Embed Size (px)
Citation preview
Introduction to Speech Processing
[email protected] team IRIT-UPS
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
2
Speech Processing• Why? Because, speech is the most natural form of
human-human communications.– No special equipment is required– No physical contact required– No visibility required– Can communicate while doing something else
• Speech is related to:– language: linguistic is a branch of social science.– human physiological capability; physiology is a branch of
medical science.– sounds and acoustics, a branch of physical science.
• Therefore, speech is one of the most intriguing signals that humans work with every day.
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
3
Speech Processing
Purpose of speech processing:– To understand speech as a means of
communication;– To represent speech for transmission and
reproduction;– To analyze speech for automatic recognition
and extraction of information;– To discover some physiological
characteristics of the talker.Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
4
Speech ProcessingSpeech applications• Speech coding• Speech synthesis• Speech recognition and understanding• Other speech applications

Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
13
Speech Recognition Demos• http://www.youtube.com/watch?v=NbCst4G-icU
(advertisement dragon French)• http://www.youtube.com/watch?v=W3DhnpLIKC
Q (advertisement dragon English)• http://www.metacafe.com/watch/yt-
nH8jfZb0Fkc/brief_demo_of_dragon_naturally_speaking_dictate_australia/ (a demo)
• http://video.google.com/videoplay?docid=-1123221217782777472# (bad work!!)
• http://voxaleadnews.labs.exalead.com/
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
14
Speech Recognition andUnderstanding
• What– This is the process of extracting usable linguistic
information from a speech signal in support of human-machine communication by voice
• Applications– Command and control applications– Voice dictation to create letters, memos, and other
documents– Natural language voice dialogues with machines to
enable Help desks, Call centers– Agent services such as calendar entry and update,
address list modification, …
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
15
Other Speech Applications• Speaker verification for secure access to special places,
information, virtual spaces
• Speaker recognition for legal and forensic purposes –national security, but also for personalized services
• Speech enhancement for use in noisy environments, to eliminate echo, to change voice qualities, to speed-up or slow-down prerecorded speech
• Language translation to convert spoken words in one language to another to facilitate natural language dialogue between people speaking different languages, e.g., tourists, business people.
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
16
Speech processing
• Need to understand the nature of the speech signal, and how techniques, communication technologies, and information theory methods can be applied to help solve the various application scenarios described above.
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
33
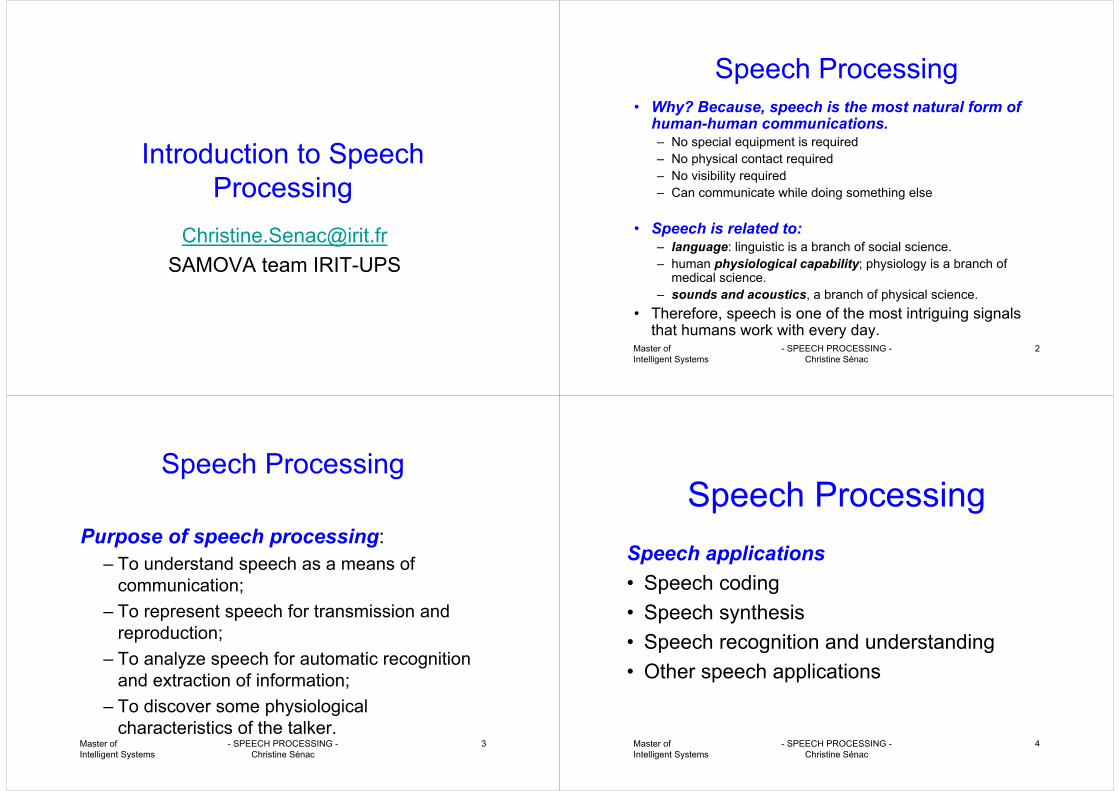
Review of basic concepts: Analog to Digital Conversion
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
34
Review of basic concepts: Analog to Digital Conversion
The Nyquist-Shannon Sampling Theorem :The sampling frequency must be twice higher than the highest
frequency of the signal (or some information will be lost)
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
35
Review of basic concepts : Analog to Digital Conversion
• When using digital storage the number of bits of each value determines the maximum signal-to-noise ratio (SNR). In this casethe noise is the error signal caused by the quantization of the signal, taking place in the analog-to-digital conversion.
• Assuming a linear quantization, the SNR is approximately:
SNRdB = 6.02 * n + 1.76dB (with n=number of bits used for the quantization)
Quantization noise. The difference between the blue and red signals in the upper graph is the quantization error, which is "added" to the quantized signal and is the source of noise.
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
36
CD Audio, Studio
numérique, DAT
5760 kBytes (for 48kHz & 16 bits)
9516-18 bits
44.1 or48 kHz
[20_20000Hz]
Hi-Fi Quality
DAB, NICAM3360 kBytes8014 bits32 kHz[50_15000 Hz]
High qualityfor radio
PC, audio-conference
960 k0 or 1320 kBytes
408 bits16 or22 kHz
[50_7000 Hz]
extendedbandwidthquality
Phone(8000*8*60)/8=480 kBytes
408 bits8 kHz[300_3400 Hz]
telehonequality
Application1 minuteof signal
SNRdBCodingSamplingfrequency
Signalexamples
Review of basic concepts : Analog to Digital Conversion
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
49
Vocal Cord Views
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
50
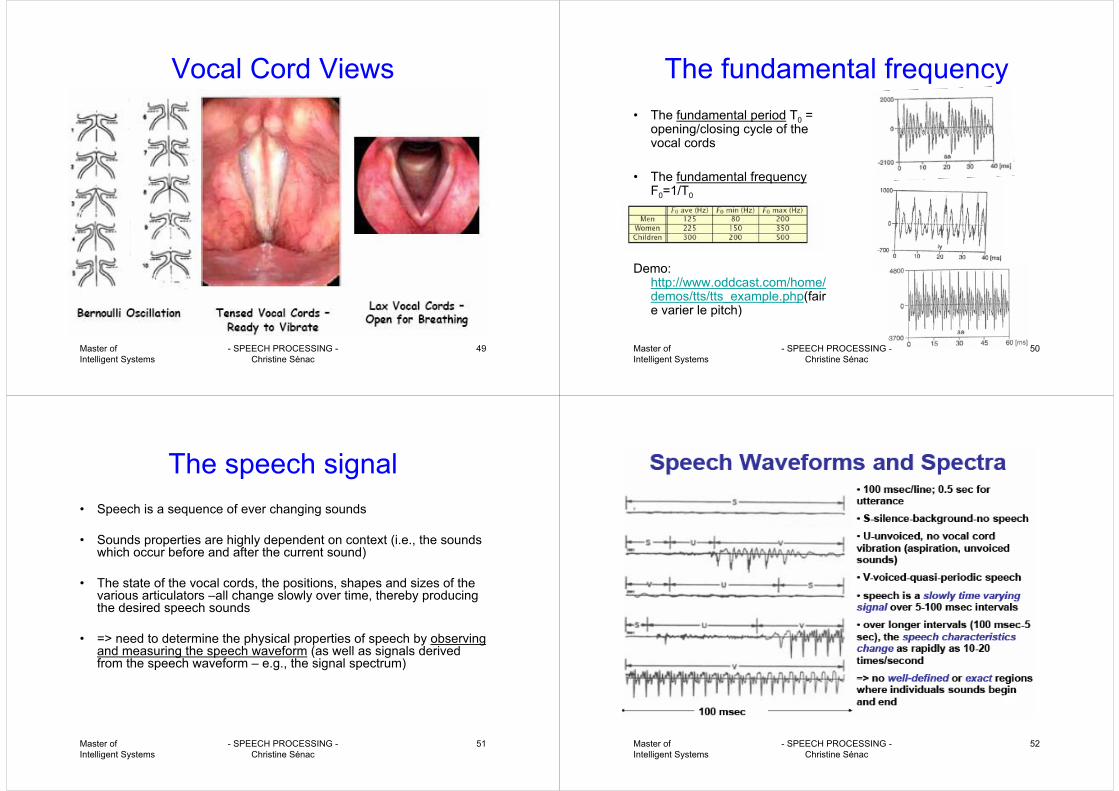
The fundamental frequency• The fundamental period T0 =
opening/closing cycle of the vocal cords
• The fundamental frequencyF0=1/T0
Demo: http://www.oddcast.com/home/demos/tts/tts_example.php(faire varier le pitch)
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
51
The speech signal• Speech is a sequence of ever changing sounds
• Sounds properties are highly dependent on context (i.e., the sounds which occur before and after the current sound)
• The state of the vocal cords, the positions, shapes and sizes of the various articulators –all change slowly over time, thereby producing the desired speech sounds
• => need to determine the physical properties of speech by observing and measuring the speech waveform (as well as signals derived from the speech waveform – e.g., the signal spectrum)
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
52
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
69
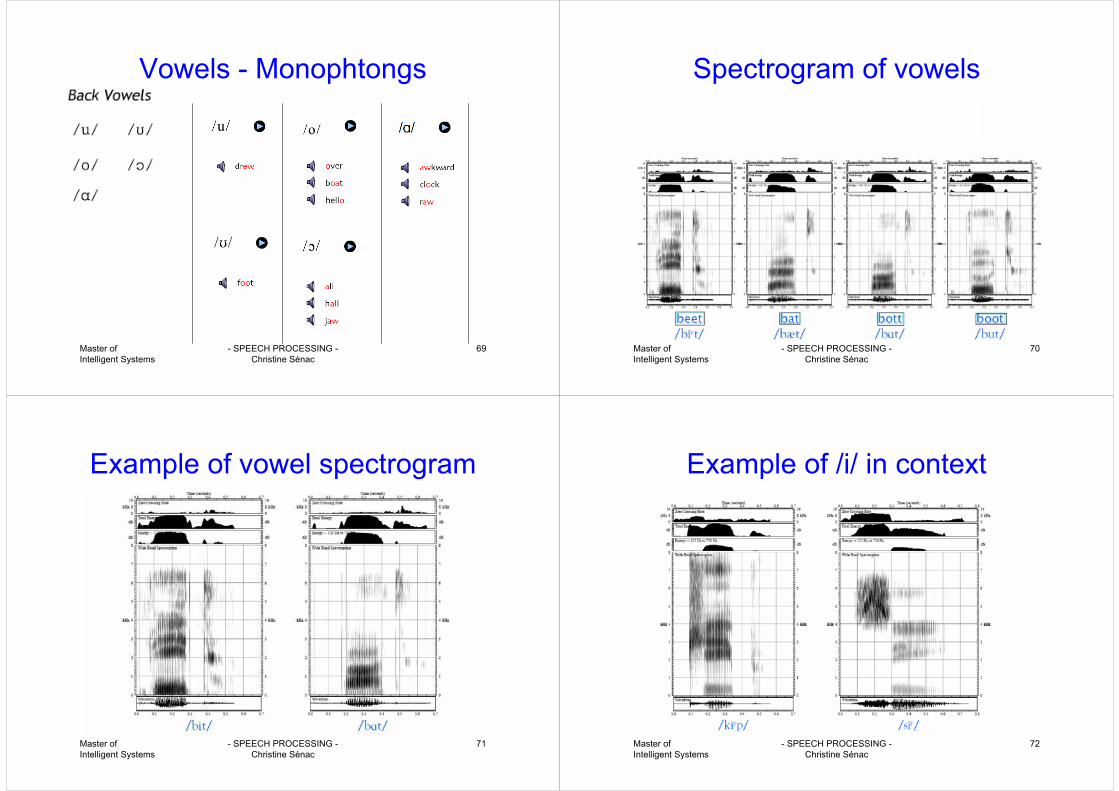
Vowels - Monophtongs
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
70
Spectrogram of vowels
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
71
Example of vowel spectrogram
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
72
Example of /i/ in context

Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
105
What is pronounced?
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
106
What we will be learning
• Review some signal basic concepts• Speech perception• Speech production•• Basic concepts of phonetics & phonemics•• MethodsMethods for speech recognitionfor speech recognition
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
107
Variability of the speech signal• Intra-speaker factors
– Articulatory factors• F0, speed of articulation, co articulation,…
– Paralinguistic factors• Type of articulation: normal, careful or no…• type of phonation: normal voice, whisper (chuchotement), crying,…• emotional state
• External factors– Inter-speakers factors
• Physical or socio cultural or psychological differences– Environment
• background noise, signal capture (microphone), transmission channel,…
• Superimposed music, superimposed voices,…meeting, …• Lecture, conversation,…
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
108
Speech recognition:then and now• Analogical era: 1949 ->1959
– Analogical filters, anechoic chamber, recognition of vowels, syllables,…• Digital era
– 1960 -> 1970• digital filters, anechoic chamber, recognition of single speaker isolated digits,
isolated word dictation,…– 1970 -> 1980
• Applicative research– Isolated words, speaker independent, global pattern recognition
• Fundamental research– Continuous speech, speaker independent, large vocabulary, introduction of
Artificial Intelligence (expert systems)=> heuristics, handcrafted rules– 1980 -> …
• Introduction of the Hidden Markov Models => mathematical formalization and automatic learning
• Then microprocessors and integrated circuits for digital signal processing

Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
121
DTW• ExerciceWe want to find the lowest-cost constrained path
between the reference {AAABBBAAAA} andthe input {ARBBDBAEA}
Using the following frames distances: d(A,A)=0, d(A,B)=2, d(A,D)=2, d(A,E)=2, d(A,R)=1,
d(B,B)=0, d(B, D)=1, d(B,E)=2, d(B,R)=1
1) without global constraints2) with the following global constraints
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
122A10A9A8A7B6B5B4A3A2A1
AEABDBBRAReference\input
987654321i\j
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
123A10A9A8A7B6B5B4A3A2A1
AEABDBBRAReference\input
987654321i\j
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
124A6A5A4B3B2B1
AEABDBBRAReference\input
987654321i\j
Same exercice between the input {ARBBDBAEA} andanother reference {BBBAAAA}

Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
153 Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
154
Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
155 Master of Intelligent Systems
- SPEECH PROCESSING -Christine Sénac
156
Alternative Viterbi implementation• Version log

Paul Sabatier University – International Master in Intelligent Systems 2009-2010
Human-Machine CommunicationPart “Speech processing”
Document (teaching aid) allowed
ATTEMPT Questions 1 and 2 and (3 or 4) If you attempt questions 3 and 4, only the best answer will be counted.
Question 1: Figure 1 shows an excerpt of audio signal corresponding to the pronunciation of phoneme /a/. Given the fundamental frequency of the speaker is equal to 200Hz for this excerpt of signal, what is the duration of this excerpt?
Figure 1 Excerpt of audio signal corresponding to the pronunciation of phoneme /a/
Question 2 : During development of an HMM-based recognition system, what is the purpose of training?
Question 3: Dynamic Time Warping3.1. Table 1 gives the frames distances between two pronunciations (A & B) of the word « repeat » (or ‘ripit’ phonetically). For this exercice, please fill the table 1.
3.2. Locate the phonemes of the word “repeat” for each pronunciation via the associated spectrograms. Using the transitions shown in figure 2 and the frames distances, calculate the intermediate scores between the two pronunciations. Mention the paths and intermediate scores.
3.3. Among all the processed paths, which one(s) correspond(s) to the lowest-cost path(s)?
3.4. For each point of the path, give the couple of phonemes which are compared.
Paul Sabatier University – International Master in Intelligent Systems 2009-2010
Question 4 : Markov models Questions 4.1, 4 .2 and 4.3 are independent.
4.1. For the HMM topology shown in figure 2, indicate which elements of its state-transition matrix would contain non-zero values.
Figure 2
4.2. Given an initial state vector � = [0.25 0.50 0.25], and state-transition probability matrix A=[0.25 0.50 0.25
0.0 0.25 0.50 0.0 0.00 0.25]
a. draw the model to show the states and permissible transitions; b. calculate the probability of the state sequence X={1,2,3,3}
4.3. Given the Markov model presented on figure 3, answer the following questions.
Figure 3 : state 1- rainy ; state 2 – cloudy ; state 3 - sunny
a. if today (Monday) has been rainy, what is the most likely weather a.1. tomorrow? a.2. in two day’s time (i.e., on Wednesday)?
b. Calculate the probabilities of rain-rain-sun, rain-cloud-sun and rain-sun-sun, assuming �rain =1.
1 432

Paul Sabatier University – International Master in Intelligent Systems 2009-2010
NAME : SURNAME :
Permissible DTW transitions
Table 1
pronuonciation
B
Pronounciation A1
1 2
Paul Sabatier University – International Master in Intelligent Systems 2009-2010

23 Mai 2008
Examen M1 : Recherche Opérationnelle
Durée : 1 heure 30
Documents de cours autorisés
Exercice 1 : (5 points)
L’office de tourisme de Toulouse propose un certain nombre de sites pouvant attirer la curiosité des visiteurs. Ces sites ainsi que le temps (exprimé en minutes) approximatif pour les rejoindre est indiqué sur un dépliant donné par cet office.
Arrivée dépliant A B C D E F G H I J K L M
A 4 3 5 3 B 2 8 2 C 10 D 12 5 E 4 F 15 7 G 2 H 2 2 I 2 1 J 3 K 8 L 4
Départ
M
Un touriste ayant retiré ce dépliant désire se rendre de l’office de tourisme noté A à son hôtel noté M en se promenant le plus longtemps possible. Pouvez-vous l’aider à établir son itinéraire ?
Question 1.1 : Représenter le graphe associé par niveaux (indiquer les étapes suivies pour construire les niveaux).Question 1.2 : Donner la durée pour atteindre chaque site depuis l’office de tourisme. Donner l’itinéraire emprunté. Combien de temps se promènera le touriste ?
Exercice 2 : Modélisation avec critère de durée par graphe potentiels tâches (3 points)
On considère le graphe potentiel tâches donné en Annexe 1. Question 2.1 : Rappeler les formules et donner les valeurs suivantes pour chaque tâche : date de début au plus tôt, date de début au plus tard, marge totale. Ces valeurs seront reportées soit directement sur le graphe (dans ce cas, donner une légende) soit dans un tableau. Question 2.2 : Donner une interprétation des résultats obtenus et le(s) chemin(s) critique(s).
Exercice 3 : Modélisation avec critères de durée et de coût par graphe étape (PERT)(8 points)
On considère le tableau donné en Annexe 2 qui représente la synthèse de la modélisation d’un projet avec critères de coût et de durée. Question 3.1 : Donner, d’après ce tableau, le graphe PERT correspondant. On mentionnera le nom des tâches (laissé au choix), leur durée et le coût unitaire de leur diminution. On donnera également la durée minimale du projet. Question 3.2 : Il s’agit ici de compléter le tableau de l’annexe 2. Remplacer les ‘*’ par la valeur adéquate et pour chaque remplacement (ou chaque type de remplacement) expliquer. Rajouter les flèches matérialisant le passage d’une étape à la suivante. Question 3.3 : Quelles tâches ont leur durée diminuée, et de combien, pour une durée du projet de 48 unités de temps ? Est-il possible de réduire la durée du projet à 40 ? Pourquoi ? Question 3.4 : Donner sous forme de graphique le coût du projet en fonction de la durée.
Exercice 4 : vive les vacances ! (4 points)
Un randonneur décide de traverser la Corse du nord au sud en suivant les sentiers du GR20. Cependant, il ne tient pas à effectuer ce périple seul et il compte bien recruter deux coéquipiers en passant une annonce dans un journal local. Comme il est très organisé, il a planifié les différentes tâches qui devront être exécutées pour mener à bien son projet.
TACHES DUREE (en jours)
TACHES ANTERIEURES
A : Achat des cartes de Corse 1 - B : Commande à l'IGN des autres cartes 15 - C : Etablissement du trajet en Corse du Nord 3 A D : Etablissement du trajet en Corse du Sud 15 B E : Passage d'une petite annonce pour recruter 2 coéquipiers 21 A, B, C, D F : Choix des coéquipiers 30 E, C, D, L G : Récupération de la tente prêtée à un copain 30 - H : Achat du matériel manquant 7 C, D, F, G I : Réservation des gîtes d'étape 15 C, D, F J : Achat des vivres pour les 3 premiers jours 1 F, G, H, I K : Réservation du taxi qui les amènera au point de départ 1 I, J L : Préparation du carnet de route 10 C
Question 4.1 : Construire le graphe PERT associé à l’ensemble du projet. Donner le calendrier au plus tôt, au plus tard ainsi que les marges libres et totales.
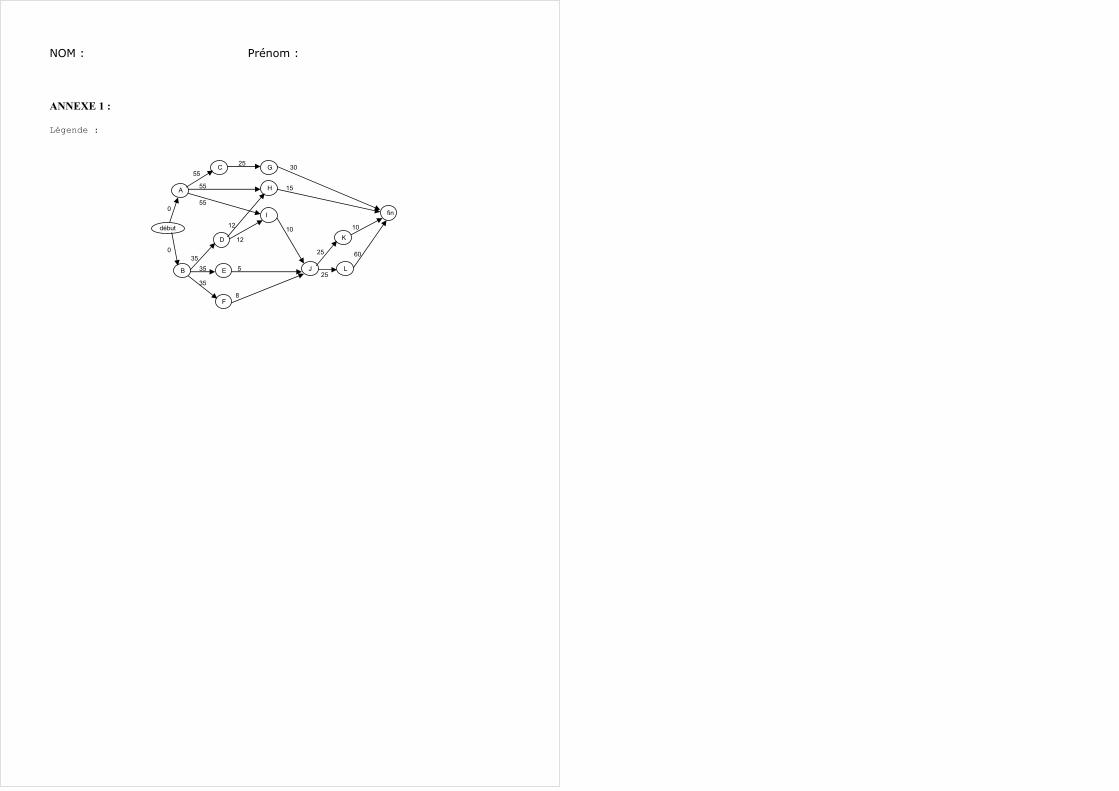
D
I
A
C
H
G
EB J
F
L
K
fin
55
55
55
35
35
35
25
15
30
12
12
5
8
10
25
25
10
60
début
0
0
NOM : Prénom :
ANNEXE 1 :
Légende :

