Embed Size (px)
Citation preview

Supplemental Table S1. Primers used in this study of amylase genetics in prickleback fishes.
Primer Sequence Name Use 5’-GTAAGACAGCTTCTCGCCATTCCAC-3’ AmyGSP1_5R 5 RACE 5’-TGACATGGGTGTGGCTGGATTCAGA-3’ AmyGSP2_3R 3 RACE 5’-CAGACGACAGTCACGCACCTGATTGGCA-3’ PC_GSP1_5R 5 RACE primer for PC 5’-ATGAAGTACTTCATTCTAGTGGCTCTGTTCGG-3’ 5_amy_CV Forward primer for CV cDNA full-length amplification 5’-TTACAGCTTGGAATTAGCGTGAATAGCAACGAAG-3’ 3_amy_CV Reverse primer for CV cDNA full-length amplification 5’-ATGAAGTACTTAATTCTAGTGGCTCTGTTTGGGC-3’ 5_amy_XM/XA Forward primer for XM and XA full-length amplification 5’-TCACAGCTTGGAGTTAGCGTGAATAGCAAC-3’ 3_amy_XM Reverse primer for XM full-length amplification 5’-TCACAGCTTGGAGTCAGCGTGAATAGCAA-3’ 3_amy_XA Reverse primer for XA full-length amplification 5’-ATGAAGTACTTCATTCTGGTGGCTCTGTTCG-3’ 5_amy_AP Forward primer for AP cDNA full-length amplification 5’-TTACAGCTTGGAGTCAGCGTGGATAGCAA-3’ 3_amy_AP Reverse primer for AP full-length amplification 5’-ATGAAGTACTTAATTCTAGTGGCTCTGTTCGGG-3’ 5_amy_PC Forward primer for PC cDNA full-length amplification 5’-TTACAGCTTGGAGTCAGCGTGAATAGCAAC-3’ 3_amy_PC Reverse primer for PC cDNA full-length amplification 5’-CTGAACTCCACCAAAGCCATTCGGACCCAAG-3’ CV_GW_GSP1 CV amylase specific primer for Genome Walking 5’-CACAATGGCGGTCCTGCCATGCTTGATG-3’ CV_GW_GSP2 CV and XM amylase nested primer for Genome Walking 5’-CTCCACCAACGCCATTAGGACCCAAGAAGC-3’ XM_GW_GSP1 XM amylase specific primer for Genome Walking 5’-CACTCTGCAGCGATGTCTGCCCAGC-3’ GW_A_GSP2 Iso A specific nested primer for Genome Walking 5’-CACTCTTTAGCGATGTCTGCCCAGC-3’ GW_L_GSP2 Iso B specific nested primer for Genome Walking 5’-ATCTCCCCTCCAAATGAGC-3’ Ex2_CV_FW Forward primer for CV and AP gene copy number 5’-ATCTCCCCTCCTAATGAACACA-3’ Ex2_XM_FW Forward primer for XM and XA gene copy number study 5’-ATCTCCCCTCCTAATGAGCAC-3’ Ex2_PC_FW Forward primer for XM gene copy number study 5’-GTGCTGGATAATCCCTGGAG-3’ Ex2_LDR_FW Forward primer for Iso A gene copy number study 5’-TGTGGTGAATAATCCCTGGAA-3’ Ex2_VNK_FW Forward primer for Iso B gene copy number study 5’-AACGTTGTTGCATCTGGTGA-3’ Ex2_CV_RV Reverse primer for all species gene copy number study 5’-ATGAAGTACTTCATTCTAGTGGCTCTGTTCGG-3’ 5_amy_CV Forward primer for CV cDNA full-length amplification 5’-TTACAGCTTGGAATTAGCGTGAATAGCAACGAAG-3’ 3_amy_CV Reverse primer for CV cDNA full-length amplification 5’-ATGAAGTACTTAATTCTAGTGGCTCTGTTTGGGC-3’ 5_amy_XM/XA Forward primer for XM and XA full-length amplification 5’-TCACAGCTTGGAGTTAGCGTGAATAGCAAC-3’ 3_amy_XM Reverse primer for XM full-length amplification 5’-TCACAGCTTGGAGTCAGCGTGAATAGCAA-3’ 3_amy_XA Reverse primer for XA full-length amplification 5’-ATGAAGTACTTCATTCTGGTGGCTCTGTTCG-3’ 5_amy_AP Forward primer for AP cDNA full-length amplification 5’-TTACAGCTTGGAGTCAGCGTGGATAGCAA-3’ 3_amy_AP Reverse primer for AP full-length amplification 5’-CTCACCTCCCAAATCAATAACCTCCT-3’ SQ_574 RV Sequencing primer for full-length Amy cDNAs 5’-CTTCGTTGACAACCACGACAACCAG-3’ SQ_761 FW Sequencing primer for full-length Amy cDNAs 5’-GATTCAGAGTGGATGCCTGCAAGC-3’ SQ_451FW Sequencing primer for full-length Amy cDNAs 5’-CAATCAGAACAGGACAGGTTAGAGGTTTCGTGCCT-3’ GSP3 Primer for extended reading of the 5 UTR and upstream
sequence 5’-GTCCAAGCTCAGTCACGTGTCACGTTGGTGAAG-3’ GSP4 Primer for extended reading of the 5 UTR and upstream
sequence distal to ATG –eliminate if not including longer seq 5’-CATTGTTATCAGTGTTATACAATTCCT-3’ Seq_0_FW Primer for internal sequencing of Genome Walking samples 5'-CTTTCATGGCTTTAAACATTACCA-3' Seq_0_RV Primer for internal sequencing of Genome Walking sample 5’-GAGTGTGAGCGCTTCTTGGGTC-3’ qUn_Amy_FW Primer for qPCR amplyfing amy cDNA in all pricklebacks 5'-CTGGTGATCATGTCTCTCAGCTCGTTC-3’ qUn_Amy_RV Primer for qPCR amplyfing amy cDNA in all pricklebacks 5’-CTGGGCAGACATCGCTGCAG-3’ ALD_SYB_FW Primer for qPCR amplyfing CV Iso A specific cDNA 5'-CCTCCAGGGATTATCCAGCACAATG-3' ALD_SYB_RV Primer for qPCR amplyfing CV Iso A specific cDNA 5’-GCTGGGCAGACATCGCTAAAGAG-3’ KVN_SYB_FW Primer for qPCR amplyfing CV Iso B specific cDNA 5’-CTTCCAGGGATTATTCACCACAATGTG-3’ KVN_SYB_RV Primer for qPCR amplyfing CV Iso B specific cDNA 5’-CATCTGCTGTCTGGAGGAGAAGC-3’ FW_L8 Primer for qPCR amplyfing CV L8 transcript 5’-CTTCAGGATGGGCTTGTCAATACG-3’ RV_L8 Primer for qPCR amplyfing CV L8 transcript

