Embed Size (px)
Citation preview

UNIVERSITÀ DEGLI STUDI DI VERONA
Facolta di Scienze Matematiche Fisiche e Naturali
Corso di Laurea in Scienze dell’Informazione
TESI DI LAUREA
Sviluppo di un ambiente software interattivo per l'addestramento e la validazione di architetture
neurali basate sul processore TOTEM
Relatrice: Prof. Letizia TANCA
Correlatore: Dott. Giampietro TECCHIOLLI
Candidato: Stefano Benamati
matr. SI000151
Anno Accademico 1996-1997

2
Dedicato ai miei genitori.

3
Ringraziamenti
Desidero ringraziare l’Istituto per la Ricerca Scientifica e Tecnologica di Povo (TN) per aver messo a mia disposizione le tecnologie e la documentazione necessaria alla realizzazione di questo lavoro. Un ringraziamento particolare lo devo al Dott. Giampietro Tecchiolli, per aver fatto da tramite tra me e l’Istituto, ma soprattutto per avermi cortesemente e costantemente seguito in questi mesi di lavoro.
Desidero inoltre ringraziare tutti coloro che, direttamente o indirettamente, hanno indirizzato le mie scelte verso la Facoltà di Scienze dell’Informazione e che mi sono stati vicini in questi anni di studi universitari. Tra questi vorrei ricordare la mia carissima amica Kerstin che mi è sempre stata di aiuto e sostegno in questi anni.
Il ringraziamento più sentito lo devo però ai miei genitori per aver creduto in me permettendomi di continuare gli studi e per aver avermi spronato ed assistito in tutti questi anni.
Infine, ringrazio Alberto Andreis per essersi preso carico di tutte quelle operazioni legate alla stampa e alla rilegatura di questa tesi.
Stefano Benamati

4
Indice
1 INTRODUZIONE............................................................................................ 6
2 BASI MATEMATICHE DEL NEURONE ARTIFICIALE................................. 9 2.1 Neuroni biologici ....................................................................................... 10 2.2 Neuroni artificiali ....................................................................................... 12
3 DAI NEURONI ARTIFICIALI ALLE RETI NEURALI ................................... 14 3.1 Reti neurali monostrato............................................................................. 14 3.2 Un calcolatore digitale in termini di percettroni ......................................... 19 3.3 Il problema della separabilità lineare ........................................................ 21 3.4 Funzioni a valori continui .......................................................................... 23 3.5 Reti neurali multistrato .............................................................................. 25 3.6 Reti ricorsive............................................................................................. 28 3.7 Un confronto ............................................................................................. 31
4 ALGORITMI DI ADDESTRAMENTO........................................................... 33 4.1 Retropropagazione (Backpropagation)..................................................... 34 4.2 RTS (Reactive Tabu Search).................................................................... 38 4.3 Un confronto ............................................................................................. 40 4.4 Una soglia addestrabile ............................................................................ 42
5 HARDWARE NEURALE.............................................................................. 43 5.1 Architetture Hardware............................................................................... 45 5.2 La scheda TOTEM ................................................................................... 45
6 SOFTWARE DI GESTIONE......................................................................... 51 6.1 Il device driver .......................................................................................... 51 6.2 La libreria.................................................................................................. 51 6.3 L’interfaccia grafica interattiva .................................................................. 58
7 IL MANUALE UTENTE................................................................................ 60 7.1 Descrizione dei componenti principali ...................................................... 61

5
8 DESCRIZIONE DEL FORMATO DEI FILE.................................................. 72
9 UN PROBLEMA DI CLASSIFICAZIONE .................................................... 83 9.1 Classificazione di punti ............................................................................. 83 9.2 Il problema Concentric.............................................................................. 84
10 APPROSSIMAZIONE DI FUNZIONI............................................................ 91 10.1 Il problema del periodo del pendolo...................................................... 91
11 FORZA 3...................................................................................................... 96
12 UN PROBLEMA REALE ........................................................................... 103 12.1 Descrizione dell’apparato.................................................................... 103 12.2 Il calcolo della differenza in frequenza................................................ 105 12.3 Un approccio alternativo ..................................................................... 106
13 CONCLUSIONI .......................................................................................... 112
14 APPENDICE .............................................................................................. 116 14.1 Appendice A........................................................................................ 117 14.2 Appendice B........................................................................................ 120 14.3 Appendice C........................................................................................ 123 14.4 Appendice D........................................................................................ 126
15 BIBLIOGRAFIA ......................................................................................... 129

6
1 Introduzione
La computazione classica, quella che si basa sul modello di von Neumann di una sequenza programmata di istruzioni, pur essendo la più appropriata per risolvere un’ampia gamma di problemi, soffre di una grave limitazione. Essa, infatti, necessita di una profonda comprensione del problema, per permettere al programmatore di costruire un algoritmo in grado di risolverlo.
Vi sono però alcuni problemi la cui natura intrinseca impedisce di conoscerne a fondo i dettagli, oppure, l’analisi è talmente complessa da renderla virtualmente impossibile. Un esempio è il problema del riconoscimento artificiale di cifre e lettere manoscritte: considerando che ognuno ha uno stile di scrittura diverso, chi può dire quale sia il limite oltre il quale un ‘8’ si confonde con una ‘B’? Ciononostante, noi, tutti i giorni leggiamo ed interpretiamo correttamente la scrittura manuale.
C’è un’evidente diversità tra il modello di von Neumann ed il modello che sta alla base del funzionamento del nostro cervello. Il primo ha bisogno di una sequenza programmata di istruzioni che proviene da una attenta analisi del problema, mentre il secondo, attraverso una serie di esempi, riesce a costruirsi una rappresentazione interna del problema che gli permette di approssimarne la soluzione.
L’ampia gamma di problemi che il cervello, pur essendo lento ed impreciso, riesce ad affrontare molto meglio di un calcolatore tradizionale, suggerisce che esiste un’altra strada da percorrere per arrivare alla soluzione di quei problemi che attualmente sono ritenuti troppo complessi per essere risolti in modo classico. A questo proposito sono stati creati e studiati alcuni modelli

7
computazionali del cervello che riescono a simularne alcune tra le caratteristiche più importanti. Questi modelli sono conosciuti con il nome di reti neurali.
Nel modello computazionale neurale, l'elaborazione dell'informazione avviene attraverso una rete composta da un numero estremamente elevato di unità di elaborazione (i neuroni) collegate fra loro da un insieme di connessioni, che hanno il duplice scopo di trasportare l'informazione e di memorizzare il modo in cui essa viene elaborata. L'aspetto fondamentale dell'elaborazione neurale consiste nella sua natura non algoritmica: l'informazione viene estratta, rappresentata ed elaborata a partire da input sensoriali senza la necessità di definire la sequenza di operazioni che devono essere eseguite su di essa. Un'altro aspetto importante consiste nel concetto di approsimazione: così come avviene nei modelli biologici nell'elaborazione neurale l'informazione viene elaborata in maniera approssimata e non esatta. Un ultimo aspetto altrettanto importante consiste nell'elevato livello di parallelismo dei modelli neurali che apre la strada ad implementazioni hardware in cui si possono raggiungere elevate rese computazionali a parità di area di silicio utilizzata.
Questo lavoro di tesi si propone di studiare alcuni tra i modelli neurali più analizzati e le loro implementazioni su dispositivi hardware dedicati. In particolare, viene dato ampio spazio al processore TOTEM, una implementazione hardware sviluppata in IRST che permette di mappare, con un buon grado di elasticità, i suddetti modelli neurali.
Un aspetto importante che facilita l'approccio ai modelli neurali è dato dalla disponibiltà di strumenti software di alto livello, che siano in grado di nascondere i dettagli implementativi ed automatizzino le procedure più comuni. Per questo motivo, una parte significativa del lavoro di tesi è stato dedicato alla messa a punto di un ambiente di sviluppo interattivo e grafico per l'utilizzo ottimale del processore TOTEM. In questa fase sono state utilizzate metodologie di sviluppo Object-Oriented, sia per la parte grafica che per la parte di interfaccia con il processore neurale.
Dopo aver introdotto la teoria che è alla base della computazione neurale, ed aver descritto nel dettaglio il sistema hardware/software, vengono analizzati quattro problemi, cercando di darne una soluzione utilizzando il paradigma neurale. I primi due sono problemi semplici, di cui si conosce molto bene la soluzione, mentre gli ultimi due riguardano problemi nuovi. Lo scopo di questa fase è duplice: testare il sistema e mostrare le caratteristiche più interessanti delle reti neurali.
• Concentric: questo problema mette in luce due proprietà che le reti neurali hanno in comune con il cervello: la capacità di generalizzazione e la tolleranza agli errori.

8
• Periodo del pendolo: questo problema mette in evidenza la capacità delle reti neurali di approssimare funzioni.
• Forza 3: la capacità di apprendimento è invece la caratteristica che emerge da questo problema.
• Laser: è un’approssimazione di funzioni applicata ad un problema reale. Questo esperimento mostra in che modo il paradigma neurale può a volte essere preferibile a quello algoritmico.
Stefano Benamati

9
2 Basi matematiche del neurone artificiale
Allo stato attuale della tecnologia, nonostante i notevoli sviluppi della microelettronica e dell’informatica che si sono avuti negli ultimi anni, esistono ancora alcuni problemi che sono ritenuti troppo complessi per essere risolti in un tempo ragionevole da un calcolatore digitale [1].
Un esempio di problema al di fuori della portata degli odierni calcolatori è senz’altro rappresentato dalle previsioni del tempo a lungo termine; il modello matematico che ne sta alla base è infatti un complesso sistema di equazioni, la cui soluzione, per previsioni a lungo termine, può impiegare un tempo così lungo da rendere inutili i risultati ottenuti.
Il problema in questo caso nasce dalla mancanza di un’adeguata potenza di calcolo. Dalle attuali tecnologie non ci si possono però aspettare aumenti della velocità di calcolo oltre un certo limite. La velocità dei processori ha infatti un limite fisiologico che è imposto dalla velocità di propagazione dei segnali elettrici all’interno dei circuiti. Non c’è modo di evitare questo limite, ma si può aggirare il problema costruendo sistemi paralleli; nei quali, numerosi processori lavorano contemporaneamente allo stesso problema, riuscendo in tal modo a raggiungere capacità di calcolo altrimenti impossibili.
Non sempre però è sufficiente la potenza di calcolo per risolvere alcuni problemi. A volte, il bisogno di potenza di calcolo nasce dalla mancanza di algoritmi efficienti. L’esempio più significativo viene senz’altro dal gioco degli scacchi, per il quale, l’unico algoritmo che finora è stato sviluppato, è quello di

10
esplorare più o meno esaustivamente lo spazio delle mosse alla ricerca di una sequenza che porta alla vittoria [2],[3],[4]. Chiaramente, a questo tipo di algoritmo gioverebbe molto qualsiasi incremento di potenza; ed infatti Deep Blue, il grande calcolatore parallelo specializzato in analisi scacchistiche della IBM, lo ha dimostrato battendo per la prima volta nella storia il campione mondiale di scacchi Gary Kasparov in un torneo regolamentare [5]. Kasparov da parte sua, ha dimostrato che pur non essendo in grado di valutare milioni di posizioni scacchistiche al secondo, è in grado comunque di trovare la sequenza di mosse vincente. Risulta quindi chiaro che esiste almeno un metodo più efficiente che può essere usato nella ricerca della mossa migliore.
Queste considerazioni vogliono mettere in evidenza l’inadeguatezza degli attuali paradigmi di calcolo quando vengono usati per risolvere alcuni problemi.
Il modello computazionale che è alla base del funzionamento del cervello umano può rappresentare una valida alternativa al modello di von Neumann. Il cervello è infatti un complesso sistema di elaborazione delle informazioni che, nonostante possa sembrare molto più lento ed impreciso di un calcolatore digitale tradizionale, riesce a compiere in un tempo straordinariamente breve alcune complesse elaborazioni; come la scelta della mossa migliore in una partita a scacchi, la comprensione del parlato o il riconoscimento di un viso.
La superiorità elaborativa del cervello non è che una delle caratteristiche che innalzano l’uomo un gradino sopra le macchine, il cervello è anche tollerante ai guasti, ed infatti le cellule del cervello muoiono ogni giorno senza degradare significativamente le sue prestazioni. Il cervello inoltre può facilmente adattarsi a situazioni nuove, elaborare informazioni probabilistiche, soggette a rumore o inconsistenti. Infine, ed è la cosa più notevole, senza istruzioni esplicite, cioè senza ubbidire ad un programma prestabilito, il cervello impara da solo a gestire ed interpretare gli input che provengono dai sensi. Sarebbe quindi un grande passo in avanti riuscire in qualche modo a riprodurre artificialmente tutte queste caratteristiche per costruire un sistema che simuli almeno in parte il comportamento del cervello.
2.1 Neuroni biologici
Il cervello umano è composto da circa 1011 cellule nervose chiamate neuroni, che possono essere considerate come piccoli elaboratori paralleli capaci di fornire in uscita una funzione non lineare dei propri ingressi. Il disegno di Fig. 2.1 schematizza la struttura di un neurone [6].

11
Il corpo della cellula nervosa è connesso ad una rete di fibre chiamate dendriti che hanno il compito di trasportare i segnali provenienti dalle altre cellule. Il segnale in uscita dal neurone è invece trasportato da una singola lunga fibra chiamata assone, la quale, per mezzo di terminazioni trasmittenti chiamate sinapsi, si collega ad altri neuroni: sia direttamente, attraverso il corpo della cellula ricevente, sia indirettamente, attraverso i dendriti.
L’assone di un tipico neurone ha alcune migliaia di sinapsi con altri neuroni formando in tal modo una fitta rete di trasmissione delle informazioni.
La trasmissione di un segnale tra un neurone ed un altro è un complesso procedimento chimico, che ha l’effetto di alzare, o di abbassare, il potenziale elettrico all’interno del corpo della cellula ricevente. Se il potenziale raggiunge una certa soglia il neurone si eccita, ed emette lungo l’assone un impulso elettrico di durata e potenza fissa. Il segnale così emesso, arriverà a tutti i neuroni che sono direttamente collegati all’assone e, modificandone il potenziale elettrico ne ecciterà alcuni, i quali emetteranno altri impulsi che ecciteranno altri neuroni, e così via. Grazie all’altissima connettività della rete neurale quindi, l’attività di ogni neurone influenza quella di un certo numero di cellule che gli sono vicine e, direttamente o indirettamente, viene influenzato dall’attività di queste ultime.
Questo complicato sistema di scambio delle informazioni è il meccanismo base di come vengono elaborate le informazioni all’interno del cervello. L’apprendimento avviene invece tramite modificazioni dell’efficienza con cui le sinapsi trasmettono i segnali da un neurone ad un altro [6].
Fig. 2.1 Il neurone biologico
Sinapsi
Nucleo
Corpo della cellula
Dendriti
Assone

12
2.2 Neuroni artificiali
I primi a proporre un modello matematico del neurone furono McCulloc e Pitts nel 1943 [7]. Il loro neurone artificiale era molto semplice in quanto era pensato solamente per simulare la più elementare funzione del neurone biologico: la soglia. Specificamente, il modello di neurone calcolava una somma pesata dei suoi ingressi e restituiva in uscita uno o zero, a seconda che la somma fosse maggiore o minore di una determinata soglia.
))(()1( ∑ −Θ=+j
ijiji tnwtn μ
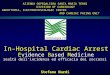
Il valore ni(t) rappresenta lo stato dell’i-esimo neurone al tempo t, esso può assumere solo due valori: zero significa neurone inibito mentre uno significa neurone eccitato. Il tempo t è inteso come discreto. Θ(x) è la funzione di soglia:
I pesi wij rappresentano la forza della connessione sinaptica che connette il neurone j al neurone i. Un valore positivo o negativo corrisponde ad una sinapsi eccitatoria o inibitoria rispettivamente, mentre zero significa che tra i due neuroni non c’è sinapsi. Il parametro μi è il valore della soglia del neurone i; la somma pesata degli input deve raggiungere o superare questa soglia per eccitare il neurone.
Nonostante la sua disarmante semplicità, il modello di neurone proposto da McCulloc e Pitts è un dispositivo di calcolo molto potente che può addirittura essere il mattone di base per costruire dispositivi in grado di eseguire tutte le computazioni tipiche di un calcolatore digitale [Capitolo 3].
A dispetto della sua potenza di calcolo però, il neurone di McCulloc-Pitts non è che una grezza approssimazione del neurone biologico. In realtà i neuroni biologici sono oggetti molto più complessi dei loro equivalenti artificiali. Prima di tutto non sono neanche approssimativamente dei dispositivi a soglia, inoltre, molti neuroni calcolano una sommatoria non lineare dei propri input, producono una sequenza di impulsi anziché un singolo livello di output, ed infine non hanno tutti lo stesso fisso ritardo (t t+1), né sono aggiornati sincronamente da un orologio centrale [6].
Una semplice generalizzazione del neurone di McCulloc-Pitts che tiene conto di alcune di queste caratteristiche è la seguente [6]:
Θ(x)= 1 se x ≥ 0
0 altrimenti (2.2)
(2.1)

13
)(∑ −=j
ijiji nwgn μ
Il numero ni adesso è un valore continuo che viene chiamato stato o attivazione dell’unità i. La funzione di soglia Θ(x) definita in (2.2) è stata sostituita da una più generale funzione non lineare g(x) chiamata funzione di trasferimento.
Lo schema di funzionamento del neurone artificiale è mostrato nel diagramma che segue.
In essenza, in ingresso al neurone viene applicato un insieme di segnali, ognuno dei quali rappresenta l’uscita di un altro neurone. Ogni input è poi moltiplicato per il corrispondente peso, analogo alla efficienza sinaptica. Tutti gli input pesati vengono successivamente sommati per determinare il livello di attivazione del neurone ed infine la funzione di trasferimento calcola il livello del segnale di uscita.
peso
peso
peso
peso
peso
somma funzione di trasferimento
attività d’ingresso
attività d’uscita ingresso pesato totale
attività di uscita
Fig. 2.2 Il neurone di McCulloc-Pitts
(2.3)

14
3 Dai neuroni artificiali alle reti neurali
La costruzione di un modello matematico del neurone, è la prima fase di un processo che forse un giorno porterà alla costruzione di sistemi intelligenti. Tuttavia il neurone artificiale, come del resto il neurone biologico, non ha alcuna utilità pratica se utilizzato da solo. La funzione calcolata da esso è infatti così semplice che la vera potenza computazionale viene dall’interconnessione di molti elementi in modo da formare una rete.
Il concetto di semplicità che è alla base del funzionamento del singolo neurone, quindi, si contrappone alla complessità della rete neurale. È pertanto verosimile, che approssimazioni come quelle del neurone proposto da McCulloc e Pitts, siano comunque in grado di costruire reti computazionalmente equivalenti a quelle presenti nel cervello umano.
In questo capitolo vengono mostrate alcune tra le topologie di connessione più comunemente utilizzate, se ne discutono le caratteristiche e se ne valutano le potenzialità.
3.1 Reti neurali monostrato
Se si prende come misura della semplicità di una rete, la facilità con la quale può essere calcolato il suo output, la disposizione di neuroni che porta alla rete più semplice è quella stratificata. In una rete di questo tipo, i neuroni sono disposti su strati e sono collegati in modo tale che ogni neurone possa comunicare solamente con quelli dello strato immediatamente seguente.

15
La rete stratificata meno complessa che possa essere costruita è chiamata percettrone semplice, ed è formata da gruppi di neuroni sistemati su un singolo strato come mostrato in Fig. 3.1.
I neuroni, che sono raffigurati dai quadrati, sono le uniche entità che eseguono effettivamente una computazione. I nodi rappresentati da un cerchio, sono invece i responsabili della distribuzione degli input; essi non calcolano assolutamente niente e quindi non devono essere considerati come facenti parte di uno strato.
Il vettore degli input X ha ognuno dei suoi elementi connessi ad ogni neurone artificiale attraverso un peso distinto. È conveniente considerare i pesi come elementi di una matrice W, le cui dimensioni sono m righe ed n colonne, dove m è il numero degli input ed n il numero dei neuroni. Per esempio, il peso che connette il terzo input al secondo neurone è w3,2 . In questo modo il calcolo del vettore degli output NET è una semplice moltiplicazione di un vettore per una matrice. Così NET=XW e l’output della rete è OUT=g(XW) dove g è la funzione di trasferimento.
Una rete di neuroni disposti in modo da formare un percettrone semplice, ha una capacità di calcolo piuttosto limitata. Ciononostante, è in grado di calcolare alcune semplici funzioni, come per esempio le tre funzioni logiche fondamentali dell’algebra booleana.
Fig. 3.1 Un percettrone semplice
w11
w12 w1n
wm1
wmn
x1
x2
xm outn
out2
out1

16
3.1.1 AND logico
Sia AND una funzione [0,1]2 [0,1] definita nel seguente modo:
x y x AND y 0 0 0 0 1 0 1 0 0 1 1 1
Il risultato è uno se e solo se x e y sono entrambi a uno, per cui la funzione AND può anche essere definita in questi termini:
xANDy =1 se e solo se x+y>1, zero altrimenti
espressa in questo modo la funzione si rivela essere una soglia, e come tale può essere facilmente calcolata da un percettrone semplice composto da un solo neurone. Il percettrone ha entrambi i pesi posti ad uno, ed una funzione di trasferimento a soglia, con soglia posta ad un valore qualsiasi compreso nell’intervallo (1,2). La Fig. 3.2 mostra il percettrone che calcola l’AND.
Più in generale, estendendo il ragionamento a funzioni AND con un numero arbitrario n di input (AND : [0,1]n [0,1]), il percettrone sarà composto da un singolo neurone con n input, tutti connessi da pesi posti ad uno, ed una soglia posta ad un valore qualsiasi compreso nell’intervallo (n-1,n).
w2=1
w1=1 x
y
OUT
Fig. 3.2. Il percettrone
1.5 x
f(x)
(a) (b)

17
3.1.2 OR logico
Sia OR una funzione [0,1]2 [0,1] definita nel seguente modo:
x y x OR y 0 0 0 0 1 1 1 0 1 1 1 1
Il risultato è uno se almeno uno degli input è uno, oppure, detto in altri termini, solo se la somma degli input è maggiore di zero. Il percettrone che calcola questa funzione è identico a quello che calcola l’AND, ma con soglia della funzione di trasferimento posta ad un valore qualsiasi appartenente all’intervallo (0,1). Per questa funzione, generalizzare i casi di spazi di input di cardinalità maggiore è immediato, perché basta semplicemente aumentare il numero di input del neurone. Infatti, dal momento che la funzione da uno come risultato se almeno un input ha valore uno, la soglia rimane invariata.
3.1.3 NOT logico
Sia NOT una funzione [0,1] [0,1] definita nel seguente modo:
x NOT x 0 1 1 0
Anche questa funzione è una soglia, infatti il risultato è uno se e solo se –x è maggiore o uguale a zero. Il percettrone che calcola questa funzione ha il peso posto a –1 e la funzione di trasferimento a soglia con soglia posta a zero.
w1=-1 x OUT
Fig. 3.3 Il percettrone che implementa il NOT

