Embed Size (px)
Citation preview

Center for Computational Sciences, Univ. of Tsukuba
Towards Exascale Systems: Activity in Japan
Taisuke Boku Deputy Director
Center for Computational Sciences University of Tsukuba
2012/10/04 ORAP Forum 2012, Paris
1

Center for Computational Sciences, Univ. of Tsukuba
Outline
n Status of K computer n HPCI (High Performance Computing Infrastructure) n SDHPC (Strategic Direction/Development for HPC) n FS (Feasibility Study) & CREST n Activity in U. Tsukuba n Towards Exascale
2012/10/04 ORAP Forum 2012, Paris
2

Center for Computational Sciences, Univ. of Tsukuba
K computer status
We are #2 in the world now :-)
2012/10/04 ORAP Forum 2012, Paris
3

Full operation: 2012/06 Public utilization: 2012/09
K computer (#1 at TOP500 on 2011/06, 2011/11)
" Final spec. of K computer (as on Nov. 2011) " Computation nodes (CPUs): 88,128 " Total core#: 705,024 " Peak perforance: 11.28 PFLOPS Linpack: 10.51 PFLOPS " Memory capacity: 1.41 PB (16GB/node)
2012/10/04 ORAP Forum 2012, Paris
4

Kei (京) represents the numerical unit of 10 Peta (1016) in the Japanese language, representing the system’s performance goal of 10 Petaflops. The Chinese character 京 can also be used to mean “ a large gateway” so it could also be associated with the concept of a new gateway to computational science.
K computer’s official name
一、 十、 百、 千、 万、 億、 兆、 京、 垓、 杼、 穰、 溝、 澗、 正、 載、 極、 100 101 102 103 104 108 1012 1016 1020 1024 1028 1032 1036 1040 1044 1048
恒河沙、阿僧祗、那由他、不可思議、 無量大数 1052 1056 1060 1064 1068
2012/10/04 ORAP Forum 2012, Paris
5
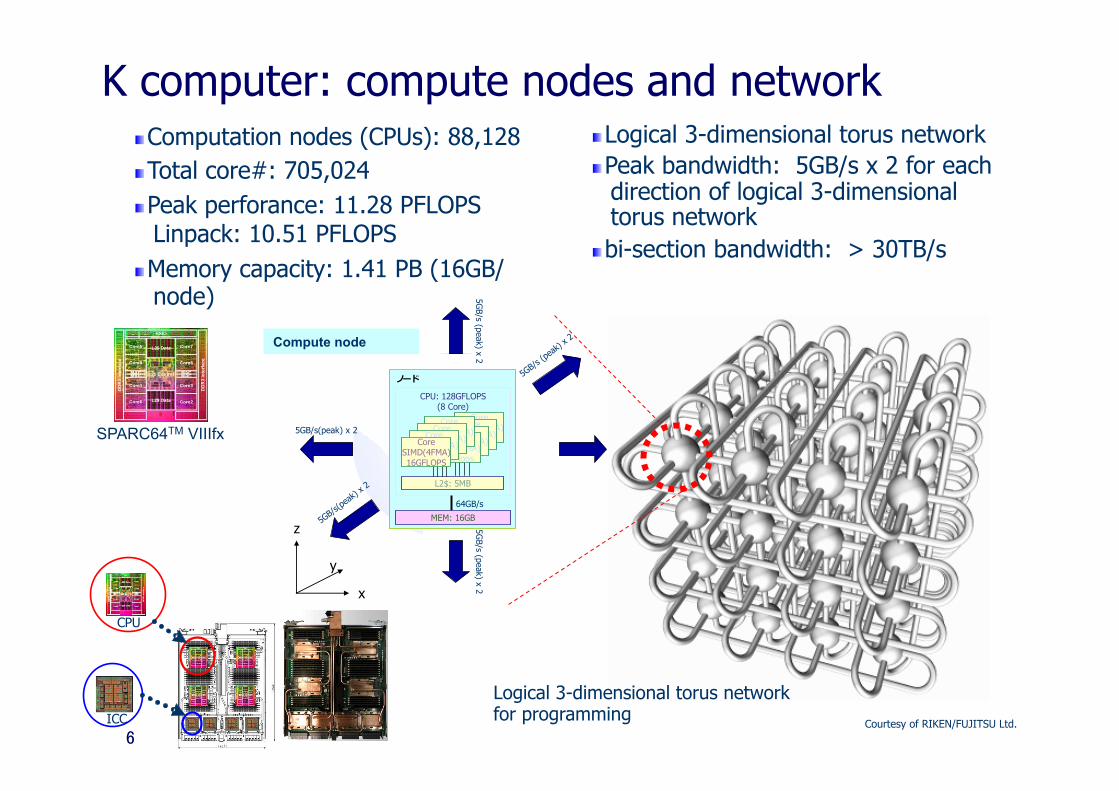
K computer: compute nodes and network " Logical 3-dimensional torus network " Peak bandwidth: 5GB/s x 2 for each
direction of logical 3-dimensional torus network
" bi-section bandwidth: > 30TB/s
SPARC64TM VIIIfx
Courtesy of RIKEN/FUJITSU Ltd.
ノード
CPU: 128GFLOPS(8 Core)
CoreSIMD(4FMA)
16GFlops
CoreSIMD(4FMA)
16GFlops
CoreSIMD(4FMA)
16GFlops
CoreSIMD(4FMA)
16GFlops
CoreSIMD(4FMA)
16GFlops
CoreSIMD(4FMA)
16GFlops
CoreSIMD(4FMA)
16GFlops
L2$: 5MB
64GB/s
CoreSIMD(4FMA)16GFLOPS
MEM: 16GB
x
y
z
5GB/s (peak) x 2
5GB/s
(peak)
x 2
5GB/s
(peak
) x 2
5GB/s(peak) x 2
5GB/s (peak) x 2
Compute node
Logical 3-dimensional torus network for programming
CPU
ICC
" Computation nodes (CPUs): 88,128 " Total core#: 705,024 " Peak perforance: 11.28 PFLOPS
Linpack: 10.51 PFLOPS " Memory capacity: 1.41 PB (16GB/
node)
6

7
CPU Features (Fujitsu SPARC64TM VIIIfx) n 8 cores n 2 SIMD operation circuit
n 2 Multiply & add floating-point operations (SP or DP) are executed in one SIMD instruction
n 256 FP registers (double precision) n Shared 5MB L2 Cache (10way)
n Hardware barrier n Prefetch instruction n Software controllable cache
- Sectored cache n Performance
n 16GFLOPS/core, 128GFLOPS/CPU n Commercial version (PRIMEHPC FX-10)
n 16 core/CPU (with reduced frequency)
Reference: SPARC64TM VIIIfx Extensions http://img.jp.fujitsu.com/downloads/jp/jhpc/sparc64viiifx-extensions.pdf
45nm CMOS process, 2GHz 22.7mm x 22.6mm 760 M transisters 58W(at 30℃ by water cooling)
16GF/core(2*4*2G)
2012/10/04 ORAP Forum 2012, Paris

Center for Computational Sciences, Univ. of Tsukuba
Operation of K computer n Operation site: AICS (Advanced Institute for Computational
Science), RIKEN (@ Kobe) n Job scheduling
n Since K computer’s interconnection network is 3-D torus, users can select one of: (1) rectangular shape aware node allocation or (2) just allocate nodes with required number without caring shape
n Currently, no priority control for the node size, but it could be modified based on user-request
n Program categories n 70%: SPIRE (Strategic, 5 of special projects) n 25%: public use (15% for general, 5% for young researchers, 5% for
industry) under HPCI n 5%: AICS research on computer science
2012/10/04 ORAP Forum 2012, Paris
8

Center for Computational Sciences, Univ. of Tsukuba 9
SPIRE (Strategic Programs for Innovative Research) n MEXT has identified five application areas that are expected to create
breakthroughs using the K computer n Field 1: Life science/Drug manufacture (PI inst. RIKEN) n Field 2: New material/energy creation (PI inst. U. Tokyo) n Field 3: Global change prediction for disaster prevention/mitigation (PI inst.
JAMSTEC) n Field 4: Mono-zukuri (Manufacturing technology) (PI inst. U. Tokyo) n Field 5: The origin of matters and the universe (PI inst. U. Tsukuba)
n MEXT funds 5 core organizations that lead research activities in these 5 strategic fields
(US$ 25M for each, for 5 years)
n Public Users -> HPCI

