Embed Size (px)
DESCRIPTION
Speaker Adaptation of Hybrid NN/HMM Model for SpeechRecognition Based on Singular Value Decomposition
Citation preview

J Sign Process Syst (2016) 82:175–185DOI 10.1007/s11265-015-1012-6
Speaker Adaptation of Hybrid NN/HMMModel for SpeechRecognition Based on Singular Value Decomposition
Shaofei Xue1 ·Hui Jiang2 ·Lirong Dai1 ·Qingfeng Liu1
Received: 15 November 2014 / Revised: 22 April 2015 / Accepted: 4 May 2015 / Published online: 10 June 2015© Springer Science+Business Media New York 2015
Abstract Recently several speaker adaptation methodshave been proposed for deep neural network (DNN) in manylarge vocabulary continuous speech recognition (LVCSR)tasks. However, only a few methods rely on tuning the con-nection weights in trained DNNs directly to optimize systemperformance since it is very prone to over-fitting especiallywhen some class labels are missing in the adaptation data.In this paper, we propose a new speaker adaptation methodfor the hybrid NN/HMM speech recognition model basedon singular value decomposition (SVD). We apply SVD onthe weight matrices in trained DNNs and then tune rect-angular diagonal matrices with the adaptation data. Thisalleviates the over-fitting problem via updating the weightmatrices slightly by only modifying the singular values. Weevaluate the proposed adaptation method in two standardspeech recognition tasks, namely TIMIT phone recognitionand large vocabulary speech recognition in the Switchboardtask. Experimental results have shown that it is effectiveto adapt large DNN models using only a small amount
� Lirong [email protected]
Shaofei [email protected]
Qingfeng [email protected]
1 National Engineering Laboratory of Speech and LanguageInformation Processing, University of Science and Technol-ogy of China, Hefei, China
2 Department of Electrical Engineering and Computer Science,York University, Toronto, Canada
of adaptation data. For example, recognition results in theSwitchboard task have shown that the proposed SVD-basedadaptation method may achieve up to 3-6 % relative errorreduction using only a few dozens of adaptation utterancesper speaker.
Keywords Deep neural network (DNN) · HybridDNN/HMM · Speaker adaptation · Singular valuedecomposition (SVD)
1 Introduction
Speaker adaptation has been an important research topicin automatic speech recognition (ASR) for decades.Speaker adaptation techniques attempt to optimize ASRperformance by transforming speaker-independent modelstowards one particular speaker or modifying the targetspeaker features to match pre-trained speaker-independentmodels based on a relatively small amount of adaptationdata from the target speaker. In the past few decades, sev-eral successful speaker adaptation techniques have beenproposed for the conventional GMM/HMM based speechrecognition systems, such as MAP [1, 2], MLLR [3, 4], andCMLLR [5]. In these methods, all trained HMM param-eters are transformed by one or a few linear functionsthat are learned from the available adaptation data. More-over, the similar transformation functions may be directlyapplied in the feature space to transform speech featurestowards any given speaker-independent HMM models [6,7]. As the hybrid deep neural network (DNN) and HMMmodels revive recently in acoustic modelling for largevocabulary continuous speech recognition (LVCSR) sys-tems, it now becomes a very interesting problem to performeffective speaker adaptation for DNNs. Unfortunately, most

176 J Sign Process Syst (2016) 82:175–185
of GMM/HMM based techniques cannot be applied to thehybrid NN/HMM speech recognition models. Recently, anumber of speaker adaptation methods have been proposedfor neural networks. A successful method is to add a linearinput network (LIN) after the input as in [8]. During adapta-tion, only those weights of the linear layer are re-estimatedbased on the adaptation data. This method alleviates theover-fitting problem to some extent. In [9], the so-called lin-ear hidden network (LHN) approach is proposed to add alinear transformation layer right before the output layer toprocess higher level features. In [10], the linear output net-work (LON) is proposed to insert a linear transformationlayer to directly transform the NNs outputs linearly. On theother hand, the retrained sub-set hidden units (RSHU) meth-od in [11] tries to retrain only weights connected with activehidden nodes. In [12], Hermitian-based MLP (HB-MLP)method achieves the adaptive capability by taking new or-thonormal Hermite polynomials as activation functions inNN. All these methods depend on modifying part or all ofthe NN parameters using the limited adaptation data. Morerecently, the feature discriminative linear regression tech-nique in [13] and the output-feature discriminative linearregression in [14] have also been proposed to performspeaker adaptation for DNNs. Furthermore, it has proposedto use Kullback-Leibler (KL) divergence as regularizationin the adaptation criterion in [15] since this method forcesthe state distribution estimated from the adapted DNN tostay close enough to the original model to avoid over-fitting.[16] uses CMLLR and FE-CMLLR in a tandem system forspeaker adaptation and [17] investigates traditional CMLLRmethod on bottleneck based GMM/HMM systems. In ourprevious works [18–21], several fast speaker adaptationmethods for DNN based on the so-called speaker codes havebeen proposed, in these methods speaker codes are directlyfed to various layers of a pre-trained DNN through a new setof connection weights. These methods are appealing be-cause the new set of connection weights can be reliablylearned from the entire training data set while only a smallspeaker code is learned from adaptation data for each speak-er. Speaker codes scheme can be viewed as a constrainedmodification of layer biases for each different speaker. Itreduces the size of free parameters for adapting to eachnew speaker and alleviates the over-fitting problem byusing a small training data set for estimating a set ofspeaker codes. Moreover, the speaker code size can be freelyadjusted according to the amount of available adaptationdata.
In this paper, we take another point of view to investi-gate speaker adaptation methods for DNN and propose anew speaker adaptation method for the hybrid NN/HMMspeech recognition model based on singular value decom-position (SVD). It can be viewed as a constrained modi-fication of connection weights for each different speaker.
It reduces the size of free parameters for adapting to eachnew speaker and alleviates the over-fitting problem likespeaker codes scheme. Some similar ideas have been inves-tigated just in ICASSP 2014 [22]. We apply SVD to theweight matrices in the well trained DNNs and then tunerectangular diagonal matrices with the adaptation data. Thismethod is appealing because it alleviates the over-fittingproblem via updating the weight matrices slightly by onlymodifying the singular values. We evaluate the proposedadaptation method in two standard speech recognition tasks,namely TIMIT phone recognition and large vocabularyspeech recognition in the Switchboard task. Experimen-tal results have shown that it is effective to adapt largeDNN models using only a small amount of adaptationdata. For example, recognition results in the Switchboardtask have shown that the proposed SVD-based adaptationmethod may achieve up to 3-6 % relative error reduc-tion using only a few dozens of adaptation utterances perspeaker.
