Embed Size (px)
Citation preview

.
UNIVERSITATEA „POLITEHNICA” din BUCUREŞTI
ŞCOALA DOCTORALĂ ETTI-B
Nr. Decizie …….. din ………
TEZĂ DE DOCTORAT
TEHNICI INTELIGENTE PENTRU ANALIZA ȘI
CLASIFICAREA COLECȚIILOR DE BAZE DE DATE
MULTIMEDIA
INTELLIGENT TECHNIQUES FOR MULTIMEDIA
DATABASES COLLECTIONS ANALYSIS AND
CLASSIFICATION
Doctorand: Ing. Ionuţ Mironică
COMISIA DE DOCTORAT
Preşedinte prof. dr. ing. Gheorghe
BREZEANU
de la Univ. Politehnica
Bucureşti
Conducător de
doctorat
prof. dr. ing. Radu DOGARU de la Univ. Politehnica
Bucureşti
Referent prof. dr. ing. Constantin
VERTAN
de la Univ. Politehnica
Bucureşti
Referent conf. dr. ing. Nicu SEBE
de la Univ. din Trento,
Italia
Referent conf. dr. ing. Laurențiu
Mihail IVANOVICI
de la Univ. Transilvania
Brașov
BUCUREŞTI 2013 ______________


.


Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
i
Mulţumiri
O dată cu finalizarea acestei etape din viața mea, îmi doresc să adresez câteva cuvinte
de mulțumire celor care m-au îndrumat sau mi-au acordat suportul pe parcursul
acestei lucrări de doctorat.
În primul rând îmi doresc să mulțumesc coordonatorului meu științific,
domnului Prof. dr. ing. Radu DOGARU, pentru permanenta sa îndrumare, sprijinire și
încurajare de-a lungul perioadei de pregătire a doctoratului și de elaborare a tezei. În
egală măsură, doresc să îi mulțumesc domnului Prof. dr. ing. Constantin VERTAN,
cel care m-a introdus în lumea prelucrării de imagini și m-a sprijinit în mod constant
pe toată perioada studiilor doctorale.
În continuare, doresc să îmi exprim gratitudinea față de membrii comisiei de
evaluare a lucrării pentru sfaturile și sugestiile oferite. Doresc să mulțumesc în mod
special domnului Prof. dr. ing. Gheorghe BREZEANU care mi-a făcut onoarea să
accepte să fie președintele comisiei de doctorat. De asemenea, doresc să mulțumesc
domnului conf. dr. ing. Mihail Laurențiu IVANOVICI pentru toate sfaturile pertinente
și constructive, oferite pe perioada corectării tezei de doctorat
Țin să mulțumesc în mod special domnului ș. l. dr. ing. Bogdan IONESCU
pentru sprijinul științific și administrativ constant acordat, dar mai ales pentru
contribuția dumnealui în formarea mea ca om. Doresc să mulțumesc în mod deosebit
pentru lungile discuții purtate, sfaturile acordate, și mai ales pentru încrederea pe care
mi-a acordat-o pe toată perioada studiilor. Mai mult, doresc să îi mulțumesc pentru
sprijinul deosebit acordat pentru pregătirea stagiului meu din Trento și sfaturile
constructive în redactarea acestei lucrări.
Mulţumesc în mod deosebit domnului conf. dr. ing. Nicu SEBE deoarece m-a
acceptat în cadrul unui stagiu în Trento, pentru sprijinul constant acordat atât
administrativ, cât și științific. De asemenea, îi mulțumesc că a acceptat să ia parte la
susținerea tezei mele. Deosebită recunoştinţă datorez domnului dr. Jasper UIJLINGS
pentru sfaturile și sprijinul științific acordat pe toată perioada stagiului meu în Trento.
Aș dori să mulțumesc echipei minunate din cadrul Universității Trento pentru
sprijinul total: Anca-Livia RADU, Radu VIERIU, Negar ROSTAMZADEH, Mojtaba
Khomami ABADI, Victoria YANULEVSKAYA, Gloria ZEN, Manuel
ZUCCHELLINI și Jacobo STAIANO. De asemenea, doresc să mulțumesc domnilor
Alejandro Hector TOSSELI și Hamed REZAZADEGAN pentru discuțiile interesante
pe care le-am avut pe perioada stagiului meu la Trento.
Doresc să mulțumesc laboratorului LAPI - Laboratorul de Analiza și
Prelucrarea Imaginilor, din Universitatea Politehnica din București, și astfel tuturor
colegilor din colectivul de cercetare, pentru prietenia arătată de-a lungul timpului cât
și pentru încadrarea prețioasă acordată pe parcursul formării mele profesionale. Aș
dori să mulțumesc colegilor mei profesori, Mihai CIUC, Laura FLOREA, Corneliu

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
ii
FLOREA, Șerban OPRIȘESCU și Christoph RASCHE pentru ajutorul acordat,
discuțiile purtate precum și pentru modelul de conduită arătat. De asemenea, le
mulțumesc domnilor dr. Horia CUCU și Andi BUZO pentru colaborarea pe care am
avut-o pe perioada competiției MediaEval 2012.
Mulţumesc tuturor colegilor din cadrul Universităţii Politehnica Bucureşti
pentru sprijinul moral acordat.
Aș dori, de asemenea, să mulțumesc domnilor dr. Klaus SEYERLEHNER, dr.
Peter KNEES, drd. Jan SCHLUTER și dr. Markus SCHEDL, din cadrul Universității
Johannes Kepler University (JKU), Linz, Austria. Sincere mulțumiri doresc să îi acord
domnului Prof. dr. Patrick LAMBERT pentru tot sprijinul acordat pe perioada tezei.
Mulțumesc în mod special soției mele Diana, care m-a sprijinit necondiționat
pe toată perioada studiilor doctorale, și care a avut răbdarea să corecteze această
lucrare. De asemenea, îmi doresc să mulțumesc în mod mod deosebit mamei mele
pentru sprijinul permanent acordat și care, întotdeauna a subliniat importanța unei
bune educații. Nu în ultimul rând, doresc să mulțumesc surorii mele, pentru ajutorul
acordat pe perioada studiilor, și pentru timpul depus pentru corectarea acestei
lucrări.
În încheiere, aș dori să mulțumesc colegilor mei, domnii Răzvan
PRUNDEANU, Marius STANCU și Dan DUMITRU, pentru sprijinul și înțelegerea
acordată pe toată perioada studiilor.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
iii
Lista tabelelor Tab. 5.1 Comparație între cele mai bune rezultate ................................................... 108
Tab. 5.2 Comparație între complexitatea computațională și lungimea descriptorilor111
Tab. 6.1 Comparație rezultate cu competiția MediaEval 2012 Tagging Task .......... 121
Tab. 6.2 Performanța inițială a descriptorilor selectați ............................................. 122
Tab. 6.3 Comparație rezultate State-of-the-Art ........................................................ 124
Tab. 6.4 Comparație rezultate State-of-the-Art ......................................................... 125
Tab. 6.5 Comparație rezultate State-of-the-Art ........................................................ 127
Tab. 7.1 Top trei performanțe pentru bazele de date Microsoft și Caltech 101 (MAP).
.................................................................................................................................... 143
Tab. 7.2 Performanța medie obținută pe baza de date de test .................................... 147
Tab. 7.3 Performanța sistemului pentru diferite ferestre de afisare. ......................... 149
Tab. 7.4 Performanța sistemului fără relevance feedback, utilizând diferite metrici .
.................................................................................................................................... 154
Tab. 7.5 Performanța sistemului utilizând diferite tehnici de normalizare. ............... 155
Tab. 7.6 Comparație acuratețe cu alți algoritmi de relevance feedback. ................... 156
Tab. 7.7 Comparație acuratețe între FKRF clasic și FKRF cu GMM global. ........... 157
Tab. 7.8 Comparație acuratețe dintre FKRF clasic și FKRF temporal. ..................... 158
Tab. 8.1 Comparație cu State-of-the-Art. .................................................................. 166
Tab. 8.2 Performanța trăsăturilor propuse pentru clasificarea genului. ..................... 174
Tab. 8.3 Performanța obținută cu diferite strategii de fuziune. ................................. 175
Tab. 8.4 Comparație cu algoritmii raportați în State-of-The-Art ............................... 177
Tab. 8.6 Comparație cu rezultatele obținute la compeția MediaEval 2012 ............... 182
Tab. 8.4 Comparație cu algoritmii raportați în State-of-The-Art ............................... 186

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
iv

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
v
Lista figurilor Fig. 1.1 Surse de informație multimedia. ....................................................................... 5
Fig. 1.2 Arhitectura de bază a unui sistem de căutare după conținut multimedia ......... 6
Fig. 2.1 Exemplificare a paradigmei semantice prin utilizarea histogramei de culoare.
...................................................................................................................................... 15
Fig. 2.2 Exemple de perechi de imagini în care paradigma semantică este prezentă . 16
Fig. 2.3 Prezentarea procesului de interacțiune utilizator-sistem în cadrul algoritmului
de relevance feedback. ................................................................................................. 17
Fig. 2.4 Schema unui sistem clasic de căutare a documentelor multimedia după
conţinut ........................................................................................................................ 18
Fig. 2.6 Exemple de browser 2D (MediaMill) ............................................................. 20
Fig. 2.7 Exemplu de browser cu navigare 3D .............................................................. 20
Fig. 2.8 Ilustrații ale unor sisteme cu browser cu navigare 3D .................................... 21
Fig. 2.9 Schema unui sistem cu fuziune „Early Fusion” ............................................. 25
Fig. 2.10 Exemplu de normalizare folosind funcții dublu sigmoide ............................ 27
Fig. 2.11 Ilustrații ale unor sisteme de „late fusion” .................................................... 28
Fig. 2.12 Interpretarea graficelor precizie-reamintire .................................................. 33
Fig. 2.13 Interpretarea curbelor ROC .......................................................................... 35
Fig. 2.14 Exemple de imagini din baza de date Image CLEF ..................................... 36
Fig. 2.15 Exemple de imagini din baza de date Image Caltech 101 ............................ 37
Fig. 2.16 Exemple de imagini din baza de date Image Pascal 2007 ............................ 38
Fig. 2.17 Exemple de documente video din baza de date MediaEval 2012 ............... 39
Fig. 3.1 Cubul RGB ..................................................................................................... 42
Fig. 3.2 Planul YCbCr cu y = 0.5. ............................................................................... 43
Fig. 3.3 Spațiul de culoare a familiei HSV. ................................................................. 43
Fig. 3.4 Sistemul de coordonate pentru HMMD.......................................................... 44
Fig. 3.5 Sistemul de coordonate pentru CIE Lab. ....................................................... 45
Fig. 3.6 Spațiul de culoare Color Naming ................................................................... 46
Fig. 3.7 Ilustrare a variaţia histogramei în cazul unor modificări minore de scenă ..... 47
Fig. 3.8 Exemple de divizări ale spațiului suport al imaginii în vederea calculului de
histograme augmentate ................................................................................................ 49
Fig. 3.9 Schemă ilustrativă a reprezentării prin piramide. ........................................... 50
Fig. 3.10 Exemple de texturi aparţinând bazei de date Vis Tex .................................. 50
Fig. 3.11 Partiții de caracterizare a texturilor în domeniul spectral Fourier ................ 58
Fig. 3.12 Schema de calcul a operatorului LBP .......................................................... 59
Fig. 3.13 Exemple de metode de extragere a punctelor de interes .............................. 63
Fig. 3.14 Procesul de antrenare în cadrul algoritmului Bag of Words ........................ 67
Fig. 3.15 Procesul de clasificare în cadrul algoritmului Bag of Words ....................... 68
Fig. 3.16 Impărţirea imaginii iniţiale pentru descriptorul Edge Histogram ................. 72
Fig. 3.17 Exemple de ferestrele detectoare de muchii ................................................. 73
Fig. 3.20 Modalități de împărțire a semnalului audio .................................................. 77
Fig. 3.21 Schema generală a unui sistem de clasificare de semnale audio. ................. 77

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
vi
Fig. 3.22 Schema generală a unui sistem de clasificare de text ................................... 82
Fig. 4.1 Ilustraţie a algorimului lui Rocchio ................................................................ 90
Fig. 4.2 Ilustraţie a algorimulor de Relevance Feedback cu estimare a importanței
trăsăturilor .................................................................................................................... 91
Fig. 4.3 Clasificare utilizând rețele SVM .................................................................... 96
Fig. 5.1. Tipuri de vecinătăți ale unui automat celular .............................................. 102
Fig. 5.2 Vecinătatea 3x3 din jurul funcției kernel ..................................................... 103
Fig 5.3 Șase funcţii kernel propuse pentru descrierea conținutului de textură .......... 104
Fig. 5.4 Exemple de texturi utilizate în experimente ................................................. 105
Fig. 5.5 Performanța MAP utilizând un număr variabil de praguri ........................... 106
Fig. 5.6 Performanța MAP utilizând un număr variabil de scale............................... 106
Fig. 5.7 Performanța obținută pentru diverse seturi de funcții utilizate..................... 107
Fig. 5.8 Graficele precizie reamintire pentru cele patru baze de date ........................ 108
Fig. 5.9 Rezultatele clasificării pe bazele Brodatz, UIUC, KTH și Vistex ................ 110
Fig. 6.1 Schema generală a unei reprezentări Fisher kernel ...................................... 115
Fig. 6.2 Influența numărului de trăsături asupra performanței sistemului ................. 118
Fig. 6.3 Influența aplicării PCA asupra performanței sistemului .............................. 119
Fig. 6.4 Influența numărului de centroizi GMM asupra performanței sistemului ..... 120
Fig. 6.5 Influența numărului de centroizi GMM asupra performanței sistemului ..... 123
Fig. 7.1 Ilustrare schematică a algoritmului modificat de estimare a relevanței
caracteristicilor. .......................................................................................................... 131
Fig. 7.2 Schema logică a algoritmului modificat de estimare a relevanței
caracteristicilor. .......................................................................................................... 131
Fig. 7.3 Graficele Precizie-Reamintire pentru o sesiune de feedback ....................... 132
Fig. 7.4 Variația MAP pentru mai multe iterații de feedback .................................... 133
Fig 7.5 Arhitectura unei reţele de clusterizare ierarhică ............................................ 134
Fig. 7.6 Versiunea în pseudocod a algoritmului de Relevance Feedback cu clusterizare
ierarhică...................................................................................................................... 135
Fig. 7.7 Metode de unificare a clusterelor ................................................................. 136
Fig. 7.8 Reprezentare grafică pentru regula arcului ................................................... 137
Fig 7.9 Exemple de imagini din bazele de date utilizate ........................................... 138
Fig 7.10 Variația MAP în funcție de numărul de clustere ......................................... 139
Fig. 7.11 Variația MAP în funcție de parametrul d de disimilaritate ........................ 140
Fig. 7.12 Curbele Precizie – Reamintire pentru bazele de date Caltech 101 și
Microsoft utilizând descriptorii de culoare, MPEG7 și Bag of Words (SURF) ........ 141
Fig 7.13 Performanța sistemului atunci când variem numărul de iterații de feedback
pe baza de date Caltech 101 si Microsoft (valori MAP) ............................................ 141
Fig. 7.14 Performanța descriptorilor pe bazele de date Microsoft si Caltech folosind
diverși descriptori în combinație cu o gamă diversă de metrici ................................. 142
Fig. 7.15 Acuratețea algoritmilor de relevance feedback pentru diverși descriptori și
metrici (valori MAP).................................................................................................. 144
Fig. 7.16 Precizia calculată pe fiecare categorie de film pentru diferiți descriptori. . 146
Fig. 7.17 Graficele precizie reamintire pentru diverși descriptori ............................. 147

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
vii
Fig. 7.18 Grafice Precizie – Reaminitire pentru o sesiune de relevance feedback .... 149
Fig. 7.19 Schema logică a algoritmului Relevance Feedback cu Fisher kernel ........ 151
Fig. 7.20 Performanța algoritmului FKRF la variația numărului de centroizi GMM
(valori MAP) .............................................................................................................. 155
Fig. 7.21 Grafice precizie-reamintire pentru metoda propusă și algoritmi state-of-the-
art ............................................................................................................................... 156
Fig. 7.22 Performanța algoritmului FKRF temporal la variația numărului de centroizi
GMM.......................................................................................................................... 158
Fig. 8.1 Schema algoritmului propus pentru clasificarea imaginilor otoscopice ....... 163
Fig. 8.2 Exemple de imagini otoscopice utilizate în experimente: prima linie conține
exemple de imagini fără otită, iar linia a doua prezintă inflamații ale urechii medii 163
Fig. 8.3 Acuratețea de clasificare. .............................................................................. 164
Fig. 8.4 Precizia medie pentru metodele de fuzionare. .............................................. 165
Fig. 8.5 Exemple de imagini medicale utilizate în experiment .................................. 167
Fig 8.6 Performanțele obținute în experimentele de retrieval utilizând descriptorii
propuși........................................................................................................................ 168
Fig. 8.7 Performanța algorimilor de clasificare pentru fiecare set de descriptori ...... 169
Fig. 8.8 Schema sistemului propus pentru clasificarea genului documentelor video
web ............................................................................................................................. 172
Fig. 8.9 Rezultatele clasificării pe fiecare gest utilizând diferite metode de clasificare:
.................................................................................................................................... 186

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
viii

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
ix
Lista abrevierilor ADL - University of Rochester Activities of Daily Living
ANMRR - Average Normalized Modified Retrieval Rank
ARR - Average Retrieval Rank- ARR
ARF - Austrian Romanian Team
ASR - Automatic Speech Recognition
AVR - Average Rank
BLOB - Binary Large Objects
BoVW - Bag of Visual Words
BoW - Bag of Words
CBMI - Content Based Multimedia Indexing
CCV - Color Coherence Vectors
CHD - Color Histogram Descriptor
CLD - Color Layer Descriptor
CN - Color Naming
CSD - Color Structure Descriptor
DCT - Discrete Cosinus Transform
EHB - E-Health and Bioengineering Conference
ERF - Extremelly Random Forests
EUSIPCO - European Signal Processing Conference
FK - Fisher Kernel
FPR - False Positive Rate
GBT - Gradient Boosted Trees
GIS - Geographic Information System
GLOH - Gradient Location-Orientation Histogram
GMM - Gaussian Mixture Model
GOOD - Good Features to Track
HAC - Hierarhical Agglomerative Clustering
HCRF - Hierarhical Clustering Relevance Feedback
HMM - Hidden Markov Model
HMMD - Hue Minim Maxim Difference
HOF - Histograms of Optical Flow
HOG - Histograms of Oriented Gradients
HSV - Hue Saturation Value
ICCP - International Conference on Intelligent Computer Communication and
Processing
ICMR - International Conference of Multimedia Retrieval
ISSCS - International Symposium on Signals, Circuits and Systems
KTH-TIPS - Textures under varying Illumination, Pose and Scale
LBP - Localy Binary Patterns
LDA - Latent Dirichlet Allocation
LLE - Local Linear Embedding

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
x
LPC - Linear Predictive Coefficients
LSP - Line Spectral Pairs
MAP - Mean Average Precision
MFCC - Mel-Frequency Cepstral Coefficients
MMR - Modified Retrieval Rank– MRR
MPEG - Moving Picture Experts Group
MSER - Maximally Stable Extremal Regions
NMRR - Normalized Modified Retrieval Rank
NN - Nearest Neaigbor
PASCAL - Pattern Analysis, Statistical Modelling and Computational Learning
PCA - Principal Component Analysis
PHP - Hypertext Preprocesor
PR - Precizie Reamintire (Precision Recall)
PLSA - Probabilistic Latent Semantic Analysis
QBE - Query by Example
RBF - Radial Basis Function
RF - Random Forests
RF - Relevance Feedback
RFE - Relevance Feature Estimation
RGB - Red Green Blue
ROC - Receiver Operating Characteristic
RR - Retrieval Rate
RSJ - Robertson Starck-Jones algorithm
SGBD - Sistem de Gestionare a Bazelor de Date
SIFT - Scale Invariant Feature Transform
SOM - Self Organizing-Map
SPAMEC - Signal Processing and Applied Mathematics for Electronics and
Communications
STIP - Space-Time-Interest-Points
SURF - Speeded Up Robust Feature
SVM - Support Vector Machines
TD-IDF - Term Frequency-InverseDocument Frequency
TPR - True Positive Rate
UIUC - University of Illinois at Urbana-Champaign
UCF - University of Central Florida
ZCR - Zero-Crossing Rate

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
xi
_____________________________________________________________________
Cuprins _____________________________________________________________________
Pag.
Mulțumiri...................................................................................................................... i
Lista tabelelor............................................................................................................. iii
Lista figurilor................................................................................................................v
Lista abrevierilor........................................................................................................ ix
PARTEA 1 .............................................................................................................................. 1
ASPECTE TEORETICE ALE DOMENIULUI DE ANALIZĂ ȘI CLASIFICARE A
BAZELOR DE DATE MULTIMEDIA ................................................................................. 1
CAPITOLUL 1 ........................................................................................................................ 3
INTRODUCERE ..................................................................................................................... 3
1.1 Prezentarea domeniului tezei de doctorat .................................................................................. 3
1.2 Scopul tezei de doctorat ............................................................................................................. 7
1.3 Conţinutul tezei de doctorat ....................................................................................................... 7
CAPITOLUL 2 ...................................................................................................................... 11
CONCEPTUL DE INDEXARE DUPĂ CONȚINUT ......................................................... 11
2.1 Introducere ............................................................................................................................. 11
2.2 Domenii de aplicabilitate ........................................................................................................ 13
2.3 Problematica sistemelor de căutare după conținut ................................................................. 14
2.4 Arhitectura unui sistem de indexare multimedia .................................................................... 17
2.4.1 Indexator ............................................................................................................................. 17
2.4.2 Browserul ............................................................................................................................ 19
2.4.3 Retriever .............................................................................................................................. 21

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
xii
2.5 Metode de fuzionare .............................................................................................................. 24
2.5.1 Metode de tip „Early Fusion” .............................................................................................. 25
2.5.2 Metode de tip „Late Fusion” ............................................................................................... 27
2.6 Măsurarea performanţelor ..................................................................................................... 31
2.6.1 Standardul MPEG 7 .............................................................................................................. 31
2.6.2 Graficul precizie-reamintire ................................................................................................. 32
2.6.3 Alţi parametri....................................................................................................................... 34
2.7 Baze de date ........................................................................................................................... 35
2.7.1 Baze de date de imagini ....................................................................................................... 36
2.7.2 Baze de date video .............................................................................................................. 38
2.8 Concluzii capitol ...................................................................................................................... 40
CAPITOLUL 3 ...................................................................................................................... 41
METODE CLASICE DE DESCRIERE A CONȚINUTULUI MULTIMEDIA............... 41
3.1 Descriptori de culoare .............................................................................................................. 41
3.1.1 Spaţii de culoare....................................................................................................................... 41
3.1.2 Histograma imaginii ............................................................................................................. 46
3.1.3 Momente de culoare ........................................................................................................... 47
3.1.4 Histograma „Color Coherence Vectors” .............................................................................. 48
3.1.5 Histograma Fuzzy ................................................................................................................. 48
3.1.6 Histograme augmentate și piramide spațiale ...................................................................... 49
3.2 Descriptori de textură ............................................................................................................. 50
3.2.1 Proprietăţile Tamura ........................................................................................................... 51
3.2.2 Matricea de coocurenţă ...................................................................................................... 52
3.2.3 Modele „Markov Random Fields” ....................................................................................... 54
3.2.4 Corelograma ........................................................................................................................ 54
3.2.5 Matricea de Izosegmente .................................................................................................... 54
3.2.6 Calcul în spațiu transformat ................................................................................................ 57
3.2.7 Operatorul „Localy Binary Patterns” ................................................................................... 58
3.3 Descriptori de formă ............................................................................................................... 59
3.3.1 Momentele Hu..................................................................................................................... 60
3.3.2 Momente Zernike ................................................................................................................ 60
3.3.3 Descriptori Fourier de contur ............................................................................................. 61
3.3.4 Aproximare poligonală ........................................................................................................ 61
3.3.5 Histograma de orientare a gradienților ............................................................................... 62
3.4 Puncte de interes ...................................................................................................................... 62
3.4.1 Introducere ............................................................................................................................... 62
3.4.2 Modelul „SIFT” ..................................................................................................................... 64
3.4.2 Modelul „SURF” ................................................................................................................... 65
3.4.3 Modelul „Harris” .................................................................................................................. 65
3.4.4 Reprezentarea „Bag of Visual Words” ................................................................................. 66

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
xiii
3.5 Descriptori MPEG 7 ................................................................................................................. 69
3.5.1 Standardul MPEG 7 ............................................................................................................. 69
3.5.2 Descriptori de culoare ......................................................................................................... 69
3.5.3 Descriptori de textură ......................................................................................................... 72
3.5.4 Descriptori de formă ........................................................................................................... 73
3.6 Descriptori de mișcare ............................................................................................................ 74
3.7 Descriptori audio .................................................................................................................... 76
3.8 Descriptori de text .................................................................................................................. 80
3.9 Concluzii ..................................................................................................................................... 84
CAPITOLUL 4 ...................................................................................................................... 87
ALGORITMI DE RELEVANCE FEEDBACK ................................................................... 87
4.1 Conceptul de Relevance Feedback .......................................................................................... 87
4.2 Metode de Relevance Feedback existente .............................................................................. 89
4.2.1 Algoritmi de schimbare a punctului de interogare .................................................................. 89
4.2.2 Algoritmi de estimare a importanței trăsăturilor .................................................................... 91
4.2.3 Algoritmi statistici .................................................................................................................... 93
4.2.4 Relevance feedback cu algoritmi de clasificare ....................................................................... 95
4.3 Concluzii ..................................................................................................................................... 97
PARTEA II ............................................................................................................................ 99
CONTRIBUȚII PERSONALE ............................................................................................ 99
CAPITOLUL 5 ................................................................................................................... 101
DESCRIEREA CONȚINUTULUI DE TEXTURĂ FOLOSIND AUTOMATE
CELULARE ........................................................................................................................ 101
5.1 Teoria automatelor celulare .................................................................................................... 101
5.2 Descrirerea texturilor utilizând automate celulare ................................................................. 103
5.3 Rezultate experimentale ....................................................................................................... 105
5.3.1 Alegerea parametrilor algoritmului ................................................................................... 105
5.3.2 Comparație cu „State-of-the-art” .......................................................................................... 107
5.3.2 Comparație de complexitate ............................................................................................. 111
5.4 Concluzii ................................................................................................................................... 112

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
xiv
CAPITOLUL 6 ................................................................................................................... 113
DESCRIEREA CONȚINUTULUI FOLOSIND REPREZENTAREA FISHER KERNEL
............................................................................................................................................. 113
6.1 Teoria Fisher kernel .............................................................................................................. 113
6.2 Reprezentarea Fisher kernel ................................................................................................. 114
6.3 Problematica modelării timpului în filme ............................................................................. 116
6.4 Clasificarea automată după gen a filmelor ............................................................................ 117
6.4.1 Descriere experiment ........................................................................................................ 117
6.4.2 Optimizarea reprezentării Fisher ....................................................................................... 118
6.4.3 Comparație cu „State-of-the-Art” ..................................................................................... 120
6.5 Recunoașterea de acțiuni sportive ........................................................................................ 121
6.5.1 Descriere experiment ........................................................................................................ 121
6.5.2 Optimizarea reprezentării Fisher ....................................................................................... 123
6.5.3 Comparație cu „State-of-the-Art” ..................................................................................... 124
6.6 Recunoaștere de acțiuni cotidiene ........................................................................................ 124
6.6.1 Descriere experiment ........................................................................................................ 124
6.6.2 Optimizarea reprezentării Fisher ....................................................................................... 126
6.6.3 Comparație cu „State-of-the-Art” ..................................................................................... 126
6.7 Concluzii capitol .................................................................................................................... 127
CAPITOLUL 7 ................................................................................................................... 129
METODE DE RELEVANCE FEEDBACK PROPUSE .................................................. 129
7.1 Algoritm propus de „Relevance Feedback” cu estimare a importanței trăsăturilor .................. 130
7.1.1 Prezentare algoritm ................................................................................................................ 130
7.3 Rezultate experimentale ............................................................................................................ 132
7.2 Relevance feedback cu clusterizare ierarhică ........................................................................... 133
7.2.1 Prezentare algoritm ................................................................................................................ 133
7.2.2 Rezultate experimentale obținute pe baze de imagini ........................................................... 137
7.2.3 Rezultate experimentale obținute pe baze de documente video........................................... 144
7.3 Aplicarea reprezentării Fisher kernel în Relevance feedback ................................................... 149
7.3.1 Prezentare algoritm ................................................................................................................ 149
7.3.2 Rezultate experimentale pe baza MediaEval 2012 ................................................................. 152
7.4 Concluzii ................................................................................................................................... 159
CAPITOLUL 8 ................................................................................................................... 161

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
xv
PARTICULARIZAREA CONCEPTELOR PENTRU DIFERITE PROBLEME DE
APLICAȚIE ........................................................................................................................ 161
8.1 Catalogarea imaginilor ORL ...................................................................................................... 162
8.1.1 Metoda propusă ..................................................................................................................... 162
8.1.2 Descrierea Experimentului ..................................................................................................... 163
8.1.3 Concluzii .................................................................................................................................. 166
8.2 Catalogarea imaginilor microscopice ........................................................................................ 166
8.2.1 Descrierea Experimentului ..................................................................................................... 166
8.2.2 Experiment de căutare ........................................................................................................... 167
8.2.3 Experiment de clasificare ........................................................................................................ 168
7.2.4 Concluzii .................................................................................................................................. 169
8.3 Catalogarea după gen a documentelor video ........................................................................... 169
8.3.1 Metodă propusă ..................................................................................................................... 171
8.3.2 Descriptori multimodali .......................................................................................................... 172
8.3.3 Rezultate Experimentale ........................................................................................................ 174
8.3.4 Concluzii .................................................................................................................................. 177
8.4 Catalogarea conținutului de violență în filme ........................................................................... 177
8.4.1 Metoda propusă ..................................................................................................................... 178
8.4.2 Detecția de concepte .............................................................................................................. 179
8.4.3 Rezultate experimentale ........................................................................................................ 180
8.4.3 Concluzii .................................................................................................................................. 183
8.5 Catalogarea pozițiilor statice ale mâinii .................................................................................... 183
8.5.1 Metoda propusă ..................................................................................................................... 184
8.5.2 Rezultate experimentale ........................................................................................................ 185
8.5.3 Concluzii .................................................................................................................................. 186
CAPITOLUL 9 ................................................................................................................... 187
CONCLUZII ........................................................................................................................ 187
9.1 Rezultate obţinute .................................................................................................................. 187
9.2 Contribuţii originale ................................................................................................................ 192
9.3 Lista lucrărilor originale ............................................................................................................ 195
Articole publicate în reviste de specialitate .................................................................................... 195
Competiții ........................................................................................................................................ 195
Rapoarte de cercetare ..................................................................................................................... 196
Articole publicate în conferințe internaționale ............................................................................... 196
Cărți ................................................................................................................................................. 198
9.4 Perspective de dezvoltare ulterioară ........................................................................................ 198
CAPITOLUL 10 ................................................................................................................ 199

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
xvi
BIBLIOGRAFIE ................................................................................................................ 199

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
1
PARTEA 1
ASPECTE TEORETICE ALE
DOMENIULUI DE ANALIZĂ ȘI
CLASIFICARE A BAZELOR DE
DATE MULTIMEDIA

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
2

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
3
Capitolul 1
Introducere
În ultimul deceniu, volumul de informație multimedia a manifestat o creștere
exponențială. Mărirea capacităților de stocare și procesare, cât și răspândirea masivă a
tehnologiei portabile au avut ca efect o explozie a conținutului multimedia. Practic,
tehnologia multimedia face acum parte din viața cotidiană a oricui. În 2012, mai mult de
72 de ore de conținut video au fost încărcate în fiecare minut pe Youtube. Ca și volum de
redare video, peste 500 de ani de filme sunt vizualizate în fiecare zi pe Facebook și peste
700 de documente video sunt rulate în fiecare minut pe Twitter. Așadar, principala
provocare pentru sistemele multmedia nu este capabilitatea acestora de a manipula
volume impresionante de date, ci aceea de a identifica și selecta numai informație
relevantă pentru utilizatori. Odată cu creșterea volumului de date multimedia, au început
să apară probleme în gestionarea și manipularea datelor. Uneori, chiar și regăsirea unui
anumit fișier multimedia pe calculatorul personal poate fi o operație comparată cu
căutarea „acului în carul cu fân”.
În această lucrare îmi propun să analizez modalități de indexare și căutare în baze
de date multimedia. Domeniul indexării după conţinut a obiectelor multimedia îşi
propune rezolvarea problemei de găsire a unor documente similare într-o bază de date
multimedia, utilizând ca şi elemente de căutare componentele descriptive: imagini / cadre
(descrierea componentelor de culoare, textură, a punctelor cheie şi a formelor obiectelor
componente), sunet, text (subtitrări extrase prin tehnici de recunoaștere automată a
vorbirii), ritm (pentru documente video / sunet), metadate etc.
1.1 Prezentarea domeniului tezei de doctorat
În prezent dinamica partajării datelor pe Internet este una copleșitoare, aceasta
realizându-se practic „în timp real” de pe orice terminal multimedia, atât mobil (de
exemplu telefonul mobil) cât și fix. Prin simpla apăsare a unui buton, o înregistrare video
sau imagine poate fi încărcată imediat „on-line”. Principala problemă pe care o cauzează
acest volum impresionant de date este cea a căutării de informație relevantă. Astfel, a fost
introdus termenul de indexare a datelor multimedia. Conceptul de indexare este definit ca
fiind procesul de adnotare a documentelor dintr-o bază de date, prin adăugarea de
informații suplimentare, numite metadate. În funcție de modul de generare a acestora,

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
4
procesul de adnotare a datelor poate fi clasificat în două categorii principale: adnotarea
manuală și cea automată.
Gradul de complexitate al adnotării este direct proporțional cu nivelul de detaliu
semantic și structural dorit pentru accesarea datelor. Spre exemplu, documentele pot fi
adnotate atât cu etichete generale, care să pună în evidență genul sau subcategoria
documentelor, sau pot fi create chiar și rezumate „semantice” ale acestora. De asemenea,
căutarea de conținut multimedia trebuie efectuată atât la nivel de cadru / secvență / scenă,
cât și cât și la nivel global al documentului. În prezent, o mare parte din cantitatea de
informație existentă este adnotată în mod manual. Astfel, diferite platforme, precum
YouTube, Dailymotion, Blip.tv, Google, Youtube utilizează metadate completate manual
de către utilizatori. Principala problemă este că acestea sunt dificil de completat şi de
foarte multe ori sunt incorect marcate și ineficiente. Mai mult, datorită modului de
interpretare proprie a conținutului, acestea conțin un nivel ridicat de zgomot. De
asemenea, procesul de adnotare manuală este unul costisitor sau nerealizabil datorită
constrângerilor de timp a aplicațiilor sau a numărului de documente implicate. Din aceste
motive adnotarea automată a documentelor multimedia reprezintă o direcție de cercetare
fundamentală.
Pentru indexarea conținutului multimedia se pot identifica trei surse majore de
surse de informație: informația vizuală (culoare, textură, formă, puncte de interes și
mișcare), informația audio (conținutul sonor: sunete, zgomot, vorbire, muzică
ambientală) și informația textuală (subtitrări sau metadate extrase). În Figura 1.1 sunt
prezentate principalele surse de informație care pot fi extrase dintr-un document
multimedia.
Culoarea reprezintă una din principalele trăsături de descriere a informației
multimedia. Aceasta ne permite recunoașterea proprietăților fizice ale obiectelor ce ne
înconjoară, precum și interacția cu acestea prin senzațiile de culoare ce ne sunt transmise.
Majoritatea metodelor de descriere se bazează pe tehnici de histogramă: histogramă
normală, augmentată, netezită, ponderată, fuzzy, utilizând diverse spaţii de culoare:
grayscale, RGB, HSV, Lab, HMMD, YcbCr etc. Textura este o altă trăsătură importantă
care caracterizează proprietățile vizuale fundamentale ale suprafeţelor obiectelor
(asperitate, uniformitate, variabilitate, direcționalitate, regularitate), supuse percepţiei
directe a ochiului uman ca o funcție de variație spațială a intensității pixelilor din
imagine. Metodele de extragere a trăsăturilor texturilor utilizează parametri statistici ca:
matricea de coocurenţă (parametri Haralick), corelogramă, autocorelogramă, matricea de
izosegmente (parametri Gallaway, Chu şi Dasarathy), măsuri de entropie, analiză fractală
şi metode auto-regresive. Forma, în metodele tradiţionale, este descrisă de către diverşi
parametri de aspect: arie, perimetru, raze, anvelope, skeletron, momente statistice
împreună cu invarianţii Hu, semnătura formei, descriptori Fourier de contur şi
transformata Hough. Punctele de interes reprezintă regiuni bine definite din spațiul
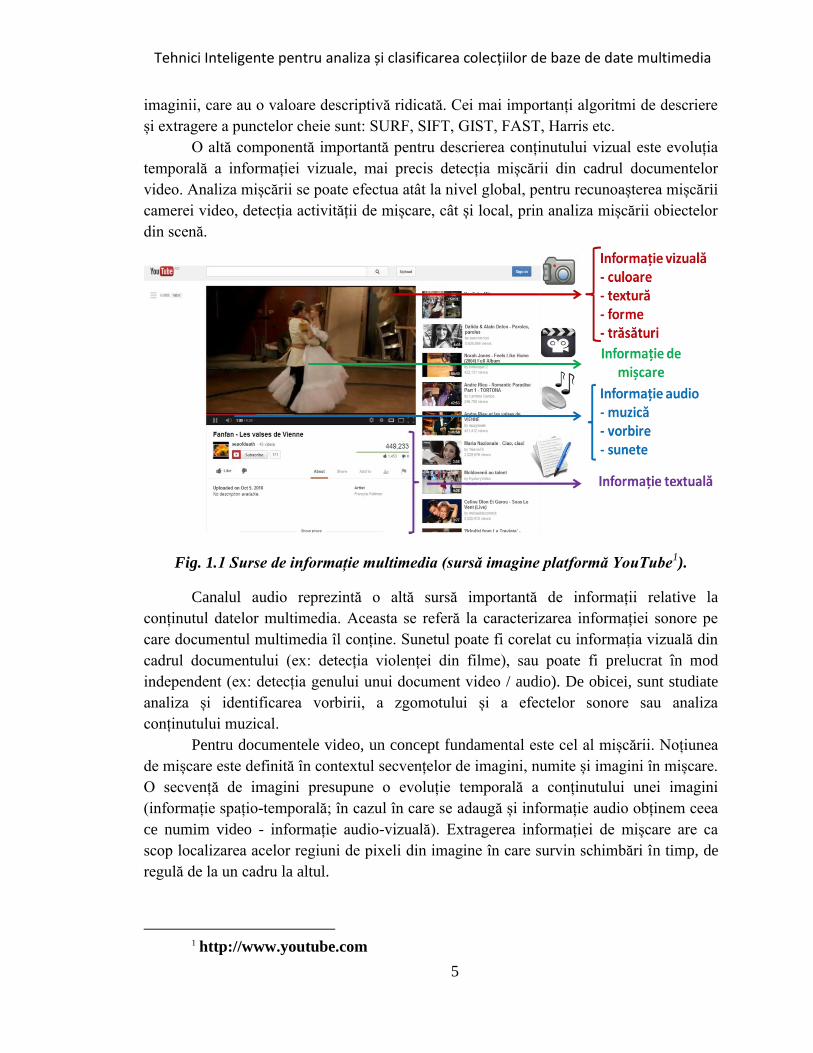
Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
5
imaginii, care au o valoare descriptivă ridicată. Cei mai importanți algoritmi de descriere
și extragere a punctelor cheie sunt: SURF, SIFT, GIST, FAST, Harris etc.
O altă componentă importantă pentru descrierea conținutului vizual este evoluția
temporală a informației vizuale, mai precis detecția mișcării din cadrul documentelor
video. Analiza mișcării se poate efectua atât la nivel global, pentru recunoașterea mișcării
camerei video, detecția activității de mișcare, cât și local, prin analiza mișcării obiectelor
din scenă.
Fig. 1.1 Surse de informație multimedia (sursă imagine platformă YouTube1).
Canalul audio reprezintă o altă sursă importantă de informații relative la
conținutul datelor multimedia. Aceasta se referă la caracterizarea informației sonore pe
care documentul multimedia îl conține. Sunetul poate fi corelat cu informația vizuală din
cadrul documentului (ex: detecția violenței din filme), sau poate fi prelucrat în mod
independent (ex: detecția genului unui document video / audio). De obicei, sunt studiate
analiza și identificarea vorbirii, a zgomotului și a efectelor sonore sau analiza
conținutului muzical.
Pentru documentele video, un concept fundamental este cel al mișcării. Noțiunea
de mișcare este definită în contextul secvențelor de imagini, numite și imagini în mișcare.
O secvență de imagini presupune o evoluție temporală a conținutului unei imagini
(informație spațio-temporală; în cazul în care se adaugă și informație audio obținem ceea
ce numim video - informație audio-vizuală). Extragerea informației de mișcare are ca
scop localizarea acelor regiuni de pixeli din imagine în care survin schimbări în timp, de
regulă de la un cadru la altul.
1 http://www.youtube.com

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
6
Însă principala componentă de descriere a conținutului multimedia o constituie
textul. Cele mai importante sisteme existente de căutare multimedia se bazează pe
descriptori textuali, avantajul acestora fiind acela că oferă un nivel de descriere semantic
a conținutului foarte apropiat de nivelul de percepție uman. Dintre metodele cele mai
frecvent folosite putem enumera reprezentarea de tip Term Frequency–Inverse Document
Frequency (TF–IDF) și Bag-of-Words (B-o-W).
Totuși, datorită puterii discriminatorii limitate a descriptorilor, utilizarea acestor
trăsături nu poate rezolva întotdeauna problema indexării, de multe ori fiind nevoie de
ajutor din partea utilizatorului. Astfel, o metodă utilizată este cea de relevance feedback.
Mai precis, utilizatorul va selecta documentele ca fiind relevante sau nerelevante
(corespund sau nu cerererii de căutare), după care se realizează o rafinare a rezultatelor și
o nouă reantrenare a sistemului. În urma acestui proces, sistemul va returna un set
îmbunătățit de documente relevante.
O altă metodă pentru îmbunătățirea performațelor este utilizarea de clasificatori.
Clasificarea datelor reprezintă un proces prin care unui descriptor i se atribuie una sau
mai multe etichete. Inițial, are loc o etapă care se numeşte şi etapă de învăţare sau de
antrenare, în care un algoritm de clasificare construieşte un model matematic al
conceptelor ce trebuie învățate. Apoi, datele vor fi clasificate în funcție de modelul creeat
anterior.
Fig. 1.2 Arhitectura de bază a unui sistem de căutare după conținut multimedia.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
7
1.2 Scopul tezei de doctorat
Obiectivul principal al acestei lucrări este propunerea de soluții în vederea optimizării
procesului de indexare automată a datelor multimedia. În cadrul Figurii 1.2 este
prezentată arhitectura de bază a unui sistem multimedia, alături de principalele contribuții
originale realizate în intervalul tezei de doctorat.
Prima componentă este interfața utilizator-calculator, care va permite
utilizatorului să localizeze informațiile dorite, pe baza unei cereri de căutare. Aceasta
poate să permită ca cererea să fie realizată într-un mod cât mai natural, la îndemâna
oricărui utilizator. Totuși, utilizatorul poate să interacționeze cu sistemul nu numai pentru
interogare, ci și pentru antrenarea acestuia, proces cunoscut sub denumirea de relevance
feedback. Acesta reprezintă un mecanism interactiv de învațare în timp real, prin
utilizarea sugestiilor oferite de utilizatorii aplicației. În cadrul aceste lucrări îmi propun să
creez mecanisme de învățare rapide și eficiente care pot fi integrate în interacțiunea
utilizator-calculator. Aceste metode vor fi utilizate atât în scopul îmbunătățirii
performanțelor de indexare a bazelor de date de imagini, cât și a celor video.
Un alt concept important pentru căutarea de informației multimedia este cel de
definire a unui sistem de similaritate dintre date și descriptorii aferenți (indexator).
Practic identificarea rezultatelor căutării se realizează prin localizarea datelor ce sunt
„similare” până la un anumit punct cu interogarea efectuată. Prezenta lucrare va expune
diferite metode de evaluare și fuziune a similarității dintre diferite documente multimedia
și aplicații ale acestora pentru probleme individuale de indexare.
Însă cea mai comună metodă de partiționare a datelor este reprezentată de
utilizarea algoritmilor de clasificare automată. Aceștia vizează împărțirea automată a
datelor prin utilizarea de tehnici supervizate și nesupervizate. În cadrul aceste lucrări voi
utiliza diferite metode de clasificare pentru rezolvarea anumitor probleme specifice, ca de
exemplu: clasificarea de imagini medicale, detecția automată a genului, a acțiunilor
sportive sau cotidiene, detecția violenței în cadrul documentelor video sau a gesturilor
mâinii.
Nu în ultimul rând, cea mai importantă componentă a unui sistem multimedia,
este reprezentat de modul de extragere automată a trăsăturilor datelor. În cadrul prezentei
lucrări, voi propune sau utiliza un set de descriptori vizuali, de mișcare, audio și text.
Algoritmii propuși vor fi utilizați pentru rezolvarea unor probleme de interes, ca
indexarea automată a bazelor de date de imagini (naturale, de textură, de formă sau
medicale) sau video (prin utilizarea de trăsături multimodale: vizuali, audio și text).
1.3 Conţinutul tezei de doctorat
Lucrarea este structurată în opt capitole după cum voi explica în continuare.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
8
În Capitolul 2 intitulat „Conceptul de indexare după conținut” este prezentată
arhitectura clasică a unui sistem de indexare după conținut. În prima parte este detaliată
problematica indexării datelor multimedia și sunt prezentate problemele și provocările
existente în domeniu. În acest scop, am efectuat o trecere în revistă a metodelor și
tehnicilor folosite în sistemele actuale de indexare a imaginilor (CBIR), a sunetului
(CBAR), a documentelor video (CBVR) precum și a documentelor text. De asemenea,
sunt prezentate metodele de fuziune a informației provenite din cadrul acestor sisteme.
Urmează o detaliere a fiecărei componente a unui sistem de indexare după conținut:
retriever, indexator și browser. În cadrul componentei de retriever, se prezintă metricile
utilizate de către algoritmi pentru calcularea similarităţii sau disimilarităţii dintre
documente. În final, sunt prezentate metode de evaluare şi măsurare a performanţelor
algoritmilor de indexare. Mai mult, sunt trecute în revistă bazele de date standard sau
competițiile internaționale care pot fi folosite pentru compararea metodelor de indexare
multimedia.
În cadrul Capitolului 3, denumit „Metode clasice de descriere a conținutului
multimedia” sunt prezentate diverse metode și algoritmi multimedia care vor fi ulterior
folosite pentru dezvoltarea contribuțiilor proprii. Prima parte este dedicată analizei
trăsăturilor vizuale: informația de culoare, textură, formă și puncte de interes. Mai mult, sunt
trecute în revistă principalele trăsături vizuale propuse în cadrul standardului MPEG 7. În a
doua parte sunt expuse metodele de descriere și analiză a mișcării, informației audio și
textuale.
În Capitolul 4, intitulat „Algoritmi de relevance feedback” se prezintă câteva
consideraţii generale privind algoritmii care procesează automat feedback-ul
utilizatorului pentru îmbunătățirea performanțelor sistemelor de indexare multimedia.
Astfel, sunt trecute în revistă aspecte importante legate de modalitățile de colectare ale
feedback-ului și clasificări generale ale algoritmilor prezentați în literatură. Apoi, în a
doua partea a capitolului sunt prezentați în detaliu diferiți algoritmi de relevance
feedback: algoritmi ce utilizează mutarea punctului de interogare, algoritmi ce modifică
importanța trăsăturilor, metode de relevance feedback cu algoritmi statistici și sisteme de
relevance feedback care utilizează algoritmi de clasificare.
Capitolul 5, intitulat „Dezvoltarea conținutului de textură folosind automate
celulare”, conţine o primă propunere originală pentru un algoritm propus pentru descrierea
şi clasificarea imaginilor de textură. Acesta este inspirat de către teoria automatelor
celulare. Performanţa descriptorului a fost validată pe o variată gamă de baze de date de
textură, fiind în același timp comparată cu diferite abordări clasice existente în literatură.
Mai mult, algoritmul va fi testat atât în contextul unui sistem de clasificare cât şi din
perspectiva unui sistem de căutare a imaginilor după conţinut. Algoritmul propus se
evidențiază atât prin complexitate redusă de calcul, simplitate de implementare, cât și
prin rezultate similare sau mai bune decât cele ale algoritmilor clasici de descriere a
texturii.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
9
În Capitolul 6, denumit „Descrierea conținutului folosind reprezentarea Fisher
kernel”, propune o nouă metodă pentru capturarea variației temporale în filme, prin
utilizarea reprezentării Fisher. Față de majoritatea algoritmilor existenți care se bazează
pe utilizarea unei reprezentări pentru toată secvența video, noțiunea temporală fiind astfel
pierdută, metoda Fisher agregă vectori de dimensiuni fixe într-o reprezentare de lungime
constantă, dar care păstrează încorporată informația temporală. Metoda propusă pentru
modelarea variației temporale are un caracter foarte general, fiind testată pe o varietate de
baze de date de referință: MediaEval 2012 (pentru clasificarea genului video), UCF Sport
50 (clasificare de activități sportive) și ADL (pentru recunoaștere de fapte cotidiene). Mai
mult, metoda a fost analizată pe o gamă largă de trăsături, de la descriptori clasici audio,
la trăsături clasice vizuale și de mișcare, până la trăsături de flux optic extrase pe
componentele corpului uman. În toate experimentele am obținut rezultate mai bune sau
asemănătoare cu cele mai bune metode existente în literatură.
În Capitolul 7, intitulat „Metode de relevance feedback propuse” sunt prezentate o
serie de algoritmi de relevance feedback propuse. Pentru început, voi prezenta un
algoritm de relevance feedback pentru îmbunătățirea căutării în cadrul bazelor de date de
imagini. Acesta combină o metodă nouă de calcul a importanței trăsăturilor împreună cu
o variantă optimală de schimbare a punctului de interogare. Următorul algoritm de
relevance feedback utilizează o structură ierarhică arborescentă aglomerativă. Această
metodă se evidențiază atât prin viteză crescută de indexare, cât și prin rezultate mai bune
față de algoritmii clasici de relevance feedback din literatură. Mai mult, algoritmul
propus poate fi implementat atât în contextul bazelor de date video cât și a celor de
imagini, fiind testat pe o gamă variată de descriptori. În ultima parte, va fi prezentată o
metodă originală de relevance feedback propusă în contextul bazelor de date video.
Algoritmul propus utilizează teoria Fisher kernel și va fi testat pe o bază de date de
dimensiuni mari (MediaEval 2012) cu o gamă largă de descriptori multimodali (vizuali,
audio și text). Experimentele vor demonstra că metoda propusă îmbunătățește
performanța de indexare, surclasând alte metode existente în literatură.
Capitolul 8, denumit „Particularizarea conceptelor pentru diferite domenii de
aplicație” este structurat în două secțiuni. Această parte conține diferite analize și soluții
pentru anumite probleme de interes de clasificare multimedia. În prima secțiune vor fi
prezentate metode testate pe două baze de date medicale: o primă bază de date de imagini
otoscopice pentru detecția otitei și o bază de date de celule canceroase sangvine canine,
pentru care vom efectua un studiu comparativ asupra mai multor descriptori și
clasificatori state-of-the-art. În cadrul celei de-a doua părți voi prezenta un set de metode
și sisteme pentru indexarea conținutului multimedia pentru diferite aplicații: detecția
automată a genului unui film, detecția violenței în filme și detecția gesturilor mâinii.
Teza se încheie cu Capitolul 9 care este dedicat prezentării concluziilor finale care
se desprind din aspectele teoretice şi practice ale cercetărilor efectuate şi care sintetizează
contribuţiile personale aduse în această lucrare. De asemenea, sunt trecute în revistă lista

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
10
publicațiilor și a contribuțiilor realizate în perioada studiilor doctorale. În final, sunt
prezentate perspectivele viitoare de cercetare.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
11
Capitolul 2
Conceptul de indexare după conținut
2.1 Introducere
Utilizarea documentelor multimedia face parte din viața cotidiană a oricui. Un exemplu
banal este influenţa televiziunii sau a jocurilor pe calculator în societatea de astăzi. Deci,
cele mai frecvente şi simple întrebuințări ale adunării, transmisiei şi afişării de
documente multimedia sunt recrearea, distracţia și crearea de reţelele sociale (ex: găsire
imagini asemănătoare pentru persoane diferite). Cea mai mare rețea de socializare,
„Facebook”, are mai mult de 1,2 miliarde de utilizatori activi, dintre care cel puțin
jumătate intră în aplicație săptamânal, iar numărul de minute petrecute pe site lunar
atinge 700 de miliarde de minute. Facebook a devenit un site global, este disponibil în
peste 70 de limbi, iar 72% din utilizatorii Facebook sunt din exteriorul SUA. De
asemenea, fotografia este un domeniu care a luat amploare exponenţială în ultimii 20 de
ani, odată cu apariţia camerelor digitale şi a internetului. Galeriile de artă online, cât şi
imaginile cu vedete / sportivi / artişti, sunt de asemenea un alt exemplu de utilizare a
imaginilor pe internet. Flickr, Picassa, Google Image sunt denumiri familiare aproape
fiecărui utilizator obișnuit de internet. Alături de întrebuințarea clasică a imaginilor,
există numeroase domenii profesionale, cu diverse constrângeri, care necesită diverse
tehnici de optimizare [1].
Abordarea clasică, utilizată de primele sisteme de căutare în bazele de date
multimedia, se bazează pe adnotarea fiecărui fişier cu metadate. Însă acestea sunt dificil
de completat şi de foarte multe ori ineficiente sau irelevante pentru conceptul adnotat.
Din acest motiv, a apărut necesitatea dezvoltării unor sisteme în care documentele
multimedia să poată fi descrise automat, pe baza conținutului acestora. Primele sisteme
de căutare după conținut au fost cele de indexare de imagini, denumite și sisteme de
căutare a imaginilor după conținut (CBIR - content based image retrieval systems),
alături de cele de indexare a documentelor text (text retrieval systems - TRS).
În anii ‘80 au apărut primele publicații în care se discută despre descrierea
conţinutului multimedia (Ballard și Brown 1982 [2], Levine1985, Haralick și Shapiro
1993 [3]), în timp ce primele sisteme de căutare a conţinutului media QBIC („Query By
Image Content”) [4] au fost create abia la mijlocul anilor ‘90: Flickner în 1995 [4] şi
Virage Bach în 1996 [5]. Inițial, sistemele multimedia au fost utilizate în domenii
specifice: pentru stocarea și regăsirea de date detaliate despre pacienti (ex: radiografii

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
12
pentru diagnostic şi determinarea evoluţiei stării pacientului), înregistrarea
componentelor de proiectare, înregistrare hărți din satelit (GIS), aplicații de securitate
(amprente, recunoaștere de fețe, înregistrări video etc). În ultimii 10 ani, evoluția
tehnologică a dispozitivelor de achiziție și prelucrare a datelor (terminale mobile, sisteme
de calcul) cât și a infrastructurii de transmisie de date au dus la creșterea exponențială a
volumului de date multimedia, prin facilitarea stocării și prelucrării acestuia. Informațiile
multimedia ocupă un loc important din datele tranzacționate pe internet, conținutul video
online reprezentând în 2006 un procent de 26% din volumul total al traficului de date
(sursa Cisco Systems). În acest sens, în ultimii ani au fost dezvoltate diferite sisteme de
indexare a documentelor audio și a documentelor video (content based video and audio
retrieval systems: CBVR și CBAR).
În prezent, volumul și dimensiunea internetului a devenit uriașă. Din acest motiv,
căutarea și selecția informației relevante ocupă un loc foarte important. Spre exemplu, în
2012, Google a indexat un număr de 50 de miliarde de pagini web și peste 5 triliarde de
căutări pe zi (sursa: http://www.statisticbrain.com).
O primă funcționalitate pe care un sistem de indexare trebuie să îl conțină este
funcția de interogare. Prin intermediul acestei funcții, utilizatorul are acces direct la
datele din bază. În funcție de tipul datelor, poate fi necesară o adoptare a unei strategii
complexe. Spre exemplu, un sistem de căutare după conținut poate fi interogat după:
metadate ajutătoare;
prezenţa unei anumite combinaţii de culoare, textură, formă;
prezenţa unui obiect sau a unui aranjament specific de obiecte (ex: mai multe obiecte
așezate într-o anumită formă) ;
prezenţa unei persoane/ locaţii/ eveniment (ex: 1 Decembrie – paradă militară);
emoţii subiective (ex: bucurie, supărare);
prezența unei anumite coloane sonore sau a unui dialog pe o anumită temă.
Eakins a clasificat sistemele multimedia, în funcție de gradul de abstractizare al
interogării, în trei nivele majore [6]:
nivelul 1: foloseşte descriptori primitivi (de nivel scăzut) precum culoarea, textura,
forma, distribuţia spaţială a elementelor unor imagini, puncte cheie, trăsături
elementare ale conținutului audio etc.
nivelul 2: căutarea unor documente care conţin anumite obiecte (aşa numita tehnică
de „subquery”). Poate fi împărţită în două tipuri de interogări:
- căutare a unor obiecte de un anumit tip (ex: documente cu maşini, animale etc);
- căutare a unor obiecte anume (ex: documente cu turnul din Pisa).
nivelul 3: căutarea se face după termeni abstracţi, sistemele având nevoie de putere
de procesare considerabilă şi au rolul de interpretare şi înţelegere a scenelor din
imagini.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
13
Acest nivel poate conține la rândul lui mai multe tipuri de interogări:
- regăsirea unor evenimente şi tipuri de activităţi (ex: căutare documente în care se
joacă hora);
- căutarea de imagini care conţin emoţii sau semnificaţii religioase deosebite.
2.2 Domenii de aplicabilitate
Medicina şi profesiile asociate utilizează la scară largă imaginile în procesul de
diagnosticare şi prevenire, utilizând o gamă variată de aparate imagistice: raze X,
ultrasunete etc. Sistemele CBIR sunt utilizate în diagnosticare şi monitorizare în domenii
ca oncologie, ortopedie, medicină internă, neurologie și radiologie. Creșterea foarte mare
a numărului de dispozitive medicale care generează un număr mare de imagini per
pacient, a dus la nevoia de creare de facilități pentru stocarea şi căutarea rapidă a fișei
pacientului. Există țări în care legislația prevede ca fișa pacientului să fie stocată pe toată
perioada vieții acestuia, iar în unele cazuri chiar şi după moartea acestuia. Acest lucru
inseamnă că pe o perioadă de câteva zeci de ani trebuie stocate un număr semnificativ de
„imagini” sau documente video și text ale pacientului. De asemeni, aceste date pot fi
utilizate pentru studii științifice: evoluația bolilor pe diverse perioade de timp, predicție
de diagnostic, generare de statistici privind evoluția anumitor afecțiuni, vizualizarea unor
forme ascunse în cadrul imaginii (pseudocolorare, schimbare de contrast) etc.
Moda şi design – Imaginile sunt foarte importante în creaţiile de modă şi în
designul industrial. Vizualizarea diverselor părţi componente sunt esenţiale în procesul de
creaţie, dar în acelaşi timp, observarea creaţiilor deja existente cu elemente asemănătoare.
Tehnici de modelare 2D şi 3D sunt utilizate pentru vizualizarea noilor produse în
perioada de proiectare şi compararea acestora cu imagini deja existente.
Arhitectura reprezintă un alt domeniu cu utilizare intensivă a imaginilor.
Fotografiile sunt folosite în arhitectură pentru a înregistra interiorul şi exteriorul
clădirilor, dar și în diverse scopuri: publicitate, căutare de modele ş.a.m.d. în inginerie,
sau pentru proiectare, utilizând tehnologiile de proiectare CAD 2D şi 3D.
Securitatea şi aplicațiile militare au jucat cel mai important rol în cercetare în
ultima sută de ani. Principala aplicație a căutarii după conținut este detecția şi
recunoașterea de fețe. Există numeroase aplicații care creează fețe ale unor suspecți
bazate pe descrieri ale martorilor, după care se generează anumite modele pe baza cărora
se efectuează o căutare în baza de date. Alte aplicații sunt reprezentate de cele biometrice
(recunoaștere de amprente şi iris, dispozitive unice de identificare pentru utilizatori),
detecția mișcarii prin intermediul documentelor video s.a.m.d.
Automatica utilizează sistemele de indexare după conținut pentru clasificarea și
controlul automat al calităţii diferitelor produse pentru diverse domenii economice. Un

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
14
exemplu concret este reprezentat de fotografierea / filmarea produselor ce trec pe bandă
rulantă, iar acestea sunt controlate automat pentru verificarea calității.
Alte domenii importante de utilizare a sistemelor de căutare după conţinut sunt:
arheologia, robotica, proprietatea intelectuală, cultura, educaţia şi lista poate continua cu
uşurinţă.
2.3 Problematica sistemelor de căutare după conținut
Sistemele de căutare a imaginilor după conţinut se deosebesc de sistemele clasice de
stocare prin tehnica nouă de indexare şi interogare a sistemului denumită interogare după
exemplu („query by example” - QBE) [4]. QBE este o tehnică de interogare prin care
utilizatorul propune sistemului un model ca exemplu de căutare, iar sistemul va returna
documentele asemănătoare cu interogarea aleasă. Spre exemplu, pentru un sistem de
căutare de imagini, există mai multe tehnici de interogare posibile:
- utilizatorul poate efectua o interogare după un set de cuvinte cheie, apoi selectează un
document care va fi folosit ca și model de interogare;
- userul desenează o aproximare a imaginii căutate utilizând pete de culoare şi exemple
de texturi;
- se încarcă o imagine de pe calculatorul personal.
Această tehnică are rolul de a elimina dificultăţile care apar în descrierea imaginii
prin utilizarea cuvintelor cheie. Query by example a fost utilizat pentru prima dată în
(QBIC) [4]. Algoritmul folosește criteriul similarităţii și utilizează caracteristicile de
nivel scăzut (low level) ca forma, culoarea și textura în recunoașterea de imagini
asemănătoare. Sistemele ca Virage [7] şi Excalibur [8] oferă utilizatorului posibilitatea de
alegere a criteriului optim de interogare prin alocare de ponderi pentru fiecare tip de
descriptor. Alte sisteme (Smith şi Chang [9]) permit definirea de regiuni şi specificarea
relaţiilor dorite între regiuni. Odată ce măsurile de similaritate sunt determinate,
utilizatorul oferă exemplul bazei de date, iar sistemul va selecta criteriul ales și va afişa
primele imagini găsite (de obicei între 10-30 de imagini). Acest model este reprezentativ
pentru simplitatea lui, deoarece reprezintă o extensie naturală a problemei de găsire a
similarităţii vectorilor în spaţiul multidimensional. Există însă mai multe neajunsuri pe
care le oferă această metodă. Prima problemă este complexitatea găsirii unui model
reprezentativ pentru imaginea căutată. De foarte multe ori este dificil de obţinut imaginea
dorită pentru a putea fi oferită sistemului, iar uneltele puse la dispoziţia utilizatorului
pentru a putea desena modelul dorit, îl pot pune într-o mare dificultate, deoarece nu toţi
au „valenţe artistice”. O altă problemă este că o schemă este o reprezentare mult
simplificată a imaginii, și uneori este insuficientă pentru regăsirea imaginilor complexe.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
15
(A) (B) (C)
Fig. 2.1 Exemplificare a paradigmei semantice prin utilizarea histogramei de culoare.
Imaginea din centru (B) este o versiune mai luminoasa a imaginii din stânga (A) dar
seturi diferite de caracteristici clasifica imaginile A şi B ca fiind mai aproape de C decat
distanta dintre ele: dist(A, B) = 0.20, dist(A, C) =0.25, dist(B, C) =0.05.
O altă metodă populară de căutare o reprezintă tehnica de reranking. Utilizatorul
generează o căutare prin utilizarea de metadate2. Sistemul returnează o listă de
documente care conține cuvântul căutat, după care utilizatorul selectează un număr de
documente care sunt relevante pentru căutarea curentă. Sistemul va genera o nouă
căutare, care va utiliza informațiile pe care le conțin documentele selectate (vizuale /
audio / text).
Oamenii sunt capabili să interpreteze documentele multimedia la nivele diferite:
atât caracteristici de nivel scăzut (culoare, textură, forme, viteza de mișcare, intensitatea
sonoră) cât şi cele de nivel semantic ridicat (obiecte abstracte, evenimente). Spre
deosebire de oameni, sistemele de indexare sunt capabile doar de a interpreta descriptorii
de nivel scăzut. De cele mai multe ori, utilizatorul doreşte să interogheze baza de date şi
la nivel semantic, şi de aici apar probleme diverse de reprezentare a informației. Această
problemă este cunoscută ca şi paradigmă semantică („semantic gap”) [10]. „Paradigma
semantică” caracterizează diferenţa dintre două descrieri ale unui obiect, utilizând diferite
reprezentări lingvistice şi simbolice. În computer vision conceptul este relevant atunci
când încercăm să reprezentăm diferite scene utilizând o reprezentare computaţională.
Interpretarea semantică a unei imagini are, de foarte multe ori, o foarte mică legătură cu
corelaţia statistică a valorilor pixelilor. Un exemplu explicativ îl găsim în Figură 2.1
Pentru descrierea acestor imagini am utilizat un descriptor clasic, și anume histograma
de culoare. Deși imaginile A și B au un conținut identic, imaginile B și C sunt mai
similare deoarece în spațiul descriptive al imaginilor, distanța dintre cele două trăsături
este mai mică.
2 metadatele sunt definite uzual ca fiind ”date despre date”, sau altfel spus, date care descriu alte date, de
orice fel și de orice tip. Cu alte cuvinte, metadatele oferă informații suplimentare la o serie de date. De
exemplu, o imagine, pe lângă conținutul acesteia propriu-zis poate conține metadate ce specifică descrierea
conținutului acestuia.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
16
Un alt exemplu relevant de semantic gap îl gasim în Figura 2.2. Imaginile au cu
aceeași formă, culoare și textură, însă înțelesul semantic este unul complet diferit.
Fig. 2.2 Exemple de perechi de imagini în care paradigma semantică este prezentă.
Perechile de imagini au culoare, textură şi formă asemanatoare, dar sensuri diferite.3
Tot în [10] este definită o a doua problemă, şi anume paradigma senzorială.
Aceasta reprezintă discrepanţa care există între informațiile prezente în scena reală 3D şi
informaţiile furnizate de imagine, imagine ce reprezintă o proiecţie discretă 2D obţinută
în momentul înregistrării scenei.
Una din tehnicile utilizate în înlăturarea acestor probleme este reprezentată de
clasa de algoritmi de relevance feedback. Ideea principală din spatele acestui concept
constă în introducerea utilizatorului ca parte integrantă a sistemului. Acesta va ajuta la
antrenarea sistemului și, deci, la imbunătățirea performanțelor de căutare. După ce
utilizatorul definește modelul de căutare, sistemul afișează un set de documente candidat.
Utilizatorul poate marca documentele relevante şi irelevante, după care sistemul se va
reantrena, astfel încât noua listă de documente să reflecte feedback-ul acordat de
utilizator. În mod particular, relevance feedback poate fi privit ca o tehnică de clasificare
de patern, sistemul utilizând răspunsul returnat de utilizator pentru o antrenare continuă a
sistemului. Relevance feedback utilizează exemplele pozitive şi negative preluate de la
utilizator, pentru a imbunătăţii performanţa sistemului (Figura 2.3).
Principalele provocări pe care un sistem de căutare după conținut trebuie să le
satisfacă sunt:
performanţa scăzută a sistemelor datorită volumelor mari de date (triliarde de
documente);
crearea de unelte software performante pentru interogare şi regăsire documentelor
după concepte complexe;
mecanisme noi de navigare, astfel încât să ajute utilizatorul în îmbunătățirea
interogării;
gradul de automatizare / reantrenare al sistemului în timp real;
conținutul: modul de întelegere al documentelor din punctul de vedere al
utilizatorului;
3 sursă imagine http://www.blog.joelx.com/dog-lookalikes.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
17
descriptori: tipul de calcul al descriptorilor și limitările numerice ale acestora;
performanța: probleme de arhitectură a sistemului, de evaluare și integrare;
ușurința utilizării sistemului de către utilizator.
Fig. 2.3 Prezentarea procesului de interacțiune utilizator-sistem în cadrul
algoritmului de relevance feedback.
2.4 Arhitectura unui sistem de indexare multimedia
Principiul de funcționare al unui sistem de indexare multimedia după conținut constă în
următorii pași: interogarea sistemului, căutarea în baza de date şi afişarea rezultatelor
căutării. Iniţial, utilizatorul accesează interfaţa sistemului (denumit browser) şi generează
o nouă interogare. Sistemul calculează descriptorul modelului căutat, după care compară
gradul de similitudine dintre acesta și descriptorii stocați în baza de date. Sistemul va
prezenta utilizatorului documentele cu gradul de similitudine cel mai ridicat. Acest modul
poartă numele de retriever. În cazul în care utilizatorul nu este satisfăcut de documentele
returnate, el are posibilitatea de a selecta documentele relevante și de a efectua o nouă
căutare în sistem. Procesul poate fi repetat până când sistemul va oferi un număr suficient
de documente relevante pentru utilizator.
Un sistem de indexare multimedia după conţinut este alcătuit din trei componente
principale: indexator, retriever şi browser. Schema unui sistem de căutare a obiectelor
multimedia după conţinut este prezentată în Figura 2.4.
2.4.1 Indexator
Indexator-ul reprezintă componenta de stocare și descriere a conținutului multimedia. De
asemenea, indexatorul are în componență și algoritmul de generare al vectorului

