Embed Size (px)
Citation preview

On the Boundaries of Phonology and
Phonetics

Sponsored by
Nederlandse Vereniging voor Fonetische Wetenschappen
Center for Language and Cognition Groningen
Stichting Groninger Universiteitsfonds
Department of Linguistics, University of Groningen
1st edition, January 20042nd edition, February 2004
ISBN 90 367 1930 5

U N I V E R S I T Y O F G R O N I N G E N
On the Boundaries of Phonology and
Phonetics
Edited by
Dicky GilbersMaartje Schreuder
Nienke Knevel

4 The Editors: Dicky Gilbers, Maartje Schreuder and Nienke Knevel
To honour Tjeerd de Graaf


Contents
On the Boundaries of Phonology and Phonetics 7The Editors: Dicky Gilbers, Maartje Schreuder and Nienke Knevel
Tjeerd de Graaf 15Markus Bergmann, Nynke de Graaf and Hidetoshi Shiraishi
Tseard de Graaf 31Oerset troch Jurjen van der Kooi
Boundary Tones in Dutch: Phonetic or Phonological Contrasts? 37Vincent J. van Heuven
The Position of Frisian in the Germanic Language Area 61Charlotte Gooskens and Wilbert Heeringa
Learning Phonotactics with Simple Processors 89John Nerbonne and Ivilin Stoianov
Weak Interactions 123Tamás Bíró
Prosodic Acquisition: a Comparison of Two Theories 147Angela Grimm
Base-Identity and the Noun-Verb Asymmetry in Nivkh 159Hidetoshi Shiraishi
The Influence of Speech Rate on Rhythm Patterns 183Maartje Schreuder and Dicky Gilbers
List of Addresses 203


On the Boundaries of Phonology and Phonetics
The Editors: Dicky Gilbers, Maartje Schreuder and Nienke Knevel
In this volume a collection of papers is presented in which the boundaries of phonology and phonetics are explored. In current phonological research, the distinction between phonology, as the study of sound systems of languages, and phonetics, as the study of the characteristics of human (speech) sound making, seems to be blurred.
Consider an example of the phonological process of /l/-substitution as exemplified in the data in Table 1.
Table 1. /l/ substitutions
/l/ [w]
Historical Dutch data:alt/olt oud 'old'kalt/kolt koud 'cold'schoo[l] schoo[w] 'school'
First Language Acquisition data (Dutch):hallo ha[w]o 'hello'lief [w]ief 'sweet'blauw b[w]auw 'blue'
In phonology, the substitution segment is expected to be a minimal deviation from the target segment. For example, boot ‘boat’ could be realized as [pot], but not as [lot], since the target /b/ and the output [l] differ in too many dimensions. In other words, sound substitutions should be characterized more commonly by single feature changes than by several feature changes. The widely attested substitution of /l/ by [w], however, cannot be accounted for adequately as a minimal deviation from the target based on articulatorily defined features, as shown in Figure 1.

On the Boundaries of Phonology and Phonetics 9
/l/ [w]
+ son + son+ cons - cons+ cont + cont+ lat - lat- lab + lab+ ant - ant+ cor - cor- high + high- back + back- round + round
Figure 1. /l/-substitutions
From an acoustic point of view, liquid-glide alternations can be described as minimal changes. The differences between the individual glides and liquids can be related to their relative second and third formant locus frequencies. Ainsworth and Paliwal (1984) found that in a perceptual-identification experiment liquids such as [l] having a mid F2 locus frequency were classified as [w] if they had a low F2 locus frequency and as [j] if they had a high F2 locus frequency.
3160 Hz w w w l l l l j j j w w w l l l l j j j
F3 locus freq. w w w r r r l j j j w w w r r r j j j j
1540 Hz w w r r r r r j j j
760 Hz F2 locus freq. 2380 Hz
Figure 2. Typical set of responses obtained from listening to glide/liquid-vowel synthetic stimuli (after Ainsworth & Paliwal, 1984 (simplified))
Based on these acoustic characteristics, liquid-glide substitutions can be described as a minimal change from the target, which cannot be done in the phonological representation of these sounds. Obviously, phonology needs

10 The Editors: Dicky Gilbers, Maartje Schreuder and Nienke Knevel
phonetic information to explain a phonological process of this kind (cf. Gilbers, 2002).
Now consider the Dutch process of schwa insertion as exhibited in Table 2.
Table 2. schwa insertion in Dutch
helm [lm] 'helmet' darm [rm] 'intestine'half [lf] 'half' durf [rf] 'courage'melk [lk] 'milk' hark [rk] 'rake'
not in: vals 'out of tune', hals 'neck', hart 'heart', start 'start'
Schwa may be inserted between a liquid /l,r/ and a non-homorganic consonant (i.e. a consonant that differs in place of articulation with /l,r/) at the end of a syllable. Therefore, schwa may be inserted between coronal /l/ or /r/ and non-coronal /m/, /f/, /k/, etc. Schwa is not allowed, however, between /l/ or /r/ and a coronal obstruent /s/ or /t/. Now, Dutch has at least two different varieties of /r/: an alveolar [r] and a uvular []. Since there is no functional difference between realizations such as [] and [] for rat 'rat', however, there is only one phoneme /r/ in the Dutch system with its allophones [r] and []. Interestingly, even Dutch speakers with a uvular [] do not show schwa insertion between their [] and non-homorganic coronal obstruent /s/ or /t/. The process of schwa insertion, apparently, takes place before the phonetic level of actual realization of segments, i.e. on the abstract phonological level, where /r/, /s/ and /t/ share their place feature [coronal]. Synchronically, the process can only be described in a phonological way, even though it may have had a phonetic - articulatory - base originally. We assume that uvular [] is a later variant of Dutch /r/ than coronal [r], just as the even younger, recently observed allophonic variant [] in Western Dutch dialects: raar 'strange' realized as [ra:]. These allophones date from times when the process of schwa insertion between non-homorganic, syllable-final liquid-consonant clusters was already 'fossilized' in the Dutch system.
The above-mentioned two accounts of phonological processes indicate the way many phonologists approach their research objects nowadays. More and more the distinction between phonology and phonetics is challenged in attempts to provide adequate accounts of the phonological phenomena. In this way, the phonologists of the so-called CLCG Klankleer

On the Boundaries of Phonology and Phonetics 11
group in Groningen study the phonology-phonetics interface, whereas other members of the group cross the boundaries of phonology and phonetics by combining the study of sound patterns with dialectology, computational linguistics, musicology, first language acquisition or ethnolinguistics.
The Center for Language and Cognition Groningen (CLCG) is a research institute within the Faculty of Arts of the University of Groningen. It comprises most of the linguistic research that is being carried out within the Faculty of Arts. One of the research groups of CLCG is this 'Klankleer' group (Phonology and Phonetics), which focuses on the structure and contents of the sounds of language.
This volume of papers by members of the Klankleer group is dedicated to Tjeerd de Graaf, who was the coordinator of this group from 1999 until 2003. It does not mean that Tjeerd no longer participates in the group, because he still supervises two PhD projects. These projects by Hidetoshi Shiraishi and Markus Bergmann combine phonetics and phonology with ethnolinguistics. As mentioned above, the research of most members of the group involves combinations of different (linguistic) areas. Wilbert Heeringa, Charlotte Gooskens and Roberto Bolognesi apply phonetics to the study of dialectology. Nanne Streekstra is one of the first linguists in our group who was interested in the phonology-phonetics interface. Wouter Jansen's work is exemplary for this so-called 'laboratory phonology'. He provides acoustic studies of voicing assimilation in obstruent clusters in Germanic languages. Maartje Schreuder and Dicky Gilbers combine phonetics and phonology with areas beyond linguistics, such as music theory. Former member Klarien van der Linde and Angela Grimm study first language acquisition, whereas Wander Lowie studies second language acquisition. Finally, Tjeerd de Graaf started his academic life as a researcher in theoretical physics, switched to phonetics, whereas his main interest is now in ethnolinguistics. This homo universalis also plays piano and oboe and speaks nine different languages. This Festschrift, however, is dedicated to the phonetician Tjeerd de Graaf. The papers cover a wide range of topics varying from ethnolinguistics to computational linguistics and from first language acquisition to dialectology. The common denominator is that all researchers work on the boundaries of phonology and phonetics.
Vincent van Heuven, as a guest author from University of Leiden, wonders whether certain distinctions in the speech signal are phonological or phonetic. He investigates whether different prosodic boundary tones form a continuum or whether they are categorical. He finds a categorical

12 The Editors: Dicky Gilbers, Maartje Schreuder and Nienke Knevel
division between low (declarative) and non-low tones, but within the non-low category the cross-over from continuation to question is rather gradual.
Charlotte Gooskens and Wilbert Heeringa measured linguistic distances between Frisian dialects and the other Germanic languages in order to get an impression of the effect of genetic relationship and language contact on the position of the modern Frisian language on the Germanic language map. Wilbert is a member of the CLCG group 'Computational Linguistics'.
John Nerbonne participates as head of CLCG. His paper with Ivilin Stoianov explores the learning of phonotactics in neural networks, in particular the so-called Simple Recurrent Networks (SRNs). SRNs provide a valuable means of exploring what information in the linguistic signal could in principle be acquired by a very primitive learning mechanism.
Tamás Bíró, who is also a member of 'Computational Linguistics' and interested in phonology, claims that the types of interactions between languages can be extremely diverse, depending on a number of factors. The paper analyses three case studies, namely the influence of Yiddish on Hungarian, Modern Hebrew and Esperanto.
Angela Grimm discusses a number of empirical and theoretical problems with respect to two models of prosodic acquisition: a template mapping model and a prosodic hierarchy model. Both models assume that the acquisition of word prosody is guided by universal prosodic principles.
Toshi Shiraishi discusses phonological asymmetries between nominal and verbal stems of Nivkh, a minority language spoken on the island of Sakhalin. These asymmetries are observed in two phonological phenomena: consonant alternation and final fricative devoicing. Though the asymmetries themselves look very different on the surface, Toshi's paper makes explicit that they are subject to a common generalization, Base-Identity.
Maartje Schreuder and Dicky Gilbers wondered whether the influence of a higher speech rate leads to adjustment of the rhythmic pattern, as it does in music, or just to 'phonetic compression' with preservation of the phonological structure. An example of an item they examined is the Dutch word perfèctioníst, which can get the rhythmic structure pèrfectioníst in fast tempo. The results indeed showed a preference for restructured rhythms in fast speech.
With this very diverse collection of papers, we hope to present the phonetician Tjeerd de Graaf a representative selection of the current activities of his CLCG-Klankleer group.

On the Boundaries of Phonology and Phonetics 13
In the 1970's and 1980's Tjeerd's phonetic research stood miles away from the feature geometries and grid representations that were customary in phonology. He used to make sonagrams, i.e. visual displays of sound spectrograms, of e.g. [p], [si] and [r]. But when the violin string of his sonagraph broke, he wasn't able to do phonetic research anymore and that is when ethnolinguistics stole his heart. Nowadays, it is much easier to do phonetic analyses on the computer using programs, such as PRAAT (Boersma and Weenink, 1992-2003). Whereas phonetics and phonology grew apart from each other since they were installed as two distinct disciplines of linguistics at the First International Congress of Linguists (The Hague 1928), current laboratory phonological research may even suggest that phonetics and phonology coincide. However, as shown in the two examples in this introductory paper, /l/-substitution and schwa-insertion, the role of both disciplines is still distinguishable. That does not alter the fact that co-operation between phoneticians and phonologists must be an integral part of the study of sound patterns. Some sound phenomena, such as ethnolinguistic and dialect differences or acquisition data, can only be explained adequately if both phonological and phonetic characteristics of sounds are considered.
University of Groningen, January 2004
This volume was presented to Tjeerd de Graaf on January 30, 2004 at the workshop 'On the Boundaries of Phonology and Phonetics'. The CLCG and the Department of Linguistics of the University of Groningen, 'de Nederlandse Vereniging voor Fonetische Wetenschappen' and GUF (Stichting Groninger Universiteitsfonds) sponsored this workshop. Keynote speakers were Vincent van Heuven and Carlos Gussenhoven.
References
Ainsworth, W.A. & K.K. Paliwal (1984). Correlation between the production and perception of the English glides /w,r,l,j/. Journal of Phonetics, 12: 237-243.
Boersma, Paul, and David Weenink (1992-2003). PRAAT, phonetics by computer. Available at http://www.praat.org. University of Amsterdam.

14 The Editors: Dicky Gilbers, Maartje Schreuder and Nienke Knevel
Gilbers, D.G. (2002). Conflicting phonologically based and phonetically based constraints in the analysis of /l/-substitutions. In: M. Beers, P. Jongmans & A. Wijnands (eds). Netwerk Eerste Taalverwerving, Net-bulletin 2001. Leiden, 22-40.


Tjeerd de Graaf
Markus Bergmann, Nynke de Graaf and Hidetoshi Shiraishi
Tjeerd de Graaf was born on January 27th 1938 in Leeuwarden, the capital of the province Fryslân in the Netherlands. Fryslân is the largest of several regions on the North Sea where Frisian is spoken, a West Germanic language whose genetically closest relative is English.
Tjeerd’s parents were both Frisians, and at home they spoke exclusively Frisian. As most other children in Fryslân at that time, Tjeerd grew up bilingually. His first native language was Frisian, and at school he learned Dutch, the official language of the Netherlands.
The coexistence of Frisian at home and Dutch at school was Tjeerd’s first experience in a fascinating world of different languages. For Tjeerd, the difference between the two languages had a very illustrative spatial implication: when he and the other children in his neighborhood went to school in the mornings, there was a railway crossing along the way. Once they had crossed it they stopped speaking Frisian and switched to Dutch, their official school language.
At the age of 18, in 1956, Tjeerd graduated from the Leeuwarden High School and became interested in languages. His other big passion was the science of physics and astronomy. The oldest planetarium in the world is located in Franeker, an old academic place in Fryslân. Intrigued by the laws governing space and time, Tjeerd studied physics at the University of Groningen from 1956 to 1963. In 1963 he received his master’s degree in science (Doctoraal examen) in theoretical physics, a combination of physics, mathematics and astronomy. From 1963 until 1969 he continued as a research associate at the Institute of Theoretical Physics at the University of Groningen.
Tjeerd was already a “polyglot” at that time, speaking not only Frisian and Dutch, but also German, English and French. Other languages would follow. In the former Soviet Union the study of astronomical sciences was enjoying an era of superiority. Tjeerd understood that learning Russian and other East European languages would be the key to enter the field of scientific knowledge. Along with his theoretical physics’ studies, he also

Tjeerd de Graaf 17
enrolled for the study of Slavic languages. The new technologies and their application for future research fascinated him. In 1967 he received his Master of Arts degree (Kandidaatsexamen) in Slavic languages and computer linguistics. In the meantime, after having obtained his MS, he continued his research in theoretical physics, combined with a study abroad in Poland, where he lived for half a year and mastered the language.
By 1969, he finished his dissertation entitled “Aspects of Neutrino Astrophysics”.
The cover page of Tjeerd’s dissertation in Theoretical Physics in 1969
Tjeerd’s quenchless thirst for knowledge led him to England together with his wife Nynke and their children where they spent a year from 1970 to 1971 and where he worked as a research associate at the Institute of Theoretical Physics at the University of Cambridge.
Upon their return to Groningen, Tjeerd became assistant professor in physics at the Institute of Astronomy, a post he held until 1975. This was to be a turning point in his professional career when he decided to switch to his second passion, namely the study of languages. One of his dissertational theses dealt with the question as to how exact a person’s identity could be defined by his or her speech. This thesis symbolically defined one of Tjeerd’s later linguistic interests: the aspects of spoken language, the study of phonetics.
In 1975, Tjeerd became associate professor at the Institute of Phonetic Sciences, Department of Linguistics, University of Groningen.
Being a native bilingual in Frisian and Dutch, Tjeerd was aware of the numerous phonetic differences between the languages. Having studied

18 Markus Bergmann, Nynke de Graaf and Hidetoshi Shiraishi
many other languages as well, Tjeerd understood how important phonetic descriptions are not only for theoretical linguistics, but also in learning and teaching foreign languages.
Language coexistence and language change would become another focal point of his research. In most regions of the world, people are bilingual or even multilingual. Language variety appears both in space and time. Listening to radio programs or TV broadcasts dating back ten or twenty years, reveals a distinct difference in speech as compared with today’s custom of speaking. It is still the same language, the same place, and yet the speech is not the same as before. Not only the lexicon of a language changes but also the manner in which people speak, their pronunciation and intonation. This is an extremely intriguing topic for a person interested in languages and their varieties.
Tjeerd started to trace the oldest recordings of spoken examples of languages. He analyzed Frisian recordings from the province of Fryslân as well as recordings from North and East Frisian regions. Recordings of the spoken language of former times are not only a historically important heritage, but they also offer valuable information pertaining to language shift processes. A practical problem with the oldest sound recordings is that they were made on wax cylinders and their quality decreases tremendously every time they are listened to. Tjeerd was aware of the fact that one of the main tasks was to transfer these recordings to modern media in order to preserve them. In the beginning of the 1990s, together with Japanese colleagues, Tjeerd started to investigate the possibilities of preserving old language recordings via modern audio technology. At that time, Tjeerd acquired yet another language, namely Japanese.
Tjeerd working on wax cylinders with old recordings of Dutch

Tjeerd de Graaf 19
Tjeerd started to contact the most important sound archives of the world, which are in Vienna, Berlin, and St. Petersburg. Through his collaboration with the sound archive of the Academy of Sciences in St. Petersburg in the 1990s, he renewed his contact with Russia, which had begun with his studies of Slavic languages in the 1960s.
After 1990, the world had experienced dramatic changes. The Iron Curtain had disappeared and Russia had once again opened her “Window to the West”. When Tjeerd came back to St. Petersburg in the 1990s, he was immediately fascinated by this city he had visited for the first time some twenty years ago when it was still known as Leningrad. As a Frisian and a Dutchman, he felt at home there. The picturesque canals and paths along the wide boulevards reminded him of his home region. This was no coincidence: Czar Peter the Great, some 300 years ago, had chosen Holland as the model for his new capital.
In the following years, Tjeerd organized joint projects with the Russian Academy of Sciences and St. Petersburg State University to preserve and transfer old Russian sound recordings onto modern digital audio media. Research on a vast collection of the most various sound recordings resulting from many linguistic field work expeditions from the end of the XIX and XX centuries served as an incentive for several projects related to different languages spoken in Russia.
Tjeerd started to initiate research projects on the language spoken by the Mennonites, a group of people in Siberia, who had originally come from regions in the Northern Netherlands and Germany and still speak the language of their ancestors – in fact a language with great similarities to the modern dialects spoken in North-Germany and northern parts of the Netherlands. The Dutch press even reported about “Siberians speak Gronings”.
Languages do not only divide people of different nations, but also build a bridge between them. Tjeerd showed this with his research work. Even in far-away Siberia there are people speaking almost the same language as in Groningen. When planning his expeditions, Tjeerd was concerned with both scientific aims and the organization of humanitarian aid from Groningen to the Siberian villages he visited.
Language as a cultural heritage became the core of Tjeerd’s linguistic activities. With his bilingual origin, he set the perfect example. Throughout his life, he showed that each individual can contribute to the survival of a language. With his Frisian wife Nynke, whom he met in his student years, Tjeerd used to converse in Dutch. After their parents had passed away, they

20 Markus Bergmann, Nynke de Graaf and Hidetoshi Shiraishi
decided to switch to Frisian. They personally experienced how a language slowly starts to become extinct if the children do not carry on the language.
This attitude defined Tjeerd’s successive research activities in Russia. Subsequent projects, which he coordinated now, had two goals: documentation of endangered languages, and revitalizing and preserving them for future generations. In the following projects, both aspects – preservation and further development – were present. Tjeerd made several expeditions, among others to Yakutia and the Island of Sakhalin, where he and other linguists recorded the speech of the local indigenous peoples.
Tjeerd de Graaf with a group of speakers of indigenous languages of the Island of Sakhalin in the Far East of Russia: Uiltas and Nivkhs, in the 1990s.
In the second half of the 1990s, Tjeerd coordinated several projects with Institutions throughout the Russian Federation funded by the Netherlands Organization for Scientific Research and the EU INTAS organization in Brussels.
His main goal was to make young people aware of their unique linguistic heritage and stimulate them in supporting minority and regional languages. In 1998, Tjeerd was appointed Knight in the Order of the Dutch Lion for his research and contribution in support of the preservation and construction of databases for the minority languages in Russia. Later that same year Tjeerd was awarded an honorary doctorate at the University of St. Petersburg for his contribution in the joint language preservation projects.

Tjeerd de Graaf 21
Tjeerd de Graaf is appointed Doctor Honoris Causa at the University of St. Petersburg, November 1998.
Tjeerd has retired from the University of Groningen in 2003 and vacated the chair of the coordinator of the 'Klankleer' (Phonology and Phonetics) group of CLCG (Center of Language and Cognition Groningen). Therefore, his colleagues compiled this Festschrift exhibiting a diversity of research subjects on the boundaries of phonology and phonetics.
It is not a goodbye to our former coordinator. Tjeerd's passionate engagement for languages and linguistic projects continues. Since his retirement he became an active honoree member at the Frisian Academy in Leeuwarden and he is still in contact with the University of St. Petersburg for future research projects. That means more than enough commitments for Tjeerd combined with his role as a grandfather for his five grandchildren. Tjeerd’s enthusiasm is a stimulation for other researchers and the young generation to continue his research.
Publications by Tjeerd de Graaf
1966The Annihilation of a Neutrino-antineutrino Pair into Photons and the Neutrino Density in the Universe. (With H.A.Tolhoek). Nuclear physics, 81: 596 and 99: 695.Neutrinoprocessen en Neutrino-astronomie [Neutrino Processes and Neutrino Astronomy]. Internal Report IR 68, Natuurkundig Laboratorium Groningen. 58 pp.

22 Markus Bergmann, Nynke de Graaf and Hidetoshi Shiraishi
1968De Rol van het Neutrino in de Astrofysica [The Role of the Neutrino in Astrophysics]. Nederlands tijdschrift voor natuurkunde, 34: 329.Phase Factors in Discrete Symmetry Operations. (With H.A.Tolhoek). Intern Rapport IR 85, Natuurkundig Laboratorium Groningen, 96 pp.Detectie van Neutrino's uit de Zon [Detection of Solar Neutrinos]. Nederlands tijdschrift voor natuurkunde, 34: 357.
1969Phase Factors in Quantum Field Theory. Physica, 43: 142.Muonen uit Kosmische Straling: het Utah Experiment [Muons from Cosmic Radiation: the Utah Experiment]. (With J. van Klinken). Nederlands tijdschrift voor natuurkunde, 36: 301.Aspects of Neutrino Astrophysics. Dissertation University of Groningen. Groningen. 119 pp.Syllabus Beknopte Theoretische Natuurkunde [Syllabus Summary of Theoretical Physics]. Natuurkundig Laboratorium Groningen, 190 pp.
1970On a Cosmic Background of Low-energy Neutrinos. Astronomy and Astrophysics, 5: 335.Neutrino Processes in the Lepton Era of the Universe. Lettere al Nuovo Cimento, 4: 638.Cosmological Neutrinos. Proceedings of the Cortona Meeting on Astrophysical Aspects of the Weak Interactions, 81.
1971Nucleaire Astrofysica in het Laboratorium [Laboratory Nuclear Astrophysics]. Nederlands tijdschrift voor natuurkunde, 38: 107.The Astrophysical Importance of Heavy Leptons. Lettere al Nuovo Cimento, 2: 979.
1972Lecture Notes on Nuclear Astrophysics. Scuola Normale Superiore, Pisa, 45 pp.The Lepton Era of the Big Bang. Proceedings of the Europhysics Conference Neutrino'72. Budapest, 167.

Tjeerd de Graaf 23
1973Neutrinos in the Universe. Vistas in Astronomy, 15: 161.
1974Nuclear Processes in the Early Universe. VIth International Seminar on Nuclear Reactions in the Cosmos. Leningrad, 329.Kernenergie in de Kosmos [Nuclear Energy in the Cosmos]. Atoomenergie en haar Toepassingen, 81.De Heliumabundantie in het Heelal [The Helium Abundance in the Universe]. (With W.J. Weeber). Nederlands tijdschrift voor natuurkunde, 40: 183.
1977De Computer en de Faculteit der Letteren [The Computer and the Faculty of Arts]. Informatiebulletin Computercommissie FdL. Groningen, 38 pp.
1978Vowel Analysis with the Fast Fourier Transform. Acustica, 41: 41Ienlûd, twa lûden, twalûden [Monophthongs, Two Sounds, Diphthongs]. (with G.L. Meinsma). Us Wurk, 27: 81.Analyse de voyelles avec des méthodes digitales [Vowel Analysis with Digital Methods]. Actes des 9èmes Journées d'Etude sur la Parole. Lannion, 233.Linear Prediction in Speech Research. Prace XXV Seminarium Otwartego z Akustyki. Poznań, 19.
1979Het kenmerk <+kort> bij hoge gespannen vokalen [The Feature <+short> in High Tense Vowels]. (With N.Streekstra). TABU, 8: 40.De Computer en Fonetisch Onderzoek [The Computer and Phonetic Research]. Informatiebulletin Computercommissie FdL. Groningen, 5 pp.Vowel Analysis with Linear Prediction. Proceedings of the 9th International Congress of Phonetic Sciences. Copenhagen, 265.Digital Methods for the Analysis of Speech. Proceedings of the 7th Colloquium on Acoustics. Budapest, 289.
1980Phonetic Aspects of Breaking in West Frisian. (With P.Tiersma). Phonetica, 37: 109.

24 Markus Bergmann, Nynke de Graaf and Hidetoshi Shiraishi
De brekking fan sintralisearjende twalûden yn it Frysk [Breaking of Centralizing Diphthongs in Frisian]. (With G.L. Meinsma). Us Wurk, 29: 131.Vannak-e Diftongusok a Magyar Köznyelvben? [Are there Diphthongs in Standard Hungarian?]. (With A.D. Kylstra). Nyelvtudományi Közlemények, 82: 313.Applications of Linear Predictive Coding in Speech Analysis. Proceedings of the Symposium on Speech Acoustics, 57.
1981Wiskundige Modellen in het Spraakonderzoek [Mathematical Models in Speech Research]. Wiskundige Modellen: Cursusboek Stichting TELEAC, 165.Syllabegrenzen en Fonetische Experimentatie [Syllable Boundaries and Phonetic Experiments]. GLOT, Tijdschrift voor Taalwetenschap, 4: 229.Book Review of: Metrical Myths – An Experimental-Phonetic Investigation into the Production and Perception of Metrical Speech. Spectator, 10: 385.
1982Vowel Contrast Reduction in Japanese Compared to Dutch. (With F.J. Koopmans-van Beinum). Proceedings of the Institute of Phonetic Sciences. Amsterdam, 7: 27.A Sociophonetic Study of Language Change. Proceedings of the 13th International Conference of Linguistics. Tokyo, 602.
1983Phonetic Sciences in the Netherlands, Past and Present. (With other authors). Publication of the Netherlands Association for Phonetic Sciences. Dordrecht, 32 pp.On the Reliability of the Intraoral Measuring of Subglottal Pressure. (With G.L.J. Nieboer and H.K. Schutte). Proceedings of the 10th International Congress of Phonetic Sciences. Utrecht, 367.Phonetic Aspects of Vowels and Breaking of Diphthongs. Fifth International Phonology Meeting. Eisenstadt, 98.Vowel Contrast Reduction in Finnish, Hungarian and Other Languages. Dritte Tagung für Uralische Phonologie. Eisenstadt, 11.

Tjeerd de Graaf 25
1984Vowel Contrast Reduction in Terms of Acoustic System Contrast. (With F.J. Koopmans-van Beinum). Proceedings of the Institute of Phonetic Sciences. Amsterdam, 8: 41.Vokaalduur en Breking van Diftongen in het Fries [Vowel Duration and Breaking of Diphthongs in Frisian]. Verslagen van de Nederlandse Vereniging voor Fonetische Wetenschappen, 54.The Acoustic System Contrast and Vowel Contrast Reduction in Various Languages. Proceedings of the 23rd Acoustic Conference on Physiological and Psychological Acoustics. Madrid, 76.Vowel Data Bases. (With A. Bladon en M. O'Kane). Speech Communication, 3: 169.Nederlandse Leerboeken voor de Fonetiek van het Engels [Dutch Teaching Methods on the Phonetics of English]. (With A. van Essen en J. Posthumus). Toegepaste Taalwetenschap in Artikelen, 20: 123-154.
1985Phonetic Aspects of the Frisian Vowel System. NOVELE, 5: 23-42.Review of: Spreken en Verstaan, een nieuwe Inleiding tot de Experimentele Fonetiek [Speaking and Understanding, A New Introduction to Experimental Phonetics]. (By S. Nooteboom en A. Cohen). Logopedie en Foniatrie, 57: 106.De Groninger Button [The Groningen Button]. (With G.L.J. Nieboer and H.K. Schutte). Verslagen van de Nederlandse Vereniging voor Fonetische Wetenschappen, 57-62.
1986Sandhi Phenomena in West Frisian. (With G. van der Meer). Sandhi Phenomena in the Languages of Europe. Berlin, 301-328.Review of: The Production of Speech. (By P.F. MacNeilage). Studies in Language, 10: 273-277.Production of Different Types of Esophageal Voice Related to the Quality and the Intensity of the Sound Produced. Folia Phoniatrica, 38: 292.De Uitspraak van het Nederlands door Buitenlanders [The Pronunciation of Dutch by Foreigners]. Logopedie en Foniatrie, 58: 343-349.Sociophonetic Aspects of Frisian. Friser Studier IV/V. Odense, 3-21.Een contrastief fonetisch onderzoek Japans-Nederlands [A Contrastive Phonetic Research Japanese-Dutch]. Verslagen van de Nederlandse Vereniging voor Fonetische Wetenschappen, 15-24.

26 Markus Bergmann, Nynke de Graaf and Hidetoshi Shiraishi
1987The Retrieval of Dialect Material from Old Phonographic Wax Cylinders. Proceedings of the Workshop on “New Methods in Dialectology”. Amsterdam, 117-125.Acoustic and Physiological Properties of the Laryngeal and Alaryngeal (Esophageal) Voice. Proceedings of the XXXIVth Open Seminar on Acoustics. Wrocław, 10-16.A Contrastive Study of Japanese and Dutch. Proceedings of the XIth International Congress of Phonetic Sciences. Tallinn, 124-128.
1988His Master's Voice: Herkenning van de Spraakmaker [His Master’s Voice: Recognition of the Speech Producer]. TER SPRAKE: SPRAAK als betekenisvol geluid in 36 thematische hoofdstukken. Dordrecht, 200-208.Book Review: Fonetiek en Fonologie [Phonetics and Phonology]. (By R. Collier en F.G. Droste). Logopedie en Foniatrie, 60: 195.The Frisian Language in America. (With T. Anema and H. Schatz). NOWELE, 6: 91-108.Esophageal Voice Quality Judgements by Means of the Semantic Differential. (With G.L.J. Nieboer and H.K. Schutte). Journal of Phonetics, 16: 417-436.Book Review: Sprechererkennung [Speaker Recognition]. (By Hermann J. Künzel). Journal of Phonetics, 16: 459-463.
1989Reconstruction, Signal Enhancement and Storage of Sound Material in Japan. Proceedings of the 2nd International Conference on Japanese Information in Science, Technology and Commerce. Berlin, 367-374.Aerodynamic and Psycho-acoustic Properties of Esophageal Voice Production. (With G.L.J. Nieboer and H.K. Schutte). Proceedings of the Conference on Speech Research '89. Budapest, 53-58.A Data Base of Old Sound Material. Proceedings of the ESCA Workshop on Speech Input/Output Assessment and Speech Data Bases. Noordwijk, 2.14.1-5.
1990Een contrastief fonetisch onderzoek, in het bijzonder Japans-Nederlands [Contrastive Phonetic Research, in Particular Japanese-Dutch]. Neerlandica Wratislaviensia IV. Wrocław, 140-148.

Tjeerd de Graaf 27
Book Review: To Siberia and Russian America, Three Centuries of Russian Eastward Expansion. Circumpolar Journal, 7: 41-46.New Technologies in Sound Reconstruction and their Applications to the Study of the Smaller Languages of Asia. Proceedings of the IVth International Symposium “Uralische Phonologie”. Hamburg, 15-19.GARASU-GLAS: Fonetische contrasten Japans-Nederlands [GARASU-GLAS: Phonetic Contrasts Japanese-Dutch]. TABU. Bulletin voor Taalwetenschap, 20: 49-57.
1991Aerodynamic and Phonetic Properties of Voice Production with the Groningen Button. TENK jaarboek, 91-97.Laser-beam Technology in Diachronic Phonetic Research and Ethnolinguistic Field Work. Proceedings of the XIIth International Congress of Phonetic Sciences. Amsterdam, 114-118.Laut aus Wachs: Der Übergang von stoffgebundenen zum elektronischen und optischen Informationstransport [Sound from Wax: The Transition from Material-Bound to Electronic and Optic Information Transport]. TU International. Berlin, 14/15: 63-66.
1992The Languages of Sakhalin. Small Languages and Small Language Communities: News, Notes, and Comments. International Journal of the Sociology of Languages, 94: 185-200.Dutch Encounters with Sakhalin and with the Ainu People. Proceedings of the International Conference 125th anniversary of the birth of Bronisaw Pisudski. Sapporo, 108-137.The Ethnolinguistic Situation on the Island of Sakhalin. Circumpolar Journal, 6: 32-58.Aerodynamische en fonetische eigenschappen van verschillende soorten slokdarmstem [Aerodynamic and Phonetic Features of Different Kinds of Esophageal Voice]. (With G.L.J. Nieboer and H.K. Schutte). Klinische Fysica, 8: 64-66.The Dutch Role in the Border Area between Japan and Russian. Round Table Conference “The Territorial Problem in Russo-Japanese Relations”. Moscow, 20-26.De Taal der Mennonieten [The Language of the Mennonites]. Syllabus NOMES Symposium Groningen, 42 pp.

28 Markus Bergmann, Nynke de Graaf and Hidetoshi Shiraishi
1993Saharin ni okeru shoosuu minzoku no gengo jookyoo [The Status of Minority Languages on Sakhalin]. (With K. Murasaki). Japanese Scientific Monthly, 46: 18-24.The Ethnolinguistic Situation on the Island of Sakhalin. Ethnic minorities on Sakhalin. Yokohama, 13-32.Vstrechi gollandtsev c Sakhalinom i Ainami [Meetings of the Dutch with Sakhalin and the Ainu Population]. Proceedings of the International Conference “B.O. Pilsudski - issledovatel' narodov Sakhalina”. Yuzhno-Sakhalinsk, 92-99.De taal der Mennonieten in Siberië en hun relatie met Nederland [The Language of the Siberian Mennonites and their Relation with the Netherlands]. (With R. Nieuweboer). Doopsgezinde Bijdragen, 19: 175-189.Languages and Cultures of the Arctic Region in the Former Soviet Union. (With R. Nieuweboer). Circumpolar Journal, 1-2: 29-42.
1994The Dutch Role in the Border Area between Japan and Russia. Circumpolar Journal, 3-4: 1-12.Nederlands in Siberië [Dutch in Siberia]. (With R. Nieuweboer). TABU Taalkundig Bulletin, 24: 65-75.The Language of the West Siberian Mennonites. (With R. Nieuweboer). RASK, Internationalt tidsskrift for sprog og kommunikation, 1: 47-63.
1995Het territoriale geschil tussen Japan en Rusland over de Koerilen [The Territorial Dispute between Japan and Russia about the Kuril Islands]. (With I. van Oosteroom). Internationale Spectator, 49: 41-46.Dutch Encounters with Sakhalin and with the Ainu People. Linguistic and Oriental Studies from Poznań, 35-61.The Language of the West Siberian Mennonites. (with R. Nieuweboer). Proceedings of the XIIIth Congress of Phonetics Sciences. Stockholm, 4: 180-184.Pitch Stereotypes in the Netherlands and Japan. (With R. van Bezooijen and T. Otake). Proceedings of the XIIIth Congress of Phonetic Sciences. Stockholm, 680-684.The Reconstruction of Acoustic Data on the Ethnic Minorities of Siberia. Proceedings of the International Conference on “The Indigenous Peoples

Tjeerd de Graaf 29
of Siberia: Studies of Endangered Languages and Cultures”. Novosibirsk, 1: 381-383.
1996Book Review of: Joshua A. Fishman, Yiddish: Turning to Life. Studies in Language, 20,1: 191-196.Language Minorities in the Sakha Republic (Yakutia). Report Nagoya City University. Nagoya, 165-179.Dutch Encounters with the Peoples of Eastern Asia. A Frisian and Germanic Miscellany, published in Honour of Nils Århammar on his Sixty-Fifth Birthday. Odense, 377-386.Dutch Immigrants in Siberia? The Language of the Mennonites. Charisteria viro doctissimo Přemysl Janota oblata, Acta Universitatis Carolinae Philologica. Prague, 75-86Archives of the Languages of Russia. (With L.V. Bondarko). Reports on the INTAS Project No. 94-4758. St.-Petersburg, 120 pp.
1997The Reconstruction of Acoustic Data and Minority Languages in Russia. Proceedings of the 2nd International Congress of Dialectologists and Geolinguists. Amsterdam.,44-54.Language and Culture of the Russian Mennonites. Around Peter the Great. Three Centuries of Russian-Dutch Relations. Groningen, 132-142.Resten van het Jiddisch in Groningen en Sint-Petersburg [Remnants of the Yiddish Language in Groningen and Saint-Petersburg]. VDW-berichten, Vereniging voor Dialectwetenschap, 1: 6-7.The Reconstruction of Acoustic Data and the Study of Language Minorities in Russia. Language Minorities and Minority Language. Gdańsk, 131-143.
1998Linguistic Databases and Language Minorities around the North Pacific Rim. Lecture on the Occasion of the Doctorate Honoris Causa, St.-Petersburg, 14 pp.Linguistic Databases: A Link between Archives and Users. Journal of the International Association of Sound Archives, 27-34.

30 Markus Bergmann, Nynke de Graaf and Hidetoshi Shiraishi
1999Russian-Yiddish: Phonetic Aspects of Language Interference. (With N. Svetozarova, Yu. Kleiner and R. Nieuweboer). Proceedings of the 14th International Congress of Phonetic Sciences. San Francisco., 1397-1401.Language Contact and Sound Archives in Russia. (With L. Bondarko). Proceedings of the 14th International Congress of Phonetic Sciences. San Francisco, 1401-1404.Lingvisticheskie bazy dannykh i yazykovye men’shinstva po obeim storonam severnogo tikho-okeanskogo poyasa [Linguistic databases and language minorities at both sides of the North-Pacific Rim]. Yazyk i rechevaya deyatel’nost’, 2: 8-18.
2000Scientific Links between Russia and The Netherlands: A Study of the Languages and Cultures in the Russian Federation. Proceedings of the Conference on the Netherlands and the Russian North. Arkhangelsk. To be published.The Language of the Siberian Mennonites. (With R. Nieuweboer). New Insights in Germanic Linguistics II. Frankfurt am Main, 21-34.
2001Nivkh and Kashaya: Two endangered Languages in Contact with Russian and English. Materialy mezhdunarodnoy konferentsii “100 let eksperimental’noy fonetike v Rossii”. St.-Petersburg, 78-83.Data on the Languages of Russia from Historical Documents, Sound Archives and Fieldwork Expeditions. Recording and Restoration of Minority Languages, Sakhalin Ainu and Nivkh, ELPR Report A2-009. Kyoto, 13-37.Kashaya Pomo and the Russian Influence around the North Pacific. Materials of the Third International Conference on Bronisław Piłsudski and His Scholarly Heritage. Kraków, 385-395.
2002Yazyk i etnos [Language and Ethnos]. (With A.S. Gerd and M. Savijärvi). Texts and Comments on Balto-Finnic and Northwestern Archaic Russian Dialects. St.-Petersburg, 206 pp.Voices from Tundra and Taiga: Endangered Languages in Russia on the Internet. Conference Handbook on Endangered Languages. Kyoto, 57-79.

Tjeerd de Graaf 31
Phonetic Aspects of the Frisian Language and the Use of Sound Archives. Problemy i metody eksperimental’no-foneticheskikh issledovaniy. St.-Peterburg, 52-57.Voices from the Shtetl: The Past and Present of the Yiddish Language in Russia. Final Report NWO Russian-Dutch Research Cooperation. Groningen, 143 pp.The Use of Sound Archives in the Study of Endangered Languages. Music Archiving in the World, Papers Presented at the Conference on the Occasion of the 100th Anniversary of the Berlin Phonogramm-Archiv. Berlin, 101-107.The Use of Acoustic Databases and Fieldwork for the Study of the Endangered Languages of Russia. Proceedings of the International LREC Workshop on Resources and Tools in Field Linguistics. Las Palmas, 29.1-4 (CD-ROM).Yiddish in St.-Petersburg: The Last Sounds of a Language. Proceedings of the Conference “Klezmer, Klassik, jiddisches Lied. Jüdische Musik-Kultur in Osteuropa.”. Potsdam. To be published.
2003Yazyki severnoy i vostochnoy Tartarii – o yazykovykh svedeniyakh v knige N. Vitsena [The Languages of North and East Tartary – About the Linguistic Data in the Book of N. Witsen]. (With M. Bergmann). Proceedings of the Conference on General Linguistics. St.-Petersburg. To be published.Description of Minority Languages in Russia on the Basis of Historical Data and Fieldwork. Proceedings of the XVIth International Congress of Linguists. Prague. To be published.Voices of Tundra and Taiga: Data on Minority Languages in Russia from Historical Data and Fieldwork. Proceedings of the Conference “Formation of Educational Programs Aimed at a New Type of Humanitarian Education in Siberian Polyethnic Society, Novosibirsk. To be published.Endangered Languages in Europe and Siberia: State of the Art, Needs and Solutions. International Expert Meeting on UNESCO Programme “Safeguarding of Endangered Languages”. Paris. To be publishedPresentation of the UNESCO Document “Language Vitality and Endangerement”. Focus on Linguistic Diversity in the New Europe. European Bureau for Lesser Used Languages, Brussels. To be published.

