Embed Size (px)
DESCRIPTION
mdcs descurcarea deatelor de facere a proiecteleo
Citation preview

Strategii pentru analiza datelorStudiu de cohortă
Dr. Vladimir Bacârea

Obiective de instruire
Tabele de analiză a datelor Organizarea datelor în tabele de contingenţă Risc relativ Incidenţă

Metode de analiză
Determinate de design Organizarea datelor în tabele Comparaţii între grupuri Tabele date demografice – comparaţii
grupuri, factori de risc Analiza – compararea ratei problemei de
sănătate între grupuri

Design-ul studiului de cohortă
Identificarea populaţiei Definire expunerii Alocarea statutului expunerii pe grupuri Urmărirea apariţiei fenomenului de sănătate
în cele două grupuri şi măsurarea acestui efect
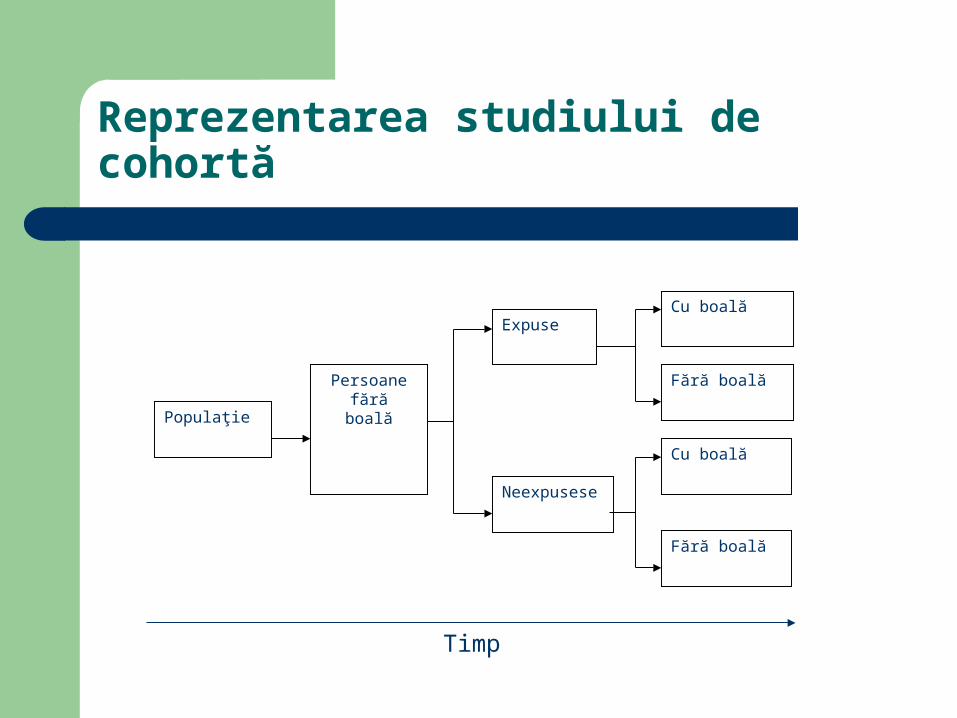
Reprezentarea studiului de cohortă
Populaţie
Persoanefără
boală
Expuse
Neexpusese
Cu boală
Cu boală
Fără boală
Fără boală
Timp
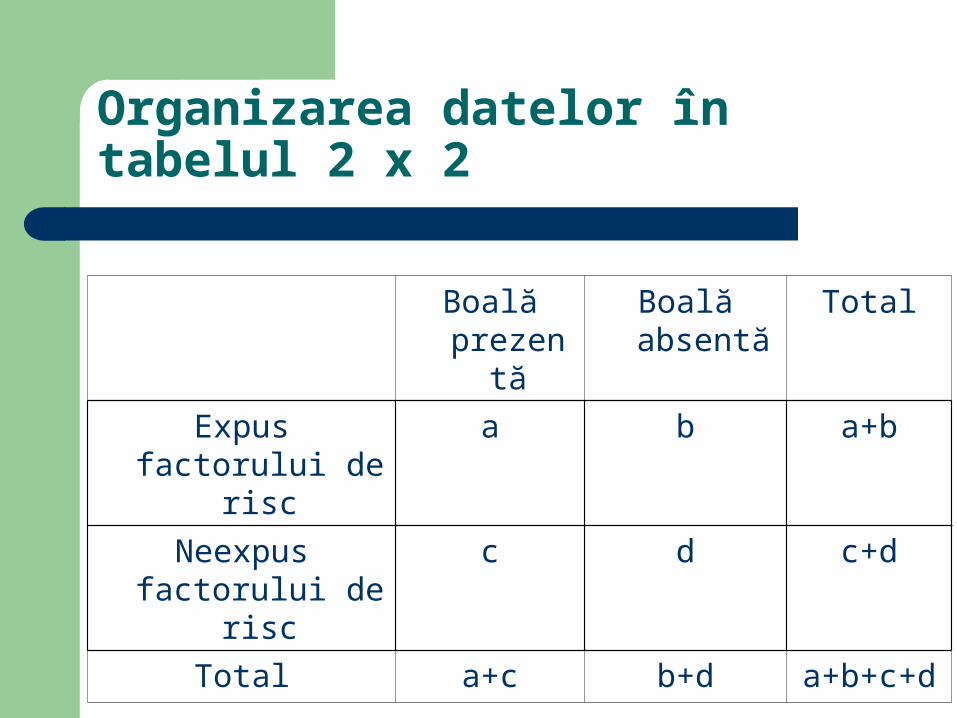
Organizarea datelor în tabelul 2 x 2
Boală prezentă
Boală absentă
Total
Expus factorului de risc
a b a+b
Neexpus factorului de risc
c d c+d
Total a+c b+d a+b+c+d

