Embed Size (px)
DESCRIPTION
Studio degli indici per query di similarità basati su matrici di distanze. Esame di Sistemi Informativi per le Decisioni L-S Presentato da: Ing. Marco Patella Mario Masciulli. Indice. Introduzione al problema; - PowerPoint PPT Presentation
Citation preview

Studio degli indici per query di Studio degli indici per query di similarità basati su matrici di distanzesimilarità basati su matrici di distanze
Esame di Sistemi Informativi per le Decisioni L-SEsame di Sistemi Informativi per le Decisioni L-S
Presentato da:Presentato da:Ing. Marco Patella Mario MasciulliIng. Marco Patella Mario Masciulli

IndiceIndiceIntroduzione al problema;Introduzione al problema;Indici per query di similarità basati su alberi;Indici per query di similarità basati su alberi;Indici per query di similarità basati suIndici per query di similarità basati su pivot; pivot;Esempi:Esempi:
AESAAESA (Approximating and Eliminating Search Algorithm); (Approximating and Eliminating Search Algorithm); LAESALAESA (Linear AESA); (Linear AESA); Spaghettis;Spaghettis; Fixed Array Queries;Fixed Array Queries;
Verifica prestazioni e conclusioni.Verifica prestazioni e conclusioni.

IntroduzioneIntroduzioneEvoluzione della tecnologia dei DB;Evoluzione della tecnologia dei DB;Maggiori difficoltà di reperimento informazioni;Maggiori difficoltà di reperimento informazioni;Indicizzazione dello spazio (vettoriale o metrico);Indicizzazione dello spazio (vettoriale o metrico);Settore di studio molto vitale;Settore di studio molto vitale;Due metodologie principali:Due metodologie principali:
Indici basati su alberi;Indici basati su alberi; Indici basati su pivot.Indici basati su pivot.

Indici basati su alberiIndici basati su alberiR-treeR-tree
Indice multidimensionale, deriva da BIndice multidimensionale, deriva da B++-tree;-tree;Organizza gli oggetti in regioni (Organizza gli oggetti in regioni (MBRMBR););Indice dinamico, bilanciato, paginato;Indice dinamico, bilanciato, paginato;Informazioni memorizzate nelle Informazioni memorizzate nelle entries:entries:
E=(key,ptr)E=(key,ptr)Ricerca oggetti Ricerca oggetti top-downtop-downProblema: lavora solo su spazi vettorialiProblema: lavora solo su spazi vettoriali

Indici basati su alberiIndici basati su alberi
M-treeM-treeEvoluzione di Evoluzione di R-treeR-tree basata su distanze metriche; basata su distanze metriche;Black box Black box per il calcolo delle distanze;per il calcolo delle distanze;Condizioni di lavoro in uno spazio metrico:Condizioni di lavoro in uno spazio metrico:
positività: d(x,y)positività: d(x,y)≥0, d(x,y)=0 ≥0, d(x,y)=0 x = y; x = y; simmetria: d(x,y) = d(y,x);simmetria: d(x,y) = d(y,x); disuguaglianza triangolare: d(x,y) ≤ d(x,z) + d(z,y).disuguaglianza triangolare: d(x,y) ≤ d(x,z) + d(z,y).
Uso di Uso di entries entries per memorizzare informazioni:per memorizzare informazioni:E=(RoutObjFeat, CovRadius, distP, ptr)E=(RoutObjFeat, CovRadius, distP, ptr)
Vantaggio: circa il 40% di calcoli in menoVantaggio: circa il 40% di calcoli in meno

Indici basati su Indici basati su pivotpivot
Pivot based techniques (I)Pivot based techniques (I)Caratteristiche generali:Caratteristiche generali:
Mapping da spazio metrico a vettoriale in Mapping da spazio metrico a vettoriale in kk dimensioni; dimensioni;
D(x,y)≤d(x,y)D(x,y)≤d(x,y)Fase di Fase di preprocessing: preprocessing: calcolo di calcolo di k*n k*n distanze;distanze;Def. Def. complessità interna = kcomplessità interna = k: numero di distanze da : numero di distanze da calcolare per ogni esecuzione query;calcolare per ogni esecuzione query;Def. Def. complessità esternacomplessità esterna: numero di punti per cui non : numero di punti per cui non vale la condizione di vale la condizione di pruning.pruning.