18/02/2010 UPS - M1 Informatique -Module 1M8106M - Christine Sénac
1
M1 informatique : Option 3Modélisation et reconnaissance
de formes audio et vidéo
Application à l’identification de personnes
18/02/2010 UPS - M1 Informatique -Module 1M8106M - Christine Sénac
2
• Présentation de méthodes permettant l’identification d’une personne par la voix et par le visage
• Exemple d’application : étiquetage d’intervenants dans les contenus audio-visuels
18/02/2010 UPS - M1 Informatique -Module 1M8106M - Christine Sénac
3
• Objectif de la formation :
– Etre capable de réaliser un logiciel permettant d’identifier lesétudiants inscrits à l’option à l’aide :
• d’une phrase clé prononcée dans un micro• de la voix• du visage présenté devant une webcam
Exemple : Sujet de TER « Serrure Biométrique »Master 1 Informatique 2007/2008
18/02/2010 UPS - M1 Informatique -Module 1M8106M - Christine Sénac
4
Eigen faces
Modèles de Markov
GMM
Stratégied’identification

18/02/2010 UPS - M1 Informatique -Module 1M8106M - Christine Sénac
5
Plan• L’AUDIO
– La communication homme-machine– Quelques rappels sur le signal Audio– Analogique/numérique– L’étude de la parole: difficultés, production,
perception…– La reco du locuteur– La reco de la parole
• LA VIDEO ….
18/02/2010 UPS - M1 Informatique -Module 1M8106M - Christine Sénac
6
Communication Humaine
Modes de communication Critères
Geste - rapidité
Dessin - liberté de la vue, du mouvement, des mains
Écriture - permanence de l’information
Parole - facilité d’accès
- secret
=> Efficacité de la parole
18/02/2010 UPS - M1 Informatique -Module 1M8106M - Christine Sénac
7
Communication Homme-Machine
Les différents domaines du Traitement Automatique de la Parole
Décodage
Analyse
Stockage
Transmission Restitution
GénérationModèles de processusde la communication
parlée
texte concepts
son (voix synthétique)son (voix humaine)
message locuteurreconnu reconnu
RECONNAISSANCE CODAGE SYNTHESE
18/02/2010 UPS - M1 Informatique -Module 1M8106M - Christine Sénac
8
Les différentes disciplines du Traitement Automatique de la Parole et du Traitement Automatique du Langage Naturel
Production de la paroleMécanique (mouvement des articulateurs)
Propagation des ondes (génération de l’effet sonore)
Physiologie (organes de la production)
Perception de la parolePhysiologie (organes du système auditif)
Psycho-acoustique (perception des sons)
Processus cognitifs (acquisition des informations sur l’environnement)
Linguistique
phonétique(articulatoire), phonologie (phonèmes), lexique, sémantique, pragmatique (étude de l’usage de la langue en situation de communication et des conditions de celle-ci)
Acoustiqueméthodes de traitement du signal vocal: analyse spectrale, statistiques et probabilités, théorie
de l’information,…
Interdisciplinarité nécessaire…pour modéliser les processus de la communication parlée

18/02/2010 UPS - M1 Informatique -Module 1M8106M - Christine Sénac
29
Reconnaissance du locuteur (1/10 )
Différentes formes du problème:Segmentation du locuteurIdentification du locuteurVérification du locuteur
Les facteurs :Quantité de données d’apprentissage (10s … 20min)Quantité de données de test (3s … 5min)Nombre de locuteurs (10 …500)Fausses acceptations vs. faux rejets
Systèmes de base de l’état de l’art:Grand modèle universel (« universal background model » ou « UBM »)
( e.g. 2000 mixture GMM avec des MFCCs)vs. Modèle spécifique à chaque locuteurVia rapport de vraisemblances
18/02/2010 UPS - M1 Informatique -Module 1M8106M - Christine Sénac
30
Reconnaissance du locuteur (2/10)
Le moyen le plus facile pour modéliser des distributions est d’utiliser des modèles paramétriques
Peu de paramètres à estimer, forme connue…Le modèle gaussien est simple et … marche bien
Pourquoi??Les observations sont des variables aléatoires dont la distribution dépend de la classe d’appartenance:
Les distributions des sources p(x/ωi)Reflètent la variabilité des paramètresReflètent le ‘bruit’ des observations
18/02/2010 UPS - M1 Informatique -Module 1M8106M - Christine Sénac
31
Reconnaissance du locuteur (3/10)
Probabilités a priori et a postériori:la règle de Baye:
On choisit la classe donnant la probabilité a posteriori maximum (maximum a posteriori (MAP) class):
18/02/2010 UPS - M1 Informatique -Module 1M8106M - Christine Sénac
32
Reconnaissance du locuteur (4/10)Le classifieur optimal est donc:
Mais on ne connaît pas Pr (ωi|x)
On utilise donc la règle de Baye et, étant donnés les modèles des distributions p(x|ωi), la recherche de
devient
Mais le dénominateur = p(x) (donc le même pour tous les ωi)
donc

18/02/2010 UPS - M1 Informatique -Module 1M8106M - Christine Sénac
33
Reconnaissance du locuteur (5/10)
Le modèle gaussien en 1-D:
18/02/2010 UPS - M1 Informatique -Module 1M8106M - Christine Sénac
34
Reconnaissance du locuteur (6/10)
Le modèle gaussien en dimension d:
18/02/2010 UPS - M1 Informatique -Module 1M8106M - Christine Sénac
35
Reconnaissance du locuteur (7/10)
Gaussian Mixture Models (GMMs)
Une gaussienne simple ne peut pas modéliser:Les distributions ayant des modes multiplesLes distributions ayant des corrélations non linéaires
Idée! Utiliser plusieurs gaussiennes:
avec {ck } un ensemble de poids et {p ( x|mk )} un ensemble de composantes gaussiennes
Interprétation:Chaque observation est générée par une des gaussiennes dont le poids:
18/02/2010 UPS - M1 Informatique -Module 1M8106M - Christine Sénac
36
Reconnaissance du locuteur (8/10)
Gaussian Mixture Models (GMMs)Exemple de corrélation non linéaire
Problème: trouver les paramètres ck et mk

18/02/2010 UPS - M1 Informatique -Module 1M8106M - Christine Sénac
57
Les modèles de Markov: Introduction 2 (HMM 2/9)
On effectue la manipulation suivante:1) piocher dans A’ un jeton, le noter (j ou k) et le remettre dans son sac 2) piocher dans A un jeton: si ce jeton est a,alors la prochaine pioche se fera dans A’ et A, sinon (jeton=b) prochaine pioche dans B’ et B
Cette manipulation génère 2 séquences:La séquence des sorties (connue) (par ex: jjkkj)La séquence de transitions (inconnue) (par ex abba)
Ce jeu peut être modélisé par un automate de Markov à états cachés où:1. Chaque groupe de sacs représente un état2. Les tirages donnant le groupe de tirage suivant sont les transitions (avec la probaassociée en fonction de la proportion de
jetons a ou b dans le sac)3. Les sacs de sortie donnent les valeurs de sortie de l’automate (avec les probabilités associées)
a1
b19
a4
b1A B
A’ B’j4
k1
j1
k4
GA GB
b1/5
a1/20
b19/20
a4/5
j : p=0.8k: p=0.2 j : p=0.2
k: p=0.8
18/02/2010 UPS - M1 Informatique -Module 1M8106M - Christine Sénac
58
Les Modèles de Markov Cachés (ou Hidden Markov Models ou HMM) (HMM 3/9)
• Ce modèle a été introduit dans un cadre purement statistique en 1970 par Baum.
• C’est l’un des modèles les plus utilisés pour la reconnaissance de la parole dans des environnements difficiles (bruités).
• Seuls les HMM permettent à l’heure actuelle de traiter de grands vocabulaires ou la parole continue indépendante des locuteurs.
• Ces systèmes requièrent une phase d’apprentissage relativement lourde, mais en contrepartie, ils présentent différents avantages : clarté, rigueur, efficacité et généralité.
18/02/2010 UPS - M1 Informatique -Module 1M8106M - Christine Sénac
59
Structure générale d’un modèle HMM (HMM 4/9)• Un modèle markovien HMM se caractérise par 2 processus X et Y.
Le premier X, non directement observable, est celui que l’on cherche à identifier(d’où le terme de modèle caché). Le second Y, externe (lié à l’aspect physique du son (MFCC)) et observable, fournit les informations pour identifier le premier.
• Les réalisations du premier processus X sont des chaînes internes (processus lié à l’aspect temporel)
• X=0 x1 x2…xT F où xt (1<= t<=T) est élément d’un ensemble d’états {1,…,N} complété de deux états particuliers :– L’état initial 0 où se trouve le système avant d’émettre :par convention on
posera que x0 = 0 ;– L’état final F où se trouve le système après avoir fini d’émettre :F sera
assimilé à N+1• Au total l’ensemble des états est donc E={0,1,…,N,F}
• Les réalisations du second processus Y sont des chaînes externes Y= y1 y2 … yT où chaque yt est élément d’un espace d’observations W (ainsi Y appartient à WT).
18/02/2010 UPS - M1 Informatique -Module 1M8106M - Christine Sénac
60
Structure générale d’un modèle HMM (HMM 5/9)
• Un HMM est régi par ses lois de probabilité de transition et d’émission (ou d’observation):
• Une matrice de transitions A qui caractérise les transitions internes entre les états
A=[a(i,j)], 0≤i≤N et 1≤j≤N+1Rque: on se placera toujours dans le cadre de HMM ‘gauche-droite’
• Une matrice d’observation qui caractérise la loi d’observationB=[b(i,j,y)], 0≤i≤N , 1≤j≤N et y appartient à Ω
b(i,j,y) se lit : proba d’observer y sachant que l’on était dans l’état i et que l’on passe dans l’état j

TD séances 9 et 10 - 1
L1 – S1 – IMP Année 2008-2009
UE9 – Informatique semestre 1
TD séances 9 et 10Les listes
Exercice 1 – Fonctions sur les listes retournant un résultat simple
Écrire les fonctions Caml suivantes (voir les exemples d’applications)�:
1) (*) nb_pair qui indique si une liste contient ou non un nombre pair d’éléments.
2) (*) dernier qui retourne le dernier élément d’une liste non vide.
3) (**) membre qui, étant donné une liste et un élément, indique si l’élément appartient ou non àla liste.
4) (*) tous_positifs qui indique si tous les éléments d’une liste d’entiers sont strictementpositifs. Par convention, tous_positifs appliquée à la liste vide devra retourner true.
5) (*) toutes_un qui, étant donné une liste de listes, indique si tous les éléments de la listeprincipale sont des listes à un seul élément. Par convention, toutes_un appliquée à la liste videdevra retourner true.
6) (**) nb_occ qui, étant donné une liste et un élément, compte le nombre d’occurrences del’élément dans la liste.
7) (**) minimum qui retourne le plus petit élément d’une liste non vide.
8) (***) ieme qui, étant donné une liste non vide et un entier i strictement positif, retourne leième élément de la liste s’il existe.
9) (**) sigma_pi qui, appliquée à une liste de paires d’entiers [(x1,y1);�(x2,y2);�…;�(xn,yn)],
construit la paire )(ni
1ii
ni
1ii yx ,��
=
=
=
=
. Par convention, sigma_pi appliquée à une liste vide devra
retourner la paire (0,1).
TD séances 9 et 10 - 2
# nb_pair [];;- : bool = true# nb_pair[1,2];;- : bool = false
# nb_pair[1;2];;
- : bool = true# dernier [1;2;3;4];;- : int = 4# dernier[1];;- : int = 1# dernier [];;
Exception: Match_failure ("", 18, 133).
# membre ([1;2;3;4;5],3);;- : bool = true# membre ([1;2;3;4;5],6);;- : bool = false
# membre ([],4);;- : bool = false
# tous_positifs [1;2;3;4;5;6];;- : bool = true# tous_positifs [1;2;3;0;4;5;6];;
- : bool = false# tous_positifs [1;-2;3;4;5;6];;- : bool = false# toutes_un[[1];[2];[3]];;- : bool = true
# toutes_un [[1];[2;3];[4]];;- : bool = false# toutes_un [[1];[];[2]];;- : bool = false
# minimum [4;6;2;5;1;7;3];;- : int = 1# minimum [];;Exception: Match_failure ("", 18, 188).
# minimum["b";"cd";"ab";"iap"];;- : string = "ab"
# ieme ([1;2;3;4;5;6],4);;- : int = 4# ieme ([1;2;3;4;5;6],8);;
Exception: Failure "ieme : n existe pas".# ieme ([],9);;Exception: Failure "ieme : n existe pas".
# sigma_pi [(1,2);(3,4);(5,6);(7,8)];;- : int * int = (16, 384)
Exercice 2 – Fonctions sur les listes retournant une liste
Écrire les fonctions Caml suivantes (voir les exemples d’applications)�:
1) (*) inverser qui, étant donné une liste, construit la liste comportant les mêmes éléments maisdans l’ordre inverse.
2) (*) liste_croissante qui, étant donné un entier n, positif ou nul, construit la liste des n+1premiers entiers naturels (de 0 à n) dans l’ordre croissant.
3) (**) inserer qui, étant donné un élément et une liste ordonnée dans l’ordre croissant, construitune liste ordonnée avec l’élément inséré en «bonne» position (la liste résultat est ordonnée).
(*) trier qui, à partir d’une liste quelconque, construit la liste des éléments triés dans l’ordrecroissant.
4) (**) prendre qui, étant donné une liste et un entier p positif ou nul, construit la liste forméedes p premiers éléments de la liste.
(**) laisser_tomber qui, étant donné une liste et un entier p, construit la liste privée de ses ppremiers éléments.

