Embed Size (px)
Citation preview

Square Root Function- Square Root Function- The Restoring AlgorithmThe Restoring Algorithm
VLSI–Lab project
Moran Amir Elior

Goals and needsGoals and needs
• The squaring function performs the basic math operation f(A) = Q such that Q2 = A.
• The root method is considered difficult to implement in hardware, and requires iterative process (or use of lookup table).
• We present a method which is accurate (not an approximation). The results are Q and R such that: 2
Q R A

MotivationMotivation
• The restoring method is based on “binary” search over the result range of the input, which is half the input bits.
• Each time, the last remainder is sign checked.
• If the remainder >= 0, we search in the upper domain, else, the lower domain.
• Since this is a square root, we can divide the input by 4 and not by 2.

The Restoring AlgorithmThe Restoring Algorithm• Initial conditions:
> Let R (the remainder) equal A, the input.
> Let Q equal 0. Q =q1… qn
• Iterative step (i is the index):
> if R>>2i >= { Q , 0 ,1 } then qj-1 = ‘1’ ; R = R – {Q , 0 , 1}
> if R>>2i < { Q , 0 ,1 } then qj-1 = ‘0’ ; R = R R and Q are best thought of as changing in width, bit wise; in reality, they will be zero padded from the left.
We Compare R, which is originally the input, to the main terms of the square of q (as was explained for the squaring function method):
26a3 , 24a2 , 22 a1, 20a0 (4 bit example)If we are bigger, we add zero to the result and keep the remainder;if we are smaller or equal we add one to the result, and subtract the term from the remainder such that we are left with the minor terms.

Example – square root of 11Example – square root of 11

Implementation issuesImplementation issues
• The operations needed are:
> Subtraction
> Shifting• We can use a simple Data-path for this
operators.• We can use multiplied Conditional
Subtraction (SC) units as well. • For each of them, there are n/2+1 iterations.

Behavioral VHDL designBehavioral VHDL designFor Data Path implementationFor Data Path implementation
• Qj := "00000000";• R2j := D;• FOR j IN 4 DOWNTO 1 LOOP• Shift8(Qj,j,'1',Q_t);• Q_t(j+j-2) := '1';• Subtract(R2j,Q_t, R_t, negative);• IF (negative = '0') THEN• Qj(j-1) := '1';• R2j := R_t;• ELSE• Qj(j-1) := '0';• END IF;• END LOOP;

Using a Data pathUsing a Data path
ALU
0 1Q R
0
1
sign
load

Using SC unitsUsing SC unitsagain the square root of 11 exampleagain the square root of 11 example

ConsiderationsConsiderations• Design reuse: ALU already exists.• Simplicity: SC units are easy to implement:procedure SC
( signal CO, S : out Std_Logic ; signal R, D, CI, Q : in Std_Logic ) isbegin CO <= (R and D) or (R and CI) or (D and CI) ;
S <= R xor ((D xor CI) and Q) ; end SC ;
• Area: ~ same as ALU.• Speed: ALU demands 4-5 cycles. The SC
units can produce output much faster.• Power: Lower than ALU• ALU iteration number: q iteration• SC unit count: 0.5*q2 +2.5*q - 1

