Embed Size (px)
Citation preview

Supporting Queries with Imprecise Constraints
Ullas NambiarDept. of Computer Science
University of California, Davis
Subbarao Kambhampati
Dept. of Computer ScienceArizona State University
18th July, AAAI -06, Boston, USA
[WebDB 2004; VLDB 2005 (d);WWW 2005 (p); ICDE 2006]

Supporting Queries with Imprecise Constraints
Dichotomy in Query Processing
Databases
• User knows what she wants
• User query completely expresses the need
• Answers exactly matching query constraints
IR Systems
• User has an idea of what she wants
• User query captures the need to some degree
• Answers ranked by degree of relevance
AutonomousUn-curated DB
Inexperienced,Impatient user population

Supporting Queries with Imprecise Constraints
Why Support Imprecise Queries ?
Want a ‘sedan’ priced around $7000
A Feasible Query
Make =“Toyota”, Model=“Camry”,
Price ≤ $7000
What about the price of a Honda Accord?
Is there a Camry for $7100?
Solution: Support Imprecise Queries
………
1998$6500CamryToyota
2000$6700CamryToyota
2001$7000CamryToyota
1999$7000CamryToyota

Supporting Queries with Imprecise Constraints
The Problem: Given a conjunctive query Q over a relation R, find a set of tuples that will be considered relevant by the user.
Ans(Q) ={x|x Є R, Rel(x|Q,U) >c}
Constraints– Minimal burden on the end user – No changes to existing database – Domain independent
What does Supporting Imprecise Queries Mean?
AutonomousUn-curated DB
Inexperienced,Impatient user population

Supporting Queries with Imprecise Constraints
Assessing Relevance Function Rel(x|Q,U)
We looked at a variety of non-intrusive relevance assessment methods– Basic idea is to learn the relevance function for user
population rather than single users Methods
– From the analysis of the (sample) data itself • Allows us to understand the relative importance of attributes,
and the similarity between the values of an attribute [ICDE 2006;WWW 2005 poster]
– From the analysis of query logs• Allows us to identify related queries, and then throw in their
answers [WIDM 2003; WebDB 2004]
– From co-click patterns• Allows us to identify similarity based on user click pattern
[Under Review]

Supporting Queries with Imprecise Constraints
The AIMQ Approach
ImpreciseQuery
Q
Query Engine
Map: Convert“like” to “=”
Qpr = Map(Q)
Dependency Miner
Use Base Set as set ofrelaxable selection
queries
Using AFDs findrelaxation order
Derive Extended Set byexecuting relaxed queries
Similarity Miner
Use Value similaritiesand attribute
importance to measuretuple similarities
Prune tuples belowthreshold
Return Ranked Set
Query Engine
Derive BaseSet Abs
Abs = Qpr(R)
[For the special case of empty query, we start with a relaxation that uses AFD analysis]

Supporting Queries with Imprecise Constraints
An Illustrative Example
ImpreciseQuery
Q Map: Convert“like” to “=”
Qpr = Map(Q)
Use Base Set as set ofrelaxable selectionqueries
Using AFDs findrelaxation order
Derive Extended Set byexecuting relaxed queries
Use Concept similarityto measure tuplesimilarities
Prune tuples belowthreshold
Return Ranked Set
Derive BaseSet Abs
Abs = Qpr(R)
Relation:- CarDB(Make, Model, Price, Year) Imprecise query
Q :− CarDB(Model like “Camry”, Price like “10k”)
Base query
Qpr :− CarDB(Model = “Camry”, Price = “10k”)
Base set Abs
Make = “Toyota”, Model = “Camry”, Price = “10k”, Year = “2000”Make = “Toyota”, Model = “Camry”, Price = “10k”, Year = “2001”

Supporting Queries with Imprecise Constraints
Obtaining Extended Set
ImpreciseQuery
Q Map: Convert“like” to “=”
Qpr = Map(Q)
Use Base Set as set ofrelaxable selectionqueries
Using AFDs findrelaxation order
Derive Extended Set byexecuting relaxed queries
Use Concept similarityto measure tuplesimilarities
Prune tuples belowthreshold
Return Ranked Set
Derive BaseSet Abs
Abs = Qpr(R)
Problem: Given base set, find tuples from database similar to tuples in base set.
Solution: – Consider each tuple in base set as a selection query.
e.g. Make = “Toyota”, Model = “Camry”, Price = “10k”, Year = “2000”
– Relax each such query to obtain “similar” precise queries.e.g. Make = “Toyota”, Model = “Camry”, Price = “”, Year =“2000”
– Execute and determine tuples having similarity above some threshold.
Challenge: Which attribute should be relaxed first?
– Make ? Model ? Price ? Year ?
Solution: Relax least important attribute first.

