Embed Size (px)
Citation preview

Molecular Cell, Volume 56
Supplemental Information
Structural Model of a CRISPR RNA-Silencing Complex Reveals the RNA-Target Cleavage Activity
in Cmr4
Christian Benda, Judith Ebert, Richard A. Scheltema, Herbert B. Schiller, Marc Baumgärtner, Fabien
Bonneau, Matthias Mann, and Elena Conti
1
SUPPLEMENTAL FIGURES
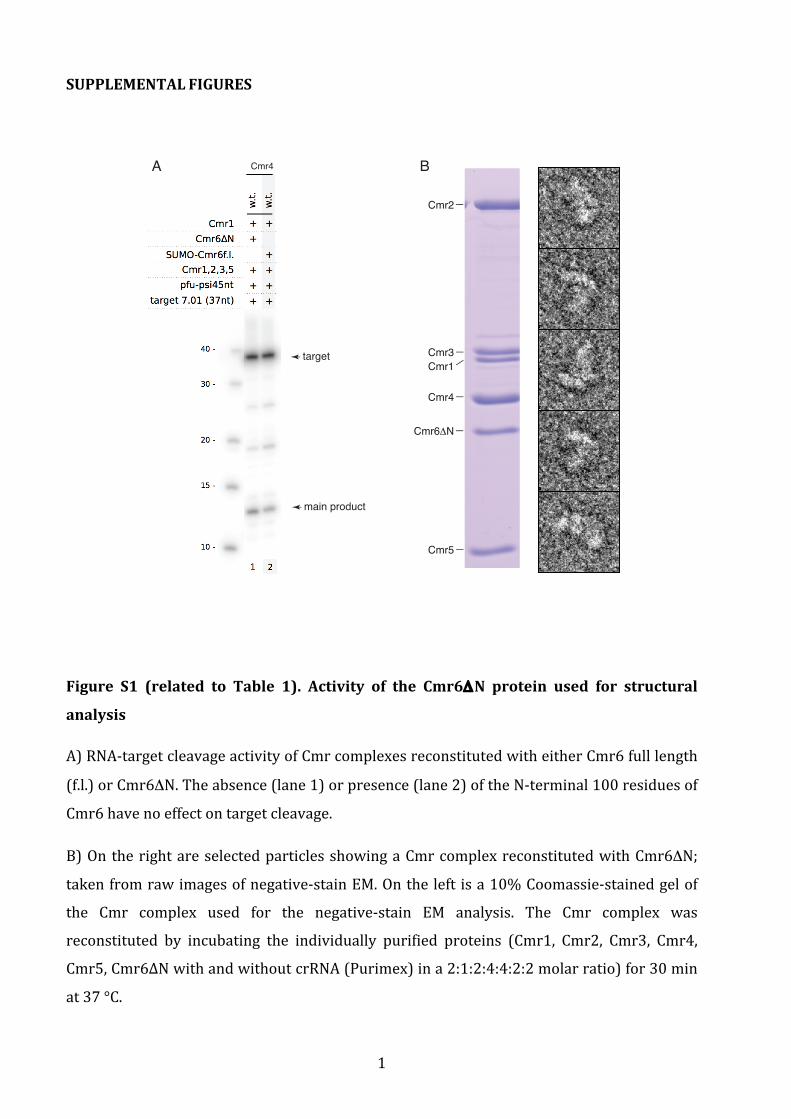
Figure S1 (related to Table 1). Activity of the Cmr6ΔN protein used for structural
analysis
A) RNA-‐target cleavage activity of Cmr complexes reconstituted with either Cmr6 full length
(f.l.) or Cmr6ΔN. The absence (lane 1) or presence (lane 2) of the N-‐terminal 100 residues of
Cmr6 have no effect on target cleavage.
B) On the right are selected particles showing a Cmr complex reconstituted with Cmr6ΔN;
taken from raw images of negative-‐stain EM. On the left is a 10% Coomassie-‐stained gel of
the Cmr complex used for the negative-‐stain EM analysis. The Cmr complex was
reconstituted by incubating the individually purified proteins (Cmr1, Cmr2, Cmr3, Cmr4,
Cmr5, Cmr6∆N with and without crRNA (Purimex) in a 2:1:2:4:4:2:2 molar ratio) for 30 min
at 37 °C.
BA
Cmr2
Cmr6ΔN
Cmr3Cmr1
Cmr4
Cmr5
Cmr4
main product
target
2
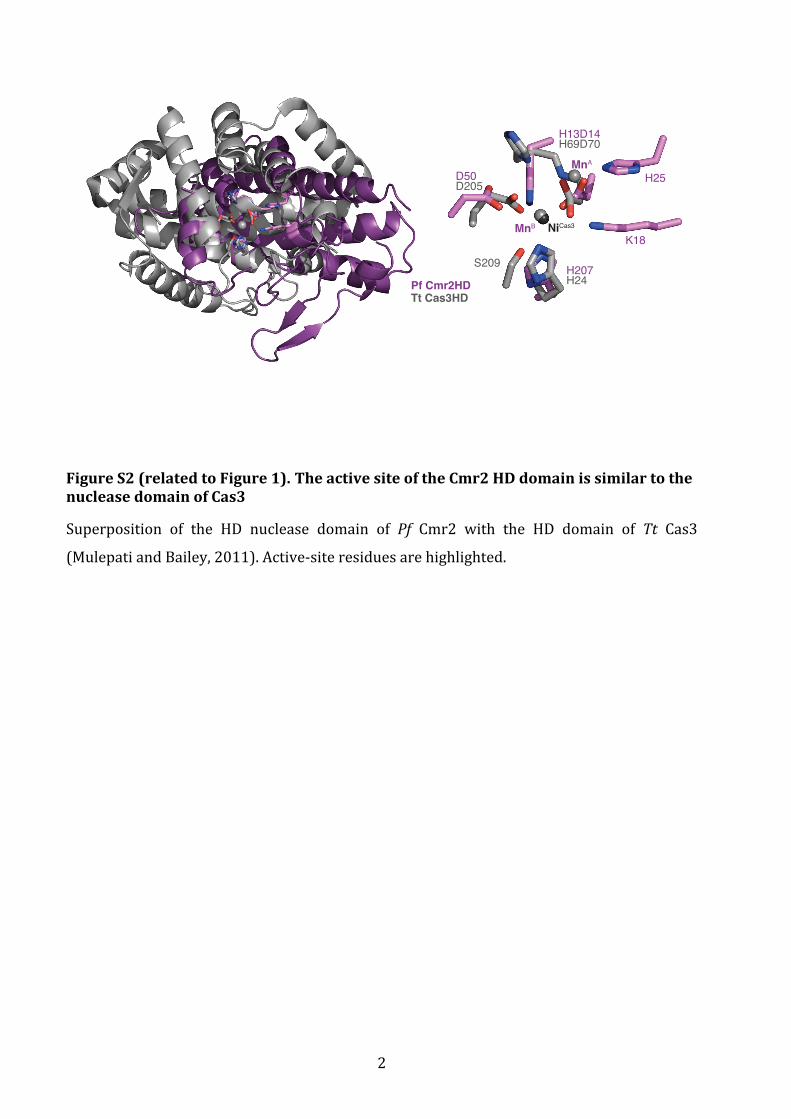
Figure S2 (related to Figure 1). The active site of the Cmr2 HD domain is similar to the nuclease domain of Cas3
Superposition of the HD nuclease domain of Pf Cmr2 with the HD domain of Tt Cas3
(Mulepati and Bailey, 2011). Active-‐site residues are highlighted.
K18
H25
H13D14H69D70
D50D205
H207H24Pf Cmr2HD
Tt Cas3HD
S209
NiCas3
MnA
MnB
3
B
D
C
A
H34B
R33B
E151A
D233A
E205A
T204A
S203A
I111I102
F151
F100
L104
F90L87
W99
L85
L17
α3AαAIIA
α6B
α1B
F67A
K71A
W149B
Y27BF153B V155B
A66A
A70A
L20
Y24 V27
T110
H15
Y114
E
Cmr6
Cmr1
Cmr4
Cmr5A
Cmr5Blid
45°
α1B
β4B
β3B
β1B
βFB
Q43C
T243C
R245C
A79C
K46C
D86C
K276B
V274B
T273B
E272B
F278B
A
B
C
β1β2 β4β3
α1
α2
insertion 4
insertion 1
insertion 2
insertion 3
C-terminalN