18
3.1.4 Un elemento di memoria
Introducendo il concetto di ricorrenza, ovvero ammettendo che l’output di un percettrone possa essere rimesso in input e contribuire in tal modo al calcolo di se stesso, è possibile costruire un sistema in grado di memorizzare uno stato.
Il concetto fondamentale sul quale si basa il principio di memoria è il ritardo che un segnale applicato in entrata subisce nel propagarsi attraverso il sistema e che è dovuto principalmente al tempo necessario ad eseguire le computazioni che portano al calcolo dell’output. A causa di questo ritardo, il valore OUT ha il tempo di ritornare in entrata e contribuire al suo calcolo. Se il peso che connette l’input al neurone è posto a uno, il valore di input, dopo aver attraversato il percettrone, ritornerà in ingresso invariato e farà entrare il sistema in un circolo infinito e stabile che memorizzerà lo stato.
Abbandonando un attimo il concetto di percettrone ad uno strato, è anche possibile costruire dispositivi di memoria connettendo in modo opportuno gli operatori logici AND, OR e NOT [8]. Il dispositivo mostrato in Fig. 3.5 si chiama flip-flop di tipo D ed è l’elemento di base con il quale si costruiscono le memorie dei calcolatori. Esso è in grado di memorizzare nell’uscita Q il segnale che gli viene presentato al morsetto D. Le frecce indicano in che direzione fluisce l’informazione all’interno del sistema; come si può vedere, anche in questo dispositivo il segnale in uscita viene riproposto in ingresso. Come il sistema precedente, il flip-flop sfrutta il ritardo di propagazione ed è costruito in modo tale da generare un ciclo stabile quando al morsetto di entrata è presente uno dei due possibili valori {0,1}.
Fig. 3.4 Un semplice elemento di memoria
w1=1
x
OUT=x
OUT= x
w2=1
Δ

19
Se si sostituisce ai blocchi NOT e NAND il corrispondente percettrone, si ottiene una rete ricorsiva con le stesse caratteristiche del flip-flop.
La capacità del percettrone di calcolare le funzioni logiche dell'algebra booleana (e quindi di poter calcolare qualsiasi mappa in cui le uscite dipendano esclusivamente dalle entrate), e la possibilità offerta dalle connessioni ricorsive di memorizzare uno stato, rappresentano gli elementi di base che dimostrano, per costruzione, che il modello computazione neurale contiene ed è in grado di riprodurre anche il modello computazionale algoritmico, così come viene illustrato nel prossimo paragrafo.
3.2 Un calcolatore digitale in termini di percettroni
Nonostante la computazione neurale si basi su un paradigma di calcolo completamente diverso da quello classico, è possibile dimostrare che una rete neurale è in grado di calcolare tutte le funzioni calcolabili da un computer digitale.
Semplificando al massimo, un calcolatore digitale è un sistema composto da un processore e da un’area di memoria connessi tra loro attraverso un canale di comunicazione chiamato bus. La comunicazione tra processore e bus avviene tramite due aree di memoria interne al processore: il MAR (Memory Address Register) e l’MDR (Memory Data Register). Questi due registri in sostanza rappresentano l’interfaccia tra il processore e la memoria. Ai fini di questa trattazione non è importante conoscerne a fondo il funzionamento, basti sapere che la scrittura di un indirizzo nel MAR produrrà il caricamento del MDR con l’informazione contenuta nell’indirizzo di memoria specificato, e che la scrittura di un dato nel MDR e di un indirizzo nel MAR provocherà la scrittura di quel dato nella locazione di memoria specificata. Come questo avvenga è un compito della circuiteria. Altri due importanti registri sono l’IR (instruction Register) ed il PC
NOT
NOT AND (NAND)
Q
not Q
D
Fig. 3.5 Il flip-flop di tipo D

20
(program counter); il primo contiene il codice dell’istruzione corrente, cioè quella che il processore deve eseguire, mentre il secondo contiene l’indirizzo della prossima istruzione.
Entriamo ora nel merito dell’esecuzione delle istruzioni. Supponiamo che sia presente in memoria un programma pronto per l’esecuzione. Il PC verrà allora caricato con il valore dell’indirizzo della prima istruzione, Il contenuto del PC verrà trascritto nel MAR che causerà il trasferimento della prima istruzione. L’istruzione così caricata verrà ospitata nel registro IR e verrà successivamente decodificata ed eseguita. Al termine dell’esecuzione, il PC verrà aggiornato con l’indirizzo della prossima istruzione ed il processo continuerà fino al termine del programma.
Ognuna di queste operazioni elementari, è innescata da un particolare stato interno del processore, stato che è completamente descritto, almeno in linea di principio, dalla sequenza binaria che rappresenta il contenuto dei registri in un dato istante. Durante l’esecuzione di un’istruzione, il processore evolve attraverso una serie di stati. In altri termini si può dire che ad ogni istruzione è associata una traiettoria nello spazio degli stati, e che il sistema è un automa a stati finiti, in cui la transizione da uno stato all’altro è una funzione che mappa stringhe di bit in stringhe di bit (gli stati) [9].
f:{0,1}n {0,1}n
L’algebra booleana afferma che qualunque funzione binaria f può essere espressa servendosi solamente dei tre operatori logici AND, OR e NOT [10]. Poiché è possibile costruire questi operatori in termini di percettroni, allora è
PC
IR MDR
MAR
bus indirizzi
bus dati
CPU Memoria
Fig. 3.6 Schema semplificato di calcolatore digitale

21
possibile costruire una rete neurale in grado di svolgere le stesse funzioni di un calcolatore digitale.
Naturalmente, non è affatto detto che un computer costruito in questo modo sia altrettanto veloce o efficiente di uno digitale, ciononostante, ora appare chiaro che una rete neurale è uno strumento di calcolo che, come potenza, non è inferiore ad un computer digitale, cosa che prima non era assolutamente evidente.
3.3 Il problema della separabilità lineare
Una funzione logica che non è possibile calcolare con un percettrone semplice, nonostante possa sembrare del tutto equivalente come complessità ad un AND oppure ad un OR, è la funzione OR-esclusivo.
x y x XOR y 0 0 0 0 1 1 1 0 1 1 1 0
Il percettrone che dovrebbe calcolare questa funzione è dello stesso tipo di quello usato per calcolare AND e OR: due ingressi, un’uscita ed una soglia. Il neurone calcola la seguente quantità
NET=xw1+yw2
e successivamente la passa alla funzione di trasferimento per produrre l’output vero e proprio.
OUT=f(NET)
Nessuna combinazione di valori per i due pesi w1 e w2, e nessun valore di soglia è in grado di produrre in output la relazione descritta nella tavola della verità dello XOR.
Per capire questa limitazione si consideri NET fissato al valore della soglia, che supporremo 0.5.
xw1+yw2=0.5

22
Questa equazione è lineare in x e y, e così tutti i valori che la soddisfano devono appartenere ad una linea retta che giace sul piano x-y. Ogni valore per x e y su questa linea perciò produce un valore di NET uguale al valore della soglia. Valori di input che stanno da una parte della retta producono un valore di NET minore della soglia e quindi OUT=0, mentre valori che sono dall’altra parte della retta producono valori maggiori e quindi OUT=1.
Cambiando i valori di w1 e w2 e della soglia, si cambia la pendenza e la posizione della retta, quindi, se una soluzione esiste, essa deve posizionare la
retta in modo tale che tutti gli stiano da una parte e tutti gli dall’altra.
Guardando la Fig. 3.7 si può facilmente constatare che tale linea non esiste, e quindi, a prescindere da come si scelgano i pesi e il valore della soglia, questa rete non è in grado di rappresentare questa funzione.
La separabilità lineare limita le reti ad un singolo strato a risolvere problemi di classificazione in cui l’insieme di punti possa essere separato geometricamente. Per il caso di due input la separazione è ottenuta da una retta, nel caso di tre input la separazione si ottiene tramite un piano che taglia il corrispondente spazio tridimensionale, mentre per input maggiori di tre la separazione è ottenuta tramite un iperpiano che interseca il corrispondente iperspazio.
Per una soluzione al problema della separabilità lineare si rimanda al paragrafo 3.5.
Fig. 3.7 Il problema dell’OR-Esclusivo come punti sul piano X-Y
xw1+yw2=soglia
0 1
1

23
3.4 Funzioni a valori continui
3.4.1 Unità non a soglia
Fino a questo momento si sono considerati solamente percettroni dotati di funzione di trasferimento a soglia, limitando di fatto le loro applicazioni a problemi di classificazione. Esistono però tantissime altre funzioni che possono essere usate, e che possono rendere ancora più interessanti i percettroni basati su di esse. Sono le funzioni a valori continui.
Quando il neurone biologico è eccitato, emette in uscita un impulso di durata e potenza costante, dopo avere emesso l’impulso però, il neurone ha bisogno di un periodo di riposo chiamato periodo refrattario prima di poterne emettere un altro. Quindi, in presenza di uno stato eccitatorio prolungato, il neurone emetterà in uscita un treno di impulsi, non un singolo valore valore binario [6]. Con l’introduzione di funzioni di atttivazione a valori continui, si intende perciò codificare con un numero l’informazione mandata da un neurone attraverso il treno di impulsi, in questo modo si approssima meglio il funzionamento del neurone biologico.
Introdurre funzioni di trasferimento continue e differenziabili, inoltre, permette di fare una cosa che con le funzioni a soglia non aveva senso, e cioè, di costruire una funzione di costo che misuri l’errore delle prestazioni della rete come una funzione dei pesi W e poi, utilizzando qualche tecnica di ottimizzazione, minimizzare questo errore ed ottenere così un’approssimazione della funzione che la rete dovrebbe calcolare. Quello che rende attraente questo modo di procedere è che non è necessario conoscere la funzione da approssimare, basta solo conoscerne alcuni valori, la rete viene poi addestrata con questi e calcola una funzione che li approssima. La rete quindi, può imparare per esempi a rappresentare realtà che non conosce.
Le funzioni di trasferimento a valori continui possono essere di qualunque tipo, ma la pratica ha favorito l’uso di due famiglie di funzioni: la Lineare e la Sigmoide.
Alla famiglia delle Lineari appartengono tutte quelle funzioni che hanno la forma f(x)=mx+q, dove m e q sono costanti. Applicare una funzione lineare all’uscita di un neurone ha l’effetto di scalare e traslare il risultato, come si vedrà più avanti, le funzioni lineari hanno un’utilità limitata.
La famiglia delle Sigmoidi è composta da tutte quelle funzioni che hanno una forma ad S e che sono limitate sia inferiormente che superiormente. Usare una sigmoide come funzione di trasferimento permette di comprimere il range di

24
uscita del neurone in modo tale che i suoi valori non eccedano mai un valore prefissato. Le sigmoidi che sono usate più spesso sono la funzione logistica (Fig. 3.8) e la tangente iperbolica (Fig. 3.9).
Le sigmoidi risolvono molto bene il problema di come una rete neurale possa gestire sia i piccoli che i grandi segnali. Piccoli input richiedono un grande guadagno in uscita dalla funzione se vogliono produrre un output usabile dagli altri neuroni, d’altro canto grandi input possono saturare l’output e renderlo inutilizzabile. La sigmoide sembra fatta a posta per risolvere questi problemi; la parte centrale di questa funzione infatti, ha una pendenza tale da amplificare i piccoli segnali ed è quindi in grado di separare le piccole variazioni, mentre gli estremi della funzione hanno una piccola pendenza e sono ideali per comprimere grandi valori.
y
x
-1
1
0
Fig. 3.9 la funzione tangente iperbolica
y=tanh(x)
Fig. 3.8 La funzione logistica
0
y
x
k
)1( xeky −+
=

25
3.5 Reti neurali multistrato
Appena più complessa del percettrone semplice è la rete mostrata in Fig. 3.10. Come nel percettrone semplice la struttura è stratificata, ma ora il numero di strati non è limitato a uno; per questo motivo, la rete prende il nome di percettrone multistrato (MLP). In questo tipo di rete, i neuroni sono collegati in modo tale che ogni neurone possa comunicare solamente con quelli dello strato immediatamente seguente. In tal modo, l’informazione contenuta nell’input potrà propagarsi, strato dopo strato, solo in avanti, fino a quando giungerà nello strato di output. Le reti che hanno questa caratteristica di unidirezionalità del flusso dell’informazione sono conosciute come “feedforward network”.
I percettroni multistrato non hanno la limitazione della separabilità lineare e possono pertanto compiere classificazioni più generali rispetto ai percettroni singoli. Si consideri per esempio la rete di Fig. 3.11: due input, due neuroni nel primo strato ed un neurone nell’ultimo. Questo percettrone può essere immaginato come composto da tre percettroni singoli che chiameremo sub-percettroni in accordo con la Fig. 3.11.
In Fig. 3.12 si può vedere come sia possibile classificare con questo percettrone i punti contenuti nell'area delimitata tra due rette. Il sub-percettrone 1 classifica tutti i punti che stanno al di sotto della retta 1, analogamente il sub-
Fig. 3.10 Un percettrone doppio
wm2
k1p
k12
k11
wmn
wm1
w11
w12 w1n
x1
x2
xm yp
y2
y1
matrice dei pesi W matrice dei pesi K

26
percettrone 2 classifica tutti i punti che stanno al di sopra della retta 2. Gli output di questi due sub-percettroni diventano gli input del sub-percettrone 3, il quale altri non è che un blocco AND; l’output di questo blocco è uno solo se entrambi i suoi input sono a uno, cioè solo per quei punti che sono contemporaneamente sotto la retta 1 e sopra la retta 2.
In modo del tutto simile, un percettrone con tre neuroni nel primo strato può suddividere ulteriormente il piano creando un’area triangolare. Includendo
x
y retta 1: xw11+yw12=soglia1 tutti i punti che stanno sotto questa retta danno 1 in uscita dal sub-percettrone 1.
retta 2: xw21+yw22=soglia2 tutti i punti che stanno sopra questa retta danno 1 in uscita dal sub-percettrone 2.
tutti i punti contenuti in questa regione danno 1 in uscita dal sub-percettrone 3.
Fig. 3.12 Il percettrone doppio classifica regioni convesse
sub-percettrone 3 sub-percettrone 1
sub-percettrone 2
k2
k1
w22
w21
w12
w11 x
y
Fig. 3.11 La scomposizione del percettrone doppio

27
abbastanza neuroni nel primo strato si può creare un qualsiasi poligono convesso, quindi, con un percettrone a due strati si possono classificare tutti quei punti che stanno in una regione convessa dello spazio degli input.
Non solo, poiché la funzione calcolata dal sub-percettrone 3 può essere una qualsiasi delle funzioni a valori binari calcolabili da un percettrone semplice, può anche succedere che per alcune topologie si possano classificare punti contenuti in alcune semplici regioni concave.
Un percettrone a tre strati è ancora più generale; le sue capacità di classificazione sono limitatate solo dal numero di neuroni artificiali che la compongono. Non ci sono più vincoli di convessità; ora il terzo strato riceve in input un gruppo di poligoni convessi e la combinazione logica di questi non è detto che sia convessa.
3.5.1 L’importanza delle funzioni di trasferimento non lineari
Per potersi avvantaggiare delle caratteristiche della topologia multistrato però, si devono usare funzioni di trasferimento non lineari. Infatti, facendo riferimento al percettrone di Fig. 3.10 la funzione calcolata da esso è:
Y=f(g(XW)K)
dove f e g sono le funzioni di trasferimento rispettivamente del primo e del secondo strato, W e K le matrici dei pesi, X è il vettore di input ed Y il vettore di output. Se g fosse una funzione lineare allora la (3.1) si potrebbe riscrivere così:
Y=f(g((XW)K))
ma poiché il prodotto di matrici è associativo, i termini di questa equazione possono essere raggruppati in questo modo
Y=f(g(X(WK)))
Questo mostra che un percettrone a doppio strato, con funzione di trasferimento g lineare, è equivalente ad un percettrone semplice con matrice dei pesi pari a WK e funzione di trasferimento f(g).
(3.1)

28
3.5.2 Approssimazione di funzioni
Sia data una rete MLP con uno strato nascosto e con funzioni di trasferimento f monotone crescenti e limitate:
f(x+dx)>f(x) ∀x
∃ c tale che |f(x)|<c ∀x
si può dimostrare [11] che tale rete è in grado di approssimare con il grado di approssimazione desiderato qualsiasi funzione g in C0.
g: ℜ n ℜ
∀ε esiste una rete NETε tale che || NETε (x) –g(x)||2< ε
L’esatta forma della funzione di trasferimento non è importante nella dimostrazione di questa proprietà, anche se può influire sul numero di neuroni necessari per raggiungere l’accuratezza desiderata nell’approssimazione di una data funzione. L’accuratezza di una approssimazione dipende quindi unicamente dal numero di neuroni negli strati nascosti. Questo è un risultato notevole perché mostra che con un adeguato numero di neuroni è possibile approssimare, con il desiderato grado di approssimazione, qualsiasi funzione continua [12].
Le funzioni non in C0 possono invece essere approssimate usando più strati nascosti [13].
3.6 Reti ricorsive
La fitta rete di dendriti presente nel cervello umano, segue schemi di connessione che non rispecchiano assolutamente il modello di rete rappresentato dal percettrone. Le cellule nervose infatti, non sono disposte secondo strati, e le connessioni che hanno con gli altri neuroni non seguono alcuna precisa regola, né sono caratterizzate da una direzione preferenziale. Il flusso dell’informazione in questo modo non avviene in un’unica direzione come nel caso del percettrone ed è quindi possibile per un segnale propagarsi all’indietro ed andare ad influenzare il comportamento di quelle cellule che li hanno generati. A causa di questa struttura, lo stato del sistema non dipende solo dalla configurazione degli input, ma anche dal tempo. Le reti ricorsive sono

29
ispirate a questo modello di connessione, e sono in grado di eseguire tutta una serie di computazioni che sono precluse ai percettroni.
In Fig. 3.13 è mostrato un tipo di rete ricorsiva monostrato. Questo tipo di rete assomiglia al percettrone, salvo il fatto che l’output viene riproposto in ingresso al neurone attraverso un peso.
L’output di questo tipo di rete è dato dalla seguente relazione:
))(()1( ∑≠
+=+ji
iijj jINtOUTwftOUT
dove f è la funzione di trasferimento. Il valore dell’output al tempo t+1 dipende dal valore dell’output al tempo t, questo significa che la rete ha un comportamento dinamico nel tempo.
La rete si dice stabile se successive iterazioni producono variazioni dell’output sempre più piccole, finché eventualmente l’output diventa costante. Se invece il processo non ha termine la rete è detta instabile.
Una rete come quella di Fig. 3.13 è stabile se la matrice dei pesi è simmetrica, ed ha gli elementi della diagonale principale posti a zero. Una dimostrazione di questa proprietà si può trovare in [14] .
Fig. 3.13 Una rete ricorsiva monostrato
w11
w12 w1n
wm1
wmn
IN1
IN2
INm outn
out2
out1

30
La dipendenza del comportamento dal tempo porta con sè un’interessante caratteristica che non era presente nelle reti non ricorsive. Questo nuovo tipo di rete è in grado di riconoscere e riprodurre sequenze temporali.
Un noto metodo per riconoscre (e talvolta riprodurre) sequenze temporali è quello di utilizzare reti parzialmente ricorrenti [6]. In questo tipo di rete le connessioni sono principalmente in avanti, ma includono un insieme opportunamente scelto di connessioni all’indietro. La ricorrenza permette alla rete di ricordare le informazioni provenienti dal passato recente, ma non complica in modo pesante l’addestramento della rete. L’aggiornamento è sincrono, con un aggiornamento per tutti gli elementi ad ogni unità di tempo. Reti di questo tipo sono anche chiamate reti sequenziali.
Le Fig. 3.14 e 3.15 mostrano alcune architetture che possono essere utilizzate. In tutte le configurazioni è presente uno speciale insieme di unità (context unit) che riceve i segnali propagati all’indietro. Si assume che la propagazione dei segnali in avanti avvenga senza riferimento al tempo, mentre i segnali che si propagano all’indietro siano regolati da un clock. In questo modo, al tempo t le context unit ricevono i segnali provenienti dallo stato della rete al tempo t-1, le quali definiscono il contesto per definire lo stato della rete al tempo t. Le context unit ricordano alcuni aspetti del passato, e così lo stato dell’intera rete in un particolare periodo di tempo dipende sia dall’insieme degli stati precedenti sia dall’input corrente. La rete può quindi riconoscere sequenze sulla base del suo stato al termine della sequenza.
Output
Hidden
Context
(a) Output
Hidden
Context
Input
(b)
Fig. 3.14 Architetture con context unit

31
Poiché lo scopo di questo lavoro di tesi è lo studio delle implementazioni in hardware di architetture semplici quali il percettrone, l’aspetto della computazione neurale ricorsiva, sebbene importantissimo, non viene sviluppato ulteriormente.
3.7 Un confronto
In termini informatici, il cervello potrebbe essere descritto come un sistema parallelo di circa 1011 processori, nel quale, ogni processore è in grado mediamente di comunicare con un migliaio di altri processori, attraverso altrettante linee di comunicazione che, con la loro efficienza rappresentano la memoria del sistema.
Usando come modello di neurone quello semplificato di McCulloc-Pitts, ogni processore ha un programma semplicissimo: calcola la somma pesata degli input provenienti dagli altri processori e restituisce in uscita un singolo numero, che è una funzione non lineare della somma pesata. Questo risultato è poi mandato ad altri processori che stanno continuamente facendo gli stessi calcoli, ma con pesi e funzioni di trasferimento diversi.
L’alta connettività della rete, cioè il fatto che la sommatoria ha molti addendi, fa sì che errori in pochi termini non influenzano di molto l’output. Pertanto, da un sistema di questo tipo, ci si può aspettare che le sue performance degradino di poco in presenza di un malfunzionamento di alcune unità, oppure processando dati contenenti errori.
Output
Hidden
Context Input
(a) Output
Hidden
Context Input
(b)
Fig. 3.15 Architetture con context unit

32
Il contrasto tra questo tipo di computazione e quello classico introdotto da von Neumann non potrebbe essere più forte. Nel cervello abbiamo tanti processori che eseguono ognuno un programma semplicissimo, invece della usuale situazione in cui uno, o al più pochi processori, eseguono programmi complicatissimi. E in contrasto con la robustezza di una rete neurale, una ordinaria computazione sequenziale può facilmente essere rovinata da un errore in un singolo bit.