Least Important Attribute
Definition: An attribute whose binding value when changed has minimal effect on values binding other attributes.• Does not decide values of other attributes• Value may depend on other attributes
E.g. Changing/relaxing Price will usually not affect other attributes but changing Model usually affects Price
Dependence between attributes useful to decide relative importance• Approximate Functional Dependencies & Approximate Keys
Approximate in the sense that they are obeyed by a large percentage (but not all) of tuples in the database• Can use TANE, an algorithm by Huhtala et al [1999]

Supporting Queries with Imprecise Constraints
Deciding Attribute Importance Mine AFDs and Approximate
Keys Create dependence graph using
AFDs– Strongly connected hence a
topological sort not possible Using Approximate Key with
highest support partition attributes into
– Deciding set– Dependent set– Sort the subsets using
dependence and influence weights
Measure attribute importance as
ImpreciseQuery
Q Map: Convert“like” to “=”
Qpr = Map(Q)
Use Base Set as set ofrelaxable selectionqueries
Using AFDs findrelaxation order
Derive Extended Set byexecuting relaxed queries
Use Concept similarityto measure tuplesimilarities
Prune tuples belowthreshold
Return Ranked Set
Derive BaseSet Abs
Abs = Qpr(R)
CarDB(Make, Model, Year, Price)
Decides: Make, YearDepends: Model, Price
Order: Price, Model, Year, Make
1- attribute: { Price, Model, Year, Make}
2-attribute: {(Price, Model), (Price, Year), (Price, Make).. }
•Attribute relaxation order is all non-keys first then keys
•Greedy multi-attribute relaxation
depends
idepends
decides
idecides
iimp
Wt
AWt
or
Wt
AWt
RAttributescount
AlaxOrderAiW
)(
)(
))((
)(Re)(

Tuple Similarity
Tuples obtained after relaxation are ranked according to their
similarity to the corresponding tuples in base set
where Wi = normalized influence weights, ∑ Wi = 1 , i = 1 to |Attributes(R)|
Value Similarity• Euclidean for numerical attributes e.g. Price, Year• Concept Similarity for categorical e.g. Make, Model
WiAitvalueAitvalueilarityAttrSimttSimilarity ]))[2(]),[1(()2,1(
ImpreciseQuery
Q Map: Convert“like” to “=”
Qpr = Map(Q)
Use Base Set as set ofrelaxable selectionqueries
Using AFDs findrelaxation order
Derive Extended Set byexecuting relaxed queries
Use Concept similarityto measure tuplesimilarities
Prune tuples belowthreshold
Return Ranked Set
Derive BaseSet Abs
Abs = Qpr(R)

Supporting Queries with Imprecise Constraints
Categorical Value Similarity Two words are semantically
similar if they have a common context – from NLP
Context of a value represented as a set of bags of co-occurring values called Supertuple
Value Similarity: Estimated as the percentage of common {Attribute, Value} pairs
– Measured as the Jaccard Similarity among supertuples representing the values
ST(QMake=Toy
ota)
Model Camry: 3, Corolla: 4,….
Year 2000:6,1999:5 2001:2,……
Price 5995:4, 6500:3, 4000:6
Supertuple for Concept Make=Toyota
JaccardSim(A,B) = BABA
m
i
imp AivSTAivSTJaccardSimAiWvvVSim1
)).2(,).1(()()2,1(
ImpreciseQuery
Q Map: Convert“like” to “=”
Qpr = Map(Q)
Use Base Set as set ofrelaxable selectionqueries
Using AFDs findrelaxation order
Derive Extended Set byexecuting relaxed queries
Use Concept similarityto measure tuplesimilarities
Prune tuples belowthreshold
Return Ranked Set
Derive BaseSet Abs
Abs = Qpr(R)

August 15th 2005 Answering Imprecise Queries over Autonomous Databases
Value Similarity Graph
Ford
Chevrolet
Toyota
Honda
DodgeNissan
BMW
0.25
0.16
0.110.15
0.12
0.22

Supporting Queries with Imprecise Constraints
Empirical Evaluation Goal
– Evaluate the effectiveness of the query relaxation and similarity estimation
Database– Used car database CarDB based on Yahoo AutosCarDB( Make, Model, Year, Price, Mileage, Location, Color)
• Populated using 100k tuples from Yahoo Autos
– Census Database from UCI Machine Learning Repository• Populated using 45k tuples
Algorithms – AIMQ
• RandomRelax – randomly picks attribute to relax• GuidedRelax – uses relaxation order determined using approximate keys
and AFDs
– ROCK: RObust Clustering using linKs (Guha et al, ICDE 1999)• Compute Neighbours and Links between every tuple
Neighbour – tuples similar to each other Link – Number of common neighbours between two tuples
• Cluster tuples having common neighbours