Root function implementationRoot function implementation
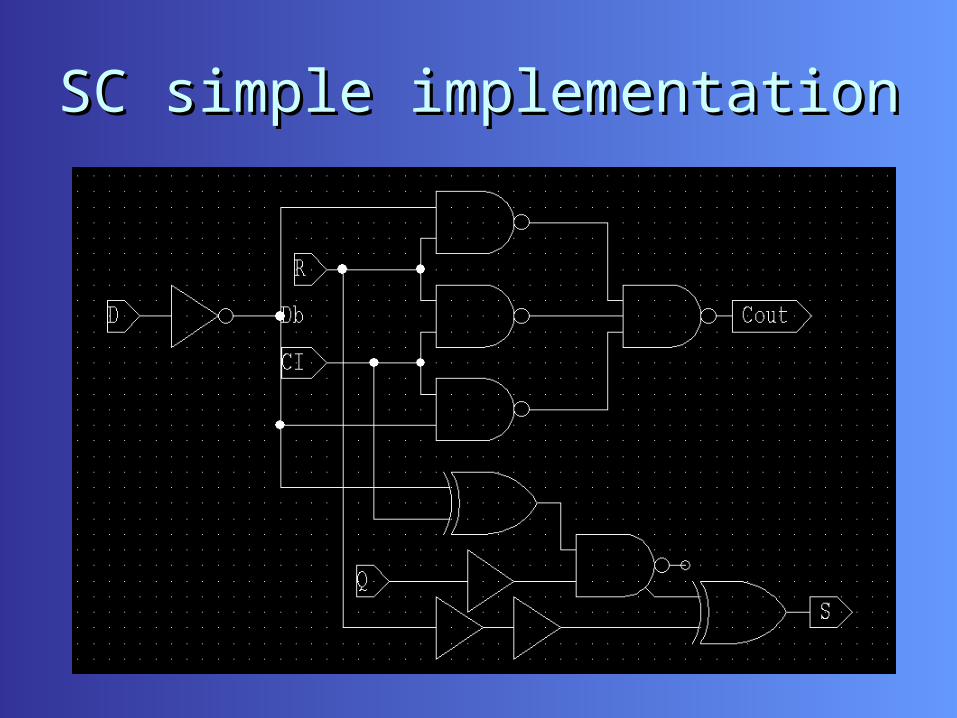
SC simple implementationSC simple implementation

SC optimized implementationSC optimized implementation

Behavioral VHDL simulationBehavioral VHDL simulation

Behavioral VHDL simulation (Cont’)Behavioral VHDL simulation (Cont’)

Behavioral VHDL simulation (Cont’)Behavioral VHDL simulation (Cont’)

Results on SchematicsResults on Schematics
A 0 1 2 3 4 5 6 7
R 0 0 0 1 2 0 1 2
Q 0 0 1 1 1 2 2 2

Results on Schematics IIResults on Schematics II
R 0 4 0 1 2 3 4 5
A 8 9 10 11 12 13 14 15
Q 0 2 3 3 3 3 3 3

Simulation results -QSimulation results -Q

Simulation results -RSimulation results -R

The SC unit maximal delayThe SC unit maximal delay
1.62nS SC max latency
Few transients with the maximal delays
103.0 103.5 104.0 104.5 105.0 105.5 106.0 106.5 107.0 107.5 108.0 108.5 109.0
Time (ns)
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
Vol
tage
(V
)
v(D)-14.10m
v(Q)5.00
v(Cin)453.84m
v(S)2.47
v(Cout)-38.27m
x1= x2= dx=105.77n 107.39n 1.62nSC_sim_wResCap
43.5 44.0 44.5 45.0 45.5 46.0 46.5 47.0 47.5 48.0 48.5 49.0 49.5
Time (ns)
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
Vo
lta
ge
(V
)
v(Cout)4.01
v(S)2.38
v(Cin)4.46
v(Q)4.87
v(D)114.45m
x1= x2= dx=45.83n 47.34n 1.51nSC_sim_wResCap

0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
Time (us)
0.0
0.5
1.0
Po
we
r (W
)p(Vdd)
noFF_sim_allCycles
PowerPowerOn 25 cycles
The most power consuming cycle is marked in red. 25mW RMS

Transistor count & latencyTransistor count & latency
• The SC unit:34 MOS devices SC max latency ~ 2.5nSec (includes margin)
• The Square Root extractor:17 SC units17 * 34 = 578 MOS devices Circuit max latency – 15XSC Latency = 40nSecMax working frequency = 25MHzRMS power on most consuming cycle = 25mWHighest power peek measured = 1W

Performance evaluationPerformance evaluation
• Using ALU scheme will require minimum of 4 cycles => 400 nSec
• Circuit improves speed by a factor of 10.
• Area is not much less than the ALU unit itself excluding the peripheries we should have add.

Credits for picturesCredits for pictures
• Alain Guyot’s site for TIMA Laboratory
• http://tima-cmp.imag.fr/~guyot/Cours/Oparithm/english/Extrac.htm




























