Embed Size (px)
Citation preview
1
THỐNG KÊ TRONG KINH TẾ VÀ KINH DOANH
CHƯƠNG 3: THỐNG KÊ MÔ TẢ - CÁC ĐẠI LƯỢNG ĐẠI SỐ
M&B – 19/5/2017
1. CÁC ĐẠI LƯỢNG ĐO LƯỜNG VỊ TRÍ
Các công thức về trung bình (mẫu, tổng thể), trung vị, vị
yếu, … sẽ không được trình bày ở đây vì đã có trong giáo
trình và phần ôn tập xác suất thống kê ở chuyên mục kinh
tế lượng cơ bản (đỡ mất công gỏ). Phần này chỉ tập trung
hướng dẫn em thực hành Stata với các ví dụ kèm theo cuốn
giáo trình.
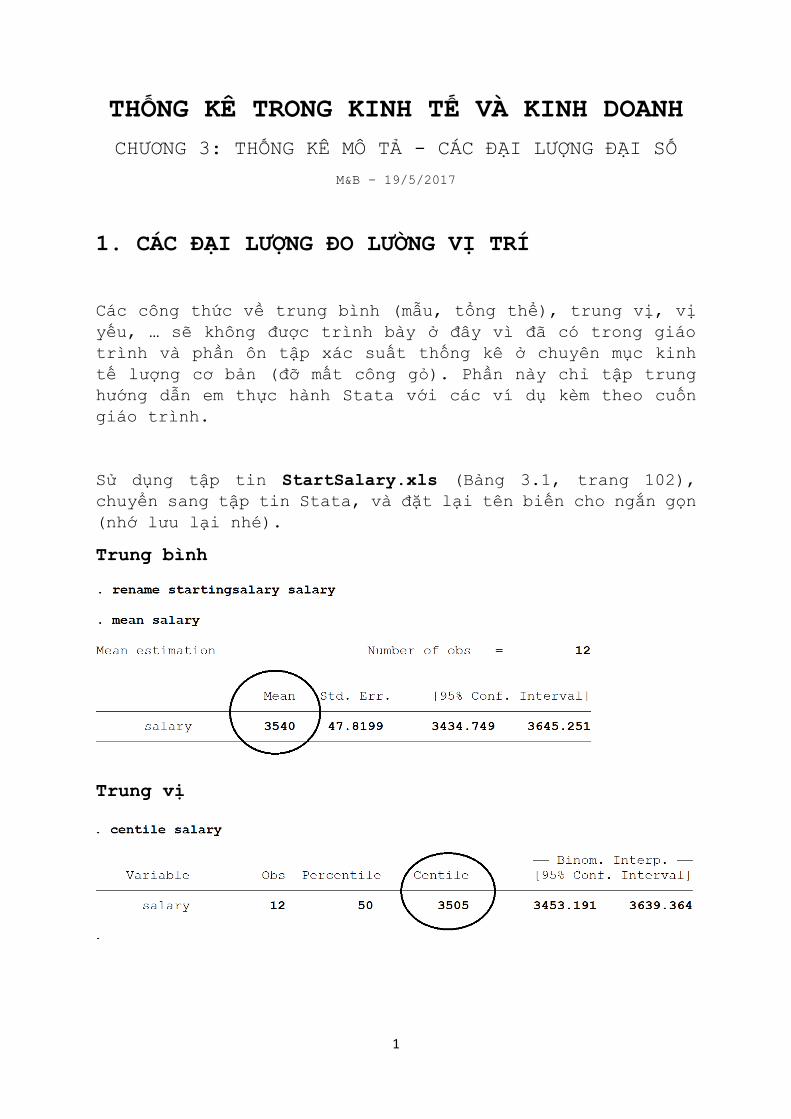
Sử dụng tập tin StartSalary.xls (Bảng 3.1, trang 102),
chuyển sang tập tin Stata, và đặt lại tên biến cho ngắn gọn
(nhớ lưu lại nhé).
