Embed Size (px)
Citation preview

Topic Models Conditioned on Arbitrary Features with
Dirichlet-multinomial Regression
David Mimno Andrew McCallum

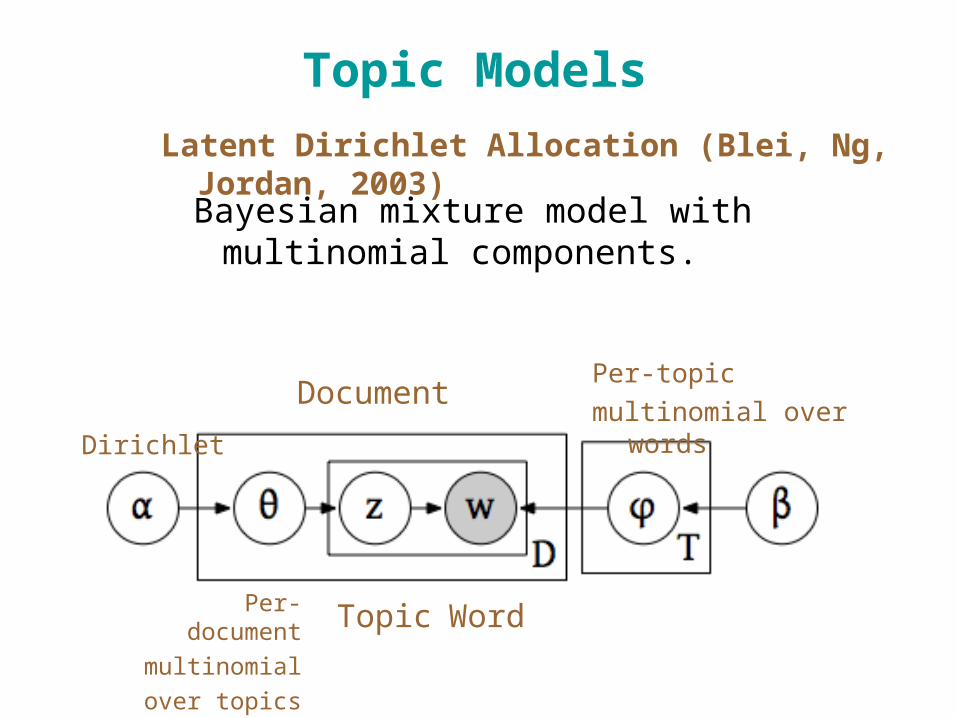
Topic Models
Bayesian mixture model with multinomial components.
Latent Dirichlet Allocation (Blei, Ng, Jordan, 2003)
DocumentPer-topic
multinomial over words
WordTopicPer-document
multinomial
over topics
Dirichlet

models model hidden markov mixture
vector support machines kernel svm
fields extraction random conditional sequence
models conditional discriminative maximum entropy
speech recognition acoustic automatic features
carlo monte sampling chain markov
bias variance error cross estimator
reinforcement control agent rl search
language word words english statistical
expression gene data genes binding
software development computer design research
Example Topics from CS Research Papers

Uses of topic models
• Summarization & Pattern Discovery– Browsable interface to document collection– Identifying trends over time
• Discovering low-dimensional representation for better generalization– Expanding queries for information retrieval– Semi-supervised learning
• Disambiguating words– “LDA”:
Latent Dirichlet Allocation?Linear Discriminant Analysis?

Structured Topic Models
Author: Blei, Ng, JordanYear: 2003Venue: JMLRCites: de Finetti 1975 Harman 1992 …
Words + Additional Meta-data

Words and ImagesCorrLDA
(Blei and Jordan, 2003)
Model can predict image captions and support image retrieval by ad hoc queries

Words and ReferencesMixed Membership Model
(Erosheva, Fienberg, Lafferty, 2004)
Model identifies influential papers by Nobel-winning authors that are not the most cited.

Words and Dates Topics over Time (ToT)
(Wang and McCallum, 2006)
Topics over Time
LDA
Model distinguishes between historical events that share similar vocabulary.

Words and Votes Group-Topic
(Wang, Mohanty and McCallum, 2005)
Model discovers a group of “maverick Republicans,” including John McCain, specific to domestic issues.

Words and Named Entities CorrLDA2(Newman, Chemudugunta, Smyth, Steyvers, 2006)
Model can predict names of entities given text of news articles.
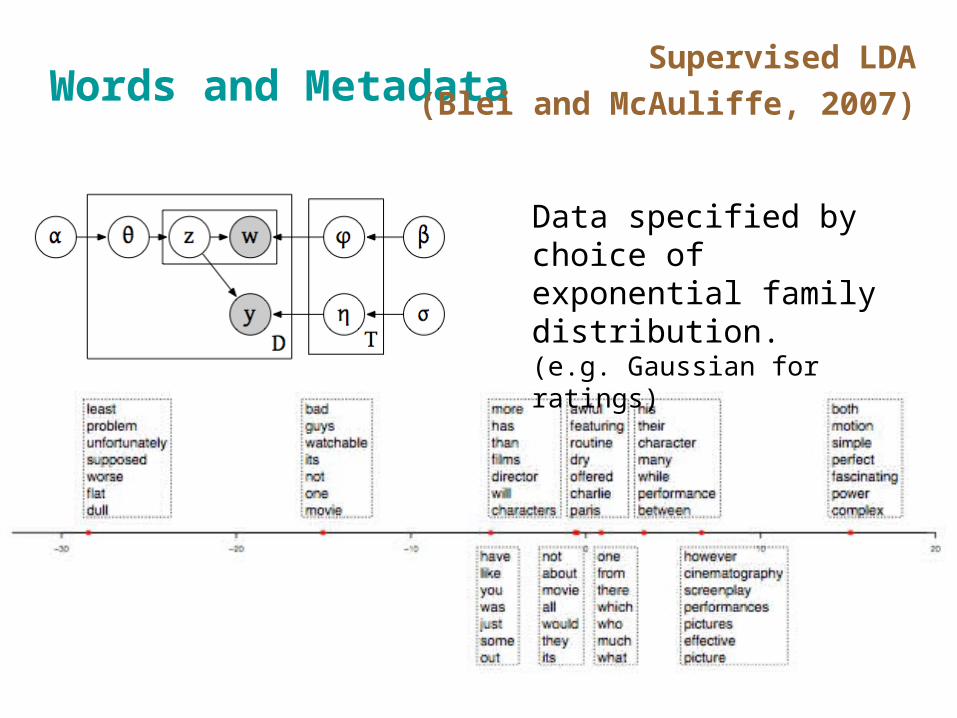
Words and MetadataSupervised LDA
(Blei and McAuliffe, 2007)
Data specified by choice of exponential family distribution. (e.g. Gaussian for ratings)