33
4 Algoritmi di addestramento
L’obiettivo dell’addestramento di una rete, è quello di aggiustare i pesi, in modo tale che l’applicazione di un vettore di input produca il desiderato vettore di output. Questo tipo di addestramento viene anche chiamato addestramento con istruttore, in quanto, conoscendo per ogni input il corrispondente output, si è in grado di stabilire quanto la rete sbagli nel rappresentare la funzione che dovrebbe calcolare; in tal modo è possibile modificare i pesi secondo qualche criterio per cercare di minimizzare, o di annullare l’errore su tutte le coppie di input/output che costituiscono l’insieme di addestramento.
Poichè il problema dell'apprendimento è riconducibile ad un problema di minimizzazione di una funzione che misura l'errore, esistono diverse tecniche di apprendimento derivate da tecniche standard di calcolo numerico [15]. In questo capitolo verrà presentato l'algoritmo più noto fra quelli appartenenti a questa categoria: backpropagation [16]. Tutte queste tecniche soffrono di un insieme di patologie comuni che derivano dall'approccio al problema definito come minimizzazione di una funzione a molte variabili in uno spazio continuo. Tali patologie sono riassumibili nel seguente elenco [17],[18]:
• convergenza locale
• presenza di molti minimi locali
• rumore, instabilità e malcondizionamento in regioni molto ampie dello spazio di ricerca
• perdita di efficacia nel trasferimento in VLSI delle configurazioni ottenute

34
Molte delle patologie sopra elencate possono essere curate modificando l'approccio alla soluzione del problema, trasformandolo da problema di ottimizzazione nello spazio continuo in un problema di ottimizzazione nello spazio discreto. La Ricerca Tabu Reattiva (RTS) che viene descritta in questo capitolo affronta il problema direttamente a partire dalla discretizzazione del problema, elimando i processi di approssimazione che sono richiesti quando si parte dal modello continuo e lo si approssima con tecniche di calcolo [18],[19]. Inoltre l'approccio discreto sembra più vicino alla controparte biologica delle reti neurali, dove l'elaborazione è senza dubbio approssimata e non basata su modelli matematici in spazi continui.
4.1 Retropropagazione (Backpropagation)
Anche se le grandi potenzialità delle reti multistrato sono state scoperte e studiate molti anni fa, fino al 1974 [16] non si aveva idea di come fare ad addestrare in modo efficiente una rete multistrato. La mancanza di un algoritmo di addestramento, insieme alla dimostrazione che solo le funzioni linearmente separabili possono essere rappresentate per mezzo di percettroni singoli, ha portato ad una perdita di interesse in questo campo.
L’algoritmo di retropropagazione è stato il primo metodo efficiente che è stato proposto per l’addestramento dei feedforward network ed ha il merito indiscusso di aver ridestato l’interesse della comunità scientifica nelle reti neurali.
Il concetto chiave sul quale si basa l’algoritmo, è che i pesi devono essere modificati di una quantità proporzionale alla velocità con cui cambia l’errore quando il peso stesso viene variato. Questa quantità, è calcolata in base alla derivata della funzione di attivazione dell’unità che è sorgente del peso in questione, e quindi, l’algoritmo di retropropagazione si può applicare solo a quelle reti feedforward composte da unità con funzioni di attivazione ovunque differenziabili. Vediamo ora nel dettaglio l’algoritmo [6],[14],[20].
1. Per evitare che la rete sia saturata a causa di grandi valori di pesi, si inizializzano tutti i pesi con un piccolo valore casuale.
2. Si seleziona la prossima coppia dall’insieme di addestramento e si applica il vettore di input alla rete.
3. Si calcola l’output della rete.
4. Si calcola l’errore E tra l’output della rete e l’output desiderato.
5. Si aggiustano i pesi della rete in modo da minimizzare l’errore.

35
6. Si ripetono i passi da 2 a 5 per ogni vettore dell’insieme di addestramento, finché l’errore sull’intero insieme non è accettabilmente basso.
Analizzando i passi dell’algoritmo, si può notare che esso consiste in due fasi distinte: i passi 2 e 3 costituiscono una fase che chiameremo ‘in avanti’, in cui i segnali si propagano dall’input verso l’output; mentre i passi 4 e 5 costituiscono una fase ‘all’indietro’, qui il segnale dell’errore calcolato si propaga all’indietro attraverso la rete dove è usato per aggiustare i pesi.
Questi passi vengono adesso espansi ed espressi in una forma più matematica.
4.1.1 La fase in avanti
Il calcolo dell’output di una rete è fatto strato per strato, partendo dagli strati più vicini agli input. Il valore NET di ogni neurone è calcolato come la somma pesata dei suoi input, la funzione di attivazione f poi, applicata a NET, produce il valore OUT per ogni neurone in quello strato. Una volta che l’insieme degli output di uno strato è trovato viene usato come input per lo strato successivo. Il processo viene ripetuto finché non si arriva al vettore finale degli output.
Questo processo può essere descritto succintamente in notazione vettoriale. Si consideri W la matrice dei pesi tra neuroni, allora NET=XW, applicando la funzione f a NET si ottiene il vettore di output OUT. Così, per un dato strato, la seguente espressione descrive il processo di calcolo:
OUT=f(XW)
Il vettore di output di uno strato diventa il vettore di input dello strato successivo, e quindi, calcolare l’output dello strato finale richiede l’applicazione dell’equazione (4.1) ad ogni strato, partendo dall’input della rete fino al suo output.
4.1.2 La fase all’indietro
Lo scopo di questa fase è quello di aggiustare i pesi della rete in modo tale da minimizzare l’errore. Poiché la correzione da apportare ai pesi è una quantità che dipende strettamente dall’errore che la rete ha commesso nel valutare l’input, la fase di aggiustamento deve partire dalla fine; ovvero dallo strato di output. Solo da questa posizione è infatti possibile calcolare l’errore come differenza tra l’output della rete ed il valore aspettato. Si possono così correggere i pesi
(4.1)

36
dell’ultimo strato. I pesi degli strati nascosti invece, non avendo la possibilità di valutare l’errore, non possono essere corretti nello stesso modo.
La fase all’indietro consiste perciò in due fasi distinte: la correzione dei pesi dello strato di output e la correzione dei pesi degli strati nascosti.
4.1.2.1 Aggiustare i pesi dello strato di output
Viene innanzitutto calcolato l’errore E, come la differenza tra il valore aspettato ed il valore dell’output dell’ultimo strato.
E=Vaspettato-OUT
successivamente, l’errore viene moltiplicato per la derivata della funzione di trasferimento dell’ultimo strato e si ottiene il valore δ
δ=Ef’
A questo proposito è utile ricordare che l’algoritmo di retropropagazione si può applicare solo nel caso in cui tutti i neuroni abbiano funzioni di trasferimento ovunque differenziabili. Solitamente si usa la funzione logistica perché, oltre ad avere le caratteristiche di controllo del guadagno di cui si è parlato in precedenza, è anche differenziabile, e la sua derivata prima è molto semplice da calcolare:
NETeNETfOUT −+
==1
1)(
)1()(' OUTOUTNETOUTNETf −=∂∂
=
Se si usa come funzione di trasferimento la logistica, δ è dato dalla seguente quantità:
δ=OUT(1-OUT)E
δ viene poi moltiplicato per OUT del neurone sorgente del peso in questione, ed infine moltiplicato per un coefficiente di addestramento η (tipicamente una quantità compresa tra 0.01 e 1.0); quello che ne risulta è il valore da aggiungere al peso. Lo stesso procedimento è fatto per tutti i pesi che connettono lo strato nascosto allo strato di output.
Le seguenti equazioni illustreranno meglio questo calcolo:

37
Δwpq,output=ηδq,outputOUTp,j
wpq,output(n+1)=wpq,output(n)+ Δwpq,output
dove:
wpq,output(n) è il valore del peso dal neurone p dello strato nascosto al neurone q nello strato di output al passo n (prima della modifica); l’indice output indica che il peso è associato al suo strato di destinazione
wpq,output(n+1) è il valore del peso al passo n+1 (dopo la modifica)
δq,output è il valore di δ per il neurone q nello strato di output
OUTp,j è il valore di OUT per il neurone p nello strato nascosto j.
4.1.2.2 Aggiustare i pesi degli strati nascosti
I pesi degli strati nascosti vengono aggiustati usando la stessa regola definita dalle equazioni (4.3) e (4.4), con l’unica differenza che la quantità δ viene calcolata in un altro modo. L’output di un neurone appartenente ad uno strato nascosto infatti, non ha un valore con il quale possa essere confrontato per determinare l’errore.
Nell’algoritmo di retropropagazione, il calcolo di δ per i neuroni di uno strato nascosto è subordinato al calcolo dei δ degli strati che lo seguono. Partendo dallo strato di output, si calcola δ per ogni neurone usando l’equazione (4.2), si aggiustano i pesi in entrata allo strato di output nel modo specificato dalle equazioni (4.3) e (4.3), ed infine si propagano i δ all’indietro di uno strato, attraverso i pesi appena modificati per generare il valore di δ per ogni neurone del penultimo strato nascosto. Questi valori di δ sono usati , in seguito, per aggiustare i pesi di questo strato e, in modo simile, sono propagati all’indietro agli strati precedenti.
Si consideri un singolo neurone posto nello strato nascosto appena prima lo strato di output. Nel passo in avanti, questo neurone propaga attraverso i pesi che li connette il suo segnale ai neuroni dello strato di output. Durante l’addestramento invece, questi pesi operano in senso inverso, passando il valore di δ dallo strato di output indietro allo strato nascosto. Ognuno di questi pesi è moltiplicato per il valore δ del neurone al quale si connette nello strato di output. Il valore δ necessario per il neurone dello strato nascosto si ottiene sommando tutti questi prodotti e moltiplicando per la derivata della funzione di trasferimento.
(4.3)
(4.4)

38
∑ ++−=q
jpqjqjpjpjp wOUTOUT ))(1( 1,1,,,, δδ
4.2 RTS (Reactive Tabu Search)
L’algoritmo RTS [18],[19] adotta un approccio radicalmente diverso da quello della retropropagazione. Poiché in un computer digitale ogni peso è rappresentato da un certo numero di bit, il problema può essere visto come un problema di ottimizzazione combinatoria. Non ha importanza se i pesi sono espressi in virgola mobile piuttosto che in virgola fissa o in complemento a due, alla fine rimangono sempre stringhe di bit, ed il problema si riduce a trovare quella sequenza di bit che minimizza l’errore totale E.
Il problema viene risolto con un metodo euristico basato sulla costruzione di una traiettoria di ricerca che vada verso punti con un basso valore di E. La ricerca viene eseguita valutando una serie di mosse elementari applicate al punto corrente e selezionando la migliore. A questa componente di base si aggiunge la proibizione delle mosse inverse a quelle fatte più di recente, in modo da scoraggiare i cicli, ed una strategia di diversificazione per evitare il confinamento della traiettoria di soluzione.
Le mosse elementari sono quelle che modificano di un solo bit la stringa che rappresenta la posizione corrente. La mossa selezionata è quella che causa il più grande decremento di E tra tutte quelle che non sono state ancora eseguite nella più recente parte della ricerca. Il periodo di proibizione è regolato da un meccanismo basato sulla precedente storia della ricerca.
RTS fugge facilmente dai minimi locali, è applicabile a funzioni di errore non differenziabili ed anche discontinue, essendo basato solo sulla disponibilità dei valori di E, è molto robusto rispetto alla scelta della configurazione iniziale ed infine può essere usato per addestrare qualsiasi topologia di rete, anche ricorsiva.
4.2.1 Descrizione del metodo
Iniziamo con il definire una notazione. Un’istanza di un problema di ottimizzazione combinatoria è una coppia (F,E), dove F è l’insieme di cardinalità finita dei punti appartenenti allo spazio di ricerca, ed E è una funzione di costo: E: F ℜ.. Una soluzione f è globalmente ottimale se
E(f)≤E(y) per ogni y∈F
(4.5)

39
La funzione di vicinanza N(f) associa ad ogni punto f un sottoinsieme di F: N: F 2|F|. Un punto f è localmente minimo con rispetto ad N, o un minimizzatore locale se
E(f)≤E(g) per ogni g∈N(f)
Il minimizzatore è stretto se E(f)<E(g).
È utile definire il vicinato N(f) come l’insieme di punti che può essere ottenuto applicando ad f un insieme di mosse elementari M
N(f)={g∈F tale che g=μ(f) per μ∈M}
Nel nostro caso F è l’insieme di tutte le stringhe binarie di lunghezza finita L: F={0,1}L e le mosse elementari μi (i=1,…,L) invertono l’i-esimo bit della stringa.
Lo schema TS (Tabu Search) usa un algoritmo locale di ricerca che si muove verso punti con bassi valori di E. La ricerca viene eseguita cercando di minimizzare l’errore globale che la rete commette nell’approssimare la funzione voluta. Diversamente dalla retropropagazione quindi, la misura di errore E non si riferisce ad una singola istanza dell’insieme di addestramento, ma alla sua globalità. Solitamente come misura si usa la somma dei quadrati degli errori.
In aggiunta, TS incorpora strategie per evitare i cicli. I due obbiettivi sono raggiunti applicando i seguenti principi:
• ricerca locale modificata. Ad ogni passo del processo iterativo, la mossa migliore viene selezionata da un insieme di mosse elementari ammissibili che portano ad un insieme di punti nel vicinato dello stato corrente. La mossa migliore è quella che va nella direzione del più basso valore della funzione di costo E. Se la mossa migliore porta ad un incremento di E, significa che si è arrivati ad un minimo della funzione di costo. L’algoritmo in questo caso esegue comunque la mossa perché potebbe essere necessaria per uscire da un minimo locale.
• evitare i cicli. Sono proibite le mosse che sono l’inverso di quelle eseguite più recentemente, il nome tabu deriva appunto da questa proibizione. Infatti, nel caso in cui l’algoritmo abbia eseguito una mossa μt che porta ad incrementare il valore di E, c’è la possibilità che la mossa migliore al passo successivo sia la sua inversa (μt+1=μt
-1). Questa situazione riporta lo stato, dopo due passi, alla configurazione iniziale Xt+2= μt+1Xt+1= μt
-1•μt Xt. A questo punto, l’insieme delle mosse ammissibili è lo stesso che si aveva all’inizio, ed il sistema sarà intrappolato per sempre in un ciclo di lunghezza 2. In questo

40
specifico esempio si può evitare il ciclo se si impedisce di eseguire la mossa inversa μt
-1 al tempo t+1. In generale, le mosse inverse a quelle eseguite nella più recente parte della ricerca dovrebbero essere proibite per un tempo T. Il periodo deve essere finito perché le mosse proibite potrebbero essere necessarie per raggiungere il minimo assoluto in una fase successiva della ricerca. Nell’algoritmo RTS, il periodo di proibizione Tt dipende dal tempo: una mossa μ è proibita se e solo se il suo uso più recente è avvenuto al tempo τ≥(t-Tt). Tt viene cambiato durante la ricerca in modo tale da adattarsi alla struttura locale del problema (da qui il termine reactive).
4.3 Un confronto
Mentre la retropropagazione si basa su un procedimento puramente matematico, l’RTS adotta una strategia combinatoria. Questo differente modo di porsi di fronte al problema si riflette nelle diverse caratteristiche che i due algoritmi presentano.
La retropropagazione, come del resto tutti gli algoritmi che si basano sulle derivate, ha il problema di fermarsi al primo minimo locale perché, quando si raggiunge un minimo, la derivata ha valore zero ed il criterio di aggiustamento dei pesi non può essere applicato.
F’(NET)=0
δ=F’(NET)(Target-OUT)=0
Δwpq,output=ηδq,outputOUTp,j=0
wpq,output(n+1)=wpq,output(n)
L’unico modo per uscire da questa situazione è ripartire da un altro punto scelto a caso e sperare di raggiungere da questo il minimo globale. Tutto il lavoro fatto fino a quel momento viene però perso.
L’RTS invece, non essendo basato sulle derivate, ma su una ricerca in uno spazio di bit, non soffre di questa limitazione, inoltre non pone come vincolo la differenziabilità della funzione di trasferimento, né è fondamentale la scelta iniziale dei pesi per la convergenza dell’algoritmo. In aggiunta, non assegnando alcun significato particolare ai bit, l’RTS è in grado di addestrare anche le reti ricorsive, cosa che è impossibile fare con la retropropagazione.

41
Dalla sua parte, l’algoritmo di retropropagazione ha il vantaggio di poter aggiustare i pesi usando un esempio alla volta; questo consente di eseguire la fase di addestramento senza stabilire a priori la dimensione dell’insieme di addestramento, ed è molto utile qualora esista una sorgente in grado di produrre un flusso di esempi. Questa caratteristica, però, se da un lato può essere molto utile, dall’altro può essere portatrice di problemi subdoli, perché il risultato dell’addestramento potrebbe essere influenzato dall’ordinamento dei pattern di esempio.
Le richieste hardware sono un’altra caratteristica che differenzia i due algoritmi. Se per la retropropagazione, che è un algoritmo puramente matematico, si ha bisogno di hardware in grado di eseguire calcoli in virgola mobile con una certa precisione, per l’RTS è sufficiente un supporto in grado di eseguire le usuali operazioni sugli interi.
In ultimo, il tempo necessario all’addestramento. Questa quantità nell’RTS dipende fortemente dalle dimensioni della rete. Infatti, la lunghezza della stringa aumenta linearmente con il numero dei pesi, e la cardinalità dello spazio di ricerca aumenta esponenzialmente con il numero di bit della stringa. Tuttavia, il funzionamento dell’algoritmo non è legato ad una particolare dimensione dello spazio dei pesi, per cui, la durata dell’apprendimento può essere diminuita a scapito di una perdita di precisione nella rappresentazione dei pesi.
Nella retropropagazione invece non esiste questo problema e la durata dell’addestramento aumenta di poco all’aumentare della dimensione della rete.
Vantaggi Svantaggi
retropropagazione
• l’addestramento si esegue valutando un esempio alla volta
• il tempo di addestramento varia di poco al variare della dimensione della rete
• l’inizializzazione casuale dei pesi non è banale
• il calcolo delle derivate è costoso e portatore di errori
• la funzione di trasferimento deve essere differenziabile
• addestra solo reti feedforward • si arresta al primo minimo locale • il risultato dell’apprendimento può
dipendere dall’ordinamento dei pattern
RTS
• addestra qualsiasi tipo di rete • non si arresta nei minimi locali • può essere usata qualsiasi
funzione di trasferimento • non ha bisogno di hardware in
virgola mobile • converge sempre • il tempo di addestramento può
essere diminuito accettando una perdita di precisione nella rappresentazione dei pesi
• il risultato dell’apprendimento non dipende dall’ordinamento dei pattern
• ammette implementazione diretta in VLSI
• l’addestramento non può essere eseguito valutando un esempio alla volta
• Il tempo di addestramento varia molto al variare della dimensione della rete

42
4.4 Una soglia addestrabile
I due algoritmi di addestramento sopra descritti mostrano come sia possibile trovare quella configurazione particolare di pesi che minimizza l’errore della rete sull’insieme addestramento; non spiegano però come sia possibile addestrare anche una soglia. Quando si sono definiti gli operatori logici in termini di percettroni, si è visto che era proprio la soglia a determinare il comportamento della rete; sarebbe quindi utile disporre di un algoritmo che, oltre ai pesi, permetta, qualora ce ne fosse bisogno, di addestrare una soglia.
Questa caratteristica è facilmente incorporabile in tutti gli algoritmi di addestramento aggiungendo un peso collegato ad un input fittizio con un valore fisso posto a +1. Questo peso è addestrabile nello stesso modo degli altri, ma l’effetto della sua modifica sarà quello di spostare l’origine della funzione di trasferimento, producendo un effetto che è del tutto simile ad aggiustare la soglia del percettrone.

43
5 Hardware neurale
Una caratteristica che rende molto attraente la computazione neurale, è il fatto che il processo di calcolo dell’output è scomponibile in un certo numero di fasi che possono essere eseguite contemporaneamente. In un percettrone per esempio, tutti i neuroni che appartengono ad uno stesso strato potrebbero in linea di principio calcolare il loro output indipendentemente dagli altri.
Il parallelismo intrinseco delle reti neurali però, è possibile sfruttarlo solo costruendo dispositivi hardware dedicati, composti da un certo numero di moduli paralleli in grado di svolgere le funzioni del neurone artificiale. Questi dispositivi non sono difficili da realizzare, in quanto il neurone artificiale è un dispositivo facilmente implementabile in termini di silicio: nella sua forma più semplice esso è costituito da un blocco di moltiplicazione, seguito da uno di accumulo dei risultati parziali. Questa semplicità di realizzazione, ha portato alla progettazione e alla costruzione di numerosissimi processori neurali, alcuni dei quali sono anche prodotti commerciali.
L’implementazione hardware di architetture neurali ha dato origine a due filoni di ricerca: quello analogico e quello digitale [21].
L’elettronica analogica ha alcune interessanti caratteristiche che potrebbero essere utilizzate direttamente nell’implementazione di reti neurali. Il transistor, per esempio, esegue automaticamente funzioni simili al neurone biologico, inclusa la non linearità dell’output.
Il processo computazionalmente intensivo del calcolo dell’output, in una rete neurale implementata con tecnologie analogiche è automaticamente eseguito da processi ficici quali la somma di correnti o di cariche elettriche. Inoltre, i

44
componenti elettronici analogici sono molto compatti, ed offrono una altissima velocità a fronte di una bassa dissipazione di energia. Gli svantaggi della tecnologia analogica, sono soprattutto legati alla sensibilità al rumore che limita la precisione computazionale.
Alcuni esempi di implementazioni analogiche sono:
• Intel 80170NX Electrically Trainable Analog Neural Network (ETANN) [22]
• The Mod2 Neurocomputer [23] (Naval Air Warfare Center Weapons Division, CA)
• Fully analog chip [24] (Kansai University, Japan)
Le tecniche digitali sono molto più mature di quelle analogiche ed inoltre offrono una altissima precisione computazionale. Gli svantaggi sono però una maggiore dimensione dei circuiti rispetto alle implementazioni analogiche.
Esempi di implementazioni digitali sono:
• SYNAPSE-1 [25] (Siemens AG, Corp, R&D, Germany)
• CNAPS [26] (Adaptive Solutions, Inc., USA)
• CNS [27] Connectionist Supercomputer (ICSI, Berkley, CA, USA)
• Hitachi WSI [28] (Hitachi Central Research Laboratory, Kokubinji Tokyo, Japan)
• LNeuro 1.0 [29] (Neuromimetic Chip, Philips, Paris, France)
• UTAK1 (Catalunya University, Spain)
• BACHUS (Darmstadt University of Technology, Univ. of Düsseldorf, Germany)
• TOTEM chip [30],[31],[32] (Università di Trento)
Nei paragrafi che seguono verrà descritto il processore neurale TOTEM, sviluppato in IRST per l’esecuzione di quella aritmetica di interi in bassa precisione che è necessaria all’algoritmo RTS.

45
5.1 Architetture Hardware
L’architettura generale di un sistema hardware neurale, consiste principalmente in un array, o in una matrice di neuroni, in cui ogni elemento ha un certo grado di indipendenza dagli altri. La caratteristica che distingue le varie implementazioni è legata principalmente alla tecnologia impiegata per costruire i neuroni artificiali, la quale, è fortemente influenzata dall’algoritmo scelto per addestrarli.
Gli algoritmi di addestramento che si basano sulle derivate, per esempio, per evitare di incorrere in possibili instabilità numeriche, tendono a richiedere un’alta precisione nell’esecuzione dei calcoli. Come conseguenza, sono necessarie strutture computazionali molto complesse, le quali, oltre a richiedere una lunga fase di sviluppo, incidono notevolmente sul costo del sistema. Algoritmi come l’RTS invece, che non hanno bisogno di precisione di calcolo, possono dar luogo ad architetture neurali più economiche e compatte.
Il non tenere in considerazione la precisione di calcolo non implica necessariamente minori prestazioni. È stato infatti osservato che i sistemi biologici operano con una bassa precisione. Von Neumann ha ipotizzato che gli stimoli tra le sinapsi verosimilmente non eccedono i cento livelli e che le operazioni eseguite dai neuroni non sono molto accurate [33].
Queste considerazioni hanno motivato un considerevole sforzo di ricerca nella direzione della costruzione di dispositivi in bassa precisione. Il processore TOTEM [30],[31],[32] sviluppato in IRST, è stato progettato tenendo in considerazione proprio questa osservazione.
5.2 La scheda TOTEM
L’architettura della scheda è mostrata nel diagramma a blocchi di Fig. 5.1.
I componenti principali della scheda sono:
• il chip TOTEM, contenente: 32 processori paralleli in virgola fissa per il calcolo della rete neurale, 32 Kbit di RAM per la memorizzazione dei pesi ed un dispositivo (barrel shifter) per adattare i 32 bit dell’output del processore ai 16 bit del bus di input delle LUT.
• due tabelle selezionabili di 64K elementi ciascuna (LUT) per il calcolo veloce della funzione di trasferimento.

