Embed Size (px)
Citation preview

The UOB Python Lectures:Part 3 - Python for Data
AnalysisHesham al-Ammal
University of Bahrain
Thursday, April 4, 13

Small DataBIG Data
Thursday, April 4, 13

Data Scientist’s TasksInteracting with the outside
worldPreparation
Reading and writing with a variety of file formats and databases.
Cleaning, munging, combining, normalizing, reshaping, slicing and dicing, and transforming data for analysis.
TransformationApplying mathematical and statistical operations to groups of data sets to derive new data sets. For example, aggregating a large table by group variables.
Modeling and computationConnecting your data to statistical models, machine learning algorithms, or other computational tools
PresentationCreating interactive or static graphical visualizations or textual summaries
Thursday, April 4, 13

Example 1: .usa.gov data from bit.ly
JSON: JavaScript Object Notation
Python has many JSON librariesIn [15]: path = 'ch02/usagov_bitly_data2012-03-16-1331923249.txt'In [16]: open(path).readline()
import jsonpath = 'usagov_bitly_data2012-03-16-1331923249.txt'records = [json.loads(line) for line in open(path)]record[0]
We’ll use list comprehension to put the data in a dictionary
Thursday, April 4, 13

In [19]: records[0]['tz']Out[19]: u'America/New_York'
In [20]: print records[0]['tz']America/New_York
Unicode strings and notice how dictionaries work
Counting timezones in PythonLet’s start by using Pyhton only and list comprehension
In [6]: time_zones = [rec['tz'] for rec in records]---------------------------------------------------------------------------KeyError Traceback (most recent call last)<ipython-input-6-db4fbd348da9> in <module>()----> 1 time_zones = [rec['tz'] for rec in records]
KeyError: 'tz'You’ll get an error because not all
records have time zonesThursday, April 4, 13

Counting timezones in PythonSolve the problem of missing tz by using an if
In [26]: time_zones = [rec['tz'] for rec in records if 'tz' in rec]In [27]: time_zones[:10]Out[27]:[u'America/New_York',u'America/Denver',u'America/New_York',u'America/Sao_Paulo',u'America/New_York',u'America/New_York',u'Europe/Warsaw',u'',u'',u'']
def get_counts(sequence): counts = {} for x in sequence: if x in counts: counts[x] += 1 else: counts[x] = 1 return counts
In [31]: counts = get_counts(time_zones)In [32]: counts['America/New_York']Out[32]: 1251In [33]: len(time_zones)Out[33]: 3440
Define a function to count occurrences in a sequence using a dictionary
Then just pass the time zones list
Thursday, April 4, 13

Finding the top 10 timezonesWe have to manipulate the dictionary by sortingdef top_counts(count_dict, n=10): value_key_pairs = [(count, tz) for tz, count in count_dict.items()] value_key_pairs.sort() return value_key_pairs[-n:]
In [35]: top_counts(counts)Out[35]:[(33, u'America/Sao_Paulo'),(35, u'Europe/Madrid'),(36, u'Pacific/Honolulu'),(37, u'Asia/Tokyo'),(74, u'Europe/London'),(191, u'America/Denver'),(382, u'America/Los_Angeles'),(400, u'America/Chicago'),(521, u''),(1251, u'America/New_York')]
Then we will have
Thursday, April 4, 13

Let’s do the same thing in pandas
In [289]: from pandas import DataFrame, SeriesIn [290]: import pandas as pdIn [291]: frame = DataFrame(records)In [292]: frame
In [293]: frame['tz'][:10]Out[293]:0 America/New_York1 America/Denver2 America/New_York3 America/Sao_Paulo4 America/New_York5 America/New_York6 Europe/Warsaw789Name: tz
Thursday, April 4, 13

What is pandas?
pandas : Python Data Analysis Library
an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language.
Features:
Effcient Dataframes data structure
Tools for data reading, munging, cleaning, etc.
Thursday, April 4, 13

