Embed Size (px)
Citation preview

Towards Robust Indexing for Ranked Queries
Dong Xin, Chen Chen, Jiawei Han
Department of Computer ScienceUniversity of Illinois at Urbana-Champaign
VLDB 2006

2
Outline
• Introduction• Robust Index• Compute Robust Index
– Exact Solution– Approximate Solution– Multiple Indices
• Performance Study• Discussion and Conclusions
3
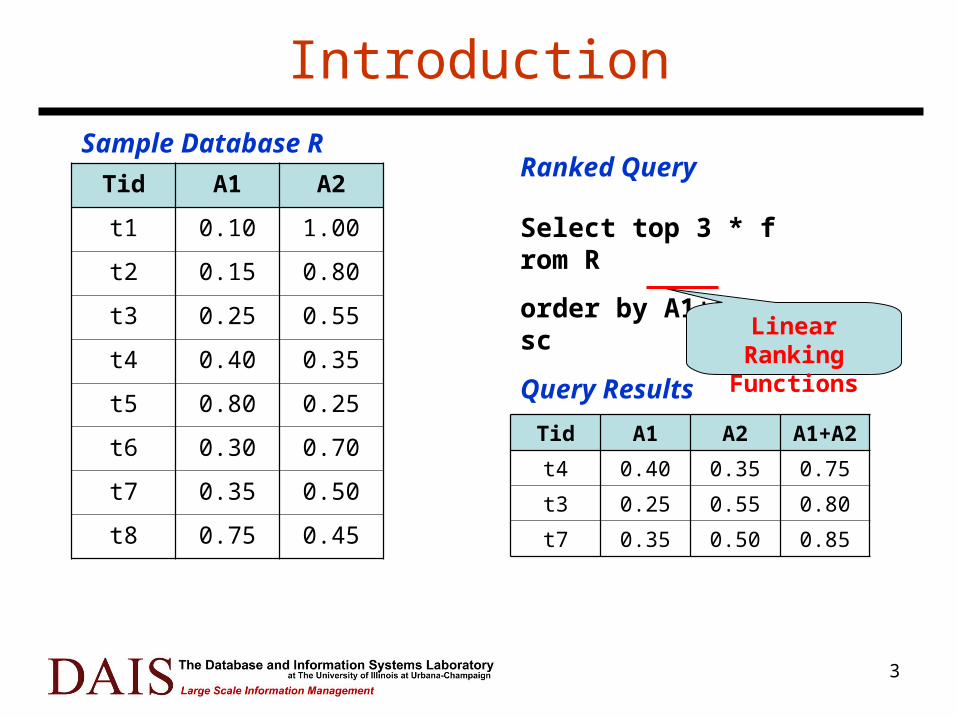
Introduction
Tid A1 A2
t1 0.10 1.00
t2 0.15 0.80
t3 0.25 0.55
t4 0.40 0.35
t5 0.80 0.25
t6 0.30 0.70
t7 0.35 0.50
t8 0.75 0.45
Sample Database R
Select top 3 * from R
order by A1+A2 asc
Tid A1 A2 A1+A2
t4 0.40 0.35 0.75
t3 0.25 0.55 0.80
t7 0.35 0.50 0.85
Query Results
Linear Ranking Functions
Ranked Query

4
Efficient Processing of Ranked Queries
• Naïve Solution: scan the whole database and evaluate all tuples
• Using indices or materialized views
– Distributed Indexing • Sort each attribute individually and merge attributes by a threshold algorithm
(TA) [Fagin et al, PODS’96,’99,’01]
– Spatial Indexing• Organize tuples into R-tree and determine a threshold to prune the search spa
ce [Goldstain et al, PODS’97]
• Organize tuples into R-tree and retrieve data progressively [Papadias et al, SIGMOD’03]
– Sequential Indexing• Organize tuples into convex hulls [Chang et al, SIGMOD’00]
• Materialize ranked views according to the preference functions [Hristidis et al, SIGMOD’01]
– And More…

