Embed Size (px)
Citation preview

Guest Editors’ Introduction.....................................................................................................................................................................................................................................................
TOP PICKS FROM THE COMPUTERARCHITECTURE CONFERENCES
OF 2007
......This special issue represents thefifth anniversary of an important tradition inthe computer architecture community: IEEEMicro’s Top Picks from the ComputerArchitecture Conferences. This tradition,initiated by IEEE Micro’s former Editor inChief, Pradip Bose, attempts to share withthe IEEE Micro readership a sampling of thetop papers published in computer architec-ture in the past year. In choosing thesepapers, we ask ourselves, ‘‘For our colleagueswho were not able to attend any conferencesthis year, which few papers would werecommend that they read?’’ We select thesepapers on the basis of the novelty of the workand its potential impact on industry—eithershort-term or long-term. As always, it is adifficult task to select only 10 from the manyhigh-quality papers that have already beendistinguished by being published in theproceedings of our field’s top conferences.This year was no different.
The review processFor each submission, we requested, in
addition to a copy of the conference paper,a three-page summary that highlighted thenovelty of the work and argued its relevancefor architects and designers of current- andfuture-generation computing systems. Wereceived 70 submissions.
To review the submissions, we assembleda program committee of 33 highly respectedarchitects from industry and academia:
N Dennis Abts, CrayN David Albonesi, Cornell UniversityN Erik Altman, IBMN David August, Princeton UniversityN Todd Austin, University of Michigan,
Ann ArborN Bryan Black, AMDN Pradip Bose, IBMN Doug Burger, University of Texas at
AustinN Calin Cascaval, IBMN Yen-Kuang Chen, IntelN Lieven Eeckhout, Ghent UniversityN Krisztian Flautner, ARMN Rajiv Gupta, University of California,
RiversideN Mark D. Hill, University of
Wisconsin–MadisonN Steve Keckler, University of Texas at
AustinN Alvin Lebeck, Duke UniversityN Mikko Lipasti, University of
Wisconsin–MadisonN Margaret Martonosi, Princeton
UniversityN Chuck Moore, AMDN Vijaykrishnan Narayanan,
Pennsylvania State UniversityN Chris J. Newburn, IntelN Mark Oskin, University of
WashingtonN Vijay Pai, Purdue UniversityN Ravi Rajwar, IntelN Partha Ranganathan, HP
Sarita V. Adve
University of Illinois at
Urbana-Champaign
David Brooks
Harvard
Craig Zilles
University of Illinois at
Urbana-Champaign.......................................................................
8 Published by the IEEE Computer Society 0272-1732/08/$20.00 G 2008 IEEE

N Eric Rotenberg, North Carolina StateUniversity
N Amir Roth, University of PennsylvaniaN Andre Seznec, IRISA/INRIAN Balaram Sinharoy, IBMN Josep Torrellas, University of Illinois
at Urbana-ChampaignN Uri Weiser, Technion—Israel
Institute of TechnologyN Chris Wilkerson, IntelN David Wood, University of
Wisconsin–Madison
Each paper was assigned and received fivereviews, all from program committee mem-bers. In assigning the reviews, we ensuredthat every paper had at least two reviews byindustry representatives. On October 23, weheld a day-long program committee (PC)meeting in Chicago, at which we had 30 ofthe 33 program committee members inattendance. (Three PC members took partby phone, due to unexpected obligations toproduct teams and a family crisis.)
Prior to this meeting, each PC memberhad read all of the reviews for their assignedpapers and, taking these other viewpointsinto account, entered a final score for eachpaper. For those papers lacking consensus inthis final scoring, committee membersdiscussed the papers by e-mail in advanceof the PC meeting to try to reach anagreement. We found this process to beinvaluable in making the PC meeting runsmoothly, as few unexpected issues came tolight at the meeting.
In anticipation of the difficulty ofselecting only 10 papers from the manyhigh-quality submissions, we used a two-pass acceptance process: On the initial pass,we voted each paper into one of threecategories—definite accept, accept-if-space,and reject. Then, at the end of the day, wevoted on which of the accept-if-space paperswe should include. This approach addressedthe concern of many PC members aboutcommitting to accept a paper before theyhad seen the whole field, but avoidedtabling an unduly large number of papers.
Each paper discussion was open to allcommittee members except those who had aconflict of interest with the work underconsideration; members were requested to
leave the room during the discussion anddecision process for papers with which theyhad conflicts. Papers that included aprogram chair among their authors werehandled completely outside the purview ofthe program chairs; David Albonesi, Editorin Chief of IEEE Micro, coordinatedreviewer assignment, collected reviews bye-mail, and led the discussion for thesesubmissions.
The papersFor this year’s Top Picks issue, the
committee selected 10 articles that demon-strate the breadth of ongoing computerarchitecture research (see the sidebar, ‘‘TopPicks of 2007’’).
The first two articles consider the rolethat compilers will play in future architec-tures. The first article, by Bridges et al.,demonstrates that there may yet be oppor-tunities for automatically parallelizing non-numeric programs, especially if program-mers use language extensions that permitprograms to have a range of legal outcomesto provide flexibility to the compiler. Thesecond, by Neelakantam et al., shows thathardware atomicity is a simple, but power-ful primitive that greatly simplifies theimplementation of speculative compileroptimizations, which can improve single-thread performance while reducing power.
The next pair of articles brings new insightsto the field of transactional memory (TM).Demonstrating that the manner in which anyhardware TM system resolves conflicts canhave a first-order impact on its performance,Bobba et al. describe several pathologies thatcan occur and propose approaches for theirmitigation. Ramadan et al. bring TM researchinto a new domain—operating systems. Theydemonstrate how key parts of the Linuxoperating system can be converted to usetransactions and present extensions to TMsemantics that simplify this conversion.
Reliability and variability issues threatento slow nanoscale technology scaling, anddesigners are increasingly looking for archi-tectural solutions. Meixner, Bauer, andSorin present a novel error detectionmechanism that breaks the work of theprocessor into four separate tasks anddetects errors by determining whether each
........................................................................
JANUARY–FEBRUARY 2008 9

of these tasks is performed correctly. Lianget al. address process variability in on-chipcache memories by proposing to replacetraditional static memory cells with high-performance dynamic memory cells.
