Embed Size (px)
Citation preview

Técnicas de Clasificación Supervisada
DRA. LETICIA FLORES PULIDO

Objetivo � El objetivo principal de las técnicas de
clasificación supervisada es obtener un modelo clasificatorio válido para permitir tratar casos futuros
� Se trata de que el sistema sea capaz de aprender de lo que tiene para poder generalizar y tratar lo que no tiene
2

Algoritmos de Clasificación por Vecindad � Dentro de las técnicas de clasificación
supervisada, una de las aproximaciones más conocidas es la que se basa en criterios de vecindad
� Bajo esta perspectiva, los métodos de clasificación exigen la definición de una cierta medida de similitud (o distancia) entre los distintos elementos del espacio de representación.
3

Algoritmos de Clasificación por Vecindad � Es decir, precisan de la definición de una
métrica que ayude a comparar las distancias entre los distintos objetos.
� La ventaja más inmediata que presentan las técnicas de clasificación basadas en criterios de vecindad con respecto a otros métodos de clasificación, hace referencia a su simplicidad conceptual, que se podría resumir del siguiente modo:
4

Algoritmos de Clasificación por Vecindad � La clasificación de un nuevo punto del
espacio de representación se calcula en función de las clases, conocidas de antemano, de los puntos más próximos a él.
� Tal y como se desprende de la afirmación anterior, la idea fundamental sobre la que se apoyan estas técnicas de clasificación, se basa en que las muestras pertenecientes a una misma clase, probablemente se encontrarán próximas en el espacio de representación.
5
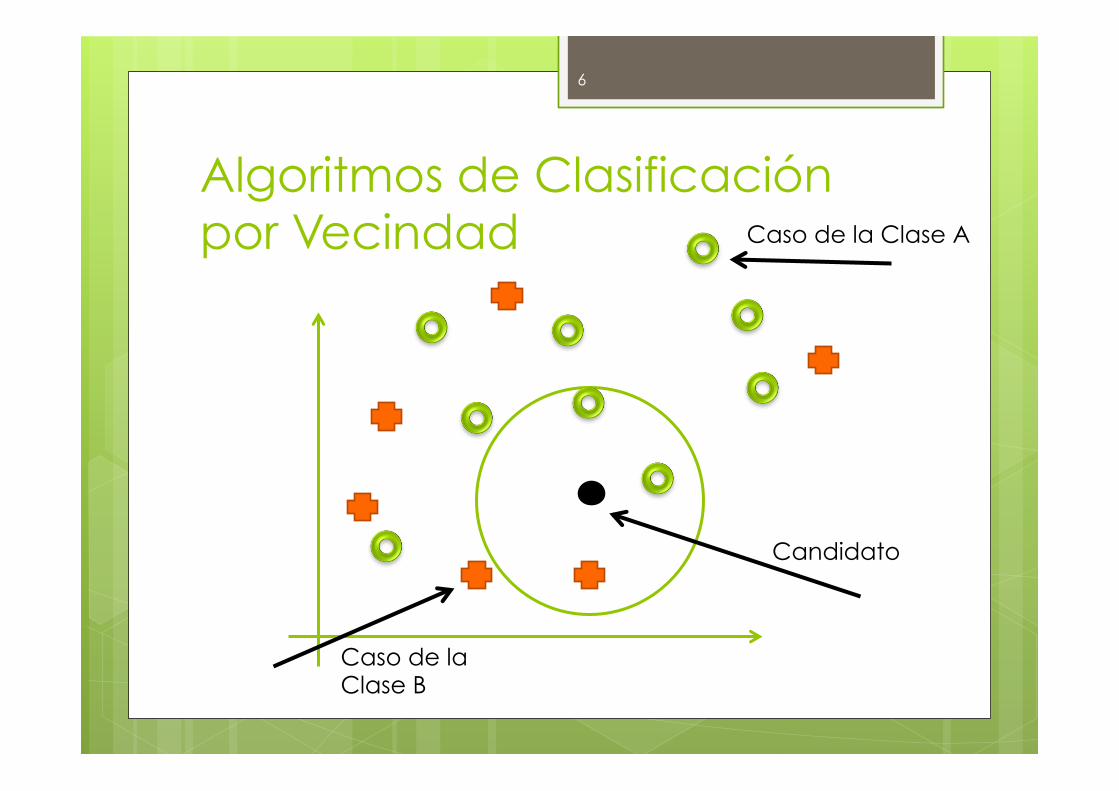
Algoritmos de Clasificación por Vecindad
6
Caso de la Clase A
Candidato
Caso de la Clase B

