Embed Size (px)
Citation preview

SISTEMI DISTRIBUITI
DEFINIZIONEInsieme di sistemi distinti per localitàche cooperano per ottenere risultati coordinati
Esempio di problemi nei sistemi distribuiti
- Due eserciti e decisione di attacco- in presenza di generali bizantini
- messaggio che deve arrivare a destinazionecon i possibili problemi
- Protocollo di coordinamento tra due processi chedevono decidere una azione comune(nessuna ipotesi sui guasti)
SISTEMI DISTRIBUITI
NON soluzioni ad-hocMA ingegnerizzazione (qualità di servizio)
Necessità di- teoria di soluzione- metodologia di soluzione- standard di soluzione- verifica e accettazione della soluzione
conoscenza dei sistemi esistenti
Sistemi Distribuiti 1
SISTEMI DISTRIBUITI
introducono la possibilità di- accedere a risorse remote- condividere localmente risorse remote
POSSIBILITÀ di• bilanciare uso delle risorse• tollerare fallimenti di risorse• replicazione delle risorse• garantire qualità delle operazioni
TRASPARENZA della ALLOCAZIONE
INDIPENDENZA dalla ALLOCAZIONEin caso di movimento delle entità
DINAMICITÀ del SISTEMAaggiungere risorse al sistema aperto
QUALITÀ dei SERVIZI (QoS)garantire modalità e proprietà
seri problemi teorici (COMPLESSITÀ)
- TERMINAZIONE DEI PROGRAMMI- COMPLESSITÀ DEI PROGRAMMI- CORRETTEZZA- EFFICIENZA
Sistemi Distribuiti 2

Sistemi Distribuiti
MOTIVAZIONI tecnologiche ed economiche
(Local Area Network LAN - Wide Area Network WAN)
��
�
,1)26
&2006
affidabilitàper tollerare guasti dependability
condivisione delle risorse
adeguamento alle richieste distribuite domande distribuite (prenotazioni aeree)
uniformità in crescita e scalabilità
apertura del sistema capacità di evolvere secondo necessità
Sistemi Distribuiti 3
APERTURA del SISTEMA distribuitoJ capacità di adeguarsi alle condizioni di stato
precedenti o successive alla messa in operaK necessità di identificare (monitor) e controllare
(gestione) lo stato del sistema
PROBLEMI della distribuzione
complessità intrinsecasistemi più complessi da specificare e risolvere
sicurezza (security)più difficile garantire integrità e correttezza
sbilanciamenti nell’uso delle risorsenecessità di sfruttare in modo giusto le risorse
capacità di esecuzione totale limitata inferiore a quella di un mainframe equivalente
Legge di Grosh migliore bilancio costo/performancecon un monoprocessore mainframe(senza problemi di memoria e I/O)
ovviamente con alcuni limiti- velocità della luce- costi elevati aumentando l'integrazione
Sistemi Distribuiti 4

AREE DI INTERESSE
- processi indipendenti (con poca comunicazione)per ottenere speed-up ed efficienza
- calcolo scientifico ed ingegneristicomolta computazione
- progetto automatico VLSIampio spazio delle soluzioni
- operazioni databasepossibilità di concorrenza
- intelligenza artificialeobiettivi a breve e lungo termine
- sistemi distribuiti ad amplissimo raggiocalcolo algoritmi NP completiaccesso ad informazioni globalmente distribuite
e applicazioni nei settori• previsioni meteorologiche• dinamica molecolare• cromodinamica quantistica• modelli biologici• evoluzione di sistemi spaziali• sistemi globali (Internet, Web, ...)• sistemi con garanzie di qualità (Multimedia)
Necessità di applicazioni:Controllo traffico aereo affidabileSistemi nomadici e mobili
Sistemi Distribuiti 5
Progetto di un programma (applicazione)
Problema
Algoritmo
Linguaggiodi Alto Livello
Architettura
Sistema Operativo
Tecnologiacodificabinding
mapping
Applicazione
Algoritmo ==>
- opportuno linguaggio di alto livello
MAPPING- decisioni di allocazione per l’architettura scelta
configurazione
BINDING- decisione di aggancio di ogni entità del programma
sulle risorse del sistema
GESTIONE STATICAil binding differito alla esecuzione ==> NECESSITÀ di
GESTIONE DINAMICA del BINDING e delle RISORSE
Sistemi Distribuiti 6

Ambiente di programmazione
Strumenti di ambiente
Linguaggio di programmazione
Supporto run-time al parallelismo
Architettura parallelaSupporto al routing
Monitoraggio sistemaBilanciamento del carico
Interfaccia graficaStrumenti debugging
Compilatori
Linguaggio
Insieme di nodiRete interconnessione
Strumenti di allocazione
Necessità di controllo della soluzione
Controllo di Qualità di Servizio
Un ambiente di programmazione tende a ottenere
indipendenza dalla architettura(portabilità su nuove architetture)
astrazione(nascondere complessità parallelismo)
corretta gestione delle risorse (statica e dinamica)
NON esistono ancora ambienti di programmazionesoddisfacenti
In ogni caso, rimedio ==> uso diretto difunzioni ad aggancio dinamico
vedi primitive di KERNELSistemi Distribuiti 7
Sistemi di reteSpesso i sistemi sono solo sistemi di rete in cui lepotenzialità non sono sfruttate
Scenario WWWInformazioni presentate in modo trasparente
abcdef
FORM
INPUT UTENTE
OUTPUT
ELABORAZIONE
elemento
RETE
VISIONE LOCALE
NODI REMOTI
ULFKLHVWD
ULVSRVWDHTTPclient
HTTPserver
TCP / IP TCP / IP
CGI
applicazioni esterneapplicazioni di supporto
rete
sistema remotosistema locale
utente
DINAMICITÀSe cominciamo a replicare i dati e memorizzare leinformazioni su siti intermedi => evoluzione
Sistemi Distribuiti 8

Sistemi operativi di Rete vs.Sistemi operativi Distribuiti
Network Operating Systems (NOS) vs.Distributed Operating Systems (DOS)
I NOS sono indipendenti e non trasparenti
GESTIONE RISORSE TRASPARENTE
I DOS sono coordinati e trasparenti e aperti
DOSparalleli al loro interno
uso di risorse parallele interne
paralleli a livello di utentecon maggior omogeneità
capaci di gestire nuove risorse non noteda aggiungere alle statiche
? La trasparenza consente di crescere edi modificare il sistema ?
? o si deve avere sia trasparenza a livello utente evisbilità a livello di sistema
3817,�',�9,67$�',9(56,�(�08/7,3/,
Sistemi Distribuiti 9
Sistemi Operativi Distribuitiottimizzano l’uso delle risorsee sono basati sullaCONDIVISIONE per
scambio di informazioniridistribuzione del caricoreplicazione delle informazioniparallelismo nella computazione
Unica macchina virtuale conProprietà
Controllo allocazione delle risorseComunicazioneAutorizzazioneTrasparenza (qualche livello)Controllo dei servizi del sistema (QoS)Capacità evolutiva (dinamicità )
Apertura del sistema (OPEN system)le risorse possono essere inserite durante la esecuzionedel sistema e non sono note staticamente prima dellaesecuzione
Sistemi Distribuiti 10

SISTEMI OPERATIVI DISTRIBUITI
come insieme di gestori di risorse
Resource managementProcessor managementProcess managementMemory managementFile management
FILONI
ReplicazioneGestione dei NomiComunicazione e SincronizzazioneProcessiSicurezzaAllocazione e riallocazione delle risorseGestione dei Servizi applicativi e della qualità
STANDARDIZZAZIONEINDIPENDENZA dalla ARCHITETTURAAPERTURA (OPEN SYSTEM)INFORMAZIONI SUL SISTEMA (MONITORAGGIO)
RIUSO dell’esistenteFramework, librerie di componenti
molte modalità diverse ed eterogeneità
Sistemi Distribuiti 11
TREND delle prestazioni
6FLHQWLILF�$PHULFDQ�
�
���
���
���
���
���
���
���
���������
���������
���������
���������
&38�0,360HPRU\�0%/$1�0ELWV:$1�0ELWV2�6�RYHUKHDG
$XPHQWR�GHOOH�YHORFLWj�LQ�:$1
Latenza
����
���
�
��
���
����
���������
���������
���������
���������
'LVN�,�2(WKHUQHW�53&$70�URXQGWULS:$1�URXQGWULS
$EEDVVDPHQWR�GHOOHODWHQ]H�/$1�FRQ�$70
ODWHQ]H�:$1�H�GLVFKL�FRVWDQWL�D�FDXVD�GLOLPLWL�ILVLFL
Banda
(millisecondi)
Sistemi Distribuiti 12

TREND overheadOverhead della parte di sistema operativocioé della gestione locale
���������
���������
���������
���������
�
�
��
��
��
��
��
��
��
���������
���������
���������
���������
2�6�RYHUKHDGULSRUWDWR�LQ�VHQVRSURSRU]LRQDOH
Anche se ci possiamo aspettare dei miglioramentiin prestazione delle diverse parti di un sistema(comunicazione, dischi remoti, accessi veloci, etc.)
Il problema da superare è la corretta gestione
Notate non stiamo ipotizzando una gestione ottimama solo evitando colli di bottigliaattraverso un monitoraggio del sistema
Sistemi Distribuiti 13
TERMINOLOGIA
LIBRERIEUn insieme di librerie costituisce un set di funzioni(interfaccia nota) che possono essere chiamate da unlivello che le usa
internet
3D rendering
Applicazione
Main LOOP
Librerie (anche OO)
internet
ADTmatematiche
Database
GUI
Ogni applicazione si deve uniformare a questa struttura
In caso di più applicazioni, ogni applicazione devereplicare la stessa organizzazione
Le librerie sono ad aggancio dinamico (DLL)Dynamic Linked Libraries
Sistemi Distribuiti 14