4
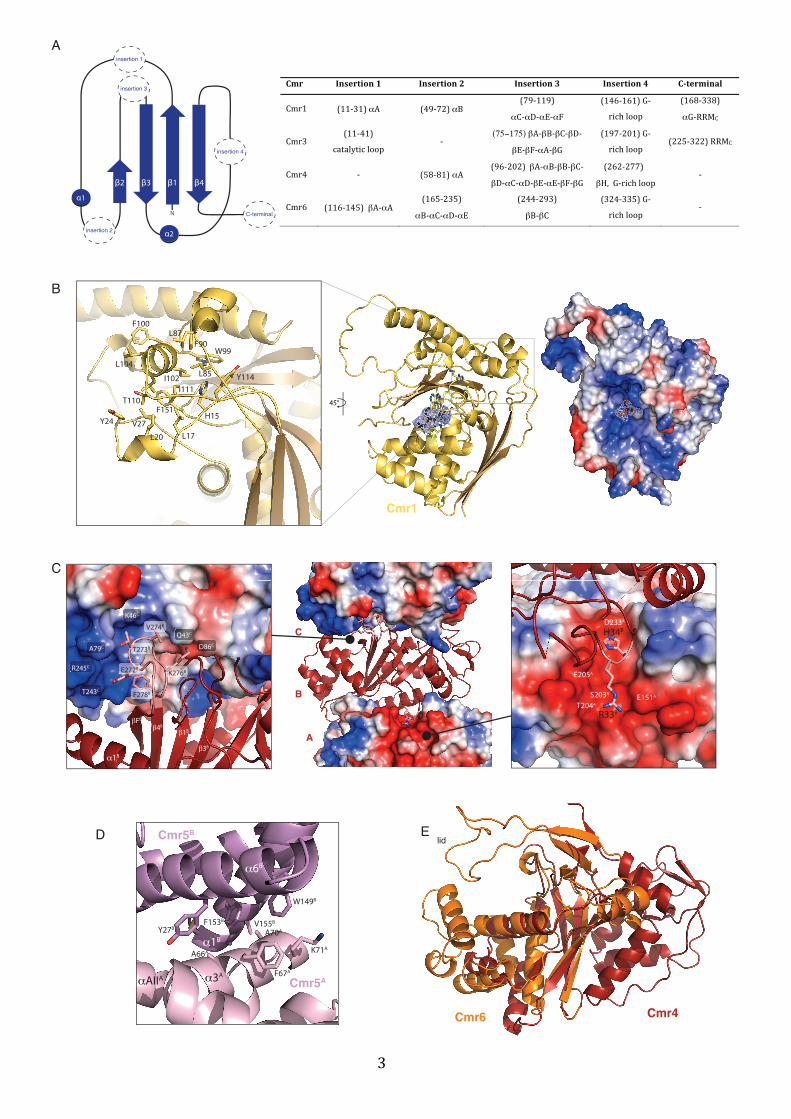
Figure S3 (related to Figure 2). Characteristic structural features of the Cas7-‐like
proteins of the P. furiosus Cmr complex
A) Left, topology diagram of the RRM-‐domain of the Cas7 protein family as in Figure 2
(Helices are represented as circles and β-‐strands as arrows, and labeled numerically). Right,
a table listing the detailed secondary structure elements as referred to in the main text.
B) Left, zoom in of hydrophobic interactions in the lid domain of Pf Cmr1. Right, overall
surface charge distribution of Pf Cmr1 showing the strongly positively charged, central
nucleotide binding cleft.
C) Zoom in of selected interactions between two Pf Cmr4 subunits (in red cartoon and
electrostatic surface representation) in the filaments of the crystal lattice (center). Left, the
glycine-‐rich loop on top of the central RRM (part of the lid domain) is engaged in
interactions with the bottom part of the subsequent molecule mainly via two charged
interactions (E272B with R245C and K276B with D86C), but also hydrophobic interactions
(F278B, T243B, V274B). Right, conserved charged interactions between R33B and H34B,
binding to a negative surface patch on the previous Cmr4 molecule (chain A).
D) Zoom in of the interactions between two different Pf Cmr5 molecules (in dark and light
pink colors) in the filaments of the crystal lattice.
E) Superposition of the lid domains of Cmr4 (in red) and Cmr6 (in orange).
5
18977498|Therm|Pyrococcus_furiosus_DSM_3638/1-29515678353|Metha|Methanothermobacter_thermautotrophicus/1-28321229457|Metha|Methanosarcina_mazei_Go1/1-308219850664|Chlor|Chloroflexus_aggregans_DSM_9485/1-31615612893|Bacil|Bacillus_halodurans_C-125/1-30015644536|Therm|Thermotoga_maritima_MSB8/1-288209966739|Alpha|Rhodospirillum_centenum_SW/1-295108762640|delta|Myxococcus_xanthus_DK_1622/1-31794985067|Deino|Deinococcus_geothermalis_DSM_11300/1-26246255189|Deino|Thermus_thermophilus_HB27/1-285153940638|Clost|Clostridium_botulinum_F_str-_Langeland/1-285297619079|Metha|Methanococcus_voltae_A3/1-28715605885|Aquif|Aquifex_aeolicus_VF5/1-297124027590|Therm|Hyperthermus_butylicus_DSM_5456/1-330284997237|Therm|Sulfolobus_islandicus_L-D-8-5/1-257
18977498|Therm|Pyrococcus_furiosus_DSM_3638/1-29515678353|Metha|Methanothermobacter_thermautotrophicus/1-28321229457|Metha|Methanosarcina_mazei_Go1/1-308219850664|Chlor|Chloroflexus_aggregans_DSM_9485/1-31615612893|Bacil|Bacillus_halodurans_C-125/1-30015644536|Therm|Thermotoga_maritima_MSB8/1-288209966739|Alpha|Rhodospirillum_centenum_SW/1-295108762640|delta|Myxococcus_xanthus_DK_1622/1-31794985067|Deino|Deinococcus_geothermalis_DSM_11300/1-26246255189|Deino|Thermus_thermophilus_HB27/1-285153940638|Clost|Clostridium_botulinum_F_str-_Langeland/1-285297619079|Metha|Methanococcus_voltae_A3/1-28715605885|Aquif|Aquifex_aeolicus_VF5/1-297124027590|Therm|Hyperthermus_butylicus_DSM_5456/1-330284997237|Therm|Sulfolobus_islandicus_L-D-8-5/1-257
18977498|Therm|Pyrococcus_furiosus_DSM_3638/1-29515678353|Metha|Methanothermobacter_thermautotrophicus/1-28321229457|Metha|Methanosarcina_mazei_Go1/1-308219850664|Chlor|Chloroflexus_aggregans_DSM_9485/1-31615612893|Bacil|Bacillus_halodurans_C-125/1-30015644536|Therm|Thermotoga_maritima_MSB8/1-288209966739|Alpha|Rhodospirillum_centenum_SW/1-295108762640|delta|Myxococcus_xanthus_DK_1622/1-31794985067|Deino|Deinococcus_geothermalis_DSM_11300/1-26246255189|Deino|Thermus_thermophilus_HB27/1-285153940638|Clost|Clostridium_botulinum_F_str-_Langeland/1-285297619079|Metha|Methanococcus_voltae_A3/1-28715605885|Aquif|Aquifex_aeolicus_VF5/1-297124027590|Therm|Hyperthermus_butylicus_DSM_5456/1-330284997237|Therm|Sulfolobus_islandicus_L-D-8-5/1-257
18977498|Therm|Pyrococcus_furiosus_DSM_3638/1-29515678353|Metha|Methanothermobacter_thermautotrophicus/1-28321229457|Metha|Methanosarcina_mazei_Go1/1-308219850664|Chlor|Chloroflexus_aggregans_DSM_9485/1-31615612893|Bacil|Bacillus_halodurans_C-125/1-30015644536|Therm|Thermotoga_maritima_MSB8/1-288209966739|Alpha|Rhodospirillum_centenum_SW/1-295108762640|delta|Myxococcus_xanthus_DK_1622/1-31794985067|Deino|Deinococcus_geothermalis_DSM_11300/1-26246255189|Deino|Thermus_thermophilus_HB27/1-285153940638|Clost|Clostridium_botulinum_F_str-_Langeland/1-285297619079|Metha|Methanococcus_voltae_A3/1-28715605885|Aquif|Aquifex_aeolicus_VF5/1-297124027590|Therm|Hyperthermus_butylicus_DSM_5456/1-330284997237|Therm|Sulfolobus_islandicus_L-D-8-5/1-257
111111111111111
8090961008182798970778576789576
M K A Y L V G L Y T L T P T H P G S G T E - L G V V DQ P I Q R E R H T G F P V I WGQ S L K G V L R S Y L K L V - - - - - - - - - - - - - - - - E K V D E E K I N K I F G P P T - - - - - - E K A - H E Q A GL E P E K V Y A R A L D P V H I G A G G Y R L G R A D N T I V R E P S T D I P K I P G T S I A G V T R E F Y T A Y L A E N E F G D K S A E E K R - K - R A E E K A K S I F G D - - - - - - - - - - - - E N K K GY T Q Q R Y L F M A L D P V H I G T GQ S Q L G R V D N T I V R E P G T N I P K I P G T S L M G A A R H Y A S M K Y G K L E A A GQ H K T L K G K N - H E K C P I I Y T F G T Y T - - E T E - - - - - G GQ Q GY Q R Q R Y L L M T I D P V H I G T G G Y R L G R V D N S I V R E P G T R V P K I P G T S L H G A A R S Y A AQ L Y E T P E A A GQ S Q D K V E - N - P DQ N P V C Y T F G Y I K - - K T G N G N N V T A Y S GN S S Q L F F V H C L S P V H I G T G E G - V G L I DM P I M R E R V T K WP L I P G S T T K G V H R D Y F V Q - - - - - - - - - - - - - - - - - Q R D K E S W I R T A F G A G K - - - - - G E A D A E G N A GM E G R V F L L Y A E T Q V H A G T G F E - I G V V D L P I Q R E R T T K F P I I H G - - I K G A L R A Y F R S L I - - - - - - - - - - - - - K E D K I D E K K I E E I F G S E P - - - - - - K S D K G T V P GG A R A S L F I H A L T G L H P G S G T A - L G V V D L P V Q R E R H T NWP L I P A S S I K G V L R A AM K R - - - - - - - - - - - - - - - - - K H N D D GQ L WA V F G P D - - - - - - - T D N A A E H A GM E S R P Y L L H A L S P L H V G T GQ S - V G V I D L P L A R L K A T G I P F V P G S S L K G V L R E L R R P R - - - - - - - - - - - - - - E E T G D A R G L H D A V F G P R R A K A G P E G D E P G D Y A GA N A E L L MWQ A L T P V H S G T GQ S S A G V I D L P I A R E G A T G F P M L P G S S I K G V L R Q G R E D - - - - - - - - - - - - - - - - - - - - - - E E A K R L F G S L - - - - - - - - - - - - D A A GS H V A L L F L H A L S P L H A G T GQ G - I G A I D L P I A R E K A T G I P Y L P G S S L K G V L R D R A S A - - - - - - - - - - - - - - - - - - - WD R D T L F A V F G P D - - - - - - - T E N A S E H A GK D K E T I Y I K A I S P I H A G S GQ S - L T S V DM P I Q R E S H S N I P K I E G S S L K G S V K H N V Y H K L - - - - - - - - - R V N K D N K K E E H K L F E K M F G S E D - - - - - - G N - - - D C A SK T G K I I G F K A I S P V H V G S G S D - L G V V DQ P I Q R E R H T S Y P K I E A S S L K G A I R Q K F V E K - - - - - - - - - - - - - - - - - - V E K N C L D A I F G P E S - - - - - - G N - - - E H S SE Y GQ L L T L Y A V T P I H I G S GQ S - I S F I D L P I Q R E R H T G F P I L R S N G I K G A L R S V A E R V W - - - - - - - - - - - - - - - - - K D K A K V E T V F G P E D - - - - - - D A S - - K F A GL A G F L V L G Y A V T P L H P G V G R A - P G A V D L P V Q R D - P M G Y P M V Y A S S V K G A L K A E C A K Q A G D K C F D D R G R I K C N D K D E D C A L C C C L F G H E - - - - - - - P E A A E A A S SP K A Y L I L A Y A V T P V H V GMG R A - P G V V D L P F Q R D - S I G Y P I V Y G S S F K G V L K S S L MD - - - - - - - - - - - - - - - - - - - K N S N L A K C V F G A E - - - - - - - P E E A N K Y MG
819197
1018283809071788677799677
163162167175176162167183153161167171172186143
L I S V G D A K I L F F P V R S L K G V Y A Y V T S P L V L N R F K R D L E L A G V K N F Q T E I P E - - - - - - - - - - - - - L T D T A I A S E - - E I - - - - - T V D N K V I L E E F A I L I Q K D - D K GV L R F Y D GQ I L F F P V S S V R G T V - W I T T E Q L F N Y WC V K D E K I S Y E D - - - - - - - - - - - - - - - - - - - - - - - - - - - E N K V Y A I R G - - E L N G R L N L GW L L F E V N S E K - - KK I S I S D AQ I L L F P V N S I A G P L - WV S T K E I L E T A G F S I Q D T - - - - - - V E I F - - - - - - - - - - - - - - - - - - - - - D E N V F T S MN - - W E K D T L N L GW L S L K A I T G L - - -V V N I F D A H V L L F P V Y S M T G P V - WV T T L G R L C E A G F T V K H N G A A L A T E P Q T - - - - - - - - - - - - - - - - - - - - - G T A L L T WD - - - - R K D V L N L GW L M V N V A G K A - - -S I V M S D A R I L A F P V A S Y Y G T F A Y V T C P M V I K R L E R DMG A A N V S Y F S N L I E K V E GW E K K L - - - S T N E D K A L I G H R C E V T D - - - E N N E K I Y L D E F E L S V V I D - - - GS L S F S E A R I L L F P V R N P D R L F V WV T C P L V L I K F A K S V G D N D V V K E L E E A N I - - - - - - - - - - - - - - - - - - D Y G K A V S F - - - - - Y G S G E V F L E E V K L E P F V G - E L PA L A L T D A R I L A F P V R S L K G V F AW I T C P T V L A R F C R D R A L V G E Q P L P A V P T V T T G K V R C P - - - - - - K V G P E Q E S P L L - - - - - - I D N T A L I L E E F D F D Y E G D - - - -A L V V G D A R L L A L P V R S F V G T F A L V T S P M L L A L A R R D L G G L S G K E G AWP K V E P L A Q R G A - - - - - - - R V A S L R D S A V V Y G A G - - T S E A C V Y L E D L D L Q V A S K - D D AR L T F T D A R L L C L P V R S Y R G T F A Y V T C P L V L S R L R R D L A A L G H P L A L P E V P E V K E N - - - - - - - - - - - T A Q V A G D T L - - - - - - - M H G GQ V L L E D L D L Q A E E T - - - AA V Q V G D A K L L L L P V R S L Y G V F A L A T S P Y L L E R F R R E A L M A G L Q P P G V P G L R D P T - - Q - - - - - - - - - V L L A P G S R L L - - - - - - G D G E K V Y L E D L D L K AQ G E - - - EA I S I T D A K L L L F P M R S A I D I Y K L I T C P Y V L K R WK E E T NQ S F E D S I L E N I E D - - - - - - - - - - - - - G H C V I NQ N S - - P L - - - - - L S N D K V M L E E Y I F E A R K E - D L -C I A F T D A R L L F F P V K S A K G T F A L I T C P K V L K R F Y E D L D Y L T K I C D K K D N K L L E E I K Y L K N L T T S N K E I I I N N D - - N L - - - - - K I K D K V I L E E Y V F K E K S N - D K -C V S I T D A R I L F Y P V R S V R G V F AW I T S P I V L R R F Q E D L R S I G K E I N I K V L K N G K E V P S N - - L N L E E N E A I L F S D - - G L - - - - - I K D G K L F L E E F A F N P I L N - A P EV L S V L D L V P L F F P V P S L S H G Y L Y I T T P Y L A R R A Y S V M E A I G T S G E Y N K L M K L L E N I A - - - - - - - - K Q E L G E G E A A G C - - - - - V D D R K V Y V G T D E L N V K K K L G N CR F I V T E L I P V F Y P I A S L D - G Y V Y I S T D Y L I K K A E D I L S V V K S N T I Y T R N N - - - - - - - - - - - - - - - - - - - - - - - - - - N - - - - - G E E V N I L L G K L K S S Y T V - - - - -
164163168176177163168184154162168172173187144
258241258266268257260277237252251256266277225
I L E S V V - - K A I E Q - A F - - - - - G N E M A E K I K G R I A I I P D D V F R D L V E L S T E I V A R I R I N A E T G T V E T G G L WY E E Y I P S D T L F Y S L I L V T P R A K D N DMA L I K E V L -E D V D L P - - D E I N E - - - - - - - - - - - - - - - W I K R A V I V P E N L F S P I V N D N L E V R T S V R I D P E T G T A V E G A L F T Y E A I P R G T I F G F E I A T E K D E K R K E V - - - - - - - -N V V P P H - - T I K E K - - - - - - - - - - D E WN S I A S R L S I V S P K L F S Q I V N S N L E V R T S V A I K P E T G T A E D K A L F T Y E A I P R T T W L F F D V V Q D D Y K N E F P P T E K Q Y K - DE V T A P N - - V WQ N E - - - - - - - - - - Q R WQ A V A N R I V L V S E S L F S H V V N S N L E V R T S V A I D P G R G A A E E G A L F T Y E A L P R A T F L T T E V V L D D Y R E A F P K D K C GQ G - KT F G E L T - - N S L A K L V F - - - K D D H F S Q E L L A S R L V L V S D E S F Q Y F V T Q C S E I T P R I R L K A E E K V V D D G A L WY E E Y L P T E T L L Y G L I WC E K MDQ V K E S W - - - - - - -R T R E L I - - S K I S N C A P - - - - - V D Y L K K K M E S D V V V V N D V L F S E I V Q AM T E V V P R V R I N R E K K T V E E G G L WY E E Y L P Q D T V M Y F V V R K T Y Y G N K E D S G K D S L M - -- P G L WP - - E V L A Q T V D - - - - - - A A T G D R M R T H L A I L S D D D F G H F V Q H A T E V V A R I G L D A K T K T V K N G A L F Y E E V L P A E T L F H A L V M A E S S R R A E V P M P A A E V - -A L G AWA - - Q G L A G L L P - - - - - - E A E R A L L T K R L V L V D D E T M S F L W E T A T Q V D T R V S MD P E T G T A A K GQ L WT E E S L P A E T L L V G V MG A T G T F N K A P R K L A A D A - -S A R AWA - - E A L A E L S G - - - - - - - - L G D E L R E R F A L L S D D E F G F L A E T A T E V T A H I R L D A E T K T V A G G A L WY E E A L P A A S L L T S F L L R P Q D V T F A - - - - - - - - - -G V A AW E - - R W L A E R T E - - - - - - - - - - A P V L G R L A V V H D D L MG F L L E T A T E V V A R I R L D D E T K T V A K G A L WY E E S L P A E S L L Y A L V R A D R S F R K G K E L R P E G V W -- S I L F N - - G S - - - - - - - - - - - - - - F E N L Q I N K V V I L S D S D F I DM V T M Y T E V I T R N K I N V E T G T AQ G T G L F S E E Y L P A E T V M Y F S V L E S A F Y K G E E E V L K Y F - - -- L K D L N - - N L - - - - - - - - - - - - - - - F E L N D K N L A I V S D D V F K Y F V N Y A T E V I T R T K I D P K T G I V V N G A L F T E E Y L P S E T I M Y T I A L A S N P F K K I E G V L S N E N N -- N V DWD - - F F N T I - I P - - - - - S D E L V G L L R T H L V I V S D N V F R D L V N Y A V E V R T R I R I NQ A T G T V E R G A L F T E E F I P S E S I F Y S L L N I S E P H N K E V F E K A E K V R -E D L S F V - - A K L G G - - - - - - - - - - - L A G D I Q S R M I V V S D A V G P L Y V E K G L I R V T R V R L R L D T K T V A E G G L WT E E Y I P Q G T I F L S G F I A A L P K K N T Y C K H V N G I E S- - - T L A - - N N V K N - - - - - - - - - - - I G S L I K D K V Y V F D N E V G L Q V V E S S L I R V T R N V L D D N T K T S Q - - N L WT E E Y L P Q G T V F I G G I I D A E R T N E L C K D I K N - - - -
259242259267269258261278238253252257267278226
295283308316300288295317262285285287297330257
- - - - - - - - - - - - - - - - - - - - - G K I N G K Y L Q I G G N E T V G K G F V K V T L K E V T N N G G T H A K - -- - - - - - - - - - - - - - - - - - L N A V S P Y L K Y L G I G GM V T R G F G R L E L A A E H S E D E Q V G T D V K PG D N E G D S L G E V WN S P I D V L N A G F H L I E Y L G I G GM V T R G F G R M K K M Y AW E V - - - - - - - - - -T D K N N P L P G D P WN C P L D V V K A G L R M I E W L G V G GMG T R G F G R L A I V G E P L K - - - - - - - - - -- - - - - - - - - - - - - - - - - - - - K R L S K G R V L Q V G G N A T V G R G R V R Y L Y T G G D Y S - - - - - - - -- - - - - - - - - - - - - - - - - E V F E N E V N G E L I N I G G K E T V G K GMMWV H AWR - - - - - - - - - - - -- - - - - - - - - - - - - - - - - L AWV R Q S E L D V V Q I G A D E T I G R G I C R L T WA D G G A R - - - - - - - -- - - - - - - - - - - - - - - - V L D A A F G G E G T V L Q L G G K A T V G R G R C R L L AWMA P D A R G G R - - - -- - - - - - - - - - - - - - - - - - - - - - - - P P S S L Q L G G K G S V G R G L L S V Q V V V R - - - - - - - - - - -- - - - - - - - - - - - - - - G L F R G V L E E G G G V L Q L G G K A T V G R G L C R V R V G R - - - - - - - - - - - -- - - - - - - - - - - - - - - - - - - - - N E N I G G I F Q V G G N E T I G K G I V K V I N H D L L K G V T E - - - - -- - - - - - - - - - - - - - - - V I D I V C N K L P K Y MQ I G G N T T L G K G I V K P L K L - - - - - - - - - - - - -- - - - - - - - - - - - - - - - E E V K D L I N R C K I I Q V G G D E S L G K G F I R L N L C - - - - - - - - - - - - -G V I K D S G D L K N L I T K L A E K L K K T N N V F Y A I I G G K E T V G R G L I K F T I A L P Q GQ Q - - - - - - -- - - - - - - - - - - - - - - V D E E F K K N L D N I S I F L G G K E T I G K G L V R I K V I - - - - - - - - - - - - -
D26H15Alignment of Cmr4 orthologs (type III B)
Alignment of Pf Cmr4 and Csm3 orthologs (type III A)
Y229E227
18977498|Therm|Pyrococcus_furiosus_DSM_3638/1-295125974541|Clost|Clostridium_thermocellum_ATCC_27405/1-252159898996|Chlor|Herpetosiphon_aurantiacus_ATCC_23779/1-24315609958|Actin|Mycobacterium_tuberculosis_H37Rv/1-23057865882|Actin|Staphylococcus/1-21155978332|Deino|Thermus_thermophilus_HB8/1-23630248152|Betap|Nitrosomonas_europaea_ATCC_19718/1-23315679091|Metha|Methanothermobacter_thermautotroph/1-24015644553|Therm|Thermotoga_maritima_MSB8/1-24014590102|Therm|Pyrococcus_horikoshii_OT3/1-284261403338|Metha|Methanocaldococcus_vulcanius_M7/1-283
18977498|Therm|Pyrococcus_furiosus_DSM_3638/1-295125974541|Clost|Clostridium_thermocellum_ATCC_27405/1-252159898996|Chlor|Herpetosiphon_aurantiacus_ATCC_23779/1-24315609958|Actin|Mycobacterium_tuberculosis_H37Rv/1-23057865882|Actin|Staphylococcus/1-21155978332|Deino|Thermus_thermophilus_HB8/1-23630248152|Betap|Nitrosomonas_europaea_ATCC_19718/1-23315679091|Metha|Methanothermobacter_thermautotroph/1-24015644553|Therm|Thermotoga_maritima_MSB8/1-24014590102|Therm|Pyrococcus_horikoshii_OT3/1-284261403338|Metha|Methanocaldococcus_vulcanius_M7/1-283
18977498|Therm|Pyrococcus_furiosus_DSM_3638/1-295125974541|Clost|Clostridium_thermocellum_ATCC_27405/1-252159898996|Chlor|Herpetosiphon_aurantiacus_ATCC_23779/1-24315609958|Actin|Mycobacterium_tuberculosis_H37Rv/1-23057865882|Actin|Staphylococcus/1-21155978332|Deino|Thermus_thermophilus_HB8/1-23630248152|Betap|Nitrosomonas_europaea_ATCC_19718/1-23315679091|Metha|Methanothermobacter_thermautotroph/1-24015644553|Therm|Thermotoga_maritima_MSB8/1-24014590102|Therm|Pyrococcus_horikoshii_OT3/1-284261403338|Metha|Methanocaldococcus_vulcanius_M7/1-283
18977498|Therm|Pyrococcus_furiosus_DSM_3638/1-295125974541|Clost|Clostridium_thermocellum_ATCC_27405/1-252159898996|Chlor|Herpetosiphon_aurantiacus_ATCC_23779/1-24315609958|Actin|Mycobacterium_tuberculosis_H37Rv/1-23057865882|Actin|Staphylococcus/1-21155978332|Deino|Thermus_thermophilus_HB8/1-23630248152|Betap|Nitrosomonas_europaea_ATCC_19718/1-23315679091|Metha|Methanothermobacter_thermautotroph/1-24015644553|Therm|Thermotoga_maritima_MSB8/1-24014590102|Therm|Pyrococcus_horikoshii_OT3/1-284261403338|Metha|Methanocaldococcus_vulcanius_M7/1-283
18977498|Therm|Pyrococcus_furiosus_DSM_3638/1-295125974541|Clost|Clostridium_thermocellum_ATCC_27405/1-252159898996|Chlor|Herpetosiphon_aurantiacus_ATCC_23779/1-24315609958|Actin|Mycobacterium_tuberculosis_H37Rv/1-23057865882|Actin|Staphylococcus/1-21155978332|Deino|Thermus_thermophilus_HB8/1-23630248152|Betap|Nitrosomonas_europaea_ATCC_19718/1-23315679091|Metha|Methanothermobacter_thermautotroph/1-24015644553|Therm|Thermotoga_maritima_MSB8/1-24014590102|Therm|Pyrococcus_horikoshii_OT3/1-284261403338|Metha|Methanocaldococcus_vulcanius_M7/1-283
11111111111
8079686868686867668171
M K A Y L V - G L Y T L T P T H P G S G - - - T E L G V V DQ P I Q R E R H T G F P V I WGQ S L K G V L R S Y L K L V E K V D E E K I N K I F G P P T E K A H E Q A G- R Y V V R G I I V A E T P I H I G A G N E S MN P V E P D N S V I K D K - D G K P Y I P G S S L K G A L R S W L E S F L R G G G N E I T G G N A P C - L C - - V N E P- R I F V N F E I H A L T G L H I G G A A G T L A I G N V D N P V I R N P F N S E P Y V P G S S L R G K M R S Q L E K L Y G L AQ N T S I - - - - - - - - - - - - - - -- K I E I T G T L T V L T G L Q I G A G D G F S A I G A V D K P V V R D P L S R L P M I P G T S L K G K V R T L L S R Q Y G A D T E T F Y - - - - - - - - - - - - - - -- K I K I S G T I E V V T G L H I G G G G E S S M I G A I D S P V V R D L Q T K L P I I P G S S I K G K M R N L L A K H F G L K M K Q E S - - - - - - - - - - - - - - -- V I R I R S V L L A K T G L R I GM S R DQMA I G D L D N P V V R N P L T D E P Y I P G S S L K G K L R Y L L E W S L G G D Y I L K A - - - - - - - - - - - - - - -- I H K I T G T L I L K S G L H I G A G D S E M R I G G T D S P V V K D P L T DQ P Y I P G S S L K G K I R S L L E WR H G L V V A T G G - - - - - - - - - - - - - - -- N Y I I T G E I L C R T G L H I G V S K D S I E I G G S D N P I I R D P V T R L P Y I P G S S I K G K M R S L L E L E L D R V S N G G - - - - - - - - - - - - - - - -- K Y I I K G K I I L E T G L R I G GQ E L G V N I G G I D N P V I R N P L T G E P Y I P G S S V K G K M R S L M E R L L N L D I S G - - - - - - - - - - - - - - - - -- K I I I S G E I E A V T G L H I G S Q R E V S E I G G I D N P V I K D P H T G L P Y I P G S S L K G R L R S L F E I Y V N T R L D E L K S K Y S S L S N Y - - S K G S- K I I F K G K I K V N T G L H I G S Q R D V S E I G G I D N P V V K D P I T Q L P Y I P G S S L K G K L R S L L E I A E N T K K P K E E Q G I - - - - - - - - - - - -
8180696969696968678272
1461371119898114117111104139126
L I S V G D A K I - L F F P V R S L K G - - - - - V Y A Y V T S P L V L N R F K R D L E L A G V K N F Q T E - - - - - - - - - - - - I P E L T D T A I A S E E I T V D NC L G - - D N P E N K E W L K E I K K K Y K N N K D A D R L V A E E I Y R K L C P V C K V F G S Q H F A - - - - - - - - - - - - - - - - - - - - - - - - S K V T I N D S- - - - - - - - - - - - - - - - - - - - - - G R D V S I H S A K T Q A E Y D N S P V L H I F G I P A S D F - - - - - - - - - - - - - - - - - - - L T E P I R L I V R D A- - - - - - - - - - - - - R K - - - - - - - - - - - - - - - - - - - P N E D H A H I R R L F G D T E - - - - - - - - - - - - - - - - - - - - - - E Y M T G R L V F R D T- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - H NQ D D E R V L R L F G S S E K G - - - - - - - - - - - - - - - - - - - - N I Q R A R L Q I S D A- - - - - - - - - - - - - - - - - - - - K - E R Q V Y A - - - - - - S P D P K D P V A R I F G L A P E N D E R S - - - - - - - - - - - L A V A R E R G P T R L L V R D A- - - - - - - - - - - - - - - - - - - - - - A P Y S F K H L AQ D E N N S A G R D V I K L F G G A P D K - A E - - - - - - - - - - - - DQ L V K N I G P T R L A F WD C- - - - - - - - - - - - - - - - - - - - - - - - - - - - - P C - - - - K C G K C E I C R V F G S A A D S S S S S - - - - - - - G P T R T D S S S S S G P T R I I V R D A- - - - - - - - - - - - - - - - - - - - - - - N K V R R H E C - - - - E E R E C K V C R V F G S T S K E - - - - - - - - - - - - - - - - - - - G N N I P S R L L V R D AC R D V G K E N C G K F F N K - - - - - K - L N N V W I H V C S T Y E M A R N C P V C R L Y G S S G K E - - - - - - - - - - - - - - - - - - - - S N F P S R L I V R D A- - - - - - - G D E K F F N R K I I R G S - K E P I W I H V C E N Y K D A K E C P V C R L F G S G G - N - - - - - - - - - - - - - - - - - - - - S N F P A R V V V R D A
1471381129999
115118112105140127
230172154138139158160154147179166
K V I L E E F A I L I Q K D D K G I L E S V V K A I E Q A F G N E M A E K I K G R I A I I P D D V F R D L V E L S T E I V A R I R I N A E T G T V E T G G L WY E E Y IK - L K S - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - E R A Y I E K R D G V A I D R D T G T S A K N K K Y D F E Q VA - L S E Q - - - - - - - T R A A F R - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - D A R T D L P Y T E V K W E A A I D R V T S A - A T - - P R Q Q E R VK - L T N K - - - - - - - D D L - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - E A R G A K T L T E V K F E N A I N R V T A K - A N - - L R Q M E R VF - F S E K - - - - - - - T K E H F - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - A Q N D I A Y T E T K F E N T I N R L T A V - A N - - P R Q I E R VY - L T E D - - - - - - - A K E A L E R - - - - - - - - - - - - - - - - - - - - - - - - - - - - - T S A R G G L Y T E I K Q E V F I P R L G G N - A N - - P R T T E R VP - L N G D - - - - - - - WK K E A A - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - D S R H L L T T E V K S E N S I N R I A G T A E H - - P R F I E R VF - P T D E - - - - - - - T V E E WK - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - E S S E V V E G A E L K Y E N N L N R I T S M - A N - - P R NQ E R VF - L T E D - - - - - - - S K T K L L - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - S M E T D L P Y T E WK T E N A L D R V T C K - A D - - P R S F E R IF - L T E E - - - - - - - WK K K W - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - E N G E A I T E A K I E V G I D R V T S Q - A N - - P R T T E R VH - L T D Y - - - - - - - WK E K W - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - E T G E E L T E I K H E N T L D R I T S A - A S - - P R K I E R I
231173155139140159161155148180167
295238218216204223222217212244231
P S D T L F Y S L I L V T P R A - - - - - - - - - - - - - - - - - K D N DMA L I K E V L G K I N G K Y L Q I G G N E T V G K G F V K V T L K E V T N N G G T H A K - -A A G T E F D F HM T A D N L D - - - - - - - - - - - - - - - E E N E K - - - I L K I I V K M L E S G D F V V G G K R S V G L G R I R L Y N T K I Y K I D E K S L E N YP A G A I F D G A L T F T L Y N - - - - - - - - - - - - - - DQ D T K L - - - F N T V I R G L E L V E E D Y L G GQ G A R G S GQ V A F K N I M I R F Q Q - - - H E K PI P G S E F A F S L V Y E V S F G T P G E E Q K A S L P S S D E I I E D - - - F N A I A R G L K L L E L D Y L G G S G T R G Y GQ V K F S N L K A R A A V - - - G A L DT R G S E F D F V F I Y N V D E - - - - - - - - - - - - - E S Q V E D D - - - F E N I E K A I H L L E N D Y L G G G G T R G N G R I Q F K D T N I E T V V - - - G E Y DP A G A R F R V E M T Y R V L D - - - - - - - - - - - - - D L D E E Y F - - - G K Y L L R A L E L L E L D G L G G H I S R G Y GQ V Y F L H P E R L T E D - - - Q E GWI A G A R F D F T L T L K V L E G - - - - - - - - - - - - - - D - - D L - - - L N T V L L G L R L L E L D S L G G S G S R G Y G K I K F A E L K L D G T D - - - L M E QP R G S K F G F E I I V S E Y D G - - - - - - - - - - - - - - - D S D N - - - L R I V L E G L R L L E D S Y L G G S G T R G Y G K I E F K N I K I R E R P - - - V E Y YP A G A E F E F E I I Y T A E N - - - - - - - - - - - - - E K H I K E D - - - L E N I A T A L E L L E D D Y L G G N G S R G Y G K V K F S I E K V I F K S - - - A D Y YV A G T R F D F E I I Y T I E D - - - - - - - - - - - - - L K E WK D D - - - L R N L L T S M L L L E D S Y L G G S G S R G Y G K V R F H V K G L E L R P - - - L E Y YP P G V E F N F E I I Y T I E D - - - - - - - - - - - - - E N DWK E D - - - V K N L L S T M K M L E D S Y L G G C G S R G Y G K V E F I F E E C K F R S - - - L N Y Y
239219217205224223218213245232
252243230211236233240240284283
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -L F N - - - - - - - - G L S - - - - - - E E M R - - WQ Y V - - - - - - - - - - - - - - - - - - - - - - - - - - -V L E - - - - - - - - K G E I G - - S L A E L R A L W - - - - - - - - - - - - - - - - - - - - A A Q G Y A A K - -G S - - - - - - L L E K L N - - - - - - - - - - - - - - - - - - H E L A A V - - - - - - - - - - - - - - - - - - -S T N - L K - - - - - I K - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -- - - - - - - - P L K E R L - - - - K V E E V V L - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -F H A - - - I T P F NQ T A - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -R G E - A G E S T M G D F E - - - - S L A D I N T T A E - - - - - - - - - - - - - - - - - - - - - - - - - - - - -K G E - G T - - P V E K E V K G - - G V E G F K K - - - - - - - - A I P E I V K G - - - - - - - - - - - - - - - -R T G - D E G K I V K K T E Y E - - R V E D L L K - - - - - - - - N F E T I T S E F D R R V G G I E G - - - - - -F G K - D Y E K P I E I K E - - - - N V E N T I N E F Y N I F N K E L E E I I K S I S Q N N G G D N G Y K N N K T
D26H15

