Embed Size (px)
Citation preview

Supervised Learning I, Cont’d
Reading: DH&S, Ch 8.1-8.4

Administrivia•Machine learning reading group
•Not part of/related to this class
•We read advanced (current research) papers in the ML field
•Might be of interest. All are welcome
•Meets Fri, 2:00-3:30, FEC325 conf room
•More info: http://www.cs.unm.edu/~terran/research/reading_group/
•Lecture notes online

www.topcoder.com/unm

Yesterday & today•Last time:
•Basic ML problem
•Definitions and such
•Statement of the supervised learning problem
•Today:
•HW 1 assigned
•Hypothesis spaces
•Intro to decision trees

Homework 1
•Due: Tues, Jan 31
•DH&S, problems 8.1, 8.5, 8.6 (a & b), 8.8 (a), 8.11

•Feature (attribute):
•Instance (example):
•Label (class):
•Feature space:
•Training data:
Review of notation

Finally, goals•Now that we have and , we have a (mostly) well defined job:
Find the function
that most closely approximates the “true” function
The supervised learning problem:

Goals?•Key Questions:
•What candidate functions do we consider?
•What does “most closely approximates” mean?
•How do you find the one you’re looking for?
•How do you know you’ve found the “right” one?

Hypothesis spaces•The “true” we want is usually called the target concept (also true model, target function, etc.)
•The set of all possible we’ll consider is called the hypothesis space,
•NOTE! Target concept is not necessarily part of the hypothesis space!!!
•Example hypothesis spaces:
•All linear functions
•Quadratic & higher-order fns.
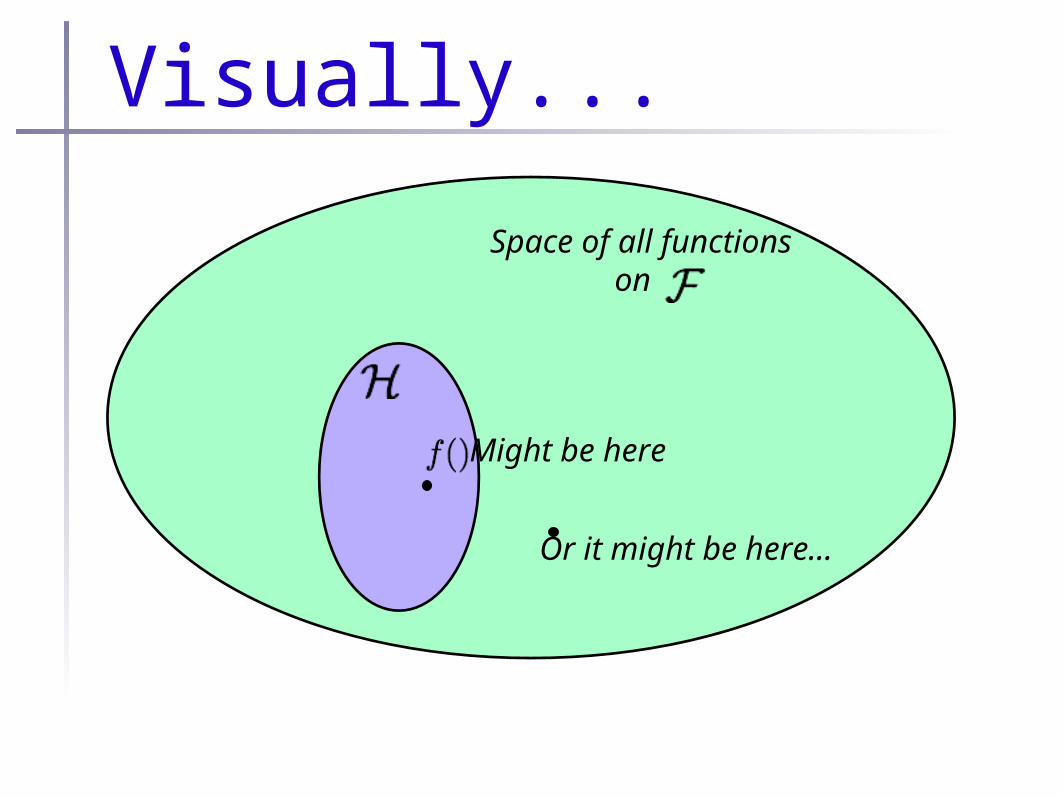
Space of all functionson
Visually...
Might be here
Or it might be here...