Trung bình
Trung vị
2
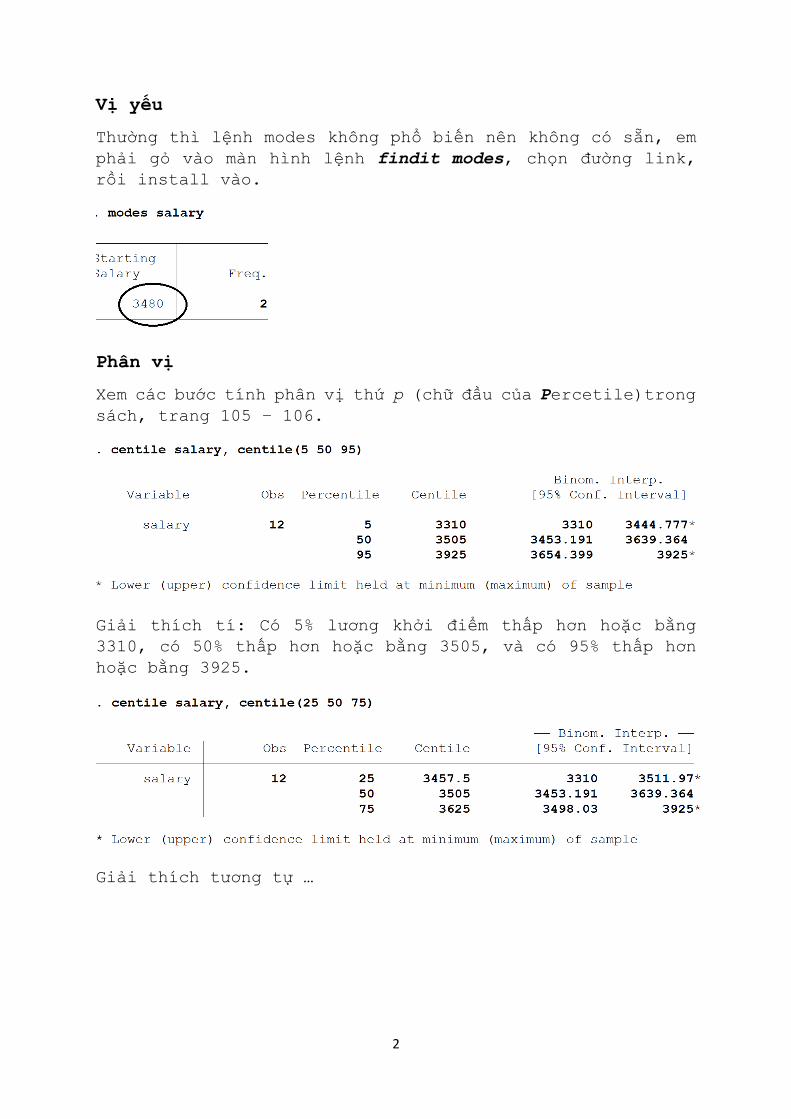
Vị yếu
Thường thì lệnh modes không phổ biến nên không có sẵn, em
phải gỏ vào màn hình lệnh findit modes, chọn đường link,
rồi install vào.
Phân vị
Xem các bước tính phân vị thứ p (chữ đầu của Percetile)trong
sách, trang 105 – 106.