2 DNN Adaptation Based on DiscriminantCondition Codes
In the first, we review some basic ideas of adaptationbased on discriminant condition codes and discuss whyit improves system performance conspicuously. The con-clusion may help us find the key of adaptation for DNNand instruct our work in this paper. In our previousresearches, we proposed a general scheme to adapt DNNbased on the so-called discriminant condition codes, whichare directly associated with various modelling conditionswith respect to adaptation. This adaptation approach iscapable of effectively adjusting a really large DNN in avery fast fashion based on a small amount of adaptationdata.
2.1 Model Description
Assume that we have an (L + 1)-layer DNN consist-ing of weight matrices, denoted as
{Wl | 1 ≤ l ≤ L + 1
}.
We know that it is difficult to adapt DNN using just asmall amount of adaptation data since DNN typically has alarge number of weights. Instead of directly adjusting DNNweights, we propose to use a separate set of the so-calleddiscriminant condition codes,
{s(c)
}, each of which is asso-
ciated with a different modelling condition, c, relevant toadaptation. As shown in Fig. 1, these condition codes are fedinto some particular layers (either hidden or output layer) ofDNN through another set of connection weights, denoted asBl (l ∈ L), where L stands for all layers of DNN that areconnected to the condition codes. For any layer l (l ∈ L),it receives input signals from both the lower layer l − 1 and

J Sign Process Syst (2016) 82:175–185 177
W1
B1
W2
Wk
Bk
B2
…
…
Condition code (s)
hk
h2
h1
Figure 1 General structure to adapt DNNs based on discriminantcondition codes.
the condition codes. The activation signals in these layersare computed as follows:
hl = σ(Wlhl−1 + Bls(c)
)(∀l ∈ L) (1)
where s(c) denotes the condition code associated with oneparticular modelling condition c and σ stands for sigmoidbased nonlinear activation function. Assume the data comesfrom C different modelling conditions in total, we shouldhave C different condition codes, s(c)(1 ≤ c ≤ C). Each ofthese condition codes is simply a real-valued vector, whichdimension can be freely adjusted based on the amount ofavailable data under each condition.
2.2 Training and Adaptation
These condition codes along with their connection weightscan also be learned from training data using the errorback-propagation (BP) algorithm. Assume F denotes theobjective function for DNN training or adaptation, such asframe-level cross-entropy (CE) or sequence-level minimummutual information (MMI) criterion [23]. The gradient withrespect to each element of the condition codes, s(c)
k , can beeasily calculated as follows:
∂F
∂s(c)k
= 1
|L|∑
l∈L
J∑
j=1
∂F
∂hlj
(1 − hl
j
)hl
jBljk = 1
|L|∑
l∈L
J∑
j=1
eljB
ljk (2)
where Bljk stands for an element in the connection weight
matrix, Bl , which connects k-th node in speaker code andj -th node in l-th layer, and el
j denotes the error signalderived for j -th node in l-th layer. In the same way, we maycalculate the gradient with respect to each element of theconnection weight matrix, Bl
kj , as follows:
∂F
∂Bljk
= ∂F
∂h(l)j
(1 − h
(l)j
)h
(l)j s
(c)k = el
j s(c)k . (3)
In the learning process, both condition codes and theirconnection weight matrices are all randomly initialized.They are all learned based on the standard stochastic gradi-ent descent (SGD) algorithm. For each mini-batch in SGD,error signals are computed as usual and the correspondingderivatives are computed as in Eqs. 2 and 3. For connectionweight matrices Bl , the gradients in Eq. 3 are used to updateall Bl in the same way as learning normal DNN weights. Onthe other hand, for condition codes, the gradients in Eq. 2 areused to update different condition codes based on what con-dition each data sample comes from. As a result, we needto provide condition labels for all training samples when welearn the condition codes in the above procedure.
In the test stage, a new condition code, s(c), is learnedbased on a small amount of adaptation data from the newtest condition while we freeze all learned DNNweights,Wl ,as well as all connection weights, Bl . The new conditioncode is first initialized to be zero and then updated based onthe derivatives in Eq. 2 of the adaptation data until conver-gence. The learned condition code will be fed to DNN as inEq. 1 for testing purpose.
We have proposed several different ways to perform fastspeaker adaptation of DNN based on the so-called conditioncodes in speech recognition. In those cases, each condi-tion code is associated with one speaker in data, whichis thus called speaker code for convenience. Each speakerhas his/her own speaker code and each speaker code is avery compact feature vector representing speaker-dependentinformation.
After a clear description of speaker codes based adapta-tion, the most interesting question is why it improves systemperformance conspicuously? In most conditions, we canachieve a great amount of data from thousands of speak-ers but only a few sentences for each speaker, which is notenough for training speaker-dependent DNN models. Usingall these data for building speaker-independent DNN mod-els makes the training of millions parameters feasible butat the same time will smooth the characteristics of differentspeakers. Adaptation techniques try to draw these differ-ences through little amount of adaptation data per speaker.Due to the over-fitting problem when tuning a large amountof parameters with just a little data, it is usually not appro-priate to adapt the whole DNN parameters with adaptationdata. We may alleviate the over-fitting problem to someextent if we can reduce the number of parameters that haveto be modified during the adaptation process. DNN modelconsists of connection weights and biases. Although we canexpand the output vector in each layer by adding an addi-tional dimension of constant 1 to incorporate the bias vectorinto the weight matrix, we prefer to treat them with dif-ferent explanations. The weight matrix can be viewed asseparating hyperplane and bias in each node as the thresh-old to decide whether it activates or not. Both of them

178 J Sign Process Syst (2016) 82:175–185
may contribute to speaker adaptation with correct methods,we choose bias at first since the size of bias is quit smallcompared with connection weights.
In our early investigation, we tried to adapt a well trainedDNN model by retraining all bias vectors for each speaker.It may give small improvement in some conditions, butis very prone to over-fitting especially when the DNN islarge and deep. The comparison between the number ofadaptation data and modified parameters may give us someinstructions. For example, if we use ten sentences (aboutthousands of frames) for speaker adaptation on a 6 hiddenlayers and 2048 nodes DNN model (bias size is more than7∗2048), we find that the number of parameters is quit largecompared with adaptation data. It is comprehensible that wemay face over-fitting problem.
In our speaker codes scheme, adding speaker codesthrough a set of connection weights to DNN models canbe viewed as a constrained modification of layer biases foreach different speaker, it reduces the size of free parametersfor adapting to each new speaker and alleviates the over-fitting problem by using a small training data set for esti-mating a set of speaker codes. Training data here is usedfor constructing the best compression of layer biases sincewe have enough labeled data. After the compression weonly have to evaluate hundreds of parameters for each newspeaker, which is very small compared with before. In sum-mary, the effective compression of free parameters is themost important factor in speaker adaptation task for DNNmodels.
