Embed Size (px)
Citation preview

Week 10What are we searching for?
The College of Saint RoseCIS 521 / MBA 541 – Introduction to Internet DevelopmentDavid Goldschmidt, Ph.D.
selected material from Search Engines: Information Retrieval in Practice, 1st edition by Croft, Metzler, and Strohman, Pearson, 2010, ISBN 0-13-607224-0

What is search?
What is search?
What are we searching for?
How many searches areprocessed per day?
What is the average number ofwords in text-based searches?

Finding things
Applications and varieties of search: Web search Site search Vertical search Enterprise search Desktop search Peer-to-peer search
search

Acquisition and indexing
where do wesearch next?
how do we acquirenew documents?

Text transformation
how do we bestconvert documentsto their index terms
how do we makeacquired documents
searchable?
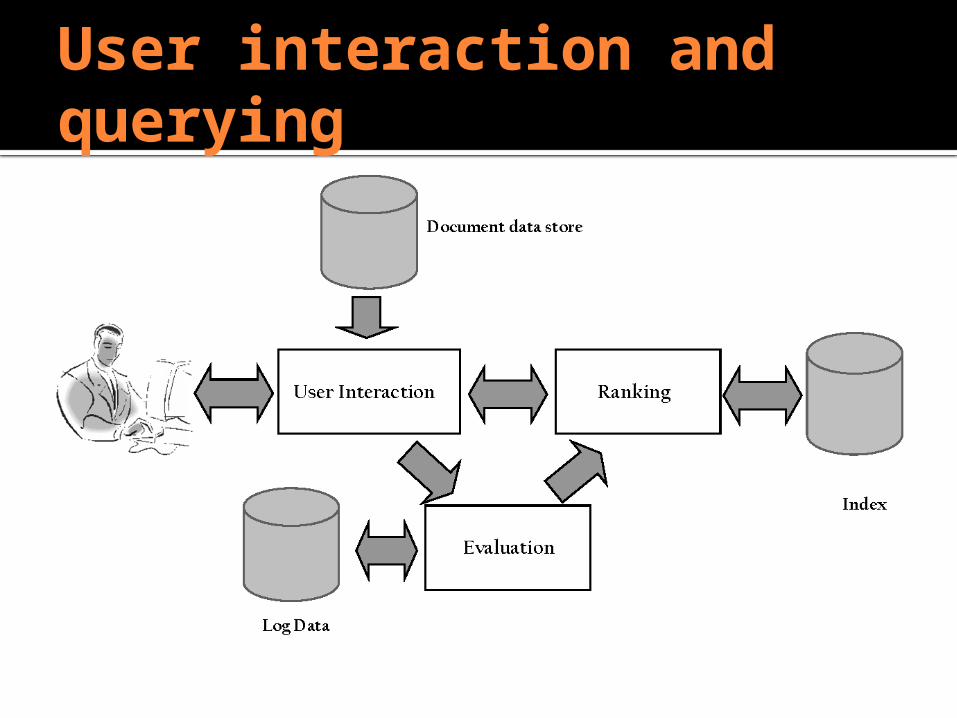
User interaction and querying

Measures of success (i)
Relevance Search results contain information
the searcher was looking for Problems with vocabulary mismatch ▪ Homonyms (e.g. “Jersey shore”)
User relevance Search results relevant to one user
may be completely irrelevant toanother user
SNOOKI

Measures of success (ii)
Precision Proportion of retrieved documents
that are relevant How precise were the results?
Recall (and coverage) Proportion of relevant documents
that were actually retrieved Did we retrieve all of the relevant
documents?
http://trec.nist.gov

Measures of success (iii)
Timeliness and freshness Search results contain information that
is current and up-to-date
Performance Users expect subsecond response times
Media Users increasingly use cellphones,
mobile devices

Measures of success (iv)
Scalability Designs that work, must perform equally well
as the system grows and expands▪ Increased number of documents, number of users,
etc.
Flexibility (or adaptability) Tune search engine components to
keep up with changing landscape
Spam-resistance

Information retrieval (IR)
Gerard Salton (1927-1995) Pioneer in information retrieval
Defined information retrieval as: “a field concerned with the
structure, analysis, organization, storage, searching, and retrieval of information”
This was 1968 (before the Internet and Web!)

(Un)structured information Structured information:
Often stored in a database Organized via predefined
tables, columns, etc. Select all accounts with balances less than
$200
Unstructured information Document text (headings, words, phrases) Images, audio, video (often relies on textual
tags)
account number
balance
7004533711 $498.19
7004533712 $781.05
7004533713 $147.15
7004533714 $195.75

Processing text
Search and IR has largelyfocused on text processingand documents
Search typically uses thestatistical properties of text Word counts Word frequencies But ignore linguistic features (noun,
verb, etc.)