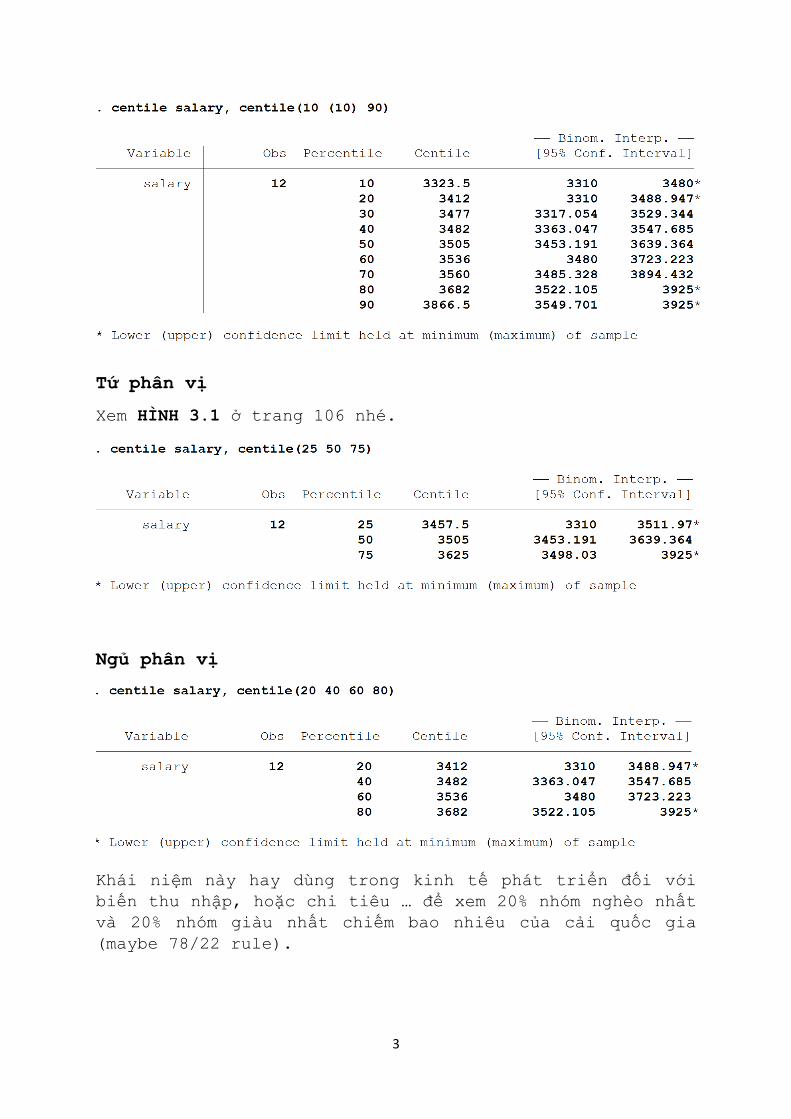
Giải thích tí: Có 5% lương khởi điểm thấp hơn hoặc bằng
3310, có 50% thấp hơn hoặc bằng 3505, và có 95% thấp hơn
hoặc bằng 3925.
Giải thích tương tự …
3
Tứ phân vị
Xem HÌNH 3.1 ở trang 106 nhé.
Ngủ phân vị
Khái niệm này hay dùng trong kinh tế phát triển đối với
biến thu nhập, hoặc chi tiêu … để xem 20% nhóm nghèo nhất
và 20% nhóm giàu nhất chiếm bao nhiêu của cải quốc gia
(maybe 78/22 rule).

4
Lưu ý: Việc sử dụng trung vị như là đại lượng đo lường vị
trí trung bình tốt hơn trung bình khi một tập dữ liệu chứa
các giá trị đột biến (outliers). Khi dữ liệu có giá trị đột
biến, ta cũng có thể dùng một đại lượng khác là trung bình
lọc (trimmed mean), tức là cắt tỉa vài % giá trị nhỏ nhất
và lớn nhất. Trong Stata, em dùng lệnh trimmean, nhưng
thường không có sẵn đâu, nên em phải findit trimmean trước,
rồi install vào.
2. CÁC ĐẠI LƯỢNG ĐO LƯỜNG ĐỘ PHÂN TÁN
Các khái niệm về khoảng biến thiên (giá trị lớn nhất – giá
trị nhỏ nhất) và độ trải giữa (IQR = Q3 – Q1) thì dễ rồi.
Để tính IQR, em cũng dùng lệnh centile + tên biến, centile
(25 50 75), giá trị ở 25% là Q1 và giá trị ở 75% là Q3.
Okie fine?
Các công thức về phương sai (mẫu, tổng thể), độ lệch chuẩn
(mẫu, tổng thể), hệ số biến thiên,… em xem trong sách (trang
113-116) hoặc ôn tập xác suất thống kê ở chuyên mục kinh
tế lượng căn bản nhé.

