Embed Size (px)
Citation preview

Statystyczne metody analizy danych
Statystyka opisowa Wykład I-III
Agnieszka Nowak - Brzezińska

Definicje
• Statystyka (ang.statistics) - to nauka zajmująca się zbieraniem, prezentowaniem i analizowaniem danych w celu odkrycia prawidłowości występujących w zjawiskach masowych oraz wspomagania i podniesienia jakości procesu podejmowania decyzji.
• Dane (ang.data) to informacje, zazwyczaj numeryczne lub w postaci kategorii

Podstawowe pojęcia
STATYSTYKA - nauka traktująca o metodach ilościowych badania prawidłowości zjawisk (procesów) masowych.
BADANIE STATYSTYCZNE - ogół prac mających na celu poznanie struktury określonej zbiorowości statystycznej.
ZBIOROWOŚĆ (POPULACJA) STATYSTYCZNA – zbiór dowolnych elementów (osób, przedmiotów, faktów) podobnych pod względem określonych cech (ale nie identycznych) poddanych badaniu statystycznemu.
JEDNOSTKA STATYSTYCZNA - składowe (elementy) zbiorowości (obiekty badania), które podlegają bezpośredniej obserwacji lub pomiarowi.

Typy statystyki
• Statystyka opisowa (ang. descriptive statistics) zajmuje się prezentacją danych w postaci tabel, diagramów i charakterystyk liczbowych.
• Statystyka matematyczna (ang. Mathematical lub inductive statistics) zajmuje się wnioskowaniem o własnościach populacji na podstawie własności próbki przy dopuszczeniu pewnego poziomu błędu, w oparciu o twierdzenia rachunku prawdopodobieństwa

n - oznaczenie liczby jednostek statystycznych w populacji
• ZBIOROWOŚĆ (POPULACJA) GENERALNA – wszystkie elementy będące przedmiotem badania, co do których chcemy formułować wnioski ogólne.
• ZBIOROWOŚĆ PRÓBNA (PRÓBA) - podzbiór populacji generalnej; wyniki badań próby są uogólniane na zbiorowość generalną. Próba musi być reprezentatywna.
• Reprezentatywność zależy od: sposobu wyboru jednostek (celowy, losowy) oraz liczebności próby.
• n>30 - duża próba
• n≤30 - mała próba

Populacja a próba
• Z oczywistych powodów nie jesteśmy w stanie opisać całej tej populacji.
• Musimy się zatem posłużyć podzbiorem populacji generalnej - pobraną wcześniej próbą.
• Na podstawie analizy tej próby będziemy jednak chcieli wyciągać wnioski na temat całej populacji.
• Aby to było możliwe należało na wstępie zadbać aby pobrana populacja w sposób możliwie reprezentatywny opisywała populację generalną.

Populacja a próba
• Do oceny i opisu populacji próby można posłużyć się samymi danymi ale jest to niewygodne.
• Z reguły badacz wykorzystuje różnorodne syntetyczne wska�źniki (statystyki) mające ilustrować badaną populację.
• Gdy opisujemy jakąś skończoną populację np. wzrost uczniów z klasy IIA (populacja generalna o skończonej liczbie elementów) mówimy o statystykach z populacji. W przypadku gdy opisujemy jedynie wycinek jakiejś większej, najczęściej niepoliczalnej populacji generalnej, mówimy o statystyce z próby.

Estymacja, estymator
• Chcemy zatem wyznaczyć wartość pewnej charakterystyki danych populacji na podstawie próby.
• Wyniki obliczane na próbie chcemy rozciągnąć na populację i wnioskować o populacji. Opisywana zależność nosi nazwę estymacji.
• Poszczególne statystyki obliczane z próby takie jak np. średnia arytmetyczna z próby jest więc tylko przybliżeniem wartości przeciętnej z populacji m.
• W związku z tym są nazywane estymatorami.


Rodzaje cech
• Cecha niemierzalna – zwana też jakościową – przyjmuje wartości nie będące liczbami (np. kolor, płeć, smakowitość)
• Cecha mierzalna– zwana też ilościową– przyjmuje pewne wartości liczbowe (np. długosc, wytrzymałosc, ciezar)
• Cecha (mierzalna) skokowa –zwana też dyskretną– nie przyjmuje wartości pośrednich (np. ilosc bakterii, ilosc pracowników, ilosc pasazerów).
• Cecha (mierzalna) ciągła przyjmuje wartości z pewnego przedziału liczbowego (np. wzrost, waga, czas obsługi)

Niech x1, x2, ..., xn będą wartościami cechy X wszystkich elementów populacji albo próby. Są to tzw. dane statystyczne. Charakterystyki liczbowe (opisowe) są to liczby charakteryzujące rozkład cechy populacji. Charakterystyki liczbowe cechy X, podobnie jak parametry rozkładu zmiennej losowej, dzielimy na: • Charakterystyki położenia (średnia, mediana, dominanta); • Charakterystyki rozproszenia (wariancja, odchylenie standardowe, współczynnik zmienności, odchylenie przeciętne, rozstęp); • Charakterystyki asymetrii (współczynnik asymetrii, wskaźnik asymetrii); • Charakterystyki spłaszczenia (kurtoza).