Algoritmos de Clasificación por Vecindad � En los algoritmos basados en vecindad, la
decisión de clasificar un caso x en la categoría θdepende de una colección de N casos previamente clasificados:
� (x1, θ1), (x2, θ2), …, (xN, θN), � Y el proceso de clasificación puede dar
lugar a errores.
7

Algoritmos de Clasificación por Vecindad � Este tipo de problemas se enmarca en el
dominio de la clasificación supervisada, y no existe un clasificador óptimo que resuelva satisfactoriamente todos los problemas que se puedan plantear.
� Si se asume que los casos ya clasificados (xi, θi) se hallan independiente e idénticamente clasificados respecto a una distribución de probabilidad, se pueden establecer ciertos argumentos heurísticos para el desarrollo de buenos procesos de clasificación.
8

Algoritmos de Clasificación por Vecindad � Por ejemplo, parece razonable asumir
que observaciones que se encuentran cercanas (con alguna métrica apropiada) tendrán aproximadamente la misma distribución de probabilidad a posteriori en sus respectivas clasificaciones.
9

Algoritmos de Clasificación por Vecindad � De este modo, para clasificar el caso x,
podríamos querer asociar más peso a la evidencia de un caso conocido cercano xi
� Quizás el procedimiento de decisión más simple es el del “vecino de distancia mínima” (nearest neighbour- NN), que asigna a x la categoría de su vecino más cercano de entre los ya clasificados
10

Algoritmos de Clasificación por Vecindad � La primera formulación de una regla del
estilo de NN parece haber sido generada por Fix and Hodges (1951) que investigaron el método conocido como K-NN (K vecinos mas cercanos), que asigna a un caso no clasificado la clase mas fuertemente representada de entre sus K vecinos mas cercanos.
11

Algoritmos de Clasificación por Vecindad � En general cualquier problema de
clasificación abordado con un enfoque basado en criterios de vecindad se puede caracterizar del siguiente modo:
1. Se dispone de N prototipos (o muestras ya clasificadas) llamado “conjunto de entrenamiento”
2. Tenemos que clasificar un nuevo caso, x, no perteneciente al conjunto de entrenamiento
12

Algoritmos de Clasificación por Vecindad 3. Existe una métrica entre los diferentes
objetos del espacio de representación 4. No se utiliza ninguna otra información
acerca de la distribución de los parámetros estadísticos asociados al conjunto de entrenamiento
13

Algoritmos de Clasificación por Vecindad � Vistas estas características, algunos autores
distinguen los algoritmos de clasificación por vecindad del resto de los algoritmos de clasificación supervisada argumentando, mientras en el resto de los algoritmos de clasificación se realiza una inducción del modelo (árbol de decisión, reglas de un sistema experto, etc.) y utilizan posteriormente el modelo inducido (inducción + deducción)….
14

Algoritmos de Clasificación por Vecindad � …en los algoritmos basados en vecindad
el modelo se halla implícito en los datos, sin llegar a explicitarse, con lo que se dice que se realiza una transducción.
15

Regla del Vecino más Próximo � En este caso, el clasificador asociará un caso
x la clase verdadera del objeto que se encuentra más próximo a x dentro del espacio de representación.
� Para esta aproximación, todos los prototipos del conjunto de entrenamiento participan en la decisión de clasificación de la nueva muestra, esto es, el modelo de clasificación está compuesto por todos los casos que componen el conjunto de entrenamiento.
16

Regla del Vecino más Próximo � Un aspecto a tener en cuenta es que la
efectividad de esta regla está condicionada a que se disponga de un número suficientemente grande de prototipos en el conjunto de entrenamiento
� Desde un punto de vista práctico, este hecho puede representar un serio inconveniente en cuanto al costo computacional requerido para buscar el prototipo más próximo dentro del conjunto de entrenamiento.
17

Regla del Vecino más Próximo � No obstante, este inconveniente se
puede mitigar con la utilización de alguno de los procedimientos existentes para reducir el numero de casos que componen el modelo, de forma que este no esté compuesto por todos los casos que forman el conjunto de entrenamiento sino por un subconjunto de los mismos. –validación-
18

Regla de K vecinos más Próximos (K-NN) � Por medio de esta regla, la clase
asignada a un nuevo caso x será la clase más votada entre los K vecinos más próximos del conjunto de entrenamiento
� Sin embargo, cabe la posibilidad de que se produzca un empate en el número de votos de la clase más votada
19