Supplemental Table S2. Accession or scaffold numbers of α-amylase 2 genes (and 5′-flanking regions) sequenced or used in this study. Rows shaded blue are from Ensembl.
Name Common Name AA Size Accession Number
Anguilla_japonica Japanese Eel 512 AB070721.1
Anoplarchus_purpurescens High Cockscomb Prickleback 512 KT920444
Astatotilapia_burtoni African Cichlid (no common name?) 512 XM_005924635.1
Astyanax_mexicanus Mexican Cave Fish 512 XM_007252532.1
Cebidichthys_violaceus_A Monkeyface Prickleback 512 KT920438
Cebidichthys_violaceus_B Monkeyface Prickleback 512 KT920439
Cebidichthys_violaceus 5′-flanking region 1
Monkeyface Prickleback 1216 KT920436
Cebidichthys_violaceus 5′-flanking region 2
Monkeyface Prickleback 1209 KT920437
Chelon_labrosus Thicklip Grey Mullet 512 KF684941.1
Ctenopharyngodon_idella_A Grass Carp 512 CI01MSC000002 (male)
Ctenopharyngodon_idella_B Grass Carp 512 CI01MSC000152 (male)
Cynoglossus_semilaevis Tongue Sole 512 NM_001294218.1
Danio_rerio_A Zebrafish 512 NM_213011.2
Danio_rerio_B Zebrafish 512 BC165756.1
Danio_rerio_C Zebrafish 512 NM_001003729.1
Dictyosoma_burgeri Dainanginpo Prickleback 512 KT920440
Diplodus_sargus White Seabream 512 EU163286.1
Epinephelus_coioides Orange Spotted Grouper 512 EU715401.1
Gasterosteus_aculeatus_A Three-Spined Stickleback 512 ENSGACG00000016740*
Gasterosteus_aculeatus_B Three-Spined Stickleback 512 ENSGACG00000016730*
Haplochromis_nyererei African Cichlid (no common name?) 512 XM_005729082.2
Ictalurus punctatus Channel Catfish 512 FD305985
Larimichthys_crocea Large Yellow Croaker 512 XM_010746219.1
Lates_calcarifer Asian Seabass 505 AF416651.1
Latimeria_chalumnae West Indian Ocean coelacanth 512 XM_006007907.1
Lepisosteus_oculatus Spotted gar 512 XM_006634878.1
Maylandia_zebra African Cichlid (no common name?) 512 XM_004555291.1

