Embed Size (px)
Citation preview

The Wisdom of the FewA Collaborative Filtering Approach Based on Expert Opinions from the Web
Xavier AmatriainTelefonica Research
Nuria OliverTelefonica Research
Josep M. PujolTelefonica Research
Neal LathiaDept. of Computer
ScienceUniversity College
of London
Haewoon KwakComputer
Science Dept.KAIST
SIGIR 2009

Standard Collaborative Filtering Collaborative filtering is the preferred
approach for Recommender Systems Recommendations are drawn from your past
behavior and that of similar users in the system
Standard CF approach: Find your Neighbors from the set of other users Recommend things that your Neighbors liked and you have
not “seen”
Problem: predictions are based on a large dataset that is sparse and noisy

Expert-based Collaborative Filtering
• Expert : individual that we can trust to have produced thoughtful, consistent and reliable evaluations (ratings) of items in a given domain
• Find neighbors from a reduced set of experts instead of regular users.1. Identify domain experts with reliable ratings2. For each user, compute “expert neighbors”3. Compute recommendations similar to standard
kNN CF

User Data Collection
• Netflix data set• 10,000 users• 17,770 movies

Experts Data Collection
Collections of expert ratings can be obtained almost directly on the web: we crawled the Rotten Tomatoes movie critics mash-up
8,000 movies overlap with Netflix
Only those (169) with more than 250 ratings in the Neflix dataset were used

Dataset Analysis (# ratings)
Sparsity coefficient: 0.01 (users) vs. 0.07 (experts)
Average movie has 1K user ratings vs. 100 expert ratings
Average expert rated 400 movies, 10% rated > 1K

Dataset Analysis (average rating) Users: average movie rating ~0.55
(3.2 );⋆
10%0.45(2.8 ),10%⋆ 0.7(3.8 )⋆
Experts: average movie rating ~0.6 (3.4 )⋆
10%0.4(2.6 ), 10%⋆ 0.8 (4.2 )⋆ user ratings centered 0.7 (3.8 )⋆
expert ratings centered 0.6 (3.4 ): ⋆small variability
only 10% of the experts have a mean score 0.55 (3.2 ) and ⋆another 10% 0.7 (3.8 )⋆

Dataset Analysis (std) Users:
per movie centered around 0.25, little variation
per user centered around 0.25, larger variability
Experts: lower std per movie (0.15) and larger variation.
average std per expert = 0.2, small variability.

Dataset Analysis Summary Experts:
Are much less sparse Rate movies all over the rating scale instead of being
biased towards rating only “good” movies (different incentives).
Have a lower overall standard deviation per movie: they tend to agree more than regular users.
Tend to deviate less from their personal average rating.

Method
{e1,e2,…,en}

Evaluation Procedure
Use the 169 experts to predict ratings from 10,000 users sampled from the Netflix dataset
Prediction MAE(Mean Absolute Error) , 5-fold cross-validation
Top-N precision by classifying items as being “recommendable” given a threshold
User Study

Role of Thresholds MAE is inversely proportional to the similarity threshold () until the 0.06 mark, when it starts to increase as we move to higher values.
below 0.0 it degrades rapidly: too many experts;
Coverage decreases as we increase .
For the optimal MAE point of 0.06, coverage is still above 70%.
MAE as a function of the confidence threshold () =0.0 and =0.01(optimal around 9)

Comparison to Standard CF
Expert-CF only works worse for the 10% of the users with lower MAE

Top-N Precision Precision of the Top-N Recommendations as a function
of the “recommendable” threshold
For a threshold of 4, NN-CF outperforms expert-based but if we lower it to 3 they are almost equal

User Study 57 participants, only 14.5 ratings/participant
50% of the users consider Expert-based CF to be good or very good
Expert-based CF: only algorithm with an average rating over 3 (on a 0-4 scale)
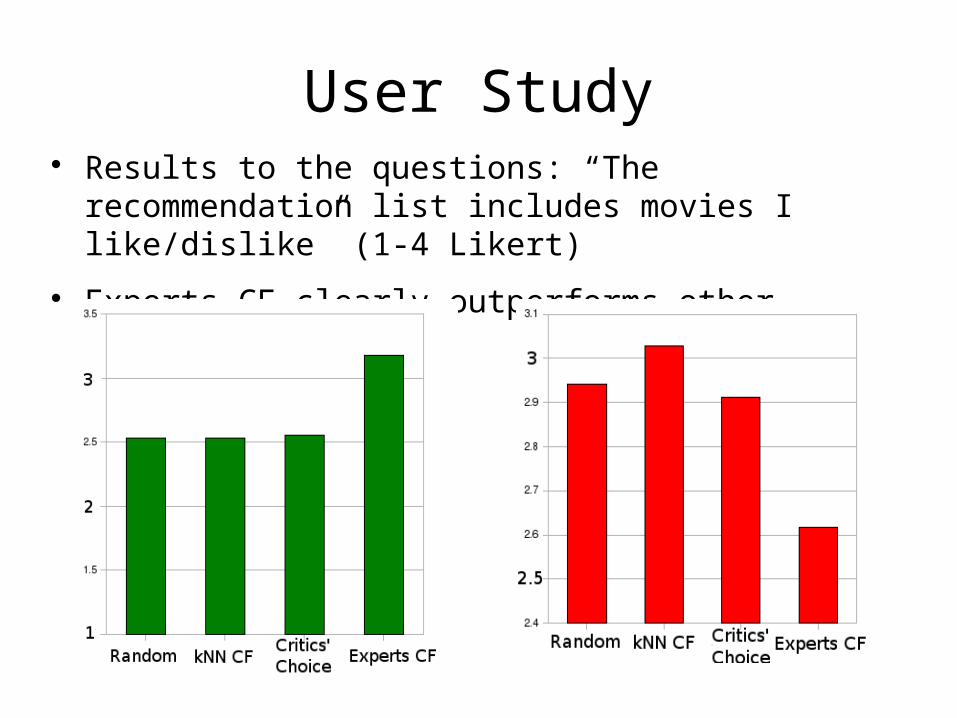
User Study Results to the questions: “The recommendation list
includes movies I like/dislike” (1-4 Likert)
Experts-CF clearly outperforms other methods

Advantages of the Approach Noise
Experts introduce less natural noise
Malicious Ratings
Dataset can be monitored to avoid shilling
Cold Start problem
Experts rate items as soon as they are available
Data Sparsity
Reduced set of domain experts can be motivated to rate items

Conclusion
• Different approach to the Recommendation problem
• In some conditions, users prefer recommendations from similar experts than similar users.
• Expert-based CF has the potential to address many of standard CF shortcomings





