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
18
descriptor. Mai multe detalii despre structura unui descriptor vor fi prezentate în
Secțiunea 3 a lucrării. În acest subcapitol îmi propun prezentarea pe scurt a tehnologiilor
care pot fi utilizate în stocarea descriptorilor și a fișierelor multimedia.
Sistemele de baze de date moderne pun la dispoziţie metode şi unelte specializate
pentru gestiunea bazelor de date multimedia. Fişierele multimedia sunt stocate sub forma
tipului de date BLOB (binary large objects) sau direct pe un fileserver, baza de date
conţinând doar calea acestora. Oracle este unul dintre SGBD-urile cu componente special
dezvoltate pentru gestiunea și stocarea bazelor de date multimedia. În Oracle există două
abordări ale bazelor de date multimedia: prima foloseşte baze de date relaţionale iar a
doua utlizează baze de date obiect-relaţionale. Prima variantă utilizează tipuri de date de
tip LOB (Large Object), care permit stocarea fisierelor multimedia sub formă binară. În
1999, Oracle introduce modulul Intermedia, care facilitează programarea obiect-
relaţională, tipurile de date utilizate permițând stocarea, gestiunea si regăsirea datelor
multimedia într-o manieră integrată cu tipuri de date tradiţionale.
Fig. 2.4 Schema unui sistem clasic de căutare a documentelor multimedia după conţinut
Serverul de baze de date MySQL4 nu oferă caracteristici speciale pentru stocarea
imaginilor, însă pune la dispoziţie tipul de date BLOB, utilizat pentru stocarea fişierelor
binare. Există patru tipuri de date BLOB: TINYBLOB, BLOB, MEDIUMBLOB şi
LONGBLOB. Singura diferenţă dintre acestea o reprezintă dimensiunea maximă pe care
îl poate avea fişierul stocat: în cazul în care fişierul va avea o dimensiune mai mare decât
cea maximă permisă, acesta va fi trunchiat. Pentru fişiere de dimensiune foarte mare se
poate utiliza tipul de date varbinary, însă cu dimensiune limitată la 1 GB.
4 www.mysql.com - MySQL 5.0 Reference Manual. (2009)

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
19
Microsoft SQL Server5 conține de asemeni tipuri de date speciale pentru fişiere
binare: VARBINARY(max) – cu valori maxime de până la 2 GB, dar şi tipul IMAGE (cu
valori maxime similare).
2.4.2 Browserul
Browserul este probabil, pentru utilizator, componenta cea mai importantă, deoarece
reprezintă interfaţa lui de interogare a bazei de date. Majoritatea sistemelor permit funcţii
clasice de interogare şi căutare a bazei de date:
afişare de documente aleatoare din baza de date;
afişare a documentelor după o anumită logică: în ordine alfabetică a denumirii, în
ordinea lungimii documentului etc;
filtrare după cuvinte cheie sau alte metadate (comentarii document, nume uploader,
secțiune încărcare document etc).
(a) (b)
(c) (d)
Fig. 2.5 Exemplu de browser pentru un sistem de căutare al imaginilor după conţinut
(Id-Image) prezentat în [11]: a) căutare de filme b) căutare de forme c) căutare de
texturi d) căutare de imagini medicale
A doua funcţie a browser-ului este navigarea în baza de date și afișarea
documentelor. Au fost propuse mai multe modalități de vizualizare și căutare a datelor:
5 http://www.microsoft.com/en-us/sqlserver - Microsoft SQL Server.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
20
vizualizare clasică – documentele sunt afişate în ordinea similarităţii acestora (ex:
Figura 2.5). Un astfel de sistem propriu a fost prezentat în [11].
vizualizare 2D – documentele sunt afişate pe o hartă bidimensională în funcţie de
gradul de similaritate dintre acestea [12] [13]. Pentru reducerea dimensiunii
descriptorului unui document şi afişarea acestuia într-un spaţiu 2D, au fost propuse
diverse variante de reducere a dimensionalității. Algoritmii clasici propuși sunt MDS,
PCA și FastMap [14] [15], însă aceștia funcţionează doar pentru tipuri de structuri
liniare. Alți algoritmi propuși sunt: „isometric mapping” (ISOMAP) [16], „local
linear embedding” (LLE) [17] şi „stochastic neighbour embedding” [18]. Exemple de
interfețe 2D dinamice sunt RetrievalLab [19] și MediaMill [20] (Figura 2.6).
vizualizare 3D – imaginile sunt prezentate într-un mediu 3D navigabil:
– navigare 3D după dimensiuni de similaritate (Figura 2.7);
– 3D în formă de galaxie, rotor, glob, cruce, furculiță, cilindru (Figura 2.8).
Fig 2.6 Exemple de browser 2D (MediaMill) [20]
Fig 2.7 Exemplu de browser cu navigare 3D (3D Mars) [21]. Sistemul permite căutarea
de imagini pe diferite direcții de similaritate (culoare, textură sau structură)

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
21
(a) (b) (c)
(d) (e)
Fig 2.8 Ilustrații ale unor sisteme cu browser cu navigare 3D în formă de: a) cruce [20],
b) sferă [20], c) galaxie [20], d) şi e) în formă de cilindru [22]
2.4.3 Retriever
Retriever-ul este componenta care face legătura dintre interfaţa utilizatorului şi baza de
date. Acesta calculează descriptorul modelului căutat şi îl compară cu cele existente în
sistem. De obicei, acest modul este construit într-un mediu de programare care permite
calcule rapide şi conţine biblioteci multimedia: C, C++, .NET, Java, Matlab, Phyton, PHP
etc.
O componentă importantă a unui sistem de indexare este reprezentată de definirea
conceptului de similaritate (sau opus, disimilaritate) dintre date sau dintre descriptorii
acestora. Practic, identificarea rezultatelor căutării se realizează prin localizarea datelor
ce sunt „similare” până la un anumit nivel cu cererea de căutare („query”). Cu alte
cuvinte, este necesară definirea unei funcții, capabilă să evalueze în ce măsură
două obiecte multimedia, și , arată în mod similar. În general, evaluarea similarității
dintre date se poate realiza fie la nivel de descriptori, la nivel de structură („layout”) sau
la nivel semantic, fie folosind combinații ale acestora.
Gradul de similaritate dintre două fișiere multimedia se efectuează în spațiul
descriptorilor, prin calcularea unei distanțe matematice dintre valorile celor două perechi
de descriptori. În continuare, vom considera funcția S() o măsura de distanță (metrică)
dintre 2 descriptori
și
. În cele ce urmează vom face o

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
22
trecere în revistă a diverselor metrici folosite în domeniul căutării informației. Marea
majoritate a acestora sunt inspirate din matematică [23].
Prima clasă de măsuri de similaritate dintre doi descriptori se bazează pe forma
Minkowski, care este definită ca:
(∑
)
(2.1)
Cele mai utilizate distanţe Minkowski sunt distanţa euclidiană (r=2), distanţa
Manhattan (r=1) şi Chebyshev (r = infinit). Căutari recente au arătat că utilizarea unui r
fracţionar poate duce la performanţe îmbunataţite, însă este cunoscut că aceste distanţe
încalcă inegalitatea triunghiului. Howarth şi Ruger [24] au demonstrat că performanţa de
regăsire poate fi crescută în multe circumstanţe pentru r=0,5. Pentru o comparație
completă dintre un document căutat și toți descriptorii din baza de date, complexitatea
metodei este O(mn), unde m reprezintă lungimea vectorului descriptor, iar n reprezintă
numărul de documente din baza de date.
În cazul în care nu toate elementele descriptorului au aceeași importanță, distanța
dintre fiecare pereche de valori poate fi ponderată diferit obținând astfel distanța
Minkowski ponderată:
(∑
)
(2.2)
unde , cu i = 1, ..., n reprezintă ponderile fiecărei valori.
Alte măsuri de distanță frecvent folosite sunt:
Distanța Canberra [25]:
∑
| |
(2.3)
Distanța Bray Curtis:
∑
| |
(2.4)
Distanţa Squared Chord [23]:
∑ √
√
(2.4)
Evident această masură nu poate fi utilizată pentru coeficienţi negativi
Funcția cosinus de disimilaritate calculează unghiul dintre doi vectori în spaţiul
multidimensional [26]:
(2.5)
Divergența Kullback-Leibler [27]: este o distanţă nesimetrică

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
23
∑
(2.6)
Divergenţa Jefrey [28]:
∑ (
)
(2.7)
unde
Statistica X2 [29]:
∑
(2.8)
unde
Coeficientul de corelaţie Pearson reprezintă o măsură derivată din coeficientul de
corelaţie Pearson
(2.9)
unde
∑
(∑
)(∑
)
√[ ∑ (∑
)(∑
)
][ ∑ (∑
)(∑
)
]
Pearson [29]:
∑
(2.10)
Neyman:
∑
(2.11)
Lorentzian:
∑
(2.12)
Soergel:
∑
∑
(2.13)
Czekanowsky:
∑
∑
(2.14)
Wave-Hadges:
∑
∑
(2.15)
Chi-Square:

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
24
∑
∑
(2.16)
În cazul în care cei doi descriptori au lungimi diferite, a fost definită intersecţia
parţială de histogramă. Când cei doi vectori au aceeaşi dimensiune, această distanţă este
echivalentă cu distanţa Manhattan [30]:
∑
(2.17)
Măsurarea disimilitudinii descriptorilor cu ajutorul formei Minkowski neglijează
compararea elementelor din histograme care sunt similare, dar nu identice. De exemplu, o
imagine cu regiuni roşii închis va fi considerată la fel de similară cu o imagine roşie
deschis cât și cu o imagine albastră. Pentru rezolvarea acestor probleme a fost introdusă
distanţa pătratică dintre histograme sau distanța Mahalanobis.
Distanţa Mahalanobis este dată de formula:
∑ ∑
(2.18)
unde [ ] iar reprezintă similitudinea între elementele cu indecşii i şi j.
De obicei, matricea A este simetrică , iar . Complexitatea
metodei este , unde m reprezintă numărul de trăsături, iar n reprezintă numărul
de documente din baza de date.
O altă perspectivă o constituie reprezentarea datelor sub formă de mulțimi.
Distanța Hausdorff evaluează gradul de apropiere a două submulțimi (A și B) într-un
anumit spațiu. Formula de calcul pentru distanța Hausdorff asimetrică de la A la B este:
(2.19)
unde d() reprezintă o anumită metrică (de exemplu distanța Minkowsky) iar max
returnează valoarea maximă a unei mulțimi.
Distanța simetrică Hausdorff este definită în modul următor:
(2.20)
Pentru seturi finite de puncte, aceasta poate fi calculată utilizând diagrame
Voronoi în complexitate O((M + N)log(M + N)). Distanța Hausdorff este sensibilă la
zgomot, una din propunerile de reducere a acestuia putând fi găsite în [31] [32].
2.5 Metode de fuzionare
În cele mai multe dintre cazuri, pentru reprezentarea conținutului multimedia este
necesară combinarea mai multor tipuri de descriptori. De exemplu, conținutul unei
secvențe de imagini poate fi reprezentat atât pe baza structurii temporale, cât și folosind
descriptori de mișcare, descriptori audio și așa mai departe. Metodele de fuzionare se
bazează pe principiul următor: o decizie agregată din partea mai multor sisteme expert
poate avea o performanță superioară celei oferite de un singur sistem. O problemă

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
25
complexă poate fi împărțită în mai multe subprobleme care sunt mai ușor de înțeles și de
rezolvat (principiul „divide et impera”). De asemenea, se cunoaște faptul că nu există un
singur model de clasificare de patern care să funcționeze pentru toate problemele
(teorema „no free lunch”), efect care poate fi însă parțial eliminat prin combinația mai
multor algoritmi. În cele mai multe dintre cazuri, pentru reprezentarea conținutului
multimedia este necesară combinarea mai multor tipuri de descriptori. De exemplu,
conținutul unei secvențe de imagini poate fi reprezentat atât pe baza structurii temporale,
cât și prin utilizarea descriptorilor de mișcare, descriptori audio și așa mai departe. În
general, există două tipuri de fuzionare: fuzionare timpurie („early fusion”) și fuzionare
târzie („Late Fusion”).
2.5.1 Metode de tip „Early Fusion”
Fuzionarea timpurie se efectuează la nivelul vectorilor descriptori, înainte de începerea
procesului de clasificare. Clasificarea va fi apoi efectuată pe un vector care combină mai
mulți descriptori. Deci, fuziunea datelor are loc în spațiul de caracteristici și constă
practic în concatenarea propriu-zisă a tuturor descriptorilor fără a ține cont de redundanța
acestora. De exemplu, dacă obiectul multimedia X este descris de descriptorii de conținut
, și respectiv , unde
a, b și c reprezintă valorile atributelor acestora, descriptorul agregat este dat de
concatenarea valorilor . Acesta
definește astfel un nou spațiu de caracteristici (n + m + l) dimensional.
Pentru a putea fi concatenați, descriptorii vor parcurge un proces individual de
normalizare [33] și de filtrare (eliminare date lipsă, valori anormale etc).
Fig. 2.9 Schema unui sistem cu fuziune „Early Fusion”
Combinația unui număr ridicat de descriptori implică mai multe probleme
elementare. Prima este generată de faptul că intervalele de variație ale descriptorilor pot fi
diferite (de exemplu, un descriptor poate lua valori în intervalul [0,1] în timp ce altul
poate varia în gama [1000,10000]).
Metodele de normalizare cele mai utilizate sunt [34]:
Descriptor 1
Descriptor 2
Descriptor n
Descriptor 1 normalizat
Descriptor n normalizat
Descriptor 2 normalizat decizie Clasificator

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
26
Min-Max (MM): această metodă mapează valorile vectorilor descriptori în
intervalul [0,1]. Scalarea elementelor se va efectua în funcție de valorile maxime și
minime ale vectorului descriptor:
(2.21)
Z-score (ZS): scalează valorile descriptorilor pe o distribuție de medie 0 și
dispersie egală cu 1.
(2.22)
Norma vectorului (vector norm): reprezintă o metodă preluată din algebra
liniară, unde, ca și în analiza funcțională sau alte arii ale matematicii, o normă reprezintă
o funcție care atribuie o lungime strict pozitivă unui vector într-un spațiu
multidimensional. Fie x un vector multidimensional: . Fie norma
vectorului x, având următoarele proprietăți:
| | pentru și | | pentru
| | | |, pentru k scalar
| | | | | |
Definim funcția normă de ordin p -| | ca fiind:
| | (∑
)
(2.23)
Valorile cele mai des întâlnite ale lui p sunt 1,2 și . Pentru , vom avea
relația:
| |
(2.24)
Tangenta hiperbolică (tanh): mapează valorile în intervalul (0,1), în funcție de
distribuția sa statistică:
[ (
)] (2.25)
Scalarea zecimală: se utilizează atunci când scala dintre diferite valori ale
vectorului descriptor diferă pe o scară logaritmică:
(2.26)
unde
Valoarea mediană sau deviația mediană absolută [33]: ia în calcul valoarea
mediană a vectorului descriptor:
(2.27)
unde
Funcția sigmoidă dublă [33]: se utilizează atunci când scala dintre diferite valori
ale vectorului descriptor diferă pe o scară nedefinită:

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
27
(
) (2.28)
unde pentru x<t și pentru restul intervalului, iar t este de cele mai
multe ori media distribuției descriptorului.
Fig. 2.10 Exemplu de normalizare folosind funcții dublu sigmoide (axa oX corespunde
valorilor inițiale iar axa oY valorilor normalizate).
Utilizarea primelor trei metode (min-max, z-score și tangenta hiperbolică) este
eficientă, însă ultimele tehnici prezentate (valoarea mediană și funcția sigmoidală dublă)
sunt mai robuste pentru o plajă mai mare de probleme.
Dezavantajele majore ale tehnicilor de tip „early fusion” sunt urmatoarele:
- există un control redus asupra contribuției pe care o are fiecare vector descriptor asupra
rezultatului. Pot exista valori ale lungimii descriptorilor total disproporționate (un vector
descriptor poate avea dimensiuni de cateva elemente în timp ce alt vector descriptor poate
avea lungime de mii sau chiar zeci de mii de trăsături);
- descriptorii pot conține valori redundante care nu au nici o influență în creșterea
performanțelor;
- concatenarea conduce la dimensiuni mari ale vectorului descriptor nou creeat. Astfel,
procesul de clasificare va fi unul intens computațional.
În ciuda dezavantajelor, fuzionarea „early fusion” are, în multe cazuri, o
performanță similară și chiar mai ridicată decât în cazul în care este utilizată metoda „late
fusion” [35].
2.5.2 Metode de tip „Late Fusion”
Algoritmii de tip „late fusion” propun îmbinarea deciziilor individuale a mai multor
sisteme expert, după ce au fost utilizați clasificatorii pe fiecare trăsătură în parte. Pe baza

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
28
răspunsurilor oferite de fiecare clasificator, se va calcula un raspuns agregat. În funcție de
metoda de combinare a clasificatorilor, „late fusion” se clasifică în patru mari categorii:
- fuziune paralelă: deciziile clasificatorilor sunt generate în mod paralel, ca apoi la
sfârșit să fie luată o decizie finală utilizând rezultatele tuturor sistemelor;
- fuziune serială: deciziile sunt acordate gradual. În funcție de fiecare răspuns
intermediar, se decide dacă se trece la alt clasificator sau decizia este finală. Mecanismul
este preluat din algoritmul AdaBoost, care creează o cascadă de clasificatori naivi [36].
- fuziune ierarhică: deciziile sunt luate în mod ierarhic, utilizând noduri de decizie. În
funcție de decizia obținută într-un nod, se va trece într-un nou nod de decizie. Există două
tipuri de abordări ierarhice: buttom-up (mai multe clasificatoare converg către un
clasificator final) sau top-down (în funcție de decizia unui clasificator inițial, decizia se
separă pe mai multe nivele). Variantele de fuziune ierarhică utilizează arhitecturi
asemanatoare cu a arborilor de decizie (ID3, C4.5) [37] sau a arborilor aleatori [38].
- fuziune mixtă: conține mai multe tipuri de fuziuni combinate.
(a) (b)
(c) (d)
Fig. 2.11 Ilustrații ale unor sisteme de „late fusion”: (a) Fuziune paralelă ierarhică,
(b)Fuziune serială, (c) Fuziune Ierarhică Bottom-Up, (d)Fuziune Ierarhică Top-Down
În continuare, vom detalia modalitatea cel mai utilizată de luare al deciziei, și
anume cazul fuzionării paralele. Acesta este ilustrat în Figura 2.11 (a). Având la
dispoziție N clasificatori antrenați cu descriptori de conținut diferit, fuzionarea de tip
„late fusion” presupune determinarea unei funcții care combină gradele de relevanță
furnizate de fiecare clasificator în parte, , reprezintă gradul de relevanță

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
29
atribuit de clasificatorul i datelor de intrare. Acestea sunt probabilitățile de apartenență la
clasele considerate, , unde c1, ..., cM reprezintă clasele considerate iar
reprezintă probabilitatea ca datele să fie atribuite ca aparținând clasei c.
În mod natural, fiecare clasificator va tinde să furnizeze grade de apartenență
diferite, fiind antrenat pentru descriptori diferiți. Funcția f (.) trebuie determinată în așa
fel încât rezultatele obținute de clasificatorul agregat să fie cât mai bune și superioare
fiecărui clasificator individual. Agregarea se va realiza pentru gradele de relevanță ale
fiecărei clase în parte.
În funcție de modul de calcul al deciziei, există două tipuri de fuziuni: fuziune
prin vot și fuziune prin combinarea scorurilor clasificatorilor.
Fuziunea prin vot creează un scor prin numărarea rezultatelor primite din partea
mai multor perechi de clasificatori. Principalele metode de „vot” sunt:
- decizia este luată în funcție de performanța celui mai bun clasificator
(2.29)
unde unde d reprezintă documentul curent, iar reprezintă decizia luată de clasificatorul
i.
- decizia este luată în funcție de numărul maxim de voturi (vot neponderat)
∑
(2.30)
unde unde d reprezintă documentul curent, iar este decizia luată de clasificatorul I
pentru descriptorul m.
- decizia este luată în funcție de scorul minim
( ) (2.31)
- decizia este luată în funcție de scorul maxim:
( ) (2.32)
- metoda „Borda” – este bazată pe anumite strategii electorale existente în anumite țări.
Algoritmul presupune ca fiecare „votant” să genereze o ordine a preferințelor pentru
fiecare clasă în parte. Astfel, primul clasat va avea n voturi, cel de pe poziția următoare n-
1 voturi. Clasa câștigatoare va fi cea în care suma preferințelor este maximă.
- metoda „Condorcet” [39]: se bazează de asemeni pe o anumită strategie
electorală, în care fiecare doi candidați se luptă reciproc, până când avem un singur
câștigător.
- metoda „rangului clasic” – presupune că fiecare „votant” poate avea mai multe
opțiuni de selecție. Se va selecta clasa cu număr maxim de voturi.
- metoda „rank position”: la fel ca în metoda Borda, fiecare clasificator va genera
o ordine a clasificării. Scorul final al fiecărei clase va fi calculat utilizând formula:

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
30
∑ (2.33)
- metoda „Pareto” – fiecare votant va genera o ordine a preferințelor. Vor fi
considerate voturi valide doar primele k preferințe ale utilizatorilor (fiecare vot valid va
avea o valoare egală). Se va selecta clasa care prezintă numărul maxim de voturi valide.
Fuziunea scorurilor de încredere va combina răspunsurile de ieșire ale
clasificatorilor.
Avantajul acestui mecanism de fuziune constă în faptul că fiecare descriptor va fi
antrenat în mod separat pe un clasificator potrivit. De asemenea, clasificarea are o viteză
mult superioară deoarece se efectuează pe seturi de date de dimensiuni reduse.
Principalul dezavantaj constă în faptul că se pierde eventuala corelație obținută prin
concatenarea grupurilor de descriptori. O primă modalitate de definire a funcției f() este
aceea a unei combinații liniare a scorurilor de relevanță:
( ) ∑
(2.34)
unde d reprezintă documentul curent, reprezintă probabilitatea de apartenență la
clasa , j = 1, ...,M cu M numărul de clase considerate, atribuită de clasificatorul i iar
reprezintă un set de ponderi. Un caz particular îl reprezintă considerarea de ponderi egale
ceea ce conduce la însumarea gradelor de relevanță pentru fiecare clasă.
Un alt exemplu este atribuirea unei ponderi superioare acelor date care
( ) ∑
(2.35)
unde F(d) reprezintă numărul de clasificatori pentru care documentul d apare în primele k
documente din punct de vedere al valorii de relevanță (k este o constantă stabilită a priori)
iar este un parametru de control.
În contextul diversificării metodelor de extragere a trăsăturilor și a apariției unui
număr ridicat de algoritmi de clasificare, fuziunea a devenit un domeniu de cercetare
foarte activ. Aceasta își propune să mărească performanța sistemelor de clasificare prin
agregarea deciziei din surse diferite de date, utilizând o varietate de etape de clasificare.
Astfel, mecanismele de fuzionare exploatează diversitatea informației provenită din surse
diferite.
Tehnicile de tip „late fusion” sunt mai avantajoase din punct de vedere
computațional, deoarece agregarea se face folosind dimensiunea inițială a descriptorilor.
Este mai eficientă clasificarea unor descriptori de dimensiuni reduse și agregarea
rezultatelor decât clasificarea unui descriptor agregat de dimensiuni semnificativ mai
mari. Principalul dezavantaj al acestor metode este, totuși, dat de pierderea eventualei
corelații dintre descriptori, corelație ce se obține în cazul concatenării acestora și care
poate furniza un nivel de discriminare superior folosirii individuale a acestora.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
31
În ciuda diferențelor dintre cele două abordări, „early fusion” și respectiv „late
fusion”, nu există o metodă preferențială în defavoarea celeilaltei, ambele abordări
dovedindu-se eficiente în contexte diferite. Astfel că tehnica de fuziune a datelor rămâne
dependentă de aplicație [35].
2.6 Măsurarea performanţelor
Evaluarea şi măsurarea performanţelor algoritmilor de indexare reprezintă o problemă
crucială. Criteriile de evaluare a performanţelor trebuie să evidenţieze diferenţele dintre
răspunsul așteptat și cel acordat de către sistem. Aceste metrici au rolul de a înlătura
subiectivismul în măsurarea performanţelor sistemului, şi de a reflecta starea obiectivă a
acestuia în comparaţie cu alte sisteme.
2.6.1 Standardul MPEG 7
Odată cu apariția primelor articole de indexare multimedia, problema principală constă în
lipsa de baze de date comune, general acceptate pentru testarea algoritmilor, şi a unor
seturi de metrici de evaluare utilizate global. Câteva popuneri au fost facute de către [40]
[41] [42]. Un prim standard de măsuri de calitate au fost specificate în standardul MPEG-
7, în 2001. Acesta cuprinde un set bine definit de parametri, și anume: rata de regăsire
(„retrieval rate” – RR), media ratei de regăsire („average retrieval rate” - ARR), media
rangului („average rank” – AVR), rangul de regăsire modificat („modified retrieval rank”
– MRR), rangul de regăsire modificat normalizat („normalized modified retrieval rank” –
NMRR), media rangului de regăsire modificat normalizat („average normalized
modified retrieval rank” – ANMRR).
Rata de regăsire reprezintă numărul de rezultate obținute pentru interogarea q din
numărul de rezultate corecte găsite în primele NF elemente:
(2.36)
unde NG(q) reprezintă numărul de documente pozitive conținute de interogarea q în
primele NF documente returnate. Rata de regăsire ia valori între 0 și 1, unde 0 reprezintă
faptul că niciun document nu a fost regăsit, iar valoarea 1 reprezintă perfomanța maximă.
În cazul în care avem mai multe interogări q, putem calcula media ratei de regăsire ARR:
∑
(2.37)
unde NQ reprezintă numărul de interogări.
Măsurile bazate pe numărul de imagini relevante returnate sunt uşor de calculat,
însă nu specifică pe ce poziţie se află documentele care nu au fost afişate, deci nu oferă o

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
32
descriere completă a performaței sistemului. De aceea, au fost introduse măsuri bazate pe
rangul imaginilor relevante returnate. Rangul unui document este calculat astfel:
(2.38)
De aici, definim media rangului („average rank”) – AVR
∑
(2.39)
Principalul dezavantaj al primelor două formule este reprezentat de faptul că
numărul de documente relevante este calculat prin utilizarea unui NF diferit de la o
interogare la alta (numărul de documente relevante poate diferi de la un concept la altul).
Pentru a minimiza variaţiile NF asupra rezultatului, s-a definit rangul de regăsire
modificat („modified retrieval rank”) – MRR:
(2.40)
MRR are valoarea 0 pentru regăsire completă a documentelor căutate. Pentru a
elimina total dependenţa faţa de NF se defineşte rangul de regăsire modificat normalizat
(normalized modified retrieval rank):
(2.41)
Iar de aici, se defineşte media rangului de regăsire modificat normalizat
(„average normalized modified retrieval rank”) – ANMRR:
∑
(2.42)
ANMRR este criteriul de evaluare folosit pentru experimentele MPEG-7. O
valoare scăzută a ANMRR indică o performanță foarte bună, în timp ce valoarea 1
reprezintă un sistem ce returnează rezultate complet eronate.
2.6.2 Graficul precizie-reamintire
Graficul Precizie-Reamintire (precision-recall) [43] reprezintă un criteriu des întâlnit în
evaluarea sistemelor de indexare. Precizia unei interogări reprezintă raportul dintre
numărul de documente corect regăsite de sistem și numărul total de documente afișate de
sistem. Reamintirea unei interogări este egală raportul dintre numărul de documente
regăsite de sistem și totalul documentelor corecte existente în baza de date:
ș (2.43)
(2.44)

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
33
Plaja de valori al acestora se găsește în intervalul [0; 1] unde 1 reprezintă cazul
ideal în care nu există nici o falsă detecție și respectiv toate documentele existente în bază
au fost găsite. Dat fiind faptul că aceste măsuri sunt evaluate pentru o anumită căutare
particulară, pentru a obține o măsură globală de performanță de regulă se calculează
valorile medii ale acestora pentru un anumit număr de căutări. Dacă baza de date este
cunoscută, atunci se poate realiza o evaluare exhaustivă în care fiecare document din bază
este folosit pentru a specifica cererea de căutare iar performanța sistemului este estimată
ca valoare medie pentru toate căutările efectuate.
Prin gruparea celor două valori se generează graficul precizie-reamintire. Precizia
și reamintirea sunt dependente de interogare, iar din acest motiv se determină o medie
aritmetică pentru mai multe măsurători. În mod normal, se utilizează toate imaginile din
baza de date. Pentru un sistem perfect, graficul trebuie să aibă forma din Figura 2.12 a, în
timp ce pentru cel mai slab sistem va arăta ca în Figura 2.12 b. De asemenea, se poate
observa că precizia este invers proporțională cu reamintirea: în timp ce precizia crește
valoarea reamintirii este în scădere. Principalul dezavantaj al curbei precizie-reamintire îl
constituie faptul că diferența de performanță dintre două sisteme se poate doar vizualiza
și nu se poate cuantifica într-o valoare exactă. De asemenea, măsurarea reamintirii este
greu de calculat deoarece de multe ori este dificil de știut numărul exact de documente
relevante pentru un anumit concept. Problema apare mai ales în situațiile când numărul
de concepte este foarte ridicat, iar evaluarea se face de către utilizatori.
(a) (b)
(c)
Fig. 2.12 Interpretarea graficelor precizie-reamintire: (a) Graficul precizie-reamintire
pentru un sistem ideal, (b) pentru un sistem cu 0% documente regăsite, (c) pentru un
sistem cu 100% documente corecte
Din precizie şi reamintire derivă eficiența:
(2.45)
unde A reprezintă numărul de documente returnate relevante, B numărul de documente
returnate nerelevante, C numărul de documente nereturnate relevante, iar D numărul de
documente nereturnate nerelevante. Inversul eficienței reprezintă eroarea (
).

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
34
Scorul - „F-measure” (cunoscut ca şi „F-score”) reprezintă un parametru de
măsurare a acurateţii. Acesta poate fi interpretat ca o medie ponderată a preciziei şi
reamintirei unui sistem:
(2.46)
Pentru avem F-measure egal cu precizia, în timp ce pentru
F-measure devine egal cu precizia. Pentru obţinem :
(2.47)
În ultimii ani, alte măsuri au devenit mai des utilizate. Cel mai important standard
utilizat de către comunitatea TREC este „Mean Average Precision” (MAP), care propune
utilizarea unei singure formule pentru a măsura performanţa printre nivelele de
reamintire. MAP a demonstrat că deţine un nivel ridicat de stabilitate şi bună
discriminare. De asemenea, MAP reprezintă media valorilor preciziilor medii obţinute pe
un număr de documente returnate. Precizia medie este egală cu:
∑
(2.48)
unde n reprezintă numărul de documente, m numărul de documente care aparţin clasei c,
iar este al k-lea document din lista returnată. În final, reprezintă funcţia care
returnează numărul de documente de gen c în primele k documente returnate dacă
aparţine conceptului c şi zero în cazul diferit.
2.6.3 Alţi parametri
Curbele ROC („Receiver Operating Characteristic”) reprezintă o măsură preluată din
teoria detecţiei de semnal şi conține un grafic ce prezintă rata de afişare a documentelor
adevărat-pozitive versus rata de afişare a imaginilor fals-pozitive. Iniţial, acest grafic a
fost utilizat în al doilea război mondial, în scopul îmbunătăţirii detecţiei radarului –
tehnică cunoscută sub numele de teoria detecției semnalului [44], fiind utilizat ulterior în
medicină, radiologie, data-mining şi machine-learning.
Pentru desenarea acestui grafic este nevoie de rata de detecţie fals-pozitivă (False
Positive Rate - FPR) şi rata de detecţie adevărat pozitivă (True Positive Rate - TPR). TPR
măsoară numărul de instanţe clasificate corect în timpul testului, în timp de FPR
evidenţiază numărul de elemente ce au fost clasificate în mod eronat.
Se pot deduce cu uşurinţă relaţille dintre TPR şi FPR cu precizia şi reamintirea:
(2.49)
(
) (2.50)

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
35
(a)
(b)
Fig. 2.13 Interpretarea curbelor ROC: (a) Curba ROC al unui sistem ideal, (b)Curba
ROC a unui sistem cu performanţe foarte slabe
Alte metode de măsurare întâlnite sunt:
Rangul primului document relevant
Rangul mediu
Rangul mediu normalizat:
.∑
/ (2.51)
unde N este numărul total de documente, NR numărul de documente relevante iar i
reprezintă rangul la care un document relevant este regăsit.
2.7 Baze de date
Cei mai mulți algoritmi de computer vision sau machine learning au în componență o
funcție de antrenare și o bază de date de testare. Pentru a dezvolta algoritmi și trăsături
performante este necesară existența unei baze de date cu exemple foarte diverse. Spre
exemplu, cunoscutul algoritm de detecție a fețelor creeat de Paul Viola și Michael Jones
utilizează o bază de date de 4916 imagini adnotate. Însă, achiziția unui volum ridicat de
documente multimedia este, de foarte multe ori, un proces foarte dificil și îndelungat. Mai
mult, operațiile de redimensionare și marcare a regiunilor de interes a documentelor
multimedia reprezintă o operațiune dificilă și consumatoare de timp.
Cele mai multe baze de date utilizate în computer vision au fost realizate pentru
anumite probleme specifice, cum ar fi: recunoașterea de forme, imagini naturale, obiecte,
recunoaștere de genuri (muzicale, video), recunoaștere de acțiuni etc.
Una dintre problemele principale pe care cercetătorii le întâmpină se datorează
faptului că multe articole sunt realizate pe baze de date proprii, astfel încât comparația
reprezintă o muncă foarte complicată. Fiecare dintre aceste baze de date conțin proprietăți
diferite, ceea ce fac ca rezultatele raportate să fie foarte greu de analizat și comparat în
mod direct. De exemplu, în căutarea de imagini, baze de date diferite conțin imagini de

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
36
dimensiuni diferite, nivele de calitate diferite, variații de obiecte, ocluziuni, ceea ce
conduc la rezultate diferite.
În continuare, vor fi prezentate o serie de baze de date multimedia utilizate de
către autor pe perioada studiilor doctorale.
2.7.1 Baze de date de imagini
ImageClef
Competiția ImageClef („The CLEF Cross Language Image Retrieval Track”) este creată
şi întreţinută de către Cross Language Evaluation Forum (CLEF). Aceasta propune în
fiecare an diferite task-uri cu baze de date diferite. În 2012, au fost propuse 4 competiții:
clasificare de imagini medicale, adnotare de fotografii, identificare plante și Robot
Vision, fiecare conținând la rândul lor mai multe task-uri.
Baza de date medicală conține 305.000 imagini, extrase din articolele publicate în
diverse domenii medicale (radiografii și ecografii). Aceasta conține trei probe:
determinarea sursei imagini preluate („Modality Classification”), regăsire de imagini
după anumite interogări („Ad-hoc image-based retrieval”) și căutare imagini după
concept („Case-based retrieval”). Competiția de indexare de fotografii conține două
probe: prima presupune detecția de concepte vizuale pentru imagini de pe Flickr, iar a
doua constă în indexarea de imagini de pe Web.
Fig. 2.14 Exemple de imagini din baza de date Image CLEF: (a) imagini din competiția
de clasificare de fotografii (primele 3 imagini prezintă conceptual de reflexie iar ultimele
două conceptual de lumini în trafic) și (b) imagini cu plante pentru competiția de
identificare de tipuri de plante (sursă imagini6)
Prima bază de date conține 25.000 de imagini downloadate de pe Flickr și constă
în detecția anumitor concepte, ca de exemplu: perioada zilei, elemente natural (soare,
nori), peisaje (floră, faună, identificare forme relief), numărul de persoane și vârsta
6 : http://www.imageclef.org/

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
37
acestora etc. Sunt permise utilizarea de trăsături vizuale cât și a metadatelor preluate de
pe Flickr. Pentru a doua problemă, baza de date are o dimensiune mult mai mare, de
250.000 de imagini și conține un număr mult mai ridicat de concepte. Pentru fiecare bază
de date sunt puse la dispoziția participanților un set de descriptori vizuali și de text. Mai
multe detalii despre competiție se pot găsi la adresa: http://www.imageclef.org/.
Caltech
Prima bază de date Caltech a fost creată de către California Institute of Technology şi
conţinea 4300 de imagini naturale grupate în modul următor: 1074 avioane, 1155 de
maşini, 450 oameni, 826 motociclete şi 900 imagini generale. Apoi, în septembrie 2003,
aceasta a fost refăcută de către Fei-Fei Li, Marco Andreetto, Marc Aurelio Ranzato și
Pietro Perona de la Caltech. Noua bază de date conținea 9146 imagini, împărțite în 101
obiecte distincte (incluzând spre exemplu fețe, ceasuri, crocodili, avioane furnici,
instrumente muzicale etc) și o categorie care conține imagini de background.
Fig. 2.15 Exemple de imagini din baza de date Image Caltech 101(sursă imagine7)
Caltech 101 conține câteva avantaje față de alte baze de date: imaginile au
dimensiune uniformă, iar, pentru aceeași categorie, obiectele au dimensiuni apropiate și
sunt așezate în poziții relative asemănătoare. Acest lucru înseamnă că utilizatorii care
utilizează baza Caltech 101 pierd timp cu localizarea automată sau manuală a obiectelor.
Obiectele sunt de cele mai multe ori în prim plan, nu există ocluziuni sau alte tipuri de
zgomot. Deși imaginile au obiectele căutate foarte bine evidențiate, acestea au un
background diferit, ceea ce face ca problema de clasificare să fie mai dificilă și mai
aproape de un scenariu real.
Principalul dezavantaj al bazei de date Caltech 101 este reprezentat de numărul
mic de clase și de faptul ca anumite clase sunt insuficient reprezentate (există clase cu 30
de imagini ceea ce este insuficient). Din acest motiv, în 2007 a fost creeată o nouă bază
de date Caltech 256. Aceasta conține 30.607 imagini grupate în 256 categorii. Fiecare
concept este mult mai bine reprezentat, numărul minim de imagini per categorie fiind
egal cu 80.
Mai multe detalii despre baza de date Caltech pot fi găsite la adresa de download
http://www.vision.caltech.edu/.
7 http://www.vision.caltech.edu/

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
38
Compeția Pascal
Scopul principal al competiției Pascal este de a recunoaște și localiza obiecte dintr-un
număr redus de clase aflate în scene foarte realistice. Baza de date conține 20 de clase
care pot fi împărțite în 4 categorii:
Persoane: persoane în diferite contexte;
Animale: păsări, pisici, vaci, câini, cai, oi;
Vehicule: avioane, biciclete, bărci, autobuze, mașini, motociclete, trenuri;
Obiecte: sticle, scaune, masă de cină, plante în ghiveci, canapele, televizor.
Competiția conține trei concursuri: clasificare (indică prezența sau absența uni
concept intr-o fotografie), detecție (localizează obiectele în fotografie) și segmentare
(extragere contur obiect).
Fig. 2.16 Exemple de imagini din baza de date Image Pascal 2007(sursă imagini8)
2.7.2 Baze de date video
MediaEval
MediaEval (inițial denumit VideoCLEF) este o competiție care își propune să dezvolte și
să evalueze probleme de analiza datelor multimedia într-un cadru multilingv. În 2013, au
fost propuse mai multe probe, ca de exemplu: Placing Task (acesta solicită participanților
să atribuie coordonate geografice anumitor documente video), Social Task (să clasifice
evenimente sociale și să detecteze articole media associate), Spoken Web Search (căutare
de cuvinte în documente audio), Tagging Task (clasificare după gen a documentelor
video web) [45], Affect Task: Violent Scenes Detection (detecție de cadre cu conținut
violent) [46], Visual Privacy Task (detecție de fețe și ascunderea identității). În cele ce
urmează, voi prezenta doar competițiile Tagging Task și Affect Task la care am
participat.
8 http://pascallin.ecs.soton.ac.uk/challenges/VOC/

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
39
Competiția Tagging Task își propune să atribuie automat etichete documentelor
video web, utilizând trăsături care sunt derivate din conținutul audio, vizual, text și din
metadata. Baza de date este alcătuită din 14.838 documente video copiate de pe blip.tv,
acestea fiind împărțite în două părți: un set de antrenare de 5.288 secvențe video (36%) și
9.550 filme de test (64%). Documentele video au fost împărțite în 26 de categorii
specifice platformelor web, și anume: artă (530), autovehicule (21), business (281),
jurnalism (401), comedie (515), conferințe și alte evenimente (247), filme documentare
(353), educaționale (957), mâncare și băutură (261), jocuri de calculator (401), sănătate și
medicină (268), literatură (222), filme și televiziune (868), muzică și divertisment (1148),
autobiografii (165), politică (1107), religie (868), școală și educație (171), sport (672),
technologie (1343), mediu încurăjător (188), media (324), călătorii (175), video blogging
(887), tutorial de web development (116) și categoria „altele” (2349 care cuprinde
documentele ce nu au fost atribuite nici unei categorii. Principala provocare a acestei
competiții a fost reprezentată de diversitate genurilor cât și de variația vizuală a
conținutului fiecărui gen. Figura 2.17 ilustrează exemple din baza de date.
Fig. 2.17 Exemple de documente video din baza de date MediaEval 2012 (Tagging
Task)(sursă imagini9)
Competiția Affect Task își propune recunoașterea de cadre cu conținut violent.
Aceasta s-a inspirat dintr-un scenariu propus de Technicolor, care își propunea să ajute
utilizatorii să selecteze filme care sunt potrivite pentru copii de diferite vârste. Utilizatorii
pot selecta / respinge anumite filme doar prin vizualizarea scenelor care sunt apreciate ca
fiind cele mai violente.
9 http://www.multimediaeval.org/

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
40
Baza de date a fost împărțită în două părți: 15 filme de antrenare și 3 filme pentru
testare: „Dead Poets Society” (34 scene violente), „Fight Club” (310 scene violente) și
„Independence Day”(371 scene violente) – un total de 715 scene violente (etichetarea
bazei de test a fost făcută publică după competiție). La competiție au participat un total de
8 echipe, care au susținut 36 de metode. Evaluarea s-a realizat atât la nivel de scenă cât și
la nivel de segment.
2.8 Concluzii capitol
Acest capitol își propune să prezinte o introducere în domeniul indexării informației
multimedia. Prima parte cuprinde un scurt istoric despre dezvoltarea sistemelor bazate pe
căutare după conținut și prezintă principalele concepte fundamentale: modalitatea de
interogare a sistemului și modul de reprezentare a datelor. Principalele surse de
informație pentru descrierea conținutului multimedia sunt: informația vizuală (se referă la
informațiile care pot fi percepute vizual: culoare, formă, textură, mișcare), informația
audio (voce, vorbire, muzică, sunete ambientale sau zgomot) și informația textuală
(datele reprezentate sub formă de text ce pot proveni din metadate sau din subtitrări). Tot
în același subcapitol sunt prezentate o serie de algoritmi de bază pentru indexarea datelor
vizuale, audio și text.
Următorul subcapitol urmărește prezentarea diverselor aplicații a sistemelor
multimedia de indexare. Conținutul multimedia face parte din viața cotidiană,
aplicabilitatea lor având un spectru foarte larg: de la activități banale cotidiene până la
domenii complexe de cercetare. Capitolul continuă cu o secțiune în care sunt prezentate
principalele provocări care apar în proiectarea unui sistem de indexare după conținut:
paradigma semantică și paradigma senzorială. Tot în cadrul aceste secțiuni, am prezentat
principalele direcții de cercetare, pe care le voi dezvolta în capitolele viitoare.
În final, am prezentat componentele principale ale unui sistem de căutare după
conținut: indexatorul, retriever-ul și browserul. Indexatorul este componenta principală a
unui sistem multimedia, acesta stochează fișierele multimedia împreună cu descriptorii
acestora. Sistemele de gestionare a bazelor de date oferă diferite metode pentru stocarea
și descrierea fișierelor multimedia. Retriever-ul are rolul de a calcula gradul de
similaritate dintre modelul căutat și documentele stocate în baza de date. Pe baza unor
metrici de similaritate, retriever-ul va selecta documentele relevante pentru căutarea
curentă. Browser-ul este componenta care face legătura între sistemul de indexare și
utilizatorul final. Principalele funcții ale browser-ului sunt alegerea sau încărcarea
modelului căutat și vizualizarea răspunsurilor generate de sistem. În capitolul 3, va fi
dezvoltat într-o manieră mai amănunțită componenta de indexare a sistemelor
multimedia.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
41
Capitolul 3
Metode clasice de descriere a
conținutului multimedia
Procesul prin care creierul uman înțelege și percepe informația vizuală și auditivă nu este
în prezent pe deplin înțeleasă. Însă, cercetarea în acest sens arată că anumite trăsături și
informații vizuale / auditive sunt mai importante în descrierea conținutului multimedia.
În cazul imaginilor, cele mai importante proprietăți sunt: culoarea, textura, forma
obiectelor componente, colțurile și frontierele obiectelor ce compun scena. O persoană
este capabilă să perceapă un obiect chiar dacă acesta este parțial opturat, sau în condiții
de vizibilitare redusă. De asemenea, pentru auz, o persoană este capabilă să înțeleagă
anumite cuvinte pe care nu le poate aude prin utilizarea informației extrase din context.
Același lucru este posibil și la citirea unor propoziții în care unele cuvinte sunt ascunse
sau scrise în mod eronat, dar pe care le putem întelege din context.
Acest capitol își propune să prezinte descriptorii multimedia după conținut:
culoarea, forma, textura, punctele proeminente, descrierea fluxului video, trăsături audio
și de text.
3.1 Descriptori de culoare
Culoarea este probabil cea mai expresivă dintre toate componentele vizuale. Primele
sisteme de căutare după conținut a imaginilor au utilizat culoarea ca și informație de bază
pentru indexare.
3.1.1 Spaţii de culoare
Primele studii despre culoare au fost efectuate de către Newton [1], prin trecerea luminii
solare într-o prismă de cristal, demonstrându-se astfel dependența culorii de compoziția
spectrală a luminii. O suprafaţă care reflectă lumina, reflectă independent fiecare
componentă spectrală (fiecare frecvenţă sau, echivalent, fiecare lungime de undă). Atunci
când un obiect este iluminat, el va absorbi o parte din radiația emisă, iar o partea din
aceasta va fi reflectată. În funcție de suprafața fiecărui material, două obiecte diferă prin
modul în care absorb, reflectă sau transmit lumina atunci când sunt iluminate, prin
urmare ochiul uman vizualizează în mod diferit, deoarece primește o cantitate diferită de
lumină.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
42
Studiile au continuat şi în secolele urmatoare fără îmbunătăţiri notabile. Abia în
secolul XIX, Young şi Maxwell au descoperit că fiecare culoare poate fi matematic
codată prin îmbinarea a trei culori fundamentale: R (roșu) G (verde) B (albastru),
principiu cunoscut sub numele de teorie a tricromaticităţii [43]. Ochiul nu distinge ca
având culori separate orice sursă luminoasă cu distribuţii spectrale diferite. Explicaţia
este că pe retină se găsesc trei tipuri de receptori, pentru diferite părți din spectrul luminii.
Fiecare tip de receptor va genera un nivel de excitație, în funcție de radiația
luminoasă pe care o primește. În cele din urmă, aceasta poate fi reprezentată ca un număr
real. Două culori sunt percepute identic dacă oricare dintre ele declanşează acelaşi
răspuns din partea fiecărui tip de receptor. Matematic, cele de mai sus se formalizează
astfel: fiecare tip de celule se caracterizează printr-o curbă de sensibilitate - o funcţie
definită pe intervalul de lungimi de undă ale luminii vizibile şi cu valori reale pozitive.
Răspunsul fiecărui tip de receptor este dat de produsul scalar al distribuţiei spectrale a
luminii incidente cu o curbă de sensibilitate a receptorului respectiv.
Prima reprezentare a culorilor aparută a fost reprezentarea XYZ. Reprezentarea
XYZ constă în trei numere reale pozitive, notate X, Y şi Z, fiecare dintre ele fiind definit
ca produsul scalar dintre distribuţia spectrală a puterii luminii şi o „curbă de sensibilitate”
standardizată [43]. Ulterior, au fost dezvoltate mai multe teorii, descrieri şi reprezentări
ale culorilor, din care voi enumera câteva mai importante [43]: teoria culorilor opuse
(dezvoltată de Hering), eclipsele MacAdams, spațiul YUV, spațiul U*V*W*, CIE Lab
1976 și familia de culori HSV.
RGB
Modelul de culoare RGB este cel mai cunoscut, fiind aplicat în majoritatea dispozitivelor
electronice. Acesta este un model aditiv în care culorile roșu, verde şi albastru sunt
adăugate împreună în diverse cantităţi pentru a reproduce o gamă largă de culori. Numele
modelului vine de la iniţialele celor trei culori aditive (Red, Green, Blue). Principalul
scop al modelului RGB fiind de a afişa imagini în sistemele electronice (monitoarele sau
aparate foto). În sistemele de căutare după conţinut, acest spaţiu de culoare este puţin
utilizat deoarece conţine un grad mare de corelare între cele trei componente. Culorile
sunt exprimate prin valori cuprinse între 0 şi 255, generând un numar de culori (24
biti per culoare). Din RGB au fost derivate diverse modele de culoare:
sRGB - spaţiul de culoare RGB standard creat de HP
şi Microsoft (monitor + Internet);
Adobe RGB - spaţiul de culoare RGB creat de Adobe
Systems în 1998.
Fig. 3.1 Cubul RGB(sursă
imagine Wikipedia).

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
43
YCbCr
YCbCr este un alt spațiu de culoare utilizat în diverse componente electronice. Y
reprezintă luminanţa, iar Cr şi Cb reprezintă diferenţele de culoare roșie şi albastră.
YCbCr reprezintă o transformare liniară a RGB şi are avantajul că separă informaţia de
culoare de cea de luminanţă.
Relaţiile de calcul ale celor trei
componente sunt:
Y = 0.299·R + 0.587·G + 0.114·B
Cb = -0.169·R – 0.331·G + 0.5·B
Cr = 0.5·R – 0.419·G + 0.081·B
Fig. 3.2 Planul YCbCr cu y = 0.5, (sursă
imagine Wikipedia).
Familia de culori HSV
Familia de culori HSV conține mai multe tipuri de spații de culoare: HSV (Hue (nuanţă),
Saturation (saturaţie), Value (valoare)), HSB (Hue (nuanţă), Saturation (saturaţie),
Brightness (strălucire)) şi HSL (Hue (nuanţă), Saturation (saturaţie), Lumination
(luminație)). Principalul avantaj al acestor reprezentări este descrierea diferențelor de
culori într-o manieră mai apropiată de sistemul vizual uman. În computer vision, spațiul
HSV prezintă o performanță de indexare mai bună în comparaţie cu RGB.
(a)
(b)
Fig. 3.3 Spațiul de culoare a familiei HSV (a) Cilindrul HSL (b) Cilindrul HSV (sursă
imagine Wikipedia).
HSV este ideal pentru manipularea culorii deoarece separă intensitatea de nuanţă
şi saturaţie. H (hue) reprezintă componenta spectrală dominantă, culoarea în forma cea
mai pură, ca de exemplu verde, roşu sau galben. A doua componentă a culorii în spațiul
HSV este reprezentat de saturație: adaugarea sau substracția de alb dintr-o culoare va

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
44
schimba intensitatea acesteia, mai precis va deveni mai mult / puțin saturată. Componenta
value (V) corespunde luminanţei culorii.
HMMD
HMMD (Hue Min Max Dif) [47] este un spaţiu de culoare definit în MPEG-7. Prima
componentă de nuanță de culoare are acelaşi înțeles ca în HSV, iar MIN şi MAX
reprezintă minimul şi maximul în cadrul valorilor RGB. Componenta DIF este definită ca
diferenţa dintre valorile minime şi maxime ale tripletei RGB. Doar trei dintre cele patru
componente sunt suficiente pentru descrierea conținutului de culoare, a patra componentă
putând fi calculată automat din primele trei. De asemenea, se poate defini o a cincea
componentă Sum care reprezintă suma componentelor Min și Max.
Interpretarea fiecărei componente din spațiul HMMD este distinctă: nuanța ia
valori în intervalul , la fel ca în cazul HSV, Max (în intervalul ) specifică
câtă culoare neagră este prezentă, Min (în intervalul ) arată cantitatea de culoare, Dif
specifică puritatea culorii albe (având o interpretare asemănătoare cu a saturaţiei), în timp
ce Sum specifică luminozitatea culorii.
Sistemul de coordonate este reprezentat printr-un con dublu (Figura ). HMMD a
fost conceput datorită proprietăților similare cu spațiul HSV, însă are avantajul că este
mult mai rapid în procesul de calcul / conversie din spaţiul RGB.
Fig. 3.4 Sistemul de coordonate pentru H.M.M.D. (sursă imagine Wikipedia).
CIE Lab
Modelul de culoare Lab îşi propune să modeleze spaţiul de culoare cât mai aproape
matematic de sistemul vizual uman. Valorile numerice din Lab descriu toate culorile care
pot fi percepute de o persoană cu vedere normală. Modelul a fost definit în 1976 de către

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
45
International Commission on Illumination, şi mai este cunoscut sub următoarele
denumiri: CIE 1976, L*a*b* sau CIELAB. Deoarece Lab descrie modul în care arată o
culoare şi nu cantitatea de culoare necesară unui dispozitiv (precum un monitor, o
imprimantă desktop sau o cameră digitală) pentru a produce culori, Lab este considerat
un model de culoare independent de dispozitiv. Sistemele de gestionare a culorii
utilizează Lab ca referinţă de culoare, pentru a transforma o culoare dintr-un spaţiu de
culoare în alt spaţiu de culoare.
Cele trei coordonate ale sistemului Lab reprezintă: luminanţa culorii (L* = 0
reprezintă negru şi L* = 100 indică un alb mat; valorile pentru alb strălucitor pot fi mai
ridicate), poziţia culorii între roşu-magenta şi verde (a*, valorile negative caracterizează
o culoare apropiată de verde și cea pozitivă indică magenta), iar ultima componentă
prezintă poziţia culorii între galben şi albastru (b*, valori negative indică o culoare
albastră în timp ce valorile pozitive reprezintă similaritatea faţă de galben).
Modelul L*a*b* tridimensional, el poate fi reprezentat sub forma unei sfere
(Figura 3.5)
Fig. 3.5 Sistemul de coordonate pentru CIE Lab (sursă imagine Wikipedia).
Transformarea între RGB şi Lab este neliniară şi este dată de relaţiile:
(
) (3.1)
( (
) (
)) (3.2)
( (
) (
)) (3.3)
unde reprezintă albul pur iar funcţia neliniară f este definit în modul următor:
2
(3.4)

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
46
Principalul dezavantaj al spațiului de culoare Lab este reprezentat de efortul
computațional ridicat (calculul radicalului de ordin trei).
Color Naming
Acest model [48] conține 11 culori elementare care au aceeași semnificație în toate
limbile pământului: negru, albastru, maro, gri, verde, portocaliu, roz, purpuriu, roșu, alb
și galben. Paleta de culori a fost antrenată şi etichetată de către un grup extins de subiecți
din diverse țări.
Figura 3.6 prezintă cele 11 culori fundamentale:
Fig. 3.6 Spațiul de culoare Color Naming (sursă imagine [48])
3.1.2 Histograma imaginii
Matematic, o imagine este o funcţie , în cazul în care imaginea este
color, sau , în cazul în care avem o imagine monocromă [44].
Histograma constituie un grafic al preponderenţei pixelilor de anumită tonalitate. Pe
scurt, ea ne oferă informaţii cu privire la distribuţia culorilor dintr-o imagine. Pentru o
imagine alb-negru avem un singur grafic, iar pentru spațiile de culoare color putem avea
trei grafice, câte unu pentru fiecare canal în parte. De asemenea, histograma RGB poate fi
vizualizată și într-un spațiu 3D, în care numărul de pixeli de o anumită culoare este
reprezentat ca o sferă de rază proporțională cu numărul de pixeli [1]. Primele aplicări ale
histogramei în domeniul indexării de imagini, au fost efectuate în 1991 de către Swain şi
Ballard [49], aceasta, devenind de altfel, o metodă de referinţă pentru descrierea
conţinutului vizual. Calculul histogramei este realizat cu formula următoare:
∑ ∑
(3.5)
unde c reprezintă o culoare dintr-un spaţiu de culoare ales, f(m,n) reprezintă culoarea unui
pixel la locaţia (m,n), iar M, N reprezintă dimensiunea imaginii.
Pentru ca histograma sa aibă o dimensiune cât mai scurtă (lungimea maximă
poate fi 3x255) se recurge la discretizarea spaţiului de culoare, iar apoi se numără de câte
ori o culoare discretizată se găseşte în imagine. Pentru performanţe optime, trebuie ajuns
la un compromis între discretizare pe intervale mai mari sau pe intervale mai mici.
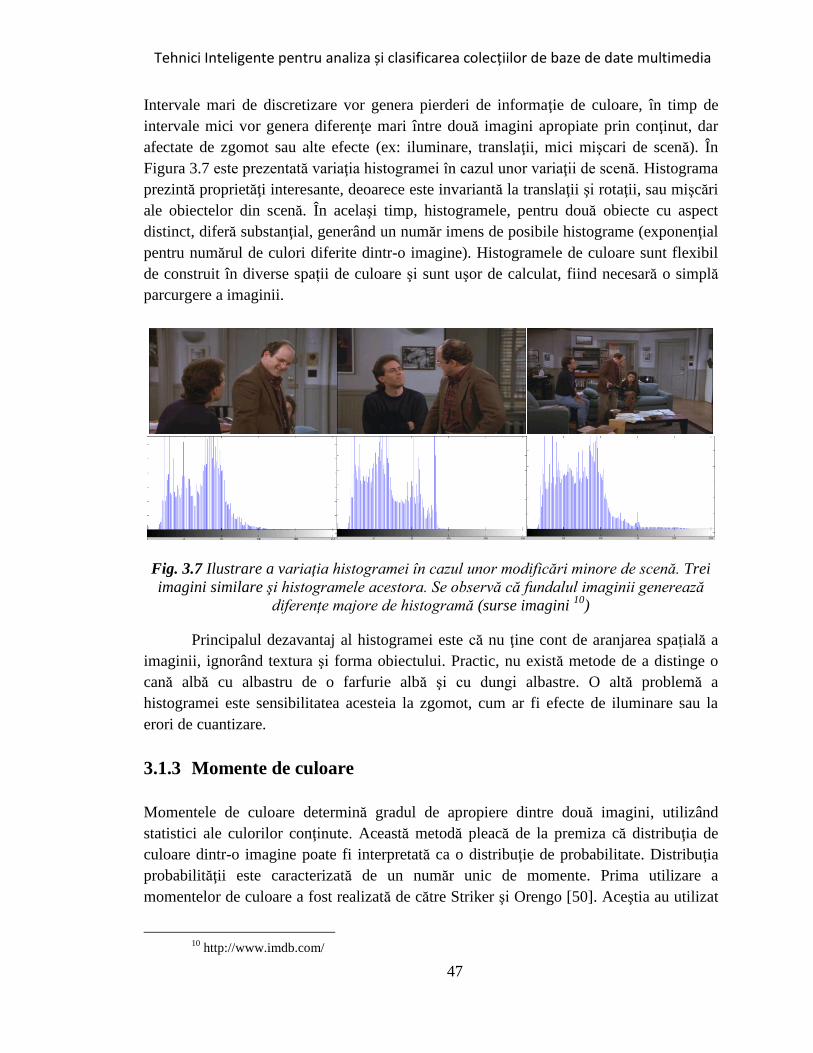
Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
47
Intervale mari de discretizare vor genera pierderi de informaţie de culoare, în timp de
intervale mici vor genera diferenţe mari între două imagini apropiate prin conţinut, dar
afectate de zgomot sau alte efecte (ex: iluminare, translaţii, mici mişcari de scenă). În
Figura 3.7 este prezentată variaţia histogramei în cazul unor variaţii de scenă. Histograma
prezintă proprietăţi interesante, deoarece este invariantă la translaţii şi rotaţii, sau mişcări
ale obiectelor din scenă. În acelaşi timp, histogramele, pentru două obiecte cu aspect
distinct, diferă substanţial, generând un număr imens de posibile histograme (exponenţial
pentru numărul de culori diferite dintr-o imagine). Histogramele de culoare sunt flexibil
de construit în diverse spații de culoare şi sunt uşor de calculat, fiind necesară o simplă
parcurgere a imaginii.
Fig. 3.7 Ilustrare a variaţia histogramei în cazul unor modificări minore de scenă. Trei
imagini similare şi histogramele acestora. Se observă că fundalul imaginii generează
diferențe majore de histogramă (surse imagini 10
)
Principalul dezavantaj al histogramei este că nu ţine cont de aranjarea spațială a
imaginii, ignorând textura şi forma obiectului. Practic, nu există metode de a distinge o
cană albă cu albastru de o farfurie albă şi cu dungi albastre. O altă problemă a
histogramei este sensibilitatea acesteia la zgomot, cum ar fi efecte de iluminare sau la
erori de cuantizare.
3.1.3 Momente de culoare
Momentele de culoare determină gradul de apropiere dintre două imagini, utilizând
statistici ale culorilor conţinute. Această metodă pleacă de la premiza că distribuţia de
culoare dintr-o imagine poate fi interpretată ca o distribuţie de probabilitate. Distribuţia
probabilităţii este caracterizată de un număr unic de momente. Prima utilizare a
momentelor de culoare a fost realizată de către Striker şi Orengo [50]. Aceştia au utilizat
10
http://www.imdb.com/

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
48
trei momente de culoare pentru fiecare canal din spaţiul de culoare (medie, variaţia
standard şi skewness):
Momentul de ordin 1: media de ordin 1
∑
(3.6)
unde reprezintă culoarea de la locaţia i, iar N numărul de pixeli din imagine.
Momentul de ordin 2: deviaţia standard
√(
∑
) (3.7)
reprezintă radacina pătrată a varianţei distribuţiei.
Momentul de ordin 3: Skewness
√(
∑
)
(3.8)
poate fi înţeleasă ca o măsură a gradului de asimetrie a distribuţiei.
3.1.4 Histograma „Color Coherence Vectors”
Pentru a măsura distribuţia spaţială a culorii dintr-o imagine a fost propus un nou tip de
histogramă în [51]. Această structură pleacă de la premiza că un pixel din interiorul unei
regiuni uniforme trebuie interpretat diferit, faţă de un pixel aflat într-o regiune de contur.
Practic, se vor calcula două histograme: o histogramă a pixelilor de tranzit şi o
histogramă a obiectelor uniforme. Histograma „Color Coherence Vectors” (CCV) previne
comparaţia de pixeli care provin din regiuni incoerente cu pixeli din zone coerente de
culoare. Acest proces asigură o distincţie fină între diverse tipuri de pixeli, ceea ce nu ar
fi fost posibil cu o histogramă clasică de culoare. Algoritmul conţine următorii paşi de
calcul:
se aplică un filtru medie (blur) asupra imaginii, astfel încât micile variaţii de culoare
între pixelii vecini să dispară;
se discretizează spaţiul de culoare, astfel încât să avem n culori distincte;
se separă pixelii coerenţi de cei incoerenţi (după diverse reguli) şi se construiesc cele
două histograme.
3.1.5 Histograma Fuzzy
Histograma clasică este un descriptor statistic global care măsoară intensitatea distribuţiei
pentru o imagine dată. Principalul ei avantaj este uşurinţa manipulării, însă este foarte

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
49
sensibilă la trecerea unei culori dintr-un interval de eşantionare în altul (efect ce apare des
din cauza iluminării, schimbării contratului etc). Pentru a rezolva această problemă, au
fost propuse mai multe metode inspirate din logica fuzzy [52] [53]. Pentru histograma
color de tip fuzzy, culorile aflate în intervale de eşantionare apropiate aparţin într-o
anumită măsură ambelor intervale, acestea fiind modelate după o funcţie de tip fuzzy.
3.1.6 Histograme augmentate și piramide spațiale
Metodele prezentate anterior nu rezolvă problema spaţială a distribuţiei culorii în
interiorul imaginii. Pentru a rezolva această problemă, au fost propuse diferite variante de
împărţire a imaginii în regiuni spaţiale. După ce imaginea a fost împărţită, pentru fiecare
regiune în parte, este calculat un descriptor, generând aşa zisele histograme augmentate
sau piramide spațiale. Histograma se augmentează prin considerarea unor mărimi
suplimentare, cu caracter spaţial: divizări ale spaţiului imaginii, parametri de ponderare
[54] [55].
Fig. 3.8 Exemple de exemple de divizări ale spațiului suport al imaginii în vederea
calculului de histograme augmentate
După ce are loc împărţirea imaginii în diverse părţi componente, pentru fiecare
regiune se calculează un descriptor independent. În final, aceşti descriptori vor fi agregaţi
într-un singur descriptor final. În cele mai multe cazuri, descriptorul final este alcătuit
prin simpla concatenare a trăsăturilor descriptorilor. În [55] a fost propus un algoritm care
împarte imaginea într-un număr variabil de nivele de piramidă spaţială (Figura 3.9), iar
pentru calculul gradulului de similaritate dintre două imagini a fost propusă o funcţie
nucleu.
Principalul dezavantaj al acestei metode se datorează sensibilităţii la translaţii şi
rotaţii.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
50
Fig. 3.9 Schemă ilustrativă a reprezentării prin piramide (sursă imagine [55]). O
piramidă reprezintă o colecţie de trăsături calculate pe nişte regiuni apriori definite. La
nivelul 0, imaginea este împărţită într-o singură regiune, trăsătura acesteia
corespunzând descriptorului global al imaginii.
3.2 Descriptori de textură
Textura [43] reprezintă un concept foarte vast, atribuit oricărei suprafeţe naturale. În
general, textura reprezintă o structură de suprafaţă spaţial repetitivă, formată prin repetiţia
de elemente în diverse poziţii relative. Repetiţia poate implica variaţii locale de scală,
orientare şi rotaţie. Imaginile de textură sunt definite ca imagini naturale texturate,
împreună cu șabloane artificial create, ce pot fi asemănătoare cu structurile reale.
Fig. 3.10 Exemple de texturi aparţinând bazei de date Vis Tex
Există două metode de descriere a texturilor [43]:
• studiul determinist se referă la căutarea de structuri de bază care se repetă în mod
spaţial. Aceasta abordare corespunde unei viziuni macroscopice, întâlnită de altfel în
cazul rocilor, ţesăturilor, sau a modelelor de tip mozaic. Elementul repetitiv de bază
poartă numele de texton sau texel - „texture element” - (prin similaritate cu denumirea de
„pixel”).