46
• tre cache separate per ottimizzare le prestazioni riducendo il trasferimento sul bus
• un set di istruzioni contenente istruzioni iterative di alto livello
Le applicazioni della scheda si possono riassumere nei seguenti campi:
• classificazione di oggetti in problemi di visione artificiale
• riconoscimento ottico di caratteri (OCR)
• strumentazione in fisica nucleare
• strumentazione medica per pattern recognition
• controlli industriali
Fig 5.1 Diagramma a blocchi della scheda TOTEM

47
5.2.1 Il chip TOTEM
Il chip TOTEM è un sistema composto da un vettore di 32 processori paralleli progettato per l’implementazione di percettroni multistrato (MLP). Esso impiega circuiti ad alta velocità e di precisione limitata per eseguire quella aritmetica di interi che è necessaria all’algoritmo RTS.
Il chip è in grado di operare singolarmente o in un array come coprocessore in un sistema ospite, e le sue prestazioni, quando opera ad una frequenza di 32 MHz, sono di un miliardo di operazioni di moltiplicazione-somma al secondo. Un percettrone con topologia 16-16-1 può essere valutato in circa 2 μs.
Fig. 5.2 Diagramma a blocchi del processore TOTEM

48
5.2.1.1 L’algoritmo di addestramento
Ispirandosi all’ipotesi di von Neumann, l’implementazione di modelli biologici in termini di circuiti digitali VLSI, richiederebbe algoritmi di addestramento che ammettano bassa precisione nella rappresentazione dei pesi e bassa accuratezza nel processare i segnali.
L’algoritmo di addestramento Reactive Tabu Search, non solo presenta queste caratteristiche, ma ha anche il pregio di richiedere solo la fase di valutazione della rete, quella che in precedenza è stata definita come la fase in avanti.
L’RTS pertanto, rende possibile la realizzazione di sistemi basati su parole piccole e aritmetica in virgola fissa, che portano ad architetture VLSI più economiche in termini di superficie di silicio, di dissipazione di energia; e più veloci delle loro controparti basate su parole lunghe ed aritmetica in virgola mobile.
5.2.1.2 Architettura del processore
L’architettura del processore è dettata principalmente dalle caratteristiche dell’RTS, ed è basata su concetti di semplicità delle strutture di base, alto paralleismo e pipelining spinto.
Il chip è composto da un array di 32 processori paralleli che possono essere usati per implementare un singolo strato del MLP. I 32 neuroni artificiali, sono realizzati con blocchi di moltiplicazione-accumulo (MAC), e ricevono tutti il loro input tramite uno schema di broadcast, che fornisce la piena connettività dello strato senza richiedere grandi larghezze di banda della porta di input; in tal modo è necessario solo un trasferimento I/O per ogni ciclo di accumulazione. L’efficienza di elaborazione è invece ottenuta tramite un’architettura per la moltiplicazione totalmente parallela, che fornisce la velocità ottimale di una operazione per ciclo di clock, mentre, il tempo richiesto per una intera operazione di moltiplicazione-accumulo è dell’ordine di Ninp cicli di clock, dove Ninp è il numero di input. Inoltre, per una maggiore velocità nella fase di addestramento, i pesi sono memorizzati all’interno del chip.
Per mantenere semplice la struttura del processore, invece, la funzione di trasferimento è implementata all’esterno del chip in una tabella memorizzata nella RAM della scheda; mentre il calcolo dei cambiamenti dei pesi durante la fase di addestramento è delegato ad altri circuiti, quali i microprocessori standard.
La dimensione delle parole è ottimizzata per l’apprendimento con l’RTS: i 16 bit di larghezza del bus del broadcast sono adeguati per rappresentare i segnali

49
provenienti da trasduttori e i risultati intermedi tra gli strati, le parole di memoria di 8 bit usate per i pesi sono sufficienti per molti problemi di classificazione, mentre i 32 bit del canale di output permettono un’alta capacità di accumulazione.
5.2.2 Memoria
Per ottimizzare la velocità, la memoria dei pesi è partizionata in 32 blocchi di 128 parole di 8 bit, ognuno dei quali è strettamente accoppiato ad un processore. Ogni blocco può essere assegnato ad un singolo neurone, permettendo di implementare neuroni con un massimo di 128 input, oppure essere partizionato tra neuroni su diversi strati, in modo da realizzare differenti topologie di MLP con un alto grado di flessibilità.
5.2.3 LUT
Le LUT sono due tabelle selezionabili di 64K elementi ciascuna usate per il calcolo veloce della funzione di trasferimento.
5.2.4 Set di istruzioni
L’insieme di istruzioni della scheda comprende le seguenti istruzioni
Istruzioni di inserimento dati
Scrivi i dati nella cache di input
Istruzioni relative alla memoria dei pesi
Scrivi nella memoria dei pesi
Attiva il decodificatore Gray
Istruzioni relative al blocco MAC
Cancella l’accumulatore
Cancella il puntatore alla memoria dei pesi
Cancella il puntatore all’output
Calcola n pattern
Ricircola n risultati dell’output in input

50
Istruzioni di lettura dati
Carica il registro di output con il contenuto dell’accumulatore
Trasferisci i risultati nella cache di output
Leggi n risultati dalla cache di output
Istruzioni di controllo
Leggi il registro di stato
Cancella la cache di input
Cancella la cache di output
Cancella la cache delle istruzioni
Rileggi la cache di input
Rileggi la cache delle istruzioni
Istruzioni di controllo delle LUT
Scrivi la LUT 0
Scrivi la LUT 1
Leggi la LUT 0
Leggi la LUT 1
Seleziona la LUT
Cancella il puntatore alla LUT
Varie
Carica il registro del barrel shifter
Disabilita il refresh
Resetta la scheda
Nota: gruppi di istruzioni possono essere iterati usando la funzione ‘Rileggi la cache delle istruzioni’. In modo del tutto simile, con la funzione ’Rileggi la cache di input’ è possibile riutilizzare i dati di input.

51
6 Software di gestione
Il software di gestione del processore TOTEM è strutturato su tre livelli. Al livello più basso c’è il device driver, sopra di esso si appoggia la libreria di programmazione, ed infine, al livello più alto è posto il software utente.
6.1 Il device driver
Il device driver rappresenta quella parte di codice dipendente dall’hardware che ha il compito di offrire un’interfaccia indipendente dal sistema ai livelli superiori. I driver del processore TOTEM sono disponibili per i sistemi operativi LINUX, MS-DOS e Windows NT e sono forniti insieme alla scheda.
La loro realizzazione è dovuta al lavoro di A. Sartori, G. Tecchiolli e C. Mezzena dell’Istituto per la Ricerca Scientifica e Tecnologica di Povo (TN).
6.2 La libreria
La libreria di programmazione [32] fornisce un’interfaccia di più alto livello, sia con il processore TOTEM attraverso il driver, sia con l’algoritmo RTS. Grazie ad essa è possibile costruire applicazioni neurali in C++ senza doversi continuamente confrontare con i dettagli implementativi.
La libreria è scritta in C++ e comprende le classi mostrate in Fig. 6.1. Le classi più importanti sono senza dubbio la TNet e la RTS, perché forniscono rispettivamente un’interfaccia di alto livello al processore TOTEM e all’algoritmo

52
di addestramento. La classe RTS si occupa di eseguire l’algoritmo di addestramento, e può essere applicata a qualsiasi oggetto che derivi dalla classe RTSable, come ad esempio TNet. La classe RTSable è virtuale pura e serve per definire l’interfaccia che deve mostrare qualsiasi classe per essere addestrabile con l’RTS.
6.2.1 Totem
La classe Totem rappresenta l’interfaccia di basso livello con il chip TOTEM. I suoi metodi più importanti sono i seguenti:
Totem::Totem(unsigned short base_seg)
Crea un oggetto di tipo Totem. base_seg specifica il numero di segmento dove è mappata la scheda (valori validi sono 0xd000, 0xd400, 0xd800, 0xdc00 e possono essere selezionati via hardware modificando la configurazione degli switch sulla scheda)
void Totem::write_lut(int lutnum,TotemLut &totlut)
Riempie la look-up table identificata da lutnum con 64k elementi di 16 bit memorizzati in totlut. Se lutnum è pari/dispari viene riempita la look-up table 0/1.
void Totem::read_lut (int lutnum, TotemLut &totlut)
RTSable
TNet Totem RTS
TotemLut
LEGENDA
Deriva
Usa
Fig. 6.1 La gerarchia delle classi nella libreria

53
Legge i 64k elementi di 16 bit contenuti nella look-up table identificata da lutnum e li copia in totlut. Se lutnum è pari/dispari viene letta la look-up table 0/1.
void Totem::lut_on(int lutnum)
Abilita la look-up table identificata da lutnum. Dopo l’esecuzione di questo metodo, i valori di output del TOTEM passano attraverso la look-up table lutnum prima di ritornare all’host o essere usati di nuovo come input.
void Totem::gray_on()
Abilita la fase di trasformazione gray-to-bin. I pesi vengono convertiti dal codice gray al codice binario in complemento a 2 prima di essere memorizzati nella ram del TOTEM.
void Totem::gray_off()
Disabilita la fase di trasformazione gray-to-bin. I pesi sono memorizzati nella memoria del TOTEM senza cambiamenti.
void Totem::shift(unsigned short val)
Fissa la quantità di shift che verrà utilizzata per scalare gli output del TOTEM. Dopo l’esecuzione di questo metodo, la stringa di bit che rappresenta il valore di output viene shiftato verso destra di val posizioni.
short Totem::get_shift()
Restituisce il valore corrente del parametro di shift.
void Totem::write_weight(int procnum,int pos,unsigned char value)
Scrive value all’indirizzo pos nella memoria del processore procnum.
void Totem::write_weights(CVect &values)
Riempie la memoria del chip TOTEM con i valori contenuti nel vettore values. La dimensione del vettore values non deve essere minore di 4096 byte. Il byte all’indirizzo values+128*p+o rappresenta il valore del peso all’indirizzo o del processore p.
CVect Totem::read_weights()
Copia l’intera memoria del TOTEM nel vettore value.
unsigned char Totem::read_weight(int procnum,int pos)
Ritorna il valore del peso all’indirizzo pos della memoria del processore procnum.
void Totem::calculate(const SVect &input)
Scrive nella porta di input del TOTEM il vettore input.

54
void Totem::read_out(SVect &output)
Legge i valori a 32 bit dell’output del TOTEM prima che passino attraverso la look-up table e li copia nel vettore output.
void Totem::circulate(unsigned short inum)
Legge inum output del TOTEM e li riscrive in input.
void Totem::load_outreg()
Copia tutti gli accumulatori del TOTEM nei registri di output del TOTEM.
void Totem::clear_acc()
Cancella gli accumulatori del TOTEM.
unsigned char Totem::to_gray(unsigned char v)
Ritorna la codifica gray del parametro v espresso in complemento a 2.
unsigned char Totem::to_bin(unsigned char v)
Ritorna la codifica in complemento a 2 del parametro v espresso in gray.
6.2.2 TotemLut
implementa l’array di 64k elementi di 16 bit usato per definire le look-up table.
short& TotemLut:::operator [](unsigned short pos)
Permette l’accesso ai 64k elementi della look-up table.
6.2.3 TNet
La classe TNet permette la creazione, la computazione e l’addestramento di reti neurali mappabili nel processore TOTEM.
Topologia, funzioni di trasferimento, numero di bit per peso vengono definiti all’atto della costruzione dell’oggetto TNet, mentre l’insieme di addestramento è definito con il metodo set_training_on. Questa classe definisce i metodi richiesti dall’oggetto RTSable per essere addestrabile dalla classe RTS.
I suoi metodi più importanti sono i seguenti:
TNet::TNet(SVect &topo,
SVect &tresh_fact,

55
SVect &shift,
int bpw,
SVect &luts,
int gray_flag,
unsigned short totem_base_addr)
Crea un percettrone multistrato mappato nel processore TOTEM. topo è il vettore che definsce la topologia della rete; l’i-esimo elemento definisce il numero di neuroni dell’i-esimo strato. tresh_fact è il vettore che contiene i valori utilizzati per implementare la soglia del neurone usando la tecnica dell’input fittizio; tresh_fact[i] è il valore mandato ai neuroni dell’i-esimo strato per realizzare la soglia. shift è il vettore che contiene i parametri di shift usati per riscalare l’output di un neurone prima di essere usato per calclare la funzione di trasferimento; l’output di un neurone dello strato i è uguale a funzione(output_i-esimo_strato/2shift[i]). bpw definisce il numero di bit per peso e deve essere un valore compreso tra 1 e 8. luts è un vettore usato per selezionare una delle due look-up table; luts[i] definisce quale look-up table verrà usata nello strato i-esimo. gray_flag è usato per abilitare (se true) o disabilitare (se false) la codifica gray dei pesi. totem_base_addr definisce l’indirizzo del segmento di memoria dove è mappato il processore TOTEM, valori validi sono 0xd000, 0xd400, 0xd800 e 0xdc00.
SVect& TNet::operator () (const SVect &input)
Calcola l’output della rete dato il vettore input come input.
void TNet::set_training_on(TrSet &trset)
Assegna l’insieme di addestramento.
double TNet::generalize(TrSet &geset)
Ritorna l’errore quadratico medio degli output calcolato usando i pattern contenuti in geset.
void TNet::save_best()
Salva la configurazione corrente in una area interna di memoria; questo metodo è richiesto perchè TNet sia un oggetto RTSable.
CVect& TNet::get_best()
Ritorna la configurazione salvata con save_best.
double TNet::EvalCurrentCfg()

56
Ritorna l’errore quadratico medio calcolato sull’insieme di addestramento, questo metodo è necessario perchè TNet sia un oggetto RTSable.
void TNet::EvalNeighCfg(TMoveVect &moves)
Calcola l’errore quadratico medio delle configurazioni ottenute da quella corrente applicando le mosse definite nel vettore moves. Questo metodo è necessario perchè TNet sia un oggetto RTSable.
void TNet::togglebit(int bitnum)
Inverte il bit bitnum. Questo metodo è necessario perchè TNet sia un oggetto RTSable.
int TNet::bits_num()
Ritorna il numero di bit usati nella configurazione, cioè la lunghezza della stringa di ricerca. Questo metodo è necessario perchè TNet sia un oggetto RTSable.
6.2.4 RTSable
RTSable è la classe virtuale pura che definisce l’interfaccia che devono avere gli oggetti a cui può essere applicata la Reactive Tabu Search. Per usare l’algoritmo, la classe che descrive il problema deve derivare da RTSable e definire i suoi metodi in accordo con i seguenti:
void RTSable::save_best()
Salva la migliore configurazione in un’area di memoria interna. Questo metodo viene chiamato da RTS quando l’algoritmo trova un’altra configurazione durante la ricerca.
int RTSable::bits_num()
Ritorna il numero di bit usati nella configurazione, cioè la lunghezza della stringa di ricerca.
double RTSable::EvalCurrentCfg()
Ritorna l’errore quadratico medio calcolato sull’insieme di addestramento; RTS cerca di minimizzare questo errore.
void RTSable::EvalNeighCfg(TMoveVect &moves)
Calcola l’errore quadratico medio delle configurazioni ottenute da quella corrente applicando le mosse definite nel vettore moves.
void RTSable::togglebit(int bitnum)

57
Inverte il bit bitnum.
6.2.5 RTS
La classe RTS implementa l’algoritmo Reactive Tabu Search e può essere applicata a qualsiasi oggetto che derivi dalla classe RTSable.
Il seguente codice è uno scheletro per programmi che usano la classe RTS:
...
...
... class Problema_da_ottimizzare::public RTSable { ... ...
}; ... ... ... Problema_da_ottimizzare prob; RTS rts(prob); do { ... rts.next(); ...
} while(...qualche condizione è soddisfatta...); ... ... ...
I suoi metodi più importanti sono i seguenti:
RTS::RTS(RTSable &fun,
unsigned hist_size,
int sample,
int repetitions,
int chaos,
double red_fact,
double enc_fact,
unsigned int min_list_size)

58
Costruisce un oggetto RTS. Il parametro fun definisce il problema da ottimizzare (fun deve essere un oggetto di una classe che deriva da RTSable, come ad esempio TNet). hist_size definisce la dimensione della tabella usata per raccogliere le informazioni durante la ricerca; hist_size deve essere maggiore del massimo numero di iterazioni, ovvero del numero di chiamate al metodo next. sample, repetitions e chaos definiscono i rispettivi parametri dell’algoritmo. red_fact, enc_fact e min_list_size definiscono rispettivamente il fattore di incremento, il fattore di decremento e la dimensione della lista delle mosse proibite.
void RTS::next()
Esegue un passo dell’algoritmo RTS.
double RTS::current_val()
Restituisce il valore della funzione da minimizzare (l’errore quadratico medio) calcolata sulla configurazione corrente.
double RTS::best_val()
Restituisce il miglior valore della funzione obbiettivo calcolata dall’algoritmo durante la ricerca.
double RTS::get_T()
Restituisce la lunghezza corrente della lista delle mosse proibite.
double RTS::get_R_ave()
Restituisce il valore corrente della media della lunghezza dei cicli incontrati durante la ricerca.
int RTS::get_escape_cnt()
Se c’è stato un escape nell’ultimo passo questo metodo ritorna il numero di mosse casuali eseguite, altrimenti ritorna zero.
6.3 L’interfaccia grafica interattiva
L’ultimo livello del software di gestione è occupato dall’interfaccia grafica interattiva chiamata Mandingo, la cui realizzazione rappresenta una parte significativa di questo lavoro di tesi.
Tramite Mandingo, è possibile definire qualsiasi percettrone multistrato rappresentabile dal processore TOTEM ed addestrarlo usando l’algoritmo RTS. Il programma permette all’utente di definire facilmente tutti i parametri relativi alla rete, tutti i parametri relativi all’addestramento, lo stato iniziale dei pesi, e le

59
funzioni di trasferimento. Qualora l’insieme di addestramento fosse troppo grande, sono inoltre presenti alcune funzioni di selezione di sottoinsiemi.
La fase di addestramento è caratterizzata da una costante visualizzazione dei risultati intermedi, sia in formato grafico che numerico, ed è possibile interromperla in qualsiasi momento senza perdere i risultati ottenuti fino a quel momento. Inoltre, una statistica permette di confrontare i risultati delle precedenti sessioni di addestramento.
La configurazione dei pesi della rete, nonché tutti i parametri sulla topologia, inclusa la definizione delle funzioni di trasferimento e tutti i parametri dell’addestramento, possono infine venire salvati sottoforma di file di testo.
Gli esperimenti presentati nei capitoli 9, 10, 11 e 12 sono stati eseguiti con l’aiuto del programma Mandingo.

60
7 Il manuale utente

61
7.1 Descrizione dei componenti principali
7.1.1 Il gruppo Setup
7.1.1.1 Network
Viene usato per definire la topologia della rete, inoltre permette di settare alcuni parametri necessari al calcolo dell’output; come le funzioni di trasferimento da usare per ogni strato, il numero di bit per i pesi e il modo in cui vengono rappresentati i pesi all’interno della rete (gray o complemento a due).
7.1.1.2 Luts
Viene usato per assegnare le funzioni di trasferimento alle due lookup table del TOTEM. Inizialmente sono definite tre funzioni tra cui scegliere: una Lineare rappresentata dalla funzione identità, una a gradino con soglia posta a zero ed ampiezza ±10.000 ed infine una Sigmoide con ampiezza massima di 32767.
Premendo Advanced si apre un dialog che permette di intervenire sui parametri di queste funzioni, o in alternativa di definirne delle nuove. Il settaggio dei nuovi parametri avviene modificando direttamente i valori che sono contenuti nei rispettivi campi, mentre per assegnare questi valori e per visualizzare la
Fig. 7.1 Il dialog di configurazione della rete
Seleziona una delle due Lut
bit per soglia
bit per peso
codifica dei pesi nella rete
numero di neuroni

62
nuova funzione si dovrà premere Update. Il significato dei parametri è il seguente:
Nella funzione Linear
• Angle si riferisce all’angolo che la retta forma con l’asse delle ascisse ed è espresso in gradi sessagesimali con frazioni in base dieci (per esempio: 22°30’ corrisponde a 22.5).
• Max Value è il valore massimo che la funzione potrà fornire in uscita; valori più alti in modulo di questo limite produrranno un valore in uscita pari a Max Value.
• Offset è lo spostamento verticale della funzione; valori positivi spostano la funzione verso l’alto, mentre valori negativi la spostano verso il basso.
Nella funzione Sigmoid
• Amplitude si riferisce alla massima ampiezza della funzione; a differenza di Max Value però, la funzione non verrà tagliata, ma convergerà asintoticamente al valore Amplitude.
• Scale indica quanto rapidamente la sigmoide cresce verso il suo valore massimo; piccoli valori indicano una crescita rapida, mentre grandi valori indicano una crescita lenta. Piccoli valori di scale sono utili nel caso in cui si debbano separare output piccoli e ravvicinati .
• Offset è lo spostamento verticale della funzione.
Nella funzione Step
• Left Value si riferisce al valore che la funzione dovrà fornire in uscita nel caso in cui non venga raggiunto il valore di soglia.
• Right Value si riferisce al valore che la funzione dovrà fornire in uscita nel caso in cui venga raggiunto il valore di soglia.
Si noti come in nessuna delle funzioni sia previsto come parametro la traslazione della funzione lungo l’asse delle ascisse; questa mancanza è intenzionale perché l’eventuale traslazione viene fatta automaticamente dall’input fittizio che rappresenta la soglia.

63
Fig. 7.2 Il dialog di configurazione delle LUT
Fig. 7.3 Il dialog di configurazioni avanzate

64
Il checkbox View the function shape presente nel dialog di configurazioni avanzate, ha significato solo quando è selezionata la sigmoide, e serve per scegliere uno dei due possibili metodi di visualizzare la funzione. Se il checkbox non è selezionato si vedrà la funzione così com’è, anche nel caso in cui l’ampiezza dovesse essere scelta così piccola da non riuscire più ad apprezzare la forma della sigmoide, nel caso invece di checkbox selezionato, la sigmoide, prima di venire disegnata, verrebbe scalata e traslata opportunamente, in modo da farla entrare perfettamente nella finestra di visualizzazione. Naturalmente questa operazione non cambia la forma reale della sigmoide.
Tramite il bottone Add si possono aggiungere nuove funzioni del tipo appena descritto, oppure si possono caricare da disco delle funzioni definite
dall’utente. Con Remove infine si possono cancellare tutte quelle funzioni che al momento non sono in uso da alcun job.
7.1.1.3 Training
Premendo questo bottone si apre un dialog che permette di definire i parametri relativi alla fase di addestramento.
• Training Set e Generalization Set indicano la posizione sul disco dei file usati rispettivamente per l’addestramento e la generalizzazione.
• Training Output File e Generalization Output File indicano la base del nome di file dove verrà salvato il risultato di una sessione di addestramento. Il nome completo del file viene generato automaticamente dal programma
Fig. 7.4 Il dialog Add Function

65
aggiungendo alla fine del nome, ma prima dell’estensione, la stringa “_n” dove n è un numero progressivo che indica il numero di ripetizione di quella sessione di addestramento. Il file di output contiene: l’errore totale, l’errore su ogni istanza dell’insieme di addestramento/generalizzazione, la topologia della rete e la configurazione dei pesi.
• Generalization Period indica dopo quante iterazioni di RTS il programma deve calcolare la generalizzazione.
• Save Best Generalization stabilisce se si deve salvare o meno la configurazione di pesi che ha portato alla migliore generalizzazione.
• Il gruppo Start With permette di scegliere la configurazione di pesi che la rete deve avere al momento della sua creazione. Le scelte possibili sono tre:
pesi azzerati (Zero Network), pesi casuali (Random Network) e pesi definiti
dall’utente (User Defined Network). In quest’ultimo caso, si può caricare nella rete un insieme predefinito di pesi che è stato salvato precedentemente in un file. Il Training/Generalization output file ha il formato adatto per essere usato.
• Il gruppo Training Mode invece permette di scegliere il tipo di addestramento. Le possibili alternative sono:
• EPOCH: l’addestramento viene eseguito cercando di minimizzare l’errore su tutto l’insieme di addestramento.
• BLOCK: l’addestramento viene eseguito su blocchi di dati contigui dell’insieme di addestramento. È possibile definire la dimensione del blocco e il tempo che deve essere usato prima di sostituirlo. La posizione del blocco è scelta a caso dal programma.
• FIXED BLOCK: l’addestramento viene eseguito su un blocco di dati contigui dell’insieme di addestramento. È possibile definire la dimensione e la posizione del blocco.
• RANDOM BLOCK: l’addestramento viene eseguito su blocchi di dati scelti casualmente dall’insieme di addestramento. È possibile definire la dimensione del blocco e il tempo che deve essere usato prima di sostituirlo.
• Niters specifica il numero di iterazioni di RTS che si vogliono eseguire.