Tseard de Graaf
Oerset troch Jurjen van der Kooi
Tseard de Graaf is berne op 27 jannewaris 1938 yn Ljouwert, de haadstêd fan de Nederlânske provinsje Fryslân, de grutste regio oan de kusten fan de Noardsee dêr’t it Frysk, in Westgermaanske taal mei as neiste sibbe it Ingelsk, sprutsen wurdt.
Tseard syn âlden wiene beide Fries en thús waard allinne Frysk praat. Syn earste taal wie dan ek it Frysk; op skoalle learde er it Nederlânsk, de offisjele taal fan Nederlân.
It Frysk waard doe noch net op skoalle jûn en de bern moasten dêr Nederlânsk leare. Troch it neistinoar fan it Frysk thús en it Nederlânsk op skoalle kaam Tseard foar it earst yn ’e kunde mei de fassinearjende wrâld fan ûnderskate talen. Foar Tseard hie it ûnderskie tusken dy twa talen ek in besûnder romtlik aspekt. As hy en de oare bern út syn buert de moarns nei skoalle ta gyngen moasten se oer it spoar. Wiene se dêr oer, dan giene se fan it Frysk oer op it Nederlânsk, de taal fan de skoalle.
18 Jier âld wie er, doe’t er yn 1956 eineksamen middelbere skoalle die en hy krige niget oan talen. Syn oare grutte leafdes wiene natuer- en stjerrekunde. It âldste planetarium fan de wrâld is yn Frjentsjer, de âlde akademystêd fan Fryslân. Yn ’e besnijing fan de wetten dy’t tiid en romte regeare, studearre Tseard fan 1956 oant 1963 natuerkunde oan de Universiteit fan Grins. Yn dat lêste jier die er doktoraal eksamen teoretyske natuerkunde, in kombinaasje fan natuerkunde, wiskunde en stjerrekunde en dêrnei wie er oant 1969 ûndersykmeiwurker oan it Ynstitút foar Teoretyske Natuerkunde fan de Grinzer universiteit.
Tseard wie doe al in ‘polyglot’. Hy spruts net allinne Frysk en Nederlânsk, mar ek Dútsk, Ingelsk en Frânsk. Oare talen soene folgje. Yn de Sowjet Uny stie de stúdzje fan de astronomy doe op in superieur nivo. Tseard seach dat en learde it Russysk en oare Eastjeropeeske talen om’t dy it paad nei nij ynsjoch yn dy fjilden fan wittenskip iepenleinen. Neist syn stúdzje fan de teoretyske natuerkunde folge er kolleezjes yn de Slavyske talen. Hy wie fassinearre troch de nije technologyen en har tapassingsmooglikheden foar takomstich ûndersyk en yn 1967 die er kandidaatseksamen Slavyske talen en kompjutertaalkunde. Yntysken wie er

Tseard de Graaf 33
nei syn doktoraal natuerkunde trochgien mei syn ûndersyk yn de teoretyske natuerkunde, dat er kombinearre mei in heal jier stúdzje yn Poalen, dêr’t er ek it Poalsk by learde.
Yn 1969 wie er klear mei syn dissertaasje, titele: “Aspects of Neutrino Astrophysics”.
It titelblêd fan Tseard syn dissertaasje teoretyske natuerkunde út 1969
Syn ûndwêstbere toarst nei witten brocht Tseard nei Ingelân, dêr’t er mei frou en bern fan 1970 oant 1971 in jier tabrocht en dêr’t er wurke as ûndersiker oan it Ynstitút foar Teoretyske Natuerkunde fan de Universiteit fan Cambridge.
Werom yn Grins waard Tseard universitêr meiwurker natuerkunde oan it Ynstitút foar Astronomy. Oant 1975. Dat jier waard in kearpunt yn syn wittenskiplike karriêre om’t er besleat de wei fan syn twadde grutte leafde te gean, dy fan de bestudearring fan talen. Ien fan de stellingen by syn dissertaasje gie oer de fraach, hoe krekt of immens identiteit definiearre wurde kin troch syn of har taal. Dy stelling kin sjoen wurde as in symboalyske paadwizer nei syn lettere wei yn de taalkunde, dy’t him liede soe nei de stúdzje fan aspekten fan de sprutsen taal, nei de fonetyk.
Yn 1975 waard Tseard meiwurker oan it Ynstitút foar Fonetyk fan de Literêre Fakulteit fan de Grinzer universiteit.
Om’t er fan jongs ôf oan twatalich wie (Frysk-Nederlânsk) hie Tseard in skerp each foar de ûntelbere fonetyske ferskillen tusken dy talen. En om’t er oare talen bestudearre hie, wist er hoe wichtich fonetyske beskriuwingen binne, net allinne foar de teoretyske taalkunde, mar likegoed ek foar it learen fan en it lesjaan yn frjemde talen.

34 Oerset troch Jurjen van der Kooi
It neistinoar fan talen en taalferoaring soene oare swiertepunten fan syn ûndersyk wurde. Rûnom yn ’e wrâld binne minsken twa- of sels meartalich. Der is taalfariaasje yn romte èn yn tiid. Harket men nei radioprogramma’s of tillevyzje-útstjoerings fan tsien of twintich jier lyn, dan heart men in oare sprektaal as at no gongber is. It is noch altiten deselde taal en itselde plak, en dochs is de taal net mear gelyk. Net allinne it leksikon fan in taal feroaret, mar ek minskene wize fan sprekken, de útspraak en de yntonaasje, in útsûnderlik nijsgjirrich ûnderwerp foar immen dy’t niget hat oan talen en har fariabiliteit.
Tseard begûn mei in syktocht nei de âldste registraasjes op lûddragers fan sprutsen taal. Hy analysearre materiaal net allinne út Westerlauwersk mar ek út Noard- en Eastfryslân. Sokke registraasjes fan eardere sprutsen taal binne net allinne wichtich histoarysk erfguod, mar se jouwe ek weardefolle ynformaasje oangeande taalferoaringsprosessen. In praktysk probleem by dy âldste lûdregistraasjes is dat se makke binne op waakssilinders en dat de kwaliteit hurd ôfnimt elke kear as se beharke wurde. Tseard seach yn dat it fan it grutste belang is en bring dizze registraasjes oer op moderne lûddragers, sadat se bewarre bliuwe. Yn it begjin fan de jierren 90 begûn Tseard mei kollega’s út Japan in ûndersyk nei de mooglikheden dêrta. Yn dy tiid makke er him noch in taal eigen, it Japansk, dat er floeiend sprekken learde.
Tseard oan ’e skrep mei waakssilinders mei âlder Nederlânsk
Tseard socht kontakt mei de wichtichste lûdargiven yn de wrâld, dy yn Wenen, Berlyn en Sint Petersboarch. Troch syn oparbeidzjen yn de 90er jierren mei it lûdargyf fan de Akademy fan Wittenskippen yn dy lêste stêd

Tseard de Graaf 35
luts er op ’en nij de relaasjes oan mei Ruslân, dy’t yn de 60er jierren begûn wiene mei syn bestudearring fan de Slavyske talen.
Sûnt 1990 is wrâld dramatysk feroare. It Izeren Gerdyn is der net mear en Ruslân hat opnij syn ‘Finster op it Westen’ iepenset. Doe’t Tseard nei 1990 weromkaam yn Sint Petersboarch rekke er daliken fassinearre troch dizze stêd dy’t er foar it earst likernôch 20 jier lyn, doe’t er noch Leningrad hiet, sjoen hie. As Fries en Nederlanner fielde er him der thús. De skildereftige kanalen en paden lâns de wide bûlevaren diene him tinke oan thús. Dat wie gjin tafal: tsaar Peter de Grutte hie sa’n 300 jier earder Hollân keazen as model foar syn nije haadstêd.
Tseard organisearre no mienskiplike projekten mei de Russyske Akademy fan Wittenskippen en de Steatsuniversiteit fan Sint Petersboarch. It doel wie âlde Russyske lûdregistraasjes te bewarjen en oer te setten op moderne digitale audio media. Undersyk nei in grutte samling fan alderhande lûdregistraasjes, resultaat fan withoe folle linguïstyske ekspedysjes fan ein 19de en út de 20ste ieu, brocht nije projekten ûnderskate yn Ruslân spruten talen oanbelangjende op ’e gleed.
Sels sette er útein mei ûndersyk nei de taal fan de Sibearyske Mennoniten, dêr’t it komôf fan socht wurde moat yn noardlik Nederlân en Dútslân en dy’t noch altiten de taal fan de foarâlden sprekke – feitliken in taal dy’t gâns hat fan de dialekten fan it hjoeddeiske Noard-Dútslân en de noardlike parten fan Nederlân. De Nederlânske parse kaam sels mei de kop “Sibeariërs sprekke Grinzers”.
Talen skiede net allinne folken en naasjes, se bouwe der ek brêgen tusken. Tseard liet ek dat mei syn ûndersyk sjen. Sels yn it fiere Sibearje wenje minsken dy’t likernôch deselde taal hawwe as de minsken yn Grinslân. By it plannen fan syn ekspedysjes tocht Tseard net allinne oan de wittenskip, mar ek om de minsken: hy organisearre ek humanitêre help út Grins wei foar de doarpen dy’t er yn Sibearje oandie.
Taal as kultureel erfskip waard de kearn fan syn linguïstyske aktiviteiten. Troch syn twatalich komôf koe er in treflik foarbyld jaan. Syn hiele libben hat er sjen litten dat elk yndividu bydrage kin oan it oerlibjen fan in taal. Mei syn frou Nynke, dy’t er met hie yn syn studintetiid en dêr’t er lang allinne Nederlânsk mei praat hie, praatte er no ôf om oer te stappen op it Frysk. Nynke is sels in Friesinne en nei de dea fan har âlden murken hja sels hoe't in taal stadichoan út begjint te stjerren as de bern him net fierder trochjouwe.
Dy taalhâlding waard de rjochtline foar Tseard syn opienfolgjende ûndersykaktiviteiten yn Ruslân. De projekten dy’t er fan dat stuit ôf oan

36 Oerset troch Jurjen van der Kooi
koördinearre krigen twa doelstellings: bedrige talen net allinne dokumintearje, mar ek revitalisearje en yn stân hâlde foar kommende generaasjes. Tseard die mei oan ferskate ekspedysjes, ûnder oaren nei Yakutia en it eilân Sakhalin, wêr’t er mei oare linguïsten de talen fan de lokale folken fêstlei.
Tseard de Graaf mei sprekkers fan talen fan it eilân Sakhalin yn it fiere easten fan Ruslân: Uiltas en Nivkhs (jierren 90)
Yn de twadde helte fan de 90er jierren koördinearre Tseard ûnderskate projekten mei ynstituten rûnom yn de Russyske Federaasje, foar de finansearring soargen Nederlânske wittenskiplike organisaasjes en de INTAS fan de EU.
Alderearsten woe er jonge minsken bybringe dat harren taal in unyk erfskip is en dat hja minderheids- en regionale talen stypje moatte. Yn 1998 waard Tseard beneamd ta ridder yn de oarder fan de Nederlânske liuw fanwegens syn ûndersyk nei en krewearjen foar it behâld fan en it opsetten fan databanken foar de minderheidstalen yn Ruslân. Letter datselde jiers krige er in earedoktoraat fan de Universiteit fan Sint Petersboarch foar syn bydragen oan de mienskiplike taalbehâldprojekten.

Tseard de Graaf 37
Tseard de Graaf earedoktor oan de Universiteit fan Sint Petersboarch, novimber 1998.
Tseard moast yn 2003 mei pinsjoen en syn plak as koördinator fan de ôfdieling 'Klanklear' (Fonology en Fonetyk) fan it CLGC (Center of Language and Cognition Groningen) fan de Grinzer Universiteit opjaan. Ta dy gelegenheid ha syn kollega's dizze earebondel mei in ferskaat oan bydragen oer ûndersyk yn de grinsgebieten fan fonology en fonetyk gearstald.
Lykwols, it is gjin ôfskie fan ús eardere koördinator. Tseard syn pasjonearre belutsenens by talen en linguïstyske projekten is bleaun. Sûnt syn pinsjoen is er aktyf as honorêr meiwurker fan de Fryske Akademy yn Ljouwert en ek it kontakt mei de Universiteit fan Sint Petersboarch oer ûndersyksprojekten dy't op kommende wei binne is bleaun. Dat betsjut dat Tseard neist syn rol as pake foar syn fiif pakesizzers noch genôch te dwaan hat. Syn entûsjasme is in oantrún foar (kommende) ûndersikers om fierder te gean mei it ûndersyk dat hy op priemmen set hat.

Boundary Tones in Dutch: Phonetic or Phonological Contrasts?
Vincent J. van Heuven
1. Introduction1
1.1. Linguistic categorization of sound
A basic problem of linguistic phonetics is to explain how the infinite variety of speech sounds in actual utterances can be described with finite means, such that they can be dealt with in the grammar, i.e. phonology, of a language. The crucial concept that was developed to cope with this reduction problem is the sound category, or – when applied to the description of segmental phenomena – the phoneme. This is best conceived of as an abstract category that contains all possible sounds that are mutually interchangeable in the context of a minimal word pair. That is, substitution of one token (allophone) of a phoneme for an other does not yield a different word (i.e., a string of sounds with a different lexical meaning).2
The phonemes in a language differ from one another along a finite number of phonetic dimensions, such as degree of voicing, degree of noisiness, degree of nasality, degree of openness, degree of backness, degree of rounding, etc. Each phonetic dimension, in turn, is subdivided into a small number (two to four) of phonologically functional categories, such as voiced/voiceless, (half)closed/(half)open, front/central/back, etc.
1 The experiments reported in this chapter were run by Susanne Strik and Josien Klink in partial fulfillment of the course requirements for the Experimental Phonetics Seminar taught by the Linguistics Programme at University of Leiden.
2 This commutation procedure is best viewed as a mental experiment; when the exchange is implemented through actual digital tape splicing, the result is more often than not an uninterpretable stream of sound.

Boundary Tones in Dutch: Phonetic or Phonological Contrasts? 39
Phonetic dimensions generally have multiple acoustical correlates. For instance, degree of voicing correlates with a multitude of acoustic cues such as voice onset time, duration of preceding vowel, steepness of intensity decay and of formant bends in preceding vowel, duration of intervocalic (near) silence, duration and intensity of noise burst, steepness of intensity attack and formant bends of following vowel. These acoustic properties typically co-vary in preferred patterns, but may be manipulated independently through speech synthesis. When non-typical (‘conflicting’) combinations of parameter values are generated in the laboratory, some cues prove to be more influential than others; so-called ‘cue trading relationships’ have been established for many phonemic contrasts. In Dutch, for instance, vowel quality (acoustically defined by F1 and F2, i.e., the centre frequencies of the lowest two resonances in the vocal tract) and vowel duration were found to be equally influential in cuing the tense/lax-contrast between / and //: a duller vowel quality (lower F1 and F2-values), normally cuing // could be compensated for by increasing the duration of the vowel so that native listeners still perceive /a/ (and vice versa, van Heuven, 1986).
Categorization of sounds may proceed along several possible lines. First, many differences between sounds are simply too small to be heard at all: these are subliminal. The scientific discipline of psycho-acoustics provides a huge literature on precisely what differences between sounds can and cannot be heard with the naked ear. Moreover, research has shown that the human hearing mechanism (and that of mammals in general) has developed specific sensitivities to certain differences between sounds and is relatively deaf to others. These predilections have been shown to be present at birth (probably even in utero), and need not be acquired through learning. However, human categorization of sound is further shaped by exposure to language. As age progresses from infancy to adulthood, sound differences that were still above threshold shortly after birth quickly lose their distinctivity. An important concept in this context is the notion of categorical perception. This notion is best explained procedurally in terms of a laboratory experiment.
Imagine a minimal word pair such as English back ~ pack. One important difference between these two tokens is that the onset of voicing in back is more or less coincident with the plosive release, whilst the voice onset in pack does not start until some 50 ms after the release. It is not too difficult in the laboratory to create a series of exemplars by interpolating the voice onset time of a prototypical back (0-ms delay) and that of a

40 Vincent J. van Heuven
prototypical pack (70-ms delay) in steps of, say, 10 ms, so that we now have an 8-step continuum ranging over 0, 10, 20, 30, 40, 50, 60, and 70 ms. These eight exemplars are shuffled in random order and played to an audience of native English listeners for identification as either back or pack (forced choice). The 0-ms voice delay token will naturally come out with exclusively back-responses (0% pack); the 70-ms token will have 100% pack-responses. But what results will be obtained for the intermediate exemplars? If the 10-ms changes in voice delay are perceived continuously, one would predict a constant, gradual increase in %-pack responses for each 10-ms increment in the delay. I.e., when the stimulus increment (from left to right) is plotted against the response increment (from bottom to top), the psychometric function (the line that captures the stimulus-response relationship) is essentially a straight line (open symbols in Figure 1B). The typical outcome of experiments with voiced/voiceless continua, however, is non-continuous. For the first part of the continuum all exemplars are perceived as back-tokens, the rightmost two or three exemplars are near-unanimously perceived as pack. Only for one or two exemplars in the middle of the continuum do we observe uncertainty on the part of the listener: here the distribution of responses is more or less ambiguous between back and pack. The psychometric function for this so-called categorical perception is sigmoid, i.e., has the shape of an S (big solid symbols in Figure 1B). In the idealized case of perfect categorical perception we would, in fact, expect to see a step-function jumping abruptly from (almost) 0 to (almost) 100% pack-responses somewhere along the continuum (thin black line with small solid symbols in Figure 1B).
The category boundary (at 35-ms VOT in Figure 1B) is defined as the (interpolated) point along the stimulus axis where the distribution of responses is completely ambiguous, i.e., 50-50%. For a well-defined cross-over from one category to the other there should be a point along the stimulus axis where 75% of the responses agree on one category, and a second point where there is 75%-agreement on the other category. The uncertainty margin is defined in absolute terms as the distance along the stimulus axis between the two 75%-points; equivalent relative measures can be derived from the steepness of the psychometric function (e.g. the slope coefficient or the standard deviation of the cumulative normal distribution fitted to the data points).

Boundary Tones in Dutch: Phonetic or Phonological Contrasts? 41
Figure 1. Panel A. Hypothetical discrimination function for physically same and different pairs of stimuli (one-step difference) reflecting categorical perception. Panel B. Illustration of continuous (open squares) versus categorical (big solid squares) perception in the identification and discrimination paradigm. The thin line with small squares represents the ideal step function that should be obtained when categorical perception is absolute. Category boundary and uncertainty margin are indicated (further, see text).
Although a pronounced sigmoid function (such as the one drawn in Figure 1B) is a clear sign of categorical perception, researchers have always been reluctant to consider it definitive proof. Listeners, when forced to, tend to split any continuum down the middle. For a continuum to be perceived categorically, therefore, two conditions should be met:

42 Vincent J. van Heuven
- results of an identification experiment should show a clear sigmoid function, and
- the discrimination function should show a local peak for stimuli straddling the category boundary.
The discrimination function is determined in a separate experiment in which either (i) identical or (ii) adjacent tokens along the stimulus continuum are presented pair-wise. Listeners then decide for each pair whether the two tokens are ‘same’ or ‘different’. Two kinds of error may occur in a discrimination task:
- a physically different pair may be heard as ‘same’, and - a pair of identical tokens may be called ‘different’.
The results of a discrimination task are best expressed as the percentage of correct decisions obtained for a ‘different’ stimulus pair minus the percentage of errors for ‘same’ pairs constructed from these stimuli (the latter percentage is often called the response bias). In the case of true categorical perception the discrimination scores show a pronounced peak for the stimulus pair straddling the category boundary, whilst all other pairs are discriminated at or only little above chance level (see panel A in Figure 1). Physically different sounds that fall in the same perceptual category are hard to discriminate. In the case of continuous perception, there is no local peak in the discrimination function.
1.2. Categorical nature of intonational contrasts
By intonation or speech melody we mean the pattern of rises and falls in the time-course of the pitch of spoken sentences. Melodic patterns in speech vary systematically across languages, and even within languages across dialects. The cross-linguistic differences can be parameterized and described in much the same way as has been done for the segmentals in language: a set of distinctive features defines an inventory of abstract units, which can be organized in higher-order units subject to wellformedness constraints. Moreover, intonational contrasts are used to perform grammatical functions that can also be expressed by lexico-syntactic means, such as turning statements into questions, and putting constituents in focus. For these reasons it has become widely accepted that intonation is

Boundary Tones in Dutch: Phonetic or Phonological Contrasts? 43
part of the linguistic system (Ladd, 1996: 8). Yet, there have always been adherents of the view that speech melody should be considered as something outside the realm of linguistics proper, i.e., that intonation is a paralinguistic phenomenon at best, to be treated on a par with the expression of attitudes or emotions. Typically, the communication of emotions (such as anger, fear, joy, surprise) or of attitudes (such as sarcasm) is non-categorical: the speaker shows himself more or less angry, fearful, or sarcastic in a continuous, gradient fashion.
A relatively recent insight, therefore, is that a division should be made in melodic phenomena occurring in speech between linguistic versus paralinguistic contrasts. Obviously, only the former but not the latter type of phenomena should be described by the grammar and explained by linguistic theory. This, however, begs the question how the difference can be made between linguistic and paralinguistic phenomena within the realm of speech melody.3 Ladd & Morton (1997) were the first to suggest that the traditional diagnostic for categorical perception should be applicable to intonational categories in much the same ways as it works for segmental contrasts. Only if a peak in the discrimination function is found for adjacent members on a tone continuum straddling a boundary between tonal categories, are the categories part of the linguistic system, i.e., phonological categories. If no categorical perception of the tone categories can be established, the categories are ‘just’ the extremes of a paralinguistic or phonetic tonal continuum. Ladd & Morton tested the traditional diagnostic on a tone continuum between normal and emphatic accent in English and noted that it failed. This – to me – indicates that the contrast is not part of the phonology of English.
Remijsen & van Heuven (1999, 2003) tested the traditional diagnostic on a tone continuum between ‘L%’ and ‘H%’ in Dutch, and showed that indeed there was a discrimination peak for adjacent members along the continuum straddling the boundary – indicating that the ‘L%’ and ‘H%’
3 The nature of the distinction between intonational categories is problematic for a further reason: inter-listener agreement on the identity of intonational events is low (Pitrelli et al., 1994), particularly in comparison with the self-evident consensus on segmental distinctions. This lack of consistency has lead Taylor (1998) to reject a basic principle of (intonational) phonology, namely its categorical nature. With respect to methodology, researchers tend to act as expert listeners, linking contours that sound distinct to pragmatic meaning in an intuitive fashion. Accordingly, inter-researcher agreement may be low, too (e.g. Caspers, 1998).

44 Vincent J. van Heuven
categories are part of the phonology of Dutch. At the same time, however, we had to take recourse to listener-individual normalization of the category boundary, a complication that is not generally needed when dealing with contrasts in the segmental phonology.4
Van Heuven & Kirsner (2002) suggested that the relatively weak categorical effects in Remijsen & van Heuven could have been the result of an incorrect subdivision of the ‘L%’ to ‘H%’ tone range. Van Heuven & Kirsner (2002) showed that Dutch listeners were perfectly able to categorize a range of final pitches between low and high in terms of three categories, functionally denoted as command intonation, continuation, and question. However, we did not run the full diagnostic involving both identification and discrimination procedures. Moreover, Van Heuven & Kirsner forced their listeners to choose between three response alternatives, viz. command, conditional and question. Although the extremes of the range, i.e. command versus question are unchallenged categories, it may well be the case that the conditional is not necessarily distinct from the question type. After all, in the grammar developed by ‘t Hart, Collier & Cohen (1990) any type of non-low terminal pitch falls into the same category, indicating non-finality. It occurred to us that we should take the precaution to run the experiment several times, using different response alternatives, such that two separate binary (‘command’ ~ ‘no command’ and ‘question ~ ‘no question’) response sets as well as the ternary response set (‘command’ ~ ‘conditional’ ~ ‘question’) were used by the same set of listeners. If the intermediate ‘conditional’ response category does constitute a clearly defined notion in the listeners’ minds, the binary and ternary divisions of the stimulus range should converge on the category boundaries.
The present paper seeks to remedy the infelicities of Van Heuven & Kirsner (2002). However, before I deal with the experiments, it is necessary to introduce the inventory of the domain-final boundary configurations that can be found in Dutch.
1.3. Dutch domain-final boundary tones
Over the past decades a major research effort has been spent on the formal description of the sentence melody of Dutch. In the present paper we concentrate on one small part of the intonation system of Dutch: the options that are available to the speaker to terminate an intonation phrase. It has become customary to model the intonation system of a language as a

Boundary Tones in Dutch: Phonetic or Phonological Contrasts? 45
hierarchically organized structure in which the tonal primitives (or ‘atoms’) are combined into tonal configurations, which in turn combine into intonation phrases. One or more of such intonation phrases are combined into an utterance, which may combine with other utterances to form a prosodic paragraph. The intonation phrase (henceforth IP), then, is situated roughly in the middle of the prosodic hierarchy. Note that a short utterance may consist of just one IP. An IP is characterized as a stretch of speech between two IP boundaries, i.e., a break in the segment string that is signaled by either a pause (physical interruption of the sound stream), pre-boundary lengthening and/or by a boundary-marking tone. If the boundary is sentence medial, then yet another IP must follow in order to finish the utterance.
The first explicit and experimentally verified grammar of Dutch intonation was developed at the Institute for Perception Research at Eindhoven (‘t Hart et al., 1990; Rietveld & van Heuven, 2001: 263-270). This grammar models the sentence melody of Dutch as a system of two gently declining reference lines, nominally 6 semitones (half an octave) apart, between which the pitch rises and falls in a limited number of patterns. The grammar provides for three different ways in which an IP may be terminated: (i) on the low reference line (‘0’), (ii) on the high reference line (‘’), or (iii) by executing a steep pitch rise (‘2’). Although the grammar is not completely explicit on this point, it appears that the offset of rise ‘2’ may exceed the level of the high reference line, specifically when the rise starts at the high reference line. The grammar then allows IPs to end at three different pitches: low, high, and extra high.
A more recent account of Dutch intonation is given by Gussenhoven and co-workers (Gussenhoven, Rietveld & Terken, 1999; Rietveld & van Heuven, 2001: 270-277). This model is constructed along the principles adopted by autosegmental intonologists, in which a sentence melody is basically a sequence of tonal targets of two types: ‘H’ (high) and ‘L’ (low). The ToDI system (Transcription of Dutch Intonation), which is an inventory of tonal configurations for surface-level transcriptions of Dutch sentence melodies using the autosegmental H/L notation format, provides three symbols for marking IP boundaries: (i) ‘L%’, i.e., the final pitch target extends below the baseline, (ii) ‘%’, i.e., the absence of a tonal IP boundary marker, and (iii) ‘H%’, i.e., the final pitch is higher than the preceding pitch.5 For details of the ToDI transcription system I refer to the ToDI website (www.lands.kun.nl/todi) or to Rietveld & van Heuven (2001: 399-401).

46 Vincent J. van Heuven
Remijsen & van Heuven (1999, 2003) report an experiment which sought to establish the perceptual boundary between sentence-final statement and question intonation. They did this by varying the pitch configuration on the utterance-final syllable of the verb-less phrase De Dennenlaan(?) ‘Pine Lane(?)’ between a fall and a steep rise in eleven perceptually equal steps. Listeners were then asked to decide for each of the eleven pitch patterns whether they perceived it as a statement or a question. At the time we tacitly assumed that the continuum spanned just two pragmatic categories, i.e. statement versus question, and that there was no relevant intermediate category that could be interpreted as ‘non-finality’. In fact, Kirsner & van Heuven (1996) suggested a single abstract meaning for the non-low tonal category: ‘appeal (by the speaker to the hearer)’, asking for the hearer’s continued attention or for a verbal response to a question or a non-verbal compliance with a request. However, Caspers (1998) suggested that there is a functional difference between the non-tonal boundary (‘%’) following an earlier ‘H*’ target and the high boundary (‘H%’) following an earlier ‘H*’. She synthesized stimuli in which the terminal pitch after the accent-marking ‘H*’ was followed by either ‘H%’ (where the final pitch was raised further) or just % (where the pitch remained high but level after the accent). Her results indicate that listeners unequivocally expect the speaker to continue after the ‘H* ... %’ configuration, in contradistinction to the ‘H* ... H%’ pattern, for which the responses were equally divided between ‘same speaker will continue’ and ‘interlocutor will take over (with a response)’.
Note that the ‘%’ tone-less boundary as studied by Caspers is found only after a preceding H* accent. Strictly speaking, then, the ‘%’ boundary cannot be used as an intermediate category in between ‘L%’ and ‘H%’ when the preceding pitch is low. After ‘L’, any rise in pitch, whether strong or intermediate, is a perceptually relevant change in pitch, which must be coded by an ‘H%’ target. On the other hand, this formal constraint is in the way of an attractive generalization which would allow us to view the high level pitch (‘H* ... %’) pattern as a surface realization of the ‘H*L...%’ pattern from which the L target has been deleted – in much the same way as was suggested by Haan (2002) in order to account for the functional similarity between the ‘H*...H%’ and the ‘H*L…H%’ interrogative patterns, as exemplified in Figure 2.

Boundary Tones in Dutch: Phonetic or Phonological Contrasts? 47
Figure 2. Underlying tonal shape (dotted) and surface realization after ‘L’-deletion (solid) of an ‘H*L … H%’ sequence.
There seems to be a mismatch between the functions expressed by Caspers’ ‘%’ and ‘H%’ after ‘H*’. If we assume an iconic relationship between the terminal pitch of the utterance and the degree of submissiveness of the speaker towards the hearer, then we would reason that ‘H%’ should make more of an appeal to the hearer (expressing greater submissiveness) than just ‘%’. On the other hand, answering a question seems a bigger favor on the part of the hearer than merely waiting for the speaker to continue the utterance. It could be the case, of course, that even the highest terminal pitches used by Caspers were not high enough to elicit unambiguous ‘other speaker will take over’ (i.e. ‘question’) responses. Also, it is unclear if the unambiguous ‘same speaker will continue’ response crucially depends on a flat stretch of high declination (as is the case after an ‘H*’ accent) or if any terminal pitch of intermediate height would yield the same response.
In Caspers’ analysis the ‘%’ boundary – and arguably an ‘L … H%’ sequence with a moderately high terminal pitch – unambiguously signals continuation. This category would then be expected to be firmly represented in the listener’s cognitive system. Varying the terminal pitch from low to extremely high should then elicit two well-defined categories: (i) unambiguous statement for low pitches, (ii) unambiguous continuations for intermediate terminal pitches, and (iii) a poorly defined or non-unique interrogative category, which is also compatible with a continuation reading.
At this time, then, we do not know whether two or three formal tone categories should be postulated in IP-final position. It seems that the status of ‘L%’ as a linguistic category is unchallenged but the non-low part of the IP-final tone range is very much a matter of debate. Does the non-low part of the range form a continuum expressing lesser or greater appeal by the speaker in a paralinguistic manner, or should this part of the range be split into two discrete phonological categories, each expressing a distinct

48 Vincent J. van Heuven
meaning of its own (i.e. ‘continuation’ ~ ‘question’, or – even worse – into two categories of which one is specific for ‘continuation’ and the other underspecified and compatible with both ‘question’ and ‘continuation’? These meanings, and a possible way of testing the categorical nature of tonal contrasts expressing them, are the topic of the next section.
1.4. Clause typing
Dutch, like any other language, has lexico-syntactic means to express a range of clause types, such as statement, command, exclamation and question. Although the lexico-syntactic means are generally adequate and sufficient to express the speaker’s pragmatic intention to the hearer, several – if not all – clause types are supported by prosodic means, specifically by appropriate intonation patterns. In fact, exceptional situations may arise where there is no lexico-syntactic differentiation between the clause types, and where the speaker’s intention can only be recovered from melodic cues. For the purposes of the present experiment we have looked for a situation in which the three prosodic categories may serve as the only cue to a ternary choice among clause types, so that prosody will be exploited to the utmost, and the listener’s choice will not be co-determined by lexical and/or syntactic cues. Such a situation may be obtained in a V1 sentence, where the finite verb has been moved into the sentence-initial position.6 In the sentence Neemt u de trein naar Wageningen ‘Take you the train to Wageningen’ the lexico-syntactic information is compatible with at least three interpretations:7
- A polite imperative (Kirsner, van Heuven & Caspers, 1998) - A conditional clause similar in meaning to ‘If you take the train to
Wageningen ...’- A yes/no question ‘Do you take the train to Wageningen?’
Which of the three readings is intended by the speaker, is expressed through prosody only. In setting up the experiment we assumed that there is no principal difference in the speech melody between a statement and a command in Dutch.8 Using a range of terminal pitch patterns on the single phrase Neemt u de trein naar Wageningen, we can determine the category boundaries between command (for statement), conditional (for

Boundary Tones in Dutch: Phonetic or Phonological Contrasts? 49
continuation), and question without any interfering differences in lexico-syntactic structure.
We may conclude this introduction by summarizing the research questions that we will address:
1. Are the domain-final boundaries ‘L%’ ~ ‘%’ ~ ‘H%’ contiguous categories along a single tonal dimension?
2. Is there a one-to-one correspondence between ‘L%’ and ‘command’, ‘%’ and ‘conditional’, and ‘H%’ and ‘question’?
3. Where are the category boundaries – if any – along the continuum between (i) ‘L%’ and ‘%’ and (ii) between ‘%’ and ‘H%’?
4. Are the category boundaries at the same positions along the stimulus range irrespective of the binary versus ternary response mode?
5. Are both boundaries truly categorical in the sense that there are discrimination peaks for adjacent stimulus pairs straddling the category boundaries?
2. Methods
2.1. Stimuli
A male native speaker of standard Dutch read the sentence Neemt u de trein naar WAgeningen? with a single ‘H*L’ accent on the first syllable of Wageningen. The utterance was recorded onto digital audio tape (DAT) using a Sennheiser MKH 416 unidirectional condenser microphone, transferred to computer disk (16 kHz, 16 bits) and digitally processed using the Praat speech processing software (Boersma & Weenink, 1996; Boersma & van Heuven, 2001). The intonation pattern of the utterance was stylized by hand as a sequence of straight lines in the ERB x linear time representation. Nine intonationally different versions were then generated using the PSOLA analysis-resynthesis technique (e.g. Moulines & Verhelst, 1995; Rietveld & van Heuven, 2001: 379-380) implemented in the Praat software. The nine versions were identical up to and including the ‘H*L’ configuration on Wageningen. From that point onwards the nine versions diverged into two falls and seven rises. The terminal frequencies of the nine versions were chosen to be perceptually equidistant, i.e., the difference

50 Vincent J. van Heuven
between any two adjacent terminal frequencies was equal in terms of the ERB scale.9 The terminal pitch of version 1 equaled 80 Hz, the increment in the terminal frequency for each following version was 0,25 ERB. The nine pitch patterns are shown in Figure 3.
Figure 3. Steps 1 through 9 along resynthesized continuum differing in terminal F0 by 0,25 ERB increments. Intensity contour (dB) and segmentation (by syllables) are indicated.
2.2. Tasks and experimental procedures
For the discrimination task, which was the first task imposed on the subjects, we followed Ladd and Morton (1997) in using the AX discrimination paradigm. Stimuli were presented in pairs that were either the same or one step apart on the continuum. In the latter case, the second can be higher or lower than the first (hereafter AB and BA, respectively). The eight AB stimulus types ran from pair {1,2} to {8,9}; the eight corresponding BA types from {2,1} to {9,8}. This yielded 9 identical pairs and 2 x 8 = 16 different pairs, which occurred in random order, yielding a set of 25 trials in all, which was presented to each listener four times in different random orders, preceded by five practice trials. Stimuli within pairs were separated by a 500-ms silence, the pause between pairs was 3000 ms. A short warning tone was sounded after every tenth trial.
For the identification task listeners responded to individual stimuli from the 9-step continuum by classifying each either in terms of a binary or a ternary choice:
neemt u de trein naar WA ge ni ngen
Time (s)0 1.510.5
60
80
80
120
160

Boundary Tones in Dutch: Phonetic or Phonological Contrasts? 51
1. ‘Command’ ~ ‘no command’. In one task the listeners were instructed to decide for each stimulus whether they interpreted it as a command or not.
2. ‘Question’ ~ ‘no question’. An alternative task involved the decision whether the stimulus sounded like a question or not.
3. ‘Command’ ~ ‘condition’ ~ ‘question’. The third task was identical to the task imposed in van Heuven & Kirsner (2002).
Half of the listeners first performed task (1), the other half of the listeners began with task (2). Task (3) was always the last identification procedure in the array of tests. For each task, the set of nine stimuli were presented five times to each listener, in different random orders, and preceded by five practice items, yielding sets of 50 identification stimuli per task.
Twenty native Dutch listeners, ten males and ten females, took part in the experiment on a voluntary basis. Participants were university students or members of their families. None of them reported any perceptual deficiencies.
The experiments were run with small groups of subjects, who listened to the stimuli at a comfortable loudness level over Quad ESL-63 electrostatic loudspeakers, while seated in a sound-treated lecture room. Subjects marked their responses on printed answer sheets provided to them, always taking the discrimination task first and the identification tasks last.
3. Results
3.1. Identification
Figures 4 and 5 present the results obtained in the binary identification tasks, i.e., the forced choice between ‘command’ ~ ‘no command’ (Figure 4) and between ‘question’ ~ ‘no question’ (Figure 5).

52 Vincent J. van Heuven
Figure 4. Percent ‘command’ responses as a function of stimulus step (terminal F0 increments in 0.25 ERB steps) in a binary identification task (‘command’ ~ ’no command’).
The psychometric function for the ‘command’ responses is very steep. The category boundary between ‘command’ and ‘no command’ is located at a step size of 2.7, and the margin of uncertainty runs between 2.2 and 3.7, i.e., a cross-over from 75% to 25% ‘command’ responses is effected by an increase in the terminal pitch of the stimulus of 1.5 step (i.e., 0.37 ERB).
Figure 5. Percent ‘question’ responses as a function of stimulus step (terminal F0 increments in 0.25 ERB steps) in a binary identification task (‘question’ ~ ’no question’
Stimulus step
987654321
Inde
ntifi
catio
ns "
ques
tion"
(%) 100
80
60
40
20
0
Stimulus step
987654321
Inde
ntifi
catio
ns "
com
man
d" (
%) 100
80
60
40
20
0

Boundary Tones in Dutch: Phonetic or Phonological Contrasts? 53
A complete cross-over is also found for the ‘question’ ~ ‘no question’ task. The category boundary finds itself at a stimulus value of 3.6, whilst the margin of uncertainty runs between 2.3 and 4.9, i.e., an interval of 2.6 increments of 0.25 ERB. We may note that the category boundaries in the ‘command’ and the ‘question’ tasks do not coincide, but are separated along the stimulus axis by almost a complete step: 2.7 versus 3.6 or 0.9 step. Note, once more, that none of the subjects had been alerted to the possible existence of an intermediate category between ‘command’ and ‘question’. Therefore, the emergence of the interval between the ‘command’ and the ‘question’ boundaries might be taken in justification of such an intermediate category.
Let us now turn to the results of the ternary identification task in which all the listeners who had already responded to the stimuli were now required to classify the nine stimulus types as either ‘command’, ‘conditional subclause’ or ‘question’. These results are shown in Figure 6.
Figure 6. Ternary identification of stimuli as ‘command’, ‘conditional clause’ or
‘question’. Category boundaries are indicated.
The boundary between ‘command’ and the ‘continuation’ categories is at 2.8; this is hardly different than the ‘command’ ~ ’no command’ boundary that was found in the binary response task. This, then, would seem to be a very robust boundary, showing that at least ‘command’ intonation has well-defined linguistic status. The boundary between ‘continuation’ and ‘question’ is less clearly defined. Also, the maximum scores in these two categories are around 80% rather than 90% or more. Although there is no
Stimulus step
987654321
Iden
tific
atio
n (%
)
100
80
60
40
20
0
'command'
'continuation'
'question'

54 Vincent J. van Heuven
ambiguity in the listeners’ minds whether a stimulus is a command or something else, the choice between ‘continuation’ and ‘question’ seems more ambiguous leaving room for a minority response in the order of 20%. This would indicate to us that we are dealing here with a continuum rather than with a dichotomy. Finally, we may note that the (soft) category boundary between ‘continuation’ and ‘question’ is located at a stimulus value of 7.2. The boundary, then, that sets off ‘question’ from ‘no question’ responses proves very unstable: there is a shift from the binary response task (3.6) to the ternary task (7.2) of no less than 3.6 points along the stimulus continuum.
It would seem, then, that the ‘command’ category is highly stable and well-established in the minds of the listeners. The ‘question’ boundary, however, is rather poorly defined, as a result of several circumstances. The cross-over points for the ‘question’ category of individual listeners vary over a wide range of stimulus values, i.e., between 2.2 and 8.5 step number, with a fairly even spread of values in between these extremes. Moreover, for two listeners no cross-over to the ‘question’ category could be found at all; here the listeners never gave the ‘question’ response in more than 75%. Also, some listeners have extremely sharp cross-overs to the ‘question’ category, but others show large margins of uncertainty.
3.2. Discrimination
Figure 7 presents the mean percentage of successfully discriminated stimuli that were actually different (hereafter ‘hits’), and the percentage of false alarms, i.e. ‘different’ responses to (identical) AA stimuli. The false-alarm rate is roughly 20% across the entire stimulus continuum. This value can be seen as a bias for responding ‘different’. Generally, an increment of 0.25 ERB is discriminated above the 20% bias level, with the exception of the difference between stimulus steps 5 and 6. The discrimination function shows two local peaks. The first one is very large, and is located between stimulus steps 2 and 3. This peak obviously coincides with the stable category boundary found between ‘command’ and the non-command responses (whether binary or ternary). A much smaller second discrimination peak may be observed between stimulus steps 6 and 7, which location may well reflect the rather poorly defined category boundary between ‘continuation’ and ‘question’.

Boundary Tones in Dutch: Phonetic or Phonological Contrasts? 55
Figure 7. Percent ‘different’ judgments to nine identical stimulus pairs (false alarms) and eight pairs differing by one step (hits).
4. Conclusions and discussion
Let us now try to formulate answers to the research questions that we asked in section 2. The first two questions, which I will attempt to answer together, asked whether the domain-final boundary tones are contiguous categories along a single tonal dimension, and map onto the command, continuation and question meaning in a one-to-one fashion. The results of our experiments clearly indicate that this is indeed the case. Our listeners had no difficulty in using the three response alternatives provided to them. When the terminal pitch was lower than the preceding pivot point in the contour the responses were almost unanimously for ‘command’. When the IP-final pitch was higher than the preceding pivot point, the incidence of ‘continuation’ responses increased up to and including step 4, and decreased for higher terminal pitches which were more readily identified as questions as the terminal pitch was higher. Although there was always some ambiguity between the ‘continuation’ and ‘question’ alternatives, the results clearly indicate that ‘continuation’ is signaled by moderate final pitch, and question by (extra) high pitch.
The latter finding corresponds with our suggestion that asking a question involves a higher degree of appeal by the speaker to hearer than
Stimulus step
9
8-9
8
7-8
7
6-7
6
5-6
5
4-5
4
3-4
3
2-3
2
1-2
1
"Diff
eren
t" ju
dgm
ents
(%
)
100
80
60
40
20
0
"same" pair
"diff" pair

56 Vincent J. van Heuven
asking the listener’s continued attention. We may also note that our result clashes with Caspers (1998). She found that the intermediate final pitch (or high level pitch in her experiment) was unambiguously identified as continuation; extra high final pitch ambiguously coded either continuation or question. Comparison of Caspers’ and our own results is hazardous since the utterance-final tone configurations differ, not so much at the underlying tone level, but at the surface. It seems to me that the discrepancy between Caspers’ and our own findings can be resolved if we accept the possibility that Caspers’ extra high terminal pitch was simply not high enough to elicit the 80% ‘question’ responses that we got in our experiment.
The results so far concur with van Heuven & Kirsner (2002). However, we may now go on to consider the third, fourth and fifth question, which asked where the category boundaries are located along the final pitch continuum between ‘L%, ‘%’ and ‘H’, in the binary and ternary response tasks, and to what extent the boundaries coincide with a peak in the discrimination function.
The results obtained in the binary (‘command’ ~ ‘no command’) and ternary (‘command’ ~ ‘continuation’ ~ ‘question’) identification tasks are virtually the same, yielding the same location of the boundary (at step 2.7) separating the ‘command’ category from the rest of the stimulus continuum. However, a very unstable boundary is found in the binary ‘question’ ~ ‘no question’ task (at step 3.6), which is reflected in the poorly defined boundary separating the ‘continuation’ and ‘question’ categories in the ternary response task (at step 7.2). Moreover, we have seen that the category boundary between ‘command’ and ‘no command’ coincides with a huge peak in the discrimination function. Although there is a modest local maximum in the discrimination function that may be associated with a boundary between ‘continuation’ and ‘question’, this peak is not very convincing.
I take these findings as evidence that there is a linguistic, or phonological, categorization of the IP-final boundary tone continuum in just two types, which is best characterized as low and non-low. The low boundary tone signals dominance or superiority on the part of the speaker. This is the boundary tone that is suited for issuing statements and commands. The non-low boundary tone signals subservience of the speaker to the hearer; the speaker appeals to the hearer for his continued attention or for an answer to a question.
The non-low part of the boundary opposition, however, represents a gradient, paralinguistic continuum between a moderate appeal (asking for

Boundary Tones in Dutch: Phonetic or Phonological Contrasts? 57
the hearer’s continued attention) and a stronger appeal (asking the hearer for a verbal reply to a question). Here the lower terminal pitches are associated with weaker degrees of appeal (or subservience), and the higher levels with strong appeal, but in a continuous, gradient, non-phonological manner.
Our results indicate that earlier findings reported by Remijsen & van Heuven (1999, 2003) are to be viewed with caution. We now know that the proper task to be imposed on listeners should not be to decide whether the stimulus is a statement (or a command) versus a question. If binary response alternatives are required, then the categories should be ‘statement’ versus ‘no statement’ but a better procedure would be to ask the listener to respond by choosing from three categories: ‘statement’ (equivalent to ‘command’ in our experiments ~ ‘continuation’ ~ ‘question’. Had such precautions been taken by Remijsen & van Heuven, their category boundary would have been much better defined with less listener-individual variation.
Methodologically, we argue that the classical identification-cum-discrimination paradigm is a useful diagnostic tool in intonation research which allows linguists to decide experimentally whether a melodic contrast is categorical and therefore part of the phonology, or continuously gradient and therefore phonetic or even paralinguistic.
Notes

58 Vincent J. van Heuven
References
Boersma, P. and Heuven, V.J. van (2001). Speak and unSpeak with Praat. Glot International, 5: 341-347.
Boersma, P. and Weenink, D. (1996). Praat, a System for Doing Phonetics by Computer. Report of the Institute of Phonetic Sciences Amsterdam, 132.
Caspers, J. (1998). ‘Who’s Next? The Melodic Marking of Question vs. Continuation in Dutch. Language and Speech, 41: 375-398.
Gussenhoven, C., Rietveld, T. and Terken, J.M.B. (1999). Transcription of Dutch Intonation. http://lands.let.kun. nl/todi.
Haan, J. (2002). Speaking of questions. An Exploration of Dutch Question Intonation. LOT Dissertation Series, nr. 52, Utrecht: LOT.
Hart, J. 't, Collier, R. and Cohen, A. (1990). A Perceptual Study of Intonation. An Experimental-phonetic Approach to Speech Perception. Cambridge: Cambridge University Press.
Hermes, D.J. and Gestel, J.C. van (1991). ‘The Frequency Scale of Speech Intonation. Journal of the Acoustical Society of America, 90: 97-102.
Heuven, V.J. van (1986). Some acoustic characteristics and perceptual consequences of foreign accent in Dutch spoken by Turkish immigrant workers. In: J. van Oosten, J.F. Snapper (eds.) Dutch Linguistics at Berkeley, papers presented at the Dutch Linguistics Colloquium held at the University of California, Berkeley on November 9th, 1985, Berkeley: The Dutch Studies Program, U.C. Berkeley, 67-84.
Heuven, V.J. van and Kirsner, R.S. (2002). Interaction of tone and particle in the signaling of clause type in Dutch. In: H. Broekhuis, P. Fikkert (eds.). Linguistics in the Netherlands 2002, Amsterdam /Philadelphia: John Benjamins, 73-84.
Kirsner, R.S. and Heuven, V.J. van (1996). Boundary Tones and the Semantics of the Dutch Final Particles hè, hoor, zeg and joh. In: M. den Dikken, C. Cremers, eds., Linguistics in the Netherlands 1996, Amsterdam/Philadelphia: John Benjamins, 133-146.
Kirsner, R.S., Heuven, V.J. van, and Caspers, J. (1998). From Request to Command: An Exploratory Experimental Study of Grammatical Form, Intonation, and Pragmatic Particle in Dutch Imperatives. In: R. van Bezooijen, R. Kager, eds., Linguistics in the Netherlands 1998. Amsterdam/Philadelphia: John Benjamins, 135-148.