What do all these models have in common?
Words and other data are generatedconditioned on topic.
other data = authors, dates, citations, entities,…
“Downstream” model

Problems with Downstream Models
• Balancing influence of modalities requires careful tuning
• Strong independence assumptions among modalities may not be valid
It can be difficult to force modalities to “share” topics
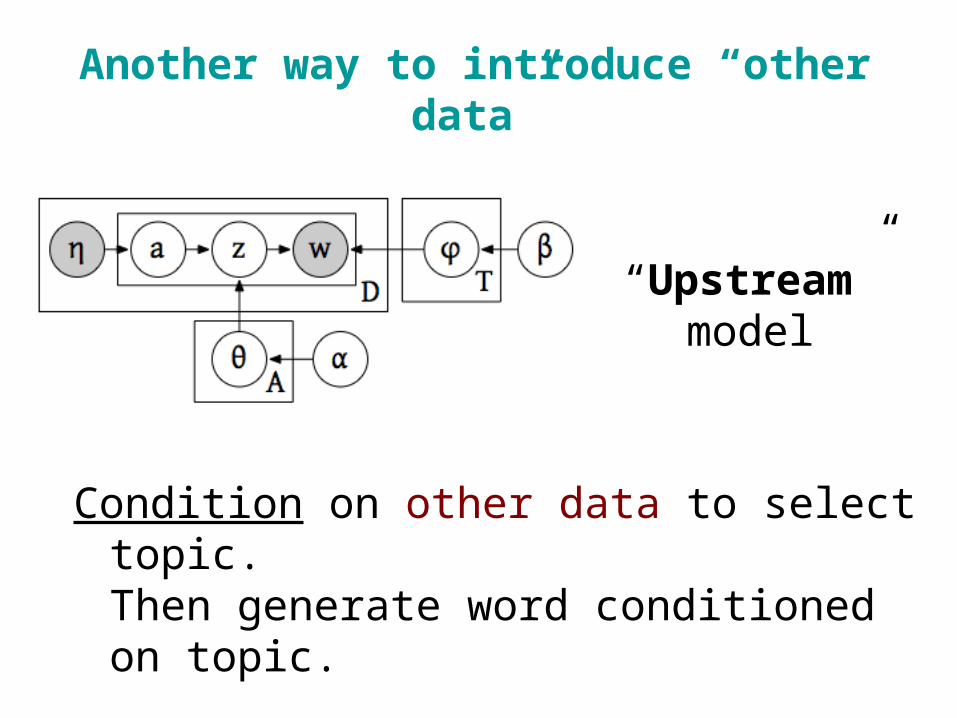
Another way to introduce “other data”
Condition on other data to select topic.Then generate word conditioned on topic.
“Upstream” model
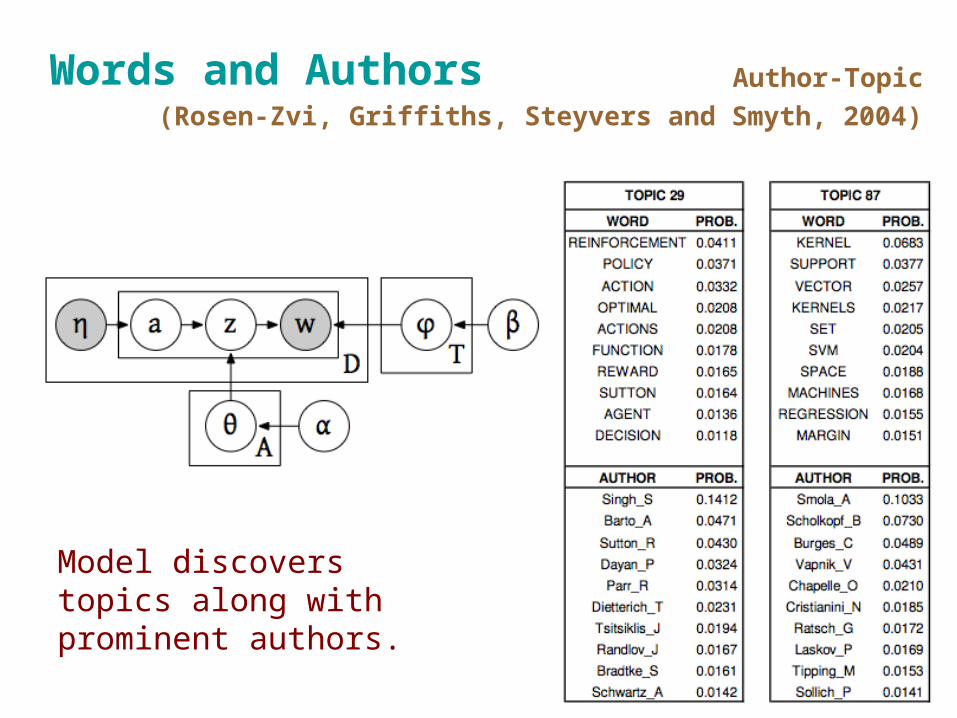
Words and Authors Author-Topic
(Rosen-Zvi, Griffiths, Steyvers and Smyth, 2004)
Model discovers topics along with prominent authors.

Words and Email HeadersAuthor-Recipient-Topic
(McCallum, Corrada-Emmanuel and Wang, 2005)
Model analyzes email relationships using text as well as links, unlike traditional SNA.