After an investigation of speaker adaptation based ontuning of bias vectors, we focus on adapting the DNNmodel for each speaker by tuning connection weights. Itis clearly that we have to construct an effective compres-sion of connection weights for helping us reducing the freeparameters of DNN models since the retraining of wholeconnection weights is not a suitable solution. In next section,we will introduce our ideas for speaker adaptation based onthe SVD method.
3 SVD Based Speaker Adaptation
In this section, we briefly review the basic idea of SVDand present a SVD based speaker adaptation method for thehybrid DNN/HMM model as well as the training method ofthis model.
3.1 Review of SVD
The singular value decomposition is a factorization of amatrix, with many useful applications in signal processingand statistics. The decomposition of a matrix A can bedescribed as follows:
Am×n = Um×mSm×nVTn×n (4)
Um×m =⎡
⎢⎣
u11 · · · u1m...
. . ....
um1 · · · umm
⎤
⎥⎦ (5)
Sm×n =
⎡
⎢⎢⎢⎢⎢⎢⎣
s11 · · · 0 · · · 0 · · · 0...
. . ....
. . ....
. . ....
0 · · · skk · · · 0 · · · 0...
. . ....
. . ....
. . ....
0 · · · 0 · · · smm · · · 0
⎤
⎥⎥⎥⎥⎥⎥⎦
(6)
VTn×n =
⎡
⎢⎣
v11 · · · v1n...
. . ....
vn1 · · · vnn
⎤
⎥⎦ (7)
Where U is an m × m unitary matrix, the matrix S is anm × n (we assume m < n) rectangular diagonal matrixwith nonnegative numbers on the diagonal, and the n × n
unitary matrix VT denotes the conjugate transpose of then × n unitary matrix V. The diagonal entries sii of S areknown as the singular values of A. A common convention isto list the singular values in descending order. In this case,the rectangular diagonal matrix S is uniquely determinedby A.
Previous researches in DNN models with matrix decom-position mainly focus on reducing the number of parametersof the neural networks, such as [24–26]. They decomposethe weights of DNN models with Low-Rank factorizationor SVD to conspicuously reduce the number of free param-eters of the neural networks and then restructure the neuralnetworks without a significant loss in final recognitionaccuracy.
3.2 Model Description
In this paper, we propose a speaker adaptation method forthe hybrid NN/HMM speech recognition model based onSVD. As shown in Figs. 2 and 3, we decompose the weightmatrix W(l) which is the l-th layer weights in the trainedneural network that consists of L+1 layers (including inputand output layer) into three layers, while the first and sec-ond have no nonlinear function, and the last one does. S(l)
is a rectangular diagonal matrix with singular values on thediagonal. The number of free parameters changes from mn
to m(m + n) + m. The model size increases after decom-posing all weights of the well trained speaker-independent
Figure 2 One layer in original DNN.

J Sign Process Syst (2016) 82:175–185 179
Figure 3 Three corresponding layers after SVD.
neural network, but the computational complexity is accept-able since we only tune the singular values in S(l) during theadaptation process.
In the following, we investigate how to execute speakeradaptation with SVD method. Assume we need to adapta well-trained DNN, the neural network computes pos-teriori probabilities of all HMM states given each inputfeature vector. The inputs are concatenated super-vectorconsisting of all speech feature vectors within a windowof a number of consecutive frames. We call this baselinespeaker-independent DNN model since it is trained withoutusing any speaker label information. We estimate the neu-ral network using the BP algorithm to minimize the crossentropy between the target state labels and the DNN outputsof all training data. After that we decompose all weights ofthe well trained speaker-independent neural network withSVD method.
For regularization, we slightly modify the SVD methodto ensure that the maximum singular value in every S(l) isone. Therefore, Eqs. 6 and 7 now should be changed asfollows:
S(l)m×n =
⎡
⎢⎢⎢⎢⎢⎢⎢⎣
1 · · · 0 · · · 0 · · · 0...
. . ....
. . ....
. . ....
0 · · · s(l)kk
s(l)11· · · 0 · · · 0
.... . .
.... . .
.... . .
...
0 · · · 0 · · · s(l)mm
s(l)11· · · 0
⎤
⎥⎥⎥⎥⎥⎥⎥⎦
(8)
VT(l)n×n =
⎡
⎢⎣
s(l)11v11 · · · s(l)11v1n...
. . ....
s(l)11vn1 · · · s(l)11vnn
⎤
⎥⎦ (9)
In the adaptation process, only singular values in S(l) aretuned with the adaptation data for each target speaker. Atthe same time, all U(l),VT
(l) and non-diagonal zero elementsof S(l) are frozen. This means each target speaker will have
unique weight matrices S(l) (for all l) after adaptation andshare the same U(l),VT
(l) with others.In the next test stage, we use S(l) learned in the adaptation
process to reconstruct speaker-dependent neural network foreach test speaker. And then use forward algorithm to com-pute posteriori probabilities of all HMM states given dataof test speakers. In this paper, we mainly use the supervisedadaptation method to learn S(l), where a small set of labelledadaptation utterances are available for each new test speaker.In this stage, the new S(l) are updated based on the SGDalgorithm of the adaptation data until convergence. Thelearned S(l) will be used to reconstruct speaker-dependentneural network for each test speaker when testing. After thatwe also execute some experiments using the unsupervisedadaptation method to further investigate the performance ofthe SVD based adaptation algorithm where the referenceadaptation labels are derived from the decoding results ofthe baseline system.
4 Experiments
In this section, we evaluate the proposed SVD based adap-tation method for rapid speaker adaptation in two speechrecognition tasks: i) the small-scale TIMIT phone recogni-tion task; ii) the well-known large-scale 320-hr Switchboardtask.
4.1 TIMIT Phone Recognition
We use the standard 462-speaker training set and removeall SA records (i.e., identical sentences for all speakers inthe database) since they may bias the results. A separatedevelopment set of 50 speakers is used for tuning all of themeta parameters. Results are reported using the 24-speakercore test set, which has no overlap with the development set.Each speaker in the test set has eight utterances.
For feature extraction, speech is analyzed using a 25-ms Hamming window with a 10-ms fixed frame rate. Thespeech feature vector is generated by a Fourier-transform-based filter-banks which include 40 coefficients distributedon a Mel scale and energy, along with their first and sec-ond temporal derivatives. This leads to a 123-dimensionfeature vector per speech frame. All speech data are nor-malized by averaging over all training samples so that allfeature vectors have zero mean and unit variance. We use183 target class labels (i.e., 3 states for each one of the61 phones) for NN training. After decoding, the 61 phoneclasses were mapped to a set of 39 classes as in [27] for scor-ing purpose. In our experiments, a bi-gram language modelin phone level, estimated from the training set, is adopted indecoding.