Boundary Tones in Dutch: Phonetic or Phonological Contrasts? 59
Ladd, D.R. (1996). Intonational phonology. Cambridge: Cambridge University Press.
Ladd, D.R. and Morton, R. (1997). The perception of intonational emphasis: continuous or categorical? Journal of Phonetics, 25: 313-342.
Ladd, D.R. and Terken, J.M.B. (1995). Modelling intra- and inter-speaker pitch range variation. Proceedings of the 13th International Congress of Phonetic Sciences, Stockholm, 2: 386-389.
Merckens, P.J. (1960). De plaats van de persoonsvorm: een verwaarloosd code-teken [The position of the finite verb: a neglected code sign]. De nieuwe taalgids, 53: 248-54.
Moulines, E. and Verhelst, E. (1995). ‘Time-domain and frequency-domain techniques for prosodic modification of speech’. In: W.B. Kleijn and K.K. Paliwal, eds., Speech coding and synthesis. Amsterdam: Elsevier Science, 519-555.
Nooteboom, S.G. and Cohen, A. (1976). Spreken en verstaan. Een inleiding tot de experimentele fonetiek [Speaking and understanding. An introduction to experimental phonetics], Assen: van Gorcum.
Pitrelli, J.F., Beckman, M.E. and Hirschberg, J. (1994). Evaluation of prosodic transcription reliability in the ToBI framework. Proceedings of the 3rd International Conference on Spoken Language Processing, Yokohama, 1: 123-126.
Remijsen, A.C. and Heuven, V.J. van (1999). Gradient and categorical pitch dimensions in Dutch: Diagnostic test’. Proceedings of the 14th International Congress of Phonetic Sciences, San Francisco, 1865-1868.
Remijsen, A.C. and Heuven, V.J. van (2003). Linguistic versus paralinguistic status of prosodic contrasts, the case of high and low pitch in Dutch. In: J.M. van de Weijer, V.J. van Heuven, H.G. van der Hulst (eds.): The phonological spectrum. Volume II: Suprasegmental structure. Current Issues in Linguistic Theory nr. 235. Amsterdam/Philadelphia: John Benjamins, 225-246.
Rietveld, A.C.M. and Heuven, V.J. van (2001). Algemene Fonetiek [General Phonetics]. Bussum: Coutinho.
Slis, I.H. and Cohen, A. (1969). On the complex regulating the voiced-voiceless distinction, Language and Speech, 80-102: 137-155.
Taylor, P. (1998). Analysis and synthesis of intonation using the TILT model. Unpublished manuscript, Centre for Speech Technology Research, University of Edinburgh.


The Position of Frisian in the Germanic Language Area
Charlotte Gooskens and Wilbert Heeringa
1. Introduction
Among the Germanic varieties the Frisian varieties in the Dutch province of Friesland have their own position. The Frisians are proud of their language and more than 350,000 inhabitants of the province of Friesland speak Frisian every day. Heeringa (2004) shows that among the dialects in the Dutch language area the Frisian varieties are most distant with respect to standard Dutch. This may justify the fact that Frisian is recognized as a second official language in the Netherlands. In addition to Frisian, in some towns and on some islands a mixed variety is used which is an intermediate form between Frisian and Dutch. The variety spoken in the Frisian towns is known as Town Frisian10.
The Frisian language has existed for more than 2000 years. Genetically the Frisian dialects are most closely related to the English language. However, historical events have caused the English and the Frisian language to diverge, while Dutch and Frisian have converged. The linguistic distance to the other Germanic languages has also altered in the course of history due to different degrees of linguistic contact. As a result traditional genetic trees do not give an up-to-date representation of the distance between the modern Germanic languages.
In the present investigation we measured linguistic distances between Frisian and the other Germanic languages in order to get an impression of the effect of genetic relationship and language contact for the position of the modern Frisian language on the Germanic language map. We included six Frisian varieties and one Town Frisian variety in the investigation. Furthermore, eight Germanic standard languages were taken into account. Using this material, we firstly wished to obtain a hierarchical classification of the Germanic varieties. From this classification the position of (Town)

62 Vincent J. van Heuven
Frisian became clear. Secondly, we ranked all varieties with respect to each of the standard Germanic languages as well as to (Town) Frisian. The rankings showed the position of (Town) Frisian with respect to the standard languages and the position of the standard languages with respect to (Town) Frisian.
In order to obtain a classification of varieties and establish rankings, we needed a tool that can measure linguistic distances between the varieties. Bolognesi and Heeringa (2002) investigated the position of Sardinian dialects with respect to different Romance languages using the Levenshtein distance, an algorithm with which distances between word pronunciations are calculated. In our investigation we used the same methodology.
In Section 2, we will present the traditional ideas about the genetic relationship between the Germanic languages and discuss the relationship between Frisian and the other Germanic languages. At the end of the section we will discuss the expected outcome of the linguistic distance measurements between Frisian and the other Germanic languages. In Section 3 the data sources are described and in Section 4 the method for measuring linguistic distances between the language varieties is presented. The results are presented in Section 5, the discussion of which is presented in Section 6.
2. Frisian and the Germanic languages
2.1. History and classification of the Germanic languages11
The Germanic branch of the Indo-European languages has a large number of speakers, approximately 450 million native speakers, partly due to the colonization of many parts of the world. However, the number of different languages within the Germanic group is rather limited. Depending on the definition of what counts as a language there are about 12 different languages. Traditionally, they are divided into three subgroups: East Germanic (Gothic, which is no longer a living language), North Germanic (Icelandic, Faeroese, Norwegian, Danish, and Swedish), and West Germanic (English, German, Dutch, Afrikaans, Yiddish, and Frisian). Some of these languages are so similar that they are only considered independent languages because of their position as standardized languages

Boundary Tones in Dutch: Phonetic or Phonological Contrasts? 63
spoken within the limits of a state. This goes for the languages of the Scandinavian countries, Swedish, Danish and Norwegian, which are mutually intelligible. Other languages consist of dialects which are in fact so different that they are no longer mutually intelligible but are still considered one language because of standardization. Northern and southern German dialects are an example of this situation.
Figure 3. The genetic tree of Germanic languages.
In Figure 1, a traditional Germanic genetic tree is shown. We constructed this tree on the basis of data in the literature. The tree gives just a rough division, and linguistic distances should not be derived from this tree. It is commonly assumed that the Germanic languages originate from the southern Scandinavian and the northern German region. After the migration of the Goths to the Balkans towards the end of the pre-Christian era, North-West Germanic remained uniform till the 5th century AD, after which a split between North and West Germanic occurred owing to dialectal variation and the departure of the Anglo-Saxons from the Continent and the colonization of Jutland.
During the Viking Age, speakers of North Germanic settled in a large geographic area, which eventually led to the five modern languages (see above). Of these languages, Icelandic (and to a lesser degree Faeroese), which is based on the language of southwestern Norway where the settlers came from, can be considered the most conservative language (Sandøy, 1994). Of the three mainland Scandinavian languages, Danish has moved

64 Vincent J. van Heuven
farthest away from the common Scandinavian roots due to influences from the south.
The parentage of the West Germanic languages is less clear. Different tribal groups representing different dialect groups spread across the area, which eventually resulted in the modern language situation. Historically Frisian and English both belong to the Ingwaeonic branch of the West Germanic language group. Originally the Frisian speech community extended from the present Danish-German border along the coast to the French-Belgian border in the south. However, expansion from Saxons and Franconians from the east and the south throughout the medieval period resulted in a loss of large Frisian areas and a division into three mutually intelligible varieties: West Frisian (spoken in the northern Dutch province of Friesland by more than 350,000 people), East Frisian or Saterlandic (spoken by a thousand speakers in three villages west of Bremen) and North Frisian (spoken by less than ten thousand people on the islands on the north-western coast of Germany).
The English language came into being as a result of immigrations of tribal Anglo-Saxon groups from the North Sea coast during the fifth and sixth centuries. Whereas other insular Germanic varieties are in general rather conservative, the English insularity lacked this conservatism. English is considered most closely related to Frisian on every linguistic level due to their common ancestorship and to continued language contact over the North Sea.
The German language is spoken in many European countries in a large number of dialects and varieties, which can be divided into Low German and High German. Yiddish, too, can be regarded as a German variety. Dutch is mainly based on the western varieties of the low Franconian area but low Saxon and Frisian elements are also found in this standard language. Scholars disagree about the precise position of Dutch and Low German in the language tree. They can be traced back to a common root often referred to as the Ingwaeonic language group, but are often grouped together with High German as a separate West Germanic group. This grouping with High German might be the best representation of the modern language situation given that the individual dialects spoken in the area in fact form a dialect continuum. Afrikaans, finally, is a contemporary West Germanic language, developed from seventeenth century Dutch as a result of colonization, but with influences from African languages.

Boundary Tones in Dutch: Phonetic or Phonological Contrasts? 65
2.2. The relationship between Frisian and the other Germanic languages.
This short outline of the relationships among the Germanic languages shows that English is the language which is genetically closest to Frisian, and still today English is considered to be most similar to Frisian. For example The Columbia Encyclopedia (2001) says: “Of all foreign languages, [Frisian] is most like English”. Pei (1966, p. 34) summarizes the situation as follows: “Frisian, a variant of Dutch spoken along the Dutch and German North Sea coast, is the foreign speech that comes closest to modern English, as shown by the rhyme: ‘Good butter and good cheese is good English and good Fries’”. This rhyme refers to the fact that the words for butter and cheese are almost the same in the two languages. However, in the course of history, contact with other Germanic languages has caused Frisian to converge to these languages. The Frisians have a long history of trade and in early medieval times they were one of the leading trading nations in Europe due to their strategic geographic position close to major trade routes along the rivers and the North Sea. Also, the Vikings and the English were frequent visitors of the Frisian language area. This intensive contact with both English and the North Germanic languages, especially Danish, resulted in linguistic exchanges (see Feitsma, 1963; Miedema, 1966; Wadstein, 1933). Later in history, the Frisian language was especially influenced by the Dutch language (which itself contains many Frisian elements). For a long period, Frisian was stigmatized as a peasant language and due to the weak social position of the Frisian language in the Dutch community it was often suppressed, resulting in a strong Dutch impact on the Frisian language. Nowadays, Dutch as the language of the administration still has a large influence on the media and there has been substantial immigration of Dutch speaking people to Friesland. However, the provincial government has decided to promote Frisian at all levels in the society.
When investigating the position of the Frisian language within the Germanic language group, there are clearly two forces which should be taken into account. On the one hand, Frisian and English are genetically closely related and share sound changes which do not occur in the other Germanic languages. This yields the expectation that the linguistic distance between these two languages is relatively small. On the other hand, the close contact with Dutch makes it plausible that the Dutch and the Frisian languages have converged. Also the distance to Danish might be smaller than expected from the traditional division of Germanic into a North

66 Vincent J. van Heuven
Germanic and a West Germanic branch at an early stage because of the intensive contacts in the past.
3. Data sources
In this section, we will first give a short characterization of the language varieties and the speakers who were recorded for our investigation. Next, we will present the nature of the recordings and the transcriptions which formed the basis for linguistic distance measurements.
3.1. Language varieties
Since our main interest was the Frisian language and its linguistic position within the Germanic language group we wished to represent this language as well as possible. For this reason, we included seven Frisian varieties, spread over the Frisian language area. Furthermore, our material contained eight Germanic standard languages. First, we will describe the Frisian varieties and next the standard languages.
As far as the Frisian varieties are concerned, we chose varieties from different parts of the province, both from the coastal area and from the inland. The varieties are spoken in different dialect areas according to the traditional classification (see below) and they represent different stages of conservatism. The precise choice of the seven varieties was determined by speaker availability for recordings in our vicinity and at the Fryske Akademy in Leeuwarden. In Figure 2, the geographical position of the seven Frisian language varieties in the province of Friesland is shown.
Due to the absence of major geographical barriers, the Frisian language area is relatively uniform. The major dialectal distinctions are primarily phonological. Traditionally, three main dialect areas are distinguished (see e.g. Hof, 1933; Visser, 1997): Klaaifrysk (clay Frisian) in the west, Wâldfrysk (forest Frisian) in the east and Súdwesthoeksk (southwest quarter) in the southwest. In our material Klaaifrysk is represented by the dialects of Oosterbierum and Hijum, Wâldfrysk by Wetsens and Westergeest, and Súdwesthoeksk by Tjerkgaast. Hindeloopen is in the area of Súdwesthoeksk. However, this dialect represents a highly conservative area. The phonological distance between Hindeloopen and the main dialects is substantial (van der Veen, 2001). Finally, our material contains

Boundary Tones in Dutch: Phonetic or Phonological Contrasts? 67
the variety spoken in Leeuwarden (see note 1). This is an example of Town Frisian, which is also spoken in other cities of Friesland. Town Frisian is a Dutch dialect strongly influenced by Frisian but stripped of the most characteristic Frisian elements (Goossens, 1977).
Figure 2. The geographical position of the seven Frisian language varieties in the province of Friesland.
In addition to the Frisian dialects, the following eight standard languages were included: Icelandic, Faroese, Norwegian, Swedish, Danish, English, Dutch, and German. We had meant to include all standard Germanic languages in our material. However, due to practical limitations a few smaller languages were not included.
As for Norwegian, there is no official standard variety. The varieties spoken around the capital of Oslo in the southeast, however, are often considered to represent the standard language. We based the present investigation on prior research on Norwegian dialects (see Heeringa and Gooskens, 2003; Gooskens and Heeringa, submitted), and we chose the recording which to Norwegians sounded most standard, namely the Lillehammer recording12. It was our aim to select standard speakers from all countries, but it is possible that the speech of some speakers contains slight regional influences. The speakers from Iceland, the Faroe Islands and

68 Vincent J. van Heuven
Sweden spoke the standard varieties of the capitals. The Danish speaker came from Jutland, the German speaker from Kiel, the English speaker from Birmingham and the Dutch speaker had lived at different places in the Netherlands, including a long period in the West during adolescence.
3.2. Phonetic transcriptions
The speakers all read aloud translations of the same text, namely the fable ‘The North Wind and the Sun’. This text has often been used for phonetic investigations; see for example The International Phonetic Association (1949 and 1999) where the same text has been transcribed in a large number of different languages. A database of Norwegian transcriptions of the same text has been compiled by J. Almberg (see note 3). As mentioned in the previous section, we only used the transcription of Lillehammer from this database. In future, we would like to investigate the relations between Norwegian and other Germanic varieties, using the greater part of the transcriptions in this database. Therefore, our new transcriptions should be as comparable as possible with the existing Norwegian ones. To ensure this, our point of departure was the Norwegian text. This text consists of 91 words (58 different words) which were used to calculate Levenshtein distances (see Section 4). The text was translated word for word from Norwegian into each of the Germanic language varieties. We are aware of the fact that this may result in less natural speech: sentences were often syntactically wrong. However, it guarantees that for each of the 58 words a translation was obtained. The words were not recorded as a word list, but as sentences. Therefore in the new recordings words appear in a similar context as in the Norwegian varieties. This ensures that the influence of assimilation phenomena on the results is as comparable as possible.
Most new recordings were transcribed phonetically by one of the authors. To ensure consistency with the existing Norwegian transcriptions, our new transcriptions were corrected by J. Almberg, the transcriber of the Norwegian recordings. In most cases we incorporated the corrections. The transcription of the Faroese language was completely done by J. Almberg. The transcriptions were made in IPA as well as in X-SAMPA (eXtended Speech Assessment Methods Phonetic Alphabet). This is a machine-readable phonetic alphabet, which is also readable by people. Basically, it maps IPA-symbols to the 7 bit printable ASCII/ANSI characters13. The

Boundary Tones in Dutch: Phonetic or Phonological Contrasts? 69
transcriptions were used to calculate the linguistic distances between varieties (see Section 4).
4. Measuring distances between varieties
In 1995 Kessler introduced the use of the Levenshtein distance as tool for measuring linguistic distances between language varieties. The Levenshtein distance is a string edit distance measure and Kessler applied this algorithm to the comparison of Irish dialects. Later on, this approach was applied by Nerbonne, Heeringa, Van den Hout, Van der Kooi, Otten, and Van de Vis (1996) to Dutch dialects. They assumed that distances between all possible pairs of segments are the same. E.g. the distance between an [] and an [e] is the same as the distance between the [] and []. Both Kessler (1995) and Nerbonne and Heeringa (1997) also experimented with more refined versions of the Levenshtein algorithm in which gradual segment distances were used which were found on the basis of the feature systems of Hoppenbrouwers (1988) and Vieregge et. al. (1984).
In this paper we use an implementation of the Levenshtein distance in which sound distances are used which are found by comparing spectrograms. In Section 4.1 we account for the use of spectral distances and explain how we calculate them. Comparisons are made on the basis of the audiotape The Sounds of the International Phonetic Alphabet (Wells and House, 1995). In Section 4.2 we describe the Levenshtein distance and explain how spectral distances can be used in this algorithm.
4.1. Gradual segment distances
When acquiring language, children learn to pronounce sounds by listening to the pronunciation of their parents or other people. The acoustic signal seems to be sufficient to find the articulation which is needed to realize the sound. Acoustically, speech is just a series of changes in air pressure, quickly following each other. A spectrogram is a “graph with frequency on the vertical axis and time on the horizontal axis, with the darkness of the graph at any point representing the intensity of the sound” (Trask, 1996, p. 328).
In this section we present the use of spectrograms for finding segment distances. Segment distances can also be found on the basis of phonological

70 Vincent J. van Heuven
or phonetic feature systems. However, we prefer the use of acoustic representations since they are based on physical measurements. In Potter, Kopp and Green’s (1947) Visible Speech, spectrograms are shown for all common English sounds (see pp. 54-56). Looking at the spectrograms we already see which sounds are similar and which are not. We assume that visible (dis)similarity between spectrograms reflects perceptual (dis)similarity between segments to some extent. In Figure 3 the spectrograms of some sounds are shown as pronounced by John Wells on the audiotape The Sounds of the International Phonetic Alphabet (Wells and House, 1995). The spectrograms are made with the computer program PRAAT14.
Figure 3. Spectrograms of some sounds pronounced by John Wells. Upper the [i] (left) and the [e] (right) are shown, and lower the [p] (left) and the [s] (right) are visualized.
4.1.1. Samples
For finding spectrogram distances between all IPA segments we need samples of one or more speakers for each of them. We found the samples on the tape The Sounds of the International Phonetic Alphabet on which all IPA sounds are pronounced by John Wells and Jill House. On the tape the

Boundary Tones in Dutch: Phonetic or Phonological Contrasts? 71
vowels are pronounced in isolation. The consonants are sometimes preceded, and always followed by an [a]. We cut out the part preceding the [a], or the part between the [a]’s. We realize that the pronunciation of sounds depends on their context. Since we use samples of vowels pronounced in isolation and samples of consonants selected from a limited context, our approach is a simplification of reality. However, Stevens (1998, p. 557) observes that
“by limiting the context, it was possible to specify rather precisely the articulatory aspects of the utterances and to develop models for estimating the acoustic patterns from the articulation”.
The burst in a plosive of the IPA inventory is always preceded by a period of silence (voiceless plosives) or a period of murmur (voiced plosives). When a voiceless plosive is not preceded by an [a], it is not clear how long the period of silence which really belongs to the sounds lasts. Therefore we always cut out each plosive in such a way that the time span from the beginning to the middle of the burst is equal to 90 ms. Among the plosives which were preceded by an [a] or which are voiced (so that the real time of the start-up phase can be found) we found no sounds with a period of silence or murmur which was clearly shorter than 90 ms.
In voiceless plosives, the burst is followed by an [h]-like sound before the following vowel starts. A consequence of including this part in the samples is that bursts often do not match when comparing two voiceless plosives. However, since aspiration is a characteristic property of voiceless sounds, we retained aspiration in the samples. In general, when comparing two voiced plosives, the bursts match. When comparing a voiceless plosive and a voiced plosive, the bursts do not match.
To keep trills comparable to each other, we always cut three periods, even when the original samples contained more periods. When there were more periods, the most regular looking sequence of three periods was cut.
The Levenshtein algorithm also requires a definition of ‘silence’. To get a sample of ‘silence’ we cut a small silent part on the IPA tape. This assures that silence has approximately the same background noise as the other sounds.
To make the samples as comparable as possible, all vowel and extracted consonant samples are monotonized on the mean pitch of the 28 concatenated vowels. The mean pitch of John Wells was 128 Hertz; the mean pitch of Jill House was 192 Hertz. In order to monotonize the

72 Vincent J. van Heuven
samples the pitch contours were changed to flat lines. The volume was not normalized because volume contains too much segment specific information. For example it is specific for the [v] that its volume is greater than that of the [f].
4.1.2. Acoustic representation
In the most common type of spectrogram the linear Hertz frequency scale is used. The difference between 100 Hz and 200 Hz is the same as the difference between 1000 Hz and 1100 Hz. However, our perception of frequency is non-linear. We hear the difference between 100 Hz and 200 Hz as an octave interval, but also the difference between 1000 Hz and 2000 Hz is perceived as an octave. Our ear evaluates frequency differences not absolutely, but relatively, namely in a logarithmic manner. Therefore, in the Barkfilter, the Bark-scale is used which is roughly linear below 1000 Hz and roughly logarithmic above 1000 Hz (Zwicker and Feldtkeller, 1967).
In the commonly used type of spectrogram the power spectral density is represented per frequency per time. The power spectral density is the power per unit of frequency as a function of the frequency. In the Barkfilter the power spectral density is expressed in decibels (dB’s). “The decibel scale is a way of expressing sound amplitude that is better correlated with perceived loudness” (Johnson, 1997, p. 53). The decibel scale is a logarithmic scale. Multiplying the sound pressure ten times corresponds to an increase of 20 dB. On a decibel scale intensities are expressed relative to the auditory threshold. The auditory threshold of 0.00002 Pa corresponds with 0 dB (Rietveld and Van Heuven, 1997, p. 199).
A Barkfilter is created from a sound by band filtering in the frequency domain with a bank of filters. In PRAAT the lowest band has a central frequency of 1 Bark per default, and each band has a width of 1 Bark. There are 24 bands, corresponding to the first 24 critical bands of hearing as found along the basilar membrane (Zwicker and Fastl, 1990). A critical band is an area within which two tones influence each other’s perceptibility (Rietveld and Van Heuven, 1997). Due to the Bark-scale the higher bands summarize a wider frequency range than the lower bands.
In PRAAT we used the default settings when using the Barkfilter. The sound signal is probed each 0.005 seconds with an analysis window of 0.015 seconds. Other settings may give different results, but since it was

Boundary Tones in Dutch: Phonetic or Phonological Contrasts? 73
not a priori obvious which results are optimal, we restricted ourselves to the default settings. In Figure 4 Barkfilters for some segments are shown.
Figure 4. Barkfilter spectrograms of some sounds pronounced by John Wells. Upper the [i] (left) and the [e] (right) are shown, and lower the [p] (left) and the [s] (right) are visualized.
4.1.3. Comparison
In this section, we explain the comparison of segments in order to get distances between segments that will be used in the Levenshtein distance measure. In a Barkfilter, the intensities of frequencies are given for a range of times. A spectrum contains the intensities of frequencies at one time. The smaller the time step, the more spectra there are in the acoustic representation. We consistently used the same time step for all samples.
It appears that the duration of the segment samples varies. This may be explained by variation in speech rate. Duration is also a sound-specific property. E.g., a plosive is shorter than a vowel. The result is that the number of spectra per segment may vary, although for each segment the same time step was used. Since we want to normalize the speech rate and regard segments as linguistic units, we made sure that two segments get the same number of spectra when they are compared to each other.

74 Vincent J. van Heuven
When comparing one segment of m spectra with another segment of n spectra, each of the m elements is duplicated n times, and each of the n elements is duplicated m times. So both segments get a length of m n.
In order to find the distance between two sounds, the Euclidean distance is calculated between each pair of corresponding spectra, one from each of the sounds. Assume a spectrum e1 and e2 with n frequencies, then the Euclidean distance is:
Equation 1. Euclidean distance
The distance between two segments is equal to the sum of the spectrum distances divided by the number of spectra. In this way we found that the greatest distance occurs between the [a] and ‘silence’. We regard this maximum distance as 100%. Other segment distances are divided by this maximum and multiplied by 100. This yields segment distances expressed in percentages. Word distances and distances between varieties which are based on them may also be given in terms of percentages.
In perception, small differences in pronunciation may play a relatively strong role in comparison with larger differences. Therefore we used logarithmic segment distances. The effect of using logarithmic distances is that small distances are weighed relatively more heavily than large distances. Since the logarithm of 0 is not defined, and the logarithm of 1 is 0, distances are increased by 1 before the logarithm is calculated. To obtain percentages, we calculate ln(distance + 1) / ln(maximum distance + 1).
4.1.4. Suprasegmentals and diacritics
The sounds on the tape The Sounds of the International Phonetic Alphabet are pronounced without suprasegmentals and diacritics. However, a restricted set of suprasegmentals and diacritics can be processed in our system.
Length marks and syllabification are processed by changing the transcription beforehand. In the X-SAMPA transcription, extra-short

Boundary Tones in Dutch: Phonetic or Phonological Contrasts? 75
segments are kept unchanged, sounds with no length indication are doubled, half long sounds are trebled, and long sounds are quadrupled. Syllabic sounds are treated as long sounds, so they are quadrupled.
When processing the diacritics voiceless and/or voiced, we assume that a voiced voiceless segment (e.g. []) and a voiceless voiced segment (e.g. [d]) are intermediate pronunciations of a voiceless segment ([t]) and a voiced segment ([d]). Therefore we calculate the distance between a segment x and a voiced segment y as the average of the distance between x and y and the distance between x and the voiced counterpart of y. Similarly, the distance between a segment x and a voiceless segment y is calculated as the mean of the distance between x and y and the distance between x and the voiceless counterpart of y. For voiced sounds which have no voiceless counterpart (the sonorants), or for voiceless sounds which have no voiced counterpart (the glottal stop) the sound itself is used.
The diacritic apical is only processed for the [s] and the [z]. We calculate the distance between [s] and e.g. [f] as the average of the distance between [s] and [f] and [] and [f]. Similarly, the distance between [z] and e.g. [v] is calculated as the mean of [z] and [v] and [] and [v].
The thought behind the way in which the diacritic nasal is processed is that a nasal sound is more or less intermediate between its non-nasal version and the [n]. We calculate the distance between a segment x and a nasal segment y as the average of the distance between x and y and the distance between x and [n].
4.2. Levenshtein distance
Using the Levenshtein distance, two dialects are compared by comparing the pronunciation of a word in the first dialect with the pronunciation of the same word in the second. It is determined how one pronunciation is changed into the other by inserting, deleting or substituting sounds. Weights are assigned to these three operations. In the simplest form of the algorithm, all operations have the same cost, e.g. 1. Assume afternoon is pronounced as [tnn] in the dialect of Savannah, Georgia, and as [] in the dialect of Lancaster, Pennsylvania15. Changing one pronunciation into the other can be done as in table 1 (ignoring suprasegmentals and diacritics for this moment)16:

Table 1. Changing one pronunciation into another using a minimal set of operations.
tnn delete 1tnn insert r 1trnn subst. / 1
3
In fact many sequence operations map [tnn] to []. The power of the Levenshtein algorithm is that it always finds the cost of the cheapest mapping.
Comparing pronunciations in this way, the distance between longer pronunciations will generally be greater than the distance between shorter pronunciations. The longer the pronunciation, the greater the chance for differences with respect to the corresponding pronunciation in another variety. Because this does not accord with the idea that words are linguistic units, the sum of the operations is divided by the length of the longest alignment which gives the minimum cost. The longest alignment has the greatest number of matches. In our example we have the following alignment:
Table 2. Alignment which gives the minimal cost. The alignment corresponds with table 1.
t n n
1 1 1
The total cost of 3 (1+1+1) is now divided by the length of 9. This gives a word distance of 0.33 or 33%.
In Section 3.1.3 we explained how distances between segments can be found using spectrograms. This makes it possible to refine our Levenshtein algorithm by using the spectrogram distances as operation weights. Now the cost of insertions, deletions and substitutions is not always equal to 1, but varies, i.e., it is equal to the spectrogram distance between the segment

The Position of Frisian in the Germanic Language Area 77
and ‘silence’ (insertions and deletions) or between two segments (substitution).
To reckon with syllabification in words, the Levenshtein algorithm is adapted so that only a vowel may match with a vowel, a consonant with a consonant, the [j] or [w] with a vowel (or opposite), the [i] or [u] with a consonant (or opposite), and a central vowel (in our research only the schwa) with a sonorant (or opposite). In this way unlikely matches (e.g. a [p] with a [a]) are prevented.
In our research we used 58 different words. When a word occurred in the text more than once, the mean over the different pronunciations was used. So when comparing two dialects we get 58 Levenshtein distances. Now the dialect distance is equal to the sum of 58 Levenshtein distances divided by 58. When the word distances are presented in terms of percentages, the dialect distance will also be presented in terms of percentages. All distances between the 15 language varieties are arranged in a 15 15 matrix.
5. Results
The results of the Levenshtein distance measurements are analyzed in two ways. First, on the basis of the distance matrix we applied hierarchical cluster analysis (see Section 5.1). The goal of clustering is to identify the main groups. The groups are called clusters. Clusters may consist of subclusters, and subclusters may in turn consist of subsubclusters, etc. The result is a hierarchically structured tree in which the dialects are the leaves (Jain and Dubes, 1988). Several alternatives exist. We used the Unweighted Pair Group Method using Arithmetic averages (UPGMA), since dendrograms generated by this method reflected distances which correlated most strongly with the original Levenshtein distances (r=0.9832), see Sokal and Rohlf (1962).
Second, we ranked all varieties in order of relationship with the standard languages, Frisian and Town Frisian (see Section 5.2). When ranking with relation to Frisian, we looked at the average over all Frisian dialects. Since the ratings with respect to each of the Frisian varieties individually were very similar averaging was justified.

78 Charlotte Gooskens and Wilbert Heeringa
5.1. The classification of the Germanic languages
Looking at the clusters of language varieties in Figure 5 we note that our results reflect the traditional classification of the Germanic languages to a large extent (see Figure 1). On the highest level there is a division between English and the other Germanic languages. When we examine the group of other Germanic languages, we find a clear division between the North Germanic languages and the West Germanic languages. Within the North Germanic group, we see a clear division between the Scandinavian languages (Danish, Norwegian and Swedish) on the one hand and the Faroese and Icelandic on the other hand. In the genetic tree (see Figure 1), Norwegian is clustered with Icelandic and Faroese. However, due to the isolated position of Iceland and the Faroes and intensive language contact between Norway and the rest of Scandinavia, modern Norwegian has become very similar to the modern languages of Denmark and Sweden. All varieties spoken in the Netherlands, including the Frisian varieties, cluster together, and German clusters more closely to these varieties than English.
Figure 5. Dendrogram showing the clustering of the 14 language varieties in our study. The scale distance shows average Levenshtein distances in percentages.
All Frisian dialects form a cluster. This clustering corresponds well with the traditional classification as sketched in Section 3.1. The dialects of Hijum and Oosterbierum belong to Klaaifrysk and these dialects form a cluster. The Wâldfrysk dialects of Westergeest and Wetsens also cluster together. The Levenshtein distance between the four dialects is small,

The Position of Frisian in the Germanic Language Area 79
ranging from 19.6% between Hijum and Oosterbierum and 23.8% between Oosterbierum and Westergeest. Also the Súdwesthoeksk dialects, represented by the Tjerkgaast dialect, are rather close to the Klaaifrysk and Wâldfrysk dialects (distances between 21.6% and 26.4%). The highly conservative dialect of Hindeloopen is more deviant from the other dialects (distances between 29.8% and 32.5%) and this is also the case for the Town Frisian dialect of Leeuwarden which is more similar to Dutch (20.3%) than to Frisian (between 32.3% and 35.8%) which confirms the characterization of Town Frisian by Kloeke (1927) as ‘Dutch in Frisian mouth’.
5.2. The relationship between Frisian and the other Germanic languages
From Table 3 and 4 it is possible to determine the distance between all Germanic standard languages. We are especially interested in the position of Frisian within the Germanic language group. For this purpose the mean distance over the 6 Frisian dialects (excluding the dialect of Leeuwarden which is considered Dutch) has been added. This makes it possible to treat Frisian as one language. Examining the column which shows the ranking with respect to Frisian, we find that Dutch is most similar to Frisian (a mean distance of 38.7%). Clearly the intensive contact with Dutch during history has had a great impact on the distance between the two languages. Moreover, German appears to be closer to Frisian than any other language outside the Netherlands. Looking at the ranking with respect to Dutch, it appears that Town Frisian is most similar (Leeuwarden 20.3%), followed by the Frisian varieties (average of 38.7%). Next, German is most similar, due to common historical roots and continuous contact (a distance of 53.3%).
As discussed in the introduction, Friesland has a long history of language contact with the Scandinavian countries, and traces of Scandinavian influences can be found in the Frisian language. The impact of this contact is reflected in our results only to a limited extent. Remarkably, the distances to the mainland Scandinavian languages (Danish, Norwegian and Swedish) are smaller (between 60.7% and 63.3%) than to English (65.3%) even though the Frisian language is genetically closer related to English than to Scandinavian (see Section 2.1).

80 Charlotte Gooskens and Wilbert Heeringa
Table 3. Ranked Levenshtein distances in percentages between each of the five West Germanic languages and the other language varieties in the investigation.
Frisian Leeuwarden Dutch English GermanDutch 20.3 Leeuw 20.3 Hindel 63.1 Dutch 53.3Wetsens 32.3 Hindel 37.5 Wetsens 64.4 Leeuw 54.2Westerg 32.7 Westerg 37.7 Dutch 64.7 Hindel 56.2Frisian 34.2 Wetsens 38.3 Swedish 64.9 Westerg 56.9Oosterb 34.3 Tjerkg 38.5 Leeuw 65.1 Oosterb 57.2Hindel 34.9 Frisian 38.7 Tjerkg 65.2 Tjerkg 57.3
Leeuw 34.2 Tjerkg 35.3 Hijum 38.9 Frisian 65.3 Frisian 57.3Dutch 38.7 Hijum 35.8 Oosterb 41.3 Hijum 65.8 Hijum 57.5German 57.3 German 54.2 German 53.3 Westerg 65.8 Wetsens 58.6Swedish 60.7 Swedish 59.2 Swedish 60.9 Danish 66.7 Swedish 61.0Norweg 60.9 Norweg 60.0 Norweg 61.4 Faroese 67.1 Danish 63.5Danish 63.3 Danish 61.1 Danish 63.4 Oosterb 67.2 Norweg 64.0English 65.3 English 65.1 English 64.7 German 68.1 Faroese 67.1Faroese 67.7 Faroese 67.5 Faroese 66.1 Norweg 68.6 English 68.1Icelandic 70.0 Icelandic 69.6 Icelandic 69.2 Icelandic 69.1 Icelandic 68.5
Table 4. Ranked Levenshtein distances in percentages between each of the five North Germanic languages and the other language varieties in the investigation.
Danish Swedish Norwegian Icelandic FaroeseNorweg 43.8 Norweg 43.4 Swedish 43.4 Faroese 54.1 Swedish 53.6Swedish 47.0 Danish 47.0 Danish 43.8 Swedish 58.7 Icelandic 54.1Faroese 58.5 Faroese 53.6 Faroese 57.2 Norweg 62.6 Norweg 57.2Leeuw 61.1 Icelandic 58.7 Westerg 59.6 Danish 62.7 Danish 58.5Westerg 62.2 Hindel 59.2 Leeuw 60.0 German 68.5 Dutch 66.1Wetsens 62.3 Leeuw 59.2 Hindel 60.2 Tjerkg 69.1 Hindel 67.0Icelandic 62.7 Westerg 59.6 Tjerkg 60.6 English 69.1 English 67.1Hijum 62.9 Tjerkg 60.0 Wetsens 60.7 Dutch 69.2 German 67.1Frisian 63.3 Frisian 60.7 Frisian 60.9 Leeuw 69.6 Westerg 67.4Hindel 63.4 Dutch 60.9 Dutch 61.4 Hijum 69.8 Leeuw 67.5Dutch 63.4 German 61.0 Oosterb 61.9 Frisian 70.0 Tjerkg 67.5German 63.5 Wetsens 61.1 Hijum 62.6 Wetsens 70.1 Frisian 67.5Tjerkg 63.8 Oosterb 61.4 Icelandic 62.6 Hindel 70.1 Oosterb 67.7Oosterb 65.2 Hijum 62.7 German 64.0 Oosterb 70.3 Wetsens 68.1English 66.7 Icelandic 64.9 English 68.6 Westerg 70.3 Hijum 68.2

The Position of Frisian in the Germanic Language Area 81
So, when looking at the results from a Frisian perspective, the close genetic relationship with English is not reflected in our results. Of the Germanic languages in our investigation, only Icelandic and Faroese are less similar to Frisian than English. However, when looking at the results from an English perspective, we discover that of all Germanic language varieties in our material the Frisian dialect of Hindeloopen is most similar to English. As mentioned before, this dialect is highly conservative and furthermore it is spoken in a coastal place, which provides for easy contact with England. Also the Frisian dialect of Wetsens is more similar to English than the remaining Germanic languages. The other Frisian varieties are found elsewhere in the middle of the ranking. Among the non-Frisian varieties, Dutch appears to be most similar to English. However, all Germanic languages, including Frisian and Dutch, show a large linguistic distance to English, all distances being above 60%. The development of the English language has thus clearly taken place independently from the other Germanic languages, which can be explained by the strong influence from non-Germanic languages, especially French.
Also Icelandic shows a large distance to all other Germanic languages (from 54.1% to 70.0%), but in the Icelandic case this is explained by the conservative nature of this language rather than by language contact phenomena. Faroese is somewhat less conservative, but still shows rather large distances to the other languages (between 53.6% and 67.7%). The distances between the other Nordic languages are smaller (between 43.4% and 47%), as was expected given that the three Scandinavian languages are mutually intelligible.
6. Conclusions and discussion
Overall, the classification of the Germanic languages resulting from our distance measurements supports our predictions. This goes for the classification of the Frisian dialects and also for the rest of the Germanic languages. We interpret this as a confirmation of the suitability of our material showing that it is possible to measure Levenshtein distances on the basis of whole texts with assimilation phenomena typical of connected speech and with a rather limited number of words.
The aim of the present investigation was to get an impression of the position of the Frisian language in the Germanic language area on the basis of quantitative data. The fact that Frisian is genetically most closely related

82 Charlotte Gooskens and Wilbert Heeringa
to English yields the expectation that these two languages may still be linguistically similar. However, the distance between English and the Frisian dialects is large. We can thus conclude that the close genetic relationship between English and Frisian is not reflected in the linguistic distances between the modern languages. Geographical and historical circumstances have caused the two languages to drift apart linguistically. Frisian has been strongly influenced by Dutch whereas English has been influenced by other languages, especially French.
It would have been interesting to include these languages in our material. This would have given an impression of their impact on the English language. At the same time it would also have given us the opportunity to test the Levenshtein method on a larger language family than the Germanic family with its relatively closely related languages. It would also be interesting to include Old English in our material since this would give us an impression of how modern Frisian is related to the English language at a time when it had only recently separated from the common Anglo-Saxon roots to which also Old Frisian belonged.
For many centuries Frisian has been under the strong influence from Dutch and the Frisian and Dutch language areas share a long common history. It therefore does not come as a surprise that Dutch is the Germanic language most similar to the language varieties spoken in Friesland.
It may be surprising that the linguistic distances between Dutch and the Frisian dialects are smaller than the distances between the Scandinavian languages (a mean difference of 6%). Scandinavian languages are known to be mutually intelligible. This means that when, for example, a Swede and a Dane meet, they mostly communicate each in their own language. This kind of communication, which is known as semi-communication (Haugen, 1966), is not typical in the communication between Dutch-speaking and Frisian-speaking citizens in the Netherlands. The two languages are considered so different that it is not possible for a Dutch-speaking person to understand Frisian and consequently the Frisian interlocutor will have to speak Dutch to a non-Frisian person. Our results raise the question whether semi-communication would also be possible in a Dutch-Frisian situation. If this is not the case, we may explain this by linguistic and non-linguistic differences between the Frisian-Dutch situation and the Scandinavian situation. The Levenshtein distance processes lexical, phonetic and morphological differences. All three types are present in our transcription, since word lists are derived from running texts. Syntactic characteristics are completely excluded from the analysis. It might be the case that certain

The Position of Frisian in the Germanic Language Area 83
characteristics play a larger role for the Levenshtein distances than desirable in the case of the Scandinavian languages if we were to use the method for the explaining mutual intelligibility. For example, it is well-known among the speakers of Scandinavian languages that many words end in an ‘a’ in Swedish while ending in an ‘e’ in Danish. Probably people use this knowledge in an inter-Scandinavian situation. However, this difference is included in the Levenshtein distances between Swedish and Danish. It is possible that Frisian-Dutch differences are less predictable or less well-known by speakers of the two languages. It is also possible that the difference in communication in the Netherlands and in Scandinavia should be sought at the extra-linguistic level. Scandinavian research on semi-communication has shown that the willingness to understand and the belief that it is possible to communicate play a large role for mutual intelligibility between speakers of closely related languages.
Staying with the Scandinavian languages, it should be noted that the mainland Scandinavian languages are in fact closer to Frisian than English, even though the Scandinavian languages belong genetically to another Germanic branch than English and Frisian. This can probably be explained by intensive contacts between Frisians and Scandinavians for many centuries. However, the common idea among some speakers of Frisian and Scandinavian that the two languages are so close that they are almost mutually intelligible is not confirmed by our results, at least not as far as the standard Scandinavian languages are concerned. Probably this popular idea is built on the fact that a few frequent words are identical in Frisian and Scandinavian. It is possible, however, that this picture would change if we would include more Danish dialects in our material. For example, it seems to be relatively easy for fishermen from Friesland to speak to their colleagues from the west coast of Denmark. Part of the explanation might also be that fishermen share a common vocabulary of professional terms. Also the frequent contact and a strong motivation to communicate successfully are likely to be important factors.
As we mentioned in the introduction, among dialects in the Netherlands and Flanders, the Frisian varieties are most deviant from Standard Dutch. However, among the varieties which are recognized as languages in the Germanic language area, Frisian is most similar to Dutch. The smallest distance between two languages, apart from Frisian, was found between Norwegian and Swedish: 43.4%. The distance between Frisian and Dutch is smaller: 38.7%. The Town Frisian variety of the capital of Friesland (Leeuwarden) has a distance of only 20.3% to Dutch. Although the

84 Charlotte Gooskens and Wilbert Heeringa
recognition of Frisian as second official language in the Netherlands is right in our opinion, we found that the current linguistic position of Frisian provide too little foundation for becoming independent from the Netherlands, as some Frisians may wish17.
Acknowledgements
This research would have been impossible without informants who were willing to translate the story of ‘the Northwind and the Sun’. We wish to thank G. Blom (Hindeloopen), J. Spoelstra (Hijum) and W. Visser (Oosterbierum). All of them are affiliated with the Fryske Akademy in Leeuwarden. We also thank S. van Dellen (Wetsens), T. de Graaf (Leeuwarden), F. Postma (Tjerkgaast) and O. Vries (Westergeest), all of them employees of the University of Groningen. We thank J. Allen (England), A. Mikaelsdóttir (Iceland), Vigdis Petersen (the Faroes), R. Kraayenbrink (the Netherlands), K. Sjöberg (Sweden) and R. Schmidt (Germany). We are also very grateful to Jørn Almberg for making available the recording of Lillehammer (Norway). The recordings and transcriptions of the Frisian transcriptions are made by the second author, and those of the standard languages (except Norway and the Faroes) by the first author. The transcriptions subsequently were checked by Jørn Almberg who we thank gratefully for correcting our transcriptions. Furthermore, we wish to express our gratitude to Peter Kleiweg for his software for creating the map (Figure 2) and visualizing the dendrogram (Figure 5). Finally we thank Maartje Schreuder for reading an earlier version of this article and giving useful comments and Angeliek van Hout for reviewing our English.