6
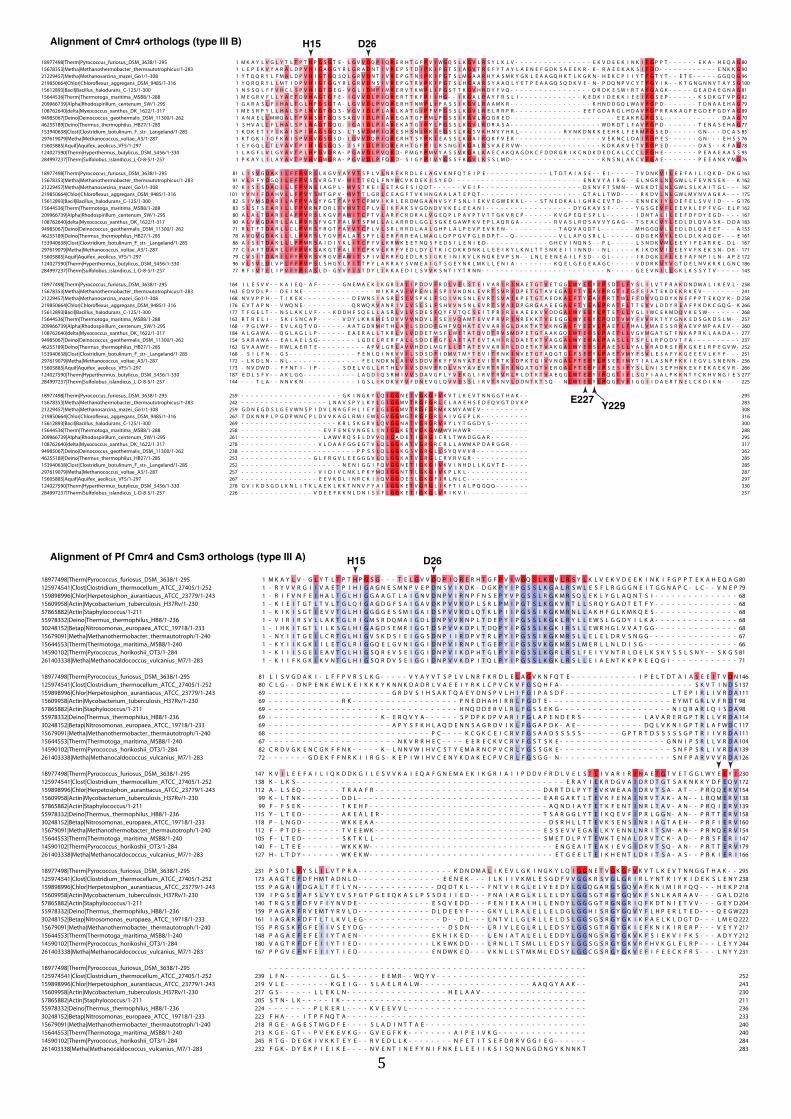
Figure S4 (related to Figure 4). Evolutionary conservation of Cmr4, the backbone
protein of the Cmr complex.
The upper panel shows the sequence alignment of Cmr4 orthologs from Pyrococcus furiosus
(Pf), Thermotoga maritima (Tm), Thermus thermophilus (Tt) and other organisms as
indicated. The lysine residues identified in the crosslinking and mass spectrometry analysis
in Figure 4 are near patches of conserved residues. Conserved residues are in colored boxes.
The position of the nucleolytically active D26 is indicated, as well as other residues that were
tested in the mutational screen in Figure 5. The lower panel shows the sequence alignment
of Pf Cmr4 with indicated Csm3 orthologs, the putative backbone Cas7-‐protein from type III-‐
A systems. The catalytically active residue D26 of Pf Cmr4 is also conserved among these
proteins.
7
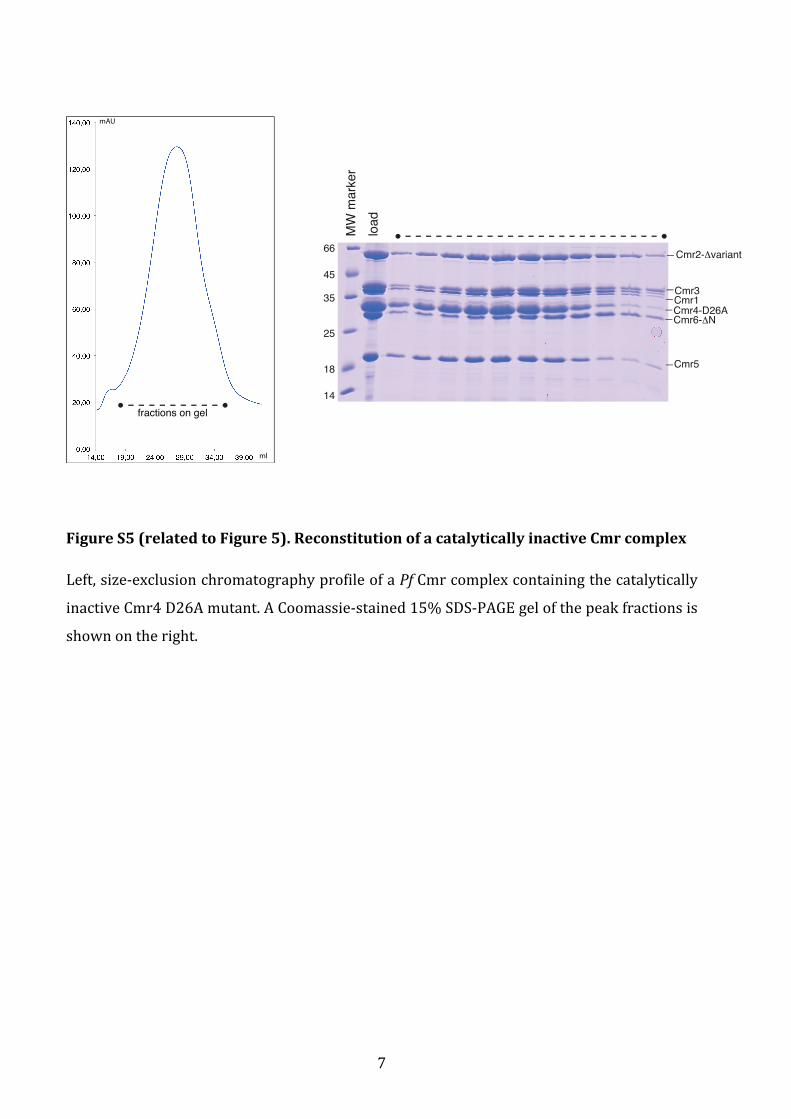
Figure S5 (related to Figure 5). Reconstitution of a catalytically inactive Cmr complex
Left, size-‐exclusion chromatography profile of a Pf Cmr complex containing the catalytically
inactive Cmr4 D26A mutant. A Coomassie-‐stained 15% SDS-‐PAGE gel of the peak fractions is
shown on the right.
14
18
35
25
45
66 Cmr2-Δvariant
Cmr3
load
MW
mar
ker
Cmr4-D26A
Cmr5
Cmr1Cmr6-ΔN
fractions on gel
ml
mAU