Kategorie charakterystyk
• Charakterystyki położenia
• Charakterystyki rozproszenia
• Charakterystyki asymetrii
• Charakterystyki spłaszczenia

Interpretacja charakterystyk położenia
Średnia arytmetyczna, mediana i dominanta są przykładami tzw. charakterystyk położenia, czyli wielkości informujących o przeciętnej wielkości cechy populacji. Wokół tych wielkości skupiają się na ogół wartości cechy populacji. Inaczej wyrażamy to mówiąc, że poznane charakterystyki są miarami tendencji centralnej wartości cechy populacji. Średnia arytmetyczna jest liczbą informującą o tym, jaką wartość cechy powinny mieć elementy populacji, gdyby wszystkie dane statystyczne były sobie równe i suma tych wartości byłaby taka sama (podział wielkości na n równych części). Mediana dzieli zbiór danych statystycznych na dwa równoliczne podzbiory: do jednego z nich należą dane mniejsze lub równe medianie, zaś do drugiego dane większe lub równe medianie. Dominanta jest najbardziej typową daną statystyczną.

Średnia arytmetyczna danych statystycznych

Mediana danych statystycznych


Jak określać przeciętny poziom cechy
• Częstość występowania
• Histogram


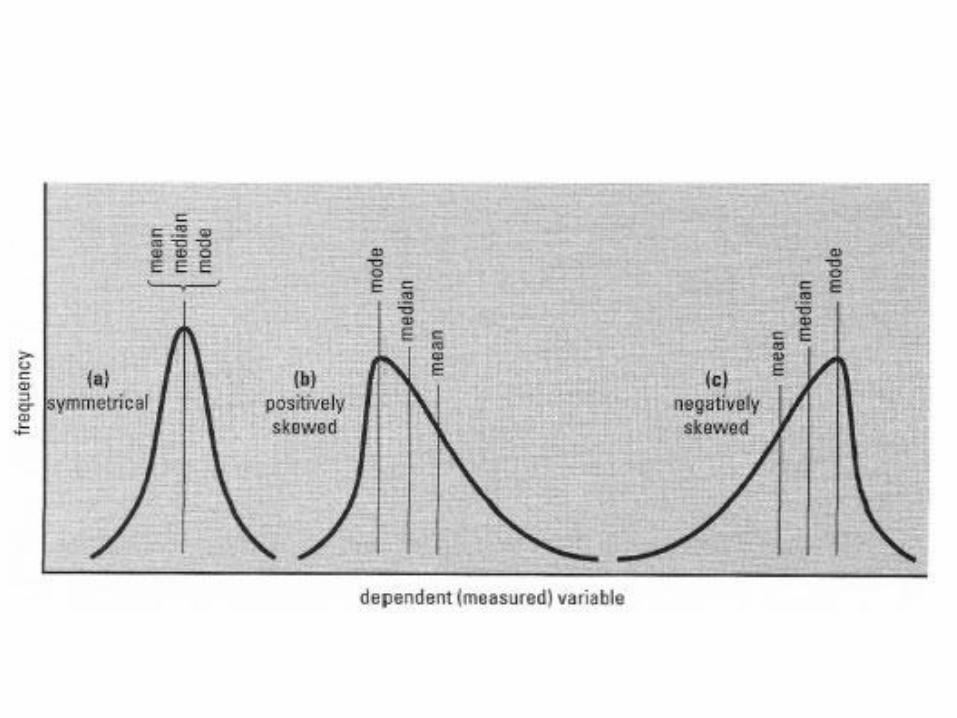

Podsumowanie – jak określać przeciętny poziom cechy
•Średnia arytmetyczna - jeżeli rozkład jest symetryczny z jedną modą
•Mediana - jeżeli rozkład jest niesymetryczny z jedną modą
•Moda – jeżeli rozkład jest wielomodalny, podając ją dla każdego obszaru zmienności

Średnia ważona
Średnia ważona danych statystycznych z odnoszącymi się do ich nieujemnymi wagami, w1, w2,..., wn z których co najmniej jedna jest dodatnia, jest określona przez:
W ten sposób dane którym przypisano większe wagi mają większy udział w określeniu średniej ważonej niż dane, którym przypisano mniejsze wagi. Jeśli wszystkie wagi są równe, wówczas średnia ważona jest równa średniej arytmetycznej.