In the adaptation process, we stop training after 10epochs with an initial learning rate of 0.005, the momentum
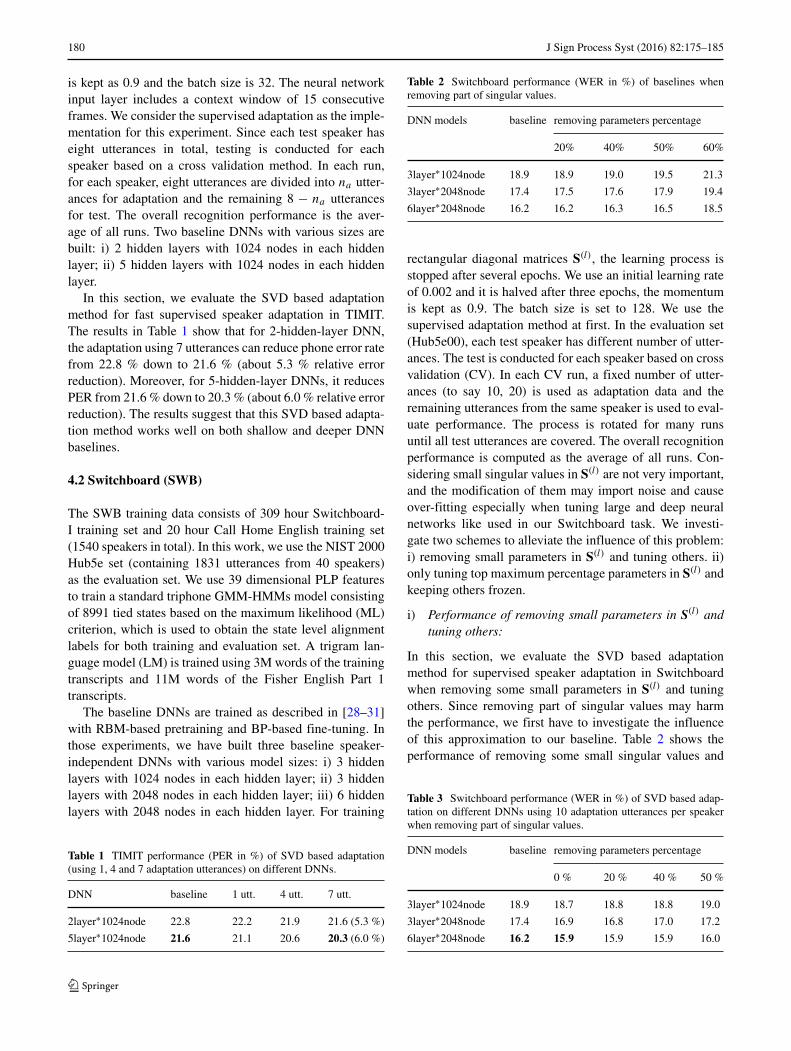
180 J Sign Process Syst (2016) 82:175–185
is kept as 0.9 and the batch size is 32. The neural networkinput layer includes a context window of 15 consecutiveframes. We consider the supervised adaptation as the imple-mentation for this experiment. Since each test speaker haseight utterances in total, testing is conducted for eachspeaker based on a cross validation method. In each run,for each speaker, eight utterances are divided into na utter-ances for adaptation and the remaining 8 − na utterancesfor test. The overall recognition performance is the aver-age of all runs. Two baseline DNNs with various sizes arebuilt: i) 2 hidden layers with 1024 nodes in each hiddenlayer; ii) 5 hidden layers with 1024 nodes in each hiddenlayer.
In this section, we evaluate the SVD based adaptationmethod for fast supervised speaker adaptation in TIMIT.The results in Table 1 show that for 2-hidden-layer DNN,the adaptation using 7 utterances can reduce phone error ratefrom 22.8 % down to 21.6 % (about 5.3 % relative errorreduction). Moreover, for 5-hidden-layer DNNs, it reducesPER from 21.6 % down to 20.3 % (about 6.0 % relative errorreduction). The results suggest that this SVD based adapta-tion method works well on both shallow and deeper DNNbaselines.
4.2 Switchboard (SWB)
The SWB training data consists of 309 hour Switchboard-I training set and 20 hour Call Home English training set(1540 speakers in total). In this work, we use the NIST 2000Hub5e set (containing 1831 utterances from 40 speakers)as the evaluation set. We use 39 dimensional PLP featuresto train a standard triphone GMM-HMMs model consistingof 8991 tied states based on the maximum likelihood (ML)criterion, which is used to obtain the state level alignmentlabels for both training and evaluation set. A trigram lan-guage model (LM) is trained using 3M words of the trainingtranscripts and 11M words of the Fisher English Part 1transcripts.
The baseline DNNs are trained as described in [28–31]with RBM-based pretraining and BP-based fine-tuning. Inthose experiments, we have built three baseline speaker-independent DNNs with various model sizes: i) 3 hiddenlayers with 1024 nodes in each hidden layer; ii) 3 hiddenlayers with 2048 nodes in each hidden layer; iii) 6 hiddenlayers with 2048 nodes in each hidden layer. For training
Table 1 TIMIT performance (PER in %) of SVD based adaptation(using 1, 4 and 7 adaptation utterances) on different DNNs.
DNN baseline 1 utt. 4 utt. 7 utt.
2layer∗1024node 22.8 22.2 21.9 21.6 (5.3 %)
5layer∗1024node 21.6 21.1 20.6 20.3 (6.0 %)
Table 2 Switchboard performance (WER in %) of baselines whenremoving part of singular values.
DNN models baseline removing parameters percentage
20% 40% 50% 60%
3layer∗1024node 18.9 18.9 19.0 19.5 21.3
3layer∗2048node 17.4 17.5 17.6 17.9 19.4
6layer∗2048node 16.2 16.2 16.3 16.5 18.5
rectangular diagonal matrices S(l), the learning process isstopped after several epochs. We use an initial learning rateof 0.002 and it is halved after three epochs, the momentumis kept as 0.9. The batch size is set to 128. We use thesupervised adaptation method at first. In the evaluation set(Hub5e00), each test speaker has different number of utter-ances. The test is conducted for each speaker based on crossvalidation (CV). In each CV run, a fixed number of utter-ances (to say 10, 20) is used as adaptation data and theremaining utterances from the same speaker is used to eval-uate performance. The process is rotated for many runsuntil all test utterances are covered. The overall recognitionperformance is computed as the average of all runs. Con-sidering small singular values in S(l) are not very important,and the modification of them may import noise and causeover-fitting especially when tuning large and deep neuralnetworks like used in our Switchboard task. We investi-gate two schemes to alleviate the influence of this problem:i) removing small parameters in S(l) and tuning others. ii)only tuning top maximum percentage parameters in S(l) andkeeping others frozen.
i) Performance of removing small parameters in S(l) andtuning others:
In this section, we evaluate the SVD based adaptationmethod for supervised speaker adaptation in Switchboardwhen removing some small parameters in S(l) and tuningothers. Since removing part of singular values may harmthe performance, we first have to investigate the influenceof this approximation to our baseline. Table 2 shows theperformance of removing some small singular values and
Table 3 Switchboard performance (WER in %) of SVD based adap-tation on different DNNs using 10 adaptation utterances per speakerwhen removing part of singular values.