Myxocyprinus_asiaticus Chinese high fin banded shark 512 EF570414.1
Notothenia_coriiceps Black Rockcod 512 XM_010784829.1
Oncorhynchus_mykiss Rainbow Trout 497 CDQ92644.1
Oreochromis_niloticus_B Nile Tilapia 512 ENSONIT00000023345
Oreochromis_niloticus_C Nile Tilapia 512 ENSONIT00000023344
Oreochromis_niloticus_A NIle Tilapia 512 ENSONIT00000023349
Oryzias_latipes Medaka 512 XM_004085067.2
Osmerus_mordax Rainbow Smelt 512 BT075242.1
Pagrus_major Japanese Seabream 512 AB678421.1
Phytichthys_chirus Ribbon Prickleback 512 KT920443
Poecilia_formosa_A Amazon molly 512 XM_007564216.1
Poecilia_formosa_B Amazon molly 512 XM_007564214.1
Poecilia_reticulata_A Fancy Guppy 521 XM_008434372.1
Poecilia_reticulata_B Fancy Guppy 512 XM_008434370.1
Poecilia_reticulata_C Fancy Guppy 522 XM_008434371.1
Pseudopleuron_americanus Winter Flounder 512 AF252633.1
Salmo_salar Atlantic Salmon 505 NM_001123602.1
Siganus_canaliculatus White Spotted Spinefoot 512 KM189832.1
Siniperca_chuatsi Chinese Perch 512 EU683734.1
Stegastes_partitus Bicolor Damselfish 512 XM_008277163.1
Takifugu_rubripes_A Japanese Pufferfish 512 XM_003975396.2
Takifugu_rubripes_B Japanese Pufferfish 512 XM_003975398.2
Tetraodon_nigroviridis_B Green Spotted Pufferfish 512 AJ308233.1
Tetraodon_nigroviridis_C Green Spotted Pufferfish 513 AJ308233.1
Tetraodon_nigroviridis_A Green Spotted Pufferfish 512 AJ308233.1
Thunnus_orientalis Tuna 512 AB678419.1
Xenopus_tropicalis Western clawed frog 526 CR761580.2
Xiphister_atropurpureus Black Prickleback 512 KT920442
Xiphister_mucosus Rock Prickleback 512 KT920441
Xiphister_mucosus 5′-flanking region
Rock Prickleback 2939 KT920435

Xiphophorus_maculatus_A Southern Platyfish 512 XM_005801954.1
Xiphophorus_maculatus_B Southern Platyfish 512 XM_005801955.1

Supplemental Table S3. Screening for Non-acceptable Polymorphisms (SNAP) analysis of the non-synonymous amino acid substitutions among the α-amylase 2A and α-amylase 2B variants in Cebidichthys violaceus.
Non-synonymous amino acid substitution
Prediction Change Reliability Index
Accuracy (%) Codon positiona
A41K Neutral non-polar to positive charge polar 6 92 1, 2 L66V Neutral non-polar to non-polar 6 92 1 D67N Neutral negative charge polar to uncharged polar 4 85 1 R71K Neutral positive charge polar to positive charge polar 7 94 2 S132T Neutral uncharged polar to uncharged polar 7 94 2 D174N Neutral negative charge polar to uncharged polar 0 53 1 E397G Non-Neutral negative charge to polar non-polar 0 58 2 T408K Neutral uncharged polar to positive charge polar 2 69 2 N439K Neutral uncharged polar to positive charge polar 7 94 3 S498R Neutral uncharged polar to positive charge polar 1 60 3
Note: Non-synonymous amino acid substitution includes the site on the active protein as the number, flanked by the source amino acid in α-amylase 2A on the left, and the destination amino acid in α-amylase 2B on the right. aThe codon position of the nucleotide polymorphism causing the amino acid change