Indici basati su pivotIndici basati su pivot
Pivot based techniques (II)Pivot based techniques (II)Caratteristiche generali:Caratteristiche generali:
Obj: Obj: trade off trade off tra complessità interna (numero di tra complessità interna (numero di pivotpivot) ed ) ed esterna => scelta del numero ottimale di esterna => scelta del numero ottimale di pivot;pivot;Sulla Sulla complessità esternacomplessità esterna si interviene con politiche di si interviene con politiche di pruningpruning più efficaci. più efficaci.Definizioni preliminari: Definizioni preliminari: spazio metrico spazio metrico E=(U,d);E=(U,d);P E: P E: insieme dei prototipi;insieme dei prototipi;y Ey E: : test sample.test sample.

AESA (Approximating and AESA (Approximating and Eliminating Search Algorithm)Eliminating Search Algorithm)
Definisce una matrice triangolare Definisce una matrice triangolare [n x n][n x n] nella fase di nella fase di preprocessing:preprocessing:
O(nO(n22) n(n-1)/2) n(n-1)/2Idea di base: Idea di base: funzionamento del tutto simile agli altri funzionamento del tutto simile agli altri algoritmi k-NN:algoritmi k-NN:
Fasi di Fasi di approximating approximating ed ed eliminating: eliminating: definizione di un definizione di un lower lower bound bound sul quale eseguire il sul quale eseguire il pruning.pruning.
Definizione di prototipi Definizione di prototipi attivi (a)attivi (a), , selezionatiselezionati (s)(s) ed ed eliminati.eliminati.

AESA (Approximating and AESA (Approximating and Eliminating Search Algorithm)Eliminating Search Algorithm)
Vantaggi:Vantaggi:LaLa “ “forza” del forza” del pruningpruning cresce man mano che si cresce man mano che si costruisce la soluzione;costruisce la soluzione;La distanza è calcolata solo per i prototipi selezionati;La distanza è calcolata solo per i prototipi selezionati;Soluzione trovata molto accurata Soluzione trovata molto accurata (k = n).(k = n).
Svantaggi:Svantaggi:Complessità spaziale e temporale: Complessità spaziale e temporale: O(nO(n22););Overhead Overhead dipendente linearmente dalla dimensione di dipendente linearmente dalla dimensione di P.P.

LAESA (Linear AESA)LAESA (Linear AESA)Evoluzione di Evoluzione di AESAAESA con con preprocessing preprocessing lineare;lineare;Scelta di Scelta di m prototipi base B (pivot) m prototipi base B (pivot) con con B P;B P;Creazione matrice Creazione matrice [m x n][m x n] delle distanze: delle distanze:
O(mn)O(mn)Scelta Scelta prototipi baseprototipi base::
Ricerca iterativa dell’elemento di Ricerca iterativa dell’elemento di P-BP-B, con distanza cumulata , con distanza cumulata massima dall’ultimo elemento massima dall’ultimo elemento selezionato in selezionato in BB

LAESA (Linear AESA)LAESA (Linear AESA)Algoritmo di ricerca (esempio Algoritmo di ricerca (esempio 1-NN query)1-NN query)::
Aggiornamento array di Aggiornamento array di pruningpruning solo per solo per s Bs B
Doppia condizione per il Doppia condizione per il pruningpruning di p Bdi p B
Distinguo tra:Distinguo tra:
pp BB e e pp P-BP-B
Due candidati ad essere Due candidati ad essere selezionati:selezionati:
b b e e q q