5
Ở đây, em cần hiểu tại sao bậc tự do (df) của mẫu là n-1
chứ không phải n (em xem phần chứng minh ở chuyên mục Kinh
tế lượng căn bản để biết cách giải thích).
Phương sai hay độ lệch chuẩn cung cấp thông tin về sự phân
tán của đối tượng quan tâm: giá trị càng cao thì sự phân
tán càng nhiều. Từ đó cung cấp rất nhiều thông tin rất hay
về các hiện tượng kinh tế - xã hội.
Ví dụ, điểm kết thúc học phần Kinh tế vi mô 1 của hai lớp
AE và AG như sau (giả sử điểm có phân phối chuẩn):
AG AE
Trung bình 7 7
Độ lệch chuẩn 1 0.5
Nếu giáo viên nhận giảng Kinh tế vi mô 2, và có quyền lựa
chọn giữa một trong hai lớp thì họ thích chọn AE hơn, vì
học lực chung của AE đồng đều hơn, còn AG thì có một số bạn
rất giỏi, nhưng cũng có vài đứa xếp vào nhóm ‘giặc‘, tức
sinh viên cá biệt á. Nhận lớp AG rất rủi ro: giảng cao thì
nhóm dưới ngủ, giảng thấp thì nhóm giỏi liên quân hoặc phây
mỗi mắt.
Sau này, các đại lượng phương sai (var) và độ lệch chuẩn
(sd) dùng nhiều trong phân tích rủi ro ở các học phần như
quản trị rủi ro, thẩm định dự án, đầu tư tài chính, quản
lý danh mục, …
Để hiểu rõ hơn về công thức, em chịu khó tính lại bằng tay
các Bảng 3.3 (trang 114), và Bảng 3.4 (trang 115).

6
Lệnh trên Stata
Phương sai
Ở đây df (degree of freedom, bậc tự do) chính là n-1 = 12
– 1 = 11, SS là sum of squares, MS là Mean of Squares, và
F là thống kê F (em sẽ học ở các phần sau).
Độ lệch chuẩn
Lệnh phổ biến nhất là sum, vừa cho giá trị trung bình, vừa
cho giá trị độ lệch chuẩn, tức căn bậc hai của phương sai.
Như vậy, em cũng có thể dễ dàng tính được khoảng biến thiên
từ lệnh sum.
Hệ số biến thiên (cv = coefficient of variation)
cv = (độ lệch chuẩn/trung bình)*100*
CV dùng chủ yếu để so sánh độ phân tán của các biến có độ
lệch chuẩn khác nhau và trung bình khác nhau. Trong ví dụ
về điểm kết thúc học phần Kinh tế vi mô 1, mình giả định
trung bình bằng nhau, nên chỉ so sánh phương sai và ra

7
quyết định. Nếu điểm trung bình của AE là 6.5 thì phải nhờ
đến CV.
Lệnh hay dùng nhất trên Stata để có tất cả các đại lượng
vừa nói trên là tabstat:
tabstat salary, stat(mean med variance sd cv)
Chú thích: p50 (phân vị thứ 50 tức là giá trị trung vị).
sd là độ lệch chuẩn.
med là trung vị đó.
Ta có thể thêm các đại lượng khác vào ngoặc đơn như: count
n range … (lưu ý: count và n là như nhau, tức đếm có bao
nhiêu quan sát trong mẫu).
tabstat salary, stat(mean count n sum max min range sd
variance cv sk k p5 p10 p25 med p50 p75 p90 p95 iqr q)

8
Các đại lượng em sẽ gặp ở phần tiếp sau:
• sk = skewness, độ nghiêng của phân phối (hay hệ số bất
đối xứng).
• k = kurtosis, độ nhọn của phân phối.
• pi = phân vị thứ i đó em.
• iqr = độ trải giữa.
