Embed Size (px)
Citation preview

Statistical Learning
Chapter 20 of AIMA
KAIST CS570
Lecture note
Based on AIMA slides, Jahwan Kim’s slides and Duda, Hart & Stork’s slides

2
Statistical Learning
We view LEARNING as a form of uncertain reasoning from observation

3
Outline
Bayesian LearningBayesian inferenceMAP and MLNaïve Bayesian method
Parameter LearningExamplesRegression and LMS
Learning Probability DistributionParametric methodNon-parametric method

4
Bayesian Learning 1
View learning as Bayesian updating of a probability distribution over the hypothesis space
H is the hypothesis variable, values h1,…,hn be possible hypotheses.
Let d=(d1,…dn) be the observed data vectors.Often (always) iid assumption is made.
Let X denote the prediction. In Bayesian Learning,
Compute the probability of each hypothesis given the data. Predict based on that basis.Predictions are made by using all hypotheses.Learning in Bayesian setting is reduced to probabilistic inference.

5
Bayesian Learning 2
The probability that the prediction is X, when the data d is observed is
P(X|d) = i P(X|d, hi) P(hi|d)
= i P(X|hi) P(hi|d)
Prediction is weighted average over the predictions of individual hypothesis.
Hypotheses are intermediaries between the data and the predictions.
Requires computing P(hi|d) for all i. This is usually intractable.

6
Bayesian Learning Basics Terms
P(hi) is called the (hypothesis) prior.We can embed knowledge by means of prior.It also controls the complexity of the model.
P(hi|d) is called posterior (or a posteriori) probability.Using Bayes’ rule,
P(hi|d)/ P(d|hi)P(hi)
P(d|hi) is called the likelihood of the data.Under iid assumption,
P(d|hi)=j P(dj|hi).
Let hMAP be the hypothesis for which the posterior probability P(hi|d) is maximal. It is called the maximum a posteriori (or MAP) hypothesis.

7
Candy Example
Two flavors of candy, cherry and lime, wrapped in the same opaque wrapper. (cannot see inside)Sold in very large bags, of which there are known to be five kinds:
h1: 100% cherry
h2: 75% cherry + 25% lime
h3: 50% -50 %
h4: 25 % cherry -75 % lime
h5: 100% lime
Priors known: P(h1),…,P(h5) are 0.1, 0.2, 0.4, 0.2, 0.1Suppose from a bag of candy, we took N pieces of candy and all of them were lime (data dN).
What kind of bag is it ?What flavor will the next candy be ?

8
Candy ExamplePosterior probability of hypotheses
P(h1|dN) / P(dN|h1)P(h1)=0,P(h2|dN) / P(dN|h2)P(h2)= 0.2(.25)N,P(h3|dN) / P(dN|h3)P(h3)=0.4(.5)N,P(h4|dN) / P(dN|h4)P(h4)=0.2(.75)N,
P(h5|dN) / P(dN|h5)P(h5)=P(h5)=0.1.
Normalize them by requiring them to sum up to 1.

9
Candy Example
Prediction Probability

10
Maximum a posteriori (MAP) Learning
Since calculating the exact probability is often impractical, we use approximation by MAP hypothesis. That is,
P(X|d)¼P(X|hMAP).
Make prediction with most probable hypothesis Summing over that hypotheses space is often intractable instead of large summation (integration), an optimization
problem can be solved.
For deterministic hypothesis, P(d|hi) is 1 if consistent, 0 otherwise MAP = simplest consistent hypothesis (cf. science)The true hypothesis eventually dominates the Bayesian prediction

11
MAP approximation MDL Principle
Since P(hi|d)/ P(d|hi)P(hi), instead of maximizing P(hi|d), we may maximize P(d|hi)P(hi).Equivalently, we may minimize
–log P(d|hi)P(hi)=-log P(d|hi)-log P(hi).We can interpret this as choosing hi to minimize the number of bits that is required to encode the hypothesis hi and the data d under that hypothesis.
The principle of minimizing code length (under some pre-determined coding scheme) is called the minimum description length (or MDL) principle.
MDL is used in wide range of practical machine learning applications.

