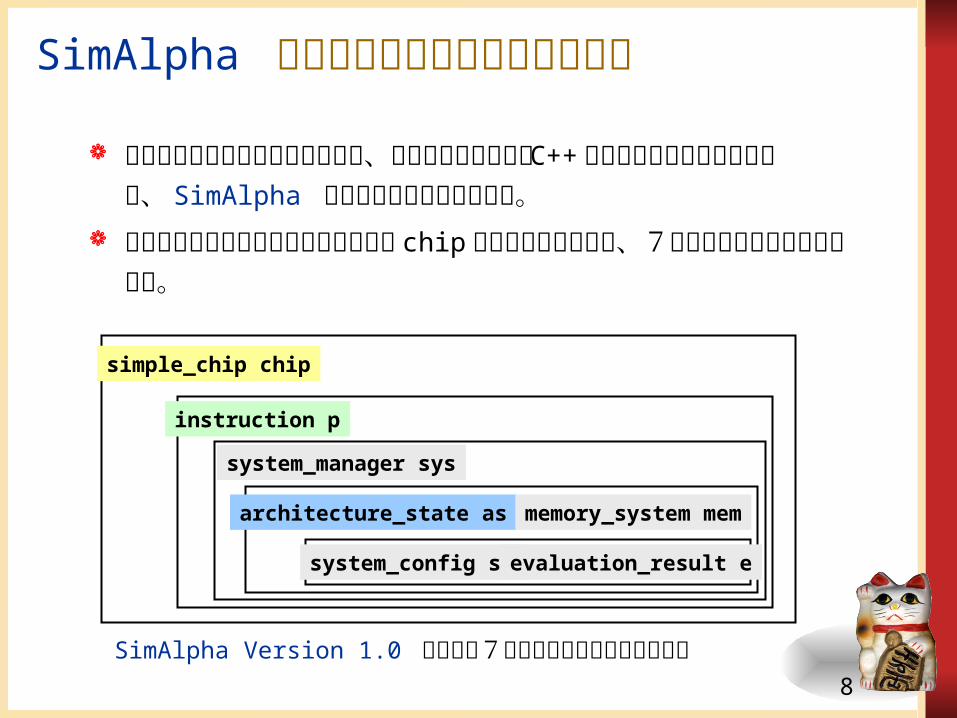
SimAlpha のソフトウェアアーキテクチャ
system_manager sys
instruction p
system_config sc evaluation_result e
architecture_state asmemory_system mem
simple_chip chip
SimAlpha Version 1.0 における7つのオブジェクトの参照関係
コードの高い可読性を示すために、変更を加えていない C++ の本物のコードを示しながら、 SimAlpha の実装内部の説明を試みる。
メイン関数で生成されるオブジェクト chip のコンストラクタが、7つのオブジェクトを生成する。
9
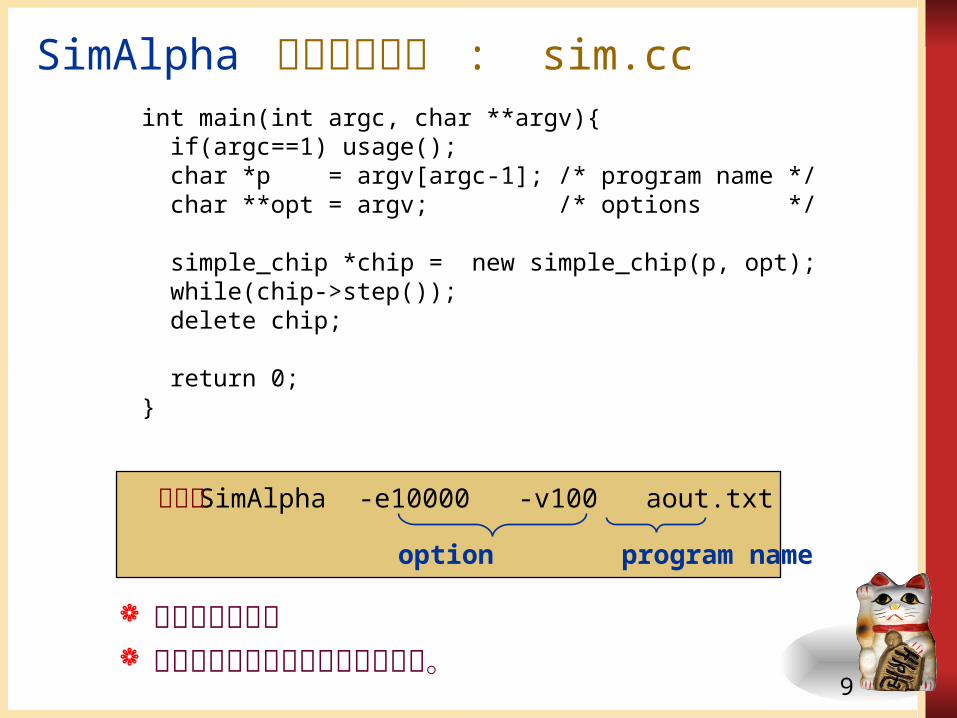
SimAlpha のメイン関数 : sim.ccint main(int argc, char **argv){ if(argc==1) usage(); char *p = argv[argc-1]; /* program name */ char **opt = argv; /* options */
simple_chip *chip = new simple_chip(p, opt); while(chip->step()); delete chip;
return 0;}
シンプルな記述 グローバル変数を利用していない。
SimAlpha -e10000 -v100 aout.txt実行例
option program name
10
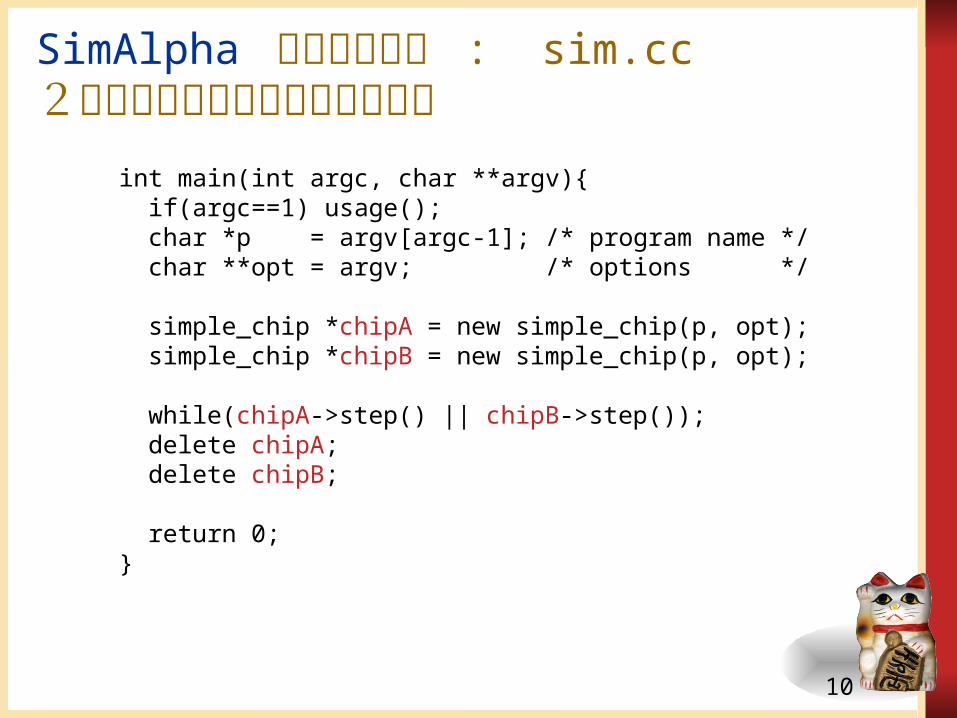
SimAlpha のメイン関数 : sim.cc 2つの実行イメージを作成する例
int main(int argc, char **argv){ if(argc==1) usage(); char *p = argv[argc-1]; /* program name
*/ char **opt = argv; /* options
*/
simple_chip *chipA = new simple_chip(p, opt);
simple_chip *chipB = new simple_chip(p, opt);
while(chipA->step() || chipB->step()); delete chipA; delete chipB;
return 0;}
11