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
51
• abordarea statistică (probabilistică) se referă la studiul atributelor haotice şi omogene în
acelaşi timp, care nu au legătură cu niciun element de bază localizabil (motiv), de nici o
frecvenţă principală de repetiţie.
Este aproape imposibil de descris texturile utilizând cuvinte. Cu toate acestea,
putem descrie suprafeţe naturale, fiecare persoană definind anumite trăsături de aspect, ca
de exemplu: asprime, fineţe, granularitate, liniaritate, direcţionalitate, rugozitate,
regularitate, nivel haotic. Aceste trăsături care definesc în principal aranjarea spaţială a
texturilor constituente ajută la o descriere amănunţită a proprietăţilor texturii, însă aceste
trăsături nu pot fi uşor asociate cantitativ. În cele ce urmează, vom prezenta diferiţi
descriptori de textură.
3.2.1 Proprietăţile Tamura
Primele studii au fost efectuate de către H. Tamura, S. Mori şi T. Yamawaki în 1978 [56].
Ei au definit şase trăsături principale care caracterizează o textură: asprimea (coarseness),
contrastul (contrast), direcţionalitatea (directionality), asemănarea liniară (line-likeness),
regularitate(regularity) şi rugozitatea (roughness). Inițial, pentru a selecta aceste trăsături,
au efectuat un studiu pe un număr de subiecţi, care au analizat diferite proprietăţi de
textură. Aceștia au selectat proprietățile care sunt relevante pentru descrierea conținutului
de textură. Odata selectate, au fost propuse reprezentări matematice pentru fiecare
proprietate.
Asprimea prezintă o relaţie directă cu scala şi rata de repetiţie. Aceasta a fost
prezentată de Tamura ca fiind caracteristica cea mai importantă a texturilor. Asprimea își
propune să identifice cea mai mare porţiune dintr-o textură în care texelul este prezent.
Matematic, se calculează media în fiecare punct în jurul unor vecinătăţi care reprezintă
puteri ale lui 2. Media vecinătăţii de mărime într-un punct (x,y) este egală cu:
∑ ∑
(3.9)
unde k reprezintă raza vecinătății, f(i,j) este valoarea pixelului la locația (i,j), iar (x,y) este
punctul în care se calculează .
După calculul acestor vecinătăţi în fiecare punct din imagine, se calculează
diferenţa dintre media vecinătăţilor calculate după orientări verticale şi orizontale:
( ) (3.10)
Pentru fiecare punct, se va calcula mărimea lui K pentru care E devine maxim.
Asprimea se va defini apoi utilizând formula:
∑∑
(3.11)
unde n – dimensiunea imaginii iar .

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
52
Contrastul îşi propune să capteze gama dinamică a distribuţiei nivelelor de gri
dintr-o imagine, împreună cu distribuţia de alb si negru. Formula de calcul a contrastului
este:
⁄ (3.12)
unde este momentul 4, iar reprezintă varianța valorilor pixelilor imaginii.
Direcţionalitatea reprezintă calculează gradul total de ordonare a texturii. Două
măşti simple sunt utilizate pentru a detecta marginile dintr-o imagine. Pentru fiecare pixel
este calculat unghiul muchiei, după care este creată o histogramă a marginilor, utilizând
un prag pentru a identifica apartenenţa punctului la un tip de direcţie. Marginile sunt
calculate utilizând un filtru Sobel.
Apoi, direcţionalitatea este calculată cu formula:
∑ ∑ ( )
(3.13)
unde np este numărul vârfurilor, este poziția celui de-al p-lea vârf, Wp este gama
unghiului atribuit celui de-al p-lea vârf, r reprezintă un factor de normalizare, iar a
reprezintă direcția.
Celelalte trei componente sunt strâns legate de primele trei trăsături şi nu aduc
noutate în descrierea texturii:
Rugozitatea se referă la variaţiile tactile pe suprafaţa fizică. O suprafaţă aspră
conţine primitive angulare, în timp ce texturile netede conţin primitive neclare (slab
delimitate). Formula de calcul este următoarea:
(3.14)
Regularitatea constă în calculul gradului de variaţie a texelilor. O textură regulată
este compusă din primitive identice sau similare, aranjate într-un mod ordonat. O textură
neregulată este compusă din diverse primitive, care sunt aşezate în mod aleatoriu.
Formula de calcul a regularităţii este următoarea:
(3.15)
unde r este un factor de normalizare (de obicei r = ¼) şi reprezintă gradul de
variaţie a caracteristicii .
Asemănarea liniară este definită ca media direcţiilor unghiurilor ce apar în
perechi de pixeli, separaţi de o distanţă d.
3.2.2 Matricea de coocurenţă
Matricea de coocurenţă reprezintă o statistică de ordin II a perechilor nivelelor de gri
dintr-o imagine. Aceasta calculează numărul de perechi de pixeli de anumite culori,
separate de o distanţă d, de-a lungul unei direcţii a.
ș (3.16)

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
53
unde reprezintă 2 culori, x poziția în cadrul imaginii.
În final, acest descriptor va fi o matrice M patrată, de dimensiune egală cu
numărul de valori posibile ale pixelilor.
Concepul de matrice de coocurenţă se poate aplica şi pentru perechi de culori, nu
numai pentru imagini cu nivele de gri, utilizând diverse nivele de cuantizare a spaţiului
culorii. După calculul matricii de coocurenţă, sunt calculați diferiţi parametri statistici
cunoscuţi sub numele de Haralick [57]:
Contrastul:
∑ ∑
(3.17)
unde reprezintă valoarea intensității pixelilor aflați la locația (i,j), iar M și N
reprezintă dimensiunile imaginii.
Corelația:
∑∑
√
(3.18)
unde ∑ ∑
, ∑ ∑
,
∑ ∑
,
∑ ∑
Entropia:
∑∑
(3.19)
Energia:
∑∑
(3.20)
Omogenitate:
∑∑
(3.21)
Moment de ordin 3:
∑∑
(3.22)
Varianța inversă:
∑∑
(3.23)
Sumă medie:

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
54
∑∑
(3.24)
Varianța:
ț
∑∑[
]
(3.25)
Tendința clusterului:
∑∑
(3.26)
3.2.3 Modele „Markov Random Fields”
Modelele „Markov Random Fields” (MRF) consideră imaginea 2D ca un şir de scalari
(valori de nivele de gri) sau de vectori (culori), aflați într-o distribuţie statistică [58]. Cu
alte cuvinte, semnalul fiecărui pixel este considerat a fi o variabilă aleatoare. Fiecare
textură este caracterizată de o probabilitate de distribuţie a semnalului, prin interacţiunea
acestuia cu alte semnale (în cazul nostru, prin interacţiunea pixelilor vecini). Modelul
Markov presupune că probabilitatea fiecărui pixel (x,y) este determinată printr-o
convoluţie a pixelilor vecini. Aceste tehnici poartă numele de modele auto-regresive
(simultaneous autoregressive - SAR), textura fiind reprezentată printr-o serie de
parametri de autoregresie:
∑
(3.27)
unde w este independent (zgomot alb de medie 0 și varianţă 1) iar parametri a(m,n) sunt
specifici modelului SAR. Problema de bază a algoritmului constă în metoda de găsire a
vecinătăţii adecvate pentru calculul vecinătății.
3.2.4 Corelograma
Corelograma este o matrice care grupează probabilitaţile de a avea o pereche de pixeli de
valori specificate, separaţi de o distanţă fixată [59]. Pentru fiecare distanţă d, corelograma
va fi o matrice pătrată de dimensiune egală cu numărul de valori diferite posibile pentru
pixeli.
3.2.5 Matricea de izosegmente
Izosegmentele („run-length”) reprezintă o tehnică de extragere a caracteristicilor statistice
a texturii. Această tehnică a fost utilizată iniţial de către Galloway [60] în 1975 şi de către
Chu în 1990. Un izosegment de nivele de gri reprezintă o mulţime liniară de pixeli
consecutivi, având acelaşi nivel de gri, orientaţi pe o anumită direcţie. Lungimea unui

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
55
izosegment este numărul de pixeli ce formează respectiva mulţime. Matricea de
Iiosegmente („Gray Level Run Length Matrix” - GLRLM) este o matrice m x n, unde m
reprezintă numărul de lungini de izosegmente posibile iar n este numărul de nivele de gri
în care este cuantizată imaginea.
Numărul de nivele de gri din imagine va fi cuantizat. De obicei, aceasta se
cuantizează pe 16 nivele de gri. Gradul de cuantizare este esenţial pentru performanţa
algoritmului.
Fie următoarele notaţii:
p(i,j|θ) este al (i,j) - lea element al matricei de izosegmente pentru direcţia θ
G – numărul de nivele de gri
R – cel mai lung izosegment
n – numărul de pixeli din imagine
Galloway a introdus cinci trăsături statistice care pot fi extrase din matricea de
izosegmente:
plaja de izosegmente scurte („Short Run Emphasis”)
∑∑
∑∑
(3.28)
prin împărţirea fiecărui izosegment cu pătratul valorii acestuia sunt accentuate
izosegmentele de lungime mică
plaja de izosegmente lungi („Long Run Emphasis”)
∑∑ ∑∑
(3.29)
prin înmulţirea fiecărui izosegment cu pătratul valorii acestuia, se accentuează valoarea
izosegmentelor lungi
neuniformitatea nivelului de gri („Gray Level Non-Uniformity”)
∑.∑
/
∑∑
(3.30)
valorile mai mari ale izosegmentelor vor contribui mai mult la calculul acestei trăsături
neuniformitatea lungimilor plajelor („Run Length Non-Uniformity”)
∑ .∑
/
∑ ∑
(3.31)
procentul de izosegmente („Run Percentage”)
∑∑
(3.32)
este raportul dintre numărul de izosegmente şi numărul de pixeli ai regiunii.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
56
Chu a introdus două trăsături adiţionale: „Low Gray Level Emphasis” (LGRE) și
„High Gray Level Emphasis” (HGRE):
∑∑
∑∑
(3.33)
∑ ∑
∑∑
(3.34)
Pentru simplificarea notaţiilor se notează cu:
∑
(3.35)
∑
(3.36)
unde r reprezintă numărul de izosegmente de lungime j şi g este numărul de izosegmente
de culoare i.
Se defineşte S ca fiind numărul total de izosegmente din imagine:
∑∑
∑
∑
(3.37)
ecuaţia putând fi scrisă în felul următor:
∑∑
∑
(3.38)
iar de aici toate formulele pot fi scrise în funcţie de r și g:
∑∑
∑
(3.39)
∑.∑
/
∑
(3.40)
∑(∑
)
∑
(3.41)
∑∑
∑
(3.42)
∑∑
∑
(3.43)
∑∑
∑
(3.44)

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
57
ceea ce înseamnă că toate trăsăturile pot fi calculate fără a determina întreaga matrice de
izosegmente. Este suficient calculul a două şiruri ( r[j] și g[i]).
3.2.6 Calcul în spațiu transformat
Transformările reprezintă o categorie de prelucrări ce includ operaţii de tip integral, la
calculul noii valori a unui pixel al imaginii transformate contribuind valorile tuturor
pixelilor din imaginea originală. Pentru o imagine pătrată I de dimensiune N, o
transformată unitară este de forma:
∑ ∑
(3.45)
unde reprezintă imaginea cu un singur pixel de culoare la locația (k,l), iar V(k, l)
sunt coeficienţii dezvoltării în serie. O transformare unitară reprezintă un operator
integral caracterizat prin faptul că valoarea fiecărui pixel din imaginea finală depinde de
valorile tuturor pixelilor din imaginea pixelilor.
Transformatele unitare prezintă anumite proprietăţi:
Energia semnalului se conservă printr-o transformare unitară;
Energia medie a semnalului se conservă printr-o transformare unitară;
Entropia unui vector cu componente aleatoare se conservă printr-o transformare
unitară:
( |
)
( |
) (3.46)
Coeficienţii din spaţiul transformatei sunt decorelaţi sau aproape decorelaţi.
Transformata optimă, care compactează maximumul de energie într-un număr dat de
coeficienţi şi care în acelaşi timp decorelează complet, este transformarea Karhunen-
Loeve.
Transformata Fourier
Transformata Fourier se aplică unei funcții complexe și produce o altă funcție complexă
care conține aceeași informație ca funcția originală, dar reorganizată după frecvenţele
componente. De exemplu, dacă funcția inițială este un semnal dependent de timp,
transformata sa Fourier descompune semnalul după frecvență și produce un spectru al
acestuia. Același efect se obține dacă funcția inițială are ca argument poziția într-un
spaţiu uni sau multidimensional, caz în care transformata Fourier relevă spectrul
frecvențelor spațiale care alcătuiesc funcția de intrare.
În cazul prelucrarii de imagini, se utilizează transformata Fourier Discretă
bidimensională unitară. Transformata Fourier bidimensională, pentru o imagine de
dimensiune NxN, se calculează cu formula următoare:

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
58
∑ ∑
(3.47)
unde f(a,b) este imaginea în domeniul real, iar F(k,l) reprezintă mediul transformat.
Într-un mod similar, se calculează transformata Fourier inversă:
∑ ∑
(3.48)
Majoritatea implementărilor plasează media componentei continue a imaginii în
centrul acesteia, utilizând proprietatea de periodicitate a transformatei Fourier.
Pentru descrierea conținutului de textură se va împărți imaginea în spațiul Fourier
și se va calcula energia totală pe fiecare partiție. Un exemplu de împărțire este prezentat
în Figura 3.11:
Fig. 3.11 Partiții de caracterizare a texturilor în domeniul spectral Fourier
Transformarea Gabor
Transformarea Gabor îmbină avantajele transformatei Fourier (localizare bună în
frecvenţă şi orientare) cu avantajele localizării bune în spaţiul cartezian [61].
Reprezentările frecvenţei și orientării filtrelor GABOR sunt similare cu cele ale
sistemului vizual uman. Transformarea 2D conţine un nucleu gaussian modulat de o
sinusoidă.
∑ ∑[ ]
(3.49)
unde
*
+ *
+ (3.50)
3.2.7 Operatorul „Localy Binary Patterns”
Operatorul „Localy Binary Patterns” (LBP) a fost prima dată introdus de către Ojala [62].
Acesta etichetează pixelii unei imagini în valori binare, prin prăguirea vecinătății fiecărui

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
59
pixel. Datorită puterii discriminative mari și a simplității computaționale, LBP a devenit
popular în diverse domenii din computer vision, ca de exemplu: descrierea texturilor,
recunoașterea de fețe [63] și recunoașterea și clasificarea de obiecte [64]. Cea mai
importantă caracteristică a aoperatorului LBP se datorează invarianței acestuia la
schimbări de iluminare și scalare.
Versiunea inițială a operatorului LBP folosea vecinătatea fiecărui pixel curent, de
obicei de dimensiune 3x3, ca apoi acesta să utilizeze diferite tipuri de vecinătăți sau
piramide spațiale.
Pașii de calcul ai descriptorului sunt următorii:
- pentru fiecare pixel din imagine, se prăguiesc valorile din vecinătatea punctului în
funcție de valoarea pixelului central (Figura 3.12);
- pentru fiecare pixel ( ) se va calcula următorul parametru:
∑
(3.51)
- se creează o histogramă a valorilor ;
- se concatenează histogramele în cazul în care se efectuează un proces de binarizare la
mai multe scale ale imaginii.
Fig. 3.12 Schema de calcul a operatorului LBP
3.3 Descriptori de formă
Forma este una dintre componentele esenţiale în procesul de recunoaștere și clasificare a
obiectelor. Aceasta reprezintă descrierea geometrică a unui obiect prin determinarea
frontierelor acestuia față de obiectele din jur. Principalele caracteristici pe care
descriptorii de formă trebuie să le conţină sunt: caracterul compact (descriptorii trebuie să
extragă trăsăturile relevante și definitorii), invarianţa la scalare, rotaţie, translaţie și la
distorsiuni ale formei conturului.
Tehnicile de calcul ale descriptorilor de formă se împart în două mari categorii:
descriptori de regiuni şi descriptori de contur.
Descriptorii de regiuni utilizează aşa numitele momente statistice, care
încapsulează distribuţia pixelilor în imaginea 2D a formei. Se pot descrie forme

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
60
complexe, compuse din mai multe regiuni deconectate sau din obiecte ce conţin „găuri”.
Aceste trăsături sunt rezistente la erori de segmentare a imaginilor sau la zgomot gen
„sare şi piper”. Cei mai cunoscuţi algoritmi bazaţi pe regiuni sunt: momente geometrice,
momente Legendre, momente Zernike şi momente pseudo-Zernike.
În schimb, algoritmii de descriere a formelor prin contur utilizează informația
spațială extrasă din linia de contur a obiectului. Exemple de algoritmi de descriere a
formelor prin contur sunt: descriptorii Fourier de contur si algoritmii de aproximare
poligonială.
3.3.1 Momentele Hu
Inițial, pentru descrierea formelor, au fost propuse momentele spațiale. Pentru o imagine
binarizată, momentul spațial de ordin (m,n) este definit de formula:
∑ ∑
(3.52)
unde
este imaginea binarizată, J și K reprezintă numărul de
linii și de coloane ale imaginii, iar 2
1 Kxk
și jJyk 2
1 (originea este in partea
stanga-jos a imaginii).
Momentele spațiale au performanţe foarte slabe, deoarece sunt foarte sensibile la
schimbări de scală. Din acest motiv s-au definit momentele centrate:
∑ ∑
(3.53)
unde și sunt coordonatele centroidului. Din momentele centrate vor fi extrase
momentele Hu [65].
Momentele lui Hu sunt invariante la schimbări de scală, la translații și la rotaţii.
3.3.2 Momente Zernike
Momentele Zernike au fost propuse pentru prima dată de către Teaque şi utilizează
principiul polinoamelor ortogonale Zernike [66]. Poligoanele Zernike au fost utilizate
pentru prima dată în descrierea formelor 1990 [67]. Un polinom tipic Zernike este
exprimat de către formula:
(3.54)
unde R este baza radială ortogonală:
∑
(
) (
)
(3.55)

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
61
unde m<=|n|, m-n este par
Pentru o funcţie continuă, momentul Zernike de ordin n va fi calculat utilizând
formula:
∬
(3.56)
în timp ce pentru o imagine digitală formula este următoarea:
∑∑
(3.57)
Momentele Zernike sunt invariante la rotaţii și robuste la zgomot. De asemenea,
ele prezintă o redundanţă scazută deoarece baza este ortogonală.
3.3.3 Descriptori Fourier de contur
Descriptorii Fourier de contur sunt obtinuţi prin aplicarea transformatei Fourier asupra
punctelor aflate pe conturul obiectelor [68]. Algoritmul de calcul al descriptorului conține
următorii paşi:
se obţin coordonatele de contur ale obiectelor
se calculează coordonatele centroidului acelui obiect şi apoi distanţa dintre acesta
şi contur utilizând, distanţa euclidiană
(3.58)
unde t = 0,1, … N-1, iar
∑
și
∑
se aplică transformata Fourier 1D asupra semnalului r(t):
∑ (
)
(3.59)
se calculează magnitudinea coeficienș=ților Fourier:
vectorul descriptor va fi format din următoarele valori:
3.3.4 Aproximare poligonală
Aproximarea poligonală este una dintre cele mai populare metode de reprezentare a
formelor. Ideea principală a algoritmului constă în reprezentarea siluetei printr-un set de
segmente de dreaptă. Mai precis, se elimină formele redundante şi insignifiante. Metoda
caută punctele de contur şi le elimină pe cele ale căror eroare pătratică are o valoare
minimă. Există două tipuri de calcul utilizate în prezent: metoda evoluției conturului [69]
şi metoda detecţiei de colţuri utilizând transformate wavelet [70]. Metoda evoluţiei
conturului reduce influenţa zgomotului şi simplifică forma, eliminând caracteristicile
irelevante ale formei. Iniţial, forma este privită ca o inşiruire de segmente de dreaptă,
după care perechile de segmente sunt comasate într-un singur segment.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
62
Pentru a măsura nivelul de relevanţă a unui segment de dreaptă se utilizează
formula:
(3.60)
unde β(s1, s2) reprezintă unghiul dintre cele două segmente, iar l(s) reprezintă lungimea
segmentului normalizat la perimetrul formei.
Procesul încetează atunci când valoarea parametrului K este mai mare decât un
prag ales. Metoda evoluţiei curbei pleacă de la premiza că formele au diverse distorsiuni,
iar acestea trebuie înlăturate printr-un process de netezire. Netezirea depinde foarte mult
şi de alegerea pragului de şlefuire. În final, fiecare poligon este reprezentat ca o funcţie
tangenţială (tangenta unghiului format de axa orizontală şi segmentul de dreaptă).
3.3.5 Histograma de orientare a gradienților
Histograma de orientare a gradientilor (HOG) [71] este un descriptor utilizat pentru prima
data de către cercetatorii INRIA, Navneet Dalal şi Bill Triggs. A fost propus în contextul
problemei de detecţie de pietoni. Tehnica constă în calculul apariției de orientări de
gradient, localizate într-o anumită parte a imaginii.
Inițial, imaginea este împărțită în regiuni spațiale mici (celule) care pot avea
diverse forme (radiale sau rectangulare). Pentru fiecare celulă, se calculează o histogramă
a direcțiilor gradienților. Pentru imagini color, se vor calcula gradienții pe fiecare canal
de culoare independent (Lab sau RGB). Histogramele sunt ponderate în functie de
anumiți parametri: magnitudine, pătratul magntudinii, prezența / absența muchiilor etc.
Pentru corectarea erorilor provocate de schimbarea iluminării și zgomot, se efectuează
anumite corecţii pe fiecare bloc în parte: corecție de gamă și egalizare de histogramă.
Au fost propuse diverse extensii pentru histograma de orientare a gradienților și
anume: histograma piramidală de orientare a gradienților (Pyramidal HOG (PHOG) [72])
și histograma 3D de orientare a gradienților (3D HOG [73]).
3.4 Puncte de interes
3.4.1 Introducere
În primele secțiuni din acest capitol am prezentat algoritmi ce descriu informația globală
a unei imagini. Însă, pentru probleme în care este necesară recunoașterea de obiecte,
acești algoritmi ating o performanță scăzută, deoarece nu reușesc să extragă trăsăturile
care sunt caracteristice unui obiect. Practic, descriptorii globali nu separă informația de
fundal de cea a obiectelor constituente. Din acest motiv, au fost propuși o serie de
algoritmi care extrag punctele de interes ale obiectelor („keypoints”). Mai exact, acești
algoritmi extrag o serie de regiuni care conțin informație discriminatorie mai ridicată.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
63
Apoi, fiecare punct de interes va fi descris cu ajutorul unui descriptor. Și astfel, fiecare
imagine va fi descrisă de un set de descriptori. Punctele de interes reprezintă regiuni bine
definite din spațiul imaginii, care au o valoare descriptivă ridicată. Odată extrase,
punctele de interes vor fi utilizate în procesări ulterioare. Punctele de interes au
proprietatea de a fi stabile în cazul anumitor perturbații, ca se exemplu: rotații, scalare,
distorsiuni geometrice, zgomot, variații de iluminare.
Pentru a calcula gradul de similaritate dintre două imagini este necesar să se
calculeze numărul de puncte de interes similare. Inițial, distanța dintre două puncte de
interes a fost calculată cu distanța euclidiană. Această metodă este una intensă
computațional, deoarece are complexitatea O(mnp), unde m și n reprezintă numărul de
puncte de interes a celor două imagini care sunt comparate, iar k este lungimea
descriptorului unui punct de interes. Din acest motiv, au apărut tehnici noi de aproximare
a similarității, cea mai cunoscută dintre ele fiind algoritmul „k-nearest neighbors” [74].
După modul de aranjare spațială a punctelor cheie, algoritmii de extragere a
trăsăturilor locale se împart în două categorii: algoritmi care extrag puncte cheie la
intervale regulate din imagine („dense extraction” – extragere densă) (Figura 3.13 a) și
algoritmi care extrag numai regiunile cu zone proeminente, considerate a fi cu mai multă
informație discriminatorie (Figura 3.13 b). Dintre aceste metode, nu există o metodă
preferențială în defavoarea celeilaltei, ambele abordări dovedindu-se eficiente în contexte
diferite. Mai precis, un algoritm de extracție densă a punctelor cheie poate obține
performanțe superioare în cazul în care informația de fundal este foarte importantă. Spre
exemplu, în competiția Pascal, există 20 de clase care sunt dependente de context:
avioanele apar de obicei în imagini cu nori, animalele sunt prezente într-un spațiu natural,
iar obiectele de mobilier sunt localizate în interiorul unor camere. La extracția densă,
calculul poziției punctelor cheie este mult mai rapidă, însă numărul de descriptori extras
este mult mai ridicat, ceea ce compesează timpul căștigat pentru extracție.
(a) (b)
Fig. 3.13 Exemple de metode de extragere a punctelor de interes: (a) extracție densă și
(b) extracție a regiunilor proeminente

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
64
3.4.2 Modelul „SIFT”
Transformata SIFT („Scale Invariant Feature Transform”) a fost propusă și patentată de
către David Lowe [75]. Aceasta se bazează pe extragerea de puncte cheie, pe baza
convoluției unei imagini cu un set de nuclee gausiene:
(3.61)
unde (x,y) reprezintă locația pixelui curent, iar reprezintă deviația standard a nucleului
gausian.
După calculul convoluțiilor, pentru fiecare se vor calcula diferențele acestor
convoluții la diferite scale pentru σ.
( ) (3.62)
(3.63)
unde k este un număr natural, I(x,y) reprezintă imaginea cu nivele de gri.
Metoda extrage puncte de extrem, considerate a fi candidați în extragerea de
„puncte cheie”, utilizate în descrierea imaginii. Pentru fiecare punct, se va calcula
magnitudinea și orientarea gradientului utilizând formulele următoare:
√ (3.64)
*
+ (3.65)
Se va crea o histogramă de orientări și se vor reține acele valori maxime,
împreună cu punctele care conțin minim 80% din valoarea maximă gasită (eliminandu-se
astfel peste 95% din punctele extrase în procesul anterior).
După calculul extremelor, vor fi eliminate punctele cu contrast scăzut și muchii
mai puțin ieșite în evidență. Punctele rămase reprezintă punctele de interes ale imaginii.
Acestea sunt invariante la scalarea imaginii sau la adăugarea diferitelor forme de zgomot.
Un descriptor al unui cuvânt cheie reprezintăun vector cu 128 de dimensiuni (un byte
pentru fiecare trăsătură).
Un descriptor al unui punct cheie va fi calculat pe o vecinătate de 16x16 pixeli.
Valorile de nivel de gri vor fi ponderate cu o fereastră gaussiană, iar apoi aceasță
vecinătate va fi împărțită în 4X4 subregiuni. Pentru fiecare subregiune, se va reține o
histogramă de orientări.
Pentru îmbunătățirea vitezei algoritmului, a fost propus PCA-SIFT [76]. Acesta
aplică analiza componentelor principale (PCA) asupra vectorului descriptor a unui punct
de interes. Descriptorul va avea o dimensiune mult redusă față de a descriptorului SIFT
clasic (de la 128 la 20-36 dimensiuni), ceea ce duce la o creștere considerabilă a vitezei
de comparație dintre două imagini. O alta extensie a SIFT este GLOH („Gradient
location-orientation histogram”) [77], ce calculează descriptorii SIFT utilizând
coordonate polare.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
65
3.4.2 Modelul „SURF”
Algoritmul SURF („Speeded Up Robust Feature”) reprezintă un extractor de puncte de
interes robust și rapid, prezentat de catre Herbert Bay în 2006 [78]. Acesta a fost parțial
inspirat din algoritmul SIFT. Autorii au demonstrat că acesta este de câteva ori mai rapid
decât versiunea standard de SIFT, iar în multe cazuri chiar mai robust în condiții similare
de zgomot.
Pentru calcularea punctelor de interes, SURF utilizează imaginea integrală, o
structură de reprezentare a unei imagini care permite calculul rapid al intensității din
diferite regiuni ale imaginii.
Inițial, imaginea este transformată în imagine integrală, utilizând următoarele
formule:
∑
(3.66)
unde (x,y) reprezintă poziția curentă în cadrul imaginii.
Calculul imaginii integrale se poate face și în mod recursiv utilizând formula:
(3.67)
unde i(x,y) reprezintă valoarea pixelului aflat la poziția (x,y).
Pentru detecția punctelor cheie se utilizează matricea hessiană, care este rapidă
din punct de vedere computațional. Valoarea acesteia într-un punct I(x,y) este dată de
formula:
*
+ (3.68)
unde L(x,y,σ) reprezintă filtrul laplacian de gausiană („Laplacian of Gaussian”).
Dimensiunea descriptorului SURF poate fi mai mică sau egală decât cea a
vectorului SIFT (64 sau 128 de numere de tip float).
3.4.3 Modelul „Harris”
Detecția de muchii cu detectorul Harris, reprezintă o metodă populară de extragere a a
colțurilor și muchiilor dintr-o imagine [79]. Acesta este invariantă la rotație, scalare,
variație de iluminare și zgomot de imagine. Algoritmul detectorului Harris se bazează pe
funcția de autocorelare locală a semnalului definit în modul urmator:
∑
(3.69)
unde w(x,y) reprezintă fereastra de calcul a funcției de autocorelație, reprezintă
dimensiunea ferestrei, i(u,v) conțime valoarea pixelului aflat la poziția (u,v), iar w(u,v)
poate fi o constantă sau poate avea valori ponderate în funcție de distanță (putând lua o
formă gausiană):

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
66
(3.70)
Utilizând dezvoltarea după serie Taylor vom avea:
⌊
⌋ (3.71)
unde C(x,y) capturează structura intensității a vecinătății punctului curent și repezintă o
matrice de dimensiune 2x2:
∑ ⌊
⌋
(3.72)
unde și vor reprezenta gradienții calculați pe aceste axe.
Pentru a calcula valoarea muchiei se vor măsura vectorii proprii ai matricei C.
(3.73)
unde și , iar k are o valoare apropiată de 0,04.
Vor fi luate în considerare următoarele trei aspecte:
1. dacă , au valori mici, funcția de autocorelare va avea o valoare mică(mici
schimbări pe orice direcție), ceea ce inseamnă că fereastra va avea o intensitate constantă;
2. dacă doar una dintre cele două valori are o valoare mare indică faptul că
fereastra conține o margine;
3. dacă ambele valori proprii au o valoare ridicată indică faptul că punctul va fi
clasificat ca și punct de interes.
După calculul parametrului R pe fiecare fereastra se vor reține regiunile care
conțin o valoare R mai mare decât un prag. Pentru fiecare regiune se va selecta o valoare
maximă locală. Alți algoritmi în detectia de puncte cheie sunt: MSER („Maximally Stable
Extremal Region Detector”) [80], detectorul STAR [81], detectorul FAST [82], GOOD
(„Good Features to Track”) [83] și SUSAN [84].
3.4.4 Reprezentarea „Bag of Visual Words”
Modelul „Bag of Words” (BoW) reprezintă un algoritm utilizat pentru prima dată în
clasificarea documentelor text [85]. În cadrul acestui model, se selectează un set de
cuvinte reprezentive, numit „vocabular”, iar apoi pentru fiecare document text se creează
o histogramă de apariție a cuvintelor. Aceste histograme sunt apoi clasificate cu ajutorul
unor algoritmi de clasificare. Plecând de la acest algoritm de bază, modelul BoW a fost
transferat în diverse domenii de computer vision: clasificare de imagini [86], documente
audio [87] și video, clasificarea și recunoașterea de acțiuni [88].
În cele ce urmează, vom prezenta modelul BoW pentru clasificarea imaginilor.
Ideea principală constă în faptul că punctele cheie dintr-o imagine (keypoints) sunt
considerate a fi similare cuvintelor din documentele text. Vectorul descriptor va conține o
histograma de apariție a „cuvintelor” dintr-o imagine, după care aceste histograme vor fi

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
67
clasificate cu ajutorul unor clasificatori. Noul algoritm poartă numele de „Bag of Visual-
Words” (BoVW) [86]. În același timp, algoritmul BoVW este inspirat din sistemul uman
de recunoaștere a formelor. O persoană poate recunoaște anumite obiecte chiar dacă
vizualizează numai anumite părți componente ale obiectului.
Antrenarea algoritmului BoVW conține patru pași principali: extragerea de
cuvinte vizuale dintr-un set extins de imagini, crearea vocabularului de cuvinte vizuale,
calculul de histograme de cuvinte și antrenarea unui clasificator. Schema de antrenare a
unui sistem BoVW este prezentată în Figura 3.14. Inițial, se extrag cuvintele cheie dintr-o
imagine utilizand diverși algoritmi: SURF, SIFT, HARRIS etc. Aceste puncte cheie sunt
adăugate într-un vector de cuvinte cheie. Apoi, se va reduce numărul de cuvinte cheie
prin utilizarea anumitor algoritmi de clusterizare: kmeans, clusterizare ierarhică, cam-
shift etc. Fiecare centroid rezultat va fi considerat un cuvânt dintr-un vocabular de
cuvinte vizuale.
Numărul cuvintelor din vocabular diferă în funcție de aplicație de la cateva mii
[89], până la sute de mii [90], [91]. Generarea unui dicționar vizual reprezintă un proces
foarte costisitor. Din acest motiv, au fost propuse metode în care vocabularul de cuvinte
vizuale este generat în mod artificial. În [91] s-a demonstrat că, în cazul în care
dimensiunea vocabularului este suficient de mare (ordinul zecilor de mii), impactul
alegerii modalității de selecție a vocabularului devine mai puțin importantă.
Fig. 3.14 Procesul de antrenare în cadrul algoritmului Bag of Words
Următorul pas este reprezentat de generarea histogramelor de cuvinte vizuale.
Pentru calculul descriptorilor se vor efectua următorii pași:
- pentru fiecare imagine din baza de date se vor extrage cuvintele cheie și se va calcula
distanța minimă dintre acestea și cuvintele din dicționar;
- fiecare cuvant cheie va fi atribuit unui cluster din dicționar, pe baza unui criteriu de
similaritate maximă. De cele mai multe ori măsura de similaritate se calculează cu
distanța euclidiană;
- se va creea o histogramă de apariție a cuvintelor din dictionar.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
68
După generarea descriptorului de va utiliza un algoritm de clasificare. Cele mai
utilizate tehnici de clasificare sunt SVM [86] și Naïve Bayes [86]. Alte metode de
clasificare utilizate sunt: „Probabilistic Latent Semantic Analysis” (pLSA) [92] [93]și
„Latent Dirichlet Allocation” (LDA) [94] [95].
Principalele avantaje ale modelului Bag of Words sunt invarianța la scalări, rotații
și translații (nu contează aranjarea spațială a cuvintelor vizuale într-o imagine), prezintă
performanțe bune chiar dacă apar ocluziuni parțiale ale obiectelor și este intuitiv (datorită
analogiei cu clasificarea de documente text și a similitudinii cu modul uman de
recunoaștere a obiectelor).
Fig. 3.15 Procesul de clasificare în cadrul algoritmului Bag of Words
Principalele neajunsuri ale algoritmilor Bag of Words sunt:
- nu există nici o metodă riguroasă de reprezentare a obiectelor componente, a
distribuției spațiale dintre anumite perechi de cuvinte dintr-un document;
- segmentarea și localizarea componentelor este neclară;
- există multe cuvinte care nu sunt relevante;
- procesul de cuantizare a cuvintelor generează zgomot de cuantizare;
- costul computațional crește odată cu dimensiunea vocabularului de cuvinte.
Pentru a rezolva aceste neajunsuri au fost propuse mai multe modificări la
modelul clasic BoVW. Pentru a incapsula informația spațială a obiectelor, au fost propuse
diverse metode de corelare a localizării cuvintelor: corelograma de aparitie [96], sau
diferite metode de corelație dintre componente [97], [98]. De asemeni, pentru eliminarea
zgomotului de cuantizare au fost propuși algorimi ce utilizează distanța Earth Mover [30]
sau Fisher Kernel [99]. În [100], au fost propuse diferite modalități în vederea creșterii
vitezei de calcul.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
69
3.5 Descriptori MPEG 7
3.5.1 Standardul MPEG 7
MPEG 7 reprezintă un standard ISO/IEC dezvoltat de catre MPEG (Moving Picture
Experts Group), organizația care s-a ocupat și de standardele anterioare: MPEG 1, MPEG
2 și MPEG 4. MPEG-1 si MPEG-2 sunt cele care o facut posibilă ca informația video să
fie disponibilă pe CD-ROM sau în televiziunea digitală (formatele: Video CD, MP3,
digital audio broadcasting (DAB), DVD, televiziune digitală: DVB and ATSC), în timp
ce MPEG-4 a dezvoltat standardul de integrare multimedia în tehnologii mobile
(formatele: H.264, VRML, AAC).
Standardul MPEG 7 a fost dezvoltat deoarece era nevoie de metode și tehnici de
indexare și descriere a conținutului multimedia. Acesta propune diferiți algoritmi pentru
descrierea conținutului vizual. MPEG 7 propune trei clase de descriptori vizuali: de
culoare, de textură și de formă.
3.5.2 Descriptori de culoare
Descriptorul „Color Histogram Descriptor”
Descriptorul „Color Histogram Descriptor” (CHD) [47] propune descrierea conținutului
de culoare cu ajutorul unor histograme de culoare. Standardul conține un set bine definit
de spații de culoare care pot fi utilizate: nivele de gri, RGB, YcbCr, HSV. De asemeni,
este propus un nou spațiu de culoare HMMD (mai multe detalii în Secțiunea 3.2.1).
Pentru fiecare spațiu de culoare sunt definite metode de cuantizare a culorii.
Descriptorul „Color Structure Descriptor”
Descriptorul „Color Structure Descriptor” (CSD) [47] incapsulează structura locală a
culorii într-o imagine. Acest descriptor numără de câte ori o culoare particulară este
conţinută într-un element structurant care scanează imaginea. CSD prezintă cât de
„adunată” este o anume culoare, dacă există sau nu pete mari dintr-o anumită culoare. În
cazul în care o culoare este aplicată în pete de dimensiuni mai mari, această va avea o
pondere semnificativ mai mare decât culorile aflate în regiuni cu variaţii mari de culoare.
Practic, culorile aflate în interiorul regiunile mate (obiectelor) vor avea o pondere mai
ridicată. Spaţiul de culoare folosit de acest descriptor este HMMD. Color Structure
Descriptor utilizează patru tipuri de cuantizare: 184, 120, 64 și 32 de intervale. Pentru a
construi o histogramă de 184 intervale, HMMD este cuantizat neuniform şi împartit în
cinci subspații.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
70
Pentu a calcula dimensiunea elementului structurant se utilizează următoarele
formule:
p = max(0,round(0.5*Log(width*height,2)-8));
k = Pow(2, p);
E = 8 k;
unde W, H sunt dimensiunile imaginii, ExE reprezintă dimensiunea elementului
structurant iar K este factorul de multiplicare.
Spre exemplu, în cazul în care imaginea are dimensiunea 640x480, vom avea p =
1, k = 2 și E = 16. În cazul în care elementul structurant ar avea dimensiuni mai mici de
8x8, dimensiunea dimensiunea acestuia va fi fixată la această valoare.
Descriptorul „Dominant Color Descriptor”
Acest descriptor [47] este util în reprezentarea obiectelor şi a regiunilor din imagine, unde
un număr redus de culori este necesar pentru descrierea regiunii de interes. Imaginea este
împărțită pe mai multe regiuni și sunt extrase un număr redus de culori pentru fiecare
regiune în parte. Acest descriptor arată în acelaşi timp şi gradul de coerenţă a culorii din
imagine.
Culorile dintr-o regiune dată sunt clusterizate într-un număr redus de culori.
Descriptorul va conţine culorile reprezentative, procentajul şi varianţa acestora. Pentru
măsurarea distanţelor este definită o distanţa pătratică dintre histograme. De asemeni
culorile pot fi indexate direct în spaţiul 3D. Pentru căutarea similarităţii se vor căuta
imaginile cu regiuni similare. La final descriptorul calculat va avea următoarea structură:
(3.74)
unde c, p şi v reprezintă culoarea dominantă, procentajul și varianţa, iar s este un
parametru de calcul a omogenităţii totale a culorii.
Numărul de culori dominante variază de la o imagine la alta şi un număr de
maxim 8 culori sunt utilizate pentru reprezentarea unei regiuni. Metoda de clusterizare a
culorii este bazată pe algoritmul de clusterizare a lui Loyd [1], al cărui principiu este cel
de minimizare al erorii din fiecare cluster:
∑
(3.75)
unde este centrul centroidului , x(i) culoarea pixelului din regiune, pondere a
pixelului curent (valoare mai mare pentru regiuni texturate decât pentru regiuni neclare
(blurate)).
Fie doi descriptori de culoare:
(3.76)
(3.77)
Distanţa dintre cei doi descriptori va fi calculată cu formula:

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
71
∑
∑
∑∑
(3.78)
unde ,
-
| |- distanţa dintr cele două culori şi valoarea maximă a distanţei dintre
două culori.
Descriptorul „Color Layer Descriptor”
Color Layer Descriptor [47] a fost creeat pentru a reţine distribuţia spaţială a culorii dintr-
o imagine, acesta putând fi interpretat ca o schiţă a imaginii. Codarea are doi pași:
transformarea imaginii în formă dreptunghiulară cuantizată (64 de blocuri)
cuantizarea cu ajutorul tranformatei DCT.
Transformata DCT, în special tipul bidimensional, este foarte utilizată în studiul
sunetului şi al imaginilor, în special pentru algoritmii de compresie. Transformata DCT
beneficiază de o excelentă capacitate de „concentrare” a energiei: informaţia unui semnal
fizic tipic este repartizată în principal pe coeficienţii corespunzând armonicelor de joasă
frecvenţă (statistic vorbind). Pentru imaginile naturale, DCT este transformata care se
apropie cel mai mult de transformata Karhunen-Loève care oferă o decorelaţie optimală
între coeficienţii reprezentării unui semnal markovian. Din punct de vedere practic,
procedeele de compresie pleacă de la ipoteza ca o imagine naturală poate fi modelată ca
fiind rezultatul unui proces markovian și aproximează transformata Karhunen-Loève,
prea complexă din punct de vedere algoritmic și dependentă de date, cu o DCT.
∑ [
(
) ]
(3.79)
Doar un număr mic de coeficienți sunt ne-nuli, și pot fi utilizaţi pentru
reconstruirea imaginii iniţiale prin transformata inversă (IDCT) cu ocazia decompresiei.
Reducerea volumului datelor compresate vine din suprimarea coeficientilor nuli sau
aproape nuli corespunzând frecvenţelor înalte, aparatul vizual uman fiind foarte puţin
sensibil la aceste elemente spectrale ale imaginii (corespunzând, de exemplu, unei zone
cu contururi foarte fine dintr-o imagine), deci reproducerea exactă a acestor elemente nu
este esenţială pentru calitatea imaginii. Acest tip de mecanism este utilizat în standardele
JPEG şi MPEG, care aplică o DCT 2D pe blocuri de pixeli de talie 8x8.
Spaţiul de culoare utilizat este YCrCb. Pentru a compara doi descriptori se
utilizează formula de mai jos:
√∑
√∑
√∑
(3.80)

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
72
Numărul recomandat de biţi de codare pentru descriptor este de 13. Acesta
include şase coeficienti pentru Y și câte trei coeficienţi pentru Cr şi Cb.
3.5.3 Descriptori de textură
Descriptorul „Texture Browsing Descriptor”
Acest descriptor [47] implementează trei dintre cei şase descriptori de textură Tamura,
prezentaţi anterior în cadrul capitolului 3.2.1. Trăsăturile implementate sunt: asprimea,
contrastul şi direcţionalitatea.
Descriptorul „Edge Histogram Descriptor”
Histograma marginilor [47] captează distibuţia spaţială a muchiilor din interiorul unei
imagini. Distribuţia marginilor este o bună semnatură de textură şi este utilă în căutarea
de imagini. Calculul descriptorului este uşor de realizat: marginile sunt grupate în cinci
categorii: verticale, orizontale, diagonala 135, diagonala 145 şi izotropic, iar pentru
fiecare tip de margine vom avea un interval într-o histogramă de muchii. Imaginea va fi
împărţită în 16 imagini (4x4), fiecare histogramă având cinci intervale, de unde vom avea
5x16 = 80 intervale. Procedeul poate continua printr-o împarţire mai detaliată a imaginii.
Procedeul de împărţire în subblocuri este prezentat în figura următoare:
Fig. 3.16 Impărţirea imaginii iniţiale pentru descriptorul Edge Histogram
Pentru a calcula histogramele de muchii pentru fiecare 16 subimagini, fiecare bloc
va fi împărţit în blocuri mai mici (la fel pentru fiecare imagine indiferent de dimensiunea
imaginii). Detectoarele de margini vor fi aplicate fiecărei subimagini sub forma unei
ferestre 2x2. În fiecare subdiviziune de subimagine se va reţine media intensitătii
pixelilor. Detectorul de margini va parcurge subimaginile cu ajutorul celor 5 fereste
prezente în Figura 3.17.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
73
Fig. 3.17 Exemple de ferestrele detectoare de muchii
După calculul muchiilor se va aplica un prag pentru eliminarea variaţiilor fine, se
calculează histogramele de margini, după care valorile se cuantizează în intervalul [0, 1].
3.5.4 Descriptori de formă
MPEG 7 conține trei descriptori de formă: descriptor de regiune, descriptor de contur și
descriptor de forme 3D. Descriptorul de regiune utilizează un set de funcții numite ART
(Angular Radial Transform) care compun o transformată 2D. Acesta oferă o metodă
compactă și eficientă de descriere a unei forme în spatiul 2D. Funcțiile ART [101]
reprezintă o transformată unitară definită în coordonate polare. Coeficientul de ordin
(m,n) este calculat utilizând urmatoarea formulă:
∫ ∫
(3.81)
unde f este imaginea în coordonate polare iar este funcția ART:
(3.82)
iar
(3.83)
(3.84)
În MPEG 7 sunt utilizate un set de 12 funcții angulare și 3 funcții radiale (n<3 și
m<12). Familia de funcții ART prezintă anumite avantaje. Acestea sunt capabile să
descrie forme complexe care conțin zone necompactate, fiind robuste la zgomotul de
segmentare. De asemenea, dimensiunea acestora este redusă și prezintă o viteză de calcul
ridicată.
Descriptorul de contur utilizat de către standardul MPEG 7 este „Curvature Scale
Space” [102]. Reprezentarea Curvature Scale Space este bazată pe reținerea poziției
punctelor de inflexiune de pe contur, filtrate de o funcţie trece-jos gausiană gausiană
[103]. Metoda este similară cu tehnica de aproximare polinomială, descrisă în capitolul
anterior. Primul pas este calculul conturului suprafetei (x(t), y(t)). Apoi se normalizează
conturul la un număr finit de puncte de margine. Ca şi la aproximarea polinomială se
calculează o funcţie pentru fiecare punct care exprimă gradul de importanţă a punctului
respectiv
(3.85)

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
74
3.6 Descriptori de mișcare
Detecția mișcării reprezintă procesul de recunoaștere a schimbării poziției a unor obiecte
relativ la o vecinătate a acestora. Primele sisteme de detecție a mișcării aveau încorporate
diferite componente mecanice sau electronice și au fost folosite pentru rezolvarea unor
probleme de securitate. Mai nou, odată cu apariția necesității de analiză și interpretare a
conținutului multimedia, au apărut diferiți algoritmi de detecție a formei de mișcare.
După modul de intepretare a scenei, analiza mișcării se poate împărți în două perspective
diferite: (1) aceasta poate fi efectuată la nivel global, la nivel de cadru sau segment video
[104] sau (2) la nivel local, prin analiza mișcării la nivel de obiect [105].
În mod tradițional, analiza mișcării globale este efectuată cu ajutorul tehnicilor de
detecție a fluxului optic. Pentru estimarea acestuia, de obicei se admit anumite
simplificări ale problemei. În acest sens, se ia în considerare faptul că intensitatea
luminoasă a fiecărui pixel este constantă de-a lungul traiectoriei mişcării sau se modifică
într-un mod predictibil. Mai mult, mișcarea este lină, obiectele deplasându-se încet de la
un cadru la altul. Principiul clasic de estimare a fluxului optic constă în determinarea
deplasării unor pixeli sau a unui bloc de pixeli, între două imagini succesive ale
secvenței, pe baza minimizării variației intensității acestora.
Pentru a exprima matematic această ipoteză, se utilizează ecuația de diferență
dintre imaginile deplasate („Displaced Frame Difference” - DFD), și anume între
momentele la care se estimează fluxul optic t și :
( ) (3.86)
unde (x,y) reprezintă poziția pixelului sau a blocului de pixeli în imaginea analizată,
este vectorul de deplasare între momentele t și , iar I(x,y,t) reprezintă funcția
de intensitate la poziția (x,y) în momentul t.
Pentru a calcula ecuația DFD, în literatură au fost propuse mai multe tehnici
[106]: metodele diferențiale (se bazează pe rezolvarea matematică a ecuațiilor existente
din fluxul optic), metode parametrice (modelează deplasarea pixelilor în imagine folosind
o serie de parametri), algoritmi stohastici (utilizează modele probabilistice de estimare:
Bayesiene, Markov sau algoritmi genetici) și metode bazate pe blocuri de pixeli
(utilizează un set de simplificări a calculelor de estimare). Acestea din urmă folosesc
ipoteza de simplificare, conform căreia dimensiunea mișcării este limitată în timp, iar
căutarea direcției de mișcare poate fi micșorată doar la o zonă a imaginii curente, numită
„fereastră de căutare” (Figura 3.18). Informaţia obţinută de la un singur pixel nu este
suficient de discriminatoare pentru a asigura potriviri unice, iar din acest motiv se va
efectua presupunerea suplimentară conform căreia toţi pixelii vecini dintr-un bloc au
aceeaşi mişcare. În acest sens, se va calcula câmpul vectorial de mișcare la nivel de
regiuni de pixeli, astfel furnizând un vector de deplasare pentru fiecare dintre acestea.
Toate aceste tehnici prezentate anterior însă nu sunt eficiente pentru clasificarea și
intepretarea unor mișcări complexe, cum ar fi intepretarea de acțiuni umane. Mai mult,

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
75
apar diferite probleme specifice recunoașterii de obiecte: variația unghiului de vizualizare
și a luminozității, ocluziuni, dimensiunea obiectelelor din cadrul filmului care prezintă
diferite scale. De asemenea, trebuie specificate și alte probleme specifice care pot apărea:
mișcarea camerei, zgomotul de imagine, schimbări de fundal, dar și faptul ca anumite
acțiuni pot fi foarte similare ca și formă a mișcării (ex: acțiunile de a bea sau de a mânca).
Fig. 3.18 Principiul de estimare pe blocuri de pixeli a mișcării
În acest sens, au fost propuse o serie de metode care intepretează noțiunea de
mișcare la nivel local. În [105] a fost propusă una dintre primele metode de detecție a
punctelor de interes de mișcare. Pentru detecția punctelor de interes spațio-temporale,
este utilizat algoritmul lui Harris. Apoi, principiul algoritmului este asemănător cu cel al
BoW: se generează un dicționar de puncte spațio-temporale, iar fiecare mișcare este
descrisă cu ajutorul acestui dicționar. În final, aceste trăsături sunt utilizate pentru
antrenarea unui clasificator.
Pentru descrierea punctelor de interes spațio-temporale au fost propuse diferite
metode. Un prim algoritm propune împărțirea punctelor de interes în volume spațio-
temporale [107] (Figura 3.19), iar pentru fiecare volum se calculează o histogramă de
trăsături HOF și HOG. Alte metode de extracție a punctelor de interes spațio-temporale
propuse utilizează: algoritmul SIFT 3D [108] sau GIST 3D [109]. Pentru clasificare, au
fost propuși diferiți algoritm, și anume: AdaBoost [105], SVM [109] sau diferite forme
de fuziune probabilistică [108].

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
76
Fig. 3.19 Ilustrare a împărțirii spațio-temporale a documentului video: (a) fără
împărțire, (b) împărțire spațială, (c) împărțire spațială și (d) împărțire spațio-temporală
Modelul Bag of Words utilizat în aceste metode prezintă anumite avantaje foarte
importante, acesta fiind robust la zgomot sau la ocluziuni. Însă, în ciuda popularității sale,
algoritmul BoW prezintă anumite neajunsuri evidente. În primul rând, reprezentarea
BoW utilizează descriptori de nivel scăzut pentru descrierea unor informații cu un nivel
semantic ridicat. În al doilea rând, relația spațială dintre punctele de mișcare este ignorată
în totalitate. Mai mult, prin procesul de creare a dicționarului, iar apoi prin asocierea
unui punct de interes la un cuvânt din dicționar, se creează un zgomot de cuantizare care
generează o pierdere majoră de informație.
Pentru a evita aceste probleme, în ultimii ani au fost propuși diferiți algoritmi care
utilizează detecția de părți componente ale corpului [110]. Apoi, pentru fiecare parte
componentă a corpului este descrisă mișcarea acestuia, iar în final, aceste componente
vor fi concatenate și se va construi un descriptor agregat.
3.7 Descriptori audio
Oamenii clasifică semnalele audio cu o mare ușurință. Recunoașterea unei anumite voci
la telefon, distincția anumitor semnale specifice (sunetul unui claxon sau a unei melodii
anume) sunt lucruri firești pentru fiecare persoană. Însă, probleme pot apărea atunci când
puterea semnalului este slabă sau este forma similară cu a unui alt semnal. De exemplu,
este dificil să distingem pașii pentru două persoane sau sunetul dintre două motoare.
Astfel, se pot distinge două mari clase de aplicații, în care detecția de sunet poate juca un
rol important.
O primă aplicație este recunoașterea și clasificarea de semnale audio ușor de
intrepretat de om: clasificare sunet după gen, recunoaștere automată a vorbirii,
recunoaștere de sunete specifice. Acești algoritmi ar ajuta la indexarea automată a
conținutului multimedia existent. Pe de altă parte, a doua aplicație este cea de
recunoaștere a semnalelor care nu pot fi interpretate de către om. Spre exemplu, în
domeniul medical este nevoie de aparatură care să intepreteze automat sunetele emise de
aparatul respirator uman.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
77
(a) (b)
Fig. 3.20 Modalități de împărțire a semnalului audio: (a) împărțire în frameuri și (b)
împărțire cu ajutorul ferestrelor
Schema clasică de calcul a unui descriptor de semnal audio este prezentată în
Figura 3.21. Inițial, este extrasă amplitudinea semnalului audio. Fiecare semnal audio
poate fi considerat o funcție continuă de amplitudini (sau mai multe amplitudini pe mai
multe canale), care este cuantizată pe un număr finit de secvențe discrete. De obicei,
semnalul audio este eșantionat în intervalul 15-60 kHz.
Primul pas în cadrul schemei de calcul a unui descriptor audio constă în
împărțirea documentului audio în blocuri de dimensiune egală, denumite cadre audio.
Acestea au o lungime standard de câteva zeci de milisecunde secunde (10 - 30 ms). De
obicei, două cadre consecutive au o porțiune comună egală cu 50% din lungimea unui
frame. Cadrele trebuie să fie suficient de mici astfel încât să poată fi considerate semnale
staționare (ale căror statistică nu se schimbă), adică frecvența rămâne constantă în cadrul
unui frame. O altă modalitate de împărțire a semnalului audio este prin intermediul
ferestrelor. Ferestrele reprezintă funcții matematice care au valoarea zero în afara unui
interval specific. Apoi, semnalul audio este înmulțit cu funcția de fereastră care va fi
translatată în mod succesiv asupra semnalului.
Fig. 3.21 Schema generală a unui sistem de clasificare de semnale audio.
În cazul în care considerăm fereastra ca o funcție rectangulară, un cadru va fi
echivalent cu un bloc audio extras de o fereastră. Cea mai utilizată funcție este fereastra
Hamming:

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
78
(
)
(3.87)
unde M reprezintă lungimea ferestrei iar .
Pasul doi constă în calculul descriptorilor per bloc. Aceștia pot fi calculați în
mediu transformat (ex: transformata „Short-Time Fourier” STFT) sau direct asupra
semnalului audio. Urmează apoi un pas de antrenare cu un clasificator.
În continuare, vom prezenta un set cu cei mai importanți descriptori audio, și
anume: descriptorul „Short Time Energy”, frecvența fundamentală „Pitch”, descriptorul
„Zero Crosing-Rate” și coeficienții „Mel-frequency cepstral”.
Descriptorul „Short Time Energy”
Principala utilizare a acestei funcții este de a separa segmentele nonverbale de
cele verbale. Acestea sunt foarte utile mai ales în mediile cu zgomot ridicat, deoarece
semnalele de zgomot au această proprietate mult mai redusă decât semnalele vocale.
Pentru un bloc m de lungime N, acesta poate fi definit în felul următor:
∑
(3.85)
unde x() este semnalul audio iar w() reprezintă funcția fereastră Hamming.
Descriptorul „Zero Cross rate”
Descriptorul „Zero Cross rate” (rata trecerilor prin zero - ZCR) [111] este definit
ca numărul de ori în care semnalul sonor își schimbă sensul într-o fereastră de
dimensiune dată:
∑
(3.86)
unde
, N reprezintă lungimea blocului m al semnalului audio, x()
este semnalul audio, iar w() reprezintă funcția fereastră Hamming.
Aceste prime două trăsături sunt foarte eficiente în distingerea porțiunilor din
semnalul sonor în care este prezentă sau absentă voce umană. Astfel, porțiunile de voce
sunt caracterizate de valori mari ale energiei și rate joase ale trecerilor prin zero, în timp
ce regiunile fără voce prezintă valori inverse.
Autocorelația
Autocorelația calculează gradul de corelare între coeficienții aflați în cadrul
aceluiași cadru, utilizând formula de următoare:
∑
(3.87)

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
79
Alte trăsăsături care pot fi extrase din blocuri de semnal audio sunt:
Energia [111]:
√
∑
(3.88)
Aplatizarea spectrală („Spectral Platness”) [111]:
(
∑
)
∑
(3.89)
Fluxul spectral [111]:
∑
√∑ √∑
(3.90)
Variația spectrală [111]:
∑
√∑ √∑
(3.91)
Scăderea spectrală („Spectral decrease”):
∑
∑
(3.92)
Frecvența fundamentală „Pitch”
Frecvența fundamentală este o trăsătură foarte importantă pentru analiza audio, în
special în recunoașterea vocii umane și reprezintă frecvența principală a unui semnal
audio complex.
Coeficienții „Mel-frequency cepstral”
Coeficienții „Mel-Frequency Cepstral” (MFCCs) reprezintă o tehnică des întâlnită
în procesarea semnalului vocal [112]. A fost folosită prima data pentru clasificarea
semnalului vocal de către [113], ca apoi să devină un standard pentru clasificarea de
documente audio [114] .
Algoritmul de calcul a coeficiențlor MFCC conține următorii pași:
- fiecare cadru este multiplicat cu o fereastră Hamming;
- pentru fiecare frame se aplică transformata Fourier Discretă (STFT). Se rețin doar
valorile absolute ale frecvențelor pentru fiecare bin. Valorile de fază nu se rețin
deoarece urechea umană este mai puțin sensibilă la componenta de fază față de cea a
magnitudinii [115];
- valorile frecvențelor sunt mapate pe scara Mel. Această scară modelează sistemul
auditiv uman, care presupune o scară liniară până la 1000 Hz, ca apoi aceasta să
devină logaritmică [116]. De asemenea, transformarea Mel este utilizată pentru
reducerea dimensionalității: în frecvența normală numărul de valori posibile pentru

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
80
spectru este în intervalul [256, 1024], iar acestea sunt mapate pe un număr redus de
bande Mel. Acest lucru are o justificare biologică, urechea umană distinge numai
câteva frecvențe numite benzi critice [117];
- se aplică transformata cosinus și se rețin primele conponente ale transformării;
- deoarece MFCC nu sunt foarte robuști la zgomotul aditiv, se aplică diferite strategii
de normalizare.
După calculul trăsăturilor pe fiecare bloc în parte, este nevoie de o metodă de
agregare a acestora într-un singur descriptor. O primă abordare care trebuie luată în
considerare este agregarea acestora prin utilizarea mediei și dispersiei acestora, sau a
altor parametri statistici [118]. Alte metode utilizează modelul Bag-of-Words [87] sau
distanța Earth Mover [30].
Ultimul bloc al unui sistem de clasificare audio este cel de antrenare și clasificare
a sistemului. În literatură, au fost folosiți diferiți algoritmi, de la utilizarea clasificatorului
SVM [119] [120], Nearest Neighbor [120] și a modelului „Hidden Markov Model” [114]
până la hărți cu autoorganizare [121].
În prezent, informația audio reprezintă o componentă importantă a multor aplicații
multimedia. Ca tendință generală a sistemelor existente, se poate menționa faptul că
informația audio este folosită cu predilecție pentru caracterizarea conținutului specific de
gen a documentelor video sau audio și pentru detecția anumitor particularități specifice
(de exemplu, detecția de violență). Este un lucru știut că anumite genuri de film / muzică
conţin o semnătură audio specifică: documentarele utilizează un amestec de sunete
naturale şi monologuri, sporturile au în componență monologurile prezentatorilor sau un
anumit zgomot de fond al telespectatorilor, în timp ce emisiunile politice conțin dialoguri
între diverse persoane. Totuși, în domeniul indexării după conținut a documentelor
multimedia, metodele bazate exclusiv pe audio sunt foarte puține. Acest lucru se
datorează, în principal, faptului că informația audio, analizată individual, nu conține
suficientă putere discriminatorie pentru a oferi o caracterizare globală a conținutului. Din
această cauză, în marea majoritate a metodelor de analiză existente, informația audio este
folosită prin fuziune cu alte canale informaționale (vizuală sau cea textuală).
3.8 Descriptori de text
Clasificarea de text reprezintă sarcina de a atribui în mod automat un set de documente la
o listă predefinită de categorii. Problema detecției și a clasificării documentelor text
reprezintă un domeniu de cercetare foarte important deoarece o mare parte din informația
web existentă în momentul de față se găsește în format text: poșta electronică, site-urile
web, știri RSS feed, baze de date și librării digitale.
Printre aplicațiile acestui domeniu putem enumera: indexarea automată a
documentelor librăriilor digitale, diseminarea selectivă a informației pentru utilizatori în
funcție de anumite interogări, crearea de cataloage ierarhice automate pentru conținutul

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
81
web, filtrarea mesajelor spam, identificarea categoriei unui document și chiar rezumarea
automată a conținutului. Domeniul de adnotare automată a textului este unul atractiv
deoarece eliberează companiile de nevoia de a organiza documentele în mod manual,
ceea ce poate fi un proces costisitor sau nerealizabil datorită constrângerilor de timp a
aplicației sau a numărului de documente implicate. În prezent, acuratețea sistemelor de
clasificare de text actuale rivalizează chiar și cu metodele de adnotare manuală. În cadrul
acestui capitol voi trata arhitectura generală a unui sistem de clasificare de text.
Un sistem clasic de detecție și clasificare a textului conține trei pași principali:
preprocesarea, extragerea de trăsături și antrenarea unui sistem de clasificare. Schema
generală este prezentată în Figura 3.22.
Preprocesarea
De obicei, modulul de preprocesare conține următorii pași: eliminarea marcajelor
existente, a cuvintelor nerelevante, extragerea rădăcinii cuvintelor și crearea dicționarului
de termeni.
Inițial, se elimină diferitele marcaje care există în cadrul textului, precum
elementele HTML, dacă este cazul, sau semnele de punctuație. Apoi, urmează pasul de
normalizare și extragere a rădăcinii cuvintelor. Acesta constă în transformarea cuvintelor
într-un format similar, astfel încât aceiași termeni, dar cu forme sintactice diferite, să
poată fi considerați identici. Mai întâi, toate cuvintele sunt transformate în litere mici, iar
apoi se elimină toate sufixele și prefixele termenilor, proces cunoscut sub termenul de
„stemming”. Spre exemplu, daca avem cuvintele „experimentelor” și „experimentele”,
acestea vor fi reduse la rădăcina lor comună, și anume „experiment”. Cel mai cunoscut
algoritm de stemming este algoritmul lui Porter [122], ce prezintă implementări pentru
diferite limbi de circulație internațională.
De obicei, limbajele conțin un număr redus de cuvinte cu o frecvență de apariție
ridicată, un set mai mare de termini cu o frecvență medie și un număr foarte mare de
cuvinte care sunt utilizate rar. Cuvintele cu un grad înalt de apariție nu sunt
discriminative pentru a clasifica un document dintr-o clasă în alta, deci nu sunt
folositoare. În schimb, termenii cu frecvență de apariție scăzută, deși sunt foarte
indicativi vor fi de puține ori găsiți în seturile de antrenare. Un prim pas este eliminarea
cuvintelor din vocabular cu un grad ridicat de apariție (ex: „este”, „merge”, „cauză”,
„unu”, „departe”, „și”, „cu”, „pe” etc). Acest proces este cunoscut sub denumirea de
„stop-word”. Una dintre cele mai utilizate liste de cuvinte care trebuie eliminate este setul
„SMART stop”, propus de către MIT. De asemenea, vor fi eliminați și termenii cu
frecvență de apariție redusă, proces ce poartă numele de „Document Frequency
Thresholding”. Această tehnică elimină cuvintele care apar doar într-un singur document.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
82
Fig. 3.22 Schema generală a unui sistem de clasificare de text
În urma filtrării, se vor extrage un set de termeni ce vor compune un vocabular V,
care va sta la baza calculării de trăsături.
Extragerea de trăsături de text
Majoritatea trăsăturilor de text extrase reprezintă vectori de cuvinte care au asociate un
set de ponderi. Lungimea descriptorilor text va fi dată de numărul de termeni selectați în
pasul anterior. De obicei, lungimea trăsăturilor textuale este de câteva mii, în funcție de
dimensiunea vocabularului.
În continuare, vom considera descriptorul pentru documentul i, n
dimensiunea vocabularului, iar , ponderile asociate fiecărui cuvânt existent în
documentul i. Cele mai importante sturi de reprezentări utilizate în literatură sunt:
Reprezentarea binară sau booleană – vectorul va conţine valoarea „0” dacă
termenul respectiv nu apare în document și „1” în caz contrar.
Reprezentarea „Term Frequency” (TF) [123] - în vectorul de intrare sunt
ponderate valorile în funcţie de frecvenţa apariţiei termenului în documentul
respectiv:
(3.93)
unde f(t,d) este frecvenţa apariţiei al termenului t în documentul d, reprezintă
toți termenii pe care îi conține documentul d, k ia valori în intervalul [1..n], iar funcția
max() reprezintă frecvența maximă de apariție a unui termen.
Reprezentarea „Term Frequency” normalizată:
(3.94)
Reprezentarea „Bag of Words” - reprezintă o histogramă de apariție a cuvintelor.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
83
(3.95)
unde funcția sum() reprezintă suma frecvențelor de apariție a documentului.
Reprezentarea logaritmică [123]: frecvența este scalată pe o scară logaritmică:
(3.96)
Reprezentarea „Invers Document Frequency” (IDF) [123] – valorile sunt
ponderate în funcţie de frecvenţa apariţiei termenului în colecţia de documente:
(3.97)
Reprezentarea „Term Frequency Invers Document Frequency” (TF-IDF)
[123]:
(3.98)
Reprezentarea TFC [124]: utilizează formula TF-IDF, însă este adăugată o
împărțire a magnitudinii vectorului documentului interogat. Acest lucru
normalizează scorul fiecărui cuvânt din fiecare articol, eliminând astfel efectele
diferențelor legate de lungimea distinctă a acestora.
√∑
(3.99)
Reprezentarea LTC [125]: reprezintă o formă modificată pe o scară logaritmică a
reprezentării TFC:
√∑
(3.100)
Reprezentarea entropică: reprezintă o formă mai sofisticată de ponderare:
(
∑[
(
)]
) (3.101)
Aceste reprezentări au și anumite limitări. Documentele de lungime ridicată sunt
slab reprezentate, deoarece pot conține un număr redus de termeni reprezentativi, această
limitare putând fi parțial eliminată cu ajutorul normalizărilor. O altă limitare este
reprezentată de sensibilitatea semantică: documentele utilizate într-un context similar, dar
care conțin termeni din vocabular diferiți, nu vor putea fi asociate, ceea ce va genera un
număr ridicat de rezultate fals negative. De asemenea, prin reprezentările prezentate
anterior ordinea de apariție a termenilor în document este pierdută. Mai mult,
dimensiunea spațiului trăsăturilor este foarte mare, iar algoritmii clasici de antrenare au
probleme datorită paradigmei de dimensionalitate. Pentru rezolvarea acestei probleme, o
primă abordare utilizată este reducerea dimensionalității prin detecția trăsăturilor care au
cea mai mare variație. Variante de algoritmi de reducere a dimensionalității propuși
pentru sistemele de clasificare de text sunt PCA și MDS [126].