12
Maximum Likelihood Approximation
Assume furthermore that P(hi)’s are all equal, i.e., assume the uniform prior.
reasonable when there is no reason to prefer one hypothesis over another a priori.
For Large data set, prior becomes irrelevant
to obtain MAP hypothesis, it suffices to maximize P(d|hi), the likelihood.
the maximum likelihood hypothesis hML.
MAP and uniform prior , ML
ML is the standard statistical learning methodSimply get the best fit to the data

13
Naïve Bayes Method
Attributes (components of observed data) are assumed to be independent in Naïve Bayes Method.
Works well for about 2/3 of real-world problems, despite naivety of such assumption.
Goal: Predict the class C, given the observed data Xi=xi.
By the independent assumption,
P(C|x1,…xn) / P(C) i P(xi|C)We choose the most likely class.
Merits of NBScales well: No search is required.Robust against noisy data.Gives probabilistic predictions.

14
Learning Curve on the Restaurant Problem

15
Learning with Data : Parameter Learning
Introduce parametric probability model with parameter .
Then the hypotheses are h, i.e., hypotheses are parameterized.
In the simplest case, is a single scalar. In more complex cases, consists of many components.
Using the data d, predict the parameter

16
ML Parameter Learning Examples : discrete case
A bag of candy whose lime-cherry proportions are completely unknown.
In this case we have hypotheses parameterized by the probability of cherry.P(d|h)=j P(dj|h)=cherry(1-)lime
Find hMaximize P(d|h)
Two wrappers, green and red, are selected according to some unknown conditional distribution, depending on the flavor.
It has three parameters: =P(F=cherry), 1=P(W=red|F=cherry), 2=P(W=red|F=lime).
P(d|h)= cherry(1-)lime red,cherry(1-)green,cherry
red,lime(1-)green,lime
Find hMaximize P(d|h)

17
ML Parameter Learning Example : continuous case
Single Variable Gaussian
Gaussian pdf on a single variable:
Suppose x1,…,xN are observed. Then the log likelihood is
We want to find and that will maximize this. Find where gradient is zero.

18
ML Parameter Learning Example : continuous case Single Variable Gaussian
Solving this, we find
This verifies ML agrees with our common sense.

19
ML Parameter Learning Example : continuous case Linear Regression
Y has a Gaussian distribution whose mean is depend on X and standard deviation is fixedMaximize
= minimizing
This quantity is sum of squared errors. Thus in this case,ML , Least Mean-Square (LMS)

20
Bayesian Parameter Learning
ML approximation’s deficiency with small datae.g. ML of one cherry observation = 100% cherry
Bayesian parameter learningPlace a hypothesis prior over the possible values of parameters
Update this distribution as data arrive

21
Bayesian Learning of Parameter
The density becomes more peaked as the number of samples increaseDespite different prior dsitribution, posterior density is virtually
identical with large set of data

22
Bayesian Parameter Learning ExampleBeta Distribution : Candy example revisited.
is the value of a random variable in Bayesian view.P() is a continuous distribution.
Uniform density is one candidate.Another possibility is to use beta distributions.
Beta distribution has two hyperparameters a and b, and is given by ( normalizing constant)
a,b()=a-1(1-)b-1.mean : a/(a+b).Larger a suggest is closer to 1 than to 0More peaked when a+b is large, suggesting greater certainty about the value of .

23
Beta Distribution
a,b()=a-1(1-)b-1

24
Baysian Parameter Learning ExampleProperty of Beta Distribution
if has a prior a,b, then the posterior distribution for is also a beta distribution.
P(|d=cherry) = P(d=cherry|)P()
= ’ a,b()
= ’ ¢a-1(1-)b-1
= ’ a(1-)b-1
= a+1,b
Beta distribution is called the conjugate prior for the family of distributions for a Boolean variable.
a and b as virtual count Uniform prior a,b seen a-1 cherry and b-1 lime

25
Density Estimation
All Parametric densities are unimodal (have a single local maximum), whereas many practical problems involve multi-modal densities
Nonparametric procedures can be used with arbitrary distributions and without the assumption that the forms of the underlying densities are known
There are two types of nonparametric methods:
Estimating P(x | j ) Bypass probability and go directly to a-posteriori probability estimation

26
Density Estimation : Basic idea
Probability that a vector x will fall in region R is:
P is a smoothed (or averaged) version of the density function p(x) if we have a sample of size n; therefore, the probability that k points fall in R is then:
and the expected value for k is:
E(k) = nP (3)
(1) 'dx)'x(pP
(2) )P1(P k
nP knk
k