Supplemental Table S4. PAML analyses of Amy2 genes among taxa within specific lineages.
Lineage N Ka/Ks M7 vs. M8a Positively Selected Sites (Bayes Empirical Bayes Analysis)b
Ostariophysi 8 0.122 NS None Poeciliidae/Adrianichthyidae 8 0.154 6.492 None Cichlidae 6 0.301 22.082 20 (0.997**), 68 (0.992**), 119 (0.996**),
121 (0.996**), 139 (0.995**), 148 (0.984*), 149 (0.981*), 154 (0.995**), 159 (0.998**), 162 (0.989*), 167 (0.956*), 178 (0.970*), 179 (0.988*), 256 (0.980*), 259 (0.984*), 264 (0.968*), 387 (0.976*), 388 (0.961*), 422 (0.970*), and 500 (0.977*)
Stichaeidae 7 0.358 NS None Note: N = number of amylase sequences compared in that lineage. All amylases in these fishes are 512 amino acids in length. NS = not significant. a Neutral model (M7) vs. positive selection (M8) likelihood ratio test (see the Supplementary Methods section). b Amino acid site number in the “Positively Selected Sites” column are numbered including the signal peptide. Significant selection indicated as * = 0.050-0.011, ** > 0.010.

Supplemental Figure S1: protein model generation and discussion
Protein homology modelling was performed with the Cebidichthys violaceus α-amylase 2A
deduced amino acid sequence using the SWISS-MODEL automated server (Biasini et al. 2014).
The quality of the homology model was assessed by the QMEAN4 score (Biasini et al. 2014).
Protein models were visualized with Swiss-PdbViewer software (Kiefer et al. 2009) and
rendered with Mac-POV 3.7.0 software (MegaPOV Team 2013).
The modeled amylase protein has all of the domains and structures consistent with other
vertebrate amylases (Supplemental Figure S1). Although D174N is a significant change, the
change from D to N at this position happened frequently across fish amylase evolution
(Supplemental Figure S8), and thus appears permissible (Yampolsky and Stoltzfus 2005). We
hypothesize that the E397G substitution may affect the local flexibility of the protein and affect
(1) how the surface tryptophan residues interact with the complex branching nature of starch
molecules (Larson et al. 2010), and/or (2) the interaction of multiple amylase enzyme monomers
that have been posited by biochemists to interact with one another along chains of bound starch
molecules (Larson et al. 2010). Further biochemical analysis on the purified isoforms (α-amylase
2A vs α-amylase 2B) is required to resolve the functional consequences of these amino acid
substitutions, but given the unique presence of α-amylase 2A and α-amylase 2B across the fish
phylogeny, these isoforms appear to be of important evolutionary significance in the
diversification of C. violaceus digestive physiology.

Supplemental Figure S1. Model of C. violaceus α-amylase 2, based on the crystal structure of pig pancreatic alpha-amylase (PDB accession: 3L2M). Calcium binding sites are in green, active site residues are in red, the flexible loop region is in magenta, and non-synonymous amino acid substitutions among α-amylase 2A and α-amylase 2B are shown in yellow. D174 and E397 are highlighted as important substitution sites among the two paralogs.
References for Supplemental Figure S1
Biasini, M., S. Bienert, A. Waterhouse, K. Arnold, G. Studer, T. Schmidt, F. Kiefer, T.G. Cassarino, M. Bertoni, L. Bordoli and T. Schwede. 2014. SWISS-MODEL: modelling protein tertiary and quaternary structure using evolutionary information. Nucl Acid Res 42: W252-258.
Kiefer, F., K. Arnold, M. Künzli, L. Bordoli and T. Schwede. 2009. The SWISS-MODEL Repository and associated resources. Nucleic Acids Research 37: D387-392.
Larson, S.B., J.S. Day and A. McPherson. 2010. X-ray crystallographic analyses of pig pancreatic α-amylase with limit dextrin, oligosaccharide, and α-cyclodextrin. Biochem 49: 3101-3115.
Yampolsky, L.Y., and A. Stoltzfus. 2005. The Exchangeability of Amino Acids in Proteins. Genetics 170: 1459-1472.
Domain C
Domain A
Domain B

Supplemental Figure S2. Nucleotide alignment of the Amy2 genes in prickleback fishes.
We identified two separate sequence variants (paralogs) for C. violaceus that we called Amy2A
and Amy2B (Supplementary Figure S3 in the online version of this manuscript), whereas all other
prickleback species had only one Amy gene sequence each; no variation was observed in
numerous clones produced for each individual fish specimen for each species.
The other stichaeid taxa’s Amy gene sequences were most similar to Amy2A in C. violaceus.