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
84
Clasificarea trăsăturilor de text
În ceea ce privește ultimul bloc al unui sistem de clasificare de text, au fost propuși mai
mulți algoritmi de antrenare și clasificare. O primă abordare folosită este cea a
algoritmilor statistici, în special Naïve Bayes [127]. Clasificatorii text Naïve Bayes se
disting prin viteză, acuratețe mare de clasificare și simplitatea implementării. Acesta a
fost folosit cu succes atât în probleme de categorizare, cât mai ales în aplicații de filtrare
a mesajelor de tip spam.
Un alt algoritm de clasificare utilizat este Nearest Neighbor (KNN). Pentru o
interogare, acesta folosește media distanțelor cosinus dintre documentul de interogare și
documentele din baza de antrenare. Documentul va fi atribuit clasei la care distanța medie
calculată are valoare minimă. SVM este un alt exemplu de clasificator care lucrează
eficient pentru clasificarea documentelor text [128]. Acesta poate manipula seturi mari de
date, neseparabile liniar. Algoritmul SVM construieşte o funcţie de mapare directă între
mulţimea termenilor şi variabilele de clasă din cadrul etapei de antrenare. Apoi, acesta
construiește un hiperplan de separaţie între documentele de antrenare ce aparțin unor
clase diferite. Alți algoritmi utilizați pentru clasificarea documentelor text sunt LDA,
rețele neurale și arbori de decizie [126].
Domeniul de clasificare și regăsire a documentelor web are o istorie de peste 40
de ani. În ultimii ani, s-a intensificat activitatea de cercetare privind construcţia semantică
unei arhitecturi de web, adică informaţia despre conținutul web este stocată la un nivel
superior, iar acesta va sta la baza viitoarelor sisteme de căutare a conţinutului paginilor
web. În acest moment, clasificarea documentelor web asigură o acuratețe mare pentru
extragerea automată a sensului semantic a paginilor web, iar aceste informații pot fi
utilizate pentru a genera o ierarhie ontologică a datelor web.
3.9 Concluzii
În acest capitol am discutat diversele modalitați de analiză și caracterizare a conținutului
multimedia. O primă componentă de descriere a trăsăturilor este canalul vizual, care
cuprinde informația de culoare, formă, puncte de interes și mișcare. Culoarea este cea mai
expresivă dintre toate componentele vizuale de culoare. Un rol important în analiza de
culoare îl are spațiul de reprezentare al culorilor folosit. Acesta trebuie selectat astfel
încât să pună în evidență anumite proprietăți caracteristice problemei. Astfel, spațiile de
culoare evoluează de la reprezentările clasice precum RGB (utilizat de către majoritatea
dispozitivelor hardware), până la cele inspirate de sistemul vizual uman (HSV, Lab,
HMMD), astfel încât acesta să reflecte nivelul semantic de descriere universal, precum
spațiul Color Naming.
Pe de altă parte, descrierea informației de textură caracterizează anumite aspecte
de structură ale suprafețelor, precum: asprimea, contrastul, direcţionalitatea, asemănarea

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
85
liniară, regularitatea şi rugozitatea. De cele mai multe ori, trăsăturile de textură se
realizează prin interpretarea valorilor pixelilor ca realizări ale unor procese aleatoare
corelate. Acestea pot fi descrise sub forma unor distribuții de caracteristici (contrastul,
corelația, entropia, omogenitatea, varianța, energia) în domeniul spațial al imaginii sau în
domeniul de frecvență (Fourier, Gabor).
Caracteristica de formă reprezintă o componentă esenţială în procesul de
recunoaștere și clasificare a obiectelor. Aceasta conține descrierea geometrică a unui
obiect prin determinarea frontierelor acestuia față de obiectele din jur. Descriptorul de
formă trebuie să fie invariant, obiectele trebuind să fie recunoscute indiferent de poziție,
dimensiune și orientare. După modul de interpretare a conceptului de formă, descriptorii
se împart în două mari categorii: descriptori de regiuni, care utilizează momente statistice
şi descriptori care utilizează informația de contur.
Punctele de interes reprezintă forme geometrice cu o poziție bine definită şi pot fi
viguros detectate. De obicei, detectoarele punctelor de interes extrag colţuri, maxime sau
minime locale din regiuni de imagini care pot fi reprezentative pentru descrierea obiectelor.
Acestea trebuie să fie invariante la schimbări de luminozităte, translaţie, rotaţie sau la alte
transformări.
Evoluția temporală a informației vizuale sau informația de mișcare este una dintre
particularitățile fundamentale ale documentelor video. Metodele existente folosesc ca
punct de plecare pentru analiză estimarea câmpului de mișcare al pixelilor din imagine,
denumit și flux optic. Pornind de la problematica estimării mișcării la nivel de pixel, în
acest capitol am descris principalele direcții de studiu abordate de metodele de analiză și
caracterizare a mișcării.
Informația audio reprezintă o componentă de bază pentru multe aplicații
multimedia. În general, descriptorii audio se calculează în domeniul timp sau frecvență pe
unități fixe, denumite blocuri sau cadre audio. Aceste trăsături se agregă într-un singur
descriptor final, care va fi utilizat într-un proces de antrenare. Deși aplicațiile în care
informația audio este utilizată individual sunt puține, aceasta este de foarte multe ori utilă
în multe probleme, prin fuziunea acesteia cu alte canale informaționale.
Studiul clasificării bazelor de date de text reprezintă unul dintre cele mai
importante domenii de cercetare din ultimii 40 de ani. În prezent, o mare parte din
informația web existentă poate fi accesată în format text: de la poșta electronică, la site-
urile web și librăriile digitale. În cadrul acestui capitol am trecut în revistă principalele
metode de descriere a informației textuale: Bag of Words și TF-IDF.
Global, tendința de evoluție a sistemele actuale de indexare după conținut este
spre descrierea semantică automată a conținutului datelor, în scopul simplificării
problematicii de accesare a informației multimedia. Deși paradigma semantică nu a fost
înlăturată complet, evoluția sistemelor a fost remarcabilă în ultimii ani.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
86

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
87
Capitolul 4
Algoritmi de Relevance Feedback
4.1 Conceptul de Relevance Feedback
Relevance Feedback (RF) reprezintă un mecanism interactiv de învațare online a
preferințelor utilizatorului și are scopul de a îmbunătăți performanțele de indexare ale
sistemelor multimedia. Metodele de relevance feedback reprezintă un domeniu intens
studiat în ultimii ani, reprezentând o alternativă viabilă pentru îmbunătățirea căutării în
sistemele multimedia multimodale [129].
Mecanismul prin care funcționează un algoritm de relevance feedback este
următorul: utilizatorul selectează un document / concept care va folosi ca interogare
pentru sistem. Sistemul va returna un o listă iniţială de documente, ordonate pe baza unui
criteriu inițal de similaritate. Utilizatorul va selecta documentele care sunt relevante
pentru căutarea sa, iar sistemul își va reformula interogarea pe baza feedback-ului
utilizatorului. Apoi, sistemul va afișa o nouă listă de documente. În cazul în care
utilizatorul nu este mulțumit de noile rezultate oferite, are posiblitatea de a genera o nouă
antrenare a sistemului, prin acordarea unei noi sesiuni de feedback.
După modul în care se preia feedback-ul, algoritmii de relevance feedback se
împart în trei categorii principale: relevance feedback clasic (sau feedback explicit -
mecanism descris în paragraful anterior), pseudo-relevance feedback (cunoscut și ca
blind relevance feedback), și relevance feedback indirect (global)
Pseudo-relevance feedback [130] reprezintă o metodă în care relația cu
utilizatorul este simulată automat. Acest lucru presupune că trăsăturile utilizate pentru
descrierea documentelor sunt suficient de bune astfel încât sistemul să poată returna în
primele documente afișate un număr ridicat de rezultate relevante. Inițial, pe baza
interogării inițiale a utilizatorului, se generează o căutare în baza de date, iar apoi
sistemul presupune că primele k documente sunt relevante pentru utilizator. Pe baza
primelor rezultate returnate, urmează un proces de reantrenare a sistemului. Fiecare
document va primi un nou scor pe baza răspunsului sistemului.
Succesul unei astfel de strategii depinde foarte mult de gradul de adevăr al
presupunerii efectuate. În cazul în care presupunerea este adevarată, experimentele au
arătat că tehnica de pseudo-feedback îmbunătațeste considerabil performanțele sistemului
[130] [131] [132]. Totuși, situațiile negative sunt foarte des întâlnite și conduc la o
scădere considerabilă a preciziei, cu fiecare iterație de relevance feedback.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
88
Relevance feedback indirect [130] utilizează surse indirecte de feedback, și anume
sistemul poate utiliza informația despre documentele pe care utilizatori diferiți le-au
accesat în căutările unor documente cu conținut asemănător. Acesta este mai puțin
eficient decât feedback-ul explicit [133], însă mai util și corect decât tehnicile de pseudo-
feedback, care nu conțin în nici o măsură feedback real preluat de la utilizator. Feedback-
ul implicit poate fi stocat cu ușurință în sistemele cu volume mari de date, ca de exemplu
motoarele de căutare. Această idee a fost implementată pentru prima data de către
sistemul DirectHit [134], iar în prezent este utilizat de către cele mai importante motoare
de căutare de text. Principalul avantaj al feedback-ului implicit este faptul că utilizatorul
nu mai este nevoit să acorde feedback. Aceste tehnici rețin istoricul interacțiunii
utilizator-sistem, și utilizând anumite principii, generează automat un feedback și
reantrenează sistemul. Feedback-ul implicit este utilizat în căutarea și filtrarea informației
pentru diverse categorii cum ar fi: hiperlinkuri, documente web, emailuri, articole de știri,
filme, cărți, programe TV etc [135].
După perioada în care se execută procesul de antrenare al sistemului, algoritmii de
RF se împart în două categorii: antrenare cu termen scurt de învățare (short-term
relevance feedback) și antrenare pe termen lung de învățare („long-term relevance
feedback”).
Antrenarea cu termen scurt de învățare utilizează doar feedback-ul acordat în
sesiunea curentă, iar pentru acest proces de învațare utilizează doar vectorul descriptor al
documentului. Acești algoritmi nu utilizează feedback-ul preluat anterior de către sistem.
Această clasă de algoritmi este cea mai des studiată. Algoritmii de relevance feedback cu
antrenare cu termen scurt de învățare se împart la rândul lor în patru mari categorii:
- algoritmi de mutare a punctului de interogare;
- algoritmi de determinare a importanței trăsăturilor;
- algoritmi statistici;
- algoritmi care privesc procesul de relevance feedback ca o problemă de clasificare a
două clase: documente pozitive și documente negative.
Principalele provocări pe care algoritmiii de relevance feedback cu termen scurt
de învățare trebuie să le aibă în vedere sunt:
- numărul documentelor pe care se acordă feedback este mult mai mic decât spațiul
descriptorilor. Acest aspect generează așa numitul fenomen de „paradigmă a
dimensionalității” („curse of dimensionality”) [136];
- dezechilibru în modul de acorda feedback între utilizatori diferiți. Doi utilizatori
diferiți pot avea percepții separate asupra acelorași concepte („senzorial gap”). Un alt
motiv care generează acest aspect este diferența dintre utilizatori: userii care cunosc
mecanismul intern al unui sistem de indexare după conținut vor aprecia mai bine ce
trebuie să selecteze;

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
89
- dezechilibru între numărul de documente pozitive și negative. De cele mai multe ori
numărul de documente relevante este foarte mic, iar sistemul se află în imposibilitatea
de a învăța. Aceeași problemă apare și atunci când nu există documente nerelevante;
- viteza algoritmului (sistemul trebuie să răspundă în timp real).
Învățarea de lunga durată (Long-Term Learning) [137], poate realiza
performanțe superioare față de tehnicile tradiționale de relevance feedback. Avantajul
acestor algoritmi este că înlătură problemele de dezechilibru de acordare a feedback-ului,
prin utilizarea feedback-ului preluat în sesiuni anterioare de către utilizatori diferiți.
Feedback-ul este stocat de cele mai multe ori în fișiere de loguri, și prezintă o structură
asemănătoare unor matrici de relație între documente. De obicei, dimensiunea matricei
este una ridicată. Din acest motiv, multe metode propuse utilizează algoritmi de reducere
a dimensiunii matricei de loguri, utilizând de exemplu analiza componentelor principale,
sau alte metode statistice.
Principalele limitări ale unui astfel de sistem sunt:
- algoritmii sunt greu de implementat pe sisteme în care documentele sunt frecvent
adăugate sau șterse;
- performanța depinde mult de cantitatea de feedback anterior stocată. De preferat în
acest caz ar fi o combinație între o strategie de invațare de lungă durată cu una de
scurtă durată;
- neomogenitatea feedback-ului acordat (nu toate imaginile din baza de date primesc
feedback). O implementare care incearcă să elimine problema se gasește în [138];
- procesul trebuie realizat în sisteme real-time și să prelucreze volume mari de date ale
unui număr mare de utilizatori, cu un număr ridicat de elemente semantice. Fiecare
proces presupune o reantrenare a sistemului pentru noile căutari care vor urma. Din
acest punct de vedere este necesar împărțirea bazei de date în ierarhii arborescente.
4.2 Metode de Relevance Feedback existente
4.2.1 Algoritmi de schimbare a punctului de interogare
Primii algoritmi de relevance feedback au fost utilizați pentru îmbunătățirea căutării de
documente text (Rocchio [139]). Algorimul lui Rocchio utilizează setul de R documente
relevante şi setul de N documente nerelevante, selectate în procesul de feedback de către
utilizator, pentru a redefini un nou punct de interogare, conform formulei următoare:
∑
∑
(4.1)
unde reprezintă interogarea inițială, iar reprezintă parametru pentru ponderarea
interogării inițiale, β reprezintă factorul de importanţă al exemplelor pozitive, γ indică
factorul de importanţă al exemplelor nerelevante, și reprezintă descriptorii

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
90
documentelor relevante, respectiv a celor nerelevante, iar . De obicei, acești
parametri iau valori intevalul [0,1]. În Figura 4.1 este prezentată o reprezentare grafică
intuitivă a principiului lui Rocchio. Prima imagine ilustrează punctul inițial de interogare
și direcția de deplasare a noului punct de interogare. Imaginea a doua prezintă rezultatele
obținute cu noul punct de interogare.
Fig. 4.1 Ilustraţie a algorimului lui Rocchio (punctul de interogare este mutat spre
centroidul clasei căutate)
Există multe variante ale algorimului lui Rocchio. În [1] se demonstrează că
rezultate îmbunătăţite se obţin utilizând următoarele valori: β = 0.25 și γ = 0.75.
Motivația este una simplă, și anume, influența documentelor pozitive este mult mai
importantă decât cea a documentelor negative (β< γ). Din acest motiv, există și propuneri
de algoritmi în care doar feedback-ul pozitiv este luat în considerare, ceea ce este
echivalent cu γ = 0. Alte variante de algoritmi, asemănători cu algoritmul propus de
Rocchio, au fost propuși de către către Ide în [140] și [141]. Noile puncte de interogare
sunt calculate utilizând formulele următoare:
∑
∑
(4.2)
∑
(4.3)
unde reprezintă interogarea inițială, iar și reprezintă descriptorii documentelor
relevante, respectiv a celor nerelevante, iar max( ) reprezintă descriptorul documentului
nerelevant cu distanța cea mai mică față de punctul de interogare.
Pentru căutarea de documente text, au fost propuse alte metode de către Harper şi
Van Rijsbergen [142]:
(
) (4.4)
unde
și

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
91
şi de către Yu, și Salton:
(
) (4.5)
unde
și
r indică numărul de documente relevante care conțin termenul iar și reprezintă
numărul de documente relevante / nerelevante care conțin termenul , R și N sunt
numărul de documente relevante, respectiv nerelevante pentru interogarea Q.
4.2.2 Algoritmi de estimare a importanței trăsăturilor
Algoritmii de estimare a importanței trăsăturilor („Feature Relevance Estimation” - FRE)
[129] pleacă de la premiza că, pentru o interogare dată, în funcţie de feedback-ul
utilizatorului, anumite componente ale vectorului descriptor pot fi mai relevante decât
altele. Inițial, s-a propus adnotarea manuală de către utilizatori a importanţei fiecărei
componente în parte. Acest proces este însă chiar cu mult mai anevoios decât alocarea de
cuvinte cheie, presupunând cunoştinţe avansate de inteligență computațională din partea
utilizatorului. De aceea, a apărut nevoia unui algoritm care să calculeze automat aceste
ponderi, utilizând feedback-ul utilizatorului.
Iniţial, fiecare componentă a vectorului descriptor va avea un factor de relevanță
, care apoi se va modifica în funcţie de feedback-ul acordat. După aplicarea
feedback-ului și antrenarea ponderilor, distanţa dintre două documente va deveni egală cu
o metrică euclidiană ponderată:
√∑
∑
(4.6)
unde și reprezintă descriptorii celor două documente, iar
sunt ponderile care sunt aplicate fiecărei trăsături în parte.
Fig. 4.2 Ilustraţie a algorimulor de Relevance Feedback cu estimare a importanței
trăsăturilor

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
92
Prin modificarea ponderilor asociate unui termen individual al descriptorului,
înseamnă că, în spaţiul descriptorilor, suprafaţa selectată de către interogareva fi
modificată dintr-o sferă într-un elipsoid, așa cum sugerează Figura 4.2. Rui și Huang au
propus în [143], ca gradul de importanță al unei trăsături să fie calculat în funcție de
dispersia trăsăturilor. O trăsătură cu grad de importanță ridicat, va tinde să aibă o valoare
constantă pentru fiecare document, în timp ce, pentru o trăsătură nerelevantă pentru
conceptul căutat, va avea valori într-un interval extins. Calculul ponderii va fi calculată
conform formulei:
(4.7)
unde reprezintă dispersia trăsăturii aflate pe poziția i în cadrul documentelor
considerate relevante.
Un alt algoritm este prezentat în [144]. Aici, fiecare trăsătură va avea o pondere
proporțională cu:
(4.8)
unde este numarul de documente relevante returnate atunci când efectuăm o interogare
doar cu trăsătura i, iar T este numărul total de imagini relevante.
Salton şi Buckley [131] au propus următoarea formulă de ponderare:
(
)
√(
)
(
)
(4.9)
unde tf reprezintă frecvenţa apariţie a trăsăturii i, reprezintă numărul de documente
relevante care conțin termenul iar N este numărul de documente relevante pentru
interogarea Q.
Această ultimă metodă a fost propusă în contextul căutării de documente text.
Însă, în documentele vizuale / audio / video nu avem rată de apariţie a cuvintelor. Pentru
a putea adapta această metodă la alte tipuri de documente, se poate aproxima fiecare
trăsătură cu anumite distriburii distribuţii (exemplu distribuţie gausiană):
√ (
( )
) (4.10)
unde și indică media trăsăturii respectiv varianța trăsăturii i, iar reprezintă
valoarea trăsăturii documentului curent pe poziția i și .
O ultimă variantă de ponderare a fost propusă de către Robertson şi Spark Jones
în [1]:
(4.11)

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
93
unde r reprezintă numărul de documente relevante pentru interogarea curentă, care conţin
elementul i, R este numărul total de documente relevante pentru interogare, n numărul de
documente care conţin elementul i, N numărul total de documente din baza de date
4.2.3 Algoritmi statistici
Strategiile lui Bayes [145] sunt utilizate în scopul de a determina probabilitatea
apartenenţei evenimentelor şi a obiectelor la o anumita grupă, minimizând riscul
prognozat. În prima parte a acestui capitol vom prezenta algoritmul clasic Naive Bayes,
ca apoi să descriem algoritmii de relevance feedback care utilizează acești algoritmi
statistici.
Fie Ω, ∑, P un spaţiu de probabilitate, B un eveniment arbitrar din E și ,
.. o partiţie a spaţiului Ω. Fie:
∑
(4.12)
unde P(B)>0, , i = 1..n, reprezintă probabilitate posterioară,
este probabilitate apriorică, reprezintă verosimilitatea iar P(B) este evidenţa.
Fie regula de decizie referitoare la clasa . Regula de decizie va fi: alege
dacă P(Ωj|x) > P(Ωi|x), i є 1, … , j-1, j+1, ….r sau echivalent P(x|Ωj) P(Ωj) > P(x| )
P( ) ), i є 1, … , j-1, j+1, ….r.
Presupunem că fiecare document este reprezentat de un vector de caracteristici
aparţinănd clasei . Pentru a clasifica corect un document către clasa ,
trebuie să indeplinim condiţia ca P( | .. ) să fie maximă.
Algoritmul Naïve Bayes cuprinde următorii paşi:
1) Se calculează probabilităţile posterioare P(Ωi| … ) pentru clasele utilizând
formula:
( | )
(4.13)
2) Se alege apoi clasa Ωj care maximizează P( … | ) P( ). Pentru uşurinţa
modelului matematic, se presupune că fiecare atribut este independent de celălalte
atribute:
( | ) (4.14)
3) Vom estima probabilităţile P(Ak| ) pentru toate atributele Ak şi clasele , astfel
încât un obiect nou, necunoscut, va fi clasificat în clasa , dacă probabilitatea
corespunzătoare acestei clase ∏ este maximă faţă de celălalte.
Există două tipuri de variabile pentru care se calculează aceste probabilităţi: prin
utilizarea de tipuri de date de tip enumerare şi a tipurilor de date numerice.
Pentru coloane cu date de tip enumerare alegem:

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
94
(4.15)
unde | | reprezintă numărul instanţelor în care atributul aparţine clasei .
Cea mai frecventă situaţie este aceea în care atributele vectorului au valori
numerice. În acest caz, se aproximează că variabilele iau forma unor anumite distribuţii,
calculate cu următoarele formule:
( | )
√ (
) (4.16)
unde reprezintă media iar deviația standard a unei distribuții normale, iar acestea
respectă relațiile:
( | )
√ .
(
)
/ (4.17)
unde reprezintă parametru de scală iar parametrul de formă a unei distribuții log-
normale și .
( | ) (
)
(
) (4.18)
unde b reprezintă un parametru de scală iar c este parametrul de formă a unei distribuții
Gamma și
( | )
(4.19)
unde indică media unei distribuții Poisson, iar .
De asemenea, în funcţie de această abordare, se pot schimba și formulele de
calcul ale probabilităţilor de verosimilitate:
Numeroase tehnici de relevance feedback utilizează teoria bayesiană. Prima, si
poate cea mai cunoscută, este sistemul PicHunter dezvoltat de Cox si Miller [146].
Pentru a determina imaginea ţintă, sunt utilizate următoarele informaţii:
istoria căutărilor anterioare: Ht = D1,A1 … Dn, An – unde D1..K reprezintă imaginile
afişate la momentul k iar A1..k sunt acţiunile desfăşurate asupra documentelor
(relevante/nerelevante).
userul U care efectuează căutarea
Probabilitatea fiecărei imagini din baza de date este calculată utilizând formula lui
Bayes:
∑ ( | )
(4.20)
unde P(T=Ti) reprezintă probabilitatea apriorică şi este de obicei egala cu 1/numărul de
imagini din baza de date, reprezintă verosimilitatea calculată cu formula:

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
95
∑
(4.21)
Un alt sistem care utilizează Naïve Bayes în relevance feedback este BALAS
[147]. Algoritmul lui Bayes este utilizat în procesul de separare dintre imaginile alese
relevante si nerelevante. Probabilităţile posteriori pentru ca o imagine să fie relevantă sau
nerelevantă se vor defini ca:
(4.22)
(4.23)
unde P(R) + P(I) = 1 reprezintă probabilităţile apriori (calculate pentru imaginile cărora
li se acordă feedback ) iar sunt verosimilităţile. Imaginea Imgi este descrisă
de un descriptor de lungime , deci va deveni:
∏
(4.24)
fiecare componentă fiind apoi calculată asemeni unor variabile aleatoare ce aparţin unor
distribuţii gausiene:
( | )
√ (
) (4.25)
unde
∑
şi
∑
În cazul în care dispersia unei imagini depăşeşte un anumit prag se consideră că
parametrul respectiv nu este reprezentativ pentru imaginile căutate.
4.2.4 Relevance feedback cu algoritmi de clasificare
Odată cu dezvoltarea majoră a domenului de machine learning, algoritmii de clasificare
și-au găsit aplicabilitatea și în algorimii de relevance feedback. Aceste metode presupun
transformarea problemei de relevance feedback într-una de clasificare a două clase: o
clasă alcătuită din documente relevante și una din documente nerelevante. După un
proces de antrenare, toate documentele vor primi un nou rang, în funcție de parametrul de
ieșire al clasificatorului. Cele ma întâlnte metode de relevance feedback utilizează tehnici
ca: SVM, Nearest Neighbor , arbori de decizie și Random Forests.
Relevace feedback cu reţele „Support Vector Machines”
Reţelele SVM (Support Vector Machines) [148] reprezintă o clasă de algoritmi neuronali
cu învăţare supervizată, fiind în acest moment o referinţă în domeniul machine learning.
Algoritmii SVM sunt eficienţi pe seturi de date cu un număr mare de instanţe și de
trăsături. Aceștia creează un hiperplan, care separă clasele astfel încât să maximizeze

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
96
distanța dintre acestea. Un hiperplan este un plan care divizează spaţiul în două subspaţii.
De exemplu, în spaţiul bidimensional, separarea se poate face printr-o dreaptă. De fapt,
hiperplanele sunt funcţii de m variabile, unde m este numărul de variabile independente
după care se face clasificarea. În cazul în care problema nu este liniar separabilă, SVM
mapează trăsăturile într-un spațiu de dimensiune mai mare, în care problema poate deveni
liniar separabilă.
Fig. 4.3 Clasificare utilizând rețele SVM
În acest scop se utilizează așa numitele funcții-nucleu. Acestea pot fi de mai multe tipuri:
- Liniare: ;
- Polinomiale: ;
- Bază radială: ;
- Sigmoide: .
În mod ideal, o analiză SVM ar trebui să creeze un hiperplan care separă complet
caracteristicele a doi vectori în două grupe separabile. Există însă tipuri de date, care nu
sunt total separabile, rezultând un model cu o putere de generalizare mai mică (problemă
definită anterior ca „overfitting”). Pentru a adauga flexibilitate algoritmului, modelele
SVM au un parametru de cost C, care controlează decizia de a lua margini mai rigide şi
de a permite erori. Algoritmul va alege, astfel, hiperplanul care va maximiza decizia
corectă şi va minimiza eroarea.
Implementări ale SVM în contextul algoritmilor de felevance feedback sunt
propuse în [149] [150]. În [150], după preluarea feedback-ului de la utilizator, sistemul
antrenează un clasificator SVM care va creea un hiperplan între documentele relevante şi
nerelevante. Apoi, utilizând clasificatorul antrenat, baza de date va fii clasificată în două
clase: relevante şi nerelevante. Clasificatorul va acorda fiecărui document un scor de
relevanţă care va fi utilizat pentru reordonarea tututor documentelor. Alegerea nucleului
joacă un rol foarte important în performanţa unui sistem de relevance feedback. Un
nucleu liniar este util în cazul unui spaţiu liniar separabil cu un număr foarte mare de
dimensiuni. De asemenea, nucleul liniar reprezintă o alegere bună în cazul în care viteza

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
97
sistemului este critică. În schimb, nucleele nonlineare sunt mai robuste şi generează
hyperplane de separaţie mult mai eficiente.
SVM reprezintă o soluţie eficientă şi robustă pentru relevance feedback, deoarece
este rapid şi relativ stabil în cazurile în care numărul de documente utilizate în antrenare
este redus.
4.3 Concluzii
În acest capitol am discutat diverse metode de relevance feedback. Astfel, am făcut o
trecere în revistă a metodelor și tehnicilor folosite în sistemele actuale: relevance
feedback clasic, pseudo-relevance și relevance feedback indirect. Succesul alegerii
strategiei corecte depinde foarte mult de tipul problemei care trebuie rezolvată.
În continuare, am expus diferite metode de relevance feedback propuse în
literatură. Acestea se împart în patru categorii principale: algoritmi de mutare a punctului
de interogare, de determinare a importanței trăsăturii, RF cu algoritmi statistici și de
clasificare. Primele categorii se evidențiază prin viteză ridicată de execuție, însă
performanța acestora scade odată cu creșterea dimensiunii și a complexității bazelor de
date. Pe de altă parte, metodele care privesc procesul de relevance feedback ca o
problemă de clasificare a două clase prezintă dificultăți de învățare datorită numărului
redus de date de învățare. Mai mult, de cele mai multe ori numărul documentelor pe care
se acordă feedback este mult mai mic decât spațiul descriptorilor, sau există dezechilibre
în modul de acordare a feedbackului.
Algoritmii de RF reprezintă o componentă des întâlnită în cadrul sistemelor de
indexare după conținut. Aceștia au rolul de a îmbunătăți performanțele de indexare ale
sistemelor multimedia, prin învațarea online a preferințelor utilizatorului. Cu toate
acestea, metodele de RF prezintă anumite limitări ce țin de implementare, viteză de
execuție și dificultate de antrenare datorită numărului redus de date de învățare.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
98

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
99
Partea II
Contribuții personale

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
100

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
101
Capitolul 5
Descrierea conținutului de textură
folosind automate celulare
5.1 Teoria automatelor celulare
Un automat celular (cunoscut și ca rețea celulară) reprezintă o funcție matematică care
modelează un fenomen discret. Aceste automate prezintă o utilitate diversă, fiind propuse
aplicaţii în domenii ca: inteligență artificială, matematică, fizică, biologie, criptografie și
modelare grafică. Un automat celular presupune existența unei rețele (matrici) de celule,
care conține un număr finit de stări și dimensiuni. Fiecare reţea celulară are definită un
set de reguli, iar acestea sunt aplicate reţelei de la o iterație la alta. În funcție de tipul
aplicației, regulile sunt procesate în mod iterativ, de câte ori este necesar pentru
finalizarea fenomenului.
Von Neumann a fost una dintre primele persoane care a folosit un astfel de model,
pe care ulterior l-a integrat în „automatul său universal” [151]. Apoi, în anii ‘50,
automatul celular a fost studiată în contextul sistemelor biologice. Începând cu anii ’90,
Wolfram a dezvoltat teoria automatelor celulare [152], după care a publicat o colecție
impresionantă de automate celulare și diferite aplicații ale acestora.
Automatele celulare prezintă o varietate de forme. Una dintre proprietățile
fundamentale ale unei rețele celulare este reprezentată de forma matricei sau, mai precis,
de modul în care sunt concepute vecinătățile. Această proprietate constă în numărul de
vecini ai unei celule (de obicei, numărul vecinătăților ia în calcul și celula curentă). Cea
mai simplă matrice este cea unidimensională, și anume rețeaua are forma unei linii în
care fiecare celulă are doi vecini. În cazul bidimensional, pot fi considerate mai multe
tipuri de vecinătăți: triangulară (Brickwall), pentagonală (von Nemann), heptagonală și
eneagonală (Moore). Reprezentări grafice ale vecinătăților 2D pot fi vizualizate în Figura
5.1. De asemenea, automatele celulare pot fi concepute în spații multidimensionale, cele
mai des întâlnite fiind cele cu trei dimensiuni (rețele reacție-difuzie [153]), intens
utilizate în modelarea reacțiilor chimice.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
102
Fig. 5.1. Tipuri de vecinătăți ale unui automat celular: (a) vecinătate Brickwall, (b)
pentagonală (von Nemann), (c) eneagonală (Moore) și heptagonală; celulele albastre
reprezintă imaginea curentă iar cele albastre indică vecinătatea
O altă caracteristică importantă a automatelor celulare este reprezentată de
numărul de stări, care trebuie impus la configurarea inițială a rețelei. Cea mai simplă
arhitectură de automat celular clasic conține două stări: denumite generic ca 0 și 1, sau
„alb” și „negru”. Totuși, de cele mai multe ori, o rețea celulară conține un număr mai
mare de stări.
Ținând cont de comportamentul lor, Wolfram [152] a împărțit rețelele celulare în
patru categorii principale:
clasa 1 - conține celularele automate care evoluează rapid într-o stare stabilă și
omogenă, chiar dacă starea inițială are o formă aleatoare.
clasa 2 – include celularele automate care evoluează rapid într-o stare stabilă dar
oscilantă. În cadrul acestor tipuri de automate celulare, influența stărilor inițiale
are o pondere scăzută în modul de evoluție al automatului
clasa 3 – conține acele automate celulare al căror comportament poate fi
considerat pseudo-aleator sau chiar haotic. Forma stării inițiale influențează
evoluția ulterioară a automatului celular. De asemenea, în cazul în care apar
structuri stabile, acestea vor fi distruse de către „zgomotul” din vecinătate.
clasa 4 – cuprinde acele automate celulare în care apar modele complexe cu
structuri bine definite, care sunt capabile de calcule universale. Exemple de
automate celulare din această categorie, pot fi enumerate „Game of Life” [154] și
„Rule 110” [155].
Numărul de funcții posibile pe care un automat celular le poate lua este aproape
imposibil de calculat. Spre exemplu, în cazul celui mai simplu automat celular posibil, cel
cu doi vecini și cu două stări, avem un număr de 256 de posibilități de funcții posibile.
Dar, odată cu creșterea numărului stărilor și al vecinătăților, numărul de posibilități crește

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
103
exponențial. În [152] sunt prezentate cele 256 de posibilități de funcții pe care un automat
celular le poate lua și aplicațiile acestora.
5.2 Descrirerea texturilor utilizând automate celulare
În acest capitol voi prezenta un algoritm inspirat din teoria automatelor celulare, cu
aplicabilitate în descrierea şi clasificarea imaginilor de textură. Rezultatele experimentale
din cadrul acestui capitol au fost publicate în cadrul revistei Buletin UPB [156].
Automatul celular folosit va avea două stări (0 şi 1) şi va folosi o vecinătate
Moore. Primul pas care trebuie efectuat în vederea aplicării teoriei rețelelor celulare în
procesarea de imagini este binarizarea imaginii. În vederea binarizării, vom utiliza un
număr variabil de praguri. În timpul etapei de stabilire a pragurilor, pixelii individuali vor
fi marcați cu valoarea 1 dacă valoarea acestuia va fi mai ridicată decât a pragului și 0 în
caz contrar. Pentru o mai bună descriere a conţinutului vizual, vom folosi un număr
variabil de praguri. În cadrul experimentelor au fost testate un număr variabil de praguri
(de la 1 la 64). Valorile acestora vor fi alese în mod uniform pe tot intervalul grayscale:
[0..255]. Spre exemplu, dacă alegem un număr de 3 praguri, acestea vor avea valorile:
64, 128 şi 196. Prin aplicarea acestor praguri vom obține un set de imagini binare. Pentru
fiecare imagine binară, vom aplica un set de reguli şi vom extrage un set de parametri
care descriu informaţia din cadrul imaginii binare. Metoda de extracţie a parametrilor este
dată de formula:
∑ 0∑
1
(5.1)
unde M și N reprezintă dimensiunile imaginii, iar F(i,j) reprezintă o funcție nucleu
calculată cu ajutorul vecinătăţii pixelului curent. Funcția kernel este definită în felul
următor:
∑ | |
(5.2)
unde jiN , este vecinătatea de dimensiune 3x3, centrată în jurul punctului curent (i,j),
este valoarea pixelului de la poziția k (k=1..9), iar A(k) reprezintă ponderile care
sunt aplicate fiecărui element din vecinătatea punctului curent. În Figura 5.2 este
prezentată atât forma vecinătății punctului curent (i,j) cât și notațiile folosite.
Fig. 5.2 Vecinătatea 3x3 din jurul funcției kernel

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
104
Numărul de funcții posibile care pot fi utilizate are o valoare foarte mare.
De exemplu, pentru o vecinătate von Newmann avem un număr de funcții
posibile. Însă, testarea acestui număr ridicat de posibilități este un proces
consumator de timp. Din acest motiv, am utilizat un număr redus de posibilități: și anume
șase perechi de funcții. Aceste funcții sunt similare cu operatorii utilizați în detecția de
contur (Prewitt, Sobel, operatorul Laplacian și operatorul cruce Robertson). Figura 5.3
prezintă funcțiile kernel utilizate în experimentul nostru.
Fig 5.3 Șase funcţii kernel propuse pentru descrierea conținutului de textură
Acest proces de binarizare succesivă şi de calcul a unor parametri de aspect îşi are
motivaţia în încercarea de a extrage anumite caracteristici esenţiale ale texturii, şi anume
contrastul, direcţionalitatea şi gradul de omogeneitate a texturii. Prin procesul de
binarizare, vom extrage gama dinamică a distribuţiei nivelelor de gri dintr-o imagine,
împreună cu distribuţia de alb și negru. Cu cât numărul de praguri este mai ridicat, cu atât
trăsătura de contrast a texturii va fi mai bine extrasă. Cea de-a doua trăsătură extrasă este
cea de direcţionalitate a texturii. Prin aplicarea operatorilor de contur, se vor extrage
direcţiile fundamentale ale texturii.
Gradul de omogeneitate a texturii reprezintă o ultimă trăsătură fundamentală
descrisă cu parametrii C. În [157] a fost demonstrat că o valoare a parametrului C
apropiată de 1 indică o omogenitate a stărilor, în timp ce o valoare C=0,5 reprezintă un
haos perfect. În celălaltă extremă C=0 indică o valoare constantă a imaginii (variații
apropiate de zero).
Acest model este apropiat de modul de percepție uman. În scopul de a extrage
informaţia referitoare la scala şi rata de repetiţie a texelilor, vom repeta algoritmul asupra
mai multor scale ale imaginii. Astfel, vom calcula asprimea texturii la diverse rezoluții. În
secţiunea experimentală, vom utiliza mai multe scale ale imaginii: 100%, 50%, 25%,
12,5% și 6,25%.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
105
5.3 Rezultate experimentale
Pentru validarea metodei propuse, vom testa acest algoritm pe patru baze de date de
textură foarte cunoscute:
Baza de date VisTex a fost concepută de către Massachusetts Institute of
Technology (MIT) [158] [159]. Aceasta conţine un set de 900 de imagini de textură (9
imagini pe clasă), şi are în componenţă nu numai texturi omogenene fotografiate frontal,
ci şi elemente de textură naturale, cu anumite variaţii de luminozitate.
Baza de date UIUC [160], alcătuită dintr-un număr de 25 de clase (40 de imagini
pe fiecare clasă). Toate imaginile sunt în format grayscale și au dimesiunea 640x480.
Albumul foto Brodatz [161] conţine un număr de 111 imagini de textură. Fiecare
imagine reprezintă o clasă distinctă. Pentru a genera un număr mai mare de imagini per
clasă, s-a împărțit fiecare imagine în nouă regiuni. În acest fel au fost generate un număr
de 999 imagini cu o rezoluție de 215x215 pixeli.
Baza de date KTH [162] care conține 10 clase de textură, imaginile conţinând un
grad ridicat de zgomot: alterate prin iluminare, scalare și translații. Fiecare clasă conţine
81 de imagini.
Exemple de imagini de textură din cadrul bazelor de date sunt prezentate în
Figura 5.4.
Fig. 5.4 Exemple de texturi utilizate în experimente: prima linie – baza de date Brodatz,
baza de date VisTex în a doua linie, UIUC pe linia a treia și KTH pe ultimul rând
5.3.1 Alegerea parametrilor algoritmului
În acest capitol, vom analiza influența parametrilor algoritmului asupra performanței
sistemului. În primul experiment, vom varia numărul de praguri (utilizând o singură scală
a imaginii), apoi vom schimba numărul de scale ale imaginii pentru un număr fix de
praguri. În final, vom analiza performanța fiecărui set de funcții.
În cadrul acestui experiment vom utiliza de fiecare dată o singură valoare prag, o
singură scală de textură și prima funcție nucleu (Figura 5.3. (a)).

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
106
În primul experiment vom prezenta influenţa numărului de praguri asupra
performanţei sistemului. Rezultatele experimentale sunt prezentate în Figura 5.5. Se
observa că pentru fiecare bază de date, performanţa creşte odată cu creşterea numărului
de imagini binare extras, însă la un moment dat aceasta se plafonează. De asemenea, se
poate vizualiza că un număr de 7 praguri este suficient pentru a obține rezultate optime.
Un număr mai ridicat de imagini binare nu va îmbunătăţi în mod notabil performanţa
algoritmului.
Fig. 5.5 Performanța MAP utilizând un număr variabil de praguri (o singură scală de
imagine)
În al doilea experiment, vom evidenţia influenţa numărului de scale de imagini.
Rezultatele experimentale sunt prezentate în Figura 5.6. Aşa cum era de aşteptat, se poate
observa că rezultatul este similar cu cel din experimentul anterior. Precizia creşte odată
cu numărul de scale, însă se plafonează la un moment dat. Primele trei scale sunt
suficiente pentru ca sistemul să atingă performanţă maximă.
Fig. 5.6 Performanța MAP utilizând un număr variabil de scale (folosind un singur prag)
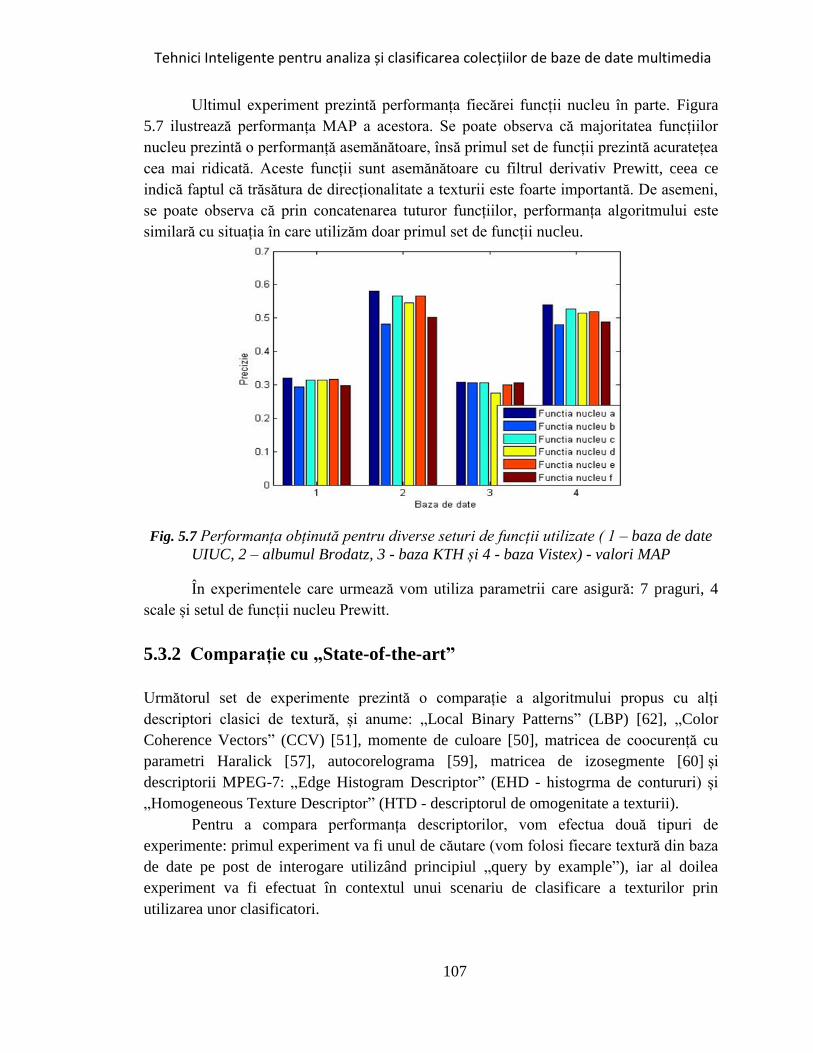
Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
107
Ultimul experiment prezintă performanța fiecărei funcții nucleu în parte. Figura
5.7 ilustrează performanța MAP a acestora. Se poate observa că majoritatea funcțiilor
nucleu prezintă o performanță asemănătoare, însă primul set de funcții prezintă acuratețea
cea mai ridicată. Aceste funcții sunt asemănătoare cu filtrul derivativ Prewitt, ceea ce
indică faptul că trăsătura de direcționalitate a texturii este foarte importantă. De asemeni,
se poate observa că prin concatenarea tuturor funcțiilor, performanța algoritmului este
similară cu situația în care utilizăm doar primul set de funcții nucleu.
Fig. 5.7 Performanța obținută pentru diverse seturi de funcții utilizate ( 1 – baza de date
UIUC, 2 – albumul Brodatz, 3 - baza KTH și 4 - baza Vistex) - valori MAP
În experimentele care urmează vom utiliza parametrii care asigură: 7 praguri, 4
scale și setul de funcții nucleu Prewitt.
5.3.2 Comparație cu „State-of-the-art”
Următorul set de experimente prezintă o comparație a algoritmului propus cu alți
descriptori clasici de textură, și anume: „Local Binary Patterns” (LBP) [62], „Color
Coherence Vectors” (CCV) [51], momente de culoare [50], matricea de coocurență cu
parametri Haralick [57], autocorelograma [59], matricea de izosegmente [60] și
descriptorii MPEG-7: „Edge Histogram Descriptor” (EHD - histogrma de contururi) și
„Homogeneous Texture Descriptor” (HTD - descriptorul de omogenitate a texturii).
Pentru a compara performanța descriptorilor, vom efectua două tipuri de
experimente: primul experiment va fi unul de căutare (vom folosi fiecare textură din baza
de date pe post de interogare utilizând principiul „query by example”), iar al doilea
experiment va fi efectuat în contextul unui scenariu de clasificare a texturilor prin
utilizarea unor clasificatori.
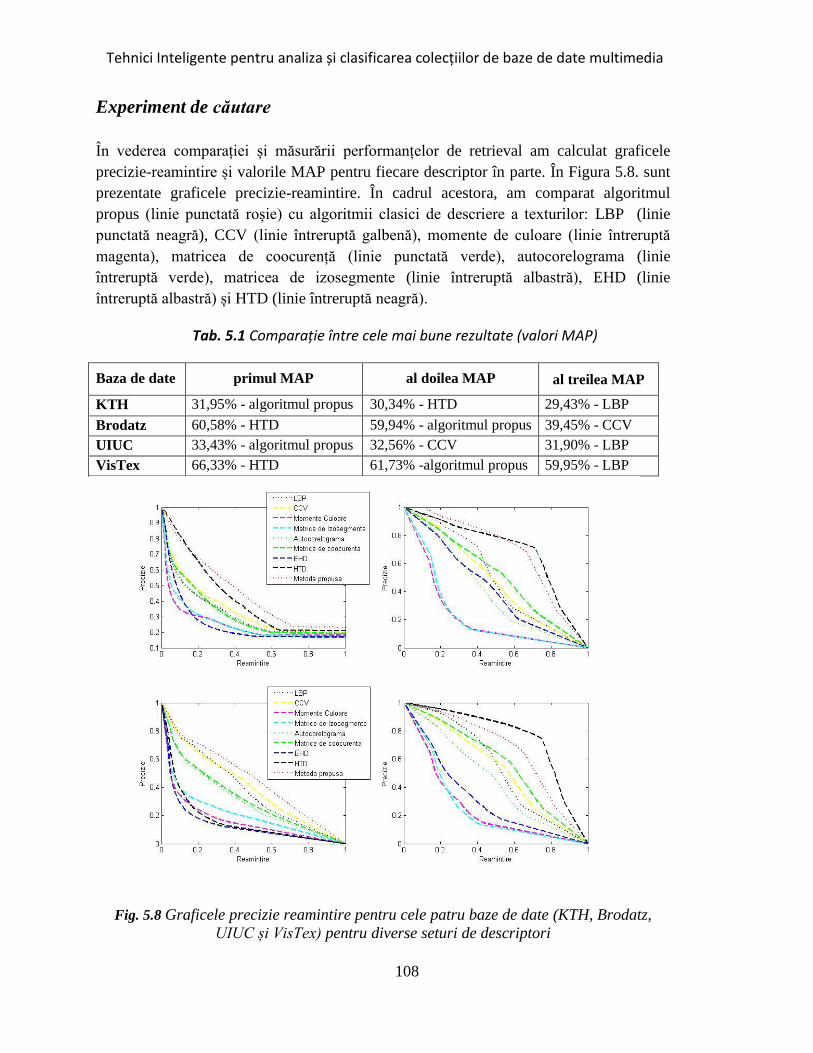
Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
108
Experiment de căutare
În vederea comparației și măsurării performanțelor de retrieval am calculat graficele
precizie-reamintire și valorile MAP pentru fiecare descriptor în parte. În Figura 5.8. sunt
prezentate graficele precizie-reamintire. În cadrul acestora, am comparat algoritmul
propus (linie punctată roșie) cu algoritmii clasici de descriere a texturilor: LBP (linie
punctată neagră), CCV (linie întreruptă galbenă), momente de culoare (linie întreruptă
magenta), matricea de coocurență (linie punctată verde), autocorelograma (linie
întreruptă verde), matricea de izosegmente (linie întreruptă albastră), EHD (linie
întreruptă albastră) și HTD (linie întreruptă neagră).
Tab. 5.1 Comparație între cele mai bune rezultate (valori MAP)
Baza de date primul MAP al doilea MAP al treilea MAP
KTH 31,95% - algoritmul propus 30,34% - HTD 29,43% - LBP
Brodatz 60,58% - HTD 59,94% - algoritmul propus 39,45% - CCV
UIUC 33,43% - algoritmul propus 32,56% - CCV 31,90% - LBP
VisTex 66,33% - HTD 61,73% -algoritmul propus 59,95% - LBP
Fig. 5.8 Graficele precizie reamintire pentru cele patru baze de date (KTH, Brodatz,
UIUC și VisTex) pentru diverse seturi de descriptori

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
109
Algoritmul propus a obținut cele mai bune rezultate în două din cele patru cazuri:
pentru bazele de date KTH și UIUC, în timp ce pentru bazele Brodatz și VisTex am
obținut poziția a doua. Rezultate foarte bune au fost obținute și cu descriptorii: HTD,
LBP, CCV și cu matricea de coocurență.
Cele mai slabe rezultate au fost obținute cu momentele de culoare, histograma de
margini și matricea de izosegmente. În cele mai multe cazuri, performanța acestora este
de două ori mai mică față de a algoritmului propus. Rezultate mai bune au fost obținute în
cazul autocorelogramei, însă diferențele sunt majore și în aceste cazuri (MAP de la 10%
la 25%).
Experiment de clasificare
În al doilea experiment, ne propunem să testăm descriptorii din perspectiva clasificării.
Au fost testați o gamă largă de algoritmi de clasificare, care au obținut rezultate bune la
competițiile de „machine learning”: Naive Bayes [145], Nearest Neighbor [163], SVM
[148] (cu nucleu liniar și RBF), Random Trees [38], Gradient Boosted Trees [164],
Extremelly Random Forest [165]. Parametrii algoritmilor au fost inițial setați în funcție
de experimentele preliminare. Bazele de date au fost împărțite în două părți egale: una de
antrenament și una de testare. Pentru a măsura performanța s-a utilizat parametrul de
medie a preciziilor (acuratețe).
În Figura 5.9 prezentăm procentajul global de clasificare corectă pe o selecție de
șapte algoritmi de clasificare pe cele patru baze de date: KTH, UIUC, Brodatz și Vistex.
Rezultatele au valori promițătoare. Cele mai bune rezultate au fost obținute utilizând
trăsăturile propuse, în combinație cu clasificatorii Extremelly Random Forests, Random
Trees, Naive Bayes și SVM cu RBF kernel. Cea mai bună performanță de clasificare are
o valoare puțin peste 97% în timp ce cea mai scăzută are o valoare apropiată de 92%.
Cele mai bune performanțe de clasificare au fost obținute de către metoda
propusă, și anume: KTH cu Nearest Neighbour (96,92%), Brodatz cu Naive Bayes
(92,17%), UIUC cu Extremelly Random Forest (88.2%) și Vistex cu Extremelly Random
Forest (90.22%).
Pe de altă parte, cele mai slabe rezultate se obțin cu momentele de culoare și
descriptorul EHD, în timp ce clasificatorii cu performanțe mici sunt Gradient Random
Trees și SVM cu nucleu liniar.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
110
Fig. 5.9 Rezultatele clasificării pe bazele Brodatz, UIUC, KTH și Vistex utilizând diferite
metode de clasificare (Naive Bayes, Nearest Neighbor, SVM liniar, SVM cu nucleu RBF,
Random Trees, Gradient Boosted Trees, Extremelly Random Forest) și diferiți descriptori
(1. LBP, 2. CCV, 3. Momente de culoare, 4. Matricea de izosegmente, 5.
Autocorelograma, 6. Matricea de Coocurență, 7. EHD 8. HTD, 9. algoritmul propus) pe
baza de date Vistex

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
111
5.3.2 Comparație de complexitate
În Tabelul 5.2 sunt prezentate complexitatea algoritmilor împreună cu lungimea
vectorului descriptor. Algoritmul propus are o complexitate redusă, similară cu algoritmi
ca histograma de nivele de gri, CCV, EHD și momente de culoare.
Tab. 5.2 Comparație între complexitatea computațională și lungimea descriptorilor
Descriptor Complexitatea computațională Lungime
descriptor
Histograma de nivele
de gri
O(n) 24
CCV O(n) 48
Momente de imagine O(n) 9
Matricea de
izosegmente
O(n) + O(k·m) – unde k este numărul de culori
obținut în urma cuantizării iar m reprezintă lungimea
maximă a izosegmentului
23
Autocorelograma O(n) + O(k·m) – unde k este numărul de culori
obținut în urma cuantizării iar m reprezintă numărul
de vecinătăți
96
Matricea de
coocurență
O(n) + O( ) – unde k este numărul de culori obținut
în urma cuantizării
16
Histograma de
margini
O(n) 80
Descriptorul de
omogenitate a texturii
O( log(n)) 64
Algoritmul propus k·O(n) unde k reprezentă numărul de parametri
calculați
42
Descriptorul HTD prezintă cea mai mare complexitate de calcul (O( 2n log(n))), în
timp ce matricea de izosegmente, autocorelograma și matricea de coocurență au o
complexitate mai ridicată decât a algoritmului propus. Un alt criteriu de comparație este
lungimea vectorului descriptor. Descriptorul standard, utilizat în comparație are o
lungime de 42 de caracteristici (trei scale și șapte praguri). Patru descriptori au o
dimensiune mai redusă (histograma de niveluri de gri, momente de culoare, matricea de
izosegmente, și matricea de coocurență), în timp ce CCV, autocorelograma, HTD și EHD
au o lungime mai ridicată.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
112
5.4 Concluzii
În acest capitol am prezentat o abordare neliniară pentru descrierea şi clasificarea
imaginilor de textură. Performanţa descriptorului este validată atât în contextul unui
sistem de clasificare cât şi din perspectiva unui sistem de căutare a imaginilor după
conţinut. În acest scop, am utilizat patru baze de date de textură, pentru a compara
descriptorul nostru cu algoritmii existenţi. Algoritmul propus, în ciuda simplității sale,
reprezintă o bună alternativă la descriptorii clasici de textură. În cele mai multe
experimente, algorimul propus oferă cele mai bune rezultate în probleme de căutare și
clasificare. De asemenea, algoritmul propus se impune prin simplitate și complexitate
redusă de calcul.
Ca direcție viitoare de cercetare, îmi propun să îmbunătățesc performanța
algoritmului și să îl adaptez altor tipuri de categorii de imagini, ca de exemplu imagini
medicale sau imagini naturale. De asemenea, îmi propun să testez alte tipuri de funcții
nucleu și tehnici adaptive de binarizare a imaginilor.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
113
Capitolul 6
Descrierea conținutului folosind
reprezentarea Fisher kernel
6.1 Teoria Fisher kernel
Reprezentarea Fisher kernel a fost inițial proiectată ca un model care combină beneficiile
algoritmilor generativi și ai celor discriminativi. Ideea generală este de a reprezenta un
semnal ca fiind gradientul funcției de densitate de probabilitate. Acesta poate fi antrenat
prin utilizarea un model generativ, de cele mai multe ori acesta fiind modelul Gaussian
Mixture Model (GMM). Odată calculați vectorii Fisher, aceștia se combină cu un
clasificator, cum ar fi de exemplu SVM.
Fie un set de T descriptori video multimodali. X va fi
reprezentat ca un vector gradient față de modelul GMM cu parametri λ:
( ) (6.1)
Vectorul gradient este, prin definiție, concatenarea derivatelor parțiale față de
modelul GMM antrenat. Fie și , media și deviația standard a clusterului gausian i,
probabilitatea de apartenență a descriptorului față de centroidul I al GMM, iar D
dimensiunea descriptorului Definim ca fiind gradienţii densităţii de probabilitate a
setului de descriptori X de dimensiune D față de mediile și gradienţii faţă de
deviația standard a gausienei i. Matematic, aceste derivate sunt egale cu:
√
∑
(6.2)
√
∑ ⌊
⌋
(6.3)
Vectorul gradient final Gx reprezintă concatenarea vectorilor și
pentru i =
[1...K]. Fisher kernel a fost introdus prima dată de către Jaakkola și Haussler în 1999
[166], denumirea fiind dată în cinstea lui Sir Ronald Fisher (un statistician, biolog
evoluționist, eugenist și genetician englez). În această lucrare, a fost propus un mecanism
de agregare a modelelor probabilităţilor generative cu modelele de clasificare
discriminative, ca de exemplu modelul SVM. Apoi, în [167] Fisher kernel a fost introdus
în detecţia şi clasificarea de proteine. În următorii ani, modelul Fisher kernel a fost

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
114
utilizat în diferite domenii, de la clasificare audio, identificare de voce până la clasificare
de imagini. În [168], a fost propus un framework care utilizează Fisher kernel în
contextul clasificării de documente audio web, în contextul unor baze de date de
dimensiuni ridicate (large-scale). De asemenea, ei au propus un set de justificări
experimentale pentru utilizarea modelului, arătând că Fisher kernel limitează
dimensiunea spațiului descriptorului, ceea ce oferă anumite beneficii discriminatorii. Alte
domenii în care modelul Fisher kernel a fost propus cu succes sunt clasificarea de baze de
date de documente [169] și în probleme de recunoaștere și identificare a vocii [170].
Însă, domeniul în care Fisher kernel a fost aplicat cu performanțe foarte bune, este
clasificarea de imagini. Cele mai multe sisteme de căutare multimedia după conținut sunt
compuse din două etape principale: extragerea de trăsături și ordonarea documentelor în
funcţie de trăsături. Prima componentă presupune calculul unei trăsături per document,
iar aceasta trebuie să cuprindă cât mai multă informație relevantă pentru categoria din
care face parte. De exemplu, pentru imagini, se extrag un set de puncte cheie iar apoi
acestea sunt agregate în modelul Bag of Words. Dar, prin agregarea acestora apare un
zgomot de cuantizare. Acesta poate fi eliminat prin utilizarea unui dicționar de
dimensiune ridicată, însă presupune un efort computațional ridicat. Pe de altă parte, o altă
metodă propusă este să se calculeze distanța Earth Mover între seturile de cuvinte cheie
dintre două imagini. Spre exemplu, în [171] s-a extras un dicționar de 40 cuvinte, iar apoi
pentru fiecare imagine se calculează distanța dintre setul de cuvinte cheie al acesteia și
dicționarul antrenat. Totuși, aceste metrici implică un cost computațional foarte ridicat,
mai ales pentru baze de date cu dimensiuni mari.
Prin utilizarea reprezentării Fisher, se obține o soluție naturală la problema
descrisă anterior deoarece modelul Fisher kernel a fost inițial conceput pentru a agrega
vectori de dimensiuni fixe într-o reprezentare de lungime constantă. În [172] a fost
propus un model constelație care agregă probabilitățile de apariție a cuvintelor cheie, în
timp ce în [173] au fost agregați chiar descriptorii cuvintelor cheie. Apoi, în [99], au fost
propuse un set de îmbunătățiri care pot crește performanța Fisher kernel (aplicare de
normalizări și piramide spațiale), ca apoi, în [174] modelul să fie extins pentru baze de
date de imagini large-scale. Reprezentarea gradient a vectorilor Fisher prezintă un avantaj
major față de reprezentarea clasică Bag-of-Visual-Words, deoarece este mult mai rapid
(utilizează dicționare de dimensiuni reduse) și permite utilizarea unor algoritmi rapizi de
clasificare, ca de exemplu SVM cu nucleu liniar.
6.2 Reprezentarea Fisher kernel
În Figura 6.1. este prezentată schema de aplicare a unui model Fisher kernel. Acesta
cuprinde patru părți componente: extragerea de trăsături din documente, generarea unui
dicționar din trăsăturile selectate, calculul și normalizarea vectorilor Fisher și antrenarea
unui algoritm de clasificare.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
115
Fig. 6.1 Schema generală a unei reprezentări Fisher kernel
Extragere trăsături documente. Inițial, pentru fiecare document se extrage un set
de descriptori. Acești descriptori vor fi caracteristici aplicației în care vom aplica metoda,
și anume: pentru imagini putem extrage puncte de interes, în timp ce pentru documente
video putem selecta trăsături de mișcare, audio sau puncte de interes din cadrele vizuale
extrase.
Un parametru care trebuie luat în considerare în acest pas este numărul de
descriptori care trebuie extrași, pentru ca apoi să poată fi agregați cu Fisher kernel. Spre
exemplu, pentru documentele video, se pot calcula descriptori vizuali doar pentru un
număr redus de cadre, sau putem utiliza o strategie de extragere densă de cadre. În acest
caz, trebuie găsit un compromis între performanță și putere computațională utilizată.
Generare dicționar. Următorul pas este reprezentat de generarea unui dicționar
relevant pentru conceptele ce vor urma să fie antrenate. În acest sens, se antrenează un
model gausian „Gaussian Mixture Model” (GMM) care va genera un dicționar de
concepte. Din rațiuni de optimizare, clusterii GMM pot fi inițializați cu un algoritm „k-
means”. Un parametru important în antrenarea modelului GMM îl reprezintă numărul de
centroizi c. Având în vedere că pentru fiecare cluster adăugat, dimensiunea noii
reprezentări se va dubla, pentru ca sistemul să ruleze real-time, c trebuie să aibă o valoare
redusă. Influența parametrului c va fi testată pentru fiecare aplicație în parte în secțiunea
experimentală.
Un alt parametru, care poate influența performanța GMM este aplicarea de
algoritmi de reducere a dimensiunii descriptorilor. Un prim aspect, care trebuie
evidențiat, este faptul că lungimea unei reprezentări Fisher este egală cu , unde N
reprezintă lungimea unui descriptor extras din document. Astfel, orice modalitate de
reducere a dimensiunii finale a descriptorului este fundamentală. În al doilea rând, ne
așteptăm că un algoritm de reducere a dimensiunii va selecta trăsăturile mai relevante, în

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
116
timp ce trăsăturile „zgomotoase” vor fi eliminate. În vederea reducerii dimensiunii
vectorilor descriptori, vom utiliza analiza componentelor principale.
Generare vectori Fisher. Vectorii Fisher vor fi calculați cu formulele (6.2) și
(6.3). Apoi, pentru fiecare vector Fisher se va aplica un proces de normalizare. În [99], s-
a demonstrat că aplicarea normalizării asupra vectorilor Fisher crește performanța
acestora în mod considerabil. În acest capitol, vom testa diverse variante de normalizare:
și , normalizare de putere ( √ ), normalizarea logaritmică
( , împreună cu combinări ale acestora, unde sgn(x)
reprezintă funcția de semn.
Clasificare vectori Fisher. Clasificatorii SVM reprezintă o alegere foarte populară
în multe probleme de clasificare, mai ales deoarece este robust la trăsături cu dimensiuni
ridicate și valori rare. Alegerea unui nucleu SVM corespunzător, va avea un impact
hotărâtor în performanța sistemului. Vom testa diferite variante de nuclee SVM, de la cel
liniar, la cele neliniare: „Radial Basis Function” (RBF), „Histogram Intersection” (HI) și
„Chi-Square” (CHI). În cadrul experimentelor inițiale efectuate, cele mai bune rezultate
au fost obținute cu primele două nuclee, astfel, că toate experimentele prezentate vor
folosi primele două nuclee. SVM liniar are ca principal avantaj viteza mare clasificare și
antrenare pentru trăsături de descriptori de de dimeniuni ridicate, în timp ce SVM RBF
obține rezultate mai bune atunci când clasele nu sunt liniar separabile.
6.3 Problematica modelării timpului în filme
În domeniul clasificării documentelor video, o direcție importantă de cercetare este cum
să fie capturată în mod adecvat informația temporală. Până recent, cele mai multe sisteme
de clasificare de documente video se bazau pe utilizarea unei reprezentări pentru toată
secvența video, însă în acest caz noțiunea temporală este pierdută din diferite motive.
Multe propuneri de descriptori video doar acumulează trăsăturile pe toate cadrele, prin
utilizarea unor metode statistice, ca media sau varianța. Însă, acest tip de abordare, deși se
evidențiază prin simplitate și putere mare de acumulare, amestecă mai multe tipuri de
informație fără a ține cont de aspectul temporal al filmului. De exemplu, când o mașină
se apropie și apoi realizează anumite curbe, media informației de mișcare poate fi
interpretată ca o mișcare rectilinie, sau nu ține cont de cât de diferite erau curbele
respective. Deci, avem nevoie de o abordare în care să se facă distincția între aceste tipuri
de informație.
În acest capitol, voi propune o nouă reprezentare video pentru capturarea variației
temporale în filme, prin utilizare reprezentării Fisher. În cele mai multe abordări,
reprezentarea Fisher este propusă în contextul îmbunătățirii modelului Bag-of-Words.
Într-o abordare clasică de Fisher kernel, o imagine este convertită într-o colecție de
descriptori locali, care apoi sunt modelați cu ajutorul unei reprezentări GMM. În acest
capitol, ne propunem să extragem trăsături pe fiecare cadru, rezultând o mulțime de