CLIENTE/SERVITOREtipico caso di invocazione procedurale: il cliente aspetta ilcompletamento del servizio
Se mettiamo in gioco due processi:potremmo anche avere schemi diversi
Se il cliente ha bisogno di una informazione la richiede => in genere aspetta fino a che non è disponibile
Se il cliente non vuole bloccarsi, aspettando
CICLO di richieste ad intervallo (polling)che deve essere o esaudita subitoo restituire un insuccesso
Questo modo carica il cliente della responsabilitàdell'ottenere le informazioni
modello pull
Si potrebbe anche risolvere in modo diverso, dividendo leresponsabilità
il cliente segnala il proprio interesse, poi fa altroè compito del server di inviare la informazionese e quando disponibile
Questa interazione divide i compiti tra cliente e servitore
modello push (per il servitore)che forza le informazioni rovesciando i ruoli
Sistemi Distribuiti 15
FRAMEWORK
Un FRAMEWORK costituisce un modello di esecuzione edun ambiente di richiesta di funzionalità più integratotende:• a non replicare la struttura implicita• a rovesciare il controllo (per eventi di sistema)
vedi Windows struttura a loop di attesa di eventi chevengono smistati ai richiedenti
meccanismi di supporto della cornice
Classi esistenti
Funzioni e servizi
ADTs
matematiche
GUI
LOOP
gestioneeventi
di sistema
internet
Database
logica specifica
della applicazione
3D rendering
BACKCALL
Sono possibili backcall o upcall (push del framework)dal Framework alle applicazioni
eventi asincroni
Sistemi Distribuiti 16

MODELLO ad EVENTIin contrapposizione ad un modello sincrono di richiesta e diattesa della risposta
si gestisce la possibilità di inviare messaggi su necessitàdisaccoppiando gli interessati• I consumatori eseguono le attività• I produttori segnalano le necessità• Il gestore degli eventi segnala l'occorrenza degli eventi
significativi agli interessati
Servizio di Notifica Eventi
SURGXFH�TXRWD]LRQH
6,67(0$�JHVWRUHGHOORIIHUWD�GHJOL�HYHQWL
SURGXFH�TXRWD]LRQH
FRQVXPD�RIIHUWD
FRQVXPD�RIIHUWD
PRODUTTORE
PRODUTTORE
CONSUMATORE
CONSUMATORE
Push dell'evento alle entità interessate eche si sono registrate
Sistemi Distribuiti 17
CONCETTI di BASEnei sistemi distribuitiEsistono? Servono?
MODELLI di SERVIZIOmodelli statici/dinamicimodelli preventivi /reattivi
modello di esecuzione nel sistemamonoutente/multiutenteprocessore/processori
modello di namingconoscenza reciproca
modello di allocazione / riallocazioneentità del sistema sulle risorse del sistema
modello di esecuzioneprocessi/oggetti replicazione
modello dei processi processi pesanti/ processi leggeri
modello di comunicazione
modelli di guastomodelli di replicazione
modelli di monitoring e controllo qualitàtrasparenzanecessità di standard per superare eterogeneità
Sistemi Distribuiti 18

modello di esecuzione nel sistema
monoutente/multiutente
in genere, l'uso di un sistema in modo dedicato è tipicodelle fasi prototipali
l'uso di più utenti, consente di formare un migliore mix dientità eseguibili sul/sui sistemi per un migliore equilibrio
L Problemi di configurazione del sistema edinterferenza tra le attività
processore/processori usati con trasparenza
modello workstationsi utilizzano le risorse locali preferenzialmentepoi si possono considerare le risorse di rete
Sistemi distribuiti in rete (tradizionali)
modello processor poolsi utilizzano le risorse in modo trasparentea secondo del loro utilizzo e disponibilità
Sistemi distribuiti veri e propri
L maggiore overhead di coordinamento
Sistemi Distribuiti 19
modello preventivi /reattivimodelli ottimisti e pessimisti
Esempi
approcci per gestire il deadlock➪ approcci che prevengono il deadlock
avoidance si evita a priori tramite introduzione di fortivincoli (sequenzializzazione completa)
prevention si evita la specifica situazione conalgoritmi (accesso in ordine)
➪ approcci che fanno fronte all’occorrenza del deadlock
recovery se succede, interveniamo
il problema della interferenza/congestione➪ ring previene la congestione con regole precise di
controllo di accesso➪ CSMA/CD tenta l’accesso senza controllo e deve tenere
conto della interferenza possibile, con opportunestrategie
I primi sono approcci pessimisti/preventiviI secondi sono approcci ottimisti/reattivi
Naturalmente, in generei sistemi preventivi sono statici per l’aspetto consideratoi sistemi reattivi sono dinamici
Sistemi Distribuiti 20

modello di namingnecessità di conoscenza reciproche delle entità e deiservizi
NON TRASPARENZA vs. TRASPARENZAdei servizi ai nodidegli indirizzi all'interno del nodo
Relazione cliente/servitoreil cliente deve avere un riferimento al servitore
BINDING statico vs. dinamicostatico: i riferimenti sono risolti prima della esecuzionedinamico: i riferimenti sono risolti al bisogno
In caso dinamico, nasce la necessità di un entità che realizziil servizio di nome (name server) che viene interrogata perconoscere il nome
CASO STATICOinvarianza dei nomi e della allocazione delle entità
si risolve il tutto staticamente enon si necessita di un servizio di nomi
E se le entità si muovono? NOMI entitàtrasparenti invarianti (anche con movimento delleentità)
INDIPENDENZA dalla ALLOCAZIONEnon trasparenti dipendenti dalla locazione corrente
solo TRASPARENZA dalla ALLOCAZIONE
Sistemi Distribuiti 21
invarianza dei nomi e variazione allocazionetrasparenti invarianti (anche con movimento delleentità)il sistema di nomi deve associare ai riferimenti le nuoveallocazioni
variazione dei nomi alla variazione allocazionenon trasparenti dipendenti dalla locazione corrente
si devono riqualificare i nomi di tutti i possibili clientiche quindi devono essere trovati
CASO DINAMICO entità non staticamente fissateUso di tabelle di allocazione ==>controllate da opportuni GESTORI dei NOMI
Si progettano più gestori (e tabelle) per evitarecongestioni e problemi di singolarità con visibilitàparziali
consistenza delle tabellespesso organizzate in gerarchia
Sistemi Distribuiti 22