DNN models baseline removing parameters percentage
0 % 20 % 40 % 50 %
3layer∗1024node 18.9 18.7 18.8 18.8 19.0
3layer∗2048node 17.4 16.9 16.8 17.0 17.2
6layer∗2048node 16.2 15.9 15.9 15.9 16.0
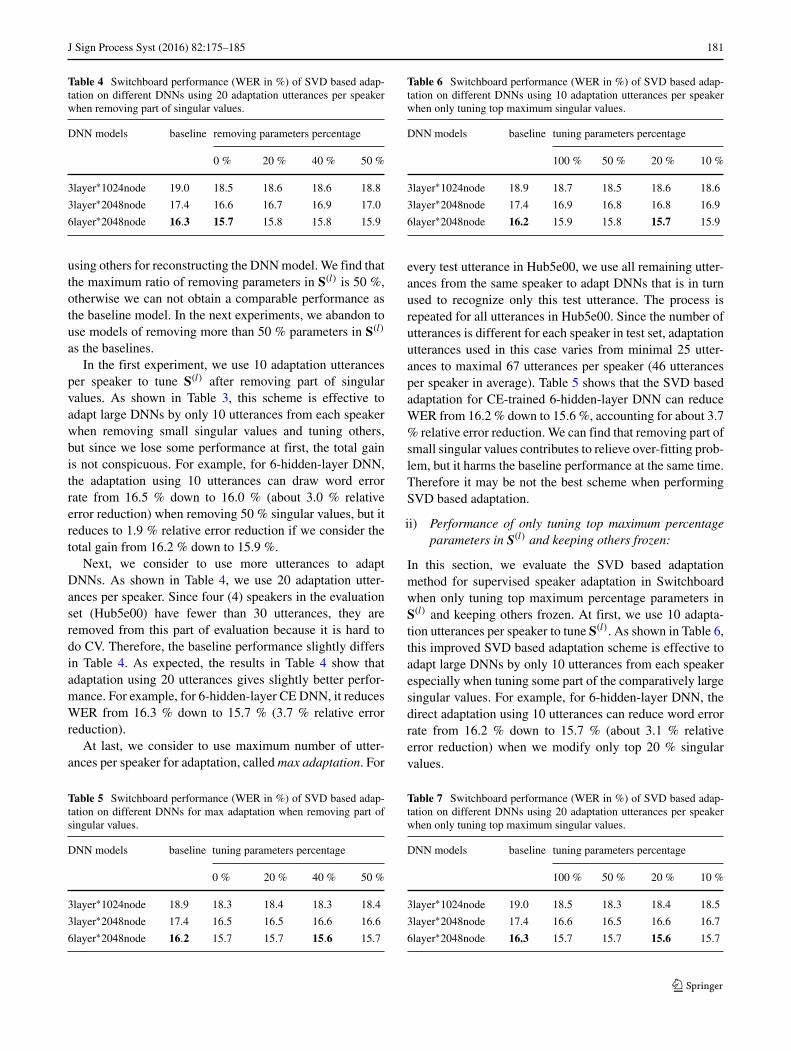
J Sign Process Syst (2016) 82:175–185 181
Table 4 Switchboard performance (WER in %) of SVD based adap-tation on different DNNs using 20 adaptation utterances per speakerwhen removing part of singular values.
DNN models baseline removing parameters percentage
0 % 20 % 40 % 50 %
3layer∗1024node 19.0 18.5 18.6 18.6 18.8
3layer∗2048node 17.4 16.6 16.7 16.9 17.0
6layer∗2048node 16.3 15.7 15.8 15.8 15.9
using others for reconstructing the DNNmodel. We find thatthe maximum ratio of removing parameters in S(l) is 50 %,otherwise we can not obtain a comparable performance asthe baseline model. In the next experiments, we abandon touse models of removing more than 50 % parameters in S(l)
as the baselines.In the first experiment, we use 10 adaptation utterances
per speaker to tune S(l) after removing part of singularvalues. As shown in Table 3, this scheme is effective toadapt large DNNs by only 10 utterances from each speakerwhen removing small singular values and tuning others,but since we lose some performance at first, the total gainis not conspicuous. For example, for 6-hidden-layer DNN,the adaptation using 10 utterances can draw word errorrate from 16.5 % down to 16.0 % (about 3.0 % relativeerror reduction) when removing 50 % singular values, but itreduces to 1.9 % relative error reduction if we consider thetotal gain from 16.2 % down to 15.9 %.
Next, we consider to use more utterances to adaptDNNs. As shown in Table 4, we use 20 adaptation utter-ances per speaker. Since four (4) speakers in the evaluationset (Hub5e00) have fewer than 30 utterances, they areremoved from this part of evaluation because it is hard todo CV. Therefore, the baseline performance slightly differsin Table 4. As expected, the results in Table 4 show thatadaptation using 20 utterances gives slightly better perfor-mance. For example, for 6-hidden-layer CE DNN, it reducesWER from 16.3 % down to 15.7 % (3.7 % relative errorreduction).
At last, we consider to use maximum number of utter-ances per speaker for adaptation, calledmax adaptation. For
Table 5 Switchboard performance (WER in %) of SVD based adap-tation on different DNNs for max adaptation when removing part ofsingular values.
DNN models baseline tuning parameters percentage
0 % 20 % 40 % 50 %
3layer∗1024node 18.9 18.3 18.4 18.3 18.4
3layer∗2048node 17.4 16.5 16.5 16.6 16.6
6layer∗2048node 16.2 15.7 15.7 15.6 15.7
Table 6 Switchboard performance (WER in %) of SVD based adap-tation on different DNNs using 10 adaptation utterances per speakerwhen only tuning top maximum singular values.