Center for Computational Sciences, Univ. of Tsukuba
Prizes on K computer n #1 in TOP500 on 2011/06, 2011/11 n HPCC (HPC Challenge) at SC11, all 4 categories are occupied by K
computer n HPL n Bandwidth n Random Access n FFT
n ACM Gordon Bell Prize, Peak Performance Award n Joint team of AICS RIKEN, U. Tokyo, U. Tsukuba and Fujitsu n Achieved 3.4 PFLOPS sustained performance on first principle material
simulation on semiconductor with 100,000 atoms n Silicon nano-wire simulation based on Real Space Density Function Theory
10
Center for Computational Sciences, Univ. of Tsukuba
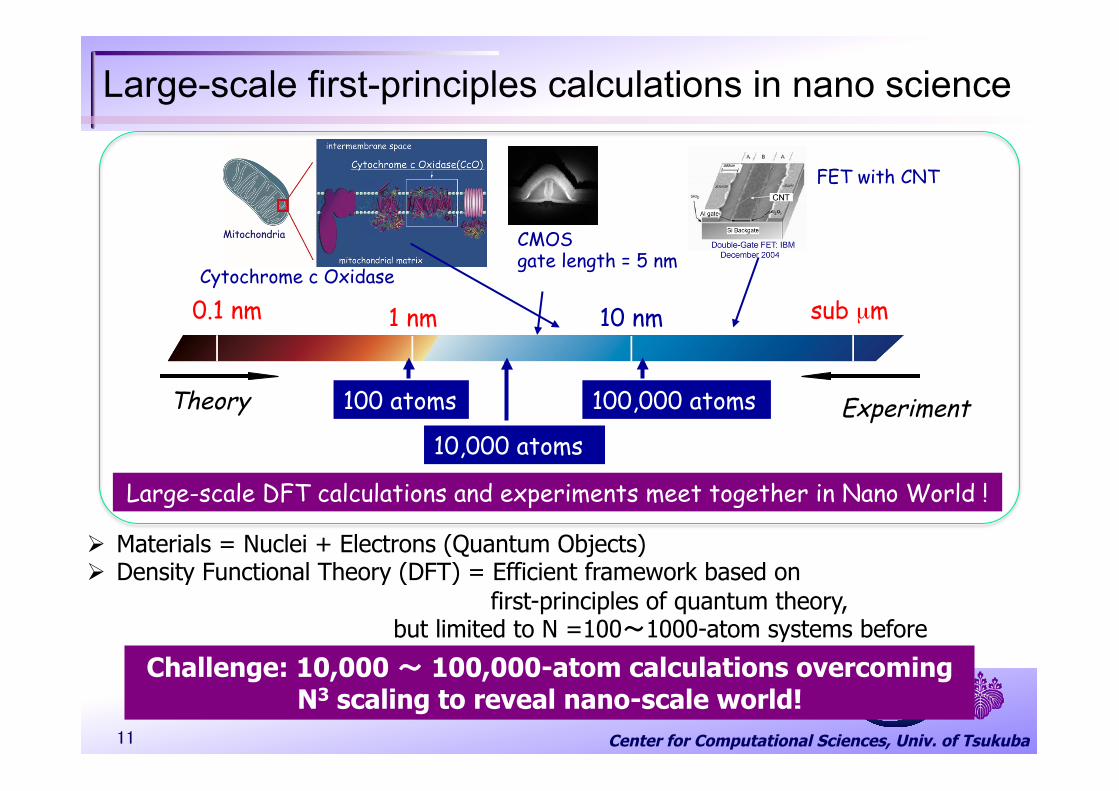
Large-scale first-principles calculations in nano science
11
0.1 nm
CMOS gate length = 5 nm
FET with CNT
Cytochrome c Oxidase
1 nm 10 nm sub µm
100 atoms
10,000 atoms
100,000 atoms Theory Experiment
Ø Materials = Nuclei + Electrons (Quantum Objects) Ø Density Functional Theory (DFT) = Efficient framework based on first-principles of quantum theory, but limited to N =100〜1000-atom systems before
Large-scale DFT calculations and experiments meet together in Nano World !
Challenge: 10,000 ~ 100,000-atom calculations overcoming N3 scaling to reveal nano-scale world!

Center for Computational Sciences, Univ. of Tsukuba
2011 ACM Gordon Bell Prize for Peak Performance Award “First-principle calculation of electronic states of a silicon nanowire with 100,000 atoms on the K computer”

Center for Computational Sciences, Univ. of Tsukuba
HPCI (High Performance Computing Infrastructure)
2012/10/04 ORAP Forum 2012, Paris
13

Center for Computational Sciences, Univ. of Tsukuba
What is HPCI ? n Nation-wide High Performance Computing Infrastructure in Japan n Gathering main supercomputer resources in Japan including K computer and
all universities’ supercomputer centers n Grid technology to enable “SSO (single sign-on)” utilization of any
supercomputers and file systems nation-widely n Large scale distributed file system in two sites (West and East) as data pool to
be accessed from any supercomputer resources under HPCI n Science-driven project base proposals to utilize HPCI resources are submitted,
then free CPU budget is decided n Operation just started on 2012/09/28 (just last week)
n Project proposals: 2012/05 n Project selection: 2012/06~08
2012/10/04 ORAP Forum 2012, Paris
14
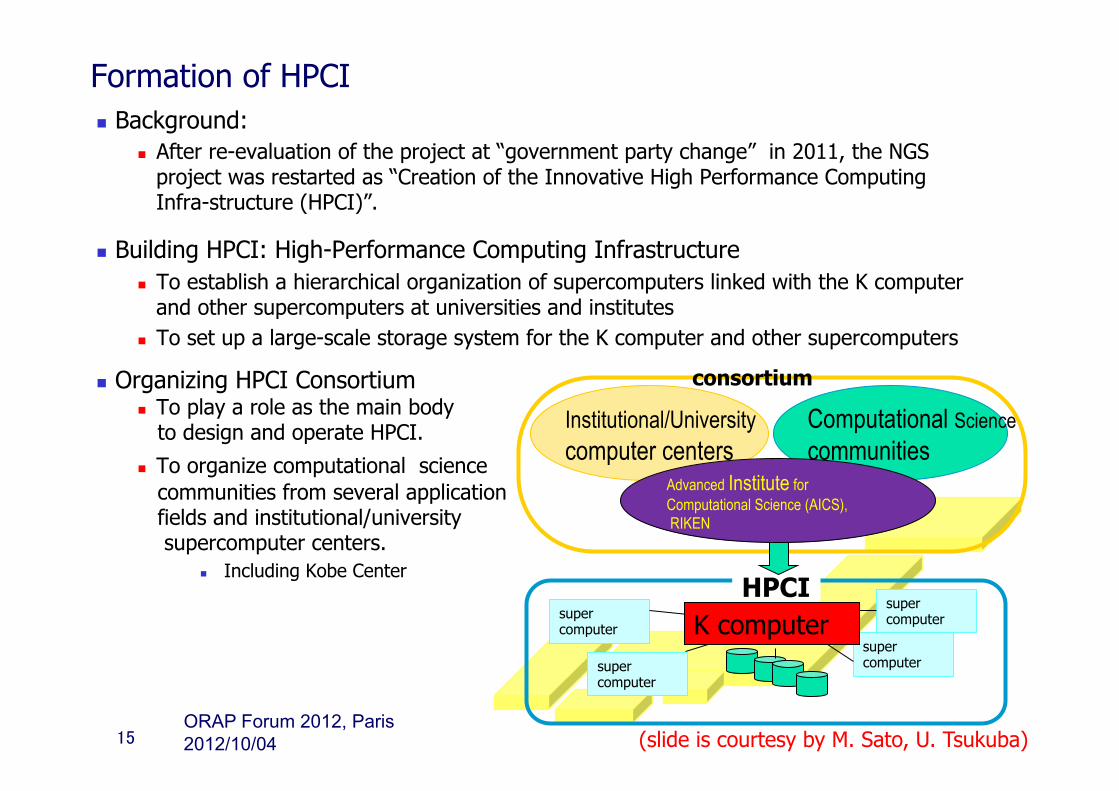
Formation of HPCI n Background:
n After re-evaluation of the project at “government party change” in 2011, the NGS project was restarted as “Creation of the Innovative High Performance Computing Infra-structure (HPCI)”.
n Building HPCI: High-Performance Computing Infrastructure n To establish a hierarchical organization of supercomputers linked with the K computer
and other supercomputers at universities and institutes n To set up a large-scale storage system for the K computer and other supercomputers
n Organizing HPCI Consortium n To play a role as the main body to design and operate HPCI.
n To organize computational science communities from several application fields and institutional/university supercomputer centers.
n Including Kobe Center
consortium
super computer
super computer
super computer
super computer
HPCI K computer
Institutional/University computer centers
Computational Science communities
Advanced Institute for Computational Science (AICS), RIKEN
(slide is courtesy by M. Sato, U. Tsukuba) 2012/10/04 ORAP Forum 2012, Paris
15

