Embed Size (px)
Citation preview

The DHS Ontology Case
Presentation by OntologyStream Inc
Paul Stephen Prueitt, PhD
19 March 2005
Ontology Tutorial 1, copyright, Paul S Prueitt 2005

Ontology technology exists in the market
However, practical problems block progress in designing and implementing DHS wide ontology technology. Business process mythology, like Earned Value program management, is not focusing on the right questions and maturity models for software development have precluded most innovations that come from outside the relational database paradigm.
These practical problems are also partially a consequent of
1. Some specific institutional behaviors related to traditional program management.
2. Confusion caused by long term, and heavily funded Artificial Intelligence marketing activities

As a general proposition, through out the federal government, quality metrics are not guiding management decisions supporting:
1) Quick transitions from database centered information technology to XML based Semantic Web technology.
2) Transitions from XML repositories to ontology mediated Total Information Awareness, with Informational Transparency, in Secure Channels.
Emerging Semantic Web
Standards
DHS Ontology
1) World-wide Trade Data
2) Investigation Targeting
3) Risks, Threats and Vulnerabilities
4) Policy Enforcement
?

Diagram from Prueitt, 2003

Diagram from Prueitt, 2003
First two steps are missing
Seven step AIPM
is not complete
RDBMS

The measurement/instrumentation task
First two steps in the AIPM
Measurement is part of the “semantic extraction” task, and is accomplished with a known set of techniques”
• Latent semantic technologies
• Some sort of n-gram measurement with encoding into hash tables or internal ontology representation (CCM and NdCore, perhaps AeroText and Convera’s process ontology (?), Orbs, Hilbert encoding, CoreTalk/Cubicon.
• Stochastic and neural/ genetic architectures

One model for semantic extraction explicitly focuses on the first two aspects of the AIPM; e.g. instrumentation/measurement and data-encoding/interpretation

Actionable Intelligence Process Model has an action-perception event cycle.
Stratified ontology supports the use of this cycle to produce knowledge of attack and anticipatory mechanisms based on the measurement of sub-structural categorical invariance.
Work flow and process ontology is available as a basis for encoding knowledge of anticipatory response mechanisms.
Categorical Invariance is measured, using Orbs (Ontology referential bases) for example or CCM (Contiguous Connection Model) encoding, and organized as a resource for RDF triples using some lite OWL OIL.

Distributed ontology management is already available in some military activities

distributed Ontology Management Architecture
d-OMA
Ontology ArchitectureMarch 10, 2005
Version 3.0
Part of a series on the nature of machine encoding of sets of concepts
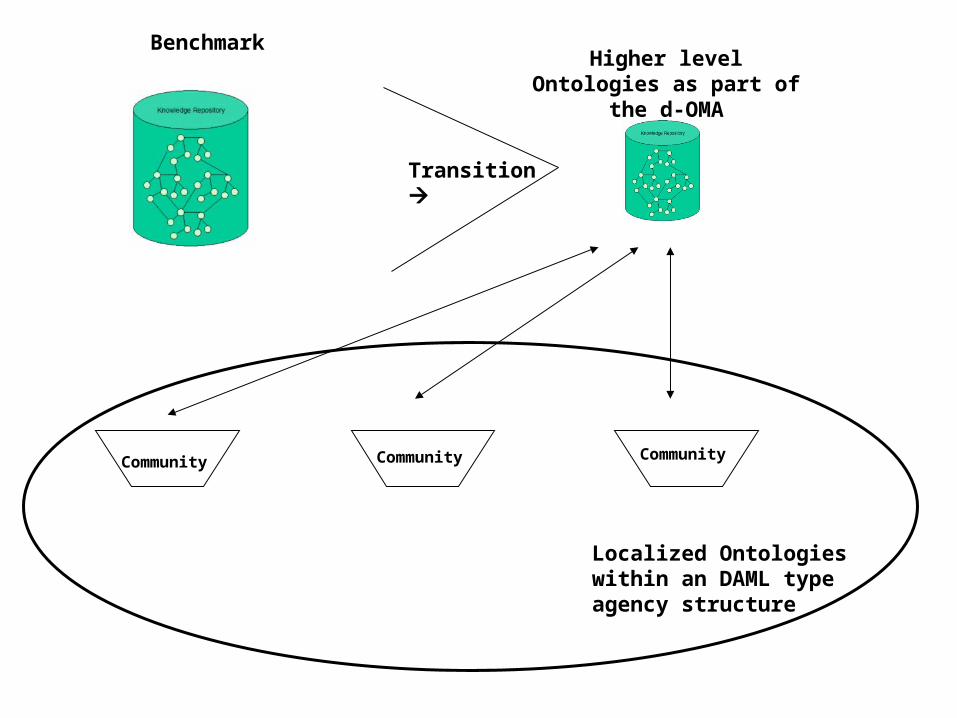
Community
Transition
BenchmarkHigher level Ontologies as
part of the d-OMA
Localized Ontologies within an DAML type agency structure
CommunityCommunity