modello di naming
sistemi aperti possibilità di inserire nuove entità compatibili con il sistema già esistente
COORDINAMENTO di gestori di nomi distinti
partizionamento dei gestoriciascuno responsabile di una sola partizione deiriferimenti - località(in generale i riferimenti più richiesti)
replicazione dei gestoriciascuno responsabile con altri di partizione deiriferimenti - coordinamento
Spesso organizzazioni a livelligestore generale che coordina gestori di più basso
livello in molti livelli con località informazioni (vedi CORBA o DNS)
reston
cc
us
cc cs ecn
purduedec
com edu
xinu
gov
nfs
dipmatdeis
unibo
it
cineca
Sistemi Distribuiti 23
modello di comunicazione
schema di base cliente servitore
I servizi sono forniti da un servitore cherisponde a diversi clienti (molti:1)
- i clienti conoscono il servitore- il servitore rappresenta la astrazione dei servizi e
non conosce i possibili clienti
MODELLO astrattointerazione sincrona (default)
asincrona / non bloccante
schemi più complessoclienti / servitori multipli
I servizi sono forniti da più servitori (molti:molti)con diverse possibilità
- 1 solo servizio per ogni richiesta (stampa di un file)- 1 servizio da ogni possibile servitore
(aggiorna copie di un file)
Necessità di coordinamento tra i servitoricon Replicazione o Suddivisione
Sistemi Distribuiti 24
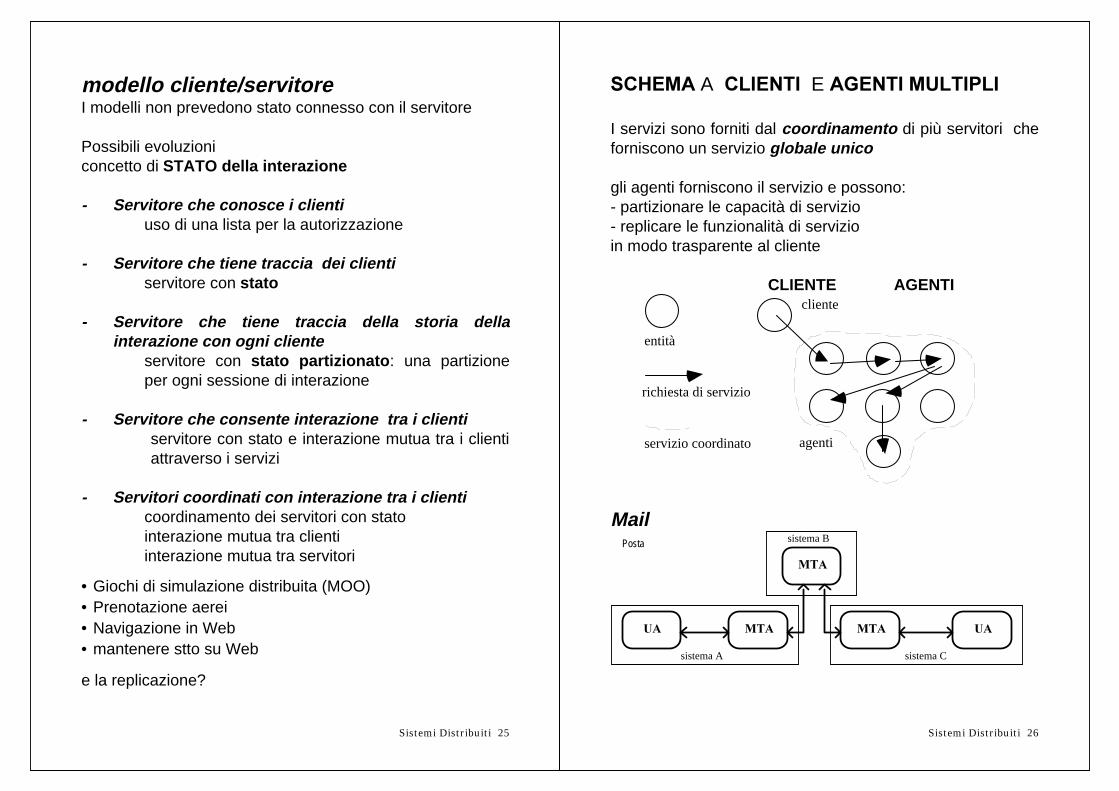
modello cliente/servitoreI modelli non prevedono stato connesso con il servitore
Possibili evoluzioniconcetto di STATO della interazione
- Servitore che conosce i clientiuso di una lista per la autorizzazione
- Servitore che tiene traccia dei clientiservitore con stato
- Servitore che tiene traccia della storia dellainterazione con ogni cliente
servitore con stato partizionato: una partizioneper ogni sessione di interazione
- Servitore che consente interazione tra i clientiservitore con stato e interazione mutua tra i clientiattraverso i servizi
- Servitori coordinati con interazione tra i clienticoordinamento dei servitori con statointerazione mutua tra clientiinterazione mutua tra servitori
• Giochi di simulazione distribuita (MOO)• Prenotazione aerei• Navigazione in Web• mantenere stto su Web
e la replicazione?
Sistemi Distribuiti 25
6&+(0$ A �&/,(17,��E�$*(17,�08/7,3/,
I servizi sono forniti dal coordinamento di più servitori cheforniscono un servizio globale unico
gli agenti forniscono il servizio e possono:- partizionare le capacità di servizio- replicare le funzionalità di servizioin modo trasparente al cliente
CLIENTE AGENTI
entità
richiesta di servizio
cliente
servizio coordinato agenti
07$8$ 07$ 8$
07$
sistema B
sistema A sistema C
Posta
Sistemi Distribuiti 26
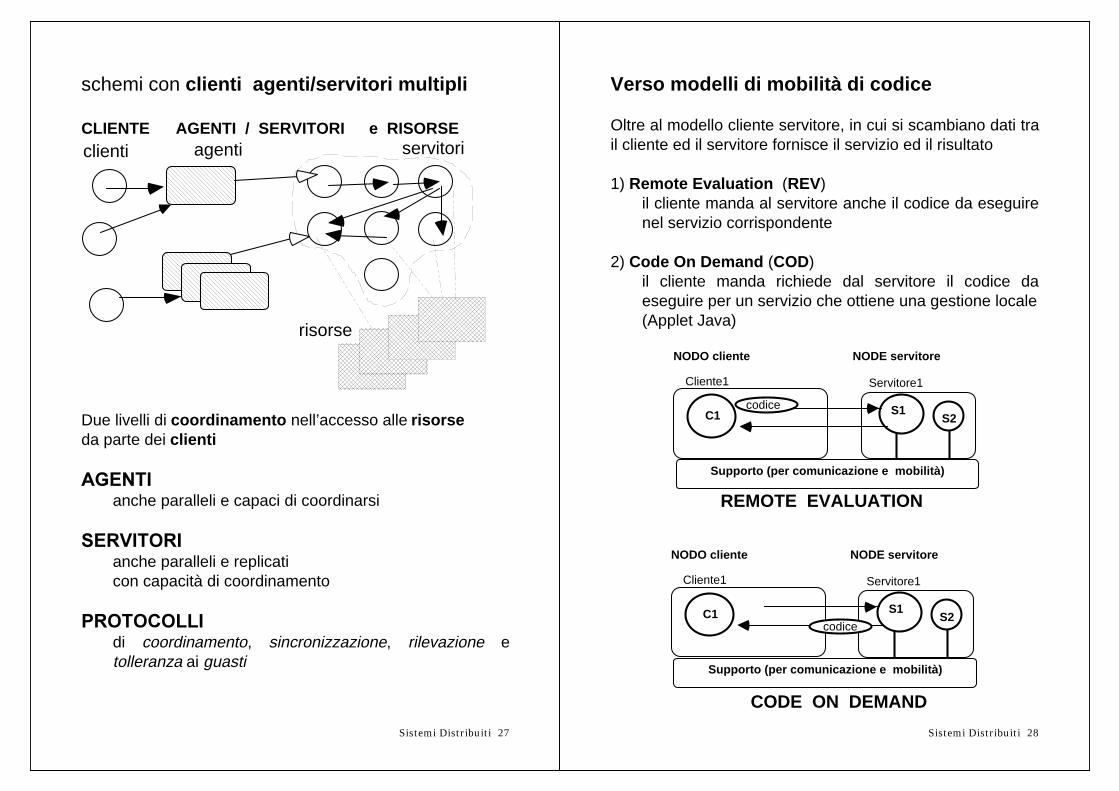
schemi con clienti agenti/servitori multipli
CLIENTE AGENTI / SERVITORI e RISORSEagenticlienti servitori
risorse
Due livelli di coordinamento nell’accesso alle risorseda parte dei clienti
$*(17,anche paralleli e capaci di coordinarsi
6(59,725,anche paralleli e replicaticon capacità di coordinamento
35272&2//,di coordinamento, sincronizzazione, rilevazione etolleranza ai guasti
Sistemi Distribuiti 27
Verso modelli di mobilità di codice
Oltre al modello cliente servitore, in cui si scambiano dati trail cliente ed il servitore fornisce il servizio ed il risultato
1) Remote Evaluation (REV)il cliente manda al servitore anche il codice da eseguirenel servizio corrispondente
2) Code On Demand (COD)il cliente manda richiede dal servitore il codice daeseguire per un servizio che ottiene una gestione locale(Applet Java)
NODO cliente NODE servitore
Servitore1
Supporto (per comunicazione e mobilità)
Cliente1
C1 S1S2
codice
REMOTE EVALUATION
NODO cliente NODE servitore
Servitore1
Supporto (per comunicazione e mobilità)
Cliente1
C1 S1S2
codice
CODE ON DEMAND
Sistemi Distribuiti 28

Modelli di mobilità
Mobilità debolepossibilità di eseguire delle attività su un nodo e diriprendere la esecuzione dall'inizio su un nodo diverso
Mobilità fortepossibilità di eseguire delle attività su un nodo e diriprendere la esecuzione su un nodo diverso
MODELLI ad AGENTI
I modelli ad agenti hanno rivevuto molto interessenegli ultimi anni
PROBLEMAcome trasferire il codice e farlo riprendere sul nuovonodo, superando le eterogeneità
Soluzione ad InterpreteSi usa un codice intermedio indipendente dallaarchitettura interpretato dalla macchina virtuale presentein ogni nodo
Applet e Applicazioni Java
Classi Base Estensione di Classi di Java
Java Virtual Machine
Interfaccia di portabilitàAdattatoreBrowser
S.O.
Hw
AdattatoreBrowser
S.O.
Hw
AdattatoreBrowser
S.O.
Hw
AdattatoreBrowser
S.O.
Hw
Interconnessione via Rete
Sistemi nomadici e mobilicome mantenere i servizi in movimento
Sistemi Distribuiti 29
INSIEME DI NODI E DI AGENTI
NODO VIRTUALE di un sistema ad agenti
Agenti
Supporto (per la riallocazione)
Risorse locali
R1 Ag1 Ag2 Ag3
Agenti
Supporto (per la riallocazione)
Località
Ag1 Ag2 Ag3
Agenti
Supporto (per la riallocazione)
Località
Ag3 Ag4 Ag5
Agenti
Supporto (per la riallocazione)
Località
Ag6 Ag7 Ag8
Agenti
Supporto (per la riallocazione)
Località
Ag9 A10 Ag11
In Java, ci sono problemi nel trasferire lo stato diesecuzione dei thread
Nel settore degli apparati di telecomunicazioni, sicominciano a considerare migrazoni di codice anche perrouter e bridge (reti intelligenti e reti attive)
Sistemi Distribuiti 30

altri modelli di comunicazionepipeline, farm, etc.tuple
pattern di interconnessione concorrentiper la decomposizione automatica
Pipeline
6WDJH� 6WDJH� 6WDJH�
Insieme di entità che comunicano in modo ordinato:uscita di uno stage è l'ingresso del successivoOgni stage lavora sui dati elaborati dal precedente
Possibilità di concorrenza nei servizidi richieste diverse
Aumento del throughput (efficienza)
throughput numero di servizi per unità di tempo
Farmsuddivisione del lavoro
0DVWHU
6ODYH�
6ODYH1
6ODYH,����
con attese diverse degli slave da parte del master
Sistemi Distribuiti 31
TupleAstrazione della memoria condivisa + comunicazione
Lo spazio delle tuple è un insieme strutturato di relazioni,intese come attributi e valori
Operazioni di scrittura e lettura concorrentiAccesso in base al contenuto degli attributi
Operazioni di In e OutIn inserisce una tupla nello spazio
Out estrae una tupla, se esisteattende nel caso la tupla non sia ancora presente==> una tupla con alcuni attributi non specificati
esempio relazione messaggio (dachi, achi, corpo)
In: messaggio (P, Q, testo1)Out: messaggio (?, Q, ?)
tuple meccanismo generaleper la comunicazione e sincronizzazione
Linda (Gelertner)realizzazione della memoria condivisa a confronto con loscambio di messaggi
Sistemi Distribuiti 32

MODELLO interconnessionelocalità vs. globalità
modelli globalinon impongono restrizioni alle interazioni
entità
comunicazione
operazioni non scalabilidipendenti dal diametro del sistema
modelli locali (RISTRETTI)prevedono una limitazione alla interazione
entità
comunicazione
località
operazioni (forse) scalabilipoco dipendenti dal diametro del sistema
verso la località , i domini , i vincoliper la scalabilità
Sistemi Distribuiti 33
modello di comunicazione a connessione/ senza connessione
CONNESSIONEle entità stabiliscono di preallocare le risorse per lacomunicazione (statico)
risorse
dedicatestatiche
SENZA CONNESSIONEle entità comunicano utilizzando le risorse che sonodisponibili al momento della azione (dinamico)
dinamico
Alcuni modelli, detti a connessione (TCP), non impegnanorisorse intermedieVedremo meglio questi comportamenti più avanti...
Sistemi Distribuiti 34