TD séances 9 et 10 - 3
5) (*) liste_des_positifs qui, étant donné une liste d’entiers, construit la liste de tous lesentiers strictement positifs de la liste argument.
(*) liste_des_singletons qui, étant donné une liste de listes, construit la liste de toutes leslistes à un seul élément.
# inverser [1;2;3;4;5];;- : int list = [5; 4; 3; 2; 1]
# liste_croissante 5;;
- : int list = [0; 1; 2; 3; 4; 5]# liste_croissante 0;;- : int list = [0]
# inserer(4,[1;2;6;7;8]);;- : int list = [1; 2; 4; 6; 7; 8]
# inserer(4,[1;2;3]);;- : int list = [1; 2; 3; 4]
# trier [4;2;6;8;1;9;5];;- : int list = [1; 2; 4; 5; 6; 8; 9]
# prendre ([1;2;3;4;5;6;7;8],8);;
- : int list = [1; 2; 3; 4; 5; 6; 7; 8]# prendre ([1;2;3;4;5;6;7;8],3);;- : int list = [1; 2; 3]# prendre ([1;2;3;4;5;6;7;8],0);;- : int list = []
# prendre ([1;2;3;4;5;6;7;8],9);;
Exception: Failure "prendre :impossible".
# laisser_tomber([1;2;3;4;5;6;7;8],8);;
- : int list = []# laisser_tomber([1;2;3;4;5;6;7;8],3);;- : int list = [4; 5; 6; 7; 8]# laisser_tomber([1;2;3;4;5;6;7;8],0);;- : int list = [1; 2; 3; 4; 5; 6; 7; 8]
# laisser_tomber([1;2;3;4;5;6;7;8],9);;Exception: Failure "laisserTomber :impossible".
# liste_des_positifs[1;-2;3;4;5;6;0;-2;5];;
- : int list = [1; 3; 4; 5; 6; 5]# liste_des_positifs [-1;-2;-3];;- : int list = []
#liste_des_singletons[[2;3];[4];[];[5];[5;5;5]];;
- : int list list = [[4]; [5]]
Exercice 3 – Fonctions avec deux listes en argument ou résultat
Écrire les fonctions Caml suivantes (voir les exemples d’applications)�:
1) (**) combiner qui, étant donné une paire de listes, construit la liste des paires d’élémentsde même rang dans les deux listes (la liste résultat a la même longueur que la plus courte des deux listesargument).
2) (**) eclater qui, appliquée à une liste de paires [(x1,y1);�(x2,y2);�…;�(xn,yn)], construitla paire de listes ([x1;�x2;�…;�xn)]�, [y1;�y2;�…;�yn]).
3 ) (**) fusion qui, étant donné 2 listes triées dans l’ordre croissant, construit la listecontenant tous les éléments des 2 listes triés dans l’ordre croissant.
4) (***) partage qui, étant donné une liste l d’entiers, construit la paire formée de la liste desentiers de l multiples de 3 et celle des entiers de l qui ne sont pas multiples de 3.
5) (**) On appelle nombres «�presque jumeaux�» deux nombres entiers impairs p1 et p2 tels quep1=p2+2. Écrire une fonction presque_jumeaux qui, étant donné une liste d’entiers, construitla liste des paires de nombres «�presque jumeaux�».
TD séances 9 et 10 - 4
# combiner(["a";"b";"c"],[1;2;3;4;5]);;- : (string * int) list = [("a", 1); ("b", 2); ("c", 3)]
# eclater[("a", 1); ("b", 2); ("c", 3)];;- : string list * int list = (["a"; "b"; "c"], [1; 2; 3])
# fusion([1;5;6;9;25],[2;4;10]);;- : int list = [1; 2; 4; 5; 6; 9; 10; 25]
# partage[1;2;3;4;5;6;7;8;9];;- : int list * int list = ([3; 6; 9], [1; 2; 4; 5; 7; 8])
# presque_jumeaux [3;5;7;11;13;17;19;20;22];;- : (int * int) list = [(3, 5); (5, 7); (11, 13); (17, 19)]# presque_jumeaux [3;5;7;11;13;17;18;19;20;21;22];;- : (int * int) list = [(3, 5); (5, 7); (11, 13)]
Exercice 4 – Fonctions d’ordre supérieur
Écrire les fonctions Caml suivantes (voir les exemples d’applications)�:
1) (**) tous_prop qui, étant donné une liste et une propriété, indique si tous les éléments de laliste vérifient la propriété donnée. Par convention, tous_prop appliquée à la liste vide devraretourner true.
(***)les 2 fonctions tous_positifs et toutes_un écrites à l’aide de tous_prop.
2) (**) inserer_suivant_pred qui, étant donné un prédicat binaire p permettant de comparer2 éléments, un élément et une liste déjà triée suivant l’ordre induit par p, construit la listeordonnée suivant le prédicat p avec l’élément inséré en «�bonne position�».
3) (*) trier_suivant_pred qui, à partir d’une liste quelconque et d’un prédicat binaire ppermettant de comparer 2 éléments, construit la liste des éléments triés dans l’ordre induit parp.(*) trier_croissant et trier_decroissant permettant de trier une liste dans l’ordrecroissant, respectivement décroissant.
4) (**) liste_prop qui, étant donné une liste et une propriété, construit la liste de tous leséléments de la liste qui vérifient la propriété donnée.
(***) les 2 fonctions liste_des_positifs et liste_des_singletons à l’aide deliste_prop.
# tous_prop ([1;2;3;4;5;6],function x -> x > 0);;: bool = true# tous_prop ([1;2;3;0;4;5],function x -> x > 0);;: bool = false# tous_prop ([[1];[2];[3]],
function [_] -> true | _ -> false);;: bool = true# tous_prop ([[1];[2;3];[4]],function [_] -> true | _ -> false);;

TD séances 9 et 10 - 5
# liste_prop ([1;2;3;4;5;6;7;8;9;10],function x ->(x mod 2) = 0);;
: int list = [2; 4; 6; 8; 10]
5) (***) partition qui, étant donné une liste et une propriété, construit la paire formée de laliste contenant les éléments qui vérifient la propriété et de la liste contenant ceux deséléments ne la vérifiant pas.
(***) A l’aide de partition, écrire partage ainsi que la fonction mem_ou_pas_mem qui étantdonné une liste l de listes et un élément x, construit la paire formée de la liste des listes de lcontenant l’élément x et la liste des listes de l ne contenant pas l’élément x.
# partition([1;2;3;4;5;6;7;8;9], function n -> (n mod 3) = 0);;- : int list * int list = ([3; 6; 9], [1; 2; 4; 5; 7; 8])
# partition([1;2;-3;4;-5;-6;0;9;-10], function n -> n > 0);;- : int list * int list = ([1; 2; 4; 9], [-3; -5; -6; 0; -10])
# let (a,b) =partition ([1;2;-3;4;-5;-6;0;9;-10], function n -> n > 0);;
val a : int list = [1; 2; 4; 9]
val b : int list = [-3; -5; -6; 0; -10]
# fusion (trier a, trier b);;- : int list = [-10; -6; -5; -3; 0; 1; 2; 4; 9]
# partage [1;2;3;4;5;6;7;8;9];;- : int list * int list = ([3; 6; 9], [1; 2; 4; 5; 7; 8])
# mem_ou_pas_mem([[1;2;3];[];[4];[5;6;1;7];[8;9]],1);;- : int list list * int list list = ([[1; 2; 3]; [5; 6; 1; 7]], [[]; [4]; [8; 9]]

Université Paul Sabatier IUP ISI-L3 Automne 2006
Mémoires caches
Exercice 1. Analyse du taux de défauts dans un cache
On considère le programme ci-dessous. Il calcule, dans un premier temps, la moyenne des 8192éléments (codés sur 1 octet) d’un tableau image. Il indique ensuite, dans un tableau seuil, quels éléments du tableau image sont supérieurs à la moyenne. Le programme est chargé en mémoire à l’adresse 0x1000, et chaque instruction est codée sur 4 octets.
.equ N, 8192 .equ log2_N,13 00001000 main : adr r0,image 00001004 mov r1, #0 @ r1 = compteur de boucle 00001008 mov r2,#0 @ r2 = somme 0000100C boucle1: cmp r1,#N @ r1 > N ? 00001010 bcs analyse 00001014 ldrb r3,[r0],#1 @ r3 <- un élément de image 00001018 add r2,r2,r3 @ somme <- somme + element 0000101C add r1,r1,#1 @ incr. compteur de boucle 00001020 b boucle1 00001024 analyse: mov r2,r2,LSR #log2_N @ moyenne <- somme / N 00001028 adr r0,image 0000102C adr r1,seuil 00001030 mov r3,#0 @ r3 = compteur de boucle 00001034 boucle2: cmp r3,#N 00001038 bcs fin 0000103C ldrb r4,[r0],#1 @ r4 <- un élément de image 00001040 cmp r4,r2 @ r4 >= r2 (moyenne) ? 00001044 bcs sup 00001048 inf: mov r4,#1 @ si oui, r4 <- 1 0000104C b suite 00001050 sup: mov r4,#0 @ si non, r4 <- 0 00001054 b suite 00001058 suite: strb r4,[r1],#1 @ écrire résultat r4 dans seuil 0000105c add r3,r3,#1 @ incr. compteur de boucle 00001060 b boucle2 00001064 fin: ... ... 00003000 image : .byte xx, xx, xx, (N valeurs) 00005000 seuil : .fill N, 1
On souhaite étudier le comportement de ce programme lors de son exécution sur un processeur muni de deux caches, l’un pour les instructions et l’autre pour les données.
1ère partie : cache d’instructions
Le cache d’instructions a une capacité de 8 KO, avec des blocs de 16 octets, et est à application directe.
a) Donner le schéma de projection mémoire � cache. Indiquer comment se décompose une adresse mémoire (étiquette ou tag, n° cadre, n° octet).
b) Calculer le taux de défauts des accès au cache d’instructions au cours de l’exécution de ce programme.
c) Si l’on suppose qu’en cas de succès dans le cache, l’accès à la hiérarchie mémoire est 100 fois plus rapide qu’en cas de défaut, quel est le gain apporté par la présence du cache d’instructions ? A quel type de localité (temporelle ou spatiale) ce gain est-il lié ?
2nde partie : cache de données
Le cache de données a également une capacité de 8 KO. On considère deux tailles de blocs : 8 octets et 32 octets. Le cache est à écriture directe (write-through), avec chargement du bloc sur écriture (write allocate)On suppose que les deux tableaux de données sont en mémoire aux adresses 0x3000 et 0x5000.
1. Cache de données à application directe
Dans un premier temps, on suppose que le cache de données est un cache à application directe.
a) Donner le schéma de projection mémoire � cache. Indiquer comment se décompose une adresse mémoire (étiquette ou tag, n° cadre, n° octet).
b) Dans un premier temps, on s’intéresse à la première partie du programme (calcul de la somme). Calculer le taux de défauts des accès aux données dans le cache lors de l’exécution de cette partie du programme pour les deux tailles de blocs considérées. Analyser les différences de résultats.
c) On s’intéresse maintenant à la seconde partie du programme (calcul des seuils). Au début de cette seconde partie, le tableau image est totalement présent dans le cache. Calculer le taux de défauts pour l’exécution de cette seconde partie, dans le cas de blocs de 32 octets. Analyser les raisons pour lesquelles le programme ne profite pas complètement de la présence du cache de données.
d) Quel est le taux de défauts global (exécution du programme complet) dans le cas de blocs de 32 octets ?
2. Cache de données associatif par ensembles
On considère maintenant que le cache de données est associatif par ensembles de degré 2, avec une politique de remplacement de type LRU. Les blocs sont de 32 octets.
a) Donner le schéma de projection mémoire � cache. Indiquer comment se décompose une adresse mémoire (étiquette ou tag, n° ensemble, n° octet).
b) Quel est le taux de défauts des accès aux données lors de l’exécution du programme ?
Exercice 2. Calcul de temps d’accès à la hiérarchie mémoire
On considère un processeur muni d’un cache de 16 KO, à application directe, avec des blocs de 32 octets. Le temps d’accès à ce cache est égal à un cycle d’horloge du processeur, soit 0,5 ns.Le cache est connecté à la mémoire par un bus d’adresse de 32 bits et un bus de données de 64 bits, fonctionnant chacun à une fréquence de 200 MHz.
La mémoire est constituée de bancs entrelacés et les 32 octets d’un bloc peuvent être lus en parallèle, en 50 ns. Une écriture en mémoire dure également 50 ns.