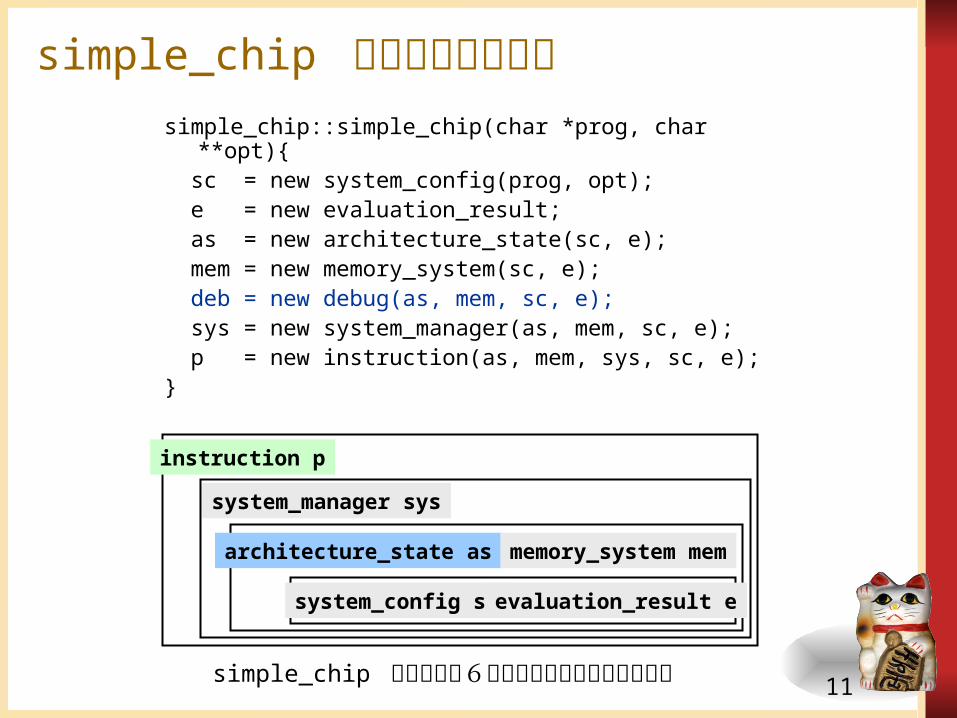
simple_chip のコンストラクタsimple_chip::simple_chip(char *prog, char
**opt){ sc = new system_config(prog, opt); e = new evaluation_result; as = new architecture_state(sc, e); mem = new memory_system(sc, e); deb = new debug(as, mem, sc, e); sys = new system_manager(as, mem, sc, e); p = new instruction(as, mem, sys, sc,
e);}
simple_chip で作られる6つのオブジェクトの参照関係
system_manager sys
instruction p
system_config sc evaluation_result e
architecture_state asmemory_system mem

12
データオブジェクトとアーキテクチャステートの定義
class architecture_state{ public: data_t pc; /* program counter */ data_t r[32]; /* general purpose regs */ data_t f[32]; /* floating point regs */ architecture_state(system_config *, evaluation_result *);};
class data_t{ uint64_t value; public: int cmov; uint64_t ld(); int
st(uint64_t); int
init(uint64_t);};
SimAlpha の利用するデータはメモリを含め 左に示す data_t型のオブジェクトにより表現する。
データ値以外の特性を持たせることができる。様々なデータを収集できる。
data_t型の配列によりレジスタファイルを構成する。
整数レジスタ、浮動小数点レジスタ、プログラムカウンタによりアーキテクチャステートを定義
13
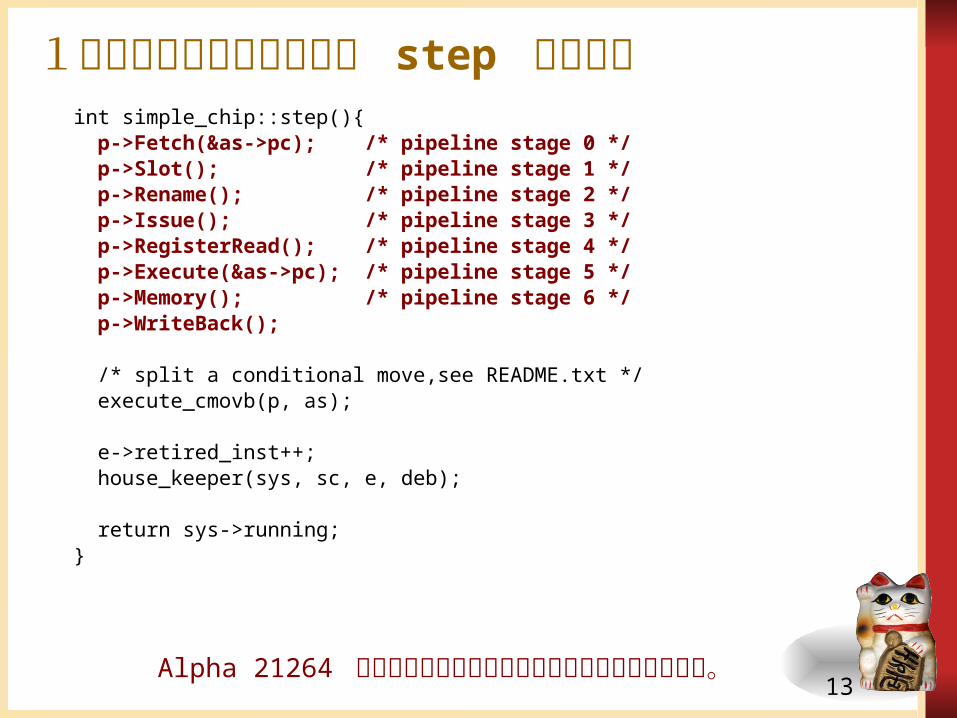