66
7.1.1.4 RTS
Viene usato per specificare i parametri dell’algoritmo di addestramento.
Fig. 7.5 Il dialog training parameters
Fig. 7.6 Il dialog di configurazione dei parametri dell’RTS

67
7.1.2 Il gruppo Batch Elaboration
Il gruppo Batch Elaboration si usa per definire una serie di lavori (job) da elaborare sequenzialmente. Sono possibili quattro azioni in questo gruppo:
• Rename viene usato per rinominare un job esistente. Se il nuovo nome coincide con uno già in uso, ad esso verrà aggiunto automaticamente un numero progressivo tra parentesi quadre. Questo è necessario per garantire che ogni job sia identificato univocamente dal nome.
• New Job viene usato per creare un nuovo job.
• Remove cancella il job corrente a meno che non sia l’unico job esistente.
• Per selezionare un job e renderlo corrente è sufficiente cliccare il suo nome nella lista.
7.1.3 Il gruppo Rep
Con lo slider contenuto in questo gruppo si può decidere quante sessioni di addestramento deve fare il job corrente.
7.1.4 Il gruppo Network Topology
In questa finestra viene visualizzata graficamente la topologia della rete.
Fig. 7.7 Network topology

68
I nodi rappresentati da un quadrato sono gli input, mentre i nodi rappresentati da un cerchio sono i neuroni. È inoltre possibile con il bottone
Settings definire alcuni parametri legati alla rete:
• Bias Factor è il fattore di soglia, cioè il valore di quell’input fittizio che viene usato per simulare la soglia. La scelta di questa quantità non è critica, l’importante è che il suo valore sia dello stesso ordine di grandezza degli input reali.
• Output Shift indica quante volte l’output della rete debba essere diviso per due prima di passare attraverso la funzione di trasferimento. Questo serve per scalare l’output della rete in modo tale che il suo range di uscita sia sempre compreso nel range degli short int.
Se non si ha alcuna voglia di settare manualmente i suddetti parametri, il
programma lo farà automaticamente se il checkbox Autocalculate è selezionato.
7.1.5 Il gruppo Statistics
Questo gruppo normalmente non si vede perché condivide lo stesso spazio
di Network Topology. Si può visualizzarlo da menù con View\Statistics oppure cliccando sul sesto button gadget da sinistra (quello con il disegno di una pagina scritta).
Fig. 7.8 Setup Network Parameters

69
Per ogni job viene costruita una statistica che contiene; sia per l’addestramento che per l’eventuale generalizzazione:
• l’errore più basso
• l’errore più alto
• la media degli errori
• la deviazione standard
Una serie di bottoni posizionati nella parte inferiore permettono di muoversi
lungo le statistiche passate. Con Elaboration/Clear Elaboration Statistics si possono cancellare le statistiche passate.
7.1.6 Il gruppo Elaboration
Una volta che sono stati definiti tutti i parametri si può iniziare l’elaborazione.
Ci sono due possibilità: se si preme Start Batch l’addestramento viene eseguito per tutti i job che sono definiti nel gruppo Batch Elaboration, se invece si preme
Start Current si addestra solo il job corrente. È possibile fermare in qualsiasi
momento l’addestramento premendo Stop oppure Pause.
In questo gruppo sono contenuti alcuni utili indicatori:
Fig. 7.9 Le statistiche
L’errore più piccolo
L’errore più grande
La media degli errori
La deviazione standard

70
• Il titolo del gruppo durante l’addestramento cambia da Elaboration a Elaborating: nome job Rep: numero ripetizione
• Start Time indica l’ora in cui si è iniziato ad elaborare il job (non la lista)
• Estimated End Time indica l’ora stimata di fine elaborazione del job
• Elapsed Time è il tempo trascorso dall’inizio dell’elaborazione.
• Estimated Remaining Time è il tempo stimato che rimane prima della fine dell’elaborazione.
• L’area colorata di nero viene usata per visualizzare in modo grafico e numerico l’andamento dell’addestramento (verde) e dell’eventuale generalizzazione (rosso).
• La barra di progresso indica graficamente la percentuale di lavoro eseguito.
7.1.7 I menù
7.1.7.1 File
• New: ripristina la configurazione che si aveva alla partenza del programma
Fig 7.10 il gruppo Elaboration
Indicatore di progresso

71
• Save: salva la configurazione corrente
• Save as…: salva con nome
• Print Results: stampa le statistiche
• Quit: esci dal programma
7.1.7.2 Elaboration
• Evaluate: valuta input da tastiera usando i pesi e la rete del job corrente. Gli input devono essere separati tra loro da almeno un carattere di spaziatura (spazio, tab…)
• Evaluate File: come Evaluate, ma gli input vengono presi da un file. Gli output sono scritti su un file che avrà lo stesso nome del file di input ma con estensione .out.
• Clear Elaboration Statistics: cancella la lista delle statistiche associate ai job finora elaborati.
7.1.7.3 View
• Network: visualizza la finestra Network Topology
• Statistics: visualizza la finestra Statistics
7.1.7.4 Help
• About: visualizza un dialog con alcune informazioni sul programma.

72
8 Descrizione del formato dei file
8.1.1 Descrizione del linguaggio
I rettangoli con il bordo squadrato rappresentano i simboli mentre i rettangoli con il bordo arrotondato rappresentano gli identificatori. Le frecce tratteggiate indicano che la definizione continua.
8.1.1.1 commento
8.1.1.2 identificatore
; any symbol new line
any symbol

73
8.1.1.3 valore
A causa dell’eterogeneità dei possibili valori verrà definito più avanti.
8.1.1.4 whitespace
8.1.1.5 dato
new line whitespace
whitespace valore
identificatore
:
=
whitespace
space
new line
tab
line feed
carriage return

74
8.1.2 File di salvataggio dei dati
formato: ASCII
estensione: .lst
Il file è composto da due blocchi fondamentali: il primo è quello che definisce le funzioni di trasferimento mentre il secondo definisce i job.
8.1.2.1 lut definition
8.1.2.2 lut list definition
8.1.2.3 topologia
È un tipo di dato in cui il nome è “topology” ed il valore è definito come segue
lut_ start new line dato
lut_end new line
lut_ definition_start new line lut definition
new line lut_ definition_end

75
il separatore è definito in questo modo:
8.1.2.4 weights
8.1.2.5 job definition
spazio - spazio
[
< Not Defined >
int separatore int
]
topologia
< No Weights >
(layer,neu) -> (layer,neu) = valore
weight_ start
weight_ end new line
new line
new line
new line

76
8.1.2.6 job list definition
8.1.2.7 Struttura del file
8.1.2.8 Esempio commentato di file
;================================================================ ;Mandingo 1.0 written by Stefano Benamati ; ;October 13, 1997 11:51:28 am ;================================================================ luts_definition_start ;====================================== ;Luts Definitions ;====================================== lut_start ;-------------------------------------- ;Definition of lut: Sigmoid ;-------------------------------------- ; type: Sigmoid name: Sigmoid
job_ start new line dato
job_end new line weights weights
job_ definition_start new line job definition
new line job_ definition_end
lut list definition job list definition
Versione del programma
data e ora di creazione
Questa riga è un tipico esempio di dato. ATTENZIONE: per non appesantire troppo la procedura di caricamento NON VIENE ESEGUITO ALCUN CONTROLLO SUL CAMPO NOME; esso è stato messo unicamente per aiutare la modifica manuale del file. Sono ammesse eventuali modifiche a questo campo, si presti però attenzione a non modificare l’ordinamento delle righe.

77
Amplitude: 32767 Scale: 7000 Offset: 0 ;---------------------------------------------------------------- lut_end lut_start ;---------------------------------------------------------------- ;Definition of lut: Linear ;---------------------------------------------------------------- ; type: Linear name: Linear Angle: 45 Max Value: 32767 Offset: 0 ;---------------------------------------------------------------- lut_end lut_start ;---------------------------------------------------------------- ;Definition of lut: Step ;---------------------------------------------------------------- ; type: Step name: Step Left Value: -10000 Right Value: 10000 ;---------------------------------------------------------------- lut_end lut_start ;---------------------------------------------------------------- ;Definition of lut: corto ;---------------------------------------------------------------- ; type: User Defined name: corto filename: G:\Mandingo\corto.pat ;---------------------------------------------------------------- lut_end ;================================================================ luts_definition_end job_list_start ;================================================================ ;Jobs Definitions ;================================================================ job_start ;================================================================ ;Configuration of primo ;================================================================ name: primo ;---------------------------------------------------------------- ;Net Configuration: ;
può essere uno tra: • Sigmoid • Linear • Step • User Defined
Per informazioni sul formato di questo file si guardi il relativo paragrafo.
double per tutte le funzioni

78
topology: [2 - 1] bias_factor: [2500] output_shift: [7] output_lut: [0] bpt: 8 bpw: 8 gray: true autocalculate: true ;------------------------------------------ ;Training: ; training_set: G:\Mandingo\2sqrt.pat training_output_file: < Not Defined > generalization_set: G:\Mandingo\3sqrt.pat generalization_output_file: < Not Defined > user_defined_network: < Not Defined > start_with: ZERO training_kind: GENERALIZE training_mode: EPOCH change_block_period: 0 training_block_size: 0 training_block_start: 0 generalization_period: 1 number_of_iterations: 10 save_best_generalization: false use_training_output: false use_generalization_output: false use_never: true use_optimum: true ;---------------------------------------------------------------- ;RTS parameters: ; sample: 6 repetitions: 3 chaos: 3 red_fact: 0.9 enc_fact: 1.1 min_list_size: 1 max_list_size: 1 clear_history: true clear_repetition_counter: true clear_tabu_list: false reset_T: false reset_running_average: false reset_tT: false ;---------------------------------------------------------------- ;Luts: ; lut_zero_type: Sigmoid lut_zero_name: Sigmoid lut_one_type: Sigmoid lut_one_name: Sigmoid ;---------------------------------------------------------------- ;Other Parameters: ; repetitions: 1
ha lo stesso formato di topology ma con un valore in meno
ha lo stesso formato di topology ma con un valore in meno: range [0,7]
uno tra • ZERO • RANDOM • USER_DEFINED
uno tra • GENERALIZE • LEARN
uno tra • EPOCH • BLOCK • FIXED_BLOCK • RANDOM_BLOCK
può essere uno tra: • Sigmoid • Linear • Step • User Defined
deve essere il nome di una funzione definita nel blocco delle Luts
int
float
int
boolean
ha lo stesso formato di topology ma con un valore in meno: range [0,1]
int: range[0,7]
boolean
int
boolean
Nome di file valido oppure < Not Defined >

79
;---------------------------------------------------------------- ;Learn Weights ; topology: [2 - 1] weight_start (0,0) -> (1,1) = -121 (0,1) -> (1,1) = -128 (0,2) -> (1,1) = 1 weight_end ;---------------------------------------------------------------- ;Generalization Weights ; topology: [2 - 1] weight_start (0,0) -> (1,1) = -121 (0,1) -> (1,1) = -128 (0,2) -> (1,1) = 1 weight_end ;---------------------------------------------------------------- job_end job_list_end
signed char
Questo è l’unico caso in cui il dato usa il segno di uguale per separare il nome dal valore. Mettere più righe di quanti pesi ha la rete, oppure metterne di meno provocherà un errore che abortirà il caricamento del job in questione. Anche qui l’ordinamento delle righe è fondamentale.
Qualsiasi cosa verrà scritta dopo questa riga verrà ignorata.

80
8.1.3 File dei pesi
formato: ASCII
estensione: .log,.wei
Questo file contiene l’informazione relativa alla topologia della rete e alla configurazione dei pesi all’interno di essa. Viene usato quando si vuole fare partire l’addestramento con una configurazione di pesi prestabilita.
La struttura di questo file è semplicissima: contiene solo un blocco weights.
8.1.4 File di training/generalization output
formato: ASCII
estensione: .log
Questo file contiene i dati che vengono salvati durante l’addestramento se è abilitata l’opzione di salvataggio dell’output.
8.1.4.1 Esempio commentato di file
;================================================================= ; Training Output File of Nome del Job ; ; Learn (oppure Generalization) Error = 24165.3 ;================================================================= ; ; ; Input: 19365 1661 ; Output: -1000 ; Calculated Output: -9601 ; Error: 8601 ; ; ; ; ; ; ; ;
Questo schema viene ripetuto per tutte le coppie di input/output del set di addestramento (o di generalizzazione)
È la radice quadrata della somma dei quadrati dell’errore su ogni componente dell’output. In altre parole è la distanza euclidea del valore calcolato con l’output reale.
È l’errore totale calcolato su tutto il set di addestramento (o di generalizzazione). È la stessa quantità che viene visualizzata dal programma nel gruppo elaboration.

81
topology: [2 - 1] weight_start (0,0) -> (1,1) = -40 (0,1) -> (1,1) = 41 (0,2) -> (1,1) = -103 weight_end
Il formato di questo file è tale da poter essere usato anche come file di pesi.
8.1.5 File di funzione di trasferimento
formato: ASCII
estensione: .asc
Questo file contiene i 64k elementi che definiscono la funzione di trasferimento che l’utente può specificare al posto delle tre predefinite. Ogni elemento è uno short int e deve essere separato dagli altri da almeno un whitespace; all’interno del file i valori hanno il significato specificato in Fig 8.1.
Blocco weights
32767 32768 0
da 0 a 32767da 65535 a 32768
Fig. 8.1 La funzione all’interno del file

82
8.1.6 File di pattern
formato: ASCII
estensione: .pat
È il file che contiene l’insieme degli input e degli output che vengono usati per addestrare la rete. Il formato è semplicissimo: siano m ed n le dimensioni rispettivamente dei vettori di input ed output; allora il file è composto da una sequenza di m+n short int separati da almeno un whitespace. Non c’è alcun separatore speciale tra gli input e gli output né tra i pattern.
Il file deve contenere un numero di short int divisibile per (m+n), in caso contrario il caricamento dei pattern fallirà.
8.1.7 File di input
formato: ASCII
estensione: .in
È il file che contiene l’insieme degli input che devono essere valutati dalla
funzione Elaboration/Evaluate file. Il formato è identico al file di pattern eccetto per il fatto che contiene solo gli input.
8.1.8 File di output
formato: ASCII
estensione: .out
È il file di uscita della funzione Elaboration/Evaluate file. Il formato è identico al file di pattern.

83
9 Un problema di classificazione
In questo Capitolo, e nei tre che seguono, viene usato il programma Mandingo per addestrare quattro reti neurali a risolvere altrettanti problemi. Il sistema usato per portare a termine tutti gli esperimenti è un Pentium 120, fornito di scheda TOTEM ISA, e sopra al quale gira il sistema operativo Windows NT.
In Appendice sono listati i file di salvataggio del Mandingo relativi ad ogni esperimento. Essi contengono una descrizione completa di tutti i parametri della rete e dei criteri di addestramento.
Il problema trattato in questo Capitolo è un classico della computazione neurale, e riguarda la classificazione di punti distribuiti secondo un certo criterio. Lo scopo di questo esperimento è mettere in evidenza le capacità di generalizzazione e di tolleranza agli errori delle reti neurali.
9.1 Classificazione di punti
Sia A un insieme non vuoto di punti in uno spazio n-dimensionale e sia B un sottoinsieme di A. Un classificatore è una funzione G:A {0,1} definita nel seguente modo:
G(x)= 1 se x∈ A
0 se x∈ A-B (9.1)

84
Dato A e B, un problema di classificazione consiste nel trovare una funzione che associ correttamente tutti gli input alla rispettiva classe di appartenenza.
I problemi di classificazione sono interessanti da studiare con le reti neurali perché mettono in luce una caratteristica che le reti neurali hanno in comune con il cervello umano, e cioè la capacità di generalizzare.
Come è stato dimostrato nel Capitolo 3, una rete neurale con una topologia adatta, è in grado di classificare correttamente punti disposti secondo una qualsiasi configurazione. L’esempio che segue mostra come questo sia possibile e mette in evidenza le problematiche legate a questa classe di problemi.
9.2 Il problema Concentric
Un problema interessante è quello che riguarda la classificazione di punti quando una classe è inserita nell’altra senza sovrapposizioni. È chiaro che problemi di questo tipo non godono della proprietà della separabilità lineare e quindi non possono essere risolti usando un percettrone semplice.
Nel problema ’Concentric’, i punti dello spazio di input appartengono allo spazio bidimensionale e sono tutti gli interi contenuti nel cerchio di raggio 5000 centrato in (5000,5000). I punti della classe 0 sono quelli all’interno di un cerchio concentrico al primo e di raggio 3000, mentre i punti della classe 1 sono quelli che ne rimangono fuori1.
1 Questo ed altri problemi di classificazione si possono trovare nel Database Elena
ftp://ftp.dice.ucl.ac.be/pub/neural-nets/ELENA/databases/ARTIFICIAL
10000
10000
8000
2000
2000 8000
Classe 0
Classe 1
Fig. 10.1 Il problema Concentric

85
9.2.1 L’addestramento
9.2.1.1 La topologia
Si supponga per il momento di conoscere abbastanza della distribuzione dei punti da poter dire che l’insieme da separare appartiene ad una regione convessa, ma di non avere nessuna informazione riguardo la forma di questa regione. Tale conoscenza, permette facilmente di stabilire un importante parametro della topologia della rete chiamata a risolvere questo problema: non è necessario più di uno strato nascosto.
Stabilire il numero ottimale di neuroni necessari nello strato nascosto, invece, è un compito piuttosto difficile, perché questa quantità dipende direttamente dalla forma della regione che il percettrone deve discriminare. Infatti, come è stato messo in evidenza nel Capitolo 3, la regione discriminata da un percettrone a due strati è delimitata da rette, ognuna generata da un neurone dello strato nascosto. Appare chiaro quindi che a prescindere dalla forma della regione, più neuroni ci sono nello strato nascosto, e meglio la rete classifica i punti. Ma maggiore è il numero di neuroni, maggiore sarà il numero dei pesi e più lungo sarà il processo di addestramento. Addestrare una rete neurale, presuppone quindi una mediazione tra due quantità: l’esattezza dei risultati contro la velocità di apprendimento.
Non si deve dimenticare, inoltre, che solitamente l’addestramento viene eseguito su una piccola frazione dello spazio di input, e che quindi, quello che si richiede alla rete non è di classificare correttamente i punti dell’insieme di addestramento, ma di generalizzare, partendo da essi, per trovare una regola che permetta di classificare correttamente la maggior parte dei punti appartenenti allo spazio di input.
9.2.1.2 L’insieme di addestramento
Lo spazio di input contiene 78.539.675 punti; il 36% dei quali appartengono alla classe 0, mentre il restante 64% è composto da punti della classe 1.
Da questo spazio di input sono stati estratti casualmente 2500 punti, metà dei quali usati per l’addestramento, mentre l’altra metà è usata per controllo.
9.2.2 La fase di addestramento
Poiché non si dispongono di sufficienti informazioni riguardo alla forma della regione che include i punti della classe 0, la scelta della topologia viene fatta in base ad osservazioni empiriche dei risultati di addestramenti di prova.