średnia geometryczna
• Średnia geometryczna znajduje zastosowanie w badaniu średniego tempa zmian zjawisk, których rozwój jest przedstawiony w postaci szeregów dynamicznych, np. do uśredniania indeksów
łańcuchowych (iloraz poziomu zjawiska w okresie badanym, do poziomu zjawiska w okresie poprzedzającym okres badany)

średnia harmoniczna
• średnia harmoniczna (dla danych statystycznych różnych od zera) jest odwrotnością średniej arytmetycznej odwrotności danych statystycznych.
• Średnią harmoniczną stosuje się w przypadku gdy wartości zmiennej podane są w jednostkach względnych (np. m/s, cm/osoba).

Charakterystyki rozproszenia
• Wariancja i odchylenie standardowe
• Współczynnik zmienności danych
• Rozstęp danych

Charakterystyki rozproszenia (dyspersji, zróżnicowania)
• Wariancja
• Odchylenie standardowe wyznaczane jest jako pierwiastek z wariancji.
Średnia arytmetyczna kwadratów odchyleń poszczególnych wartości zmiennej od średniej arytmetycznej całego zbioru danych.
Miara przeciętnego odchylenia wyników pomiarów od średniej; im większe jest odchylenie standardowe, tym bardziej rozproszone są dane.

• Wariancja, odchylenie standardowe, odchylenie przeciętne, współczynnik zmienności (klasyczny)
• Wariancję (s2) definiuje się jako średnią arytmetyczną kwadratów odchyleń wartości cechy od średniej arytmetycznej zbiorowości. Wariancja jest wielkością mianowaną w kwadracie miana badanej cechy i nie interpretujemy jej.
• Odchylenie standardowe (s) jest pierwiastkiem kwadratowym z wariancji. Jest ono wielkością mianowaną tak samo jak badana cecha. Odchylenie standardowe określa przeciętne zróżnicowanie badanej cechy od średniej arytmetycznej.
• Odchylenie przeciętne (d) jest średnią arytmetyczną bezwzględnych odchyleń wartości cechy od jej średniej arytmetycznej. Jest ono wielkością mianowaną tak samo jak badana cecha. Odchylenie przeciętne interpretujemy podobnie jak odchylenie standardowe.
• Współczynnik zmienności (klasyczny) (Vs lub Vd) jest to iloraz odchylenia standardowego (lub przeciętnego) przez średnia arytmetyczną.


Współczynnik zmienności i rozstęp
• Współczynnik zmienności:
• Rozstęp:
gdzie: xmin najmniejsza dana statystyczna, xmax – największa dana statystyczna.

Podsumowanie…
Wariancja, odchylenie standardowe, współczynnik zmienności i rozstęp są przykładami charakterystyk rozproszenia (zmienności, zróżnicowania). Każda z tych charakterystyk ma wartość równą zeru tylko w przypadku równych wszystkich danych statystycznych (nie ma wtedy zróżnicowania danych) i ma coraz większą wartość, gdy dane są bardziej zróżnicowane. Wariancja i odchylenie standardowe mierzą rozproszenie danych statystycznych od ich średniej arytmetycznej. Jeśli dane statystyczne są wyrażone w pewnych jednostkach, to wariancja jest wyrażona w tej jednostce do kwadratu. Tej niedogodności nie ma odchylenie standardowe. Współczynnik zmienności wyraża, jaki procent stanowi odchylenie standardowe względem wartości średniej arytmetycznej. Jest wielkością niemianowaną (bez jednostki). Nadaje się więc do porównywania zróżnicowania cech populacji wyrażonych w różnych jednostkach. Rozstęp wyraża długość najkrótszego przedziału, do którego należą wszystkie dane statystyczne.

Charakterystyki asymetrii
• Współczynnik asymetrii
• Wskaźnik asymetrii
gdzie s jest odchyleniem standardowym, zaś licznik nazywa się momentem centralnym rzędu 3,
gdzie x , d, s są odpowiednio średnią, dominantą i odchyleniem standardowym cechy X. Jest to tzw. klasyczny miernik asymetrii standaryzowany.

Charakterystyki spłaszczenia
• Miernik spłaszczenia
• Współczynnik spłaszczenia (kurtoza)
Kurtoza jest miarą skupienia wokół średniej arytmetycznej, im większa jest jej wartość, tym bardziej wartości zmiennej koncentrują się wokół średniej – miarą odniesienia jest rozkład normalny. Jeśli kurtoza jest ujemna, to rozkład jest bardziej spłaszczony od normalnego, jeśli dodatnia, to rozkład jest bardziej wysmukły niż normalny.