1つの命令を処理する関数 step のコードint simple_chip::step(){ p->Fetch(&as->pc); /* pipeline stage 0 */ p->Slot(); /* pipeline stage 1 */ p->Rename(); /* pipeline stage 2 */ p->Issue(); /* pipeline stage 3 */ p->RegisterRead(); /* pipeline stage 4 */ p->Execute(&as->pc); /* pipeline stage 5 */ p->Memory(); /* pipeline stage 6 */ p->WriteBack();
/* split a conditional move,see README.txt */
execute_cmovb(p, as); e->retired_inst++; house_keeper(sys, sc, e, deb); return sys->running;}
Alpha 21264 の命令パイプラインを参考にして処理を分割した。
14
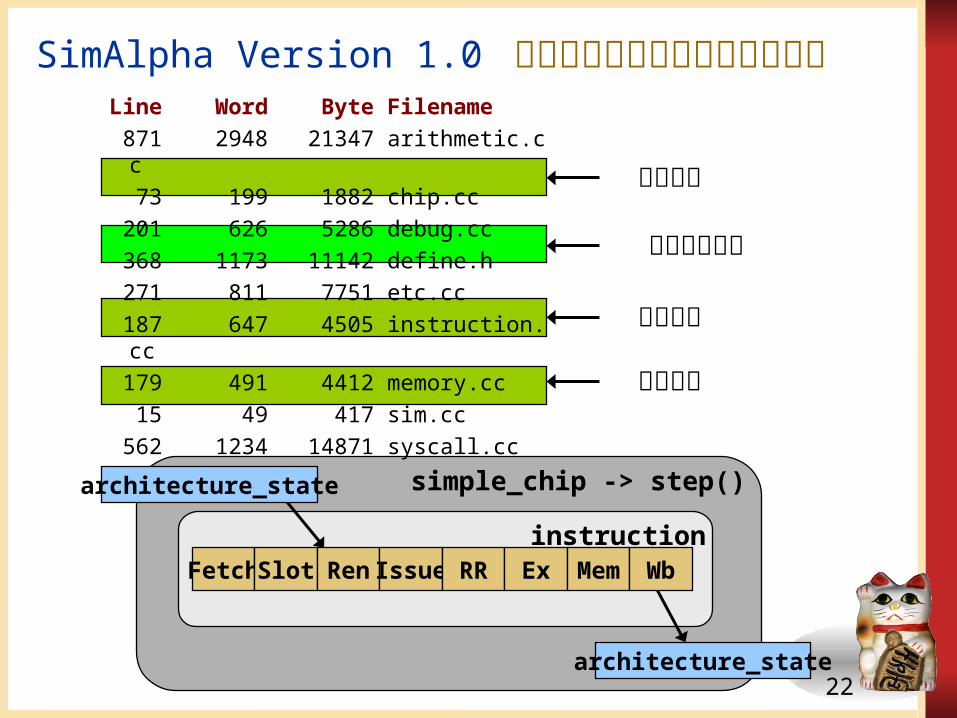
SimAlpha Version 1.0 のソフトウェアアーキテクチャ
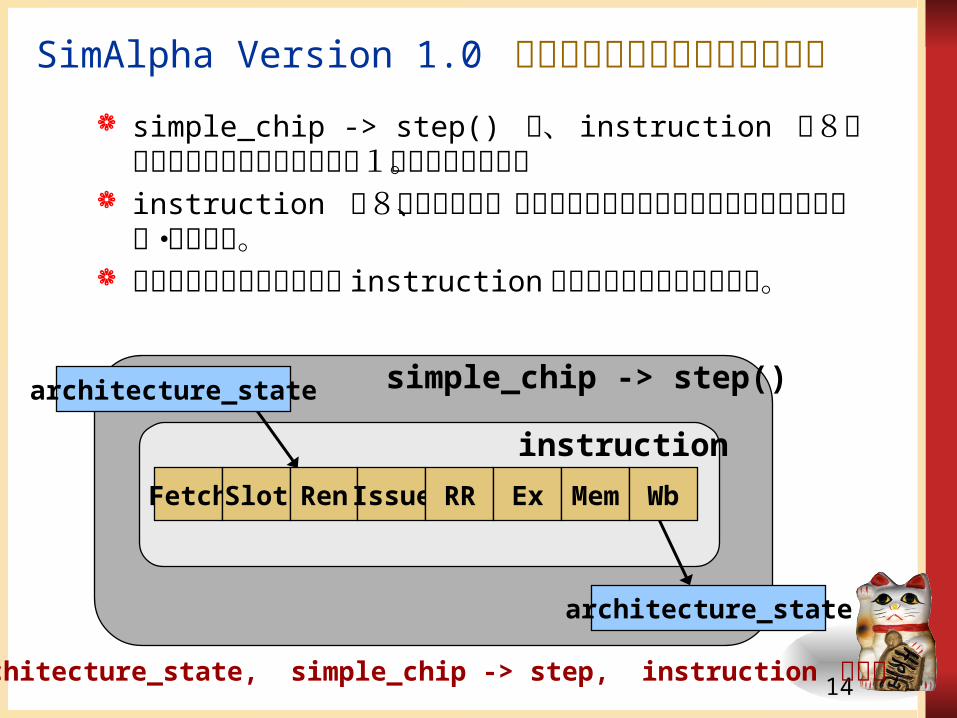
Fetch Slot Ren Issue RR Ex Mem Wb
simple_chip -> step()
instruction
architecture_state, simple_chip -> step, instruction の関係
simple_chip -> step() は、 instruction の8つの関数を呼び出すことにより1命令を処理する。
instruction の8つの関数は、必要に応じてアーキテクチャステートを参照・更新する。
重要な役割を果たすクラス instruction の定義とコードを説明する。
architecture_state
architecture_state

15
クラス instruction の定義class instruction{ evaluation_result *e; architecture_state *as; system_manager *sys; memory_system *mem;
