Embed Size (px)
Citation preview

Talend + DatabricksJune 2020

Databricks Pillasrs

Serverless Spark
Serverless Spark Clusters with Autoscaling
Transient or Interactive Clusters
Data scientist friendly Notebooks for SQL, Scala, Spark, Python
Embedded Support for Libs on Spark Tensorflow, Pytorch, Sklearn

44
VALUE OF SERVERLESS BIG DATA
NO SERVERTO PROVISION/MANAGE
SAVEWHEN IDLING
NEVER PAY FOR IDLESERVERS GET AUTO-TERMINATED
GET ELASTICITY AT RUNTIMESCALE UP/DOWN ON YOUR NEEDS
SERVERLESS BRINGS EASE OF ADMINISTRATION
SCALEWITH USAGE
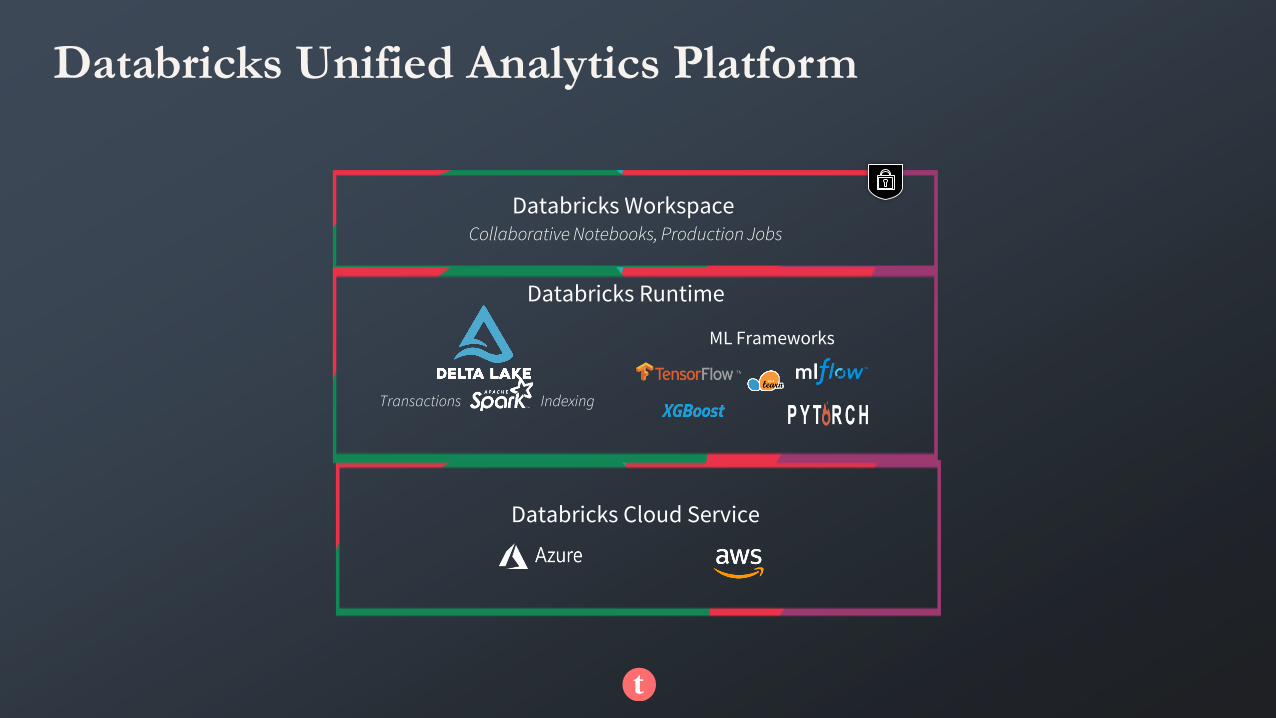
Databricks Unified Analytics Platform
Databricks WorkspaceCollaborative Notebooks, Production Jobs
Databricks Runtime
Databricks Cloud Service
Transactions Indexing
ML Frameworks

Talend Databricks Spark Support
Studio▪ AWS & Azure
▪ Interactive & Transient auto scale clusters
▪ Pools
▪ Triggering Notebooks with API
▪ DBFS Components
Pipeline Designer▪ AWS & Azure
▪ Interactive & Transient auto scale clusters
Serverless Spark

Open Format Based on Parquet
With Transactions
Apache Spark API’s
A New Standard for Building Data Lakes

88
Why Parquet?
WHY PARQUET?• Columnar storage suitable for
wide tables and analytics.• Optimized for – Write once
read many
• Saves Space: Columnar Layout compresses better
• Enables better scans: Loads only the columns that needs to be scanned (Advantage: Projection & Predicate Pushdown)
• Schema Evolution: Partially supported

99
Parquet – pros and cons
PROS (vs Text) CONS
Good for distributed processing Updates/Delta – FULL Read Write - Expensive
Great for Wide tables Limited Schema Evolution (Append columns)
Predicate Push and projection pushdown (Basic behavior + partitioning )
Historization / Versioning -requires manual partitioning
Good compression Query optimization –folder structure / partitioning / resize

Transactional
Log
Parquet Files
Delta Lake ensures data reliability
Streaming
● ACID Transactions● Schema Enforcement
● Unified Batch & Streaming● Time Travel/Data Snapshots
Key Features
High Quality & Reliable Dataalways ready for analytics
Batch
Updates/Deletes

Delta Lake optimizes performance
Highly Performantqueries at scale
● Indexing● Compaction
● Data skipping● Caching
Key Features
Transactional
Log
Parquet Files
Databricks
optimized engine

1212
DATABRICKS DELTA Support conditional updates (ELT)

Talend Databricks Delta Lake Support
Studio▪ Delta Files Input & Output
▪ Spark batch
▪ Integration with the time travel capability of Delta Lake
▪ Partitioning options
▪ Delta Tables Create / Append / Merge
Stitch Data Loader▪ Destination AWSTransactional
Log
Parquet Files
Databricks
optimized engine

Data Scientist
Likes
Wants to
80% of the time
Python, neural network, NLP
Build accurate ML Models
Finding, cleaning, and reorganizing huge amounts of data
Why Talend & Databricks?

1515
Data Engineer
Talks about
Wants to
Kafka, Parquet & Kubernetes
Build repeatable, durable, data pipelines to integrate data and provide Data quality


Movies data set demo

1818
Talend & Spark on Databricks
Get Data Scientist to Insights Faster

1919
Movies data Analytics
Demo Use Case Design
credits
movies+
ratings
cleanse / parse join / transform
aggregate / filter
S3 / ADLS / Blob / DBFS
S3 / ADLS / Blob / DBFS

Take away
• Talend with Databricks help the cooperation between Data Engineers and Data Scientist
• Serverless Spark support for Studio and Pipeline designer
• Delta Lake integration• Tables Updates
• Transactions support
• Time travel
• Query optimization






