As we enter the era of multimegabyteshared on-chip caches and many-coresystems, interconnect design is increasinglyimportant. Muralimanohar, Balasubramo-nian, and Jouppi present the latest versionof the CACTI cache modeling tool, withimproved support for modeling intercon-nects between large cache arrays. Kumar etal. consider the problem of interconnects inmany-core chips, with a novel virtual-channel approach that bypasses intermedi-ate routers for long-distance interconnects.
Finally, as we integrate more cores onto achip, memory and coherence systems needto become more efficient to effectivelyutilize pin and internal interconnect band-widths. Qureshi et al. demonstrate that aleast-recently-used (LRU) policy is fre-quently ineffective for second-level caches,because the data working set exceeds the
cache size. They show a simple, effective,and robust extension that improves perfor-mance in these cases by adaptively settingthe recency of new blocks. Marty and Hillpropose a technique targeting server con-solidation workloads that permits the local-ization of coherence traffic within a virtualserver on a many-core chip, improvingperformance and performance isolationbetween virtual machines.
W e hope you enjoy reading thesearticles, and we encourage you to
read the original works as well. We welcomeyour feedback on this year’s Top Picks andany suggestions on how to improve thespecial issue for the future. MICRO
AcknowledgmentsMany people contributed to this special
issue of IEEE Micro. We must firstacknowledge the outstanding support fromEditor in Chief David Albonesi, formerEditor in Chief Pradip Bose, and the IEEEMicro staff—especially Robin Baldwin,Cheryl Baltes, Lindsey Buscher, ThomasCentrella, Noel Deeley, Carmen Garvey,Patricia Hildenbrand, Keith Parsons, JoanTaylor, Margaret Weatherford, and AlkeniaWinston. We particularly thank the mem-bers of the program committee for theirhard work and outstanding professionalismthroughout the process. A special thanksgoes to Edward S. Lee of University ofIllinois, who went beyond the call of dutyto ensure that the submission and reviewprocess went smoothly. Finally, we thankall authors who submitted papers; thedepth of quality present in our topconferences makes selecting so few papersvery difficult, but we wouldn’t want it anyother way.
Sarita V. Adve is a professor in theDepartment of Computer Science at theUniversity of Illinois at Urbana-Cham-paign. Her research interests are in com-puter architecture and systems, with acurrent focus on reliability and multicoreprogramming. She has a PhD in computerscience from the University of Wisconsin–Madison.
.....................................................................................................................................................................
Top Picks of 2007
Compiler-architecture interactions
N Revisiting the Sequential-Programming Model for the Multicore Era
N Hardware Atomicity: An Effective Abstraction for Reliable Software Speculation
Transactional memory
N Performance Pathologies in Hardware Transactional Memory
N MetaTM/TxLinux: Transactional Memory for an Operating System
Reliability and variability
N Argus: Low-Cost, Comprehensive Error Detection in Simple Cores
N Replacing 6T SRAMs with 3T1D DRAMs in the L1 Data Cache to Combat Process Variability
On-chip interconnects
N Architecting Efficient Interconnects for Large Caches with CACTI 6.0
N Toward Ideal On-Chip Communication Using Express Virtual Channels
Memory system design
N Set-Dueling-Controlled Adaptive Insertion for High-Performance Caching
N Virtual Hierarchies
.........................................................................................................................................................................................................................
.......................................................................
10 IEEE MICRO

David Brooks is an associate professor ofcomputer science at Harvard University.His research interests include architecturaland software approaches to address power,thermal, and reliability issues for embeddedand high-performance computing systems.Brooks has a PhD in electrical engineeringfrom Princeton University.
Craig Zilles is an assistant professor incomputer science at the University ofIllinois at Urbana-Champaign. His researchinterests include interaction between com-pilers and computer architecture, especiallyin the context of managed and dynamic
languages. Zilles has a PhD in computerscience from the University of Wisconsin–Madison. He is a member of IEEE and theACM.
Direct questions and comments aboutthis special issue to the guest editors: SaritaAdve, [email protected]; David Brooks,[email protected]; Craig Zilles,[email protected].
For more information on this or any
other computing topic, please visit our
Digital Library at http://computer.org/
csdl.
........................................................................
JANUARY–FEBRUARY 2008 11

........................................................................................................................................................................................................................................................
ARCHITECTING EFFICIENTINTERCONNECTS FOR LARGE CACHES
WITH CACTI 6.0........................................................................................................................................................................................................................................................
INTERCONNECTS PLAY AN INCREASINGLY IMPORTANT ROLE IN DETERMINING THE POWER
AND PERFORMANCE CHARACTERISTICS OF MODERN PROCESSORS. AN ENHANCED VERSION
OF THE POPULAR CACTI TOOL PRIMARILY FOCUSES ON INTERCONNECT DESIGN FOR LARGE
SCALABLE CACHES. THE NEW VERSION CAN HELP EVALUATE NOVEL INTERCONNECTION
NETWORKS FOR CACHE ACCESS AND ACCURATELY ESTIMATE THE DELAY, POWER, AND
AREA OF LARGE CACHES WITH UNIFORM AND NONUNIFORM ACCESS TIMES.
......Efficiently executing multi-threaded applications on future multicoreswill require fast intercore communication.Most of this communication happens viareads and writes to large shared caches in thememory hierarchy. Microprocessor perfor-mance and power will be strongly influ-enced by the long interconnects that mustbe traversed to access a cache bank. Thecoming decade will likely see many innova-tions to the multicore cache hierarchy:policies for data placement and migration,logical and physical cache reconfiguration,optimizations to the on-chip networkfabric, and so on.
A large multimegabyte cache, shared bymultiple threads, will likely be partitionedinto many banks, connected by an inter-connect fabric. The cache is referred to as anonuniform cache architecture (NUCA) ifthe latency for an access is a function of thevariable distance traversed on the fabric.Our analysis1,2 shows that the contributionof the fabric to overall large cache access
time and power is 30 to 60 percent, andevery additional cycle in average L2 cacheaccess time can worsen performance byapproximately 1 percent. Most NUCAevaluations to date have made simpleassumptions when modeling the cache’sparameters; it’s typically assumed that thecache is connected by a grid network suchthat every network hop consumes one cycle.By modeling network parameters in detailand carrying out a comprehensive designspace exploration, our research shows thatan optimal NUCA cache organization hasremarkably different layout, performance,and power than prior studies have assumed.