INST_TYPE ir; /* 32bit instruction code */ int Op; /* Opcode field */ int RA; /* Ra field of the inst */ int RB; /* Rb field of the inst */ int RC; /* Rc field of the inst */ int ST; /* store inst ? */ int LD; /* load inst ? */ int LA; /* load address inst ? */ int BR; /* branch inst ? */ int Ai; /* Rav is immediate ? */ int Bi; /* Rbv is immediate ? */ int Af; /* Rav from floating-reg ? */ int Bf; /* Rbv from floating-reg ? */ int WF; /* Write to the f-reg ? */ int WB; /* Writeback reg index */ data_t Npc; /* Update PC or PC + 4 */ data_t Imm; /* immediate */ data_t Adr; /* load & store address */ data_t Rav; /* Ra */ data_t Rbv; /* Rb */ data_t Rcv; /* Rc */
public: int Fetch(data_t *); int Fetch(data_t *,
INST_TYPE); int Slot(); int Rename(); int Issue(); int RegisterRead(); int Execute(data_t *); int Memory(); int WriteBack();
INST_TYPE get_ir(); int data_ld(data_t *, data_t
*); int data_st(data_t *, data_t
*); instruction(architecture_state
*, memory_system *, system_manager *, system_config *, evaluation_result
*);};
16
命令フェッチステージのコード
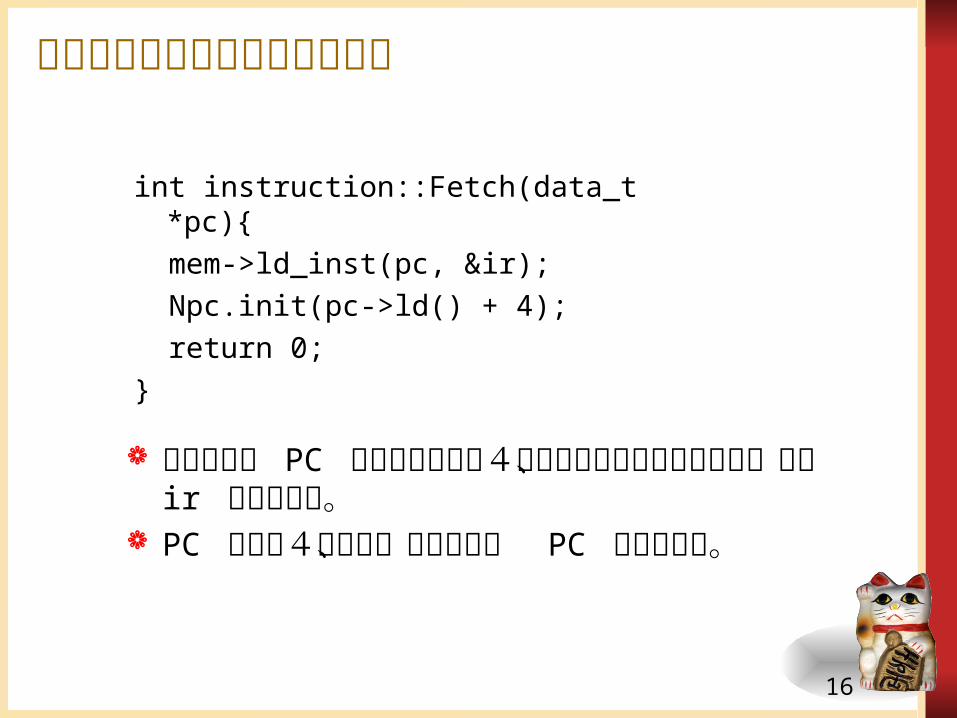
int instruction::Fetch(data_t *pc){
mem->ld_inst(pc, &ir); Npc.init(pc->ld() + 4); return 0;}
メモリ上の PC のアドレスから4バイトの命令をフェッチし、変数 ir に格納する。
PC の値に4を加え、更新された PC を生成する。

