Embed Size (px)
Citation preview

서울대학교
Software Platform Lab 소개
전병곤
2021년 10월 15일

§ AI 및 빅데이터시스템분야최고연구수행, 초거대 AI 모델연구수행
§ 리더전병곤교수와 1명박사후연구원, 8명박사과정, 9명석사과정으로구성
§ 2021년여름까지 5명의박사졸업생, 6명의석사졸업생배출
§ 초거대 AI 개발플랫폼스타트업 FriendliAI 창업
§ 마이크로소프트, 페이스북, 구글, 삼성, 네이버등글로벌기업과협업, 인턴십
§ 아파치재단등을포함활발한공개소프트웨어활동참여
Software Platform Lab은?

전병곤교수약력
!"# $%
• 서울대컴퓨터공학부교수
• FriendliAI 대표
• 서울대 AI�연구원 부원장
• 서울대-네이버초거대(Hyperscale) AI연구 센터장
• 초거대 AI플랫폼기술개발
• (전) MS,�Yahoo!,�Intel�
• (전) Facebook,�네이버 방문연구원
• UC�Berkeley 박사,�Stanford�석사, 서울대 석사, 학사
• 지난 10년간 가장 impact있는 시스템연구로유럽과미국에서수상 (2021,�2020)
• 다수의연구상수상:�구글(2020),�아마존(2018),�페이스북(2017),�마이크로소프트(2014)
• 논문 14,500회 이상인용됨 (Google�Scholar)

§ WindTunnel: Towards Differentiable ML Pipelines Beyond a Single Model (VLDB 2022)§ Terra: Imperative-Symbolic Co-Execution of Imperative Deep Learning Programs (NeurIPS2021)
§ Finding Consensus Bugs in Ethereum via Multi-transaction Differential Fuzzing (OSDI 2021)§ Refurbish Your Training Data: Reusing Partially Augmented Samples for Faster Deep Neural Network Training (ATC 2021)
§ Nimble: Lightweight and Parallel GPU Task Scheduling for Deep Learning (NeurIPS 2020 Spotlight)
§ Apache Nemo: A Framework for Building Distributed Dataflow Optimization Policies (ATC 2019)§ JANUS: Fast and Flexible Deep Learning via Symbolic Graph Execution of Imperative Programs (NSDI 2019)
§ Parallax: Sparsity-aware Data Parallel Training of Deep Neural Networks (EuroSys 2019)§ PRETZEL: Opening the Black Box of Machine Learning Prediction Serving Systems (OSDI 2018)§ Improving the Expressiveness of Deep Learning Frameworks with Recursion (EuroSys 2018)
최근 3년발표중요연구 (OSDI, NSDI, EuroSys, ATC, VLDB, NeurIPS 등)
https://spl.snu.ac.kr/publications/

§ (초거대) AI 시스템§ 컴파일러
§ 런타임
§ 수행모델
§ 분산처리
§ AutoML
§ AI 클러스터자원관리
§ 모바일 AI 시스템
AI Systems & Models, Data Processing Systems
§ 초거대 AI 모델§ 언어모델
§ 멀티모달모델
§ 데이터처리시스템§ 배치처리
§ 스트림처리
§ 자동최적화

AI Systems
Serving
ML Framework (Compiler, Runtime)
Cluster Manager
Hardware
Training
WorkflowAutoML
SystemY
NimbleTerra
WindTunnel
Band
SystemX