The Position of Frisian in the Germanic Language Area 85
Notes
10 Dr. Tjeerd de Graaf, the central figure in this volume, was born in Leeuwarden, the capital of Friesland. Leeuwarden is one of the places where Town Frisian is spoken. Tjeerd de Graaf is a native speaker of this dialect, but later on he also learned (standard) Frisian. The Leeuwarden speaker in the present investigation was Tjeerd de Graaf (see Section 3.1).
11 Most of this section is based on König and Van der Auwera (1994).12 The Lillehammer recording can be found at
http://www.ling.hf.ntnu.no/nos/ together with 52 recordings of other Norwegian dialects.
13 Since our material included two toneme languages, Swedish and Norwegian, also the two tonemes I and II were transcribed. For the other varieties primary stress was noted. Stress and tonemes were, however, not included for calculation of linguistic distances.
14 The program PRAAT is a free public-domain program developed by Paul Boersma and David Weenink at the Institute of Phonetic Sciences of the University of Amsterdam and available at http://www.fon.hum.uva.nl/praat.
15 The data is taken from the Linguistic Atlas of the Middle and South Atlantic States (LAMSAS) and available via: http://hyde.park.uga.edu/lamsas/.
16 The example should not be interpreted as a historical reconstruction of the way in which one pronunciation changed into another. From that point of view it may be more obvious to show how [] changed into [tnn]. We just show that the distance between two arbitrary pronunciations is found on the basis of the least costly set of operations mapping one pronunciation into another.
17 Tjeerd de Graaf has never taken such an extreme position. Possibly speakers of Town Frisian have a more moderate opinion towards this issue since Town Frisian is more closely related to standard Dutch, as appeared in Figure 5 and Table 3.
References
Bolognesi, R. and W. Heeringa (2002). De invloed van dominante talen op het lexicon en de fonologie van Sardische dialecten. In: D. Bakker, T. Sanders, R. Schoonen and Per van der Wijst (eds.). Gramma/TTT: tijdschrift voor taalwetenschap. Nijmegen University Press, Nijmegen, 9 (1): 45-84.

86 Charlotte Gooskens and Wilbert Heeringa
Feitsma, T. (1963). Sproglige berøringer mellem Frisland og Skandinavien. Sprog og kultur, 23: 97-121.
Gooskens, Ch. and W. Heeringa (submitted). Perceptive Evaluation of Levenshtein Dialect Distance Measurements Using Norwegian Dialect Data. (submitted to Language Variation and Change).
Goossens, J. (1977). Inleiding tot de Nederlandse Dialectologie. Wolters-Noordhoff, Groningen.
Haugen, E. (1966). Semicommunication: The Language Gap in Scandinavia. Sociological Inquiry, 36 (2): 280-297.
Heeringa, W. (2004). Measuring Dialect Pronunciation Differences using Levenshtein Distance. Doctoral dissertation. University of Groningen.
Heeringa, W. and C. Gooskens (2003). Norwegian Dialects Examined Perceptually and Acoustically. In: J. Nerbonne and W. Kretzschmar (eds.). Computers and the Humanities. Kluwer Academic Publishers, Dordrecht, 37 (3): 293-315.
Hof, J. J. (1933). Friesche Dialectgeographie. ‘s Gravenhage (Noord- en Zuid-Nederlandse Dialectbibliotheek 3).
Hoppenbrouwers, C and G. Hoppenbrouwers (1988). De featurefrequentie methode en de classificatie van Nederlandse dialecten. TABU: Bulletin voor Taalwetenschap, 18 (2): 51-92.
Jain, A.K. and R.C. Dubes (1988). Algorithms for Clustering Data. Prentice Hall, Englewood Cliffs, New Yersey.
Johnson, K. (1997). Acoustic and Auditory Phonetics. Blackwell Publishers, Cambridge etc..
Kessler, B. (1995). Computational dialectology in Irish Gaelic. In: Proceedings of the 7th Conference of the European Chapter of the Association for Computational Linguistics. EACL, Dublin, 60-67.
Kloeke, G. G. (1927). De Hollandsche expansie in de zestiende en zeventiende eeuw en haar weerspiegeling in de hedendaagsche Nederlandsche dialecten. Nijhoff, ‘s-Gravenhage.
König, E. and J. van der Auwera (1994). eds. The Germanic Languages. Routledge, London.
Miedema, H.T.J. (1966). Van York naar Jorwerd. Enkele problemen uit de Friese taalgeschiedenis. J.B. Wolters, Groningen.
Nerbonne, J., W. Heeringa, E. van den Hout, P. van der Kooi, S. Otten, and W. van de Vis, (1996). Phonetic Distance between Dutch dialects. In: G. Durieux, W. Daelemans, and S. Gillis (eds.). CLIN VI, Papers from the sixth CLIN meeting. Antwerpen. University of Antwerp, Center for Dutch Language and Speech, 185-202.

The Position of Frisian in the Germanic Language Area 87
Nerbonne, J. and W. Heeringa (1997). Measuring dialect distances phonetically. In: J. Coleman (ed.). Workshop on Computational Phonology. Madrid, 11-18.
Pei, M. (1966). The story of language. Allen & Unwin, London.Potter, R.K., G.A. Kopp and H.C. Green (1947). Visible Speech. The Bell
Telephone Laboratories Series. Van Nostrand, New York.Rietveld, A.C.M. and V.J. Van Heuven (1997). Algemene fonetiek. Coutinho,
Bussum.Sandøy, H. (1994). Utan kontakt og endring? In: U.-B. Kotsinas and J.
Helgander (eds.). Dialektkontakt, språkkontakt och språkförändring i Norden. Almqvist & Wiksell International, Stockholm, 38-51.
Sokal, R.R. and F.J. Rohlf (1962). The comparison of dendrograms by objective methods. Taxon, 11: 33-40.
Stevens, K.N. (1998). Acoustic Phonetics. MIT Press, Cambridge.The Columbia Encyclopedia (2001). www.bartleby.com/65/fr/Frisianl.htmlThe International Phonetic Association (1949). The principles of the
International Phonetic Association: being a description of the International Phonetic Alphabet and the manner of using it, illustrated by texts in 51 languages. International Phonetic Association, London.
The International Phonetic Association (1999). Handbook of the International Phonetic Association: a guide to the use of the International Phonetic Alphabet. Cambridge University Press, Cambridge.
Trask, R.L. (1996). A Dictionary of Phonetics and Phonology. Routledge, London and New York.
Van der Veen, K. F. (2001). West Frisian Dialectology and Dialects. In: H. H. Munske (ed.). Handbook of Frisian Studies. Niemeyer, Tübingen, 83-98.
Vieregge, W. H., A.C.M. Rietveld and C. Jansen (1984). A distinctive feature based system for the evaluation of segmental transcription in Dutch. In: M.P.R. van den Broecke and A. Cohen. Proceedings of the 10th International Congress of Phonetic Sciences. Foris Publications, Dordrecht and Cinnaminson, 654-659.
Visser, W. (1997). The syllable in Frisian. Holland Academic Graphics, The Hague.
Wadstein, E. (1933). On the Relations between Scandinavians and Frisians in Early Times. University of London, London.
Wells, J. and J. House (1995). The sounds of the International Phonetic Alphabet. UCL, London.
Zwicker, E. and H. Fastl (1990). Psychoacoustics and Models. Springer Verlag, Berlin.

88 Charlotte Gooskens and Wilbert Heeringa
Zwicker, E. and R. Feldtkeller (1967). Das Ohr als Nachrichtemfänger. Monographien der elektrischen Nachrichtentechnik. 19, 2nd revised edition. Hirzel, Stuttgart.


Learning Phonotactics with Simple Processors
John Nerbonne and Ivilin Stoianov
Abstract
This paper explores the learning of phonotactics in neural networks. Experiments are conducted on the complete set of over 5,000 Dutch monosyllables extracted from CELEX, and the results are shown to be accurate within 5% error. Extensive comparisons to human phonotactic learning conclude the paper. We focus on whether phonotactics can be
4 Nevertheless, large between-listener variability has been reported, for instance, in the cuing of the voiced/voiceless contrast by the duration of the pre-burst silent interval: the boundary was at 70 ms for subject #1 and over 100 ms for subject #7 (Slis & Cohen, 1969). These results are commented on by Nooteboom & Cohen (1976: 84) as follows: ‘Although the cross-over from /d/ to /t/ proceeds rather gradually when averaged over all listeners, the boundary is quite sharply defined for individual listeners’ (my translation, VH).
5 The ‘%’ sign following the tone letter (as in ‘L%’, ‘H%’) denotes a domain-final boundary; domain-initial boundaries are coded by the ‘%’ sign preceding a tone letter (as in ‘%L’, ‘%H’). A ‘%’ sign unaccompanied by a tone letter may only occur in domain-final positions, where it is phonetically coded by a physical pause and/or pre-boundary lengthening only.
6 It has been argued by structuralists at least as far back as Merckens (1960) that V1 (‘verb first’) is directly opposed to V2 ('verb second') in signaling, for example, ‘non-assertion’ rather than ‘assertion’, since neither a command nor a question nor a condition expresses an ongoing state of affairs.
7 A sequence like Neemt u de trein naar Wageningen might in addition be interpretable as a topic-drop-sentence (e.g. [Dan/Daar] neemt u de trein naar Wageningen ‘[Then/There] you take the train to Wageningen’, analogous to Doen we! ‘We'll do [it]’ or Weet ik! ‘[That] I know’. Although this added interpretation (with a ‘deleted’ element) is theoretically possible, we believe that it was highly unlikely under the controlled conditions of the experiment. Furthermore, none of the experimental subjects volunteered the information that we had forgotten such an extra interpretation.

Learning Phonotactics with Simple Processors 91
effectively learned and how the learning which is induced compares to human behavior.
1. Introduction18
Phonotactics concerns the organization of the phonemes in words and syllables. The phonotactic rules constrain how phonemes combine in order to form larger linguistic units (syllables and words) in that language (Laver, 1994). For example, Cohen, Ebeling & van Holk (1972) describe the phoneme combinations possible in Dutch, which will be the language in focus in this study.
Phonotactic rules are implicit in natural languages so that humans require no explicit instruction about which combinations are allowed and which are not. An explicit phonotactic grammar can of course be abstracted from the words in a language, but this is an activity linguists engage in, not language learners in general. Children normally learn a language's phonotactics in their early language development and probably update it only slightly once they have mastered the language.
Most work on language acquisition has arisen in linguistics and psychology, and that work employs mechanisms that have been developed for language, typically, discrete, symbol-manipulation systems. Phonotactics in particular has been modeled with n-gram models, Finite State Machines, Inductive Logic Programming, etc. (Tjong Kim Sang, 1998; Konstantopoulos, 2003). Such approaches are effective, but a cognitive scientist may ask whether the same success could be possible using less custom-made tools. The brain, viewed as a computational machine, exploits other principles, which have been modeled in the
8 This position does not exclude the possibility that statement and imperative are subtly different in their paralinguistic use of prosody. For instance, the overall pitch of the imperative may be lower, and it may be said with greater loudness and larger/higher pitch excursions on the accented syllables. This does not invalidate our claim that both statements and imperatives are coded by the ‘L%’ terminal boundary.
9 The ERB scale (Equivalent Rectangular Bandwidth) is currently held to be the most satisfactory psychophysical conversion for pitch intervals in human speech (Hermes & van Gestel, 1991; Ladd & Terken, 1995). The conversion from Hertz (f) to ERB (E) is achieved by a simple formula: E = 16.6 * log (1 + f / 165.4).

92 John Nerbonne and Ivilin Stoianov
approach known as Parallel Distributed Processing (PDP), which was thoroughly described in the seminal work of Rumelhart & McClelland (1986). Computational models inspired by the brain structure and neural processing principles are Neural Networks (NNs), also known as connectionist models.
Learning phonotactic grammars is not an easy problem, especially when one restricts one's attention to cognitively plausible models. Since languages are experienced and produced dynamically, we need to focus on the processing of sequences, which complicates the learning task. The history of research in connectionist language learning shows both successes and failures even when one concentrates on simpler structures, such as phonotactics (Stoianov, Nerbonne & Bouma, 1998; Stoianov & Nerbonne, 2000; Tjong Kim Sang, 1995; Tjong Kim Sang & Nerbonne, 1999; Pacton, Perruchet, Fayol & Cleeremans, 2001).
This paper will attack phonotactics learning with models that have no specifically linguistic knowledge encoded a priori. The models naturally do have a bias, viz., toward extracting local conditioning factors for phonotactics, but we maintain that this is a natural bias for many sorts of sequential behavior, not only linguistic processing. A first-order Discrete Time Recurrent Neural Network (DTRNN) (Carrasco, Forcada & Neco, 1999; Tsoi & Back, 1997) will be used: the Simple Recurrent Network (SRNs) (Elman, 1988). SRNs have been applied to different language problems (Elman, 1991; Christiansen & Chater, 1999; Lawrence, Giles & Fong, 1995), including learning phonotactics (Shillcock, Levy, Lindsey, Cairns & Chater, 1993; Shillcock, Cairns, Chater & Levy, 1997). With respect to phonotactics, we have also contributed reports (Stoianov et al., 1998; Stoianov & Nerbonne, 2000; Stoianov, 1998).
SRNs have been shown capable of representing regular languages (Omlin & Giles, 1996; Carrasco et al., 1999). Kaplan & Kay (1994) demonstrated that the apparently context-sensitive rules that are standardly found in phonological descriptions can in fact be expressed within the more restrictive formalism of regular relations. We begin thus with a device which is in principle capable of representing the needed patterns.
We then simulate the language learning task by training networks to produce context-dependent predictions. We also show how the continuous predictions of trained SRNs - likelihoods that a particular token can follow the current context - can be transformed into more useful discrete predictions, or, alternatively, string recognitions.

Learning Phonotactics with Simple Processors 93
In spite of the above claims about representability, the Back-Propagation (BP) and Back-Propagation Through Time (BPTT) learning algorithms used to train SRNs do not always find optimal solutions - SRNs that produce only correct context-dependent successors or recognize only strings from the training language. Hence, section 3 focuses on the practical demonstration that a realistic language learning task may be simulated by an SRN. We evaluate the network learning from different perspectives - grammar learning, phonotactics learning, and language recognition. The last two methods need one language-specific parameter - a threshold - that distinguishes successors/words allowed in the training language. This threshold is found with a post-training procedure, but it could also be sought interactively during training.
Finally, section 4 assesses the networks from linguistic and psycholinguistic perspectives: a static analysis extracts acquired linguistic knowledge from network weights, and the network performance is compared to humans' in a lexical decision task. The network performance, in particular the distribution of errors as a function of string position, will be compared to alternative construals of Dutch syllabic structure - following a suggestion from discussions of psycholinguistic experiments about English syllables (Kessler & Treiman, 1997).
1.1. Motivations for a Phonotactic Device
This section will review standard arguments that demonstrate the cognitive and practical importance of phonotactics. English phonotactic rules such as:
‘/s/ may precede, but not follow /t/ syllable-initially’
(ignoring loanwords such as `tsar' and `tse-tse') may be adduced by judging the well-formedness of sequences of letters/phonemes, taken as words in the language, e.g. /stp/ vs. */tsp/. There may also be cases judged to be of intermediate acceptability. So, even if all of the following are English words:
/m/ `mother', /f/ `father', /sst/ `sister'
None of the following are, however:

94 John Nerbonne and Ivilin Stoianov
*/m/, */f/, */tss/
None of these sound like English words. However, the following sequences:
/m/, /fu/, /snt/
"sound" much more like English, even if they mean nothing and therefore are not genuine English words. We suspect that, e.g., /snt/ 'santer', could be used to name a new object or a concept.
This simple example shows that we have a feeling for word structure, even if no explicit knowledge. Given the huge variety of words, it is more efficient to put this knowledge into a compact form - a set of phonotactic rules. These rules would state which phonemic sequences sound correct and which do not. In this same vein, second language learners experience a period when they recognize that certain phonemic combinations (words) belong to the language they learn without knowing the meaning of these words.
Convincing psycholinguistic evidence that we make use of phonotactics comes from studying the information sources used in word segmentation (McQueen, 1998). In a variety of experiments, this author shows that word boundary locations are likely to be signaled by phonotactics. The author rules out the possibility that other sources of information, such as prosodic cues, syllabic structure and lexemes, are sufficient for segmentation. Similarly, Treiman & Zukowski (1990) had shown earlier that phonotactics play an important role in the syllabification process. According to McQueen (1998), phonotactic and metrical cues play complementary roles in the segmentation process. In accordance with this, some researchers have elaborated on a model for word segmentation: the Possible Word Constraints Model (Norris, McQueen, Cutler & Butterfield, 1997), in which likely word-boundary locations are marked by phonotactics, metrical cues, etc., and in which they are further fixed by using lexicon-specific knowledge.
Exploiting the specific phonotactics of Japanese, Dupoux, Pallier, Kakehi & Mehler (2001) conducted an experiment with Japanese listeners who heard stimuli that contained illegal consonant clusters. The listeners tended to hear an acoustically absent vowel that brought their perception into line with Japanese phonotactics. The authors were able to rule out lexical influences as a putative source for the perception of the illusory

Learning Phonotactics with Simple Processors 95
vowel, which suggests that speech perception must use phonotactic information directly.
Further justification for the postulation of a neurobiological device that encodes phonotactics comes from neurolinguistic and neuroimaging studies. It is widely accepted that the neuronal structure of Broca’s area (in the brain's left frontal lobe) is used for language processing, and more specially that it represents a general sequential device (Stowe, Wijers, Willemsen, Reuland, Paans & Vaalburg, 1994; Reilly, 2002). A general sequential processor capable of working at the phonemic level would be a plausible realization of a neuronal phonotactic device.
Besides cognitive modeling, there are also a number of practical problems that would benefit from effective phonotactic processing. In speech recognition, for example, a number of hypotheses that explain the speech signal are created, from which the impossible sound combinations have to be filtered out before further processing. This exemplifies a lexical decision task, in which a model is trained on a language L and then tests whether a given string belongs to L. In such a task a phonotactic device would be of use. Another important problem in speech recognition is word segmentation. Speech is continuous, but we divide it into psychologically significant units such as words and syllables. As noted above, there are a number of cues that we can use to distinguish these elements - prosodic markers, context, but also phonotactics. Similarly to the former problem, an intuitive strategy here is to split the phonetic/phonemic stream at the points of violation of phonotactic constraints (see Shillcock et al. (1997) and Cairns, Shillcock, Chater & Levy (1997) for connectionist modeling). Similarly, the constraints of the letters forming words in written languages (graphotactics) are useful in word processing applications, for example, spell-checking.
There is another, more speculative aspect to investigating phonotactics. Searching for an explanation of the structure of the natural languages, Carstairs-McCarthy presented in his recent book (1999) an analogy between syllable structure and sentence structure. He argues that sentences and syllables have a similar type of structure. Therefore, if we find a proper mechanism for learning the syllabic structures, we might apply a similar mechanism to learning syntax as well. Of course, syntax is much more complex and more challenging, but if Carstairs-McCarthy is right, the basic principles of both devices might be the same.

96 John Nerbonne and Ivilin Stoianov
2. Simple Recurrent Networks
This section will briefly present Simple Recurrent Networks (Elman, 1988; Robinson & Fallside, 1988) and will review earlier studies of sequential, especially phonotactic learning. Detailed descriptions of the SRN processing mechanisms and the Back-Propagation Through Time learning algorithm that is used to train the model are available elsewhere (Stoianov, 2001; Haykin, 1994), and will be reviewed only superficially.
Figure 1. Learning phonotactics with the SRNs. If the training data set contains the words /nt#/, /nts#/ and /ntrk#/ then after the network has processed a left context /n/, the reaction to an input token /t/ will be active neurons corresponding to the symbol '#' and the phonemes /s/, and //.
Simple Recurrent Networks (SRNs) were invented to encode simple artificial grammars, as an extension of the Multilayer Perceptron (Rumelhart, Hinton & Williams, 1986) with an extra input - a context layer that holds the hidden layer activations at the previous processing cycle. After training, Elman (1988) conducted investigations on how context evolves in time. The analysis showed graded encoding of the input sequence: similar items presented to the input were clustered at close, but different, shifting positions. That is, the network discovered and implicitly represented in a distributed way the rules of the grammar generating the training sequences. This is noteworthy, because the rules for context were not encoded, but rather acquired through experience. The capacity of SRNs

Learning Phonotactics with Simple Processors 97
to learn simple artificial languages was further explored in a number of studies (Cleeremans, Servan-Schreiber & McClelland, 1989; Gasser, 1992).
SRNs have the structure shown in Figure 1. They operate as follows: Input sequences SI are presented to the input layer, one element SI(t) at a time. The purpose of the input layer is just to transfer activation to the hidden layer through a weight matrix. The hidden layer in turn copies its activations after every step to the context layer, which provides an additional input to the hidden layer - i.e., information about the past, after a brief delay. Finally, the hidden layer neurons output their signal through a second weight matrix to the output layer neurons. The activation of the latter is interpreted as the product of the network. Since the activation of the hidden layer depends both on its previous state (the context) and on the current input, SRNs have the theoretical capacity to be sensitive to the entire history of the input sequence. However, practical limitations restrict the time span of the context information to maximally 10-15 steps (Christiansen & Chater, 1999). The size of the layers does not restrict the range of temporal sensitivity.
The network operates in two working regimens - supervised training and network use. In the latter, the network is presented the sequential input data SI(t) and computes the output N(t) using contextual information. The training regimen involves the same sort of processing as network use and also includes a second, training step, which compares the network reaction N(t) to the desired one ST(t), and which uses the difference to adjust the network behavior in a way that improves future network performance on the same data.
The two most popular supervised learning algorithms used to train SRNs are the standard Back-Propagation algorithm (Rumelhart et al., 1986) and the Back-Propagation Through Time algorithm (Haykin, 1994). While the earlier is simpler because it uses information from one previous time step only (the context activation, the current network activations, and error), the latter trains the network faster, because it collects errors from all time steps during which the network processes the current sequence and therefore it adjusts the weights more precisely. However, the BPTT learning algorithm is also cognitively less plausible, since the collection of the time-spanning information requires mechanisms specific for the symbolic methods. Nevertheless, this compromise allows more extensive research, and without it the problems discussed below would require much longer training time when using standard computers for simulations. Therefore, in the experiments reported here the BPTT learning algorithm

98 John Nerbonne and Ivilin Stoianov
will be used. In brief, it works in the following way: the network reaction to a given input sequence is compared to the desired target sequence at every time step and an error is computed. The network activation and error at each step are kept in a stack. When the whole sequence is processed, the error is propagated back through space (the layers) and time, and weight-updating values are computed. Then, the network weights are adjusted with the values computed in this way.
2.1. Learning Phonotactics with SRNs
Dell, Juliano & Govindjee (1993) showed that words could be described not only with symbolic approaches, using word structure and content, but also by a connectionist approach. In this early study of learning word structure with neural nets (NNs), the authors trained SRNs to predict the phoneme that follows the current input phoneme, given context information. The data sets contained 100 - 500 English words. An important issue in their paper is the analysis and modeling of a number of speech-error phenomena, which were taken as strong support for parallel distributed processing (PDP) models, in particular SRNs. Some of these phenomena were: phonological movement errors (reading list - leading list), manner errors (department - jepartment), phonotactic regularity violations (dorm - dlorm), consonant-vowel category confusions and initial consonant omissions (cluster-initial consonants dropping as when `stop' is mispronounced [tp]).
Aiming at segmentation of continuous phonetic input, Shillcock et al. (1997) and Cairns et al. (1997) trained SRNs with a version of the BPTT learning algorithm on English phonotactics. They used 2 million phonological segments derived from a transcribed speech corpus and encoded with a vector containing nine phonological features. The neural network was presented a single phoneme at a time and was trained to produce the previous, the current and the next phonemes. The output corresponding to the predicted phoneme was matched against the following phoneme, measuring cross-entropy; this produced a varying error signal with occasional peaks corresponding to word boundaries. The SRN reportedly learned to reproduce the current phoneme and the previous one, but was poor at predicting the following phoneme. Correspondingly, the segmentation performance was quite modest, predicting only about one-fifth of the word boundaries correctly, but it was more successful in

Learning Phonotactics with Simple Processors 99
predicting syllable boundaries. It was significantly improved by adding other cues such as prosodic information. This means that phonotactics might be used alone for syllable detection, but polysyllabic word detection needs extra cues.
In another connectionist study on phonological regularities, Rodd (1997) trained SRNs on 602 Turkish words; the networks were trained to predict the following phonemes. Analyzing the hidden layer representations developed during the training, the author found that hidden units came to correspond to graded detectors for natural phonological classes such as vowels, consonants, voiced stops and front and back vowels. This is further evidence that NN models can capture important properties of the data they have been trained on without any prior knowledge, based only on statistical co-occurrences.
Learning the graphotactics and phonotactics of Dutch monosyllables with connectionist models was first explored by Tjong Kim Sang (1995) and Tjong Kim Sang & Nerbonne (1999), who trained SRNs to predict graphemes/phonemes based on preceding segments. The data was orthogonally encoded, that is, for each phoneme or grapheme there was exactly one neuron activated at the input and output layers (see below 3.1). To test the knowledge learned by the network, Tjong Kim Sang and Nerbonne tested whether the activation of the neurons corresponding to the expected symbols are greater than a threshold determined as the lowest activation for some correct sequence encountered during the training data. This resulted in almost perfect acceptance of unseen Dutch words (generalization), but also in negligible discrimination with respect to (ill-formed) random strings. The authors concluded that “SRNs are unfit for processing our data set” (Tjong Kim Sang & Nerbonne, 1999).
These early works on learning phonotactics with SRNs prompted the work reported here. First, Stoianov et al. (1998) demonstrated that the SRNs in Tjong Kim Sang and Nerbonne's work were learning phonotactics rather better than those authors had realized. By analyzing the error as a function of the acceptance threshold, Stoianov et al. (1998) were able to demonstrate the existence of thresholds successful at both the acceptance of well-formed data and the rejection of ill-formed data (see below 3.6.2 for a description of how we determine such thresholds). The interval of high-performing thresholds is narrow, which is why earlier work had not identified it (see Figure 2 on how narrow the window is). More recently, Stoianov & Nerbonne (2000) have studied the performance of SRNs from a cognitive perspective, attending to the errors produced by the network and

100 John Nerbonne and Ivilin Stoianov
to what extent it correlates with the performance of humans on related lexical decision tasks. The current article ties these two strands of work and presents it systematically.
3. Experiments
The challenge in connectionist modeling is not only developing theoretical frameworks, but also obtaining the most from the network models during experimentation. This section focuses on experiments on learning the phonotactics of Dutch syllables with Simple Recurrent Networks and discusses a number of related problems. It will be followed by a study on the network behavior from a linguistic point of view.
3.1. Some implementation decisions
SRNs were presented in section 2. A first implementation decision concerns how sounds are to be represented. A simple orthogonal strategy is to choose a vector of n neurons to represent n phonemes, to assign each phoneme (e.g. //) to a neuron (e.g., neuron 5 in a sequence of 45), and then to activate that one neuron and deactivate all the others whenever the phoneme is to be represented (so a // is represented by four deactivated neurons, a single activated one, and then forty more deactivated neurons). This orthogonal strategy makes no assumptions about phonemes being naturally grouped into classes on the basis of linguistic features such as consonant/vowel status, voicing, place of articulation, etc. An alternative strategy exploits such features by assigning each feature to a neuron and then representing a phoneme via a translation of its feature description into a sequence of corresponding neural activations.
In phonotactics learning, the input encoding method might be feature-based or orthogonal, but the output decoding should be orthogonal in order to obtain a simple prediction of successors, and to avoid a bias induced from the peculiarities of the feature encoding scheme used. The input encoding chosen was also orthogonal, which also requires the network discover natural classes of phonemes by itself.
The orthogonal encoding implies that we need as many neurons as we have phonemes, plus one for the end-of-word '#' symbol. That is, the input and output layers will have 45 neurons. However, it is usually difficult to

Learning Phonotactics with Simple Processors 101choose the right size of the hidden layer for a particular learning problem. That size is rather indirectly related to the learning task and encoding chosen (as a subcomponent of the learning task). A linguistic bias in the encoding scheme, e.g., feature-based encoding, would simplify the learning task and decrease the number of the hidden neurons required learning it (Stoianov, 2001). Intuition tells us that hidden layers that are too small lead to an overly crude representation of the problem and larger error. Larger hidden layers, on the other hand, increase the chance that the network wanders aimlessly because the space of possibilities it needs to traverse is too large. Therefore, we sought an effective size in a pragmatic fashion. Starting with a plausible size, we compared its performance to nets with double and half the number of neurons in the hidden layer. We repeated in the direction of the better behavior, keeping track of earlier bounds in order to home in on an appropriate size. In this way we settled on a range of 20-80 neurons in the hidden layer, and we continued experimentation on phonotactic learning using only nets of this size.
However, even given the right size of the hidden layer, the training will not always result in an optimal weight set W* since the network learning is nondeterministic - each network training process depends on a number of stochastic variables, e.g., initial network weights and an order of presentation of examples. Therefore, in order to produce more successful learning, several SRNs with different initial weights were trained in a pool (group).
The back-propagation learning algorithm is controlled by two main parameters - a learning coefficient η and a smoothing parameter α. The first one controls the speed of the learning and is usually set within the range (0.1…0.3). It is advisable to choose a smaller value when the hidden layer is larger. Also, this parameter may vary in time, starting with a larger initial value that decreases progressively in time (as suggested in Kuan, Hornik & White (1994) for the learning algorithm to improve its chances at attaining a global minimum in error). Intuitively, such a schedule helps the network approximately to locate the region with the global minima and later to make more precise steps in searching for that minimum (Haykin, 1994; Reed & Marks, II 1999). The smoothing parameter α will be set to 0.7, which also allows the network to escape from local minima during the search walk over the error surface.
The training process also depends on the initial values of the weights. They are set to random values drawn from a region (-r...+r). It is also

102 John Nerbonne and Ivilin Stoianov
important to find a proper value for r, since large initial weight values will produce chaotic network behavior, impeding the training. We used r = 0.1.
The SRNs used for this problem are schematically represented in Fig. 1, where the SRN reaction to an input sequence /n/ after training on an exemplary set containing the sequences /nt#/, /nts#/, /ntrk#/ is given. For this particular database, the network has experienced the tokens '#', /s/ and // as possible successors to /n/ during training and therefore it will activate them in response to this input sequence.
3.2. Linguistic Data - Dutch syllables
A data base LM of all Dutch monosyllables - 5,580 words - was extracted from the CELEX (1993) lexical database. CELEX is a difficult data source because it contains many rare and foreign words among its approximately 350,000 Dutch lexical entries, which additionally complicate the learning task. Filtering out non-typical words is a formidable task and one which might introduce experimenter prejudice, and therefore all monosyllables were used. The monosyllables have a mean length of 4.1(σ = 0.94; min = 2; max = 8) tokens and are built from a set of 44 phonemes plus one extra symbol representing space (#) used as a filler specifying end-of-word.
The main dataset is split into a training (L1) and a testing (L2) database in proportion approximately 85% to 15%. The training database will be used to train a Simple Recurrent Network and the testing one will be used for evaluating the success of word recognition. Negative data also will be created for test purposes. The complete database LM will be used for some parts of evaluation.
In language modeling it is important to explore the frequencies of word occurrences which naturally bias humans' linguistic performance. If a model is trained on data in proportion to its empirical frequency, this focuses the learning on the more frequent words and thus improves the performance of the model. This also makes feasible a comparison of the model's performance with that of humans performing various linguistic tasks, such as a lexical decision task. For these reasons, we used the word frequencies given in the CELEX database. Because the frequencies vary greatly ([0...100,000]), we presented training data items in proportion with the natural logarithms of their frequencies, in accordance with standard practice (Plaut, McClelland, Seidenberg & Patterson, 1996). This approach resulted in frequencies in a range of [1...12].

Learning Phonotactics with Simple Processors 1033.3. Difficulty
One way to characterize the complexity of the training set is to compute the entropy of the distribution of successors, for every available left context. The entropy of a language L viewed as a stochastic process measures the average surprise value associated with each element (Mitchell, 1997). In our case, the language is a set of words and the elements are phonemes, hence the appropriate entropy measures the average surprise value for phonemes c preceded by a context s. Entropy is measured for a given distribution, which in our case is the set of all possible successors. We compute entropy Entr(s) for a given context s with (1):
Equation 1. Entropy
where α is the alphabet of segment symbols, and p(c) the probability of a given context. Then the average entropy for all available contexts sL, weighted with their frequencies, will be the measure of the complexity of the words. The smaller this measure, the less difficult are the words. The maximal possible value for one context would be log2(45), that is, 5.49, and this would only obtain for the unlikely case that each phoneme was equally likely in that context. The actual average value of the entropy measured for the Dutch monosyllables, is 2.24, σ = 1.32. The minimal value was 0.0, and the maximal value was 3.96. These values may be interpreted as follows: The minimal value of 0.0 means that there are left contexts with only one possible successor (log2(1) = 0). A maximal value of 3.96 means that there is one context which is as unpredictable as one in which 23.96 = 16 successors were equally likely. The mean entropy is 2.24, which is to say that in average 4.7 phonemes follow a given left context.
3.4. Negative Data
We noted above that negative data is also necessary for evaluation. Since we are interested in models that discriminate more precisely the strings

104 John Nerbonne and Ivilin Stoianov
from L (the Dutch syllables), the negative data for the following experiments will be biased toward L.
Three negative testing sets were generated and used: First, a set RM
containing strings with syllabic form [C]0...3V[C]0...4, based on the empirical observation that the Dutch mono-syllables have up to three onset (word initial) consonants and up to four coda (word final) consonants. The second group consists of three sub-sets of RM: {R1
M , R2M , R M
3 + }, with fixed distances of the random strings to any existing Dutch word at 1, 2, and 3+ phonemes, respectively (measured by edit distance (Nerbonne, Heeringa & Kleiweg, 1999)). Controlling for the distance to any training word allows us to assess more precisely the performance of the model. And finally, a third group: random strings built of concatenations of n-grams picked randomly from Dutch monosyllables. In particular, two sets - R2
N and R3N
- were randomly developed, based on bigrams and trigrams, correspondingly.
The latter groups are the most "difficult" ones, and especially R3N ,
because it consists of strings that are closest to Dutch. They are also useful for the comparison of SRN methods to n-gram modeling. The corresponding n-gram models will always wrongly recognize these random strings as words from the language. Where the connectionist predictor recognizes them as non-words, it outperforms the corresponding n-gram models, which are considered as benchmark models for prediction tasks such as phonotactics learning.
3.5. Training
This section reports on network training. We will add a few more details about the training procedure, then we will present pilot experiments aimed at determining the hidden layer size. The later parts will analyze the network performance.
3.5.1. Procedure
The networks were trained in a pool on the same problem, and independently of each other, with the BPTT learning algorithm. The training of each individual network was organized in epochs, in the course of which the whole training data set is presented in accordance with the

Learning Phonotactics with Simple Processors 105word frequencies. The total of the logarithm of the frequencies in the training data base L1
M is about 11,000, which is also the number of presentations of sequences per epoch, drawn in a random order. Next, for each word, the corresponding sequence of phonemes is presented to the input, one at a time, followed by the end-of-sequence marker `#'. Each time step is completed by copying the hidden layer activations to the context layer, which is used in the following step.
The parameters of the learning algorithm were as follows: the learning coefficient η started at 0.3 and dropped by 30% each epoch, finishing at 0.001; the momentum (smoothing) term α = 0.7. The networks required 30 epochs to complete training. After this point, very little improvement is noted.
3.5.2. Pilot experiments
Pilot experiments aiming at searching for the most appropriate hidden layer size were done with 20, 40 and 80 hidden neurons. In order to avoid other nondeterminism which comes from the random selection of negative data, during the pilot experiments the network was tested solely on its ability to distinguish admissible from inadmissible successors. Those experiments were done with a small pool of three networks, each of them trained for 30 epochs, which resulted in approximately 330,000 word presentations or 1,300,000 segments. The total number of individual word presentations ranged from 30 to 300, according to the individual word frequencies. The results of the training are given in Table 1, under the group of columns "Optimal phonotactics". In the course of the training, the networks typically started with a sharp error drop to about 13%, which soon turned into a very slow decrease (see Table 2, left 3 columns).
The training of the three pools with hidden layer size 20, 40 and 80, resulted in networks with similar performance, with the largest network performing best. Additional experiments with SRNs with 100 hidden neurons resulted in larger errors than a network with 80 hidden neurons, so that we settled experimentally on 80 hidden neurons as the likely optimal size. It is clear that this procedure is rough, and that one needs to be on guard against premature concentration on one size model.