Higher level Ontologies
Localized Ontologies
Links to Web services
and Internal R&D
Community
Community
Community

A reconciliation process is required between ontology services.
Ontology users have the following roles:
Knowledge engineers
Information mediators ( e.g. ontology librarians )
Community workers
(e.g. analysts)
Knowledge Engineers
Ontology librarian
Intelligence Targeting
Analyst
Community

Higher level Ontologies
Localized Ontologies
Real time acquisition of new concepts, and modifications to existing concepts are made via an piece of software called
Ontology Use Agent
Ontology Use Agents
have various type of functions expressed in accordance with roles
Mature scholarship from evolutionary psychology research communities.
Community

Human and system interaction with a common Ontology Structure
Ontology PresentationPart of a series on the nature of machine encoding
of sets of concepts

First, and before all else, an computer based ontology is a
{ concepts }
In the natural, physical, sciences an ontology is the causes of those things that one can interact with in Nature.
Physical science informs us that a formative process is involved in the expression of natural ontology in natural settings.
First principles
The set of “our” personal and private concepts is often thought to be the causes of how we reason as humans. This metaphor is operational in many peoples’ understanding about the nature and usefulness of machine encoded ontology. But this metaphor can also mislead us!!!!
Extensive literatures indicate that the Artificial Intelligence (AI) mythology has lead many to believe that the “reasoning” of an ontology might be the same as the reasoning of a human in all cases.
•This inference is not proper because the truthful-ness of this inference has not been demonstrated by natural science, and perhaps cannot be demonstrated no matter what the levels of government funding for AI.
•AI is discounted in Tim Berner’s Lee’s notion of the Semantic Web.

Tim Berner’s Lee Notion of Semantic Web
One consequence of acknowledging this difference is to elevate the work of the authors of the OASIS standards, in particular Topic Maps. In Topic Maps we have an open world assumption and very little emphasis on computational inference. Human knowledge is represented in a “shallow form, and visualization is used to manage this representation.
Computation with topic maps AND OWL ontologies work together with XML repositories.
The point being made here is that the notion of “inference” is very different depending if one is talking about the human side or the machine side of the Semantic Web.

{ concepts }First principles
Let is use only set theory to consider Tim Berners Lee’s notion of Semantic Web.
Let C = { concepts } and B be a subset of C
Human and/or machine computation creates a well formed query
Some software
B is a subset of C
Subsetting function
The subsetting function might be an
“ask-tell”
interaction between two ontologies

{ concepts }
First principles
B is a subset of C
Subsetting function
At this point we have various possible consequences.
1) The small(er) B ontology might simply be viewed by a human and actions taken outside of the information system
2) The smaller ontology might be used in several different ways
a) Imported into a reasoner to be considered in conjunction with various different data sources.
b) Send messages to other ontologies via a distributed Ontology Management System

First principles
Situational Ontology
Software The knowledge repository acts as a “perceptual ground” in a “figure-ground” relationship.
The ontology sub-setting function has pulled part, but not all, of the background into a situational focus. This first principle is consistent with perceptual physics and thus is “informed” by natural science.

Extending Ontology Structure over legacy information systems
Part of a series on the nature of machine encoding of sets of concepts
(The following slides are from OntologyStream’s Ontology Presentation VII – General Background)

Functional specs
Ontology Use Start-up Use Model
Model: Steady State Ontology System
Components: Framework for Query Entity
Data Access: Steady State Ontology System
Framework for Query Entity
Building ontology from data flow
Using Ontology
Ontology Generating Framework
The inverse problem: generating synthetic data
Finding data regularity in its natural contextualization
Presentation Contents

Functional specs
Functional specs:
1. Human-centric: must be human (individual) centric in design and function
2. Support data retrieval: must act as a data retrieval mechanism
3. Event structure measurement: must assist in the definition of data acquisition requirements on an on-going basis
4. Interactive: must support multiple interacting ontologies
5. Real Time: must aid in real time problem solving and in the long term management of specific sets of concepts
Note: Ontology mediated knowledge systems have operational properties that are quite different from traditional relational database information systems. These five functional specs have been reviewed by a small community of professional ontologists, as has been deemed correct for knowledge systems.