On veut analyser l’accès à la hiérarchie mémoire pour les données uniquement lors de l’exécution du code suivant : main: adr r1, op1 adr r2, op2 adr r0, res mov r3, #255 loop: cmp r3, #0 bcc endloop ldr r4, [r1], #4 ldr r5, [r2], #4 … … r10 � fonction (r4,r5) (une centaine d’instructions sans accès mémoire) … str r10, [r0], #4 sub r3, r3, #1 b loop endloop: ... op1: .int xx,xx,xx, … (256 valeurs) op2: .int xx,xx,xx, … (256 valeurs) res: .fill 256,4
On suppose que op1 est à l’adresse 0x00001000 et que les tableaux op1, op2 et res sont rangés consécutivement en mémoire.
Calculer la durée totale des accès à la hiérarchie mémoire (pour les données seulement) au cours de l’exécution de ce programme, pour les configurations suivantes :
a) le cache est à écriture immédiate sans chargement du bloc (write-through/ no-write-allocate) et le processeur ne dispose pas de tampon d’écriture : il est bloqué pendant toute la durée de l’écriture.
b) le cache est à écriture différée avec chargement du bloc (write-back/ write-allocate), toujours sans tampon d’écriture.
Pour que la comparaison avec le cache à écriture immédiate soit juste, comptabiliser l’écriture des blocs modifiés dans le cache en fin de programme.
c) le cache est à écriture immédiate sans chargement du bloc (write-through/ no-write-allocate) et le processeur dispose d’un tampon d’écriture
Exercice 3. Optimisation de code vis-à-vis du cache de données
Programme 1.
On considère le code suivant, où x est un tableau de 4096 � 64 entiers : somme = 0 ; for (j=0 ; j<64 ; j++) for (i=0 ; i<4096 ; i++) somme += x[i][j];
On suppose que le cache de données a une capacité de 256 KO, avec des blocs de 64 octets. C’est un cache à accès direct. Les tableaux sont rangés en mémoire ligne par ligne.
1. Quel est le taux de défauts dans le cache lors de l’exécution de ce code ?
2. Comment transformer ce code pour réduire le taux de défauts ? Quel est le taux de défautsobtenu ?
Programme 2.
Le programme suivant calcule l’histogramme h des niveaux de gris d’une image. Il y a 512 niveaux de gris possibles. L’image contient 1024 � 1024 pixels, et est traitée comme un vecteur de 220
éléments (octets).
for (j=0 ; j<512 ; j++) { h[j] = 0; for (i=0 ; i<1024*1024 ; i++) { if (image[i] == niveau[j]) h[j]++; } }
On suppose que le cache de données a une capacité de 16 KO. Pour simplifier, on suppose également que seule l’image est rangée dans le cache.
1. Quel est le taux de défauts dans le cache ? 2. Comment pourrait-on transformer ce code pour améliorer la localité temporelle ? Quel serait
alors le taux de défauts ?

Université Paul Sabatier IUP-ISI-L3Année 2006-2007
Programmation assembleur ARM
----------------------------------------------------------------------------------------------------------
Prérequis(ces notions fondamentales d’informatique sont considérées acquises)
� Conversion binaire<->hexadécimal � Représentation sur n positions binaires des naturels (0� N �2n-1) et des relatifs (-(2n-1) � N
�2n-1-1)� Les opérations logiques � Les opérations arithmétiques (+,- et * par décalages et addition/soustraction) et la notion de
débordement� La représentation des caractères (ASCII)� Les notions d’algorithmique : l’étape d’écriture d’un algorithme sera obligatoire avant de
coder en ARM. Et oui !!----------------------------------------------------------------------------------------------------------
Révisions
Exercices 1 à 7 : accès à des données dans des registres.
1) Calculer le maximum de 2 valeurs rangées dans les registres r1 et r2. Résultat dans r0. 2) Effectuer la somme des 10 premiers entiers naturels (i.e. 0+1+…+9) 3) Calculer la factorielle d’un nombre positif rangé dans r1. Résultat dans r0 4) Calculer le nombre de 1 dans la représentation binaire d’un naturel rangé dans r1. Résultat dans r0. 5) Calculer le résultat de la division entière de r0 par r1. Résultat dans r2 pour le quotient et
r3 pour le reste 6) Calculer le PGCD de 2 nombres A et B contenus dans les registres r0 et r1. Résultat dans
r0.7) Calculer le maximum des valeurs absolues de deux nombres stockés dans r1 et r2. Résultat
dans r0.
Exercices 8 à 13 : Accès à des données en mémoire.
8) Initialiser un tableau avec les 10 premiers entiers naturels (format octet et mot) 9) Compter le nombre d’éléments nuls, >0 et <0 dans un tableau de 10 relatifs 10) Rechercher le maximum et sa position dans un tableau de 10 entiers relatifs 11) Recopier une zone mémoire (= tableau) de N octets vers une autre zone mémoire (sans recouvrement entre les zones) 12) Inverser toutes les cases d'un tableau 13) Ecrire un programme qui calcule (de manière itérative) la factorielle d’un nombre rangé dans r0.
Exercices à chercher (travail autonome + correction au tableau ou individualisée)
Exercice 14. Accès à un vecteur en mémoire.
Ecrire un programme qui détermine, dans un tableau d’entiers TAB de longueur N, le nombre maximum d’éléments consécutifs identiques. Exemple : si le tableau contient {0, 1, 1, 2, 3, 3, 3, 3, 4, 5, 5, 5}, le résultat est 4.
Exercice 15. Accès à une matrice en mémoire.
On considère une matrice de dimension m�m rangée en mémoire à l’adresse MAT. En supposant que r0 et r1 contiennent les numéros de ligne et de colonne i et j, écrire le code permettant d’initialiser à 0 l’élément MAT[i,j] :
1) si les éléments sont des octets 2) si les éléments sont des mots longs
Exercice 16. Sous-programme sans paramètres.
Ecrire un sous-programme qui initialise à 0 tous les éléments d’un vecteur dont l’adresse TAB et la taille N sont connues statiquement. Faire en sorte que ce sous-programme restaure, quand il se termine, les valeurs contenues dans les registres lors de son appel. Ecrire un programme principal qui appelle ce sous-programme.
Exercice 17. Sous-programme avec paramètres passés par registres.
a) Ecrire le sous-programme itoa qui transforme une valeur entière en une chaîne de N+1 caractères (permettant de représenter une valeur décimale sur N chiffres, le dernier caractère devant être un 0). Les paramètres valeur et adresse_de_la_chaine seront passés par registres. b) Ecrire un programme qui appelle le sous-programme itoa pour convertir la valeur présente en mémoire à l’adresse VAL en une chaîne de caractères rangée à l’adresse CHAINE. c) écrire un sous-programme div qui reçoit deux valeurs en entrée dans r0 et r1 et calcule le résultat de la division entière de r0 par r1. Le quotient sera rangé dans r2 et le reste dans r3. d) modifier le sous-programme itoa pour qu’il utilise le sous-programme div.
Exercice 18. Sous-programme avec paramètre en entrée passé par la pile.
Ecrire le sous-programme atoi qui transforme une chaîne de caractères en une valeur entière. On suppose que tous les caractères sont des chiffres, et que la chaîne se termine par le code ASCII 0. Le paramètre adresse_de_la_chaine sera passé par la pile, et le résultat renvoyé dans r0.

Exercice 19. Sous-programmes imbriqués.
Ecrire : - un sous-programme AJOUTE_UN qui reçoit en paramètre par la pile un nombre X et
renvoie dans le registre r0 la valeur X+1. - un sous-programme COMPLEMENT_A_2 qui reçoit en paramètre, dans le registre r0, un
nombre Y et renvoie, dans le registre r1, le complément à 2 de Y. Ce complément à 2 sera calculé en inversant Y (l'instruction mvn r3,r4 permet de mettre dans le registre r3 le complément à 1 de r4) puis en appelant le sous-programme AJOUTE_UN.
- le programme principal qui appelle le sous-programme COMPLEMENT_A_2 pour calculer le complément à 2 d'une valeur présente dans le registre r0. Au retour du sous-programme, on veut que r0 contienne toujours la valeur de départ. Le résultat sera récupéré dans r1.
Faire la trace de l’exécution de ce programme.
Exercice 20. Sous-programmes imbriqués.
Ecrire : - un sous-programme MINtoMAJ qui convertit en majuscule un caractère passé en paramètre
par la pile. Si le caractère n’est pas une lettre minuscule (le code ASCII d’une lettre minuscule est compris entre les codes ASCII des caractères ‘a’ et ‘z’), il n’est pas modifié (c’est-à-dire que le résultat est égal au caractère d’origine). Ce sous-programme doit renvoyer son résultat dans le registre r0.
- un sous-programme CONV qui reçoit en paramètre passé par la pile l’adresse d’une chaîne de caractères en mémoire, et convertit tous les caractères de cette chaîne en majuscules, en utilisant le sous-programme MINtoMAJ (les caractères convertis seront rangés dans la chaîne, à la place des caractères d’origine).
- un programme principal qui appelle le sous-programme CONV pour transformer une chaîne dont l’adresse en mémoire est représentée par l’étiquette chaine. Cette chaîne est initialisée de la manière suivante :
chaine : .byte ‘p’,’A’,’R’,’i’,’s’,’ ‘,’7’,’5’,0 Rappel : une chaîne de caractère se termine par le code ASCII 0 Faire la trace de l’exécution de ce programme.
Exercice 21. Sous-programme récursif.
On considère le code suivant :
main: mov r0,#5 stmfd r13!,{r0} bl fact add r13,r13,#4 exit: nop fact: stmfd r13!,{r1,r2,r14} ldr r1,[r13,#12] @ r1 = operande cmp r1,#0 beq un sub r2,r1,#1 stmfd r13!,{r2} bl fact add r13,r13,#4 mul r0,r1,r0 b finfact un: mov r0,#1 finfact: ldmfd r13!,{r1,r2,r14} mov r15,r14
Faire la trace de l’exécution de ce programme. Déterminer ce qu’il calcule.
Exercice 22. Exécution conditionnelle.
Traduire en assembleur, en utilisant les possibilités d’exécution conditionnelle des instructions, le code suivant:
r2 � MAX(r0,r1)
Exercice 23. Compilation d’un switch.
Proposer une traduction en assembleur du code C suivant : switch(a) { case 0 : *b = 0 ; break ; case 1 : if (c>100) *b = 0 ; else *b = 3 ; break ; case 2 : *b = 1 ; break ; case 3 : break ; case 4 : *b = 2 ; break } On suppose que a, b, et c sont des valeurs contenues dans r0, r1, r2, et que *b représente un octet en mémoire.
Exercice 24. Addition de grands nombres.
Soient 2 nombres naturels N1 et N2 codés tous les 2 sur N octets. Faire l’addition de ces 2 nombres, le résultat sera stocké en mémoire dans N3 codé également sur N octets. On traitera le débordement éventuel.