Image search?
Image search currently relies on textual tags Therefore just another form of text-
based search
Edie; little girlkid’s laptop
bare foot
drink; sippy cup

Uniform Resource Locator (URL)
A URL identifies a resource on the Web,and consists of: A scheme or protocol (e.g. http, https) A hostname (e.g. academic2.strose.edu) A resource (e.g.
/math_and_science/goldschd)
e.g. http://cs.strose.edu/courses-ug.html
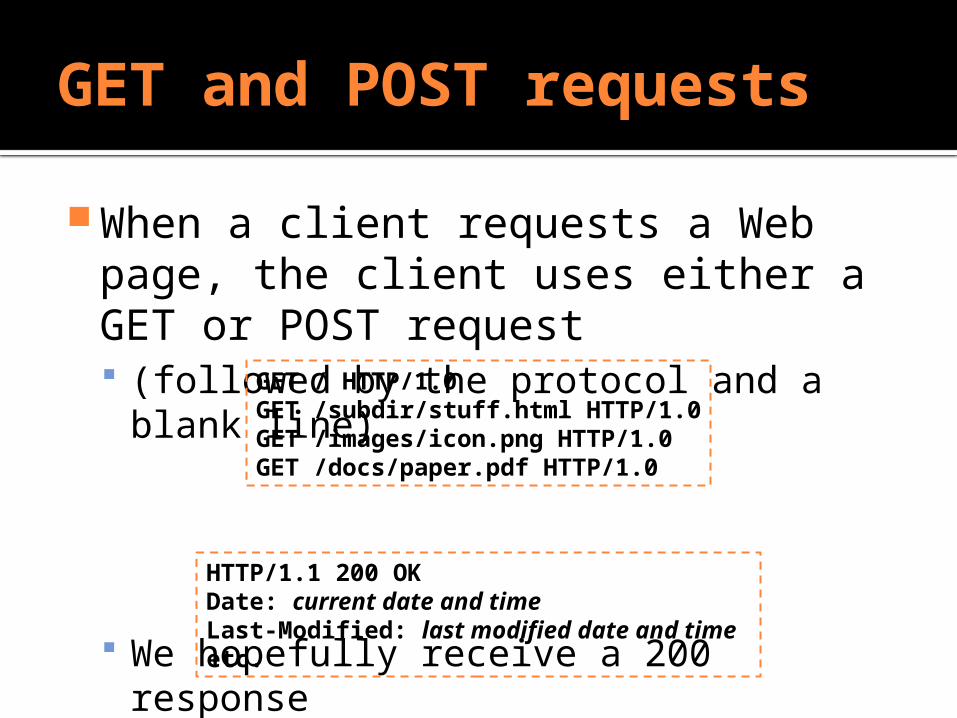
GET and POST requests
When a client requests a Web page, the client uses either a GET or POST request (followed by the protocol and a blank
line)
We hopefully receive a 200 response
GET / HTTP/1.0GET /subdir/stuff.html HTTP/1.0GET /images/icon.png HTTP/1.0GET /docs/paper.pdf HTTP/1.0
HTTP/1.1 200 OKDate: current date and time Last-Modified: last modified date and time etc.

Politeness and robots.txt
Web crawlers adhere to a politeness policy: GET requests sent every few seconds or
minutes A robots.txt file
specifies whatcrawlers areallowed to crawl:

Sitemaps
default priority is 0.5
some URLs might not be discovered by crawler

Text transformation
how do we bestconvert documentsto their index terms
how do we makeacquired documents
searchable?

Find/Replace
Simplest approach is find, whichrequires no text transformation Useful in user applications,
but not in search (why?) Optional transformation
handled during the findoperation: case sensitivity

Text statistics (i)
English documents are predictable: Top two most frequently occurring words
are “the” and “of” (10% of word occurrences)
Top six most frequently occurring wordsaccount for 20% of word occurrences
Top fifty most frequently occurring words account for 50% of word occurrences
Given all unique words in a (large) document, approximately 50% occur only once

Text statistics (ii)
Zipf’s law: Rank words in order of decreasing
frequency The rank (r) of a word times its
frequency (f) is approximately equal to a constant (k)
r x f = k In other words, the frequency of the rth
most common word is inversely proportional to r
George Kingsley Zipf(1902-1950)

Text statistics (iii)
The probability of occurrence (Pr)of a word is the word frequencydivided by the total number ofwords in the document
Revise Zipf’s law as: r x Pr = c
for English,c ≈ 0.1

Text statistics (iv)
Verify Zipf’s law using the AP89 dataset: Collection of Associated Press (AP) news
stories from 1989 (available at http://trec.nist.gov):
Total documents 84,678Total word occurrences39,749,179Vocabulary size 198,763Words occurring > 1000 times 4,169Words occurring once 70,064

Text statistics (v)
Top 50wordsof AP89

It all boils down to text
For each document we process, the goal is to isolate each word occurrence This is called tokenization or lexical
analysis
We might also recognize various typesof content, including: Metadata (i.e. invisible <meta> tags) Images and video (via textual tags) Document structure (sections, tables,
etc.)