PROCESSI
Processi differenziati
Processo pesante
Dati
Stack /Heap
Codice
Processi leggeri
Dati
Stack
Codice
Thread 1Thread 2Thread 3
Thread 1
Thread 2
Thread 3
modello dei processi processi pesanti/ processi leggeri
ProcessoIMPLEMENTATIVAMENTE
SPAZIO di indirizzamentoSPAZIO di esecuzione
insieme di codice, dati (statici e dinamici),parte di supporto, cioè di interazione con il sistema
operativo (file system, shell, etc.)
un'aggregazione di parecchi componentiProcesso pesantead esempio in UNIX
cambiamento di contesto operazione molto pesanteoverhead
Sistemi Distribuiti 35
SOLUZIONEPossibilità di creare entità più leggerecon limiti precisi di visibilità e barriere di condivisione
Processi leggeriattività che condividono visibilità tra di loro e chesono caratterizzata da uno stato limitatooverhead limitato
ad esempio in UNIX, i thread olightweight processes
Tutti i sistemi vanno nel senso di offriregranularità differenziate per ottenereun servizio migliore e più adatto ai requistii dell'utente
Si useranno processi pesanti quando è il caso e processileggeri se si vuole avere un overhead più limitato
Il processo pesante funzona anche dacontenitore di processi leggeri
In caso di mobilità , si deve considerare cosa muoveree se siamo facilitati nel farlo
Sistemi Distribuiti 36

modello di esecuzioneEntità ed interazione
modello a processi
Processoentità in esecuzione che possono eseguire ecomunicare direttamente o indirettamente conaltri processi attraverso- memoria condivisa- scambio di messaggi
Uso di dati esterni ai processi stessi(scarso confinamento)
modello ad oggetti (e processi)
Oggettoentità dotata di astrazione che• racchiude risorse interne (astrazione) su cui
definisce operazioni• agisce su risorse interne alla richiesta di
operazioni dall'esterno
- oggetti passiviastrazioni su cui agiscono processi esterni
- oggetti attivicapaci di esecuzione e scheduling
Sistemi Distribuiti 37
OGGETTI E PARALLELISMO
come inserire il parallelismo in un modello ad oggettia) affiancando il concetto
di PROCESSOa quello di
OGGETTOSTATO
OGGETTO PROCESSO
===> modelli ad oggetti PASSIVISVANTAGGI:perdita di uniformità di concetti protezione
STATO STATO
b) integrando il concetto di PROCESSO ed OGGETTO===> modelli ad oggetti ATTIVI
VANTAGGI:uniformità di concettiprotezioneinformation hiding
STATO STATO
Si propone il modello a maggior confinamento
Sistemi Distribuiti 38

introduzione della CONCORRENZA
SOLUZIONI DISOMOGENEEProcessi & Oggetti Passivi
uso di semafori e monitorSmalltalk-80, Trellis/Owl, Emerald, Guide, Java
SOLUZIONI OMOGENEENO Processi ma Active Objects
decisioni di concorrenza independentiABCL, Clouds, Amoeba, POOL, COOL, Procol, PO
Oggetti Attivi decidono independentemente enascondono meglio il comportamentointerno (information hiding)
Ogni oggetto racchiude al proprio interno la necessariacapacità di concorrenza e definisce la propria politica digestione della concorrenza
Non esiste più alcun processo che si muove da oggetto adoggettoOgni oggetto deve prevedere le necessarie politiche digestione della concorrenza e delle prevenzione di eventualiinterferenze
Sistemi Distribuiti 39
Esempio di oggetto attivo
CODA DELLE
ATTIVITA’
CODA DELLE
RICHIESTE
SCHEDULER
RICHIESTE DAALTRI OGGETTI
Parte Parallela
Parte non Parallela
v0v1v2v3
ATTIVITA’
m3m2m1m0
METODI
STATO
m4
Stato di Scheduling
Oggetto
GESTORE
dimensione interoggettodimensione intraoggetto
ProblemiAllocazione dei processi ed attivitàComunicazioneDinamicità
È più facile riallocare un processo od un oggetto?e i suoi riferimenti?
Sistemi Distribuiti 40

modelli di allocazionele entità di una applicazione possono essere
o statiche o dinamiche o miste
Allocazione staticadata una specifica configurazione, le risorse sonodecise prima della allocazione
Allocazione dinamicala allocazione delle risorse sono decise durante laesecuzione ==> sistemi dinamici
In sistemi dinamici, è possibile la riallocazione (migrazione)le risorse possono muoversi sulla configurazione
- APPROCCIO IMPLICITO (AUTOMATICO)il sistema che si occupa del mappaggio dell’applicazionesull’architettura ===> ALLOCATION TRANSPARENCE
- APPROCCIO ESPLICITO===> l’utente deve specificare il mappaggio di ognioggetto
APPROCCIO MISTOil sistema adotta una politica di default (obiettivobilanciamento di carico computazionale)
politica applicata sia inizialmente che dinamicamentemediante allocazione dei nuove risorse e migrazione diquelli già esistenti
se l’utente fornisce delle indicazioni, il sistema ne tieneconto nella politica di bilanciamento di carico permigliorare le prestazioni
Nel caso di agenti mobili, allocazione esplicita
Sistemi Distribuiti 41
modelli di guastoerrore qualunque comportamento diverso da quello
previsto dai requisiti (fault)failure comportamento nel sistema che può causare errori
Programma che sbaglia eaggiorna un database in modo sbagliato
fault ==> transienti, intermittenti, permanentiBohrbug ⇒ errori ripetibili, sicuri, e spesso facili da
correggereEisenbug ⇒ errori poco ripetibili, difficili da riprodurre e
difficili da correggereGli Eisenbug sono spesso legati a problemi transienti equindi molto difficili da eliminare
Strategie diIdentificazione dell'erroreRecovery dell'errore
Numero di errori che si possono tollerare(insieme o durante il protocollo di recovery)
Ipotesi sui guasti semplificano il trattamento
Un guasto alla volta (Guasto Singolo)il tempo di identificazione e recovery deve essereinferiore (TTR Time to Repair) al tempo tra due guasti(TBF o Time Between Failure o MTBF Mean TBF)
Con 3 copie si tollera un guasto, due sono identificatiCon 3t + 1 copie, si tollerano t guasti
Sistemi Distribuiti 42

Protocolli necessariI protocolli impegnano le risorse
durata degli algoritmirealizzazione degli algoritmi (affidabilità)
Il supporto (hw e sw) per il protocollo di recovery deveessere più affidabile del resto (come si garantisce?)
Principio di minima intrusionelimitare l'impegno di risorse (overhead) introdotto dailivelli di supporto di sistema
DefinizioniDEPENDABILITY FAULT TOLERANCE
possibilità di affidarsi al sistema nel completamento diquanto richiestosia in senso hardware, sia software, in generaleconfidenza per ogni aspetto progettuale
RELIABILITYpossibilità del sistema di fornire risposte corrette(accento sulla correttezza delle risposte)es. disco per salvare dati ==> tempo di risposta?
AVAILABILITY (continuità)possibilità del sistema di fornire comunque risposte inun tempo limitato accento sul tempo di rispostareplicazione con copie attive e sempre disponibili
RECOVERABILITYConsistenza, Sicurezza, Privacy, ...
Sistemi Distribuiti 43
ReliabilityconsideriamoMTBF mean time between failuresMTTR mean time to repairil primo è il tempo di disponibilità della risorsail secondo di indisponibilità
Availability definita come$� �07%)����07%)���0775�
anche diversa per letture e scritturese si hanno copie, la lettura può essere fornita anchese una o più copie sono non disponibili
5HOLDELOLW\ probabilità che il servizio siacontinuamente disponibile su un intervallo ∆tR (∆t) = reliable sul tempo ∆t
R(0) = A, più generale
Costi della replicazionedipendenti da molti fattori diversi
costi di memoriaoverhead di communication overheadcomplessità di implementazionecosa replicare, quante repliche, dove allocarle, etc.
Sistemi Distribuiti 44

ipotesi di fault nel distribuitoFAIL-STOP
un processore fallisce fermandosi (halt) e gli altripossono verificarne lo stato
FAIL-SAFE (CRASH o HALT)un processore fallisce fermandosi (halt) e gli altripossono non conoscerne lo stato
CRASH & LINKun processore fallisce fermandosi (halt) e i link dicomunicazione possono perdere messaggi
SEND & RECEIVE OMISSIONun processore fallisce ricevendo/trasmettendosolo una parte dei messaggi che dovrebbetrattare
GENERAL OMISSIONun processore fallisce ricevendo/trasmettendosolo una parte dei messaggi che dovrebbetrattare o fermandosi
NETWORK FAILUREl’interconnessione non garantisce comportamenticorretti
NETWORK PARTITIONla rete di interconnessione può partizionarsi,perdendo ogni collegamento tra le due parti
FAILURE BIZANTINEun processore fallisce esibendo un qualunquecomportamento
Replicazione come soluzione
Sistemi Distribuiti 45
MEMORIA STABILE
uso di replicazione per ottenere certezza di non perdereinformazioni (uso di disco)
Ipotesi di guasto limitative: si considera di avere unsistema con una probabilità trascurabile di guasti multipli subanchi di memoria scorrelati
In ogni caso, la probabilità di guasto durante uneventuale protocollo di recovery deve essere minima
Memoria con blocchi sicuri: ogni errore viene trasformatoin omissione (codice di controllo associato al blocco eblocco guasto)I blocchi sono associati in due copie distinte su dischi abassa probabilità di errore congiunto: le due copie hanno lostesso contenuto di informazioni
Ogni lettura da un blocco errato viene trasformata infailure di omissioneLa lettura procede da una delle copie e poi dall’altra.Se uno dei blocchi fallisce, si tenta il recovery
Ogni scrittura procede su una delle copie e poisull’altra
In caso di recovery, si attiva un protocollo che ripristinauno stato consistente:se le copie sono uguali nessuna azione,se una scorretta si copia il valore dell'altra,se diverse e corrette si ripristina la consistenza
Costo elevato della realizzazione
Sistemi Distribuiti 46