106 John Nerbonne and Ivilin Stoianov
Table 1. Results of a pilot study on phonotactics learning by SRNs with 20, 40, and 80 (rows) hidden neurons. Each network is independently trained on language LM three times (columns). The performance is measured (left 3 columns) using the error in predicting the next phoneme, and (right 3 columns) using L2 (semi-Euclidean) distance between the empirical context-dependent predictions and the network predictions for each context in the tree. Those two methods do not depend on randomly chosen negative data.
Optimal Phonotactics ||SRNL, TL||L2
Hidd Layer Size SRN1 SRN2 SRN3 SRN1 SRN2 SRN3
20 10.57% 10.65% 10.57% 0.0643 0.0642 0.064240 10.44% 10.51% 10.44% 0.0637 0.0637 0.063780 10.00% 9.97% 10.02% 0.0634 0.0634 0.0632
Table 2. A typical shape of the SRN error during training. The error drops sharply in the beginning and then slowly decreases to convergence.
Epoch 1 2-4 5-10 11-15 16-30Error (%) 15.0 12.0 10.8 10.7 10.5
3.6. Evaluation
The performance of a neural predictor trained on phonotactics may be evaluated with different methods, depending on the particular task the network is applied to. In this section we evaluate the neural networks performing best during the pilot studies.
3.6.1. Likelihoods
The direct outcome of training the sequential prediction task is learning the successors' distribution. This will therefore be used as a basic evaluation method: the empirical context-dependent successor distribution Ps
L (C) will be matched against the network context dependent predictions NPs
L (C). For this purpose, the output of the network will be normalized and matched against the distribution in the language data. This procedure resulted in a mean L2 (semi-Euclidean) distance of 0.063 - 0.064, where the optimal value would be zero (see Table 1, right 3 columns).19 These values are close

Learning Phonotactics with Simple Processors 107to optimal but baseline models (completely random networks) also result in approximately 0.085 L2 distance.
3.6.2. Phonotactic Constraints
To evaluate the network's success in becoming sensitive to phonotactic constraints, we first need to judge how well it predicts individual phonemes. For this purpose we seek a threshold above which phonemes are predicted to be admissible and below which they are predicted to be inadmissible. This is done empirically - we perform a binary search for an optimal threshold, i.e. the threshold θ* that minimizes the network error E(θ). The classification obtained in this fashion constitutes the network's predictions about phonotactics.
We now turn to evaluating the network's predictions: the method to evaluate the network from this point of view compares the context-dependent network predictions with the corresponding empirical distributions. For this purpose, the method described by Stoianov (2001) will be used. The algorithm traverses a trie (Aho, Hopcroft & Ullman, 1983: 163-169), which is a tree representing the vocabulary where initial segments are the first branches. Words are paths through this data structure. The algorithm computes the performance at the optimal threshold determined using the procedure described in the last paragraph, i.e., at the threshold which determines which phonemes are admissible and which inadmissible (see also 2.1). This approach compares the actual distribution with the learned distribution, and we normally use the complete database LM
for training and testing. Figure 2 shows the error of SRN1
8 0 at different values of the threshold. The optimal threshold searching procedure resulted in 6.0% erroneous phoneme prediction at a threshold of 0.0175. This means that if we want to predict phonemes with this SRN, they would be accepted as allowed successors if the activation of the correspondent neurons are higher than 0.0175.
3.6.3. Word Recognition
Using an SRN trained on phoneme prediction as a word recognizing device shifts the focus from phoneme prediction to sequence classification. We
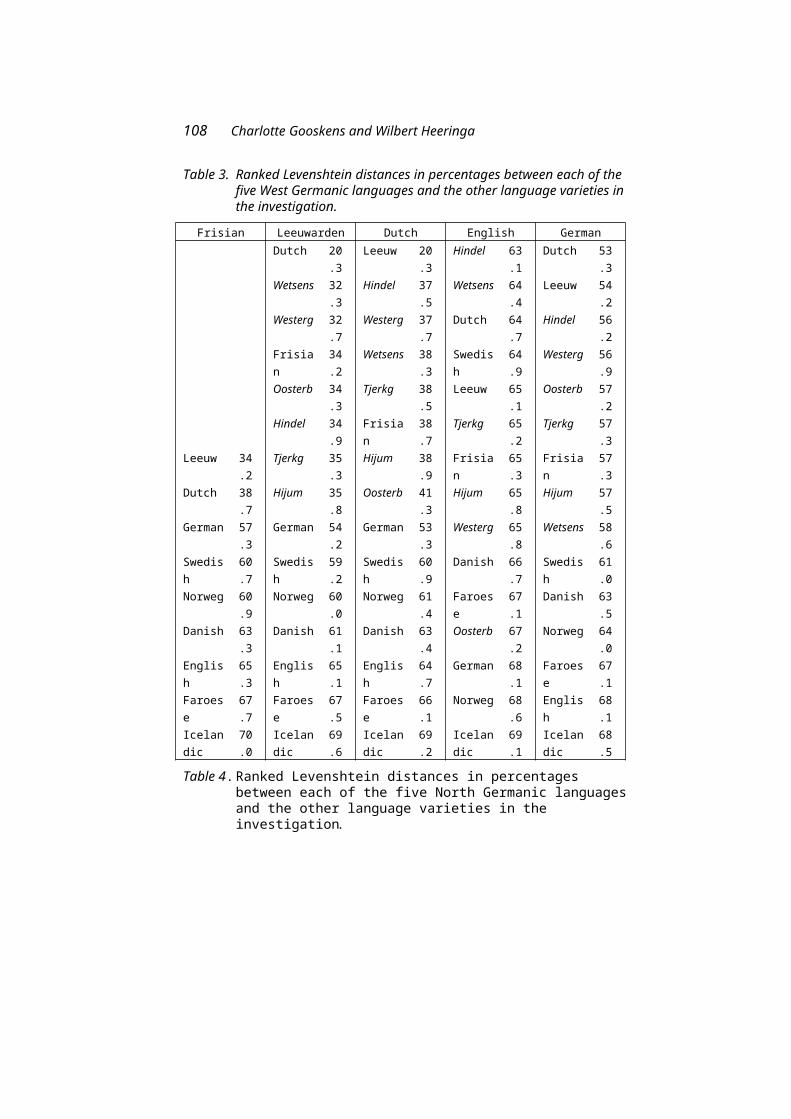
108 John Nerbonne and Ivilin Stoianov
wish to see whether it can classify sequences of phonemes into well-formed words on the one hand and ill-formed non-words on the other. To do this we need to translate the phoneme (prediction) values into sequence values. We do this by taking the sum of the phoneme error values for the sequence of phonemes in the string, normalized to correct for length effects. But to translate this sum into a classification, we again need to determine an acceptability threshold, and we use a variant of the same empirical optimization described above. The threshold arrived at for this purpose is slightly lower than the optimal threshold from the previous algorithm. This means that the network accepts more phonemes, which, however, is compensated for by the fact that a string is accepted only if all its phonemes are predicted. In string recognition it is better to increase the phoneme acceptance rate, because the chance to detect a non-word is larger when more tokens are tested.
Figure 2. SRN error (in %) as a function of the threshold θ. The False Negative Error increases as the threshold increases because more and more admissible phonemes are incorrectly rejected. At the same time, the False Positive Error decreases because fewer unwanted successors are falsely accepted. The mean of those two errors is the network error, which finds its minimum 6.0% at threshold θ* = 0.0175. Notice that the optimal threshold is limited to a small range. This illustrates how critical the exact setting of threshold is for good performance.
Since the performance measure here is the mean percentage of correctly recognized monosyllables and correctly rejected random strings, we incorporate both in seeking the optimal threshold. The negative data is as described above in 3.4. Concerning the positive data, this approach allows us to test the generalization capacity of the model, so that the training L1
M
and testing L2M subsets may be used here - the first for training the model
and evaluating it during training, and the second to test the generalization capacity of the trained network.
Once we determine the optimal sequence-acceptance threshold (0.016), we obtain 5% error on the positive training dataset L1
M and the negative strings from RM , where the error varied 0.5% depending on the random data set generated.
The model was tested further on the second group of negative data sets. As expected, strings which are more unlike Dutch resulted in smaller error. Performance on random strings from RN
3 + is almost perfect. In the opposite case, the strings close to real words (from R1
N ) resulted in larger error.
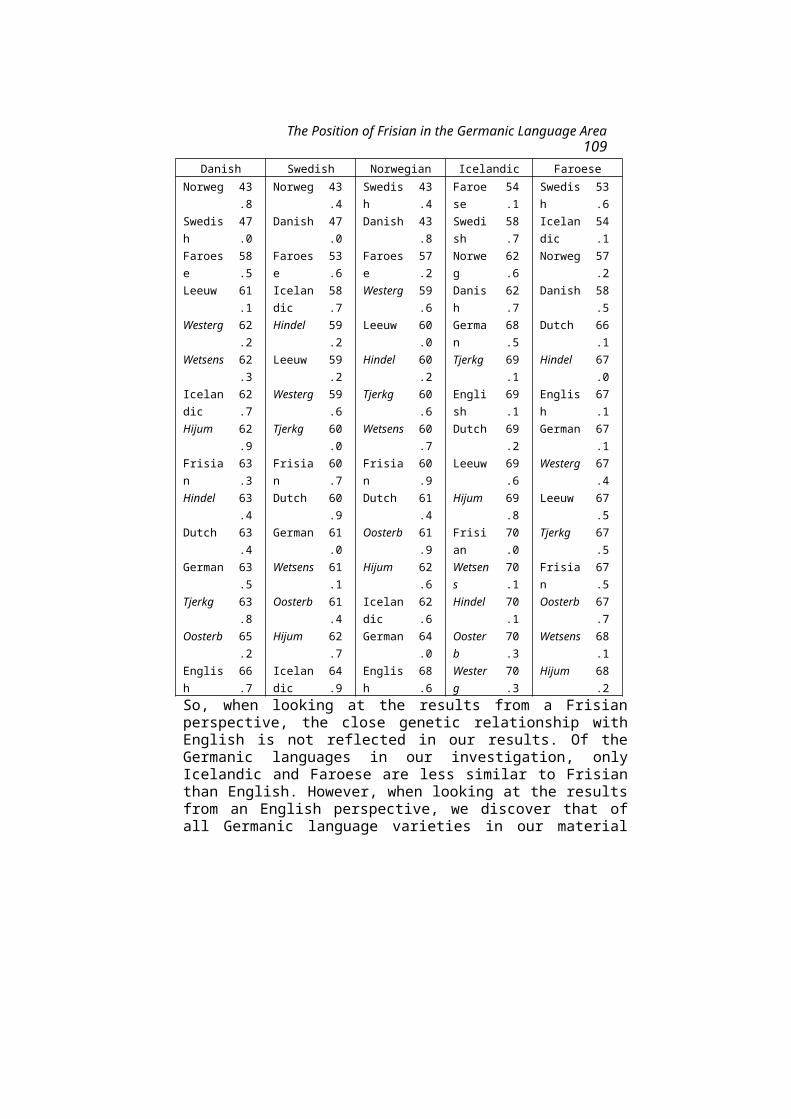
Learning Phonotactics with Simple Processors 109
The generalization capabilities of the network were tested on the L2M
positive data, unseen during training. The error on this test set was about 6%. An explanation of the increase of the error will be presented later, when the error will be studied by varying its properties.
Another interesting issue is how SRN performance compares to other known models, e.g. n-grams. The trained SRN definitely outperformed bigrams and trigrams, which was shown by testing the trained SRNs on the non-words from R2
N and R3N sets, yielding 19% and 35% error,
respectively. This means that the SRN correctly rejected four out of five non-word strings composed of correct bigrams and two out of three non-word strings made of trigrams. To clarify, note that bigram models would have 100% error on R2
N , and trigram models 100% error on R3N .
4. Network Analysis
The distributed representations in Neural Networks prevent the analysis of generalizations in trained models by simple observation, which symbolic learning methods allow. Smaller NNs may be analyzed to some extent by examination, but for larger networks this is practically impossible.
It is possible, however, to analyze trained networks to extract abstract knowledge about their behavior. Elman (1988), for example, trained an SRN to learn sentences and then analyzed the hidden layer activations of that SRN in various contexts, from which he showed that the network had internally developed syntactical categories. Similarly, we trained SRNs on phonotactics (Stoianov et al., 1998), and then analyzed the network statically, by viewing the weight vectors of each neuron as pattern classifiers. We showed that the SRN had induced generalizations about phonetic categories. We follow that earlier work in order to study network behavior, and we present the results of this study in the first subsection.
Another approach to the analysis of connectionist models assumes that they are black boxes and examines the variation of network performance while varying some properties of the data (Plaut et al., 1996; Stoianov, Stowe & Nerbonne, 1999). For example, one can vary word frequency, length, etc., and study the network error. When modeling human cognitive functions with this approach one can compare the behavior of the cognitive system and its artificial models. For example, in phonotactic modeling, one can compare results from psycholinguistic studies of a lexical decision task

110 John Nerbonne and Ivilin Stoianov
with the network reaction. This will be subject of study in the rest of the section.
4.1. Weight Analysis
The neurons of a neural network act as pattern classifiers. The inputs selectively activate one or another neuron, depending on the weight vectors. This means that information about network structure may be extracted from the weight vectors.
In this section we will present a cluster analysis of the neurons in the output layer. For that purpose, the mean weight vectors of the output layer of one of the networks - SRN2
4 0 (from Table 1) - were clustered using a minimum variance (Ward's) method, and each vector in the resulting dendrogram was labeled with the phoneme it corresponds to.20 The resulting diagram is shown in Figure 3.

Learning Phonotactics with Simple Processors 111
Figure 3. Cluster analysis of the vector of the output neurons, labeled with the phonemes they correspond to. The weight vectors are split into clusters which roughly correspond to existing phonetic categories.

112 John Nerbonne and Ivilin Stoianov
We can see that the weight vectors (and correspondingly, the phonemes) cluster into some well-known major natural classes - vowels (in the bottom) and consonants (the upper part). The vowels are split into two major categories: low vowels and semi-low, front vowels (/, , a, e/), and high, back ones. The latter, in turn, are clustered into round+ and round- classes. Consonants appear to be categorized in a way less congruent with phonetics. But here, too, some established groups are distinguished. The first subgroup contains non-coronal consonants (/f, k, m, p, x/) with the exceptions of /l/ and /n/. Another subgroup contains voiced obstruents (/, d, , /). The delimiter '#' is also clustered as a consonant, in a group with /t/, which is also natural. The upper part of the figure seems to contain phonemes from different groups, but we can recognize that most of these phonemes are quite rare in Dutch monosyllables, e.g., //, perhaps because they have been 'loaned' from other languages, e.g. /g/.
4.2. Functional analysis
We may also study NNs by examining their performance as a function of factors such as word frequency, similarity neighborhood, and word length. Such an analysis relates computational language modeling to psycholinguistics, and we submit that it is useful to compare the models' performance with humans'. In this section we introduce several factors which have played a role in psycholinguistic theorizing. We then examine the performance of our model as a function of these factors.
4.2.1. Psycholinguistic Factors
Frequency is one of the most thoroughly investigated characteristics of words that affect performance. Numerous previous studies have demonstrated that the ease and the time with which spoken words are recognized are monotonically related to the experienced frequency of words in the language environment (Luce, Pisoni & Goldinger, 1990; Plaut et al., 1996). The general tendencies found are that the more frequent words are, the faster and the more precise they are recognized.
Our perception of a word is likewise known to depend on its similarity to other words. The similarity neighborhood of a word is defined as the collection of words that are phonetically similar to it. Some neighborhoods

Learning Phonotactics with Simple Processors 113are dense with many phonetically similar words while others are sparse with few.
The so-called Colthearth-N measure of a word w counts the number of words that might be produced by replacing a single letter of w with some other. We modify this concept slightly to make it sensitive to similarity of sub-syllabic elements, so that we regard words as similar when they share two of the subsyllabic elements - onset, nucleus and coda. Empty onsets or codas are counted as the same. The word neighborhood is computed by counting the number of the similar words. If implemented precisely, the complexity of the measuring process just explained is high, so we reduce it by probing for sub-syllables rather than for units of variable size, starting from a single phoneme. This simplifies and speeds up processing. The neighborhood size of the corpus we used ranged from 0 to 77 and had mean value of μ= 30; σ = 13.
For example, the phonological neighborhood of the Dutch word broeds /bruts/ is given below. Note that the neighborhood contains only Dutch words.
/brts/, /brots/, /bruj/, /brujt/, /bruk/, /brur/, /brus/, /brut/, /buts/, /kuts/, /puts/, /tuts/
These represent the pronunciations of Brits `British', broods `bread' (gen.sg.), broei `brew', broeit `brew' (3rd. sg.), broek `pants', broer `brother', broes `spray nozzle', broed `brood', boots `boots' (Eng. loan), koets `coach', poets `clean' and toets `test'. Among the words with very poor neighborhood are // schwung, /brts/ boards, /jnt/ joint, and /skrs/ squares, all of which are of foreign origin. Words such as /hk/ hek, /bs/ bas, /lxt/ lacht, and /bkt/ bakt have large neighborhoods.
It is still controversial how similarity neighborhood influences cognitive processes (Balota, Paul & Spieler, 1999). Intuitively, it seems likely that words with larger neighborhoods are easier to access due to many similar items, but from another perspective these words might be more difficult to access due to the nearby competitors and longer selection process. However, in the more specific lexical decision task, the overall activity of many candidates has been shown to facilitate lexical decisions, so we will look for the same effect here.
The property word length might affect performance in the lexical decision task in two different ways. On one hand, longer words provide more evidence since more phonemes are available to decide whether the

114 John Nerbonne and Ivilin Stoianov
input sequence is a word so that we expect higher precision for longer words, and lower precision for particularly short words. On the other hand, network error accumulating in iteration increases the error in phoneme predictions at later positions, which in turn will increase the overall error for longer words. For these reasons we expect U-shaped patterns of error as word length increases. Such a pattern was observed in a study on modeling grapheme-to-phoneme conversion with SRNs (Stoianov et al., 1999). Static NNs are less likely (than dynamic models such as SRNs) to produce such patterns.
So far we have presented three main characteristics of the individual words, which we expect to affect the performance of the model. However, a statistical correlation analysis (bivariate Spearman test) showed that they are not independent, which means that an analysis of the influence of any single factor should control for the rest. In particular, there is high negative correlation between word neighborhood and word length (r = -0.476), smaller positive correlation between neighborhood and frequency (r = 0.223), and very small negative correlation between frequency and word length (r = -0.107). Because of the large amount of data all these coefficients are significant at the 0.001 level.
Finally, it will be useful to seek a correlate in the simulation for reaction time, which psycholinguists are particularly fond of using as a probe to understanding linguistic structure. Perhaps we can find an SRN correlate to Reaction Time (RT) for the lexical decision task in network confidence, i.e., the amount of evidence that the test string is a word from the training language. The less confident the network, the slower the reaction, which can be implemented with a lateral inhibition (Haykin, 1994; Plaut et al., 1996). The network confidence for a given word might be expressed as the product of the activations of the neurons corresponding to the phonemes of that word. A similar measure, which we call uncertainty U, is the negative sum of (output) neuron activation logarithms, normalized with respect to word length |w| (2). Note that U varies inversely with confidence. Less certain sequences get higher (positive) scores.
Equation 2.

Learning Phonotactics with Simple Processors 115To analyze the influence of these parameters, the network scores and U-values were recorded for each monosyllabic word at the optimal threshold θ*= 0.016. The data was then submitted to the statistical package SPSS for analysis of variance using SPSS's General Linear Model (GLM). When analyzing network score, the analysis revealed main effects of all three parameters discussed above: word neighborhood size (F = 18.4; p < 0.0001), word frequency (F = 19.2; p < 0.0001), word length (F = 11.5; p < 0.0001). There was also interaction between neighborhood size and the other parameters: the interaction with word frequency had an F -score 6.6 and the interaction of the neighborhood with word length had an F-score of 4.9, both significant at 0.0001 level. Table 3 summarizes the findings. Error decreases both as neighborhood size and as frequency increases, and error dependent on length shows the predicted U-shaped form (Table 3c).
Table 3. Effect of (a) frequency, (b) neighborhood density and (c) length on word uncertainty U and word error.
a.Frequency Low Mid HighU 2.30 2.20 2.18Error (%) 8.6 4.1 1.5
b.Neighb. size Low Mid HighU 2.62 2.30 2.21Error (%) 12.7 3.9 0.8
c.Length Low Mid HighU 2.63 2.20 2.13Error (%) 5.2 4.4 13.1
Analysis of variance on the U-values revealed similar dependencies. There were main effects of word neighborhood size (F = 58.2; p < 0.0001), word frequency (F = 45.9; p < 0.0001), word length (F = 137.5; p < 0.0001), as well as the earlier observed interactions between neighborhood density and the other two variables: word length (F = 10.4; p < 0.001) and frequency (F = 5.235; p < 0.005).

116 John Nerbonne and Ivilin Stoianov
The frequency pattern of error and uncertainty variance was expected, given the increased evidence to the network for more frequent words. The displayed length effect showed that the influence of error gained in recursion is weaker than the effect of stronger evidence for longer words. Also, the pattern of performance when varying neighborhood density confirmed the hypothesis of the lexical decision literature that larger neighborhoods makes it easier for words to be recognized as such.
4.3. Syllabic structure
Phonotactic constraints might hint at how the stream of phonemes is organized in the language processing system. The popular phoneme, syllable and word entities may not be the only units that we use for lexical access and production. There are suggestions that in addition, some sub-syllabic elements are involved in those processes, that is, the syllables might have not linear structure, but more complex representations (Kessler & Treiman, 1997). For that purpose, we will analyze how the phoneme prediction error at a threshold of 0.016 - where the network resulted in best word recognition - is located within words with respect to the following sub-syllabic elements - onset, nucleus and coda. The particular hypothesis that will be tested is whether Dutch monosyllables follow the structure below that was found in English as well (Kessler & Treiman, 1997).
( Onset - Rhyme (Nucleus - Coda) )
The distribution of phoneme error within words (Table 4a) shows that the network makes more mistakes at the beginning than at the end of words, where SRN becomes more confident in its decision. This could be explained with increasing contextual information that more severely restricts possible phonemic combinations. A more precise analysis of the error position in the onset, the nucleus and the coda further reveals other interesting phenomena (Table 4b).
Table 4. Distribution of phoneme prediction error at a threshold of 0.016 by (a) phoneme position within words and (b) phoneme position within sub-syllables. Word and Onset positions start from 2, because the prediction starts after the first phoneme.
a.

Learning Phonotactics with Simple Processors 117Word Position 2 3 4 5 6 7 8Error (%) 4.3 1.7 1.4 0.6 0.3 0.3 0.00
b.Sub-syllabes Onset Nucleus CodaRelative Position 2
2.63
0.01
4.51
1.02
1.53
2.04
2.6Error (%)
First, error within the coda increases at the coda's end. We attribute this to error accumulated toward the end of the words, as was predicted earlier. The mean entropy in the coda (1.32; σ = 0.87) is smaller than the mean entropy in the onset (1.53; σ = 0.78), where we do not observe such effects. So looser constraints are not the reason for the relatively greater error in the coda. Next, the error at the transition onset-nucleus is much higher than the error at the surrounding positions, which means that the break between onset and rhyme (the conjunction nucleus-coda) is significant. This distribution is also consistent with the statistical finding that the entropy is larger in the body (the transition point onset-nucleus) (3.45; σ = 0.39), than in the rhyme (1.94; σ = 1.21). All this data support the hypothesis that onset and rhyme play significant roles in lexical access and that the syllabic structure confirmed for English by Kessler & Treiman (1997) is valid for Dutch, too.
5. Conclusions
Phonotactic constraints restrict the way phonemes combine in order to form words. These constraints are empirical and can be abstracted from the lexicon - either by extracting rules directly, or via models of that lexicon. Existing language models are usually based on abstract symbolic methods, which provide good tools for studying such knowledge. But linguistic research from a connectionist perspective can provide a fresh perspective about language because the brain and artificial neural networks share principles of computations and data representations.
Connectionist language modeling, however, is a challenging task. Neural networks use distributed processing and continuous computations, while languages have a discrete, symbolic nature. This means that some special tools are necessary if one is to model linguistic problems with connectionist models. The research reported in this paper attempted to

118 John Nerbonne and Ivilin Stoianov
provide answers to two basic questions: first, whether phonotactic learning is possible at all in connectionist systems, which had been doubted earlier (Tjong Kim Sang, 1995; Tjong Kim Sang, 1998). In the case of a positive answer, the second question is how NN performance compares to human ability. In order to draw this comparison, we needed to extract the phonotactic knowledge from a network which has learned the sequential structure. We proposed several ways of doing this.
Section 3 studied the first question. Even if there are theoretical results demonstrating that NNs have the needed finite-state capacity for phonotactic processing, there are practical limitations, so that we needed experimental support to demonstrate the practical capability of SRNs to learn phonotactics. A key to solving the problems of earlier investigators was to focus on finding a threshold that optimally discriminated the continuous neuron activations with respect to phoneme acceptance and rejection simultaneously. The threshold range at which the network achieves good discrimination is very small (see Figure 2), which illustrates how critical the exact setting of the threshold is. We also suggested that this threshold might be computed interactively, after processing each symbol, which is cognitively plausible, but we postpone a demonstration of this to another paper.
The network performance on word recognition - word acceptance rate of 95% and random string rejection rate of 95% at a threshold of 0.016 - competes with the scores of symbolic techniques such as Inductive Logic Programming and Hidden Markov Models (Tjong Kim Sang, 1998), both of which reflect low-level human processing architecture with less fidelity.
Section 4 addressed the second question of how other linguistic knowledge encoded into the networks can be extracted. Two approaches were used. Section 4.1 clustered the weights of the network, revealing that the network has independently become sensitive to established phonetic categories.
We went on to analyze how various factors which have been shown to play a role in human performance find their counterparts in the network's performance. Psycholinguistics has shown, for example, the ease and the time with which spoken words are recognized are monotonically related to the frequency of words in language experience (Luce et al., 1990). The model likewise reflected the importance of neighborhood density in facilitating word recognition, which we speculated stems from the supportive evidence which more similar patterns lend to the words in their neighborhood. Whenever network and human subjects exhibit a similar

Learning Phonotactics with Simple Processors 119sensitivity to well-established parameters, we see a confirmation of the plausibility of the architecture chosen.
Finally, the distribution of the errors within the words showed another linguistically interesting result. In particular, the network tended to err more often at the transition onset-nucleus - which is also typical for transitions between adjacent words in the speech stream and used for speech segmentation. Analogically, we can conclude from this that the nucleus-coda unit - the rhyme - is a significant linguistic unit for the Dutch language, a result suggested earlier for English (Kessler & Treiman, 1997).
We wind up this conclusion with one disclaimer and a repetition of the central claim. We have not claimed that SRNs are the only (connectionist) model capable of dynamic processing, nor that they are biologically the most plausible neural network. Our central claim is to have demonstrated that relatively simple connectionist mechanisms have the capacity to model and learn phonotactic structure.
Notes
References
Aho, Alfred, John Hopcroft & Jeffrey Ullman (1983). Data Structures and Algorithms. Addison Wesley.
Balota, David, Stephen Paul & Daniel Spieler (1999). Attentional control of lexical processing pathways during word recognition and reading. In: S. Garrod & M. Pickering (eds). Studies in cognition: Language processing. UCL Press, London, England, 15-57.
Cairns, Paul, R. Shillcock, Nick Chater & Joe Levy (1997). Bootstrapping word boundaries: A bottom-up corpus-based approach to speech
segmentation. Cognitive Psychology, 33(2): 111-153.Carrasco, Rafael, Mikel Forcada & Ramon Neco (1999). Stable encoding of
finite-state machines in discrete-time recurrent neural networks with sigmoid units. Neural Computation, 12(9): 2129-2174.
Carstairs-McCarthy, Andrew (1999). The Origins of Complex Language. Oxford Univ Press.

120 John Nerbonne and Ivilin Stoianov
CELEX (1993). The CELEX Lexical Data Base (cd-rom), Linguistic Data Consortium. http://www.kun.nl/celex.
Christiansen, Morton H. & Nick Chater (1999). Toward a connectionist model of recursion in human linguistic performance. Cognitive Science, 23: 157-205.
Cleeremans, A., D. Servan-Schreiber & J.L. McClelland (1989). Finite state automata and simple recurrent networks. Neural Computation, 1(3): 372-381.
Cohen, A., C. Ebeling & A.G.F. van Holk (1972). Fonologie van het Nederlands en het Fries. Martinus Nijhoff, The Hague.
Dell, Gary, Cornell Juliano & Anita Govindjee (1993). Structure and content in language production: A theory of frame constraints in phonological speech errors. Cognitive Science, 17: 145-195.
Dupoux, Emmanuel, Christophe Pallier, Kazuhiko Kakehi & Jacques Mehler (2001). New evidence for prelexical phonological processing in word recognition. Language and Cognitive Processes, 5(16): 491-505.
Elman, Jeffrey L. (1988). Finding structure in time. Technical Report 9901, Center for Research in Language, UCSD, CA.
Elman, Jeffrey L. (1991). Distributed representations, simple recurrent networks, and grammatical structure. Machine Learning, 7(2/3): 195-226.
Gasser, Michael (1992). Learning distributed representations for syllables. In: Proc. of 14th Annual Conference of Cognitive Science Society, 396- 401.
Haykin, Simon (1994). Neural Networks. Macmillian Publ, NJ.Kaplan, Ronald & Martin Kay (1994). Regular models of phonological rule
systems. Computational Linguistics, 20/3: 331-378.Kessler, Brett & Rebecca Treiman (1997). Syllable structure and the
distribution of phonemes in English syllables. Journal of Memory and Language, 37: 295-311.
Konstantopoulos, Stasinos (2003). Using Inductive Logic Programming to Learn Local Linguistic Structures. PhD thesis, Rijksuniversiteit Groningen.
Kuan, Chung-Ming, Kurt Hornik & Halbert White (1994). A convergence result for learning in recurrent neural networks. Neural Computation, 6: 420-440.
Laver, John (1994). Principles of Phonetics. Cambridge University Press, Cambridge.
Lawrence, Steve, C. Lee Giles & S. Fong (1995). On the applicability of neural networks and machine learning methodologies to natural language processing. Technical report, Univ. of Maryland.

Learning Phonotactics with Simple Processors 121Luce, Paul L., David B. Pisoni & Steven D. Goldinger (1990). Similarity
neighborhoods of spoken words. In: G. T. M. Altmann (ed.). Cognitive Models of Speech Processing. A Bradford Book, Cambridge, Massachusetts, USA, 122-147.
McQueen, James (1998). Segmentation of continuous speech using phonotactics. Journal of Memory and Language, 39: 21-46.
Mitchell, Thomas (1997). Machine Learning. McGraw Hill College.Nerbonne, John, Wilbert Heeringa & Peter Kleiweg (1999). Edit distance and
dialect proximity. In: D. Sankoff & J. Kruskal (eds). Time Warps, String Edits and Macromolecules: The Theory and Practice of Sequence Comparison, 2nd ed.. CSLI, Stanford, CA, v-xv.
Norris, D., J.M. McQueen, A. Cutler & S. Butterfield (1997). The possible-word constraint in the segmentation of continuous speech. Cognitive Psychology, 34: 191-243.
Omlin, Christian W. & C. Lee Giles (1996). Constructing deterministic finite-state automata in recurrent neural networks. Journal of the ACM, 43(6): 937-972.
Pacton, S., P. Perruchet, M. Fayol & A. Cleeremans (2001). Implicit learning in real world context: The case of orthographic regularities. Journal of Experimental Psychology: General, 130(3): 401-426.
Plaut, D.C., J. McClelland, M. Seidenberg & K. Patterson (1996). Understanding normal and impaired word reading: Computational principles in quasi-regular domains. Psychological Review, 103: 56-115.
Reed, Russell D. & Robert J. Marks II (1999). Neural Smithing. MIT Press, Cambridge, MA.
Reilly, Ronan (2002). The relationship between object manipulation and language development in Broca's area: A connectionist simulation of Greenfield's hypothesis. Behavioral and Brain Sciences, 25: 145-153.
Robinson, A. J. & F. Fallside (1988). Static and dynamic error propagation networks with application to speech coding. In: D. Z. Anderson (ed.). Neural Information Processing Systems. American Institute of Physics, NY.
Rodd, Jennifer (1997). Recurrent neural-network learning of phonological regularities in Turkish. In: Proc. of Int. Conf. on Computational Natural Language Learning. Madrid, 97-106.
Rumelhart, David E. & James A. McClelland (1986). Parallel Distributed Processing: Explorations of the Microstructure of Cognition. The MIT Press, Cambridge, MA.
Rumelhart, D.E., G.E. Hinton & R.J. Williams (1986). Learning internal representations by error propagation. In: D. E. Rumelhart & J. A.

122 John Nerbonne and Ivilin Stoianov
McClelland (eds.). Parallel Distributed Processing: Explorations of the Microstructure of Cognition, Volume 1, Foundations. The MIT Press, Cambridge, MA, 318-363.
Shillcock, Richard, Paul Cairns, Nick Chater & Joe Levy (1997). Statistical and connectionist modelling of the development of speech segmentation. In: Broeder & Murre (eds.). Models of Language Learning. MIT Press.
Shillcock, Richard, Joe Levy, Geoff Lindsey, Paul Cairns & Nick Chater (1993). Connectionist modelling of phonological space In: T. M. Ellison & J. Scobbie (eds.). Computational Phonology. Edinburgh Working Papers in Cognitive Science, Edinburgh, 8: 179-195
Stoianov, Ivilin Peev (1998). Tree-based analysis of simple recurrent network learning. In: 36 Annual Meeting of the Association for Computational Linguistics and 17 Int. Conference on Compuational Linguistics. Vol. 2, Montreal, Canada, 1502-1504.
Stoianov, Ivilin Peev (2001). Connectionist Lexical Modelling. PhD thesis, Rijksuniversiteit Groningen.
Stoianov, Ivilin Peev & John Nerbonne (2000). Exploring phonotactics with simple recurrent networks. In: F. van Eynde, I. Schuurman & N. Schelkens (eds.). Computational Linguistics in the Netherlands, 1998. Rodopi, Amsterdam, NL, 51-68.
Stoianov, Ivilin Peev, John Nerbonne & Huub Bouma (1998). Modelling the phonotactic structure of natural language words with simple recurrent networks. In: P.-A. Coppen, H. van Halteren & L. Teunissen (eds.). Computational Linguistics in the Netherlands, 1997. Rodopi, Amsterdam, NL, 77-96.
Stoianov, Ivilin Peev, Laurie Stowe & John Nerbonne (1999). Connectionist learning to read aloud and correlation to human data. In: 21st Annual Meeting of the Cognitive Science Society, Vancouver, Canada. Lawrence Erlbaum Ass., London, 706-711.
Stowe, Laurie, Anton Wijers, A. Willemsen, Eric Reuland, A. Paans & Wim Vaalburg (1994). Pet studies of language: An assessment of the reliability of the technique. Journal of Psycholinguistic Research, 23(6): 499-527.
Tjong Kim Sang, Erick (1995). The limitations of modeling finite state grammars with simple recurrent networks. In: Proceedings of the 5th Computational Linguistics in The Netherlands, 133-143.
Tjong Kim Sang, Erick (1998). Machine Learning of Phonotactics. PhD thesis, Rijksuniversiteit Groningen.
Tjong Kim Sang, Erik & John Nerbonne (1999). Learning simple phonotactics. In: Proceedings of the Workshop on Neural, Symbolic, and

Learning Phonotactics with Simple Processors 123
Reinforcement Methods for Sequence Processing, Machine Learning Workshop at IJCAI '99, 41-46.
Treiman, R. & A. Zukowski (1990). Toward an understanding of English syllabification. Journal of Memory and Language, 34: 66-85.
Tsoi, Ah Chung & Andrew Back (1997). Discrete time recurrent neural network architectures: A unifying review. Neurocomputing, 15: 183-223.


Weak Interactions
Yiddish influence in Hungarian, Esperanto and Modern Hebrew
Tamás Bíró
When I arrived in Groningen, I was introduced to Tjeerd de Graaf as somebody speaking Hungarian. Then it turned out that both of us were interested in Yiddish. Furthermore, we shared the fact that we started our scientific life within physics, although, unlike Tjeerd, I have not worked as a physicist since my graduation. Nevertheless, as a second year physics student I received a research question from the late leading Hungarian physicist George Marx that was also somehow related to Tjeerd’s earlier research topic, neutrino astrophysics.
Neutrinos are funny particles. They are extremely light, if they have any mass, at all.21 Therefore, they cannot interact through gravitation. Because they do not have any electrical charge either, electromagnetic interaction is also unknown to them. The only way they can interact with the universe is the so-called weak interaction, one of the four fundamental forces.22 Nowadays physicists spend an inconceivable amount of budget building gigantic, underground basins containing millions of liters of heavy water just to try to detect a few neutrinos per year out of the very intense stream of neutrinos flowing constantly from the Sun and going through the Earth, that is, us. Even though they almost never interact with regular material, through weak interaction they play a fundamental role both in shaping what the universe looks like and in the Sun’s energy production. Therefore our life would not be possible without neutrinos and without weak interaction.
Something similar happens in ethnolinguistics. The interaction between two languages may not always be very salient, and it cannot necessarily be explained by the most famous types of interactions. A weak interaction in linguistics might be an interaction which is not acknowledged by the speakers’ community, for instance for ideologically reasons.
In the present paper I shall present three cases of weak interaction between languages, understood in this sense, namely Yiddish affecting

126 Tamás Bíró
Hungarian, Modern Hebrew (Israeli Hebrew) and Esperanto. All the stories take place in the late nineteenth or early twentieth century, when a new or modernized language had to be created. We shall observe what kind of interactions took place under which conditions. A model for interactions combined with the better understanding of the social-historical setting will enable us to do so.
1. Language interactions within a given socio-historical setting
1.1. Modeling interactions
In physics, the interaction between two bodies depends on three factors: the two “eligibilities” of the parties to interact, as well as their distance. For gravity and electromagnetism, the formula probably familiar from high-school physics states that the force is proportional to the product of the “eligibilities” - mass or electric charge - of the two bodies, divided by the square of their distance. In other words, the higher the two masses (or electric charges) and the smaller the distance, the stronger the interaction.
For Newton, who formulated this formula first, gravity was a long-range interaction. Modern physics has completed this picture with introducing exchange particles intermediating between the interacting bodies.23 That way, contemporary science has also incorporated the view of Newton’s opponents who argued for the only possibility of short-range interactions.
To transplant this image, vaguely, into the phenomenon of language interaction, we have to identify the eligibilities of the two interacting languages, their distance and the exchange particles. In fact, we can do that even on two levels. On a purely linguistic level, one can easily point to words and grammatical phenomena - “exchange particles” - wandering from language to language. But it would be harder to identify in general the properties of the phenomena and of the given languages that make the interaction more probable or less probable.
23 The photons (particles of the light) are the exchange particles for the electromagnetic interaction; the hypothetical gravitons should transmit gravi-tation; in the case of the weak interaction, the W +, W - and Z vector bosons play that role; whereas the strong interaction is mediated by pions.

Weak Interactions 127
The sociolinguistic level is more promising for such an approach. In this case, the human beings are the exchange particles: people who leave one linguistic community in order to join a new one. By the very fact of their moves, they affect their new language by a linguistic quantum. The closer the two language communities, the more people will act as an exchange particle. Here distance should be understood not only based on geography, but on the intensity of the social network, as well. Thus, the more people wander to the target community, the more linguistic impulse is brought to the second language and therefore the stronger the interaction. Note that the physical analogy is not complete, since the symmetry of action and reaction is not guaranteed for interacting languages.
The three cases to be discussed share the feature that the role of the carriers of the interaction is played by late nineteenth century Eastern European Jews. In order to understand the historical background, we have to recall what is called Haskala or Jewish Enlightenment.
1.2. The Haskala
By the late eighteenth century, the French and German Aufklärung had raised the question whether to emancipate and integrate - or assimilate - the Jewish population on the one side, and an increasing wish to join the European culture on the other. Although in the second half of the siècle des lumières there were only a few Jewish intellectuals who articulated these ideas, most of them belonging to the circle of the philosopher Moses Mendelssohn (1729-1786) in Berlin, the next decades witnessed the acculturation of a growing segment of the Jewish population in the German territories, as well as within the Austrian Empire. The eighteenth century Berlin Haskala is called the first stage of the Jewish Enlightenment, whereas the early nineteenth century social and cultural developments represent its second stage.
What the first two stages of the Haskala yielded was including a Jewish color on the contemporary Western European cultural palette. “Jewish” was understood exclusively as one possible faith within the list of European religions, and nothing more than a religious conviction. An enlightened Jew was supposed to fully master the educated standard variant of the language of the society he lived in (Hochdeutsch¸ in most of the cases), without any “Jewish-like” feature. Propagating the knowledge of Hochdeutsch and rolling back Jüdischdeutsch had already been the program of Moses

128 Tamás Bíró
Mendelssohn when he began writing a modern targum24 of the Bible, the Biur. Further, the same Jew was expected to fully master the contemporary European culture, including classical languages, sciences and arts. The only sphere in which this Jew could express his or her being Jewish was the diminished and europeanized arena of religious life. Diminished, because of a secularization of life style; and Europeanized, due to the inclusion of philosophical ideals of the Enlightenment together with aesthetic models of the Romanticism. The traditional religious duty of constantly learning the traditional texts with the traditional methods was sublimated into the scholarly movement of the Wissenschaft des Judentums.
The picture changed dramatically in the middle of the nineteenth century, when the Haskala, in its third stage, reached the Eastern European Jewry, including Jews in Poland and Lithuania (under Russian government), Eastern Hungary, and Rumania. Here the Jewish population was far denser, whereas the surrounding society was far behind Western Europe in the process of the social and economic development. In fact, Jews would play an important role in the modernization of those areas. Therefore, several people of Jewish origin could take the initiative and invent absolutely new alternatives to the social constructs that people had been living with so far.
One type of those social alternatives still preserved the idea of the earlier Haskala according to which Jews should become and remain an organic part of the universal human culture. These alternatives proposed thus some forms of revolutionary change to the entire humankind, as was the case in the different types of socialist movements, in which Jews unquestionably played an important role. Esperantism also belongs here, for its father, Ludwig Zamenhof was a Polish-Lithuanian Jew proposing an alternative to national language as another social construct.
The second type of radical answer that Eastern European Jews gave to the emergence of Enlightenment in the underdeveloped Eastern European milieu was creating a new kind of Jewish society. Recall that there was a dense Jewish population living within a society that itself did not represent a modern model to which most Jews wished to acculturate. Different streams of this type of answer emerged, although they did not mutually exclude each other. Many varieties of political activism, such as early forms of Zionism, political Zionism, territorialism or cultural autonomism, embody one level of creating an autonomous Jewish society.
The birth of a new Jewish secular culture, including literature, newspapers or Klezmer music is another one. The question then arose

Weak Interactions 129whether the language of this new secular culture should be Yiddish - and thus a standardized, literary version of Yiddish was to be developed - or Hebrew - and therefore a renewal of the Hebrew language was required. In the beginning, this point was not such an enormous matter of dispute as it would later develop into, when “Hebraists”, principally connected with Zionism, confronted “Yiddishists”, generally claiming a cultural and / or political autonomy within Eastern Europe. It is the irony of history that the far more naïve and seemingly unrealistic ideology, calling for the revival of an almost unspoken language in the distant Palestine, was the one that later would become reality.
1.3. Language interactions in the Haskala
Let us now return to our model of language interactions. As we have seen, the intensity of the interaction depends on the number of “exchange particles” - language changing individuals - , that is a kind of “distance” measured in the social network; furthermore on the “eligibility” of the languages to transmit and to adopt features. We shall now confront this model with the linguistic reality of the different stages of the Haskala.
Concerning the first stage, when only a handful of followers of Moses Mendelssohn rejected the Jüdischdeutsch and started speaking Hochdeutsch, our model will correctly predict that the number of exchange particles is insufficient to affect German in a perceptible way.
The number of exchange particles increases dramatically when we reach the first half of the nineteenth century. However, the people changing language more or less consciously adopted the idea of their original idiom being an unclean and corrupt version of the target language. Consequently, by nature their language change consisted of not bringing any influence on the target language with them. By applying our vague physical model to this situation, we might say that although the two languages were indeed close - from the viewpoints of geography, linguistic similarity and social contacts - , Hochdeutsch was not “eligible” enough to be seriously affected.
What happened in the third stage of the Haskala? The following three case studies represent three possibilities. The first one, the influence of Yiddish on Hungarian, was actually a case where some elements of stage 2 Haskala were still present. The emancipation of the Jews was closely related to their assimilation into the Hungarian society, culture and language. As Jews wished to become an equal part of that society, let us

130 Tamás Bíró
call this case type e. Each of the many people brings only a very “light” quantum of influence, similarly to the very little mass, if any, of the electron neutrinos. The type mu designates a case when Jews migrated to a newly created Jewish “land, language and culture”, namely to Modern Hebrew. Here less people carry possibly more “weight”, that is why they can be paralleled by the heavier muon neutrinos. In the third case, that is the birth of Esperanto, only one person of Jewish cultural background wished to transform the entire word, with a total rejection of reference to any form of Jewishness, at least on a conscious level (type tau, referring to the probably heaviest type of neutrinos).
2. Three examples of weak interaction
2.1. Type e: Yiddish and Hungarian
Nineteenth century Hungary was situated on the border of Western European Jewry, affected already by the first two stages of Haskala, and Eastern European Jewry, which would be reached only by its third phase. From the second half of the previous century onward, the Jewish immigration from Bohemia and Moravia had been importing a rather urbanized population speaking Western Yiddish, or even Jüdischdeutsch, whereas Eastern Yiddish speaking Galician Jews inhabiting Eastern Hungary represented the westernmost branch of Eastern European Jewry. Not only were the linguistic features of the two groups strikingly different, but also their social, economic and cultural background.
In the social and economic fields, Hungary met a first wave of modernization in the 1830s and 1840s, which is referred to as the reform age, reaching its peak in the 1848-49 revolution. After the so-called Compromise with Austria in 1867, the consequence of which had been the creation of the Austro-Hungarian Empire with a dualistic system, the most urbanized parts of the country showed an especially remarkable economic and cultural growth.
Parallel to the phenomenon of general modernization, the Jewish population underwent a similar process to the one we have already seen apropos of the French and German Jewry that had gone through these social changes fifty years earlier. The second quarter of the century already

Weak Interactions 131witnesses a few Jewish thinkers, mainly rabbis arriving from Germany or Bohemia, and bringing modern ideals with them. Yet, their effect cannot be perceived on a larger social scale before the last third of the century.
A few differences should, however, be noted between German and Hungarian Haskala. First, for the larger society into which Hungarian Jews wished to integrate, Enlightenment was not so much the consequence of the Embourgeoisement, rather its catalyst. Enormous heterogeneities in the degree of development could be found within the country, both in social, as well as economic terms. This general picture was paralleled with a heterogeneous distribution of Eastern and Western type of Jewry. Thus, even if the most Europeanized Jews may have wished, they could not disown their pre-Haskala coreligionists living close to them.
Moreover, the modern Hungarian society and culture had to be created in spite of the Austrian occupation. Social constructs underwent huge changes, and any group of people identifying themselves as Hungarian - and not Austrian - could influence the new shapes of society and culture. Immigrants from all directions played a fundamental role in laying down the bases of modern Hungarian urban culture. These are the circumstances under which most of the Jews chose the Hungarian, rather than the German or Yiddish culture and language. This decision was far from being evident. Even most of the orthodoxy adopted Hungarian, though more slowly and by keeping simultaneously Yiddish.
By putting together the pieces, we obtain an image in which the dynamically changing Hungarian culture and society is searching new, modern forms, and is ready to integrate foreign influences - as long as the carriers identify themselves as new Hungarians. Further, a major part of the Jewish population is seeking its place in this new society, wants to adopt the new culture, but is still strongly connected - often against its will - to the pre-Haskala Jewry living not so far from them. Consequently, we have both a high “eligibility” for being influenced on the part of the Hungarian language, and a large number of “exchange particles” flowing from Yiddish to Hungarian.25
What is the outcome of such a situation? Let us consider a few examples of Yiddishisms in Hungarian. I shall distinguish between three registers that Yiddishisms entered considerably: the Jewish sociolect of Hungarian, argot (slang), and standard Hungarian.
The vocabulary of Hungarian speaking Jews unsurprisingly includes a large number of words specific to domains of Jewish culture and religion.

