Embed Size (px)
Citation preview

Thomas E. CantyServerCare, Inc.Session #126
Data Guard Best Practices & Tuning

Speaker Qualifications
• Thomas E. Canty, Senior Oracle DBA, ServerCare, Inc.• 19 years of Oracle experience, starting with version 5• Has presented at IOUG, OpenWorld, NoCOUG, IASA, • Has been a DBA, Developer, Architect, and IT Manager
• Has worked with Fortune 100 companies in Healthcare, Technology, Pharmaceuticals, and Telecom, as well as Major Universities
888-918-6309http://www.ServerCare.com

Outline
• Overview• Network Optimization• ARCn & LGWR Redo Transport• Checkpoint, Redo Read/Apply & Recovery• Wait Events• 10g R2 & 11g Improvements• Best Practices

Data Guard Modes
• Maximum Performance Mode– Least performance impact– Default mode
• Maximum Protection Mode– Emphasis on data safety– Requires at least one secondary
• Maximum Availability Mode– Emphasis on uptime– Continues if secondary unavailable
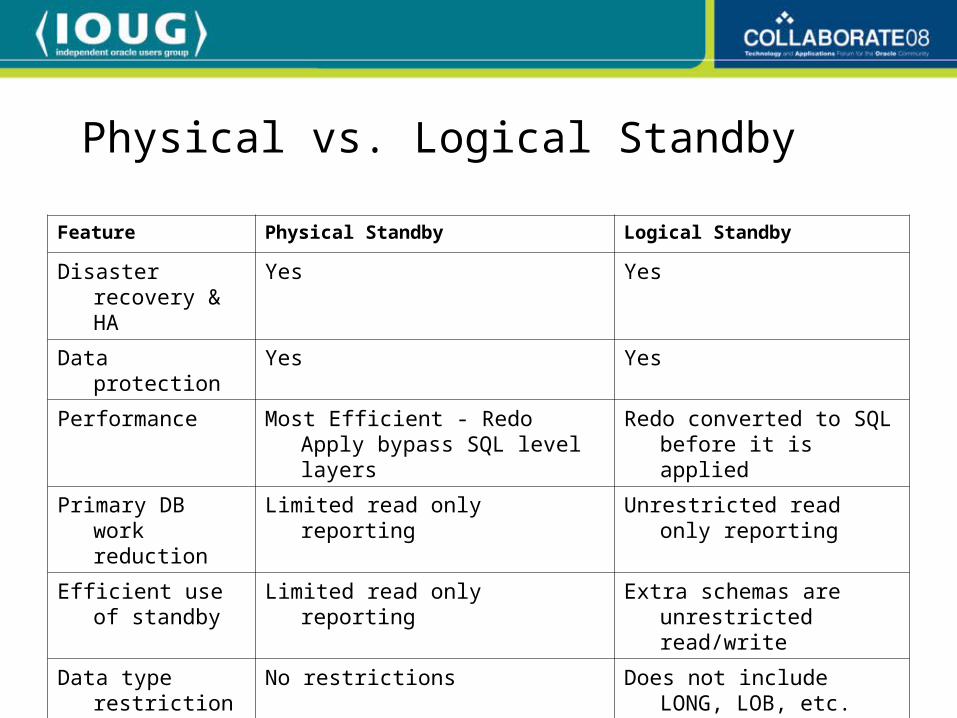
Physical vs. Logical Standby
Feature Physical Standby Logical Standby
Disaster recovery & HA
Yes Yes
Data protection Yes Yes
Performance Most Efficient - Redo Apply bypass SQL level layers
Redo converted to SQL before it is applied
Primary DB work reduction
Limited read only reporting Unrestricted read only reporting
Efficient use of standby
Limited read only reporting Extra schemas are unrestricted read/write
Data type restrictions
No restrictions Does not include LONG, LOB, etc.
Rolling upgrades Not available Yes