More hypothesis spacesRulesif (x.skin==”fur”) { if (x.liveBirth==”true”) { return “mammal”; } else { return “marsupial”; }} else if (x.skin==”scales”) { switch (x.color) { case (”yellow”) { return “coral snake”; } case (”black”) { return “mamba snake”; } case (”green”) { return “grass snake”; } }} else { ...}
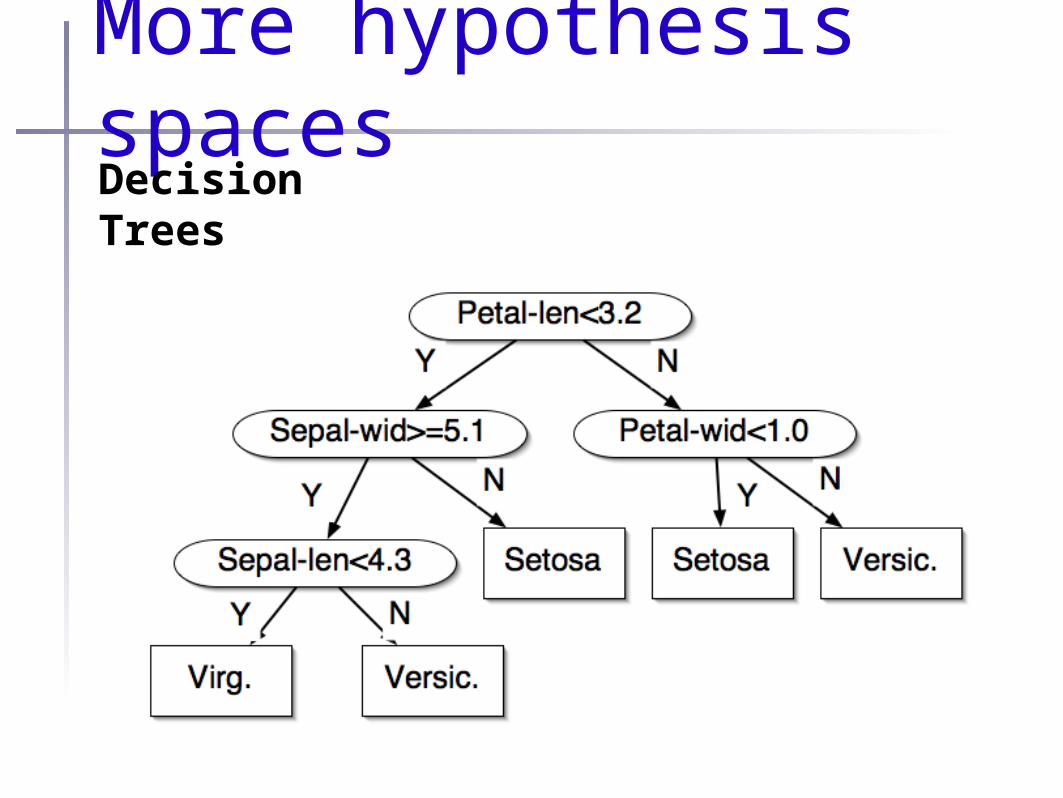
More hypothesis spacesDecisionTrees
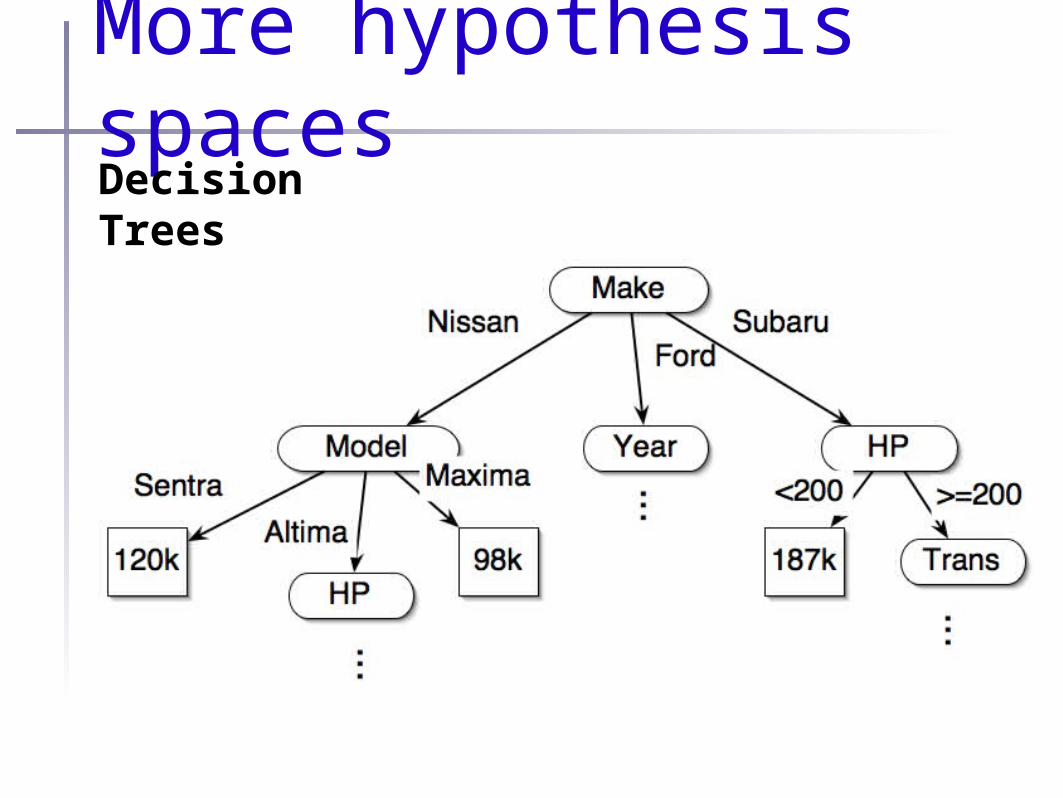
More hypothesis spacesDecisionTrees
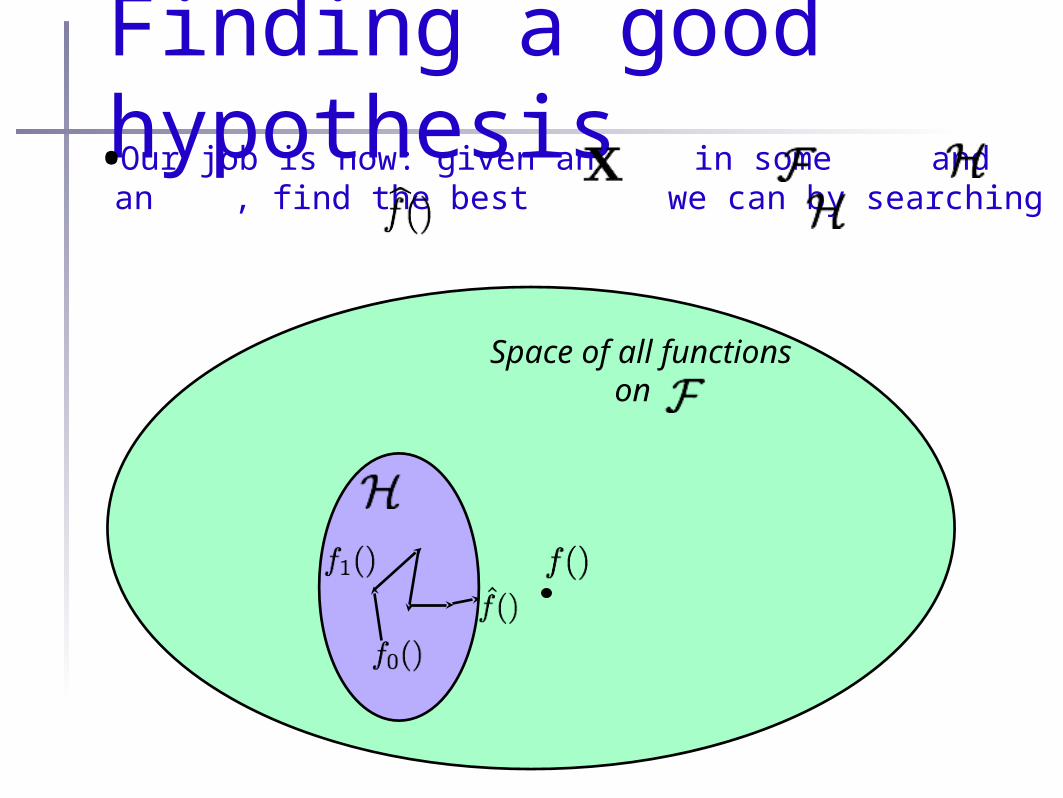
Finding a good hypothesis•Our job is now: given an in some and an , find the best we can by searching
Space of all functionson