Most cache evaluations today rely on thecache access modeling tool CACTI (cacheaccess and cycle time information).3 Al-though CACTI accurately models small andmedium-sized caches, it has many inade-quacies when modeling multimegabytecaches. Creating a tool that accuratelymodels the properties of large caches andprovides the flexibility to model new ideas
Naveen
Muralimanohar
Rajeev
Balasubramonian
University of Utah
Norman P. Jouppi
Hewlett-Packard
Laboratories
0272-1732//$20.00 G 2008 IEEE Published by the IEEE Computer Society
........................................................................
69

and trade-offs can strengthen future re-search evaluations.
With these challenges in mind, we’vecreated such a tool, CACTI 6.0, that wehope will greatly improve future evaluationsby introducing more rigor in the estimationof cache properties. Because strict powerbudgets constrain all processors today,CACTI 6.0 is more power-aware: Itconsiders several low-power circuit compo-nents and, with an improved interface, helpsresearchers make latency-power trade-offs.Not only will researchers employ validbaseline architectures, but the tool’s analysiswill steer them toward bottlenecks andstimulate innovation. To demonstrateCACTI 6.0’s features, we architected anon-chip network fabric that takes advantageof different wiring options the tool providesto improve cache access latency.
NUCA and UCA models in CACTI 6.0Traditional uniform cache access (UCA)
models suffer from severe scalability issuesprimarily due to the fixed worst-case latencyassumed for all cache banks. A more scalableapproach for future large caches is to replacethe H-tree bus in a UCA with a packet-switched on-chip grid network. Then theaccess latency is determined by the delay toroute the request and response between thebank that contains the data and the cachecontroller. This results in the NUCAmodel,4 which has been the subject of manyarchitectural evaluations.
CACTI 6.0 incorporates network com-ponents for NUCA models and shows thata combined design space exploration overcache and network parameters yields power-and performance-optimal points that aredifferent from those assumed in priorstudies. (See the sidebar for details on howCACTI 6.0 differs from previous versions.)
NUCA design space explorationThe CACTI 6.0 tool performs an
exhaustive search. It first iterates over anumber of bank organizations: the cache ispartitioned into 2N banks (where N variesfrom 1 to 12); for each N, the banks areorganized in a grid with 2M rows (where Mvaries from 0 to N). For each bankorganization, CACTI 5.0 determines theoptimal subarray partitioning for the cachewithin each bank. Each bank is associatedwith a router. The average delay for a cacheaccess is computed by estimating thenumber of network hops to each bank, thewire delay encountered on each hop, andthe cache access delay within each bank. Wefurther assume that each traversal through arouter takes R cycles, where R is a user-specified input. We can design routerpipelines in many ways: A four-stagepipeline is a common approach,5 butresearchers have recently proposed specula-tive pipelines that take up three, two, andone pipeline stages.5–7 Although we give theuser the option to pick an aggressive orconservative router, the CACTI 6.0 tooldefaults to employing a moderately aggres-sive router pipeline with three stages.
In the NUCA model, more partitionslead to smaller delays (and power) within
.....................................................................................................................................................................
Significance of CACTI 6.0
CACTI versions 1 through 5 assumed a uniform cache access (UCA) model, in which a
large cache is partitioned into a number of banks and connected by an H-tree network that
offers uniform latency for every subarray. Even though the interbank network contributes 30
to 60 percent of large cache delay and power, CACTI was restricted to the use of this single
network model and a single wire type (global wires with optimal repeater placement).
CACTI 6.0 is a significantly enhanced version of the tool that primarily focuses on
interconnect design for large scalable caches. The tool includes two major extensions over
earlier versions: the ability to model scalable NUCA caches and a drastically improved search
space with the ability to model different types of wires and routers. The salient
enhancements in CACTI 6.0 include
N incorporation of many different wire models for the interbank network (local/intermediate/
global wires, repeater sizing and spacing for optimal delay or power, and low-swing
differential wires);
N incorporation of models for router components (buffers, crossbar, and arbiter);
N introduction of grid topologies for nonuniform cache architecture (NUCA) and a shared bus
architecture for UCA with low-swing wires;
N an algorithm for design-space exploration that models different grid layouts and estimates
average bank and network latency—the design space exploration also considers different
wire and router types;
N introduction of empirical network contention models to estimate the impact of network
configuration, bank cycle time, and workload on average cache access delay; and
N a validation analysis of all new circuit models: low-swing differential wires and distributed
resistance-capacitance (RC) model for wordlines and bitlines within cache banks (router
components have been validated elsewhere).
In addition to these enhancements to the cache model, CACTI 6.0 also provides an
improved user interface that enables trade-off analysis for latency, power, and area.
.........................................................................................................................................................................................................................
TOP PICKS
.......................................................................
70 IEEE MICRO

each bank but greater delays (and power) onthe network because of the constant over-heads associated with each router anddecoder. Hence, this design space explora-tion is required to estimate the cachepartition that yields optimal delay or power.Although the algorithm is guaranteed tofind the cache structure with the lowestpossible delay or power, the cache organi-zation might not offer sufficient bandwidthto handle all the requests emerging from amulticore processor.
To address this problem, CACTI 6.0 alsomodels contention in the network in detail.This contention model itself has two majorcomponents. If the cache is partitioned intomany banks, there are more routers andlinks on the network, and the probability oftwo packets conflicting at a router decreases.Thus, a many-banked cache is more capableof meeting the bandwidth demands of amany-core system. Furthermore, we can’teasily pipeline certain aspects of the cacheaccess within a bank. The longest such delaywithin the cache access (typically, the bitlineand sense-amp delays) represents the bank’scycle time, which is the minimum delaybetween successive accesses to that bank. Amany-banked cache has relatively smallbanks and a relatively low cycle time, so itcan support a higher throughput and lowerwait times once a request is delivered to thebank. Both these components (lower con-tention at routers and banks) tend to favor amany-banked system. CACTI 6.0 includesthis aspect when estimating the averageaccess time for a given cache configuration.
