Embed Size (px)
Citation preview

Super fast identification and optimization of high quality drug candidates

Our Goals Constructing highly enriched and efficient
molecular libraries for the development of new and selective drug-like leads
Minimizing false positives by early identification of drug failures, resulting in reduced cost/time of drug development

Preclinical Drug Discovery
We reduce lead identification and optimization to 1-3 months, and identify highest quality drug candidates

Rules for drug-like properties (Lipinski, Veber): binary, many false
positives
Data Mining from HTS: requires innovative algortihms
“Similarity” searches (mostly structural) : limit innovation
Drug-target “Docking” algorithms: at their infancy, false
positives & negatives
ADME/Tox models: can not accurately predict a molecule’s
chance to become a drug
Competing state-of-the-art computational drug discovery technologies in Pharma

Experimental
Datasets
(drugs, Non-drugs,
agonists,
antagonists, inhibitors)
DLIand/or
MBI
ISE (Iterative Stochastic Elimination) engine
Our Technology: what do we do best ?
Grading drug likeness and molecular bioactivity
Drug-Target: “Molecular Bioactivity Index” (MBI)
Drug-Body: “Drug Like Index” (DLI)

MBI and DLI
MBI is a number that expresses the chance of a molecule being a high affinity ligand for a specific biological target
DLI is a number that expresses the chance of a molecule to become a drug
Double focusing using MBI and DLI provides: combined target specificity and drug-likeness

High Throughput Screening
Combinatorial Synthesis
Hit to lead development
Lead optimization
Construction of Focused libraries
Molecular scaffold optimization
Selectivity optimization
MBI and DLI can make a difference in:

Iterative Stochastic Elimination:A new tool for optimizing highly complex problems
First prize in emerging technologies symposium of ACS
Patent in National phase examination in several countries
PCT on the derived technology of DLI

IPA stochastic method to determine in silico the drug like
character of molecules
By Rayan, Goldblum, Yissum (PCT stage)
A new provisional patent application covering the MBI algorithm will be submitted

ISE for identification of high quality leads
ISE Engine
Huge CommercialDatabase of chemicals
TRAINING SET TEST SET
MBI MODEL
ValidationINPUT
Database orderedBy Bioactivity
Index
1-2
day
s

Huge CommercialDatabase ofchemicals
Database orderedBy Bioactivity
Index
Assumed high affinity leads
Validations: Docking, Scifinder, “fishing” tests
DLI Optimized leads for in vitro and animal tests
MBI MODEL
2 - 4 days
Few hours
Double focusing with MBI and DLI

MODELS
Matrix metalloproteinase-2 (MMP-2)
Endothelin receptor
D2- dopaminergic receptor
DHFR
Histaminergic receptors
HIV-1 protease
Cannabinoid receptor
And others..