Projet L3 Architecture : Gestion d’une imprimante
Premier Semestre 2005 - 2006
Soit une imprimante munie d’un processeur ARM exécutant un programme qui pi-lote l’impression. Le panneau de commandes situé en façade permet d’interagir avecl’imprimante.
Le projet consiste à concevoir et à développer le code exécuté par le processeur em-barqué dans l’imprimante. Il doit être réalisé sous forme d’incréments, chaque incré-ment ajoutant des fonctionnalités aux précédents.
L’ imprimante simulée est une imprimante à jet d’encre monochrome dont la têted’impression comporte 64 buses La figure 1 montre que si on actives les buses 4, 5, 12,13, 19, 20, 21, 22, 30, 34, 35, 38, 39, 42, 43, 44, 45, 46, 47, 50, 55, 58 et 63, l’encre qui en sortse dépose sur le papier et forme le caractère “A”. Sur la figure, les buses sont numérotéesde gauche à droite et de haut en bas. La numérotation commence à “1”.
Le programme de l’imprimante ne gère que l’envoi de l’encre aux buses. La pla-quette de TP représente cette imprimante. Les caractères à imprimer sont reçus vial’USART. Un affichage sur l’écran simule leur impression. Le panneau de contrôle estreprésenté par les boutons et les LEDs de la plaquette.
1 Caractéristiques communes à tous les incréments : Prin-
cipes de base
Pour imprimer les caractères, l’imprimante active la bonne combinaison de busesd’impression. Elle possède donc le motif d’impression de chaque caractère. Ce sont desmatrices de 8×8 points qui correspondent aux 64 buses de la tête d’impression. Ils voussont fournis dans un fichier à inclure dans votre projet sous forme de tableaux de 8octets. Chaque bit représente un point de la matrice. Si le bit est à 0, la buse est inactive
1
Motif d’impression
19
172533414957 A
FIG. 1 – Fonctionnement des buses
pour l’impression de ce caractère, s’il est à 1, la buse est active pour l’impression dece caractère. Tout caractère dont l’imprimante ne possède pas le motif d’impression estignoré.
Pour qu’un caractère s’impriment correctement, les buses doivent rester actives pen-dant un certain temps afin que l’encre soit déposée correctement. Cette opération estreprésentée par l’affichage du motif d’impression à l’écran sur 8 lignes de 8 caractères.Les buses actives sont représentées par un caractère “%”, alors que les buses inactivesseront représentées par des espaces. A l’issue du quart de seconde nécessaire au dépôtde l’encre, les caractères “%” deviennent des caractères “#”. On passe alors au caractèresuivant. La tête d’impression doit avancer et les rouleaux doivent éventuellement faireavancer le papier ce qui correspond aussi à une latence d’un quart de seconde à l’issueduquel l’impression du caractère suivant peut commencer.
2 Premier incrément : le mode ligne
2.1 Fonctionnement
L’impression se fait ligne par ligne. La taille maximale d’une ligne est de 7 caractères.Le caractère “entrée” (code ASCII 10) permet de changer de ligne.
Les caractères reçus par l’imprimante ne sont imprimés que lorsque une ligne com-plète a été reçue, c’est à dire lorsqu’on a rencontré un symbole de fin de ligne ou bienlorsque la ligne est pleine. Cela signifie que les caractères formant une ligne sont mé-morisés dans un tampon et imprimés lorsque celui-ci est plein ou qu’on a rencontré un
2

caractère “entrée”. Un tampon est un tableau de caractères qui permet cette mémorisa-tion.Pour représenter ce mode de fonctionnement, l’organisation de l’affichage devra per-
mettre la visualisation d’une ligne complète à l’écran. Cette ligne devra s’afficher sousforme de 7 motifs d’impression dans la largeur de l’écran. Au début de l’impressiond’une ligne, l’écran est effacé.
2.2 Interactions avec l’imprimante
Elles se font au travers du panneau de commande. Il se compose de boutons quicommandent le comportement de l’imprimante et de LEDs qui indiquent son activité.Ils sont simulés par ceux de la plaquette :– Le témoin de marche (LED1 ) est allumée tout le temps du fonctionnement del’imprimante.– Le Témoin d’activité (LED2) est clignotante pendant une impression. Sonclignotement correspond à l’impression des caractères : allumée pendant l’activitédes buses, éteinte pendant le déplacement de la tête. Lorsque aucune impressionn’est en cours cette diode est éteinte.– Le bouton Remise à zéro (SW1) permet de stopper l’impression en cours et devider tous les tampons de l’imprimante.
3 Second incrément : le mode page
Dans cette version, on introduit un nouveau mode de fonctionnement de l’impri-mante : le mode page. Celui-ci s’ajoute aumode ligne utilisé dans la version précédente.L’utilisateur a le choix entre les 2 modes et peut basculer de l’un à l’autre. Le mode pardéfaut est le mode ligne.
3.1 Fonctionnement
Dans le mode page, l’impression se fait page par page. Le changement de page se faitlorsqu’on rencontre deux caractères “entrée” consécutifs. Une page comporte, au plus, 3lignes de 7 caractères chacune.L’impression de la page commence lorsque elle est complète, c’est à dire lorsqu’on a
rencontré un symbole de saut de page ou bien lorsque la page est pleine (21 caractères).
3
Il faut donc mémoriser les caractères dans un tampon. Dans ce mode, il faut gérer auto-matiquement le passage à la ligne. Chaque ligne ne devant pas dépasser 7 caractères, ilfaut insérer des symboles de changement de ligne dans la page si besoin.Pour représenter ce mode de fonctionnement, l’organisation de l’affichage devra per-
mettre la visualisation d’une page complète à l’écran. Cette page devra s’afficher sousforme de 3 lignes de 7 motifs d’impression. Une ligne doit contenir dans la largeur del’écran. Au début de l’impression d’une page, l’écran est effacé.
3.2 Interactions avec l’imprimante
– Après l’activation de la commande de remise à zéro (SW1), l’impression re-prend toujours en mode ligne.– Le bouton changement de mode de l’imprimante (SW2) permet le basculemententre le mode page et le mode ligne. Sa prise en compte ne se fait qu’à la fin de laligne (ou de la page) courante.– Le témoin de mode de fonctionnement (LED3) est allumé quand l’imprimanteest en mode page, elle est éteinte en mode ligne.
4 Troisième incrément : Gestion du papier et de l’encre
On ajoute aux fonctions précédentes la gestion du papier et de l’encre. L’imprimanteest munie d’un bac de 3 feuilles et sa cartouche d’encre permet l’impression de 127caractères.
4.1 Fonctionnement
A l’allumage, on considère que le bac de feuilles et la cartouche d’encre sont pleins.Au fur et à mesure des impressions, ils se vident. On ne commence l’impression d’uneligne (ou d’une page) que si on dispose du papier et de l’encre nécessaire pour la ter-miner (i.e. si on dispose de l’encre pour imprimer la moitié de la ligne (ou de la page)à imprimer, la cartouche doit être changée avant de commencer l’impression de la ligne(ou de la page)).Lors du chargement de cartouche, un délai de 5 secondes est nécessaire entre l’in-
sertion de la nouvelle cartouche et la reprise de l’impression afin de permettre à l’encred’atteindre les buses d’impression.
4

Le changement de cartouche n’est possible que lorsque la cartouche en cours d’uti-lisation est vide. Par contre, on peut compléter le bac de feuilles à tout moment. Onsuppose que l’utilisateur remplit systématiquement au maximum le bac de feuilles.
4.2 Interactions avec l’imprimante
– Le témoin de manque de papier (LED4) s’allume lorsque le bac de papier estvide. Elle s’éteint dès qu’il est rechargé. Le chargement du bac de feuilles se fait entapant le caractère “CONTROL+P” (code ASCII 16).– Le témoin de manque d’encre (LED5) s’allume lorsque la cartouche d’encre estvide. Elle s’éteint dès qu’elle a été changée. Le changement de cartouche se fait entapant le caractère “CONTROL+E” (code ASCII 5).– Le témoin de maintenance (LED6) s’allume pendant le changement de la car-touche d’encre.
5 Quatrième incrément
Des fonctions supplémentaires doivent être ajoutées :
– Le bouton forcer l’impression (SW3) permet de forcer l’impression du contenudu tampon même si on a pas de ligne (ou de page) complète. Il ne change pas lemode courant d’impression. L’impression reprend ensuite sur une nouvelle ligne(ou page). L’activation de cette fonction pendant une impression aura pour consé-quence de forcer l’impression de la page en cours de remplissage. Les règles re-latives au manque d’encre et de papier s’appliquent aux pages forcées par cettefonction.– Le bouton réimpression (SW4) permet de réimprimer la dernière ligne (ou ladernière page) imprimée. Il n’est pris en compte qu’à la fin d’une ligne (ou d’unepage).
6 Consignes complémentaires
Les consignes ci-dessous sont valables quel que soit l’incrément développé :
– Les boutons de la plaquette devront être gérés par interruptions.
5
– Les temporisations (temps d’impression des caractères, temps de passage d’uncaractère à l’autre et changement de cartouche) devront être gérées par des timers.– L’utilisateur doit pouvoir continuer son envoi de caractères pendant que l’impri-mante est occupée. L’impression ne bloque pas la réception des caractères, le char-gement de papier ou de cartouche non plus.– La plage mémoire allouée à votre programme va de 0x2000 à 0x20000. Cette plagecomporte le code de votre programme, ses données et sa pile. A vous de gérer aumieux l’espace dont vous disposez. Dans tous les cas, votre programme doit êtrerobuste.– Toutes les constantes devront être regroupées et facilement modifiables (durée destemporisation... ).– Pour toute question concernant le projet, n’hésitez pas à utiliser le forum. C’est enparticulier sur le forum que doivent être postées toutes demandes d’éclaircisse-ment concernant le sujet.
6