27
ML estimation of P = is reached for
Therefore, the ratio k/n is a good estimate for the probability P and hence for the density function p.
p(x) is continuous and that the region R is so small that p does not vary significantly within it, we can write:
where x’ is a point within R and V the volume enclosed
by R.
Combining equation (1) , (3) and (4) yields:
)|P(Max k
Pn
kˆ
(4) V)x(p'dx)'x(p
V
n/k)x(p

28
Parzen Windows
Parzen-window approach to estimate densities assume
that the region Rn is a d-dimensional hypercube
((x-xi)/hn) is equal to unity if xi falls within the hypercube of volume Vn centered at x and equal to zero otherwise.
otherwise0
d , 1,...j 2
1u 1
(u)
:functionwindow following the be (u) Let
) ofedge the of length :(h hV
j
nndnn

29
The number of samples in this hypercube is:
By substituting kn in equation (7), we obtain the following estimate:
Pn(x) estimates p(x) as an average of functions of x and
the samples (xi) (i = 1,… ,n). These functions can be general!
ni
1i n
in h
xxk
n
ini
1i nn h
xx
V1
n1
)x(p

30
Illustration of Parzen Window
The behavior of the Parzen-window methodCase where p(x) N(0,1)
Let (u) = (1/(2) exp(-u2/2) and hn = h1/n (n>1) (h1: known parameter)
Thus:
is an average of normal densities centered at the samples xi.
n
ini
1i nn h
xx
h
1
n
1)x(p

31
For n = 1 and h1=1
For n = 10 and h = 0.1, the contributions of the individual samples are clearly observable !
)1,x(N)xx(e2
1 )xx()x(p 1
21
2/111
Numerical results

32

33
34
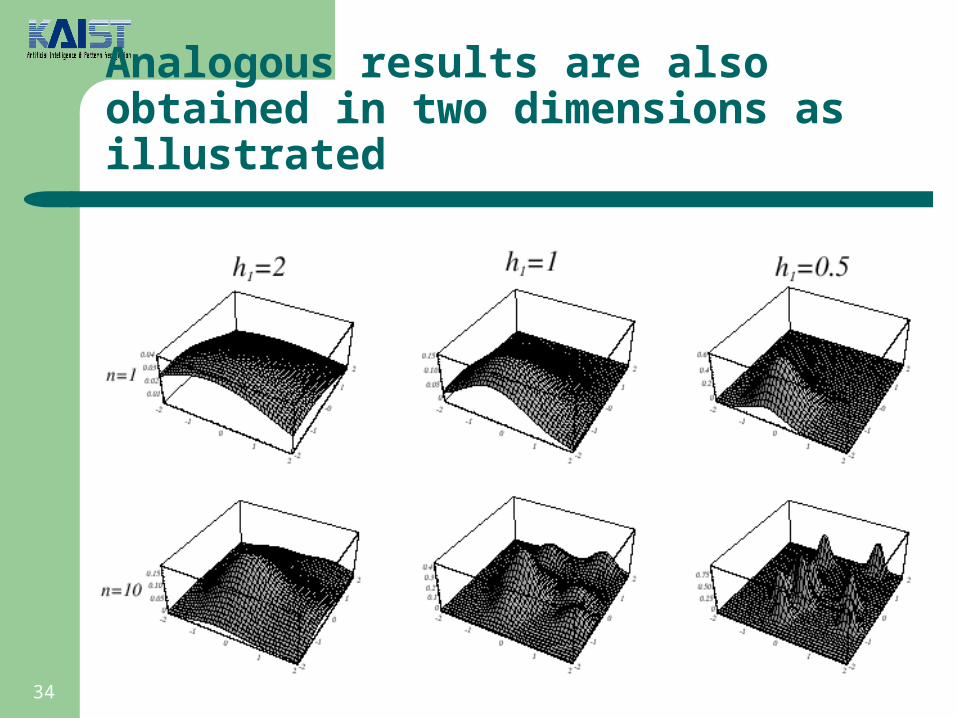
Analogous results are also obtained in two dimensions as illustrated

35
Case where p(x) = 1.U(a,b) + 2.T(c,d) (unknown density) (mixture of a uniform and a triangle density)

36

37
Summary
Full Bayesian learning gives best possible predictions but is intractable
MAP Learning balances complexity with accuracy on training data
ML approximation assumes uniform prior, OK for large data sets
Parameter estimation is often used





