Outline
• Overview• Network Optimization• ARCn & LGWR Redo Transport• Checkpoint, Redo Read/Apply & Recovery• Wait Events• 10g R2 & 11g Improvements• Best Practices

Session Data Unit (SDU)
• In Oracle Net connect descriptor:sales.servercare.com=
(DESCRIPTION=
(SDU=32767)
(ADDRESS=(PROTOCOL=tcp)
(HOST=sales-server)(PORT=1521))
(CONNECT_DATA=
(SID=sales.servercare.com)))
• Globally in sqlnet.ora:– DEFAULT_SDU_SIZE=32767

Session Data Unit (SDU) (Cont.)
• On standby DB, set in listener.ora:SID_LIST_listener_name=
(SID_LIST=
(SID_DESC=
(SDU=32767)
(GLOBAL_DBNAME=sales.servercare.com)
(SID_NAME=sales)
(ORACLE_HOME=/u01/app/oracle/product/10.2.0/db_1)))

TCP Socket Buffer Size
• Set TCP socket buffer size = 3 * BDP– Data Guard broker config. – Set in sqlnet.ora– Non Data Guard broker – set in connect descriptor
• BDP - Bandwidth Delay Product• RTT- Round Trip Time

TCP Socket Buffer Size
• Assume gigabit network with RTT 25 msBDP= 1,000 Mbps * 25msec (.025 sec)
1,000,000,000 * .025
25,000,000 Megabits / 8 = 3,125,000 bytes
• In this example:socket buffer size = 3 * bandwidth * delay
= 3,125,000 * 3
= 9,375,000 bytes
• sqlnet.ora:RECV_BUF_SIZE=9375000
SEND_BUF_SIZE=9375000

Network Queue Sizes
• Between kernel net. subsystems & NIC driver• txqueuelen - transmit queue size• netdev_max_backlog - receive queue size• Assumes gigabit network with 100ms latency• Set queues:
– ifconfig eth0 txqueuelen 10000– sysctl.conf:
• net.core.netdev_max_backlog=20000

Overall Network
• Ensure sufficient bandwidth to standby• Verify TCP_NODELAY set to YES (default)• RHEL3 - increase /proc/sys/fs/aio-max-size on standby
– From 131072(default) to 1048576• Set RECV_BUF_SIZE & SEND_BUF_SIZE = 3 *
Bandwidth Delay Product (BDP)• Use Session Data Unit (SDU) size of 32767• Increase send & receive queue sizes
– TXQUEUELENGTH– NET_DEV_MAX_BACKLOG