UE AVI 6 Christine Sénac 21 UE AVI 6 Christine Sénac 22
UE AVI 6 Christine Sénac 23
Text-dependent Vs. Text-independentspeaker recognition
• In text-dependent applications (with PersonalIdentification Numbers-PINs or passwords) the user must reproduce during the testing, the same words or sentences that he pronounced during the enrollmentstep => speech recognition implementations.
• For text-prompted scenarios, during the test step, thespeaker has to pronounce sentences imposed by thesystem (different sentences each time => increases thesecurit but requires additional speech recognition implementations.
• In text-independent applications the speaker can speakfreely during the training and testing phases.
UE AVI 6 Christine Sénac 24
Outline• Features
– Extraction– Speech frames selection
• Models and classifiers– Different models– Decision making
• Score normalization
– Performance evaluation metrics• Speaker verification evaluation campaigns and
databases– NIST-SRE– Speaker recognition databases
UE AVI 6 Christine Sénac 29
Features extraction
UE AVI 6 Christine Sénac 30
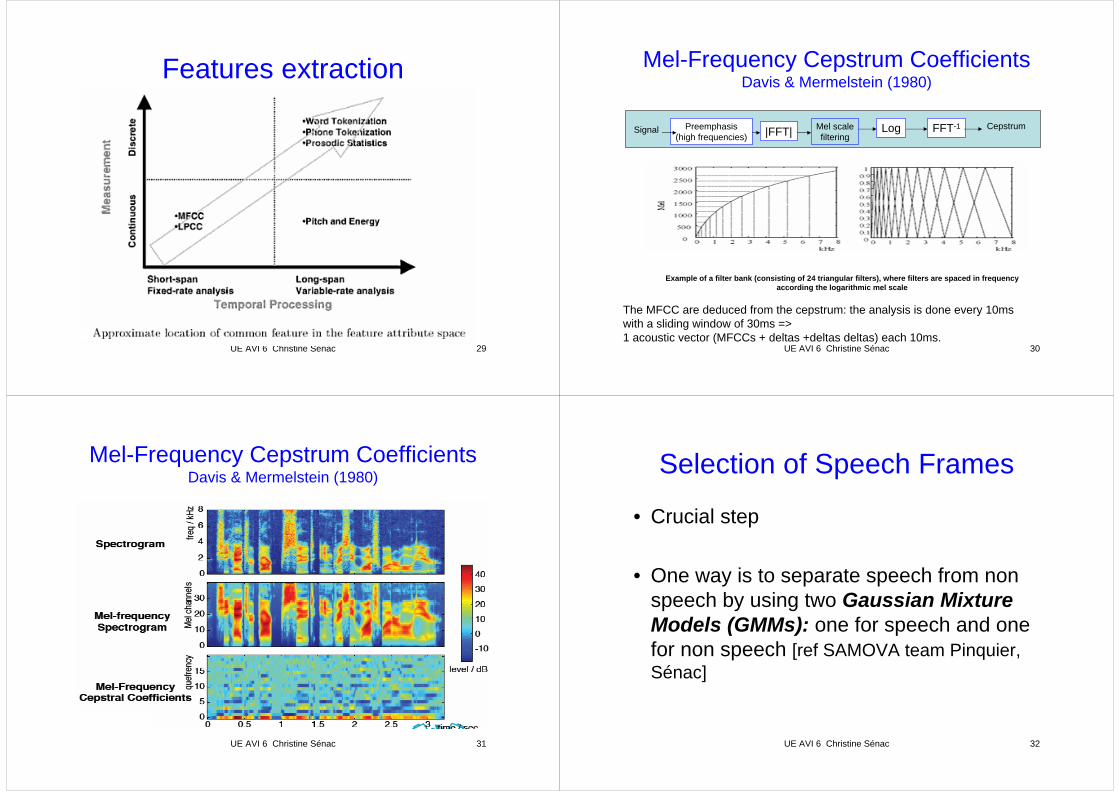
Mel-Frequency Cepstrum CoefficientsDavis & Mermelstein (1980)
Example of a filter bank (consisting of 24 triangular filters), where filters are spaced in frequencyaccording the logarithmic mel scale
Signal CepstrumPreemphasis(high frequencies) |FFT| Mel scale
filteringLog FFT-1
The MFCC are deduced from the cepstrum: the analysis is done every 10ms with a sliding window of 30ms =>1 acoustic vector (MFCCs + deltas +deltas deltas) each 10ms.
UE AVI 6 Christine Sénac 31
Mel-Frequency Cepstrum CoefficientsDavis & Mermelstein (1980)
UE AVI 6 Christine Sénac 32
Selection of Speech Frames
• Crucial step
• One way is to separate speech from non speech by using two Gaussian Mixture Models (GMMs): one for speech and onefor non speech [ref SAMOVA team Pinquier, Sénac]
UE AVI 6 Christine Sénac 37
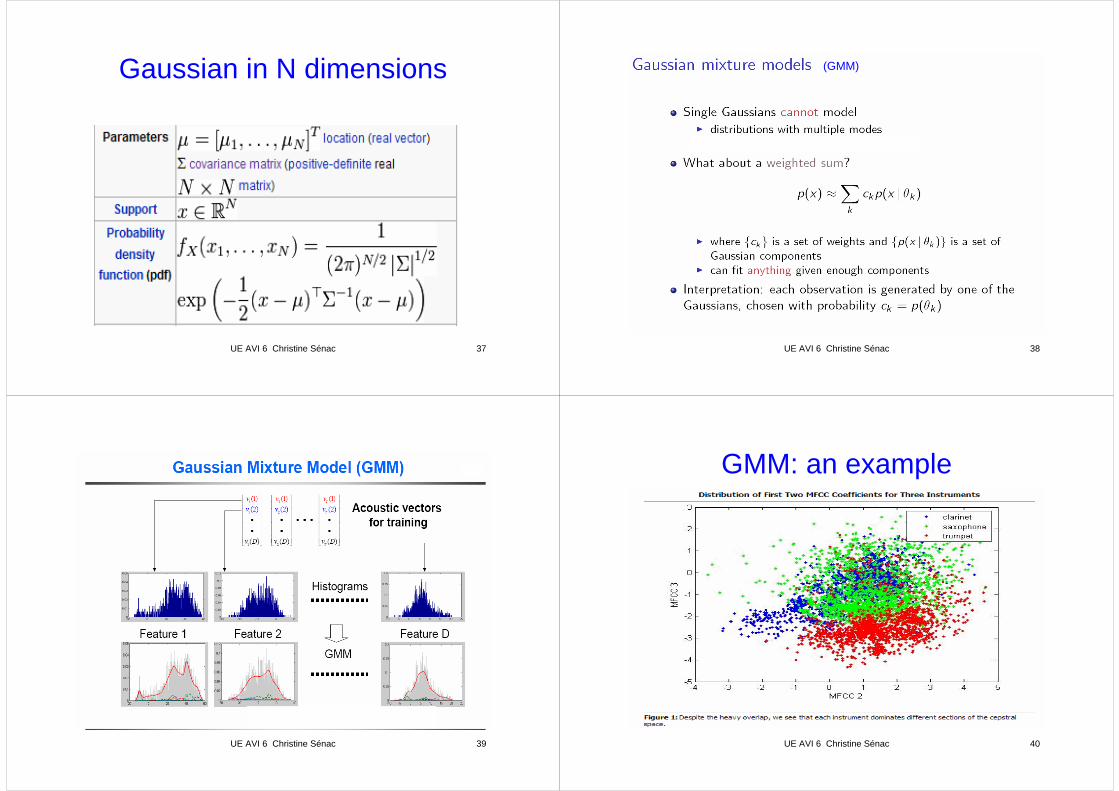
Gaussian in N dimensions
UE AVI 6 Christine Sénac 38
(GMM)
UE AVI 6 Christine Sénac 39 UE AVI 6 Christine Sénac 40
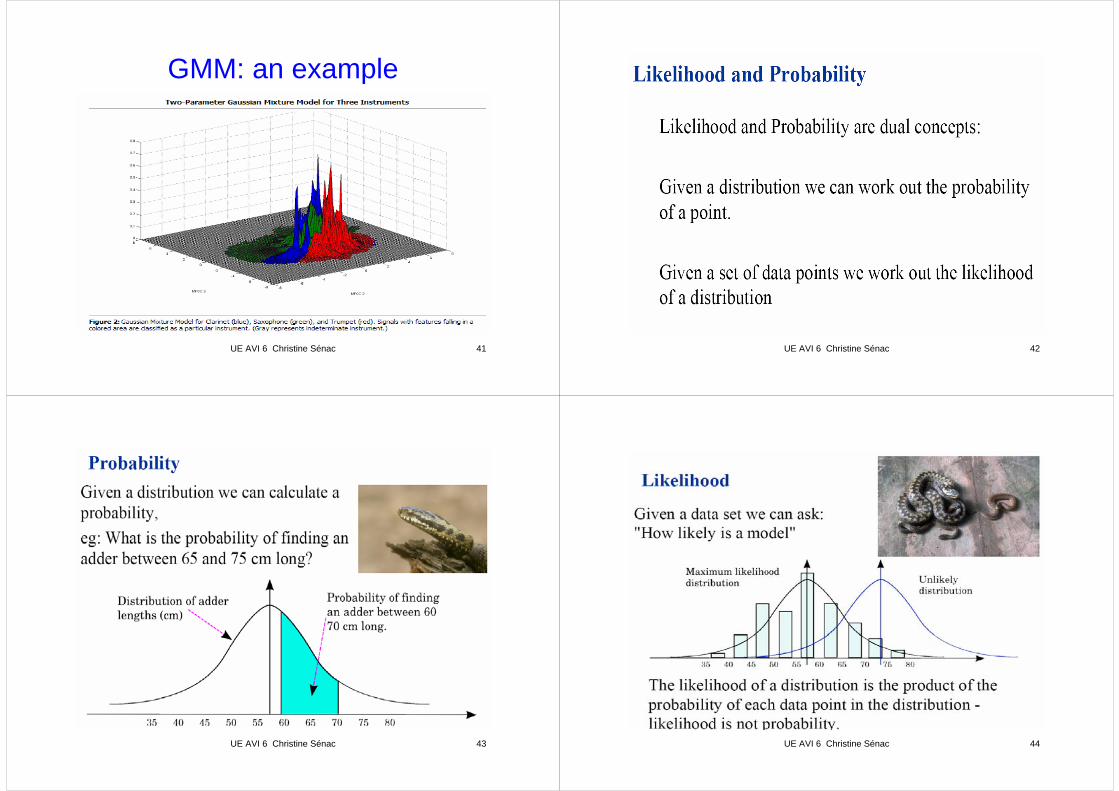
GMM: an example
UE AVI 6 Christine Sénac 41
GMM: an example
UE AVI 6 Christine Sénac 42
UE AVI 6 Christine Sénac 43 UE AVI 6 Christine Sénac 44
UE AVI 6 Christine Sénac 49
GMM = HMM à 1 étatUE AVI 6 Christine Sénac 50
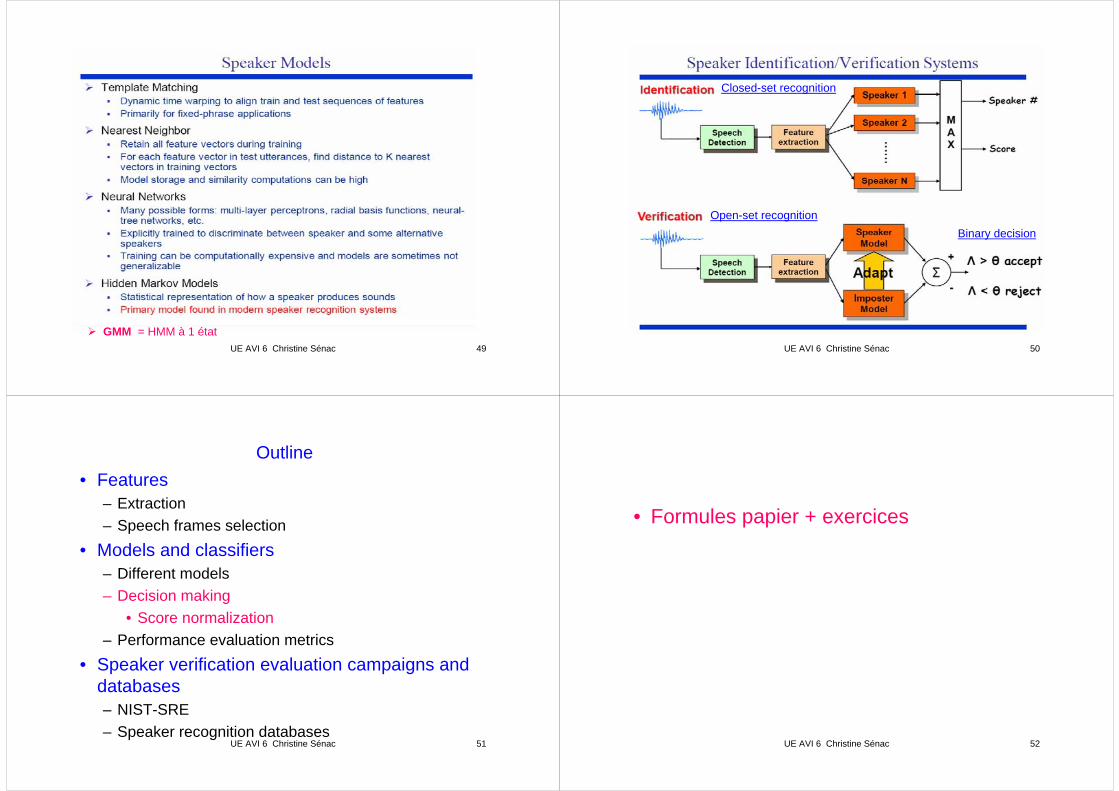
Closed-set recognition
Open-set recognitionBinary decision
UE AVI 6 Christine Sénac 51
Outline• Features
– Extraction– Speech frames selection
• Models and classifiers– Different models– Decision making
• Score normalization– Performance evaluation metrics
• Speaker verification evaluation campaigns anddatabases– NIST-SRE– Speaker recognition databases
UE AVI 6 Christine Sénac 52
• Formules papier + exercices
UE AVI 6 Christine Sénac 53
Outline• Features
– Extraction– Speech frames selection
• Models and classifiers– Different models– Decision making
• Score normalization
– Performance evaluation metrics• Speaker verification evaluation campaigns and
databases– NIST-SRE– Speaker recognition databases
UE AVI 6 Christine Sénac 54
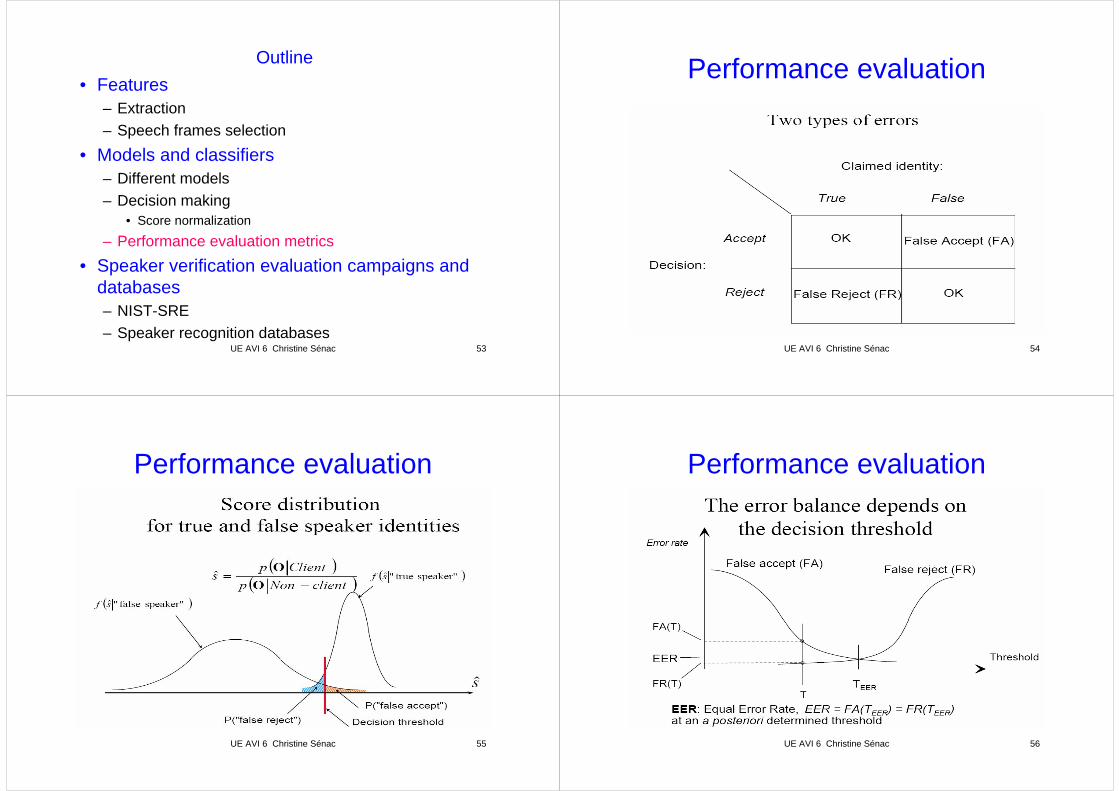
Performance evaluation
UE AVI 6 Christine Sénac 55
Performance evaluation
UE AVI 6 Christine Sénac 56
Performance evaluation
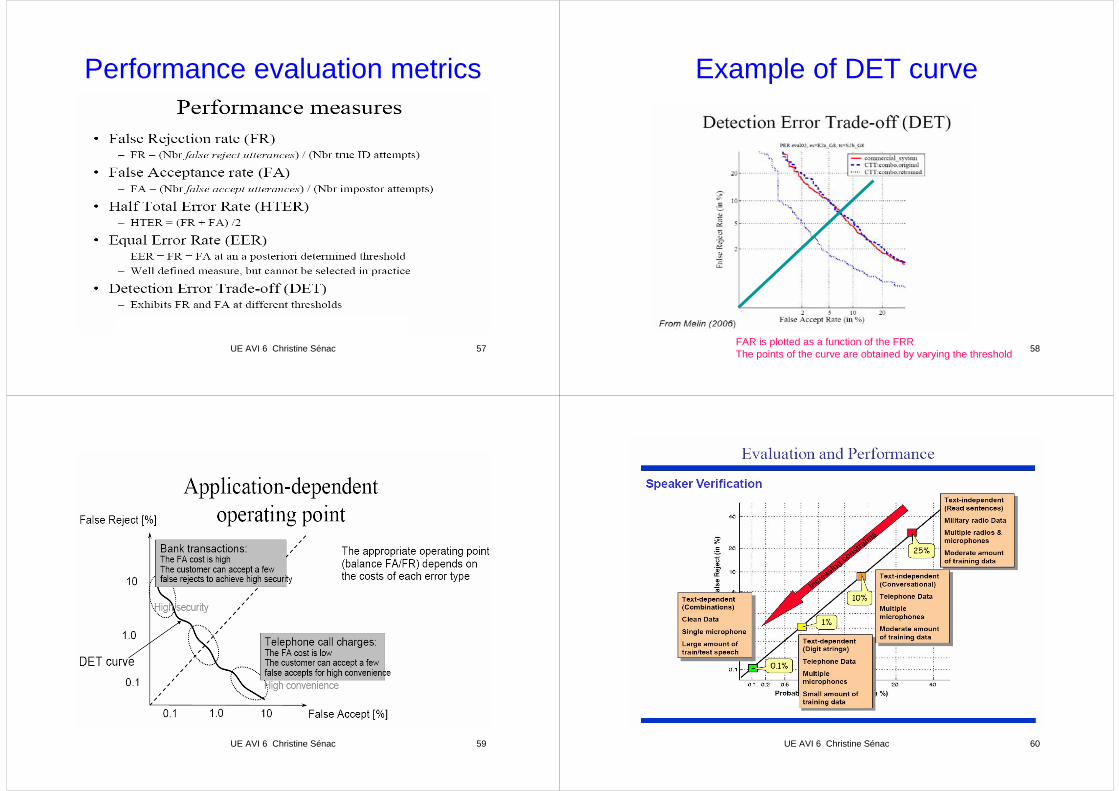
UE AVI 6 Christine Sénac 57
Performance evaluation metrics
UE AVI 6 Christine Sénac 58
Example of DET curve
FAR is plotted as a function of the FRRThe points of the curve are obtained by varying the threshold
UE AVI 6 Christine Sénac 59 UE AVI 6 Christine Sénac 60