17
スロットステージ(デコード)のコードint instruction::Slot(){ Op = (ir>>26) & 0x3F; RA = (ir>>21) & 0x1F; RB = (ir>>16) & 0x1F; RC = (ir ) & 0x1F; WF = ((Op&MSK2)==0x14 || (Op&MSK2)==0x20); LA = (Op==0x08 || Op==0x09); LD = (Op==0x0a || Op==0x0b || Op==0x0c || (Op&MSK2)==0x20 || (Op&MSK2)==0x28); ST = (Op==0x0d || Op==0x0e || Op==0x0f || (Op&MSK2)==0x24 || (Op&MSK2)==0x2c); BR = ((Op&MSK4)==0x30); WB = (LD || (Op&MSK2)==0x08 || Op==0x1a || Op==0x30 || Op==0x34) ? RA : ((Op&MSK3)==0x10 || Op==0x1c) ? RC :
31; Af = (Op==0x15 || Op==0x16 || Op==0x17 || Op==0x1c || (Op&MSK2)==0x24 || (Op&MSK3)==0x30); Bf = ((Op&MSK2)==0x14); Ai = (Op==0x08 || Op==0x09 || LD); Bi = (BR || (Op&MSK2)==0x10 && (ir &
BIT12));
/** For the CMOV Split Code (CMOV1) **/ if(cmov_ir_create(ir)){ RB = RC; Bi = 0; } return 0;}
フェッチした命令 ir をデコードする。
Verilog-HDL を意識した記述。

18
発行ステージ(即値計算)のコード
int instruction::Issue(){ DATA_TYPE Lit, D16, D21, tmp, d21e, d16e; d21e = ((ir & MASK21) | EXTND21) << 2; d16e = (ir & MASK16) | EXTND16;
Lit = (ir>>13) & 0xFF; D21 = (ir & BIT20) ? d21e :
(ir&MASK21)<<2; D16 = (ir & BIT15) ? d16e : (ir&MASK16); if(Op==0x09) D16 = (D16 << 16);