Words and Experts Author-Persona-Topic
(Mimno and McCallum, 2007)
Model distinguishes between topical “personas” of authors, helping to find reviewers for conference papers. “Expert Finding”
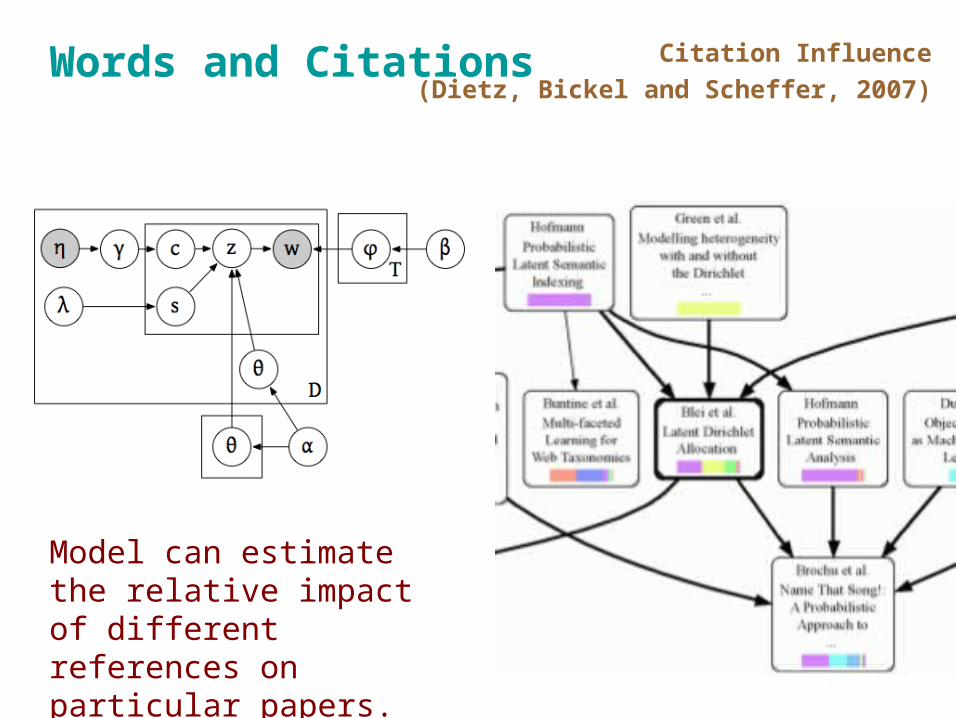
Words and Citations Citation Influence
(Dietz, Bickel and Scheffer, 2007)
Model can estimate the relative impact of different references on particular papers.

How do you create a new topic model?
1. Create a valid generative storyline
2. Write down a graphical model
3. Figure out inference procedure
4. Write code5. (Fix errors in math and
code)

What type of model accounts for arbitrary, correlated inputs?
Conditional models take real valued features, which can be used to encode discrete, categorical, and continuous inputs
Naïve Bayes :: MaxEnt
HMM :: Linear-chain CRF
Topic models :: ??Down-stream