To improve the NUCA model’s searchspace, and thereby enable a user to finelytune the cache configuration, CACTI 6.0also explores different router and wire typesfor the links between adjacent routers. Thewires are modeled as low-swing differentialwires and global wires with differentrepeater configurations to yield many pointsin the power, delay, and area spectrum. Thesizes of buffers and virtual channels within arouter have a major influence on routerpower consumption and router contentionunder heavy load. By varying the number ofvirtual channels per physical channel andthe number of buffers per virtual channel,
we can achieve different points on therouter power-delay trade-off curve.
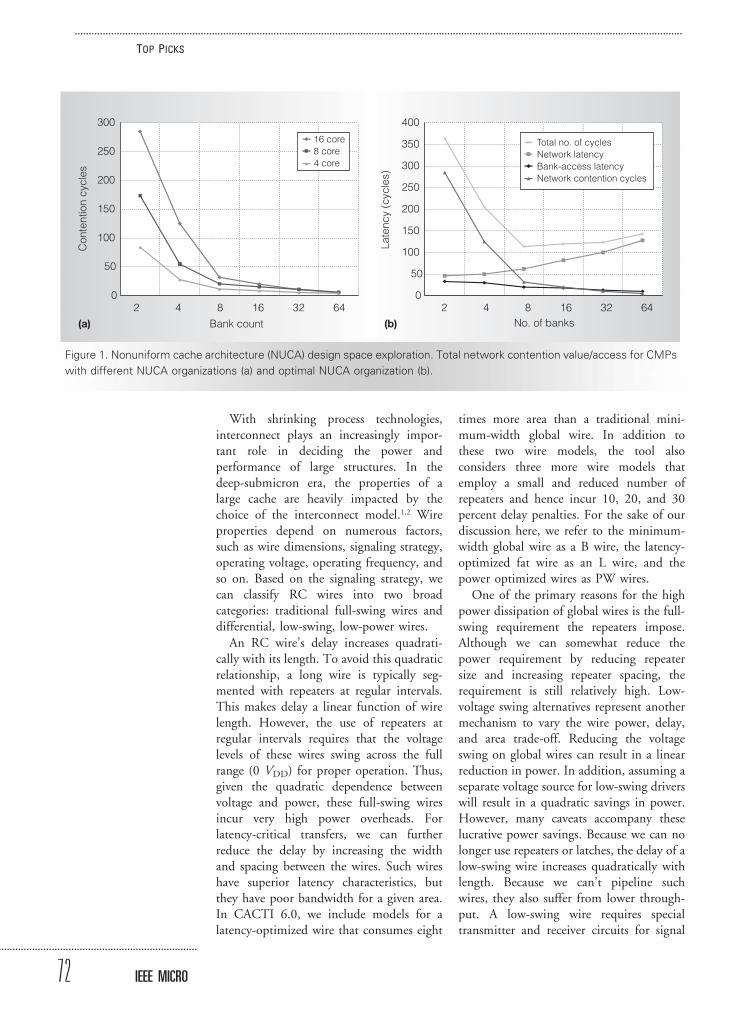
The contention values we use in CACTI6.0 are empirically estimated for chipmultiprocessor (CMP) models with differ-ent number of cores, cache hierarchy depth(L2 or L3), bank cycle time, and routerconfigurations. (This methodology is de-scribed elsewhere.2) Figure 1a shows exam-ple contention data for multicore systems asthe number of banks varies. We plan tocontinue augmenting the tool with empir-ical contention values for other relevant setsof workloads such as commercial, multi-threaded, and transactional benchmarkswith significant traffic from cache coher-ence. Users can also easily plug in their owncontention data if they are dealing withworkloads and architectures much differentfrom the generic models we assume inCACTI 6.0.
Figure 1b shows an example design spaceexploration for a 32-Mbyte NUCA L2cache attempting to minimize latency. Thex-axis shows the number of banks that thecache is partitioned into. For each point onthe x-axis, many different bank organiza-tions are considered, and the graph showsthe organization with optimal delay (aver-aged across all banks). The y-axis representsthis optimal delay, and we further break itdown to represent the contributing compo-nents: bank access time, link and routerdelay, and router and bank contention. Weachieve the optimal delay when the cache isorganized as a 2 3 4 grid of eight banks.
Improvements to the interconnect modelPower is a major problem in modern
processors and will continue to be the first-order design constraint for future proces-sors. With this trend, designing cachemodules focusing singularly on performanceis insufficient. Different research proposalsmight require different cache organizationsthat best match the required power andfrequency budget. To address this issue, weenlarged CACTI 6.0’s search space toconsider design points with varying cacheaccess power and latency values. Severalinterconnect choices specifically help im-prove the tool’s search space.
........................................................................
JANUARY–FEBRUARY 2008 71
With shrinking process technologies,interconnect plays an increasingly impor-tant role in deciding the power andperformance of large structures. In thedeep-submicron era, the properties of alarge cache are heavily impacted by thechoice of the interconnect model.1,2 Wireproperties depend on numerous factors,such as wire dimensions, signaling strategy,operating voltage, operating frequency, andso on. Based on the signaling strategy, wecan classify RC wires into two broadcategories: traditional full-swing wires anddifferential, low-swing, low-power wires.
An RC wire’s delay increases quadrati-cally with its length. To avoid this quadraticrelationship, a long wire is typically seg-mented with repeaters at regular intervals.This makes delay a linear function of wirelength. However, the use of repeaters atregular intervals requires that the voltagelevels of these wires swing across the fullrange (0 VDD) for proper operation. Thus,given the quadratic dependence betweenvoltage and power, these full-swing wiresincur very high power overheads. Forlatency-critical transfers, we can furtherreduce the delay by increasing the widthand spacing between the wires. Such wireshave superior latency characteristics, butthey have poor bandwidth for a given area.In CACTI 6.0, we include models for alatency-optimized wire that consumes eight
times more area than a traditional mini-mum-width global wire. In addition tothese two wire models, the tool alsoconsiders three more wire models thatemploy a small and reduced number ofrepeaters and hence incur 10, 20, and 30percent delay penalties. For the sake of ourdiscussion here, we refer to the minimum-width global wire as a B wire, the latency-optimized fat wire as an L wire, and thepower optimized wires as PW wires.