Replicazionecosti molto elevati per la implementazione in due dimensionispazio sia in risorse a disposizionetempo sia in tempo di risposta
Spesso le ipotesi di guasto più ampie rendonodifficile il progetto dei protocolli einaccettabile il costo delle soluzioni
TREND
Sistemi special-purposeTANDEM
replicazione in doppio di ogni unità di sistema(due processori, due bus, due dischi)
Obiettivo: sistema fail-safeUn errore viene identificato attraverso la replicazione diCPU (doppio caldo)Memoria su disco stabile con accesso attraverso unodi due bus a blocchi di memoria replicati
costo del sistema molto elevato
Sistemi Distribuiti 47
Sistemi general-purpose
replicazione su memoria di massadiventata comune
RAIDRedundant Array of Inexpensive Diskinsieme di dischi a basso costo ma coordinati in azioniper ottenerne diversi standard di tolleranza ai guasti
costo limitatospesso considerati in sistemi commerciali
Raid 0:striping
elevata velocitàI/O parallelo
nessunaridondanza,peggior MTBF
applicazioni conI/O intensivo
Raid 1:mirroring
alta availability,buone perf. inlettura
alto costoridondanzamassima)
alto numero letture(transaction proc.)
Raid 3:striping condisco di paritàdedicato
alta velocità txper blocchi digrandidimensioni
volumi moltograndi, un I/Oalla volta
trasferimentogrossi blocchi(es. immagini)
Raid 5:striping senzadisco di paritàdedicato
buona velocitàmolte letture dipiccoli blocchi
read beforewrite
I/O misto conbuona velocità ditrasferimento (es.LAN servers)
Sistemi Distribuiti 48

modello di replicazione
Possibilità di risorse nel distribuitorisorse partizionaterisorse replicate
Uso della replicazionedati replicatiprocessi replicati
grado di replicazionenumero di copie della entità da replicare
ModelliMaster Slave (modello passivo)Copie attive (modello attivo)
modello passivomaster/slave (primary/backup)
Un solo processo (attivo) esegue le azioni sui datiLa altre copie (passive) servono in caso di guasto
una sola copia corretta, le altre anche non aggiornate
Scollamento dello stato tra il master e gli slaveIn caso di guasto, si dovrebbe riprendere dall’inizio
Il master aggiorna lo stato degli slave (checkpoint)
La politica separale azioni necessarie per garantire una risposta sicura:
aggiornamento copia primariadalle azioni successive
aggiornamento copie secondarie (checkpointing)
Sistemi Distribuiti 49
REPLICAZIONE
Astrazione di risorsa unica
CN-1 CN
2JJHWWR�5HSOLFDWR
Richieste
CLIENTE 1 CLIENTE 2
COPIE
Richieste
C1 C2 C3 ...
Modello Passivo
2JJHWWR�5HSOLFDWR
MASTER CHECKPOINTING
CONTROLLO
Il master fornisce i servizi e aggiorna gli slaveGli slave controllano il master
Modello Attivo2JJHWWR�5HSOLFDWR
DISTRIBUZIONE
...
VOTO e RISPOSTA
Dalla TMR (Triple Modular Redundancy)si ovvia ad un errore e se ne identificano fino a due
Sistemi Distribuiti 50
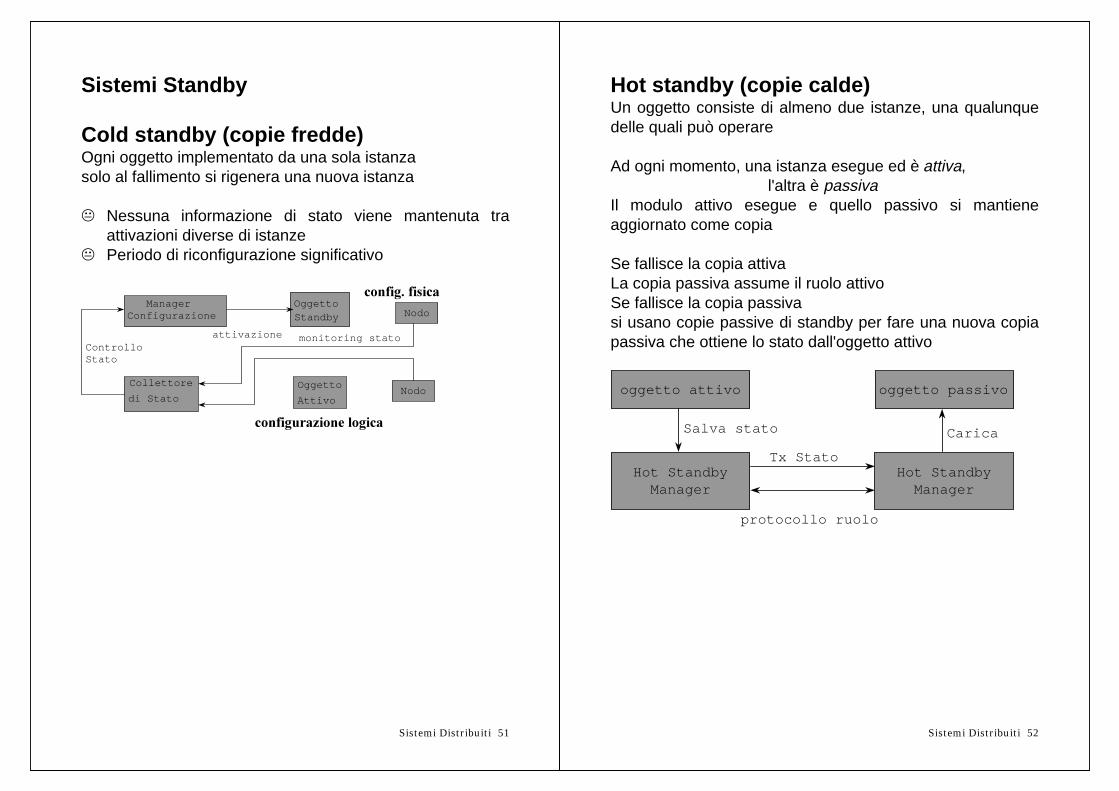
Sistemi Standby
Cold standby (copie fredde)Ogni oggetto implementato da una sola istanzasolo al fallimento si rigenera una nuova istanza
K Nessuna informazione di stato viene mantenuta traattivazioni diverse di istanze
K Periodo di riconfigurazione significativo
ConfigurazioneManager
di Stato
Collettore
Standby
Attivo
OggettoNodo
StatoControllo
attivazione monitoring stato
FRQILJXUD]LRQH�ORJLFD
FRQILJ��ILVLFDOggetto
Nodo
Sistemi Distribuiti 51
Hot standby (copie calde)Un oggetto consiste di almeno due istanze, una qualunquedelle quali può operare
Ad ogni momento, una istanza esegue ed è attiva,l'altra è passiva
Il modulo attivo esegue e quello passivo si mantieneaggiornato come copia
Se fallisce la copia attivaLa copia passiva assume il ruolo attivoSe fallisce la copia passivasi usano copie passive di standby per fare una nuova copiapassiva che ottiene lo stato dall'oggetto attivo
oggetto attivo
Hot StandbyManager
Hot StandbyManager
Tx Stato
protocollo ruolo
Salva stato Carica
oggetto passivo
Sistemi Distribuiti 52

stato delle copieIl cliente ottiene una risposta con tempi inferiorigestione con protocolli all’interno dell’oggetto
checkpointing ==> azione di aggiornamento
checkpointAzione periodica time-drivenAzione scatenata da evento event-driven
In caso la risorsa sia sequenziale, lo stato è evidenteIn caso di risorsa parallela, bisogna pensare a tutte leazioni in atto insieme
RECOVERY DEL GUASTO
Rilevazione del guasto: da parte di chi? quando?Recovery del guasto
La copie secondarie devono identificare il guasto tramiteuna osservazione del master� uso di messaggi esistenti e assunzioni sugli intervalli di
tempo� messaggi ad-hoc per stimolare risposte dal master
Può bastareuno slave per il protocollo (se guasto singolo)gerarchia di slave e protocolli molto più complessi
(se guasto multiplo)
La risorsa, fornita all'esterno tollera, a secondo dellestrategie, un numero diverso di errori ed è in grado di fornireoperatività in caso di errori (fault transparency)
Sistemi Distribuiti 53
modello attivocopie attive
Un processo per ogni copia di datoComunicazione del cliente con i servitori in modo
esplicito od implicito
Se il controllo del cliente esplicito => manca astrazione
Controllo implicito interno alla risorsao esiste un solo gestore (schema statico)
schema a farm centralizzatoe poi da lì si dirigono le richieste verso gli altri
o esiste un gestore (schema dinamico)per ogni richiesta un gestore diversoda lì si dirigono le richieste verso gli altri
gestori decisi per località / a rotazionenecessità di evitare interferenza di gestori
In genere, nei modelli attiviperfetta sincronia
tutte le copie devono agire d'accordo, soprattutto in casodi risposta o di azioni verso l'esterno (innestamento)
approssimazioni alla sincronia meno costosequasi tutte lo copie devono essere in accordo,ma le azioni possono procedere prima del completoaccordo
Si assume che queste strategie siano meno costose intempo di risposta per il cliente
Sistemi Distribuiti 54

COORDINAMENTO TRA LE COPIE
Ogni azione richiede di aggiornare lo stato di tuttiazione di aggiornamento
Se si lavora con gestori diversi è compito del gestorecomandare le azioni degli altridecisioni sulla durata dell’azione
In caso di guasto, si deve dichiararlo e poterecontinuare a fornire una qualche risposta
ACCORDO prima di dare rispostaTutte le copie devono avere fatto l'azioneVoting (non tutte la copie)
a maggioranza (quorum)pesati
le copie non aggiornate sono in uno stato non utlizzabileimmediatamente, ma solo dopo un reinserimento nelgruppo (recovery)
Rilevazione del guasto: da parte di chi? quando?Rilevazione del reinserimento: da parte di chi? quando?
Semantica di gruppoSi possono approssimare semantiche molto diverse anchenei confronti delle azioni che si attuano nel gruppo e degliordini di esecuzione delle azioni
Sistemi Distribuiti 55
modello di servizio qualità della connessione e servizioQoS qualità del servizio
le entità stabiliscono di garantire una certa banda e tempidi risposta per i servizi ripetuti o di flusso
? perchè interesse?stream di informazioni audio e videocon cui cominciano a giocare fattori real-timebanda trasmissiva, ritardi ammissibili, variazionijitter variazioni di ritardo ammissibile
SENZA CONNESSIONEle entità comunicano utilizzando le risorse che sonodisponibili al momento della azione (dinamico)come garantire il flusso
CON CONNESSIONE TCP/IPle entità che comunicano con connessione TCP, nonimpegnano risorse e non possono dare garanzie
IN OSIle entità OSI impegnano risorse e possono anche forniregaranzie, che devono essere rispettate da tutte le entità delpercorso
Come garantire QoS in TCP/IP
Sistemi Distribuiti 56