In [294]: tz_counts = frame['tz'].value_counts()In [295]: tz_counts[:10]Out[295]:America/New_York 1251521America/Chicago 400America/Los_Angeles 382America/Denver 191Europe/London 74Asia/Tokyo 37Pacific/Honolulu 36Europe/Madrid 35America/Sao_Paulo 33
To get the counts
In [296]: clean_tz = frame['tz'].fillna('Missing')In [297]: clean_tz[clean_tz == ''] = 'Unknown'In [298]: tz_counts = clean_tz.value_counts()In [299]: tz_counts[:10]Out[299]:America/New_York 1251Unknown 521America/Chicago 400America/Los_Angeles 382America/Denver 191Missing 120
To clean missing values
Remember “data cleaning”
Thursday, April 4, 13

To plot the results (presentation)
import matplotlib.pyplot as pltplt.show
In [301]: tz_counts[:10].plot(kind='barh', rot=0)
Thursday, April 4, 13

Example 2: Movie Lens 1M Dataset
GroupLens Research (http://www.grouplens.org/node/73)
Ratings for movies 1990s+2000s
Three tables: 1 million ratings, 6000 users, 4000 movies
Thursday, April 4, 13

Interacting with the outside world
Preparation
Reading and writing with a variety of file formats and databases.
Cleaning, munging, combining, normalizing, reshaping, slicing and dicing, and transforming data for analysis.
Extract the data from a zip file and load it into pansdas DataFrames
import pandas as pd
unames = ['user_id', 'gender', 'age', 'occupation', 'zip']users = pd.read_table('ml-1m/users.dat', sep='::', header=None,names=unames)
rnames = ['user_id', 'movie_id', 'rating', 'timestamp']ratings = pd.read_table('ml-1m/ratings.dat', sep='::', header=None,names=rnames)
mnames = ['movie_id', 'title', 'genres']movies = pd.read_table('ml-1m/movies.dat', sep='::', header=None,names=mnames)
Thursday, April 4, 13

Verify
In [334]: users[:5]
In [335]: ratings[:5]
In [336]: movies[:5]
PreparationCleaning, munging, combining, normalizing, reshaping, slicing and dicing, and transforming data for analysis.
Thursday, April 4, 13

Merge
Using pandas’s merge function, we first merge ratings with users then merging that result with the movies data. pandas infers which columns to use as the merge (or join) keys based on overlapping names
PreparationCleaning, munging, combining, normalizing, reshaping, slicing and dicing, and transforming data for analysis.
Thursday, April 4, 13

Merge resultsIn [338]: data = pd.merge(pd.merge(ratings, users), movies)In [339]: dataOut[339]:<class 'pandas.core.frame.DataFrame'>Int64Index: 1000209 entries, 0 to 1000208Data columns:user_id 1000209 non-null valuesmovie_id 1000209 non-null valuesrating 1000209 non-null valuestimestamp 1000209 non-null valuesgender 1000209 non-null valuesage 1000209 non-null valuesoccupation 1000209 non-null valueszip 1000209 non-null valuestitle 1000209 non-null valuesgenres 1000209 non-null valuesdtypes: int64(6), object(4)
Thursday, April 4, 13