HPCI Consortium Members User Communities (13)
n RIKEN n Computational Materials Science Initiative n Japan Agency for Marine-Earth Science and Technology n Institute of Industrial Science at University of Tokyo n Joint Institute for Computational Fundamental Science n Industrial Committee for Super Computing Promotion n Foundation for Computational Science n BioGrid Center Kansai n Japan Aerospace Exploration Agency n Center for Computational Science & e-Systems, Japan Atomic Energy Agency n National Institute for Fusion Science n Solar-Terrestrial Environment Laboratory, Nagoya University n Kobe University
Resource Providers (25) n Information Initiative Center, Hokkaido University n Cyberscience Center, Tohoku University n Information Technology Center, University of Tokyo n Information Technology Center, Nagoya University n Academic Center for Computing and Media Studies, Kyoto University. n Cybermedia Center, Osaka University n Research Institute for Information Technology, Kyushu University
n Center for Computational Sciences, University of Tsukuba n Global Scientific Information and Computing Center, Tokyo
Institute of Technology n Institute for Materials Research, Tohoku University n Institute for Solid State Physics, University of Tokyo n Yukawa Institute for Theoretical Physics, Kyoto University n Research Center for Nuclear Physics, Osaka University n Computing Research Center, KEK(High Energy Accelerator
Research Organization) n National Astronomical Observatory of Japan n Research Center for Computational Science, Institute for
Molecular Sciencce n The Institute of Statistical Mathematics n JAXA’s Engineering Digital Innovation Center n The Earth Simulator Center n Information Technology Research Institute, AIST n Center for Computational Science & e-Systems, Japan Atomic
Energy Agency n Advanced Center for Computing and Communication, RIKEN n Advanced Institute for Computational Science n National Institute of Informatics n Research Organization for Information Science & Technology
(slide is courtesy by M. Sato, U. Tsukuba) 2012/10/04 ORAP Forum 2012, Paris
16
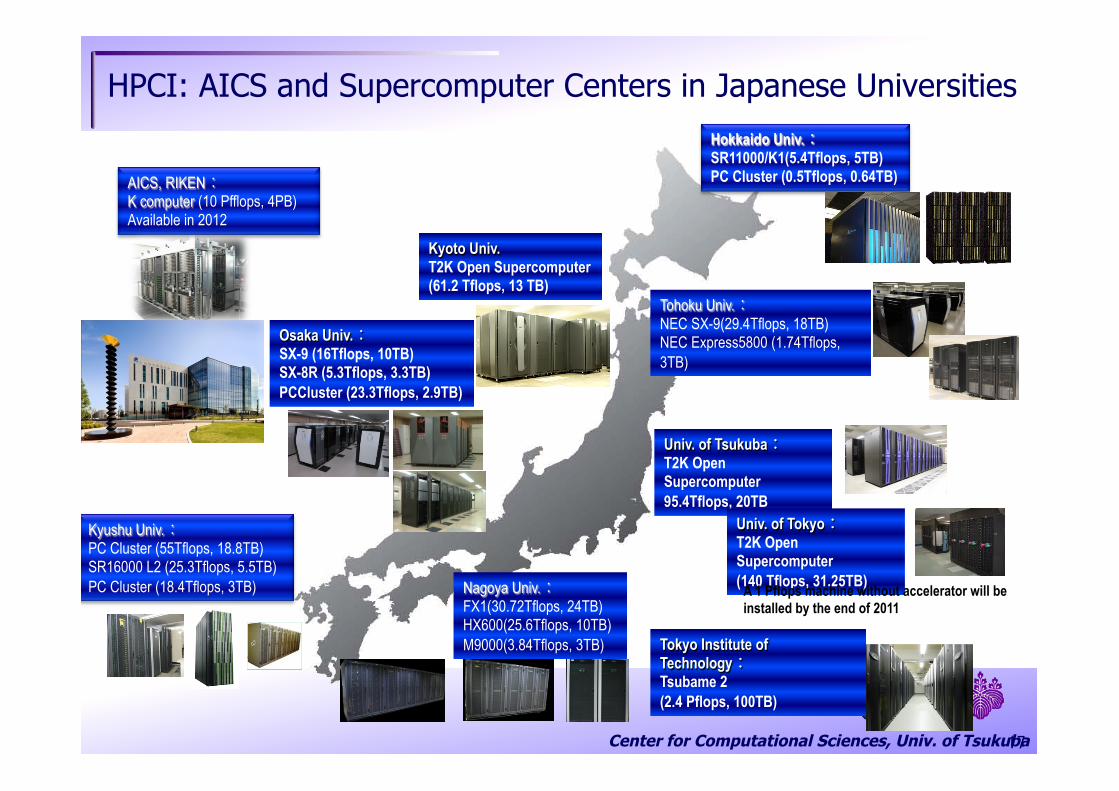
Center for Computational Sciences, Univ. of Tsukuba
HPCI: AICS and Supercomputer Centers in Japanese Universities
Kyushu Univ.: PC Cluster (55Tflops, 18.8TB) SR16000 L2 (25.3Tflops, 5.5TB) PC Cluster (18.4Tflops, 3TB)
Hokkaido Univ.:SR11000/K1(5.4Tflops, 5TB) PC Cluster (0.5Tflops, 0.64TB)
Nagoya Univ.:FX1(30.72Tflops, 24TB) HX600(25.6Tflops, 10TB) M9000(3.84Tflops, 3TB)
Osaka Univ.: SX-9 (16Tflops, 10TB) SX-8R (5.3Tflops, 3.3TB) PCCluster (23.3Tflops, 2.9TB)
Kyoto Univ. T2K Open Supercomputer (61.2 Tflops, 13 TB)
Tohoku Univ.: NEC SX-9(29.4Tflops, 18TB) NEC Express5800 (1.74Tflops, 3TB)
Univ. of Tsukuba: T2K Open Supercomputer95.4Tflops, 20TB
Univ. of Tokyo: T2K Open Supercomputer(140 Tflops, 31.25TB)
AICS, RIKEN: K computer (10 Pfflops, 4PB) Available in 2012
A 1 Pflops machine without accelerator will be installed by the end of 2011
Tokyo Institute of Technology: Tsubame 2 (2.4 Pflops, 100TB)
17
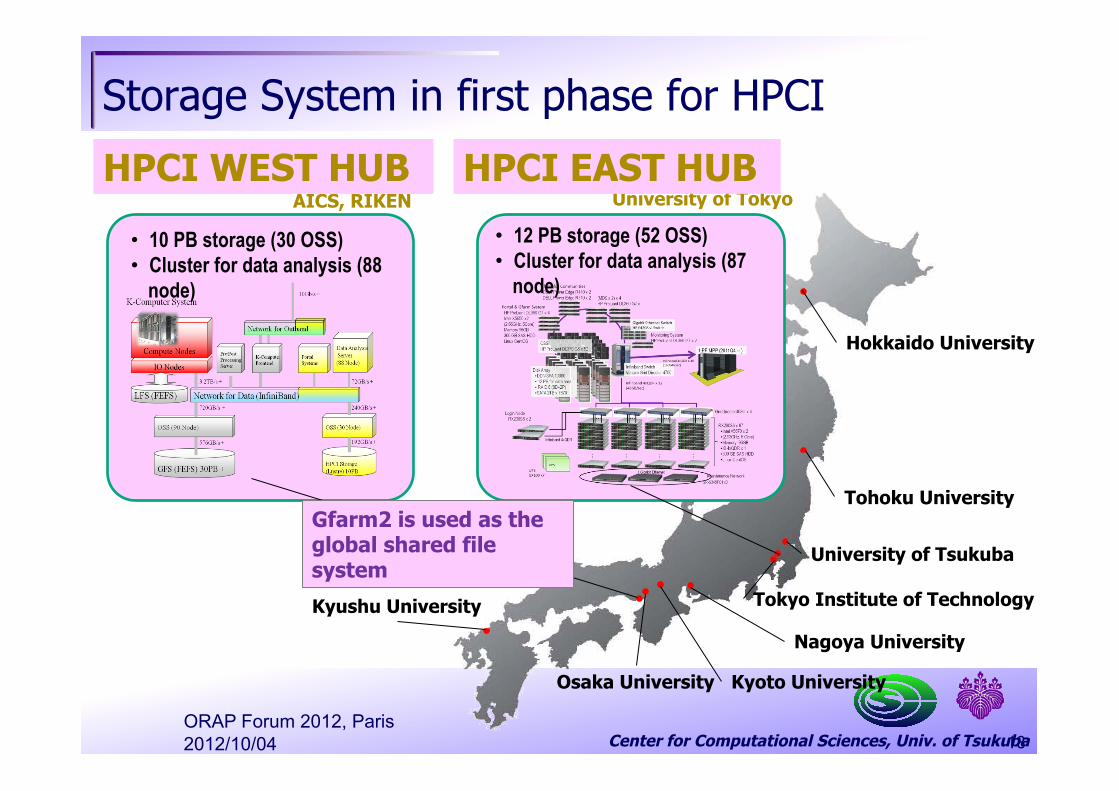
Center for Computational Sciences, Univ. of Tsukuba
Storage System in first phase for HPCI
Hokkaido University
Tohoku University
University of Tokyo
University of Tsukuba
Tokyo Institute of Technology
Nagoya University
Kyushu University
Osaka University Kyoto University
AICS, RIKEN
• 12 PB storage (52 OSS) • Cluster for data analysis (87
node)
• 10 PB storage (30 OSS) • Cluster for data analysis (88
node)
HPCI WEST HUB HPCI EAST HUB
Gfarm2 is used as the global shared file system
18 2012/10/04 ORAP Forum 2012, Paris