• q = quartile, tức là tứ phân vị (25 50 75)
3. HÌNH DÁNG PHÂN PHỐI ….
Hình dáng phân phối
Phụ thuộc vào giá trị sk (skewness) – Em xem Hình 3.3,
trang 121 nhé:
• sk = 0: đối xứng (như phân phối chuẩn).
• sk < 0: lệch (nghiêng) trái (nghĩa là đuôi trái dài
hơn).
• sk > 0: lệch (nghiêng) phải (nghĩa là đuôi phải dài
hơn).
• Giá trị âm hoặc dương càng lớn thì độ lệch càng nhiều.
Em xem công thức trang 121 nhé, nhớ là có LŨY THỪA 3 CỦA
ĐỘ LỆCH nha, các thành phần còn lại trong công thức này đều
là số dương: n, n-1, n-2, và độ lệch chuẩn.
Ý nghĩa gì trên thực tế vậy em?
• Ví dụ: Điểm trung bình Kinh tế vi mô 1 của AE42 là 7,
nếu có một bạn điểm 7.1 thì đối lại có một đứa 6.9;
một bạn 7.2 thì một đứa 6.8; … như vậy khi tổng lại
các lũy thừa 3 của các độ lệch thì chắc chắn bằng 0.
Đối xứng. Nhưng, đa số gần điểm 7 (học lực xấp xỉ
nhau), chỉ có một vài bạn có điểm 0 (giả sử thôi), thì