QoSmolti aspetti legati alla qualità del servizio anche nonfunzionali
Prontezza di rispostaritardo, tempo di risposta,jitter (definito come variazione del ritardo di consegna)
Bandabit o byte al secondo di sistema e di applicazione
Throughoutnumero di operazioni al secondo
Affidabilitàpercentuale di successi/insuccessi
In caso di sistemi multimediali, proprietà non funzionali• dettagli dell'immagine• accuratezza dell'immagine• velocità di risposta• sincronizzazione audio/video ...In genere, una QoS può essere garantita solo attraverso unaccordo negoziato e controllatoosservando il sistema in esecuzione eadegunado dinamicamente il servizio
Sistemi Distribuiti 57
Management QoSSia funzioni statiche
specifica dei requisiti e variazioninegoziazionecontrollo di ammissioneriservare risorse necessarie
Sia funzioni dinamichemonitoring delle proprietà e delle variazionicontrollo del rispetto e sincronizzazionevariazione delle risorse per mantenere QoSrinegoziazione delle risorse necessarieadattamento a nuove situazioni
sono necessari dei modelli precisi di gestione
modello di monitor e qualità
Problema del costo della strumentazioneNecessità di avere meccanismi di raccolta di datidinamici e di politiche che non incidano troppo sullerisorse (usate anche dalle applicazioni)
Principio di minima intrusione
Sistemi Distribuiti 58

requisiti di qualità delle applicazionida garantire a livelli diversi (OSI N/T)
Applicazioni Elastiche e Non Elastiche
elastiche
Interattive
telnet, X-windows
Interactive bulk
FTP, HTTP
Asincrone
e-mail, voce
Tolleranti
Adattative
tradizionali
real-timeapplicazioni
Non elastiche - Real Time
real-timeapplicazioninuove
Non tolleranti
Non-adattative
Adattative in banda
Adattative in banda
Adattative al ritardo
Le elastiche non introducono vincoli di qualitàseppure con requisiti diversi indipendenti da ritardipur lavorando meglio con ritardi bassiInterattve meglio con ritardi inferiori a 200ms
Le non elastiche hanno necessità di garanziee presentano tipicamente vincoli di tempoe sono poco tolleranti per essere usabili
Il livelli di servizio si possono adeguare ai requisitiadattative al ritardo => audio scarta pacchettiadattative alla banda => video che si adatta la qualità
Sistemi Distribuiti 59
SERVIZI
best-effort adatto per servizi elasticivedi servizi Internetnessun throughput garantito, ritardi qualunque,non controllo duplicaizoni o garanzie di ordine azioni
controlled loadsimili a best-effort con basso caricoma con limiti superiori al ritardo
servizi elastici e real-time tolleranti
guaranteed loadlimite stretto al ritardoma non al jitter
servizi real-time non tolleranti
IP => best- effortTCP => elastico con garanzie di ordinamento, unicità,
controllo flusso
OSI => le qualità di servizio di N e T
Uso di nuovi protocolli per adeguare anche Internetper il controllo delle operazioni e risorse
RTP => Real-Time Protocol(RFC 1889) messaggi generaliin datagrammi UDP invio con
reliability e multicastRTCP=> Real-Time Control Protocol
segnalazionebasandosi su QoS garantito
Sistemi Distribuiti 60

Trasparenza (Network Transparency)Accesso
omogeneità accesso alle risorse locali e remote
Allocazionelocazione delle risorse locali e remote trasparente
Nomenome non dipende dal nodo di residenza
Esecuzionecapacità di eseguire usando risorse locali e remote
Performancenon degrado nell'uso dei servizi locali o remoti
Faultcapacità di fornire servizi in caso di guasto
Replicazione
VANTAGGI
Più facile sviluppo delle applicazioni e maggiore affidabilitàSviluppo dinamico ed incrementaleMaggiore complessità
necessità di STANDARDEterogeneità come diversità di
HardwareRete di interconnessioneSistema Operativo
Sistemi Distribuiti 61
TEORIA E MODELLI
Classificazioni diverse delle architetture edei modelli
alla base del parallelismo
MODELLOAstrazione della architettura
==>
Possibilità di guidare nelprogetto della soluzione
Associato ad una metodologia di sviluppoCosto della possibile soluzioneEfficienza implementativa
Alcuni modelli standard di riferimentoModello ISO/OSI
sono inizialmente specifiche astratte di standardizzazionenon sono modelli operazionali
Modello CORBA OMG, DCE OSFsono proposte di standard di comitato / fatto
Sistemi Distribuiti 62

MODELLI COMPUTAZIONALImodello Von Neumann
modello sequenziale conuna sola capacità di esecuzione
modelli di esecuzioneconsiderando la molteplicità dei flussidi dati e di esecuzione
Single Instruction Multiple Data (SIMD) Multiple Instruction Multiple Data (MIMD)
Flynn
data stream
instruction stream
unico flussodi dati
flussi multiplidi dati
unico flussodi istruzioni
SISD(Von Neumann)
SIMD(vettoriali)
flussi multiplidi istruzioni
MISD(pipeline ?)
MIMD(macchinemultiple)
Altri modelli più complessi non sono stati poi largamenteaccettati
Sistemi Distribuiti 63
Tipica architettura MIMDProcessori
Rete diInterconnessione
e Controllo
MIMD
Pe
Pe
Pe
Tipica architettura SIMDProcessori
Rete diInterconnessione
e Controllo
SIMD
Unità diControllo
Unica
Pe
Pe
Pe
Sistemi Distribuiti 64

SISTEMI MULTICOMPUTER MIMD
Nodo processore collegato alla memoria privataanche organizzata a livelli
Sistema distribuito Non Uniform Resource Access
P
M
Rete diInterconnessione
P
M
P
M
P
M
P
M
Nodo P
M
Nodo
Nodo
Nodo
NodoRete diInterconnessione
P
M
P
M
P
M
P
M
Processore
Processore
Cache
Processore
ProcessoreMemoria
Reti di workstationCalcolatori indipendenti connessi da una rete locale (LAN)
LAN
Rete di workstation
Sistemi Distribuiti 65
INTERCONNESSIONE
ProcessoriMemorie
Rete diInterconnessionetra processori
e memorie
Topologia della rete di interconnessione tra processori e memorie
con uso di cache
Processori Memorie
Rete diInterconnessionetra processori
e memorie
Uniform Memory Access
Pe
Pe
Pe
M
M
M
Processori Memorie
Rete diInterconnessione
tra processori
e memorie
NON Uniform Memory Access
PeM
M
M
M
Pe
M
Pe
M
UMA NUMA
Idea di località
Sistemi Distribuiti 66

Modello di Trealeven
basato su due componenti
controllo della esecuzioneda esplicito a più implicito
control-driven, pattern-driven,demand-driven, data-driven
Possibilità dimemoria condivisa vs message passing
dati
controllo dellaesecuzione
memoriacondivisa
memoriaprivata
control-driven Von Neumann processi incomunicazione
pattern-driven logica attori
demand-driven grafi a riduzione riduzione distringhe
data-driven dataflow dataflowcon token
Altri modelli
Sistemi Distribuiti 67
/,1*8$**,�',�352*5$00$=,21(
controllo dellaesecuzione
dati memoriacondivisa
datimemoriaprivata
control-driven C, Pascal, ... Ada, occam,CSP, DP,
Oggetti Parallelipattern-driven Prolog Actors, ACT2
demand-driven Lisp FPFunzionali
data-driven ValSISAL
Control-driven ==> linguaggi tradizionali e paralleliespressione esplicita del controllo
Pattern-driven ==> le clausole da applicare sono ricercatein modo implicito
Demand-driven ==> composizione di funzioni astratte chenon specifica il parallelismo
Data-driven ==> i dati fluiscono e determinano laattivazione delle strutture della computazione
Sistemi Distribuiti 68

Modelli RAM
Una macchina ad accesso random(Random Access Machine)
è costituita da:- un programma inalterabile composto di istruzioni in
sequenza;- una memoria composta di una sequenza di parole,
ciascuna capace di contenere un intero;- un solo accumulatore capace di operare;- un nastro di input (read-only);- un nastro di output (write-only);
Durante un passo la RAM esegue una istruzionein sequenza, a parte i salti.
Istruzioni sono, ad esempio:read, write, load, store, add, sub, mul, div, jump (acc), ...,halt
Modi di indirizzamento:immediato, diretto, indiretto
La RAM è una macchina special-purpose per la risoluzionedi un problema specifico
limiti:- non c'è limite alla memoria di programma- le istruzioni richiedono lo stesso tempo
(vedi SIMD)
Sistemi Distribuiti 69
Modelli PRAM
Una macchina parallela ad accesso random(Parallel Random Access Machine)
è costituita da una collezione di RAM.Una PRAM si dimensione P è composta da:- P programmi inalterabili fatto di istruzioni in sequenza;-una sola memoria composta di una sequenza di parole
capaci di contenere un intero;- P accumulatori capace di operare;- un nastro di input ed uno di output;
Durante un passo, la PRAM esegue P istruzioni, una perogni programma(modello MIMD o meglio MIMD sincrono)
DISTINZIONE semanticacome si eseguono le operazioni su una stessacella di memoria (operazioni di lettura/scrittura)
operazioni simultanee (Concorrenti)operazioni sequenzializzate (Esclusive)
lettura scritturaCREW concorrente esclusiva
EREW esclusiva esclusiva
CRCW concorrente concorrente
ERCW esclusiva concorrente
Sistemi Distribuiti 70