8
Table S1 (related to Figure 3). Crosslink mass spectrometry raw data
A table with crosslink mass spectrometry raw data generated in this study and containing
the following information:
Linker The short name, as defined in the application AndromedaConfig, of the used CID cleavable crosslink chemical. All the fragmentation rules and how they relate to each other for this linker are also defined in this application. For example, the CID labile crosslinker DSSO fragments asymmetrically into an alkene and sulfenic acid (which can also lose a water to become a thiol). After cleavage, these products remain attached to the peptides and are treated as variable modifications during the peptide identification stage.
MaxQuant automatically extracts the precursor (where the peptide crosslink is still intact) and associates that to the fragments by use of precise mass relationships and elution profile correlations (during data acquisition the complete elution profile is recorded for the crosslinked peptide pair and the individual peptides after cleaving the crosslinker).
Raw files The semi-‐colon separated list of mass spectrometry files from which the particular crosslink was extracted. In case of pre-‐fractionation, it can occur that the crosslinked peptides are found in two or more different fractions if the resolution of separation was not sufficient.
Fractions The semi-‐colon separated list of fraction numbers in which the particular crosslink was detected.
Fraction intensities The semi-‐colon separated list of detected pre-‐cursor intensities in each fraction (i.e. the intensity of the crosslinked peptides).
Sequences The two peptide amino acid sequences separated by a dash of the detected crosslink pair. In case of a looplink or a monolink only 1 sequence is displayed.
Modified sequences The two peptide amino acid sequences with the part of the linker annotated between parantheses separated by a dash of the detected crosslink pair. In case of a looplink or a monolink only 1 sequence is reported.
Gene names The gene names of the proteins from which the peptides were derived separated by a dash when the names are available (for more exotic organisms than Human, E. coli and Yeast MaxQuant does not maintain a translation table). In the case of interlink the protein name is reported twice. In the case of a looplink or a monolink only 1 name is reported.
Link type Defines the type of the detected crosslink: ‘InterProtein’ is a crosslink between two different proteins; ’IntraProtein’ is a crosslink within a protein; ‘LoopLink’ is a crosslink within a single peptide; ‘Mono’ is a quenched crosslinker attached to a peptide.
Mass The detected monoisotopic mass of the crosslinked peptide pair.
Intensity The detected intensity of the crosslinked peptide pair.
Min score The minimum Andromeda peptide identification score of the two separate identifications. The minimum is reported as a conservative estimate.
Max PEP The maximum Andromeda Posterior Error Probability (PEP) of the two separate identifications. The maximum is reported as a conservative estimate.