tmp = (LA||LD||ST) ? D16 : (BR) ? D21 : Lit;
Imm.init(tmp); return 0;}
即値 Imm を計算 命令により以下から選択
8ビットの Lit 21ビットの符号拡張 16ビットの符号拡張

19
レジスタリードステージのコード
int instruction::RegisterRead(){ Rav = Ai ? Imm : Af ? as->f[RA] : as-
>r[RA]; Rbv = Bi ? Imm : Bf ? as->f[RB] : as-
>r[RB]; return 0;} デコードしたフラグに従って整数レジスタ、浮動小数点レジスタ、即値のどれかを入力オペランドとして Rav, Rbv に格納する。
20
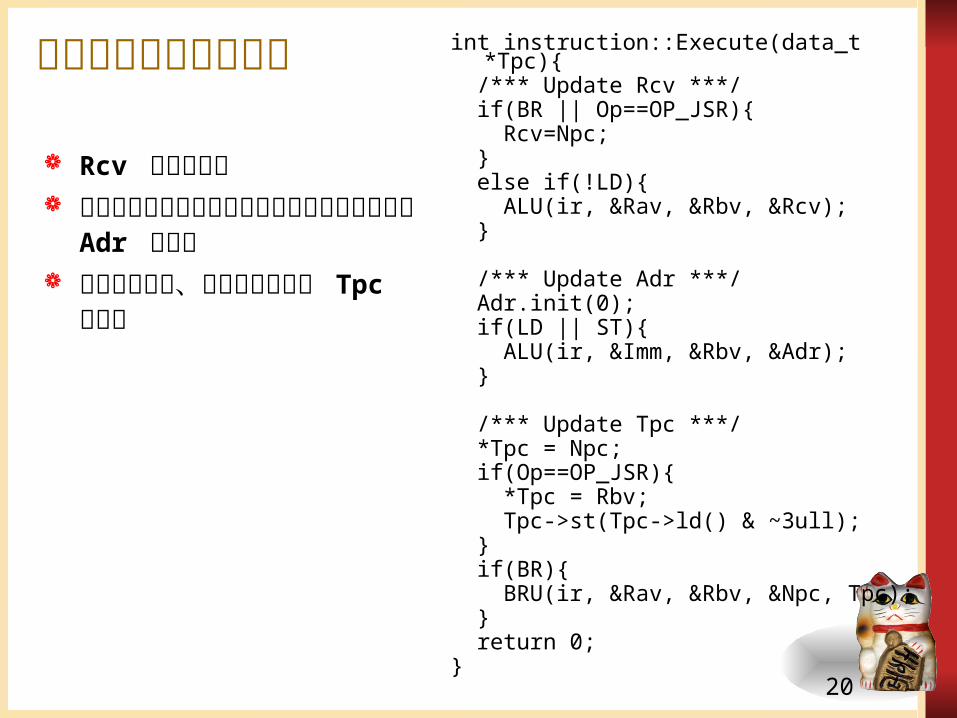
実行ステージのコードint instruction::Execute(data_t *Tpc){
/*** Update Rcv ***/ if(BR || Op==OP_JSR){ Rcv=Npc; } else if(!LD){ ALU(ir, &Rav, &Rbv, &Rcv); }
/*** Update Adr ***/ Adr.init(0); if(LD || ST){ ALU(ir, &Imm, &Rbv, &Adr); }
/*** Update Tpc ***/ *Tpc = Npc; if(Op==OP_JSR){ *Tpc = Rbv; Tpc->st(Tpc->ld() & ~3ull); } if(BR){ BRU(ir, &Rav, &Rbv, &Npc,
Tpc); } return 0;}
Rcv の値を計算 ロードストア命令のために
メモリ参照アドレス Adr を計算
分岐命令では、分岐先アドレス Tpc を計算
21
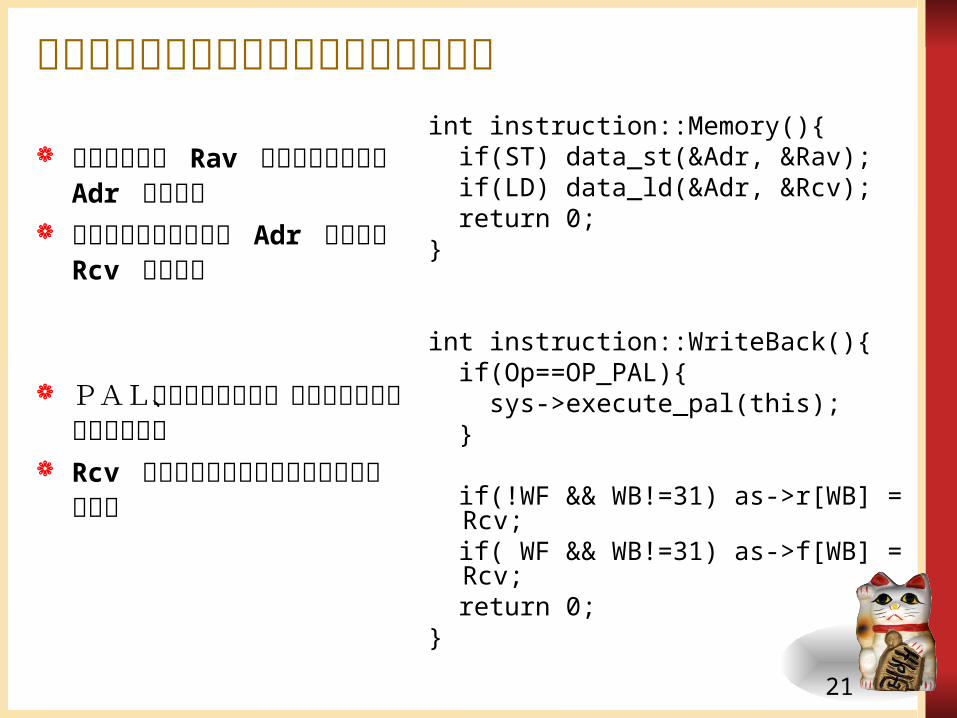
メモリアクセスとライトバックのコードint instruction::Memory(){ if(ST) data_st(&Adr, &Rav); if(LD) data_ld(&Adr, &Rcv); return 0;}
int instruction::WriteBack(){ if(Op==OP_PAL){ sys->execute_pal(this); }
if(!WF && WB!=31) as->r[WB] = Rcv;