What type of model accounts for arbitrary, correlated inputs?
Naïve Bayes :: MaxEnt
HMM :: Linear-chain CRF
Topic models :: THIS PAPER
Conditional models take real valued features, which can be used to encode discrete, categorical, and continuous inputs
Down-stream
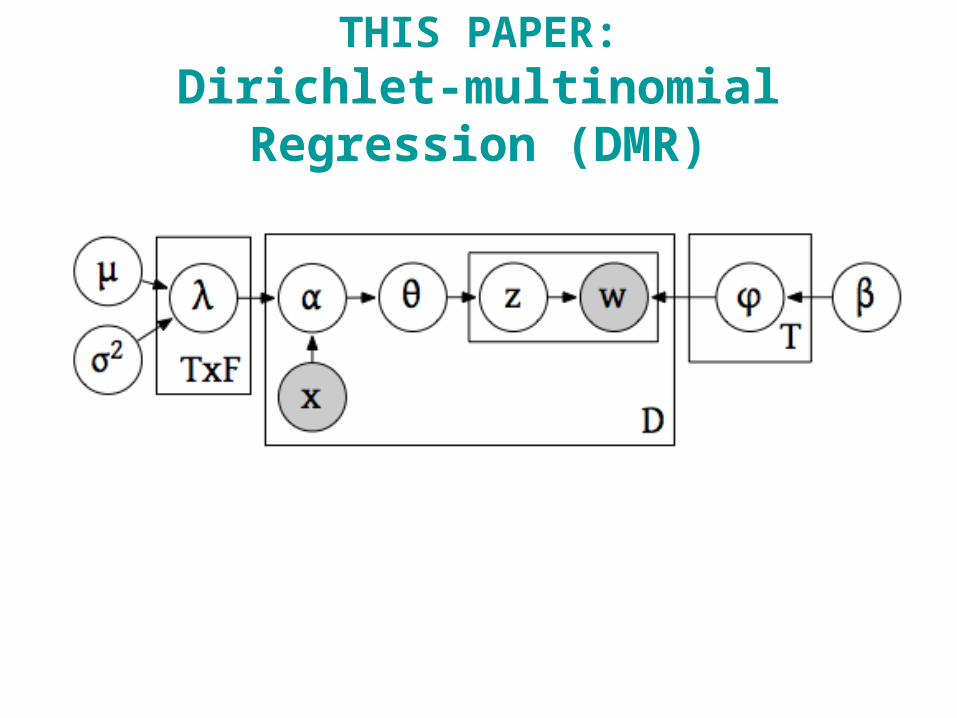
THIS PAPER:Dirichlet-multinomial Regression (DMR)
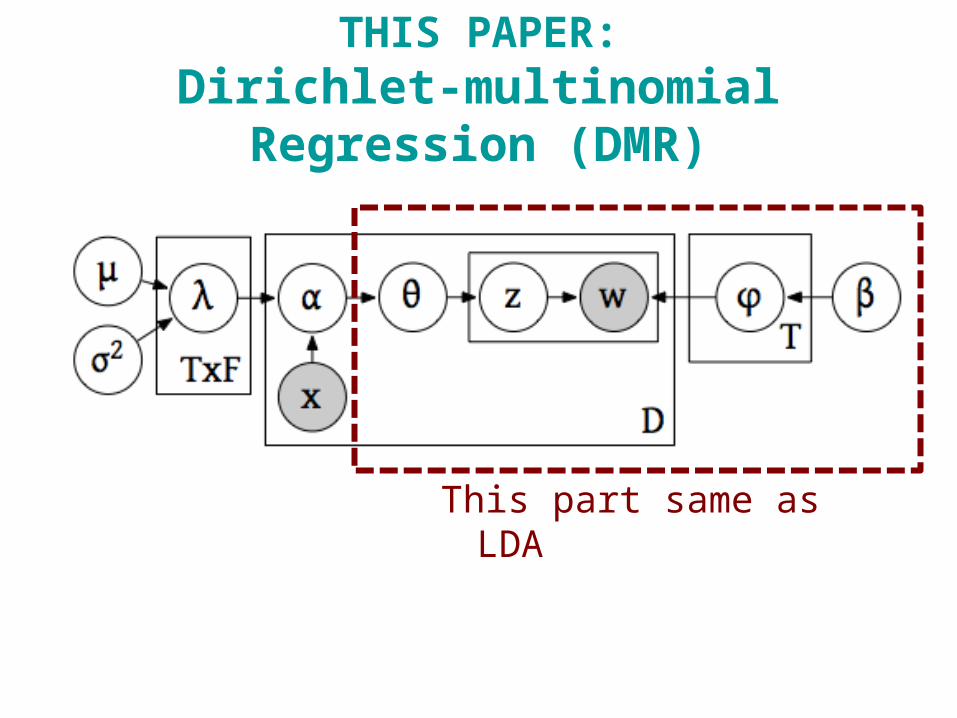
THIS PAPER:Dirichlet-multinomial Regression (DMR)
This part same as LDA
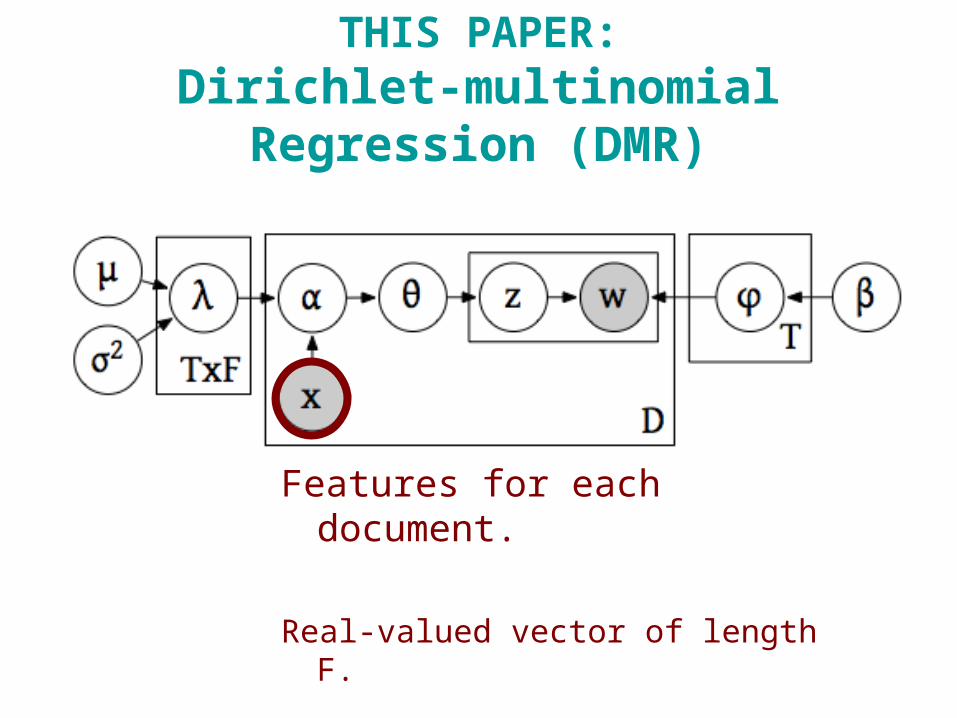
THIS PAPER:Dirichlet-multinomial Regression (DMR)
Features for each document.
Real-valued vector of length F.

Encoding Features
• Binary Indicators– Does N. Wang appear as an author?
Does the paper cite Li and Smith, 2006?
• Log position within an interval– (i.e. beta sufficient statistics)– Year within a range
• Survey response– 2 strongly for
0 indifferent-2 strongly against
• …

THIS PAPER:Dirichlet-multinomial Regression (DMR)
Dirichlet parameters
from which θ is sampled.
Document specific.
Depends on document features x
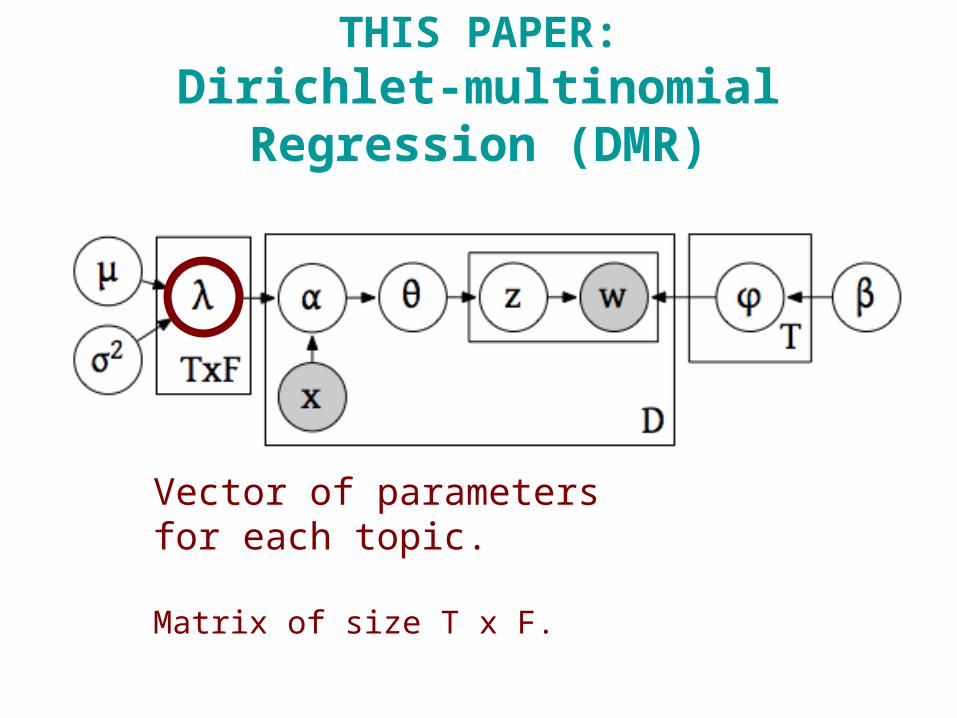
THIS PAPER:Dirichlet-multinomial Regression (DMR)
Vector of parametersfor each topic.
Matrix of size T x F.