Outline
• Overview• Network Optimization• ARCn & LGWR Redo Transport• Checkpoint, Redo Read/Apply & Recovery• Wait Events• 10g R2 & 11g Improvements• Best Practices
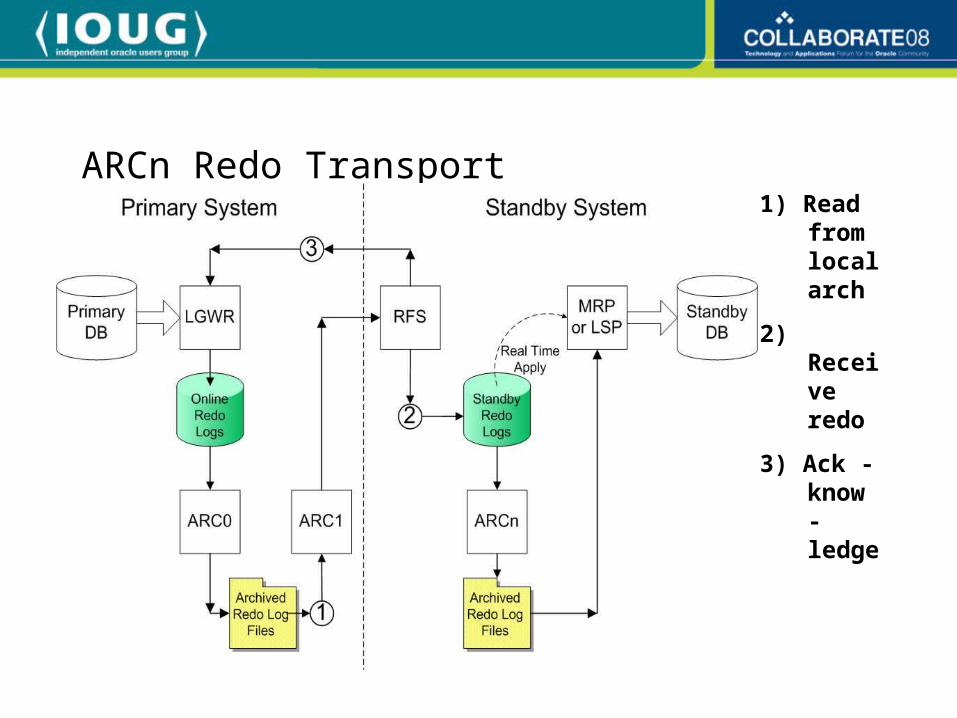
ARCn Redo Transport1) Read
from local arch
2) Receive redo
3) Ack - know -ledge
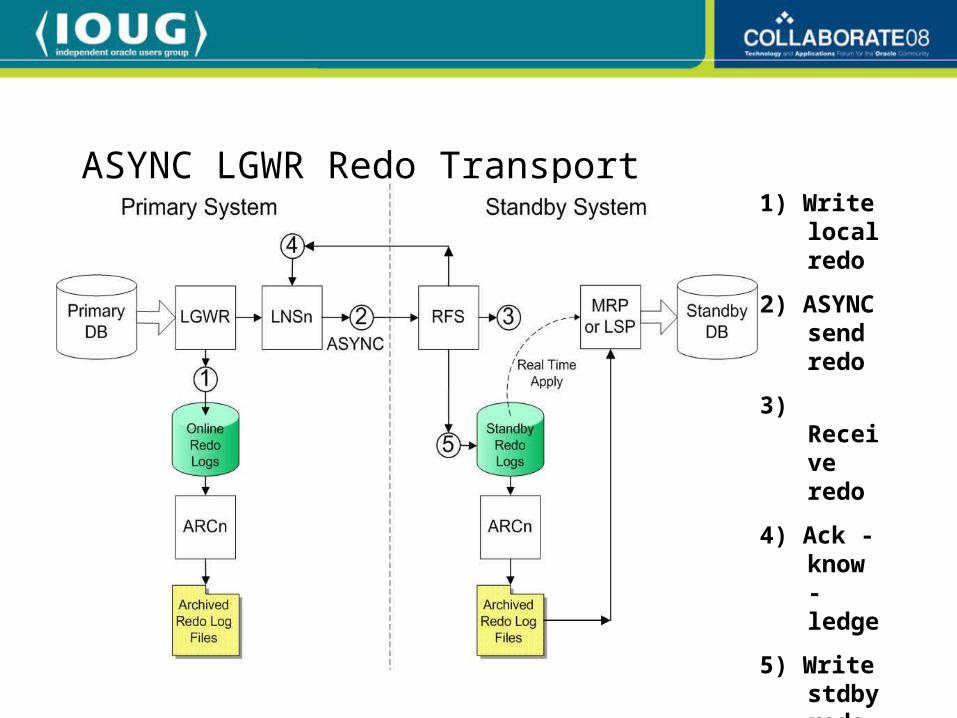
ASYNC LGWR Redo Transport1) Write
local redo
2) ASYNC send redo
3) Receive redo
4) Ack - know -ledge
5) Write stdby redo
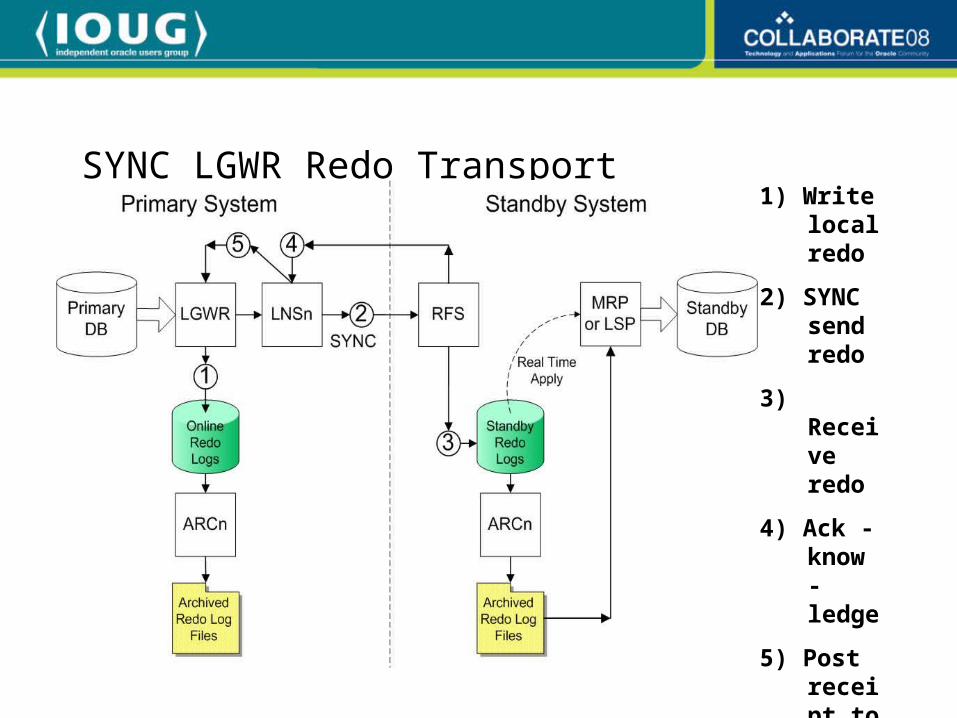
SYNC LGWR Redo Transport1) Write
local redo
2) SYNC send redo
3) Receive redo
4) Ack - know -ledge
5) Post receipt to LGWR