LAESA (Linear AESA)LAESA (Linear AESA)Le funzioni Le funzioni CHOICECHOICE e e CONDITIONCONDITION definiscono le definiscono le strategie di uso ed eliminazione dei strategie di uso ed eliminazione dei prototipi base;prototipi base;In particolare:In particolare:
Scelgo sempre Scelgo sempre bb, se esiste, se esiste
Due esempi di politiche di Due esempi di politiche di eliminazione dei eliminazione dei prototipi base:prototipi base:

LAESA (Linear AESA)LAESA (Linear AESA)
Vantaggi:Vantaggi:Elevata riduzione della complessità spaziale e temporale Elevata riduzione della complessità spaziale e temporale del del preprocessingpreprocessing: : O(mn).O(mn).
Svantaggi:Svantaggi:Minor accuratezza della soluzione trovata (k < n);Minor accuratezza della soluzione trovata (k < n);Leggera crescita del numero di distanze calcolate Leggera crescita del numero di distanze calcolate (LAESA (LAESA ≈ 1.5 AESA).≈ 1.5 AESA).

SpaghettisSpaghettis
Idea di base: Idea di base: PBTPBT lavorano su spazi vettoriali lavorano su spazi vettoriali k-k-dimensionali dimensionali =>=> unauna query query può essere vista come un può essere vista come un ipercubo k-dimensionale;ipercubo k-dimensionale;Perché un punto Perché un punto xx faccia parte della soluzione: faccia parte della soluzione:
|d(x,p|d(x,pii)-d(q,p)-d(q,pii)|≤r p)|≤r pii
Scomponendo, lungo ogni coordinata Scomponendo, lungo ogni coordinata ii::xxii [a [aii ,b ,bii]]
dove: dove: aaii = d(q,p = d(q,pii) – r, b) – r, bii = d(q,p = d(q,pii) + r) + r
Nel Nel preprocessing Spaghettispreprocessing Spaghettis crea crea k arrays, k arrays, uno per ogni uno per ogni dimensione (dimensione (pivotpivot).).
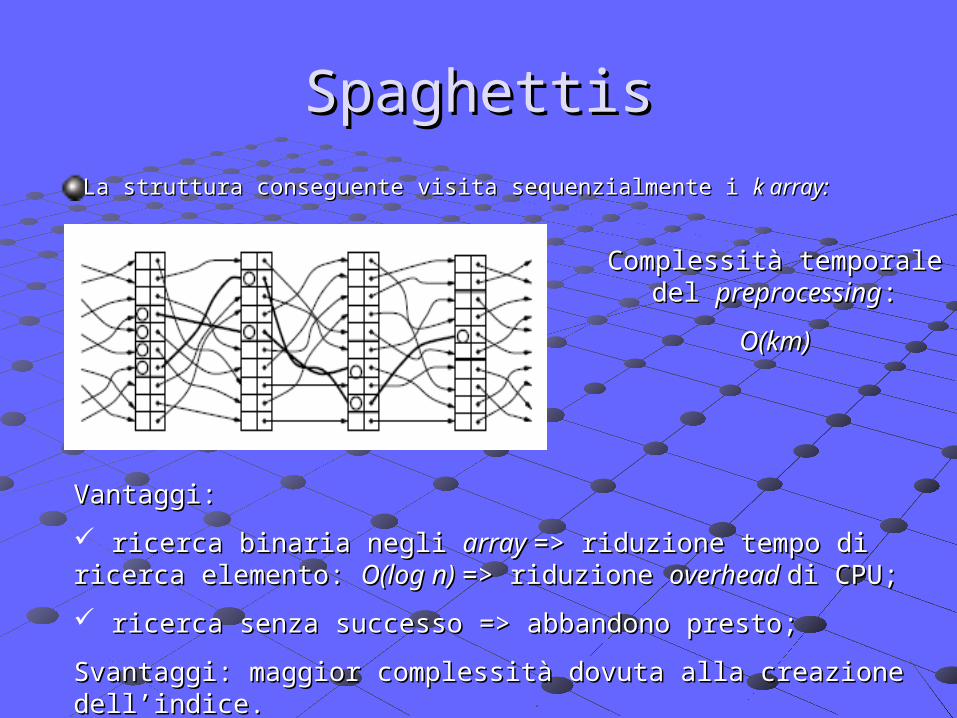
SpaghettisSpaghettis
La struttura conseguente visita sequenzialmente i La struttura conseguente visita sequenzialmente i k array:k array:
Complessità temporale del Complessità temporale del preprocessingpreprocessing::
O(km)O(km)
Vantaggi:Vantaggi:
ricerca binaria negli ricerca binaria negli array array => riduzione tempo di ricerca elemento: => riduzione tempo di ricerca elemento: O(log n) O(log n) => riduzione => riduzione overhead overhead di CPU;di CPU;
ricerca senza successo => abbandono presto;ricerca senza successo => abbandono presto;
Svantaggi: maggior complessità dovuta alla creazione dell’indice.Svantaggi: maggior complessità dovuta alla creazione dell’indice.