86
Questa fase consiste nell’addestrare varie topologie di rete tramite l’esecuzione di 10000 iterazioni dell’algoritmo RTS.
9.2.2.1 Topologia 2-2-1
Questa è la topologia più semplice. Con una rete di questo tipo si possono discriminare tutti i punti contenuti in una regione delimitata tra due rette. L’addestramento di questa rete non ha portato a grossi risultati ed infatti l’errore di classificazione, calcolato usando l’insieme di controllo, è del 30,6%.
La Figura 9.2 riassume i risultati di questo addestramento, e mostra graficamente la regione delimitata dalle due rette. Per ottenere questo grafico si sono plottati i risultati della classificazione dei punti appartenenti all’insieme di controllo, e poi si sono tracciate le linee rette che delimitano il confine tra le due classi. La visualizzazione grafica pertanto, pur essendo corretta, dovrebbe essere interpretata come ausilio all’esposizione dei risultati, non come prova della bontà della classificazione.
9.2.2.2 Topologia 2-3-1
Aumentando il numero dei neuroni contenuti nello strato nascosto si aumenta la capacità discriminatoria della rete. Un percettrone con topologia 2-3-1, è in grado di separare correttamente i punti contenuti in una qualsiasi area triangolare.
In questo caso, si può notare un netto miglioramento rispetto al caso precedente; anche se non si può ancora dire di aver raggiunto un risultato soddisfacente.
Fig. 9.2 Topologia 2-2-1
Punti classificati correttamente 69.4% Punti classificati erroneamente 30.6% di cui: della classe 0 attribuiti alla classe 1 34.7% della classe 1 attribuiti alla classe 0 65.3%
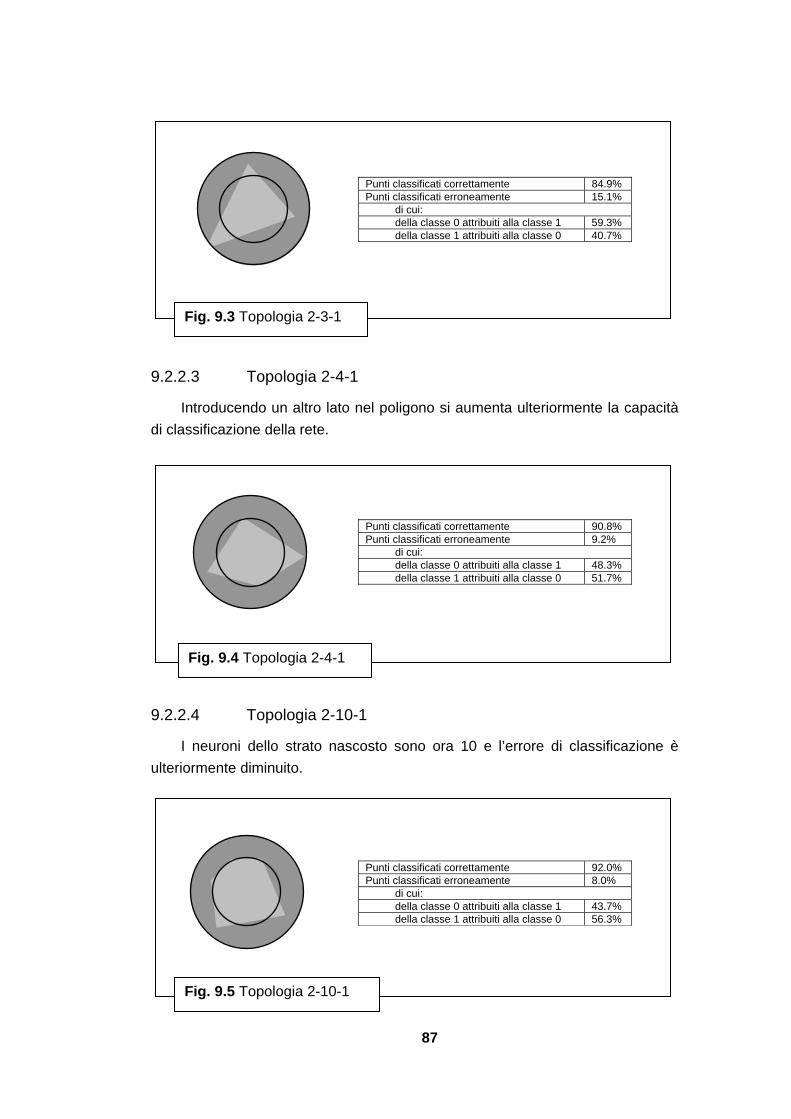
87
9.2.2.3 Topologia 2-4-1
Introducendo un altro lato nel poligono si aumenta ulteriormente la capacità di classificazione della rete.
9.2.2.4 Topologia 2-10-1
I neuroni dello strato nascosto sono ora 10 e l’errore di classificazione è ulteriormente diminuito.
Fig. 9.3 Topologia 2-3-1
Punti classificati correttamente 84.9% Punti classificati erroneamente 15.1% di cui: della classe 0 attribuiti alla classe 1 59.3% della classe 1 attribuiti alla classe 0 40.7%
Fig. 9.4 Topologia 2-4-1
Punti classificati correttamente 90.8% Punti classificati erroneamente 9.2% di cui: della classe 0 attribuiti alla classe 1 48.3% della classe 1 attribuiti alla classe 0 51.7%
Fig. 9.5 Topologia 2-10-1
Punti classificati correttamente 92.0% Punti classificati erroneamente 8.0% di cui: della classe 0 attribuiti alla classe 1 43.7% della classe 1 attribuiti alla classe 0 56.3%

88
Osservando la Fig. 9.5, si può notare che nonostante i dieci neuroni dello strato nascosto, il poligono che racchiude i punti classificati come classe 0 non è formato da dieci lati. Questa situazione può essere un indizio del fatto che la rete non è stata addestrata abbastanza, oppure, che i punti della classe 0 sono effettivamente racchiusi entro una regione approssimabile da un poligono con meno di dieci lati.
Per indagare sono state eseguite 20 sessioni di addestramento, consistente ognuna in 10000 iterazioni di RTS. Il risultato migliore è esposto qui di seguito.
Ora il poligono ha 10 lati, e la capacità di classificazione della rete, seppur di poco, è aumentata.
9.2.3 Conclusioni
Dal momento che i punti della classe 0 sono contenuti entro un’area circolare, sarebbe necessario un gran numero di neuroni nello strato nascosto per arrivare ad una classificazione esatta. Tuttavia, già con 10 neuroni l’errore di classificazione è molto basso. Aggiungerne altri significherebbe aumentare la complessità della rete a fronte di aumenti sempre più piccoli della sua capacità classificatoria. Da 4 a 10 neuroni infatti, l’incremento è di soli 5 punti percentuali.
La capacità di classificare correttamente però, non è l’unica caratteristica che la rete ha mostrato in questo esperimento. La cosa forse più importante è stata la sua capacità di generalizzare.
I 1250 pattern che sono stati analizzati dalla rete durante il periodo di addestramento, rappresentano solo lo 0,0016% dello spazio di input. Tuttavia, nonostante l’esigua porzione dell’insieme di addestramento, la rete ha imparato molto bene a circoscrivere l’area entro la quale sono contenuti tutti i punti della classe 0.
Fig. 9.6 Il migliore risultato
Punti classificati correttamente 95.8% Punti classificati erroneamente 4.2% di cui: della classe 0 attribuiti alla classe 1 88.9% della classe 1 attribuiti alla classe 0 11.1%

89
Risultati simili, o addirittura migliori, si sarebbero potuti ottenere anche in modo classico, utilizzando algoritmi per la ricerca della minima regione convessa che racchiude un certo insieme di punti [34].
La differenza sostanziale tra questi due modi di procedere è che, mentre gli algoritmi classici necessitano di insiemi di addestramento esatti, per produrre output esatti, le reti neurali sono in grado di affrontare informazioni soggette a rumore, o addirittura sbagliate, e fornire in uscita valori accettabili.
Se per esempio, nell’insieme di addestramento ci fosse anche un solo valore sbagliato, un classificatore basato sulla ricerca della minima regione convessa potrebbe fallire miseramente, mentre una rete neurale saprebbe cavarsela anche in presenza di una quantità molto maggiore di errori.
Per indagare su questa proprietà della computazione neurale, è stato ripetuto l’addestramento della rete 2-10-1 usando, come insieme di addestramento, lo stesso insieme che era stato usato in precedenza, ma modificato in modo tale che il 10% dei punti sia associato alla classe sbagliata.
Fig. 9.8 Classificazione in presenza di errori
Punti classificati correttamente 94.4% Punti classificati erroneamente 5.6% di cui: della classe 0 attribuiti alla classe 1 26.4% della classe 1 attribuiti alla classe 0 73.6%
Fig. 9.7 I limiti nella ricerca della minima regione convessa
Un solo valore sbagliato nell’insieme di esempio può far degradare di molto le prestazioni di un classificatore basato sulla ricerca della minima regione convessa.

90
Come si può vedere, a fronte di un errore del 10% nell’insieme di addestramento, l’errore di classificazione è aumentato di una piccolissima quantità, passando da 4.2% a 5.6%. Difficilmente un classificatore basato sulla minima regione convessa sarebbe riuscito ad ottenere questi risultati.
Un’ultima considerazione riguarda l’assunto che era stato fatto all’inizio, e cioè che i punti della classe 0 appartenevano ad una regione convessa. Questa informazione si è rivelata utile nella scelta del tipo di rete, ma non era fondamentale per un corretto approccio al problema. Infatti, l’insieme dei percettroni di n strati è sottoinsieme dell’insieme dei percettroni di n+1 strati; per cui, addestrare una rete sovradimensionata al problema da risolvere non porta ad ottenere risultati diversi da quelli che si sarebbero ottenuti da una rete ottimale, ma solo ad una perdita di tempo durante la fase di addestramento.

91
10 Approssimazione di funzioni
Questo Capitolo mostra l’utilità delle funzioni di trasferimento a valori continui.
10.1 Il problema del periodo del pendolo
Il pendolo è un sistema costituito da una massa sospesa mediante un filo di massa trascurabile e di lunghezza l. In condizioni di quiete, il centro di massa del sistema è fermo in un punto detto punto di equilibrio, ma se si sposta la massa da questo punto, essa oscillerà con moto periodico. Se lo spostamento è piccolo, il moto che si genera è approssimabile al moto armonico semplice con il periodo dell’oscillazione che varia in accordo con la seguente legge:
glT π2=
dove l è la lunghezza del filo e g è l’accelerazione di gravità.
Si supponga di non conoscere questa relazione e di voler trovare un sistema per predire il periodo del pendolo per ogni lunghezza del filo. Un metodo per risolvere questo problema consiste nel campionare la funzione in alcuni punti e a partire da questi provare ad individuare la curva che meglio si adatta ai punti campionati.
Campionare la funzione, introduce però inevitabilmente due tipi di errore: un primo tipo di errore riguarda la capacità dello sperimentatore di usare lo strumento di misura, il secondo tipo di errore è invece proporzionale alla misura,
(10.1)

92
e può dipendere da molti fattori, quali la massa della corda, gli allungamenti della stessa a causa di imperfezioni o di dilatazione termica, l’errore introdotto da spostamenti d’aria, da variazioni di densità o da altri fattori non ripetibili. La misura ottenuta è quindi perturbata da una certa quantità di rumore casuale e la quantità misurata è data da:
T=t+a+b*t
dove a e b sono rispettivamente l’errore fisso e l’errore proporzionale e t è il tempo reale che si sarebbe misurato se non ci fosse stato nessun errore.
10.1.1 L’insieme di addestramento
Nella convinzione che il primo tipo di errore, quello fisso, possa essere eliminato ripetendo la misurazione un opportuno numero di volte, si è proceduto alla generazione, tramite simulazioni al computer, di tre insiemi di addestramento, tenendo in considerazione solo l’errore proporzionale.
La generazione è avvenuta come segue: si è in primo luogo calcolato la funzione in 20 punti scelti a caso nel range compreso tra 1000 e 20000 millimetri; successivamente, a questi valori è stato sommato un errore casuale proporzionale, distribuito secondo una gaussiana di media zero e deviazione standard σ=0.005, σ=0.05, σ=0.1, in modo tale da mantenere (nella maggior parte delle volte) l’errore introdotto rispettivamente sotto al 1%, al 10% e al 20%.
Infine, poiché il TOTEM è stato progettato per operare con gli interi e non con i numeri in virgola mobile, i valori ottenuti dalla simulazione sono stati riscalati in modo tale che un metro corrisponda ad un intervallo di 1000 unità ed un secondo ad un intervallo di 3000 unità.
10.1.2 La rete
Dopo aver sperimentato varie configurazioni di neuroni, si è deciso di usare per l’addestramento un percettrone di quattro strati con la seguente topologia: 1-3-3-3-1. Le funzioni di trasferimento tra tutti gli strati sono sigmoidi.
L’addestramento è avvenuto attraverso 50000 iterazioni di RTS, usando come controllo un insieme calcolato nello stesso modo dell’insieme di addestramento ma su punti diversi. Una volta terminato l’addestramento, la configurazione di pesi che ha portato alla generalizzazione migliore è stata usata per calcolare la funzione in ogni suo punto compreso tra 1000 mm e 20000 mm. La funzione così calcolata è stata poi confrontata con quella reale.

93
I grafici che seguono mostrano la distribuzione dell’errore percentuale ed assoluto che la rete ha introdotto nell’approssimare la funzione.
Pattern perturbati da un errore minore del 20%
-0,8-0,6-0,4-0,2
00,20,40,6
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Lunghezza pendolo (m)
Erro
re a
ssol
uto(
s)
Pattern perturbati da un errore minore del 20%
-15
-10
-5
0
5
10
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Lunghezza pendolo (m)
Err
ore
perc
entu
ale
La rete addestrata usando pattern perturbati da un errore contenuto entro il 20% ha mostrato una buona capacità di trascendere dagli errori, arrivando a creare un modello che, nel caso peggiore, differisce dalla funzione reale poco più del 13%. Gli errori sono distribuiti molto simmetricamente attorno allo zero, essendo la media degli errori percentuali il –0.809%. Infine, come si può notare osservando il grafico, la maggior parte degli errori sono contenuti entro il 10%.
Pattern perturbati da un errore minore del 10%
-0,4
-0,3
-0,2
-0,1
0
0,1
0,2
0,3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Lunghezza pendolo (m)
Erro
re a
ssol
uto
(s)

94
Pattern perturbati da un errore minore del 10%
-10
-5
0
5
10
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Lunghezza pendolo (m)
Erro
re p
erce
ntua
le
Anche quando la rete viene addestrata usando pattern perturbati da un errore contenuto entro il 10% si hanno dei buoni risultati. Gli errori sono contenuti entro l’intervallo [-7.138%,8.256%] e sono distribuiti molto simmetricamente attorno allo zero, essendo la media degli errori percentuali il 0.344%. Infine, come si può notare osservando il grafico, dopo gli 8 metri, l’errore percentuale rimane al di sotto del 2.5%, segno che la rete, nonostante gli errori introdotti nell’insieme di addestramento, è riuscita a creare una buona approssimazione della funzione.
Pattern perturbati da un errore minore del 1%
-0,06-0,04-0,02
00,020,040,060,08
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Lunghezza pendolo (m)
Erro
re a
ssol
uto
(s)
Pattern perturbati da un errore minore del 1%
-1,5
-1
-0,5
0
0,5
1
1,5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Lunghezza pendolo (m)
Erro
re p
erce
ntua
le

95
Il caso in cui la rete viene addestrata usando pattern perturbati da un errore contenuto entro l’1% è leggermente diverso. Essendoci infatti solo 20 punti su cui costruire un’approssimazione, è inevitabile che la rete introduca degli errori anche partendo da pattern esatti. Non si può quindi trarre alcuna conclusione se non che l’approssimazione è molto buona.
10.1.3 Conclusioni
Nonostante la scelta della funzione da approssimare fosse molto semplice, l’esperimento ha messo in evidenza la robustezza dell’approssimazione tramite rete neurale, anche in presenza di una considerevole quantità di rumore sommato al segnale originario. In essenza, in presenza di rumore, la rete si comporta come una sorta di filtro passa basso che, dopo l’addestramento, riesce a rappresentare una versione migliore della funzione “rumorosa” fornita in ingresso.

96
11 Forza 3
Forza 3 è la versione semplificata del noto gioco Forza 4, distribuito in Italia dalla MB. Il gioco consiste in una matrice 5×6, nelle cui colonne, a turno, due giocatori inseriscono dei gettoni colorati. Vince chi per primo riesce ad allineare tre gettoni del proprio colore: in orizzontale, in verticale oppure in diagonale.
Forza 3 rappresenta un buon test per valutare le capacità delle reti neurali perché, pur essendo semplice, è abbastanza complesso da non risultare banale. Ci sono infatti ben 648 possibili modi di giocare le prime 5 mosse. Inoltre, esiste una strategia che permette al giocatore che inizia la partita di vincere sempre. Questa strategia, anche se semplice, non è evidente ad una analisi superficiale del gioco.
Lo scopo di questo esperimento è di vedere quanto e come la strategia imparata dalla rete dopo l’addestramento differisce dalla strategia vincente.
11.1.1 La strategia vincente
Facendo riferimento alla Fig. 11.1, il giocatore che inizia la partita ha la vittoria certa se, come prima mossa, mette il gettone nella colonna 3 oppure nella colonna 4. In questo modo l’avversario è obbligato a rispondere riempiendo una delle due caselle adiacenti. Se così non facesse, il primo giocatore avrebbe la possibilità di mettere il successivo gettone adiacente al primo, in modo tale da creare una configurazione in cui è possibile fare tris in due modi, il secondo giocatore a questo punto, non avendo la possibilità di impedirli entrambi perderà alla mossa successiva.

97
La strategia del primo giocatore continua posizionando i gettoni in modo tale da non lasciare all’avversario altra mossa che quella di impedire un tris.
Dopo la quinta mossa l’avversario è in trappola, perché non potrà evitare di cadere in una configurazione in cui, il primo giocatore può completare un tris in tre modi diversi. A questo punto, per il secondo giocatore non ci sono più speranze.
11.1.2 L’insieme di addestramento
Per generare l’insieme di addestramento, si sono programmati tre giocatori: Random, Beginner ed Expert; ognuno con uno stile di gioco diverso. Random è il giocatore peggiore perché non segue nessuna strategia, essendo le sue mosse
1 2
1 2 3 4 5 6
3 1 2 4
1 2 3 4 5 6
3 1 2 4
5
6
1 2 3 4 5 6
3 1 2 4
8 7 5
6 9
1 2 3 4 5 6
3 1 2 4
8 7 5
6
1 2 3 4 5 6
Fig. 11.1 La strategia vincente
(c)
(b) (a)
(e)
(d)

98
dettate dal caso. Beginner gioca un po’ meglio; la sua strategia consiste nel trovare due gettoni allineati che possono essere completati in modo da fare tris, se non ne trova, cerca nello stesso modo di impedire un eventuale tris all’avversario, se non ci sono tris da fare o tris da impedire fa una mossa a caso. Expert va un po’ più in avanti di Beginner; se non riesce a fare o ad impedire un tris, anziché scegliere una mossa a caso, cerca di creare coppie di gettoni allineati, in modo tale da mettere l’avversario in difficoltà, oppure, se non può farlo, cerca di impedire di essere messo in difficoltà nello stesso modo.
La seguente tabella riassume brevemente le caratteristiche dei tre giocatori.
Nome Strategia commenti
Random gioca a caso pessimo giocatore
Beginner esegue la mossa che gli procura un immediato vantaggio senza curarsi delle possibili conseguenze
sufficientemente bravo ma facile preda di tranelli
Expert guarda un po’ più avanti di Beginner buon giocatore ma con alcuni punti deboli
Questi giocatori sono stati fatti poi giocare in un torneo nel quale ognuno ha giocato con gli altri 10000 partite.
Partita Vinte dal primo Random vs Random 6046Random vs Beginner 792Random vs Expert 312Beginner vs Random 9802Beginner vs Beginner 5970Beginner vs Expert 5644Expert vs Random 9961Expert vs Beginner 7584Expert vs Expert 8359
Il 10% delle partite vinte dal primo giocatore, in ogni sequenza di 10000 partite, è andato a costituire un insieme di addestramento. Ci sono in tutto nove insiemi, ognuno dei quali riflette le strategie di gioco di ogni coppia di giocatori.
Ogni insieme di addestramento è composto da sequenze di 15 elementi: i primi 14 codificano, per ogni colonna, la configurazione delle celle della matrice di gioco indicate nella Fig. 11.2, mentre l’ultimo elemento indica quanto è conveniente mettere il gettone proprio in quella colonna: il valore 30000 indica una mossa vincente, 20000 una buona mossa e zero una pessima mossa.

99
Ogni insieme di addestramento è stato utilizzato per addestrare un percettrone di topologia 14-5-5-1.
11.1.3 I giocatori neurali
Si sono infine costruiti due giocatori neurali: Net ed Adv. Entrambi, usando la stessa rete calcolano l’output relativo ad ogni colonna, in modo da ottenere un vettore di sei elementi. I due giocatori si differenziano nel criterio che usano per scegliere la mossa. Net esegue la mossa corrispondente dall’elemento del vettore più grande. Adv invece, dopo averli opportunamente scalati, interpreta i sei elementi come una probabilità: maggiore è il valore e maggiore sarà la probabilita che venga scelta quella colonna. È chiaro che a parità di configurazione della matrice di gioco, il primo giocatore genererà sempre la stessa mossa, mentre il secondo avrà un gioco più vario.
Si sono addestrate nove reti, tutte con topologia 14-5-5-1, facendo eseguire 1000 iterazioni di RTS su ogni insieme di addestramento. Le reti così addestrate sono state poi usate da Net ed Adv per giocare in un torneo di 10000 partite contro Random, Beginner ed Expert.
La tabella che segue riassume i risultati di questo torneo. Le colonne indicano su quale insieme è stata addestrata la rete: no vuol dire che la rete non è stata addestrata, RR significa che l’insieme di addestramento proviene dalle partite giocate tra Random e Random e così via…
no RR RB RE BR BB BE ER EB EE Net vs Random 8870 9151 9694 7852 9487 9498 9455 9466 9734 7972 Net vs Beginner 123 3302 1606 2014 1780 1947 640 83 2048 2002 Net vs Expert 0 10000 0 0 0 0 0 0 0 0 Adv vs Random 6062 9088 9126 8573 9054 8610 8654 9133 9440 8264 Adv vs Beginner 851 5561 5149 5080 4404 4356 3356 3494 4943 2589 Adv vs Expert 306 5984 4823 5928 3749 5252 2224 1697 4084 3782
Fig. 11.2 I quattordici input
I pezzi sono codificati nel seguente modo: 10000 se si tratta di un pezzo avversario -10000 se si tratta di un proprio pezzo 0 se la cella è vuota

100
La prima cosa che si può notare è come, in un caso, il giocatore Net vince tutte le partite contro Expert, ma ha dei risultati scadenti contro Beginner, che in realtà è meno forte. La spiegazione di questa apparente contraddizione è semplicissima, e riguarda la forte limitazione che ha il giocatore Net, il quale a parità di configurazione della matrice di gioco risponde sempre con la stessa mossa. Se allora Net gioca contro un giocatore che, come Expert, fa sempre la stessa contromossa, i casi sono due: o vince sempre o perde sempre. Il fatto che non vinca sempre anche contro gli altri due giocatori dipende dal fatto che nella loro strategia di gioco è compresa una parte casuale che confonde la rete.
Se si confronta questo torneo con quello giocato in precedenza tra i giocatori programmati, si può vedere che una volta addestrato, il giocatore neurale ha acquisito delle capacità di gioco paragonabili a quelle del giocatore Beginner.
Si può notare inoltre, che i risultati migliori si sono ottenuti addestrando la rete con i pattern generati dalle partite giocate tra i due giocatori casuali. Paradossalmente quindi, la rete ha imparato un gioco migliore osservando dei giocatori incapaci. Questo non dovrebbe sorprendere, se si pensa che solo dei giocatori casuali hanno la possibilità di fare un gioco più vario, e quindi, di fornire un insieme di addestramento più carico di informazioni. Un’ulteriore conferma di quanto detto viene dall’analisi dei risultati ottenuti dalla rete addestrata con i pattern generati dalle partite tra Random ed Expert. In questo caso l’insieme di addestramento, oltre ad essere molto piccolo, è anche poco vario. Come sarebbe prevedibile, il numero di partite vinte contro Expert non cambia di molto, ma nelle partite contro Random e Beginner, dove cioè esiste una forte componente casuale nella scelta delle mosse, si può notare un significativo calo di prestazioni.
La cosa forse più interessante viene però dal confronto tra la rete prima e dopo l’addestramento. Nella tabella che segue viene mostrato in che rapporto sono aumentate le capacità di gioco della rete addestrata rispetto alla rete non addestrata. Anche nel caso peggiore, la rete addestrata ha più che triplicato il numero di partite vinte contro i due giocatori più bravi, mentre in un caso è migliorata quasi di un fattore venti, e questo, senza fornire esplicitamente al giocatore neurale alcuna informazione relativa ad una possibile strategia di gioco. Tutta l’informazione relativa ad una eventuale strategia è contenuta interamente nell’insieme di addestramento.
RR RB RE BR BB BE ER EB EE Net vs Random 1.03 1.09 0.89 1.07 1.07 1.07 1.07 1.1 0.9 Net vs Beginner 26.8 13.1 16.4 14.5 15.8 5.2 0.67 16.7 16.3 Net vs Expert -- -- -- -- -- -- -- -- -- Adv vs Random 1.5 1.51 1.41 1.49 1.42 1.43 1.51 1.56 1.36 Adv vs Beginner 6.53 6.05 5.97 5.18 5.12 3.94 4.11 5.81 3.04 Adv vs Expert 19.6 15.8 19.4 12.3 17.2 7.3 5.5 13.3 12.4

101
Non si esclude che con una fase di addestramento più lunga, ed un insieme di addestramento più ampio, la rete possa imparare a giocare un gioco perfetto.
11.1.4 Conclusioni
Addestrando la rete su un insieme di partite giocate a caso, si è riusciti a conferire ad un giocatore inesperto delle discrete capacità di gioco. Questo esempio, mostra più di ogni altro come non sia sempre necessaria la conoscenza del problema, per addestrare una rete neurale a risolverlo.
Questa interessante caratteristica potrebbe forse essere sfruttata nel gioco degli scacchi. Attualmente tutti i programmi che giocano a scacchi, incluso Deep Blue [5], sono basati su uno schema di ricerca intensiva sull’albero delle possibili mosse/contromosse che possono essere generate da una specifica configurazione della scacchiera [2],[3],[4].
Idealmente, un computer sarebbe in grado di giocare un gioco perfetto se partendo dalla prima mossa riuscisse ad esaminare tutto l’albero delle possibili mosse, fino ad individuare la sequenza vincente. Sfortunatamente questa soluzione è impraticabile, dato che il numero di possibili mosse da esplorare è dell’ordine di 1044. La soluzione praticata da tutti i programmi scacchistici consiste perciò nell’usare un qualche criterio per restringere il numero di possibili mosse da valutare, ovvero per potare l’albero di ricerca.
Nel 1950, Claude Shannon propose due strategie per raggiungere questo scopo, la prima, chiamata Strategia di Shannon di tipo A, considera tutte le possibili mosse fino ad una certa profondità, scegliendo quella che in base ad un certo criterio porta ad una configurazione della scacchiera migliore. Nella Strategia di Shannon di tipo B, invece, un generatore di mosse seleziona ad ogni livello un sottoinsieme di mosse ragionevolmente buone, ed esplora il sottoalbero che si genera a partire da esse.
Tutti i programmi scacchistici adottano una di queste due strategie, e si differenziano solamente nel criterio che usano per valutare la bontà di una posizione o, nel caso di strategia di tipo B, nel criterio che usano per potare l’albero di ricerca. I suddetti criteri sono individuati studiando attentamente il gioco e cercando di estrapolare da esso l’informazione necessaria a fare la scelta migliore.
Il fatto che i computer, pur riuscendo a valutare milioni di posizioni scacchistiche al secondo, non siano ancora in grado di battere facilmente il campione mondiale, è però un segnale del fatto che i criteri di valutazione, o di potatura dell’albero di ricerca, sono ancora lontani da quelli ideali.