One of the primary reasons for the highpower dissipation of global wires is the full-swing requirement the repeaters impose.Although we can somewhat reduce thepower requirement by reducing repeatersize and increasing repeater spacing, therequirement is still relatively high. Low-voltage swing alternatives represent anothermechanism to vary the wire power, delay,and area trade-off. Reducing the voltageswing on global wires can result in a linearreduction in power. In addition, assuming aseparate voltage source for low-swing driverswill result in a quadratic savings in power.However, many caveats accompany theselucrative power savings. Because we can nolonger use repeaters or latches, the delay of alow-swing wire increases quadratically withlength. Because we can’t pipeline suchwires, they also suffer from lower through-put. A low-swing wire requires specialtransmitter and receiver circuits for signal
Figure 1. Nonuniform cache architecture (NUCA) design space exploration. Total network contention value/access for CMPs
with different NUCA organizations (a) and optimal NUCA organization (b).
.........................................................................................................................................................................................................................
TOP PICKS
.......................................................................
72 IEEE MICRO

generation and amplification. This not onlyincreases the area requirement per bit, but italso assigns a fixed cost in terms of bothdelay and power for each bit traversal. Inspite of these issues, the power savingspossible through low-swing signaling makeit an attractive design choice. (The detailedmethodology for the design of low-swingwires and their overhead is describedelsewhere.2)
We can also use low-swing wires withinmoderately sized UCA organizations. CAC-TI’s prior versions model a large cache bypartitioning it into multiple subarrays,connected with an H-tree network. Thisenables uniform access times for each bankand simplifies the pipelining of requestsacross the network. Because we can’tpipeline low-swing wires and they betteramortize the transmitter and receiver over-head over long transfers, instead of the H-tree network, we adopt a collection ofsimple broadcast buses that span all thebanks (each bus spans half the banks in acolumn of subarrays).
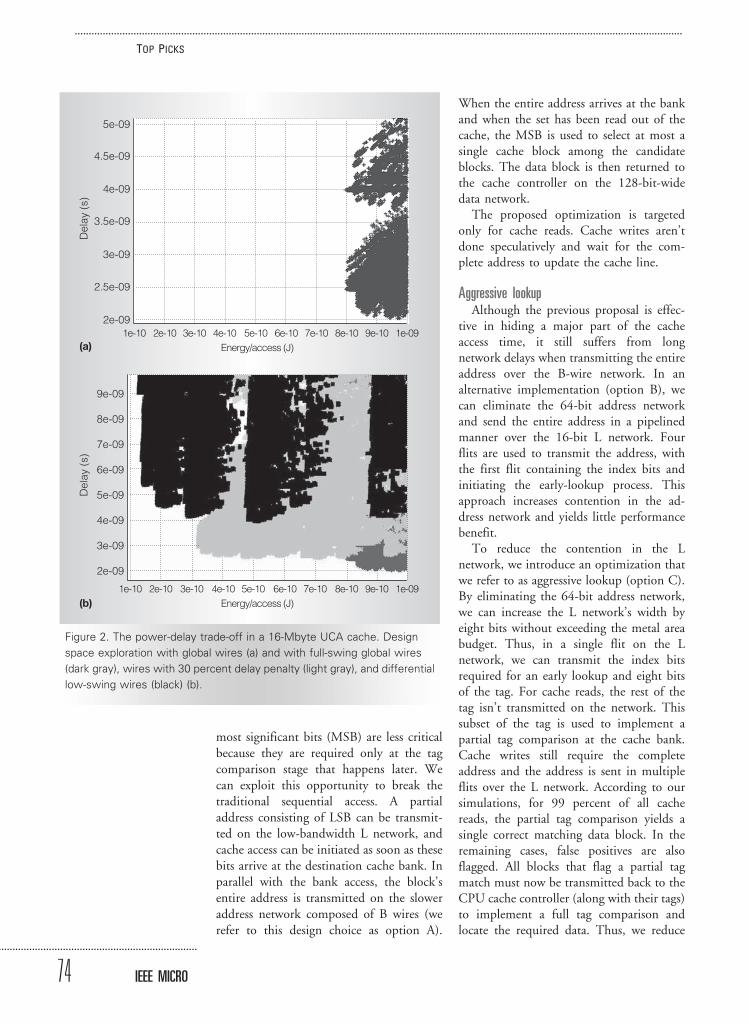
As an example of the power-delay trade-offs made possible by CACTI, we candemonstrate a design space exploration forthe 16-Mbyte UCA cache in Figure 2.Figure 2a shows a power-delay curve inwhich each point graphed represents one ofthe many hundreds of cache organizationsCACTI 5.0 considers while employing asingle wire type (global wire with delay-optimal repeaters). The light gray points inFigure 2b represent cache organizationswith power-optimized global wires consid-ered by CACTI 6.0. The black points inFigure 2b represent the cache organizationsthat use low-swing wires.
This detailed design space explorationreveals cache organizations that can con-sume three times less power while incurringa 25 percent delay penalty.
Leveraging interconnect choices forperformance optimizations
Most of the CACTI tool extensions we’vediscussed so far pertain to detailed inter-connect models that represent the dominantcontributors to cache access delay andpower. Because interconnects are the pri-mary bottleneck, we believe that researchers
will actively study interconnect optimiza-tions in the coming years. CACTI 6.0facilitates such research by making theinterconnect’s contribution more explicitand incorporating various interconnectmodels. Using a case study of the tool’sfeatures, we can show how an architect canimprove the design of the interconnectfabric employed for cache access.
Specifically, we present several techniquesthat leverage the special characteristics offast L wires to improve overall processorperformance. Delays within the routerrepresent another major component ofcache access time. Although we don’tpropose any changes to a router’s micro-architecture, one of our proposals attemptsto reduce the number of routers and henceits effect on access time.
Consistent with most modern implemen-tations, we assume that each cache bankstores the tag and data arrays and that all theways of a set are stored in a single cachebank. For most of the discussion, we alsoassume that there’s enough metal area tosupport a baseline interbank network thataccommodates 256 data wires and 64address wires, all implemented as mini-mum-width wires on the 8X metal plane.
Early lookupWe can leverage L wires for low latency,
but they consume eight times the area of a Bwire on the 8X metal plane. A 16-bit L-network implementation will require that128 B wires be eliminated to maintainconstant metal area. Consider the followingheterogeneous network that has the samemetal area as the baseline: 128 B wires forthe data network, 64 B wires for the addressnetwork, and 16 additional L wires.