Fixed Queries ArraysFixed Queries ArraysNovità: crescita sublineare dell’Novità: crescita sublineare dell’overheadoverhead con creazione di con creazione di un indice meno “pesante”;un indice meno “pesante”;Crea un Crea un arrayarray di di kn kn elementi ordinati elementi ordinati lessicograficamente lessicograficamente in base alla loro distanza dai pivot (in base alla loro distanza dai pivot (hphp: distanze discrete): distanze discrete)::
d(q,p1) d(q,p2) d(q,p3)
1 1 3 4 5 5 2 3 3 4 5 6 1 3 3 4 4 6
k=1 k=2 k=3
Ricerca binaria nell’Ricerca binaria nell’arrayarray => confronto tra interi => => confronto tra interi => extra-extra-CPU time = CPU time = costo ricerca = costo ricerca = O(log n);O(log n);
Crescita complessità Crescita complessità preprocessingpreprocessing per l’ordinamento per l’ordinamento dell’dell’array:array:
O(kn log n)O(kn log n)

Fixed Queries ArraysFixed Queries ArraysAlgoritmo per una Algoritmo per una range query.range query.Ad ogni colonna corrisponde un Ad ogni colonna corrisponde un pivot;pivot;in ogni riga abbiamo le distanze di in ogni riga abbiamo le distanze di un prototipo dai un prototipo dai k pivot.k pivot.Nell’esempio: Nell’esempio: k=4, {d(q,pk=4, {d(q,p11),),…,d(q,p…,d(q,p44)}={3,4,5,4} e r=2:)}={3,4,5,4} e r=2:
prendo il prendo il pivot ppivot p11: : per ogni valore per ogni valore intero intero ii contenuto in contenuto in [d(q, p[d(q, p11)-r, d(q, )-r, d(q, pp11)+r] )+r] cerco nell’cerco nell’arrayarray i punti i punti xx t.c. t.c. d(x,pd(x,p11) = i;) = i;
questi punti costituiscono la lista questi punti costituiscono la lista dei candidati provvisoria;dei candidati provvisoria;
Itero la ricerca per Itero la ricerca per pp22, p, p33, …, p, …, pkk..
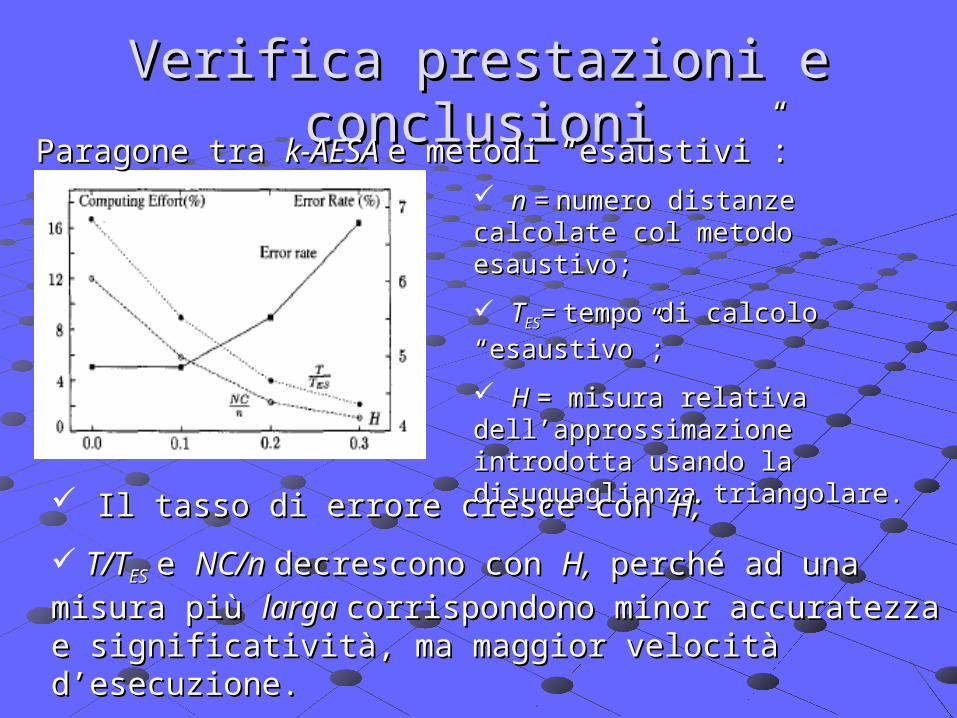
Verifica prestazioni e conclusioniVerifica prestazioni e conclusioniParagone tra Paragone tra k-AESA k-AESA e metodi “esaustivi”:e metodi “esaustivi”:
n = n = numero distanze calcolate col numero distanze calcolate col metodo esaustivo;metodo esaustivo;
TTESES= = tempo di calcolo “esaustivo”;tempo di calcolo “esaustivo”;
H H = misura relativa = misura relativa dell’approssimazione introdotta dell’approssimazione introdotta usando la disuguaglianza triangolare.usando la disuguaglianza triangolare.
Il tasso di errore cresce con Il tasso di errore cresce con H;H;
T/TT/TESES e e NC/n NC/n decrescono con decrescono con H,H, perché ad una misura più perché ad una misura più larga larga corrispondono minor accuratezza e significatività, ma corrispondono minor accuratezza e significatività, ma maggior velocità d’esecuzione.maggior velocità d’esecuzione.