5
Sequential Indexing
• Sequential Index (ranked view)– Linearly sort tuples– No sophisticated data structures– Sequential data access (good for database I/O)
• Representative work– Onion [Chang et al, SIGMOD’00]– PREFER [Hristidis et al, SIGMOD’01]
• Our proposal: Robust Index
6
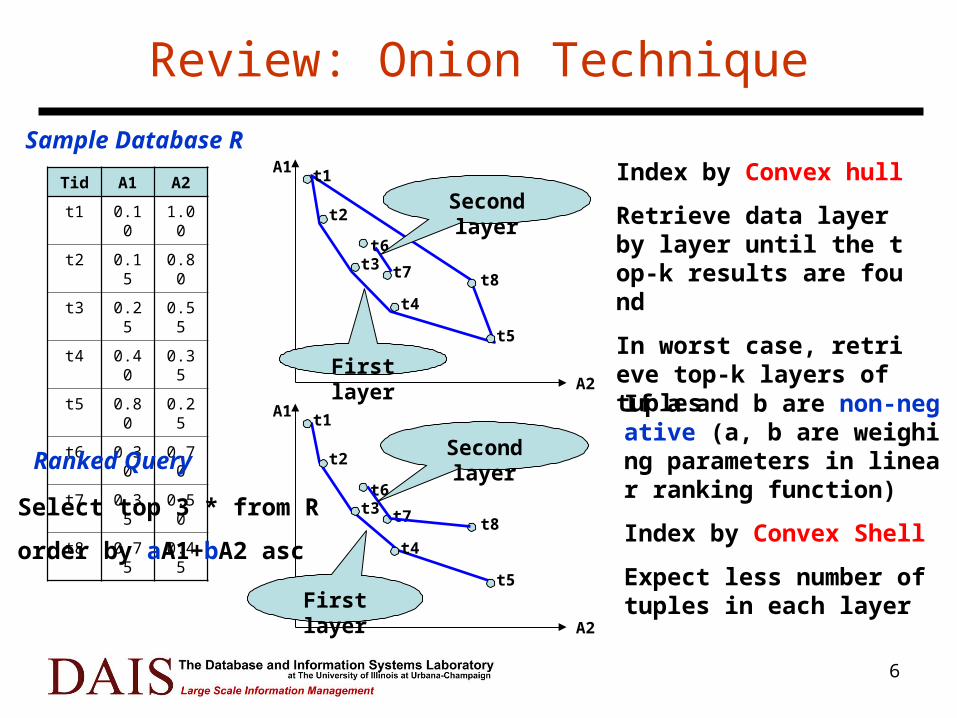
Review: Onion Technique
Tid A1 A2
t1 0.10 1.00
t2 0.15 0.80
t3 0.25 0.55
t4 0.40 0.35
t5 0.80 0.25
t6 0.30 0.70
t7 0.35 0.50
t8 0.75 0.45
Sample Database Rt1
t2
t3
t4
t5
t6
t7 t8
A1
A2
t1
t2
t3
t4
t5
t6
t7 t8
A1
A2
Second layer
First layer
First layer
Second layer
Index by Convex hull
Retrieve data layer by layer until the top-k results are found
In worst case, retrieve top-k layers of tuples
If a and b are non-negative (a, b are weighing parameters in linear ranking function)
Index by Convex Shell
Expect less number of tuples in each layer
Select top 3 * from R
order by aA1+bA2 asc
Ranked Query

7
Review: PREFER System
Tid A1 A2
t1 0.10 1.00
t2 0.15 0.80
t3 0.25 0.55
t4 0.40 0.35
t5 0.80 0.25
t6 0.30 0.70
t7 0.35 0.50
t8 0.75 0.45
Sample Database R
t1
t2
t3
t4
t5
t6
t7 t8
A1
A2
Index by the ranking function: A1+A2
Select top 3 * from R
order by w1A1+w2A2 asc
Ranked Query
Given query ranking function: A1+2A2
Map query ranking function to index ranking function
Will retrieve t1, t2, t3, t4, t6, t7
Index on preference ranking function
Query ranking function
Map from query to preference