9
Min correlation The minimum elution profile correlation between the elution profile of the crosslinked peptide pair and the individual peptides after cleaving the crosslinker. The minimum is reported as a conservative estimate.
Crosslink frequency The frequency in percent (between 0 and 1) at which the crosslink between the two peptides actually formed. This is calculated by dividing the sum of the individual peptide intensities by the intensities of the monolinked version of the same peptides.
Uniprot [A|B] The uniprot identifier of the protein associated to the identified peptide.
Protein name [A|B] The name of the protein associated to the identified peptide (for more exotic organisms than Human, E. coli and Yeast MaxQuant does not maintain a translation table).
Gene name [A|B] The gene name of the protein associated to the identified peptide (for more exotic organisms than Human, E. coli and Yeast MaxQuant does not maintain a translation table).
Positions [A|B] The semi-‐colon separated list of positions of the amino acid(s) where the crosslink was formed within the protein associated to the identified peptide. In case of multiple crosslinks on the same peptides multiple positions will be reported.
Score [A|B] The Andromeda peptide identification score for the identified peptide.
PEP [A|B] The Andromeda peptide identification Posterior Error Probability (PEP) for the identified peptide.
Correlation [A|B] The correlation of the elution profile of this individual peptide after crosslink cleavage to that of the crosslinked peptide pair.
Miscleavages [A|B] The number of missed cleavages based on the cleavage rules for the used proteases for the identified peptide.
Mass [A|B] The detected mono isotopic mass for the identified peptide.
Intensity [A|B] The detected intensity for the identified peptide.
MS/MS scannumbers [A|B] The scan numbers for the ms/ms scans leading to the identification of this peptide.
MS/MS precursor numbers [A|B] The MaxQuant internal precursor number of the elution profile of this peptide.
Reverse Marked with TRUE when one of the identified peptides was marked as a reverse hit in the decoy search strategy employed during the peptide identification process. FALSE otherwise.
Contaminant Marked with TRUE when one of the identified peptides was associated to a protein marked as a common contaminant.
Number detections The number of individual MS/MS detections leading to the identification of the crosslinked peptide pair.