132 Tamás Bíró
In some cases only phonological assimilation takes place. The Hungarian phonological system lacks a short /a/, and the short counterpart of / is //. Therefore the Yiddish word [] (‘Rosh Ha-shana, name of the Jewish New Year’, from Hebrew [], i.e. [ in standard Hungarian Ashkenazi pronunciation) becomes optionally []. Although the original Yiddish pronunciation [] is still possible, the latter emphasizes the foreign origin of the word. An analogous example is the word barchesz ([] or [], ‘chala, a special bread used on Shabbat and holidays’), which is clearly from Yiddish origin, but is unknown outside Hungary; it may have belonged to the vocabulary of Hungarian Yiddish.
Other words immediately underwent Hungarian morphological processes. In fact, it is a well known phenomenon in many languages of the world that borrowed verbs, unlike borrowed nouns, cannot be integrated directly into the vocabulary of a given language. This is the case in words like lejnol (‘to read the Torah-scroll in the synagogue’), lejnolás (‘the reading of the Torah-scroll’) as well as snóder (‘money given as donation’), snóderol (‘to donate money, especially after the public Torah-reading’), snóderolás (‘the act of money donation’). In the first case, the Yiddish verb leyenen (‘idem’)26 was borrowed and one of the two most frequent denominal verbal suffixes, -l, was added.27 The word lejnolás is the nomen actionis formed with the suffix -ás. The expression tfilint légol (‘to put on the phylacteries’) originates from German and Yiddish legen, and has gone through the same processes. For snóderol, Hungarian borrows a Yiddish noun,28 which then serves as the base of further derivations.
The Jewish sociolect of Hungarian includes further lexical items, which do not belong to the domain of religious practice or Jewish culture. One such word is unberufn (‘without calling [the devil]’), which should be added out of superstition to any positive statement that the speaker hopes to remain true in the future. For instance: ‘My child grows in beauty, unberufn’ (Blau-Láng, 1995:66). Nowadays, many people of the generation born after World War II and raised already in an almost non-Yiddish speaking milieu judge this expression as having nothing to do with superstition, but qualifying a situation as surprisingly good, like ‘You don’t say so! It’s incredible!’ and definitely including also some irony.29 Others of that generation say in the same surprising-ironic context: “My grandma would have said: unberufn…”, even if Grandma had used that word in a slightly different way. This second meaning of unberufn clearly lacks any

Weak Interactions 133reference to superstition, since the same people would use another expression (lekopogom) to say ‘touch wood! knock on wood!’.
Unlike the previous interjections, the adjective betámt (‘nice, intelligent, smart, sweet, lovely’) already enters the “real” syntax of the target language, even if morphological and phonological changes have not taken place yet - which happened in the case of lejnol and snóderol. The word betámt consists of the Hebrew root taam (‘taste’), together with the Germanic verbal prefix be- and past participle ending –t. The resulting word denotes a person who “has some taste”: somebody who has some characteristic traits, who is interesting, who has style and some sense of humour, which is kind, polite, and so on. It is typically used by “Yiddishe mammes” describing the groom they wish their daughter had.
So far, we have seen examples where the language changing population has kept its original expression to denote something that could be best expressed using items of their old vocabulary. This Jewish sociolect has become an organic part of modern Hungarian, acknowledged, and partially known by many non-Jewish speakers, as well. But do we also find influences of Yiddish outside of the Jewish sociolect?
The register that is the most likely to be affected under such circumstances is probably always slang: it is non-conformist by definition, and, therefore, it is the least conservative. Slang is also the field where social norms, barriers and older prejudices play the least role. This may be the reason why Hungarian slang created in the nineteenth century borrowed so much from the languages of two socially marginal groups: the Gipsy (Roma) languages and Yiddish. In contemporary Hungarian slang, one can find well-known words from Yiddish origin such as: kóser (‘kosher’, meaning ‘good’ in slang); tré (‘bad, crappy, grotty’, from Hebrew-Yiddish-Hungarian tréfli ‘ritually unclean, non kosher food’); majré (‘fear, dread, rabbit fever’, from Hebrew mora ‘fear’ > Ashkenazi [] > Yiddish moyre [] > Hungarian []), further derived to majrézik (‘to fear, to be afraid of sg.’); szajré (‘swag, loot, hot stuff’, from Hebrew sehora ‘goods, merchandise’), and so on (Benkő et al., 1967-76). An interesting construction is stikában, meaning ‘in the sly, in secret, quitely’. Its origin is the Aramaic-Hebrew noun ] ‘remaining silent’, which receives a Hungarian inessive case ending, meaning ‘in’.
Through slang, some of the Yiddish words have then infiltrated into the standard language and become quasi-standard. Thus, the word haver - from the Hebrew ] ‘friend’ - is used nowadays as an informal synonym for a ‘good acquaintance, a friend’. Similarly, dafke means in spoken

134 Tamás Bíró
Hungarian ‘For all that! Only out of spite!’. Furthermore, there are words of Yiddish origin which did not enter Hungarian through the slang, but through cultural interaction: macesz (‘matzo, unleavened bread’, from Hebrew matzot, plural form of matza; its ending clearly shows that the word arrived to Hungarian through Yiddish) or sólet (‘tsholent’, a typically Hungarian Jewish bean dish, popular among non-Jews, too).30
To summarize, the high amount of “exchange particles”, that is, Jewish people gradually changing their language from Yiddish to Hungarian, has affected the target language in three manners. One of them has been the creation of a special Jewish sociolect. This was not a secret language though, and non-Jews have borrowed quite a few expressions. This fact led to the second manner of influence, namely to the high amount of Yiddish words entering the slang. Some of these words have infiltrated even into the relatively more informal registers of the standard language. The third manner is cultural interaction: the exchange of cultural goods - for instance in the field of gastronomy - inevitably has resulted the exchange of the vocabulary designating those goods.
2.2. Type : Yiddish and Modern Hebrew
The fruit of Western European Haskala in the field of science was the birth of Wissenschaft des Judentums. The Jewish scholars belonging to this group aimed to introduce modern approaches when dealing with traditional texts, Jewish history, and so forth. Their approach contrasted traditional rabbinical activity the same way as the romanticist cantorial compositions by Salomon Sulzer and Louis Lewandowski contrasted traditional synagogal music: modernists aimed to produce cultural goods that were esteemed by the modern society, both by Jews and the recipient country. A further motivation of the Wissenschaft des Judentums was to expose the values of post-Biblical Jewish culture, and to present them as an organic part of universal culture: by emancipating Jewish past, they hoped to be also emancipated by contemporary society.
This background illuminates why early Haskala honored so much Hebrew - the language of the contribution par excellence of the Jewish nation to universal culture, which is the Hebrew Bible, and a language that had been long studied by Christian Hebraists. And also why Yiddish, the supposedly jargon of the uneducated Jews and a corrupt version of German, was so much scorned in the same time.

Weak Interactions 135
Although the goal of the earlier phases of Haskala was to promote the literary language of the recipient country among Jews, that is practically Hochdeutsch, and Hebrew was principally only the object of scholarly study, still some attempts were made to use the language in modern domains, at least for some restricted purposes. After a few pioneering experiments to establish Hebrew newspapers in the middle of the eighteenth century, the Hebrew literary quarterly Ha-Meassef appeared as early as 1784 (Sáenz-Badillos, 1993:267).
However, it was not before the middle of the next century, when Haskala reached Russia, that the need of reviving the Hebrew language was really articulated. As already discussed, the major reasons for this switch were that the Jewish population did not see the underdeveloped surrounding society as a model to which they wanted to assimilate; the Russian society and policy did not show any real sign of wanting to emancipate and integrate Jews, either; furthermore, the huge Jewish population reached the critical mass required to develop something in itself. The summation of these factors led to the idea of seeing Jewry as separate a nation in its modern sense. A further factor reinforcing Jewish national feelings both in Eastern and Western Europe was the emergence of modern political anti-Semitism in the 1870s in the West, accompanied by events such as the huge Russian pogroms in 1881, the blood libel of Tiszaeszlár, Hungary (1882-3) or the Dreyfus-affair in France (starting in 1894).
The claims following from this idea were that the Jewish nation has the right to have a country - in Palestine or elsewhere, but at least it should receive some local autonomy - , and also that the Jewish nation must have its own national language. The two major candidates for the Jewish national language were Yiddish and Hebrew, although German was not out of the competition, either (cf. e.g. Shur, 1979:VII-VIII).
The first wave of attempts to revive Hebrew consisted mainly of purists, seeing Biblical Hebrew as the most precious layer of the language: some of them went so far that they preferred to create very complicated expressions to designate modern concepts, rather than using non-Biblical vocabulary. The fruits of this early period are among others the first regular Hebrew weekly, Ha-Maggid (1856), the first modern play by D. Zamoscz (1851), novels by A. Mapu, as well as works of S. J. Abramowitsch (Mendele Moykher Seforim), who can be considered one of the founders of both modern Hebrew and modern Yiddish literature.
The real upswing was observable in the last quarter of the century, especially after the 1881 pogroms, and when Haskala had reached the

136 Tamás Bíró
broadest masses, as well. Traditionally, the publication of Eliezer Ben-Yehuda’s article in 1879 entitled ‘A burning question’ is considered to be the opening of the new era (Sáenz-Badillos, 1993:269). Ben-Yehuda (1858-1922) has been portrayed as the hero of the revival: he moved to Jerusalem in 1881, where he forced himself and his family to speak Hebrew. To speak a language, that is to produce everyday, spontaneous sentences “in real-time”, on a language that had been mostly used for writing and reading and only in restricted domains. His son, Ithamar (1882-1943), was the first person after millennia who grew up in an exclusively Hebrew-speaking environment. Ben-Yehuda constantly introduced new words designating weekday concepts, while he was editing a newspaper and working on his monumental Thesaurus, which incorporated material from ancient and medieval literature. In 1890, he founded the Va’ad ha-Lashon (‘Language Committee’), the forerunner of the Hebrew Language Academy, hereby creating a quasi-official institution for language planning.
However, Shur (1979) has argued against an overestimation of Ben-Yehuda’s role. Out of Fishman’s five stages of language planning (in Shur, 1979) (1. code selection; 2. ideologization of the choice; 3. codification; 4. elaboration and modernization; 5. standardization, i.e. the acceptance by the community), Ben-Yehuda was salient especially in codification and elaboration, as well as in vitalization, which was also necessary under the given circumstances. But for socio-political reasons, he had not much influence on the initial language choice and its ideologization, as well as on the final acceptance of the codified and elaborated standard.
It is clear that Yiddish was the mother tongue, or one of the main languages for a major fraction of the members of the Va’ad ha-Lashon, including Ben-Yehuda himself. Moreover, people with Yiddish as first language represented an important part of the speaker community of the old-new tongue in the first half of the twentieth century. Yiddish was not scorned anymore, as it had been a century before, but it was not considered as a major source for language reform, either. Especially for the later generations, Yiddish would symbolize the Diaspora left behind by the Zionist movement.
Yiddish speaking “exchange particles” dominated the community, much more than in the Hungarian case. Yet, a very conscious ideology required changing the previous ethnic language to the old-new national language, especially after the 1913-14 “Language Quarrel”, wherein the defenders of Hebrew defeated those of German and Yiddish (Shur, 1979:VII-VIII, X). This ideology was actively present in almost each and every individual who

Weak Interactions 137had chosen to move to the Land of Israel in a given period - contrary to the European case, where ideology of changing the language was explicit only in the cultural elite. Further, the language change was not slow and gradual, but drastic in the life of the people emigrating to Palestine, combined with a simultaneous radical change in geographical location, social structure and lifestyle. What phenomena would this constellation involve?
Yiddish influence on Modern Hebrew vocabulary has been investigated by - among others - Haim Blanc. For instance, the Modern Hebrew interjection davka (approx. ’necessarily, for all that’) is clearly a Hebraisation of Yiddish dafke, of Hebrew origin itself, and mentioned also in relation with Hungarian. Similarly, kumzitz ‘get-together, picnic, campfire’ undoubtedly originates from the Yiddish expression ‘come [and] sit down!’, since only in Yiddish do we find [u] in the verb ‘to come’. However, the expression was probably coined in Hebrew, as standard Yiddish dictionaries do not mention it. One can easily imagine the early pioneers sitting around a campfire in the first kibbutzim, chatting in a mixture of Yiddish and Hebrew, and inviting their comrades to join them.
Nissan Netzer (1988) analyses the use of the Modern Hebrew verb firgen and the corresponding de-verbal noun firgun. Officially, the word is still not considered to belong to the language, for it is not attested in any dictionary of Hebrew that I know. Definitions for this word I have found on the Internet are: “the ability to allow someone else to enjoy if his or her enjoyment does not hurt one,” and “to treat favorably, with equanimity, to bear no grudge or jealousy against somebody,” and also “to be delighted at the success of the other”. The word can be traced back to Yiddish farginen ‘not begrudge, not envy, indulge’. As Netzer has demonstrated, there is a linguistic gap in Hebrew, for the expressions darash et tovato shel… or lo hayta eno tsara be- that should bear that meaning are cumbersome, circuitous, overly sophisticated in style and seems to cloud the true linguistic message. Therefore, they were not accepted by the linguistic community. When a leading Hebrew linguistics professor used the Yiddish equivalent in the early sixties, the situation made the listeners of an academic lecture smile, because in that time the Yiddishism was considered to be a folk idiom that would finally withdraw in favor of a “real Hebrew expression”. However, firgen would have become more and more accepted in daily conversation and even in journalistic writings by the eighties.31
This example has led us to the issue of the sociolinguistic status of Yiddish words in Modern Hebrew. Ora Schwarzwald (1995) shows that the vocabulary of the most used classical texts, such as the Hebrew Bible and

138 Tamás Bíró
liturgy, has become the base of Modern Hebrew, in all its registers. Furthermore, loanwords of European languages are also used both in formal and non-formal language. However, from less esteemed languages, such as Jewish languages (e.g. Yiddish and Ladino), as well as Arabic, words would infiltrate primarily into lower registers and everyday informal speech.
For instance, chevre ‘friends’ is used mainly when addressing informally a group of people, and it is the borrowing of the similar word in Yiddish (khevre ‘gang, bunch of friends, society’). The latter obviously comes from Hebrew chevra ‘society, company, gathering’, whose root is chaver ‘friend’, a well-known word for speakers of Hungarian and Dutch (gabber), too. The originally Hebrew word thus arrived back to Modern Hebrew, but keeping the phonological traces of its trajectory. Also note the minor shifts in the semantics during the two borrowings.
Another example for Yiddish influence on informal speech is the use of the -le diminutive suffix: abale from aba ‘dad’, Sarale ‘little Sarah’, Chanale ‘little Hanah’, and so forth. Observe that the suffix follows the Hebrew word, whereas in Yiddish one would have Sorele and Chanele expect.
Thus, the influence of Yiddish on Modern Hebrew is indeed similar to its influence on Hungarian: lower registers and informal speech constitute one of the canals through which this interaction takes place. To make the similarity even more prominent, we can point to two further canals, shared by the Modern Hebrew case and the Hungarian case. Similarly to Hungarian, the designation of goods of general culture, such as food names (beygelach ‘bagels or pretzel’) represent a domain for word borrowings. Moreover, Yiddish loan words, or Hebrew words with a Yiddish or Ashkenazi pronunciation are likely to appear in religious vocabulary (e.g. rebe ‘Chasidic charismatic leader’); typically in the sociolect of religious groups (especially within the ultra-orthodox society), and in the language used by secular Israelis to mock the stereotypically Yiddish-speaking ultra-orthodox Jews (e.g. dos ‘an ultra-orthodox person’, from Hebrew dat ‘religion’; vus-vus-im ‘the Ashkenazi ultra-orthodox Jews’, who often say Vus? Vus? ‘What? What?’ followed by the Hebrew plural ending -im).

Weak Interactions 1392.3. Type : Yiddish and Esperanto
Esperanto emerged in the very same context as Modern Hebrew. Its creator, Lazar Ludwik Zamenhof (1859-1917), was born one year after Eliezer Ben-Yehuda, similarly from a Jewish family living in a small Lithuanian town, whose population was composed of Russian, Polish and Lithuanian people, but was dominated by a Jewish majority. The Litvak (Lithuanian-Jewish) Haskala background of both men encouraged traditional Jewish education combined with studies in a secular Gymnasium; both of them went on to study medicine. Following the 1881 wave of pogroms, in the year in which Ben-Yehuda moved to Jerusalem, Zamenhof published an article calling for mass emigration to a Jewish homeland. For a few years, he became one of the first activists of the early Zionist movement Hovevei Tzion (“Lovers of Zion”). Berdichevsky (1986) points out the similarities even in the mentality and the physical appearance of Zamenhof and Ben-Yehuda.
Nevertheless, two key differences should be pointed out. The first one is Zamenhof’s pragmatism. In his 1881 article, Zamenhof imagined the Jewish homeland to be in the western part of the United States, a relatively unsettled area those days, which would have arisen much less sensibility from all sides. Furthermore, Zamenhof shared the skepticism of many of his contemporaries in the feasibility to revive the Hebrew language. According to the anecdote, Theodor Herzl said once that he could not buy even a train ticket in Hebrew. Leading Jewish writers, such as Mendele Moykher Seforim, oscillated between writing in Yiddish and in Hebrew; both of these languages called for the establishment of a modern, secular literary tongue. The young and pragmatic Zamenhof chose to reform Yiddish, the language with millions of native speakers; whereas the first native speaker of Modern Hebrew, the son of Ben-Yehuda was not born yet.
In his early years, Zamenhof wrote a comprehensive Yiddish grammar (completed in 1879, partially published in 1909 in the Vilna Journal, Lebn un Vissenschaft, and fully published only in 1982). He argued for the modernization of the language and fought for the use of the Latin alphabet, instead of the Hebrew one. How is it possible then that a few years later Zamenhof changed his mind, and switched to Esperanto (1887)?
Here comes the second key difference into the picture. Ben-Yehuda was sent by his orthodox family to a yeshiva (traditional school teaching mainly the Talmud), where one of the rabbis introduced him secretly into the revolutionary ideas of the Haskala. On the contrary, Zamenhof’s father and

140 Tamás Bíró
grandfather were enlightened high-school teachers of Western languages (French and German). For him, being Jewish probably meant a universal mission to make the world a better place for the whole humankind. This idea originates from eighteenth century German Haskala philosophers claiming that Judaism is the purest embodiment so far existing of the universal moral and of the faith of the Pure Reason; even today a major part of Jews worldwide perceive Judaism this way.
Zamenhof did not therefore content himself with the goal of creating a Jewish national language. For him, similarly to his semi-secularized coreligionists joining the socialist movement in the same decades, unifying the human race and building a new word order presented the solution for - among others - the problems of the oppressed Eastern European Jewry. And also the other way around: the secular messianic idea of the unification of the dispersed and oppressed Jews into a Jewish nation was just one step behind from the secular messianic idea of the unification of the whole mankind into a supra-national unit. This explains not only the motivations of Zamenhof himself, but also why Jews played such an important role in the pre-World War II Esperanto movement in Central and Eastern Europe (Berdichevsky, 1986:60). Whereas socialists fought for a social-economic liberation of the oppressed, Zamenhof spoke about the liberation of the humans from the cultural and linguistic barriers. It is not a coincidence that the twentieth century history of the Esperantist movement was so much intermingled with the one of the socialist movements.
Zamenhof’s initiative was to create a language that would be equally distant from and equally close to each ethnic language, thus each human being would have equal chance using this bridge connecting cultures and people. Hence Zamenhof created a vocabulary and a grammar using elements of languages he knew: Russian (the language his father spoke home and the language of his highschool), German and French (the languages his father and grandfather were teachers of), Polish (the language of his non-Jewish fellow children), Latin and Greek (from highschool), as well as English and Italian. Note that the resulting language, similarly to most artificial languages, is inherently European and Indo-European in its character, though extremely simplified.
However, one should not forget that Zamenhof’s native tongue was Yiddish, this was the language he used with his school mates in the Jewish primary school (kheyder, cf. Piron, 1984), and most of his life he kept contact with circles where Yiddish was alive. So one would wonder why Yiddish is not mentioned overtly among the source languages of Esperanto.

Weak Interactions 141Seeing Zamenhof’s former devotion for the Jewish sake and the Yiddish language, as well as his later remark that Yiddish is a language similar to any other (in Homo Sum (1901), cf. Piron (1984:17) and Berdichevsky (1986:70)), the possibility that he despised “the corrupt version of German” or that he felt shame at his Yiddish origins, are out of question.
The challenging task now is to find at least covert influences of Yiddish on Esperanto.
As strange as it may sound, a considerable literature has been devoted to etymology within Esperanto linguistics. One of the biggest mysteries is the morpheme edz. As a root, it means ‘married person’ (edzo ‘husband’; edzino ‘wife’, by adding the feminine suffix -in-). While as a suffix, it turns the word’s meaning into the wife or husband of the stem: lavistino ’washer-woman’ vs. lavistinedzo ‘washerwoman’s housband’; doktoro ‘doctor’ vs. doktoredzino ‘doctor’s wife’. Hungarian Esperantists have tried to use this suffix to translate the Hungarian suffix -né (‘wife of…’, e.g.: Deákné ‘wife of Deák, Mrs. Deák’; cf. Goldin (1982:28)). The phonemic content of the morpheme is not similar to any word with related meaning in any of the languages that Zamenhof might have taken into consideration.
Zamenhof himself wrote in a letter to Émile Boirac that the morpheme was the result of backformation, and that originally it was a bound form (Goldin, 1982:22f). Boirac suggested in 1913 the following reconstruction: if the German Kronprinz (‘heir apparent’) became kronprinco in Esperanto, while Kronprinzessin (‘wife of a crown prince’, note the double feminine ending: the French feminine suffix -esse is followed by the Germanic feminine -in) turns to kronprincedzino, then the ending -edzin- can be identified as ‘a woman legally bound to a man’. By removing the feminine suffix -in-, we obtain the morpheme -edz-. Goldin adds to this theory that the morphemes es and ec had already been used with other meanings, that is why the surprising [] combination appeared. Summarizing, the etymology of the Esperanto morpheme edz would be the French feminine ending -esse, which had been reanalyzed with a different meaning due to the additional feminine suffix in German.However, this is not the end of the story. Other alternatives have been also proposed. Waringhien and others (in Goldin, 1982) have brought forward the idea that the word serving as the base of backformation was the Yiddish word rebetsin (‘wife of a rabbi’). In fact, this word can be reanalyzed as reb+edz+in, and we obtain the edz morpheme using the same logic as above. Goldin’s counterargument that the Yiddish word is actually rebetsn with a syllabic [] is not at all convincing: old Yiddish spelling often uses
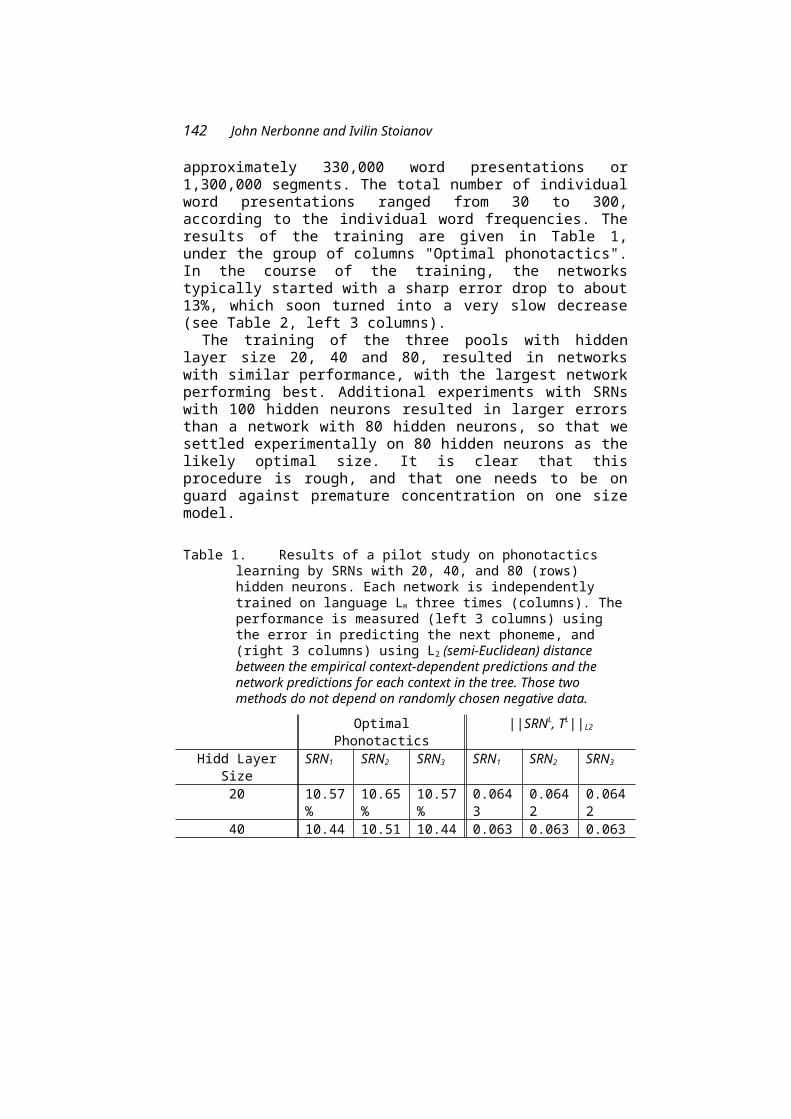
142 Tamás Bíró
the letter yod to designate a schwa, or even more the syllabicity of an [], similarly to the <e> in German spelling, like in wissen. Consequently, I can indeed accept the idea that a pre-YIVO spelling rebetsin was in the mind of Zamenhof.
Piron (1984) adds further cases of possible Yiddish influence. In words taken from German, the affricate [] always changes to []: German pfeifen ‘to whistle’ became Esperanto fajfi. This coincides with Yiddish fayfn. Though, one is not compelled to point to Yiddish as the origin of this word: the reason can simply be that the affricate [] is too typical to German, not occurring in any other languages that served “officially” as examples for Zamenhof. In other words, [] was not seen as universal enough. But what about the consonant clusters ], ], ], which are also characteristic solely to German (and to Yiddish)? May the solution be that while [] becomes [] in Yiddish, these clusters are unchanged; therefore, Zamenhof felt less discomfort with regard to the latter clusters than with regard to [] which truly occurs exclusively in German? I do not believe that we can do more than speculate about the different unconscious factors acting within a person more than a hundred years ago. The only claim we can make is that some of these factors must have been related to Yiddish, as expected from the fact that Yiddish was one of the major tongues of Zamenhof.
In the field of semantics, Piron brings the differentiation in Esperanto between landa (‘national, related to a given country’, adjective formed from lando ‘country’) as opposed to nacia (‘national, related to a given nation’, adjective from nacio ‘nation’). This differentiation exists in Yiddish (landish and natsional), but not in any other languages that Zamenhof might have taken into consideration. Piron also argues against the possible claim that this is not a Yiddish influence, rather an inner development related to the inner logic of Esperanto.
The most evident example of Piron is Esperanto superjaro ‘leap year’, a compound of super ‘on’ and jaro ‘year’. No known language uses the preposition on or above to express this concept. However, Yiddish has iberyor for ‘leap year’, from Hebrew ibbur (‘making pregnant’), the term used in rabbinic literature for intercalating an extra month and making the year a leap year (e.g. Tosefta Sanhedrin 2:1-7). On the other hand, iber also means ‘above’ in Yiddish, which explains the strange expression in Esperanto. I do not know if Zamenhof realized that the Yiddish expression iberyor is not related to German über, but this is probably not relevant.

Weak Interactions 143
Let us summarize this section. Yiddish influence on Esperanto is a case where there is only one exchange particle - in the first order approximation, at least, since we have not dealt with the possible influences related to the numerous later speakers of Esperanto of Yiddish background. Though, this one particle had a huge impact on the language for a very obvious reason. Even if he did not overtly acknowledge that Yiddish had played a role in creating Esperanto, it is possible to discover the - either consciously hidden or unconscious - traces of Yiddish.
Did Zamenhof want to deny that he had also used Yiddish, as a building block of Esperanto? Perhaps because his goal was indeed to create a universal, supra-national language, and not the language of the Jewish nation? Or, alternatively, was this influence unconscious? I do not dare to give an answer.
3. Conclusion
In linguistics, we could define weak interaction as an interaction that is not overtly acknowledged. No one would deny the influence of the French-speaking ruling class on medieval English, or the impact of the Slavic neighbors on Hungarian. But sometimes, conscious factors hide the effect. Yet, weak interactions are as crucial for the development of a language, as the nuclear processes emitting neutrinos in the core of the Sun that produce the energy which is vital for us.
We have seen three cases of weak interaction between languages. In fact, all three stories were about the formative phase of a new or modernized language, in the midst of the late nineteenth century Eastern Europe Jewry. In the cases of Yiddish influencing Hungarian and Modern Hebrew, the number of “exchange particles”, that is, the amount of initially Yiddish-speaking people joining the new language community, were extremely high: roughly one tenth of the Hungarian speaking population in nineteenth century Hungary, and probably above 50% of the Jews living in early twentieth century Palestine. Nonetheless, in both cases we encounter an ideology promoting the new language and disfavoring Yiddish.
Because the level of consciousness of this ideology seems to be inversely proportional to the ratio of “exchange particles” - stronger in Palestine than in Hungary - , the two factors extinguish each other, and we find similar phenomena. For instance, Yiddish has affected first and foremost lower registers, which are less censored by society; therefrom it

144 Tamás Bíró
infiltrates into informal standard language. Additional trends are Yiddish words entering specific domains, such as gastronomy or Jewish religious practice. Although it is essential to note that not all concepts that are new in the target culture are expressed by their original Yiddish word: many new expressions in these domains have been coined in Hungarian and Modern Hebrew, and accepted by the language community.
The third case that we have examined is different. Zamenhof was a single person, but as the creator of Esperanto, he had an enormous influence on the new language. The influence of Yiddish was again weak in the sense that it was not overtly admitted; however, we could present examples where the native tongue of Zamenhof influenced the new language. We could have cited, as the articles mentioned had done, numerous further instances where the influence of Yiddish cannot be proven directly, the given phenomenon could have been taken from other languages, as well; however, one can hypothesize that Yiddish played - consciously or unconsciously - a reinforcing role in Zamenhof’s decisions.
I do hope that I have been able to prove to the reader that seemingly very remote fields, such as physics, social history and linguistics, can be interconnected, at least for the sake of a thought experiment. Furthermore, “exchange particles” in the field of science, and Tjeerd is certainly among them, have hopefully brought at least some weak interaction among the different disciplines.
Notes
References
Benkő, Lorand et al. (eds.) (1967, 1970, 1976). A Magyar Nyelv Történeti-Etimológiai Szótára [The Historical-Etymological Dictionary of The Hungarian Language]. Akadémiai Kiadó, Budapest.
Berdichevsky, Norman (1986). Zamenhof and Esperanto. Ariel, A Review of Arts and Letters in Israel, 64: 58-71.
Blau Henrik, Károly Láng (1995). Szájról-szájra, Magyar-jiddis szógyűjtemény, Pápa, 1941; Chabad, Budapest, 19952.
Goldin, Bernard (1982). The Supposed Yiddish Origin of the Esperanto Morpheme. edz, Jewish Language Review, 2: 21-33.

Weak Interactions 145Graaf, Tjeerd, de (1969). Aspects of neutrino astrophysics. Wolters-Noordhoff
nv, Groningen.Netzer, Nissan (1988). “Fargen” - Employing a Yiddish Root to Bridge a
Linguistic Gap in the Hebrew Language (in Hebrew, with English abstract). Hebrew Computational Linguistics, 26: 49-58.
Piron, Claude (1984). Contribution à l’étude des apports du yidiche à l’ésperanto. Jewish Language Review, 4: 15-29.
Sáenz-Badillos, Angel (1993). A History of the Hebrew Language. University Press, Cambridge.
Schwarzwald, Ora (Rodrigue) (1995). The Components of the Modern Hebrew Lexicon: The Influence of Hebrew Classical Sources, Jewish Languages and Other Foreign Languages on Modern Hebrew (in Hebrew, with English abstract). Hebrew Linguistics, 39: 79-90.
Shur, Shimon (1979). Language Innovation and Socio-political Setting: The Case of Modern Hebrew. Hebrew Computational Linguistics, 15: IV-XIII.


Prosodic Acquisition: a Comparison of Two Theories
Angela Grimm
1. Introduction
During language development, children’s word productions are target of a variety of prosodic processes as e.g. syllable deletions, syllable additions and stress shift. Using current phonological theory, investigators have explained the production pattern in a number of different ways.
In this paper, I review two approaches to the development of word stress: Fikkert’s (1994) theory of trochaic template mapping and Demuth & Fee’s (1995) prosodic hierarchy account. Both theories assume that children build up the prosodic representation of words step-by-step, starting with the smallest unit and ending with an adult-like representation. I argue that both theories are problematic because they overgenerate certain structures (e.g. level stress), but that the model of Demuth & Fee can better account for the data presented so far.
This paper is organized as follows: since it is crucial in both theories, paragraph 2 briefly introduces the basic assumptions of the prosodic hierarchy. In paragraph 3, I will give a survey of Fikkert’s (1994) model of stress development and Demuth and Fee’s (1995) model based on the prosodic hierarchy. In paragraph 4, I discuss the problems arising with the models and paragraph 5 concludes.
2. The prosodic hierarchy of words
The prosodic hierarchy up to the word level consists of four constituents. The lowest element of the prosodic hierarchy is the mora (). Since there are often no segmental slots in moraic models, the mora has a double function as the unit of syllable weight and as the unique sub-syllabic constituent. The moraic level is dominated by the syllabic level (), and syllables are parsed into feet (F) at the foot level above. The highest unit is

148 Angela Grimm
the prosodic word (Wd) which directly dominates the foot level (see Figure 1):
Prosodic word (Wd)
Foot (F)
Syllable ()
Mora ()
Figure 4. The prosodic hierarchy (Selkirk, 1980)
Syllables differ with respect to the number of moras they contain. Light syllables contain one mora, while heavy syllables contain at least two. The tendency of languages to assign stress to heavy syllables is expressed by the Weight-to-Stress-Principle (WSP). In a parametric approach to word stress (cf. Hayes, 1995), languages either respect this principle (quantity-sensitive languages) or do not (quantity-insensitive languages).
The next constituent of the prosodic organization above the syllable level is the foot. Ideally, the foot is binary branching which implies that it should consist of two moras or of two syllables. Thus, a binary foot can be monosyllabic if it contains two moras (e.g. ‘duck’) or it can be disyllabic if it consists of two syllables or two moras (e.g. ‘papa’). The head constituent of the foot receives stress.
The prosodic word is the domain of stress application. It can also coincide with a single foot. Because the foot size is the smallest shape a prosodic word can have, it is called Minimal Word. Many languages have restrictions such that content words must not be smaller than the minimal word. There is ample evidence that the minimal word restriction also governs the shape of the early words in language acquisition (Demuth & Fee, 1995; Demuth, 1996; Fikkert, 1994; Ota, 2001).
A very important principle of the prosodic hierarchy is the Strict Layer Hypothesis (Selkirk, 1984) which demands that layers must not be skipped, i.e. that a given prosodic constituent(n-1) is contained in the constituent(n)
immediately above. Furthermore, it requires that constituents have one and only one head, which implies that there is always a difference in prominence among the elements forming a given prosodic unit.

Prosodic Acquisition: a Comparison of Two Theories 1493. The acquisition of word stress: two current models
3.1. Fikkert (1994)
Fikkert’s study of Dutch children is the most detailed research on stress acquisition to date. Fikkert mainly focused on disyllabic words and argued for the foot as the basic unit of development.
Although Fikkert’s model is based on Dutch, she claims that the trochaic template is universal in child language since it is the only quantity-insensitive foot in the typology of Hayes (1991). Thus, children should not show sensitivity to syllable weight at the earliest stages of prosodic acquisition. The postulation of a universal foot template implies that the child always makes reference to the foot level in the word productions. Consequently, it is a foot, not a syllable that is being truncated in forms like below:
Example 1.
child form adult target gloss ‘ballon’ ‘holiday’
Fikkert assumes that the output a child produces is directed by the mapping of a melody template onto a trochaic template via prosodic circumscription. Based on phenomena such as truncation, stress shift and epenthesis, four different stages of prosodic development are postulated.
Stage 1
According to Fikkert, the child circumscribes the stressed syllable of the adult form together with its segmental material and maps it onto a trochaic template. The presumed representation of the child is given in Figure 2 (‘S’ denotes the prominent position and ‘W’ the non-prominent position within the foot):
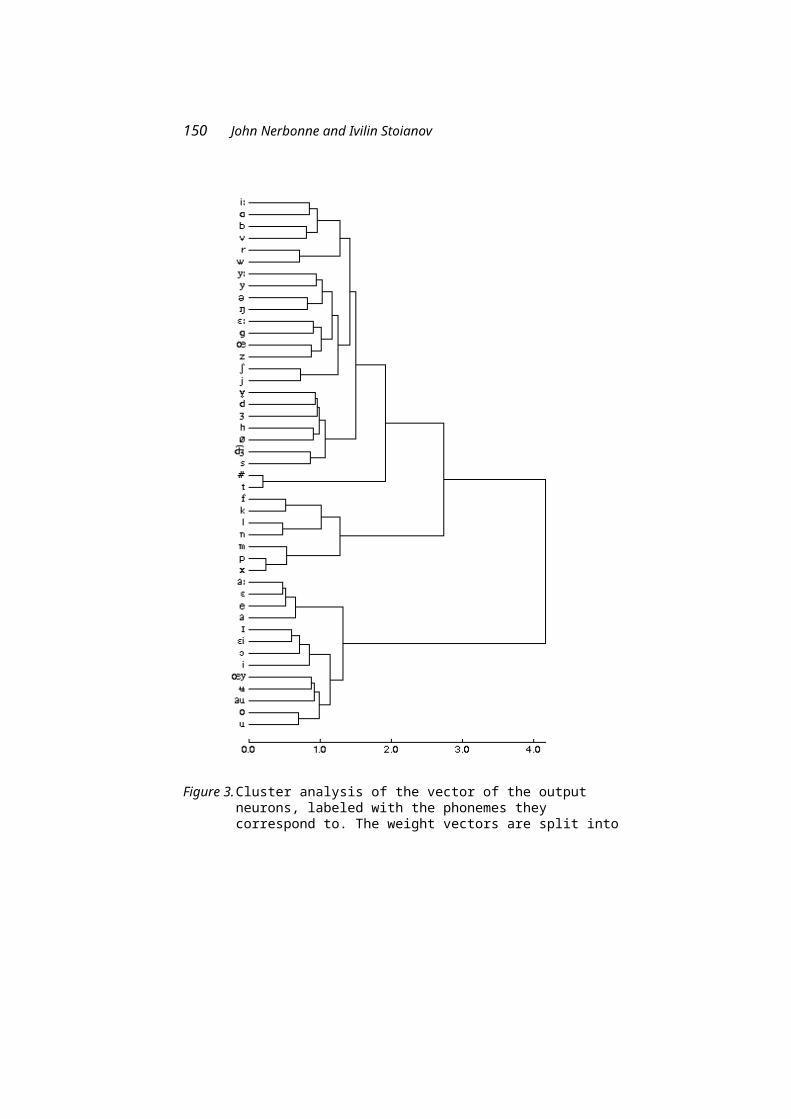
150 Angela Grimm
Wd
F
S W
Figure 5. The prosodic representation at stage 1
Prosodic circumscription forces the child to divide the input into two parts, the kernel (i.e. the stressed syllable) and the residue. In the mapping process, the kernel () is mapped onto the strong position in the prosodic template. The residue (//) becomes truncated because there are no empty positions in the template. The mapping onto the trochaic template accounts for the fact that, if the result of prosodic circumscription is a monosyllabic foot, sometimes a syllable is added to receive a disyllabic output, for example instead of .
Stage 2
At stage 2, the child circumscribes a trochaic foot. Thus, if the prosodic circumscription already results in a trochee as in / ‘holiday’, the trochee remains unchanged in the output and appears as . Words consisting of more than a single foot are circumscribed differently. Fikkert argues that the child selects the next stressed syllable to the left in addition to the stressed final syllable. For instance, Dutch / ‘crocodile’ should be realized as because the ultimate, main stressed syllable and the antepenultimate, secondary stressed syllable are kept. The disyllabic representation is then mapped onto the trochaic template resulting in a trochaic pattern. Since the production template still consists of one single trochaic foot, stress shifts to the initial syllable. The representation of the child is depicted in Figure 3:

Prosodic Acquisition: a Comparison of Two Theories 151
Wd
F
S W
Figure 6. The prosodic representation at stage 2
Stage 3
At stage 3, the productions are extended to two feet. According to Fikkert, the children have noticed that the target words can consist of more than a single foot. She claims that her subjects realized two syllables of the target word with equal prominence (level stress). However, her argument for the level stress stage is rather weak: she stipulates that the children have to produce two equally stressed feet because they are unable to realize stress at word level.
The prosodic representation at stage 3 is depicted in Figure 4 below:
Wd
F F
S W S W
Figure 7. The prosodic representation at stage 3
Since the trochaic foot still governs the productions, weak positions in the template can be filled with extra syllables.

152 Angela Grimm
Stage 4
The representations are now adult-like. The word level stress has been acquired and the child is able to operate at the level of the prosodic word.
3.2. Demuth & Fee (1995)
Demuth & Fee propose a more abstract approach which, although primarily based on data of English acquiring children, aims to capture the prosodic development universally. The basic assumption in Demuth & Fee’s model is that prosodic development goes along the prosodic hierarchy (see Figure 1). In contrast to Fikkert, Demuth & Fee avoid the notion of prosodic circumscription and trochaic template mapping. According to them, sensitivity to the moraic structure of the mother tongue is already there from the onset of word production on. They distinguish between the following stages:
Stage 1
The first stage is characterized by sub-minimal (monomoraic) words. The productions consist of a single CV-syllable and there are no vowel length distinctions yet. Thus, the phonological representation of the words also is CV.
Stage 2
At stage 2, children realize words of foot-size (Minimal Words). Stage 2 is characterized by three successional sub-stages: at the beginning, the foot is disyllabic as for example in ‘papa’. Second, as soon as the child is able to produce coda consonants the foot can also have a monosyllabic form, e.g. ‘duck’. Third, the vowel length distinction becomes phonemic. The child is now aware of the fact that the stressed syllable of Dutch ‘banana’ has to be realized with a long vowel , while in ‘giraffe’ the second vowel remains short (examples from Robin, see Fikkert, 1994). Demuth & Fee assume a direct relationship between distinctive vowel length and the appearance of coda consonants. Thus, a CVV structure counts as sub-minimal, and a CVVCVV structure as minimal as long as the child does not produce coda consonants.