(0-7)3 của nhóm này làm có tổng các lập phương sẽ có
giá trị âm, nên phân phối bị kéo qua phía trái. Vậy em
rút ra được điều gì? (1) Nhìn phân phối có thể suy ra
9
được tình hình của lớp; (2) Có thể nhận ra lớp mình có
giặc (tức là các outliers) hay không.
• Ví dụ khác: Thường thì biến chi tiêu của sinh viên UEH
có xu hướng lệch phải (nghĩa là sk > 0). Vì sao? Vì
trong mẫu khảo sát có một vài sinh viên nhà quá giàu,
xài nhiều.
• Các biến giá trị dương (như chi tiêu), khi phân tích
hồi quy người ta thường chuyển sang dạng logarithm (tức
lấy log) để làm mượt/trơn dữ liệu, nhằm giảm bớt tính
đột biến. Sau này em sẽ thấy trong phân tích hồi quy.
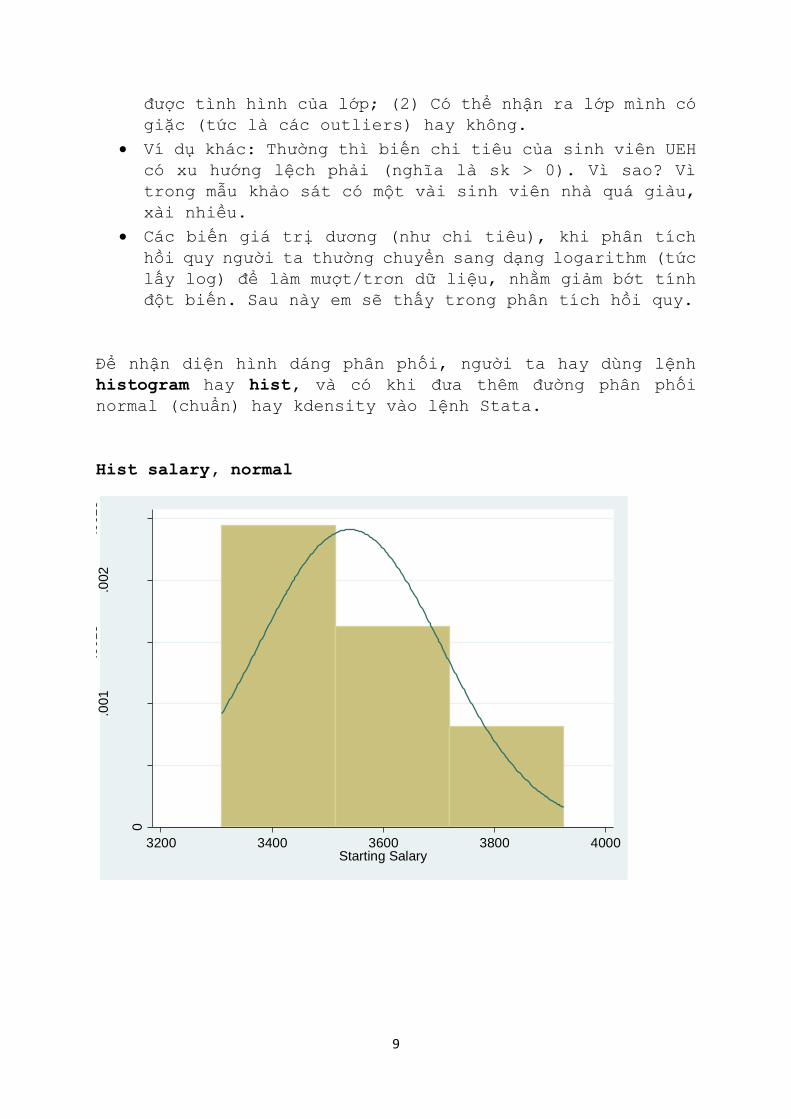
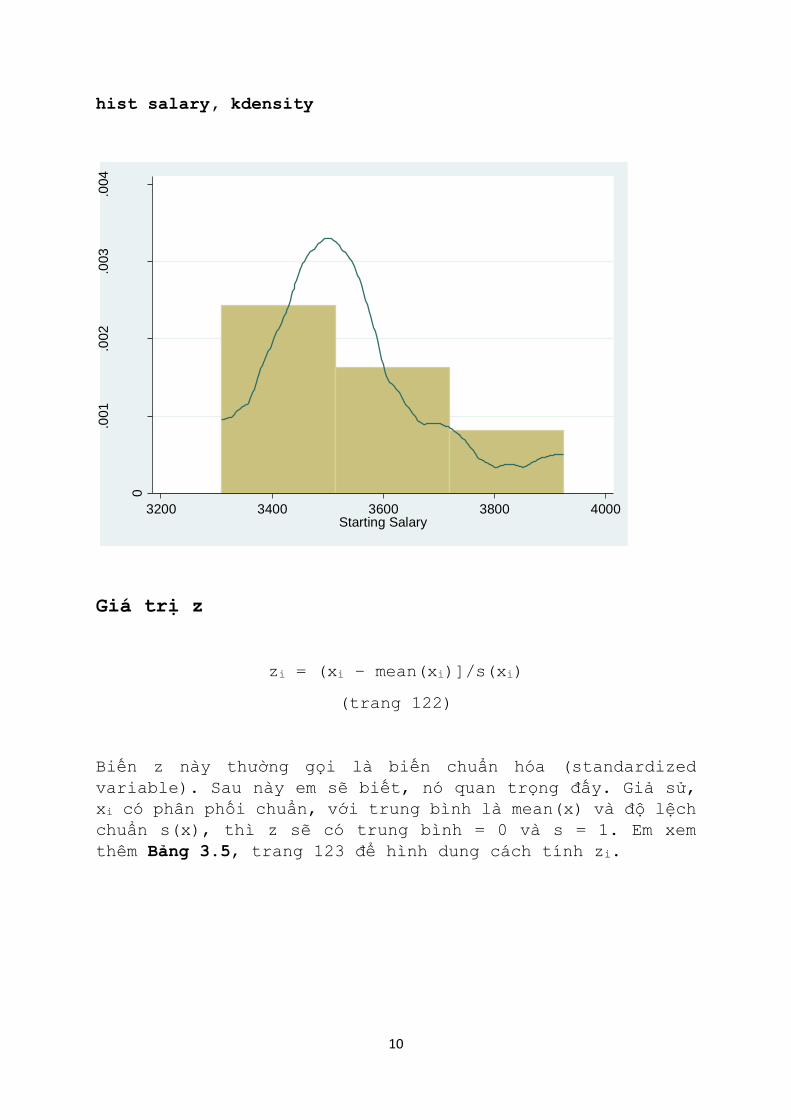
Để nhận diện hình dáng phân phối, người ta hay dùng lệnh
histogram hay hist, và có khi đưa thêm đường phân phối
normal (chuẩn) hay kdensity vào lệnh Stata.