Topic parameters for feature “published in JMLR”
2.27 kernel, kernels, rational kernels, string kernels, fisher kernel
1.74 bounds, vc dimension, bound, upper bound, lower bounds
1.41 reinforcement learning, learning, reinforcement
1.40 blind source separation, source separation, separation, channel
1.37 nearest neighbor, boosting, nearest neighbors, adaboost
-1.12 agent, agents, multi agent, autonomous agents
-1.21 strategies, strategy, adaptation, adaptive, driven
-1.23 retrieval, information retrieval, query, query expansion
-1.36 web, web pages, web page, world wide web, web sites
-1.44 user, users, user interface, interactive, interface

Topic parameters for feature “published in UAI”
2.88 bayesian networks, bayesian network, belief networks
2.26 qualitative, reasoning, qualitative reasoning, qualitative simulation
2.25 probability, probabilities, probability distributions,
2.25 uncertainty, symbolic, sketch, primal sketch, uncertain, connectionist
2.11 reasoning, logic, default reasoning, nonmonotonic reasoning
-1.29 shape, deformable, shapes, contour, active contour
-1.36 digital libraries, digital library, digital, library
-1.37 workshop report, invited talk, international conference, report
-1.50 descriptions, description, top, bottom, top bottom
-1.50 nearest neighbor, boosting, nearest neighbors, adaboost

Topic parameters for feature “Loopy Belief Propagation (MWJ, 1999)”
2.04 bayesian networks, bayesian network, belief networks
1.42 temporal, relations, relation, spatio temporal, temporal relations
1.26 local, global, local minima, simulated annealing
1.20 probabilistic, inference, probabilistic inference
1.20 back propagation, propagation, belief propagation, message passing, loopy belief propagation
-0.62 input, output, input output, outputs, inputs
-0.65 responses, signal, response, signal processing
-0.67 neurons, spiking neurons, neural, neuron
-0.68 analysis, statistical, sensitivity analysis, statistical analysis
-0.78 number, size, small, large, sample, small number

Topic parameters for feature “published in 2005”
2.04 semi supervised, learning, data, active learning
1.94 ontology, semantic, ontologies, ontological, daml oil
1.50 web, web pages, web page, world wide web
1.48 search, search engines, search engine, ranking
1.27 collaborative filtering, filtering, preferences
-1.11 neural networks, neural network, network, networks
-1.16 knowledge, knowledge representation, knowledge base
-1.17 expert systems, expert, systems, expert system
-1.25 system, architecture, describes, implementation
-1.31 database, databases, relational, xml, queries