102
Un approccio alternativo potrebbe essere quello di addestrare una rete neurale con un insieme di partite fatte da giocatori esperti e da giocatori dilettanti; in tal modo la rete potrebbe imparare sia il giusto criterio di valutazione, sia la migliore direzione da prendere nella ricerca della mossa migliore.
NeuroChess [35],[36] è un programma scacchistico, sviluppato da Sebastian Thrun del dipartimento di Computer Science dell’università di Bonn, che applica in parte questo concetto. Il suo algoritmo di ricerca è quello classico usato dalla maggior parte dei programmi scacchistici, ed è stato preso da GnuChess, ma la parte preposta alla valutazione delle posizioni scacchistiche è basata su una rete neurale. I risultati ottenuti da questo programma, quando è stato fatto giocare contro GnuChess, sono stati soddisfacenti anche se non buonissimi. L’autore di NeuroChess ritiene comunque che la capacità di gioco del programma potrebbe essere incrementata aumentando il periodo di addestramento e, soprattutto, usando hardware neurale al posto di simulazioni software.
Probabilmente si potrebbero ottenere risultati migliori usando una rete neurale per potare l’albero di ricerca.

103
12 Un problema reale
Il problema proposto in questo Capitolo, è un problema reale che trova applicazione nel campo della spettroscopia laser.
Uno dei maggiori problemi in questo campo, è la generazione di un segnale laser con una frequenza costante nel tempo, e può essere risolto costruendo sistemi composti da un laser regolabile, una sorgente di riferimento ed un sistema che riesca a mantenere costante la differenza in frequenza tra le due sorgenti.
Il sistema qui proposto utilizza una rete neurale per calcolare velocemente ed efficientemente la differenza in frequenza tra le due sorgenti laser. La sua realizzazione è dovuta al lavoro di Leonardo Ricci del Dipartimento di Fisica dell’Università di Trento e di Giampietro Tecchiolli dell’Istituto per la Ricerca Scientifica e Tecnologica di Trento [37]. Il presente lavoro intende ripetere la loro esperienza.
12.1 Descrizione dell’apparato
Il sistema è composto da due sorgenti laser, A e B, che emettono radiazione con una lunghezza d’onda approssimativamente di 670 nm. Una porzione di entrambi i raggi viene sovrapposta, ed entra in un risonatore di Fabry-Perot pilotato da una forma d’onda triangolare.
La luce trasmessa dal risonatore dipende dalla lunghezza istantanea della cavità: la trasmissione avviene se questa è un multiplo intero della

104
semilunghezza d'onda della radiazione incidente. Lo spettro trasmesso contiene quindi l'informazione necessaria per calcolare la differenza in frequenza tra le due sorgenti. Questa luce viene raccolta da un fotodiodo e dopo essere stata amplificata viene campionata dalla scheda I/O.
Ciascuno spettro viene acquisito in 1 ms e la sua acquisizione è innescata dal cambiamento di pendenza della rampa triangolare, in questo modo si è certi di avere entrambi i picchi all’interno della finestra di campionamento. Vengono presi in tutto 21 campioni.
Segnale Campionato
-20
0
20
40
60
80
0 0,5 1 1,5 2
Tempo (ms)
Segn
ale
(mV)
A B Diodi Laser
Risonatore di
Fabry-Perot
NN PC Scheda I/O
Fotodiodo
Trigger Rampa
triangolare
Specchi semitrasparenti
Fig. 12.1 L’apparecchiatura
Δt Δt
Fig.12.2 Il segnale campionato

105
La separazione temporale Δt tra i due picchi è proporzionale alla differenza in frequenza tra i due laser.
Successivamente, il buffer di acquisizione viene letto e preprocessato da un personal computer. Tutte le operazioni necessarie per arrivare alla misura della differenza in frequenza sono controllate da un programma scritto in C++ che lavora sotto DOS. Il codice pilota la scheda di I/O, gestisce la pre e post processione e controlla la scheda che contiene la rete neurale. L’output del controller infine, viene utlizzato per generare un segnale proporzionale alla differenza che verrà usato per stabilizzare la sorgente.
12.2 Il calcolo della differenza in frequenza
Il metodo più semplice ed immediato per misurare la separazione temporale tra i due picchi, ed in tal modo calcolare la differenza in frequenza tra le due sorgenti laser, consiste nel misurare la distanza tra i due picchi del segnale campionato (metodo diretto). Questo modo di procedere però non è molto preciso perché, considerando che il campionamento avviene ad intervalli di tempo fissi, non è assolutamente detto che i picchi del segnale campionato corrispondano ai picchi della funzione reale. In Fig. 12.3 è mostrata graficamente questa situazione.
Il valore calcolato con questo metodo differirà da quello reale di una quantità casuale compresa tra ± 5% (±1/20).
Δtreale
Δt
Fig. 12.3 La differenza tra picchi reali e campionatura

106
Un secondo metodo, che fornisce risultati molto più precisi, consiste nell’usare i 21 campioni per cercare di approssimare una funzione che rispecchi l’andamento del segnale campionato; individuando il centro di entrambi i picchi della funzione approssimata, si può facilmente calcolarne la distanza e così la differenza in frequenza.
L’approssimazione dell’insieme di dati con una appropriata funzione, consiste nel determinarne i parametri attraverso la minimizzazione di una qualche funzione di costo, come ad esempio l’errore quadratico. Poiché però il modello della funzione approssimante dipende in maniera non lineare dall’insieme di parametri sconosciuti, determinare questi ultimi risulta molto difficile.
Il metodo di Levemberg-Marquardt è probabilmente l’algoritmo più usato per la ricerca dei parametri in questo tipo di problemi non lineari. Tuttavia, il successo di una approssimazione ottenuta con questo metodo, o con altri similari algoritmi iterativi, dipende fortemente dalla scelta del vettore di parametri iniziale. Una scelta impropria del vettore porta frequentemente l’algoritmo a convergere in qualche minimo locale ben lontano dal corretto insieme di parametri. In aggiunta, la convergenza può essere molto lenta, rendendo il tempo di approssimazione non predicibile. Il metodo risulta pertanto improponibile per applicazioni in tempo reale come quella in discussione [37].
12.3 Un approccio alternativo
Le reti neurali offrono un approccio alternativo al problema. In questo esperimento, una rete neurale viene addestrata per calcolare direttamente la differenza in frequenza partendo dai 21 campioni.
L’insieme di addestramento è stato costruito, per la parte relativa all’input, campionando il segnale di interferenza in uscita dal risonatore di Fabry-Perot; mentre l’output è stato calcolato usando metodo di Levemberg-Marquardt. I pattern sono stati raggruppati in quattro classi di 2000 elementi ciascuna. Ogni classe, che è caratterizzata da un certo rapporto segnale/rumore (S/N), è stata divisa in due parti uguali; una parte viene utilizzata per l’addestramento, mentre l’altra serve per il calcolo della generalizzazione e per controllo.
Classe Rapporto S/N Tr5 60 Tr6 35 Tr7 18 Tr8 10

107
12.3.1 La rete
Nell’esperimento di Ricci e Tecchiolli veniva usata una rete con uno strato nascosto di 32 neuroni. Probabilmente questa è la scelta migliore, perché per approssimare questo tipo di funzione, non dovrebbe essere necessario più di uno strato nascosto, e 32 neuroni in un singolo strato sono il limite per il chip TOTEM. Inoltre, essendo il requisito principale in questo tipo di problemi quello della velocità di calcolo, la scelta di questa topologia risulta adatta in quanto il suo output può essere calcolato dal chip TOTEM in maniera molto rapida (circa 2 μs).
Per non ripetere esattamente questa esperienza, si è deciso di provare alcune topologie un po’ più complesse, per vedere quanto la scelta della topologia influisca sui risultati finali.
Dopo numerosi tentativi si è deciso di utilizzare la topologia 21-21-5-1, si è cioè diminuito il numero di neuroni nel primo strato nascosto e si è aggiunto un nuovo strato di cinque neuroni. Questa soluzione pare sia la migliore tra quelle provate, in quanto converge con una certa velocità e riesce a generalizzare abbastanza bene.
12.3.2 L’addestramento
Poiché la campionatura è sempre perturbata da una certa quantità di rumore, lo scopo dell’addestramento è quello di insegnare alla rete ad approssimare la soluzione indipendentemente dall’esattezza dell’input. Per raggiungere questo scopo, si deve addestrare la rete su un certo insieme, calcolare la generalizzazione su un insieme diverso, ed infine prendere il risultato della generalizzazione migliore.
La fase di addestramento ha avuto luogo ripetendo 10 volte 10000 iterazioni di RTS usando configurazioni iniziali scelte a caso, e prendendo la generalizzazione migliore. Per valutare la capacità di generalizzazione in presenza di quantità diverse di rapporto segnale/rumore, la generalizzazione è avvenuta per ogni possibile coppia di insiemi.
Nella tabella che segue sono mostrati i risultati di tutti gli addestramenti. Le righe indicano quale insieme è stato usato per l’addestramento, le colonne indicano l’insieme sul quale è stata fatta la generalizzazione, mentre all’interno delle celle sono specificati gli errori relativi ad ogni classe di pattern.
Gli errori sono espressi in RMS e SYST, rispettivamente definiti come l’errore quadratico medio e la media degli errori. Il primo indica la quantità di errore, mentre il secondo misura la simmetria della distribuzione dell’errore attorno allo zero.

108
I risultati di questa esperienza sono paragonabili a quelli ottenuti da Ricci e Tecchiolli nel loro esperimento.
Tr5 Tr6 Tr7 Tr8 Tr5
RMS 2.9888 SYST 0.7066
Tr5 RMS 3.3785 SYST 0.8084
Tr5 RMS 3.4043 SYST 0.2508
Tr5 RMS 10.9411 SYST -4.9025
Tr6 RMS 3.0104 SYST 0.5464
Tr6 RMS 2.9387 SYST 0.4046
Tr6 RMS 3.2919 SYST -0.1108
Tr6 RMS 11.5107 SYST -6.1071
Tr7 RMS 55.5590 SYST 25.8540
Tr7 RMS 51.6700 SYST 16.8848
Tr7 RMS 45.8234 SYST 1.4643
Tr7 RMS 48.7464 SYST 11.1984
Tr5
Tr8 RMS 32.1529 SYST 10.7276
Tr8 RMS 30.0537 SYST 1.7667
Tr8 RMS 30.7938 SYST -12.9111
Tr8 RMS 29.2778 SYST -3.6256
Tr5 RMS 3.0340 SYST 0.9680
Tr5 RMS 3.1045 SYST 0.6008
Tr5 RMS 4.2713 SYST 2.1653
Tr5 RMS 4.5632 SYST 1.5707
Tr6 RMS 3.2612 SYST 0.6061
Tr6 RMS 2.9498 SYST 0.3851
Tr6 RMS 3.9731 SYST 1.1131
Tr6 RMS 4.1979 SYST 1.4353
Tr7 RMS 55.8005 SYST 29.4991
Tr7 RMS 50.5072 SYST 14.7303
Tr7 RMS 45.4263 SYST -5.0030
Tr7 RMS 50.1887 SYST 15.4145
Tr6
Tr8 RMS 32.7210 SYST 14.9291
Tr8 RMS 29.6886 SYST -0.2357
Tr8 RMS 33.3217 SYST -19.0940
Tr8 RMS 29.2226 SYST 0.6130
Tr5 RMS 21.2947 SYST -17.5250
Tr5 RMS 18.1056 SYST -5.4372
Tr5 RMS 137.4284 SYST -28.4153
Tr5 RMS 139.8326 SYST -11.1152
Tr6 RMS 21.4344 SYST -16.5972
Tr6 RMS 16.7248 SYST -4.5185
Tr6 RMS 118.5122 SYST -51.2640
Tr6 RMS 116.2472 SYST -44.0245
Tr7 RMS 49.0024 SYST 5.5962
Tr7 RMS 48.3275 SYST 3.7063
Tr7 RMS 6.0230 SYST 0.2759
Tr7 RMS 6.3763 SYST 1.1472
Tr7
Tr8 RMS 31.0589 SYST -9.8321
Tr8 RMS 31.7946 SYST -11.3652
Tr8 RMS 5.7632 SYST 0.3439
Tr8 RMS 5.7058 SYST 0.1994
Tr5 RMS 15.5670 SYST -7.6080
Tr5 RMS 23.1297 SYST -11.1291
Tr5 RMS 121.4356 SYST -8.8013
Tr5 RMS 103.4327 SYST -9.9273
Tr6 RMS 13.6615 SYST -5.2828
Tr6 RMS 21.6206 SYST -7.1439
Tr6 RMS 113.4735 SYST -30.6064
Tr6 RMS 86.6531 SYST -38.2866
Tr7 RMS 48.1287 SYST -2.7394
Tr7 RMS 52.8295 SYST 4.9534
Tr7 RMS 5.7419 SYST 0.1449
Tr7 RMS 5.7014 SYST 0.1812
Tr8
Tr8 RMS 34.4308 SYST -17.4898
Tr8 RMS 34.2270 SYST -11.8771
Tr8 RMS 5.8926 SYST 0.3248
Tr8 RMS 5.7985 SYST 0.3801
Osservando la tabella, si può notare che i risultati migliori sono concentrati lungo la diagonale principale. Questo è dovuto principalmente al fatto che si addestra e si generalizza utilizzando insiemi caratterizzati dallo stesso rapporto segnale/rumore. Per lo stesso motivo, si hanno buoni risultati anche quando si utilizzano pattern con un rapporto S/N confrontabile, come Tr5/Tr6 e Tr7/Tr8. Mentre, generalmente non porta a buoni risultati addestrare con l’insieme di un gruppo e generalizzare con un insieme dell’altro.

109
Gli addestramenti eseguiti sui pattern caratterizzati da un rapporto S/N alto (Tr5 e Tr6), hanno fornito, per ogni generalizzazione, risultati migliori rispetto e quelli eseguiti su pattern con un basso rapporto S/N.
I grafici che seguono mostrano la distribuzione degli errori relativa a quegli addestramenti che nella tabella precedente erano sulla diagonale principale. Le barre verticali indicano, per ogni rapporto S/N, in che percentuale l’errore della rete rimane al di sotto del 1%, 2%, 3%, 4% e 5%. La prima barra, quella contrassegnata da M-D permette il confronto tra il metodo neurale e quello della misura diretta.
0%
20%
40%
60%
80%
100%
1% 2% 3% 4% 5%
Distribuzione degli errori Tr5
M-DS/R=60S/R=35S/R=18S/R=10
L’addestramento effettuato con pattern disturbati da una piccola quantità di rumore (S/N=60), ha portato ad una rete in grado di dare ottime prestazioni in caso di segnali poco rumorosi (S/N=60, S/N=35) e pessime prestazioni in caso di segnali molto rumorosi (S/N=10, S/N=18). Questa differenza di prestazioni tra input molto puliti ed input molto disturbati sarà presente in tutti gli addestramenti.
0%
20%
40%
60%
80%
100%
1% 2% 3% 4% 5%
Distribuzione degli errori Tr6
M-DS/R=60S/R=35S/R=18S/R=10

110
Il secondo addestramento ha dato risultati molto buoni per S/N=35, buoni risultati per S/N=60 e pessimi risultati per S/N=10 e S/N=18.
0%
20%
40%
60%
80%
100%
1% 2% 3% 4% 5%
Distribuzione degli errori Tr7
M-DS/R=60S/R=35S/R=18S/R=10
0%
20%
40%
60%
80%
100%
1% 2% 3% 4% 5%
Distribuzione degli errori Tr8
M-DS/R=60S/R=35S/R=18S/R=10
Gli ultimi due addestramenti, quelli effettuati con pattern molto disturbati, hanno portato a reti in grado di dare prestazioni molto buone, ma inferiori a quelle ottenute dai due addestramenti precedenti. In tutti gli addestramenti comunque, le prestazioni si sono rivelate migliori di quelle ottenibili con il metodo diretto.
12.3.3 Conclusioni
Poiché il requisito principale in questo problema è la velocità del calcolo della differenza in frequenza, il metodo di Levemberg-Marquardt, pur essendo in grado di fornire una soluzione più precisa, non è adatto allo scopo. L’altro metodo invece, quello cioè in cui la differenza in frequenza viene calcolata misurando la differenza tra i due picchi del segnale campionato, è molto veloce ma fornisce risultati con una tolleranza piuttosto alta (±5%).

111
La soluzione neurale rappresenta un buon compromesso tra queste due quantità: l’accuratezza dei risultati e la velocità di calcolo; ed è pertanto preferibile alle due soluzioni precedenti.
In questo esperimento la rete ha mostrato una certa elasticità, riuscendo a fornire buoni risultati anche in presenza di segnali di input molto disturbati. Quando però gli input hanno un rapporto S/N troppo diverso da quello per cui la rete è stata addestrata, questa elasticità viene meno, e le prestazioni calano molto velocemente.
Nel tentativo di rendere meno brusco il calo di prestazioni, è stato eseguito un ultimo esperimento, utilizzando un insieme di addestramento composto da: ¼ di pattern con S/N=10, ¼ di pattern con S/N=18, ¼ di pattern con S/N=35 ed ¼ di pattern con S/N=60.
Misto Tr5
RMS 10.4381 SYST -0.7255
Tr6 RMS 9.4616 SYST -3.5612
Tr7 RMS 25.1783 SYST -11.6279
Misto
Tr8 RMS 23.9437 SYST -18.5592
0%
20%
40%
60%
80%
100%
1% 2% 3% 4% 5%
Distribuzione degli errori Misto
M-DS/R=60S/R=35S/R=18S/R=10
Contrariamente a quello che ci si potrebbe aspettare, la rete non presenta lo stesso comportamento di fronte a input con rapporti S/N molto diversi tra loro. La rete, preferisce i segnali di input poco rumorosi, per i quali fornisce risultati paragonabili in esattezza a quelli ottenibili con il metodo diretto.

112
13 Conclusioni
Riconoscere una persona, comprendere le sue parole, capirne il significato ed elaborare una risposta sensata: sono problemi a cui il cervello umano riesce a dare buone soluzioni in tempo reale, ma sono invece molto difficili da risolvere per qualsiasi calcolatore digitale. Al contrario, problemi quali l’estrazione di radici quadrate, la scomposizione di interi in fattori primi, l’inversione di matrici, ed in generale tutti quei problemi per i quali la soluzione si trova applicando rigorosamente un certo procedimento, sono molto semplici da risolvere per un calcolatore, ma piuttosto difficili per il cervello umano. Questa differenza di comportamento tra i due sistemi di calcolo deriva dalla profonda diversità dei concetti che stanno alla base del loro funzionamento.
Le reti artificiali di neuroni cercano in qualche modo di replicare il meccanismo di elaborazione delle informazioni che è alla base del funzionamento del cervello. Gli aspetti fondamentali di questo modello computazionale sono riassumibili nei seguenti punti:
• Elaborazione non algoritmica
• Approssimazione
• Parallelismo
• Capacità di apprendere
• Capacità di generalizzare
• Tolleranza agli errori

113
In questo lavoro di tesi si sono studiati alcuni tra i modelli neurali più analizzati. Si è visto che nonostante le semplificazioni che inevitabilmente si introducono quando si cerca di simulare strutture complesse come quelle del cervello, le reti neurali artificiali manifestano alcuni dei comportamenti tipici dei sistemi biologici. Non solo. Dimostrando che le reti neurali sono in grado di svolgere le stesse computazioni di un calcolatore digitale tradizionale si è anche dimostrato che il modello neurale rappresenta uno strumento di calcolo superiore a quello algoritmico.
Si è inoltre messo in evidenza che il parallelismo intrinseco di questi modelli apre la strada ad implementazioni hardware in cui si possono raggiungere elevate rese computazionali. Si sono pertanto discusse le possibili implementazioni hardware di alcuni sistemi neurali. Dalla discussione è emerso che le architetture dei suddetti dispositivi sono fortemente influenzate dall’algoritmo che si decide di utilizzare per l’addestramento. Il Reactive Tabu Search (RTS) è un algoritmo di addestramento che ammette bassa precisione nella rappresentazione dei pesi, bassa accuratezza nel processare i segnali ed inoltre ha bisogno solamente della fase di valutazione della rete. Queste caratteristiche hanno reso possibile la costruzione del processore neurale TOTEM, un dispositivo altamente parallelo in grado di mappare con una certa elasticità alcuni modelli neurali.
La costruzione di un ambiente software grafico interattivo (Mandingo) per l’utilizzo ottimale del processore TOTEM rappresenta una parte significativa di questo lavoro di tesi. L’interfaccia grafica, unita alla potenza del processore neurale, fornisce un facile strumento per effettuare alcune sperimentazioni.
Utilizzando l’accoppiata TOTEM/Mandingo si è cercato infine di mettere in evidenza alcune delle differenze che esistono tra il tradizionale sistema di calcolo algoritmico ed il sistema di calcolo che è alla base del funzionamento del cervello. Questa fase si è svolta attraverso quattro esperimenti:
• Concentric
• Pendolo
• Forza 3
• Laser
Tutti i suddetti esperimenti hanno messo in evidenza una delle caratteristiche più importanti del paradigma neurale, e cioè la capacità di imparare attraverso esempi di problemi risolti. Contrariamente al modello algoritmico quindi, quello neurale non ha bisogno di una descrizione formale del