S N Paralog
2A var2* D
A L D R S
Exon 1 Exon 3 Exon 4 Exon 2 Exon 7 Exon 9 Exon 8
A L D R S D E T
K K T N G K R K
AMY2A
AMY2B
41 66 67 71 131 174 397 408 498 439
V N
Position
A L D R S G K R K 2A var1† N G K R K
A L D R T N G K R K 2A var3 K L D R S D E T S N 2A var4
K K T N E T S N 2B var1† V N K K T D E T S N 2B var2* V N K K T N G K S K 2B var3 V N K K T N E K R K 2B var4 V N
Supplemental Figure S3. Amino acid sequences of α-amylase 2A and 2B expressed in C. violaceus, an herbivorous stichaeid. Only the 10 sites featuring amino acid substitutions are shown, the remaining sequence (totaling 512 amino acids) is identical among paralogs. Each paralog has several subvariants, some of which show evidence of crossing over among the two main paralogs: subvariants 1 (†) and 2 (*). Approximately 90% of all cloning experiments recovered the main AMY2A and AMY2B paralogs, but the other sequences were regularly observed. Exons inferred from sequence alignments with amylase from Danio rerio.
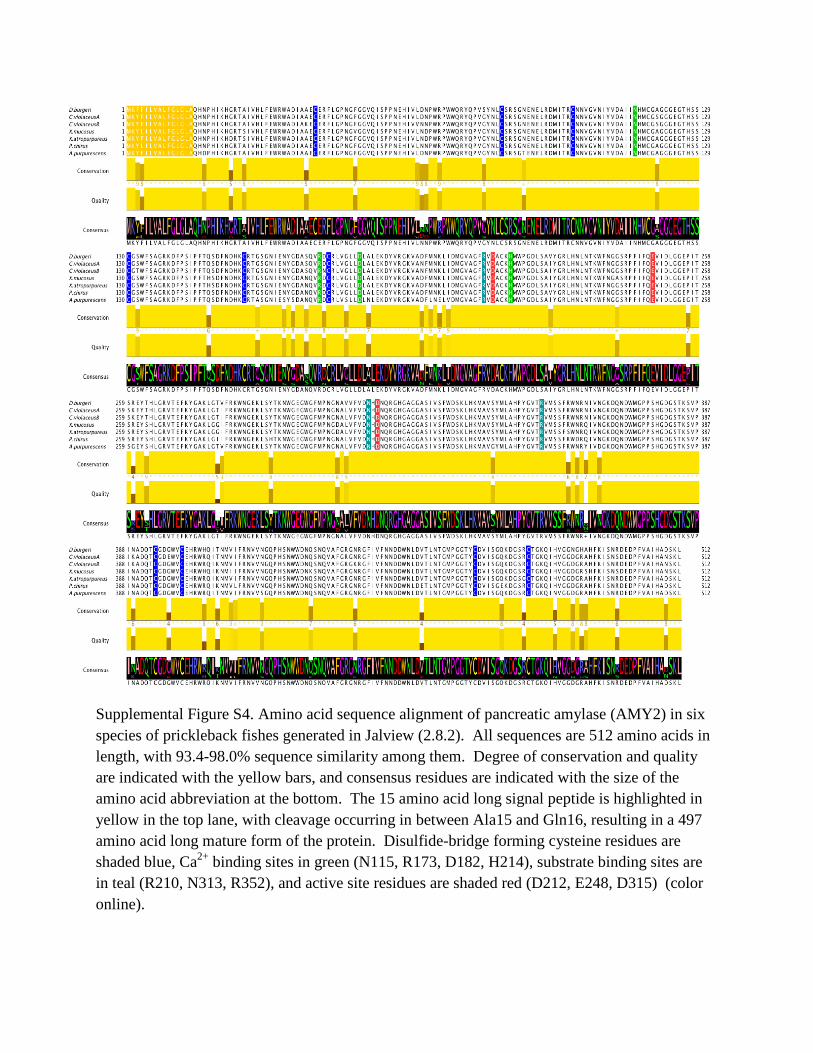
Supplemental Figure S4. Amino acid sequence alignment of pancreatic amylase (AMY2) in six species of prickleback fishes generated in Jalview (2.8.2). All sequences are 512 amino acids in length, with 93.4-98.0% sequence similarity among them. Degree of conservation and quality are indicated with the yellow bars, and consensus residues are indicated with the size of the amino acid abbreviation at the bottom. The 15 amino acid long signal peptide is highlighted in yellow in the top lane, with cleavage occurring in between Ala15 and Gln16, resulting in a 497 amino acid long mature form of the protein. Disulfide-bridge forming cysteine residues are shaded blue, Ca2+ binding sites in green (N115, R173, D182, H214), substrate binding sites are in teal (R210, N313, R352), and active site residues are shaded red (D212, E248, D315) (color online).