In a typical cache implementation, thecache controller sends the complete addressas a single message to the cache bank. Afterthe message reaches the cache bank, it startsthe lookup and selects the appropriate set.The tags of each block in the set arecompared against the requested address toidentify the single block that is returned tothe cache controller. The address’s leastsignificant bits (LSB) are on the critical pathbecause they are required to index into thecache bank and select candidate blocks. The
........................................................................
JANUARY–FEBRUARY 2008 73
most significant bits (MSB) are less criticalbecause they are required only at the tagcomparison stage that happens later. Wecan exploit this opportunity to break thetraditional sequential access. A partialaddress consisting of LSB can be transmit-ted on the low-bandwidth L network, andcache access can be initiated as soon as thesebits arrive at the destination cache bank. Inparallel with the bank access, the block’sentire address is transmitted on the sloweraddress network composed of B wires (werefer to this design choice as option A).
When the entire address arrives at the bankand when the set has been read out of thecache, the MSB is used to select at most asingle cache block among the candidateblocks. The data block is then returned tothe cache controller on the 128-bit-widedata network.
The proposed optimization is targetedonly for cache reads. Cache writes aren’tdone speculatively and wait for the com-plete address to update the cache line.
Aggressive lookupAlthough the previous proposal is effec-
tive in hiding a major part of the cacheaccess time, it still suffers from longnetwork delays when transmitting the entireaddress over the B-wire network. In analternative implementation (option B), wecan eliminate the 64-bit address networkand send the entire address in a pipelinedmanner over the 16-bit L network. Fourflits are used to transmit the address, withthe first flit containing the index bits andinitiating the early-lookup process. Thisapproach increases contention in the ad-dress network and yields little performancebenefit.
To reduce the contention in the Lnetwork, we introduce an optimization thatwe refer to as aggressive lookup (option C).By eliminating the 64-bit address network,we can increase the L network’s width byeight bits without exceeding the metal areabudget. Thus, in a single flit on the Lnetwork, we can transmit the index bitsrequired for an early lookup and eight bitsof the tag. For cache reads, the rest of thetag isn’t transmitted on the network. Thissubset of the tag is used to implement apartial tag comparison at the cache bank.Cache writes still require the completeaddress and the address is sent in multipleflits over the L network. According to oursimulations, for 99 percent of all cachereads, the partial tag comparison yields asingle correct matching data block. In theremaining cases, false positives are alsoflagged. All blocks that flag a partial tagmatch must now be transmitted back to theCPU cache controller (along with their tags)to implement a full tag comparison andlocate the required data. Thus, we reduce
Figure 2. The power-delay trade-off in a 16-Mbyte UCA cache. Design
space exploration with global wires (a) and with full-swing global wires
(dark gray), wires with 30 percent delay penalty (light gray), and differential
low-swing wires (black) (b).
.........................................................................................................................................................................................................................
TOP PICKS
.......................................................................
74 IEEE MICRO

the bandwidth demands on the addressnetwork at the cost of higher bandwidthdemands on the data network. Our resultsshow this is a worthwhile trade-off.
Clearly, depending on the application’sbandwidth needs and the available metalarea, any one of these three design optionsmight perform best. The point here is thatthe choice of interconnect can have a majorimpact on cache access times and is animportant consideration in determining anoptimal cache organization.
Hybrid networkThe delay-optimal cache organization
selected by CACTI 6.0 often employsglobal B wires for data and address transfers.Our previous discussion makes the case thatdifferent types of wires in the address anddata networks can improve performance.Hence, the CACTI tool facilitates architec-tural innovation and exposes avenues foradditional optimizations within the networkarchitecture. If we use fat L wires for theaddress network, it often takes less than acycle to transmit a signal between routers.Therefore, part of the cycle time is wastedand most of the address network delay isattributed to router delay. Hence, wepropose an alternative topology for theaddress network. By using fewer routers,we can take full advantage of the low-latency L network and lower the overheadfrom routing delays. The correspondingpenalty is that the network supports a loweroverall bandwidth.
Figure 3 shows the proposed hybridtopology to reduce the routing overheadin the address network for uniprocessormodels. The address network is now acombination of point-to-point and busarchitectures. Each row of cache banks isallocated a single router, and these routersare connected to the cache controllers with apoint-to-point network composed of Lwires. The cache banks in a row share abus composed of L wires. When a cachecontroller receives a request from the CPU,the address is first transmitted on the point-to-point network to the appropriate rowand then broadcast on the bus to all thecache banks in the row. Each hop on thepoint-to-point network takes a single cycle
(for the 4 3 4-bank model) of link latencyand three cycles of router latency. Thebroadcast on the bus doesn’t suffer fromrouter delays and is only a function of linklatency (two cycles for the 4 3 4-bankmodel). Because the bus has a single master(the router on that row), there are noarbitration delays involved. If the buslatency is more than a cycle, the bus canbe pipelined.8 For the simulations in thisstudy, we assume that the address network isalways 24 bits wide (as in option C) and theaggressive-lookup policy is adopted—thatis, blocks with partial tag matches are sentto the CPU cache controller. As before,the data network continues to employ thegrid-based topology and links composed ofB wires (128-bit network, just as in optionC).
A grid-based address network (especiallyone composed of L wires) suffers from hugemetal area and router overheads. Using abus composed of L wires helps eliminate themetal area and router overhead, but itcauses an inordinate amount of contentionfor this shared resource. The hybrid topol-ogy that employs multiple buses connectedwith a point-to-point network strikes agood balance between latency and band-width because multiple addresses can simul-taneously be serviced on different rows.Thus, in this proposed hybrid model, weintroduce three forms of heterogeneity:different types of wires in data and addressnetworks, different topologies for data andaddress networks, and different architec-tures (bus-based and point-to-point) indifferent parts of the address network.
EvaluationWe evaluated the proposed models in a
single-core processor and an eight-coreCMP. Both uniprocessor and CMP employa 32-Mbyte L2 cache, with the L2 sharedamong all cores in the CMP model. (Seerelated work for detailed evaluation meth-odologies and workload choices.1,2)
Table 1 summarizes the behavior ofprocessor models with eight different cacheconfigurations. The first six models helpdemonstrate the improvements from ourmost promising novel designs, and the lasttwo models show results for other design
........................................................................