Prosodic Acquisition: a Comparison of Two Theories 153Stage 3
Beyond the minimal word stage, syllable structure can be more complex and words can have a larger size than a single foot. This is also the stage where the largest progress in the development of the word stress is predicted. The child seems to become aware that feet have to be stressed and that there are language-specific stress rules. Demuth & Fee do not assume a trochaic template. However, they adopt Fikkert’s assumption of an obligatory intermediate stage of level stress where two feet are produced with primary stress.
At the end of stage 3, children acquire stress at the word level and they realize one primary stress per word.
Stage 4
At the final stage, extrametrical (i.e. unfooted) syllables are permitted. Children at this stage operate at the level of the prosodic word.
4. Discussion of the models
Although both models can explain a number of frequently observed patterns like syllable deletions and word size restrictions, there are a number of empirical and theoretical problems related with the models.
First, Fikkert and Demuth & Fee assume that the prosodic development proceeds bottom-up, i.e. from a lower level of representation (the foot or the mora) to the top of the prosodic hierarchy (the prosodic word). Children invariably have to pass trough one stage before they can go to the next. For example, multisyllabic words like ‘elephant’ or ‘crocodile’ have to show a level stress pattern before they can be produced adult-like.
Fikkert explicitly points to that fact. Missing evidence in her data is explained by the recording modalities or is due to the fact that a given stage took a very short time. Demuth & Fee, in contrast, are not explicit with respect to the ordering of the stages. However, they claim that prosodic development proceeds along the prosodic hierarchy. Since in the prosodic hierarchy one constituent strictly dominates the constituent below, stages cannot vary with respect to their temporal order. According to the models, the following realizations for / ‘crocodile’ of Jule, a girl acquiring German, should be chronologically impossible (data from my own corpus):

154 Angela Grimm
Example 2.
child form age description (1;08,12) the main stressed syllable is realised (1;08,29) a foot with final stress is realized (1;10,14) level stress emerges
As the examples illustrate, level stress can occur after a finally stressed variant of the target word was produced, contrary to the predictions of the models. Such an acquisition order provides empirical evidence against level stress as an obligatory component of prosodic development. Additional empirical support comes from the data of English acquiring children examined by Kehoe & Stoel-Gammon (1997) who also could not find a systematic emergence of level stress.
Level stress as assumed in the models above is problematic also from a grammatical point of view: the representation intended to create level stress (see Figure 4 above) essentially violates the strict layer hypothesis because the two feet are not correctly bounded into the prosodic word. The problem is that the strict layer hypothesis never can be kept by such a representation because there is no gradation in prominence at the word level. According to prosodic theory, two equally stressed feet must not occur within a single prosodic word:
*Wd
FS FS
S W S W
Figure 8. The ill-formed representation of the prosodic hierarchy as implied by Fikkert (1994) and Demuth & Fee (1995)
Both models remain vague with respect to the source of level stress: it is unclear how the stages of level stress fit to the assumption that prosodic development is directed by universal prosodic principles. Since they do not discuss the possibility of a child-specific representation, the representation according to the prosodic hierarchy should look like illustrated in Figure 6:

Prosodic Acquisition: a Comparison of Two Theories 155
Wd Wd
FS FS
S W S W
Figure 9. A prosodic representation that incorporates the requirements of the prosodic hierarchy and that allows for level stress
The representation in Figure 6 admits the co-occurrence of two equally stressed feet because every foot projects its own prosodic word. The drawback is that this assumption is ad hoc. There is no motivation for separating a single prosodic word like Dutch / ‘crocodile’ into two prosodic words. In addition, it is an open question which factors could trigger the merging of the two prosodic words into a single one later.
Another problem is that the models described above are primarily based on truncation patterns in multisyllabic words. This is critical from a methodological point of view because it is presupposed that the truncation of syllables is exclusively triggered by prosodic size restrictions. Recent evidence, however, suggests that segmental properties of syllables can also affect the truncation rate. For example, syllables with sonorant onsets seem to be more prone to truncation than syllables with obstruent onsets (Kehoe & Stoel-Gammon 1997).
A comparison of both models suggests that the predictions of the template mapping model of Fikkert (1994) are sometimes too strong. Thus, the prosodic hierarchy model of Demuth & Fee (1995) seems to be superior because of its greater flexibility. First of all, it prevents Fikkert’s circular process of assigning a trochaic structure via prosodic circumscription that actually should be created by the foot template. Furthermore, the prosodic hierarchy model allows for more variability in the productions of children. For example, it allows for the co-occurrence of monosyllabic and disyllabic feet in contrast to Fikkert’s model that only proposes disyllabic trochees for a very long period of time. As the data of children acquiring English suggest, there are doubts on Fikkert’s view that the disyllabic trochee is the unique representation at the early stages (Kehoe & Stoel-Gammon, 1997;

156 Angela Grimm
Salidis & Johnson, 1997). Moreover, Fikkert predicts a systematic stress shift to the left in disyllabic iambs, a pattern that still needs empirical evaluation. It is also possible that stress shift is rather the result of a complex interplay of factors like edge preferences, weight sensitivity and segmental factors than of a simple template mapping mechanism. If this is true, stress shift can be bidirectional to the left or to the right, depending on the relative importance of the factors involved.
Fikkert’s model is more detailed than the model of Demuth & Fee. It is at best elaborated for stage 1 and 2. With respect to the later stages she remains somewhat inconsistent. For example, she strongly argues for the foot as the relevant prosodic unit, but already at stage 2 the syllable, not the foot, becomes the target of circumscription:
“[...] the child realises both syllables of the target word. However, stress falls on the first syllable. The segmental material of both syllables of the adult word is taken out and mapped onto the child’s trochaic template [...]” (p. 210).
Fikkert also considers the possibility of circumscribing a foot. She concludes that the children circumscribe syllables because the surviving syllables do not constitute a foot in the adult word. But the examples she presents (p. 211) do form two feet within a weight-sensitive model, with each foot containing at least two moras (Example 3):
Example 3.
child form adult target gloss ‘elephant’ ‘pelican’ ‘locomotive’ ‘farm’
Fikkert cannot account for this fact because she exclusively assumes weight-insensitive trochees at stage 2. Demuth & Fee’s model, in contrast, would allow for the retention of the foot as the relevant unit since it assumes sensitivity to syllable weight with the emergence of the foot structure.
Demuth & Fee, in contrast, have problems to explain the stress shift to the first syllable in the examples above for two reasons: first, recent evidence suggests that the relationship between distinctive vowel length and the emergence of coda consonants is not as categorial as they claim. In an examination of Fikkert’s data, Salidis & Johnson (1997) found that,

Prosodic Acquisition: a Comparison of Two Theories 157contrary to their English acquiring child, the vowel length was not controlled by the Dutch children even if they correctly produced coda consonants. If in turn, children cannot control vowel length appropriately, they cannot assign two moras to a long vowel. The authors relate the divergence between the languages to the impact of vowel quantity on the stress pattern: in English, the long vowels in (C)VV(C) syllables count as heavy and thus attract stress, contrary to Dutch which rather relies on the open-closed distinction. In Dutch, a (C)VC syllable counts as heavy, while a (C)VV does not. Thus, a learner of Dutch presumably does not rely on vowel length as an indicator for stress, while it is crucial for a learner of English to identify the relationship between vowel quantity and stress. Second, given that the absence of the vowel length distinction is an artifact of the investigation and children have mastered the vowel length distinctions if they produce bimoraic feet. Then neither universal nor language-specific constraints could account for the fact that the superheavy finals lose their primary stress in favor of the less heavy ultimates because Dutch follows the universal generalization that a (C)VCC (e.g. //) or a (C)VVC (e.g. //) syllable is heavier than a (C)VV syllable (//,//).
The observation that Dutch children need more time to acquire vowel length distinctions indicates that language-specific properties may influence the prosodic representation in a more detailed way than assumed so far. Thus, further empirical work is needed to shed light on the interplay of universal principles and language-specific conditions in prosodic development.
5. Conclusion
In the present paper, two models of prosodic development are introduced and examined. As they evidence, the acquisition of word prosody largely conforms to the prosodic hierarchy in such a way that universal prosodic constituents as the foot or the mora govern children’s word productions. This is essential in both models. However, it has turned out in the discussion that there are empirical, theoretical and methodical shortcomings. Common problems of both accounts are the absence of empirical and theoretical motivation of level stress and the reliance on truncations as the primary diagnostics of prosodic development.
In sum, the evidence so far rather supports the prosodic hierarchy model of Demuth & Fee (1995) because it is more flexible than Fikkert’s template mapping model.

158 Angela Grimm
References
Demuth, K. (1996). The prosodic structure of early words. In: J. Morgan & K. Demuth (eds.) From signal to syntax: Bootstrapping from speech to grammar in early acquisition. Lawrence Erlbaum Associates, Hillsdale, N.J., 171-184.
Demuth, C. & Fee, J. (1995). Minimal words in early phonological development. Ms., Brown University and Dalhousie University.
Fikkert, P.M. (1994). On the acquisition of prosodic structure. Holland Institute of Generative Linguistics, Dordrecht,
Hayes, B. (1991). Metrical stress theory: principles and case studies. Ms, UCLA.
Hayes, B. (1995). Metrical stress theory. Chicago University Press, Chicago.Johnson, J. & Salidis, J.S. (1997). The production of minimal words: A
longitudinal case study of phonological development. Language Acquisition, 6 (1): 1-36.
Kehoe, M. & Stoel-Gammon, C. (1997). The acquisition of prosodic structure: An investigation of current accounts of children’s prosodic development. Language, 73 (1): 113-144.
Ota, M. (2001). Phonological Theory and the Development of Prosodic Structure: Evidence from Child Japanese. Available at http://www.ling.ed.ac.uk/~mits/downloadables.shtml
Selkirk, E. (1980). The role of prosodic categories in English word stress. Linguistic Inquiry, 11: 563-605.
Selkirk, E. (1984). Phonology and Syntax: The relation between Sound and Structure. MIT Press, Cambridge, MA.

Base-Identity and the Noun-Verb Asymmetry in Nivkh
Hidetoshi Shiraishi
1. Introduction
1.1. Background
Morphologically complex words often exhibit phonological similarities with their morphologically related base forms which they are derived from. In a number of cases, these similarities yield a marked phonological pattern given the general rules or phonotactics of the language (Kenstowicz, 1996; Burzio, 1997, 2002 etc.). In Optimality-Theory (OT), similarity between existing words is captured by Output-to-Output (OO) correspondence constraints (Burzio, 1996, 2002; Kenstowicz, 1996, 1997; Benua, 1997ab; Ito and Mester, 1997; Steriade, 2000 etc.). The marked phonological pattern arises when similarity between words takes priority over the canonical phonology of the language. OT expresses this situation by ranking OO-correspondence constraints above phonological markedness constraints. OO-correspondence constraints evaluate the output candidates and select the one which is most similar to the base.
Since the base plays a crucial role in computing the phonology of its derivatives, it is important to identify the correct surface form as the base. Many authors have observed that OO-constraints have access to the base only if the latter occurs as an independent word (Kenstowicz, 1996; Benua, 1997a; Ito and Mester, 1997).32 Consider the s-voicing observed in the northern dialects of Italian. In these dialects, s and z are in complementary distribution. Z appears intervocalically, when the flanking vowels belong to the same phonological word (examples from Kenstowicz, 1996: 373-374).

160 Hidetoshi Shiraishi
1.1a. a[z]ola ‘button hole’
a[z]ilo ‘nursery school’ca[z]-a ‘house’ca[z]-ina ‘house - diminutive’
b. lo [s]apevo ‘I knew it’telefonati [s]i ‘having called each other’
The distribution of s-voicing in lexical items containing a prefix is more complicated. When the target precedes the boundary, s-voicing applies (1.2a). But when the target follows the boundary, s-voicing may or may not apply, even if the structural description of s-voicing is met (1.2b, c).
1.2a. di[z]-onesto ‘dishonest’
di[z]-ugale ‘unequal’b. re-[z]istenza ‘resistance’
pre-[z]entire ‘to have a presentiment’c. a-[s]ociale ‘asocial’
bi-[s]essuale ‘bisexual’pre-[s]entire ‘to hear in advance’
The unexpected blocking of s-voicing in 1.2c is in sharp contrast with the items in 1.2b where z surfaces intervocalically, following the phonological norm of the language. Nespor and Vogel (1986) pointed out that the crucial difference between the items in 1.2b and 1.2c lies in the lexical status of the stem to which the prefix is attached; in 1.2c the stem occurs as an independent word (sociale, sessuale, etc.) whereas in 1.2b it does not (*sistenza, etc.). Following this view, Kenstowicz (1996) claimed that there is a lexico-morphological pressure from the independently occurring stem to surface its derivative as similar as possible. The presence of such an independently occurring immediate constituent is thus crucial in computing the phonology of a morphologically complex item. Kenstowicz dubbed this generalization Base-Identity; the base forces its derivative to be formally as similar as possible in order to “improve the transparency of morphological relationships between words and enhance lexical access” (Kenstowicz, 1996: 372).

Base-Identity and the Noun-Verb Asymmetry in Nivkh 1611.3 Base-Identity: Given an input structure [X Y] output candidates are
evaluated for how well they match [X] and [Y] if the latter occur as independent words. (Kenstowicz, 1996: 372)
The languages in East Asia provide an interesting test for this generalization. Languages as Korean or Japanese show a systematic difference in the composition of verbs and nouns; while verbal stems always surface with a morphological extension, nominal stems may surface without such an extension. This means that complex words formed from a nominal stem always have an independently occurring base to which they phonologically should conform, whereas verbal derivatives lack such a base and hence should not show such conformity. This prediction is borne out in Korean in which derivatives of nominal and verbal stems are subject to different phonology (Kenstowicz, 1996. See section 2.3 below.). In this paper, I discuss another language of East Asia, Nivkh, which also has an asymmetric composition of nouns and verbs like Korean and Japanese. I will focus on two phonological phenomena, Consonant Alternation and Final Fricative Devoicing and show that both phenomena exhibit asymmetries between nominal and verbal phonology. I will discuss each case in detail and argue that Base-Identity is the driving force of these asymmetries.
The article is organized as follows. I will start with a descriptive sketch of Consonant Alternation (section 2.1) and then illustrate the exceptional behavior of nominal stems as a case of noun-verb asymmetry (section 2.2). While most previous works, including my own, somehow stipulated the asymmetric behavior of nominal and verbal stems, I will argue that Base-Identity provides a superior analysis which is free from such a stipulation. Section 3 discusses the second phenomenon, Final Fricative Devoicing. I will illustrate the asymmetric behavior of fricative-final nominal and verbal stems when followed by a suffix. The pattern of asymmetry is as in CA: while verbal phonology is subject to canonical phonology, nominal phonology is not. Section 4 concludes.
1.2. About Nivkh
Nivkh (also called Gilyak) is an isolated language spoken by the people of Nivkh, who live on the island of Sakhalin and in the lower reaches of the Amur River in the Russian Far East. The language has four dialects and the

162 Hidetoshi Shiraishi
major discrepancy is between the Amur dialect, spoken in the Amur area on the continent and the west coast of north Sakhalin, and the Sakhalin dialect spoken in the east coast of Sakhalin. Nivkh is listed in the UNESCO Red Book on endangered languages as being seriously endangered. According to the census of 1989, the percentage of speakers is 23, 3% of the total population of 4,681.33 This article concerns the phonology of the Amur dialect spoken by the continental Nivkh. All the examples are from the following sources, unless otherwise mentioned: Krejnovich (1937), and Saveleva and Taksami (1970).
2. Consonant Alternation
2.1. A descriptive sketch
I will first outline the segmental inventory of Nivkh.
2.1 Consonantal inventory of Nivkh(I) aspirated plosives p t c k q(II) non-aspirated plosives p t c k q(III) voiceless fricatives f r s x (IV) voiced fricatives v r 34 z
nasals m n lateral lglides j h
2.2 Vowelsi u e o a
33 See www.let.rug.nl/~toshi/ for more information.34 The rhotic r of Nivkh is classified here and elsewhere in the literature (e.g.
Trubetzkoj 1939) as a voiced fricative since it patterns as such in the CA system. Its voiceless counterpart r is an apical trill containing portions without vocal cord vibration (Ladefoged and Maddieson 1996: 236).

Base-Identity and the Noun-Verb Asymmetry in Nivkh 163Consonant Alternation (henceforth CA) is a phonological process which changes the feature [continuant] in obstruents when they are placed in certain phonological and morphosyntactic contexts. Descriptively, CA consists of two processes: spirantization, in which a plosive changes to a fricative, and hardening, in which a fricative changes to a plosive. Laryngeal features are also relevant since aspirated plosives only alternate with voiceless fricatives and non-aspirated plosives with voiced fricatives, i.e. the alternation is strictly between the obstruents of row (I) and (III), or (II) and (IV).35, 36
2.3 Spirantization: (I) > (III), (II) > (IV)a. (I) > (III) maca [r]om (< tom) ‘fat of a seal’
seal fatcoli []os (< qos ) ‘neck of a reindeer neck reindeer’
b. (II) > (IV) peq [v]x (< px ) ‘chicken soup’chicken soupmaca [z]us (< cus) ‘meat of a seal’seal meat
2.4 Hardening: (III) > (I), (IV) > (II)a. (III) > (I) cxf [q]a- (< a-) ‘to shoot a bear’
bear shootcus [t]a- (< ra-) ‘to bake meat’meat bake
b. (IV) > (II) tux [k]e- (< e-) ‘to take an axe’axe takepnnx [t]u- (< ru-) ‘to teach one's one's sister teach sister’
The phonological contexts of spirantization and hardening are in complementary distribution. Spirantization takes place when the target (plosive) follows a vowel, a glide, or a plosive (2.5). There is no spirantization when the target follows a fricative or a nasal (2.6).
2.5 Spirantization Preceding segmentVowel maca [r]om ‘fat of a seal’Glide knraj [r]om ‘fat of a duck’
knraj [v]x ‘duck soup’

164 Hidetoshi Shiraishi
Plosive t [r]om ‘fat of a species of duck’
amsp [v]x ‘soup of a species of seal’
2.6 No spirantizationFricative cxf tom ‘bear fat’
cxf px ‘bear soup’Nasal ke ti ‘sun ray’
rum df ‘Rum(person)’s house’
On the other hand, hardening occurs when the target (fricative) follows either a fricative or a nasal (2.7). When a segment other than fricative precedes the target, hardening does not occur (2.8).
2.7 Hardening Preceding segmentFricative cxf [q]a- (< a-) ‘to shoot a bear’
lovr [c]osq-(< zosq-) ‘to break a spoon’Nasal qan [d]u-37 (<ru-) ‘to teach a dog’
2.8 No hardeningVowel a- ‘to shoot an otter’
ma ra- ‘to bake dried fish’Plosive t a- ‘to shoot a species of
duck’Glide kj seu- ‘to dry a sail’
Although phonological conditions of these alternations seem to be complex, it turns out to be less so once we focus on the output strings they create. Namely, the accomplished segmental sequence is always vowel-fricative, glide-fricative, plosive-fricative on the one hand and fricative-plosive, sonorant-plosive on the other. In sum, spirantization and hardening conspire to achieve the segmental sequences illustrated below.
2.9 Structural goals of spirantization and hardeninga. vowel
glide fricativeplosive

Base-Identity and the Noun-Verb Asymmetry in Nivkh 165
b. fricativenasal plosive
Whether this sequence is accomplished by spirantization or hardening is a matter of input. Spirantization activates when a plosive is in the input, whereas hardening activates when a fricative is in the input. In the past, many approaches have overlooked this generalization and described the rules as if they had independent structural goals. This is not the case.
Let us now move to the morphosyntactic conditioning. CA targets a segment at the left edge of a derived morphosyntactic unit in the presence of a preceding segment. CA applies cyclically to every left edge of a morpho-syntactic unit until the maximal projection (NP, VP) is reached.
2.10 Means of derivationPrefixation p-[r]u (< tu) ‘one’s own sledge’
REF-sledgePostposition tx-tox ‘towards the top’
top-ALLtu-rox ‘towards a lake’qan-dox ‘towards a dog’
Reduplication tk[r]k- ‘to be silent’(Sakhalin dialect, Hattori, 1962: 107)
NP formation maca [r]om ‘fat of a seal’VP formation cxf [q]a- (< a-) ‘to shoot a bear’
On the other hand, CA never targets segments in a non-derived environment, nor does it apply across XP boundary, as shown in 2.11 and 2.12, respectively.
2.11 CA does not apply in non-derived environmentutku *ut[]u ‘man’ns *n[c] ‘teeth’
2.12 No CA across XP boundary (subject-predicate)el ro- ‘The child holds (something)’= [NPel] [VPro-] (‘child’ is subject)

166 Hidetoshi Shiraishi
Example 2.13 below differs minimally from example 2.12 above with respect to the application of CA. In the former, CA applies since the noun is the object of the following predicate. Thus these two words form a VP, differing minimally from example 2.12.
2.13el [t]o- ‘(Someone) holds the child’= [VP[NPel][V to-]] (‘child’ is object)
2.2. The spirantization – hardening asymmetry
There is one environment in which the regular pattern of CA as depicted above fails to apply. Nouns beginning with a fricative never undergo hardening. In such a case, the structural goal of CA (2.9) is not achieved. In this context the otherwise illicit fricative-fricative or nasal-fricative sequence appears.
2.14a. tulv vo *tulv [b]o ‘winter village’
winter villageb. cr vox *cr [b]ox 'a hill covered with grass'
grass hillc. tf r *tf [t] ‘entrance door’
house doord. te vaqi *te [b]aqi ‘coal box’
coal box
Previous works have either described this context as an exception to CA, or did not discuss it. In most cases, these works simply stipulated that a) nouns do not undergo hardening, or alternatively b) only transitive verbs undergo hardening. Once stated as a condition this way, the application of hardening to nouns can indeed be avoided. However, adding such a condition (in either form) to a phonological rule pairs prosodic phonology with specific category labels (transitive verb, noun), which is unlikely to occur in natural languages (Nespor and Vogel, 1986; Selkirk, 1986 etc.).38 But most critically, it is explanatorily unsatisfying; why should hardening be

Base-Identity and the Noun-Verb Asymmetry in Nivkh 167restricted to transitive verbs (or alternatively, why should nouns be an exception to hardening)? No literature provides a satisfactory answer to this question.
The tacit assumption prevailing in the previous works is that the input to CA is the citation form, i.e. the form that appears in isolation. Following this assumption, the transitive verbs ought to undergo hardening since they initiate with a fricative in the citation form. However, there is no a priori reason that the citation form should be the underlying form. In Shiraishi (2000), I defended the position that the citation form of these transitive verbs cannot be the underlying form, if we want to advocate a phonologically plausible analysis for the observed spirantization-hardening asymmetry. The lack of hardening in nouns could be interpreted as evidence that CA consists solely of spirantization, without hardening. I argued that transitive verbs of Nivkh initiate with a plosive at the underlying level, instead of a fricative that appears in the citation form. Initiating with a plosive, transitive verbs now undergo spirantization in the same way as nouns do.39, 40
2.15Previous analyses Shiraishi (2000)
VP 'shoot a bear'
NP 'bird soup' VP 'shoot a bear'
NP 'bird soup'
Underlying form
cxf a- peq px cxf qa- peq px
Spirantization not applicable
peq [v]x blocked peq [v]x
Hardening cxf [q]a- not applicableSurface form cxf qa- peq vx cxf qa- peq vx
The analysis in Shiraishi (2000) leaves hardening out of the list of phonological processes; nouns do not undergo hardening since there is no hardening in the phonology of the language.

168 Hidetoshi Shiraishi
2.16Previous analyses
Shiraishi (2000)
Underlying form
tulv vo tulv vo
Spirantization not applicable not applicableHardening tulv [b]oSurface form tulv bo tulv vo : incorrect output
This analysis is free from category-specific specification in the structural description of the rule, which was inevitable in the previous analyses.
Although this analysis explains nicely why fricative-initial nouns never undergo hardening in Nivkh, it is not without problems. First, it manipulates the underlying form of a specific lexical category (transitive verb) in order to explain phonologically exceptional behavior. Although such a 'prespecification' at the underlying level is not an uncommon way to approach phonological exceptions (cf. Inkelas, Orgun and Zoll, 1997 amongst others), such an approach does not explain why only this particular class of words needs to undergo such manipulation. Since prespecification puts unpredictable information into the lexicon, it is a strong descriptive device which leaves little space for phonological generalizations. Contrary to what seems to be the case at first glance, the analytical gain of Shiraishi (2000) from previous analyses is not so obvious. One may ask correctly what the difference between the two analyses is, which claim that a) nouns are exceptions to hardening (previous analyses) or b) transitive verbs undergo spirantization because they initiate with plosives underlyingly (Shiraishi 2000). In other words, it remains an arbitrary choice that only transitive verbs, and not other categories, undergo prespecification.
Secondly, the relationship between the underlying form and the citation form is obscured in transitive verbs. By positing a form other than the citation form as the underlying form, the citation form would always be derived from the underlying form by some morphological operation. That is, Shiraishi (2000) created asymmetry between the morpholexical make-up between nominal and verbal stems.
2.17Nominal stem Verbal stem
Underlying form px qa-

Base-Identity and the Noun-Verb Asymmetry in Nivkh 169
Surface form px a-
In fact, this asymmetry describes the historical path of derivation of transitive verbs (Jakobson, 1957; Austerlitz, 1977). On synchronic grounds, however, it is highly doubtful whether such a morphological operation can be justified.
In the next section I propose an alternative approach to the spirantization-hardening (or noun-transitive verb) asymmetry, which makes use neither of prespecification nor of information about category labels. Instead, I will argue that correspondence relation between output forms plays a decisive role in distinguishing the phonological behavior of the two groups. Once stated this way, nothing ought to be stipulated in order to derive the surface form; this follows naturally from the phonological principles of the language.
2.3. Noun-verb asymmetry as Base-Identity
In Nivkh, verbal and nominal stems differ from each other in one crucial morphological aspect; verbal stems should always end in a morphological extension but nominal stems do not. Or put differently, verbal stems never surface in isolation, whereas nominal stems do. This means that bare verbal stems cannot function as citation forms. Usually, the form with an infinitival suffix (-d, -t) provides the citation form.
2.18Stem /a/ ‘to shoot~’ /ro/ ‘to take’Infinitive a-d ro-d(citation form)‘when~’ a-an ro-an
2.19/vo/ ‘village’ /ota/ ‘town’
Citation form vo otaAllative vo-rox ota-rox
As mentioned in section 1, independent forms often exercise special influence on the realization of morphologically related forms in derived contexts. For instance, in certain varieties of English the existence of the

170 Hidetoshi Shiraishi
form condense guarantees that the vowel of the second syllable in the morphologically related word condensation does not reduce to a schwa.
2.20cond[]nsation comp[]nsationcond[]nse comp[]nsate
Phonology would expect the unstressed vowel of condensation to surface with a schwa, as is the case with the structurally similar compensation. The usual explanation for this asymmetry is that the vowel reduction in condensation is blocked by virtue of the existence of the morphologically related form condense, which appears with a full vowel [] (Chomsky and Halle, 1968: 110-116). On the other hand, compensation lacks such a morphologically related form with a full vowel. Hence unstressed vowel reduces to a schwa, following the phonological norm of the language.
Another example comes from Korean. In Korean a stem-final consonant cluster surfaces only when it is followed by a vowel-initial suffix. In combination with a consonant-initial suffix, the cluster is simplified to a single consonant (Kenstowicz, 1996: 375).
2.21Stem /kaps/ ‘price’ /talk/ ‘chicken’Citation form kap takNominative kaps-i talk-iComitative kap-k'wa tak-k'wa
In the speech of younger generation of Seoul, however, simplification over-applies to contexts where vowel-initial suffix follows the stem.
2.22Nominative kap-i tak-i
Interestingly, this overgeneralization does not apply to verbal stems. Here the consonant cluster surfaces.
2.23Stem /ps/ ‘not have’ /palk/
‘be bright’Past-informal ps-ss- (*p-ss-) palk-ss-

Base-Identity and the Noun-Verb Asymmetry in Nivkh 171
(*pak-ss-)Non-past-formal p-t'a pak-t'a
Kenstowicz analyzed the absence of the cluster simplification in verbal stems to be due to a lack of corresponding citation forms. As in Nivkh, verbal stems in Korean never appear in isolation; they should always appear with an inflectional ending. In contrast, nominal stems are free to appear without any inflectional ending, so they exercise strong influence on the realization of their derivatives. Verbal stems, on the other hand, surface with consonant clusters since there are no isolated counterparts which forces conformity to it. This is an instance of Base-Identity, which requires forms in derived contexts to be formally similar to the base. This is the generalization captured in the Base-Identity constraint of Kenstowicz (1.3), repeated below.
2.24 (=1.3) Base-Identity: Given an input structure [X Y] output candidates are evaluated for how well they match [X] and [Y] if the latter occur as independent words. (Kenstowicz, 1996: 372)
We can account for the noun-verb asymmetry in Korean using Base-Identity as a high-ranked constraint. By ranking Base-Identity above a faithfulness constraint which prohibits deletion of a segment in the input (MAX), nominal stems surface with a single consonant in concordance with the base.
2.25constraints /kaps+i/ base: kapcandidates
Base-Identity *CLUSTER MAX
kapsi *!kapi *
Base-Identity is vacuously satisfied in verbal stems. Since there is no base to which verbal stems should conform, verbal stems exhibit canonical phonology. Consonant clusters surface only if a vowel-initial suffix follows, elsewhere they are simplified. A phonological markedness

172 Hidetoshi Shiraishi
constraint *CLUSTER penalizes every output candidate containing a tri-consonantal cluster.
2.26constraints /ps+ss+/ base: ø candidates
Base-Identity *CLUSTER MAX
ps-ss-p-ss- *!
2.27constraints /ps-t'a/ base: ø candidates
Base-Identity *CLUSTER MAX
ps-t'a *!p-t'a *
The noun-verb asymmetry of hardening in Nivkh is strikingly similar to the case of Korean. As in Korean, verbal stems of Nivkh are not allowed to surface in isolation; they always require a morpho-syntactic extension (2.18). This is in contrast to nominal stems, which may surface in isolation (2.19). The difference is reflected directly in their phonological behavior; verbal stems undergo hardening, nominal stems do not. In the next section I will show how this analysis formally works.
2.4. Base-Identity blocks hardening
I assume that the phonological markedness constraint that induces hardening to be the Obligatory Contour Principle (OCP) [fric].41 OCP [fric] prohibits adjacent fricatives. Base-Identity, as defined in the previous section, prefers output candidates which are similar to the base. With the ranking Base-Identity >> OCP [fric], we obtain the desired output; hardening does not apply to nominal stems.
2.28

Base-Identity and the Noun-Verb Asymmetry in Nivkh 173constraints /tulv vo/ base: vo candidates
Base-Identity OCP [fric] IDENT [cont]
tulv vo *tulv bo *! *
Base-Identity is satisfied vacuously in verbal stems since they lack a base. Being free from Base-Identity, an initial fricative now hardens to a plosive in order to circumvent an OCP violation.
2.29constraints /cxf a-/ base: ø candidates
Base-Identity OCP IDENT [cont]
cxf a- *!cxf [q]a- *
Since Base-Identity refers to the base and not to the input, this ranking always derives the correct output no matter of the input value. This is illustrated in the tableau below in which the verbal stem initiates with a plosive in the input (cf. Shiraishi, 2000).
2.30constraints /cxf qa-/ base: ø candidates
Base-Identity OCP IDENT [cont]
cxf qa-cxf []a- *! *
The present analysis correctly derives the observed output no matter of the input. There is thus no prespecification, in which input strings are fixed to take a particular form. Nor does it make use of information of category labels, a condition that was inevitable in previous descriptions in order to let hardening apply appropriately. The current analysis makes a totally different claim. There is no exception to the hardening rule (nominal stems), nor should the specific undergoer (verbal stems) be prespecified at

174 Hidetoshi Shiraishi
the underlying level. Rather, the asymmetry of nominal and verbal stems follows from the existence of a base, which is an independent fact of the language. By making use of such morpho-lexical information, the current analysis accounts for the noun-verb asymmetry without appealing to language-specific stipulations.
3. Final Fricative Devoicing
Base-Identity plays a crucial role in another phonological phenomenon of Nivkh. In this section, I will discuss such a case.
3.1. Distribution of laryngeal features
Like Danish, a full contrast of laryngeal features of Nivkh obstruents is realized only at the stem-initial position, which is the most prominent position as in many other languages (cf. Beckman, 1996). In other positions, laryngeal features do not exercise a phonemic contrast and the feature value at the surface level is predictable from the context (Jakobson, 1957: 83). In principle, non-prominent (stem-medial and final) positions only allow non-aspirated plosives and voiced fricatives. Aspirated plosives and voiceless fricatives, on the other hand, are excluded from these positions. Following Jakobson (1957), I will call them the lenis and fortis series, respectively.
3.1Lenis obstruents non-aspirated plosives : p t c k q
voiced fricatives : v r z Fortis obstruents aspirated plosives : p t c k q
voiceless fricatives : f r s x
3.2pal ‘forest’ tk ‘father’pal ‘floor’ kn ‘mother’ra-d ‘to drink’ ova ‘flour’ra-d ‘to bake’ muvi ‘porridge’
eri ‘river’

Base-Identity and the Noun-Verb Asymmetry in Nivkh 175There are two exceptional contexts in which a voiceless fricative appears in a non-prominent position: i) when preceding a plosive, and/or ii) before an I[ntonational] P[hrase] boundary (Jakobson, 1957: 83).
3.3a. esqa-d ‘to hate’
taft ‘salt’kins ‘evil spirit’ kins ku-d ‘to kill an evil spirit’cxf ‘bear’cxf ku-d ‘to kill a bear’als ‘berry’als pe- ‘to pick berries’
b. nivx ‘human’erx ‘to him/her’
The examples in 3.3b indicate that it is only the absolute final position that matters; the fricative second from the right appears as voiced. In Nivkh, there are no words ending in consecutive voiceless fricatives, indicating that voicelessness is required only for the very last fricative in an IP. I assume this to be due to a restriction which I will call Final Fricative Devoicing (FFD). FFD targets every final fricative within an IP.
Stem-final voiceless fricatives appear as voiced, however, as soon as the above-mentioned conditions are removed. Thus if a stem-final fricative is embedded in an IP, i.e. not final in the domain, and if it is not adjacent to a plosive it becomes voiced (3.4a). This is in concordance with the phonotactics of stem-medial fricatives which are always voiced (3.4b) unless adjacent to a plosive. This distribution is not surprising since stem-medial fricatives are expected not to coincide with an IP-boundary.
3.4a. [kinz it-]I ‘go insane’
[cxv lj-]I 'to kill a bear'[alz a-]I ‘to pick berry’
b. ezmu- ‘to like~’urla ‘good’pala ‘red’

176 Hidetoshi Shiraishi
Outside of these two contexts, only lenis obstruents appear in non-prominent positions. Apparently, lenis obstruents have more distributional freedom than fortis obstruents, indicating their unmarked status in the phonology of Nivkh. Since non-prominent positions are predictably occupied by lenis obstruents, I assume that obstruents in these positions are unspecified for laryngeal features in the underlying form. Unless context-sensitive requirements contravene, obstruents without laryngeal specifications surface as lenis, the unmarked obstruent of the language.
3.2. Base-Identity in suffixation
Having discussed the unmarked nature of the lenis obstruents, we are now ready to look at the way FFD interacts with Base-Identity. Such a case arises when a suffix attaches to a fricative-final stem.
Like stem-medial and final positions, the initial obstruent of a suffix does not exhibit a laryngeal contrast, indicating that it is a non-prominent position. Except for a few exceptional cases, only lenis obstruents are allowed.42
3.5-tox/rox/dox allative (case suffix)-u/gu/ku plural-t/d infinitive-gu/ku causative
When affixed to a stem, the redundant [+voice] specification of the stem-final segment spreads to the initial obstruent of the suffix.
3.6ra-d ‘to drink-INF’pil-d ‘big-INF’amam-d ‘to walk-INF’ifk-t ‘to harness-INF’jup-t ‘to bind-INF’ro-gu-d ‘to help-CAU-INF’lt-ku-d ‘to do-CAU-INF’cam-gu ‘shaman-PL’cam-dox ‘shaman-ALL’

Base-Identity and the Noun-Verb Asymmetry in Nivkh 177
There is an interesting discrepancy between fricative-final nominal and verbal stems in this context; following a verbal stem, the initial segment of a suffix is always voiced (3.7a), while following a nominal stem, it is always voiceless (3.7b).
3.7a. fuv-d ‘to blow/to saw-INF’
i-d ‘to kill-INF’tv-d ‘to go inside the house-INF’jar-d ‘to feed-INF’roz-gu-d ‘to divide-CAU-INF’tmz-gu-d ‘drop-CAU-INF’
b. kins-ku ‘evil spirit-PL’cxf-ku ‘bear-PL’orr-ku ‘Uilta-PL’tf-tox ‘house-ALL’tir-tox ‘wood-ALL’
The reason of this discrepancy is not immediately clear. In particular, the final voiceless fricative of nominal stems is a mystery. Being affixed by a suffix, it is no longer in the context of FFD, so nothing prevents it from appearing in the unmarked voiced fricative. In fact, this is the case with verbal stems; final fricatives of verbal stems are systematically voiced (3.7a). The other context-sensitive requirement, namely, the precedence to a plosive cannot be the reason either since these suffixes have a voiced variant, which surfaces when following a (redundant) [+voice] segment (3.6, 3.7a). The derivatives of verbal stems in 3.7a show that the initial plosive of these suffixes can accommodate a (preceding) voiced fricative, unlike plosives in a stem. But in fact, this option is not adopted in nominal stems. In short, these context-sensitive requirements cannot explain the different behavior of final-fricatives in nominal and verbal stems.
Under Base-Identity, however, such a discrepancy is explicable. Recall that nominal and verbal stems have different morpho-lexical compositions. Nominal stems can surface without any morphological ending, making the last fricative target of FFD. In contrast, final fricative of a verbal stem is always followed by a morphological extension, making it irrelevant to FFD. Since Base-Identity claims that derivatives should phonologically conform to the base, nominal derivatives conform to their base, which ends

178 Hidetoshi Shiraishi
in a voiceless fricative (due to FFD). This is not the case, however, for verbal stems since they have no base and therefore do not underlie such pressure. As a consequence, verbal stems undergo canonical phonology and fricatives in non-prominent positions do appear as lenis, the unmarked obstruents of the language.
Finally, it is important to note that reference to laryngeal specifications using Input-to-Output correspondence constraints is not a viable option in this context. Recall that there is no laryngeal contrast in stem-final position in Nivkh. A phonological theory which minimizes the specification of predictable features in underlying representations, which is the one adopted here, makes it impossible for Input-to-Output constraints to refer to the voiceless status of stem-final fricatives.43 Thus their voicelessness should come from somewhere else. According to the current analysis it originates from the base, the independently occurring isolated form.
4. Conclusion
In this paper I have discussed phonological asymmetries between nominal and verbal stems of Nivkh, as observed in two phonological phenomena CA and FFD. Though the asymmetries themselves look very different on the surface, this article has made explicit that they are subject to a common generalization, Base-Identity. Given the asymmetric composition of nouns and verbs, Base-Identity makes two predictions: i) nominal and verbal derivatives exhibit different phonological patterns, and ii) it is the nominal stem which exhibits the non-canonical phonology given the strong pressure from the base. Both predictions were borne out in the phonological phenomena discussed above. The base plays a decisive role in computing the phonology of nominal and verbal derivatives in both CA and FFD. As for CA, the current analysis correctly predicts that nominal derivatives accommodate the otherwise illicit segmental sequence (fricative-fricative, nasal-fricative), while verbal derivatives do not. This analysis is superior to previous accounts since it makes no direct use of the notion of exception, which was inevitable in previous works. Rather, the suggested analysis relates the asymmetry in phonology to the compositional asymmetry between nouns and verbs.
As for FFD, nominal derivatives showed conformity to their base, in ending in a voiceless fricative. Verbal stems on the other hand, do not show such conformity since they lack a base. Unlike nominal derivatives, the

Base-Identity and the Noun-Verb Asymmetry in Nivkh 179stem-final fricatives of verbal derivatives appear as lenis, following the canonical phonology of Nivkh. Base-Identity provides us with the mechanism underlying the noun-verb asymmetry, and it correctly predicts their phonological behavior with respect to the canonical phonology of the language.
Acknowledgements
I would like to thank Dicky Gilbers, Angela Grimm, Maartje Schreuder, Jeroen van de Weijer and the audiences of ULCL Phonology meeting at Leiden (27-05-2003) and TABU dag (20-06-2003, Groningen) for comments on parts of this article. I bear all responsibility for errors.
Notes
References
Austerlitz, R. (1977). The study of Paleosiberian languages. In: D. Armstrong and C. van Schoonveld (eds.). Roman Jakobson: Echoes of His Scholarship. Peter de Ridder Press, Lisse, 13-20.
Beckman, J. (1996). Positional Faithfulness. PhD Dissertation, University of Massachusetts, Amherst.
Benua, L. (1997a). Transderivational Identity: Phonological Relations between Words. PhD dissertation, U.Mass, Amherst.
Benua, L. (1997b). Affix classes are defined by faithfulness. In: V. Miglio and B. Moren (eds.), 1-26.
Blevins, J. (1993). Gilyak lenition as a phonological rule. Australian Journal of Linguistics, 13: 1-21.
Burzio, L. (1996). Surface constraints versus underlying representation. In: J. Durand and B. Laks (eds.),125-144.
Burzio, L. (1997). Strength in Numbers. In: V.Miglio and B.Moren (eds.), 27-52.
Burzio, L. (2002). Missing players: Phonology and the past-tense debate. Lingua, 112: 157-199.
Chomsky, N. and M. Halle (1968). The Sound Patterns of English. Harper & Row, New York.

180 Hidetoshi Shiraishi
Durand, J. and B. Laks (eds.) (1996). Current Trends in Phonology: Models and Methods. University of Salford Publications, Salford, Manchester.
Hattori, T. (1962). Versuch einer Phonologie des Südostgiljakischen (II) - Alternation. Journal of Hokkaido Gakugei University (Sapporo), 13-2: 29-96.
Inkelas, S, O. Orgun and C. Zoll (1997). The Implications of Lexical Exceptions for the Nature of Grammar. In: I.Roca (ed.), 393-418.
Ito, J. and A. Mester (1997). Correspondence and Compositionality: The Ga-gyo Variation in Japanese Phonology. In: I.Roca (ed.), 419-462.
Jakobson, R. (1957). Notes on Gilyak. Roman Jakobson. Selected Writings II. Word and language. Mouton, The Hague and Paris, 72-102.
Kaisse, E. (1985). Connected Speech. Academic Press, Orlando.Kenstowicz, M. (1996). Base-Identity and Uniform Exponence: Alternatives to
Cyclicity. In: J. Durand and B. Laks (eds.), 365-395.Kenstowicz, M. (1997). Uniform exponence: Exemplification and extension.
In: V. Miglio and B. Moren (eds.), 139-155.Kenstowicz, M. and C. Kisserberth. (1979). Generative Phonology: description
and theory. Academic Press, New York.Krejnovich, E. (1937). Fonetika nivxskogo (giljackogo) jazyka [Phonetics of the
Nivkh (Gilyak) language]. Uchpedgiz, Moskva - Leningrad.Ladefoged, P. and I. Maddieson. (1996). The Sounds of the World’s Languages.
Blackwell, Oxford.Miglio, V. and B. Moren (eds.) (1997). University of Maryland Working
Papers in Linguistics, vol.5.Nepor, M. and I. Vogel (1986). Prosodic Phonology. Foris, Dordrecht.Roca, I. (ed.) (1997). Derivations and Constraints in Phonology. Clarendon
Press, Oxford. Rushchakov, V. (1981). Akusticheskie xarakteristiki soglasnyx nivxskogo
jazyka (avtoreferat). Ph.D.dissertation, Akademija Nauk CCCP, Leningradskoe otdelenie instituta jazykoznanija.
Savel’eva,V. and C.Taksami. (1970). Nivxsko-russkij slovar. [Nivkh-Russian dictionary] Sovetskaja Enciklopedija, Moskva.
Selkirk, E. (1986). On derived domains in sentence phonology. Phonology Yearbook, 3: 371-405.
Shiraishi, H. (2000). Nivkh consonant alternation does not involve hardening. Journal of Chiba University Eurasian Society. No.3. 89-119 (Also available at www.let.rug.nl/˜toshi/list_of_publication.htm). Abridged version has appeared in the Proceedings of the 120th meeting of the Japanese Society of Linguists, 42-47.

Base-Identity and the Noun-Verb Asymmetry in Nivkh 181Shternberg, L. (1908). Materialy po izucheniju gilijackogo jazyka i fol’klora.
In: Obrachy narodnoj slovesnosti. Vol. 1, Part I. Imper. Akademii Nauk, St.Petersburg.
Steriade, D. (2000). Paradigm Uniformity and the Phonetics-Phonology boundary. In: M. Broe and J. Pierrehumbert (eds.). Papers in Laboratory Phonology 5. Cambridge University Press, Cambridge, 313-334
Trubetzkoj, N. (1939). Grundzuge der Phonologie. Travaux du Cercle Linguistique de Prague, Prague.