Text normalization
Before we tokenize the given sequence of characters, we might normalize the text by: Converting to lowercase Omitting punctuation and special
characters Omitting words less than 3 characters
long Omitting HTML/XML/other tags
What do we do with numbers?

Stopping and stopwords (i)
Certain function words (e.g. “the” and “of”) are typically ignored during text processing These are called stopwords, because
processing stops when they are encountered
Alone, stopwords rarely helpidentify document relevance
Stopwords occur very frequently,which would bog down indexes

Stopping and stopwords (ii)
Top 50wordsof AP89
Mostlystopwords!

Stopping and stopwords (iii)
Constructing stopword lists: Created manually (by a human!) Created automatically using word
frequencies▪ Mark the top n most frequently
occurring words as stopwords
What about “to be or not to be?”

Stopping and stopwords (iv)
Stopword lists may differ based on what part of the document we are processing Additional stopwords for an <a> tag:▪ click▪ here▪ more▪ information
▪ read▪ link▪ view▪ document

Stemming (i)
Stemming reduces different forms of aword down to a common stem
swimswimswimsswimmerswimmingswametc.
▪ Stemming reduces the number of unique words in each document▪ Stemming increases the
accuracy of search (by 5-10% for English)

Stemming (ii)
A stem might not be an actual valid word
causcausecausingcausescausedcauseretc.

Stemming (iii)
How do we implement stemming? Use a dictionary-based approach to map
words to their stems (http://wordnet.princeton.edu/)
Use an algorithmic approach▪ Suffix-s stemming: remove last ‘s’ if present▪ Suffix-ing stemming: remove trailing ‘ing’▪ Suffix-ed stemming: remove trailing ‘ed’▪ Suffix-er stemming: remove trailing ‘er’▪ etc.

Porter stemmer (i)
The Porter stemmer is an algorithmic stemmer developed in the 1970/80s http://tartarus.org/~martin/PorterStemm
er/ Consists of a sequence of rules and
steps focused on reducing or eliminating suffixes▪ There are 5 steps, each with many “sub-
steps” Used in a variety of IR experiments Effective at stemming TREC datasets
Dr. Martin Porter

Porter stemmer (ii)

Porter stemmer (iii)
Nothing is perfect...
▪ also see http://snowball.tartarus.org
detects arelationshipwhere onedoes not
actually exist(same stem)
does notdetect a
relationshipwhere onedoes exist
(different stem)

Phrases and n-grams (i)
An n-gram refers to any consecutive sequence of n words
▪ The more frequently an n-gram occurs,the more likely it is to correspond to ameaningful phrase in the language
World news about the United States
overlappingn-grams with n = 2
(a.k.a. bigrams)
World newsnews about
about thethe United
United States

Phrases and n-grams (ii)
Phrases are: More precise than single words▪ e.g. “black sea” instead of “black” and “sea”
Less ambiguous than single words▪ e.g. “big apple” instead of “apple”
Drawback: Phrases and n-grams tend to
make ranking more difficult

Phrases and n-grams (iii)
By applying apart-of-speech(POS) tagger,high-frequencynoun phrasesare detected
(but too slow!)
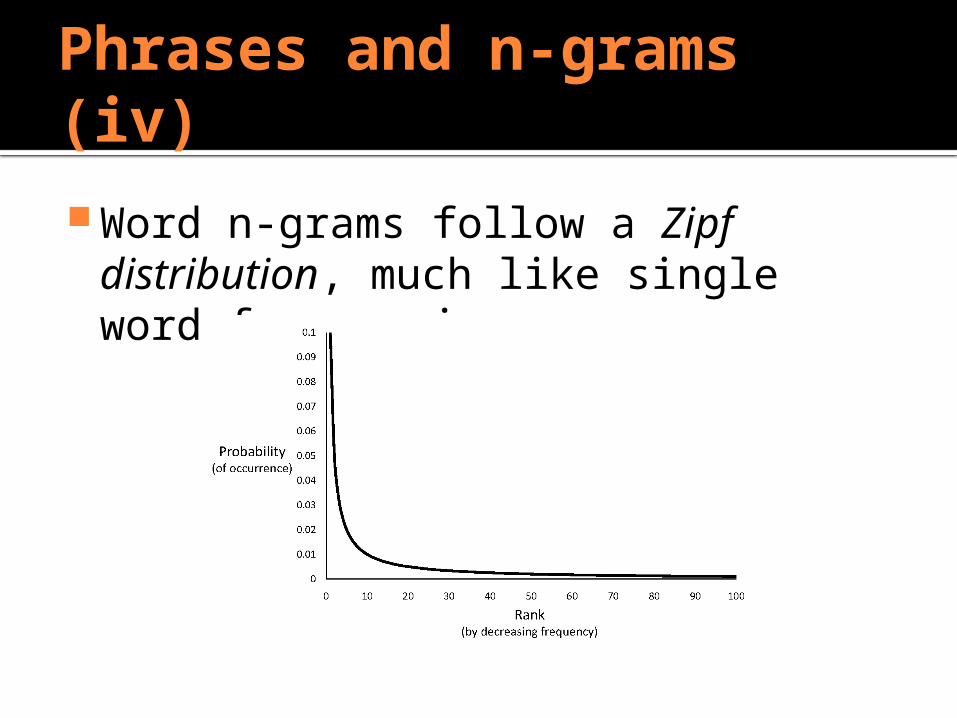
Phrases and n-grams (iv)
Word n-grams follow a Zipf distribution, much like single word frequencies