• Jeśli ak i as są równe 0, to rozkład cechy X jest symetryczny, jeśli są różne od zera, to rozkład jest asymetryczny, przy czym, jeśli są dodatnie, to asymetria rozkładu jest prawostronna, jeśli są ujemne, to asymetria jest lewostronna.
• Wartość bezwzględna współczynnika i wskaźnika asymetrii mierzy siłę asymetrii, im jest większa tym asymetria jest silniejsza.
• Współczynnik i wskaźnik asymetrii są jednostkami niemianowanymi, mogą więc służyć do porównywania asymetrii cech populacji wyrażonych w różnych jednostkach


Interpretacja asymetrii za pomocą wykresu szeregu rozdzielczego
• Jeśli wykres szeregu rozdzielczego cechy populacji jest symetryczny względem pewnej prostej prostopadłej do osi odciętych (prostej o równaniu postaci x = a), to cecha ta ma rozkład symetryczny - (średnia, mediana i dominanta są równe a).
• Jeśli wykres szeregu rozdzielczego cechy populacji nie jest symetryczny względem żadnej prostej prostopadłej do osi odciętych i jego prawa część jest wydłużona, to cecha ta ma rozkład asymetryczny o asymetrii dodatniej, czyli prawostronnej.
• Jeśli wykres szeregu rozdzielczego cechy populacji nie jest symetryczny względem żadnej prostej prostopadłej do osi odciętych i jego lewa część jest wydłużona, to cecha ta ma rozkład asymetryczny o asymetrii ujemnej, czyli lewostronnej patrz.

• Rozkłady różnią się między sobą kierunkiem i siła asymetrii (miary klasyczne):
• dla szeregów symetrycznych
• jeżeli asymetria prawostronna
• jeżeli asymetria lewostronna.
• Wskaźnik skośności - jest to wielkość bezwzględna wyrażona jako różnica między średnią arytmetyczną, a modalną.

Ocena rozproszenia na podstawie obserwacji diagramów
Na rysunku pokazano dwa diagramy częstości (1) i (2).
Dla uproszczenia miary położenia (średnia, mediana i modalna) są sobie równe i identyczne dla obu zbiorowości.
Mniejsze rozproszenie wokół średniej występuje w zbiorowości (1).
Diagram jest smuklejszy i wyższy. Większe rozproszenie wokół średniej
występuje w zbiorowości (2). Diagram jest bardziej rozłożysty i niższy. Odchylenie standardowe w zbiorowości (1)
jest mniejsze niż w zbiorowości (2) s1 < s2

Miary pozycyjne
• Kwantyle - definiuje się jako wartości cechy badanej zbiorowości, przedstawionej w postaci szeregu statystycznego, które dzielą zbiorowość na określone części pod względem liczby jednostek, części te pozostają do siebie w określonych proporcjach.
• Kwartyl pierwszy Q1 dzieli zbiorowość na dwie części w ten sposób, że 25% jednostek zbiorowości ma wartości cechy niższe bądź równe kwartylowi pierwszemu Q1, a 75% równe bądź wyższe od tego kwartyla.
• Kwartyl drugi (mediana Me) dzieli zbiorowość na dwie równe części; połowa jednostek ma wartości cechy mniejsze lub równe medianie, a połowa wartości cechy równe lub większe od Me; stąd nazwa wartość środkowa.
• Kwartyl trzeci Q3 dzieli zbiorowość na dwie części w ten sposób, że 75% jednostek zbiorowości ma wartości cechy niższe bądź równe kwartylowi pierwszemu Q3, a 25% równe bądź wyższe od tego kwartyla.
• Decyle np. decyl pierwszy oznacza, że 10% jednostek ma wartości cechy mniejsze bądź równe od decyla pierwszego, a 90% jednostek wartości cechy równe lub większe od decyla pierwszego.




Środowisko R
• Odczyt danych z plików zewnętrznych

Środowisko R
• Odczyt danych z plików zewnętrznych

Sepal length Sepal width Petal length Petal width Species




Iris setosa

versicolor

virginica


Statystyka opisowa w środowisku R
sapply( ) Funkcja ta dostarcza informacji typu: mean, sd, var, min, max, med, range, quantile.






Przykładowe analizy…

Petal length

Interpretacja wyników
• Min = 1
• Max = 6.9
• Średnia = 3.75
• Mediana = 4.35
• Rozstęp = 5.9
• Odchylenie standardowe = 1.76
• Wariancja = 3.11
• Kurtoza = -1.42
• Skośność = -0.27
Asymetria lewostronna (ujemna), większość danych jest większa od wartości średniej. Gdy kurtoza jest ujemna -> rozkład jest bardziej spłaszczony od normalnego.





