Xm CTACACCAAAAGGCTTCACTCAGGTTTGGTAATCAATGTAAAATAGTTTCTGTCTGCACA -798 Cv 1 ATACTTCAAATCTTAAAATTCCGAGTTAACATAAAATGTGATACTGCTATTTGAAGCGCA -756 Cv 2 ATACTTCAAATCTTAAAATTC-------ACATAAAATGTGATACTGCTATTTGAAGCGCA -756 *** **** * ** * ***** * * * * * ** ** Xm GGTTTTAC--TGTTAC----------------AGACAGAACTGCCAGGAATACACAGGCG -756 Cv 1 TTGTTATCAGTGTTATACAATTCCTAATTCATGTCAAGGACAGATGGAAAGTCACATGTT -696 Cv 2 TTGTTATCAGTGTTATACAATTCCTAATTCATGTCAAGGACAGATGGAAAGTCACATGTT -696 ** * ***** ** ** * * ** **** * Xm ATATAAAGGAATACAGTTATTACAATTCAGTGAAAGTAAGTACAATTTTCTTCTAGGTCA -696 Cv 1 TGATTAGGGAAAACCATT---CCATTTGCTTTGCCAAAAATAGATTT-----GTGTTTAA -644 Cv 2 TGATTAGGGAAAACCATT---CCATTTGCTTTGCCGAAAATAGATTT-----GTGTTTAA -644 ** * **** ** ** ** ** * ** ** * ** * * * Xm TCTAATATGACCAATACGATCAGATGTTGGATGTTGATGAACAGATCTTTACAACTCAAT -636 Cv 1 TCAAAGTTTTGTAACTCAGGGAAATTTTGAACT--GTTGCAACATTATCTGGTTATTGAA -586 Cv 2 TCAAAGTTTTGTAACTCAGGGAAATTTTGAACT--GTTGCAACATTATCTGGTTATTGAA -586 ** ** * ** * * ** *** * * ** * * * * * * Xm TTGTCAGCAAGAATCTTTAAAAAATGATCTAACAACATAACAACACATTTTAATATCTTG -576 Cv 1 CTGAGCAGAAG--------AAAAGTACTGAGGCACGAAACCTCTAA-----CCTGTCCTG -539 Cv 2 CTGAGCAGAAG--------AAAAGTACTGAGGCACGAAACCTCTAA-----CCTGTCCTG -539 ** *** **** * * ** * * * * * ** ** Xm ATAGAAATCCAAGGTAAACTTCAAAATTCAAAATTCCGAATTAACATAAAATGTGATAC- -517 Cv 1 TTCTGATTGGTTAAAATATTTT----------------TAATATATTAATATTTGAATCA -495 Cv 2 TTCTGATTGGTTAAAATATTTT----------------TAATGTATTAATATTTGAATCA -495 * * * * * ** * * *** ** *** * Xm -CGCTATTTCCCTGCTGGACAGAGGCTCGCTGGTATCAGTGTTATTTAATTCCTAATTCA -458 Cv 1 GTGCAAGATTAA-TCTAAAAAGAAACC-----CCATAGATGTTATTATGGTAATGTTTAA -441 Cv 2 GTGCAAGATTAA-TCTAAAAAGAAACC-----CCATAGATGTTATTATGGTAATGTTTAA -441 ** * * ** * *** * ** ******* * * ** * Xm TGTCAAGGACGGATAGACAGTCACATGT-----TCGATTAGATAAAACTGTAAAAAAGTA -403 Cv 1 AGCCATGAAAGGCTATTTTTGGACTAGTGCTGAAATCCTTGATTTTACTGCTACAAGGCA -381 Cv 2 AGCCATGAAAGGCTATTTTTGGACTAGTGCTGAAATCCTTGATTTTACTGCCACAAGGCA -381 * ** * * ** ** ** ** * *** **** * ** * * Xm ACTTTCCATTTGCTTTGCCCCAAAATAGATTTCTGTTCTCAGGGAAATTTTGAACTGTTG -343 Cv 1 AGTGTTGTTCTTTG--------------AAGTATGATTTTAAATTTGTTTTGACCTATAG -335 Cv 2 AGTGTTGTTCTTTG--------------AAGTATGATTTTAAATTTGTTTTGACCTATAG -335 * * * * * * * ** * * * ****** ** * * Xm CAACAACATCTGTTTATTGAACTGAGCAGAAGAAAA----GTACTGAAGCACGAAACCTC -287 Cv 1 CGAGGATAAAAGTCAGAGCCACAGATAATATCAATGTTAGAAACTGAATA-AGAAAGCAT -276 Cv 2 CGAGGATAAAAGTCAGAGCTACAGATAATATCAATGTTAGAAACTGAATA-AGAAAGCAT -276 * * * * ** ** ** * * ** ****** **** * Xm TAACTTGTCCTGTTCTGAGTGGTTAAAATATTTTTATTATTTGAATCAGTGCAAGATTAA -227 Cv 1 TAG-----GATCTTTGGCACATTCAGCCACTTGTTTTTAAATTT--AGGGATGACATTAT -223 Cv 2 TAG-----GATCTTTGGCACATTCAGCCACTTGTTTTTAAATTT--AGGGATGACATTAT -223 ** * ** * * * ** ** *** * * * ****
HNF
TC