Scopul / utilitatea
Măsurarea şi compararea incidenţei apariţiei unui fenomen de sănătate între una sau mai multe cohorte
Estimarea riscurilor, ratelor de apariţie a stării de sănătate, legate de un factor de risc (expunere)

Analiza
Definirea caracteristicilor cohortei Decizia de a utiliza datele despre cazuri şi
non cazuri sau datele despre participarea subiecţilor la studiu (persoană – timp)
Calcularea riscurilor/ratelor în grupuri în funcţie de caracteristici

Rata
Proporţia de persoane care dezvoltă boala într-o perioadă de timp specificată
Din totalul populaţiei la risc luate iniţial în calcul:
Rata = nr. Persoane cu boală / populaţia totală la risc
Ex. Din 1000 persoane urmărite 5 ani 42 dezvoltă boala şi 958 nu dezvoltă boala
Rata = 42/1000 =0.042

Riscul
Probabilitatea de a dezvolta boala Incidenţa = numărul de cazuri noi apărute
într-o perioadă de timp dată / populaţia la risc în aceeaşi perioadă de timp x 10n– Unde: – Numitorul poate fi:
Numărul mediu al populaţiei în perioada de timp studiată Mărimea populaţiei în mijlocul perioadei de studiu Mărimea populaţiei la începutul studiului

Riscul relativ
Este o măsură a asocierii dintre un factor de risc şi apariţia unei boli
dccbaa
RR

Interpretarea valorii RR:– Boala este de RR mai frecventă în grupul de
expuşi faţă de grupul de neexpuşi– Cu cât RR este mai mare cu atât asocierea dintre
factorul de risc şi apariţia bolii este mai mare– Valorile RR apropiate de 1 indică lipsa oricărei
legături între factor şi boală– Valorile subunitare indică o asociere negativă
între factorul de risc studiat şi boală
Riscul relativ

Intervalul de confidenţă pentru RR
Se calulează pornind de la premiza unei distribuţii a variabilelor care respectă normalitatea
Practic: IC = RR (1 ± z/x) Unde x2 = [(t - 1) x (ad - bc)2] / (a+c) x (b+d) x
(a+b) x (c+d)

Riscul relativ
Interpretarea RR in funcţie de IC– Pentru RR cu valoare mai mare de 1 şi IC cu
valori apropiate de RR calculat care nu include valoarea 1putem decide că există asociere pozitivă între factorul de risc şi boală
– Pentru valori RR mai mari de 1 dar IC care include valoarea 1 se poate concluziona că factorul de risc studiat este indiferent (oricât de mare ar fi valoarea lui calculată)

Riscul relativ
Interpretarea RR in funcţie de IC– Pentru RR cu valoare mai mică de 1 şi IC cu
valori apropiate de RR calculat care nu include valoarea 1putem decide că există asociere negativă între factorul de risc şi boală (este factor protector)
– Pentru valori RR mai mici de 1 dar IC care include valoarea 1 se poate concluziona că factorul de risc studiat este indiferent

Exemplu
Directorul unei DSP constată că numărul de perderi de sarcină în regiunea rurală este mai mare decât în regiunea urbană în acelaşi judeţ. Principala ocupaţie în mediu rural este agricultura, existând contact cu pesticide organofosforice. Ipoteza lui este: cauza acestor pierderi de sarcină este intoxicarea cu compuşi organofosforici. Se doreşte evaluarea acestei ipoteze cu un nivel de semnificaţie α = 0.05.