Optimize ARCn Transport
• Increase MAX_CONNECTIONS to 5 on standby (if possible)– default (2), maximum (5)
• Increase LOG_ARCHIVE_MAX_PROCESSES– Larger than MAX_CONNECTIONS– Up to network bandwidth– default (2), maximum (30)
Optimize LGWR Transport
• Decrease NET_TIMEOUT (default 180 secs.)– Be careful! - Not too low
• New COMMITS– COMMIT IMMEDIATE WAIT (default)– COMMIT NOWAIT– COMMIT NOWAIT BATCH

All Redo Transport
• Standby redo logs– Use fastest disks– No RAID5– Don’t multiplex– Use the recommended number of SRLs
• (maximum# of online logfiles + 1) * maximum# of threads

Outline
• Overview• Network Optimization• ARCn & LGWR Redo Transport• Checkpoint, Redo Read/Apply & Recovery• Wait Events• 10g R2 & 11g Improvements• Best Practices

Checkpoint Phase
• Checkpoint occurs– During log switch– LOG_CHECK_TIMEOUT expiration– LOG_CHECKOUT_INTERVAL reached
• Reduce log switch interval– Resize redo log to 1GB - primary and secondary– Recommended - checkpoint every 15 minutes

Checkpoint Phase (Cont.)
• Determine checkpoint frequencyCOL NAME FOR A35;SELECT NAME, VALUE, TO_CHAR(SYSDATE, ‘HH:MI:SS’) TIMEFROM V$SYSSTAT WHERE NAME = 'DBWR checkpoints';
NAME VALUE TIME----------------------------------- ---------- --------DBWR checkpoints 264 08:15:43
SQL> /NAME VALUE TIME----------------------------------- ---------- --------DBWR checkpoints 267 08:34:06