JANUARY–FEBRUARY 2008 75

options that we considered as usefulcomparison points.
Model 1 is based on simpler methodol-ogies in prior work,4 where the bank size iscalculated such that the link delay across abank is less than one cycle. All other modelsemploy the CACTI 6.0 tool to calculate theoptimum bank count, bank access latency,and link latencies (vertical and horizontal)for the grid network. Model 2 is thebaseline cache organization obtained withCACTI 6.0 that uses minimum-width wireson the 8X metal plane for the address anddata links. Models 3 and 4 augment thebaseline interconnect with an L network toaccelerate cache access. Model 3 implementsthe early-lookup proposal, and model 4implements the aggressive-lookup proposal.Model 5 simulates the hybrid network,using a combination of bus and point-to-point network for address communication.As we already discussed, the bandwidths ofthe links in all these simulated models areadjusted so that the net metal area isconstant. All these optimizations help speed
up the address network but don’t attempt toimprove the data network. To get an idea ofthe best performance possible with suchoptimizations to the address network, wesimulated an optimistic model (model 6),where the request carrying the addressmagically reaches the appropriate bank inone cycle. The data transmission back to thecache controller happens on B wires just asin the other models. Models 7 and 8 are theadditional organizations we’re using forreference (more details are available else-where1).
Figure 4 shows the instructions per cycle(IPCs) (average across the SPEC2k suite)for all eight processor models, normalizedagainst model 1. It also shows the averageacross programs in SPEC2k that aresensitive to L2 cache latency. In spite ofhaving the least-possible bank access latency(three cycles as opposed to 17 cycles forother models), Model 1 has the poorestperformance due to the high networkoverhead associated with each L2 access.Model 2, the optimal performance cache
Figure 3. Hybrid network topology for a uniprocessor.
.........................................................................................................................................................................................................................
TOP PICKS
.......................................................................
76 IEEE MICRO

organization derived from CACTI 6.0,performs significantly better than model 1.On an average, model 2’s performance is 73percent better across all the benchmarks and114 percent better for benchmarks that aresensitive to L2 latency. This performanceimprovement is accompanied by reducedpower and area because it uses fewer routers.
The early-lookup optimization improveson model 2’s performance. On average,model 3’s performance is 6 percent better,compared to model 2 across all thebenchmarks and 8 percent better for L2-sensitive benchmarks. Model 4 furtherimproves the cache’s access time by per-forming the early lookup and aggressivelysending all the blocks that exhibit partial tagmatches. This mechanism has 7 percenthigher performance, compared to model 2across all the benchmarks, and 9 percent forL2-sensitive benchmarks. The low perfor-mance improvement of model 4 is mainlydue to the high router overhead associatedwith each transfer. The increase in datanetwork traffic from partial tag matches isless than 1 percent.
The aggressive- and early-lookup mech-anisms trade off data network bandwidthfor a low-latency address network. Byhalving the data network’s bandwidth, thedelay for the pipelined transfer of a cacheline increases by two cycles (because thecache line takes up two flits in the baselinedata network). This enables a low-latencyaddress network that can save two cycles onevery hop, resulting in a net win in terms ofoverall cache access latency. The narrowerdata network is also susceptible to more
contention cycles, but this wasn’t a majorfactor for the evaluated processor modelsand workloads.
The hybrid model overcomes the short-comings of model 4 by reducing thenumber of routers in the network. Aggres-sive lookup implemented in a hybridtopology (model 5) performs the best andis within a few percent of the optimisticmodel 6. Compared to model 2, the hybridmodel performs 15 percent better across allbenchmarks and 20 percent better for L2-sensitive benchmarks.
Figure 5 shows the IPC improvement ofdifferent models in a CMP environment.
Table 1. Summary of different models simulated, assuming global 8X wires for the interbank links.
Model Network link contents count* Description
1 B wires (256D, 64A) Based on prior work
2 B wires (256D, 64A) Derived from CACTI 6.0
3 B wires (128D, 64A) and L wires (16A) Implements early lookup
4 B wires (128D) and L wires (24A) Implements aggressive lookup
5 L wires (24A) and B wires (128D) Latency-bandwidth trade-off
6 B wires (256D), 1-cycle Add Implements optimistic case
7 L wires (40A/D) Latency optimized
8 b-wires (128D) and L wires (24A) Address-L wires and data-B wires................................................................................................................................................................................................................* A and D denote the address and data networks, respectively.
Figure 4. Normalized instructions per cycle for different L2 cache
configurations on SPEC2000 benchmarks (B wires implemented on the 8X
metal plane).
........................................................................