DNN models baseline tuning parameters percentage
100 % 50 % 20 % 10 %
3layer∗1024node 18.9 18.7 18.5 18.6 18.6
3layer∗2048node 17.4 16.9 16.8 16.8 16.9
6layer∗2048node 16.2 15.9 15.8 15.7 15.9
every test utterance in Hub5e00, we use all remaining utter-ances from the same speaker to adapt DNNs that is in turnused to recognize only this test utterance. The process isrepeated for all utterances in Hub5e00. Since the number ofutterances is different for each speaker in test set, adaptationutterances used in this case varies from minimal 25 utter-ances to maximal 67 utterances per speaker (46 utterancesper speaker in average). Table 5 shows that the SVD basedadaptation for CE-trained 6-hidden-layer DNN can reduceWER from 16.2 % down to 15.6 %, accounting for about 3.7% relative error reduction. We can find that removing part ofsmall singular values contributes to relieve over-fitting prob-lem, but it harms the baseline performance at the same time.Therefore it may be not the best scheme when performingSVD based adaptation.
ii) Performance of only tuning top maximum percentageparameters in S(l) and keeping others frozen:
In this section, we evaluate the SVD based adaptationmethod for supervised speaker adaptation in Switchboardwhen only tuning top maximum percentage parameters inS(l) and keeping others frozen. At first, we use 10 adapta-tion utterances per speaker to tune S(l). As shown in Table 6,this improved SVD based adaptation scheme is effective toadapt large DNNs by only 10 utterances from each speakerespecially when tuning some part of the comparatively largesingular values. For example, for 6-hidden-layer DNN, thedirect adaptation using 10 utterances can reduce word errorrate from 16.2 % down to 15.7 % (about 3.1 % relativeerror reduction) when we modify only top 20 % singularvalues.
Table 7 Switchboard performance (WER in %) of SVD based adap-tation on different DNNs using 20 adaptation utterances per speakerwhen only tuning top maximum singular values.
DNN models baseline tuning parameters percentage
100 % 50 % 20 % 10 %
3layer∗1024node 19.0 18.5 18.3 18.4 18.5
3layer∗2048node 17.4 16.6 16.5 16.6 16.7
6layer∗2048node 16.3 15.7 15.7 15.6 15.7
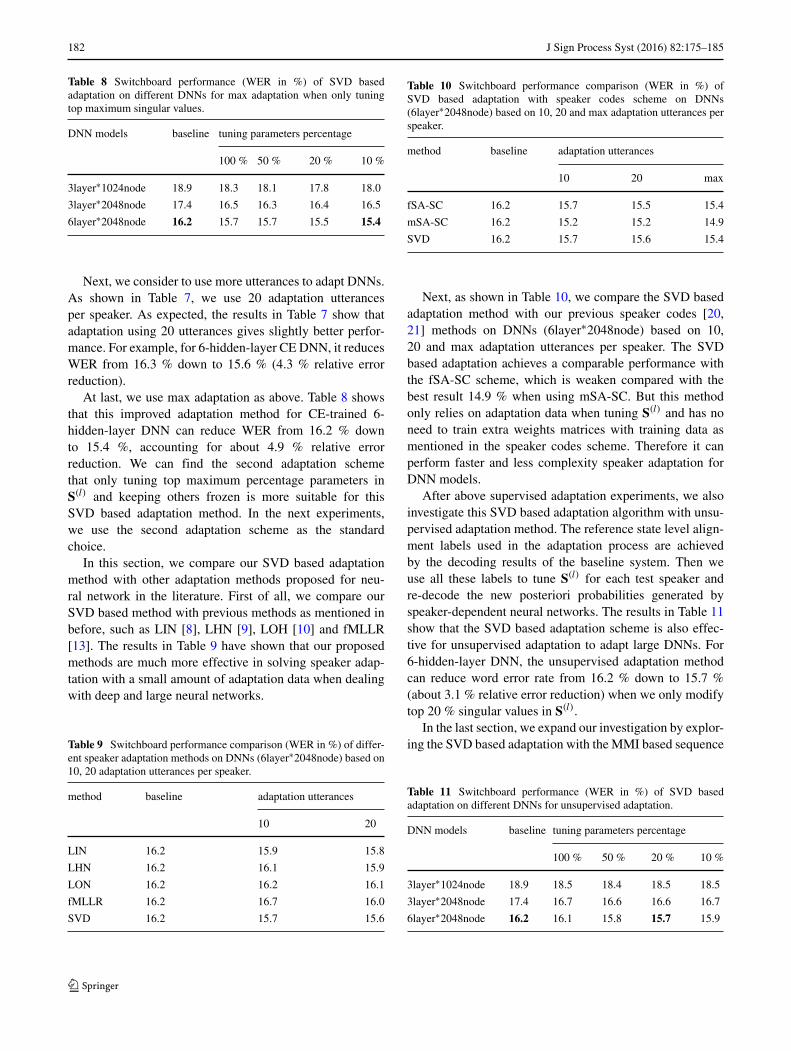
182 J Sign Process Syst (2016) 82:175–185
Table 8 Switchboard performance (WER in %) of SVD basedadaptation on different DNNs for max adaptation when only tuningtop maximum singular values.
DNN models baseline tuning parameters percentage
100 % 50 % 20 % 10 %
3layer∗1024node 18.9 18.3 18.1 17.8 18.0
3layer∗2048node 17.4 16.5 16.3 16.4 16.5
6layer∗2048node 16.2 15.7 15.7 15.5 15.4
Next, we consider to use more utterances to adapt DNNs.As shown in Table 7, we use 20 adaptation utterancesper speaker. As expected, the results in Table 7 show thatadaptation using 20 utterances gives slightly better perfor-mance. For example, for 6-hidden-layer CE DNN, it reducesWER from 16.3 % down to 15.6 % (4.3 % relative errorreduction).
At last, we use max adaptation as above. Table 8 showsthat this improved adaptation method for CE-trained 6-hidden-layer DNN can reduce WER from 16.2 % downto 15.4 %, accounting for about 4.9 % relative errorreduction. We can find the second adaptation schemethat only tuning top maximum percentage parameters inS(l) and keeping others frozen is more suitable for thisSVD based adaptation method. In the next experiments,we use the second adaptation scheme as the standardchoice.
In this section, we compare our SVD based adaptationmethod with other adaptation methods proposed for neu-ral network in the literature. First of all, we compare ourSVD based method with previous methods as mentioned inbefore, such as LIN [8], LHN [9], LOH [10] and fMLLR[13]. The results in Table 9 have shown that our proposedmethods are much more effective in solving speaker adap-tation with a small amount of adaptation data when dealingwith deep and large neural networks.
Table 9 Switchboard performance comparison (WER in %) of differ-ent speaker adaptation methods on DNNs (6layer∗2048node) based on10, 20 adaptation utterances per speaker.
method baseline adaptation utterances
10 20
LIN 16.2 15.9 15.8
LHN 16.2 16.1 15.9
LON 16.2 16.2 16.1
fMLLR 16.2 16.7 16.0
SVD 16.2 15.7 15.6
Table 10 Switchboard performance comparison (WER in %) ofSVD based adaptation with speaker codes scheme on DNNs(6layer∗2048node) based on 10, 20 and max adaptation utterances perspeaker.
method baseline adaptation utterances
10 20 max
fSA-SC 16.2 15.7 15.5 15.4
mSA-SC 16.2 15.2 15.2 14.9
SVD 16.2 15.7 15.6 15.4
Next, as shown in Table 10, we compare the SVD basedadaptation method with our previous speaker codes [20,21] methods on DNNs (6layer∗2048node) based on 10,20 and max adaptation utterances per speaker. The SVDbased adaptation achieves a comparable performance withthe fSA-SC scheme, which is weaken compared with thebest result 14.9 % when using mSA-SC. But this methodonly relies on adaptation data when tuning S(l) and has noneed to train extra weights matrices with training data asmentioned in the speaker codes scheme. Therefore it canperform faster and less complexity speaker adaptation forDNN models.