Phrases and n-grams (v)
A sampling from Google:
▪ Most common English trigram: all rights reserved ▪ see
http://googleresearch.blogspot.com/2006/08/all-our-n-gram-are-belong-to-you.html

Storage and retrieval
Computers store and retrieve information Retrieval first requires finding information
once we find the data, we often must extract what we need...

Identifying traffic patterns
Weblogs record each and every access to the Web server Use the data to answer questions Which pages are the most popular? How much spam is the site
experiencing? Are certain days/times busier than
others? Are there any missing pages (bad links)? Where is the traffic coming from?

Weblogs (not blogs!)
Apache software records an access_log file:
75.194.143.61 - - [26/Sep/2010:22:38:12 -0400] "GET /cis460/wordfreq.php HTTP/1.1" 200 566HTTP request server response code
(for server response codes, see http://en.wikipedia.org/wiki/List_of_HTTP_status_codes)
size in bytes of data returned
requesting IP (or host) username/password access timestamp

Links
Links are useful to us humans fornavigating Web sites and finding things
Links are also useful to search engines <a href="http://cnn.com"> Latest News
</a> anchor textdestination link (URL)

Anchor text
How does anchor text apply to ranking? Anchor text describes the
content of the destination page Anchor text is short, descriptive,
and often coincides with query text Anchor text is typically written
by a non-biased third party

The Web as a graph (i)
We often represent Web pages as vertices and links as edges in a webgraph
http://www.openarchives.org/ore/0.1/datamodel-images/WebGraphBase.jpg

The Web as a graph (ii)
http://www.growyourwritingbusiness.com/images/web_graph_flower.jpg
An example:

Using webgraphs for ranking Links may be interpreted as describing
a destination Web page in terms of its: Popularity Importance
We focus on incoming links (inlinks) And use this for ranking matching documents Drawback is obtaining incoming link data
Authority Incoming link count

PageRank (i)
PageRank is a link analysis algorithm PageRank is accredited to Sergey Brin
and Lawrence Page (the Google guys!) The original PageRank paper:▪ http://infolab.stanford.edu/~backrub/google.h
tml

PageRank (ii)
Browse the Web as a random surfer: Choose a random number r between 0 and 1 If r < λ then go to a random page else follow a random link from the current
page Repeat!
The PageRank of page A (noted PR(A)) is the probability that this “random surfer” will be looking at that page

PageRank (iii)
Jumping to a random pageavoids getting stuck in: Pages that have no links Pages that only have broken links
Pages that loop back to previously visited pages

Link quality (and avoiding spam)
A cycle tends to negate theeffectiveness of thePageRank algorithm

Retrieval models (i)
A retrieval model is a formal (mathematical) representation of the process of matching a query and a document
Forms the basis of ranking results
doc 234
doc 345
doc 455
doc 567
doc 678
doc 789
doc 881
doc 972
doc 123
doc 257
user query terms ?
doc 913

Retrieval models (ii)
Goal: Retrieve exactly the documents that users want (whether they know it or not!) A good retrieval model finds documents
that are likely to be consideredrelevant by the user submittingthe query (i.e. user relevance)
A good retrieval model alsooften considers topical relevance

Topical relevance
Given a query, topical relevance identifies documents judged to be on the same topic Even though keyword-based document
scores might show a lack of relevance!Abraham Lincoln
query: Abraham Lincoln
Civil War
Tall Guys with
Beards
Stovepipe Hats
U.S. President
s

User relevance
User relevance is difficult to quantify because of each user’s subjectivity Humans often have difficulty
explaining why one documentis more relevant than another
Humans may disagree abouta given document’s relevancein relation to the same query
R
R





