Center for Computational Sciences, Univ. of Tsukuba
SDHPC (Strategic Direction/Development of High Performance Computing Systems)
2012/10/04 ORAP Forum 2012, Paris
19
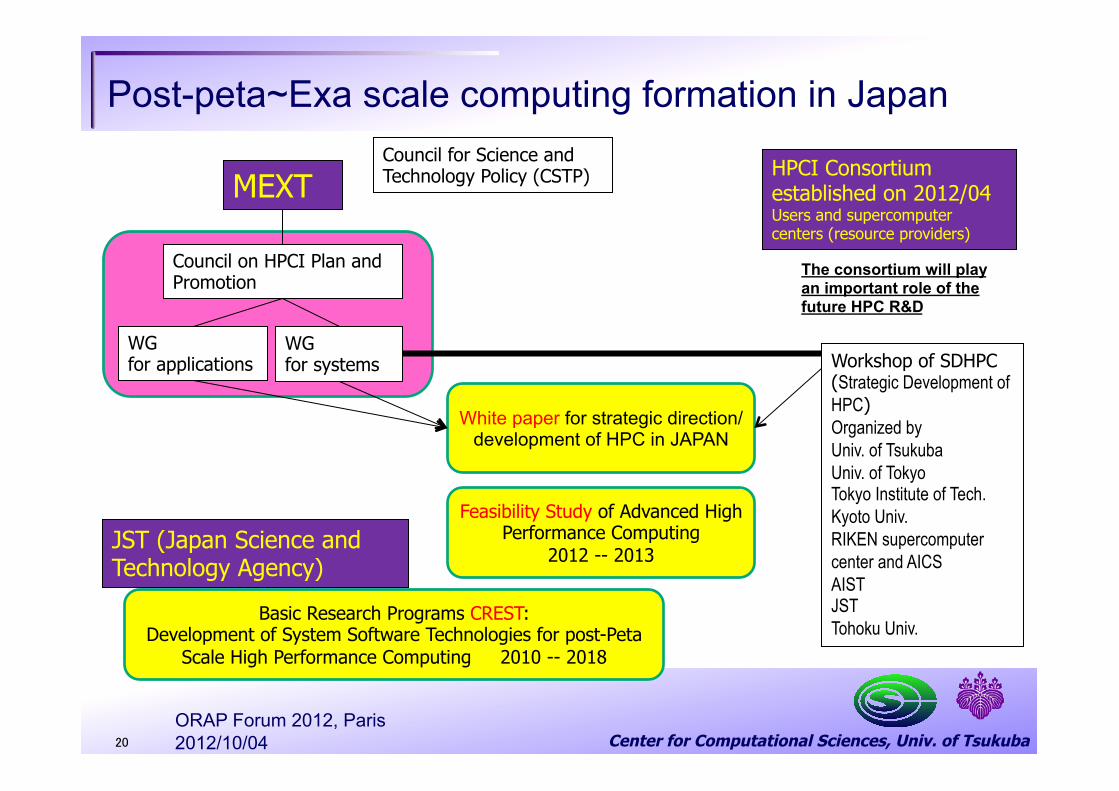
Center for Computational Sciences, Univ. of Tsukuba
Post-peta~Exa scale computing formation in Japan
20
MEXT HPCI Consortium established on 2012/04 Users and supercomputer centers (resource providers)
Workshop of SDHPC (Strategic Development of HPC) Organized by Univ. of Tsukuba Univ. of Tokyo Tokyo Institute of Tech. Kyoto Univ. RIKEN supercomputer center and AICS AIST JST Tohoku Univ.
WG for applications
WG for systems
JST (Japan Science and Technology Agency)
Basic Research Programs CREST: Development of System Software Technologies for post-Peta
Scale High Performance Computing 2010 -- 2018
Feasibility Study of Advanced High Performance Computing
2012 -- 2013
White paper for strategic direction/development of HPC in JAPAN
The consortium will play an important role of the future HPC R&D
Council for Science and Technology Policy (CSTP)
Council on HPCI Plan and Promotion
2012/10/04 ORAP Forum 2012, Paris
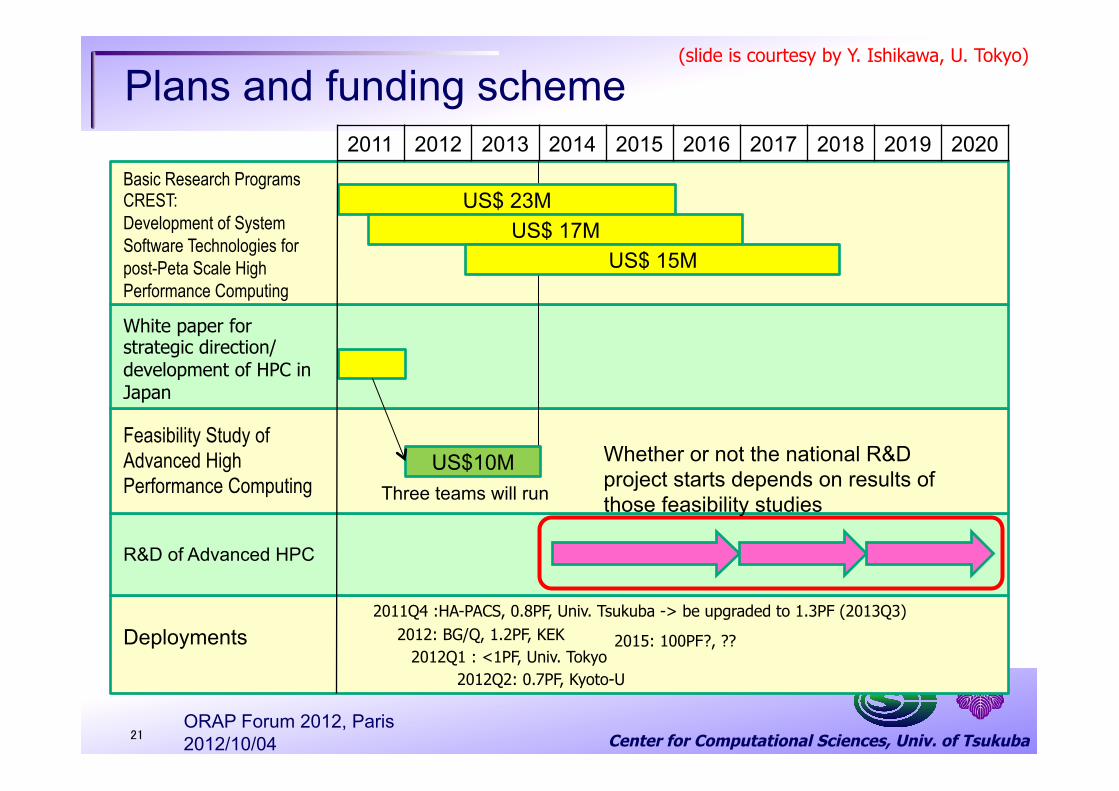
Center for Computational Sciences, Univ. of Tsukuba
Plans and funding scheme
21
2011 2012 2013 2014 2015 2016 2017 2018 2019 2020
Basic Research Programs CREST: Development of System Software Technologies for post-Peta Scale High Performance Computing
Feasibility Study of Advanced High Performance Computing
US$ 23M
US$ 17M
US$ 15M
US$10M
White paper for strategic direction/development of HPC in Japan
Deployments
2011Q4 :HA-PACS, 0.8PF, Univ. Tsukuba -> be upgraded to 1.3PF (2013Q3)
2012Q1 : <1PF, Univ. Tokyo 2012Q2: 0.7PF, Kyoto-U
2012: BG/Q, 1.2PF, KEK
Three teams will run
2015: 100PF?, ??
R&D of Advanced HPC
Whether or not the national R&D project starts depends on results of those feasibility studies
(slide is courtesy by Y. Ishikawa, U. Tokyo)
2012/10/04 ORAP Forum 2012, Paris

Center for Computational Sciences, Univ. of Tsukuba
What is SDHPC ?
n White paper for Strategic Direction/Development of HPC in JAPAN was written by young Japanese researchers with advisers (seniors)
n The white paper was provided to Council for HPCI Plan and Promotion on 2012/03
n Contents n Expected scientific and technological values in exa-scale computing n Challenges towards exa-scale computing n Current research efforts in Japan and other countries n Approaches n Competitive vs Collaboration n Plan of R&D and organization
n The white paper is referred for call for proposals in “Feasibility Study of Advanced High Performance Computing”
22 2012/10/04 ORAP Forum 2012, Paris