After above supervised adaptation experiments, we alsoinvestigate this SVD based adaptation algorithm with unsu-pervised adaptation method. The reference state level align-ment labels used in the adaptation process are achievedby the decoding results of the baseline system. Then weuse all these labels to tune S(l) for each test speaker andre-decode the new posteriori probabilities generated byspeaker-dependent neural networks. The results in Table 11show that the SVD based adaptation scheme is also effec-tive for unsupervised adaptation to adapt large DNNs. For6-hidden-layer DNN, the unsupervised adaptation methodcan reduce word error rate from 16.2 % down to 15.7 %(about 3.1 % relative error reduction) when we only modifytop 20 % singular values in S(l).
In the last section, we expand our investigation by explor-ing the SVD based adaptation with the MMI based sequence
Table 11 Switchboard performance (WER in %) of SVD basedadaptation on different DNNs for unsupervised adaptation.
DNN models baseline tuning parameters percentage
100 % 50 % 20 % 10 %
3layer∗1024node 18.9 18.5 18.4 18.5 18.5
3layer∗2048node 17.4 16.7 16.6 16.6 16.7
6layer∗2048node 16.2 16.1 15.8 15.7 15.9

J Sign Process Syst (2016) 82:175–185 183
Table 12 Switchboard performance comparison (WER in%) of CE orMMI based SVD adaptation on MMI-trained DNN (6layer∗2048node)for unsupervised adaptation based on 10, 20 and maximum numberadaptation utterances per speaker.
DNN baseline adaptation adaptation utterances
per speaker
WER criterion 10 20 max
MMI-trained 14.0 CE 13.7 13.5 13.4 (4.3 %)
+ MMI 13.7 13.4 13.3 (5.0%)
training criterion. We conduct sequence training based onthe MMI criterion and it has shown that the sequence train-ing further improves the baseline performance to 14.0 % inWER. After that the SVD based method is applied to adaptthe MMI-trained DNN for supervised speaker adaptation. Inthis case, we use CE followed by sequence-level MMI crite-rion and tuning only top 10% singular values in S(l). Resultsin Table 12 have shown that adaptation based CE criterionmay also benefits the MMI-trained DNN to some extent.But it seems to have little further profits with adaptationbased on the sequence-level MMI criterion. For example,for 6-hidden-layer MMI DNN, it reduces WER from 14.0 %down to 13.4 % (about 4.3 % relative error reduction) withCE based adaptation, and only drops to 13.3 % after MMIbased adaptation.
In summary, this SVD based adaptation method iseffective not only for small and shallow neural networks butalso for large and deep neural networks.
5 Conclusions
In this paper, we propose a new speaker adaptation methodfor the hybrid NN/HMM speech recognition model basedon SVD. We apply SVD on the weight matrices in trainedDNNs and then tune rectangular diagonal matrices withthe adaptation data. This alleviates the over-fitting problemvia updating the weight matrices slightly by only modify-ing the singular values. Experimental results have shownthat it is effective to adapt large DNN models using only asmall amount of adaptation data. For example, the Switch-board results have shown that the proposed SVD basedadaptation method may achieve up to 3-6 % relative errorreduction using only a few dozens of adaptation utterancesper speaker.
Acknowledgments This work was partially supported by theNational Nature Science Foundation of China (Grant No. 61273264)and the electronic information industry development fund of China(Grant No. 2013-472).
References
1. Gauvain, J.L., & Lee, C.-H. (1994). Maximum a posterioriestimation for multivariate Gaussian mixture observations ofMarkov chains. IEEE Transactions on Speech and Audio Process-ing, 2, 291–298.
2. Ahadi, S.M., & Woodland, P.C. (1997). Combined Bayesian andpredictive techniques for rapid speaker adaptation of continuousdensity hidden Markov models. Computer Speech & Language,11, 187–206.
3. Leggetter, C., & Woodland, P.C. (1995). Maximum likelihoodlinear regression for speaker adaptation of continuous densityhidden Markov models. Computer Speech & Language, 9,171–185.
4. Gales, M.J.F. (1998). Maximum likelihood linear transformationsfor HMM-based speech recognition. Computer Speech & Lan-guage, 12, 75–98.
5. Digalakis, V.V., Rtischev, D., & Neumeyer, L.G. (1995). Speakeradaptation using constrained estimation of Gaussian mixtures.IEEE Transactions on Speech and Audio Processing, 3, 357–Lb366.
6. Lee, L., & Rose, R.C. (1996). Speaker normalization usingefficient frequency warping procedures. IEEE International Con-ference of Acoustics Speech and Signal Processing (ICASSP), 1,353–356.
7. Jiang, H., Soong, F., & Lee, C.-H. (2001). Hierarchical stochasticfeature matching for robust speech recognition. IEEE Interna-tional Conference of Acoustics Speech and Signal Processing(ICASSP), 1, 217–220.
8. Neto, J., Almeida, L., Hochberg, M., Martins, C., Nunes,L., Renals, S., & Robinson, T. (1995). Speaker-adaptationfor hybrid HMM-ANN continuous speech recognition system,EUROSPEECH.
9. Gemello, R., Mana, F., Scanzio, S., Laface, P., & De Mori, R.(2007). Linear hidden transformations for adaptation of hybridANN/HMM models. Speech Communication, 49, 827–835.
10. Li, B., & Sim, K.C. (2010). Comparison of discriminative inputand output transformations for speaker adaptation in the hybridNN/HMM systems.
11. Stadermann, J., & Rigoll, G. (2005). Two-stage speaker adaptationof hybrid tied-posterior acoustic models. In IEEE internationalconference of acoustics, speech and signal processing (ICASSP).
12. Siniscalchi, S.M., Li, J., & Lee, C.-H. (2013). Hermitianpolynomial for speaker adaptation of connectionist speechrecognition systems. IEEE Transactions on Audio Speech, andLanguage Processing, 21, 2152–2161.
13. Seide, F., Li, G., Chen, X., & Yu, D. (2011). Feature engineer-ing in context-dependent deep neural networks for conversationalspeech transcription. In 2011 IEEE workshop on automatic speechrecognition and understanding (ASRU).
14. Yao, K., Yu, D., Seide, F., Su, H., Deng, L., & Gong, Y.(2012). Adaptation of context-dependent deep neural networksfor automatic speech recognition, spoken language technologyworkshop (SLT).