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
117
descriptori globali de cadru, ca apoi aceștia să fie modelați cu o reprezentare Fisher. În
această modelare ordinea spațială este pierdută, la fel ca și în modelul Bag-of-Words,
însă variația temporală este modelată. În particular, cadrele diferite vor fi reprezentate în
diferite componente, evitând astfel amestecul de noțiuni diferite. Spre exemplu, în
emisiunile de știri sau în talk show-uri nu este necesară memorarea succesiunii de
evenimente ci doar extragerea cadrelor și intepretarea informației din ele. Mai mult,
secvențele similare vor fi mapate în componente asemănătoare în funcție de distribuția
modelului GMM antrenat.
Metoda propusă pentru modelarea variației temporale are un caracter foarte
general. În acest scop am experimentat o varietate de baze de date de referință: de la
clasificare de gen (MediaEval 2012) până la recunoaștere de acțiuni sportive (UCF Sport
50) sau de acțiuni cotidiene (ADL). Mai mult, am studiat metoda propusă pe o varietate
de trăsături, de la histograme HOG, CN și HOF până la trăsături HoF extrase pe
componentele corpului uman și trăsături clasice audio. În experimentele viitoare vom
arăta că simpla acumulare a descriptorilor va obține rezultate cu mult inferioare
reprezentării Fisher. Mai mult, în toate experimentele am obținut rezultate mai bune sau
asemănătoare cu cele obținute de alte metode din literatură.
Pentru a concluziona, principalele contribuții ale acestui capitol sunt: (1) am
introdus reprezentarea Fisher pentru modelarea variației temporale, (2) am demonstrat că
modelul propus are un caracter general în funcție de problema selectată: de la
recunoaștere de gen, la recunoaștere de secvențe sportive la acțiuni cotidiene, (3) am
arătat generalitatea metodei în funcție de trăsăturile alese: de la descriptori vizuali, la
descriptori de mișcare și trăsături audio și (4) cu metoda propusă am obținut rezultate
similare sau mai bune decât cele propuse în literatură, deși am utilizat un set de trăsături
mai ușor de calculat.
6.4 Clasificarea automată după gen a filmelor
6.4.1 Descriere experiment
O primă aplicație propusă este clasificarea filmelor după gen. Pentru a testa algoritmul
vom utiliza baza de date MediaEval 2012 din cadrul competiției de clasificare a filmelor
după gen (Tagging Task) [45]. Baza de date conține 14.838 de filme grupate în 26 de
genuri, cum ar fi: automobile, artă, comedie sau politică. Mai multe detalii despre baza de
date pot fi citite în Capitolul 2.7. Pentru descrierea conținutului video vom utiliza două
canale de informație: audio și vizuală. Pentru descrierea conținutului vizual vom folosi
două tipuri de descriptori: descriptori HOG globali care reprezintă media trăsăturilor
„Histograms of Gradients” (HOG) [71] pe fiecare frame împărțit în 3x3 blocuri
(dimensiune 81 numere per descriptor), și descriptori „Color Naming” (CN) [48] calculat
pe fiecare cadru în parte (dimensiune 11 numere per descriptor). Am ales Color Naming

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
118
deoarece acest model a fost antrenat pe seturi de imagini de pe web, la fel cum este cazul
și pentru baza MediaEval. Pentru descrierea conținutului audio vom folosi un set standard
de descriptori audio [175]: Linear Predictive Coefficients (LPC), Line Spectral Pairs
(LSP), descriptori MFCC, Zero-Crossing Rate (ZCR), spectral centroid, flux, rolloff și
kurtosis, toate ponderate cu varianța pe fiecare trăsătură în parte pe o anumită fereastră
(în cazul nostru 1,28 secunde). Performanța pentru toate experimentele de clasificare de
gen au fost măsurate cu Mean Average Precision (MAP).
6.4.2 Optimizarea reprezentării Fisher
Pentru optimizarea parametrilor Fisher kernel vom începe cu următoarele setări inițiale:
100 de centroizi GMM, deoarece pare un compromis bun între viteză de calcul și calitate,
și normalizare de putere [99] și SVM cu kernel RBF. În toate experimentele inițiale
SVM RBF a obținut rezultate mai bune decât SVM liniar. De asemenea, nu am aplicat
nici o transformare sau comprimare vreunei trăsături (cum ar fi PCA). Toți parametrii vor
fi evaluați pe baza de date de antrenare, aceasta fiind împărțită în două părți egale.
În primul experiment vom evalua influența numărului de trăsături asupra
performanței sistemului. Pentru a efectua acest experiment, vom lua în calcul două
strategii de extragere a cadrelor: (1) printr-o strategie densă și (2) prin utilizarea unui
rezumat de cadre utilizând metoda propusă în [176]. În Figura 6.2 sunt prezentate
rezultatele experimentale efectuate pe trăsăturile vizuale. Se poate observa că
performanța sistemului crește odată cu marirea numărului de cadre folosite, însă creșterea
de performanță se plafonează la un moment dat. În toate experimentele viitoare vom
folosi o strategie de extragere densă a cadrelor.
Fig. 6.2 Influența numărului de trăsături asupra performanței sistemului

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
119
Următorul experiment prezintă influența PCA asupra performanței sistemului.
Avem două motive pentru a aplica PCA: în primul rând dorim să micșorăm dimensiunea
finală a vectorului descriptor, iar în al doilea rând credem că PCA va elimina elimina o
parte din zgomotul trăsăturilor, ceea ce va conduce la o creștere a acurateții. Teoretic,
GMM prezintă performanțe atunci când zgomotul este redus iar datele sunt necorelate.
Experimentele arată că PCA îmbunătățește performanțele atunci când este aplicat pe
trăsăturile audio și HOG. În schimb, pentru trăsăturile de culoare nu au performanțe
superioare cu PCA deoarece acestea deja conțin informație necorelată. Cea mai bună
performanță este obținut atunci când reducem dimensiunea descriptorilor cu 20%. În
continuare, vom utiliza HOG și audio cu PCA redus la 80% din dimensiunea inițială, în
timp ce asupra descriptorilor de culoare nu vom aplica PCA.
Fig. 6.3 Influența aplicării PCA asupra performanței sistemului
În ultimul experiment vom prezenta influența numărului de centroizi GMM
asupra performanței sistemului. Figura 6.4 prezintă variația performanței MAP atunci
când variem numărul de centroizi GMM cât și diferența de performanță între performanța
primilor descriptori plus a acestora atunci când aplicăm reprezentare Fisher kernel. În
primul rând trebuie să notăm că performanța acestora crește chiar și atunci când utilizăm
un singur centroid. Spre exemplu, pentru descriptorii de culoare, performanța crește de la
0.18 la 0,28, pentru descriptorii HOG de la 0,22 la 0,38, în timp ce pentru audio creșterea
de performanță este de la 0,34 la 0,45. Se observă deci o creștere de performanță
superioară atunci când combinăm Fisher kernel cu alți descriptori. De asemenea, prin
variația numărului de clusteri, performanța acestora încă poate fi îmbunătățită. Atât CN
cât și HOG prezintă câștig de performanță de 0,05 atingând 0,33 MAP și 0,43 MAP la
800 respectiv 200 de clusteri GMM. Descriptorii audio prezintă o performanță de 0,47

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
120
pentru 50 de clustere. Acesta va fi numărul de clustere care va fi utilizat în următorul
experiment. Dimensiunea descriptorilor utilizați în următoarele experimente vor fi de
mărime acceptabilă: 17.600 pentru descriptorii de culoare, 42.000 pentru HOG și 9.000
pentru descriptorii audio. De notat, că odată cu creșterea numărului de centroizi,
performanța sistemului scade, datorită dimensiunii ridicate a trăsăturilor (paradigma
dimensionalității).
Fig. 6.4 Influența numărului de centroizi GMM asupra performanței sistemului (valori
MAP)
6.4.3 Comparație cu „State-of-the-Art”
În Tabelul 6.1 sunt prezentate rezultatele finale obținute cu metodele propuse și
comparația acestora cu rezultatele raportate la MediaEval 2012 Tagging Task. Pentru
trăsăturile audio obținem o perfomanță 0,475 MAP, cu mult mai bine decât performanța
raportată la MediaEval 2012 de 0,1892 (echipa ARF) [119]. De asemeni, și descriptorii
vizuali au o performanță superioară în fața celor raportați la MediaEval 2012 de către
[177]. În schimb, rezultate remarcabile sunt obținute prin combinarea trăsăturilor vizuale
cu cele audio. Acestea obțin o performanță de 0,55 ceea ce este chiar superioară
performanței obținute de cele mai bune echipe la MediaEval 2012, care au o performanță
de 0,53 MAP, însă acestea din urmă utilizează descriptori de nivel semantic de nivel
înalt, cum ar fi textul extras prin metode de recunoaștere automată vorbirii sau cu ajutorul
metadatelor. De asemeneA, în cazul în care combinăm trăsăturile noastre cu trăsături de
text, obținem un rezultat de 0,66 MAP, ceea ce depășește cu mai mult de 0,13 MAP
performanța obținută de cea mai importantă echipă din competiție.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
121
Tab. 6.1 Comparație rezultate cu competiția MediaEval 2012 Tagging Task (valori
MAP)
Tip trăsătură Metodă raportată la MediaEval
2012
MAP metodă raportată
MediaEval 2012
MAP metodă
propusă
Audio Descriptori pe bază de blocuri
audio & SVM Liniar [119]
0,192 0,475
Vizual descriptori vizuali (Color,Texture,
rgbSIFT) [177]
0,350 0,460
Audio & Vizual - - 0,550
Text Bag of Words - Metadata & Text
ASR
0,526 -
Audio & Vizual
& Text
- - 0,66
6.5 Recunoașterea de acțiuni sportive
6.5.1 Descriere experiment
Așa cum am prezentat în secțiunile anterioare, Fisher kernel este potrivit nu numai pentru
clasificare de gen, cât și pentru alte probleme multimedia. În această secțiune vom evalua
metoda propusă din perspectiva problemei de recunoașterii de acțiuni sportive. În această
privință, vom aplica algoritmul pe o bază de date de acțiuni sportive, și anume UCF Sport
50. Aceasta conține 6.680 documente video preluate de pe YouTube care conțin variații
majore de mișcare a camerei, pozitii, condiții de iluminare, scale și unghiuri de
vizualizare diferite. Baza de date conține 50 de categorii diferite cum ar fi: baseball,
aruncari, aruncări la coș de basket, plimbat cu bicicleta, biliard, înot, ridicare de greutăți,
scufundări, bătut la tobă, scrima, golf, cântat la chitară, sărituri cu prăjina, curse de cai,
Hula Hoop, aruncarea suliței, sărituri în lungime, Jumping Jack, caiac, exerciții de
încășzire, paradă militară, cântat la pian, făcut pizza, cal cu mânere, tracțiuni, box, urcări
pereți artificiali, urcare pe frânghie, canotaj, salsa, skate boarding, sky, skijet, fotbal,
leagăn, taichi, tennis, sărituri la trambulină, cîntat la vioară, volei, plimbări cu câinele și
Yo Yo etc.
Toate cele 50 de categorii sunt efectuate de cel puțin 25 de grupuri de persoane,
fiecare grup avînd cel puțin patru documente video. Filmele aparținând fiecărui grup
conțin câteva elemente similare, cum ar fi fundalul, unghiul de vizualizare sau contexte
asemănătoare. Măsurătorile finale vor fi efectuate folosind 25 de validări încrucișate și
anume: de fiecare dată un grup va fi exclus din grupul total de documente, antrenarea
făcându-se pe restul de 24 de grupuri de documente iar testarea pe documentul exclus.
Performanța măsurată este raportată cu ajutorul parametrului de acuratețe.
Optimizările tuturor parametrilor au fost realizate pe jumătate din baza de date. În

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
122
schimb, rezultatele oficiale au fost calculate pe toată baza de date utilizând metoda
clasică „leave-one-group-out cross-validation”.
Cele mai multe metode de descriere și clasificare a conținutului de acțiune încep
prin calculul punctelor de interes în spațiul temporal [105], fiecare informație locală fiind
descrisă cu autorul unor trăsături, ca de exemplu: HOG, HOF sau 3-D SIFT [108]. Aceste
metode au obținut rezultate bune pe baza de date UCF Sport 50, însă acești algoritmi sunt
mari consumatori de resurse. În această secțiune vom demonstra că putem obține
rezultate apropiate de state-of-the-art fără a utiliza descriptori care extrag puncte de
interes, folosind doar descriptori globali, cum ar fi HOG, HOF și histograme de culoare
CN.
Pentru descrierea conținutului de mișcare am utilizat următoarele trăsături: (1)
Histograme globale de gradienți orientați (36, 81 și 144 dimensiuni) care calculează HoG
pe primele 4 nivele de piramide spațiale, (2) histograme globale de Optical Flow (36, 81
și 144 dimensiuni) care masoară mișcarea pixelilor pe o regiune 9 orientări și (3)
histograma Color Naming (44, 99 și 176 dimensiuni). În toate experimentele, am
combinat aceste trăsături cu „late fusion”. Descriptorul HoF calculează unghiul de
mișcare a fiecărui pixel de la un frame la altul. Pentru a calcula unghiul de deplasare am
utilizat metoda clasică a lui Lucas-Kanade [104], iar pentru a clasifica pixelul ca staționar
/ nestaționar am utilizat o valoare prag. În Tabelul 6.2 prezentăm performanța inițială a
descriptorilor HOG, HOF și CN atunci când cadrul este împărțit în 3x3 regiuni, iar
agregarea frame-urilor se face printr-o simplă medie.
Tab. 6.2 Performanța inițială a descriptorilor selectați (acuratețe)
Metodă Acuratețe
Trăsături HoG & SVM liniar 26,01%
Trăsături HoG & SVM RBF 40,06%
Trăsături CN & SVM liniar 13,22%
Trăsături CN & SVM RBF 22,49%
Trăsături HOF & SVM liniar 28,21%
Trăsături HOF & SVM RBF 47,41%
Trăsături HOF & HOG & CN & SVM RBF 53,11%
Cea mai bună performanță este obținută de către descriptorii HOF, și anume
47,41%. Pe de altă parte, cea mai scăzută performanță este obținută cu histogramele de
culoare. Acest lucru se datorează faptului că informația de culoare nu este atât de
importantă ca informația de acțiune. Am utilizat informația de culoare deoarece ne
așteptăm ca pentru unele clase să capturăm informație contextuală de background,
deoarece anumite sporturi prezintă anumite nuanțe caracteristice, ca de exemplu: tenis și
fotbal conțin verde, schi și hockey conține culoarea alb și asa mai departe. De asemeni,
sporturile sunt asociate cu locurile, ca de exemplu: scufundările se petrece în mediul
subacvatic, golful de desfășoară într-un mediu natural, ș.a.m.d. De asemeni, și utilizarea
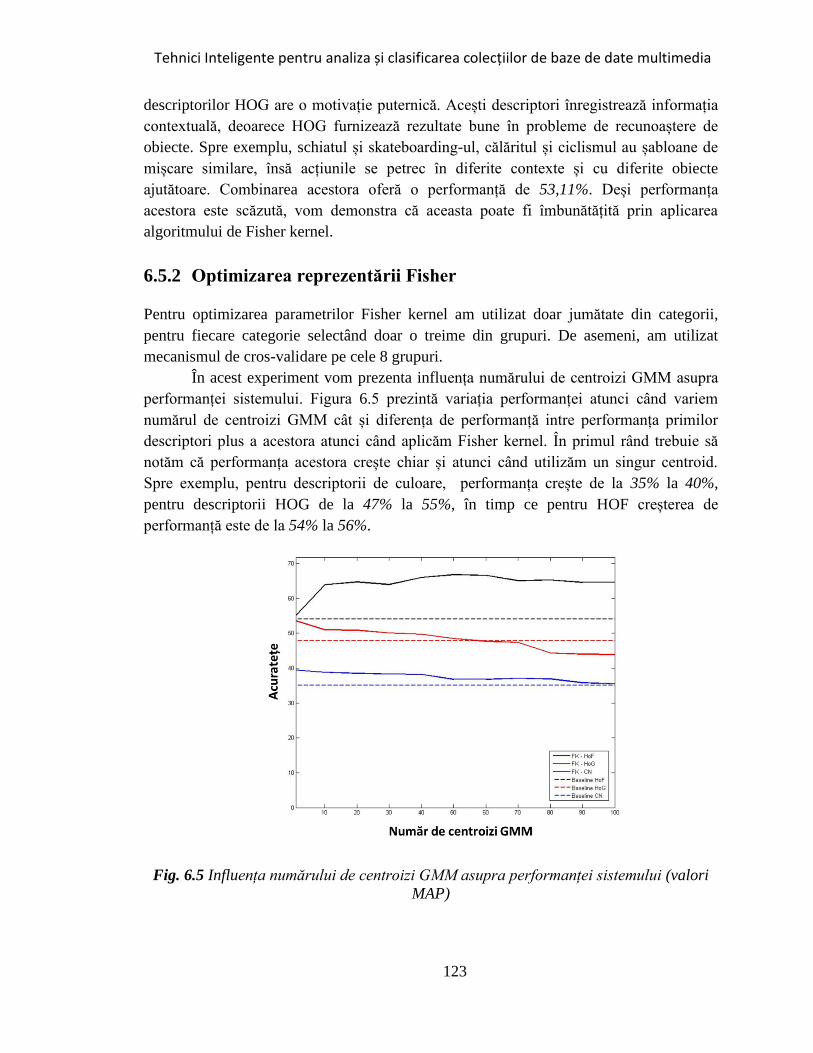
Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
123
descriptorilor HOG are o motivație puternică. Acești descriptori înregistrează informația
contextuală, deoarece HOG furnizează rezultate bune în probleme de recunoaștere de
obiecte. Spre exemplu, schiatul și skateboarding-ul, călăritul și ciclismul au șabloane de
mișcare similare, însă acțiunile se petrec în diferite contexte și cu diferite obiecte
ajutătoare. Combinarea acestora oferă o performanță de 53,11%. Deși performanța
acestora este scăzută, vom demonstra că aceasta poate fi îmbunătățită prin aplicarea
algoritmului de Fisher kernel.
6.5.2 Optimizarea reprezentării Fisher
Pentru optimizarea parametrilor Fisher kernel am utilizat doar jumătate din categorii,
pentru fiecare categorie selectând doar o treime din grupuri. De asemeni, am utilizat
mecanismul de cros-validare pe cele 8 grupuri.
În acest experiment vom prezenta influența numărului de centroizi GMM asupra
performanței sistemului. Figura 6.5 prezintă variația performanței atunci când variem
numărul de centroizi GMM cât și diferența de performanță intre performanța primilor
descriptori plus a acestora atunci când aplicăm Fisher kernel. În primul rând trebuie să
notăm că performanța acestora crește chiar și atunci când utilizăm un singur centroid.
Spre exemplu, pentru descriptorii de culoare, performanța crește de la 35% la 40%,
pentru descriptorii HOG de la 47% la 55%, în timp ce pentru HOF creșterea de
performanță este de la 54% la 56%.
Fig. 6.5 Influența numărului de centroizi GMM asupra performanței sistemului (valori
MAP)

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
124
De asemenea, prin variația numărului de clusteri, performanța acestora încă poate
fi îmbunătățită. Toți descriptorii înregistrează un câștig de performanță între 5% și 10%.
Numărul de clustere care va fi utilizat în următorul experiment este: 60 de clustere pentru
HOF și un cluster pentru HOG și pentru CN.
6.5.3 Comparație cu „State-of-the-Art”
În Tabelul 6.3 este prezentată performanța obținută de metoda propusă, alături de a altor
metode din literatură. Se poate observa că metoda noastră obține a doua poziție cu o
performanță de 74,01%, după cea propusă de Reddy [108]. Totuși, metoda propusă
utilizează descriptori foarte simpli, cum ar fi HOG, HOF si CN în timp ce metoda din
prima poziție utilizează un set de descriptori care generează un efort computațional foarte
ridicat. Doar metoda propus de Solmaz [178] utilizează descriptori globali (GIST 3D),
însă aceștia au o performanță mai mică cu 9%.
În final, putem concluziona că metoda propusă obține rezultate similare cu cele
prezentate în state-of-the-art, însă aceasta utilizează descriptori mult mai rapizi și ușor de
implementat.
Tab. 6.3 Comparație rezultate State-of-the-Art (acuratețe)
Metodă Acuratețe
Reddy et al. [108] 76,9%
Metoda propusă 74,01%
Solmaz et al. [178] 73,7%
Everts et al. [109] 72,9%
Kliper-Gross et al. [179] 72,6%
Solmaz et al. [178]: GIST3D 65,3%
6.6 Recunoaștere de acțiuni cotidiene
6.6.1 Descriere experiment
O ultimă aplicație propusă este cea de recunoaștere de acțiuni obișnuite. În acest context
vom utiliza baza de date ADL (University of Rochester Activities of Daily Living) [180]
care conține 10 tipuri de activități: a răspunde la telefon, a suna pe cineva la telefon, a
scrie un număr la telefon, a căuta un număr de telefon, a a bea un pahar cu apă, a mânca
cips-uri, a desface o banană, a mânca o banană și a mânca mâncare cu furculița. În total,
baza de date conține 150 de documente video, înregistrate cu 30 de frame-uri pe secundă
la rezoluția de 1280 x 720. Baza de date conține un set important de provocări: diferite
forme, diferite persoane de naționalități și etnii diferite, cât și o serie de acțiuni care sunt
foarte similare ca: a mânca o banană sau cipsuri, sau a răspunde sau a vorbi la telefon.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
125
Multe din activitățile prezentate anterior ca măncatul unei banane sau vorbitul la
telefon pot fi definite ca și noțiuni de mișcare în funcție de anumite părți componente ale
corpului unei persoane. Din acest motiv, am extras părțile componente ale persoanelor
care efectuează acțiunile respective, utilizând metoda propusă în [110]. Estimarea părților
componente ale corpului uman prezintă performanțe ridicate atunci când filmele conțin
un număr mic de ocluziuni iar persoanele sunt vizualizate integral. Un exemplu de
estimare a părților componente îl găsim în Figura 6.6 (a). Apoi, vom selecta o suprafață
adiacentă fiecărei componente a corpului uman (Figura 6.6 (b)), iar pentru fiecare regiune
vom extrage o histogramă de trăsături HoF.
(a) (b)
Fig. 6.6 (a) Exemplu de estimare părților componente a corpului uman (b)
suprafață de extragere a trăsăturilor HoF
Fiecare trăsătură HoF reprezintă o histogramă de lungime 8, iar detectorul extrage
18 regiuni. Prin concatenarea histogramelor HOF pentru fiecare regiune vom obține un
descriptor de lungime 144. Acest tip de trăsături reprezintă o practică comună în multe
din metodele propuse pentru detecția de acțiuni obișnuite. Nu am utilizat descriptori
uzuali HOG și CN deoarece pentru această bază de date informația de context nu este
importantă. Toate acțiunile se petrec in interiorul unei camere, iar fudalul este similar
pentru toate filmele.
Performanța descriptorilor propuși este prezentată în Tabelul 6.4. Se poate
observa că SVM RBF obține un rezultat de 88,10%, ceea ce este similar cu rezultatele
obținute în state-of-the-art.
Tab. 6.4 Comparație rezultate State-of-the-Art (acuratețe)
Metodă Acuratețe
HoF extras pe părți componente ale corpului & SVM liniar 88,10%
HoF extras pe părți componente ale corpului & RBF 66,41%

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
126
6.6.2 Optimizarea reprezentării Fisher
Pentru optimizarea reprezentării Fisher vom folosi jumatate din baza de date împărțită în
două părți componente: 37 de filme pentru antrenare și 37 de filme pentru testare, fiecare
având o distribuție uniformă pentru fiecare activitate.
Singurul parametru care va fi optimizat va fi numărul de centroizi GMM. Figura
6.7 prezintă variația performanței atunci când variem numărul de centroizi GMM cât și
diferența de performanță intre performanța primilor descriptori plus a acestora atunci
când aplicăm Fisher kernel. În primul rând trebuie să notăm că performanța acestora
crește chiar și atunci când utilizăm un singur centroid (de la 86% la 92%).
Fig. 6.7 Influența numărului de centroizi GMM asupra acurateței sistemului
6.6.3 Comparație cu „State-of-the-Art”
În Tabelul 6.5 poate fi vizualizat rezultatul final obținut de metoda propusă, împreună cu
alte metode propuse în literatură. Se poate observa că algoritmul Fisher kernel aplicat
părților componente ale corpului prezintă cea mai mare performanță, de 97,3% , în timp
ce ceilalți algoritmi au obținut o performanță cu câteva procente mai redusă. În metoda
propusă de Wang [181], se utilizează un algoritm care printr-o augmentare spațială ia în
considerare relația spațială dintre punctele de mișcare de interes. Pe de altă parte, în
metoda propusă de Lin [182] distribuția spațială este incorporată prin crearea unei
structuri arborescente.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
127
Tab. 6.5 Comparație rezultate State-of-the-Art (acuratețe)
Metodă Acuratețe
Metodă propusă 97,3%
Wang et al. [181] 96,0%
Lin et al. [182] 95,0%
Messing et al. [183] 89,0%
6.7 Concluzii capitol
În acest capitol am propus modelul Fisher kernel pentru agregarea și modelarea variației
temporale în documentele video. În timp de ordinea temporală este pierdută, variația
temporală este capturată la două nivele: trăsăturile similare sunt grupate împreună și rețin
variația intra-cluster, în timp ce trăsăturile nesimilare sunt împărțite separat, prevenind
amestecarea informației de mișcare din diferite părți componente.
De asemenea, am demonstrat că metoda propusă este foarte generală: am arătat că
metoda propusă îmbunătățește o mare varietate de trăsături, de la trăsături care utilizează
părți componente ale corpului uman, la trăsături vizuale pentru detecția de gen, până la
descriptori audio clasici. Mai mult, am demonstrat că metoda obține rezultate foarte bune
pe o varietate de baze de date: am obținut rezultate apropiate cu state-of-the-art pentru
baza de date UCF Sport 50 utilizând descriptori globali în locul descriptorilor mult mai
complecși locali, am reușit să obținem performanțe îmbunătățite pe baza de date ADL de
acțiuni uzuale prin utilizarea algoritmilor de detecție de părți componente ale corpului
uman, și am obținut rezultate superioare pe baza de date MediaEval 2012 pentru
competiția de detecție de genuri.
În viitor, îmi propun să combin metoda Fisher cu alte trăsături mai complexe, cum
ar fi trăsăturile locale de mișcare [105]. De asemenea, îmi propun să testez metodele
propuse pe baze de date mai mari: pentru detecția de gen îmi propun să utilizez baza de
date Youtube, pentru detecția de acțiuni sportive să utilizez baza UCF 101, în timp ce
pentru bazele de date de acțiuni cotidiene să creez baze de date mai complexe.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
128

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
129
Capitolul 7
Metode de Relevance Feedback
propuse
În acest capitol voi prezenta o serie de algoritmi de relevance feedback propuși în cadrul
diferitelor conferințe internaționale. În prima parte voi înfățișa un algoritm de relevance
feedback care combină principii inspirate din metoda clasică de RF Rocchio (Capitolul
7.1) cu trăsături similare celor utilizate în metodele de estimare a importanței
descriptorilor (Capitolul 5.2.3). Această metodă a fost propusă în cadrul conferinței
EURASIP: „Signal Processing and Applied Mathematics for Electronics and
Communications” (SPAMEC), desfășurată la Cluj-Napoca, Romania, august, 2011 [184].
Al doilea algoritm de relevance feedback propus utilizează o structură
arborescentă capabilă să învețe rapid și eficient preferințele utilizatorului chiar dacă
utilizăm un set restrâns de exemple de învățare. Inițial, algoritmul a fost propus într-o
variantă inițială în contextul bazelor de date de imagini la conferința „Signals, Circuits
and Systems” (ISSCS), 2011 [185], ca apoi, acesta să fie dezvoltat în cadrul conferinței
„Content Based Multimedia Indexing”, CBMI 2012, Annecy, Franța [186]. Rezultate
experimentale mai ample au fost apoi prezentate în cadrul conferinței „European Signal
Processing Conference” EUSIPCO 2012, desfășurată la Bucucurești în august 2012 [187].
Mai mult, algoritmul a fost adaptat și în contextul indexării de baze de date multimedia în
cadrul conferinței „International Conference on Intelligent Computer Communication”
ICCP 2012 [188], ca apoi algoritmul să fie extins și testat pe baze de date de dimensiuni
mai mari în revista cotată ISI „Media Tools and Applications” [120].
Ultimul algoritm propus este inspirat din modelul Fisher kernel și a fost acceptat
la conferința „International Conference on Multimedia Retrieval” ICMR 2013,
desfășurată la Dallas, USA în aprilie 2013 [189]. Acest algoritm a fost special creeat
pentru baze de date multimedia, fiind testat pe baza de date MediaEval 2012. Mai mult,
algoritmul a fost testat pe o gamă variată de trăsături multimodale: de la trăsături vizuale,
la cele audio și textuale, fiind comparat cu diferiți algoritmi de relevance feedback
existenți.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
130
7.1 Algoritm propus de „Relevance Feedback” cu
estimare a importanței trăsăturilor
7.1.1 Prezentare algoritm
Algoritmul de estimare a relevanței trăsăturilor [129] pleacă de la premiza că anumite
valori din vectorul descriptor sunt mai importante decât altele. În cazul în care anumite
obiecte au valori similare înseamnă ca acestea au un grad de relevanță mai mare în
descrierea grupului de documente căutat. Pe de altă parte, dacă valorile componentelor
diferă în mod substanțial, indică faptul că acele valori pot să nu fie luate în considerare.
Bazându-se pe această analiză simplă, Rui și Huang [143] au considerat că valoarea
deviației standard este invers proporțională cu gradul de relevanță al parametrului. Marele
neajuns al algoritmului este că nu utilizează feedback-ul negativ al utilizatorului. În cazul
în care o caracteristică a vectorului descriptor are o distribuție similară atât pentru valori
negative cât și pentru cele pozitive, algoritmul nu va fi capabil să le separe. Din această
cauză algoritmul trebuie să fie capabil sa aplice penalizări bazate pe feedback negativ.
O altă proprietate definitorie pentru creșterea importanței unei trăsături este media
acesteia. O trăsătură cu medie mai ridicată este mai importantă decât una cu medie
scăzută, deoarece existența unei trăsături comune este mult mai importantă din punct de
vedere perceptual, decât absența sau prezența într-o proporție mult redusă. Un alt factor
care poate fi luat în considerare este reprezentat de gradul de corelare al trăsăturilor. În
cazul în care o trăsătură este strâns înlănțuită de o altă trăsătură, aceasta este mult mai
important deoarece sugerează că trăsăturile respective sunt definitorii pentru conceptul
nostru. O altă modificare propusă algoritmului lui Rui [143] este modificarea punctului
de interogare. Plecând de la premiza că fiecare document reprezintă o variabilă aleatoare
într-un spațiu multidimensional de distribuție gausiană, prin mutarea punctului de
interogare în centroidul clasei, vom maximiza probabilitatea de găsire a documentelor din
cadrul clasei respective. Acest principiu de mutare a punctului de interogare fost
împrumutat din algoritmul lui Rocchio, însă, spre deosebire de acesta, vom utilizeaza
numai feedback pozitiv. Conform algoritmului propus, noul punct de interogare va fi
calculat ca medie a feddbackului pozitiv, , în timp ce ponderile de importanță a
trăsăturilor vor fi calculate în modul următor:
∑
(7.1)
unde reprezintă dispersia trăsăturilor obiectelor nerelevante,
dispersia
trăsăturilor pentru obiectele relevante, k reprezintă un parametru empiric ales,
este media trăsăturilor relevante iar este gradul de corelare a trăsăturilor.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
131
O reprezentare grafică a conceptului de mișcare a punctului de interogare și de
reestimare a importanței trăsăturilor este prezentă în Figura 7.1.
Fig. 7.1 Ilustrare schematică a algoritmului modificat de estimare a relevanței
caracteristicilor.
Schema logică a algoritmului este prezentată în Figura 7.2. Primul pas constă în
calculul ponderilor trăsăturilor relevante şi nerelevante (valorile ). Apoi, se calculează
centroidul documentelor relevante şi se va muta noul punct de interogare. În final, se
generează o nouă interogare şi se va afişa un nou set de rezultate. Utilizatorul poate
selecta noile imagini relevante iar ciclul se poate repeta pînă când rezultatele returnate
sunt satisfăcătoare.
Fig. 7.2 Schema logică a algoritmului modificat de estimare a relevanței
caracteristicilor.
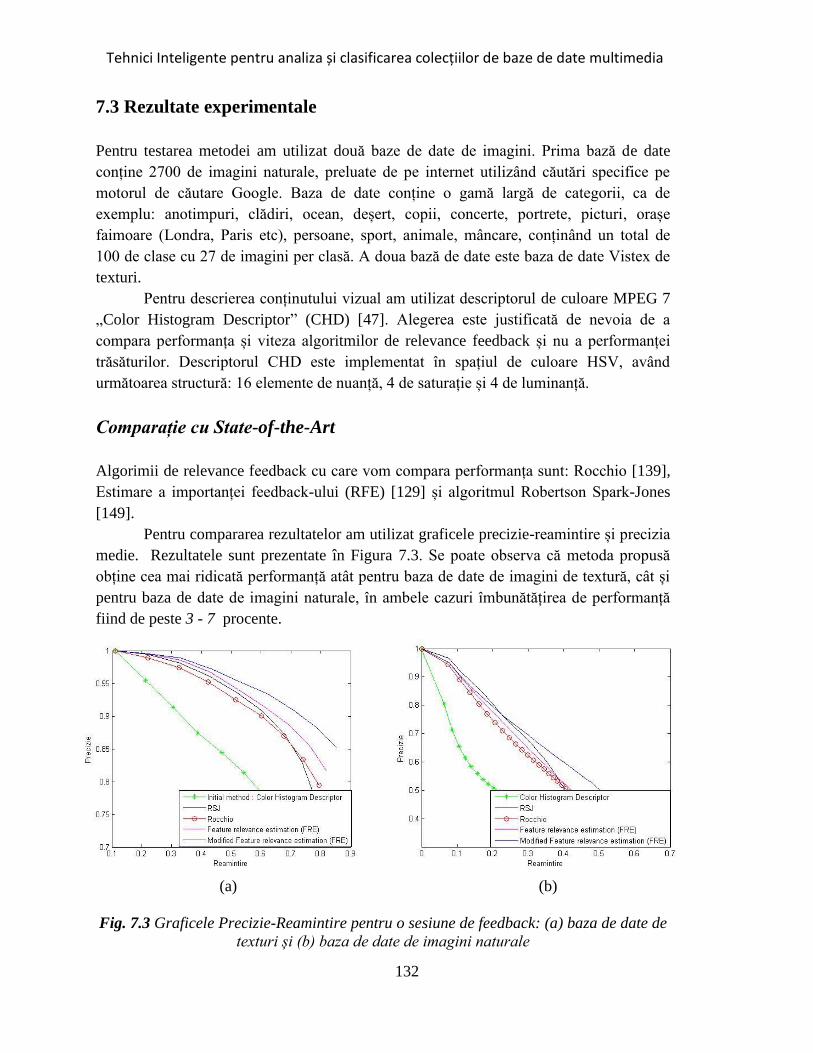
Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
132
7.3 Rezultate experimentale
Pentru testarea metodei am utilizat două baze de date de imagini. Prima bază de date
conține 2700 de imagini naturale, preluate de pe internet utilizând căutări specifice pe
motorul de căutare Google. Baza de date conține o gamă largă de categorii, ca de
exemplu: anotimpuri, clădiri, ocean, deșert, copii, concerte, portrete, picturi, orașe
faimoare (Londra, Paris etc), persoane, sport, animale, mâncare, conținând un total de
100 de clase cu 27 de imagini per clasă. A doua bază de date este baza de date Vistex de
texturi.
Pentru descrierea conținutului vizual am utilizat descriptorul de culoare MPEG 7
„Color Histogram Descriptor” (CHD) [47]. Alegerea este justificată de nevoia de a
compara performanța și viteza algoritmilor de relevance feedback și nu a performanței
trăsăturilor. Descriptorul CHD este implementat în spațiul de culoare HSV, având
următoarea structură: 16 elemente de nuanță, 4 de saturație și 4 de luminanță.
Comparație cu State-of-the-Art
Algorimii de relevance feedback cu care vom compara performanța sunt: Rocchio [139],
Estimare a importanței feedback-ului (RFE) [129] și algoritmul Robertson Spark-Jones
[149].
Pentru compararea rezultatelor am utilizat graficele precizie-reamintire și precizia
medie. Rezultatele sunt prezentate în Figura 7.3. Se poate observa că metoda propusă
obține cea mai ridicată performanță atât pentru baza de date de imagini de textură, cât și
pentru baza de date de imagini naturale, în ambele cazuri îmbunătățirea de performanță
fiind de peste 3 - 7 procente.
(a) (b)
Fig. 7.3 Graficele Precizie-Reamintire pentru o sesiune de feedback: (a) baza de date de
texturi și (b) baza de date de imagini naturale

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
133
În Figura 7.4 sunt prezentate performanțele algoritmilor pentru mai multe sesiuni
de feedback. Se poate observa că performanța sistemului crește în mod semnificativ în
toate cazurile atunci când aplicăm algoritmii de relevance feedback. Spre exemplu, prin
aplicarea algoritmului propus în cazul bazei de date de textură, performanța crește de la
71% la 87%, în timp ce pentru baza de imagini naturale rata de recunoaștere aproape se
dublează de la 37% la 60% MAP. Mai mult, algoritmul propus obține rezultate superioare
față de ceilalți algoritmi. Spre exemplu, în cazul imaginilor de textură metoda propusă are
o performanță mai ridicată cu peste 2 procente mai ridicată decât RFE și cu 8 procente în
cazul bazei de imagini naturale.
(a) (b)
Fig. 7.4 Variația MAP pentru mai multe iterații de feedback: (a) baza de date de texturi
și (b) baza de date de imagini naturale
7.2 Relevance feedback cu clusterizare ierarhică
7.2.1 Prezentare algoritm
Algoritmul de clusterizare ierarhică [190] reprezintă o metodă de analiză a datelor care își
propune partiționarea datelor în clustere. După modul de realizare a clusterizării,
algoritmul se clasifică în două categorii: aglomerativ („clustering bottom-up”) și diviziv
(„clustering top-down”). Clusterizarea ierarhică aglomerativă (HAC) caută în mod
repetitiv cele mai similare perechi de clusteri, după care perechile cele mai similare se
unesc în partiții mai mari. Astfel, numărul clusterilor scade în mod succesiv cu fiecare
iteraţie. Pe de altă parte, clusterizarea divizivă grupează iniţial spaţiul descriptorilor într-o
singură partiţie, iar apoi acesta de împarte succesiv în mai multe clustere.
În continuare, vom propune un algoritm de relevance feedback care utilizează
algoritmul de clusterizare ierarhică aglomerativ. Iniţial, utilizatorul selectează un model

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
134
pe baza căruia se efectuează o interogare în baza de date. Sistemul returnează o serie de
documente, după care, utilizatorul va selecta doar documentele care sunt relevante pentru
căutarea sa. Pe baza feedback-ului utilizatorului, clusterizarea ierarhică creează o ierarhie
arborescentă a datelor (denumită dendogramă). Documentele vor fi grupate în două tipuri
de clustere: partiţii de documente ce conţin numai documente relevante şi grupări de
documente nerelevante. Pentru ca acest algoritm să poată funcţiona, se pornește de la
ideea că descriptorul este suficient de bun astfel încât printre documentele iniţial
prezentate de sistem să se găsească cel puțin câteva documente relevante pentru a fi
selectate de către utilizator. La fiecare feedback al utilizatorului, documentele prezentate
sunt clusterizate în partiții de documente similare / nesimilare. Pe baza acestor partiţii
antrenate cu feedback-ul utilizatorului, sistemul va reordona restul de documente din baza
de date în funcţie de apartenenţa lor la o partiţie de documente.
(a) (b)
Fig 7.5 Arhitectura unei reţele de clusterizare ierarhică a) aglomerativă, b) divizivă
Schema algoritmului propus conține următorii pași:
- sistemul returnează o listă de documente;
- se inițializează algoritmul de clusterizare ierarhică cu documentele iniţial afişate de
către sistem;
- utilizatorul marcheză documentele relevante;
- se iniţializează mecanismul de clusterizarea ierarhică. Partiţiile de documente cele
mai similare se combină în mod succesiv. Clusterizarea se termină atunci când
numărul de clustere rămase este relevant pentru conceptul curent. Există mai multe
condiții de finalizare ale clusterizării care vor fi prezentate ulterior;
- se clasifică imaginile neafișate de către sistem ca fiind relevante sau nerelevante în
funcție de distanța acestora către clusterele de imagini relevante / irelevante;
- în cazul în care rezultatele nu sunt satisfăcătoare se poate repeta încă un pas de
relevance feedback.
D
4

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
135
-
Fig. 7.6 Versiunea în pseudocod a algoritmului de Relevance Feedback cu clusterizare
ierarhică
Versiunea în pseudocod a algoritmului este prezentată în Figura 7.6. Au fost
utilizate următoarele notații: reprezintă numărul de imagini aflate într-o fereastră de
căutare, este numărul de clustere din arborele final, sim[i][j] indică distanța
dintre clusterii și (de exemplu distanța dintre centroizi), τ reprezintă numărul de
minim clase din arborele final în faza de antrenare (va fi prezentat mai târziu), este
numărul maxim de imagini în care are loc căutarea (setat la un sfert din numărul total de
imagini din baza de date), numărul maxim de imagini care pot fi clasificate ca și
pozitive (care este setat implicit la valoarea dimensiunii ferestrei de căutare), TP
reprezintă numărul de imagini care sunt relevante, iar imagine_curentă este indexul
curent al documentului analizat. Un pas important în algoritmul de clusterizare ierarhică
este reprezentat de selecția metricii care calculează gradul de similaritate dintre două
clustere. Cele mai utilizate măsuri sunt:
- legătură simplă („single linkage”) – distanța dintre clustere este determinată de
distanța dintre cele mai apropiate obiecte:

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
136
- legătură completă („complete linkage”) - distanța dintre clustere este determinată de
distanța dintre cele mai îndepărtate puncte:
- legătură medie („average linkage”) - în acest caz distanța este calculată ca o medie a
tuturor distanțelor dintre obiecte
- legătura „ward” - reprezintă suma pătratelor distanțelor din interiorul unui cluster și
centroidul acestora:
(7.2)
unde clusterul A conține m obiecte iar B conține n obiecte.
- legătura între centroizi (centroid linkage) – reprezintă distanța dintre centroizi.
Această distanță poate fi utilizată doar dacă se folosește distanța euclidiană:
unde
∑
Fig. 7.7 Metode de unificare a clusterelor: a) legătură completă, b) legătură simplă, c)
legătură medie şi d)legătură între centroizi
Tipul metricii este foarte important deoarece influențează forma clusterelor. Spre
exemplu, în cazul în care alegem ca și criteriu de similaritate distanța cea mai apropiată
dintre două elemente (single linkage), forma clusterelor poate deveni neuniformă
(asemenea unei banane sau gogoși). Pe de altă parte, alegerea unei legături medii va
genera clusteri uniformi.
Clusterizarea se realizează până când se execută o condiție de finalizare. Există
două variante de finalizare: când un număr fix de clustere este atins, sau un număr
variabil adaptiv de clustere în funcție de un algoritm. O primă variantă de calcul a
metodei adaptive a fost propus în [185] şi utilizează formula următoare:

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
137
(7.3)
unde reprezintă distanța minimă dintre doi clusteri iar reprezintă
distanța maximă dintre doi clusteri. În cazul în care d are o valoare apropiată de zero
înseamnă că vom avea un set de clusteri compact (distanțele dintre clustere vor avea
valori foarte apropiate), iar în cazul valoarea lui d va tinde la unu vom avea perechi de
clustere neregulate.
O altă variantă de algoritm propus este criteriul „arcului” [186]. Numărul minim
de clustere este determinat în punctul în care daca vom creea un nou cluster acesta nu va
adăuga un plus de informație (diferența varianței inter-cluster va fi minimă). Mai precis,
punctul de inflexiune este cel în care valoarea gradientului distanței inter-cluster este
maximă.
Fig. 7.8 Reprezentare grafică pentru regula arcului
7.2.2 Rezultate experimentale obținute pe baze de imagini
Aceste rezultate experimentale au fost publicate în cadrul conferinței „Content Based
Multimedia Indexing” (CBMI) 2012 Annecy și în cadrul conferinței Eusipco 2012
București. În cadrul acestor lucrări am propus o nouă metodă de relevance feedback care
utilizează algoritmi de clusterizare ierarhică.
Descriere experiment
Experimentele au fost rulate pe câteva baze de date clasice și anume:

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
138
baza de date Microsoft (Microsoft Object Class Recognition) baza de date Microsoft
(Microsoft Object Class Recognition) [191] – care cuprinde un număr de 4300
imagini grupate în 21 de categorii;
baza de date Caltech 101 [192] – cu un număr de 9146 de imagini împărțite în 101 de
categorii distincte (persoane, animale, instrumente, evenimente etc). Exemple de
imagini din baza de date se găsesc în Figura 6.13.
Pentru descrierea conținutului vizual au fost utilizate trei categorii de descriptori:
descriptori MPEG-7 [47]: Color Histogram Descriptor, Color Layout Descriptor,
Edge Histogram Descriptor și Color Structure Descriptors;
descriptori clasici de culoare: autocorelograma [59], vectori coerenți / necoerenți [51]
și momente de culoare [50].
Bag-of-Visual-Words utilizând SURF [78].
Fig 7.9 Exemple de imagini din bazele de date utilizate (primele două rânduri reprezintă
imagini din baza de date Microsoft iar următoarele două rânduri din baza de date
Caltech 101 – 2 imagini per categorie)
Feedback-ul utilizatorului a fost simulat automat (gradul de apartenență al fiecărei
imagini la o categorie fiind știut anterior). Acest tip de simulare reprezintă o practică des
folosită în algoritmii de relevance feedback [143] [149] [193]. Acest tip de simulare
înlătură însă cazurile în care utilizatorul marchează eronat anumite imagini. Pentru a
măsura performanța algoritmilor sunt utilizate curbele precizie reamintire și media
preciziilor medii (MAP). Fiecare imagine din baza de date a fost folosită ca imagine de
interogare, aceasta fiind eliminată din setul de rezultate. Experimentele au fost efectuate
pe diverse dimensiuni de ferestre cuprinse între 20 și 50. Algoritmii comparați sunt:
„Rocchio” [139], Estimare a importanței feedback-ului (RFE) [129], SVM (Support
Vector Machines) [149], relevance feedback cu arbori de decizie (TREE) [194],

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
139
relevance feedback cu AdaBoost (Boost) [193], relevance feedback cu Random forests
(RF) [195] și metoda propusă de RF cu clusterizare ierarhică (HCRF) [185].
Alegerea parametrilor algoritmului
Primele teste efectuate asupra algoritmului de clusterizare ierarhică au rolul de a găsi
configurația optimă a parametrilor pentru alegerea numărului de clustere. În Figura 7.10
este prezentată variația performanței pe bazele de date Microsoft și Caltech 101 în funcție
de variația numărului de clustere. Pentru generarea graficului am variat numarul de
clustere de la valoarea minimă de două clustere (un cluster cu documente relevante și un
cluster cu documente nerelevante) până la numărul maxim de clustere (dimensiunea
ferestrei de afișare). Se observă că numărul optim de clustere diferă de la o bază de date
la alta, în funcție de metoda de unificare a clusterelor. Tot în această figură este
prezentată și performanța algoritmului în cazul în care se selectează metoda „arcului”.
Se observă că utilizând un număr fix de clustere putem avea performanța cea mai
ridicată, dar, acesta trebuie calculat în funcție de experiment și baza de date utilizată.
Fig 7.10 Variația MAP în funcție de numărul de clustere utilizând cele patru metode de
unificare a clusterelor (distanța medie, minimă, maximă si distanța dintre centroizi)
Utilizând metoda arcului obținem rezultate foarte apropiate de cele în care
utilizăm un număr fix de clustere, însa nu vom avea nevoie sa calculăm valoarea optimă a
numărului de clustere. În Figura 7.11 este prezentată performanța algoritmului prin
varierea parametrului d definit în prin Formula 7.3. Se observă că o variantă bună, ar fi
alegerea unei valori de tăiere în intervalul [0.88; 0.92].
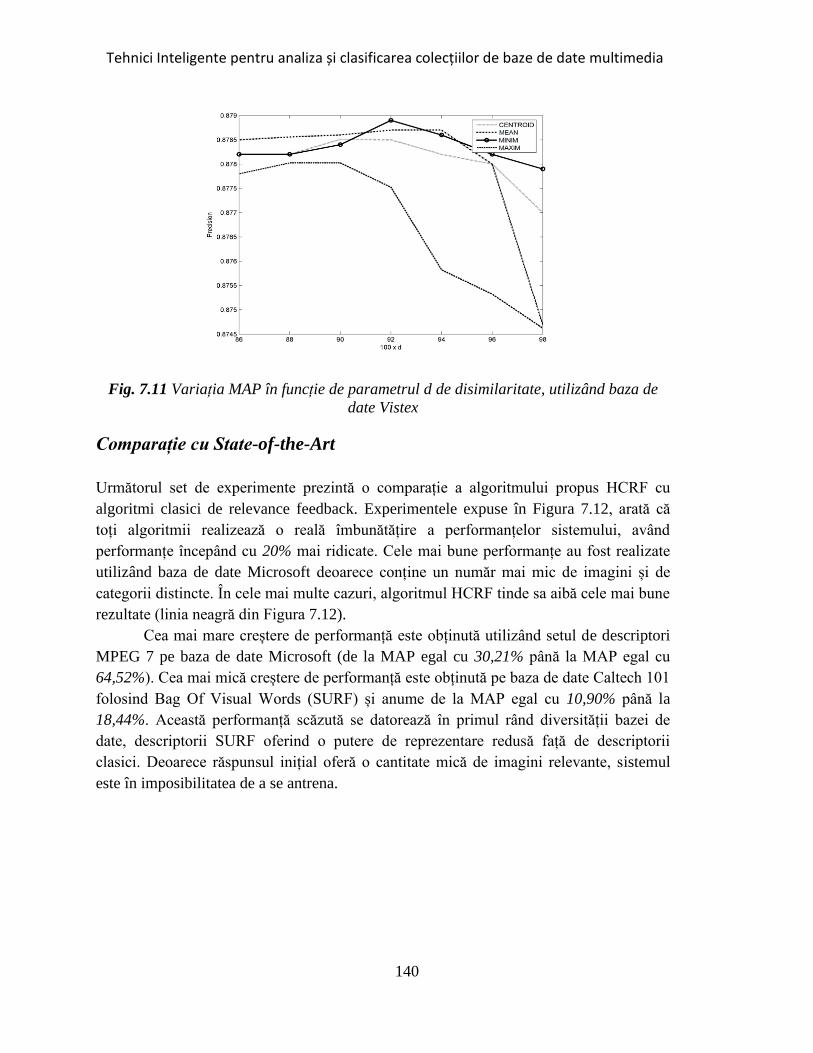
Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
140
Fig. 7.11 Variația MAP în funcție de parametrul d de disimilaritate, utilizând baza de
date Vistex
Comparație cu State-of-the-Art
Următorul set de experimente prezintă o comparație a algoritmului propus HCRF cu
algoritmi clasici de relevance feedback. Experimentele expuse în Figura 7.12, arată că
toți algoritmii realizează o reală îmbunătățire a performanțelor sistemului, având
performanțe începând cu 20% mai ridicate. Cele mai bune performanțe au fost realizate
utilizând baza de date Microsoft deoarece conține un număr mai mic de imagini și de
categorii distincte. În cele mai multe cazuri, algoritmul HCRF tinde sa aibă cele mai bune
rezultate (linia neagră din Figura 7.12).
Cea mai mare creștere de performanță este obținută utilizând setul de descriptori
MPEG 7 pe baza de date Microsoft (de la MAP egal cu 30,21% până la MAP egal cu
64,52%). Cea mai mică creștere de performanță este obținută pe baza de date Caltech 101
folosind Bag Of Visual Words (SURF) și anume de la MAP egal cu 10,90% până la
18,44%. Această performanță scăzută se datorează în primul rând diversității bazei de
date, descriptorii SURF oferind o putere de reprezentare redusă față de descriptorii
clasici. Deoarece răspunsul inițial oferă o cantitate mică de imagini relevante, sistemul
este în imposibilitatea de a se antrena.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
141
Fig. 7.12 Curbele Precizie – Reamintire pentru bazele de date Caltech 101 și Microsoft
utilizând descriptorii de culoare, MPEG7 și Bag of Words (SURF)
În Figura 7.13 prezentăm variația MAP în funcție de sesiuni multiple de feedback. În
cadrul acestui experiment, cele mai bune rezultate au fost obținute utilizând RF cu
clusterizare ierarhică. Performanțe mai mici, dar apropiate, se obțin utilizând relevance
feedback cu estimare a importanței trăsăturilor. După fiecare sesiune de feedback se
poate observa că performanța crește cu fiecare sesiune (însă diferența de creștere de
performanță este descrescătoare). Spre exemplu, după patru sesiuni de feedback, cea mai
bună creștere de performanță este obținută pe Microsoft de la 30,21% la 84,71%, în timp
ce pentru Caltech 101 se obține o creștere de la 10,66% la 55,78%. Prin comparație,
metoda de relevance feedback cu estimare a importanței trăsăturilor realizează o creștere
a performanței cu cateva procente mai scăzute (3% până la 6% mai scăzute).
Fig 7.13 Performanța sistemului atunci când variem numărul de iterații de feedback pe
baza de date Caltech 101 si Microsoft (valori MAP)
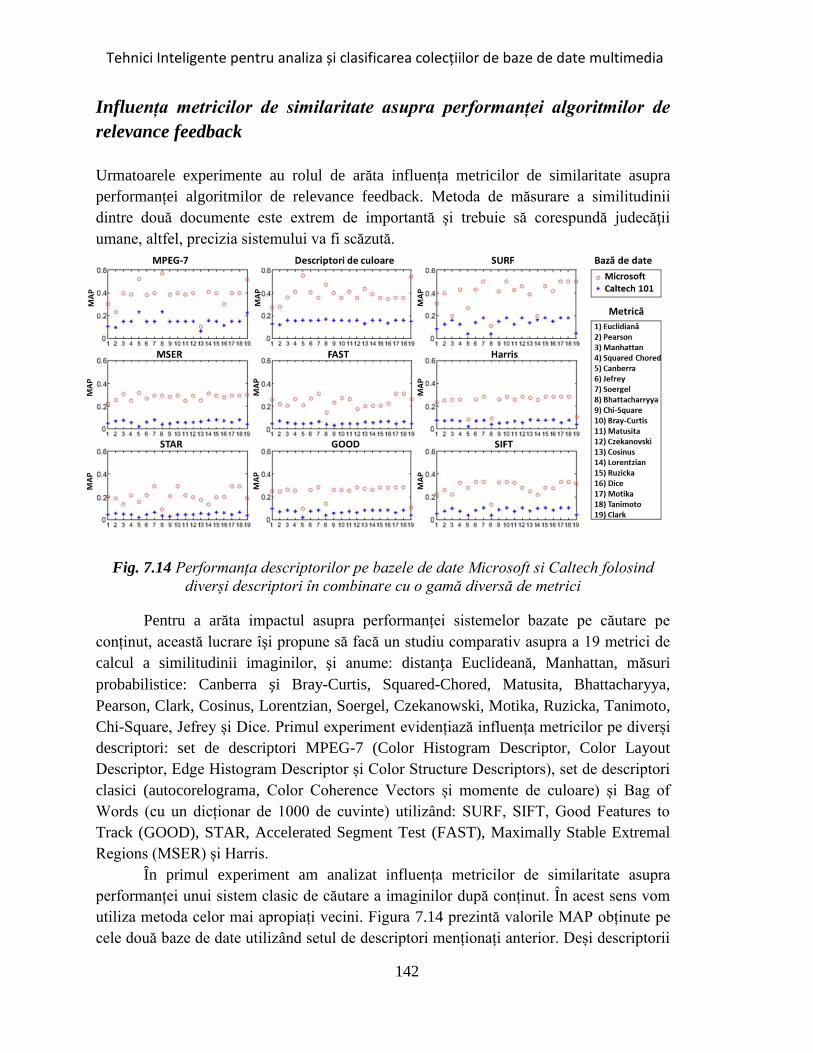
Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
142
Influența metricilor de similaritate asupra performanței algoritmilor de
relevance feedback
Urmatoarele experimente au rolul de arăta influența metricilor de similaritate asupra
performanței algoritmilor de relevance feedback. Metoda de măsurare a similitudinii
dintre două documente este extrem de importantă şi trebuie să corespundă judecăţii
umane, altfel, precizia sistemului va fi scăzută.
Fig. 7.14 Performanța descriptorilor pe bazele de date Microsoft si Caltech folosind
diverși descriptori în combinare cu o gamă diversă de metrici
Pentru a arăta impactul asupra performanței sistemelor bazate pe căutare pe
conținut, această lucrare îşi propune să facă un studiu comparativ asupra a 19 metrici de
calcul a similitudinii imaginilor, şi anume: distanța Euclideană, Manhattan, măsuri
probabilistice: Canberra și Bray-Curtis, Squared-Chored, Matusita, Bhattacharyya,
Pearson, Clark, Cosinus, Lorentzian, Soergel, Czekanowski, Motika, Ruzicka, Tanimoto,
Chi-Square, Jefrey și Dice. Primul experiment evidențiază influența metricilor pe diverși
descriptori: set de descriptori MPEG-7 (Color Histogram Descriptor, Color Layout
Descriptor, Edge Histogram Descriptor și Color Structure Descriptors), set de descriptori
clasici (autocorelograma, Color Coherence Vectors și momente de culoare) și Bag of
Words (cu un dicționar de 1000 de cuvinte) utilizând: SURF, SIFT, Good Features to
Track (GOOD), STAR, Accelerated Segment Test (FAST), Maximally Stable Extremal
Regions (MSER) și Harris.
În primul experiment am analizat influența metricilor de similaritate asupra
performanței unui sistem clasic de căutare a imaginilor după conținut. În acest sens vom
utiliza metoda celor mai apropiați vecini. Figura 7.14 prezintă valorile MAP obținute pe
cele două baze de date utilizând setul de descriptori menționați anterior. Deși descriptorii

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
143
prezintă performanțe medii mult diferite, se observă că utilizarea unei metrici adecvate
poate juca un rol critic în rezultatele finale ale sistemului. În cazul bazei de date
Microsoft, cele mai bune rezultate sunt obținute utilizând combinația: set descriptori
MPEG 7 și distanța Bhattacharyya, cu un MAP de 57%. Următoarele rezultate sunt egale
cu 55% și 54%, utilizând distanțele Canberra, respectiv Clark, pe setul de descriptori de
culoare. Aceste valori reprezintă o îmbunatățire de 18 procente fața de valoarea
performanței medii a descriptorului MPEG 7.
Rezultatele vor fi sensibil mai mici în cazul bazei de date Caltech 101. Principalul
motiv pentru care baza Caltech 101 conține rezultate mai slabe se datorează numărului de
cinci ori mai ridicat de clase care trebuie clasificat. Acuratețea cea mai mare este obținută
utilizând descriptorii Bhattacharyya și Canberra (valori MAP de 23,4% respectiv 23,2%).
În acest caz vom avea îmbunătățiri de cel puțin 5% față de valoarea medie a performanței
descriptorului. În ceea ce privește efortul computațional, trebuie luat în considerare că
distanța Bhattacharyya este soluția cea mai costisitoare. De asemenea, se observă că
anumite metrici sunt adaptate pe structura anumitor descriptori. Spre exemplu, distanțele
Bhattacharyya și Canberra au perfomanțe slabe pe setul de descriptori Bag-of-Visual-
Words (de observat SURF, SIFT, Harris și GOOD în Figura 7.15). Un alt caz interesant
este cel al distanței euclidiene, care în ciuda popularității sale obține rezultate scăzute în
marea majoritate a experimentelor.
În experimentele anterioare se observă că performanțele pe testere de căutare este
relativ scăzută. Din acest motiv, încercăm să aplicăm algoritmi de relevance feedback
asupra experimentelor de căutare. Vom compara metoda propusă HCRF asupra altor
algoritmi clasici de Relevance Feedback: algoritmul Rocchio [139], Relevance Feature
Estimation (RFE) [143], RF utilizând Vectori Suport (SVM) [150], Arbori de decizie
(Tree) [194], AdaBoost (BOOST) [193], Random Trees [193], Gradient Boosted Trees
(GBT) [193] și algoritmul celor mai apropiați vecini (Nearest Neighbor - NN) [196].
Pentru fiecare descriptor și metrică vom efectua un experiment cu fiecare algoritm de
relevance feedback. Din motive evidente, nu vom prezenta decât rezultatele cele mai
importante în Tabelul 7.1:
Tab. 7.1 Top trei performanțe pentru bazele de date Microsoft și Caltech 101 (MAP).
Baza de date Microsoft
Descriptor primul MAP al doilea MAP al treilea MAP
MPEG 7 HCRF - 80% BOOST - 72% NN – 72%
Descriptori de culoare HCRF – 80 RFE - 68% BOOST - 68%
Baza de date Caltech 101
Descriptor primul MAP al doilea MAP al treilea MAP
MPEG 7 HCRF - 32% RFE - 28% GBT - 27%
SURF HCRF - 32% BOOST - 27% NN - 26%
În toate experimentele efectuate, algoritmii de relevance feedback îmbunătățesc
performanțele de sistemelor CBIR. Spre exemplu în cazul bazei de date Microsoft,

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
144
performanța este mai ridicată la MAP 80%, față de 57% cât obținem fără relevance
feedback (îmbunătățire de 23 procente). Pe baza de date Caltech 101 vom avea o
îmbunătățire de 9 procente de la 23% la 32%. Clusterizarea ierarhică are cele mai bune
rezultate în marea parte a experimentelor. Pentru baza de date Microsoft, cea mai mare
creştere de performanță este obținută cu descriptorii MPEG-7, cu 8% față de a doua
poziție obținută prin utilizarea algoritmului BOOST; pe baza Caltech-101, cele mai bune
performanţe se obțin pe setul de descriptori SURF, pe a doua poziție aflându-se tot
BOOST la o diferență de cinci procente.
Fig. 7.15 Acuratețea algoritmilor de relevance feedback pentru diverși descriptori și
metrici (valori MAP).
Precizii scăzute au fost obținute cu descriptorii FAST, STAR și MSER pe toți
algoritmii de relevance feedback. De asemeni experimentele arată că performanța
algoritmilor de relevance feedback depinde mult de alegerea metricii folosite și a
descriptorului utilizat. Metricele Canberra și Bhattacharyya au cele mai bune performanțe
pentru seturile de descriptori clasici ca MPEG 7 și descriptori de culoare, în timp ce
Tanimoto are cea mai bună performanță pe Bag of Visual Words.
În urma efectuării experimentelor prezentate anterior, pe doua baze de date
publice cu imagini naturale, cele mai bune rezultate le-am obţinut în mod constant
utilizând algoritmul relevance feedback cu clusterizare ierarhică.
7.2.3 Rezultate experimentale obținute pe baze de documente video
Aceste rezultate experimentale au fost publicate în două articole și anume: un articol la
conferința ICCP Cluj 2011 și un articol de revistă la revista Media Tools and
Applications 2012. Pentru testare am utilizat două baze de date: o baza de date de test (cu

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
145
un număr redus de clase și număr de documente), împreună cu baza de date MediaEval
2011 utilizată în cadrul competiției de MediaEval Tagging Task 2011 (Pisa, Italia).
Prima bază de date de documente video conține material multimedia cu o durată
totală de 91 de ore dintre care: 20 ore și 30 minute pentru filme de animație (filme scurte,
lungi și seriale), 15 minute de reclame, 22 ore de documentare (viața sălbatică, ocean,
orașe și istorie), 21 ore și 57 minute de filme, 2 ore și 30 minute de videoclipuri (pop,
rock și dance), 22 ore de știri și o ora și 55 minute de sport (fotbal) (un total de 210
documente video, 30 pe gen).
A doua bază de date este MediaEval 2011, creeată pentru taskul de clasificare a
filmelor după gen în cadrul concursului MediaEval. Filmele au fost preluate de pe
platforma de televiziune online blip (vezi http://blip.tv/). Baza de date constă în alegerea
a 2375 de documente video (aproape 300 de ore) și anume: artă (66), autoturisme (36),
business (41), jurnale de calatorie (92), comedie (35), conferințe și evenimente (42),
documentare (25), educațional (111), mâncare și băutură (63), jocuri (41), sănătate (60),
literatura (83), filme de televiziune (77), muzică și divertisment (54), bibliografie (13),
politică (597), religie (117), scoalăși educatie (11), sport (117), tehnologie (194), mediu
înconjurator (33), media (47), călătorii (62), videoblogging (70), dezvoltare de site-uri
web (40) și fără nici o categorie (248).
Pentru măsurarea performanței vom calcula aceiași doi parametri: curbele
precizie-reamintire și media preciziilor medii (MAP). Feedback-ul utilizatorului este
simulat automat pe baza informației de apartenența cu care a fost adnotat fiecare
document video. Experimentele au fost efectuate pe o ferestre de dimensiune fixă de 20,
30 și 40 de documente video. Observațiile generale asupra algoritmilor și interpretarea
acestora rămân valide însă pentru ferestre de dimensiuni variabile.
Rezultate experimentale pe baza date video de test
Aceste rezultate experimentale au fost publicate în cadrul conferintei ICCP Cluj 2011
[188]. În cadrul acestei conferințe am propus metoda de relevance feedback cu clasificare
ierarhică cu aplicare pe bazele de date multimedia. Conținutul vizual a fost descris
implementând trei tipuri de descriptori: de culoare, acțiune și contur. Pentru testare am
ales trei combinații de descriptori: culoare împreună cu acțiune, contur individual și un
descriptor ce conține combinarea celor trei descriptori concatenați. Pentru comparație cu
metoda aleasă am folosit patru algoritmi clasici de relevance feedback: Rocchio [139],
Robertson Starck-Jones, algoritmul de estimație a importanței descriptorului [143],
relevance feedback utilizând vectori suport (SVM) [150] și Relevance Feedback cu
clustering ierarhic [188].