Topic parameters for feature“written by G.E. Hinton”
1.96 uncertainty, symbolic, sketch, primal sketch
1.70 expert systems, expert, systems, expert system
1.35 recognition, pattern recognition, character recognition
1.34 representation, representations, represent, representing, represented, compact representation
1.22 high dimensional, dimensional, dimensionality reduction
-0.67 systems, system, dynamical systems, hybrid
-0.77 theory, computational, computational complexity
-0.80 general, case, cases, show, special case
-0.80 neurons, spiking neurons, neural, neuron
-0.99 visual, visual servoing, vision, active
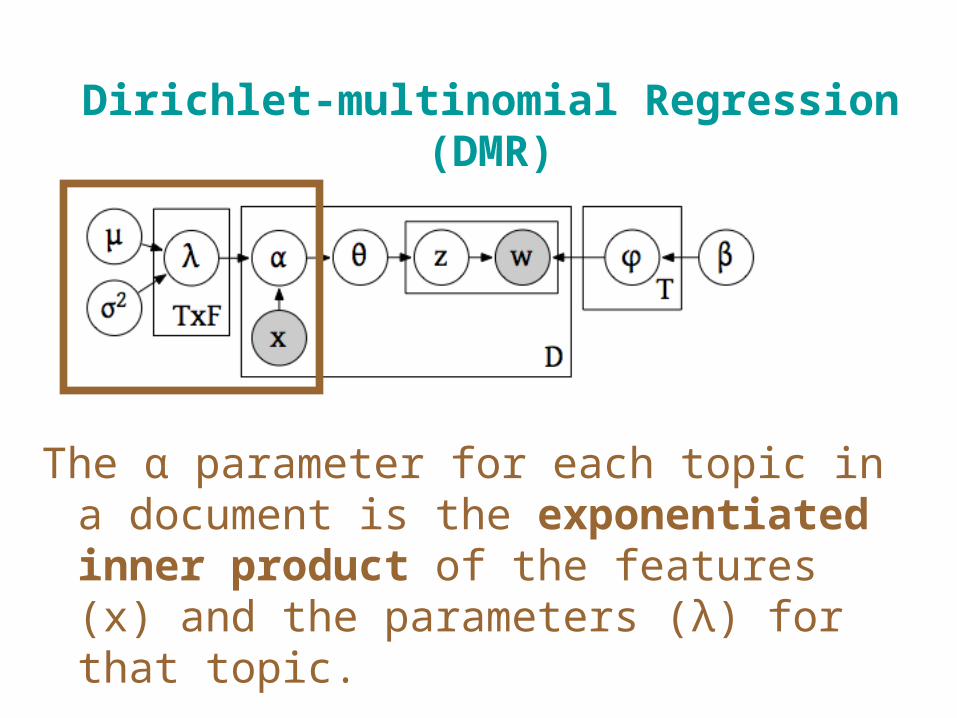
Dirichlet-multinomial Regression (DMR)
The α parameter for each topic in a document is the exponentiated inner product of the features (x) and the parameters (λ) for that topic.
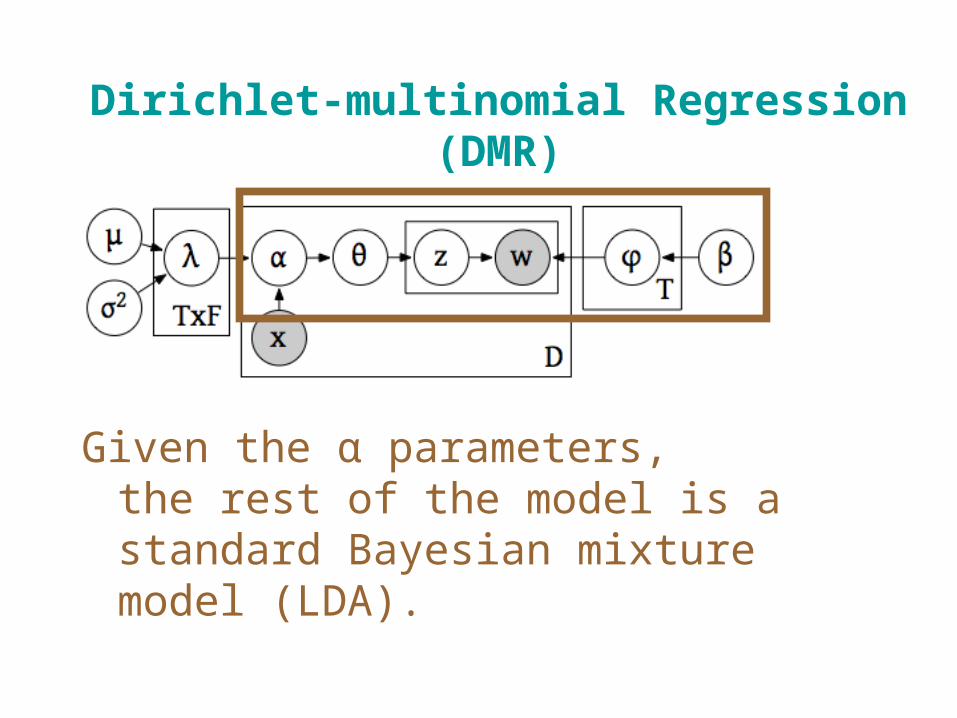
Dirichlet-multinomial Regression (DMR)
Given the α parameters, the rest of the model is a standard Bayesian mixture model (LDA).

DMR understood as an extension of Dirichlet Hyperparameter Optimization
Commonly, Dirichlet prior on θ:Symmetric, flat.All topics equally prominent.
Learning Dirichlet parameters from data:
In DMR, features induce a different prior for each document, conditioned on features.

Training the model
• Given topic assignments (z), we can numerically optimize the parameters (λ).
• Given the parameters, we can sample topic assignments.
• … alternate between these two as needed.
Note that this approach combines two off-the-shelf components: L-BFGS and a Gibbs sampler for LDA!

Log likelihood for topics and parameters
Dirichlet-multinomial distribution (aka Polya, DCM) with exp(…) instead of α

Log likelihood for topics and parameters
Gaussian regularization on parameters

Gradient equation for a single λ parameter
Gradient is quite simple.Can plug into standard optimizer we have for MaxEnt classifier
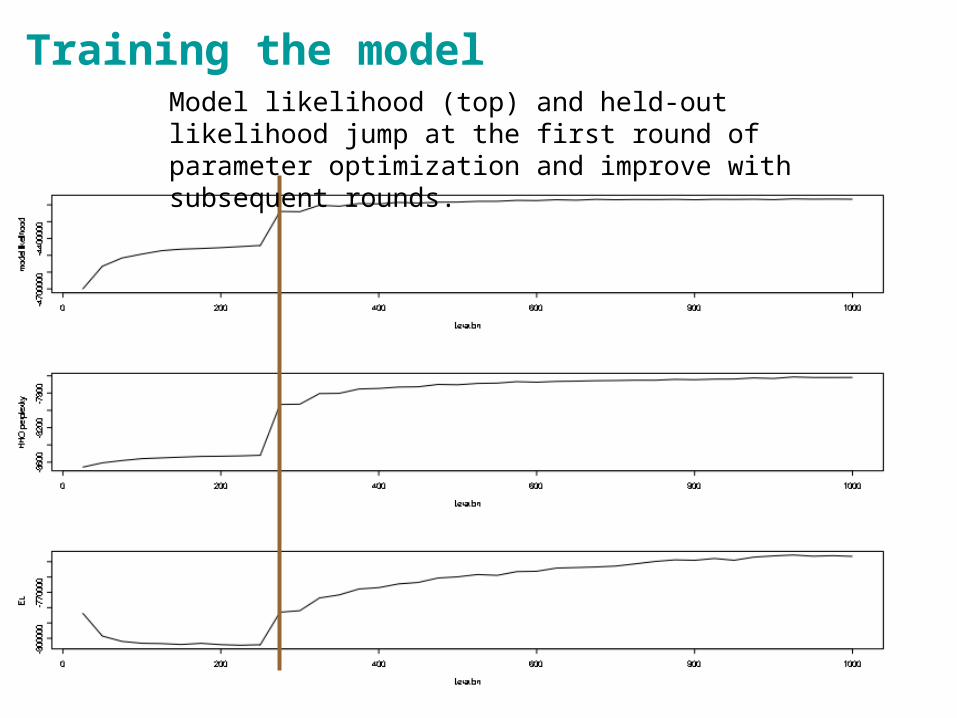
Training the model
• (maybe show a figure with model likelihood and EL to demonstrate that this is working)
Model likelihood (top) and held-out likelihood jump at the first round of parameter optimization and improve with subsequent rounds.