Terra: Imperative-Symbolic Co-Execution of Imperative Deep Learning Programs (NeurIPS 2021)
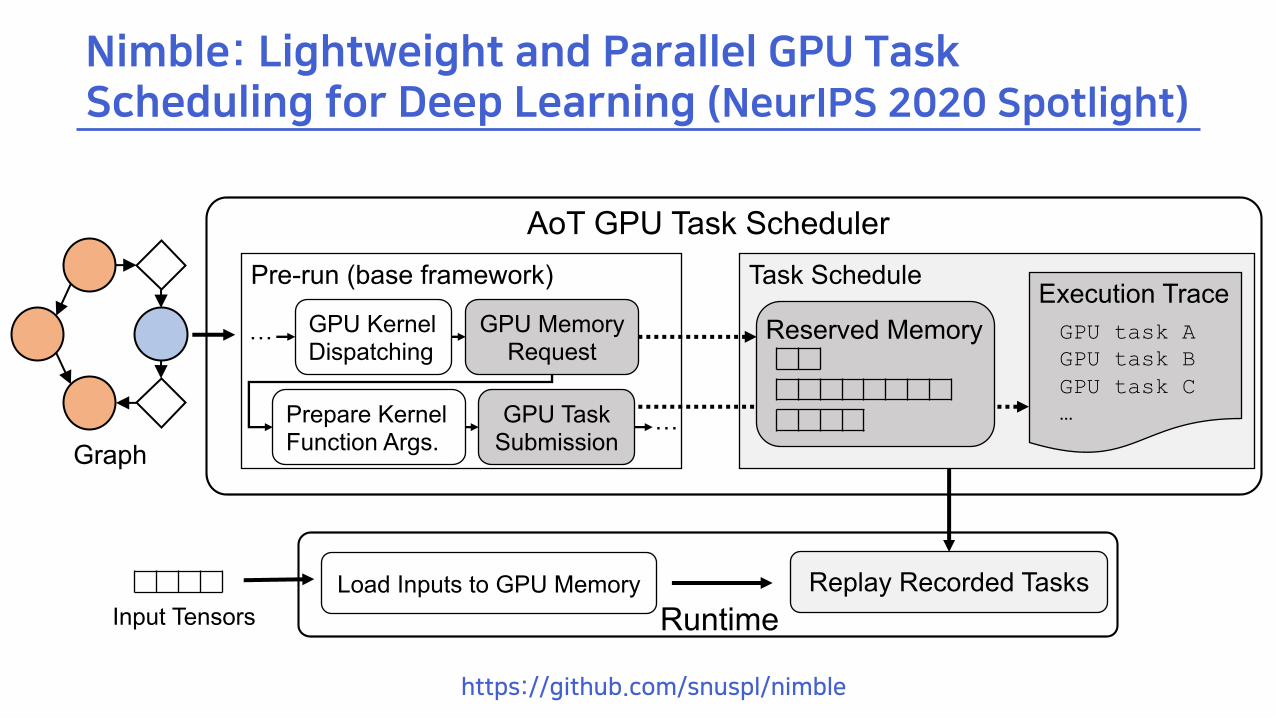
Nimble: Lightweight and Parallel GPU Task Scheduling for Deep Learning (NeurIPS 2020 Spotlight)
Graph
Pre-run (base framework)
GPU KernelDispatching
GPU MemoryRequest
Prepare KernelFunction Args.
GPU Task Submission