JANUARY–FEBRUARY 2008 77
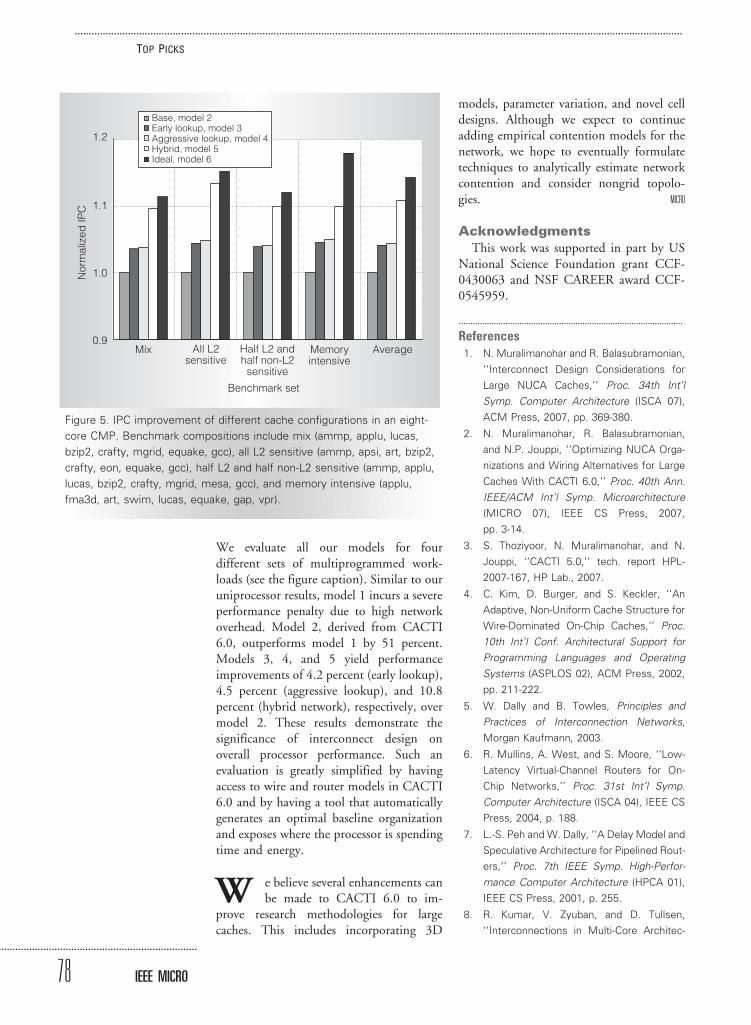
We evaluate all our models for fourdifferent sets of multiprogrammed work-loads (see the figure caption). Similar to ouruniprocessor results, model 1 incurs a severeperformance penalty due to high networkoverhead. Model 2, derived from CACTI6.0, outperforms model 1 by 51 percent.Models 3, 4, and 5 yield performanceimprovements of 4.2 percent (early lookup),4.5 percent (aggressive lookup), and 10.8percent (hybrid network), respectively, overmodel 2. These results demonstrate thesignificance of interconnect design onoverall processor performance. Such anevaluation is greatly simplified by havingaccess to wire and router models in CACTI6.0 and by having a tool that automaticallygenerates an optimal baseline organizationand exposes where the processor is spendingtime and energy.
W e believe several enhancements canbe made to CACTI 6.0 to im-
prove research methodologies for largecaches. This includes incorporating 3D
models, parameter variation, and novel celldesigns. Although we expect to continueadding empirical contention models for thenetwork, we hope to eventually formulatetechniques to analytically estimate networkcontention and consider nongrid topolo-gies. MICRO
AcknowledgmentsThis work was supported in part by US
National Science Foundation grant CCF-0430063 and NSF CAREER award CCF-0545959.
................................................................................................
References1. N. Muralimanohar and R. Balasubramonian,
‘‘Interconnect Design Considerations for
Large NUCA Caches,’’ Proc. 34th Int’l
Symp. Computer Architecture (ISCA 07),
ACM Press, 2007, pp. 369-380.
2. N. Muralimanohar, R. Balasubramonian,
and N.P. Jouppi, ‘‘Optimizing NUCA Orga-
nizations and Wiring Alternatives for Large
Caches With CACTI 6.0,’’ Proc. 40th Ann.
IEEE/ACM Int’l Symp. Microarchitecture
(MICRO 07), IEEE CS Press, 2007,
pp. 3-14.
3. S. Thoziyoor, N. Muralimanohar, and N.
Jouppi, ‘‘CACTI 5.0,’’ tech. report HPL-
2007-167, HP Lab., 2007.
4. C. Kim, D. Burger, and S. Keckler, ‘‘An
Adaptive, Non-Uniform Cache Structure for
Wire-Dominated On-Chip Caches,’’ Proc.
10th Int’l Conf. Architectural Support for
Programming Languages and Operating
Systems (ASPLOS 02), ACM Press, 2002,
pp. 211-222.
5. W. Dally and B. Towles, Principles and
Practices of Interconnection Networks,
Morgan Kaufmann, 2003.
6. R. Mullins, A. West, and S. Moore, ‘‘Low-
Latency Virtual-Channel Routers for On-
Chip Networks,’’ Proc. 31st Int’l Symp.
Computer Architecture (ISCA 04), IEEE CS
Press, 2004, p. 188.
7. L.-S. Peh and W. Dally, ‘‘A Delay Model and
Speculative Architecture for Pipelined Rout-
ers,’’ Proc. 7th IEEE Symp. High-Perfor-
mance Computer Architecture (HPCA 01),
IEEE CS Press, 2001, p. 255.
8. R. Kumar, V. Zyuban, and D. Tullsen,
‘‘Interconnections in Multi-Core Architec-
Figure 5. IPC improvement of different cache configurations in an eight-
core CMP. Benchmark compositions include mix (ammp, applu, lucas,
bzip2, crafty, mgrid, equake, gcc), all L2 sensitive (ammp, apsi, art, bzip2,
crafty, eon, equake, gcc), half L2 and half non-L2 sensitive (ammp, applu,
lucas, bzip2, crafty, mgrid, mesa, gcc), and memory intensive (applu,
fma3d, art, swim, lucas, equake, gap, vpr).
.........................................................................................................................................................................................................................
TOP PICKS
.......................................................................
78 IEEE MICRO

tures: Understanding Mechanisms, Over-
heads, and Scaling,’’ Proc. 32nd Ann. Int’l
Symp. Computer Architecture (ISCA 05),
IEEE CS Press, 2005, pp. 408-419.
Naveen Muralimanohar is pursuing a PhDin computer science at the University ofUtah. His research focuses on interconnectdesign for future communication-boundprocessors and large cache hierarchies.Muralimanohar has a BS in electrical andelectronics engineering from the Universityof Madras, India.
Rajeev Balasubramonian is an assistantprofessor in the School of Computing at theUniversity of Utah. His research interestsinclude the design of high-performancemicroprocessors that can efficiently toleratelong on-chip wire delays, high powerdensities, and frequent errors. Balasubra-monian has a PhD in computer science
from the University of Rochester. He isa member of the IEEE.
Norm Jouppi is a fellow and director ofHP’s Advanced Architecture Lab. Hisresearch interests include computer memorysystems, networking for cluster computing,blade system architectures, graphics acceler-ators, and video, audio, and physicaltelepresence. Jouppi has a PhD in electricalengineering from Stanford University. He isa Fellow of the IEEE and ACM.
Direct questions and comments aboutthis article to Rajeev Balasubramonian, 50S. Central Campus Dr., Rm. 3190, SaltLake City, Utah 84112; [email protected].
For more information on this or any
other computing topic, please visit our
Digital Library at http://computer.org/
csdl.
........................................................................
JANUARY–FEBRUARY 2008 79





