Ontology Use Start-up Use Model I
Transaction process
KnowledgeBase
Entity updates
One of the Ontology Reasoners
Query entities
startup
Inferences about
Start-up Use Case – Step 1
At start-up, resources are loaded into the reasoner.
1) Some part of the knowledge base is expressed as reasoner complaint RDF
2) Some inference logic is loaded into the reasoner
3) Query entities are loaded to reflect interests of analyst(s)
4) Transaction processes are occurring in real time

Start-up Use Model II
Transaction process
KnowledgeBase
Entity updates
ReasonerQuery entities
startup
inferences
Start-up Use Case Step 2
Since instance data is much larger (2 or more magnitudes larger) than the knowledge base, the instance data is managed in a separate start-up process.
Instance data

Model: Steady State Ontology System
Transaction process
KnowledgeBase
Entity updates
Query entities
inferences
Inference Mgr
Query Mgr
Data Access Mgr
Reasoner
Ontology Mgr
Instance dataInstance data may be remote or local. Local data is on the same network as the knowledge base.

Components: Framework, User Visualization point of view
Transaction processes
KnowledgeBase
updates
Query entities
inferences
Data Reasoner
Ontology Mgr
Data Access Mgr
Use Case: Steady State Ontology System
Query Manager
Inference Manager

KnowledgeBase
Data
Data Access Mgr
Data Access: Steady State Ontology Systemusing the OWL standard **
The RDF knowledge base ** is a set of concepts expressed as a set:
{ < subject, verb, predicate > }
and the data is either “XML” or a data structure such as one would have as a C construct.
The Data Access Manager must manage the mapping between local data stores (sometimes having millions of elements) and the set of concepts.
The remote data may have many persistence forms, and will be accessed via a data object.
Instance data
Data Object
Pipes and
Threads
** We use RDF and OWL as a standard to create minimal and well knowledge inference capabilities.

Framework from Query Entity point of view
Transaction processes
KnowledgeBase
updates
Query entities
inferences
Data Reasoner
Data Access Mgr
Query Manager
Inference Manager
Ontology Mgr A Query Entity is itself a type of light ontology. It develops “knowledge” about the user(s) and about the query process.

Framework from Knowledge Management point of view
Transaction processes
Query entities
Query Manager
Real time analysis is supported through the development and use of query entities.
These entities have “regular” structure and are managed within a Framework.

Building ontology from data flow
Transaction processes A model of the "causes" of transaction data.
The model is based on, grounded in, the concept of "occurrence in the real world", or "event".
Associated with each event, we may have a "measurement".
So we have a set of events
{ e(i) }
where i is a counter.
Some of the fields MAY not be used.
Later the number of fields in any "findings data flow" may increase or decrease without us caring at all.
Objective: We convert a stream of event measurements into an “transaction” ontology, and create auxiliary processes that will use a general risk ontology, an ontology about process optimization, and other “utility ontologies”.

Using Ontology
Transaction processes
Query entities
Query Manager
Consider a set of events { e(i) } where i is a counter.
Each event will have a weakly w structured (free form text) and structured s component. So we use the notation
e = w/s or
e(i) = w(i)/s(i) .
KnowledgeBase
Data
Instance data

Ontology Generating Framework
Transaction processes
Notation
e(i) = w(i)/s(i)
An event is measured by filling in slots in a data entry form, and by typing in natural language into comments fields in these entry forms.
Observation: Given real data, one can categorize the set of events due to the nature of the information filled in.
{ e(i) }{ w(i) }
{ s(i) }
Semantic extraction
Discrete analysis
Semantic extraction is performed using one of several tools, or tools in combination with each other
Discrete analysis is mostly the manual development of ontology through the study of natural categories in how the data is understood by humans.