if( WF && WB!=31) as->f[WB] = Rcv;
return 0;}
ストア命令は Rav の内容をアドレス Adr にストア
ロード命令はアドレス Adr の内容を Rcv にロード
PAL命令の場合には、それを実行する関数をコール
Rcv の値をレジスタファイルにライトバック
22
SimAlpha Version 1.0 のソフトウェアアーキテクチャ
Fetch Slot Ren Issue RR Ex Mem Wb
simple_chip -> step()
instruction
architecture_state
architecture_state
Line Word Byte Filename 871 2948 21347 arithmetic.cc 73 199 1882 chip.cc 201 626 5286 debug.cc 368 1173 11142 define.h 271 811 7751 etc.cc 187 647 4505 instruction.cc 179 491 4412 memory.cc 15 49 417 sim.cc 562 1234 14871 syscall.cc
説明済み
ほぼ説明済み
説明済み
説明済み
23
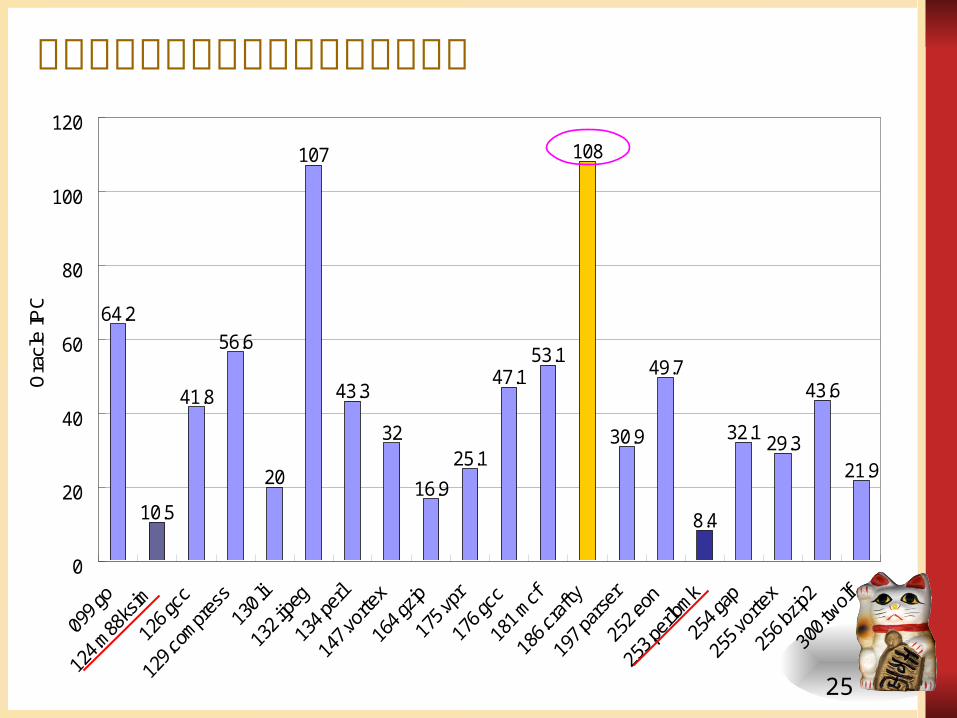
SimAlpha の利用例
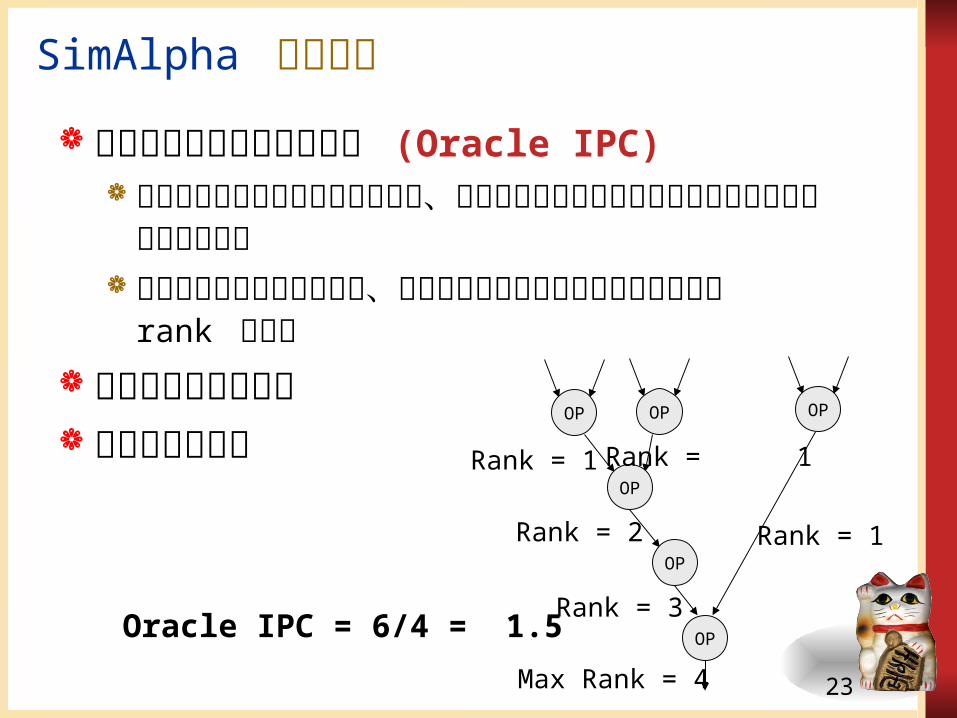
理想的な命令レベル並列性 (Oracle IPC)制御依存関係や資源競合を解消し、データ依存関係のみを制約として得られる並列性を測定
それぞれのデータについて、データフローグラフの高さに相当する rank を計算
測定した結果を報告 拡張性を示す例
OP OP
OP
OP
OP
OP
Rank = 1 Rank = 1
Rank = 1Rank = 2
Max Rank = 4
Oracle IPC = 6/4 = 1.5Rank = 3
24
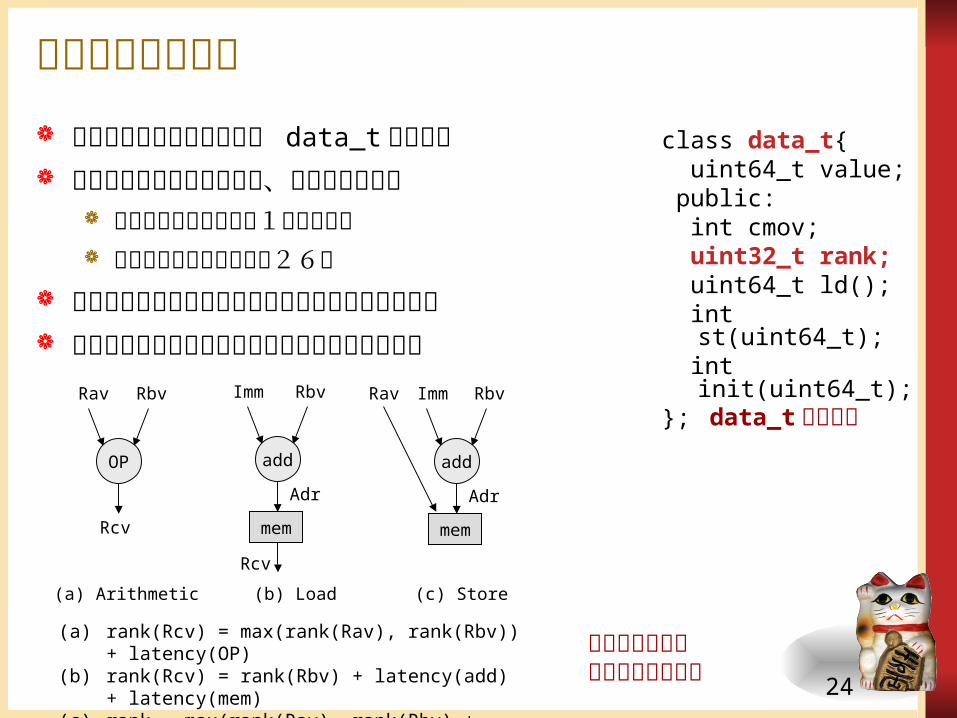
ランクの計算方法
(a) rank(Rcv) = max(rank(Rav), rank(Rbv)) + latency(OP)(b) rank(Rcv) = rank(Rbv) + latency(add) + latency(mem)(c) rank = max(rank(Rav), rank(Rbv) + latency(add))
(a) Arithmetic (b) Load
Imm Rbv
add
Rcv