Supporting Queries with Imprecise Constraints
Efficiency of Relaxation
0
100
200
300
400
500
600
700
800
900
1 2 3 4 5 6 7 8 9 10
Queries
Wor
k/Re
leva
nt T
uple
Є= 0.7
Є = 0.6
Є = 0.5
•Average 8 tuples extracted per relevant tuple for Є =0.5. Increases to 120 tuples for Є=0.7.
•Not resilient to change in Є
0
20
40
60
80
100
120
140
160
180
1 2 3 4 5 6 7 8 9 10Queries
Wor
k/R
elev
ant T
uple
Є = 0.7
Є = 0.6
Є = 0.5
•Average 4 tuples extracted per relevant tuple for Є=0.5. Goes up to 12 tuples for Є= 0.7.
•Resilient to change in Є
Random Relaxation Guided Relaxation

Supporting Queries with Imprecise Constraints
Accuracy over CarDB
•14 queries over 100K tuples
• Similarity learned using 25k sample
• Mean Reciprocal Rank (MRR) estimated as
• Overall high MRR shows high relevance of suggested answers
1|)()(|
1)(
ii tAIMQRanktUserRankAvgQMRR
0
0.2
0.4
0.6
0.8
1
1 2 3 4 5 6 7 8 9 10 11 12 13 14Queries
Avera
ge M
RR .
GuidedRelax
RandomRelax
ROCK

Supporting Queries with Imprecise Constraints
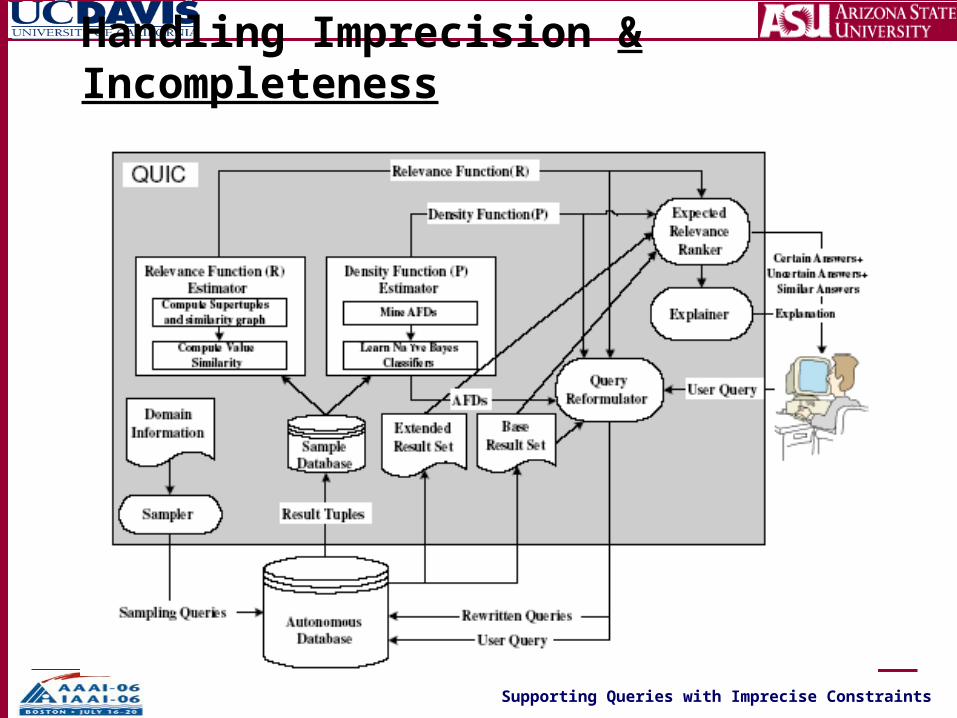
Handling Imprecision & Incompleteness
Incompleteness in data– Databases are being
populated by• Entry by lay people• Automated extraction
E.g. entering an “accord” without mentioning “Honda”
Imprecision in queries– Queries posed by lay users
• Who combine querying and browsing
General Solution: “Expected Relevance Ranking”
Relevance Function
DensityFunction
Challenge: Automated & Non-intrusive assessment of Relevance and Density functions
Supporting Queries with Imprecise Constraints
Handling Imprecision & Incompleteness





















![NAMBIAR HEALTH CARE PROJECT[1]](https://img.pdfslide.net/doc/110x75/577d2bb11a28ab4e1eab2379/nambiar-health-care-project1.jpg)