Measuring goodness•What does it mean for a hypothesis to be “as close as possible”?
•Could be a lot of things
•For the moment, we’ll think about accuracy
•(Or, with a higher sigma-shock factor...)

Aside: Risk & Loss funcs.•The quantity is called a risk function
•A.k.a., expected loss function
•Approximation to true loss:
•(Sort of) measure of distance between “true” concept and approximation to it
All functionson

Constructing DT’s, intro•Hypothesis space:
•Set of all trees, w/ all possible node labelings and all possible leaf labelings
•How many are there?
•Proposed search procedure:
•Propose a candidate tree, ti
•Evaluate accuracy of ti w.r.t. X and y
•Keep max accuracy ti
•Go to 1
•Will this work?

A more practical alg.
•Can’t really search all possible trees
•Instead, construct single tree
•Greedily
•Recursively
•At each step, pick decision that most improves the current tree

A more practical alg.DecisionTree buildDecisionTree(X,Y) {// Input: instance set X, label set Yif (Y.isPure()) {return new LeafNode(Y);
}else {Feature a=getBestSplitFeature(X,Y);DecisionNode n=new DecisionNode(a);[X0,...,Xk,Y0,...,Yk]=a.splitData(X,Y);for (i=0;i<=k;++i) {n.addChild(buildDecisionTree(Xi,Yi));
}return n;
}}
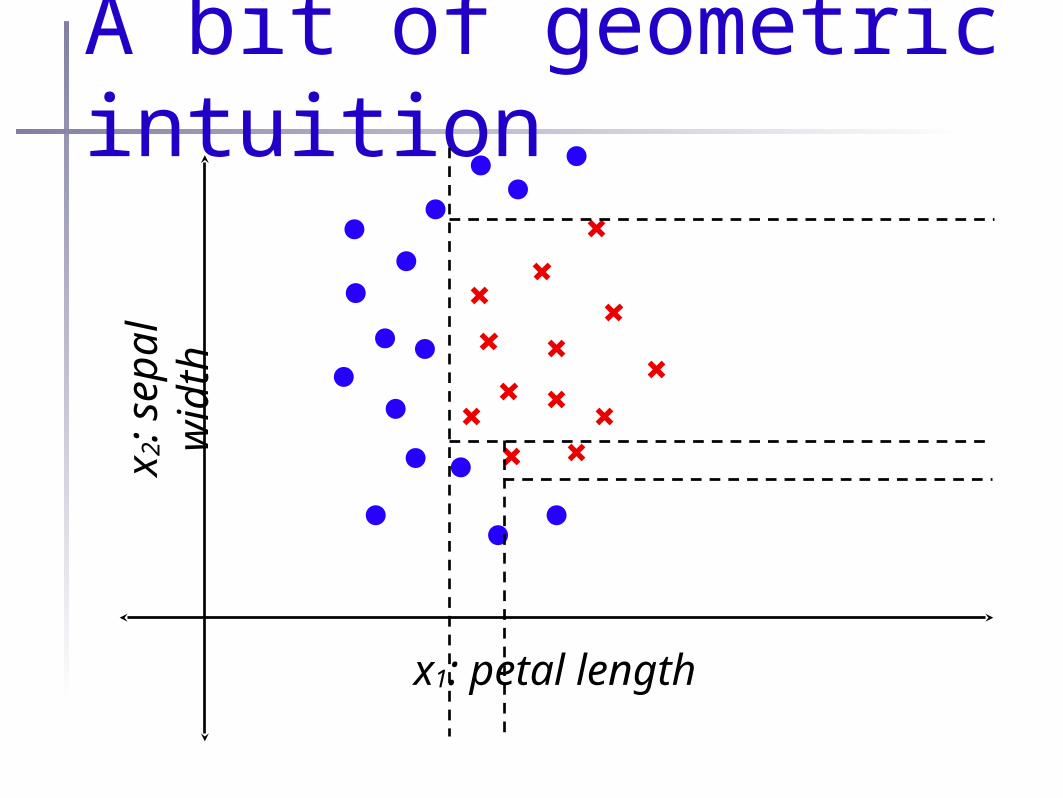
A bit of geometric intuition
x1: petal length
x 2:
sepa
l wid
th

The geometry of DTs•Decision tree splits space w/ a series of axis orthagonal decision surfaces
•A.k.a. axis parallel
•Equivalent to a series of half-spaces
•Intersection of all half-spaces yields a set of hyper-rectangles (rectangles in d>3 dimensional space)
•In each hyper-rectangle, DT assigns a constant label
•So a DT is a piecewise-constant approximator over a sequence of hyper-rectangular regions

Filling out the algorithm•Still need to specify a couple of functions:
•Y.isPure()
•Determine whether we’re done splitting set
•getBestSplitFeature(X,Y)
•Find the best attribute to split X on, given labels Y
•Y.isPure() is the easy (easier, anyway) one...

Splitting criteria•What properties do we want our getBestSplitFeature() function to have?
•Increase the purity of the data
•After split, new sets should be closer to uniform labeling than before the split
•Want the subsets to have roughly the same purity
•Want the subsets to be as balanced as possible




