Strategic Development of Exascale Systems n Exascale systems
n Cannot be built upon traditional technological advances. n Needs special efforts in architecture / system software for
developing effective (useful) Exascale systems n Strategy
n HW/SW/Application co-design n Close cooperation with the application WG n Architecture design suited for target application
requirements n Exploring best-matching between available technologies
and application requirements
23 2012/10/04 ORAP Forum 2012, Paris
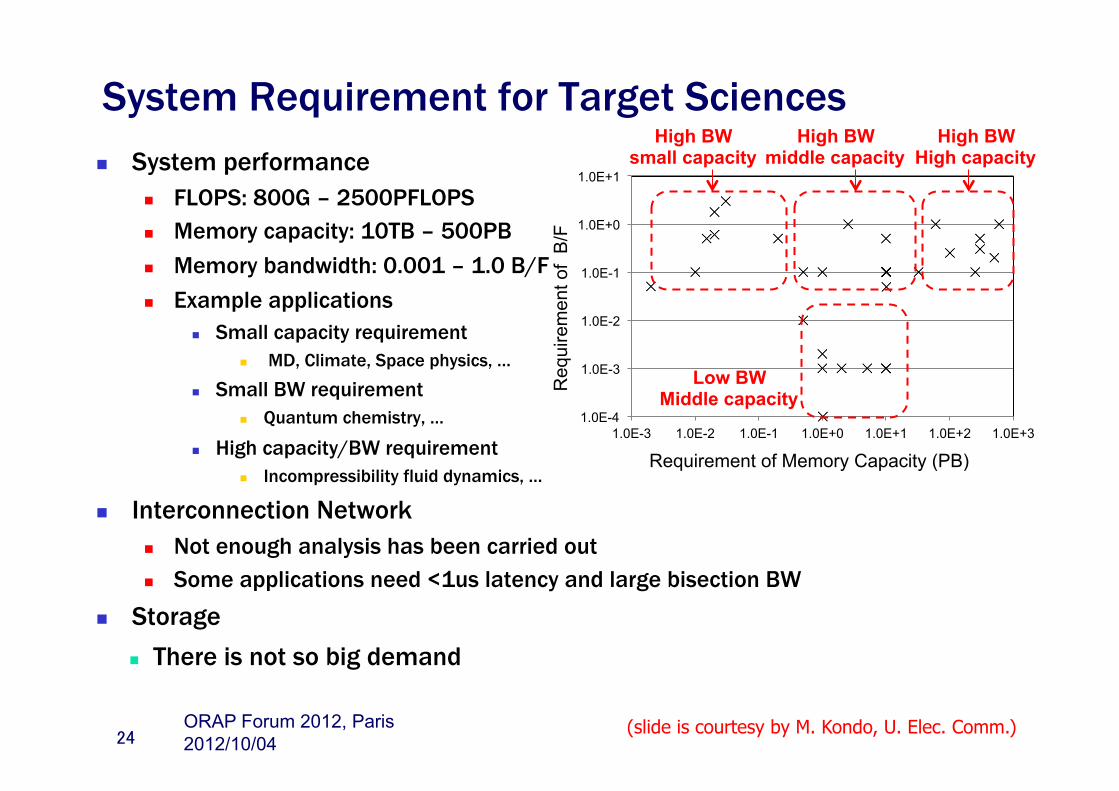
System Requirement for Target Sciences n System performance
n FLOPS: 800G – 2500PFLOPS n Memory capacity: 10TB – 500PB n Memory bandwidth: 0.001 – 1.0 B/F n Example applications
n Small capacity requirement n MD, Climate, Space physics, …
n Small BW requirement n Quantum chemistry, …
n High capacity/BW requirement n Incompressibility fluid dynamics, …
n Interconnection Network n Not enough analysis has been carried out n Some applications need <1us latency and large bisection BW
n Storage n There is not so big demand
24
1.0E-4
1.0E-3
1.0E-2
1.0E-1
1.0E+0
1.0E+1
1.0E-3 1.0E-2 1.0E-1 1.0E+0 1.0E+1 1.0E+2 1.0E+3
Req
uire
men
t of
B/F
Requirement of Memory Capacity (PB)
Low BW Middle capacity
High BW small capacity
High BW middle capacity
High BW High capacity
(slide is courtesy by M. Kondo, U. Elec. Comm.) 2012/10/04 ORAP Forum 2012, Paris
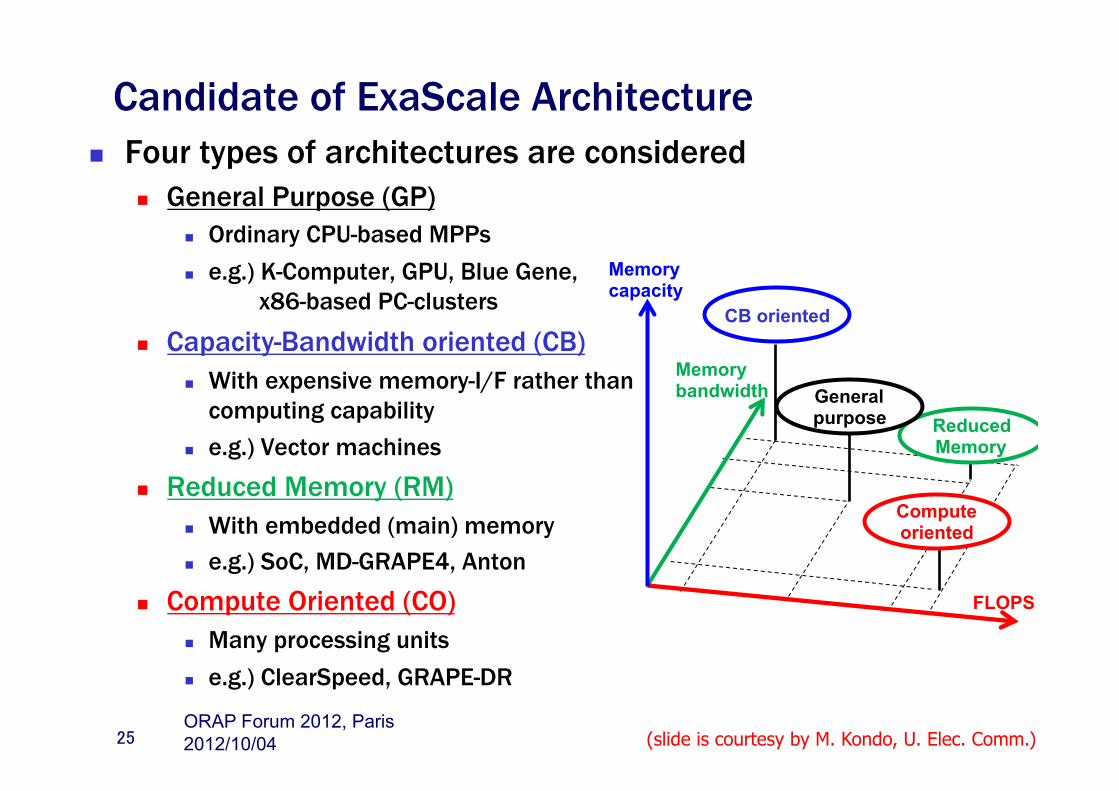
Candidate of ExaScale Architecture n Four types of architectures are considered
n General Purpose (GP) n Ordinary CPU-based MPPs n e.g.) K-Computer, GPU, Blue Gene,
x86-based PC-clusters
n Capacity-Bandwidth oriented (CB) n With expensive memory-I/F rather than
computing capability n e.g.) Vector machines
n Reduced Memory (RM) n With embedded (main) memory n e.g.) SoC, MD-GRAPE4, Anton
n Compute Oriented (CO) n Many processing units n e.g.) ClearSpeed, GRAPE-DR
25
Memory bandwidth
Memory capacity
FLOPS
CB oriented
Compute oriented
Reduced Memory
General purpose
(slide is courtesy by M. Kondo, U. Elec. Comm.) 2012/10/04 ORAP Forum 2012, Paris
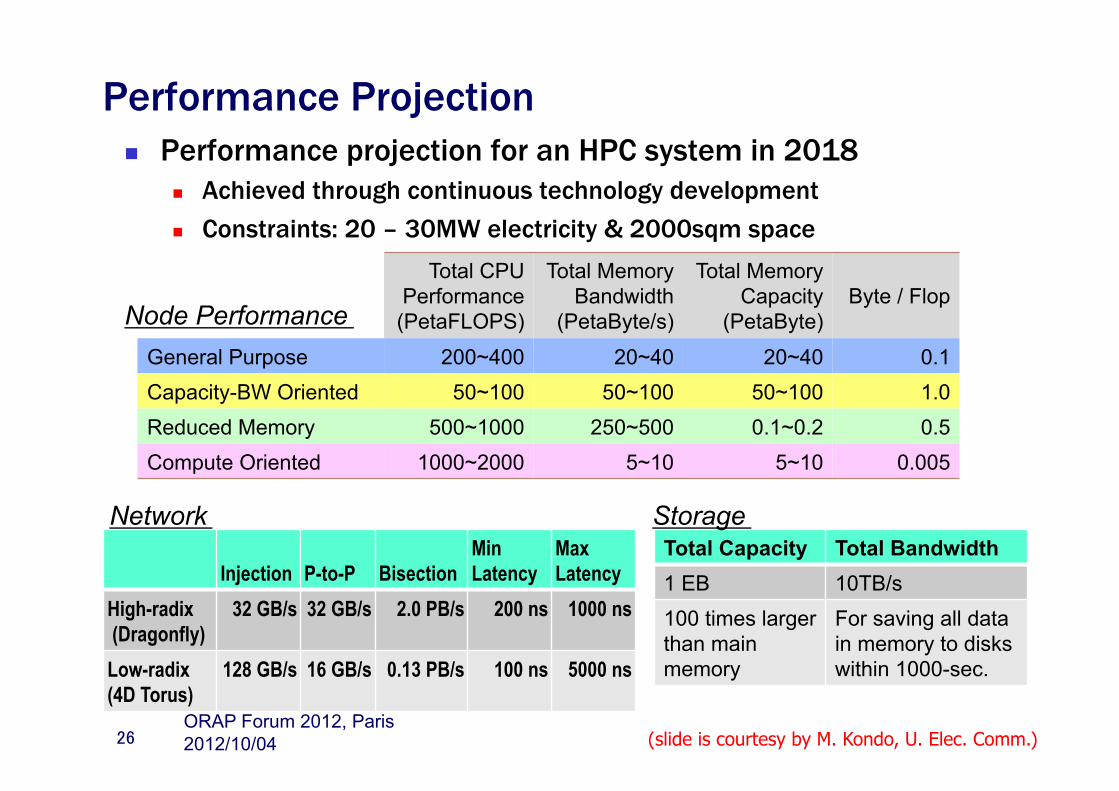
Performance Projection n Performance projection for an HPC system in 2018
n Achieved through continuous technology development n Constraints: 20 – 30MW electricity & 2000sqm space
26
Injection
P-to-P
Bisection
Min Latency
Max Latency
High-radix (Dragonfly)
32 GB/s 32 GB/s 2.0 PB/s 200 ns 1000 ns
Low-radix (4D Torus)
128 GB/s 16 GB/s 0.13 PB/s 100 ns 5000 ns
Total Capacity Total Bandwidth
1 EB 10TB/s
100 times larger than main memory
For saving all data in memory to disks within 1000-sec.
Network Storage
Total CPU Performance (PetaFLOPS)
Total Memory Bandwidth
(PetaByte/s)
Total Memory Capacity
(PetaByte)
Byte / Flop
General Purpose 200~400 20~40 20~40 0.1
Capacity-BW Oriented 50~100 50~100 50~100 1.0 Reduced Memory 500~1000 250~500 0.1~0.2 0.5 Compute Oriented 1000~2000 5~10 5~10 0.005
Node Performance
(slide is courtesy by M. Kondo, U. Elec. Comm.) 2012/10/04 ORAP Forum 2012, Paris
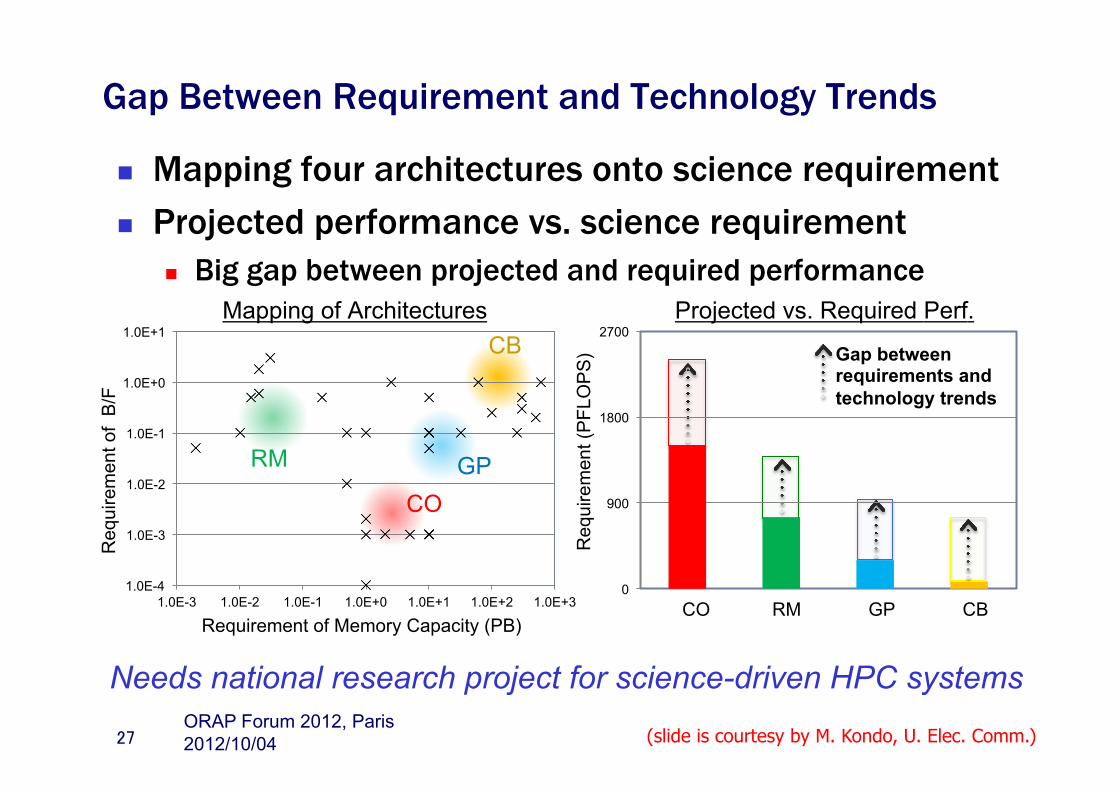
Gap Between Requirement and Technology Trends n Mapping four architectures onto science requirement n Projected performance vs. science requirement
n Big gap between projected and required performance
27
CB
GP
CO
RM
Gap between requirements and technology trends
1.0E-4
1.0E-3
1.0E-2
1.0E-1
1.0E+0
1.0E+1
1.0E-3 1.0E-2 1.0E-1 1.0E+0 1.0E+1 1.0E+2 1.0E+3
Req
uire
men
t of
B/F
Requirement of Memory Capacity (PB)
Mapping of Architectures
Needs national research project for science-driven HPC systems
0
900
1800
2700
Req
uire
men
t (P
FLO
PS
) CO RM GP CB
Projected vs. Required Perf.
(slide is courtesy by M. Kondo, U. Elec. Comm.) 2012/10/04 ORAP Forum 2012, Paris