Excellent enrichment of “actives” from “non-actives” using MBI
Excellent separation of drugs from “non-drugs” using DLI
Discovering molecules for a known drug target, validated by a docking algorithm
Successful validation of MBI technology by big Pharma
Current technological status:
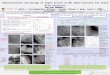
Molecular Bioactivity Index (MBI):Fishing actives from a “bath” of “non-actives”
Mix 10 in 100,000 - find 9 in best 100, 5 in best 10
Enrichment of 5000
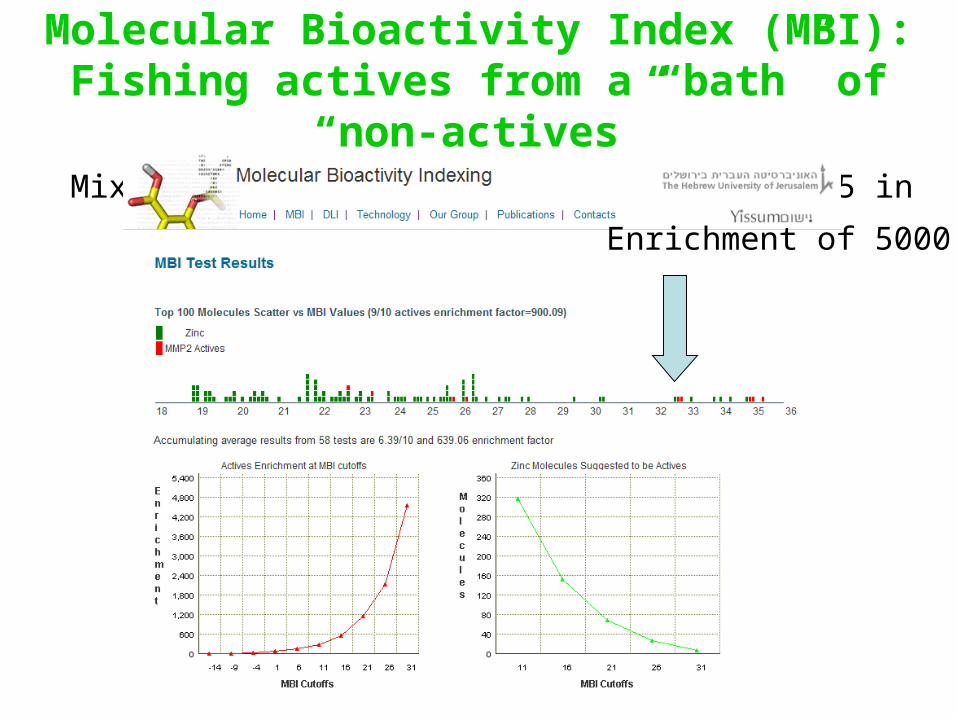
Drug Likeness Index (DLI):Randomly mixing 10 Drugs + 100 Non-drugs
Enrichment of ~7
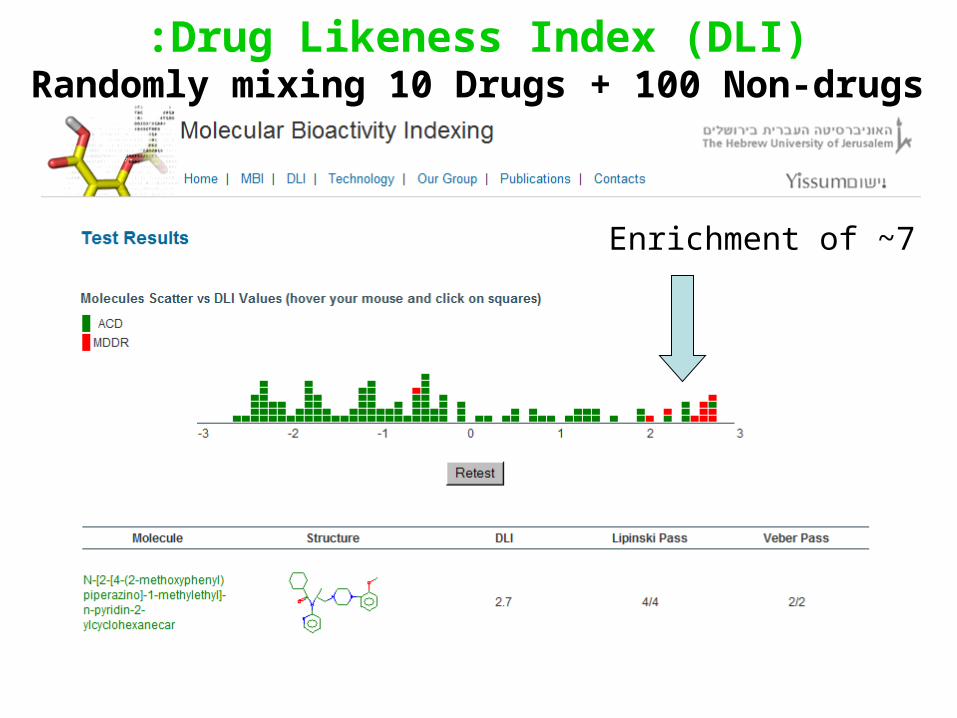
DLI vs. the Medicinal Chemist-1