Concurrent Read Exclusive Write (CREW PRAM)Exclusive Read Exclusive Write (EREW PRAM)Concurrent Read Concurrent Write (CRCW PRAM)
Exclusive Read Concurrent Write (ERCW PRAM)vedi MISD
Operazioni concorrenti: quali effetti?
Principio di serializzazione ==>gli effetti come se una fosse fatta per prima, poiun’altra in successione, un’altra ancora, etc.
limiti:- le istruzioni richiedono lo stesso tempo- il tempo di operazione non dipende da P
accesso a memoria comune in un tempo che noncresce con P
- il tempo di operazione di input/output trascuratoaccesso ad un unico nastro non cresce con P
I/O bottleneck
➪ Uso di concorrenza per la gestione delsottosistema I/O
Sistemi Distribuiti 71
Modelli message passing MP-RAM
Una macchina message passing ad accesso random(Message Parallel Random Access Machine)
è costituita da una collezione di RAM ciascuna con unamemoria privata e connesse da canali punto a punto.Una MP-RAM si dimensione P è composta da:- P programmi inalterabili fatto di istruzioni in sequenza;- P memorie composta di una sequenza di parole;- P accumulatori capaci di operare sulla propria memoria;- un nastro di input ed uno di output;- un grafo di interconnessione punto-a-punto.
Per esempio ad albero, a stella, etc.Ogni nodo ha un certo numero di vicini ed ungrado di interconnessionePossibilità di comunicazione bidirezionale
Le istruzioni sono accresciute con:send e receive neighbor
Durante un passo, la MP-RAM esegue P istruzioni, una perogni programma
DISTINZIONE semanticacosa succede se una receive arriva prima dellasend sul canale corrispondente?
semantica sincrona
Sistemi Distribuiti 72

limiti:modello meno potente della PRAM
MP-RAM introduce localitàPRAM è ancora un modello globale
modello PRAM può emulare il modello MP-RAMla memoria comune viene vista come un insiemedi spazi per i diversi canaliIl canale come lo spazio per il dato ed un flagsend e receive come istruzioni che agiscono sulflag e poi sul valore da ricevere/inviare
vice versala realizzazione del multicast/broadcast richiede moltipassi intermedi e router intermedi
ProblemaIl modello PRAM è troppo potente ed astratto
Gli algoritmi sono più veloci sul modello che nei sistemi realimodellati
COMPLESSITÀ DEGLI ALGORITMI
dipendenza dalla dimensione del problema N
complessità in tempo CT(n) (abbreviato in T(N))complessità in spazio CS(n)
Sistemi Distribuiti 73
COMPLESSITÀT(1,N) soluzione sequenzialeT(P,N) soluzione parallela con P processori
SPEED-UPMiglioramento dal sequenziale al parallelo
T(1,N) T1(N)S(P,N) = ----------- SP(N) = ----------- T(P,N) TP(N)
EFFICIENZAUso delle risorse
Speed up SP(N)E(P,N) = ----------------------- = ------------ Numero Processori P
T1(N)EP(N) = ------------- P TP(N)
SP(N) al massimo P ed EP(N) al massimo 1
No. processori
Speed-up
6SHHG�XS�LGHDOH
ragioniamo sui valori medi
Sistemi Distribuiti 74

Correlazione tra N e P
possibilità di considerareN indipendente da PN dipendente da P
FATTORE DI CARICO (LOADING FACTOR)
NL = ----- P
dependent size (N funzione di P)independent sizeidentity size (N == P)
OBIETTIVOtrovare la migliore approssimazione perl’algoritmo che ci interessa verificare
anche
Heavily Loaded LimitTHL(N) = infP TP(N)
il valore di P tale per cui si ottiene la minore complessitàdel problema (cioè T minimo)
in genere, per N molto elevato,cioè ogni processore molto caricato
Sistemi Distribuiti 75
SPEED-UPMassimo speed-up ottenibile
nel passaggio dal sequenziale al parallelo
LEGGE DI AMDHAL
Un programma è diviso in una parte parallela ed in una parte sequenziale
lo speed-up è limitato dalla parte sequenziale
Se un programma è costituito di 100 operazioni e solo80 possono andare in parallelo e20 richiedono sequenzialità
Anche con 80 processori ==>lo speed-up non può arrivare sopra a 5
Situazione ideale ==>considerando la migliore allocazione possibile
TP(N) = TCompP + TCommP
TCompP = TCompPar + TCommSeq
Limite di Amdhal rapporto tra le due parti dell'algoritmo
Tenendo presente casi di speed-up anomalo==> dipendenti dall’algoritmo
Sistemi Distribuiti 76

Problema di dimensione N con uso di P processoriper il caso di problema di somma di N interi
Complessità del sequenziale O(N)
Complessità del modello paralleloidentity size (N == P)
Con un numero di processori pari a POgni nodo foglia contiene un valoreInterconnessioni ad albero
N = P = 2H+1-1H = O (log P) = O (log N)TP(N) = O (H) = O (log N)
I valori fluiscono dalle foglie in su edogni nodo li somma ad ogni passo
NL = ----- = 1 P
T1(N) O(N) N PSP(N) = ----------- = ------------ = O(-------) = O(-------) TP(N) O(log N) log N logP
T1(N) 1 1EP(N) = ------------- = O(----------) = O(-------) P TP(N) log N log P
Efficienza tende a zero
Sistemi Distribuiti 77
Complessità del modello paralleloindependent size
Se possiamo dividere il problema parallelizzandolo con uncerto fattore di caricoUna fase locale di lavoro ed una fase di scambio diinformazioni per combinare i risultati parziali
L = N/PT(P,N) = O(N/P + log P) = O (L + log P)
per lo speed-up
T1(N) N PSP(N) = -----------= O( ---------------) = O( ------------------) TP(N) N/P + log P 1 + P/N log P
per l’efficienza
1EP(N) = O (-------------------- ) 1 + P/N log P
Se N>>Pallora lo speed-up può diventare anche P (efficienza 1)
Se P>>Nallora inefficienza
Sistemi Distribuiti 78

Complessità del modello paralleloheavily loaded limit
L cresce
TP HL (P,N) = O (L + log P) => OHL (L)
O(LP)SP HL (N) = ------------------- => OHL (P) O( L + log P)
EP HL(N) = => OHL (1)
Cioè, intuitivamente
se carichiamo ogni nodo molto ==>L molto elevato
Si può raggiungere anche uno speed-up idealeed una efficienza ideale
PROBLEMI- schematizziamo a meno di fattori costanti- a volte il caso peggiore può essere più significativo
trascuriamo completamente- trascuriamo
movimento di dati I/O e il mappaggiosono necessarie comunicazioni
Sistemi Distribuiti 79
MAPPAGGIO
Assumiamo di avere mappato il problema nel modo migliore
Spesso non si possono fare allocazioni così faciliproblemi dinamici nella comunicazione
dopo la allocazione
A volte si usa anche:funzione di Overhead Totale T0
cioè tenendo in contole risorse ed il tempo speso in comunicazione
T1(N) tempo sequenziale di esecuzioneT0(N) = T0 (T1, P) = P * TP (N) - T1(N)
Se si lavora con efficienza massima, overhead nulloT0(N) = 0 => P * TP (N) = T1(N)
T0(N) + T1(N)TP(N) = ------------------------
P
T1(N) T1(N) PSP(N) = --------- = -----------------------
TP(N) T0(N) + T1(N)
S T1(N) 1EP(N) = ---- = ---------------------- = -----------------------
P T0(N) + T1(N) T0(N)/T1(N) + 1
Si possono fare misure precise
Sistemi Distribuiti 80

Nel caso della somma di N numeri con P processori
Consideriamo unitarioil costo della somma e della comunicazione
TP(N) = N/P - 1 + 2 log P ≈ N/P + 2 log P
T0(N) = P TP (N) - T1(N) nodi totali kn
T0(N) = P (N/P + 2 log P) - N
T0(N) ≈ 2 P log P
N N PSP(N) ≈ -------------------- = --------------------
N/P + 2 log P N + 2 P log P
NEP(N) ≈ -----------------------
N + 2 P log P
I due indicatori dipendono sia dal numero di processorisia dalla dimensione del problema
Sistemi Distribuiti 81
PER IL CASO PRECEDENTE
SPEED-UP
0
2
4
6
8
10
12
14
16
18
20
1 4 8 16 32
N=64
N=192
N=320
N=512
EFFICIENZA
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
1 4 8 16 32
N=64
N=192
N=320
N=512
Gli indicatori possono anche rimanere costanti(al variare di P)
Sistemi Distribuiti 82

ISOEFFICIENZA
1EP(N,P) = ----------------------- T1(N) è il lavoro utile
T0(N)/T1(N) + 1
Obiettivo ==> mantenere l'efficienza costante
1 - E 1 - ET0(N)/T1(N) = --------- T0(N) = --------- T1(N)
E E
1 - ET0(N,P) = --------- T1(N,P) = K T1(N, P)
E
Lo costante K caratterizza il sistemaNel caso precedente (1 nodo /1 valore) K non costanteNel caso di albero, K vale 2 P log P
Funzione isoefficienzaSe teniamo costante N e variamo P, K determina se unsistema parallelo possa mantenere un'efficienzacostante ==> cioè uno speed-up ideale
Se K è piccola ==> alta scalabilitàSe K è elevata ==> poca scalabilitàK può non essere costante ==>
sistemi non scalabili
Albero, K vale 2 P log Psistema scarsamente scalabile
Sistemi Distribuiti 83
ARCHITETTURA ASTRATTA
composta di risorseprocessori (Processing Element)memoriainput/outputcanali
Sistema distribuito con memoria e canali
NON UNIFORM RESOURCE ACCESS
ARCHITETTURA REALE
Quali risorse?
Processing elements PEquanti?quali?
I/Omemorieinterconnessione reciproca
Si noti la complessità introdotta dalla eterogeneità
Sistemi Distribuiti 84
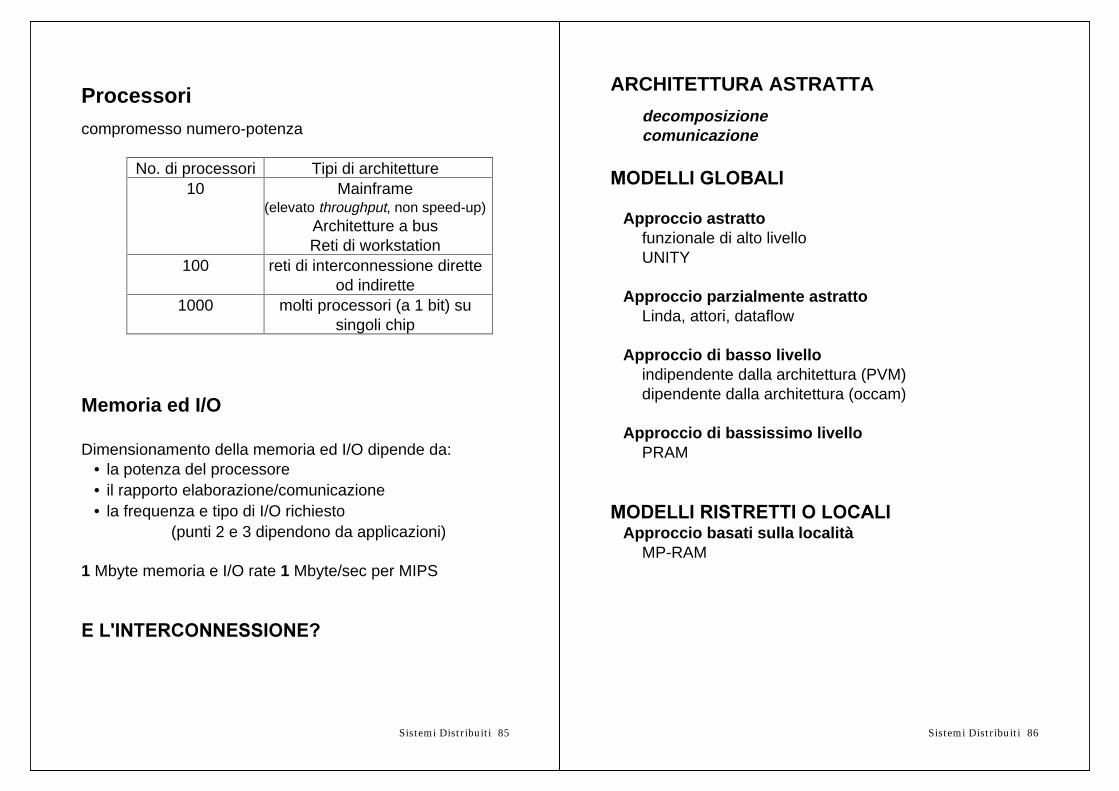
Processoricompromesso numero-potenza
No. di processori Tipi di architetture10 Mainframe
(elevato throughput, non speed-up)Architetture a busReti di workstation
100 reti di interconnessione diretteod indirette
1000 molti processori (a 1 bit) susingoli chip
Memoria ed I/O
Dimensionamento della memoria ed I/O dipende da:• la potenza del processore• il rapporto elaborazione/comunicazione• la frequenza e tipo di I/O richiesto
(punti 2 e 3 dipendono da applicazioni)
1 Mbyte memoria e I/O rate 1 Mbyte/sec per MIPS
(�/,17(5&211(66,21("
Sistemi Distribuiti 85
ARCHITETTURA ASTRATTA
decomposizionecomunicazione
02'(//,�*/2%$/,
Approccio astrattofunzionale di alto livelloUNITY
Approccio parzialmente astrattoLinda, attori, dataflow
Approccio di basso livelloindipendente dalla architettura (PVM)dipendente dalla architettura (occam)
Approccio di bassissimo livelloPRAM
02'(//,�5,675(77,�2�/2&$/,Approccio basati sulla località
MP-RAM
Sistemi Distribuiti 86