114
problema, né di un rigoroso procedimento da seguire per arrivare alla sua soluzione, ma solo della disponibilità di esempi.
Nel primo esperimento si è mostrato come sia possibile per una rete neurale classificare un insieme di punti disposti secondo un certo criterio. La caratteristica che ha mostrato la rete in questa occasione è stata la capacità di generalizzare. Partendo da pochi esempi, la rete è riuscita infatti a costruirsi una rappresentazione interna che l’ha messa in grado di risolvere con buona approssimazione il problema. Nell’esperimento è stato inoltre messo in evidenza come i risultati ottenuti con il paradigma neurale siano inferiori a quelli ottenibili da un sistema algoritmico, tuttavia, il modello neurale ha mostrato la sua netta superiorità mostrandosi molto più tollerante agli errori.
Il secondo esperimento invece, mostra come sia possibile approssimare funzioni partendo da pochi campioni. Anche da questo esperimento emergono le caratteristiche di generalizzazione e di tolleranza agli errori.
Il terzo esperimento mostra come, in contrasto con il modello classico, le reti artificiali di neuroni non abbiano bisogno di istruzioni esplicite per risolvere un problema. In questo esperimento, il problema era quello di insegnare ad un giocatore neurale la strategia di un semplice gioco. Al termine dell’ addestramento, nonostante nell’insieme di esempio non fosse esplicitata in alcun modo alcuna strategia, il giocatore neurale ha raggiunto un buon livello di gioco. Non solo, il giocatore neurale è anche riuscito ad isolare la sequenza di mosse che porta alla vittoria il primo giocatore, ed è stato in grado di applicarla correttamente in un significativo numero di occasioni. Questo esperimento mostra meglio di ogni altro la fondamentale differenza tra il modello algoritmico e quello neurale. Adottando quest’ultimo infatti, ed accontentandosi di un’approssimazione, è possibile risolvere problemi per i quali non esiste, oppure non è stata ancora trovata, una efficiente soluzione algoritmica.
Un esempio di applicazione pratica di questa caratteristica viene dall’ultimo esperimento. Il problema da risolvere era quello di trovare un metodo veloce e tollerante agli errori in grado di calcolare con precisione la distanza tra due picchi di una funzione. Anche in questo caso, dopo aver mostrato alla rete un certo numero di esempi, il sistema è stato in grado di fornire risultati molto precisi in tempi estremamente ridotti. In questo caso, l’approccio neurale si è dimostrato nettamente preferibile ai due algoritmi proposti come alternativa, riuscendo a raggiungere un buon compromesso tra l’esattezza dei risultati e la velocità di calcolo.
Al termine di questi esperimenti, l’idea che ci si può fare del paradigma di calcolo neurale è che in taluni casi (ma non sempre) esso è di gran lunga preferibile al modello algoritmico tipico dei calcolatori digitali. In altre occasioni è

115
invece il modello algoritmico ad uscirne vincente. La combinazione dei due modelli potrebbe portare a sistemi computazionali interessanti. Nell’esperimento ‘Forza 3’ per esempio, sono stati costruiti due giocatori neurali, il primo era puramente neurale, nel senso che usava direttamente i risultati della rete, e dava risultati tutto sommato scarsi. Il secondo giocatore invece processava i risultati della rete, li interpretava come una probabilità ed in base a quella sceglieva la mossa. Questo metodo di procedere per metà neurale e per metà algoritmico ha portato ad un sistema in grado di fornire buoni risultati anche utilizzando una rete molto piccola.
La possibilità offerta dai modelli neurali di essere facilmente implementabili in termini di circuiti hardware altamente paralleli, insieme alla maturità tecnologica dell’eleborazione digitale, potrebbe portare a sistemi molto potenti, anche senza bisogno di costruire strutture neurali complesse quanto quelle del cervello.

116
14 Appendice

117
14.1 Appendice A
File di salvataggio di Mandingo riguardante l’esperimento di classificazione ‘Concentric’.
;================================================================ ;Mandingo 1.0 written by Stefano Benamati ; ;December 1, 1997 10:46:47 pm ;================================================================ luts_definition_start ;================================================================ ;Luts Definitions ;================================================================ lut_start ;---------------------------------------------------------------- ;Definition of lut: Sigmoid ;---------------------------------------------------------------- ; type: Sigmoid name: Sigmoid Amplitude: 1000 Scale: 500 Offset: 0 ;---------------------------------------------------------------- lut_end lut_start ;---------------------------------------------------------------- ;Definition of lut: Step ;---------------------------------------------------------------- ; type: Step name: Step Left Value: -1000 Right Value: 1000 ;---------------------------------------------------------------- lut_end ;================================================================ luts_definition_end job_list_start ;================================================================ ;Jobs Definitions ;================================================================ job_start ;================================================================ ;Configuration of dieci

118
;================================================================ name: dieci ;---------------------------------------------------------------- ;Net Configuration: ; topology: [2 - 10 - 1] bias_factor: [1000 - 1000] output_shift: [5 - 8] output_lut: [0 - 0] bpt: 8 bpw: 8 gray: true autocalculate: false ;---------------------------------------------------------------- ;Training: ; training_set: < Not Defined > training_output_file: < Not Defined > generalization_set: < Not Defined > generalization_output_file: < Not Defined > user_defined_network: < Not Defined > start_with: RANDOM training_kind: LEARN training_mode: EPOCH change_block_period: 0 training_block_size: 0 training_block_start: 0 generalization_period: 100 number_of_iterations: 10000 save_best_generalization: false use_training_output: true use_generalization_output: false use_never: true use_optimum: true ;---------------------------------------------------------------- ;RTS parameters: ; sample: 6 repetitions: 3 chaos: 3 red_fact: 0.9 enc_fact: 1.1 min_list_size: 1 max_list_size: 1 clear_history: true clear_repetition_counter: true clear_tabu_list: false reset_T: false reset_running_average: false reset_tT: false ;---------------------------------------------------------------- ;Luts: ; lut_zero_type: Step lut_zero_name: Step lut_one_type: Sigmoid lut_one_name: Sigmoid ;----------------------------------------------------------------

119
;Other Parameters: ; repetitions: 1 ;---------------------------------------------------------------- ;Learn Weights ; topology: [2 - 10 - 1] weight_start < No Weights > weight_end ;---------------------------------------------------------------- ;Generalization Weights ; topology: [2 - 10 - 1] weight_start < No Weights > weight_end ;---------------------------------------------------------------- job_end job_list_end

120
14.2 Appendice B
File di salvataggio di Mandingo riguardante l’esperimento di approssimazione di funzioni ‘Pendolo’.
;================================================================ ;Mandingo 1.0 written by Stefano Benamati ; ;December 24, 1997 9:29:52 pm ;================================================================ luts_definition_start ;================================================================ ;Luts Definitions ;================================================================ lut_start ;---------------------------------------------------------------- ;Definition of lut: Sigmoid ;---------------------------------------------------------------- ; type: Sigmoid name: Sigmoid Amplitude: 20000 Scale: 3000 Offset: 0 ;---------------------------------------------------------------- lut_end lut_start ;---------------------------------------------------------------- ;Definition of lut: Linear ;---------------------------------------------------------------- ; type: Linear name: Linear Angle: 45 Max Value: 32767 Offset: 0 ;---------------------------------------------------------------- lut_end lut_start ;---------------------------------------------------------------- ;Definition of lut: Step ;---------------------------------------------------------------- ; type: Step name: Step Left Value: -10000 Right Value: 10000

121
;---------------------------------------------------------------- lut_end lut_start ;---------------------------------------------------------------- ;Definition of lut: altra sigmoide ;---------------------------------------------------------------- ; type: Sigmoid name: altra sigmoide Amplitude: 32767 Scale: 7000 Offset: 0 ;---------------------------------------------------------------- lut_end ;================================================================ luts_definition_end job_list_start ;================================================================ ;Jobs Definitions ;================================================================ job_start ;================================================================ ;Configuration of due ;================================================================ name: due ;---------------------------------------------------------------- ;Net Configuration: ; topology: [1 - 3 - 3 - 3 - 1] bias_factor: [2500 - 2500 - 2500 - 2500] output_shift: [8 - 8 - 8 - 8] output_lut: [0 - 0 - 0 - 1] bpt: 8 bpw: 8 gray: true autocalculate: false ;---------------------------------------------------------------- ;Training: ; training_set: < Not Defined > training_output_file: < Not Defined > generalization_set: < Not Defined > generalization_output_file: < Not Defined > user_defined_network: < Not Defined > start_with: RANDOM training_kind: GENERALIZE training_mode: EPOCH change_block_period: 0 training_block_size: 0 training_block_start: 0 generalization_period: 1 number_of_iterations: 50000 save_best_generalization: true use_training_output: false use_generalization_output: false

122
use_never: true use_optimum: true ;---------------------------------------------------------------- ;RTS parameters: ; sample: 6 repetitions: 3 chaos: 3 red_fact: 0.9 enc_fact: 1.1 min_list_size: 1 max_list_size: 1 clear_history: true clear_repetition_counter: true clear_tabu_list: false reset_T: false reset_running_average: false reset_tT: false ;---------------------------------------------------------------- ;Luts: ; lut_zero_type: Sigmoid lut_zero_name: Sigmoid lut_one_type: Sigmoid lut_one_name: altra sigmoide ;---------------------------------------------------------------- ;Other Parameters: ; repetitions: 1 ;---------------------------------------------------------------- ;Learn Weights ; topology: [1 - 3 - 3 - 3 - 1] weight_start < No Weights > weight_end ;---------------------------------------------------------------- ;Generalization Weights ; topology: [1 - 3 - 3 - 3 - 1] weight_start < No Weights > weight_end ;---------------------------------------------------------------- job_end job_list_end

123
14.3 Appendice C
File di salvataggio di Mandingo riguardante l’esperimento ‘Forza 3’.
;================================================================ ;Mandingo 1.0 written by Stefano Benamati ; ;November 11, 1997 11:20:28 pm ;================================================================ luts_definition_start ;================================================================ ;Luts Definitions ;================================================================ lut_start ;---------------------------------------------------------------- ;Definition of lut: Sigmoid ;---------------------------------------------------------------- ; type: Sigmoid name: Sigmoid Amplitude: 32767 Scale: 2000 Offset: 0 ;---------------------------------------------------------------- lut_end lut_start ;---------------------------------------------------------------- ;Definition of lut: Linear ;---------------------------------------------------------------- ; type: Linear name: Linear Angle: 45 Max Value: 32767 Offset: 0 ;---------------------------------------------------------------- lut_end lut_start ;---------------------------------------------------------------- ;Definition of lut: Step ;---------------------------------------------------------------- ; type: Step name: Step Left Value: -10000 Right Value: 10000 ;---------------------------------------------------------------- lut_end

124
lut_start ;---------------------------------------------------------------- ;Definition of lut: limitata a 10000 ;---------------------------------------------------------------- ; type: Sigmoid name: limitata a 10000 Amplitude: 15000 Scale: 3000 Offset: 15000 ;---------------------------------------------------------------- lut_end lut_start ;---------------------------------------------------------------- ;Definition of lut: sigmoide ;---------------------------------------------------------------- ; type: Sigmoid name: sigmoide Amplitude: 32767 Scale: 7000 Offset: 0 ;---------------------------------------------------------------- lut_end ;================================================================ luts_definition_end job_list_start ;================================================================ ;Jobs Definitions ;================================================================ job_start ;================================================================ ;Configuration of Forza 3 ;================================================================ name: Forza 3 ;---------------------------------------------------------------- ;Net Configuration: ; topology: [14 - 5 - 5 - 1] bias_factor: [1 - 1 - 1] output_shift: [0 - 0 - 0] output_lut: [0 - 0 - 1] bpt: 8 bpw: 1 gray: true autocalculate: false ;---------------------------------------------------------------- ;Training: ; training_set: < Not Defined > training_output_file: < Not Defined > generalization_set: < Not Defined > generalization_output_file: < Not Defined > user_defined_network: < Not Defined > start_with: RANDOM

125
training_kind: LEARN training_mode: EPOCH change_block_period: 0 training_block_size: 0 training_block_start: 0 generalization_period: 100 number_of_iterations: 1000 save_best_generalization: false use_training_output: false use_generalization_output: false use_never: true use_optimum: true ;---------------------------------------------------------------- ;RTS parameters: ; sample: 6 repetitions: 3 chaos: 3 red_fact: 0.9 enc_fact: 1.1 min_list_size: 1 max_list_size: 1 clear_history: true clear_repetition_counter: true clear_tabu_list: false reset_T: false reset_running_average: false reset_tT: false ;---------------------------------------------------------------- ;Luts: ; lut_zero_type: Step lut_zero_name: Step lut_one_type: Sigmoid lut_one_name: limitata a 10000 ;---------------------------------------------------------------- ;Other Parameters: ; repetitions: 1 ;---------------------------------------------------------------- ;Learn Weights ; topology: [14 - 5 - 5 - 1] weight_start < No Weights > weight_end ;---------------------------------------------------------------- ;Generalization Weights ; topology: [14 - 5 - 5 - 1] weight_start < No Weights > weight_end ;---------------------------------------------------------------- job_end job_list_end

126
14.4 Appendice D
File di salvataggio di Mandingo riguardante l’esperimento ‘Laser’.
;================================================================ ;Mandingo 1.0 written by Stefano Benamati ; ;February 4, 1998 10:03:52 pm ;================================================================ luts_definition_start ;================================================================ ;Luts Definitions ;================================================================ lut_start ;---------------------------------------------------------------- ;Definition of lut: Sigmoid ;---------------------------------------------------------------- ; type: Sigmoid name: Sigmoid Amplitude: 16000 Scale: 3000 Offset: 0 ;---------------------------------------------------------------- lut_end lut_start ;---------------------------------------------------------------- ;Definition of lut: Linear ;---------------------------------------------------------------- ; type: Linear name: Linear Angle: 45 Max Value: 32767 Offset: 0 ;---------------------------------------------------------------- lut_end lut_start ;---------------------------------------------------------------- ;Definition of lut: Step ;---------------------------------------------------------------- ; type: Step name: Step Left Value: 0 Right Value: 20000 ;---------------------------------------------------------------- lut_end lut_start

127
;---------------------------------------------------------------- ;Definition of lut: altra Sigmoide ;---------------------------------------------------------------- ; type: Sigmoid name: altra Sigmoide Amplitude: 10000 Scale: 500 Offset: 10000 ;---------------------------------------------------------------- lut_end lut_start ;---------------------------------------------------------------- ;Definition of lut: Sigmoide classica ;---------------------------------------------------------------- ; type: Sigmoid name: Sigmoide classica Amplitude: 17000 Scale: 7000 Offset: 0 ;---------------------------------------------------------------- lut_end ;================================================================ luts_definition_end job_list_start ;================================================================ ;Jobs Definitions ;================================================================ job_start ;================================================================ ;Configuration of 5-5 ;================================================================ name: 5-5 ;---------------------------------------------------------------- ;Net Configuration: ; topology: [21 - 21 - 5 - 1] bias_factor: [2500 - 2500 - 2500] output_shift: [8 - 8 - 8] output_lut: [0 - 0 - 1] bpt: 8 bpw: 8 gray: true autocalculate: false ;---------------------------------------------------------------- ;Training: ; training_set: < Not Defined > training_output_file: < Not Defined > generalization_set: < Not Defined > generalization_output_file: < Not Defined > user_defined_network: < Not Defined > start_with: RANDOM training_kind: GENERALIZE

128
training_mode: EPOCH change_block_period: 0 training_block_size: 0 training_block_start: 0 generalization_period: 100 number_of_iterations: 1 save_best_generalization: true use_training_output: false use_generalization_output: false use_never: true use_optimum: true ;---------------------------------------------------------------- ;RTS parameters: ; sample: 6 repetitions: 3 chaos: 3 red_fact: 0.9 enc_fact: 1.1 min_list_size: 1 max_list_size: 1 clear_history: true clear_repetition_counter: true clear_tabu_list: false reset_T: false reset_running_average: false reset_tT: false ;---------------------------------------------------------------- ;Luts: ; lut_zero_type: Sigmoid lut_zero_name: altra Sigmoide lut_one_type: Linear lut_one_name: Linear ;---------------------------------------------------------------- ;Other Parameters: ; repetitions: 1 ;---------------------------------------------------------------- ;Learn Weights ; topology: [21 - 21 - 5 - 1] weight_start < No Weights > weight_end ;---------------------------------------------------------------- ;Generalization Weights ; topology: [21 - 21 - 5 - 1] weight_start < No Weights > weight_end ;---------------------------------------------------------------- job_end job_list_end

129
15 Bibliografia
[1] A. V. Aho, J. E. Hopcroft, J. D. Ullman “The Design and Analysis of Computer Algorithms” Addison Wesley Capitolo 11.
[2] T. A. Marsland “The anatomy of Chess Programs” http://www.cs.unimaas.nl/icca/anatomy.htm
[3] A. Lopez Ortiz “Computer Chess: Past to Present” 1993 http://daisy.uwaterloo.ca/~alopez-o/divulge/chimp.html
[4] P. Verhelst “Chess Tree Search” novembre 1997 http://www.xs4all.nl/~verhelst/chess/search.html
[5] http://www.chess.ibm.com
[6] J.Hertz, A. Krogh, R. G. Palmer “Introduction to the theory of neural computation” Addison-Wesley 1991
[7] W. S. McCulloch e W. Pitts, “A logical calculus of ideas immanent in nervous activity” Bulletin of Mathematical Biophisics, vol. 5, pp. 115-133, 1943
[8] M. Maiocchi “Teoria e applicazioni delle macchine calcolatrici” Casa Editrice Ambrosiana-Milano 1986, pp.274-284.
[9] O. D’antona, E. Damiani “Ambienti esecutivi e di sviluppo dei linguaggi di programmazione” Addison-Wesley Masson 1992, pp.15-40.
[10] M. Maiocchi “Teoria e applicazioni delle macchine calcolatrici” Casa Editrice Ambrosiana-Milano 1986, pp.235-251.

130
[11] L. K. Jones “Constructive Approximations for Neural Networks by Sigmoidal Functions” IEEE Proceedings, vol. 78, no 10, pp 1586-1589, 1990.
[12] J. G. Taylor “Mathematical Approaches to Neural Networks” 1993 North-Holland Mathematical Library.
[13] D. Chester “Why Two Hidden Layers are Better than One” Proc Int. Joint Conference on Neural Networks, IEEE Pubblications, pp 265-268, 1990
[14] P. D. Wasserman “Neural computing: theory and practice” van Nostrand Reinhold 1989
[15] _____, “Learning with first, second, and no derivatives: A case study in high energy physics” Neurocomput.,vol. 6, pp. 181-206, 1994
[16] P. J. Werbos “Beyond regression: New tools for prediction and analysis in the behavioral sciences” Masters thesis, Harward University.
[17] M. Gori e A. Tesi “On the problem of local minima in backpropagation” IEEE Trans. Pattern Anal. Machine Intell., vol. 14, no 1, pp 76-86, 1992.
[18] R. Battiti, G. Tecchiolli “Training Neural Nets with the Reactive Tabu Search” IEEE Transactions on Neural Networks, Vol 6, n. 5, settembre 1995, pp.1185-1200
[19] R. Battiti, P. Lee, A. Sartori, G. Tecchiolli “TOTEM: A Digital Processor for Neural Networks and Reactive Tabu Search” in Proceedings of the Fourth International Conference on Microelectronics for Neural Networks and Fuzzy Systems, settembre 1994.
[20] G. E. Hinton ”L’apprendimento delle reti artificiali di neuroni” Le Scienze n.291, novembre 1992
[21] Jan N. H. Heemskerk “Overview of neural hardware” 1995 ftp://ftp.mrc-apu.cam.ac.uk/pub/nn.
22 M. Holler, S. Tam, H. Castro, R. Benson (1989). “An Elettrically Trainable Artificial Neural Network (ETANN) with 10240 'F‘oating Gate Synapses'”. Proceedings of the IJCNN-89-Washinton DC, II pp 191-196. Inoltre 80170NX Specification booklet, Intel Corp. June 1991.
23 M. L. Mumford, D. K. Andes, & L. R. Kern (1992). “The Mod2 Neurocomputer System Design”. IEEE Transactions on Neural Networks, 3, 3, pp. 423-433.

131
24 Y. Maeda, H. Hirano, & Y. Kanata (1993). “An analog Neural Network Circuit with a Learning Rule via Simultaneous Perturbation”. Proceedings of the IJCNN-93-Nagoya, pp. 853-856.
25 U. Ramacher, W. Raab, J. Anlauf, U. Hachmann, J. Beichter, N. Brüls, M. Weßeling, & E. Sicheneder (1993). “Multiprocessor and Memory Architecture of the Neurocomputer SYNAPSE-1”. Proceedings of the 3rd International Conference on Microelettronics for Neural Networks (Micro Neuro), aprile 1993, Edinburgh, pp 227-231.
26 H. McCartor, "Back Propagation Implementation on the Adaptive Solutions CNAPS Neurocomputer Chip", proc. of NIPS-3, "Advances in Neural Information Processing Systems 3",ed. R. Lippmann et al., 1991, pp. 1028-1031, Morgan Kaufmann Pub.
27 K. Asanovic, J. Beck, J. Feldman, N. Morgan, & J. Wawrzynek (1993) Development of a Connectionist Network Supercomputer. Proceedings of the 3rd International on Microelettronics for Neural Networks (Micro Neuro), aprile 1993, Edinburgh, pp 253-262.
28 M. Yasunaga, N. Masuda, M. Yagyu, M. Asai, K. Shibata, M. Ooyama, & M. Yamada (1991). “A Self-Learning Neural Network composed of 1152 Digital Neurons in Wafer-Scale LSIs”. Proceedings of the IJCNN-91-Singapore, pp 1844-1849.
29 N. Mauduit, M. Duranton, J. Gobert, & J. A. Sirat (1992). “Lneuro 1.0: A Piece of Hardware LEGO for Building Neural Network Systems” IEEE Transactions on Neural Networks, 3, 3, pp 414-422.
[30] A. Sartori, G. Tecchiolli “TOTEM VME BOARD: Technical Reference Manual” Istituto per la Ricerca Scientifica e Tecnologica, Povo (TN), marzo 1996, versione 1.0.
[31] A. Sartori, G. Tecchiolli “TOTEM – A Digital Processor for Neural Networks and Reactive Tabu Search” Istituto per la Ricerca Scientifica e Tecnologica, Povo (TN), agosto 1995, versione 2.0.
[32] A. Sartori, G. Tecchiolli “TOTEM PC ISA BOARD: Technical Reference Manual” Istituto per la Ricerca Scientifica e Tecnologica, Povo (TN), agosto 1995, versione 1.0.
[33] J. von Neumann “The computer and the Brain” Yale Univ. Press, New Haven, CT 1958.
[34] R.Sedgewick “Algorithms in C” Addison Wesley 1990, capitolo 25.

132
[35] S. Thrun “Learning To Play the Game of Chess” in Advances in Neural Information Processing Systems 7 G. Tesauro, D. Touretzky e T. Leen, eds., 1995, oppure http://www.cs.cmu.edu/~thrun/papers/thrun.nips7.neuro-chess.html
[36] http://forum.swarthmore.edu/~jay/learn-game/systems/neurochess.html
[37] L. Ricci, G. Tecchiolli “A neural system for frequency control of tunable laser sources” IEEE Instrumentation and Measurement Technology Conference Ottawa, Canada, maggio 1997.
[38] Y. S. Abu-Mostafa “Macchine che apprendono tramite suggerimenti” Le Scienze n.322, giugno 1995.