10
SUPPLEMENTAL EXPERIMENTAL PROCEDURES
Purification of Pf Cmr proteins and reconstitution of Cmr complexes
Pf Cmr1 was cloned in a pET-‐derived Kanamycin-‐resistant vector with a non-‐cleavable
C-‐terminal 6His-‐tag and expressed in BL21-‐Gold (DE3) pLysS cells (Stratagene) in Terrific
Broth (TB) medium at 37 °C for 3 hours, induced with 30µM IPTG. Cells were resuspended in
lysis buffer (20 mM Tris/HCl pH 7.5, 1 M NaCl, 10 mM imidazole, 5 mM 2-‐mercaptoethanol,
10% glycerol, 0.1% Triton X100), with the addition of Complete EDTA-‐free Protease
Inhibitor Cocktail Tablets (Roche) and DNase I, lysed by sonification and subjected to cobalt
affinity purification. The eluate was then treated with 500U DNAse for 30 min at 37 °C and
dialyzed into 20 mM Tris/HCl pH 7.5, 200 mM NaCl, 2 mM DTT, 10% glycerol. The protein
was further purified by ion exchange chromatography (Heparin, GE Healthcare) at pH 7.5
and size exclusion chromatography (Superdex 75, GE Healthcare) in 20 mM Tris/HCl pH 7.5,
500 mM NaCl, 2 mM DTT, 10% glycerol.
Pf Cmr2 was cloned in a pET-‐derived Ampicillin-‐resistant vector with a TEV-‐cleavable
N-‐terminal 6His-‐tag and expressed in BL21-‐Gold (DE3) pLysS cells (Stratagene) in Terrific
Broth (TB) medium at 18 °C overnight, induced with 0.5 mM IPTG. Cells were resuspended
in lysis buffer (20 mM Tris/HCl pH 7.5, 500 mM NaCl, 10 mM imidazole, 5 mM
2-‐mercaptoethanol, 10% glycerol) with the addition of Complete EDTA-‐free Protease
Inhibitor Cocktail Tablets (Roche) and DNase I, lysed by sonificaion and subjected to cobalt
affinity purification. The tag was cleaved overnight in dialysis buffer (20 mM Tris/HCl pH 7.5,
200 mM NaCl, 10 mM imidazole, 5 mM 2-‐mercaptoethanol, 10% glycerol) with TEV protease
followed by removal of the uncleaved protein and TEV by another cobalt affinity step. The
cleaved protein was then further purified by ion exchange chromatography (Heparin, GE
Healthcare) at pH 7.5 and a size exclusion chromatography (Superdex 200, GE Healthcare) in
20 mM Tris/HCl pH 7.5, 200 mM NaCl, 2 mM DTT, 10% glycerol.
Pf Cmr3 was cloned in a pET-‐derived Kanamycin-‐resistant vector with a non-‐cleavable
C-‐terminal 6His-‐tag and expressed in BL21-‐Gold (DE3) pLysS cells (Stratagene) in Terrific
Broth (TB) medium at 18 °C overnight, induced with 30µM IPTG. Cells were resuspended in
lysis buffer (20 mM Tris/HCl pH 7.5, 1 M NaCl, 10 mM imidazole, 5 mM 2-‐mercaptoethanol,
10% glycerol, 0.1% Triton X100) and DNase I, lysed by sonification and subjected to cobalt
affinity purification. The protein was then dialyzed into 20 mM Tris/HCl pH 7.5, 200 mM