DLI vs. the Medicinal Chemist-2
5 top Medicinal chemists examined

MMP-2 as a target for POC
Identifying high affinity ligands for Matrix
metalloproteinase-2 (MMP-2) was chosen as proof of
concept for our technology
MMP-2 (or Gelatinase A) is involved in several types of
cancer, such as Breast cancer, Hepatocellular carcinoma,
Smooth muscle hyperplasia and possibly others
We have large datasets for training
Chemicals easy to purchase
In vitro assay available
Animal model available (murine leukemia)
Israel Science Foundation collaboration

Typical MMP-2 actives - nanomolar
Typically - hydroxamates and sulphonamides
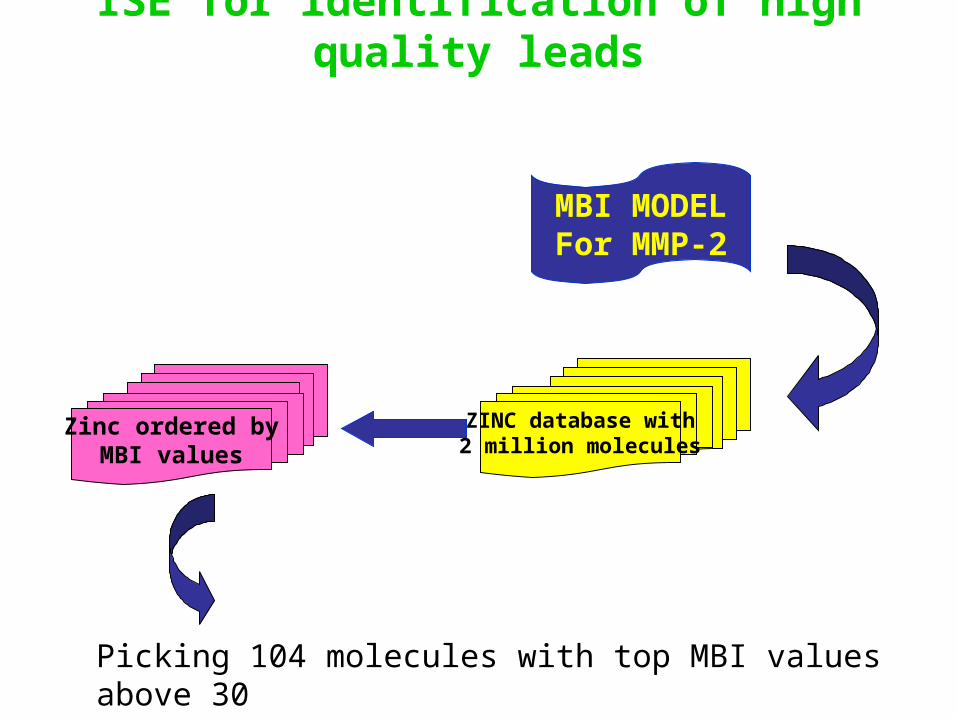
ISE for identification of high quality leads
MBI MODELFor MMP-2
ZINC database with2 million molecules
Zinc ordered byMBI values
Picking 104 molecules with top MBI values above 30

Similarity between 104 prospective MMP-2 leads and the 650 MMP-2 leads used for model construction
0
10
20
30
40
50
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Tanimoto Index
Nu
mb
er o
f m
ole
cule
s
SimilarLess
Similar
NewChemicalEntities(> 90 !)

Non-typical MMP-2 suspected nanomolar candidates
1.00 0.04 0.02 0.09 0.04 0.08 0.11 0.020.04 1.00 0.16 0.04 0.26 0.15 0.17 0.090.02 0.16 1.00 0.07 0.14 0.08 0.09 0.060.09 0.04 0.07 1.00 0.12 0.06 0.21 0.110.04 0.26 0.14 0.12 1.00 0.15 0.15 0.140.08 0.15 0.08 0.06 0.15 1.00 0.20 0.060.11 0.17 0.09 0.21 0.15 0.20 1.00 0.070.02 0.09 0.06 0.11 0.14 0.06 0.07 1.00
8 of highest diversity were pickedScifinder – none ever examined on any MMP
The first MMP-2 candidate inhibitors picked for purchasing and testing in the lab are devoid of the characteristics of MMP-2 or other MMP inhibitors. These molecules are not known to have any prior biological activity and have a very low similarity index (Tanimoto) to each other (the highest similarities are marked in yellow in the matrix above).