Xm TTTAAAAAGAAACCCCTGAGATGTTATTATGGTAATGTTTAAAGCCATGAATTATCCTTC -167 Cv 1 GCT---CACCTCATGTTTCTTAGTTTCCAACCTGTACGTGCCTCTAAAGTATTGACCGTC -166 Cv 2 GCT---CACCTCATGTTTCTTAGTTTCCAACCTGTACGTGCCTCTAAAGTATTGACCGTC -166 * * * *** * * * * * *** ** ** Xm TACTAGTTTTGAAACAACGTAGGAAGCCGTGAGAAAGAAGCACCTGTTTAACCCCCACGC -107 Cv 1 TACTAGTTTTGAAACAATGTAGGAAGCCGTGAGAAAGAAGCACCTGTTTAACCCCCACGC -106 Cv 2 TACTAGTTTTGAAACAATGTAGGAAGCCGTGAGAAAGAAGCACCTGTTTAACCCCCACGC -106 ***************** ****************************************** Xm TGATATTTGCCAGTCGCCCATTGGTCCAGGATAGAGACAAAATGAGTACAAATACTAACA -47 Cv 1 TGATATTTGCCAGTCGCTCATTGGTCCAGGATAGAGACAAAAAGAGTATAAATTGTAACA -46 Cv 2 TGATATTTGCCAGTCACTCATTGGTCCAGGATAGAGACAAAAAGAGTATAAATAGTAACA -46 *************** * ************************ ***** **** ***** Xm CTGAGGCAGCAGGTGAGTGTGGCTTTCTCTCTCATCAAGGGAAAACATGAAGTACTTAAT Cv 1 GTGAGGCAGCAGGTAAGTGTGGCTTTCTCTCTCATCAAGGGAAAC-ATGAAGTACTTCAT Cv 2 GTGAGGCAGCAGGTAAGTGTGGCTTTCACTCTCATCAAGGGAAAC-ATGAAGTACTTCAT ************* ************ **************** *********** ** Xm TCTAGTGGCTCTGTTT Cv 1 TCTAGTGGCTCTGTTC Cv 2 TCTAGTGGCTCTGTTC ***************
Supplemental Figure S5. The proximal 5′-flanking region of the α-amylase genes in Cebidichthys violaceus and Xiphister mucosus. Two sequences are regularly recovered for C. violaceus (Cv 1 and Cv 2), whereas a single sequence is known for X. mucosus. Asterisks indicate conserved nucleotides at that site. The ATG start codon for all three genes is bolded in red (with +1 above the A). The first 167 bp upstream from this start codon are highly conserved (95% sequence identity)—including the underlined putative promoter region—but diverge after this point. The greyed sequence identifies the TATA-box, whereas the green and the yellow highlighted regions are known as the putative “E” and “TC” boxes, respectively, and both are known pancreas-specific transcription factor 1A (PTF1A) binding sites (Wiebe et al. 2007). Another potential TC box (shaded dark green) is apparent in the X. mucosus sequence 504-511 nucleotides upstream from the ATG. A putative Hepatocyte Nuclear Factor-3 binding site (Ma et al. 2004) is highlighted in blue. Differences between the two C. violaceus sequences are denoted with an inverted triangle, and an indel (denoted in orange) is apparent 788-794 nucleotides upstream from the ATG for these two sequences. Each of the C. violaceus 5′-flanking regions is associated with Amy2A and Amy2B in C. violaceus, suggesting that an apparent duplication and subsequent diversification of these 5′-flanking regions occurred before a duplication event generating Amy2B in C. violaceus.
References for Supplemental Figure S5
Wiebe P.O., Kormish J.D., Roper V.T., Fujitani Y., Alston N.I., Zaret K.S., Wright C.V.E., Stein R.W., Gannon M. 2007 Ptf1a Binds to and activates area III, a highly conserved region of
+1 E
TC
TATA