11
NaCl, 2 mM DTT, 10% glycerol 100 mM L-‐arginine and further purified by ion exchange
chromatography (Heparin, GE Healthcare) at pH 7.5 and size exclusion chromatography
(Superdex 200, GE Healthcare) in 20 mM Tris/HCl pH 7.5, 200 mM NaCl, 2 mM DTT, 10%
glycerol.
Pf Cmr4 was cloned in a pET-‐derived Ampicillin-‐resistant vector with a TEV-‐cleavable
N-‐terminal 6His-‐tag and expressed in BL21-‐Gold (DE3) pLysS cells (Stratagene) in Terrific
Broth (TB) medium at 18 °C overnight, induced with 0.5 mM IPTG. Cells were resuspended
in lysis buffer (20 mM Tris/HCl pH 7.5, 500 mM NaCl, 10 mM imidazole, 5 mM
2-‐mercaptoethanol, 10% glycerol, DNase I), lysed by sonification and subjected to cobalt
affinity purification. The tag was cleaved overnight in dialysis buffer (20 mM Tris/HCl pH 7.5,
200 mM NaCl, 10 mM imidazole, 5 mM 2-‐mercaptoethanol, 10% glycerol) with TEV protease
followed by removal of the uncleaved protein and the protease by a cobalt affinity step.
Finally, a size exclusion chromatography (Superdex 75, GE Healthcare) in 20 mM Tris/HCl
pH 7.5, 150 mM NaCl, 2 mM DTT, 10% glycerol yielded a monomeric protein.
Pf Cmr5 was cloned, expressed and purified like Cmr4, except that the size exclusion step
was carried out in a buffer with 200 mM NaCl.
Pf Cmr6 and Cmr6∆N (101-‐end) were cloned in a pET-‐derived Kanamycin-‐resistant vector
with a non-‐cleavable C-‐terminal 6His-‐tag and expressed in BL21-‐Gold (DE3) pLysS cells
(Stratagene) in Terrific Broth (TB) medium at 18 °C overnight, induced with 0.5 mM IPTG.
Cells were resuspended in lysis buffer (20 mM Tris/HCl pH 7.5, 500 mM NaCl, 10 mM
imidazole, 5 mM 2-‐mercaptoethanol, 10% glycerol), 1 mM PMSF and DNase I, lysed by
sonification and subjected to cobalt affinity purification. The protein was then dialyzed into
20 mM Tris/HCl pH 7.5, 150 mM NaCl, 2 mM DTT, 10% glycerol and further purified by ion
exchange chromatography (Heparin, GE Healthcare) at pH 7.5 and a size exclusion
chromatography (Superdex 200, GE Healthcare) in 20 mM Tris/HCl pH 7.5, 150 mM NaCl,
2 mM DTT, 10% glycerol.
The Cmr2-‐3-‐4-‐5-‐6ΔN complex for the CXMS experiment was reconstituted from purified
components in a step-‐wise manner. First, Cmr2 and Cmr3 were combined in a 1:1.5 molar
ratio for 10 min at 37 °C, followed by the addition of Cmr4 and Cmr5 in a 1.5x molar excess
and incubation for 30 min at 37 °C. To separate the full complex from subcomplexes, an
intermediate size exclusion chromatography (Superose 6, GE Healthcare) in 20 mM Tris/HCl
pH 7.5, 200 mM NaCl, 2 mM DTT, 10% glycerol was performed. Finally, Cmr6∆N was added

12
in a 2x molar excess to the fractions containing Cmr2, Cmr3, Cmr4, Cmr5 and incubated for
30 min at 37 °C, followed by another size exclusion chromatography (Superose6, GE
Healthcare) in the conditions above.
Reconstitution of a Cmr complex containing Cmr4-‐D26A
Large scale reconstitution and purification of a Cmr complex containing Cmr1, 2, 3, 5, 6 and
Cmr4-‐D26A mutant was basically done as described above. After reconstitution, the complex
was purified on a custom made Superose 6 (GE Healthcare) column (column volume 48 ml)
in running buffer (20 mM Tris/HCl pH 7.5, 200 mM NaCl, 1mM TCEP). Peak fractions were
analyzed on an SDS gel.
Crystallization and structure determination
All diffraction data were collected at the Swiss Light Source (SLS) synchrotron facility at
beam lines PXII and PXIII. The data were processed with XDS (Kabsch, 2010). All crystal
structures were solved using AutoSol from the PHENIX suite (Adams et al., 2010). The
atomic models were built with Coot (Emsley et al., 2010) and refined using either the
PHENIX suite (Adams et al., 2010) or the CCP4 suite (Winn et al., 2011). Validation was
performed with Molprobity (Davis et al., 2007). Figures were made using either PyMOL (The
PyMOL Molecular Graphics System, Version 1.2 Schrödinger, LLC.) or Chimera (Pettersen et
al., 2004).
Pf Cmr1 crystallized at 10 mg/ml from an optimized crystallization buffer (100 mM
bicine/Trizma base pH 6.0, 10% PEG 8000, 20% ethylene glycol, 20 mM each of sodium
DL-‐alanine, sodium L-‐gutamate, gylcine, DL-‐lysine HCl, DL-‐serine (Gorrec, 2009) and either
3% DMSO or 3% D-‐sorbitol) after 5-‐10 days. Crystals were flash-‐frozen in liquid nitrogen
after soaking them for 20 min in a cryo-‐protectant solution based on the crystallization
buffer but with 15% PEG 8000 and 20% ethylene glycol. The best crystals diffracted to 2.7 Å.
For experimental phasing, crystals were soaked in the same cryo-‐solution supplemented
with 20 mM AuCl3 for 3 hours, back-‐soaked in cryo-‐solution without the heavy metal for 10
minutes and flash-‐frozen. The structure of Cmr1 was solved by SAD phasing, using PHENIX
AutoSol and AutoBuild (Terwilliger et al., 2008). The final model includes residues 1-‐336
(with the exception of a partially disordered loop between residues 202 -‐ 210). The

13
structure of Pf Cmr1 superposes with a root mean square deviation (rmsd) of 1.1 Å over all
Cα atoms with the structure of Archeoglobus fulgidus (Af) Cmr1 that was reported recently
(Sun et al., 2014).
Crystals of full-‐length Pf Cmr2 were obtained from a crystallization buffer containing
100 mM bicine/Trizma base pH 8.5, 10% PEG 8000, 20% ethylene glycol, 20 mM
1,6-‐hexanediol, 20 mM 1-‐butanol, 20 mM (RS)-‐1,2-‐propanediol, 20 mM 2-‐propanol, 20 mM
1,4-‐butanediol and 20 mM 1,3-‐propanediol (Gorrec, 2009) and 1.5-‐2 % dextrane. Seleno-‐
methionine (SeMet) incorporated Cmr2 crystallized in a similar condition. Prior to freezing,
crystals were dehydrated in mother liquor containing 20% PEG 8000 and 25 % ethylene
glycol for 24 to 48 hours; supplemented with MnCl2 in case of Mn-‐bound Cmr2. Dehydrated
crystals were flash-‐frozen directly from this condition. The best crystals diffracted to around
3 Å (native) or 3.5 Å (SeMet). The structure was solved by SAD phasing using anomalous
data collected on a SeMet crystal. An initial model was built with the help of Buccaneer
(Cowtan, 2008) and completed and refined until model statistics converged. This model was
then used to phase all other data, collected on native and derivative crystals.
Pf Cmr4 was crystallized from a mother liquor containing (1) 30% Jeffamine M-‐600 and
100 mM HEPES pH 7.0, (2) 200 mM magnesium formate, 25% PEG 3350, or (3) 100 mM
bicine/Trizma base pH 8.5, 10% PEG 4000, 20% glycerol, 30 mM sodium fluoride, 30 mM
sodium iodide, 30 mM sodium bromide. Native crystals from (1) were soaked in a
crystallization buffer containing 40% Jeffamine M-‐600 and flash-‐frozen in liquid nitrogen.
For phasing, crystals from (2) were soaked in mother liquor supplemented with 15%
ethylene glycol and 1 mM AuCl3 for 1 hour, back-‐soaked in the same solution without AuCl3
and flash-‐frozen. Four initial gold sites were found with AutoSol (Terwilliger et al., 2009)
using data up to 6.5 Å. The experimental map obtained was used to place poly-‐alanine
helices into tube-‐like electron density. This initial coarse model was fed back into an MR-‐
SAD run at full resolution and the model was completed by iterative cycles of building (Coot)
and refinement (phenix.refine, (Afonine et al., 2012)).
Cmr6ΔN and SeMet-‐incorporated Cmr6ΔN were both crystallized from a mother liquor
containing 2.4 M sodium malonate. Prior to flash freezing, all crystals were soaked in 3.5 M
sodium malonate for dehydration and cryo-‐protection. The structure was phased using
PHENIX AutoSol and a partial model was generated with Autobuild. Completion and

14
refinement of the model was performed with Coot and phenix.refine.
Fitting of a pseudo-‐atomic model
The crystal structures were fit in the EM density using the “fit in map” feature in Chimera
(Pettersen et al., 2004). No flexible fitting was applied. First, Cmr2-‐Cmr3 was fit into the foot
region of the map, as previously shown by (Spilman et al., 2013). Next, a hexameric filament
of Cmr4 was fit into to major ridge of the segmented map as a rigid body. The correct
orientation of the hexamer (subunits A-‐F) was validated via distance restraints from the
CXMS data. The two units close to the tip of the map (E and F) were then used to superpose
and place Cmr6ΔN (on E) and Cmr1 (on F). A trimer of Crm5 was fit into the small ridge and
again, the orientation was validated via CXMS. Finally, all structures were sequentially fit
with the sequential fit command in Chimera, using 15 Å resolution simulated maps for the
individual structures. In cases where crystal structures had missing loop regions due to
flexibility, Modeller (Sali and Blundell, 1993) was used to complete the models for the final
distance restraints analysis.
Chemical crosslinking mass spectrometry
A total of 170 µg of the reconstituted Cmr complex (2.3 µg/µl) in 500 mM NaCl, 20 mM Hepes pH 7.6,
2 mM DTT and 10% glycerol was incubated with 2 mM DSSO crosslinker (Kao et al., 2011) for 1 hour
at room temperature. The crosslink reaction was stopped by addition of 100 mM Tris/HCl pH 8. The
crosslinked protein complexes were cleaned up by precipitation using acetone and digested
in-‐solution using trypsin and LysC. The resulting peptide mixture was desalted on a C18 reversed
phase cartridge and separated into six fractions using size exclusion chromatography on a Superdex
Peptide 3.2/300 column (GE Healthcare Bio-‐Sciences AB) and a Äkta-‐micro system (GE Healthcare),
as described (Leitner et al., 2012)
All data were acquired with a Q Exactive benchtop quadrupole-‐Orbitrap mass spectrometer (Thermo
Scientific). Online liquid chromatography was performed with a Thermo easy ultra-‐LC (Thermo
Scientific) coupled to a 50 cm analytical column with an inner diameter of 75 μm and packed with
1.9 μm reprosil C18 reversed beads (Dr. Maisch). The gradient was programmed as follows:
2% – ‘fraction percentage’ over 5 minutes; ‘fraction percentage’ – 50% over 90 minutes; 50% – 60%
over 5 minutes; 60% – 95% over 5 minutes; 95% – 95% over 5 minutes; 95% – 5% over 5 minutes;
5% – 5% over 10 minutes. Given that size exclusion at the peptide level is not completely orthogonal
with the employed reversed phase chromatography, the ‘fraction percentage’ was empirically