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
146
Fig. 7.16 Precizia calculată pe fiecare categorie de film pentru diferiți descriptori (de
sus in josși de la stânga la dreapta): Color & Acțiune, Contur, Contur & Culoare &
Actune; după o singură sesiune de preluare feedback. În toate graficele sunt prezentate
performantele descriptorului inițial (bluemarin), Rochio (albastru), Robertson Spark
Jones RF (cyan), FRE RF (galben), SVM (roșu) și HCRF (magenta).Categoriile
prezentate sunt: 1 – Animații, 2 –Reclame, 3 – Documentare, 4 – Filme, 5 – Videoclipuri,
6 –Știri, 7 – Sport.
Curbele precizie-reamintire sunt prezentate în Figura 7.16. Graficele arată că
algoritmul de clusterizare ierarhică, împreună cu SVM și RFE, îmbunătățesc performanța
obținută cu cel mai mare procent: clusterizarea ierarhică în nouă cazuri (animații,
reclame, videoclipuri și sport), RFE în opt experimente (știri, filme documentare și sport)
iar SVM în patru experimente(animații și sport).
În Figura 7.16 sunt prezentate preciziile medii pentru fiecare gen în parte. Cea
mai mare crestere în performanță este obținută cu clusterizarea ierarhică pe categoria
știri: de la 17,7% la 82%, în timp ce cea mai mică rată este obținută pentru filme și
documentare (de la 32% la 42% și de la 54% la 82%). Motivul pentru care căutarea de
știri are o performanță foarte ridicată se datorează faptului că este o clasă foarte
compactă, în timp ce filmele și documentarele sunt foarte diversificate. La nivel global,
metoda de clusterizare ierarhică prezintă, din nou, cele mai bune rezultate. Cea mai mare
diferență de performanță a fost obținută pe setul doi și setul trei de descriptori (de la 57%
la 90%, în timp ce SVM și FRE au avut 82% respectiv 84%).
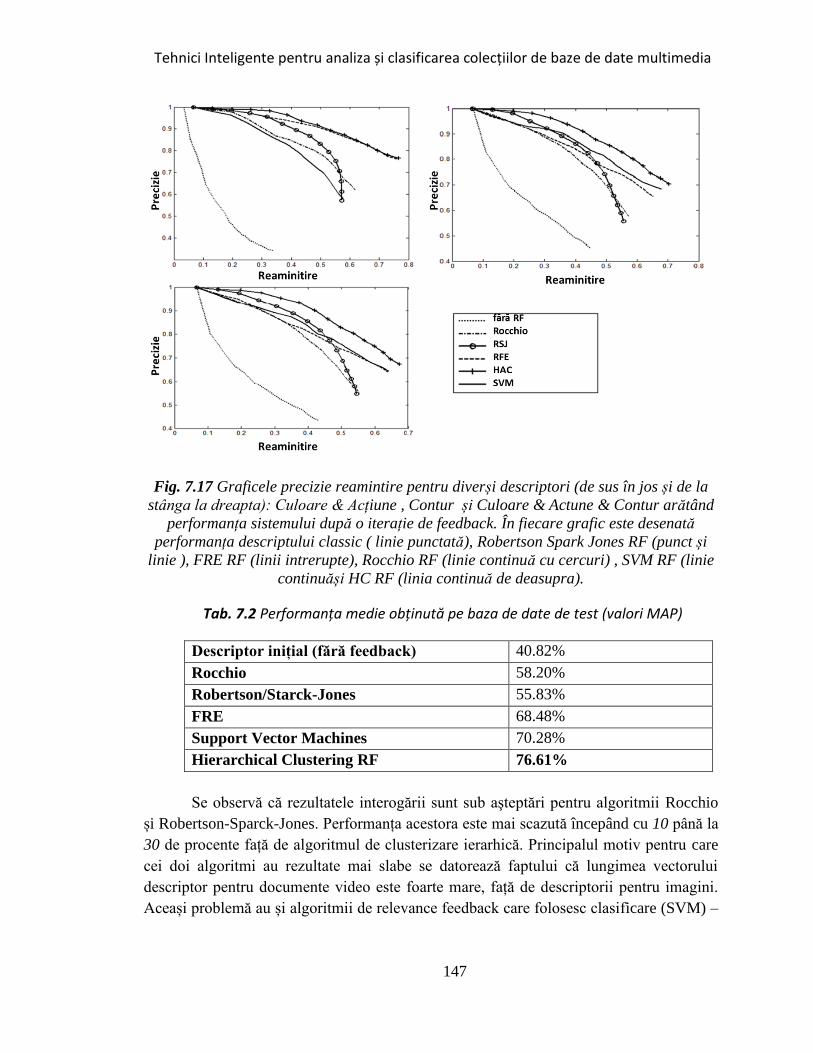
Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
147
Fig. 7.17 Graficele precizie reamintire pentru diverși descriptori (de sus în jos și de la
stânga la dreapta): Culoare & Acțiune , Contur și Culoare & Actune & Contur arătând
performanța sistemului după o iterație de feedback. În fiecare grafic este desenată
performanța descriptului classic ( linie punctată), Robertson Spark Jones RF (punct și
linie ), FRE RF (linii intrerupte), Rocchio RF (linie continuă cu cercuri) , SVM RF (linie
continuăși HC RF (linia continuă de deasupra).
Tab. 7.2 Performanța medie obținută pe baza de date de test (valori MAP)
Descriptor inițial (fără feedback) 40.82%
Rocchio 58.20%
Robertson/Starck-Jones 55.83%
FRE 68.48%
Support Vector Machines 70.28%
Hierarchical Clustering RF 76.61%
Se observă că rezultatele interogării sunt sub aşteptări pentru algoritmii Rocchio
și Robertson-Sparck-Jones. Performanța acestora este mai scazută începând cu 10 până la
30 de procente față de algoritmul de clusterizare ierarhică. Principalul motiv pentru care
cei doi algoritmi au rezultate mai slabe se datorează faptului că lungimea vectorului
descriptor pentru documente video este foarte mare, față de descriptorii pentru imagini.
Aceași problemă au și algoritmii de relevance feedback care folosesc clasificare (SVM) –

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
148
lungimea spațiului descriptorului este mult mai mare decât numărul de documente folosit
pentru antrenare.
Rezultate experimentale pe baza MediaEval 2011
Aceste rezultate experimentale au fost publicate în cadrul revistei cotate ISI „Multimedia
Tools and Applications” [120]. În cadrul acestei lucrări am propus un nou algoritm de
relevance feedback care utilizează algoritmul de clusterizare ierarhică.
Pentru descrierea conținutului multimedia am utilizat trei tipuri de descriptori:
- descriptori de culoare: histograma globală ponderată [120], histograma elementară
de culoare (distribuția nuanțelor elementare de culoare din document), histograma
proprietăților de culoare (proporția de culori puternic saturate, slab saturate, culori
reci și culori calde) și histograma relațiilor de culoare (procentul de culori perceptual
apropiate și procentul de culori perceptual diferite)
- descriptori audio: Descriptorii audio folosiți sunt descriptori pe bază de blocuri
audio, și au o lungime egală cu 11.242 valori per descriptor. Aceștia au rolul de a
captura înformația și proprietățile temporale ale semnalului audio. Semnalul audio
este împărțit în blocuri de dimensiune fixă, iar apoi pentru fiecare bloc se calculează
paternul spectral (Spectral Pattern – care capturează puterea semnalului audio),
paternul de fluctuație logaritmică (Logarithmic Fluctuation Pattern care prelucrează
informația de ritm), Spectral Contrast Pattern și Correlation Pattern care reprezintă
relația temporală a intesității de schimbare a semnalului și trăsături de timbru: Local
Single Gaussian Model și Mel-Frequency Cepstral Coefficients. Secvențele sunt
agregate utilizând media, varianța și medianul pentru toate blocurile audio calculate.
- descriptori temporali: Aceștia analizează gradul de dinamizare a cadrelor video. În
acest scop sunt extrase „cuts” și tranzițiile graduale. Cut-urile sunt detectate prin
utilizarea unei metode pe bază de schimbare de histogramă, în timp de „fades” și
„dissolves” sunt detectate prin algoritmi statistici. Parametrii calculați în descriptorii
temporali sunt: ritmul, acțiunea și rata graduală de tranziție.
Figura 7.18 prezintă graficele precizie-reamintire pentru ferestre de 20, 30, 40 și
50 de documente video. Algoritmul de relevance feedback cu clusterizare ierarhică
prezintă cele mai bune rezultate față de algoritmii clasici de RF: Rocchio [139], Feature
Relevance Estimation (RFE) [143], Support Vector Machines [120]. Se poate observa că
cele mai bune performanțe se realizează pe ferestre de vizualizare mai mici (20-30 de
documente).
Tabelul 7.3 prezintă performanțele MAP ale algoritmilor pe cele 4 ferestre de
vizualizare. Pentru metoda propusă gama de variație cuprinde intervalul 41.8% până la
51.3%, care reprezintă o creștere de performanță cu cateva procente față de algoritmii
clasici de relevance feedback. Relevance feedback se dovedește a fi o alegere bună pentru

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
149
a mări performanța sistemelor de căutare a documentelor video, fiind capabil sa aducă
performanțe similare cu descriptorii de text de nivel inalt.
Fig. 7.18 Grafice Precizie – Reaminitire pentru o sesiune de relevance feedback pe patru
ferestre de afisare (20, 30, 40 si 50 de documente afișate)
Tab. 7.3 Performanța sistemului pentru diferite ferestre de afisare (valori MAP).
Algoritmul de Relevance
Feedback
20
documente
30
documente
40
documente
50
documente
Rocchio 46,8% 43,84% 42,05% 40,73%
FRE 48,45% 45,27% 43,67% 42,12%
SVM 47.73% 44,44% 42,17% 40,26%
HCRF 51.27% 46,79% 43,96% 41,84%
7.3 Aplicarea reprezentării Fisher kernel în Relevance
feedback
7.3.1 Prezentare algoritm
Acest algoritm de relevance feedback [189] este inspirat din teoria Fisher kernel,
prezentat în Capitolul 6. Metoda propusă de relevance feedback conține următorii pași:
alterarea trăsăturilor prin utilizarea feedback-ul și etapa de reordonare a noilor trăsături.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
150
Utilizând un singur document ca și înterogare („query by example”), ordonăm toate
documentele din baza de date prin utilizarea unei metrici de similaritate. Apoi,
utilizatorul marchează din primele n documente acele documente care sunt relevante,
unde n este de obicei un număr mic (de obicei între 10 și 50 – pentru experimentul nostru
am utilizat 20 documente). Pe baza feedback-ului oferit de utilizator, se antrenează un
model GMM.
Următorul pas este de a transforma descriptorii următoarelor k documente (k în
intervalul [300..2000]), ca și derivate parțiale față de modelul GMM antrenat. Parametrul
k se alege din rațiuni de viteză, dar şi deoarece probabilitatea de regăsire a documentelor
relevante este mai mare în jurul documenteului de interogare). Experimental s-a constatat
că probabilitatea de a avea documente relevante având inițial un rang mare este redusă.
Apoi, se antrenează un clasificator SVM cu kernel liniar / RBF cu primele n
elemente marcate de către utilizator. În final, documentele din baza de date sunt
reordonate în funcţie de scorul de încredere generat de către clasificator. Schema
algoritmului este prezentată în Figura 7.19.
Aşa cum am amintit anterior, algoritmul cuprinde două module principale:
alterarea trăsăturilor prin utilizarea feedback-ului userului și reordonarea trăsăturilor cu
ajutorul unui algoritm de clasificare. În cele ce urmează oferim o descriere mai
amănunțită a algoritmului.
Alterarea trăsăturilor după feedback-ul utilizatorului
Inițial de efectuează o căutare în baza de date, utilizând o căutare cu algoritmul KNN.
Apoi, se antrenează un model gausian GMM. Din rațiuni de optimizare, inițial, clusterii
GMM sunt inițializați cu un algoritm kmeans. Un parametru important în antrenarea
modelului GMM îl reprezintă numărul de centroizi c. Având în vedere că pentru fiecare
cluster adăugat, dimensiunea noii reprezentări se va dubla, pentru ca sistemul să ruleze în
timp real, c trebuie să aibă o valoare redusă.
În secțiunea de experimente va fi analizată influența numărului de centroizi
asupra performanței algoritmului. Pentru reducerea dimensiunii vectorului final, aplicăm
pentru fiecare trăsătură în parte algoritmul PCA. Experimental am obținut valori egale ale
performanței pentru aplicarea PCA cu un factor de reducere a dimensionalității cu 10-
20%. După obținerea modelului GMM, descriptorii aparținând primelor k documente se
transformă în noua reprezentare Fisher utilizând ecuațiile descrise anterior.
Atât pentru antrenarea, cât și pentru calculul vectorilor Fisher, am utilizat același
program utilizat în [99]. Pentru creșterea acurateți algorimului, aplicăm normalizarea
vectorilor Fisher. În [99] s-a demonstrat că aplicarea normalizării asupra vectorilor Fisher
crește performanța vectorilor Fisher considerabil. Vom testa diverse variante de
normalizare: și , normalizare de putere ( √ ), normalizarea
algortmică ( , împreună cu combinații ale acestora.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
151
Fig. 7.19 Schema logică a algoritmului Relevance Feedback cu Fisher kernel
Reordonarea trăsăturilor
Primii n vectori Fisher calculați sunt antrenați cu un descriptor SVM. SVM este o soluție
bună pentru RF deoarece este robust la situații în care sunt utlizate un număr redus de
documente pentru antrenare. Întradevăr, SVM a mai fost utilizat în RF [149] [150], însă
nu în combinare cu reprezentarea Fisher kernels. În acest experiment am utilizat două
tipuri de SVM: liniar și SVM cu nucleu nonlinear RBF. În timp SVM liniar se remarcă
prin viteza ridicată în antrenare și clasificare, SVM RBF obține performanțe mai ridicate
în multe probleme de clasificare.
Utilizarea informaţiei temporale pentru RF
Cele mai multe sisteme de căutare multimedia după conținut sunt compuse din două
etape principale: extragerea de trăsături și ordonarea documentelor în funcţie de trăsături.
Prima componentă presupune calculul unei trăsături per document, iar aceasta trebuie să

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
152
cuprindă cât mai multă informație relevantă pentru categoria din care face parte. De
exemplu, pentru documentele video, cele mai multe metode calculează trăsăturile pentru
fiecare descriptor în parte, iar apoi agregă aceste rezultate prin utilizarea mediei și
dispersiei acestora, sau a altor parametri statistici. Dar, prin agregarea acestor statistici,
noțiunea temporală este pierdută. Pe de altă parte, un video poate fi reprezentat prin mai
multe trăsături per vector, iar apoi se poate calcula o distanță dintre cele două seturi de
descriptori utilizând, spre exemplu, distanța Earth Mover [30]. Totuși, aceste metrici
implică un cost computațional foarte ridicat, mai ales pentru baze de date cu dimensiuni
mari.
Prin utilizarea reprezentării Fisher kernel, se obține o soluție naturală la problema
descrisă anterior. Fisher kernel a fost inițial conceput pentru a mapa vectori de
dimensiuni fixe într-o reprezentare de lungime constantă. Pentru spargerea documentului
în mai multe cadre, o metodă este aceea de a calcula un descriptor pentru fiecare imagine
în parte. Totuși, pentru baze mari de date, numărul de cadre este uriaș (25 frame-uri pe
secundă înmulțit cu mii de ore de conținut video), iar această metodă poate creea
probleme de calcul. O altă metodă este de a prelua un număr fix de cadre per secundă,
însă chiar și asa o mare parte din informație nu este relevantă. În acest caz, un algoritm de
sumarizare video este necesar. În acest caz vom extrage un număr redus de imagini
reprezentative, care vor reprezenta într-un mod cât mai precis conținutul video. Pentru
antrenarea modelului GMM vom folosi trăsăturile pentru primele n documente video.
Odată ce modelul generativ este antrenat, pentru fiecare secvență de vectori
, compus din trăsături per document, vom transforma acești descriptori
într-un vector de dimensiune fixă. Singura diferența dintre cele două modele este
reprezentată de numărul de frame-uri cu care modelul generativ este antrenat. În loc să
utilizăm o singură trăsătură agregată pentru calculul Fisher, vom calcula o nouă
reprezentare Fisher utilizând un număr variabil de trăsături per document. Vectorul
rezultat pentru fiecare video în parte va avea aceiași dimensiune constantă.
7.3.2 Rezultate experimentale pe baza MediaEval 2012
Descriptori utilizați
Pentru descrierea conținutului multimedia am utilizat o gamă largă de descriptori
incluzând: descriptori vizuali, audio și text. Acești descriptori au obținut rezultate bune în
cadrul competiției MediaEval Genre Tagging Task 2012 [197].
- Descriptori pe bază de blocuri audio - 11.242 valori per descriptor [120]. Acestea au
rolul de a captura înformația și proprietățile temporale ale semnalului audio. Acest
descriptor conține următoarele trăsături: „Spectral Pattern”, „Logarithmic Fluctuation
Pattern”, „Spectral Contrast Pattern”, „Correlation Pattern”, „Local Single Gaussian

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
153
Model” și coeficienții „Mel-Frequency Cepstral” (MFCC). Secvențele sunt agregate
utilizând media, varianța și medianul pentru toate blocurile audio calculate.
- Descriptori audio standard [175] – am folosit o gamă variată de descriptori audio
standard: „Linear Predictive Coefficients” (LPC), „Line Spectral Pairs” (LSP),
MFCC, „Zero-Crossing Rate” (ZCR), spectral centroid, flux, rolloff și kurtosis,
fiecare împărțite la valoarea acestora pentru o fereastră de o anumită dimensiune
(dimensiunea ferestrei este egală cu 1,28 secunde). Pentru agregarea lor am utilizat
media și dispersia.
- Descriptori globali MPEG-7 (1.009 valori) [47] – am utilizat o gamă largă de
descriptori vizuali globali pe bază de culoare și textură ca de exemplu: „Local Binary
Pattern” (LBP), autocorelogramă, „Color Coherence Vector” (CCV), „Color Layout
Pattern” (CLD), „Edge Histogram” (EHD), „Scalable Color Descriptor” (SCD),
histograma de culoare și momente de culoare. Fiecare secvența a fost agregată prin
calculul mediei, dispersiei, skewness, kurtosis, mediane iși a rădăcinii medie pătrate
asupra tuturor cadrelor.
- Histograme „HOG” și „Color Naming” (CN) globale (81 valori pentru HOG și 11
pentru histograma CN) [71] [48] – am calculat descriptori HOG și CN pentru fiecare
cadru după care i-am agregat utilizând media tuturor trăsăturilor extrase din film.
- Descriptori de structură (1.430 valori) [198] – descriptorii de structură se bazează pe
caracterizarea atributelor geometrice a fiecărui contur indvdual luat în parte, ca de
exemplu: grad al curvaturii, angularitate, circularitate, simetrie și „wigglines”. Acești
descriptori au fost raportați ca fiind de succes în problemele de adnotare a
fotografiilor și în cadrul problemelor de clasificare de obiecte.
- Descriptori vizuali Bag of Words – am utilizat un dicționar de 4096 „cuvinte”, iar ca
și descriptor de ale punctelor cheie am folosit SIFT rgb [100].
- Descriptori textuali Term Frequency - Inverse Document Frequency (TF-IDF) –
conține 3.466 valori. Descriptorii au fost calculați de către organizatorii competiției
MediaEval 2012 [197]. Textul a fost extras cu ajutorul algorimilor de recunoaștere
automată a vorbirii [199].
Pentru testarea conținutului vizual am utilizat 9 combinări de descriptori: vizuali
(1 – descriptori MPEG-7, 2 - descriptori HOG CN, 3 – descriptori de structură, 4 – Bag
of Words, 5 - Combinare cu toți descriptorii vizuali), Audio (6 – trăsături audio standard,
7 – descriptori pe bază de blocuri audio), 8 - descriptori de text și 9 combinări pentru toți
descriptorii. Toți descriptorii au fost normalizați la în timp de descriptorii de text au
fost normalizați cosinus.
În secțiunile următoare vom prezenta experimentele noastre. Primul experiment
motivează alegerea celei mai bune metrici care oferă cea mai bună performanță pentru
fiecare trăsătură în parte. În a doua secțiune studiem influența fiecărui parametru Fisher
kernel asupra acurateței de clasificare a sistemului. Următoarea secțiune prezintă o
comparație cu metodele prezente în state-of-the-art. Urmează o nouă secțiune în care
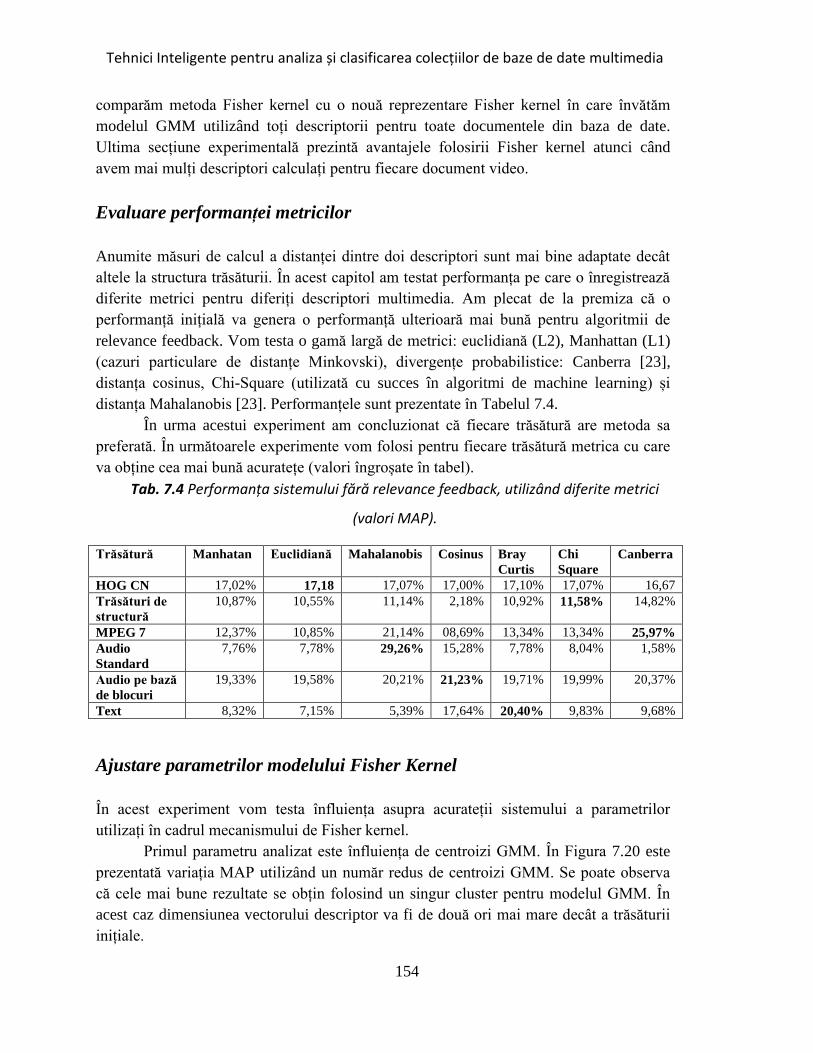
Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
154
comparăm metoda Fisher kernel cu o nouă reprezentare Fisher kernel în care învătăm
modelul GMM utilizând toți descriptorii pentru toate documentele din baza de date.
Ultima secțiune experimentală prezintă avantajele folosirii Fisher kernel atunci când
avem mai mulți descriptori calculați pentru fiecare document video.
Evaluare performanței metricilor
Anumite măsuri de calcul a distanței dintre doi descriptori sunt mai bine adaptate decât
altele la structura trăsăturii. În acest capitol am testat performanța pe care o înregistrează
diferite metrici pentru diferiți descriptori multimedia. Am plecat de la premiza că o
performanță inițială va genera o performanță ulterioară mai bună pentru algoritmii de
relevance feedback. Vom testa o gamă largă de metrici: euclidiană (L2), Manhattan (L1)
(cazuri particulare de distanțe Minkovski), divergențe probabilistice: Canberra [23],
distanța cosinus, Chi-Square (utilizată cu succes în algoritmi de machine learning) și
distanța Mahalanobis [23]. Performanțele sunt prezentate în Tabelul 7.4.
În urma acestui experiment am concluzionat că fiecare trăsătură are metoda sa
preferată. În următoarele experimente vom folosi pentru fiecare trăsătură metrica cu care
va obține cea mai bună acuratețe (valori îngroșate în tabel).
Tab. 7.4 Performanța sistemului fără relevance feedback, utilizând diferite metrici
(valori MAP).
Trăsătură Manhatan Euclidiană Mahalanobis Cosinus Bray
Curtis
Chi
Square
Canberra
HOG CN 17,02% 17,18 17,07% 17,00% 17,10% 17,07% 16,67
Trăsături de
structură
10,87% 10,55% 11,14% 2,18% 10,92% 11,58% 14,82%
MPEG 7 12,37% 10,85% 21,14% 08,69% 13,34% 13,34% 25,97%
Audio
Standard
7,76% 7,78% 29,26% 15,28% 7,78% 8,04% 1,58%
Audio pe bază
de blocuri
19,33% 19,58% 20,21% 21,23% 19,71% 19,99% 20,37%
Text 8,32% 7,15% 5,39% 17,64% 20,40% 9,83% 9,68%
Ajustare parametrilor modelului Fisher Kernel
În acest experiment vom testa înfluiența asupra acurateții sistemului a parametrilor
utilizați în cadrul mecanismului de Fisher kernel.
Primul parametru analizat este înfluiența de centroizi GMM. În Figura 7.20 este
prezentată variația MAP utilizând un număr redus de centroizi GMM. Se poate observa
că cele mai bune rezultate se obțin folosind un singur cluster pentru modelul GMM. În
acest caz dimensiunea vectorului descriptor va fi de două ori mai mare decât a trăsăturii
inițiale.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
155
Fig. 7.20 Performanța algoritmului FKRF la variația numărului de centroizi GMM
(valori MAP)
Al doilea experiment prezintă influența strategiei de normalizare utilizate. În [99]
s-a demonstrat că o strategie de normalizare inteligent selectată poate imbunatăți drastic
performanța sistemului. Rezultatele sunt prezentate în Tabelul 7.5. Se poate observa că,
combinația normalizare cu normalizare pătratică îmbunătățește perfomanța pentru
descriptorii vizuali și audio, în timp ce normalizarea logaritmică îmbunătățește
performanțele pentru trăsăturile extrase din text. O observație interesantă este faptul că
normalizarea și au performanțe mai scăzute decât Fisher kernel fără normalizare.
Acestea aduc un plus de performanță numai daca sunt combinate cu alte
normalizări. În următoarele secțiuni vom folosi următoarele setări pentru algoritmul de
Fisher Kernels: un centroid GMM, normalizare și pătratică pentru descriptori vizuali și
audio, și normalizare logaritmică pentru trăsăturile de text. Pentru clasficare vom folosi
două tipuri de SVM – liniar și RBF.
Tab. 7.5 Performanța sistemului utilizând diferite tehnici de normalizare (valori
MAP).
Normalizare Descriptori
Vizuali Audio Text
Fără normalizare 37.25% 38.68% 31.13%
L1 36.82% 37.97% 29.83%
L2 39.22% 41.94% 30.51%
Normalzare logaritmică 38.61% 42.01% 35.07%
Normalizare pătratică 38.51% 41.37% 34.93%
Normalizare pătratică + L1 39.20% 42.98% 30.12%
Normalizare pătratică + L2 39.46% 43.23% 31.71%

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
156
Comparația FKRF cu state-of-the-art
În această secțiune vom compara algoritmul propus cu alți algoritmi propuși în literatură
ca de exemplu: Rocchio [139], algoritmul de extimare a relevanței (RFE) [143], Support
Vector Machines (SVM) [150], AdaBoost (BOOST) [193], Random Forests (RF) [193] și
Nearest Neighbor [196]. Figura 7.21 prezintă curbele precizie reamintire pentru diferite
categorii de descriptori. Ca și observație generală, toate motodele de relevance feedback
îmbunătățesc performanța de retrieval în comparație cu performanța sistemului în care nu
se utilizează feedback. Performanțe mai bune sunt obținute cu descriptorii de audio, în
timp de textul și descriptorii vizuali au o performanță similară. Cea mai bună performanță
se obține cu descriptorii standard audio, o creștere a preciziei de la 29,35% (fără RF) la
46.34% și cu toți descriptorii combinați de la 30,29% la 45,80%. Tabelul 7.6 prezintă
valorile MAP pentru diferite combinări de trăsături.
Tab. 7.6 Comparație acuratețe cu alți algoritmi de relevance feedback (valori MAP).
Trăsătură Fără
RF
Rocchio NB Boost SVM RF RFE FK
Liniar
FK RBF
HoG 17,18% 25,57% 24,18% 26,72% 26,49% 26,89% 27,50% 29,46% 29.59%
Trăsături de
structură
14,82% 21,96% 23,73% 23,63% 24,62% 24,69% 23,91% 26,28% 23,96%
MPEG 7 25,97% 30,88% 34,09% 32,55% 32,90% 36,85% 31,93% 40,50% 40,80%
All Visual 26,11% 32,76% 34,15% 35,76% 35,88% 39,08% 32,43% 38,01% 38,23 %
Standard audio 29,26% 32,71% 34,88% 32,88% 38,58% 40,46% 44,32% 44,80% 46,34%
Block Based 21,23% 35,39% 35,22% 39,87% 31,46% 33,41% 31,96% 43,96% 43,69%
Text 20,40% 32,55% 26,91% 26,93% 34,70% 34,70% 25,82% 34,84% 35,14%
Toate trăsăturile
concatenate
30,29% 37,91% 39,88% 38,88% 40,93% 45,31% 44,93% 45,43% 45,80%
Fig. 7.21 Grafice precizie-reamintire pentru metoda propusă și algoritmi state-
of-the-art

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
157
Algoritmul FKRF obține cele mai bune rezultate pentru marea majoritate a
cazurilor, cu excepția combinației de descriptori vizuali, acolo unde algoritmul cu arbori
aleatorii are cea mai bună performanță. Cea mai mare diferență de performanță se obține
folosind descriptorii MPEG 7 – mai bine de 4 procente (de la 40,80% cu FKRF RBF la
36,85% cu random forests) și pentru descriptori pe bază de blocuri audio (de la 43,96%
cu FK RF liniar la 39,87% cu RF Boost). Pe de altă parte, cea mai scăzută diferență în
performanță este obținută pentru toți descriptorii concatenați (de la 45,80% folosind
FKRF RBF la 45,31% utilizând random forests).
În cele mai multe din cazuri RFE și RF obțin rezultate foarte bune, însă nu atât de
bune decât algoritmul propus. Metoda noastră obține rezultate superioare faţă de toţi
ceilalţi algoritmi clasici de relevance feedback, ca de exemplu: Rocchio, RFE, SVM,
Random Trees etc.
Reprezentarea Fisher Kernel cu GMM global
O altă metodă de antrenare GMM este de a reprezenta și antrena GMM pe toată
baza de date. În acest fel, metoda ar deveni mult mai rapidă deoarece nu ar mai trebui să
antrenăm modelul GMM pentru fiecare interogare în parte. O întrebare care poate fi pusă
în acest sens este dacă obținem rezultate bune deoarece reprezentarea Fisher kernel este
mai puternică decât descriptorii utilizați inițial, sau creșterea de performanță este cauzată
de alterarea trăsăturilor față de primele n rezultate returnate. În acest caz putem testa dacă
Fisher kernel este cel îmbunătățește performanța descriptorilor și nu combinația de
relevance feedback cu FK.
În acest test vom antrena un model GMM inițial pe toate trăsăturile pentru toate
documentele din baza de date. Deci, vom obține în acest fel un model GMM global care
va fi folosit pentru fiecare interogare în parte. În continuare vom folosi această
configurație pentru a o compara cu metoda RF propusă.
Rezultatele sunt prezentate în tabelul următor. Se poate observa că performanța
scade mai mult de patru procente pentru descriptorii vizuali şi 8 procente pentru
descriptorii audio. În acest caz deducem că alterarea datelor pe baza feedback-ului primit
este crucial pentru obținerea de rezultate bune. Acest lucru demonstrează că Fisher kernel
aduce un aport important pentru problema specifică de relevance feedback.
Tab. 7.7 Comparație acuratețe între FKRF clasic și FKRF cu GMM global (valori MAP).
Trăsături FKRF cu GMM global FKRF clasic
Vizuale 34,02% 38,23%
Audio 38,25% 46,34%
Text 32,37% 35,14%

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
158
Utilizarea informației temporale în FKRF
În această secțiune vom prezenta îmbunătățirea performanței algoritmului FKRF atunci
când utilizăm mai mult decât un vector descriptor pentru un document video. Deoarece
acestea reprezintă experimente preliminare, vom folosi doar două tipuri de trăsături
vizuale: descriptori HOG și descriptori MPEG 7, care obțin rezultatele cele mai bune
pentru trăsăturile vizuale. Pentru acest experiment vom extrage un număr redus de
imagini reprezentative pentru fiecare document video în parte, iar apoi calculăm vectorul
descriptor pentru fiecare imagine extrasă în parte. Deoarece acum avem mai multe date
de antrenare, modelul GMM va fi mult mai complex. Această afirmație este susținută de
Figura 7.22 în care este prezentată variația MAP pentru un număr diferit de centroizi
GMM. Se poate observa că cele mai bune rezultate se obțin folosind de la 6 la 10
centroizi pe GMM.
În final, Tabelul 7.8 prezintă o comparație intre model FKRF clasic și modelul
FKRF temporal. Se poate observa că în acest caz obținem o creștere de performanță mai
mare de trei procente MAP (de la 29,59% la 32,87% pentru trăsăturile HoG și de la
40,80% la 45,43% pentru descriptorii MPEG 7). Se poate observa în acest caz că
utilizând doar informație vizuală obținem aceleași rezulate ca în cazul în care combinăm
toți descriptorii.
Fig. 7.22 Performanța algoritmului FKRF temporal la variația numărului de centroizi
GMM (valori MAP)
Tab. 7.8 Comparație acuratețe dintre FKRF clasic și FKRF temporal (valori MAP).
Trăsătură FKRF Liniar
(T=1)
FKRF RBF
(T=1)
FKRF Temporal
Liniar
FKRF Temporal
RBF
Trăsături HOG 29,46% 29,59% 32,12% 32,87%
Descriptori MPEG 7 40,50% 40,80% 44,69% 45,43%

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
159
7.4 Concluzii
În acest capitol am discutat diverse metode propuse de relevance feedback.
Inițial, am prezentat un algoritm de relevance feedback inspirat din algoritmii de
relevance feedback de schimbare a punctului de interogare și de estimare a importanței
trăsăturilor. Testarea a fost efectuată pe două baze de date clasice (o bază de date de
textură și una de imagini naturale), utilizând o gamă variată de metrici și descriptori.
Algoritmul propus obține rezultate superioare față de algoritmi de relevance feedback
clasici, performanța sistemului fiind îmbunătățită cu peste 8% (valoare MAP).
În următoarea secțiune au fost expuse două subiecte principale: influența
metricilor asupra performanței unui sistem de căutare de imagini după conținut și am
propus un nou algoritm de relevance feedback inspirat de clasificarea ierarhică. Testarea
a fost efectuată pe două baze de date clasice (Caltech 101 și Microsoft), utilizând o gamă
variată de metrici și descriptori. Algoritmul propus obține rezultate superioare față de
algoritmi de relevance feedback clasici, performanța sistemului fiind îmbunătățită cu
peste 23% (valoare MAP). De asemenea, am demonstrat că alegerea unei metrici
potrivite poate fi decisivă pentru acuratețea sistemului. Distanțe ca Canberra și
Bhattacharyya s-au dovedit a obține rezultate bune pentru descriptori clasici (ca de
exemplu MPEG 7 sau descriptori de culoare), în timp ce metrici ca Tanimoto obțin
rezultate superioare pe descriptori de tip Bag of Words. În următoarea secțiune am aplicat
acest algoritm și în contextul problemei de indexare a documentelor video. Algoritmul
propus a obținut rezultate îmbunătățite față de majoritatea algoritmilor RF state-of-the-
art.
În finalul capitolului, am propus o nouă metodă de relevance feedback utilizând
reprezentarea Fisher kernel. Experimentul a fost efectuat în contextul aplicării tehnicilor
de relevance feedback pe bazele de date multimedia, iar noi am propus o metodă care
combină modelele generative cu cele descriminative, pentru problema de relevance
feedback. Testată pe o bază de date mare (MediaEval 2012), și utilizând o serie de
descriptori care reprezintă state-of-the-art (vizuali, audio și text), metoda noastră FKRF
îmbunătățește performanța rezultatelor, surclasând alte metode existente ca: Rocchio,
Nearest Neighbors RF, Boost RF, SVM RF, Random Forest RF și RFE.
De asemenea, am prezentat o metodă de a captura înformația temporală utilizând
Fisher Kernel, astfel încât să folosim mai mult de un vector descriptor pentru un
document video. Experimentele efectuate pe trăsături vizuale au arătat că performanța
este drastic îmbunătățită de la 40,80% la 45,83% pentru MPEG 7 și de la 29,59% la
32,87% pentru trăsăturile HOG. De asemeni, am arătat ca nu este necesar un număr
ridicat de centroizi GMM pentru a antrena metoda, aceasta obținând rezultate bune cu
numai 5-10 centroizi. Acest lucru face ca metoda să poată fi implementabilă în timp real.
Principala direcție de dezvoltare în viitor o va reprezenta aplicarea metodei pe
baze de date mai mari, pentru a crește diversitatea conceptelor antrenate. Mai mult, dorim

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
160
extinderea metodei Fisher kernel temporale către alte modalități, ca de exemplu text și
audio, sau a trăsăturilor mai elaborate ca cele spațio-temporale.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
161
Capitolul 8
Particularizarea conceptelor pentru
diferite probleme de aplicație
În cadrul acestui capitol voi prezenta diferiți algoritmi și soluții pentru anumite probleme
de interes de clasificare multimedia. În prima parte voi înfățișa metode și studii efectuate
pe două baze de date medicale. O primă bază conține imagini medicale otoscopice, iar
algoritmul propus este un sistem utilizat în detecția otitei la copii. A doua bază de date
conține o diversitate de tipuri de celule canceroase sangvine canine, pentru care vom
efectua un studiu comparativ asupra mai multor descriptori și clasificatori state-of-the-art.
O parte din experimentele prezentate au fost publicate în cadrul a trei conferințe cotate
ISI: „E-Health and Bioengineering Conference” (EHB) [200] care a avut loc la Iași în
noiembrie 2011, Signals, Circuits and Systems (ISSCS) desfășurată tot la Iași în iulie
2011 [201] și Communications 2010 – București [202], cât și în cadrul primului raport de
cercetare: „Sisteme de Căutare a Imaginilor după Conținut” [203].
În cadrul celei de-a doua părți voi propune un set de metode și sisteme pentru
indexarea conținutului video pentru diferite aplicații. O primă problemă este detecția
categoriei din care face parte un film. Inițial, un sistem de clasificare a genului a fost
propus în cadrul competiției MediaEval 2012 Video Genre Retrieval Task [204]. În
cadrul acestei competiții am fost membru al echipei ARF (Austrian Romanian France
team) cu care am obținut locul 2 (din 29 de sisteme propuse), locul 1 fiind obținut de
către echipa organizatoare. Apoi, sistemul a fost extins și am propus o nouă abordare
multimodală a problemei, pe care o voi prezenta în acest capitol. Aceste rezultate
experimentale au fost publicate în cadrul conferințelor Content-Based Multimedia
Indexing - CBMI 2013 desfășurată la Veszprém, Ungaria [128] și Symposium on Signals,
Circuits and Systems (ISSCS) 2013, Iași, România [205]. Rezultatele obținute sunt cu
mult superioare celor raportate în cadrul competiției. A doua aplicație propusă este
detecția secțiunilor violente în filmele de la Hollywood. O primă variantă a sistemului a
fost propusă în cadrul workshop-ului MediaEval 2012, competiția „Affect Task”. În
cadrul acestei competiții am fost membru al echipei ARF (Austrian Romanian France
Team) cu care am obținut locul 1 (din 35 de sisteme propuse) [206]. O variantă extinsă a
algoritmului a fost propusă în cadrul conferinței internaționale ICMR [118], desfășurată
la Dallas, 2013 (al treilea autor). În finalul capitolului voi prezenta o metodă de

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
162
clasificare a gesturilor (al doilea autor), aceasta fiind publicată în cadrul conferinței
Symposium on Signals, Circuits and Systems (ISSCS) 2013, Iași, România [207].
8.1 Catalogarea imaginilor ORL
Otoscopia reprezintă metoda de examinare a canalului auditiv extern și a timpanului cu
ajutorul otoscopului. Deși metodele de diagnosticare și preluare de imagini medicale au
evoluat, otoscopia rămâne piatra de temelie a diagnosticării afecțiunilor urechii. Pentru a
putea diagnostica corect afecțiunile urechii, fiecare otolaringolog sau pediatru trebuie să
aibă cunoștințe de otoscopie. Cu ajutorul acestuia medicul poate vedea direct aspectul
timpanului dacă acesta este iritat și bombat din cauza presiunii lichidului infectat. Cea
mai întâlnită afecțiune a urechii este otita medie. Aceasta reprezintă o infecție a urechii
medii, în zona din spatele timpanului. Infecția apare atunci când canalul lui Eustachio,
care conectează urechea medie cu nasul, se blochează cu fluid, aceasta cauzând presiune
și implicit durere. Copii între 6 și 36 de luni au o predispoziție mai mare față de infecții,
însă de cele mai multe ori este dificilă o diagnosticare corectă.
Pentru o diagnosticare cât mai corectă, medicul trebuie să examineze cât mai atent
membrana timpanului, însă acest lucru este problematic în cazul copiilor foarte mici,
deoarece este aproape imposibilă cercetarea amănunțită a urechii. Din acest motiv se
încearcă o diagnosticare automată prin utilizarea unei simple poze, prin această metodă
reușind chiar să elimine un operator uman specializat. Metode de diagnosticare automată
sunt utilizate de mulți ani în domenii ca dermatologie sau radiologie, însă în domeniul
otoscopic există un număr restrâns de studii. Principalul scop al studiului este designul
complet al unui sistem expert de achiziție a imaginilor otoscopice și diagnosticare
automată a pacienților (în special copii).
8.1.1 Metoda propusă
Pentru a descrie imaginea otoscopică, au fost propuși diverși algoritmi de descriere a
culorii, însă până în prezent rezultatele nu au fost promițătoare. O primă analiză a culorii
imaginilor otoscopice a fost propusă în [208]. Însă pentru a îmbunătăți performanțele
unui sistem de detecție a otitei este nevoie să fie luate în considerare informații extrase
din mai multe canale, cum ar fi textura și punctele de interes. Dar pentru a combina mai
multe surse de informație trebuie dezvoltate strategii de fuziune adecvate. În general,
avem două strategii de fuziune: „early fusion” și „late fusion” (mai multe detalii în
Capitolul 2.5). Aceste strategii se bazează pe ipoteza că o decizie agregată a mai multor
clasificatori și descriptori este superioară unei decizii bazate pe un singur expert. Dacă o
strategie de early fusion combină descriptorii înainte de clasificare, algoritmul de late
fusion combină scorurile de relevanță a clasificatorilor după procesul de categorisire.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
163
Pentru a combina informația fiecărei trăsături am hotărât să utilizăm o strategie de
late fusion deoarece aceasta prezintă mai multe beneficii: (1) este mai puțin costisitor din
punct de vedere computațional deoarece descriptorii utilizați pentru fiecare descriptor în
parte sunt mai mici decât atunci când utilizăm un descriptor concatenat și (2) late fusion
se modelează și scalează mai ușor deoarece nu este nevoie de o reantrenare a sistemului
de fiecare dată când o trăsătură nouă este adăugată în algoritm.
Schema sistemului popus este prezentată în Figura 8.1. Primul pas este cel de
evaluare și selecție a unui set de trăsături care descriu cât mai eficient informația de
culoare, textură și puncte de interes. Apoi, se vor selecta clasificatorii potriviți pentru
fiecare descriptor extras. În final, deciziile clasificatorilor se vor combina prin utilizarea
unei strategii de late fusion.
Fig. 8.1 Schema algoritmului propus pentru clasificarea imaginilor otoscopice
8.1.2 Descrierea Experimentului
În cadrul experimentelor s-a utilizat o bază de date de imagini otoscopice preluată de
către o echipa de medici pediatrii în timpul investigațiilor medicale: 111 de imagini cu
cazuri normale Figura 8.2 linia 1) și 75 de imagini cu cazuri de otită (Figura 8.2 linia 2).
Imaginile au rezoluția de 768 pe 576 pixeli, iar fiecare poză prezintă o componentă de
fundal negru în formă circulară.
Fig. 8.2 Exemple de imagini otoscopice utilizate în experimente: prima linie conține
exemple de imagini fără otită, iar linia a doua prezintă inflamații ale urechii medii
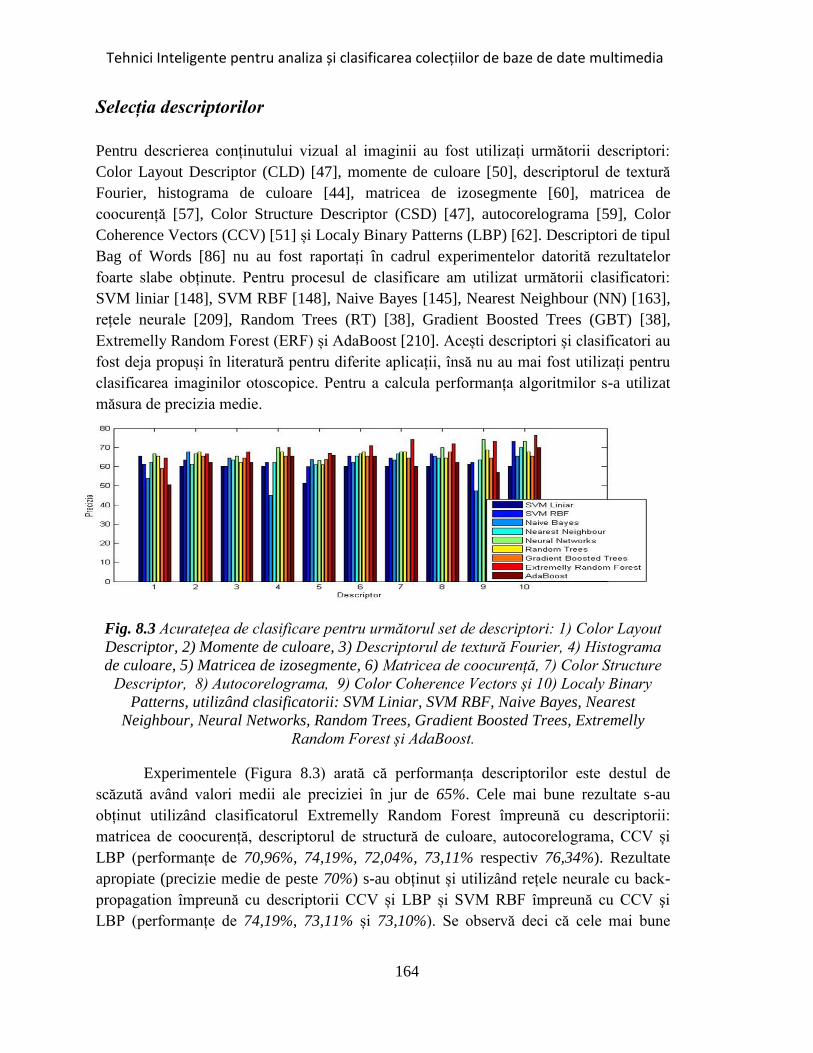
Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
164
Selecția descriptorilor
Pentru descrierea conținutului vizual al imaginii au fost utilizați următorii descriptori:
Color Layout Descriptor (CLD) [47], momente de culoare [50], descriptorul de textură
Fourier, histograma de culoare [44], matricea de izosegmente [60], matricea de
coocurență [57], Color Structure Descriptor (CSD) [47], autocorelograma [59], Color
Coherence Vectors (CCV) [51] și Localy Binary Patterns (LBP) [62]. Descriptori de tipul
Bag of Words [86] nu au fost raportați în cadrul experimentelor datorită rezultatelor
foarte slabe obținute. Pentru procesul de clasificare am utilizat următorii clasificatori:
SVM liniar [148], SVM RBF [148], Naive Bayes [145], Nearest Neighbour (NN) [163],
rețele neurale [209], Random Trees (RT) [38], Gradient Boosted Trees (GBT) [38],
Extremelly Random Forest (ERF) și AdaBoost [210]. Acești descriptori și clasificatori au
fost deja propuși în literatură pentru diferite aplicații, însă nu au mai fost utilizați pentru
clasificarea imaginilor otoscopice. Pentru a calcula performanța algoritmilor s-a utilizat
măsura de precizia medie.
Fig. 8.3 Acuratețea de clasificare pentru următorul set de descriptori: 1) Color Layout
Descriptor, 2) Momente de culoare, 3) Descriptorul de textură Fourier, 4) Histograma
de culoare, 5) Matricea de izosegmente, 6) Matricea de coocurență, 7) Color Structure
Descriptor, 8) Autocorelograma, 9) Color Coherence Vectors și 10) Localy Binary
Patterns, utilizând clasificatorii: SVM Liniar, SVM RBF, Naive Bayes, Nearest
Neighbour, Neural Networks, Random Trees, Gradient Boosted Trees, Extremelly
Random Forest și AdaBoost.
Experimentele (Figura 8.3) arată că performanța descriptorilor este destul de
scăzută având valori medii ale preciziei în jur de 65%. Cele mai bune rezultate s-au
obținut utilizând clasificatorul Extremelly Random Forest împreună cu descriptorii:
matricea de coocurență, descriptorul de structură de culoare, autocorelograma, CCV și
LBP (performanțe de 70,96%, 74,19%, 72,04%, 73,11% respectiv 76,34%). Rezultate
apropiate (precizie medie de peste 70%) s-au obținut și utilizând rețele neurale cu back-
propagation împreună cu descriptorii CCV și LBP și SVM RBF împreună cu CCV şi
LBP (performanțe de 74,19%, 73,11% și 73,10%). Se observă deci că cele mai bune

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
165
perfomanțe se obțin atunci când în combinația clasificator - descriptor apare Extremelly
Random Forest sau LBP.
Cele mai slabe rezultate se obțin cu descriptorii: CLD și matricea de izosegmente
împreună cu clasificatorii AdaBoost, random forests, Naïve Bayes și SVM liniar.
Combinarea descriptorilor cu Late Fusion
Totuși, un rezultat de 76,34% este mult sub așteptări, așa ca vom încerca să îmbunătățim
performanța sistemului prin utilizarea de tehnici de fuzionare. Metodele de fuzionare se
bazează pe principiul că o decizie agregată din partea mai multor sisteme expert poate
avea o performanță superioară față de cea oferită de un singur sistem. Vom testa patru
tehnici de late fusion și anume fuziunea prin vot egal (CombSum), fuziunea prin vot
ponderat CombMean, CombMNZ și fuziune prin rang (CombRank). Pentru procesul de
vot am selectat primele șapte perechi descriptor – clasificator din punct de vedere a
performanței obținute.
Rezultatele experimentelor sunt prezentate în Figura 8.4. În primul rând se poate
observa că performanțele obținute cu o strategie late fusion sunt superioare fiecărui
descriptor individual.
Fig. 8.4 Precizia medie pentru metodele de fuzionare:1)performanța maximă obținută
fără late fusion 2) fuzionare prin utilizarea rangului 3) fuzionare prin vot egal 4)
fuzionare prin vot ponderat și 5) fuzionare CombMNZ.
Fuzionarea CombMNZ prezintă performanța cea mai ridicată, și anume 84,2%,
însă rezultate bune se obțin și cu strategiile clasice CombMean (83,11%), CombSum
(82,45%) și CombRank (80,95%).
În Tabelul 8.1 sunt prezentate cele mai bune rezultate obținute cu și fără algoritmi
de fuziune. De asemenea, este prezentat și un alt rezultat raportat pe aceeași bază de date
[208]. Se poate observa că metoda propusă obține un rezultat mai bun cu 14% mai bun
decât acesta, ceea ce reprezintă o îmbunătățire considerabilă.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
166
Tab. 8.1 Comparație cu State-of-the-Art (precizie).
Metode Acuratețe
Metoda propusă (Late Fusion CombMNZ) 84,2%
Metoda propusă (LBP și ERF) - fără late fusion 76,34%
Vertan și alții [208] 68.25%
8.1.3 Concluzii
În cadrul acestui experiment am abordat problema analizei și clasificării imaginilor
otoscopice. Analiza și diagnosticarea automată de imagini ORL reprezintă un domeniu
care nu a mai fost studiat, această secțiune propunându-și să instituie un punct de plecare
pentru cercetări ulterioare. Astfel, am studiat atât contribuția unui set extins de trăsături
de culoare, textură și puncte de interes, cât și rolul unui mecanism de fuziune în creșterea
performanțelor de clasificare. Studiul a fost efectuat pe un scenariu real, o bază de date cu
imagini otoscopice, adunată de către un colectiv de medici ORL de la Spitalul Universitar
București. Utilizarea strategiei de late fusion a dus la o îmbunătățire cu mai mult de 8
procente față de setul clasic de descriptori propuși, în timp ce performanța obținută este
cu 14% mai ridicată decât cea raportată în literatură. În viitor, îmi propun să extind baza
de date medicală și să testez o gamă mai largă de descriptori medicali. De asemenea, îmi
propun să dezvolt noi algoritmi vizuali care să obțină rezultate îmbunătățite.
8.2 Catalogarea imaginilor microscopice
8.2.1 Descrierea Experimentului
Al doilea experiment își propune să ofere un studiu comparativ asupra performanței
diverșilor algoritmi pentru detecția și clasificarea de imagini medicale. Experimentul a
fost realizat pe o bază de imagini cu celule sanguine care conține un număr de 31 de clase
(10 imagini per clasă). Toate imaginile conțin imagini celulare preluate de un microscop
de înaltă rezoluție și colorate cu metoda May-Grünwald-Giemsa. Imaginile reprezintă
celule canceroase preluate de la câini. Fiecare clasă a fost obținută prin decuparea
aleatorie a unei părți dintr-o imagine principală. Exemple de imagini din baza de date
sunt prezentate în Figura 8.5.
În cadrul experimentelor am comparat performanța unei game largi de algoritmi
clasici: (a) de descriere a culorii: descriptorii MPEG 7 Color Structure Descriptor (CSD)
și Color Layer Descriptor [47], momente de culoare [50], histograma de culoare [44],
Color Coherence Vectors (CCV) [51], (b), de textură: autocorelograma [59], Localy
Binary Paterns (LBP) [62] și (c) Bag of Words [86] utilizând descriptorii Scale Invariant
Feature Transform (SIFT) [75] și Speeded Up Robust Feature (SURF) [78].

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
167
Fig. 8.5 Exemple de imagini medicale utilizate în experiment:(1) prima linie conține
exemple de imagini celulare din clase diferite și (2) a doua linie prezintă un exemplu de
imagini aparținând aceleiași clase
Pentru testarea performanţei descriptorilor, vom testa sistemul din două
perspective diferite. O primă perspectivă va fi aceea de a interoga sistemul utilizând
principiul de „query by example”. Al doilea experiment va fi unul de clasificare. Vom
compara performanța descriptorilor utilizând diferiți algoritmi de clasificare.
8.2.2 Experiment de căutare
Pentru a compara performanța descriptorilor am utilizat graficele precizie-reamintire.
Acestea sunt prezentate în Figura 8.6.
Algoritmii Bag of Words (SURF și SIFT), alături de autocorelogramă au cele mai
bune performanțe: 77,62%, 77,02% și 78,01%. Rezultate mai mici, dar apropiate, au fost
obținute și cu descriptorii CCV și Color Structure Descriptor (74,53% și 73,63%). Cele
mai slabe rezultate au fost obținute cu momentele de culoare, EHD și descriptorul MPEG
7 – Color Layout (sub 50%).
Descriptorii Bag Of Words au cea mai mare complexitate de calcul dintre toți
descriptorii utilizați. De asemenea, ei au și cea mai mare lungime (am utilizat un dicționar
de 300 de puncte cheie). Autocorelograma are o viteză de calcul mult mai scăzută decât
SIFT și SURF, însă lungimea este similară cu cea folosită în Bag of Words. CCV și Color
Structure Descriptor au complexități de calcul similare cu ale autocorelogramei, lungimea
acestora fiind mult redusă față de descriptorii anteriori (96, respectiv 48 de valori).
Principalul dezavantaj al acestora este însă reprezentat de performanța cu 5 procente mai
scăzută.
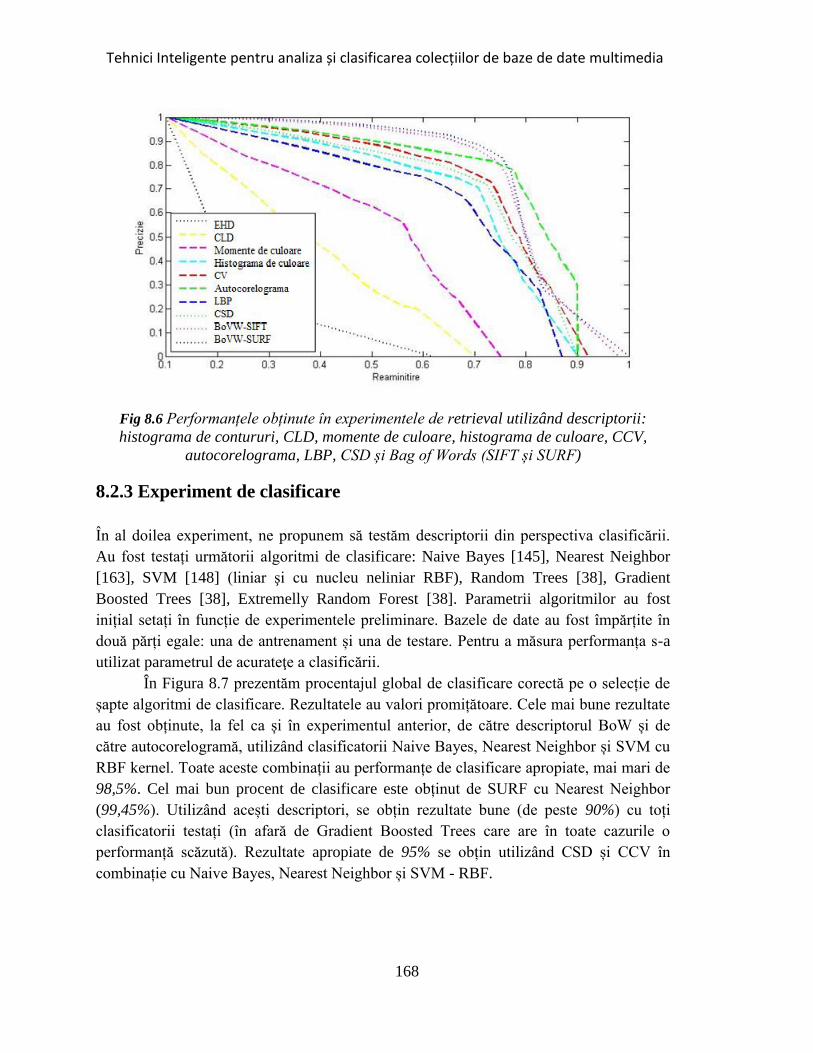
Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
168
Fig 8.6 Performanțele obținute în experimentele de retrieval utilizând descriptorii:
histograma de contururi, CLD, momente de culoare, histograma de culoare, CCV,
autocorelograma, LBP, CSD și Bag of Words (SIFT și SURF)
8.2.3 Experiment de clasificare
În al doilea experiment, ne propunem să testăm descriptorii din perspectiva clasificării.
Au fost testați următorii algoritmi de clasificare: Naive Bayes [145], Nearest Neighbor
[163], SVM [148] (liniar şi cu nucleu neliniar RBF), Random Trees [38], Gradient
Boosted Trees [38], Extremelly Random Forest [38]. Parametrii algoritmilor au fost
inițial setați în funcție de experimentele preliminare. Bazele de date au fost împărțite în
două părți egale: una de antrenament și una de testare. Pentru a măsura performanța s-a
utilizat parametrul de acurateţe a clasificării.
În Figura 8.7 prezentăm procentajul global de clasificare corectă pe o selecție de
șapte algoritmi de clasificare. Rezultatele au valori promițătoare. Cele mai bune rezultate
au fost obținute, la fel ca și în experimentul anterior, de către descriptorul BoW și de
către autocorelogramă, utilizând clasificatorii Naive Bayes, Nearest Neighbor și SVM cu
RBF kernel. Toate aceste combinații au performanțe de clasificare apropiate, mai mari de
98,5%. Cel mai bun procent de clasificare este obținut de SURF cu Nearest Neighbor
(99,45%). Utilizând acești descriptori, se obțin rezultate bune (de peste 90%) cu toți
clasificatorii testați (în afară de Gradient Boosted Trees care are în toate cazurile o
performanță scăzută). Rezultate apropiate de 95% se obțin utilizând CSD și CCV în
combinație cu Naive Bayes, Nearest Neighbor și SVM - RBF.
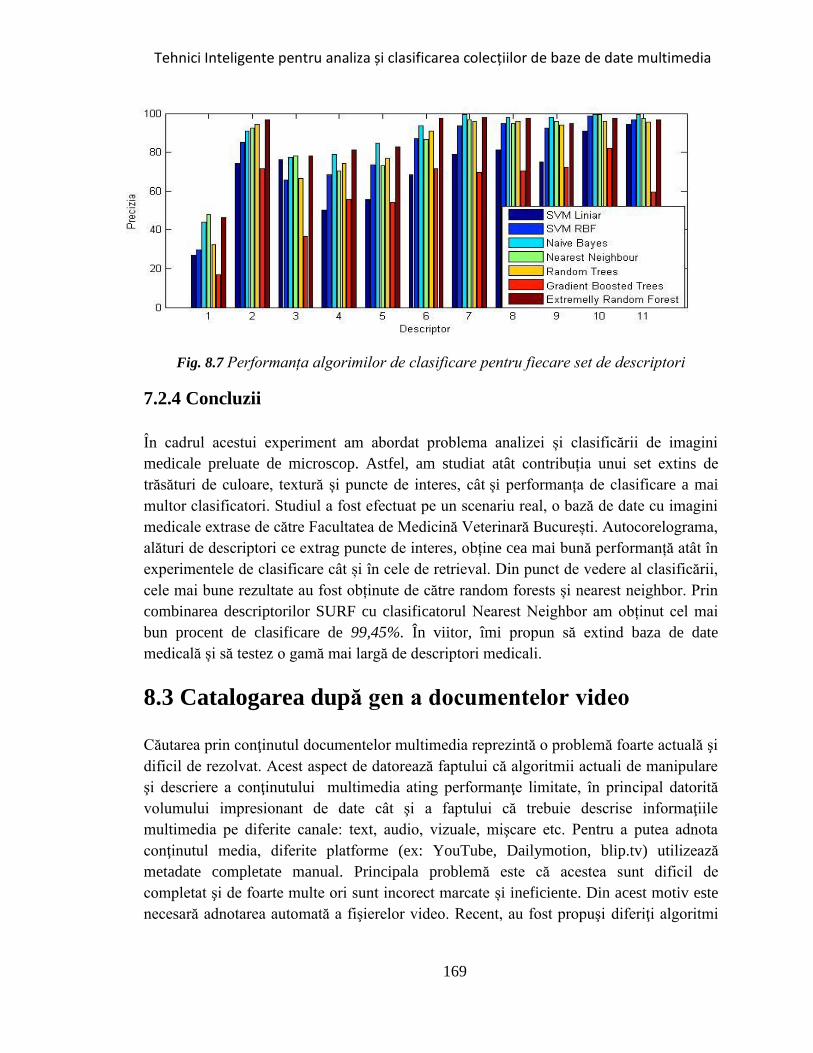
Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
169
Fig. 8.7 Performanța algorimilor de clasificare pentru fiecare set de descriptori
7.2.4 Concluzii
În cadrul acestui experiment am abordat problema analizei și clasificării de imagini
medicale preluate de microscop. Astfel, am studiat atât contribuția unui set extins de
trăsături de culoare, textură și puncte de interes, cât și performanța de clasificare a mai
multor clasificatori. Studiul a fost efectuat pe un scenariu real, o bază de date cu imagini
medicale extrase de către Facultatea de Medicină Veterinară București. Autocorelograma,
alături de descriptori ce extrag puncte de interes, obține cea mai bună performanță atât în
experimentele de clasificare cât și în cele de retrieval. Din punct de vedere al clasificării,
cele mai bune rezultate au fost obținute de către random forests și nearest neighbor. Prin
combinarea descriptorilor SURF cu clasificatorul Nearest Neighbor am obținut cel mai
bun procent de clasificare de 99,45%. În viitor, îmi propun să extind baza de date
medicală și să testez o gamă mai largă de descriptori medicali.
8.3 Catalogarea după gen a documentelor video
Căutarea prin conţinutul documentelor multimedia reprezintă o problemă foarte actuală şi
dificil de rezolvat. Acest aspect de datorează faptului că algoritmii actuali de manipulare
şi descriere a conţinutului multimedia ating performanţe limitate, în principal datorită
volumului impresionant de date cât şi a faptului că trebuie descrise informaţiile
multimedia pe diferite canale: text, audio, vizuale, mişcare etc. Pentru a putea adnota
conţinutul media, diferite platforme (ex: YouTube, Dailymotion, blip.tv) utilizează
metadate completate manual. Principala problemă este că acestea sunt dificil de
completat şi de foarte multe ori sunt incorect marcate și ineficiente. Din acest motiv este
necesară adnotarea automată a fişierelor video. Recent, au fost propuşi diferiţi algoritmi