mem
Adr
Imm Rbv
add
Rav
mem
Adr
Rav Rbv
OP
Rcv
(c) Store
class data_t{ uint64_t value; public: int cmov; uint32_t rank; uint64_t ld(); int
st(uint64_t); int
init(uint64_t);};data_t型の拡張
ランク値を保存する変数を data_t型に追加 データが生成される時点で、ランク値を計算
全ての命令のコストを1として計算 追加したコードはわずか26行
データが生成される時点でランク値の最大値を計算
ランク値の最大値と実行命令数から並列性を計算
命令タイプ毎のランクの計算方法
25
理想的な命令レベル並列性の測定結果
64.2
10.5
41.8
56.6
20
107
43.3
32
16.9
25.1
47.153.1
108
30.9
49.7
8.4
32.1 29.3
43.6
21.9
0
20
40
60
80
100
120
Ora
cle
IPC
26
おわりに
プロセッサアーキテクチャ研究とプロセッサ教育における利用を目的として、プロセッサシミュレータ SimAlpha Version 1.0 を構築した。
実際の C++ のコードを示しながらソフトウェアアーキテクチャを明らかにした。
利用例として、理想的な命令レベル並列性を測定する方法と SPEC CINT95, CINT 2000 の測定結果を示した。
もうひとつの Alpha プロセッサシミュレータとして、プロセッサ研究の選択肢の一つ
謝辞SimAlpha の初期のバージョンをテストし、貴重なコメントやパッチを頂いた飯塚大介氏に深く感謝致します。
27
SimAlpha のダウンロード
SimAlpha Version 1.0 のダウンロード Version 1.0 のソースコードと、理想的な命令レベル並列性
を得るために変更を加えたソースコードは次の URL からダウンロードできる。http://www.yuba.is.uec.ac.jp/~kis/SimAlpha/
SimAlpha Version 1.0 に関する記述 吉瀬謙二 , 本多弘樹 , 弓場敏嗣:
SimAlpha: シンプルで理解しやすいコード記述を目指した Alpha プロセッサシミュレータ ,
Technical Report UEC-IS-2002-2,
電気通信大学 大学院情報システム学研究科 (July 2002).





