Regla de K vecinos más Próximos (K-NN) � En ese caso, para seleccionar la clase a
asignar, es necesario utilizar algún método de resolución de empates;
� Entre ellos, podremos encontrar los siguientes: 1. Asignar al caso a clasificar la clase que tenga
el primer vecino más próximo de entre las empatadas en votos
2. Seleccionar como clase a asignar aquella entre las empatadas cuya media de distancias de sus vecinos sea menor.
20

Regla de K vecinos más Próximos (K-NN) � La principal ventaja de la regla K-NN con
respecto a la regla NN radica en que, al utilizar varios vecinos en lugar de uno sólo para la clasificación de un nuevo caso, se aprovecha de una forma más eficiente la información que se puede extraer del conjunto de entrenamiento.
21

Regla de K vecinos más Próximos (K-NN) � Sin embargo, esto no quiere decir que el
método K-NN sea siempre más exacto que el de NN, sino que se ha comprobado empíricamente que el primero comete menos errores de clasificación que el segundo, para algún valor de la constante K
� En la literatura, se obtiene que los mejores
resultados se obtienen con k=3 o k=5, aunque esto depende en gran manera del problema que se quiera abordar
22

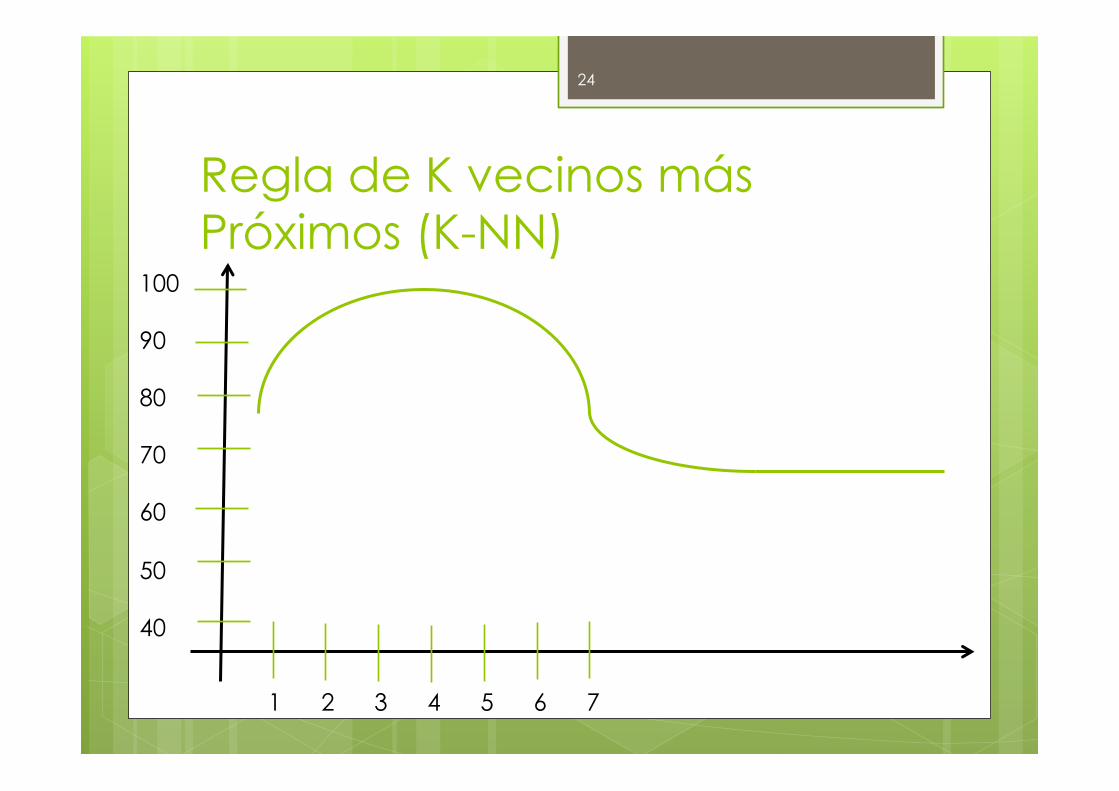
Regla de K vecinos más Próximos (K-NN) � En la siguiente figura se puede observar cual es el
comportamiento típico del algoritmo K-NN para diferentes valores del número de vecinos a tener en cuenta en problemas clasificatorios de dos clases
� Para un número mayor de clases, la gráfica es
parecida, desplazada a la derecha
� Pero para cada problema el comportamiento puede diferir del que se muestra
23
Regla de K vecinos más Próximos (K-NN)
24
100 90 80 70 60 50 40
1 2 3 4 5 6 7





