Center for Computational Sciences, Univ. of Tsukuba
Challenges Toward Exascale System Development
n Challenges in all architectures n Power efficiency, Power management, Dependability
n Challenges in each architecture n General Purpose (GP)
n Multi-level memory hierarchy n Management of heterogeneity
n Capacity-Bandwidth oriented (CB) n Memory system power reduction (3D-ICs, smart memory)
n Reduced Memory (RM) n On-chip network n Small memory algorithm n Huge-scale system management
n Compute Oriented (CO) n Flexibility to wide variety of sciences
28
GP CB
RM
CO
Power reduction
Memory Hierarchy
3D-integration
Huge-scale system
Flexibility
Small memory
Dependability
Heterogeneity
Power management
2012/10/04 ORAP Forum 2012, Paris
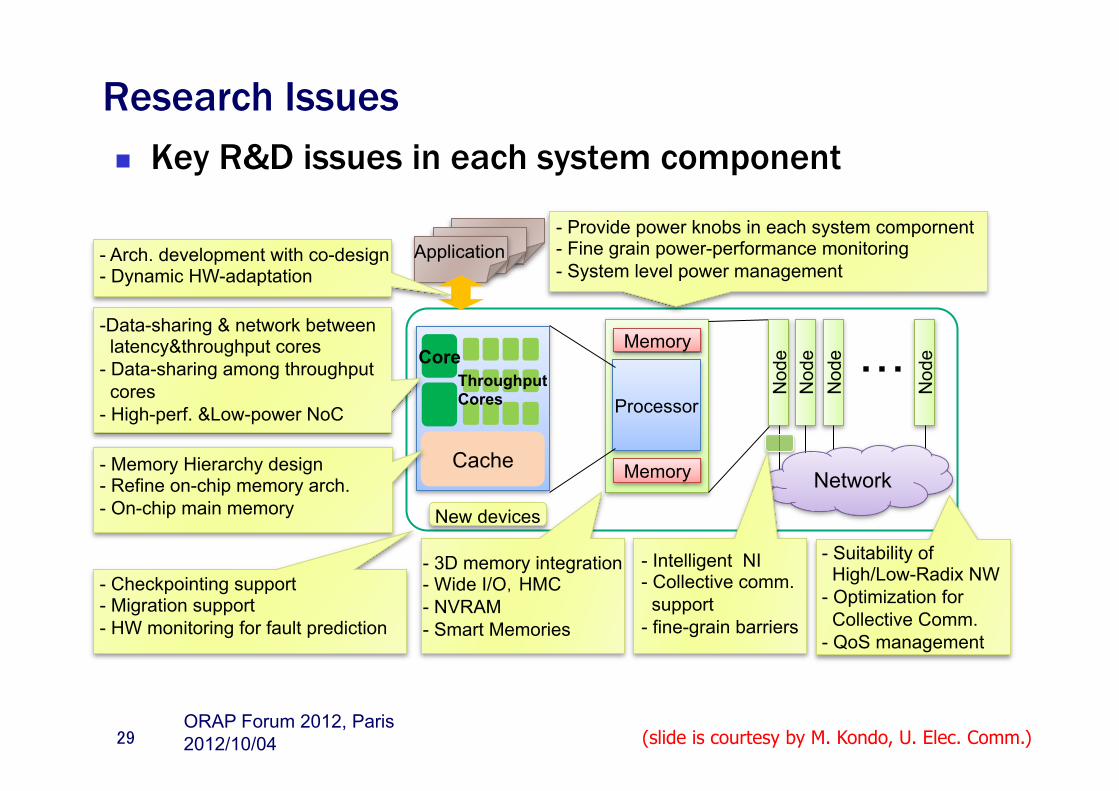
Research Issues n Key R&D issues in each system component
29
Core
Cache
Throughput Cores Processor
Memory
Memory
Nod
e
Nod
e N
ode
Nod
e
・・・
Network
Application
- Data-sharing & network between latency&throughput cores - Data-sharing among throughput cores - High-perf. &Low-power NoC
- Suitability of High/Low-Radix NW - Optimization for Collective Comm. - QoS management
- Checkpointing support - Migration support - HW monitoring for fault prediction
- Provide power knobs in each system compornent - Fine grain power-performance monitoring - System level power management
New devices
- Memory Hierarchy design - Refine on-chip memory arch. - On-chip main memory
- 3D memory integration - Wide I/O,HMC - NVRAM - Smart Memories
- Intelligent NI - Collective comm. support - fine-grain barriers
- Arch. development with co-design - Dynamic HW-adaptation
(slide is courtesy by M. Kondo, U. Elec. Comm.) 2012/10/04 ORAP Forum 2012, Paris

Center for Computational Sciences, Univ. of Tsukuba
FS (Feasibility Study for Exascale Systems)
2012/10/04 ORAP Forum 2012, Paris
30

Center for Computational Sciences, Univ. of Tsukuba
Feasibility Study of Advanced High Performance Computing
n MEXT (Ministry of Education, Culture, Sports, Science, and Technology) has just proposed two-year project for feasibility study of advanced HPC which started on 2012/07 (end at 2014/03)
n Objectives n The high performance computing technology is an important
national infrastructure n Keeping development of top-level HPC technologies is one of
Japanese international competitiveness and contributes national security and safety
n This two-year project is to study feasibilities of such development that Japanese community should focus on
n Vendor(s) must join to the research team for “feasibility” on power and cost
n Budget n Approximately US$ 10M / year
31 2012/10/04 ORAP Forum 2012, Paris

Center for Computational Sciences, Univ. of Tsukuba
Projects in FS n Four projects (3 system-side + 1 application-side) were selected
based on proposals, on 2012/07
2012/10/04 ORAP Forum 2012, Paris
32
Focus & Challenge
general purpose (base) system
accelerated computing
vector processing
core applications
Leading PI Y. Ishikawa (Univ. of Tokyo)
M. Sato (Univ. of Tsukuba)
H. Kobayashi (Tohoku Univ.)
H. Tomita (AICS, RIKEN)
Member Institutes & Vendors
U. Tokyo, Kyushu U. Fujitsu, Hitachi, NEC
U. Tsukuba, TITECH, Aizu U., AICS, Hitachi
Tohoku U., JAMSTEC, NEC
AICS, TITECH