GRADO di PARALLELISMOMIMD vs. SIMD
- MIMD più flessibili- SIMD possono essere emulate con
macchine MIMD
Sistemi Moderatamente/Massicciamente paralleliSistemi paralleli
allo stato attuale della tecnologia possono esserecomposti da alcune decine di processori.
Sistemi massicciamente parallelicaratterizzati da architetture che scalano fino a migliaia diprocessori (massimo circa sessantaquattromila)
Sistemi globalicaratterizzati da numeri illimitati di processori (WEB)
Sistemi ParalleliMassicciamente Paralleli migliaia di PE
numero di processori da 30 a 64000iPSC(/2 e /860), NCUBE, MEIKO, SuperNode, ...
Moderatamente Paralleli decine di PEnumero di processori fino al massimo 30
CRAY, Convex, Sequent, Encore, Alliant FX, ...
Per i secondi, anche memoria condivisaPer i primi, impossibile
Sistemi Distribuiti 87
0(025,$�&21',9,6$
senza bususo di reti con switch dinamico
multistageo memoria veramente condivisa
con bus unicoproprietariostandard (Multibus, VMEbus)
solo memoria condivisamemoria locale e globale condivisamemoria locale e condivisa solo in un cluster (vicinato)
6(1=$�0(025,$�&21',9,6$
gerarchia di bus per scambio messaggicon gerarchia un cluster di PE connessi con un busproprietario o standard
reti di interconnessione tra PE con diverse topologiecon possibilità di variare anche la topologia,generalmente regolare
reti di interconnessione tra workstationin particolare con le nuove possibilità diinterconnessione veloce
Sistemi Distribuiti 88

PROCESSORI- CPU proprietarie progettate appositamente
CRAY, Convex, IBM 3900, ...
- CPU ’off-the-shelf’RISC, SPARC, ...
- CPU progettate per il calcolo parallelo e distribuito, ingenere con integrazione con la comunicazioneT800, T9000, nCUBE, iWARP, ...
2 CATEGORIE PRINCIPALIA) ARCHITETTURE con memoria distribuita
scalabili
B) SISTEMI ETEROGENEI basatisu reti diverse
Esempi:Sistemi a Memoria Distribuita A)
Meiko CS ...
Sistemi Distribuiti B)reti di workstation e multiprocessori
Sistemi Distribuiti 89
Sistemi a Mem Distribuita: Meiko A)
Meiko CS-1Fino a 2048 nodi MIMD con processori T800Topologia statica riconfigurabile (4 link per nodo)Comunicazione con message passing proprietario(CSTools)
Meiko CS-2Struttura modulare, fino a centinaia di nodi MIMD conprocessori off-the-shelf SPARCTopologia ad albero di switchComunicazione con message passing proprietario
Introduzione di cluster di processori
Sistemi Distribuiti 90

SISTEMI DISTRIBUITI B)
Reti di workstation e multiprocessoriSistemi eterogenei
retihardware e software parallelo
Mancanza di sistemi operativi e di strumenti di sviluppo
LAN
Macchina a parallelismo massiccio
Uso della MEIKO dalla rete
Soluzioni con clusterintroducendo l'idea di località a livello di architettura
Località introdotta con vincoli,sia attraverso reti, sia attraverso bus,sia attraverso memoria comune
Sistemi Distribuiti 91
&20387$=,21(�(7(52*(1($Computazione eterogenea usa sistemi esistentiper produrre un ambiente integrato
modularità decomposizione eparallelismo differenziato
Ogni applicazione presenta più tipi di parallelismole parti vengono così eseguite sui componenti piùadatti su esplicita richiesta o in modo implicito
ConnessioniConnessioni
Connection Machine
Macchina a parallelismo massiccio
Rete di workstation
Cray
Macchina a parallelismo massiccio
Differenze a livello di• architettura, dati, protocolli, sistemi operativi, risorse
e con necessità di standard
Sistemi globali interconnessi da Internet e WEBcon possibilità di condividere capacità di esecuzione
Web computing
Sistemi Distribuiti 92

Stato dell’arteesaminando i sistemi operativi
dal concentrato verso il distribuito
UNIX rappresenta un modello di conformitàper caratteristiche di accesso ai fileper possibilità di concorrenza
I sistemi operativi general-purpose tendono a forniresoluzioni ispirate o analoghe
si pensi a Microsoft Windows NT che introduce processi econtrollo di accessoma anche ad evoluzioni che fanno ancora i conti con leproprietà di UNIX (vedi anche Linux)
UNIX rappresenta un limiteper caratteristiche di concorrenzaprocessi pesanti
I sistemi operativi evoluti preservano la compatibilità maforniscono migliori prestazione per la gestione delle risorse➪ per i processi (leggeri) e per la distribuzione delle
risorse (processi e dati)
Inoltre si cerca di ispirarsi agli standard in definizione per laeterogeneitàObject-Oriented CORBALinguaggio Java
Sistemi Distribuiti 93
67$72�'(//$57(Anziché usare kernel monolitici (vedi UNIX)e che si accettano in blocco (o meno)e che pesano sulle performance
Uso di microkernelrealizzazioni minimali del supporto di un S.O.le politiche specificate al disopra del kernela livello applicativoa livello utente processi applicativi e di sistema
J apertura a nuove strategie (generalità)L costi superiori delle strategie realizzate
(rispetto a soluzione ad-hoc)I microkernel contengono il supporto per i processi e perle comunicazioni tra processi
I microkernel non sono sviluppati soloda ambienti tipo UNIX, ma anche come modelloper ambienti tipo Windows
in cui l'accento e'sulle interfacce grafiche,sulla interazione visuale, etc.
In ogni caso, anche gli approcci proprietari devono teneree tengono in conto di questa evoluzione
Sistemi Distribuiti 94

INTEROPERABILITÀ e RIUSO
livelli di omogeneizzazione della eterogeneità
STRATI INDIPENDENTI DAL SISTEMA ==>problemi di efficienza
SUPPORTI UNIFICANTI PER LACOMUNICAZIONE TRA PROCESSI
SISTEMI per la COMUNICAZIONEPVM (Parallel Virtual Machine)
Sun Transputer Sun HP HP
390
Processi Processi
APPLICAZIONE 1 APPLICAZIONE 2
Network
Gli approcci tipo PVM (anche altri: MPI, etc.) sono basatisulla standarddizzazionedello scambio di messagi tra nodieterogenei
Si mantengono ambienti locali differenziati che sono resiomogenei dalle primitive unificate(usao di linguaggi diversi e S.O. diversi)
Sistemi Distribuiti 95
Approcci ad ambienti apertisi è affermato la possibilità di avere un ambiente aperto persuperare la eterogeneità delle diverse piattaforme anchedurente la esecuzione senza chiudere il sistema
Il primo aspetto richiede un ambiente standardANSA; DCE, OSF, etc.
Il secondo aspetto richiede un ambiente interpretato edaperto
linguaggi scripttipo Shell, TCL/Tk, Perl, Python
Java legato allo scenario Web
Java si basa su un interprete e una macchina virtuale
Applet e Applicazioni Java
Classi Base Estensione di Classi di Java
Java Virtual Machine
Interfaccia di portabilitàAdattatoreBrowser
S.O.
Hw
AdattatoreBrowser
S.O.
Hw
AdattatoreBrowser
S.O.
Hw
AdattatoreBrowser
S.O.
Hw
Interconnessione via Rete
Java consente una facile integrazione con le informazioniWeb attraverso applet e la facile integrabilità
Inoltre, comincia ad avere strumenti per il supporto:• sicurezza• riflessione• distribuzione del codice• gestione risorse (??? in attesa)
Sistemi Distribuiti 96





