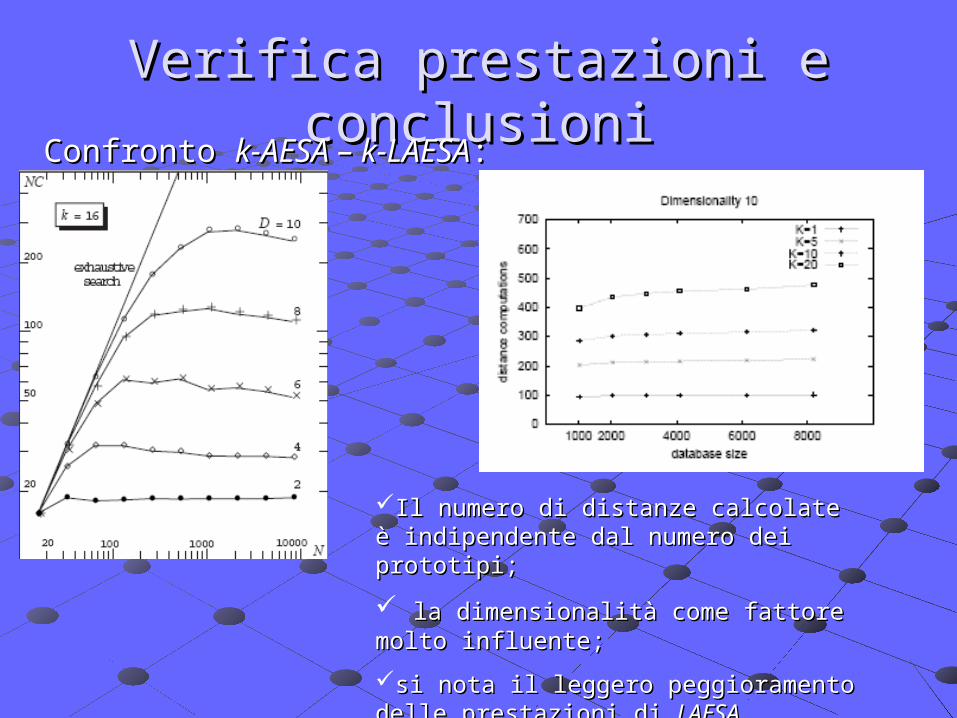
Verifica prestazioni e conclusioniVerifica prestazioni e conclusioniConfronto Confronto k-AESA – k-LAESAk-AESA – k-LAESA::
Il numero di distanze calcolate è Il numero di distanze calcolate è indipendente dal numero dei prototipi;indipendente dal numero dei prototipi;
la dimensionalità come fattore molto la dimensionalità come fattore molto influente;influente;
si nota il leggero peggioramento delle si nota il leggero peggioramento delle prestazioni di prestazioni di LAESA.LAESA.
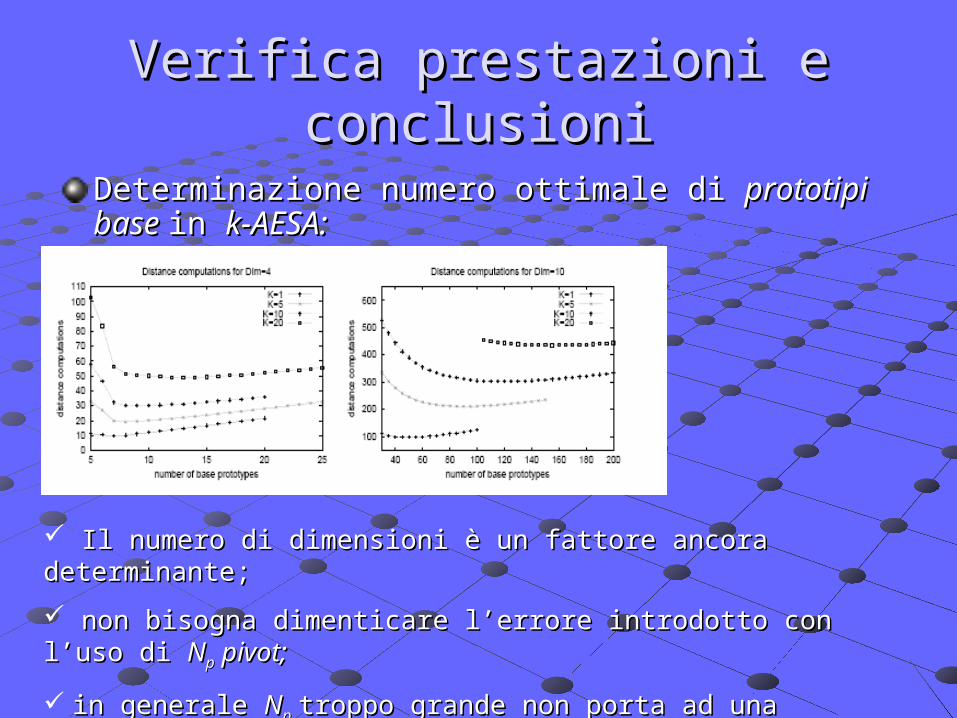
Verifica prestazioni e conclusioniVerifica prestazioni e conclusioni
Determinazione numero ottimale di Determinazione numero ottimale di prototipi base prototipi base in in k-k-AESA:AESA:
Il numero di dimensioni è un fattore ancora determinante;Il numero di dimensioni è un fattore ancora determinante;
non bisogna dimenticare l’errore introdotto con l’uso di non bisogna dimenticare l’errore introdotto con l’uso di NNpp pivot; pivot;
in generale in generale NNpp troppo grande non porta ad una corrispondente crescita troppo grande non porta ad una corrispondente crescita di significatività.di significatività.





