Center for Computational Sciences, Univ. of Tsukuba
Basic concept of U. Tsukuba’s FS n Fully concentrated for FLOPS (CO+RM)
n A number of SIMD cores (500~1K/chip) with very low dynamism n Very limited memory capacity/core -> on-chip SRAM n Reduced I/O to allow limited communication patterns
n High density accelerated chip n Simple and small CPU core with some number of registers and on-chip SRAM n Tightly coupled with on-chip interconnection network n Interconnection network
n 2-D torus on-chip (up to 1K cores), 2-D torus on-board (# of chips not decided) and tree network among boards
n special feature for broadcast/reduction tree
n Co-design issues n Deciding memory capacity and # of cores on chip (trading-off) n Instruction set and performance n Network bandwidth and # of ports n Based on target applications and algorithms
2012/10/04 ORAP Forum 2012, Paris
33
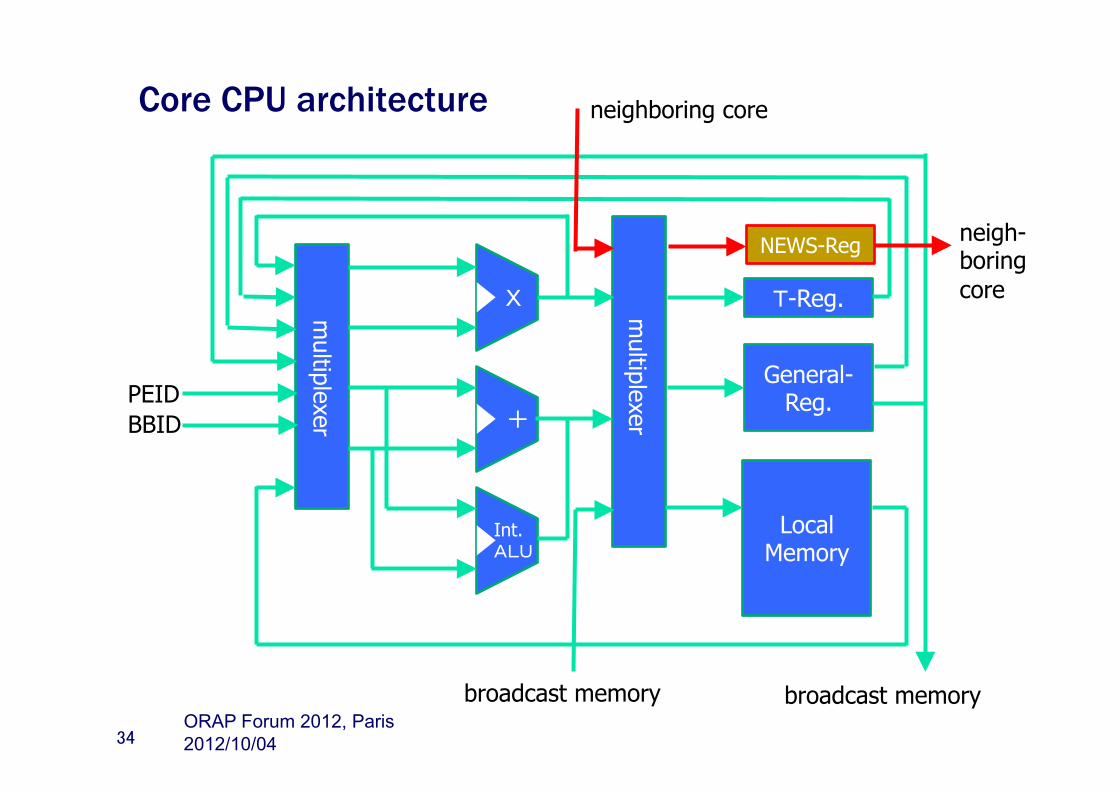
Core CPU architecture
34
X
+
Int. ALU
T-Reg.
General-Reg.
Local Memory
broadcast memory broadcast memory
PEID
BBID
NEWS-Reg neigh-boring core
neighboring core
2012/10/04 ORAP Forum 2012, Paris
multiplexer
multiplexer
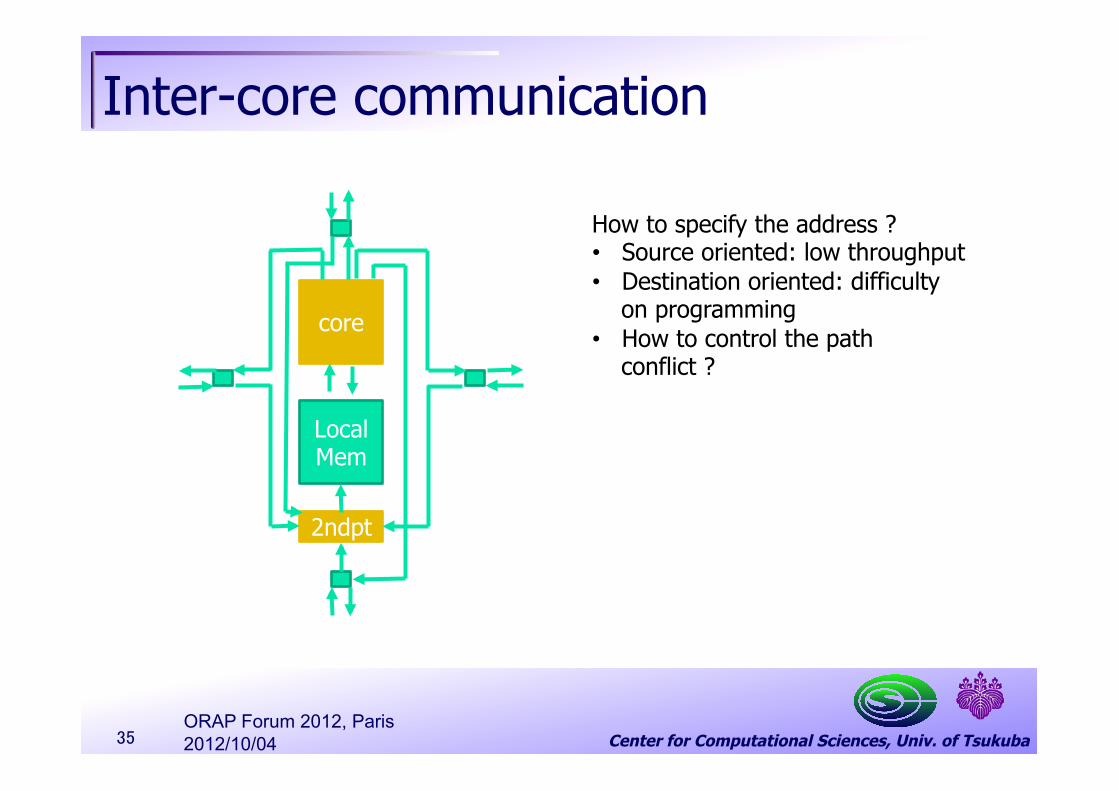
Center for Computational Sciences, Univ. of Tsukuba
Local Mem
core
2ndpt
How to specify the address ? • Source oriented: low throughput • Destination oriented: difficulty
on programming • How to control the path
conflict ?
Inter-core communication
35 2012/10/04 ORAP Forum 2012, Paris
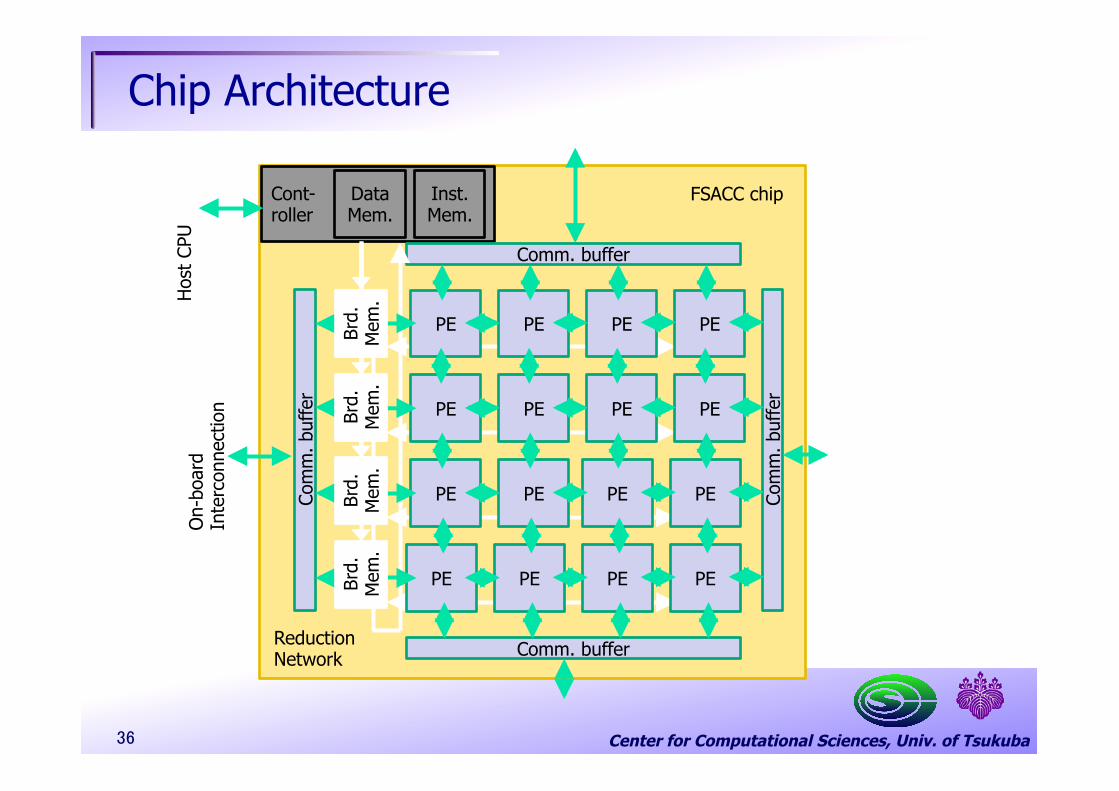
Center for Computational Sciences, Univ. of Tsukuba 36
Cont- roller
Hos
t CP
U
Data Mem.
Inst. Mem.
Comm. buffer
Comm. buffer
Com
m. b
uffe
r
Reduction Network
PE PE PE PE
PE PE PE PE
PE PE PE PE
PE PE PE PE
Com
m. b
uffe
r
On-
boar
d In
terc
onne
ctio
n
Brd.
M
em.
Brd.
M
em.
Brd.
M
em.
Brd.
M
em.
FSACC chip
Chip Architecture

Center for Computational Sciences, Univ. of Tsukuba
System configuration image n Performance target: 1EFLOPS
n core: 1GHz, 2FLOP/clock = 2GFLOPS n chip: 32x32 cores = 1K cores = 2TFLOPS n node: 8x8 chips = 64K cores = 128TFLOPS/node n system: 8000 nodes = 1EFLOPS
n Power consumption limit: 20MW n 20MW/8000 = 2.5kW/node n 2.5kW/64=40W/chip
n This balance is possible if we limit the SRAM memory capacity/core to only 512 words or same range
n It is quite strange compared with today’s general purpose system, but this is a sort of style of “how to achieve EFLOPS”
n Need to be very carefully designed and configured for application demand
2012/10/04 ORAP Forum 2012, Paris
37

Center for Computational Sciences, Univ. of Tsukuba
For the case of 2-D stencil computation (n x n grid / core, p x p core/chip) comp. on core = O(n2), comm. among core = O(n), comm. among chip = O(np) (ex: n=32 -> 1K core/chip p=8 -> 64 chip/board = 64Kcores/board) To reduce comm. overhead • larger “n” (memory capacity is limiting factor)
• tradeoff between memory apacity/core and # of cores • comm. during time development to upload data to host CPU = O(n2 x p2) • large interval for data uploading (m>>p2) is required
• make available the overhead of comp. and comm. • if we have 2-D torus between chips, p of buffers with size n is required • using this buffer for general comm. for other usage
• high throughput for inter-chip comm. To improve the comp. performance • SIMD inst. even in core -> comm. ratio is worse • increase # of cores -> comm. ratio is worse
Trade-off between # of cores and I/O
38 2012/10/04 ORAP Forum 2012, Paris

Center for Computational Sciences, Univ. of Tsukuba
JST-CREST (Core Research for Evolutional Science and Technology by Japan Science and Technology Agency)
2012/10/04 ORAP Forum 2012, Paris
39

Center for Computational Sciences, Univ. of Tsukuba
Post-petascale system software in CREST n Area director: A. Yonezawa (AICS, RIKEN)
“Development on System Software Technologies for Post-Peta Scale High Performance Computing”
n 3 stages starting in 2010, 2011 and 2012 n 4~5 projects / stage n 5 years / project n US$ 3~5M / project (for 5 years)
n Purpose n besides of hardware development, system software, language, library and
application should be developed by different fund n leadership and education of (relatively) young researchers to support next
generation of Japan’s HPC
2012/10/04 ORAP Forum 2012, Paris
40

n Stage-1 (2010-2015) n T. Sakurai (U. Tsukuba): Development of an Eigen-Supercomputing Engine using a Post-Petascale
Hierarchical Model n O. Tatebe (U. Tsukuba): System Software for Post Petascale Data Intensive Science n K. Nakajima (U. Tokyo): ppOpen-HPC: Open Source Infrastructure for Development and Execution of Large-
Scale Scientific Applications on Post-Peta-Scale Supercomputers with Automatic Tuning (AT) n A. Hori (AICS): Parallel System Software for Multi-core and Many-core n N. Maruyama (AICS): Highly Productive, High Performance Application Frameworks for Post Petascale
Computing
n Stage-2 (2011-2016) n R. Shioya (U. Tokyo): Development of a Numerical Library based on Hierarchical Domain Decomposition for
Post Petascale Simulation n H. Takizawa (Tohoku U.): An evolutionary approach to construction of a software development environment
for massively-parallel heterogeneous systems n S. Chiba (TITECH): Software development for post petascale super computing --- Modularity for Super
Computing n T. Nanri (Kyushu U.): Development of Scalable Communication Library with Technologies for Memory Saving
and Runtime Optimization n K. Fujisawa (Chuo U.): Advanced Computing and Optimization Infrastructure for Extremely Large-Scale
Graphs on Post Peta-Scale Supercomputers
n Stage-3 (2012-2017) n T. Endo (TITECH): Software Technology for Deep Memory Hierarchy for Post-Peta Scale Era n M. Kondo (U. Elec. Comm.): Development of Power Management Framework for Post-Peta Scale System n I. Noda (AIST): Management and Execution Framework for Ultra Large Scale Society Simulation n T. Boku (U. Tsukuba): Development of Unified Environment of Accelerators and Communication System for
Post-Peta Scale Era
41