Redo Read (Secondary)
• Obtain read rate for the standby redo log SQL> ALTER SYSTEM DUMP LOGFILE '/u01/oradata/docprd/sredo01.log’
validate;
System altered.
$vi docprd_ora_3560.trc
Mon Mar 12 08:59:52 2007
………………
----- Redo read statistics for thread 1 -----
Read rate (ASYNC): 4527Kb in 0.58s => 6.90 Mb/sec
Longest record: 19Kb, moves: 0/7586 (0%)
Change moves: 4340/18026 (24%), moved: 2Mb
Longest LWN: 92Kb, moves: 1/1365 (0%), moved: 0Mb Last redo scn: 0x0000.01272351 (19342161)

Redo Apply (Secondary)
• Goal– Redo apply rate (secondary) > Redo create rate (primary)
• Carefully consider enabling DB_BLOCK_CHECKING– LOW, MEDIUM and FULL options– Possible performance impact

Redo Apply (Cont.)
• Determine Log Block Size (LEBSZ)SELECT LEBSZ FROM X$KCCLE WHERE ROWNUM=1;
• Get recovery blocks - at least two snapshots– Managed Recovery CaseSELECT PROCESS, SEQUENCE#, THREAD#, block#, BLOCKS,TO_CHAR(SYSDATE, 'DD-MON-YYYY HH:MI:SS') timefrom v$MANAGED_STANDBY WHERE PROCESS='MRP0';
• Determine the recovery rate (MB/sec) for a specific archive sequence number– Managed Recovery Case: ((BLOCK#_END - BLOCK#_BEG) * LOG_BLOCK_SIZE) /(TIME_END - TIME_BEG) * 1024 * 1024

Redo Apply (Cont.)
Redo Generation Rate vs. Redo Apply Rate Recommendation
2 * Max Primary DB Redo Generation Rate < Redo Apply Rate
Excellent - No Tuning Required
Max Primary DB Redo Generation Rate < Redo Apply Rate < 2 * Max Primary DB Redo Generation Rate
Good - Tuning is Optional
Avg. Primary Redo Generation Rate < Redo Apply Rate OK - Need Tuning
Avg. Primary Redo Generation Rate > Redo Apply Rate Bad - Need Tuning
• Oracle Recommends:

Recovery
• Parallel Recovery (before 10.1.0.5)– Set to number of CPUsrecover managed standby database parallel <#>;
• PARALLEL_EXECUTION_MESSAGE_SIZE– Can increase to 4096 or 8192
• Uses additional shared pool memory– Problems if set too high
• DB_CACHE_SIZE– Can set secondary DB_CACHE_SIZE >= primary
• Must set to primary before changing roles

Outline
• Overview• Network Optimization• ARCn & LGWR Redo Transport• Checkpoint, Redo Read/Apply & Recovery• Wait Events• 10g R2 & 11g Improvements• Best Practices

Arch Wait Events - Primary
• ARCH wait on ATTACH– Time for all arch processes to spawn RFS connection
• ARCH wait on SENDREQ– Time for all arch processes to write received redo to disk +
open & close remote archived redo logs
• ARCH wait on DETACH– Time for all arch processes to delete RFS connection

LGWR SYNC Wait Events - Primary
• LGWR wait on ATTACH– Time for all log writer processes to spawn RFS connection
• LGWR wait on SENDREQ– Time for all log writer processes to write received redo to disk +
open & close the remote archived redo logs
• LGWR wait on DETACH– Time for all log writer processes to delete RFS conn.