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
170
pentru adnotarea automată a conţinutului multimedia şi adnotarea documentelor
multimedia cu anumite genuri.
Algoritmii de învățare au fost utilizați în mod intensiv pentru a rezolva diferite
scenarii pentru categorisirea conținutului multimedia, deoarece aceștia sunt capabili să
manipuleze volume impresionante de date, ca de exemplu: trăsături cu lungimi variate și
sute de mii de documente utilizate în procesul de învățare. Cu toate acestea, cele mai
multe metode prezentate în literatură sunt limitate la un număr redus de categorii, cum ar
fi determinarea unor genuri clasice TV (ex: comedie, dramă, desene animate, sport). În
prezent, cele mai bune performanțe sunt determinate de metodele multimodale care
exploatează beneficiile fuzionării mai multor modalități: text, vizual și audio.
În cele mai multe probleme de categorisire, utilizarea de informații textuale
(metadate, taguri și comentarii adăugate de utilizatori, subtitrări) oferă cele mai bune
performanțe. Însă principalul dezavantaj al acestora este că nu poate fi generat automat,
ceea ce limitează mult aria lor de aplicabilitate. Informația textuală poate fi extrasă în
mod automat, atât din textul ce apare în scene (bannere, titluri, adrese), cât și prin
extragerea subtitrărilor utilizând metode automate de extragere a textului (ASR). Însă
documentele video pot conține diferite limbi sau zgomot de fundal, ceea ce face ca
tehnicile de recunoaștere automată să fie foarte ineficiente. Un alt canal de informație
intens studiat este cel audio. Informația audio poate fi prelucrată atât în domeniul
frecvență cât și în domeniul timp. Metode comune utilizate pentru descrierea conținutului
multimedia sunt rădăcina pătrată medie a energiei semnalului, Zero-Crosing Rate și
coeficienții Mel-Frequency Cepstral [175]. Pe de altă parte, informația vizuală
exploatează atât aspectele dinamice cât și pe cele statice, utilizând informația de culoare,
structură temporară, obiecte, puncte de interes și mișcare. Unele dintre cele mai eficiente
metode de descriere a conținutului vizual sunt reprezentate de BoVW [86], Space-Time-
Interest-Points (STIP) [105], histograme de gradienți orientați (HOG) [71], 3D-SIFT
[75], însă multe dintre acestea sunt costisitoare din punct de vedere computațional
deoarece presupun crearea de dicționare de cuvinte vizuale.
Detecția automată a genului a fost studiat intensiv în literatură în ultimii zece ani
[120]. Cea mai multă muncă s-a concentrat pe categorisirea de genuri pentru seriale TV
[211] sau pentru documente video online [212].
Metodele existente exploatează atât o singură sursă de informație cât și mai multe
canale, prin integrarea mai multor modalități. De exemplu, metoda propusă în [213]
utilizează doar informația textuală. Astfel, este propusă o metodă SVM care ia decizii în
funcție de diferite surse de informație de pe internet, ca de exemplu descrierea existentă
pe Wikipedia. Apoi sunt combinate aceste informații cu informațiile sociale, precum
metadatele, comentariile, comportamentul utilizatorilor și scorul de relevanță al filmului.
Pe de altă parte, un sistem de clasificare a genului care utilizează doar informația vizuală
este prezentat în [214]. În cadrul acestei metode, pentru descrierea conținutului vizual,
sunt utilizați o serie de algoritmi BoVW precum Opponent SIFT [75], care apoi sunt

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
171
clasificați cu ajutorul unui model probabilistic. În [211] este prezentat un prim model
multimodal, care utilizează atât text cât și informația vizuală. O detecție a genului este
inițial efectuată prin clasificarea unor descriptori textuali (metadate, titlu, nume utilizator,
comentarii), ca apoi informația vizuală să fie utilizată pentru detecția unor subgenuri.
Însă, un sistem multimodal trebuie să încapsuleze și informația audio. În [215] este
combinată informația vizuală (descriptori MPEG 7 și descriptori de mișcare HOF) cu
descriptori audio. Apoi, filmele sunt clasificate cu ajutorul unui model Gaussian Mixture
Model (GMM).
Însă cele mai multe metode prezentate anterior sunt limitate la un număr redus de
genuri. Recent, competiția Genre Tagging Task din cadrul MediaEval 2012 [197] a
instituit o nouă perspectivă pentru sistemele de clasificare de gen, propunând atât o bază
de date publică de dimensiuni mari (15.000 de documente video), cât și posibilitatea de
de a utiliza metode multimodale. Aceasta a propus un scenariu din lumea reală, în care
filmele provin de pe o platformă online11
, iar categoriile existente cuprind o gamă largă:
de la documentare la talkshow-uri și videoblogging.
8.3.1 Metodă propusă
În acest capitol îmi propun să efectuez un studiu amănunțit a metodelor și tehnicilor
existente pentru categorisirea genului. Voi investiga diferite seturi de descriptori pentru
descrierea conținutului vizual, audio și text cât și diferite tehnici de fuzionare a acestor
canale. De asemenea, voi încerca să răspund la anumite întrebări: (1) pot descriptorii
vizuali și audio să atingă performanțe similare cu ale metadatelor? (2) cât de eficiente
sunt metodele de fuzionare și care strategie este mai eficientă? și (3) care este contribuția
fiecărui canal de informație la performanța globală a sistemului. Toate experimentele vor
fi efectuate pe baza de date MediaEval 2012, în contextul competiției de Genre Tagging
Task.
Deși metodele propuse au fost mai mult sau mai puțin explorate anterior în
literatură, principalele contribuții ale acestui capitol sunt: (1) am efectuat o analiză în
profunzime a unui set multimodal de descriptori, în contextul unui scenariu real de
detecție de gen, (2) am demonstrat potențialul pe care îl are o strategie adecvată de late-
fusion pentru a atinge o performanță foarte bună, (3) am demonstrat că, deși descriptorii
de metadate sunt superiori, descriptorii multimodali în combinație cu late fusion pot
atinge performanțe similare, (4) am instituit un nou punct de plecare pentru baza de date
MediaEval, obținând rezultate superioare celor raportate în cadrul competiției și (5)
evaluarea s-a efectuat pe o bază de date standard făcând ca rezultatele să poată fi
relevante și reproductibile.
Schema sistemului popus este prezentată în Figura 8.8. Primul pas este cel de
evaluare și selecție a unui set de trăsături care descriu cât mai eficient informația vizuală,
11
blip.tv

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
172
audio și textuală. Apoi, se vor selecta clasificatorii potriviți pentru fiecare descriptor
extras. În final, deciziile clasificatorilor se vor combina prin utilizarea unei strategii
adecvate de fuziune.
Fig. 8.8 Schema sistemului propus pentru clasificarea genului documentelor video web
8.3.2 Descriptori multimodali
Este un lucru ştiut că diferite canale de informaţie multimedia (text, audio, informaţii
vizuale) conţin informaţii cu o putere complementară discriminativă. Pentru acest
experiment au fost utilizate toate sursele de informaţie disponibile: de la conţinutul vizual
şi audio pînă la descriptorii cu un nivel ridicat semantic cum ar fi informaţia extrasă din
text (prin utilizarea de algoritmi de recunoaştere a vorbirii) sau metadatele completate de
către utilizatori (titlul, descrierea conţinutului, comentarii etc).
Informaţia audio. Anumite genuri de filme conţin o semnătură audio specifică. Spre
exemplu, documentarele utilizează un amestec de sunete naturale şi monologuri,
videoclip-urile conţin diferite genuri de muzică (ex: rock, jazz etc), sporturile au în
componență mult zgomot şi monologuri, în timp ce talk-show-urile cuprind dialoguri
între diverse persoane. Pentru a descrie aceste aspecte, am dezvoltat un set de descriptori
audio standard care au furnizat rezultate bune în problemele de categorisire a genurilor
muzicale. Descriptorii audio utilizaţi au lungimea de 196 de valori şi conţin un set
general de descriptori audio [175]: Linear Predictive Coefficients, Line Spectral Pairs,

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
173
MFCC, Zero-Crossing Rate, spectral centroid, flux, rolloff și kurtosis, toţi aceşti
descriptori fiind ponderaţi cu varianţa pe fiecare trăsătură pe o anumită fereastră (de
obicei o lungime comun utilizată este de 1,28 s).
Informaţia vizuală. Din punct de vedere a informaţiei vizuale, distribuţia de culoare şi a
diverselor obiecte pun în evidenţă diferite genuri. De exemplu, videoclip-urile şi
reclamele conţin culori mai închise şi o paletă largă de efecte vizuale, sporturile au în
componenţă diferite nuanţe specifice, buletinele de ştiri conţin o frecvenţă ridicată de
persoane, anumite genuri conţin obiecte specifice sau informaţie de context specific.
Pentru a captura aceste particularităţi, am dezvoltat o serie de descriptori clasici de
descriere a imaginilor:
- descriptori globali înrudiţi MPEG-7 (1.007 valori): descriu informaţia globală de
culoare şi textură. Am selectat următorul set de descriptori care: Local Binary Pattern
(LBP), autocorelograma, Color Coherence Vector (CCV), ColorLayout Pattern (CLP),
Edge Histogram (EHD), Scalable Color Descriptor (SCD), histograma color clasică HSV
şi momente de culoare. Pentru fiecare secvenţă am agregat descriptorii prin calculul
mediei, varianţei, skewness, kurtosis, medianului şi a rădăcinii pătrate medii pe toate
frame-urile.
- descriptori structurali (1.430 valori): descriu informaţia de contur (atributele
geometrice ale acestora) şi relaţiile dintre acestea. În acest scop, am utilizat metoda
propusă în [198].
- histograme globale de gradienţi orientaţi (HoG 81 valori) [71]: reprezintă o medie
globală a descriptorilor HoG calculaţi pe fiecare frame în parte. Aceştia descriu forma
obiectelor dintr-o imagine prin utilizarea distribuţiei de orientări de muchii.
- Bag Of Visual-Words (HoG 20.480 valori) [86] am calculat un model Bag of Visual-
Words pe o selecţie de keyframe-uri. Pentru acest task am extras un dicţionar de 4096
cuvinte vizuale. Cuvintele vizuale sunt extrase prin folosirea unei strategii de eşantionare
dense şi prin folosirea descriptorilor rgbSIFT. Pentru a calcula acest descriptor am utilizat
metoda propusă în [216].
Informaţia textuală. Textul reprezintă cea mai reprezentativă informaţie pentru
clasificarea după gen. Doar un set restrâns de anumite cuvinte cheie specific (ex: religie,
economie, muzică) generează informaţii foarte importante din punct de vedere al genului
documentului. De exemplu, metadata de obicei conţine informaţii ca titlul sau descrierea
documentului, care sunt foarte corelate cu conceptele de gen. Pentru descrierea genului,
am adaptat o abordare clasică, și anume metoda Term Frequency-InverseDocument
Frequency (TF-IDF). Textul extras din documentul video poate proveni din două canale
diferite: convorbirile care pot fi extrase cu ajutorul algoritmilor de recunoaştere automată
a vorbirii (Automatic Speech Recognition - ASR) şi metadatele completate de către
utilizatori. Pentru fiecare dintre cele două canale am generat un descriptor TD-IDF: TD-
IDF pentru ASR (3466 valori) şi TD-IDF pentru metadate (504 valori).
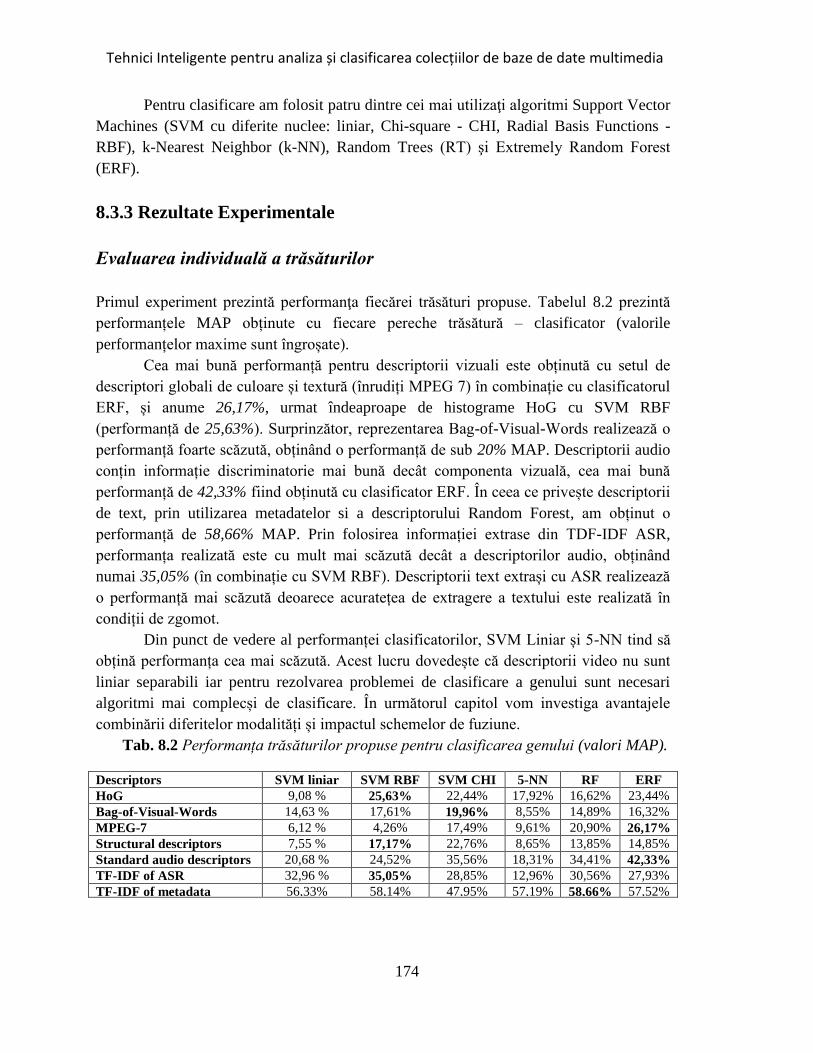
Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
174
Pentru clasificare am folosit patru dintre cei mai utilizaţi algoritmi Support Vector
Machines (SVM cu diferite nuclee: liniar, Chi-square - CHI, Radial Basis Functions -
RBF), k-Nearest Neighbor (k-NN), Random Trees (RT) şi Extremely Random Forest
(ERF).
8.3.3 Rezultate Experimentale
Evaluarea individuală a trăsăturilor
Primul experiment prezintă performanţa fiecărei trăsături propuse. Tabelul 8.2 prezintă
performanțele MAP obținute cu fiecare pereche trăsătură – clasificator (valorile
performanțelor maxime sunt îngroșate).
Cea mai bună performanță pentru descriptorii vizuali este obținută cu setul de
descriptori globali de culoare și textură (înrudiți MPEG 7) în combinație cu clasificatorul
ERF, și anume 26,17%, urmat îndeaproape de histograme HoG cu SVM RBF
(performanță de 25,63%). Surprinzător, reprezentarea Bag-of-Visual-Words realizează o
performanță foarte scăzută, obținând o performanță de sub 20% MAP. Descriptorii audio
conțin informație discriminatorie mai bună decât componenta vizuală, cea mai bună
performanță de 42,33% fiind obținută cu clasificator ERF. În ceea ce privește descriptorii
de text, prin utilizarea metadatelor si a descriptorului Random Forest, am obținut o
performanță de 58,66% MAP. Prin folosirea informației extrase din TDF-IDF ASR,
performanța realizată este cu mult mai scăzută decât a descriptorilor audio, obținând
numai 35,05% (în combinație cu SVM RBF). Descriptorii text extrași cu ASR realizează
o performanță mai scăzută deoarece acuratețea de extragere a textului este realizată în
condiții de zgomot.
Din punct de vedere al performanței clasificatorilor, SVM Liniar și 5-NN tind să
obțină performanța cea mai scăzută. Acest lucru dovedește că descriptorii video nu sunt
liniar separabili iar pentru rezolvarea problemei de clasificare a genului sunt necesari
algoritmi mai complecși de clasificare. În următorul capitol vom investiga avantajele
combinării diferitelor modalități și impactul schemelor de fuziune.
Tab. 8.2 Performanța trăsăturilor propuse pentru clasificarea genului (valori MAP).
Descriptors SVM liniar SVM RBF SVM CHI 5-NN RF ERF
HoG 9,08 % 25,63% 22,44% 17,92% 16,62% 23,44%
Bag-of-Visual-Words 14,63 % 17,61% 19,96% 8,55% 14,89% 16,32%
MPEG-7 6,12 % 4,26% 17,49% 9,61% 20,90% 26,17%
Structural descriptors 7,55 % 17,17% 22,76% 8,65% 13,85% 14,85%
Standard audio descriptors 20,68 % 24,52% 35,56% 18,31% 34,41% 42,33%
TF-IDF of ASR 32,96 % 35,05% 28,85% 12,96% 30,56% 27,93%
TF-IDF of metadata 56,33%
58,14% 47,95% 57,19% 58,66% 57,52%

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
175
Performanța realizată prin fuziunea trăsăturilor
Tehnicile de fuziune exploatează informația complementară din diferite surse de
informații. În acest experiment, noi evaluăm performanța obținută cu diferite modalități
de fuzionare a informației: early fusion (simpla concatenare a descriptorilor) și late fusion
(CombSum, CombMean, CombRank și CombMNZ). Pentru late fusion, ponderile
corespunzătoare fiecărei strategii de fuzionare au fost inițial optimizate pe baza de
antrenare. Acest lucru a fost realizat pentru a se evita overfitting-ul. Performanțele
strategiilor de fuzionare sunt prezentate în Tabelul 8.3 (perfomanțele maxime au valori
îngroșate).
În toate cazurile late fusion obține performanțe mai bune decât early fusion.
Numai pentru descriptorii vizuali, diferența de performanță depășește 8% (cea mai ridică
performanță este obținută cu CombSum – 38,21% MAP). În schimb, creșterea de
performanță a descriptorilor audio este mai redusă (CombMNZ cu 44,5% MAP). Acest
lucru se datorează faptului că fuzionăm un singur descriptor cu mai mulți clasificatori iar
în acest caz nu avem surse distincte de informație complementară. Cu toate acestea,
descriptorii audio mențin o performanță superioară față de informația vizuală.
O îmbunătățire substanțială este obținută cu descriptorii text. Cea mai bună
performanță a fost obținută cu CombMean, și anume 62,81%, ceea ce reprezintă o
diferență de performanță de peste 7% față de early fusion. În ceea ce privește metodele de
late fusion, ComRank tinde să obțină cele mai slabe rezultate în toate combinațiile, în
timp ce celelalte strategii obțin valori similare. Prin urmare, late fusion se dovedește a fi o
alegere mai bună decât early fusion. În primul rând, late fusion realizează o performanță
superioară. În al doilea rând, late fusion este mai rapid decât early fusion deoarece
descriptorii utilizați pentru fiecare clasificator sunt mai scurți decât concatenarea tuturor
descriptorilor. Mai mult, sistemul integrează mult mai ușor noi clasificatori deoarece nu
este necesară reantrenarea tuturor clasificatorilor.
Tab. 8.3 Performanța obținută cu diferite strategii de fuziune (valori MAP).
Descriptori CombSum CombMean CombMNZ CombRank Early Fusion
Vizuali 35,82% 36,76% 38,21% 30,90% 30,11%
Audio 43,86% 44,19% 44,50% 41,81% 42,33%
Text 62,62% 62,81% 62,69% 50,60% 55,68%
Toți descriptorii 64,24% 65,61% 65,82% 53,84% 60,12%
Comparație cu MediaEval 2012
În această parte, vom compara performanța algoritmilor de late fusion cu alte rezultate
obținute pe baza MediaEval 2012. În acest sens, vom lua ca referință cele mai bune
rezultate raportate la concursul MediaEval 2012. Rezultatele sunt prezentate în Tabelul
8.4 în ordinea descrescătoare a performanței (trebuie notat că rezultatele obținute la

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
176
MediaEval 2012 au fost realizate sub anumite constrângeri de timp și fără a cunoaște
categoria documentelor din baza de test).
În cadrul competiției, descriptorii textuali (metadate și ASR) au obținut cea mai
ridicată performanță și anume 52,25% (echipa TUB [217]). Aceștia au propus un sistem
unimodal care incorporează trăsături textuale, ce cuprind atât metadate cât și ASR.
Însă, rezultatele obținute de către descriptorii textuali propuși sunt mult mai
ridicate. Astfel, am obținut 58,66% cu descriptorii de metadate. În ciuda ratei mari de
clasificare, late fusion îmbunătățește semnificativ performanța descriptorilor, spre
exemplu CombMean aplicat pe ASR și metadate obține performanța de 62,81%, care
reprezintă o diferență de performanță de peste 10% procente față de echipa TUB [217] și
peste 25% decât RAF [119].
În ceea ce privește descriptorii vizuali, cel mai bun rezultat este obținut de echipa
KIT [218]. Aceștia au propus un set de descriptori clasici de culoare și textură
(histograma de culoare HSV, momente de culoare L*a*b*, autocorelograma, matricea de
coocurență, descriptori de textură wavelet și histograme de contur), acestea fiind
combinate cu Bag-of-Visual-Words (rgbSIFT). În ciuda performanțelor ridicate realizate
pentru probleme de clasificare de imagini, descriptorul Bag-of-Visual-Words a obținut
rate de detectiție scăzute (23,29% MAP cu rgbSIFT și 23,01% MAP cu SURF-PCA),
asemănătoare cu cele obținute de metoda BoW utilizată în secțiunea anterioară. Prin
utilizarea descriptorilor vizuali propuși și combinarea acestora cu late fusion, am obținut
o performanță cu trei procente mai ridicată (MAP 38,21%) decât cel mai bun sistem cu
trăsături vizuale raportat la MediaEval 2012.
Prin utilizarea doar a informației audio, rezultatele sunt promițătoare. Astfel, am
obținut un rezultat remarcabil de 44,5% MAP, în condițiile în care cel mai bun rezultat
obținut în cadrul competiției a fost de numai 18,92% (echipa RAF), ceea ce reprezintă o
îmbunătățire cu mai bine de 25% MAP.
Combinând toți descriptorii am obținut cea mai mare rată de clasificare de
65,82%, ceea ce reprezintă o îmbunățire a performanței cu peste 13 procente față de cea
mai bună performanță de la MediaEval 2012.
Așa cum am arătat, metadatele obțin cea mai ridicată performanță. Totuși, trebuie
reținut că aceste informații sunt generate manual de către utilizator și nu pot fi generate în
mod automat, ceea ce limitează utilizarea lor pentru sisteme multimedia. Prin utilizarea
unor tututor descriptorilor, mai puțin metadate, obținem o performanță de 51,9%, ceea ce
reprezintă o performanță foarte ridicată, similară cu cea mai ridicată performanță din
concurs. Deci, prin utilizarea descriptorilor ce pot fi extrași în mod automat putem obține
rezultate apropiate cu cele ale metadatelor, iar prin combinația acestora performanța este
drastic îmbunătățită (în cazul nostru cu mai mult de 8 procente).

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
177
Tab. 8.4 Comparație cu algoritmii raportați în State-of-The-Art (valori MAP).
Echipă Descriptori Descriere metodă MAP
Propusă Vizuali &
Audio & Text
Late Fusion CombMNZ cu toți descriptorii 65,82%
Propusă Text Late Fusion CombMean cu TF-IDF aplicat pentru ASR și
metadate
62,81%
TUB [217] Text Naive Bayes cu Bag of Words aplicat pe text (ASR & metadata) 52,25%
Propusă Vizuali &
Audio & Text
Late Fusion CombMNZ pe toți descriptorii mai puțin metadata 51,9%
Propusă Audio Late Fusion CombMean cu descriptorii audio 44,50%
Propusă Text Late Fusion CombMean cu descriptorii MPEG-7, de structură,
HoG și B-o-VW cu rgbSIFT
38,21%
ARF [119] Text SVM liniar cu early fusion și TF-IDF aplicate pe ASR și metadate 37,93%
TUD [219] Vizual &
Text
Fusion Dynamic Bayesian networks cu BoW (cuvinte vizuale,
ASR & metadata)
36,75%
KIT [218] Vizual SVM cu descriptori vizuali (culoare, textură, BoVW cu rgbSIFT) 35,81%
TUD-MM
[220]
Text SVM with Latent Dirichlet Allocation on text (ASR & metadata) 25,00%
UNICAMP
[221]
Vizual Late fusion (KNN, Naive Bayes, SVM, Random Forests) cu BOW
(ASR)
21,12%
ARF [119] Vizual SVM liniat cu trăsături audio 18,92%
8.3.4 Concluzii
În cadrul acestei secțiuni am prezentat diferite metode pentru rezolvarea problemei de
clasificare automată a conținutului video. În acest sens, am studiat contribuția diferitelor
trăsături și influența unui algoritmilor de fuziune. Studiul a fost efectuat pe un scenariu
real, și anume concursul MediaEval 2012, proba de detecție de gen. Performanța maximă
atinsă este de 65,8%, ceea ce reprezintă o îmbunătățire cu mai mult de 13 procente față de
prima poziție. De asemenea, am demonstrat că în ciuda superiorității metadatelor,
descriptorii automați pot atinge performanțe asemănătoare.
8.4 Catalogarea conținutului de violență în filme
Accesarea conținutului multimedia a devenit o ocupație de rutină. Dezvoltarea
internetului, a rețelelor sociale și a platformelor multimedia online (BlipTv, Youtube), a
dus la o explozie a conținutului multimedia pe o mulțime de terminale (telefoane, tablete,
notebook-uri). În prezent, distribuția de documente multimedia reprezintă categoria cea
mai importantă pe internet, ocupând peste 25% din totalul de trafic. În acest context, una
dintre cele mai importante direcții de cercetare este filtrarea automată a conținutului
video. Obiectivul este acela de a selecta și distribui numai conținut adecvat categoriei de
utilizatori care accesează materialul multimedia. Un caz particular de filtrare a
informației este detecția conținutului violent. Definirea termenului de violență nu
reprezintă o problemă facilă, deoarece noțiunea reprezintă un concept subiectiv [222].

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
178
Definiţia violenţei poate însemna „acţiuni sau cuvinte cu intenţia de a răni persoane” sau
„violenţă fizică sau accidental care are ca rezultat rănirea sau suferinţa provocată unei
persoane”, însă din punct de vedere al analizei violenţei în filme aceasta poate fi definită
şi prin prezenţa unor indicatori audio-vizuali, ca de exemplu acţiunea sau muzica cu ritm
alert.
Problema de detecție a violenței este una complexă deoarece apar probleme atât
cu definirea conceptului cât și cu realizarea de descriptori cu o putere discriminatorie
ridicată. Metoda propusă îşi propune să abordeze detecţia violenţei în contextul filmelor
de la Hollywood. Aceasta se bazează pe o metodă de fuziune a conceptelor de nivel
mediu prin utilizarea unor reţele neurale multi-layer perceptron.
Cele mai multe metode propuse la MediaEval Violence Detection Task s-au
concentrat pe dezvoltarea de trăsături care descriu cât mai bine conceptul de violență.
Deoarece majoritatea trăsăturilor prezentate descriu concepte de nivel scăzut, intervine
paradigma semantică [10], iar sistemele propuse au de cele mai multe ori o performanță
scăzută. În schimb, metoda propusă în [206] [118], utilizează un nou tip de arhitectură,
care inițial estimează conceptele de nivel mediu și apoi le utilizează în detecția
conceptelor de nivel înalt (în cazul nostru violența). Prin predicția inițială a conceptelor
de nivel mediu și abia apoi a termenului de violență ar trebui obținute performanțe
superioare cazului în care încercăm să detectăm direct conceptele de nivel ridicat. În
cadrul acestui algoritm, contribuția mea a costat în selecția și calculul trăsăturilor vizuale
utilizate, restul contribuțiilor aparținând celorlaltor autori.
8.4.1 Metoda propusă
Algoritmul propus în [118] [206], prezintă mai mulți pași. Inițial, trăsăturile sunt extrase
la nivel de frame, iar apoi acestea sunt utilizate ca date de intrare pentru un prim nivel de
clasificatori. Apoi, fiecare clasificator din acest prim nivel va estima conceptele de nivel
mediu. Fiecare scor, al unui clasificator din primul nivel va fi folosit pentru estimarea
gradului de violență. În cele ce urmează vom detalia fiecare nivel în parte. Pentru
antrenarea sistemului vom folosi etichetarea conceptelor la două nivele: conceptele care
sunt de obicei prezente în scenele violente: ca de exemplu exploziile, prezența armelor de
foc și a acțiunii și etichetele care arată că un segment este sau nu violent. O diagramă a
metodei propuse este prezentată în Figura 8.9.
Metoda propusă se evidențiază față de metodele prezentate în State-of-the-Art
prin următoarele aspecte:
- am testat sistemul propus pe un scenariu complex, în care violența implică atât
înjurături cât și durere
- datorită fuziunii predicțiilor conceptelor de nivel mediu, metoda este independentă de
trăsături, în sensul că nu sunt necesari descriptori adaptați.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
179
- violența este detectată la nivel de frame ceea ce facilitează detecția violenței în
secțiuni de lungime variată
- evaluarea este efectuată pe o bază de date standard, ceea ce face ca rezultatele să fie
atât relevante cât și reproductibile.
Fig. 8.9 Schema sistemului propus pentru detecția violenței în documentele video
8.4.2 Detecția de concepte
Pentru a antrena sistemul am utilizat două tipuri de etichete: cele care sunt asociate
conceptelor ce presupun prezența scenelor violente (ca de exemplu prezența focului de
armă, a exploziilor și a incendiilor) și cele care conțin prezența sau absența gradului de
violență (violent/nonviolent). Pentru antrenare am utilizat datele puse la dispoziție de
organizatorii MediaEval Affective Task [222]. Detecția conceptelor de nivel mediu se
obține prin utilizarea unui set de clasificatori care sunt antrenați pentru a clasifica primul
set de concepte asociate violenței. Pentru antrenarea acestor descriptori am efectuat mai
multe seturi de cros-validări pe baza de date de antrenare, și am utilizat parametri care
oferă performanța maximă.
Pentru a selecta clasificatorul care realizează cele mai bune performațe, am testat
o serie de clasificatori cunoscuți: SVM, arbori de decizie și rețele neurale. Cele mai multe
dintre ele au eșuat în a asigura rezultate relevante. Arhitectura rețelelor neurale s-a
potrivit cel mai bine acestor cerințe, în particular prin utilizarea unei arhitecturi multi-
layer cu perceptroni. Prin urmare, pentru a clasifica conceptele de violență am utilizat o
arhitectură cu un singur strat ascuns și cu 512 perceptroni (funcții sigmoid). Rețeaua a
fost antrenată cu algoritmul „gradient descent” și „backpropagation” [209], utilizând

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
180
ideea prezentată în [223] pentru a îmbunătăți performanța. Pentru fiecare set de antrenare,
o fracțiune din perceptronii din stratul de intrare și cel ascuns sunt lăsați la o parte.
Această arhitectură poartă numele de „dropped-out”. Setul de unități lăsate la o parte sunt
alese în mod aleatoriu pentru fiecare frame de antrenare, astfel că o gamă mare de variații
vor fi antrenate doar într-o singură epocă. Acest lucru ajută procesul de generalizare prin
următoarele aspecte: prin omiterea unui număr aleatoriu de unități, rețeaua nu se va putea
adapta unei combinații specifice. Însă, prin omiterea doar a unei fracțiuni, modelul care
trebuie clasificat și antrenat va fi recunoscut cu ușurință. Spre exemplu, scrisul de mână
este recunoscut chiar daca anumite litere sunt lipsă. Rețeaua cu dropped-out va lua în
considerare doar anumite corelații între trăsături, ceea ce va conduce la o antrenare doar a
trăsăturilor care sunt mai robuste. În [223] s-a demonstrat că rețeaua cu „drop-out”
prezintă un grad de generalizare mai ridicat, obținând rezultate superioare pe un număr
ridicat de probleme. Astfel, deoarece aceste rețele neurale nu au probleme de
„overfitting”, este eliminată nevoia de utilizare a unei baze de validare pentru optimizarea
parametrilor.
8.4.3 Rezultate experimentale
Experimentele au fost efectuate în cadrul competiției MediaEval, proba de „Affect Task:
Violent Scenes Detection”. A fost propusă o bază de date de antrenare compusă din 15
filme : „Armageddon”, „Billy Elliot”, „Eragon”, „Harry Potter 5”, „I am Legend”,
„Leon”, „Midnight Express”, „Pirates of the Caribbean 1”, „Reservoir Dogs”, „Saving
Private Ryan”, „The Sixth Sense”, „The Wicker Man”, „Kill Bill 1”, ”The Bourne
Identity”, și „The Wizard of Oz” (cu o durată totală de 27 ore și 58 min, 26.108 frame-uri
video, cu o durată a violenței de 9,39% din volumul total); baza de test alcătuită din trei
filme: „Dead Poets Society”, „Fight Club” și „Independence Day” (o durată totală de 6
ore 44 minute și 6.570 cadre, conținutul violent reprezentând 4,92% din totalul
materialului video). Întreaga bază de date conține 1.819 segmente violente. Gradul de
violență este marcat la două nivele: pentru fiecare frame este marcată prezența/absența
conceptelor de nivel mediu, corelate cu violența: prezența sângelui, a armelor albe, a
armelor de foc, înjunghierii, focurilor de armă, țipetelor, urmăririlor de mașini,
exploziilor, luptelor și a focului, dar și la nivel de segment, prin marcarea segmentelor ca
fiind violente sau non-violente. Toate aceste marcaje au fost creeate de o echipă de 9
oameni.
Descriptori video
Pentru descrierea conținutului video am utilizat o serie de descriptori care au obținut
rezultate bune în diverse scenarii de clasificare audio și video. Având în vedere

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
181
specificitatea problemei, vom extrage informații atât de culoare, audio cât și despre
structura temporală:
- descriptori audio [175]: am utilizat un set general de descriptori audio, și anume:
Linear Predictive Coefficients (LPC), Line Spectral Pairs (LSP), MFCC, Zero-
Crossing Rate (ZCR), spectral centroid, rolloff și kurtosis, toate acestea fiind
ponderate cu o fereastră de 0,8. Lungimea descriptorului este de 96 parametri.
- descriptori de culoare [48]: pentru descrierea culorii am utilizat histograma Color
Naming (11 culori), cu o lungime de 11 trăsături
- trăsături de formă HOG [71]: imaginea a fost împărțită în 3x3 regiuni, iar pentru
fiecare regiune se calculează 9 orientări.
- structura temporală (o singură trăsătură) calculează gradul de activiate vizuală. Am
utilizat un detector de cut [224] care măsoară gradul de discontinuitate dintre 2
histograme de culoare consecutive. Pentru a lua în considerare orice schimbare de
acțiune, am setat o valoare redusă care ia în considerare schimbările importante de
acțiune. Un nivel ridicat de acțiune va putea fi corelat și cu conceptual de violență.
Pentru antrenarea sistemului am folosit baza de date de 15 filme. Procesul de
antrenare și testare a fost efectuat prin utilizarea tehnicii de cross-validare (antrenare
succesivă cu 14 filme și evaluare cu filmul rămas).
Rezultate MediaEval 2012
În acest experiment va fi prezentat o comparație între metoda propusă și algoritmii
prezentați în cadrul competiției MediaEval 2012, proba de Affect Task: Violent Scenes
Detection [222]. În cadrul acestei probe, participanții au utilizat baza de 15 filme pentru
antrenare, în timp ce testarea a fost efectuată pe un set de 3 filme: „Dead Poets Society”
(34 scene violente), „Fight Club” (310 scene violente) și „Independence Day” (371 scene
cu violență) - un total de 715 scene violente (marcajele pentru baza de test au fost facute
publice după competiție). Un număr total de 8 echipe participante au propus 36 de
metode. Evaluarea a fost făcută atât la nivel de frame cât și la nivel de segment video.
Rezultatele sunt prezentate în Tabelul 8.6 (în ordine descrescătoare a performanței). Prin
utilizarea a două nivele de clasificatori (pentru concepte și violență), am obținut cea mai
ridicată performanță, cu mai mult 6% decât a doua echipă clasată (echipa
ShanghaiHongkong [225]), care a obținut un scor de 43,73%. Cea mai scăzută
performanță obținută de către metoda noastră a fost de 35,65%, prin utilizarea numai a
descriptorilor vizuali. Însă, prin utilizarea doar a descriptorilor audio, performanța
obținută este de 46,27%, ceea ce este mai mare cu 11 procente. Prin combinarea celor
două trăsături (early fusion) se obține un rezultat de 44,58% (vezi ARF-(av)), în timp ce
prin combinarea acestora cu setul de probabilități a conceptelor se obține o performanță
de 42,44% (vezi ARF-(avc)). O altă observație este că metoda propusă oferă o
performanță superioară în fața unor metode mai elaborate ca SIFT, BoAW de MFCC sau

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
182
trăsături de mișcare. De asemenea, utilizarea doar a scorurilor conceptelor oferă o
performanță semnificativ mai mare decât utilizarea trăsăturilor individuale audio-vizuale.
Următorul experiment prezintă esperimentele la nivel de segment. Segmentele
video sunt marcate ca „violente” și „non-violente”. Prin utilizarea conceptelor de nivel
mediu am obținut o precizie și reamintire de 42,21%, respectiv 40,38%, în timp ce scorul
este de 41,27%. Acest lucru conduce la o rată de eroare de 50,69%, în timp ce rata
alarmelor false este foarte mică, de numai 6%. Aceste rezultate sunt foarte promițătoare
având în vedere dificultatea problemei, cât și a subiectivității umane asupra conceptului
de violență.
Tab. 8.6 Comparație cu rezultatele obținute la compeția MediaEval 2012
Echipă Trăsături Canale Metodă Precizie Reamintire Scor
ARF-(c) concepte audio-
vizual
propusă 46.14% 54.40% 49.94%
ARF-(a) audio audio propusă 46.97% 45.59% 46.27%
ARF-(av) audio, color, HoG,
descriptori temporali
audio-
vizual
propusă 32.81% 67.69% 44.58%
Shanghai
Hongkong
[225]
traiectorii, SIFT, STIP,
MFCC
audio-
vizual
Netezire temporală+
SVM cu nucleu
41.43% 46.29% 43.73%
ARF-(avc) Descriptori audio, de
culoare, HoG,
temporali și concepte
audio-
vizual
propusă 31.24% 66.15% 42.44%
TEC [226] TF-IDF B-o-AW [16],
descriptori de culoare
audio-
vizual
Fuzionare: SVM
HIK & Bayes
Net. & Naive Bayes
31.46% 55.52% 40.16%
TUM [227] energie și spectru
audio
audio SVM liniar 40.39% 32.00% 35.73%
ARF-(v) color, HoG, temporal vizual propusă 25.04% 61.95% 35.67%
LIG [228]
color, texture, SIFT,
B-o-AW, MFCC
audio-
vizual
Fuziune ierarhică
SVM & k-NN și
feedback conceptual
26.31% 42.09% 32.38%
TUB [229] B-o-AW MFCC,
Descriptori de mișcare
audio-
vizual
SVM RBF 19.00% 62.65% 29.71%
DYNI [230] MS-LBP vizual SVM liniar 15.55% 63.07% 24.95%
NII [231]
Concepte învățate din
textură și culoare
vizual SVM RBF 11.40% 89.93% 20.24%
Notații: SIFT - Scale Invariant Features Transform, STIP - Spatial-Temporal Interest Points, MFCC - Mel-
Frequency CepstralCoefficients, SVM - Support Vector Machines, TF-IDF - Term Frequency-Inverse
Document Frequency, B-o-AW - Bag-of-Audio-Words, HIK - Histogram Intersection Kernel, k-NN - k
Nearest Neighbors, RBF - Radial Basis Function, MS-LBP - Multi-ScaleLocal Binary Pattern.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
183
8.4.3 Concluzii
În acest capitol am prezentat o abordare naivă pentru problema detecției violenței în
filmele de la Hollywood. În loc să fie utilizați descriptori care să învețe și să detecteze în
mod direct violența, așa cum fac de altfel cele mai multe sisteme, a fost prezentată o
metodă care utilizează un pas intermediar care constă în predicția conceptelor de nivel
mediu. Predicția conceptelor corelate cu violența reprezintă o problemă mai ușor de
implementat, decât detecția directă a gradului de violență. Clasificarea a fost efectuată cu
o arhitectură paralelă multiperceptron, care se potrivește foarte bine atunci când avem de
detectat un volum mare de cadre. Mai mult, eficiența detectării segmentelor cu conținut
violent este remarcabilă. Această metodă s-a clasat pe locul 1 în cadrul competiției
MediaEval 2012, proba de Affect Task. Totuși, metoda prezintă o limitare, și anume,
pentru antrenare este nevoie de adnotarea detaliată a conceptelor violente, ceea ce poate
conduce la erori din cauza subiectivității umane.
8.5 Catalogarea pozițiilor statice ale mâinii
În cadrul acestei secţiuni voi aborda problema recunoaşterii de poziții statice şi voi
propune, alături de autorul principal, o metodă simplă bazată pe modelul Hidden Markov
Models, care utilizează trăsături extrase din conturul mâinii [232].
Recunoaşterea de gesturi reprezintă un domeniu intens studiat în computer vision
(interpretare de gesturi ale feţei, mâinilor sau ale corpului). Aceste metode îşi propun să
deducă comportamentul uman prin analiza mişcărilor diferitelor părţi componente ale
corpului. Detecţia şi interpretarea comportamentului uman poate fi utilizată într-o
multitudine de aplicaţii. Spre exemplu, când vine vorba de interpretarea gesturilor cu
mâna, acestea pot fi utilizate pentru navigarea automată în meniuri fără utilizarea de
telecomenzi, sau pentru interpretarea sau postarea automată a diferitelor mesaje.
Dezvoltarea recentă a dispozitivelor cu senzori de adâncime (spre exemplu MS Kinect12
şi Asus Xtion13
) a deschis noi perspective în rezolvarea paradigmei senzoriale, eliminând
pierderea de performanţă datorită proiecţiei 2D, ocluziunilor sau a extragerii de fundal.
Un sistem eficient de recunoaştere a gesturilor mâinii necesită o combinaţie între
un set de trăsături discriminative care sunt rapid de extras şi clasificatori capabili să
valorifice descriptorii anteriori. În literatură sunt prezentate diferite metode care prezintă
o multitudine de avantaje şi dezavantaje. Spre exemplu, descriptorii de nivel înalt sunt
preferaţi deoarece sunt compacţi şi prezintă structura gestului din punct de vedere
semantic, însă sunt dificil de implementat în aplicaţii ce rulează în timp real [233] [234].
12
http://www.microsoft.com/en-us/kinectforwindows/ 13
http://www.asus.com/Multimedia/Xtion_PRO_LIVE/

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
184
Pe de altă parte, trăsăturile de nivel scăzut (muchii, contururi) sunt de preferat datorită
vitezei ridicate de extracție [235].
În continuare, voi prezenta o metodă utilizată în contextul recunoaşterii de gesturi
statice cu mâna prin utilizarea unui senzor de Kinect. În acest sens, am utilizat atât
informaţia de culoare cât şi cea de adâncime a senzorului. Robusteţea metodei propuse
face ca sistemul să fie imun la schimbările de fundal şi invariant la modificările de scală
şi a uşoarelor rotaţii. Mai mult, fiecare cadru individual este procesat în 32 ms, suficient
de rapid pentru cele mai multe dintre aplicaţiile în timp real. Această metodă a fost
propusă de autorul principal al articolului, contribuția mea în cadrul acestui algoritm
constând în proiectarea bazei de date de testare, selecția și calculul performaței
algoritmilor utilizați în literatură, cât și a anumitor elemente din cadrul algoritmului.
8.5.1 Metoda propusă
Primul pas al algoritmului constă în izolarea gesturilor. Se va pleca de la premiza că
mâna va fi obiectul cel mai apropiat de senzor, după care se vor segmenta atât informaţia
de adâncime cât şi cea de culoare. Prima segmentare constă în prăguirea adaptivă a
informaţiei de adâncime care va separa obiectele mai apropiate de cele mai îndepărtate. A
doua segmentare constă în detecţia regiunilor care sunt posibile a fi de piele. Această
procedură în doi paşi asigură faptul că mâna este extrasă chiar dacă avem în cadrul
fundalului obiecte ce conţin culoarea pielii (spre exemplu faţa).
După izolarea mâinii de fundal se va aplica un filtru median pentru eliminarea
neregularităţilor din contur şi extragerea unei imagini binare a formei mâinii. În cazul în
care vor fi extrase mai multe obiecte, se va selecta cel cu aria cea mai mare. Pentru
descrierea conturului se va utiliza descriptorul de aproximare poligonală descris în
Secţiunea 3.3.7. Ultimul bloc al sistemului este cel de antrenare și clasificare. În acest
sens, autorul principal a propus utilizarea modelului Hidden Markov Model (HMM).
Acesta reprezintă un model probabilistic des întâlnit în numeroase probleme de
inteligență artificială.
Modelul HMM reprezintă un graf orientat cu trei parametri principali:
– matricea de tranziții de stări care conține probabilitățile de trecere de la o
stare la alta
– distribuția probabilităților stărilor la un moment k
– starea inițială a vectorilor de probabilități
Pentru aplicarea acestui model vom considera descriptorii extrași ca un set
staționar de trăsături, conturul fiind modelat printr-un process probabilistic descris de un
automat secvențial cu stări finite care trece de la o stare la alta în funcție de probabilitățile
de tranziție. Pentru antrenarea modelului se va utiliza algoritmul lui Viterbi.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
185
Fig. 8.9 Schema sistemului propus pentru clasificarea gesturilor
8.5.2 Rezultate experimentale
Pentru antrenare și validare am utilizat baza de date propusă în [236]. Această bază este
împărțită în două părți. Prima conține 9 gesturi (50 pentru fiecare categorie)
înregistrate în condiții lipsite de zgomot. Aceasta cuprinde gesturi înregistrate de către
o singură persoană și include mici variații de scală, translație și rotație. Modelul
markovian este antrenat cu ajutorul acestor imagini. Pentru validarea sistemului este
folosit un al doilea set, imaginile fiind preluate de la aceeași persoană (în jur de 7300
de imagini). Pentru testare, a fost înregistrată o a doua bază de date, aceasta având o
arhitectură mult mai complicată, și anume include diferite grade de variație a
luminozității, fundal diferit și variație amplă a unghiurilor de rotație. În total, aceasta
cuprinde peste 8500 de imagini, înregistrate de către 6 persoane în fața unui dispozitiv
de Kinect. Subiecții au efectuat o gamă variată de mișcări într-un interval de 1-1,5
metri în fața dispozitivului de Kinect.
În continuare, vom compara performanța metodei propuse cu algoritmii [237]
și [238]. Primul algoritm utilizează o descriere structurală a fiecărui gest bazat pe o
serie de trăsături de nivel înalt, ca de exemplu numărul de vârfuri ale degetelor,
numărul de segmente și poziția lor în cadrul poziției mâinii. Clasificarea este
efectuată cu ajutorul unor arbori de decizie. A doua metodă extrage un set de
descriptori de culoare împreună cu momentele invariante Hu, pe care le combină apoi
cu un clasificator SVM. Mai mult, pentru a demonstra că algoritmul de clasificare
HMM este o soluție bună, voi compara performanța acestuia cu un algoritm clasic de
clasificare: SVM.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
186
Rezultatele experimentale sunt expuse în Figura 8.9, aceasta conținând
precizia de clasificare pentru fiecare gest în parte. Metoda propusă obține rezultate
medii superioare față de toate celelalte metode (Tabel 8.4). Astfel, SVM obține un
rezultat cu 5 procente mai redus, în timp ce diferența de performanță dintre metoda
propusă și celelalte metode din literatură este mai mare de 20 de procente. În toate
cazurile, metoda propusă obține rezultate foarte bune, de peste 80%, mai puțin pentru
ultimul gest, acolo unde acuratețea de clasificare este egală cu 79.38%.
Tab. 8.4 Comparație cu algoritmii raportați în State-of-The-Art
Algoritm Acuratețe de clasificare Metodă propusă 93,38%
Oprișescu și alții [237] 72,30%
Yun și alții [238] 69,22%.
SVM cu nucleu Chi 88,31%
Fig. 8.9 Rezultatele clasificării pe fiecare gest utilizând diferite metode de clasificare:
Metoda 1 [237], Metoda 2 [238], SVM și metoda propusă
8.5.3 Concluzii
În cadrul acestei secțiuni am prezentat o metodă eficientă pentru rezolvarea problemei
de clasificare a gesturilor statice de mână. Aceasta constă în extragerea unor trăsături
clasice de contur și antrenarea sistemului cu un model statistic Hidden Markov
Model. Sistemul este robust la schimbări de persoane, scală, translații și rotații. De
asemenea, robustețe adițională este adăugată și de către senzorul Kinect care, cu
ajutorul senzorului de adâncime, separă obiectele din prim plan de cele din fundal.
Rezultatele experimentele au confirmat puterea discriminatorie a trăsăturilor alese
alături de flexibilitatea și abilitatea de generalizare a modelelor statistice.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
187
Capitolul 9
Concluzii
Lucrarea de față reprezintă o formalizare a contribuțiilor teoretice și practice în domeniul
indexării și analizei bazelor de date multimedia. Prin intermediul acesteia, am rezumat
munca depusă în ultimii trei ani, în perioada de formare științifică a studiilor doctorale.
Punctul de plecare comun al tuturor metodelor și algoritmilor noi descriși pe
parcursul acestei lucrări a fost corelat cu nevoia de a creea sisteme care să indexeze și să
interpreteze conținutul multimedia. Utilizarea documentelor multimedia face parte din
viața cotidiană a oricui. Fie ca este vorba de muzică, informații text, filme, sau imagini,
un sistem de indexare a conținutului are în componență anumite elemente comune, chiar
dacă structura informației este una diferită.
În cadrul acestei teze am abordat mai multe scenarii și tipuri de sisteme de
indexare. Un prim tip de sistem de indexare a fost cel al bazelor de date de imagini
(sisteme CBIR). Astfel, am propus metode noi și am efectuat analize pe baze de date de
imagini medicale, imagini de textură sau imagini naturale. De asemeni, am încercat să
reduc influența paradigmei semantice (semantic gap), prin propunerea și utilizarea unor
algoritmi de relevance feedback. Sistemele de indexare a documentelor video reprezintă
un alt subiect discutat în această lucrare. În această direcție, a fost propus un set de
metode pentru indexarea și clasificarea bazelor de date video în diferite contexte: detecția
genului, a violenței sau interpretarea conținutului prin clasificarea acțiunilor din cadrul
filmelor. În acest sens, conținutul video a fost analizat din mai multe perspective și
modalități, informația prelucrată fiind atât de natură vizuală, cât și audio și textuală.
9.1 Rezultate obţinute
În Capitolul 1 am realizat o trecere în revistă a acestei teze. Astfel, am evidenţiat
componentele unui sistem de indexare a sistemelor după conținut și am evidențiat
secțiunile în care am adus contribuții.
În cadrul Capitolului 2 am prezentat o sinteză a componentelor consacrate pentru
un sistem de indexare multimedia: browser, retriever și indexator. Se pune accentul pe
problematica actuală a sistemelor de căutare după conținut și sunt prezentate diferite
domenii în care indexarea joacă un rol important. De asemenea, am prezentat principalele
canale de informație pe care un sistem le poate analiza: vizual, audio și textual. Apoi, am
ilustrat comparativ aspecte generale referitoare la fuzionarea acestor canale
informaționale: tehnici de early și late fusion. Se prezintă metricile utilizate de către

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
188
algoritmi pentru calcularea similarităţii sau disimilarităţii dintre documente. Pentru
evaluarea rezultatului algoritmilor de indexare sunt prezentate şi măsurile de evaluare. De
asemenea, se prezintă seturile de date standard existente sau utilizate pentru algoritmii de
clasificare și indexare în etapele de antrenare şi respectiv de testare.
Capitolul 3 ilustrează o analiză detaliată a descriptorilor utilizați pentru diferite
canale de informație. În prima parte sunt analizați descriptorii vizuali și sunt trecute în
revistă trăsăturile de culoare, textură, formă și de detecție a punctelor de interes. Mai
mult, un modul special este creeat pentru prezentarea standardului MPEG-7 și a
descriptorilor aferenți. Apoi, câte o secțiune separată este oferită prezentării conceptelor
și trăsăturilor audio, de mișcare și text.
În cadrul Capitolului 4 am prezentat o serie de algoritmi de Relevance Feedback.
Au fost descriși algoritmi de relevance feedback cu schimbare a punctului de interogare,
cu estimare a importanței trăsăturilor, statistici și algoritmi RF cu algoritmi de clasificare.
În Capitolul 5 am prezentat o abordare neliniară pentru descrierea şi clasificarea
imaginilor de textură. Textura reprezintă o componentă de bază atât pentru algoritmii de
recunoaștere de patern, cât și pentru sistemele de indexare a imaginilor si documentelor
video. Metoda propusă a fost inspirată din teoria automatelor celulare. În acest scop, a
fost utilizat un automat celular simplu, cu două stări (0 și 1) și vecinătate Moore. Inițial,
textura este binarizată cu ajutorul unor seturi de praguri, ca apoi, asupra acestor imagini
binarizate să fie aplicate un set de funcții neliniare. Performanţa descriptorului a fost
validată atât în contextul unui sistem de clasificare cât şi din perspectiva unui sistem de
căutare a imaginilor după conţinut. Astfel, am utilizat patru baze de date de textură,
pentru a compara descriptorul nostru cu alte trăsături existente. Algoritmul propus, în
ciuda complexității sale reduse (kO(n)), poate reprezenta o bună alternativă la descriptorii
clasici de textură. În toate experimentele propuse, algorimul a obținut rezultate similare
sau îmbunătățite, pe toate cele 4 baze de date. De asemenea, metoda a fost validată din
două perspective, atât pentru un sistem clasic de căutare (query by example), cât și din
prisma unui sistem de clasificare.
În cadrul Capitolului 6 este prezentată cea de-a doua contribuție propusă. Aceasta
se reflectă în aplicarea modelului Fisher kernel pentru aplicațiile de indexare multimedia,
privit ca o modalitate nouă de a captura în mod adecvat informația temporală. Dacă cele
mai multe sisteme de clasificare de documente video se bazează pe utilizarea unei
reprezentări pentru toată secvența video, iar noțiunea temporală este pierdută din diferite
motive, modelul Fisher Kernel creează o reprezentare de lungime fixă, dar care ia în
calcul structura informației temporale. Acest model combină beneficiile algoritmilor
generativi și discriminativi, având un caracter general, în funcție de problema selectată:
de la recunoaștere de gen, până la recunoaștere de secvențe sportive și acțiuni cotidiene.
Metoda propusă a obținut rezultate cu mult îmbunătățite față de simpla acumulare
a informației (de la 8% până la 27% performanța este mai mare). Asfel, pentru
experimentul de detecție a genului, am îmbunătățit performanța (valori MAP)

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
189
descriptorilor clasici de culoare Color Naming de la 0,18 la 0,33, al descriptorilor
Histograms of Oriented Gradients de la 0,23 la 0,43, în timp ce performanța descriptorilor
audio a crescut de la 0,34 la 0,47. În cadrul celui de-al doilea experiment efectuat, și
anume cel de detecție de acțiuni sportive, performanța este mult mai ridicată. Astfel,
pentru setul de descriptori Histograms of Optical Flow, acuratețea a fost îmbunătățită de
la 45% la 72%, a descriptorilor HOG de la 34% la 52%, în timp ce a descriptorilor Color
Naming de la 20% la 42%. De asemenea, în cadrul celui de-al treilea experiment propus,
cel de detecție de acțiuni cotidiene, performanța a fost îmbunătățită de la 78% la 89%,
pentru setul de descriptori HOF. Rezultatele obținute sunt de cele mai multe ori mai bune,
sau cel puțin similare cu cele raportate în literatură. Astfel, pentru problema detecției de
gen, performanțele obținute depășesc cu mult rezultatele raportate în cadrul competiției
MediaEval 2012 Tagging Task. Pentru trăsăturile audio, am obținut o perfomanță de
0,475 MAP, cu mult mai bine decât performanța raportată la MediaEval 2012 de 0,1892
(echipa ARF). De asemenea, și descriptorii vizuali au o performanță superioară în fața
celor raportați la MediaEval 2012, descriptorii propuși obținând o performanță de 46,5%
cu peste 11 procente mai ridicată față de maximul raportat. Mai mult, rezultate
remarcabile sunt obținute prin combinația trăsăturilor vizuale cu cele audio. Acestea obțin
o performanță de 0,55 ceea ce este chiar superioară performanței obținute de cele mai
bune echipe la MediaEval 2012, care au o performanță de 0,52 MAP. Însă, rezultatul din
urmă utilizează descriptori de nivel semantic de nivel înalt, cum ar fi textul extras prin
metode de recunoaștere automată vorbirii sau cu ajutorul metadatelor. De asemenea, în
cazul în care combinăm trăsăturile noastre cu trăsături de text, obținem 0,66 MAP, un
rezultat mai bun cu 0,13 MAP față de cea mai bună echipă din competiție.
În ceea ce privește problema de detecție a acțiunilor sportive, am obținut rezultate
similare celor raportate în literatură. Totuși, metoda propusă utilizează descriptori foarte
simpli, cum ar fi HoG, HoF si CN, în timp ce metodele cu rezultate similare utilizează un
set de descriptori care generează un efort computațional foarte ridicat. Mai mult,
algoritmul Fisher kernel aplicat părților componente ale corpului a obținut cea mai mare
performanță, de 97,3%, în timp ce ceilalți algoritmi au obținut o performanță cu câteva
procente mai redusă.
Așadar, putem concluziona că metoda Fisher kernel obține rezultate similare sau
mai bune decât cele prezentate în literatură, însă aceasta utilizează descriptori globali care
sunt mult mai rapizi și ușor de implementat.
În Capitolul 7, am propus o serie de algoritmi de relevance feedback pentru
diverse probleme de indexare a bazelor multimedia. Inițial, am prezentat un algoritm de
relevance feedback care combină principii inspirate din metoda clasică de RF Rocchio,
cu trăsături similare celor utilizate în metodele de estimare a importanței descriptorilor.
Algoritmul a fost testat pe baze de date de textură și de imagini naturale. Strategia de
relevance feedback îmbunătățește performanțele sistemului în mod considerabil, un
exemplu ar fi aplicarea algoritmului propus pentru setul de imagini de textură, unde

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
190
performanța crește de la 71% la 87%, în timp ce pentru baza de imagini naturale rata de
recunoaștere aproape se dublează de la 37% la 60% MAP. Mai mult, algoritmul propus
obține rezultate superioare față de ceilalți algoritmi: spre exemplu, în cazul imaginilor de
textură, performanța crește cu peste 2 procente și cu 8 procente în cazul bazei de imagini
naturale.
Al doilea algoritm de relevance feedback propus utilizează o structură
arborescentă capabilă să învețe rapid și eficient preferințele utilizatorului, chiar dacă
utilizăm un set restrâns de exemple de învățare. Inițial, algoritmul a fost propus pentru
îmbunătățirea performanței bazelor de date cu imagini naturale. În acest scop, am testat
pe două baze de date publice și foarte cunoscute: Caltech 101 și Microsoft. Prin utilizarea
setului de descriptori MPEG 7, metoda propusă prezintă o creștere de performanță de la
30,21% la 64,52%. Cea mai mică creștere de performanță este obținută pe baza de date
Caltech 101, folosind Bag of Visual-Words (SURF): de la MAP egal cu 10,90% până la
18,44%. Mai mult, în cazul în care efectuăm sesiuni multiple de feedback, performanța
poate fi îmbunătățită până la 84,71%, pentru baza Microsoft, în timp ce pentru Caltech
101 se obține o creștere până la 55,78%. Pentru ambele baze de date, metoda propusă
obține rezultate mai bune decât cele raportate în literatură (3% pentru Caltech 101 și 6%
pentru baza Microsoft).
Ultimul algoritm de relevance feedback este inspirat de modelul Fisher kernel,
fiind propus în contextul indexării de bazelor de date video web. Algoritmul a fost testat
pe o varietate de descriptori multimedia: vizuali, audio și textuali. Testată pe o bază de
date mare (MediaEval 2012), și utilizând o serie de descriptori care reprezintă state-of-
the-art (vizuali, audio și text), metoda noastră FKRF îmbunătățește performanța
rezultatelor, surclasând alte metode existente ca: Rocchio, Nearest Neighbors RF, Boost
RF, SVM RF, Random Forest RF și RFE. Mai mult, în cazul în care capturăm informația
temporală utilizând Fisher kernel, performanța este drastic îmbunătățită de la 40,80% la
45,83% pentru MPEG 7 și de la 29,59% la 32,87% pentru trăsăturile HoG. De asemeni,
am arătat că nu este necesar un număr ridicat de centroizi GMM pentru a antrena metoda,
aceasta obținând rezultate bune cu numai 5-10 centroizi. Astfel, agoritmul este rapid,
putând fi implementat în sisteme în timp real.
În Capitolul 8 am prezentat diferiți algoritmi și soluții pentru anumite probleme
de interes de clasificare multimedia. În prima parte a capitolului, am ilustrat metode și
studii efectuate pe două baze de date medicale. Primul experiment a fost creat pe o bază
de date de imagini otoscopice și își propunea detecția otitei din imagini extrase de
otoscop. O primă bază conține imagini medicale otoscopice, iar algoritmul propus este un
sistem utilizat în detecția otitei la copii. În cadrul acestui experiment am propus un set de
descriptori și o arhitectură de fuziune clasică pentru combinarea trăsăturilor de culoare,
textură și puncte de interes. Sistemul propus a obținut un rezultat mai bun cu 14% decât
cele raportate în literatură, ceea ce reprezintă o îmbunătățire considerabilă.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
191
A doua bază de date conține o diversitate de tipuri de celule canceroase sangvine
canine, preluate la microscop. În cadrul acestui experiment, am abordat problema analizei
și clasificării de imagini medicale. În acest sens, am studiat contribuția unui set extins de
trăsături de culoare, textură și puncte de interes, dar și performanța a mai multor
clasificatori. Studiul a fost efectuat pe un scenariu real, o bază de date cu imagini
medicale extrase de către Facultatea de Medicină Veterinară București. Rezultatele
obținute au fost încurajatoare. Spre exemplu, cel mai bun procent de clasificare, de
99,45%, a fost obținut prin combinarea descriptorilor SURF cu clasificatorul Nearest
Neighbor.
În a doua parte a capitolului, am propus un set de metode și sisteme pentru
indexarea conținutului multimedia. O primă aplicație propusă a fost detecția genului
pentru fișierele video web. Inițial, un sistem de clasificare a genului a fost propus în
cadrul competiției MediaEval 2012 Video Genre Retrieval Task. În cadrul acestei
competiții, am fost membru al echipei ARF (Austrian Romanian French team). Au fost
propuse 5 metode, dintre care a treia s-a clasat pe locul 2 (din 29 de sisteme propuse).
Mai mult, ulterior am propus o nouă abordare multimodală a problemei, în care
rezultatele obținute au fost cu mult superioare celor raportate în cadrul competiției.
În cadrul MediaEval, descriptorii textuali (metadate și ASR) au obținut cea mai
ridicată performanță, și anume 52,25%. Însă, rezultatele descriptorilor textuali propuși
sunt mult mai ridicate. Astfel, am obținut 58,66% cu descriptorii de metadate. Apoi, prin
fuziunea descriptorilor text (ASR și metadate), performanța crește până la 62,81% - o
diferența de performanță este de peste 10% față de prima echipă clasată și cu peste 25%
față de a doua echipă clasată. În ceea ce privește descriptorii vizuali, am obținut o
performanță cu trei procente mai ridicată (MAP 38,21%) decât cel mai bun sistem cu
trăsături vizuale, raportat la MediaEval 2012. Setul de trăsături audio a obținut și el
performanțe superioare: 44,5% MAP, în condițiile în care cel mai bun rezultat obținut în
cadrul competiției a fost de numai 18,92% (se poate observa o îmbunătățire cu mai bine
de 25% MAP). Prin combinarea tuturor modalităților, am obținut cea mai mare rată de
clasificare de 65,82%, ceea ce reprezintă o îmbunățire a performanței cu peste 13
procente față de cea mai bună performanță de la MediaEval 2012. De asemeni, am
demonstrat că performanțe foarte bune se pot obține doar cu trăsături care pot fi extrase
automat. Prin utilizarea tuturor descriptorilor, mai puțin metadate, obținem o performanță
foarte mare de 51,9%, similară celui mai bun rezultat din concurs.
A doua aplicație propusă este detecția secțiunilor violente în filmele de la
Hollywood. O primă variantă a sistemului a fost propusă în cadrul workshop-ului
MediaEval 2012, competiția „Affect Task”. În cadrul acesteia, am fost membru al echipei
ARF (Austrian Romanian France Team) cu care am obținut locul 1 (din 35 de sisteme
propuse). În cadrul acestei secțiuni au fost propuse un set de tehnici pentru rezolvarea
problemei de detecție a violenței în filmele de la Hollywood. Cele mai multe metode au
propus un set de descriptori pentru descrierea conținutului video și un clasificator pentru