Task Schedule
AoT GPU Task Scheduler
Load Inputs to GPU MemoryRuntime
Replay Recorded Tasks
…
…
Execution TraceReserved Memory GPU task A
GPU task BGPU task C…
Input Tensors
https://github.com/snuspl/nimble
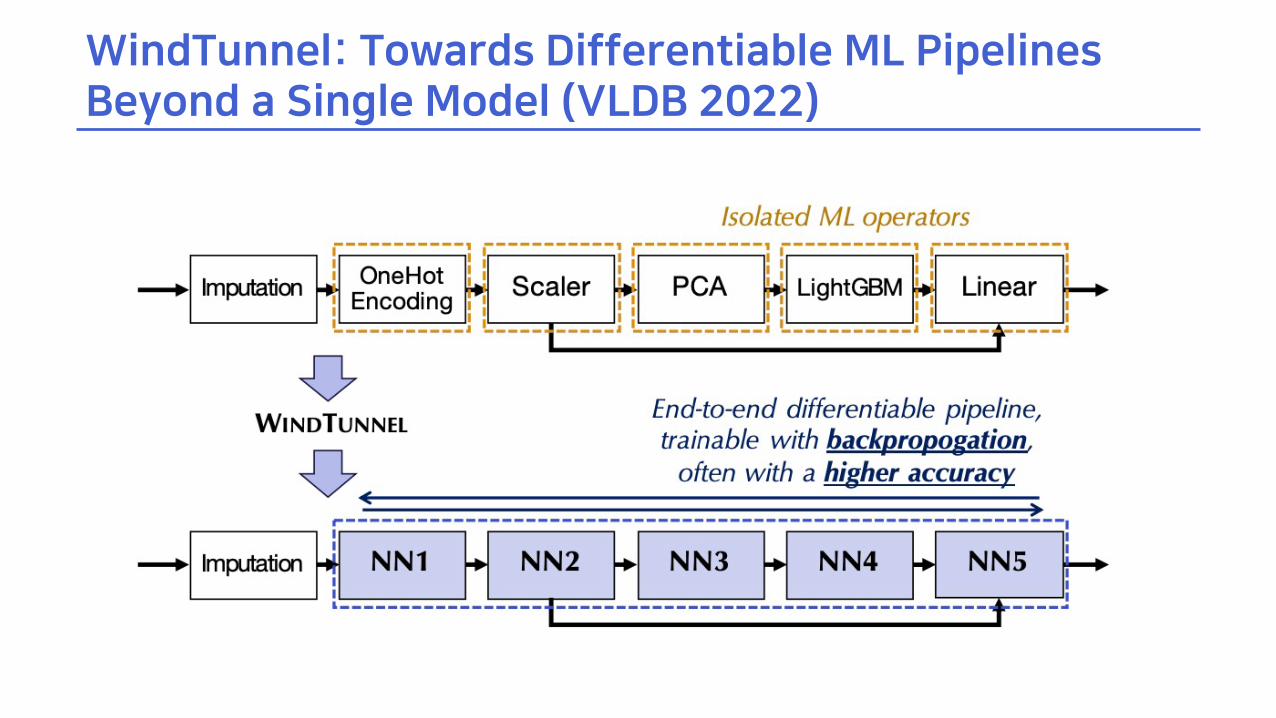
WindTunnel: Towards Differentiable ML Pipelines Beyond a Single Model (VLDB 2022)