UE AVI 6 Christine Sénac 61
Outline• Features
– Extraction– Speech frames selection
• Models and classifiers– Different models– Decision making
• Score normalization
– Performance evaluation metrics• Speaker verification evaluation campaigns and
databases– NIST-SRE– Speaker recognition databases
UE AVI 6 Christine Sénac 62
Evaluation Campaigns
• National Institute of Standards andTechnology Speaker Recognition Evaluations (NIST-SRE) : evaluations oftext-independent speaker verification since1997 (telephonic lines)
• A unique data-set and a core evaluationprotocol to each participating laboratory: one month later results are delivered for evaluation, then workshop
UE AVI 6 Christine Sénac 63
Evaluation Campaigns
• NIST-SRE 2008 data are composed of:• Enrollment data using different amounts of
speech data (from 8s to 5mn) and withmismatched enrollment –test conditions (different phones).
• Duration of test data is: Excerpt (8-10s) + Two-channel Conversations(5mn) +Short Interview Segments(3mn) +Long Interview Segments(8mn).
UE AVI 6 Christine Sénac 64
Audio + Video
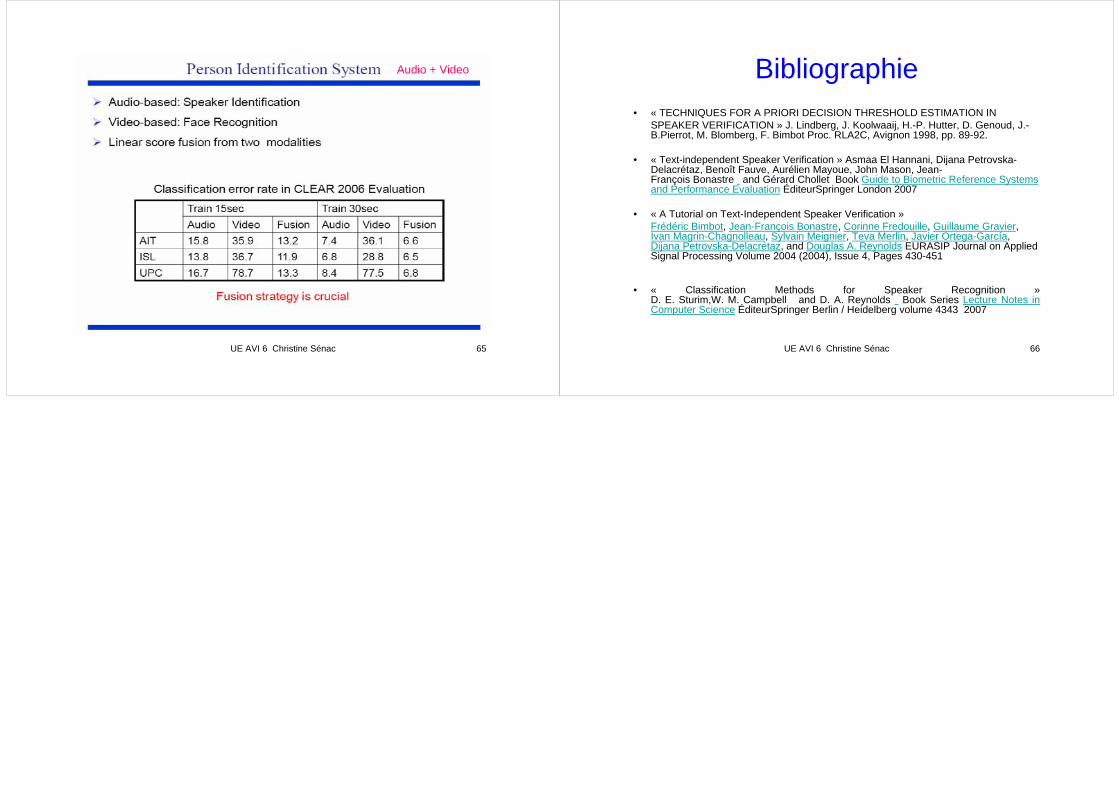
UE AVI 6 Christine Sénac 65
Audio + Video
UE AVI 6 Christine Sénac 66
Bibliographie• « TECHNIQUES FOR A PRIORI DECISION THRESHOLD ESTIMATION IN
SPEAKER VERIFICATION » J. Lindberg, J. Koolwaaij, H.-P. Hutter, D. Genoud, J.-B.Pierrot, M. Blomberg, F. Bimbot Proc. RLA2C, Avignon 1998, pp. 89-92.
• « Text-independent Speaker Verification » Asmaa El Hannani, Dijana Petrovska-Delacrétaz, Benoît Fauve, Aurélien Mayoue, John Mason, Jean-François Bonastre and Gérard Chollet Book Guide to Biometric Reference Systemsand Performance Evaluation ÉditeurSpringer London 2007
• « A Tutorial on Text-Independent Speaker Verification »Frédéric Bimbot, Jean-François Bonastre, Corinne Fredouille, Guillaume Gravier, Ivan Magrin-Chagnolleau, Sylvain Meignier, Teva Merlin, Javier Ortega-García, Dijana Petrovska-Delacrétaz, and Douglas A. Reynolds EURASIP Journal on AppliedSignal Processing Volume 2004 (2004), Issue 4, Pages 430-451
• « Classification Methods for Speaker Recognition » D. E. Sturim,W. M. Campbell and D. A. Reynolds Book Series Lecture Notes in Computer Science ÉditeurSpringer Berlin / Heidelberg volume 4343 2007





