Hist salary, normal
0
5.0
e-0
4
.001
.001
5.0
02
.002
5
De
nsity
3200 3400 3600 3800 4000Starting Salary
10
hist salary, kdensity
Giá trị z
zi = (xi – mean(xi)]/s(xi)
(trang 122)
Biến z này thường gọi là biến chuẩn hóa (standardized
variable). Sau này em sẽ biết, nó quan trọng đấy. Giả sử,
xi có phân phối chuẩn, với trung bình là mean(x) và độ lệch
chuẩn s(x), thì z sẽ có trung bình = 0 và s = 1. Em xem
thêm Bảng 3.5, trang 123 để hình dung cách tính zi.
0
.001
.002
.003
.004
De
nsity
3200 3400 3600 3800 4000Starting Salary
11
Quy tắc Chebyshev và quy tắc thực nghiệm
Quy tắc
Chebyshev
Quy tắc thực
nghiệm
Phạm vi áp dụng Bất kỳ dữ liệu
nào, bất kể hình
dáng phân phối.
Dữ liệu có phân
phối chuẩn
1.
Ít nhất 75% các
giá trị nằm
trong khoảng z =
2 độ lệch chuẩn
so với trung
bình (+/-2)
Khoảng 68% các
giá trị nằm
trong khoảng +/-
một độ lệch so
với trung bình
2.
Ít nhất 89% các
giá trị nằm
trong khoảng z =
3 độ lệch chuẩn
so với trung
bình (+/-3)
Khoảng 95% các
giá trị nằm
trong khoảng +/-
hai độ lệch so
với trung bình
3.
Ít nhất 94% các
giá trị nằm
trong khoảng z =
4 độ lệch chuẩn
so với trung
bình (+/-4)
Hầu như tất cả
các giá trị nằm
trong khoảng +/-
ba độ lệch so
với trung bình
Phát hiện giá trị bất thường
Khi nào là một giá trị bất thường?
• Giá trị quá nhỏ hoặc quá lớn nhưng do lỗi ghi chép hoặc
nhập liệu không chính xác => chỉnh lai5i cho đúng.
• Có thể quan sát đó không nằm trong tập dữ liệu => loại
bỏ ra.
• Giá trị quá nhỏ hoặc quá lớn, được ghi chép chính xác
và thuộc trong tập dữ liệu. Đây được xem là quan sát
outlier.

12
Cách nhận biết ra sao?
• Sử dụng giá trị z: Bỏ các quan sát có z nhỏ hơn -3 và
z > 3.
• Vẻ đồ thị và quan sát: Đồ thị histogram (1 biến), đồ
thị scatter (hai biến), …
4. PHÂN TÍCH DỮ LIỆU THĂM DÒ
Bộ tóm tắt năm số
(1) Giá trị nhỏ nhất (min)
(2) Tứ phân vị thứ nhất (Q1)
(3) Trung vị (Q2)
(4) Tứ phân vị thứ 3 (Q3)
(5) Giá trị lớn nhất (max)
Như vậy, dùng lệnh tabstat là nhanh nhất, em còn nhớ hay
em đã quên?
Biểu đồ hộp
Em xem Hình 3.5, trang 131.
Lệnh trên Stata là graph box
13
Graph box salary
Biểu đồ hộp thường dùng để so sánh giữa các nhóm của cùng
một biến. Ví dụ, so sánh khác biệt chi tiêu giữa nam và nữ
theo nhóm tuổi (với y là chi tiêu, x là giới tính (biến giả
1 là nam, 0 là nữ), và z là nhóm tuổi (giả sử có 3 nhóm
tuôi):
graph box y, over(x) over(z)
3,2
00
3,4
00
3,6
00
3,8
00
4,0
00
Sta
rtin
g S
ala
ry

14
5. CÁC ĐẠI LƯỢNG ĐO LƯỜNG MỐI LIÊN HỆ GIỮA
HAI BIẾN
Hai đại lượng hay dùng (ở rất nhiều môn học khác) là hiệp
phương sai (covariance) và hệ số tương quan (correlation).