the Pdx1 promoter that mediates early pancreas-wide Pdx1 expression. Molecular and Cellular Biology 27(11), 4093-4104.
Ma P., Liu Y., Reddy K.P., Chan W.K., Lam T.J. 2004 Characterization of the seabass pancreatic α-amylase gene and promoter. General and Comparative Endocrinology 137(1), 78-88.

X. atropurpureus
A. purpurescens
Potato Corn Amylopectin Amylose Starch type
Panc
reat
ic a
myl
ase
activ
ity
(µm
ol g
luco
se m
in-1
g-1
)
40
80
120
5
4
3
2
1
(a)
80
100
60
40
20
10 9 8 7 6 5 pH
Perc
ent o
f max
imal
am
ylas
e ac
tivity
(b)

Supplemental Figure S6. (a) Pancreatic amylase activity in X. atropurpureus (omnivore) and A. purpurescens (carnivore) as a function of starch type. For starch type, there were significant effects of starch type, species, and the interaction of starch type and species on amylase activity (2-way ANOVA starch type: F3,56 = 16.88, P < 0.001; species: F1,3 = 16.88, P < 0.001; starch type x species: F3,56 = 13.66, P < 0.001). (b) percent maximal pancreatic amylase activity as a function of pH in these same two species. For pH, there was a significant effect of pH, but not species or the interaction of pH and species on percent amylase activity (2-way ANOVA pH: F10,138 = 65.55, P < 0.001; species: F1,10 = 0.427, P = 0.515; pH x species: F10,138 = 1.84, P = 0.061). Values are mean (± SEM). Shaded area in (b) shows biologically relevant pH values.

Supplemental Figure S7. Amino acid sequence alignment
The amylase amino acid alignments among all of the pricklebacks from this study and the 34 additional fish species show highly conserved cysteine, Ca2+ binding, substrate binding, and active site amino acid residues in all of the taxa (Supplemental Figure S6). The sequences shared >66.1% sequence identity, and these percent identities were greater in more closely related taxa.
Supplemental Figure S7. Amino acid sequence alignment of pancreatic amylase (Amy2) in 40 species of fish, plus Xenopus tropicalis. Degree of conservation and quality are indicated with the yellow bars, and consensus residues are indicated with the size of the amino acid abbreviation at the bottom. The 15 amino acid long signal peptide is highlighted in yellow in the top lane. Cysteine residues are shaded blue, Ca2+ binding sites in green, substrate binding sites are in teal, and active site residues are shaded red.


Supplemental Figure S8. Amylase amino acid sequence alignment for 58 taxa, including each class of vertebrates and select insect taxa. Important site (equivalent of E397G) highlighted in red.





