The Influence of Speech Rate on Rhythm Patterns
Maartje Schreuder and Dicky Gilbers
18 The authors are particularly pleased to offer this piece to a Festschrift honoring Dr. Dr. h.c. Tjeerd de Graaf, who graciously agreed to cooperate in the supervision of Stoianov's Ph.D. project 1997-2001 at the University of Groningen. Even if Tjeerd is best known for his more recent work on descriptive linguistics, minority languages and language documentation, his early training in physics and earlier research on acoustic phonetics made him one of the best-suited supervisors for projects such as the one reported on here involving advanced learning algorithms. Tjeerd's sympathy with Eastern European languages and cultures is visceral and might have led him to agree in any case, but we particularly appreciated his phonetic acumen.
19 The distance is related to Euclidean, but more exactly the distance between the two n-dimensional vectors is
20
? The cluster analysis in Figure 3 was produced by programs written by Peter Kleiweg, available at http://www.let.rug.nl/alfa.
21 According to http://cupp.oulu.fi/neutrino/nd-mass.html, the mass of the electron neutrino (e) is less than 2.2 eV, the mass of the muon neutrino () does not exceed 170 keV, while the mass of the tau neutrino () is reported to be bellow 15.5 MeV. For the sake of comparison, the mass of an electron is 511 keV, while the mass of a proton is almost 940 MeV.

184
1. Introduction44
The topic of this paper is how rhythmic variability in speech can be accounted for both phonologically and phonetically. The question is whether a higher speech rate leads to adjustment of the phonological structure, or just to 'phonetic compression', i.e. shortening and merging of vowels and consonants, with preservation of the phonological structure. We claim that the melodic content of a phonological domain is indeed adjusted
22 Physical phenomena are thought to be reducible to four fundamental forces. These are gravity, electromagnetism, weak interaction and strong interaction. The last two play a role in sub-atomic physics.
24 Targumim (plural of targum) are the Jewish Aramaic versions of the Hebrew Bible from the late antiquity, including also many commentaries beside the pure translation. The same way as late antiquity Jews created the commented translation of the Holy Scriptures to their native tongue and using their way of thinking, Moses Mendelssohn expected his version of the Bible to fit the modern way of thinking and the “correct language” of its future readers. Obviously, the Biur should first have to fulfil its previous task, namely to teach the modern way of thinking and the “correct tongue” to the first generation of its readers. Interestingly enough, script was not such a major issue for Mendels-sohn as “language purity”, thus he wrote Hochdeutsch in Hebrew characters; in order to better disseminate his work among the Jewish population.
25 I assume that the formative phase of modern Dutch society and culture in the 17th and 18th century is comparable to that of 19 th century Hungary; even more is so the role of Jewry in both countries, as a group which was simultaneously integrating into the new society and also forming it. In both cases, the presence of the continuous spectrum from the pre-Haskala Yid to the self-modernizing Israelite led to a gradual, though determined giving up of the Yiddish language. This socio-historical parallelism could partially explain why phenomena of Yiddish influence on Dutch are often similar to that on Hungarian.Concerning Dutch-Jewish linguistic interactions, readers interested in Jewish aspects of Papiamentu, a creole language spoken in the Netherlands Antilles, are referred to Richard E. Wood’s article in Jewish Language Review 3 (1983):15-18.
26 The etymology of the Yiddish word itself is also interesting. The origin is the late Latin or Old French root [] ‘to read’ (cf. to Latin lego, legere, modern French je lis, lire), which was borrowed by the Jews living in early medieval Western Europe. The latter would then change their language to Old High German, the ancestor of Yiddish. At some point, the meaning of the Old French word was restricted to the public reading of the Torah-scroll in the

The Influence of Speech Rate on Rhythm Patterns 185optionally when the speech rate increases. In other words, every speech rate has its own preferred register, in terms of Optimality Theory (Prince and Smolensky, 1993) its own ranking of constraints.
We will investigate prosodic variability as part of our main research project, which involves a comparison of the analyses of music and language. Our ultimate aim is to provide evidence for the assumption that every temporal behavior is structured similarly (cf. Liberman, 1975). Gilbers and Schreuder (to appear) show that Optimality Theory owes a lot
synagogue.27 Compare to sí ‘ski’ > síel ‘to ski’, tűz ‘fire’ > tüzel ‘to fire’; also: printel
‘to print with a computer printer’. It is extremely surprising that the word lejnol does not follow vowel harmony, one would expect *lejnel. Even though the [] sound can be transparent for vowel harmony, this fact is not enough to explain the word lejnol. Probably the dialectal Yiddish laynen was originally borrowed, and this form served as the base for word formation, before the official Yiddish form leynen influenced the Hungarian word. Some people still say lájnol.
28 When being called to the Torah during the public reading, one recites a blessing, the text of which says: “He Who blessed our forefathers Abraham, Isaac and Jacob, may He bless [the name of the person] because he has come up to the Torah / who has promised to contribute to charity on behalf of… etc.” The part of the text ‘who has promised’ sounds in the Ashkenazi pronunciation []. This is most probably the source of the word snóder, after vowel in the unstressed last syllable has become a schwa, a process that is crucial for understanding the Yiddishization of Hebrew words. The exciting part of the story is that the proclitic [] (‘that’) was kept together with the following finite verbal form ([] ‘he promised’), and they were reanalysed as one word.
29 When I asked people about the meaning of unberufn on the mailing list [email protected], somebody reported that her non-Jewish grandmother also used to say unberufn with a similar meaning.
30 Other Hungarian words of Hebrew origin do not come from Yiddish, as shown by their non-Askenazi pronunciation: Tóra ([] ‘Torah’, as opposed to its Yiddish counterpart Toyre) or rabbi (and not rov or rebe). Words like behemót (‘big hulking fellow’), originally from Biblical Hebrew behema (‘cattle’, plural: behemot; appearing also as a proper name both in Jewish and in Christian mythology) should be rather traced back to Christian Biblical tradition.
31 Note, that the word has kept its original word initial [], without transforming it into [], which would have been predicted by Hebrew phonology. Although this is a remarkable fact for Netzer, it turns out that almost no word borrowed by Modern Hebrew would change its initial [] to []. Even not verbs that have had to undergo morpho-phonological processes (e.g.

186
to the constraint-based music theory of Lerdahl and Jackendoff (1983). Based on the great similarities between language and music we claim that musical knowledge can help in solving linguistic issues.
In this paper, we will show that clashes are avoided in allegro tempo. In both language and music distances between beats are enlarged, i.e. there appears to be more melodic content between beats. To illustrate this, we ran a pilot experiment in which we elicited fast speech. As expected, speech rate plays a role in rhythmic variability.
The paper is organized as follows. In section 2 the data of the experiment is introduced. Section 3 is addressed to the phonological
fibrek from English to fabricate). The only exception I have found in dictionaries is the colloquial form pilosofiya for filosofiya ‘philosophy’, as well as the verb formed from it, pilsef ‘to philosophise’. Furthermore, it can be argued that pilosofiya is not even a modern borrowing. The only reason why one would still expect firgen ]. On the other hand, one may claim that // and // should be considered as distinct phonemes in Modern Hebrew, even if no proposed minimal pair that I know of is really convincing.
32 “…identity effects will come into play only to the extent that the immediate constituents composing the complex structure constitute independently occurring outputs…(Kenstowicz 1996: 373)”, “The base of an OO-correspondence relation is a licit output word, which is both morphologically and phonologically well-formed (Benua 1997a: 29)”, “The bound form of a stem is segmentally identical with its corresponding free form (Ito and Mester 1997: 431)”.
35 Regarding this nature of CA, one may postulate a single laryngeal feature (rather than two) for both plosives and fricatives, e.g. [+spread glottis] for both aspirated plosives and voiceless fricatives. Such an analysis is proposed by Jakobson (1957) and Blevins (1993). See also section 3 below.
36 Segments that underwent CA are put in square brackets. Abbreviations are: ALL= allative, asp= aspiration, I=Intonational phrase, INF=infinitive, NP = noun phrase, PL= plural, VP = verb phrase, XP = maximal projection.
37 The alternation (r >) t > d is due to post-nasal voicing.38 CA exhibits aspects of prosodic phonology (I am using this term to
contrast with lexical phonology); it is sensitive to pause insertions and to speech rate. I would classify it as a P-structure rule in the terminology of Selkirk (1986). P-structure rules exhibit phonological properties of prosodic phonology, yet they are sensitive to syntactic bracketing (Selkirk 1986).

The Influence of Speech Rate on Rhythm Patterns 187framework of Optimality Theory and the different rankings of andante and allegro speech. The method of the experiment is discussed in section 4 and the auditive and acoustic analyses plus the results follow in section 5. The perspectives of our analysis will be discussed in the final section.
2. Data
We will discuss three types of rhythmic variability in Dutch. The first we will call “stress shifts to the right”; the second “stress shifts to the left” and the third “beat reduction”. In the first type as exemplified in stúdietòelage (s w s w w) ‘study grant’, we assume that this compound can be realized as stúdietoelàge (s w w s w) in allegro speech. Perfèctioníst (w s w s) is an example of “stress shift to the left” and we expect a realization pèrfectioníst (s w w s) in allegro speech. The last type does not concern a stress shift, but a stress reduction. In zùidàfrikáans (s s w s) ‘South African’ compounding of zuid and afrikaans results in a stress clash. In fast speech this clash is avoided by means of reducing the second beat: zùidafrikáans (s w w s). Table 1 shows a selection of our data.
Table 1. Data
Type 1: stress shift to the right (andante: s w s w w; allegro: s w w s w)stu die toe la ge ‘study grant’weg werp aan ste ker ‘disposable lighter’ka mer voor zit ter ‘chairman of the House of Parliament’
39 This line of analysis has antecedents. Amongst them are: Kenstowicz and Kisserberth (1979), Rushchakov (1981), Kaisse (1985), and Blevins (1993). Interestingly, Lev Shternberg, the pioneer of Nivkh study, assumed plosive-initial forms to be the input to transitive structures, as well (Shternberg 1908).
40 Spirantization and hardening are not ordered relative to each other in the tableau below.
41 Post-nasal context requires different markedness constraint but I omit it from the discussion below. See Shiraishi (2000) for details.
42 Following a velar or a uvular plosive, the initial velar of a suffix appears as [x], spirantizing the former at the same time: tx-xu <tk+PL ‘fathers’.
43 On the other hand, OO-constraints are known to be able to make reference to non-contrastive features. See Benua (1997b) and Steriade (2000) for such cases.

188
Type 2: stress shift to the left (andante: w s w s; allegro: s w w s)per fec tio nist ‘perfectionist’a me ri kaan ‘American’vi ri li teit ‘virility’
Type 3: beat reduction (andante: s s w s; allegro: s w w s)zuid a fri kaans ‘South African’schier mon nik oog ‘name of an island’gre go ri aans ‘Gregorian’
The different rhythmic patterns are accounted for phonologically within the framework of OT.
3. Framework and phonological analysis
The mechanism of constraint interaction, the essential characteristic of OT, is also used in the generative theory of tonal music (Lerdahl and Jackendoff, 1983). In both frameworks, constraint satisfaction determines grammaticality and in both frameworks the constraints are potentially conflicting and soft, which means violable. Violation, however, is only allowed if it leads to satisfaction of a more important, higher ranked constraint. The great similarities between these theoretical frameworks make comparison and interdisciplinary research possible.
For example, restructuring rhythm patterns as a consequence of a higher playing rate is a very common phenomenon in music. In Figure 1 we give an example of re-/misinterpretation of rhythm in accelerated or sloppy playing.
Dotted notes rhythm triplet rhythm
Figure 1. Rhythmic restructuring in music
In Figure 1, the “dotted notes rhythm” (left of the arrow) is played as a triplet rhythm (right of the arrow). In the dotted notes rhythm the second note has a duration which is three times as long as the third, and in the

The Influence of Speech Rate on Rhythm Patterns 189triplet rhythm the second note is twice as long as the third. In fast playing it is easier to have equal durations between note onsets. Clashes are thus avoided and one tries to distribute the notes, the melodic content, over the measures as evenly as possible, even if this implies a restructuring of the rhythmic pattern. To ensure that the beats do not come too close to each other in fast playing, the distances are enlarged, thus avoiding a staccato-like rhythm. In short, in fast tempos the musical equivalents of the Obligatory Contour Principle (OCP), a prohibition on adjacency of identical elements in language (McCarthy, 1986), become more important.
We claim that - just as in music - the allegro patterns in all the different types of data in Table 1 are caused by clash avoidance. There is a preference for beats that are more evenly distributed over the phrase. The different structures can be described phonologically as a conflict between markedness constraints, such as FOOT REPULSION (*ΣΣ) (Kager, 1994), and OUTPUT - OUTPUT CORRESPONDENCE constraints (cf. Burzio, 1998) within the framework of OT. FOOT REPULSION prohibits adjacent feet and consequently prefers a structure in which feet are separated from each other by an unparsed syllable. This constraint is in conflict with PARSE-, which demands that every syllable is part of a foot. OUTPUT - OUTPUT CORRESPONDENCE compares the structure of a phonological word with the structure of its individual parts. For example, in a word such as fototoestel 'photo camera', OUTPUT - OUTPUT CORRESPONDENCE demands that the rhythmic structure of its part tóestel 'camera' with a stressed first syllable is reflected in the rhythmic structure of the output. In other words, OUTPUT - OUTPUT CORRESPONDENCE prefers fótotòestel, with secondary stress on toe, to fótotoestèl, with secondary stress on stel.
Whereas the normal patterns in andante speech satisfy OUTPUT - OUTPUT CORRESPONDENCE, the preference for triplet patterns in fast speech is accounted for by means of dominance of the markedness constraint, FOOT REPULSION, as illustrated in Table 2.45
Table 2. Rhythmic restructuring in language
a. ranking in andante speech:
constraints fototoestelcandidates
OUTPUT - OUTPUT CORRESPONDENCE
*ΣΣ PARSE-
(fóto)(tòestel) *

190
(fóto)toe(stèl) *! *
b. ranking in allegro speech:
constraints fototoestelcandidates
*ΣΣ OUTPUT - OUTPUT CORRESPONDENCE
PARSE-
(fóto)(tòestel) *! (fóto)toe(stèl) * *
Dutch is described as a trochaic language (Neijt and Zonneveld, 1982). Table 2a shows a preference for an alternating rhythm. The dactyl pattern as preferred in Table 2b, however, is a very common rhythmic pattern of prosodic words in languages such as Estonian and Cayuvava: every strong syllable alternates with two weak syllables (cf. Kager, 1994). We assume that the rhythm grammar, i.e. constraint ranking, of Dutch allegro speech resembles the grammar of these languages. In the next section we will explore whether we can find empirical evidence for our hypothesis.
4. Method
To find out whether people indeed prefer triplet patterns in allegro speech, we ran a pilot experiment in which we tried to elicit fast speech. Six subjects participated in a multiple-choice quiz in which they competed each other in answering twenty simple questions as quickly as possible. In this way, we expected them to speak fast without concentrating too much on their own speech. In Table 3 one of the quiz items is depicted.
Table 3. Quiz item
Q4 President Bush is een typische ‘President Bush is a typical ’A1 intellectueel ‘intellectual’A2 amerikaan ‘American’A3 taalkundige ‘linguist’
We categorized the obtained data as allegro speech. As a second task the subjects were asked to read out the answers at a normal speaking rate

The Influence of Speech Rate on Rhythm Patterns 191embedded in the sentence ik spreek nu het woord … uit 'now I pronounce the word … '. This normal speaking rate generally means that the subjects will produce the words at a rate of approximately 180 words per minute, which we categorize as andante speech. All data were recorded on minidisk in a soundproof studio and normalized in CoolEdit in order to improve the signal-noise (S/N) ratio. Normalizing to 100% yields an S/N ratio approaching 0 dB.
Six trained listeners judged the data auditively and indicated where they perceived secondary stress. After this auditive analysis the data were phonetically analyzed in PRAAT (Boersma and Weenink, 1992). We compared the andante and allegro data by measuring duration, pitch, intensity, spectral balance and rhythmic timing (Sluijter, 1995; Couper-Kuhlen, 1993; Cummins & Port, 1998; Quené & Port, 2002; a.o.). Sluijter claims that, respectively, duration and spectral balance are the main correlates of primary stress. In our experiment, we are concerned with secondary stress.
For the duration measurements, the rhymes of the relevant syllables were observed. For example, in the allegro style answer A2 amerikaan in Table 3, we measured the first two rhymes and compared the values in Msec. with the values for the same rhymes at the andante rate. In order to make this comparison valid, we equalized the total durations of both realizations by multiplying the duration of the allegro with a so-called 'acceleration factor', i.e. the duration of the andante version divided by the duration of the allegro version. According to Eefting and Rietveld (1989) and Rietveld and Van Heuven (1997), the just noticeable difference for duration is 4,5%. If the difference in duration between the andante and the allegro realization did not exceed this threshold, we considered the realizations as examples of the same speech rate and neglected them for further analysis.
For the pitch measurements, we took the value in Hz in the middle of the vowel. The just noticeable difference for pitch is 2,5% ('t Hart et al, 1990). For the intensity measurements, we registered the mean value in dB of the whole syllable.
The next parameter we considered concerns spectral balance. Sluijter (1995) claims that the spectral balance of the vowel of a stressed syllable is characterized by more perceived loudness in the higher frequency region, because of the changes in the source spectrum due to a more pulse-like shape of the glottal waveform. The vocal effort, which is used for stress, generates a strongly asymmetrical glottal pulse. As a result of the shortened

192
closing phase, there is an increase of intensity around the four formants in the frequency region above 500 Hz. Following Sluijter (1995) we compared the differences in intensity of the higher and lower frequencies of the relevant syllables in both tempos.
Finally, we considered rhythmic timing. The idea is that the beats in speech are separated from each other at an approximately equal distance independent of the speech rate. In other words, a speaker more or less follows an imaginary metronome. If he/she speaks faster, more melodic content will be placed between beats, which results in a shift of secondary stress. This hypothesis will be confirmed if the distance between the stressed syllables in the andante realization of an item, e.g. stu and toe in studietoelage, approximates the distance between the stressed syllables in the allegro realization of the same item, e.g. stu and la. If the quotient of the andante beat interval duration divided by the allegro beat interval duration approximates 1, we expect perceived restructuring.
5. Results
5.1. Auditive analysis
Before we can present an auditive analysis of the data, we have to find out whether or not the quiz design was successful. The results show that the quiz indeed triggers faster speech by all subjects. Figure 2 shows their acceleration factors. Subjects 1, 2 and 4 turned out to be the best accelerating speakers, whereas subjects 3, 5 and 6 showed less difference in duration between andante and allegro realizations. The mean acceleration factor for the three fast speakers is 1.31, whereas the mean acceleration factor for the three slow speakers is 1.13.

The Influence of Speech Rate on Rhythm Patterns 193
Figure 2. Acceleration factors of all subjects
Figure 3 shows the mean durations of the items at both speech rates. It shows that the best accelerating speakers are also the fastest speakers. We expect to find more restructured patterns for these speakers, mainly subjects 1 and 4, in comparison to the slower speakers, such as subjects 3 and 6.
Figure 3. Mean word durations
Figure 4 shows that most subjects prefer patterns in which from a phonological point of view markedness constraints dominate the correspondence constraints at both rates for right and left shift data, but not for beat reduction data. There are slightly more restructured patterns in allegro tempo, although the differences are quite small.
mean word durations
0.65
0.75
0.85
0.95
1.05
1.15
p1 p2 p3 p4 p5 p6
subjects
seco
nds andante
allegro

194
Figure 4. All subjects: Number of restructured items per type
When we take the results of two fast subjects apart, subjects 1 and 4, we observe a stronger preference for restructuring in allegro speech and no restructuring in andante speech, as shown in Figure 5. In other words, the fast subjects display both a greater difference in word durations in andante and allegro speech, and more variability in their speech patterns due to tempo than the slow subjects do.
Figure 5. Fast subjects: Number of restructured items per type
Obviously, the preference for restructuring the rhythmic pattern in allegro speech is not an absolute preference. Sometimes restructuring does not take place in allegro speech, but on the other hand restructured patterns also show up in andante speech.46 Some items were realized with the same rhythmic pattern irrespective of the tempo. Therefore, we also looked at the word pairs with a different rhythmic pattern in both tempos for each subject. We observe that the relatively fast speakers p1, p2 and p4, show the expected pattern according to our hypothesis, which means that they show a restructured pattern in allegro tempo, as shown in Figure 6 for the right shifts.

The Influence of Speech Rate on Rhythm Patterns 195Figure 6. Right Shifts: Expected combinations
Two of the relatively slow speakers, p3 and p6, show one counterexample each, where the subject prefers the restructured patterns in andante tempo. The other slow speaker, P5, displays no different patterns in andante and allegro at all. Clearly, we have two different groups of speakers and this observation strengthens our claim that restructuring relates to speech rate.
Some items, such as hobbywerkruimte (Type 1) 'hobby room', never show a stress shift and other items, such as viriliteit (Type 2) ‘virility’, prefer the shifted pattern in both tempos for all subjects. Possibly, the syllable structure plays an important role; open syllables seem to lose stress more easily than closed ones.
5.2. Acoustic analysis
In the current state of phonological research, embodied in e.g. laboratory phonology, much value is set on acoustic evidence for phonological analyses. Studies such as Sluijter (1995) and Sluijter and Van Heuven (1996) provide acoustic correlates for primary stress. In our study we are concerned with beat reduction and secondary stress shifts and we wonder whether or not the same acoustic correlates hold for secondary stress. Shattuck Hufnagel et al (1994) and Cooper and Eady (1986) do not find acoustic correlates of rhythmic stress at all. They claim that it is not entirely clear which acoustic correlates are appropriate to measure, since these correlates are dependent on the relative strength of the syllables of an utterance. The absolute values of a single syllable can hardly be compared without reference to their context and the intonation pattern of the complete phrase. Huss (1978) claims that some cases of perceived rhythmic stress shift may be perceptual rather than acoustic in nature. Grabe and Warren (1995) also suggest that stress shifts can only be perceived in rhythmic contexts. In isolation, the prominence patterns are unlikely to be judged reliably. In the remainder of this paper we try to find out if we can support one of these lines of reasoning. In other words, are we able to support our perceived rhythmic variability with a phonetic analysis? Therefore, we measured the duration, pitch, intensity, spectral balance and rhythmic timing of the relevant syllables as realized by subject P1.
Because Dutch is a quantity-sensitive language, the duration of the relevant syllable rhymes was considered. Onsets do not contribute to the

196
weight of a syllable. In Figure 7, the duration analysis is shown for Type 2 data (left shifts). The four columns indicate, respectively, the duration of the rhyme of the first and second syllable in andante speech, and the duration of the first and second one in allegro speech. According to Sluijter (1995), duration is the main correlate of primary stress. As a starting point, we adopt her claim for our analysis of secondary stress. Our measurements would confirm our hypothesis and our auditive analysis, if the second column were higher than the first one and if the fourth column were lower than the third one. In that case, the subject would realize a word such as perfectionist as perfèctioníst in andante tempo and as pèrfectioníst in allegro tempo.
In the andante tempo, three out of six items show the dominant correspondence pattern and in the allegro tempo, four out of six items show the dominant markedness pattern. That is hardly a preference and it does not confirm our auditive analysis of the same data. Furthermore, if we consider the word pairs with different patterns, there is only one pair that has the ideal ratio: the patterns of amerikaan.
Figure 7. Duration (Left Shifts by Subject P1)
If duration does not enable us to confirm our auditive findings, maybe pitch is the main stress correlate for this speaker. However, pitch measurements reveal the same fuzzy result as the duration measurements. Again, only one pattern confirms the auditive analysis. This time it is not the item amerikaan, but the item perfectionist. Moreover, the differences in pitch in this item do not exceed the threshold of the 2.5%, which is the just noticeable difference for pitch. We also analyzed the mean intensity value of the relevant vowels without recognizable patterns between allegro and

The Influence of Speech Rate on Rhythm Patterns 197andante style. These results support the analyses of Sluijter (1995) and Sluijter and Van Heuven (1996), who also claim that the intensity parameter does not contribute much to the perception of stress.
Next, we considered the spectral balance. In order to rule out the influence of the other parameters, we monotonized the data for volume and pitch. Then we selected the relevant vowels and analyzed them as a cochleagram in PRAAT. The cochleagram simulates the way the tympanic membrane functions, in other words the way in which we perceive sounds. In Figure 8 we show two cochleagrams of the vowel [a] in the fourth syllable of, respectively, stúdietòelage 'study grant' (Type 1) in andante tempo and stúdietoelàge in allegro tempo. This item was taken from a pre-study. The allegro data show the expected increased perceived loudness in the higher frequencies, indicated by means of shades of gray; the darker gray the more perceived loudness.
Figure 8. Cochleagrams of [] in studietoelage
The right cochleagram (stressed [a]) in Figure 8 shows increased perceived loudness in the regions of approximately 5 to 22 Bark in the allegro version of [a] in comparison with the left cochleagram (unstressed [a]). This confirms the results of the study of primary stress in Sluijter (1995). If we convert this perceptive, almost logarithmic, Bark scale into its linear counterpart, the Hertz scale, this area correlates with the frequency region of 3 to 10 kHz.
In order to measure perceived secondary stress, we will measure the relative loudness in the different frequency regions in Phon.47 According to Sluijter (1995) stressed vowels have increased loudness above 500 Hz compared to the same vowel in an unstressed position. This can be shown if
Time (s)0 0.169371
0
5
10
15
20
25
Time (s)0 0.143209
0
5
10
15
20
25

198
we take a point in time from both cochleagrams in Figure 8 in which the F1 reaches its highest value (following Sluijter, 1995). In Figure 9 the values in Phon are depicted for these points and plotted against the Bark values in 25 steps.
Figure 9. Loudness in Phon
The white line in Figure 9 indicates the pattern of the allegro stressed [a] in studietoelage and the black line indicates the pattern of the andante unstressed [a]. We see increased loudness in the region of 13 to 21 Bark, which correlates with the most sensitive region of our ear. The mean Phon value in Figure 9 between 5 and 21 Bark is 43.6 Phon for the andante unstressed [a] and 47.4 Phon for the allegro stressed [a]; a mean difference of 3.8 Phon.
Now, let us see whether or not we can find similar results for our subject P1. Figure 10 shows that the spectral balance confirms the leftward stress shift we perceived in the allegro realization of amerikaan. The first syllable vowel in allegro tempo is characterized by more loudness in the higher frequency regions than its andante counterpart. In the second syllable vowel it is just the other way around.
Figure 10. Spectral balance comparison of the first two vowels of amerikaan
Stressed and unstressed [a] in [a]merikaan
01020304050
1 4 7
10 13 16 19 22 25
Bark
Phon andante
allegro
Stressed and unstressed [e] in a[me]rikaan
0
20
40
60
1 4 7
10 13 16 19 22 25
Bark
Phon andante
allegro

The Influence of Speech Rate on Rhythm Patterns 199
Unfortunately, not all spectral balance data confirm our auditive analysis. For example, we claimed that the pitch analysis of the stress shift in perfectionist did confirm our auditive analysis. Therefore, we expected more loudness in the allegro realization of the first vowel and less loudness in the allegro realization of the second vowel, but it appeared that there is relatively more loudness in the andante realization of per. This result contradicts our auditive and our pitch analysis.
We have to conclude that the different phonetic analyses contradict each other. Sometimes the perceived stress shift is characterized by a longer duration of the stressed syllable; sometimes a relatively higher pitch characterizes it. The results of our spectral balance analysis show that the differences in loudness pattern with differences in duration. In our perceived stress shift in allegro perfectionist, pitch turned out to be the decisive correlate, whereas duration and spectral balance measurements indicated no shift at all. On the other hand, the perceived shift in allegro amerikaan was confirmed by the duration and spectral balance analyses together, whereas pitch measurements indicated the opposite pattern. For most perceived stress shifts, however, the acoustic correlates did not give any clue.
Finally, we will consider whether the perception of restructuring depends on rhythmic timing. Just as in music, speech can be divided into a melodic string and a rhythmic string as partly independent entities. With respect to speech, the melodic string seems to be more flexible than the rhythmic one. Imagine that the rhythm constitutes a kind of metronome pulse to which the melodic content has to be aligned. The listener expects prominent syllables to occur with beats. This behavior is formulated as the Equal Spacing Constraint: prominent vowel onsets are attracted to periodically spaced temporal locations (Couper-Kuhlen, 1993; Cummins & Port, 1998; Quené & Port, 2002; a.o.). Dependent on speech rate the number of intervening syllables between beats may differ. Suppose the beat interval is constant at 300 msec., there will be more linguistic material in between in allegro speech, e.g. the two syllables die and toe in stúdietoelàge, than in andante speech, e.g. only one syllable die in stúdietòelage.
If indeed the perception of secondary stress shifts depends on rhythmic timing, i.e. the beat interval between prominent syllables in andante and allegro speech is approximately equal, than we expect that the duration quotient of the interval between, for example, stu and toe in the andante

200
realization of studietoelage and stu and la in the allegro realization approximates 1.
In our pre-study, the interval between the vowel onsets of the first and third syllable in studietoelage (andante) is 0.358 sec, whereas the interval between the first and the fourth syllable in the allegro realization of the same word is 0.328 sec. This means that the duration quotient is 1.091, which indeed approximates 1. In other words, this example supports the idea of the Equal Spacing Constraint.
Does the same result hold for our present data? We measured the beat intervals between all possible stress placement sites for all six subjects. Figure 11 depicts the duration quotients for subject 1. Figure 12 shows the beat intervals of the same data. It depicts as well the duration interval between the first and the third, as the first and fourth syllable for both speech rates. We expect restructuring for those data in which the line of the first to third syllable interval (andante (black line)) coincides with the line of the first to fourth syllable interval (allegro (white line)).
Figure 11. Quotient beat intervals of Subject P1
Figure 12. Beat intervals of Subject P1

The Influence of Speech Rate on Rhythm Patterns 201The Figures 11 and 12 indicate that the relevant beat intervals of the items 1, 4 and 7, studietoelage 'study grant', kamervoorzitter 'chairman of the House of Parliament' and winkelopheffing 'closing down of a shop', respectively, coincide. In other words, we expect to hear restructuring in exactly these three items.
Unfortunately, our auditive analysis indicates only attested combinations of restructuring in items 2 and 6: wegwerpaansteker 'disposable lighter' and gemeente-inschrijving 'municipal registration', respectively. Obviously, rhythmic timing is not the decisive characteristic of perceived restructuring in allegro speech either.
6. Discussion and Conclusion
In section 4, we presented our phonological account of the restructuring within the framework of OT. Our main conclusion is that phonetic compression cannot be the sole explanation of the different rhythm patterns. Although the results cannot really confirm our hypothesis that there are different grammars, i.e. constraint rankings for different rates of speaking, there seems to be something that relates to speech rate. The fast speakers display different grammars, i.e. constraint rankings, for different rates of speaking. In their andante tempo, correspondence constraints prevail, whereas in allegro tempo markedness constraints dominate the correspondence ones. These preferences resemble the preferences of andante and allegro music. In both disciplines clashes are avoided in allegro tempo by means of enlarging the distances between beats.
In section 5, we attempted to confirm our phonological account with a phonetic analysis. Unfortunately, the phonetic correlates of stress - duration, pitch, intensity and spectral balance - do not show the expected and perceived differences in rhythm patterns in all pairs. Sluijter (1995) found out that duration is the main correlate of primary stress with spectral balance as an important second characteristic. In our analysis, however, neither differences in duration nor differences in spectral balance could identify secondary stress. Therefore, we have to conclude that our analysis supports earlier work by Shattuck Hufnagel et al (1994), Cooper and Eady (1986), Huss (1978) and Grabe and Warren (1995), who all claim that acoustic evidence for secondary stress cannot be found unambiguously. Although we did find some differences in duration, spectral balance or pitch, these differences were not systematically found in all pairs in which

202
we perceived rhythmic variability. Finally, we discussed rhythmic timing as a cue for variable patterns. However, the hypothesis that the duration between prominent syllables is approximately equal in both andante and allegro speech was not confirmed by the auditive analysis of the data. It seems that rhythmic restructuring is more a matter of perception than of production. At this point, the question remains: are we fooled by our brains and is there no phonetic correlate of the perceived phonological stress shifts in the acoustic signal or do we have to conclude that the real phonetic correlate of secondary stress has yet to be found?
Notes
References
Boersma, Paul, and David Weenink (1992-2002). PRAAT, phonetics by computer. Available at http://www.praat.org, University of Amsterdam.
Burzio, Luigi (1998). Multiple Correspondence. Lingua, 104: 79-109.Cooper, W., and J. Eady (1986). Metrical phonology in speech production.
Journal of Memory and Language, 25: 369-384.Couper-Kuhlen, Elizabeth (1993). English speech rhythm: form and function in
everyday verbal interaction. Benjamins, Amsterdam.Cummins, Fred, and Robert Port (1998). Rhythmic constraints on stress timing
in English. Journal of Phonetics, 26(2): 145-171. Eefting, Wieke, and Toni Rietveld (1989). Just noticeable differences of
articulation rate at sentence level. Speech Communication, 8: 355-351.
Gilbers, Dicky, and Wouter Jansen (1996). Klemtoon en ritme in Optimality Theory, deel 1: hoofd-, neven-, samenstellings- en woordgroepsklemtoon in het Nederlands [Stress and rhythm in Optimality Theory, part 1: primary stress, secondary stress, compound stress and phrasal stress in Dutch]. TABU, 26(2): 53-101.
Gilbers, Dicky, and Maartje Schreuder (to appear). Language and Music in Optimality Theory. Proceedings of the 7th International Congress on Musical Signification 2001, Imatra, Finland. Extended manuscript available as ROA-571.

The Influence of Speech Rate on Rhythm Patterns 203Grabe, Esther, and Paul Warren (1995). Stress shift: do speakers do it or do
listeners hear it? In: Connell, Bruce and Amalia Arvaniti (eds.). Phonology and phonetic evidence. Papers in Laboratory Phonology IV.
Hart, Johan, René Collier, and Antonie Cohen (1990). A perceptual study of intonation. An experimental-phonetic approach to speech melody. Cambridge University Press, Cambridge.
Huss, V. (1978). English word stress in the postnuclear position. Phonetica, 35: 86-105.
Kager, René (1994). Ternary rhythm in alignment theory. ROA-35.Legendre, Geraldine, Yoshiro Miyata, and Paul Smolensky (1990). Harmonic
Grammar - A formal multi-level connectionist theory of linguistic well- formedness: An application. In: Proceedings of the Twelfth Annual Meeting of the Cognitive Science Society, 884-891.
Lerdahl, Fred, and Ray Jackendoff (1983). A Generative Theory of Tonal Music. The MIT Press, Cambridge, Massachusetts, London, England.
Liberman, Mark (1975). The Intonational System of English. Garland, New York and London.
McCarthy, John J. (1986). OCP Effects: Gemination and antigemination. Linguistic Inquiry, 17: 207-263.
Neijt, Anneke, and Wim Zonneveld (1982). Metrische fonologie - De representatie van klemtoon in Nederlandse monomorfematische woorden. [Metrical phonology – The representation of stress in Dutch monomorphemic words] De nieuwe Taalgids, 75: 527-547.
Prince, Alan, and Paul Smolensky (1993). Optimality Theory: constraint interaction in generative grammar. Ms., ROA-537.
Quené, Hugo, and Robert F. Port (2002). Rhythmical factors in stress shift. Paper presented at the 38th Meeting of the Chicago Linguistic Society, Chicago.
Rietveld, Toni, and Vincent van Heuven (1997). Algemene Fonetiek. [General Phonetics]. Dick Coutinho, Bussum.
Schreuder, Maartje, and Dicky Gilbers (submitted). Restructuring the melodic content of feet. In: Proceedings of the 9th International Phonology Meeting 2002, Vienna, Austria.
Shattuck Hufnagel, Stephanie, Mari Ostendorf, and Ken Ross (1994). Stress shift and early pitch accent placement in lexical items in American English. Journal of Phonetics, 22: 357-388.
Sluijter, Agaath (1995). Phonetic Correlates of Stress and Accent. HIL dissertations 15, Leiden University.

204
Sluijter, Agaath, and Vincent van Heuven (1996). Spectral balance as an acoustic correlate of linguistic stress. Journal of the Acoustical Society of America, 100(4): 2471-2485.


List of Addresses Drs. Markus BergmannUniversity of Groningen, Faculty of Arts, Department of LinguisticsOude Kijk in 't Jatstraat 26, 9712 EK Groningen, The Netherlands+31 50 3635982, [email protected]
Drs. Tamás BíróUniversity of Groningen, Faculty of Arts, Department of Computational LinguisticsOude Kijk in 't Jatstraat 26, 9712 EK Groningen, The Netherlands+31 50 3636852, [email protected]
Dr. Dicky GilbersUniversity of Groningen, Faculty of Arts, Department of LinguisticsOude Kijk in 't Jatstraat 26, 9712 EK Groningen, The Netherlands+31 50 3635983, [email protected]
Dr. Charlotte GooskensUniversity of Groningen, Faculty of Arts, Department of Scandinavian Languages and CulturesOude Kijk in 't Jatstraat 26, 9712 EK Groningen, The Netherlands+31 50 3635827, [email protected]
Dr. Dr. Tjeerd de Graaf and Drs. Nynke de GraafUniversity of Groningen, Faculty of Arts, Department of LinguisticsOude Kijk in 't Jatstraat 26, 9712 EK Groningen, The Netherlands+31 50 3635982, [email protected]
Drs. Angela GrimmUniversity of Groningen, Faculty of Arts, Department of LinguisticsOude Kijk in 't Jatstraat 26, 9712 EK Groningen, The Netherlands+31 50 3635920, [email protected]
Dr. Ing. Wilbert HeeringaUniversity of Groningen, Faculty of Arts, Department of Computational LinguisticsOude Kijk in 't Jatstraat 26, 9712 EK Groningen, The Netherlands+31 50 3635970, [email protected]
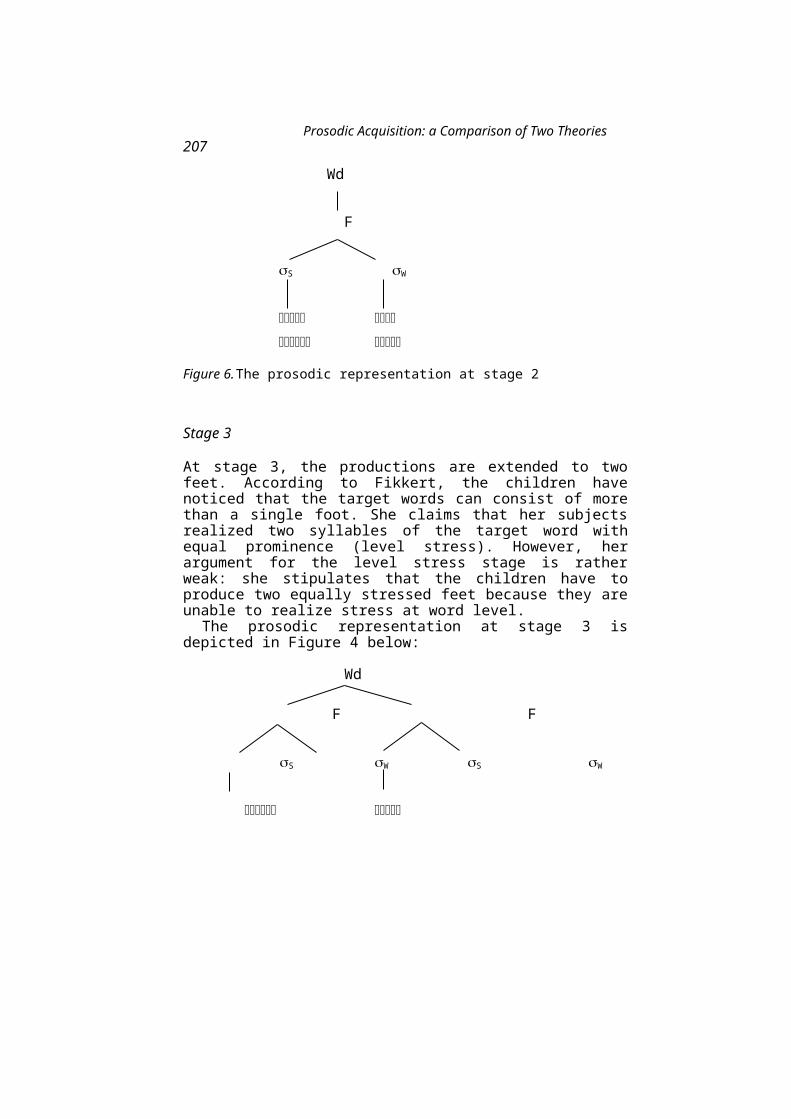
Prof. Dr. Vincent J. van HeuvenUniversity of Leiden, Faculty of Arts, Department of LinguisticsVan Wijkplaats 4, 2311 BX Leiden, The Netherlands+31 71 5272105, [email protected]
Nienke Knevelp/a University of Groningen, Faculty of Arts, Department of LinguisticsOude Kijk in 't Jatstraat 26, 9712 EK Groningen, The Netherlands
44 This paper is an extension of our paper "Restructuring the melodic content of feet", which is submitted to the proceedings of the 9 th International Phonology Meeting: Structure and melody, Vienna 2002. We wish to thank Grzegorz Dogil, Hidetoshi Shiraishi plus the participants of the 9 th International Phonology Meeting, Vienna 2002 and the participants of the 11th Manchester Phonology Meeting, Manchester 2003 for their useful comments. We are also grateful to Sible Andringa, Nynke van den Bergh, Gerlof Bouma, John Hoeks, Jack Hoeksema, Wander Lowie, Dirk-Bart den Ouden, Joanneke Prenger, Ingeborg Prinsen, Femke Wester for participating in our experiment. We especially thank Wilbert Heeringa and Hugo Quené for supplying us with the PRAAT scripts that we could use for our spectral balance and rhythmic timing analyses.
45 For reasons of clarity, we abstract from constraints such as FOOTBINARITY (FTBIN) and WEIGHT-TO-STRESS PRINCIPLE in Table 2. Although these constraints play an important role in the Dutch stress system (cf. Gilbers & Jansen, 1996), the conflict between OUTPUT-OUTPUT CORRESPONDENCE and FOOT REPULSION is essential for our present analysis.
46 With respect to the phonological analysis of the data, we suggest a random ranking of weighed correspondence and markedness constraints. By means of weighing constraints we adopt an OT variant that more or less resembles the analyses in OT’s predecessor Harmonic Grammar (cf. Legendre, G., Y. Miyata & P. Smolensky, 1990). Note that we do not opt for a co-phonology for allegro-style speech in our analysis. In a co-phonology, the output of the andante-style ranking is input or base for the allegro-style ranking. We opt for a random ranking with different preferences for allegro and andante speech, because our data show variable rhythmic structures at both rates. Both rankings evaluate the same input form.
47 The perceived loudness depends on the frequency of the tone. The Phon entity is defined using the 1kHz tone and the decibel scale. A pure sinus tone at any frequency with 100 Phon is as loud as a pure tone with 100 dB at 1kHz (Rietveld and Van Heuven, 1997: 199). We are most sensitive to frequencies around 3kHz. The hearing threshold rapidly rises around the lower and upper frequency limits, which are respectively about 20Hz and 16kHz.

+31 50 3635983, [email protected]
Dr. Jurjen van der KooiUniversity of Groningen, Faculty of Arts, Department of Frisian Oude Kijk in 't Jatstraat 26, 9712 EK Groningen, The Netherlands+31 50 3635966, [email protected]
Prof. Dr. Ir. John NerbonneUniversity of Groningen, Faculty of Arts, Department of Computational LinguisticsOude Kijk in 't Jatstraat 26, 9712 EK Groningen, The Netherlands+31 50 3635815, [email protected]
Drs. Maartje SchreuderUniversity of Groningen, Faculty of Arts, Department of LinguisticsOude Kijk in 't Jatstraat 26, 9712 EK Groningen, The Netherlands+31 50 3635920, [email protected]
Drs. Hidetoshi ShiraishiUniversity of Groningen, Faculty of Arts, Department of LinguisticsOude Kijk in 't Jatstraat 26, 9712 EK Groningen, The Netherlands+31 50 3635982, [email protected]
Dr. Ivilin StoianovUniversity of Padova, Department of General PsychologyVia Venezia 8, 35100 AS Padova, Italy+39 049 8276676, [email protected]

