[trong chuỗi thời gian thì có thêm đại lượng hệ số tự tương
quan, autocorrelation]. Em xem các công thức (3.10) –
(3.13), trang 135 đến 142 hoặc phần ôn tập xác suất thống
kê, nhé.
Em tính lại Bảng 3.8 trang 137, xem Hình 3.8 trang 138 để
hiểu cov.
• Ví dụ 1: Giả sử lấy mẫu 31 sinh viên AE với điểm 2 môn
Vi mô và Vĩ mô. Trung bình vi mô của mẫu là 7, độ lệch
chuẩn là 1, và trung bình vĩ mô của mẫu là 8, độ lệch
chuẩn là 0.5. Dĩ nhiên, điểm của 31 sinh viên này khác
nhau. Lấy tích độ lệch điểm vi mô và độ lệch điểm vĩ
mô của từng bạn, rồi cộng tất cả lại, nếu tổng này âm,
hoặc = 0, thì chương trình đào tạo thất bại; nếu dương
(giả sử là 12), có nghĩa việc học vi mô có ảnh hưởng
tích cực đến việc học vĩ mô.
• Ví dụ 2: Giả sử lấy mẫu 31 sinh viên AE với điểm 2 môn
Vi mô và NLKT. Trung bình vi mô của mẫu là 7, độ lệch
chuẩn là 1, và trung bình NLKT của mẫu là 6, độ lệch
chuẩn là 1.2. Dĩ nhiên, điểm của 31 sinh viên này khác
nhau. Lấy tích độ lệch điểm vi mô và độ lệch điểm NLKT
của từng bạn, rồi cộng tất cả lại, và tổng này là 18,
có nghĩa việc học vi mô cũng có ảnh hưởng tích cực đến
việc học NLKT.
• Vậy có phải Vi mô có ảnh hưởng đến kết quả NLKT nhiều
hơn so với Vĩ mô? Không chắc đâu. Vậy làm sao?
• Phải dùng hệ số tương quan để so sánh. Và kết quả là
hệ số tương quan giữa Vi mô và Vĩ mô là 0.8 (=0.4/0.5)
và hệ số tương quan giữa Vi mô và NLKT là 0.5
(=0.6/1.2).
Ngoài ra, lập luận ở cuối trang 138 cho rằng cùng một vấn
đề (ví dụ mối quan hệ giữa chiều cao và cân nặng), thì cov

15
bị ảnh hưởng bởi đơn vị đo lường (chiều cao là m hay cm),
còn corr thì không bị ảnh hưởng bởi đơn vị đo lường.
Lệnh trên Stata:
Ví dụ, sử dụng tập tin PCs.xls (Bảng 3.10, trang 144),
chuyển sang Stata, và đặt lại tên biến PC và rating (nhắc
lại, Stata phân biệt chữ HOA và chữ thường, PC khác với pc
nhé). Tính ma trận hệ số tương quan (trường hợp nhiều biến,
và hay dùng trong chương về Đa cộng tuyến ở kinh tế lượng
căn bản) bằng lệnh corr:
6. TRUNG BÌNH CÓ TRỌNG SỐ VÀ DỮ LIỆU ĐÃ ĐƯỢC PHÂN NHÓM
Công thức thì em xem ở các trang 146, 148, và 149.
Lưu ý: Công thức (3.15, trang 146) có gì đó sai!
Ở đây, em đặc biệt quan tâm đến cách tính trung bình và
phương sai của dữ liệu đã được phân nhóm, thực hành bài tập
nhiều vào, vì liên quan đến các chương sau. Cách tạo nhóm
với Stata cho trường hợp dữ liệu liên tục đã được trình bày
ở chương 2, em xem lại để nhớ.





