Effect of different features on document-topic Dirichlet prior
2.10 Models model gaussian mixture generative
.93 Bayesian inference networks network probabilistic
.69 Classifier classifiers bayes classification naive
.64 Probabilistic random conditional probabilities fields
.61 Sampling sample monte carlo chain samples
4.05 Kernel density kernels data parametric
2.06 Space dimensionality high reduction spaces
1.78 Learning machine learn learned reinforcement
1.50 Prediction regression bayes predictions naive
.88 Problem problems solving solution solutions
2003JMLRD.BleiA.NgM.I.Jordan
2004JMLRM.I.JordanF. BachK. Fukumizu
Document features

Evaluation
• Difficult with topic models– Exponential number of possible topic
assignments, over which we cannot marginalize.
• We use two methods on held-out documents
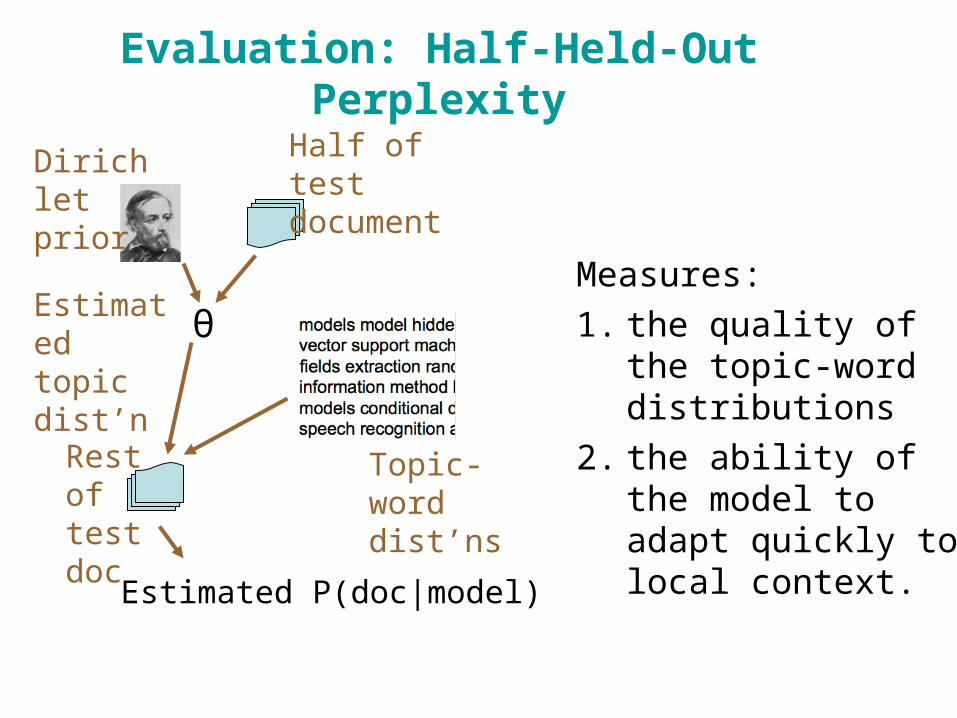
Evaluation: Half-Held-Out Perplexity
Measures:
1. the quality of the topic-word distributions
2. the ability of the model to adapt quickly to local context.
Dirichlet prior
Half of test document
θEstimated topic dist’n
Topic-word dist’ns
Rest of test doc
Estimated P(doc|model)

Evaluation: Empirical Likelihood
Measures:
1. the quality of the topic-word distributions
2. the prior distribution.
Dirichlet prior
θSampled topic dist’n
Topic-word dist’ns
Test doc
Estimated P(doc|model)
[Diggle & Gratton, 1984]

Results:Emulating Author-Topic
• By using author indicator features, we can emulate the Author-Topic model.
(Rosen-Zvi, Griffiths, Steyvers and Smyth 2004)
DMR
Author-Topic
LDA