{ w(i) }
{ s(i) }
Semantic extraction
Discrete analysis
Each s(i) is a record from a single table.
Suppose there are 120 columns. Each column has values, sometimes empty. Fix the counter at *.
Let s(*, j) , j = 1, . . . , 120 be the columns. We can call these columns also using the term “slot”.
Now for each s(*, j) list the values that are observed to be in that column. These values are the possible “fillers” for the associated slot.
Free form text is weakly structured.
The set
{ w(i) }
is a text corpus that we would like to “associate” with several ontologies.
Each association is made as exploratory activities with specific goals.
For each event we may have zero or more free text fields. Suppose we concatenate these, into one text unit, and perhaps also develop some metadata (in some way) that will help contextualize the semantic extraction process. We label this unit as “ w(i) ”.
Finding data regularity in its natural contextualization
Regularity in data flow is “caused” by the events occurring in the external world. Thus the instances of specific data in data records provide to the knowledge system a “measurement” of the events in the external world.

Data regularity in context …. Patterns and invariance
• XML and related standards
• community open and protected standards (CoreTalk, Rosetta Net, ebXML)
• .NET component management
• J2EE frameworks – Spring
• General framework constructions
• autonomous extraction (Hilbert encoding of data into keyless hash tables, SLIP Shallow Link analysis Iterated Scatter-Gather an Parcelation) Core, AeroText (etc) semantic extraction using process knowledge and text input

The role of community
1) A community of practice provide a reification process that is Human centric (geographical-community / functional-community)
2) Each community may have locally instantiated OWL ontology with topic map visualization.
a) Consistently and completeness is managed locally as a property of the human individuals, acting within a community, and a locally persisted history of informational transactions with his/her agent
b) Individual agents can query for and acquire XML based Web Services, negotiate with other agents and create reconciliation processes involving designated agencies.
3) Knowledge engineers act on the behalf of policy makers to • reify new concepts,
• delete concepts and to
• instantiate reconciliation containers

Establishing coherence in “natural” knowledge representation
1) Coherence is a physical phenomenon seen in lasers
a) Brain function depends critically on electromagnetic coherenceb) Incoherence, e.g. non-rationality, and in-completeness are two separate contrasting issues
to the issue of coherencec) Mathematics, and therefore computer science and logic, have completeness and
consistency issues that are well established and well studied
2) Logical coherence is sometimes treated as consistency in logic
a) One may think that one has logical consistency and yet this property of the full system was lost at the last transaction within the Ontology
b) The act of attempting to find a complete representation of information organization is sometimes called “reification”, and reification efforts works against efforts to retain consistency
3) Human usability often is a function of a proper balance between logic and agility

Understanding multiple viewpoints
1) Logical consistency and single minded-ness are operational linked together in most current generation decision support systems. Database schema legacy issues. Schema servers, FEA (Federal Enterprise Architecture) standards, schema independent data systems
2) Observation: Human cognitive capabilities have far more agility than current generation decision support systems
3) The topic map standard (2001, Newcomb and Briezski ) was specifically developed to address the non-agility of Semantic Web standards based on OWL and RDF. (Ontopia, Steve Pepper)
4) Combining XML repositories, OWL, distributed agent architectures and Topic Maps is expressed as Stratified Ontology Management

Detection of novelty
Scenario: an targeting and search analyst at the Port of Seattle is only partially aware of why she feels uncomfortable about some characteristic of a shipment from Sweden. The feeling is expressed in a hand written finding and fed into a document management repository for findings. A targeting and search analyst at the Port of LA expresses a fact about a similar shipment without knowing of her colleague’s sense of discomfort.
1) Conceptual roll-up techniques are used on a minute by minute basis to create a viewable topic map over occurrences of concepts expressed in findings.
2) Link analysis connects an alert about uncertainty in the Seattle finding to the fact from LA to produce new information related to a known vulnerability and attack pattern.
3) New knowledge forms are propagated into OWL instantiated ontology
and rules and viewed using Topic Maps.

Agent architecture
Scenario: Human analysts provide situational awareness via tacit knowledge, personally agent mediated interactions with agent structures, and human to human communications. A model of threats and vulnerabilities has evolved but does not account for a specific new strategy being developed by a smart smuggler. The smuggler games the current practices in order to bring illegal elements into the United States
1) The model of threats and vulnerabilities expresses as a reification process from various techniques and encoded OWL/Protégé ontology with rules
2) Global Ontology: The model is maintained via near real time agency processes under the observation, active review, of knowledge engineers and program managers working with knowledge of policy and event structure
3) Local Ontology: Information is propagated to individual analysts via alerts and ontology management services controlled by the localized agent (of the person)

New (1/30/2005) tutorial on automated extraction of ontology from free form text:
http://www.bcngroup.org/beadgames/anticipatoryWeb/23.htm





