Parallax: Sparsity-aware Distributed Training (EuroSys 2019) & Elastic Parallax
10
Machine
GPU GPU
Machine
GPU GPU
2 1 5 2 1 5 2 1 5 2 1 5
Server Server
GradAgg(AR)
GradAgg(PS)
GPU GradAgg(PS)
Local Agg
Dense var.
Sparse var.
Local Agg
https://github.com/snuspl/parallax

Crane: A Declarative GPU Cluster Manager
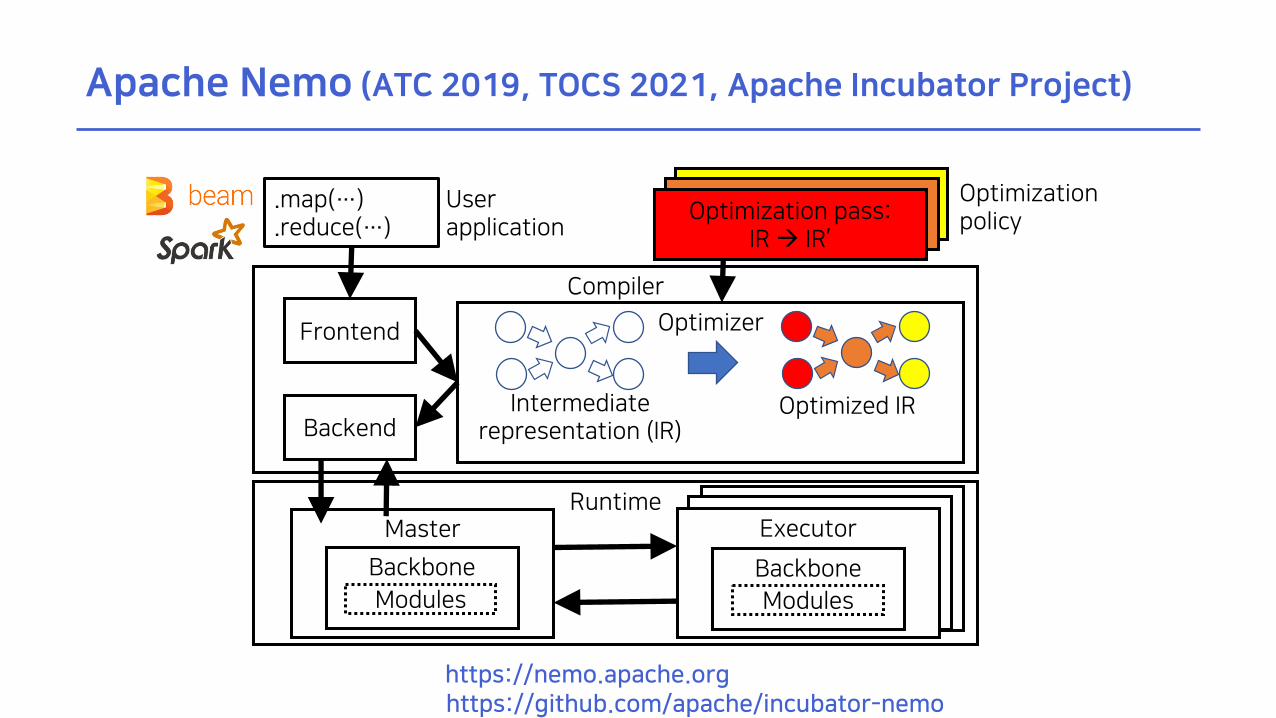
Apache Nemo (ATC 2019, TOCS 2021, Apache Incubator Project)
.map(…)
.reduce(…)
RuntimeMaster
Frontend Optimizer
Backend
Compiler
BackboneModules
Optimization pass:IR à IR’
Optimization policy
User application
Executor
BackboneModules
Intermediaterepresentation (IR)
Optimized IR
https://nemo.apache.orghttps://github.com/apache/incubator-nemo

Blaze & Sponge
BlazeRunner
Spark App
ProfilingPhase
(1)
Shared disaggregated storage memory
SparkExecutor
EM
Spark Master
rdd1_1 rdd1_2 rdd2_1rdd1_1rdd1_1 rdd1_2rdd1_2 rdd2_1rdd2_1
SparkExecutor SparkExecutor
UtilityFunction
Caching/EvictionPolicy
caching/eviction on
disaggregated SM
SM EM SM EM SM
Application DAG(2) Execution
Phase(4)
(3) caching/eviction
on local SM
(2)
Inter-job Caching for Iterative Data Processing Fast Stream Processing Scaling on Lambda
Blaze Sponge

Fluffy: Finding Consensus Bugs in Ethereum via Multi-transaction Differential Fuzzing (OSDI 2021)
Found two new consensus bugs in Ethereumvia a new fuzzing technique
https://github.com/snuspl/fluffy

§ Neural Architecture Search
§ Hyper-Parameter Optimization
§ Inter-job Caching
§ Stream Processing on Serverless Frameworks
§ Mobile Deep Learning Runtime
§ …
Under Submission

서울대-네이버하이퍼스케일 AI 센터

FriendliAI: 초거대 AI 개발플랫폼스타트업
https://friendli.ai (2022년 병역특례업체신청예정)

서울대학교
Thank you!
bgchun (at) snu.ac.krbgchun (at) friendli.ai
Software Platform Lab 소개





