15. Yu, D., Yao, K., Su, H., Li, G., & Seide, F. (2013). KL-divergenceregularized deep neural network adaptation for improvedlarge vocabulary speech recognition. In IEEE internationalconference of acoustics, speech and signal processing (ICASSP)(pp. 7893–7897).
16. Wang, Y.Q., & Gales, M.J.F. (2013). Tandem system adaptationusing multiple linear feature transforms. In IEEE internationalconference of acoustics, speech and signal processing (ICASSP)(pp. 7932–7936).

184 J Sign Process Syst (2016) 82:175–185
17. Tuske, Z., Schluter, R., & Ney, H. (2013). Deep hierarchicalbottleneck MRASTA features for LVCSR. In IEEE internationalconference of acoustics, speech and signal processing (ICASSP)(pp. 6970–6974).
18. Abdel-Hamid, O., & Jiang, H. (2013). Fast speaker adaptationof hybrid NN/HMM model for speech recognition based ondiscriminative learning of speaker code. In IEEE internationalconference of acoustics, speech and signal processing (ICASSP)(pp. 7942–7946).
19. Abdel-Hamid, O., & Jiang, H. (2013). Rapid and effective speakeradaptation of convolutional neural network based models forspeech recognition, INTERSPEECH.
20. Xue, S., Abdel-Hamid, O.s., Jiang, H., & Dai, L. (2014). Directadaptation of hybrid DNN/HMM model for fast speaker adap-tation in LVCSR based on speaker code. In IEEE internationalconference of acoustics, speech and signal processing (ICASSP).
21. Xue, S., Abdel-Hamid, O., Jiang, H., & Dai, L. (2014). Speakeradaptation of deep neural network based on discriminant codes. InIEEE/ACM transactions on acoustics, speech and signal process-ing (p. 22).
22. Xue, J., Li, J., Yu, D., Seltzer, M., & Gong, Y. (2014). Singularvalue decomposition based low-footprint speaker adaptation andpersonalization for deep neural network. In IEEE internationalconference of acoustics, speech and signal processing (ICASSP).
23. Vesely, K., Ghoshal, A., Burget, L., & Povey, D. (2013).Sequence-discriminative training of deep neural networks,INTERSPEECH.
24. Denil, M., Shakibi, B., Dinh, L., de Freitas, N., et al. (2013).Predicting parameters in deep learning, advances in neural infor-mation processing systems.
25. Sainath, T.N., Kingsbury, B., Sindhwani, V., Arisoy, E., &Ramabhadran, B. (2013). Low-rank matrix factorization for deepneural network training with high-dimensional output targets. InIEEE international conference of acoustics, speech and signalprocessing (ICASSP) (pp. 6655–6659).
26. Xue, J., Li, J., & Gongm, Y. (2013). Restructuring of deep neu-ral network acoustic models with singular value decomposition,INTERSPEECH.
27. Lee, K.-F., & Hon, H.-W. (1989). Speaker-independent phonerecognition using hidden Markov models. IEEE Transactions onAcoustics, Speech and Signal Processing, 37, 1641–1648.
28. Pan, J., Liu, C., Wang, Z., Hu, Y., & Jiang, H. (2012). Investigationof deep neural networks (DNN) for large vocabulary continuousspeech recognition: Why DNN surpasses GMMs in acoustic mod-eling. In 8th international symposium on chinese spoken languageprocessing (ISCSLP) (pp. 301–305).
29. Bao, Y., Jiang, H., Liu, C., Hu, Y., & Dai, L. (2012). Investi-gation on dimensionality reduction of concatenated features withdeep neural network for LVCSR systems. IEEE 11th InternationalConference on Signal Processing (ICSP), 1, 562–566.
30. Bao, Y., Jiang, H., Dai, L., & Liu, C. (2013). Incoherent train-ing of deep neural networks to de-correlate bottleneck features forspeech recognition. In IEEE international conference of acoustics,speech and signal processing (ICASSP).
31. Zhang, S., Bao, Y., Zhou, P., Jiang, H., & Dai, L. (2014). Improv-ing deep neural networks for LVCSR using dropout and shrinkingstructure. In IEEE international conference of acoustics, speechand signal processing (ICASSP).
Shaofei Xue was born inChina in 1988. He receivedthe B.S. degree in ElectricalEngineering from the Univer-sity of Science and Technol-ogy of China (USTC), Hefei,China in 2006. He is currentlya Ph.D. candidate in USTCworking on speech recog-nition. His current researchinterests include deep learn-ing for speech recognitionand other pattern recognitionapplications.
Hui Jiang (M’00-SM’11)received B.Eng. and M.Eng.degrees from University ofScience and Technology ofChina (USTC), and his Ph.D.degree from the Universityof Tokyo, Tokyo, Japan inSeptember 1998, all in electri-cal engineering. From 2000 to2002, he worked in DialogueSystems Research, Multime-dia Communication ResearchLab, Bell Labs, Lucent Tech-nologies Inc., Murray Hill,NJ. He joined Department ofComputer Science and Engi-
neering, York University, Toronto, Canada as an Assistant Professoron fall 2002 and was promoted to Associate Professor in 2007 andto Full Professor in 2013. He served as an associate editor for IEEETrans. on Audio, Speech and Language Processing between 2009 and2013. His current research interests lie in machine learning methodswith applications to speech and language processing.
Li-Rong Dai was born inChina in 1962. He receivedthe B.S. degree in electricalengineering from Xidian Uni-versity, Xian, China, in 1983and the M.S. degree fromHefei University of Technol-ogy, Hefei, China, in 1986,and the Ph.D. degree in sig-nal and information process-ing from the University of Sci-ence and Technology of China(USTC), Hefei, in 1997. Hejoined University of Scienceand Technology of China in1993. He is currently a Profes-
sor of the School of Information Science and Technology, USTC. Hiscurrent research interests include speech synthesis, speaker and lan-guage recognition, speech recognition, digital signal processing, voicesearch technology, machine learning, and pattern recognition. He haspublished more than 50 papers in these areas.

J Sign Process Syst (2016) 82:175–185 185
Liu Qingfeng was born inChina in 1973. He receivedB.S degree in Electronic Engi-neering in 1995 and M.S.degree in communication andElectronic system in 1998,and Ph.D. degree in sig-nal and information process-ing in 2003, all from Univer-sity of Science and Technol-ogy of China (USTC). Dr. Liufounded iFLYTEK in 1999and has been the presidentsince then and assumed theChairman of the Board inApril 2009. Dr. Liu is cur-
rently Director of National Engineering Laboratory of Speech andLanguage Information Processing, USTC and an adjunct professor ofUSTC. His current research interests lie in speech technology andits industrial applications, particularly for mobile Internet. He haspublished more than 20 papers in these areas.





























