Embed Size (px)
Citation preview

Spark introduction ������RDD ������Building and running Spark applications
Lightning-fast cluster computing

2
2009 NoSQL
Along with Pig
2007 Hive 2012 RDD concept paper published

The beginning of Spark
• Originator: Matei Zaharia • Start in 2009 as a class project in UC Berkeley’s AMPlab
• Need to do machine learning faster on HDFS • Doctoral dissertaHon (2013) • hMp://www.eecs.berkeley.edu/Pubs/TechRpts/2014/EECS-‐2014-‐12.pdf
• Hear Matei talking • hMps://www.youtube.com/watch?v=BFtQrfQ2rn0
3

4

5

IBM
• 2015.6 • hMps://www-‐03.ibm.com/press/us/en/pressrelease/47107.wss
6

2015.9
7

What is Spark?
• A general execuHon engine to improve/replace MapReduce
• Spark’s operators are a strict superset of MapReduce
8

What’s wrong with the original MapReduce?
9

10

What’s wrong with the original MapReduce? • LimitaHons of MapReduce.
• Originated around year 2000. Old technology. • Designed for batch-‐processing large amount of webpages in Google
• And it does that job very well! • Not fit for
• Complex, mulH-‐passing algorithms • InteracHve ad-‐hoc queries • Real-‐Hme stream processing
11

We are asking too much from MapReduce
12
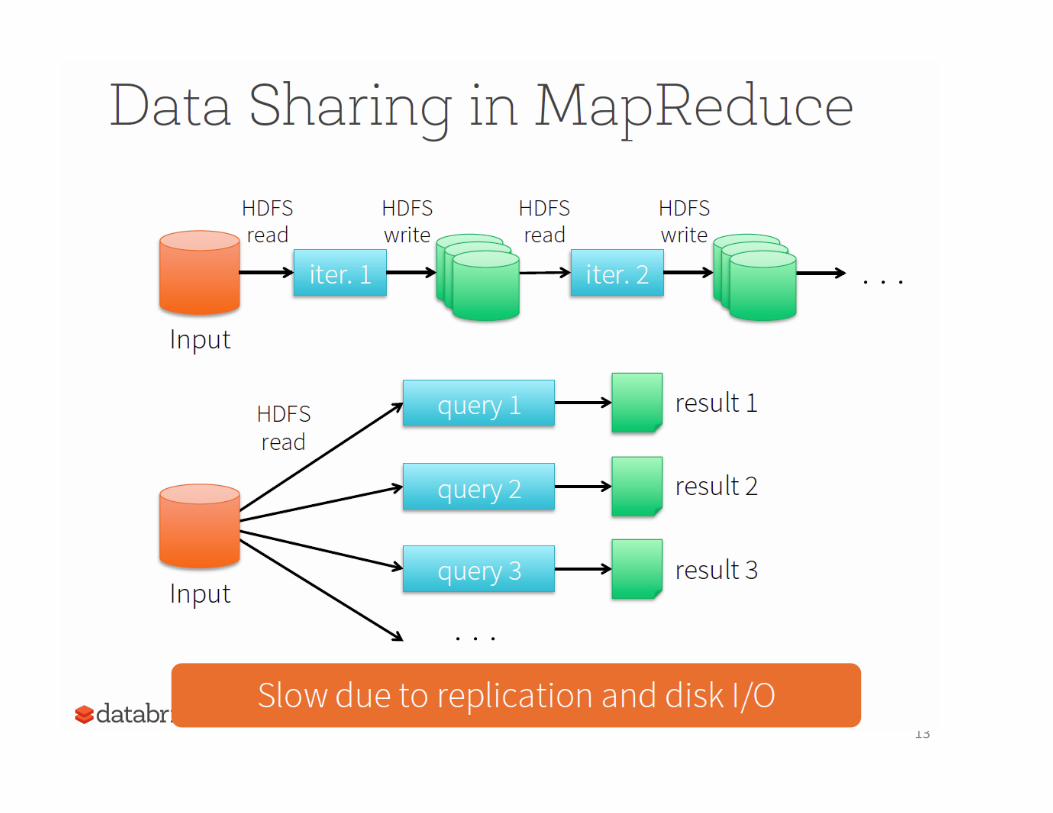
13

The Spark way!
14

15

16

Easier to develop on Spark
• Think of Assembly language
• Python print “Hello world!”
17
Original MapReduce
Spark

Word count
• Mapreduce: • hMps://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html#Example%3A+WordCount+v2.0
• Spark • hMps://spark.apache.org/examples.html
18