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
192
antrenarea sistemului. Primul autor a propus o metodă care utilizează un pas intermediar,
ce constă în predicția conceptelor asociate cu violența, ca de exemplu: țipete, explozii,
sunete de arme etc. Predicția conceptelor corelate cu violența a reprezentat o problemă
mai ușor de implementat decât detecția directă a gradului de violență. Prin utilizarea
acestei arhitecturi, s-a obținut cea mai ridicată performanță, cu mai mult 6% decât a doua
echipă clasată (echipa ShanghaiHongkong), care a obținut un scor de 43,73%. În
cadrul acestui algoritm am avut contribuții pentru descrierea vizuală a conținutului
multimedia. Nu în ultimul rând, metoda propusă a fost singura din competiție care a putut
fi implementată atât la nivel de segment cât și la nivel de cadru.
În finalul capitolului am prezentat o metodă nouă de recunoaștere a gesturilor
statice de mână. Algoritmul propus constă în extragerea unor trăsături clasice de contur și
antrenarea sistemului cu un model statistic Hidden Markov Model. Acesta este robust la
schimbări majore de fundal, persoane, luminozitate, obținând în același timp performanțe
mai bune decât alți algoritmi prezentați în literatură.
Prezenta teză se încheie cu Capitolul 9 care este dedicat prezentării concluziilor
care se desprind din aspectele teoretice şi practice ale cercetărilor prezentate în această
lucrare şi care sintetizează rezultatele și contribuţiile personale originale, precum şi
perspectivele de cercetare.
9.2 Contribuţii originale
Din punct de vedere științific, contribuțiile originale din perioada de cercetare a lucrării
de doctorat sunt următoarele:
în [c1] am propus o abordare neliniară pentru descrierea şi clasificarea imaginilor de
textură. Performanţa trăsăturilor propuse este validată atât în contextul unui sistem de
clasificare cât şi din perspectiva unui sistem de căutare a imaginilor după conţinut,
testarea fiind efectuată pe o gamă variată de baze de textură. Algoritmul propus se
impune prin simplitate și complexitate redusă de calcul, reprezentând o bună
alternativă la descriptorii clasici de textură, deoarece prezintă performanțe similare
sau mai ridicate față de algoritmii prezentați în literatură.
în [c2], alături de autorii principali, am propus un sistem pentru analiza și clasificarea
filmelor web. Descrierea conținutului multimedia a fost efectuată atât prin analiza
informației vizuale, cât și a celei audio. În acest sens, au fost propuse metode care
exploatează atât informația audio și structura temporală, cât și conținutul de culoare.
Experimentele au fost efectuate pe o bază de date publică, MediaEval 2011 pentru
proba de Genre Retrieval Task, considerată a fi un scenariu real de testare. Metoda
propusă a obținut cele mai bune performanțe față de toți descriptorii audio-vizuali
propuși în cadrul competiției MediaEval 2011, dar și performanțe apropiate cu cele
ale descriptorilor textuali.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
193
am participat la competiția MediaEval 2012 - proba de Genre Retreival Task [c3] și
am propus împreună cu echipa ARF un set de descriptori multimodali (vizuali, audio
și text) pentru detecția genului în filme. În cadrul acestei competiții, am obținut locul
2 pentru cel mai bun sistem de detecție (din 29 de sisteme propuse).
alături de ceilalți membrii ai echipei ARF [c4], am participat la competiția MediaEval
2012 - proba de Genre Retrieval Task unde am elaborat un sistem de detecție a
violenței în filmele de la Hollywood. Algoritmul propus s-a clasat pe locul 1 din 35
de sisteme propuse.
în [c8] am investigat influența aplicării algoritmilor de relevance feedback asupra
unui sistem generic biomedical, bazat pe un set de descriptori MPEG 7. Rezultatele
au demonstrat că relevance feedback poate îmbunătăți performanțele cu peste 20%.
în [c9] am propus un studiu de comparație între diferite metode de clasificare pentru
diferite scenarii ale unui sistem CBIR: baze de date biomedicale, de textură și de
imagini naturale. Astfel, am analizat algoritmii de clasificare din mai multe
perspective, a performanței de clasificare și a vitezei de execuție.
în [c10, c14, c16] am prezentat o nouă metodă de relevance feedback bazată pe un
algoritm de clusterizare ierarhică. Metoda propusă a prezentat performanțe superioare
față de alte metode propuse în literatură. De asemenea, algoritmul a fost testat pe o
arie largă de baze de date de imagini: biomedicale, de textură, naturale și web.
în [c1, c12, c15] am extins algoritmul de relevance feedback propus anterior pentru
baze de date multimedia. Astfel, am arătat că relevance feedback poate avea un
impact major asupra performanței unui sistem multimedia web. De asemenea, metoda
propusă a prezentat performanțe superioare față de alte metode propuse în literatură,
fiind testată pe o arie largă de baze de date video: baza de date MediaEval 2011
pentru proba de Genre Retrieval Task și baze de date de video-uri web. Algoritmul de
relevance feedback cu clusterizare ierarhică se evidențiază atât prin performanța mai
ridicată, cât și prin viteza sa computațională, aceasta fiind cu mult superioară altor
agoritmi, ca de exemplu SVM.
în [c16] am analizat influența diferitelor metrici asupra performanței unui sistem de
căutare a imaginilor după conținut.
în [c11] am prezentat un nou algoritm de relevance feedback care propune o nouă
metodă de estimare a importanței trăsăturilor, alături de o nouă strategie de schimbare
a punctului de interogare. Algoritmul a fost testat pe baze de date de textură și de
imagini naturale și s-a evidențiat printr-o creștere considerabilă a performanțelor, în
timp de viteza computațională a rămas similară cu cea a algoritmilor clasici.
în [c6, c13] am abordat problema analizei și clasificării imaginilor otoscopice. În
acest sens, au fost analizate contribuțiile unui set extins de descriptori vizuali de
culoare, textură și puncte de interes. De asemenea, a fost propusă utilizarea unui
mecanism de fuzionare „late fusion” a acestor trăsături.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
194
am ajutat la construirea mai multor baze de date multimedia. În [c9, c10, c11] am
utilizat o bază de date de imagini naturale, cu un total de 2700 documente, preluate de
pe internet prin utilizarea unor căutări specifice pe motorul de căutare Google.
Aceasta are în componență 100 de categorii de imagini clasice naturale, ca de
exemplu: anotimpuri, clădiri, ocean, deșert, copii, concerte, portrete, picturi, orașe
faimoare (Londra, Paris etc), persoane, sport, animale, mâncare. O a doua bază de
date este cea utilizată în [c12]. Aici, am propus o bază de date video, iar aceasta a fost
folosită pentru antrenarea unui sistem de categorizare a genului unui film. Această
bază cuprinde 91 de ore de conținut video împărțit în 7 categorii: filme de animație
(filme scurte, lungi și seriale), reclame, documentare (viața sălbatică, ocean, orașe și
istorie), videoclipuri (pop, rock și dance), știri și sport (fotbal). În total, baza conține
210 documente video, 30 pe gen. De asemenea, am ajutat la crearea bazei de date de
gesturi statice utilizate în [c25]. În final, în [c5] am ajutat la construirea bazei pentru
secțiunea de Diversity Task din cadrul MediaEval 2013.
în [c20] am propus un nou algoritm de relevance feedback pentru bazele de date
video, utilizând Fisher kernels. Testată fiind pe o bază de date mare (MediaEval
2012) și utilizând o serie de descriptori state-of-the-art (vizuali, audio și text), metoda
noastră FKRF îmbunătățește performanța rezultatelor, surclasând alte metode
existente ca: Rocchio, Nearest Neighbors RF, Boost RF, SVM RF, Random Forest
RF și RFE. De asemeni, am prezentat o metodă de a captura informația temporală,
utilizând Fisher Kernel, astfel încât să folosim mai mult de un vector descriptor
pentru un document video. Am arătat că nu este necesar un număr ridicat de centroizi
GMM pentru a antrena metoda, aceasta obținând rezultate bune cu numai 5-10
centroizi, fapt ce implică posibilitatea implementării în timp real.
în [c21, c22] am propus o metodă pentru detecția automată a genului unui film. În
această direcție am studiat contribuțiile diferitelor modalități și rolul mecanismului de
fuzionare în combinarea informației și creșterea performanței. Deși metodele propuse
au fost mai mult sau mai puțin explorate anterior în literatură, principalele contribuții
ale acestui capitol sunt: (a) o analiză în profunzime a unui set multimodal de
descriptori, în contextul unui scenariu real de detecție de gen, (b) dovedirea
potențialului pe care îl are o strategie adecvată de late-fusion, pentru a atinge o
performanță foarte bună, (c) demonstrarea că, în ciuda superiorității descriptorilor de
metadate, descriptorii multimodali în combinație cu late fusion pot atinge
performanțe similare, (d) instituirea unui nou punct de plecare pentru baza de date
MediaEval, obținând rezultate superioare celor raportate în cadrul competiției și (e)
relevanța rezultatelor ce le face să fie și reproductibile întrucât evaluarea s-a făcut pe
o bază de date standard.
în [c23] am extins modelul variației temporale propus în [c20], pentru un set larg de
probleme. Metoda propusă pentru modelarea variației temporale are un caracter foarte
general, fiind testată pe o varietate de baze de date de referință: de la clasificare de

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
195
gen (MediaEval 2012) până la recunoaștere de acțiuni sportive (UCF Sport 50) sau de
acțiuni cotidiene (ADL). Mai mult, algoritmul propus a fost evaluat pe o varietate de
trăsături, de la histograme HOG, CN și HoF până la trăsături HoF extrase pe
componentele corpului uman și trăsături clasice audio. Sistemul propus a obținut
rezultate similare sau mai bune decât cele propuse în literatură, deși am utilizat un set
de trăsături mai ușor de calculat.
în [c6] am propus o interfață grafică (Id-Image) pentru indexarea și manipularea
bazelor de date de imagini.
în [c25], alături de primul autor, am propus o metodă pentru clasificarea automată a
gesturilor clasice ale mâinii.
9.3 Lista lucrărilor originale
Articole publicate în reviste de specialitate
[c1] Ionuț Mironică, Radu Dogaru, „A novel feature-extraction algorithm for efficient
classification of texture images”, in Scientific Bulletin of UPB, Seria C - Electrical
Engineering, vol 75(2), pp. 101-114, ISSN 2286 – 3540, 2013.
[c2] Bogdan Ionescu, Klaus Seyerlehner, Ionuț Mironică, Constantin Vertan, Patrick
Lambert, „An Audio-Visual Approach to Web Video Categorization”, Multimedia
Tools and Applications, pp. 1-26, DOI 0.1007/s11042-012-1097-x 2012 (factor
impact ISI 0.91).
Competiții
[c3] participare MediaEval 2012 – secțiunea Tagging Task – membru în cadrul echipei
ARF, cu membrii: Bogdan Ionescu, Ionuț Mironică, Klaus Seyerlehner, Peter
Knees, Jan Schlüter, Markus Schedl, Horia Cucu, Andi Buzo, Patrick Lambert
Am obținut locul 2 pentru pentru cel mai bun sistem (din 29 de sisteme propuse)
[c4] participare MediaEval 2012 – secțiunea Violence Detection – membru în cadrul
echipei ARF, cu membrii: Jan Schlüter, Bogdan Ionescu, Ionuț Mironică, Markus
Schedl Am obținut locul 1 pentru pentru cel mai bun sistem (din 35 de sisteme
propuse)
[c5] organizare Mediaeval 2013 - secțiunea Diversity Task - membru organizator în
echipa formată de: Bogdan Ionescu, Maria Menéndez, Adrian Popescu,
Henning Müller, Anca-Livia Radu, Ionuț Mironică și Bogdan Boteanu

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
196
Rapoarte de cercetare
[c6] Raport de cercetare numărul 1: „Sisteme de Căutare a Imaginilor după Conținut”,
prezentat în iunie 2011
[c7] Raport de cercetare numărul 2: „Sisteme de Relevance Feedback”, prezentat în
iunie 2012
Articole publicate în conferințe internaționale
[c8] Ionuț Mironică, Constantin Vertan, „Relevance feedback approaches for MPEG-7
content-based biomedical image retrieval”, in Proc. of Communications COMM,
pp. 185-188, IEEE Catalog Number: CFP1041J-ART, ISBN: 978-1-4244-6363-3,
iunie 2010, București, Romania - indexată ISI.
[c9] Ionuț Mironică, Radu Dogaru, „A comparison between various classification
methods for image classification stage in CBIR”, Signals, Circuits and Systems
(ISSCS), pp. 301-304, (IEEE Catalog number CFP11816-PRT, ISBN 978-1-4577-
0201-3), iulie 2011, Iași Romania - indexată ISI.
[c10] Ionuț Mironică, Constantin Vertan „An Adaptive Hierarchical Clustering
Approach for Relevance Feedback in Content-based Image Retrieval Systems”,
Signals, Circuits and Systems (ISSCS), pp. 133-136, (IEEE Catalog number
CFP11816-PRT, ISBN 978-1-4577-0201-3), iulie 2011, Iași, Romania - indexată
ISI.
[c11] Ionuț Mironică, Constantin Vertan „A Modified Feature Relevance Estimation
Approach to Relevance Feedback in Content-Based Image Retrieval Systems”,
Signal Processing and Applied Mathematics for Electronics and Communications,
Eurasip, pp. 109-113, 26-28 august, 2011, Cluj-Napoca, Romania.
[c12] Ionuț Mironică, Constantin Vertan, Bogdan Ionescu „A Relevance Feedback
Approach to Video Genre Retrieval”, International Conference on Intelligent
Computer Communication and Processing, pp. 327-330, (ISBN 978-1-4577-1478-8,
IEEE Catalog No. CFP1109D-PRT), august, 2011, Cluj-Napoca, Romania -
indexată ISI.
[c13] Ionuț Mironică, Constantin Vertan, Dan Cristian Gheorghe „Automatic Pediatric
Otitis Detection by Classification of Global Image Features”, International
Conference on e-Health and Bioengineering, EHB, pp. 427-430, ISBN: 978-606-
544-078-4, noiembrie, 2011, Iași, Romania - indexată ISI.
[c14] Ionuț Mironică, Bogdan Ionescu, Constantin Vertan, „Hierarchical Clustering
Relevance Feedback for Content-Based Image Retrieval”, IEEE/ACM 10th
International Workshop on Content-Based Multimedia Indexing, pp. 187-192,
ISBN: 978-1-4673-2369-7, IEEE Catalog Numbers: CFP1214C-ART, CFP1214C-
USB, 27-29 iunie, Annecy, Franța, 2012 - indexată ISI.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
197
[c15] Bogdan Ionescu, Klaus Seyerlehner, Ionuț Mironică, Constantin Vertan, Patrick
Lambert, ”Automatic Web Video Categorization using Audio-Visual Information and
Hierarchical Clustering Relevance Feedback”, 20th European Signal Processing
Conference - EUSIPCO 2012, pp. 375-379, ISSN 2076-1465, 27-31 august,
București, Romania - indexată ISI.
[c16] Ionuț Mironică, Bogdan Ionescu, Constantin Vertan, „The Influence of the
Similarity Measure to Relevance Feedback”, 20th European Signal Processing
Conference - EUSIPCO 2012, pp. 1573-1576, ISSN 2076-1465, 27-31 august,
București, Romania, 2012 - indexată ISI.
[c17] Jan Schlüter, Bogdan Ionescu, Ionuț Mironică, Markus Schedl, „ARF @
MediaEval 2012: An Uninformed Approach to Violence Detection in Hollywood
Movies”, MediaEval Benchmarking Initiative for Multimedia Evaluation workshop
Pisa, Italia, 4-5 octombrie, 2012.
[c18] Bogdan Ionescu, Ionuț Mironică, Klaus Seyerlehner, Peter Knees, Jan Schlüter,
Markus Schedl, Horia Cucu, Andi Buzo, Patrick Lambert, „ARF @ MediaEval
2012: Multimodal Video Classification”, MediaEval Benchmarking Initiative for
Multimedia Evaluation workshop, Pisa, Italia, 4-5 octombrie, 2012.
[c19] Bogdan Ionescu, Jan Schlüter, Ionuț Mironică, Markus Schedl, „A Naive Mid-
level Concept-based Fusion Approach to Violence Detection in Hollywood
Movies”, ACM International Conference on Multimedia Retrieval - ICMR 2013,
pp. 215-222, ISBN: 978-1-4503-2033-7, Dallas, Texas, USA, 16 – 19 aprilie, 2013
- indexată ISI.
[c20] Ionuț Mironică, Bogdan Ionescu, Jasper Uijlings, Nicu Sebe, „Fisher Kernel based
Relevance Feedback for Multimodal Video Retrieval”, ACM International
Conference on Multimedia Retrieval - ICMR 2013, pp. 65-72, ISBN: 978-1-4503-
2033-7, Dallas, Texas, USA, 16 – 19 aprilie, 2013 - indexată ISI.
[c21] Ionuț Mironică, Bogdan Ionescu, Peter Knees, Patrick Lambert, „An In-Depth
Evaluation of Multimodal Video Genre Categorization”, IEEE/ACM 11th
International Workshop on Content-Based Multimedia Indexing - CBMI,
Veszprém, Ungaria, iunie, 2013 - indexată ISI.
[c22] Ionuț Mironică, Bogdan Ionescu, Christoph Rasche, Patrick Lambert, „A Visual-
based Late-Fusion Framework for Video Genre Classification” Signals, Circuits
and Systems (ISSCS), iunie 2013, Iași, Romania - indexată ISI.
[c23] Ionuț Mironică, Jasper Uijlings, Negar Rostamzadeh, Bogdan Ionescu, „Time
Matters! Capturing Temporal Variation in Video using Fisher Kernels”, in ACM
Multimedia - ACM MM 2013, Barcelona, Spania, octombrie 2013 - indexată ISI.
[c24] Negar Rostamzadeh, Gloria Zen, Ionuț Mironică, Jasper Uijlings, Nicu Sebe,
„Daily Living Activities Recognition via Efficient High and Low Level Cues
Combination and Fisher Kernel Representation”, International Conference on

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
198
Image Analysis and Processing, ICIAP, Napoli, Italia, septembrie, 2013 - indexată
ISI.
[c25] Radu-Laurențiu Vieriu, Ionuț Mironică, Bogdan-Tudor Goraș, „Background
Invariant Static Hand Gesture Recognition based on Hidden Markov Models”,
Signals, Circuits and Systems (ISSCS), iunie 2013, Iași, Romania - indexată ISI.
Cărți
[c26] Bogdan Ionescu, Ionuț Mironică, „Conceptul de Indexare Automată după
Conținut în Contextul Datelor Multimedia”, trimisă spre editare (103 pagini).
9.4 Perspective de dezvoltare ulterioară
Deși această își propune să marcheze o perioadă de cercetare, munca descrisă în această
teză este departe de a se fi încheiat.
O primă aplicație care poate fi îmbunătățită este cea de detecție și clasificare a
imaginilor de textură. În acest sens, îmi propun să îmbunătățesc performanța algoritmului
și să îl adaptez altor tipuri de categorii de imagini, ca de exemplu imagini medicale sau
imagini naturale. De asemenea, îmi propun să testez alte tipuri de funcții nucleu și tehnici
adaptive de binarizare a imaginilor, dar și să aplic algoritmul pe toate cele trei canale ale
unei imagini color. O altă direcție pe care aș dori să o am în vedere, este utilizarea
metodei ca descriptor în cadrul modelului Bag-of-Words. Algoritmul prezintă o precizie
și viteză ridicată pentru detecția de texturi, ceea ce îl poate face o alternativă serioasă
pentru descrierea punctelor de interes.
O altă direcție de cercetare pe care îmi propun să o extind este cea de relevance
feedback. Așa cum am arătat în această lucrare, tehnicile de relevance feedback
reprezintă o bună alternativă pentru reducerea problemei generate de paradigma
semantică, ceea ce reprezintă de altfel principala problemă existentă a sistemelor de
indexare multimedia. În viitor, îmi propun să combin metoda Fisher Relevance Feedback
cu alte trăsături mai complexe, și să extind conceptul de modelare a informației
temporale, pentru descriptori ca cei de: mișcare, text sau audio. Mai mult, îmi doresc să
testez metoda propusă pe o bază multimedia de dimensiuni foarte mari. În acest sens îmi
propun crearea unei baze de date de documente video web cu filme preluate de pe cele
mai importate site-uri din domeniu: spre exemplu, Youtube sau blip.tv. De asemenea,
modelul Fisher kernel pentru relevance feedback poate fi extins și pentru baze de date de
imagini. Prin corespondență, ideea temporală de la nivel de video poate fi transformată în
modelare spațială la nivel de imagine, iar agregarea la nivel de frame poate fi
transformată în agregare la nivel de puncte de interes.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
199
Capitolul 10
Bibliografie
[1] S. Santini: „Exploratory Image Databases Content-based Retrieval”, Academic Press,
Inc. Duluth, MN, USA, ISBN:0-12-619261-8, 2001.
[2] D. H. Brown, C.M. Ballard, „Computer Vision”, Prentice-Hall, Englewood Cliffs,
N.J., 1982.
[3] R. Haralick, L. Shapiro, „Computer and Robot Vision II”, Addison-Wesley, Reading,
MA, 1993.
[4] M. Flickner, H. Sawhney, W. Niblack, J. Ashley, Q. Huang „Query by image and
video content: the QBIC system”, IEEE Computer, vol 28(9), pp. 23-32, 1995. ISSN:
0018-9162.
[5] J. Bach, C. Fuller, A. Gupta, A. Hampapur, B. Horowitz, R. Humphrey, R. C. Jain,
C.-F. Shu, „Virage image search engine: an open framework for image management”, in
Proc. of Storage and Retrieval for Still Image and Video Databases, 1996. Proc. SPIE
2670, 76.
[6] J. Eakins, M. Graham, „Content-based image retrieval”, Technical Report. JTAP-
039, JISC Technology Application Program, 2000.
[7] A. Gupta, R. Jain, „Visual information retrieval”, in Proc. of Communications of the
ACM, vol. 40(5), pp. 70-79, 1997.
[8] J. Feder, „Towards image content-based retrieval for the World-Wide Web”, in Proc.
of ACM on Advanced Imaging, vol. 11(1), pp. 26-29, 1996.
[9] R.J. Smith, F.S. Chang, „Querying by color regions using the VisualSEEk content-
based visual query system”, in Proc. of Intelligent Multimedia Information Retrieval,
pp. 23-41, 1997.
[10] A.W. Smeurdels, M. Worring, S. Santini, A. Gupta, R. Jain, „Content-based image
retrieval at the end of the early years”, in IEEE Trans. Pattern Analysis Machine
Intelligence, vol. 22(12), pp. 1349–1380, 2000.
[11] I. Mironică, „Sisteme de Căutare a Imaginilor după Conținut”, Raport de cercetare
nr.1, iunie 2011.
[12] G.P. Nguyen, M. Worring, „Optimization of Interactive Visual-Similarity-Based
Search”, in Proc. of ACM Transactions on Multimedia Computing, Communications
and Applications, vol. 4 (1), pp. 1-23, 2008.
[13] C. Vertan, M. Ciuc, C. Fernandez-Maloigne, V. Buzuloiu, „Browsing Image
Databases by 2D Image Similarity Scatter Plots”, in Proc. of System of Intelligence
Symposyum Communications, București, Romania, 5-7 Dec. 2002, „Proceedings of
International Conference Communications”, pp. 397–402, 2002.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
200
[14] J. B. Tenenbaum, V.D. Silva, J.C. Langford, „A global geometric framework for
nonlinear dimensionality reduction”, iScience(290) (5500), pp. 2319-2322, 2000.
[15] C. Faloutsos, K. I. D. Lin, „FastMap: A fast algorithm for indexing, datamining and
visualization of traditional and multimedia datasets”, in Proc. of ACM SIGMOD, vol.
24(2), pp. 163–174, 1995.
[16] M. Steyvers, „Multidimensional Scaling”, in Macmillan Encyclopedia of Cognitive
Sciences, pp. 21-27, 2002.
[17] S. Roweis, L. Saul, „Nonlinear dimensionality reduction by locally linear
embedding”, in Science, vol. 290(5500), pp. 2323–2326, 2000.
[18] G. Hinton, S. Roweis, „Stochastic neighbor embedding”, in Proc. of Advances
Neural Information Processing Systems, vol. 15, pp. 833–840, 2002.
[19] A. Oerlemans, S. M. Lew, „RetrievalLab – A programming tool for content based
retrieval”, in Proc of ACM International Conference on Multimedia Retrieval,
ICMR, Trento, 2011.
[20] O. Rooij, M. Worring, J. J. van Wijk, „MediaTable: Interactive Categorization of
Multimedia Collections”, in IEEE Proc. of Computer Graphics and Applications, vol.
30(5), pp. 42-51, 2010.
[21] M. Nakazato, S. T. Huang, „3D MARS: Immersive virtual reality for content based
image retrieval”, in Proc. of International Conference on Multimedia and Exposition
(ICME), pp. 45-48., Tokyo, 2001.
[22] K. Schoeffmann, L. Boeszoermenyi, „Image and Video Browsing with a Cylindrical
3D Storyboard”, in Proc.of ACM International Conference on Multimedia Retrieval
ICMR, Trento, 2011.
[23] E. Deza, M. M. Deza, „Dictionary of Distances”, Elsevier Science, 1st edition,
ISBN-13: 978-0-444-52087-6, 2006.
[24] P. Howarth, S. Ruger, „Fractional distance measures for content-based image
retrieval”, in Proc. of European Information Retreival Conferece ECIR , pp. 447-
456, 2005.
[25] M. Kokare, B. Chatterji, P. Biswas, „Comparison of similarity metrics for texture
image retrieval”, in Proc. of IEEE Conf. on Convergent Technologies, vol. 2, pp. 571-
575, 2003.
[26] D. Zhang, G. Lu, „Evaluation of similarity measurement for image retrieval”, in
Proc. of IEEE International Conference on Neural Networks Signal, pp. 928-931,
Nanjing, 2003.
[27] T. Ojala, M. Pietikainen, D. Harwood, „Comparative study of texture measures with
classification based on feature distributions”, in Proc. of the Pattern Recognition, vol.
29(1), pp. 51-59, 2002.
[28] J. Puzicha, T. Hofmann, J. M. Buhmann, „Non-parametric similarity measures for
unsupervised texture segmentation and image retrieval”, in Proc. of the IEEE

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
201
International Conference on Computer Vision and Pattern Recognition CVPR, pp.
27-272, San Juan, 1997.
[29] D. Zhang, G. Lu, „Evaluation of similarity measurement for image retrieval”, in
Proc. of IEEE International Conference on Neural Networks Signal, pp. 928-931,
Nanjing, 2003.
[30] Y. Rubner, C. Tomasi, L. J. Guibas, „The earth mover's distance as a metric for
image retrieval”, in International Journal of Computer Vision IJCV, vol. 40(2), pp.
99-121, 2004.
[31] H. Alt, B. Behrends, J., Blomer, „Approximate matching of polygonal shapes”, in
Annals of Mathematics and Artificial Intelligence, pp. 251–265, 1995.
[32] R. C. Veltkamp, „Shape matching : Similarity measures and algorithms”, Technical
Report UU-CS-2001-03, Universiteit Utrecht, 2001.
[33] F. R. Hampel, E. M. Ronchetti, P. J. Rousseeuw, W. A. Stahel, „Robust Statistics:
The Approach Based on Influence Functions”, John Wiley Press , New York, 1986.
[34] A. K. Jain, K. Nandakumar, A. Ross, „Score Normalization in Multimodal
Biometric Systems”, in Elsevier Pattern Recognition Letters, pp 2270 - 2285, 2005.
[35] C. G. M. Snoek, M. Worring, A. W. M. Smeulders, „Early Versus Late Fusion in
Semantic Video Analysis”, in ACM International Conference on Multimedia (ACM
MM), pp. 399–402, Singapore, 2005.
[36] G. Ratsch, O. Takashi Onoda, K-R. Muller, „Soft margins for AdaBoost”, in
Machine Learning Journal, vol. 42(3), pp. 287-320, 2001.
[37] J.R. Quinlan, „Introduction of Decision Trees”, in Machine Learning Journal, vol.
1(1), pp. 81-106, 1986.
[38] L. Breiman, „Random forests”, in Machine Learning Journal, vol. 45(1), pp. 5–32,
2001.
[39] M. Montague, J. A. Aslam, „Condorcet fusion for improved retrieval”, in Proc. of
the ACM International Conference on Information and Knowledge Management
(CIKM), pp. 538-548, 2002.
[40] N. Gunther, N. Beretta, „A Benchmark for Image Retrieval using Distributed
Systems over the Internet”, In Proc. SPIE Conference on Internet Imaging II, pp. 127-
131, San Jose, 2001.
[41] C. Leung, H. Ip, „Benchmarking for Content-Based Visual Information Search”, in
Journal of Advances in Visual Information Systems, pp. 442-456, 2000.
[42] H. Muller, W. Muller, D. M. Squire, S. Marchand-Maillet, T. Pun, „Performance
Evaluation in Content-Based Image Retrieval: Overview and Proposals”, in Pattern
Recognition Letters, vol. 22(5), pp. 593-601, 2001.
[43] C. Vertan, M. Ciuc, „Tehnici fundamentale de Prelucrarea şi Analiza Imaginilor”,
Ed. Matrix Rom, Bucuresti, ISBN 978-973-755-207-5, 2007.
[44] wikipedia. http://en.wikipedia.org/wiki/Receiver_operating_characteristic.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
202
[45] S. Schmiedeke, C. Kofler, I. Ferran, „Overview of MediaEval 2012 Genre Tagging
Task”, in Working Notes Proc. of the MediaEval 2012 Workshop, pp. 4-5, Pisa.
[46] C. H. Demarty, C. Penet, G. Gravier, M. Soleymani, „The MediaEval 2012 Affect
Task: Violent Scenes Detection in Hollywood Movies”, in Working Notes Proc. of the
MediaEval 2012 Workshop, Pisa, 2012 .
[47] B. S. Manjunath, J.R. Ohm, V. V. Vasudevan, A. Yamada, „Color and texture
descriptors”, in IEEE Transactions on Circuits and Systems for Video Technology,
vol. 11 (6), pp. 703-715, 2001.
[48] J. Van de Weijer, C. Schmid, J. Verbeek, D. Larlus, „Learning color names for real-
world applications”, in IEEE Trans. on Image Processing, vol. 18(7), pp. 1512-1523,
2009.
[49] M. Swain, D. Ballard, „Color Indexing”, in International Journal of Computer
Vision IJCV, vol. 7(1):, pp. 11-32, 1991.
[50] M. Stricker, M. Orengo, „Similarity of color images”, in SPIE Conf. on Storage
and Retrieval for Image and Video Databases, vol. 2420, pp. 381-392, 1995.
[51] G. Pass, R, Zabih, „Histogram renement for content based image retrieval”, in IEEE
Workshop on Applications of Computer Vision, pp. 96-102, 1996.
[52] K. Konstantinidis, A. Gasteratos, I. Andreadis, „Image retrieval based on fuzzy color
histogram processing”, in Optics Communications, vol. 248, pp. 375–386, 2005.
[53] J. Han, K.K. Ma, „Fuzzy colour histogram and its use in color image retrieval”, in
IEEE Trans. Image Process., vol. 11 (8), pp. 944–952, 2002.
[54] M. Stricker, A. Dimai, „Color Indexing with Weak Spatial Constraints”, in Proc.
SPIE Storage and Retrieval for Image and Video Databases, pp. 29-40, 1996.
[55] S. Lazebnik, C. Schmid, J. Ponce, „Beyond Bags of Features: Spatial Pyramid
Matching for Recognizing Natural Scene Categories”, in IEEE Conference on
Computer Vision and Pattern Recognition (CVPR), vol. 2, pp. 2169-2178, 2006.
[56] H. Tamura, S. Mori, T. Yamawaki, „Texture features corresponding to visual
perception”, in IEEE Trans. Systems Man Cybernetics, vol. 8 (6), pp. 460–473, 1978.
[57] R.M. Haralick, K. Shanmugan, I. Dinstein, „Textural Features for Image
Classification”, in IEEE Transactions on Systems, Man and Cybernetics, pp. 610-21,
1973.
[58] C. A. Bouman, K. Sauer, S. Saquib, „Random fields and stochastic image models”,
IEEE International Conference on Image Processing, pp. 621-625, 1995.
[59] J. Huang, S. R. Kumar, M. Mitra, W. J. Zhu, R. Zabih, „Image indexing using color
correlograms”, in Proc. IEEE Int. Conf. Computer Vision and Pattern Recognition,
pp. 762-768, 1997.
[60] RM. M. Galloway, „Texture Analysis Using Gray Level Run Lengths”, in IEEE
Proc. on Computer Graphics and Image Processing, vol. 4, pp. 172 - 179, 1975.
[61] D. Zhang, G. Lu, „Content-based image retrieval using Gabor texture features”, in
Proc. of IEEE Pacific Conference on Multimedia (PCM), pp. 21-29, USA, 2001.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
203
[62] T. Ojala, M. Pietikainen, T. Mäenpää, „Multiresolution gray-scale and rotation
invariant texture classification with Local Binary Patterns”, in IEEE Transactions on
Pattern Analysis and Machine Intelligence, vol. 24(7), pp. 971-987, 2002.
[63] T. Ahonen, A. Hadid, M. Pietikäinen, „Face recognition with local binary patterns”,
in European Conference of Computer Vision ECCV, pp. 469-481, 2004.
[64] M. Heikkilä, P. Matti, C. Schmid, „Description of interest regions with local binary
patterns”, in Pattern Recognition Letters, vol. 42(3), pp. 425-436, 2009.
[65] M. K. Hu, „Visual Pattern Recognition by Moment Invariants”, in Trans. of
Information Theory, vol. 8, pp. 179-187, 1962.
[66] M. R. Teague, „Image analysis via the general theory of moments”, in Journal Opt.
Soc. Am, vol. 70(8), pp. 920-930, 1980.
[67] A. Khotanzad, Y.H. Hong, „Invariant Image Recognition by Zernike Moments”, in
IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 12, no. 5, pp.
489-497, 1990.
[68] R. Chellappa, R. Bagdazian, „Fourier Coding of Image Boundaries”, in IEEE
Transactions on Pattern Analysis and Machine Intelligence PAMI, vol. 6, pp. 102-
105, 1984.
[69] A. Bengtsson, J. Eklundth, „Shape representation by multiscale contour
approximation”, in IEEE Trans. Pattern Analysis and Machine Intelligence, vol.
13(1), pp. 85-93, 1991.
[70] L. J. Latecki, R. Lakamper, „Shape similarity measure based on correspondence of
visual parts”, in IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 22, pp.
1185–1190, 2000.
[71] N. Triggs, B. Dalal, „Histograms of Oriented Gradients for Human Detection”, in
Proc. IEEE Conf. Computer Vision and Pattern Recognition, vol. 2, pp. 886-893,
2005.
[72] G. Bosch, O. Zisserman, G. Munoz, „Image classification using ROIs and multiple
kernel learning”, in IEEE Conference of Computer Vision ICCV , pp. 771-778, 2007.
[73] N. Buch, J. Orwell, S. Velastin, „3D extended histogram of oriented gradients
(3DHOG) for classification of road users in urban scenes”, in ACM Conf. of British
Machine Vision Conference, pp. 122-128, London, 2009.
[74] M. Lowe, D. G. Muja, „Fast approximate nearest neighbors with automatic
algorithm configuration”, in Int. Conf. on Computer Vision Theory and Applications
VISSAPP, pp. 331-340, 2009.
[75] D. Lowe, „Distinctive image features from scale-invariant keypoints, cascade
filtering approach”, in Journal of Computer Vision, vol. 60(2), pp. 91-110, 2004.
[76] Y. Ke, R. Sukthankar, „PCA-SIFT: A more distinctive representation for local image
descriptors”, in Proc. of Computer Vision and Pattern Recognition CVPR, vol. 2, pp.
506–513, 2004.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
204
[77] K. Mikolajczyk, C. Schmid, „A performance evaluation of local descriptors”, in
Pattern Analysis and Machine Intelligence Journal, IEEE Transactions, pp. 1615-
1630, 2005.
[78] H. Bay, A. Ess, T. Tuytelaars, L. van Gool, „Surf: Speeded up robust features”, in
Conf. of Computer Vision and Image Understanding CVIU, vol. 110(3), pp. 346-359,
2005.
[79] C. Stephens, M. J. Harris, „A combined corner and edge detector”, in Conf. of
Vision, vol. 15, pp. 147–152, 1988.
[80] M. Donoser, H. Bischof, „Efficient Maximally Stable Extremal Region (MSER)”, in
Conf. of Computer Vision and Pattern Recognition (CVPR), vol. 1, pp. 553-560,
2006.
[81] M. Agrawal, K. Konolige, M. R. Blas, „CenSurE: Center Surround Extremas for
Realtime Feature Detection and Matching”, in European Conference on Computer
Vision ECCV, vol. 53(5), pp. 102-115, 2008.
[82] E. Rosten, T. Drummond, „Machine learning for high-speed corner detection”, in
European Conference on Computer Vision ECCV, pp. 430-443, 2006.
[83] J. Shi, C. Tomasi, „Good Features to Track”, in IEEE Conference on Computer
Vision and Pattern Recognition CVPR, pp. 593 - 600, 1998.
[84] S. M. Smith, J. M. Brady, „SUSAN - a new approach to low level image
processing”, in International Journal of Computer Vision IJCV, vol. 23 (1), pp. 45–
78, 1997.
[85] K. Youngjoong, „A study of term weighting schemes using class information for
text classification”, in Proc. of ACM SIGIR Conf. on Research and Development in
Information Retrieval, pp. 1029-1031, 2012.
[86] G. Csurka, C. Dance, L. Fan, J. Willamowski, C. Bray, „Visual categorization with
bags of keypoints”, in ECCV Workshop on Statistical Learning in Computer Vision,
pp. 22-30, 2004.
[87] Y. Liu, W. L. Zhao, C. W. Ngo, C. S. Xu, H. Q. Lu, „Coherent bag-of audio words
model for efficient large-scale video copy detection”, in Proc. of the ACM Int.
Conference on Image and Video Retrieval, pp. 89-96, 2010. .
[88] H. Wang, A. Klaser, C. Schmid, C. L. Liu, „Action recognition by dense
trajectories”, in IEEE Conference on Computer Vision and Pattern Recognition
CVPR, pp. 3169-3176, 2011.
[89] S. Lazebnick, C Schmit, „Beyound Bag of features: Spatial Pyramid for recognising
natural scene categories”, in IEEE Computer Vision and Pattern Recognition
Computer Society Conference, vol. 2, pp. 2169-2178, 2006.
[90] A. Zisserman, J. Sivic, „Term weighting aproaces to object matching in videos”, in
IEEE Computer Vision and Pattern Recognition Computer Society Conference, pp.
1470-1477, 2003.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
205
[91] W. Zhao, W. G. Jiang, „Keyframe retrieval by keypoints: Can point to point
matching help”, in Conf. of Image and Video Retrieval, pp. 72-81, Springer Berlin
Heidelberg, 2006.
[92] T. Hoffman, „Probabilistic Latent Semantic Analysis”, in Proc. of Uncertainty in
Artificial Intelligence, pp. 289-296, 1999.
[93] J. Sivic, B. Russell, A. Efros, A. Zisserman, W. Freeman, „Discovering objects and
their location in images”, in Proc. of International Conference on Computer Vision,
vol. 1, pp. 370-377, 2005.
[94] A. Blei, A. Ng, M. Jordan, „Latent Dirichlet allocation”, in Journal of Machine
Learning Research, vol. 3(4), pp. 993–1022, 2003.
[95] L. Li-Jia, L. Fei-Fei, „What, where and who? classifying events by scene and object
recognition”, in Int. Conf. of Computer Vision, pp. 221-228, 2007. .
[96] S. Savarese, J. Winn, A. Criminisi, „Discriminative Object Class Models of
Appearance and Shape by Correlatons”, in Proc. of IEEE Computer Vision and
Pattern Recognition, pp. 2033-2040, 2006.
[97] E. Sudderth, A. Torralba, W. Freeman, A. Willsky, „Learning Hierarchical Models
of Scenes, Objects, and Parts” in Proc. of International Conference on Computer
Vision ICCV , vol. 2, pp. 1331-1338, 2005.
[98] E. Sudderth, A. Torralba, W. Freeman, A. Willsky, „Describing Visual Scenes using
Transformed Dirichlet Processes”, in Proc. of Neural Information Processing Systems,
vol 18, pp. 1297-1307, 2006.
[99] F. Perronnin, J. Sánchez, T. Mensink, „Improving the Fisher kernel for large-scale
image classification”, in Int. Conf. of Computer Vision ECCV, pp. 143-156, 2010.
[100] J. RR. Uijlings, A. WM. Smeulders, R. J. H. Scha, „Real-time Bag of Words,
approximately”, in Proc. of the ACM International Conf. on Image and Video
Retrieval, 2009.
[101] J. Ricard, D. Coeurjolly, A. Baskurt, „Generalization of Angular Radial
Transform”, in Int. Conf. on Image Processing ICIP, vol. 4, pp. 2211-2214, 2004.
[102] A. P. Witkin, „Scale space filtering”, in Int. Joint Conference on Artificial
Intelligence, pp. 1019–1022, 1983.
[103] F. Mokhtarian, A. Mackworth, „Scale based description and recognition of planar
curves and two-dimensional shapes”, in IEEE Trans. Pattern Analysis and Machine
Intelligence, vol. 8(2), pp.112–124, 1986.
[104] B. Lucas, T. Kanade, „An iterative image registration technique with an application
to stereo vision”, in Proc. of Imaging Understanding Workshop, pp. 121-130, 1981.
[105] I. Laptev, „On space-time interest points”, in Int. Journal of Computer Vision,
vol. 64(2), pp. 107-123, 2005.
[106] B. Ionescu, „Analiza si Prelucrarea Secventelor Video: Indexarea Automata dupa
Continut”, in Publishing House „Editura Tehnică Bucureşti”, ISBN 978-973-31-2354-5,
2009.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
206
[107] I. Laptev, M. Marszalek, C. Schmid, B. Rozenfeld, „Learning realistic human
actions from movies”, in IEEE Conf. on Computer Vision and Pattern Recognition,
CVPR, 2008.
[108] K. K. Reddy, M. Shah, „Recognizing 50 human action categories of web videos”,
in Proc. of Machine Vision and Applications MVAP, vol. 24(118), pp. 1988-2013,
2012.
[109] I. Everts, J. van Gemert, T. Gevers, „Evaluation of color stips for human action
recognition”, in Int. Conf. on Computer Vision and Pattern Recogntion CVPR, 2013.
[110] Y. Yang, D. Ramanan, „Articulated pose estimation with flexible mixtures-of-
parts”, in IEEE Conference on Computer Vision and Pattern Recognition CVPR, pp.
pp. 1385-1392, 2011.
[111] E. Scheirer, M.Slaney, „Construction and evaluation of a robust multifeature
speech/music discriminator”, in IEEE Int. Conf. on Acoustics, Speech and Signal
Processing (ICASSP), pp. 1331-1334, 1997.
[112] S. B. Davis, P. Mermelstein, „Comparison of parametric representations for
monosyllabic word recognition in continuously spoken sentences”, in IEEE
Transactions on Acoustics, Speech and Signal Processing, vol. 28(4), pp. 357–366,
1980.
[113] J. T. Foote, „Content-based retrieval of music and audio”, in Proc. of Multimedia
Storage and Archiving Systems, vol. 32(29), pp 138–147, 1997.
[114] G. Tzanetakis, P. Cook, „Musical genre classification of audio signals”, in IEEE
Transactions Speech and Audio Processing, vol. 10(5), pp. 293-302, 2002.
[115] B. C. J. Moore, „Interference effects and phase sensitivity in hearing”, in
Philosophical Transactions, vol. 360(1794), pp. 833–58, 2002.
[116] S. S. Stevens, J. Volkmann, E. B. Newman, „A scale for the measurement of the
psychological magnitude pitch”, in Journal of the Acoustical Society of America, vol.
8(3), pp. 185–190, 1997.
[117] H. Fastl, E. Zwicker, „Psychoacoustics: Facts and Models”, in Springer-Verlag
Berlin Heidelberg, vol 22, 2007.
[118] B. Ionescu, J. Schlüter, I. Mironica, M. Schedl, „A Naive Mid-level Concept-based
Fusion Approach to Violence Detection in Hollywood Movies”, in ACM International
Conference on Multimedia Retrieval - ICMR, 2013, Dallas, USA, 2013.
[119] B. Ionescu, I. Mironica, K. Seyerlehner, P. Knees, J. Schlüter, M. Schedl, H. Cucu,
A. Buzo, P. Lambert, „ARF @ MediaEval 2012: Multimodal Video Classification” in
Mediaeval Benchmarking Initiative for Multimedia Evaluation workshop, Pisa,
2012 .
[120] B. Ionescu, K. Seyerlehner, I. Mironică, C. Vertan, P. Lambert, „An Audio-Visual
Approach to Web Video Categorization”, in Multimedia Tools and Applications, pp. 1-
26, DOI 0.1007/s11042-012-1097-x 2012, 2012.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
207
[121] E. Pampalk, A. Flexer, G. Widmer, „Improvements of audio-based music similarity
and genre classification”, in International Symposium on Music Information
Retrieval ISMIR, vol. 5, 2005.
[122] M.F. Porter, „An algorithm for suffix stripping”, in Program: Electronic Library
and Information Systems, vol. 14(3), pp. 130−137, 1980.
[123] G. Salton, C. Buckley, „Term-weighting approaches in automatic texture retrieval”,
in Proc. of Information Processing and Management, vol 24 (5), pp. 513-523, 1988. .
[124] J. X. Yu, X. Lin, H. Lu, Y. Zhang, „A Comparative Study on Feature Weighting
Text Categorization”, in APWeb Springer-Verlag Berlin Heidelberg, pp. 588–597,
2004.
[125] K. Nigam, J. Lafferty, A. McCallum, „Using maximum entropy for text
classification”, in Proc. of the Workshop on Information Filtering, IJCAI, pp. 58-65,
1999.
[126] F. Sebastiani, „Machine learning in automated text categorization”, in ACM
Computing Surveys (CSUR), vol. 34(1), pp. 1-47, 2002.
[127] A. McCallum, K. Nigam, „A comparison of event models for Naive Bayes text
classification”, on Workshop on Learning for Text Categorization, AAAI 1998, vol.
752, pp. 41-48, 1998.
[128] I. Mironică, B. Ionescu, P. Knees, P. Lambert, „An In-Depth Evaluation of
Multimodal Video Genre Categorization”, in ACM/IEEE International Workshop on
Content-Based Multimedia Indexing, 2013.
[129] Y. Rui, T. Huang, S.-F. Chang, „Image retrieval: Current techniques, promising
directions and open issues”, in Journal of Visual Communication and Image
Representation, vol. 10(1), pp. 39-62, 1999.
[130] B. Yates, R. Neto, „Modern Information Retrieval”, New York.: ACM Press, vol.
463, 1999.
[131] R. Yan, A. G. Hauptmann, R. Jin, „Negative pseudo-relevance feedback in content-
based video retrieval”, in Proc. of ACM International Conference on Multimedia, vol.
41(4), pp. 288-297, 2006.
[132] S. Yu, D. Cai, J. R. Wen, W. Y. Ma, „Improving pseudo-relevance feedback in web
information retrieval using web page segmentation”, in Proc. of the Int. Conf. on World
Wide Web, pp. 11-18, 2003.
[133] D.M. Nichols, „Implicit ratings and filtering”, in Proc. of the DELOS Workshop
on Filtering and Collaborative Filtering, pp. 31-36, 1997.
[134] www.DirectHit.com. DirectHit
[135] D. Kelly, J. Teevan, „Implicit feedback for inferring user preference: a
bibliography, in Int. Conf. on Research and Development in Information Retrieval
(SIGIR), vol 37(2), pp. 18-28, 2003.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
208
[136] M. Verleysen, D. François, „The curse of dimensionality in data mining and time
series prediction”, in Computational Intelligence and Bioinspired Systems, pp. 85-
125, 2005.
[137] X. S. Zhou, T. S. Huang, „Relevance feedback in image retrieval: A comprehensive
review”, in Multimedia Systems, vol. 8(6), pp. 536-544, 2003.
[138] J. Han, N. King, Li Mingjing, H.-J. Zhang, „A Memory Learning Framework for
Effective Image Retrieval”, in IEEE Trans. on Image Processing, vol. 14(4), pp. 511-
524, 2005.
[139] J. Rocchio, „Relevance Feedback in Information Retrieval”, in The Smart
Retrieval System – Experiments in Automatic Document Processing, Prentice Hall,
Englewood Cliffs NJ, pp. 313-323, 1971.
[140] Y. Lu, C. Hu, X. Zhu, H. Zhang, Q. Yang, „A unified framework for semantics and
feature based relevance feedback in image retrieval systems”, in Proc. of the ACM
Multimedia International Conference, pp. 31-37, 2000.
[141] Y. Ishikawa, R. Subramanya, C. Faloutsos, „Mindreader: Query databases through
multiple examples”, in Proc. of the Int. Conf. on Very Large Databases VLDB, 1998.
[142] D. J. Harper, C. J. Van Rijsbergen, „An evaluation of feedback in document
retrieval using co-occurrence data”, in Journal of Documentation, vol. 34(3), pp. 189-
216, 1978.
[143] Y. Rui, T. S. Huang, M. Ortega, S. Mehrotra, „Relevance feedback: A power tool
for interactive content-based image retrieval”, in IEEE Trans. Circuits and Systems for
Video Technology, vol. 8(5), pp. 644-655, 1998.
[144] C. Dorai, S. Venkatesh, „Bridging the Semantic Gap with Computational Media
Aesthetics”, in ACM Multimedia, vol. 10(2), pp. 15-17, 2003.
[145] H. Zhang, „The optimality of Naive Bayes”, AAAI Press, vol 1(2), 2004. .
[146] I.J. Cox, M. Miller, T. P. Minka, T. Papathomas, P. Yianilos, „The Bayesian image
retrieval system, PicHunter: theory, implementation, and psychophysical experiments”, i
IEEE Trans Image Processing, vol. 9(1), pp. 20–37, 2000.
[147] R. Zhang, R.M., Zhang, „BALAS: Empirical Bayesian learning in the relevance
feedback for image retrieval”, in Journal of Image and Vision Computing, vol. 24(3),
pp. 211-223, 2006.
[148] V. N. Vapnik, „Statistical Learning Theory”, in New York: John Wiley & Sons,
1998.
[149] D. Tao, X. Tang, X. Li, X. Wu, „Asymmetric bagging and random subspace for
support vector machines-based relevance feedback in image retrieval, in IEEE
Transactions on Pattern Analysis and Machine Intelligence, vol. 28(7), pp. 1088-
1099, 2006.
[150] Y. Chen, X. S. Zhou, T. S. Huang, „One-class SVM for learning in image
retrieval”: in Int. Conference on Image Processing, vol. 1, pp. 34-37, 2001.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
209
[151] J. v. Neumann, „Theory of Self-Reproducing Automata”, on University of Illiniois
Press, Campaign IL, 1966.
[152] S. Wolfram, „A New Kind of Science”, Wolfram Media, 2002.
[153] J. R. Weimar, „Three-dimensional Cellular Automata for Reaction-Diffusion
Systems”, in Journal of Fundamental Informatics, vol. 52, pp 275-282, 2002.
[154] M. Ruth, B. Hannon, „Game of Life”, in Modeling Dynamic Biological Systems,
Springer New York, pp. 333-356, 1997.
[155] N. Gilbert, K. Troitzsch, „Simulation for the social scientist”, on Open University
press, 2005, ISBN 9789812381835.
[156] I. Mironică, R. Dogaru, „A novel feature-extraction algorithm for efficient
classification of texture images”, în Scientific Bulletin of UPB, Seria C - Electrical
Engineering, vol 75(2), pp. 101-114, ISSN 2286 – 3540, 2013.
[157] R. Dogaru, M. Glesner, „Novel tools and methods for fast identification of
emergent behaviors in CNNs with relevance to biological modeling” in IEEE Proc. of
Cellular Neural Networks and their Applications, pp. 339-345, 2004.
[158] http://vismod.media.mit.edu/vismod/imagery/VisionTexture. Vistex dataset.
[159] H. Shahera, S. Serikawa „Texture Databases - A Comprehensive Survey”, Pattern
Recognition Letters, 2013.
[160] S. Lazebnik, C. Schmid, J. Ponce. „A Sparse Texture Representation Using Local
Affine Regions”, in IEEE Transactions on Pattern Analysis and Machine
Intelligence, vol. 27, no. 8, pp. 1265-1278, 2005.
[161] P. Brodatz, „Textures: A Photographic Album for Artists and Designers”, in Dover,
vol 6, New York, 1966.
[162] B. Caputo, M. Frits, E. Hayman, J.O. Eklundh, „The kth-tips database”, online la
http://www.nada.kth.se/cvap/databases/kth-tips, 2004.
[163] K. Beyer, J. Goldstein, R. Ramakrishnan, Uri Shaft, „When Is Nearest Neighbor
Meaningful?” in Database Theory ICDT Lecture Notes in Computer Science ICDT,
vol. 1540, pp. 217-235, 1999.
[164] J. H. Friedman, „Stochastic gradient boosting”, in Proc of. Computational
Statistics & Data Analysis, vol. 38(4), pp. 367-378, 2002.
[165] P. Geurts, D. Ernst, L. Wehenkel, „Extremely randomized trees”, in Journal of
Machine Learning, vol 63(1), pp. 3–42, 2006.
[166] T. S. Jaakkola, D. Haussler, „Exploiting generative models in discriminative
classifiers”, in Advances in Neural Information Processing Systems, Bradford Books,
The MIT Press, Cambridge, MA, pp.487–493, 1999.
[167] T. Jaakkola, D. Haussler, „Probabilistic kernel regression models”, in Proc. of
Artificial Intelligece and Statistics, vol 126, pp. 116-120, 1999.
[168] P. J. Moreno, R. Rifkin, „Using the Fisher kernel method for Web audio
classification”, in IEEE International Conference on Acoustics, Speech, and Signal
Processing Proceedings ICASSP, vol. 4, pp.2417–2420, 2000.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
210
[169] A. Vinokourov, M. Girolami „Document classification employing the Fisher kernel
derived from probabilistic hierarchic corpus representations”, in Proc. European
Colloquium on Information Retrieval Research ECIR, pp.24–40., 2001.
[170] V. Wan, S. Renals, „Evaluation of kernel methods for speaker verification and
identification”, in IEEE International Conference on Acoustics, Speech, and Signal
Processing Proceedings ICASSP, vol. 1, pp.669–672, 2001.
[171] J. Zhang, M. Marszalek, S. Lazebnik, C. Schmid, „Local features and kernels for
classification of texture and object categories: An in-depth study”, in Int. Journal of
Computer Vision, vol. 73(2), pp. 213-238, 2005.
[172] A. Holub, M. Welling, P. Perona, „Combining generative models and Fisher
kernels for object recognition”. in Int. Conference of Computer Vision ICCV, vol. 1,
pp. 136-143, 2005.
[173] F. Perronnin, C. Dance, „Fisher kernels on visual vocabularies for image
categorization. in Computer Vision and Pattern Recognition CVPR, pp. 71-78, 2007”.
[174] F. Perronnin, Y. Liu, J. Sánchez, H. Poirier, „Large-scale image retrieval with
compressed Fisher vectors”, in Computer Vision and Pattern Recognition CVPR, pp.
3384-3391, 2010.
[175] B.Mathieu, S.Essid, T.Fillon, J.Prado, G.Richard, „YAAFE, an Easy to Use and
Efficient Audio Feature Extraction Software”, in International Society for Music
Information Retrieval Conference, ISMIR, 2010.
[176] P. Kelm, S. Schmiedeke, T. Sikora, „Feature-based video key frame extraction for
low quality video”, in Proc. of Image Analysis for Multimedia Interactive Services
WIAMIS, pp. 25-28, 2009.
[177] T. Semela, M. Tapaswi, H. Ekenel, R. Stiefelhagen, „Kit at mediaeval 2012 -
content-based genre classification with visual cues”, in Mediaeval 2012 Workshop,
2012.
[178] B. Solmaz, S. M. Assari, M. Shah, „Classifying web videos using a global video
descriptor”, in Journal of Machine Vision and Applications, pp. 1-13, 2012.
[179] O. Kliper-Gross, Y. Gurovich, T. Hassner, L. Wolf, „Motion interchange patterns
for action recognition in unconstrained videos” in European Conference on Computer
Vision ECCV, pp. 155-163, 2012.
[180] R. Messing, C. Pal, H. Kautz, „Activity recognition using the velocity histories of
tracked keypoints”, in Int. Conference on Computer Vision ICCV, pp. 104-111, 2009.
[181] J. Wang, Z. Chen, Y. Wu, „Action recognition with multiscale spatio-temporal
contexts”, in Computer Vision and Pattern Recognition CVPR, pp. 3185-3192, 2011.
[182] Z. Lin, Z. Jiang, L. S. Davis, „Recognizing actions by shape-motion prototype
trees”, in Int. Conference of Computer Vision ICCV, pp. 444-451, 2009.
[183] R. Messing, C. Pal, H. Kautz, „Activity recognition using the velocity histories of
tracked keypoints”, in IEEE Int. Conference on Computer Vision, pp. 104-111, 2009.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
211
[184] I. Mironică, C. Vertan, „A Modified Feature Relevance Estimation Approach to
Relevance Feedback in Content-Based Image Retrieval Systems”, in Signal Processing
and Applied Mathematics for Electronics and Communications SPAMEC, pp. 109-
113, 2011, Cluj-Napoca, Romania.
[185] I. Mironica, C. Vertan, „An adaptive hierarchical clustering approach for relevance
feedback in content-based image retrieval systems”, in Int. Sym. of Signals, Circuits
and Systems ISSCS, 2011.
[186] I. Mironică, B. Ionescu , C. Vertan, „Hierarchical Clustering Relevance Feedback
for Content-Based Image Retrieval”, in IEEE/ACM International Workshop on
Content-Based Multimedia Indexing CBMI, Annecy, 2012.
[187] I. Mironică, B. Ionescu, C. Vertan, „The Influence of the Similarity Measure to
Relevance Feedback”, in European Signal Processing Conference - EUSIPCO, 2012.
[188] I. Mironică, C. Vertan, B. Ionescu, „A Relevance Feedback Approach to Video
Genre Retrieval”, in International Conference on Intelligent Computer
Communication and Processing ICCP, Cluj-Napoca, Romania, 2011.
[189] I. Mironică, B. Ionescu, J. Uijlings, N. Sebe, „Fisher Kernel based Relevance
Feedback for Multimodal Video Retrieval”, in ACM International Conference on
Multimedia Retrieval - ICMR, pp. 65-72, ISBN: 978-1-4503-2033-7, Dallas, Texas,
USA, 2013 .
[190] W. J. Krzanowski. Principles of Multivariate Analysis: A User's Perspective,
„Clarendon Press, Oxford, 1993.
[191] Microsoft Object Class Recognition dataset - http://research.microsoft.com/en-
us/projects/objectclassrecognition/.
[192] L. Fei-Fei, R. Fergus, P. Perona, „Learning generative visual models from few
training examples: an incremental Bayesian approach” in IEEE Conf. of Computer
Vision and Patter Recognition CVPR, Workshop on Generative-Model Based Vision,
pp. 178-188, 2004.
[193] S.H. Huang, Q.J Wu, S.H. Lu, „Improved AdaBoost-based image retrieval with
relevance feedback via paired feature learning”. in ACM Multimedia Systems, vol.
12(1), pp. 14-26, 2006.
[194] S.D. MacArthur, C.E. Brodley, C.-R. Shyu, „Interactive Content-Based Image
Retrieval Using Relevance Feedback”, in Computer Vision and Image Understanding,
vol. 12(1), pp. 14-26, 2002.
[195] Y. Wu, A. Zhang, „Interactive pattern analysis for Relevance Feedback in
multimedia information retrieval”, in ACM Journal on Multimedia Systems, vol 10(1),
pp. 41-55, 2004.
[196] G. Giacinto, „A Nearest-Neighbor Approach to Relevance Feedback in Content-
Based Image Retrieval”, in ACM Confenference on Image and Video Retrieval, pp.
456-463, 2007.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
212
[197] S. Schmiedeke, C. Kofler, I. Ferran, „Overview of MediaEval 2012 Genre Tagging
Task”, in Working Notes Proc. of the MediaEval 2012 Workshop, 2012.
[198] C. Rasche, „An Approach to the Parameterization of Structure for Fast
Categorization”, in Int. Journal of Computer Vision, vol. 87(3), pp. 337-356, 2010.
[199] L. Lamel, J.-L. Gauvain, „Speech Processing for Audio Indexing”, in Int. Conf. on
Natural Language Processing, LNCS, 5221, pp. 4-15, Springer Verlag, 2008.
[200] I. Mironică, C. Vertan, D. C. Gheorghe, „Automatic Pediatric Otitis Detection by
Classification of Global Image Features”, in International Conference on e-Health and
Bioengineering EHB, 2011.
[201] I. Mironică, R. Dogaru, „A comparison between various classification methods for
image classification stage in CBIR”, in Int. Sym. of Signals, Circuits and Systems
ISSCS, pp. 301-304, (IEEE Catalog number CFP11816-PRT, ISBN 978-1-4577-0201-
3), 2011.
[202] I. Mironică, C. Vertan, „Relevance feedback approaches for MPEG-7 content-
based biomedical image retrieval”, in International Conference on Communications
COMM, pp. 185-188, IEEE Catalog Number: CFP1041J-ART, ISBN: 978-1-4244-6363-
3, 2010.
[203] I. Mironică, „Sisteme de Relevance Feedback”, Raport de cercetare nr. 2, iunie
2012.
[204] B. Ionescu, I. Mironica, K. Seyerlehner, P. Knees, J. Schlüter, M. Schedl, H. Cucu,
A. Buzo, P. Lambert, „ARF @ MediaEval 2012: Multimodal Video Classification”, i
MediaEval Benchmarking Initiative for Multimedia Evaluation Workshop, Pisa,
Italia, 2012.
[205] I. Mironică, B. Ionescu, C. Rasche, P. Lambert, „A Visual-Based Late-Fusion
Framework for Video Genre Classification”, in IEEE International Symposium on
Signals, Circuits and Systems ISSCS, Iasi, Romania, 2013.
[206] Schlüter, B. Ionescu, I. Mironica, M. Schedl, „ARF @ MediaEval 2012: An
Uninformed Approach to Violence Detection in Hollywood Movies”, in MediaEval
Benchmarking Initiative for Multimedia Evaluation Workshop Pisa, Italia, 4-5
octombrie, 2012.
[207] R. Vieriu, Ionut Mironica, B.-T. Goras, „Background Invariant Static Hand Gesture
Recognition based on Hidden Markov Models”, in IEEE International Symposium on
Signals, Circuits and Systems ISSCS, Iasi, Romania, 2013.
[208] C. Vertan, D. C. Gheorghe, B. Ionescu, „Eardrum Color Content Analysis in
Video-Otoscopy Images for the Diagnosis Support of Pediatric Otitis”, in International
Symposium on Signals Systems and Circuits ISSCS, pp. 129-132 , 2011.
[209] Y. Hirose, K. Yamashita, S. Hijiya, „Back-propagation algorithm which varies the
number of hidden units”, in Neural Networks, vol. 4(1), pp. 61-66, 1991.
[210] G. Ratsch, T. Onoda, K. R. Muller, „Soft margins for AdaBoost”, in IEEE Trans.
of Machine Jearning, vol. 42(3), pp. 287-320, 2001.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
213
[211] D. Borth, J. Hees, M. Koch, A. Ulges, C. Schulze, „An automatic web video
categorizer”, in Proc. of ACM Multimedia, pp. 1111-1112, 2009.
[212] X. Yuan, W. Lai, T. Mei, X. S. Hua, X. Qing Wu, S. Li: „Automatic video genre
categorization using hierarchical SVM”, in IEEE International Conference on Image
Processing ICIP, pp. 2905-2908, 2006.
[213] Y. Song, Y.-D. Zhang, X. Zhang, J. Cao, J.-T. Li, „Google challenge: Incremental-
learning for web video categorization on robust semantic feature space”, in ACM
Multimedia, pp. 1113-1114, 2009.
[214] J. Wu, M. Worring, „Efficient Genre-Specific Semantic Video Indexing”, in IEEE
Transactions of Multimedia, vol 14 (2), pp. 291-302, 2012.
[215] L.-Q. Xu, Y. Li, „Video classification using spatial-temporal features and PCA”, in
International Conference on Multimedia and Expo, ICME, pp. 485-488, 2003.
[216] J.R.R. Uijlings, A.W.M. Smeulders, R.J.H. Scha: „Real-Time Visual Concept
Classification”, in IEEE Transactions on Multimedia, vol. 12(7), pp. 665-681, 2010.
[217] S. Schmiedeke, P. Kelm, T. Sikora, „TUB @ MediaEval 2012 Tagging Task:
Feature Selection Methods for Bag-of-(visual)-Words Approaches”, in Working Notes
Proc. of the MediaEval 2012 Workshop, 2012.
[218] T. Semela, M. Tapaswi, H. K.l Ekenel, R, Stiefelhagen, „KIT at MediaEval 2012 -
Content-based Genre Classification with Visual Cues”, in Working Notes Proc. of the
MediaEval 2012 Workshop, 2012.
[219] P. Xu, Y. Shi, M. Larson, „TUD at MediaEval 2012 genre tagging task: Multi-
modality video categorization with one-vs-all classifiers”, in Working Notes Proc. of
the MediaEval 2012 Workshop, 2012.
[220] Y. Shi, M. A. Larson, C. M. Jonker, „MediaEval 2012 Tagging Task: Prediction
based on One Best List and Confusion Networks”, in Working Notes Proc. of the
MediaEval 2012 Workshop, 2012.
[221] J. Almeida, T. Salles, E. R. Martins, O. Penatti, R. Torres, M. Goncalves,
„UNICAMP-UFMG at MediaEval 2012: Genre Tagging Task”, in Working Notes Proc.
of the MediaEval 2012 Workshop, 2012.
[222] C.-H. Demarty, C. Penet, G. Gravier, M. Soleymani, „The MediaEval 2012 Affect
Task: Violent Scenes Detection in Hollywood Movies”, in Working Notes Proc. of the
MediaEval 2012 Workshop, 2012.
[223] G. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, R. Salakhutdinov,
„Improving Neural Networks by Preventing Co-Adaptation of Feature Detectors”, at
arXiv.org, http://arxiv.org/abs/1207.0580, 2012.
[224] B. Ionescu, V. Buzuloiu, P. Lambert, D. Coquin, „Improved Cut Detection for the
Segmentation of Animation Movies”, in IEEE Int. Conf. on Acoustics, Speech, and
Signal Processing, vol 2, pp. II, 2006.
[225] Y.-G. Jiang, Q. Dai, C.C. Tan, X. Xue, C.-W. Ngo, „The Shanghai-Hongkong
Team at MediaEval2012: Violent Scene Detection Using Trajectory-based Features”, in

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
214
Proceedings Working Notes Proc. of the MediaEval 2012 Workshop, http://ceur-
ws.org/Vol-927/mediaeval2012_submission_28.pdf.
[226] C. Penet, C.-H. Demarty, M. Soleymani, G. Gravier, P. Gros,
„Technicolor/INRIA/Imperial College London at the MediaEval 2012 Violent Scene
Detection Task”, in Working Notes Proc. of the MediaEval 2012 Workshop,
http://ceur-ws.org/Vol-927/mediaeval2012_submission_26.pdf.
[227] F. Eyben, F. Weninger, N. Lehment, G. Rigoll, B. Schuller, „Violent Scenes
Detection with Large, Brute-forced Acoustic and Visual Feature Sets”, in Working
Notes Proc. of the MediaEval 2012 Workshop, http://ceur-ws.org/Vol-
927/mediaeval2012_submission_25.pdf.
[228] N. Derbas, F. Thollard, B. Safadi, G. Quenot, „LIG at MediaEval 2012 Affect
Task: use of a Generic Method”, in Working Notes Proc. of the MediaEval 2012
Workshop, http://ceur-ws.org/Vol-927/mediaeval2012_submission_39.pdf.
[229] E. Acar, S. Albayrak, „DAI Lab at MediaEval 2012 Affect Task: The Detection of
Violent Scenes using Affective Features”, in Working Notes Proc. of the MediaEval
2012 Workshop, http://ceur-ws.org/Vol-927/mediaeval2012_submission_33.pdf.
[230] V. Martin, H. Glotin, S. Paris, X. Halkias, J.-M. Prevot, „Violence Detection in
Video by Large Scale Multi-Scale Local Binary Pattern Dynamics”, in Working Notes
Proc. of the MediaEval 2012 Workshop, http://ceur-ws.org/Vol-
927/mediaeval2012_submission_43.pdf.
[231] V. Lam, D.-D. Le, S.-P. Le, Shinichi Satoh, D.A. Duong, „NII Japan at MediaEval
2012 Violent Scenes Detection Affect Task”, in Working Notes Proc. of the MediaEval
2012 Workshop, http://ceur-ws.org/Vol-927/mediaeval2012_submission_21.pdf.
[232] R. Vieriu, Ionut Mironica, B.-T. Goras, „Background Invariant Static Hand Gesture
Recognition based on Hidden Markov Models”, in IEEE ISSCS -International
Symposium on Signals, Circuits and Systems, Iasi, Romania, 2013.
[233] R.Y. Wang, J. Popovic, „Real-time Hand-Tracking with a Color Glove”, in ACM
Trans. On Graphics, vol. 28(3), pp.63.1-63.8, 2009. .
[234] X. Zhang, X. Chen, Y. Li, V. Lantz, K. Wang, J. Yang, „A Framework for Hand
Gesture Recognition Based on Accelerometer and EMG Sensors”, in Trans. on Systems,
Man and Cybernetics, vol.41(6), pp.1064-1076, 2011. .
[235] A. Erol, G. Bebis, M. Nicolescu, R.D. Boyle, X. Twombly, „Vision based hand
pose estimation: A review”, in Computer Vision and Image Understanding, vol. 108,
pp.52-73, 2007.
[236] R.L. Vieriu, B. Goraş, L. Goraş, „On HMM static hand gesture recognition”, in Int.
Symp. on Signals, Circuits and Systems, pp.221-224, 2011.
[237] S. Oprisescu, C. Rasche, S. Bochao, „Automatic static hand gesture recognition
using ToF cameras”, in Proc. of European Signal Processing Conference EUSIPCO,
pp. 2748-2751, 2012.

Tehnici Inteligente pentru analiza și clasificarea colecțiilor de baze de date multimedia
215
[238] L. Yun, Z. Lifeng, Z. Shujun, „A Hand Gesture Recognition Method Based on
Multi-Feature Fusion and Template Matching”, in Proc. of Engineering, vol. 29, pp
1678-1684, 2012.





