Scopul
Să se evaluaze legătura între expunerea la compuşi organofosforici şi avorturile spontane

Obiective
Principal: – Calcularea rolului contaminării cu pesticide în
determinarea avorturilor spontane
Secundare: – Selectarea populaţiei ţintă– Calcularea eşantioanelor (cohortelor) pentru
criterii de reprezentativitate– Stabilirea comparabilităţii loturilor

Ipoteza de lucru
Contaminarea gravidelor cu pesticide reprezintă factori de risc factor de risc pentru avortul spontan

Eşantionarea
Culegerea datelor tip expus – non expus Criterii de includere în loturile de studiu:
– Persoane de sex feminin gravide– Persoane de sex feminin fără antecedente
obstetricale care pot duce la avort spontan Talia celor două loturi pentru o bună
reprezentativitate calitativă (conform formulei de eşantionare pentru evaluare de proporţii n = 79, se va folosi n = 100)

Formularea ipotezelor de testat
H0 = nu există nici o asociere între expunerea la pesticide şi avortul spontan
H1= există o asociere între expunerea la pesticide şi avortul spontan

Alegerea testului statistic de semnificaţie
Variabilele studiate sunt binare Loturile sunt similare demografic dar sunt
nepereche
=> testul statistic adecvat este Chi2 (dacă toate valorile obţinute sunt mai mari de 5) sau Fisher pentru valori mai mici decât 5
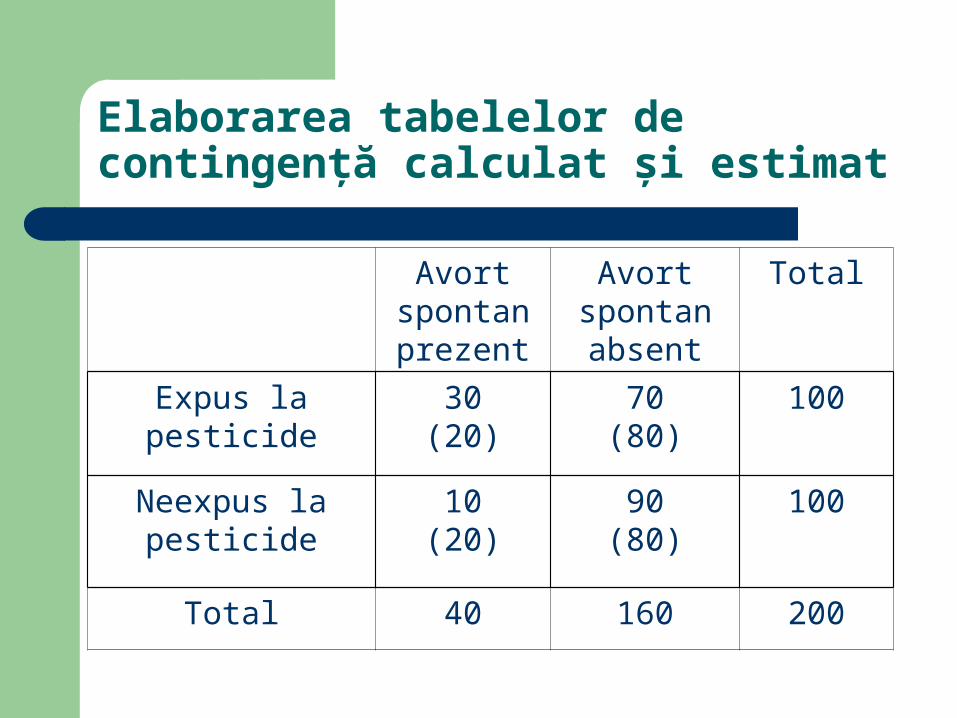
Elaborarea tabelelor de contingenţă calculat şi estimat
Avort spontan prezent
Avort spontan absent
Total
Expus la pesticide 30(20)
70(80)
100
Neexpus la pesticide
10(20)
90(80)
100
Total 40 160 200

Calcularea statisticii testului
Conform formulei de calcul Χ2 = (30 - 20)2/20 + (10 - 20)2/20 + (70 -
80)2/80 + (90 - 80)2/80 = 12.5 Din tabelul de valori pentru chi2 pentru 1
grad de libertate rezultă că p < 0.005 Concluzia este că asocierea este
semnificativă statistic (p < α)

Calcularea RR
Calcularea măsurii în care contaminarea cu pesticide duce la apariţia avortului spontan
Conform formulei de calcul pentru RR:
RR = a/(a+b) / c/(c+d) = 3 IC 95% nu include valoarea 1 = (2.44 – 3.55)

Concluzia studiului
Contaminarea cu pesticide este factor de risc pentru apariţia avortului spontan
Femeile gravide contaminate cu pesticide au de 3 ori mai mare riscul să sufere un avort spontan (p < 0.05)
Asocierea este extrem de semnificativă statistic