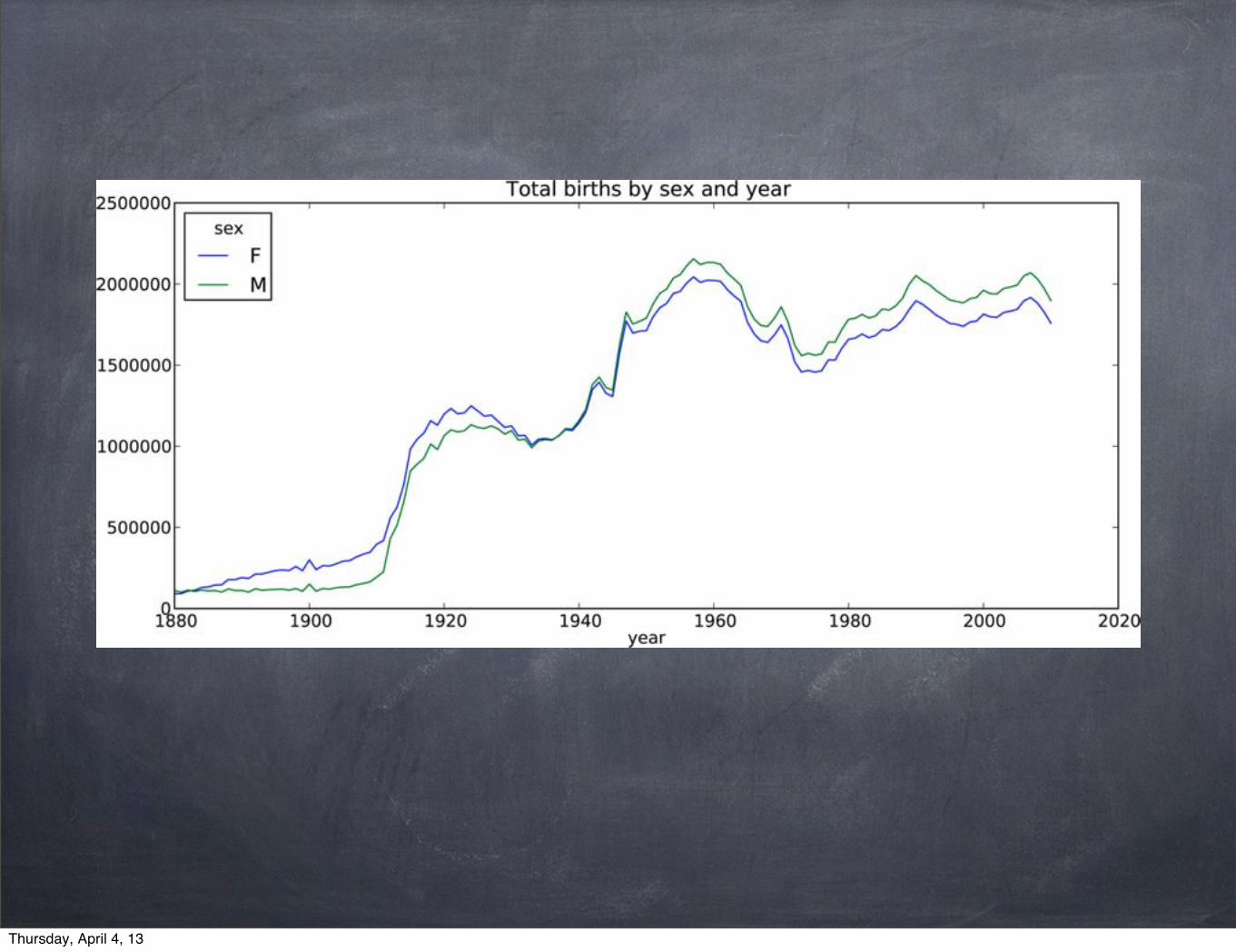
Example 3: US Baby Names 1880-2010
United States Social Security Administration (SSA) http://www.ssa.gov/oact/babynames/limits.html
Visualize the proportion of babies given a particular name
Determine the most popular names in each year or the names with largest increases or decreases
Thursday, April 4, 13
Thursday, April 4, 13

Thursday, April 4, 13

Thursday, April 4, 13

Thursday, April 4, 13

Lets do some more investigations
names[names.name=='Mohammad']
names[names.name=='Fatima']
Thursday, April 4, 13










![Python for Computational 파일입출력 을3d.sangji.ac.kr/home/lectures/Python/Python_Chap08.pdf · 2019. 3. 7. · [파일입출력]을 이용한 컴퓨팅사고력. 구분 모드(mode)](https://img.pdfslide.net/doc/110x75/613effecc500cf75ab363e94/python-for-computational-oeoeoee-3d-2019-3-7-oeoeoee.jpg)









![Creating Geometries and Handling Projections with OGRchrisg/python/2009/lectures/ospy_slides2.pdf · OS Python week 2: Geometries & projections [1] Open Source RS/GIS Python Week](https://img.pdfslide.net/doc/110x75/5e80c1c16f6725570c5ef207/creating-geometries-and-handling-projections-with-ogr-chrisgpython2009lecturesospy.jpg)