Center for Computational Sciences, Univ. of Tsukuba
AC (Accelerator-Communication) CREST n Research formation
n Leading PI: T. Boku (U. of Tsukuba) n Joint institutes: U. Tsukuba, Keio U., Osaka U. and AICS, RIKEN n 2012/10-2018/03, US$ 4.3M
n AC (Accelerator-Communication) unification n Based on TCA (Tightly Coupled Accelerator) concept, develop the technology for
direct communication among accelerators based on PCI-e technology n System software for all layers to support TCA n Application development based on the same concept n New algorithm development for AC-unified system
n Research topics n PEACH2-oriented system software (firmware, drivers, API, library) n PGAS language to support TCA model (XcalableMP/TCA) n Applications (Astrophysics, Lattice QCD, Life, Climate, ...) n Advanced PEACH (PEACH3) based on PCI-e gen3
2012/10/04 ORAP Forum 2012, Paris
42
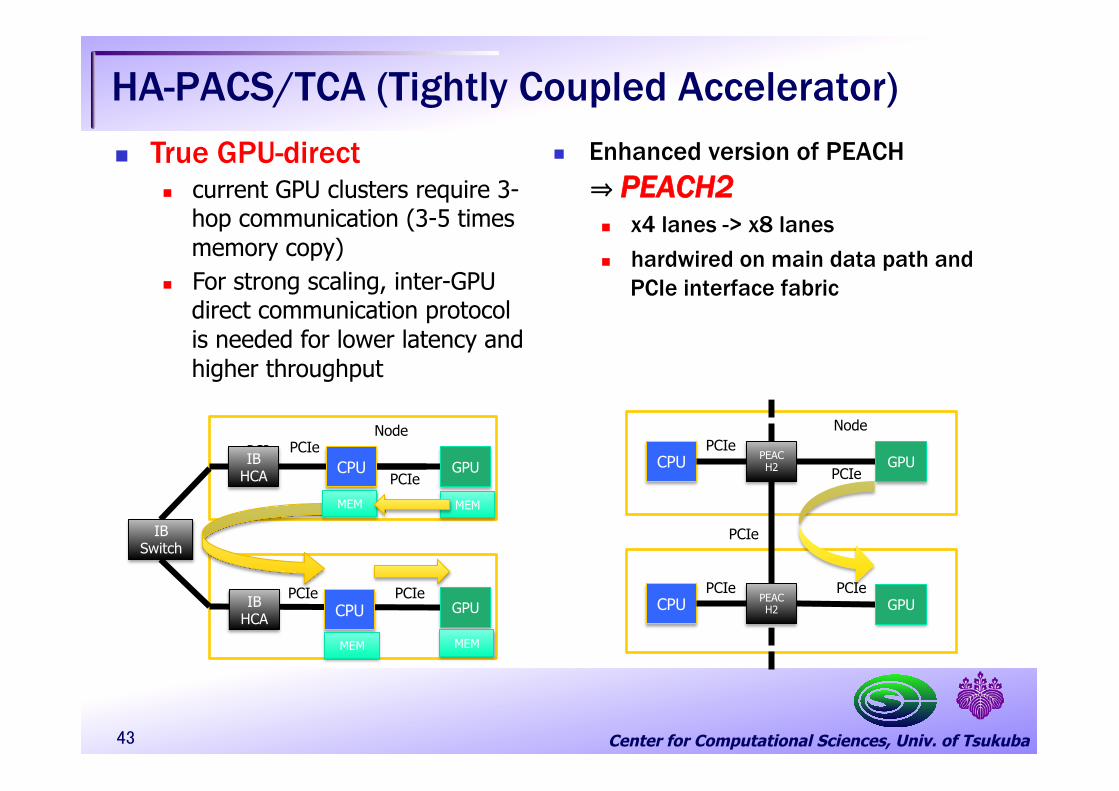
Center for Computational Sciences, Univ. of Tsukuba
HA-PACS/TCA (Tightly Coupled Accelerator) n Enhanced version of PEACH ⇒ PEACH2 n x4 lanes -> x8 lanes n hardwired on main data path and
PCIe interface fabric
PEACH2 CPU
PCIe
CPU PCIe
Node
PEACH2
PCIe
PCIe
PCIe
GPU
GPU
PCIe
PCIe
Node
PCIe
PCIe
PCIe
GPU
GPU CPU
CPU
IB HCA
IB HCA
IB Switch
n True GPU-direct n current GPU clusters require 3-
hop communication (3-5 times memory copy)
n For strong scaling, inter-GPU direct communication protocol is needed for lower latency and higher throughput
MEM MEM
MEM MEM
43

Center for Computational Sciences, Univ. of Tsukuba
Implementation of PEACH2: FPGA n FPGA based implementation
n today’s advanced FPGA allows to use PCIe hub with multiple ports n currently gen2 x 8 lanes x 4 ports are available ⇒ soon gen3 will be available (?)
n easy modification and enhancement n fits to standard (full-size) PCIe board n internal multi-core general purpose CPU with programmability is available ⇒ easily split hardwired/firmware partitioning on certain level on control layer
n Controlling PEACH2 for GPU communication protocol n collaboration with NVIDIA for information sharing and discussion n based on CUDA4.0 device to device direct memory copy protocol
44

Center for Computational Sciences, Univ. of Tsukuba
PEACH2 prototype board for TCA
45
FPGA (Altera Stratix IV GX530)
PCIe external link connector x2 (one more on daughter board)
PCIe edge connector (to host server)
daughter board connector
power regulators for FPGA
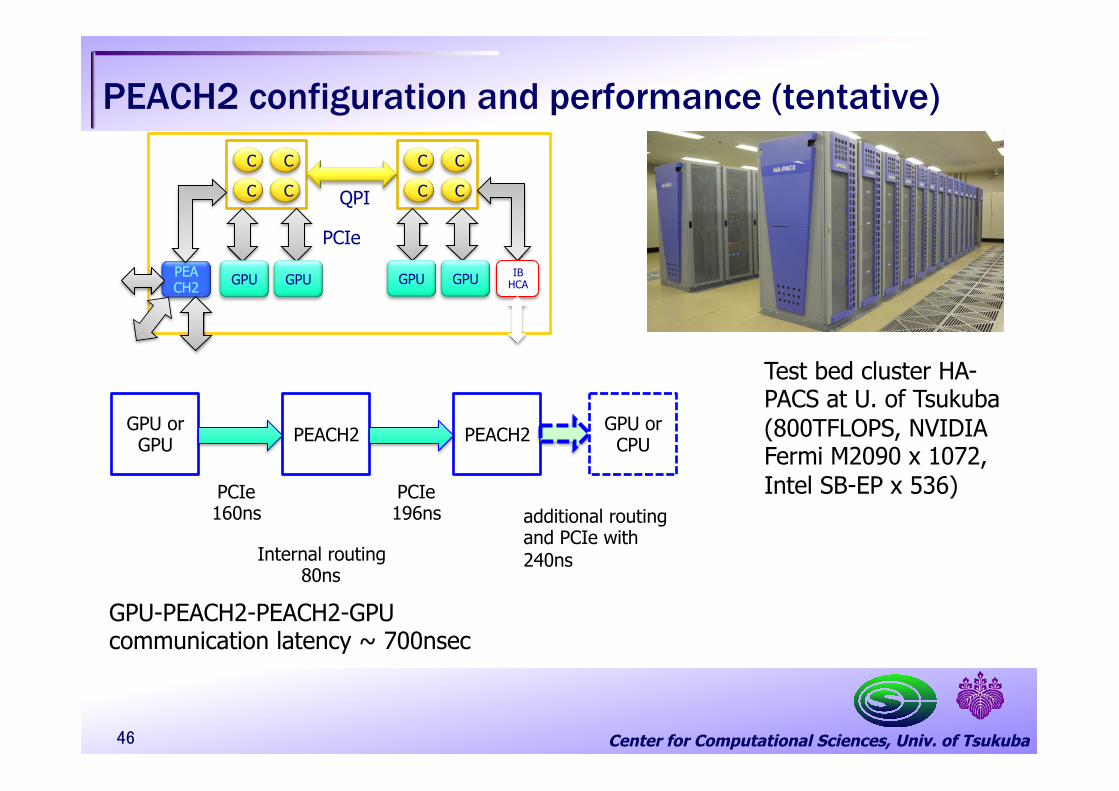
Center for Computational Sciences, Univ. of Tsukuba
PEACH2 configuration and performance (tentative)
GPU or GPU
PEACH2 PEACH2
PCIe 160ns
Internal routing 80ns
PCIe 196ns additional routing
and PCIe with 240ns
GPU or CPU
GPU-PEACH2-PEACH2-GPU communication latency ~ 700nsec
Test bed cluster HA-PACS at U. of Tsukuba (800TFLOPS, NVIDIA Fermi M2090 x 1072, Intel SB-EP x 536)
46
C C
C C
C C
C CQPI
PCIe
GPU GPU GPU IB
HCA PEACH2
GPU

Center for Computational Sciences, Univ. of Tsukuba
Summary n Japan’s activity towards exa-scale computing is now strategically performed
under governmental program (MEXT) n K computer is now in full operation with main contribution for SPIRE and
partial contribution for public projects in HPCI n HPCI provides SSO facility access to all supercomputers in Japan for K
computer and universities’ supercomputers with large scale shared file system n Feasibility Study research started to provide the hints for decision making
based on the concept of co-designing towards exa-scale n JST-CREST supports the development of system software for next generation n Center for Computational Sciences, University of Tsukuba takes important role
on all of these activities n HPCI resource provider n Shared file system in HPCI is based on Gfarm2 developed and maintained by U. Tsukuba n Feasibility Study: leading PI institute of Accelerator based System n JST-CREST: leading 3 projects as PI institute
2012/10/04 ORAP Forum 2012, Paris
47





