Independent validation by docking
7 out of the 8 dock well to the active site of MMP- 2

The Big Pharma technology testEnrichment Curves
Our ISE

Our superiority claim
Highly innovative Prize winning optimization
algorithm
The best enrichment algorithm currently available
MBI: “actives” from “non-actives”
DLI: drugs from “non-drugs”
Identification of highly diverse drug candidates
Reduction of time for lead identification and
optimization

We vs. chemical companies selling focused libraries
Company
name
Combinat.
algorithm
Novel detect
False positiv
False negat.
Enrichment Model speed
Virtual screening speed 106
3D structure required ?
Biofocus - Yes - - 10-100 - - Yes
Pharmacopeia No Yes High High 5-50 - 16,000 hours/CPU
Yes
Enamine No No S Yes D
Low S High D
High
High
10-1000 S 5-50 D
- 300-16,000 hours/CPU
No
Yes
TimeTec No No Low High 10-1000 - 300 hours/CPU
No
IBS-interbioscreen
No No Low High 10-1000 - 300 hours/CPU
No
Comgenex - No Low High 10-1000 - 300 hours/CPU
No
OSI pharmaceutical
- Yes High High 5-50 - 16,000 hours/CPU
Yes
Our algorithm Yes Yes Low Low 200 – 5,000 1-2 days
2 hours No
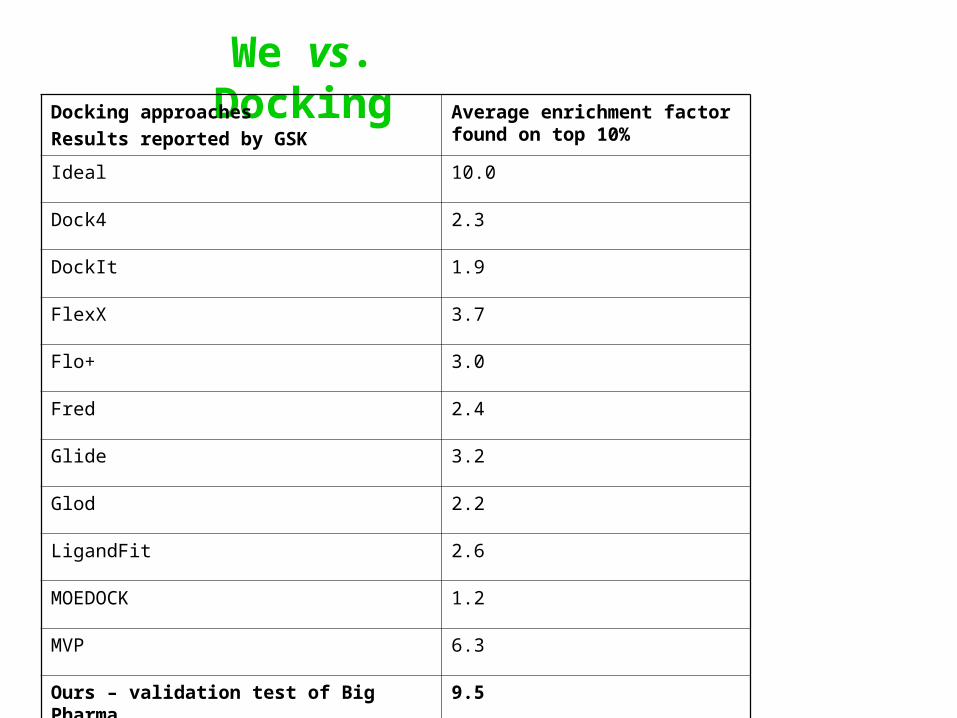
We vs. DockingDocking approaches
Results reported by GSK
Average enrichment factor found on top 10%
Ideal 10.0
Dock4 2.3
DockIt 1.9
FlexX 3.7
Flo+ 3.0
Fred 2.4
Glide 3.2
Glod 2.2
LigandFit 2.6
MOEDOCK 1.2
MVP 6.3
Ours – validation test of Big Pharma 9.5