Results: Emulating Author-Topic
• DMR shows better perplexity, and similar empirical likelihood to AT.
• LDA is worse in both metrics.
DMR
Author-Topic
LDA
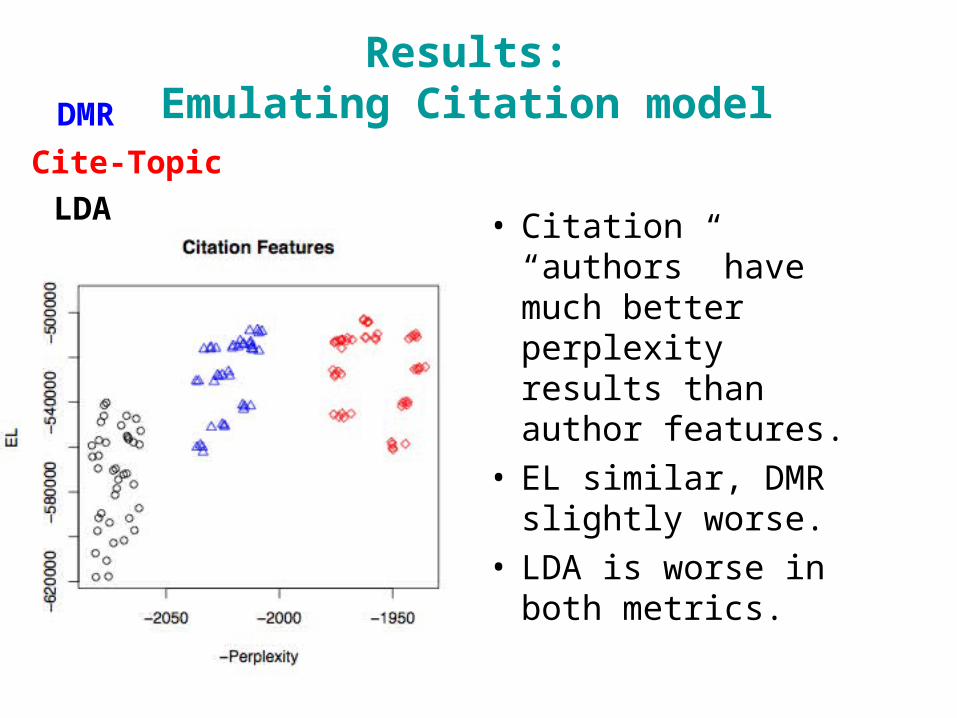
Results:Emulating Citation model
• Citation “authors” have much better perplexity results than author features.
• EL similar, DMR slightly worse.
• LDA is worse in both metrics.
DMR
Cite-Topic
LDA
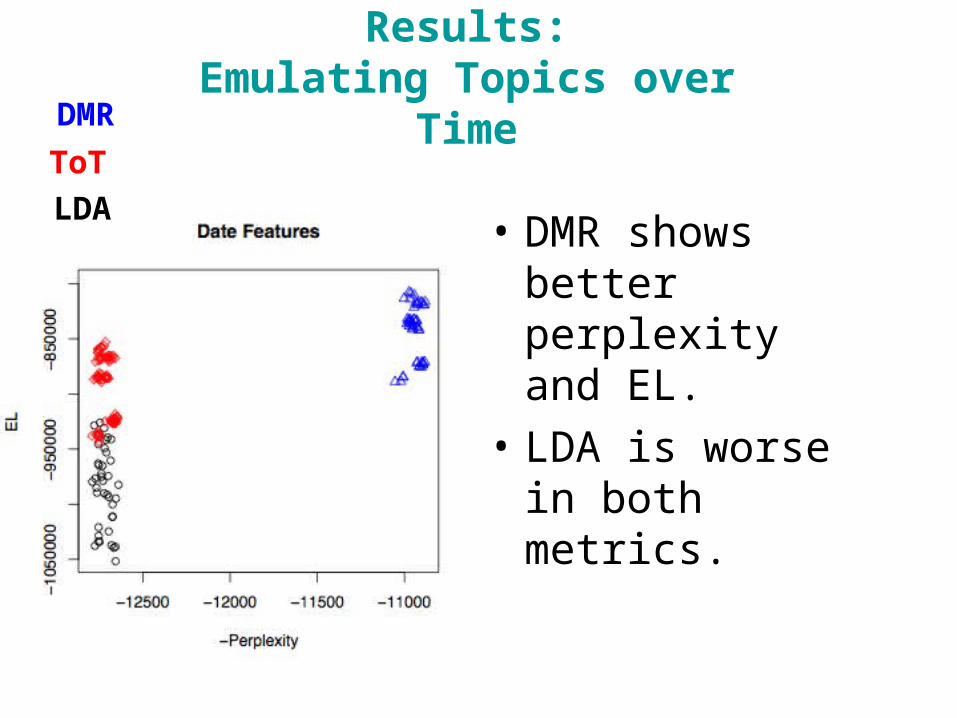
Results:Emulating Topics over Time
• DMR shows better perplexity and EL.
• LDA is worse in both metrics.
DMR
ToT
LDA

Arbitrary Queries
• Previous evaluations on ability to predict words given features.
• Can also predict features given words.
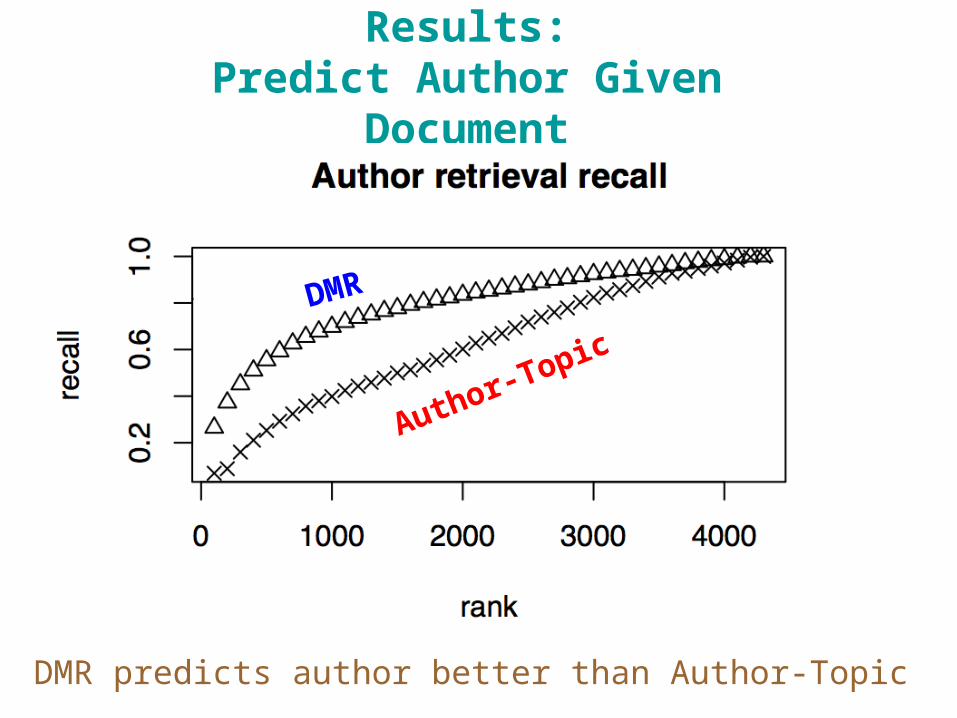
Results:Predict Author Given Document
DMR predicts author better than Author-Topic
DMR
Author-Topic

Efficiency• As upstream models
include more features, sampling grows more complicated because more variables must be sampled(e.g. author and topic for every token).
• DMR sampling is no more complicated than LDA.
DMR
A-T
At 100 topics, 38% of training wall-clock time is sampling, the rest is parameter optimization
Even with tricks to reduce complexity to O(A + T) from O(AT), DMR is faster
40 mins
32 mins
Optimization time could be improved by using stochastic gradient for L-BFGS.

Summary
DMR benefits:
• Simple to implement
• Simple to use
• Fast
• Expressive
LDA + L-BFGS
Just add features!
Faster sampling than Author-Topic
Toss in everything but the kitchen sink!





