Spark is not just in-‐memory processing -‐-‐ it is faster on disk too!
19

A unified engine
20

21

22

Core Spark data abstracIon
• Resilient Distributed Dataset (RDD)
23

RDDs
24

CreaIng RDD
25

RDD operaIons
26

RDD operaIons: AcIons
27

RDD operaIons: TransformaIon
28

Example: map and filter
29

Lazy execuIon
30

Chaining transformaIons
31

RDD lineage and toDebugString
32

FuncIonal programming in spark
33

Passing funcIons as parameters
34

Passing named funcIons
35

Anonymous funcIons
36

CreaIng RDDs from collecIons
37

CreaIng RDDs from files (1)
38

CreaIng RDDs from files (2)
39

Whole file-‐based RDDs (1)
40

Whole file-‐based RDDs (2)
41

Some other RDD operaIons
42

Example: flatMap and disInct
43

Example: mulI-‐RDD transformaIons
44

Some other RDD operaIons
45

Conclusion
46

AggregaIng data with pair RDDs
47

Pair RDDs
48

CreaIng pair RDDs
49

Example: a simple pair RDDs
50

Example: keying by user ID
51

QuesIon1: pairs with complex values
52

Answer1: pairs with complex values
53

QuesIon2: mapping single rows to mulIple pairs
54

Answer2: mapping single rows to mulIple pairs
55

Map-‐reduce
56

Map-‐reduce in spark
57

Example: word-‐count (1)
58

Example: word-‐count (2)
59

Example: word-‐count (3)
60

Example: word-‐count (4)
61

ReduceByKey (1)
62
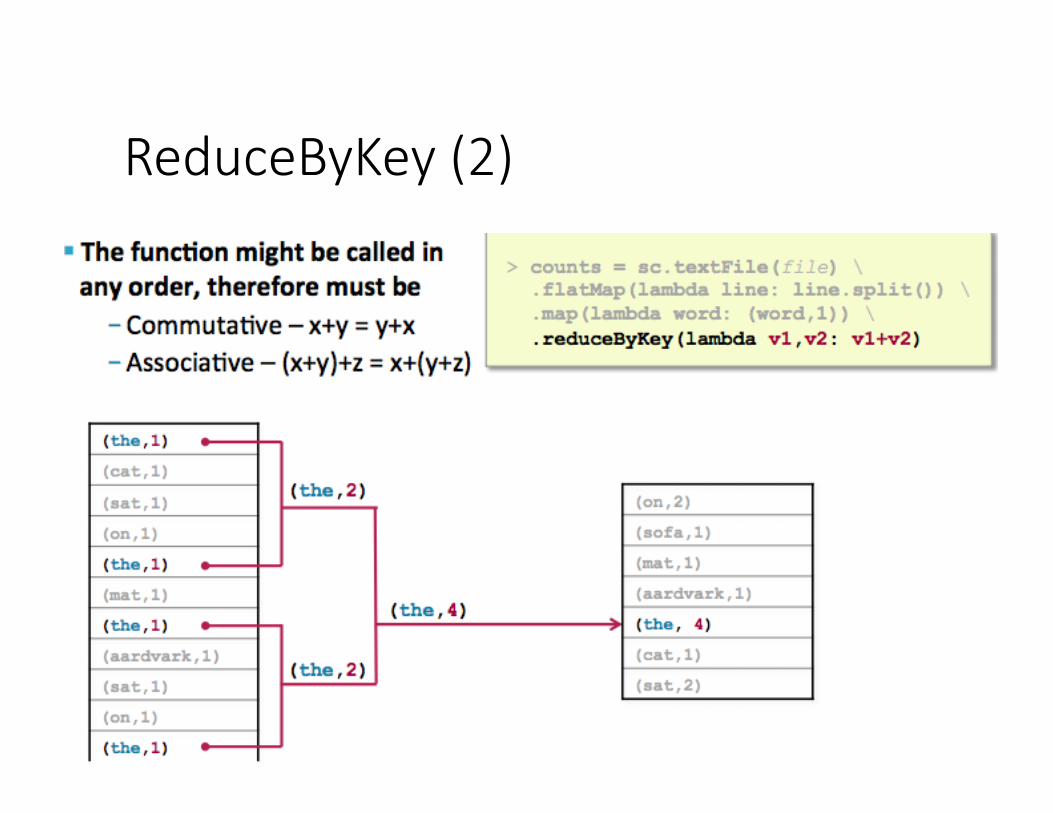
ReduceByKey (2)
63

Other pair RDD operaIons
64

Example: pair RDD operaIons
65

Example: joining by key
66

Using join
67

Example: join web log with knowledge base arIcle
68

Example: join web log with knowledge base arIcle
69

70

71

72

73

74

Example output
75

Other pair operaIons
76

Writing and deploying spark applications
77

The SparkContext
78

Python example: word-‐count
79

Building a spark applicaIon
80

81

Running a spark applicaIon
82

Running spark applicaIons locally
83

Running spark applicaIons on cluster
84

StarIng shell locally or on cluster
85

86










![spark - Cornell University · Spark Operations slide 7 Transformations define a new RDD map filter sample groupByKey reduceByKey sortByKey ... [1, 2, 3]) # …](https://img.pdfslide.net/doc/110x75/5b80fbb57f8b9a466b8b4cfa/spark-cornell-university-spark-operations-slide-7-transformations-define-a.jpg)


