LGWR ASYNC Wait Events - Primary
• LNS wait on ATTACH– Time for all network servers to spawn RFS connection
• LNS wait on SENDREQ– Time for all network servers to write received redo to disk +
open & close the remote archived redo logs• LNS wait on DETACH
– Time for all network servers to delete RFS conn.• LGWR wait on full LNS buffer
– Time for log writer (LGWR) process awaiting for network server (LNS) to free ASYNC buffer space

Wait Events on Secondary
• RFS Write– Time to write to standby redo log or archive log + non I/O
work like redo block checksum validation
• RFS Random I/O– Time to write to a standby redo log to occur
• RFS Sequential I/O– Time to write to an archive log to occur

Outline
• Overview• Network Optimization• ARCn & LGWR Redo Transport• Checkpoint, Redo Read/Apply & Recovery• Wait Events• 10g R2 & 11g Improvements• Best Practices

10g R2 Improvements
• Multiple archive processes can transmit a redo log in parallel to the standby database– MAX_CONNECTIONS attribute of the
LOG_ARCHIVE_DEST_n controls the number of these processes
• Parallel Recovery for Redo apply is automatically set equal to number of CPUs– 10.1.0.5 and 10.2.0.1
• Fast-Start Failover– Automatically fails over to a previously chosen physical
standby database

10g R2 Improvements (Cont.)
• LGWR ASYNC– Uses a new process (LNSn) to transmit the redo data
directly from the online redo log to the standby database• Physical standby database flashback
– Can flash back temporarily for reporting• Logical standby database
– Automatically deletes applied archived log• RMAN
– Automatically creates temp datafiles after recovery

11g Improvements
• Physical standby database open read/write for test or other purposes with zero compromise in data protection using new Snapshot Standby
• Automatic failover configurable for immediate response to designated events or errors
• More flexibility in primary/standby configurations– e.g. Windows primary and Linux standby
• Rolling upgrade options now in physical standby with Transient Logical Standby
• ASYNC transport enhanced to eliminate the impact of latency on network throughput

11g Improvements (Cont.)
• Fast detection of corruptions caused by lost writes in the storage layer
• SQL Apply supports XML data type (CLOB)• Many performance, manageability, and security
enhancements• Support for new Oracle Database 11g Options –
Oracle Active Data Guard and Oracle Advanced Compression
• Fast Start Failover now available for Maximum Performance mode

Outline
• Overview• Network Optimization• ARCn & LGWR Redo Transport• Checkpoint, Redo Read/Apply & Recovery• Wait Events• 10g R2 & 11g Improvements• Best Practices

Best Practices
• Geographically separate primary & standby DB• Ensure standby hardware configuration same as the
primary– Tune standby for write intensive operations
• Test Data Guard before deploy in production• Set standard OS and DB parameters to recommended
values• Perform switchover testing
– Fully document a failover procedure• Use FORCE LOGGING mode

Best Practices (Cont.)
• Use real-time apply• Use the Data Guard Broker• Enable Flashback Database on both primary and
secondary databases• Evaluate using AFFIRM attribute
– Possible performance issues on primary
• Verify Asynchronous I/O enabled• Carefully consider DB_BLOCK_CHECKING

Best Practices (Cont.)
• Don’t multiplex standby redo logs (SRLs)• Correctly set number of SRLs• Increase PARALLEL_EXECUTION_MESSAGE_SIZE• Place SRLs in fast disk group or disks• Use at lease two standby DBs with Maximum
Protection Mode • Utilize COMMIT NOWAIT if appropriate

Best Practices (Cont.)
• Ensure appropriate bandwidth between primary and secondary
• Increase default send & receive queue sizes– TXQUEUELENGTH– NET_DEV_MAX_BACKLOG
• Session Data Unit– Adjust value to 32767
• Improvement during large data transmissions
Questions?
• Lots of things we didn’t cover• If we don’t cover something you wanted to hear,
please contact me.

THANK YOU!
Please fill out evaluations!
Email Tom Canty:[email protected]
Or Call:888-918-6309
http://www.ServerCare.com
Session #126:
Data Guard Best Practices & Tuning





