15
determined to achieve the greatest spread of peptides over the available retention time range: 30%
for fraction 1, 20% for fraction 2, 15% for fraction 3, 10% for fractions 4 and 5, and 5% for fraction 6.
For each fraction a volume corresponding roughly to 2 µg of peptides was loaded. A custom shotgun
mass spectrometry acquisition method was implemented, where in each cycle a normal survey scan,
termed FULL, is followed by a survey scan, termed CXD, with low in-‐source collisional energy of
35 eV (SID) to specifically break the linker and keep the peptides intact. This process is targeted
towards breaking the linker, where a part of it remains on the peptides as a modification. In each
cycle the acquisition software samples the 10 most abundant, not yet sequenced isotope patterns
from the second scan for fragmentation with the same SID energy followed by HCD fragmentation at
NCE of 27 (a process termed pseudo-‐ms3).
Data was analyzed with a modified MaxQuant version 1.3.9.21 (Cox and Mann, 2008), to make use of
the additional data coming from the CXD scan mode (Scheltema RA, Schiller HB, and Mann M et al;
publication in preparation). Briefly, isotope patterns from the two survey scans are detected
separately. An additional component has been added to the standard MaxQuant workflow that
analyzes retention time correlation of isotope patterns and mass-‐relates the detected isotope
patterns from the FULL scans (crosslinked peptides still linked) to isotope patterns from the CXD
scans (crosslinked peptides separated). As a last step, the HCD fragmentation scans are identified
and the modified lysines are localized. If the correct mass relationship of 2 identified peptides
modified with a crosslinker remnant to their crosslinked precursor (mass A + mass B +
fragmentation loss = mass AxB) is found, a crosslink is reported. For the crosslinks the software
automatically distinguishes the crosslinks into intra-‐protein and inter-‐protein link (crosslink is
within a single protein or between two different proteins, respectively, defined by two separately
identified and linked peptides), loop-‐link (crosslink of 2 lysines within a single tryptic peptide), and
mono-‐link (a quenched linker on a single peptide, providing no spatial information).
Nuclease assays
Target RNA cleavage assays were performed in 20 µl reactions containing 100 mM Hepes
pH 7.5, 500 mM KCl, 1 mM ATP, 1 mM MgCl2 and 10 mM DTT. Proteins were added to a final
concentration of 1 µM (except for Cmr4 and 5 which were added at 3 µM), guide 7.01 RNA
(45 nucleotides, from biomers.net) was added to 100 nM final and reactions were pre-‐
incubated for 10 minutes at 55 ˚C before adding 5' 32P-‐labeled target 7.01 RNA (γ-‐32P-‐ATP
from Perkin-‐Elmer, RNA from biomers.net). The mixtures were incubated for 2 hours at
55 ˚C before quenching with 180 µl stop buffer containing 100 mM Tris-‐HCl pH 7.5, 150 mM
NaCl, 300 mM sodium acetate pH 5.2, 10 mM EDTA, 1% SDS and 30 µg/ml glycogen carrier

16
(Roche). After phenol/chloroform/isoamyl alcohol (25:24:1, v/v, Invitrogen) extraction and
ethanol precipitation, the RNA pellets were resuspended in loading dye consisting of 7 mM
EDTA, 0.07% (w/v) bromophenol blue, 0.07% (w/v) xylene cyanole FF and 10 mM cold
target 7.01 DNA (Sigma-‐Aldrich) acting as a trap for the guide RNA. Samples were boiled at
95 ˚C for 5 minutes before being separated on a 20% polyacrylamide gel containing 8 M urea.
Gels were exposed to image plates that were scanned with a Typhoon FLA 7000
phosphorimager (GE Healthcare).

17
SUPPLEMENTAL REFERENCES
Adams, P.D., Afonine, P.V., Bunkóczi, G., Chen, V.B., Davis, I.W., Echols, N., Headd, J.J., Hung, L.-‐W., Kapral, G.J., Grosse-‐Kunstleve, R.W., et al. (2010). PHENIX: a comprehensive Python-‐based system for macromolecular structure solution. Acta Crystallogr D Biol Crystallogr 66, 213–221.
Afonine, P.V., Grosse-‐Kunstleve, R.W., Echols, N., Headd, J.J., Moriarty, N.W., Mustyakimov, M., Terwilliger, T.C., Urzhumtsev, A., Zwart, P.H., and Adams, P.D. (2012). Towards automated crystallographic structure refinement with phenix.refine. Acta Crystallogr D Biol Crystallogr 68, 352–367.
Cowtan, K. (2008). Fitting molecular fragments into electron density. Acta Crystallogr D Biol Crystallogr 64, 83–89.
Cox, J., and Mann, M. (2008). MaxQuant enables high peptide identification rates, individualized p.p.b.-‐range mass accuracies and proteome-‐wide protein quantification. Nat. Biotechnol. 26, 1367–1372.
Davis, I.W., Leaver-‐Fay, A., Chen, V.B., Block, J.N., Kapral, G.J., Wang, X., Murray, L.W., Arendall, W.B., Snoeyink, J., Richardson, J.S., et al. (2007). MolProbity: all-‐atom contacts and structure validation for proteins and nucleic acids. Nucleic Acids Res 35, W375–W383.
Emsley, P., Lohkamp, B., Scott, W.G., and Cowtan, K. (2010). Features and development of Coot. Acta Crystallogr D Biol Crystallogr 66, 486–501.
Gorrec, F. (2009). The MORPHEUS protein crystallization screen. J Appl Crystallogr 42, 1035–1042.
Kao, A., Chiu, C.-‐L., Vellucci, D., Yang, Y., Patel, V.R., Guan, S., Randall, A., Baldi, P., Rychnovsky, S.D., and Huang, L. (2011). Development of a novel cross-‐linking strategy for fast and accurate identification of cross-‐linked peptides of protein complexes. Mol. Cell Proteomics 10, M110.002212.
Kabsch, W. (2010). XDS. Acta Crystallogr D Biol Crystallogr 66, 125–132.
Leitner, A., Reischl, R., Walzthoeni, T., Herzog, F., Bohn, S., Förster, F., and Aebersold, R. (2012). Expanding the chemical cross-‐linking toolbox by the use of multiple proteases and enrichment by size exclusion chromatography. Mol. Cell Proteomics 11, M111.014126.
Mulepati, S., and Bailey, S. (2011). Structural and Biochemical Analysis of Nuclease Domain of Clustered Regularly Interspaced Short Palindromic Repeat (CRISPR)-‐associated Protein 3 (Cas3). J Biol Chem 286, 31896–31903.
Pettersen, E.F., Goddard, T.D., Huang, C.C., Couch, G.S., Greenblatt, D.M., Meng, E.C., and Ferrin, T.E. (2004). UCSF Chimera-‐-‐a visualization system for exploratory research and analysis. J Comput Chem 25, 1605–1612.
Sali, A., and Blundell, T.L. (1993). Comparative protein modelling by satisfaction of spatial restraints. J Mol Biol 234, 779–815.
Spilman, M., Cocozaki, A., Hale, C., Shao, Y., Ramia, N., Terns, R., Terns, M., Li, H., and Stagg, S. (2013). Structure of an RNA Silencing Complex of the CRISPR-‐Cas Immune System.

18
Molecular Cell 52, 146–152.
Sun, J., Jeon, J.H., Shin, M., Shin, H.C., Oh, B.H., and Kim, J.S. (2014). Crystal structure and CRISPR RNA-‐binding site of the Cmr1 subunit of the Cmr interference complex. Acta Crystallogr D Biol Crystallogr 70, 535–543.
Terwilliger, T.C., Adams, P.D., Read, R.J., McCoy, A.J., Moriarty, N.W., Grosse-‐Kunstleve, R.W., Afonine, P.V., Zwart, P.H., and Hung, L.-‐W. (2009). Decision-‐making in structure solution using Bayesian estimates of map quality: the PHENIX AutoSol wizard. Acta Crystallogr D Biol Crystallogr 65, 582–601.
Terwilliger, T.C., Grosse-‐Kunstleve, R.W., Afonine, P.V., Moriarty, N.W., Zwart, P.H., Hung, L.-‐W., Read, R.J., and Adams, P.D. (2008). Iterative model building, structure refinement and density modification with the PHENIX AutoBuild wizard. Acta Crystallogr D Biol Crystallogr 64, 61–69.
Winn, M.D., Ballard, C.C., Cowtan, K.D., Dodson, E.J., Emsley, P., Evans, P.R., Keegan, R.M., Krissinel, E.B., Leslie, A.G.W., McCoy, A., et al. (2011). Overview of the CCP4 suite and current developments. Acta Crystallogr D Biol Crystallogr 67, 235–242.










![ARGONAUTE2 Mediates RNA-Silencing Antiviral...ARGONAUTE2 Mediates RNA-Silencing Antiviral Defenses against Potato virus X in Arabidopsis1[W][OA] Marianne Jaubert, Saikat Bhattacharjee,](https://img.pdfslide.net/doc/110x75/5e661ae4630f1a0b0611439a/argonaute2-mediates-rna-silencing-argonaute2-mediates-rna-silencing-antiviral.jpg)






![RNA interference (RNAi) [aka post-transcriptional gene silencing (PTGS)]](https://img.pdfslide.net/doc/110x75/56814467550346895db0fc81/rna-interference-rnai-aka-post-transcriptional-gene-silencing-ptgs.jpg)