8
Comments on Sequential Indexing• PREFER
– Works extremely well when query functions are close to the index function; Sensitive to query weights
• Onion– Less sensitive to query weights; Can we do better?
• Both methods– Require considerable online computation
• Motivation for robust indexing– Not sensitive to query weights– Push most computation to index building phase
Average #tuples retrieved for 10 random queries asking for top-5
0 answers
Query weights are randomly selected from 1,2,3,
4

9
Outline
• Introduction• Robust Index• Compute Robust Index
– Exact Solution– Approximate Solution– Multiple Indices
• Performance Study• Discussion and Conclusions

10
Robust Indexing: Motivating Example
t1
t2
t3
t4
t5
t6
t7 t8
A1
A2
First layer
Second layer
t1
t2
t3
t4
t5
t6
t7 t8
A1
A2
First layer
Index by Convex hull (shell)
Organize data layer by layer
In order to keep the convexity, each layer is built conservatively
Robust Index
Organize data layer by layer
Exploit dominating properties between data and push a tuple as deep as possible
t7: dominated by t2 and t4 (for any query, at least one of t2 and t4 ranks before t7)t7: dominated by t3 and t5
Layer 3Layer 3
Layer 4

11
Robust Indexing: Formal Definition
• How does it work?– Offline phase
• Put each tuple in its deepest layer: the minimal (best) rank of all possible linear queries
– Online phase• Retrieve tuples in top-k layers• Evaluate all of them, and report top-k
• What are expected?– Correctness– Less tuples in each layer than convex hull
• If a tuple does not belong to top-k for any query, it will not be retrieved

12
Robust Indexing: Appealing Properties
• Database Friendly– No online algorithm required– Simply use the following SQL statement
Select top k * from Rwhere layer <=korder by Frank
• Space efficient– Suppose the upper bound of the value k is given (e.g.
k<=100)– Only need to index those tuples in top 100 layers– Robust indexing uses the minimal space comparing w
ith other alternatives

13
Outline
• Introduction• Robust Index• Compute Robust Index
– Exact Solution– Approximate Solution– Multiple Indices
• Performance Study• Discussion and Conclusions

14
Robust Indexing: Algorithm Highlights
• Exact Solution– Compute the deepest layer for each tuple– Complexity:
• n: number of tuples• d: number of dimensions
• Approximate Solution– Compute the lower bound layer for each tuple– Complexity:
• Multiple Indices– Transform R to different subspaces by linear transfor
mation– Build an index in each subspace

15
Exact Solution
t1
t3t4
t5
t2
t
t6
A1
A2
Task: to compute the minimal rank over all possible linear queries for tuple t
Given a query Q, with ranking functionF=w1A1+w2A2, 0<=w1,w2<=1, and w1+w2=1
Q is one-to-one mapped to a line Le.g. A1+2A2 maps to L1
L1
L2
Naïve Proposal:
Enumerate all possible combinations of (w1,w2)
Not feasible since the enumerating space is infinite
Alternative Solution:
Only enumerate (w1,w2) whose corresponding line passes t and another tuple, e.g., L1, … ,L4
Do not consider t3 and t6 because the corresponding weights does not satisfy 0<=w1,w2<=1
L3
L4

16
Exact Solution, cont.
t1
t3t4
t5
t2
t
t6
A1
A2
Task: to compute the minimal rank over all possible linear queries for tuple t
Given a query Q, with ranking functionF=w1A1+w2A2, 0<=w1,w2<=1, and w1+w2=1
L1
L2
Complexity: to sort all lines takes O(n log n), to compute minimal rank for all t,
In general,
L3
L4
Lv=>L1: minimal rank is 4 (after t1, t2, t3)
L1=>L2: minimal rank is 3 (after t2, t3)
L2=>L3: minimal rank is 4 (after t2, t3, t4)
L3=>L4: minimal rank is 3 (after t3, t4)
L4=>LH: minimal rank is 4 (after t3, t4, t5)
Minimal rank (the deepest layer) of t is 3
LH
LV
17
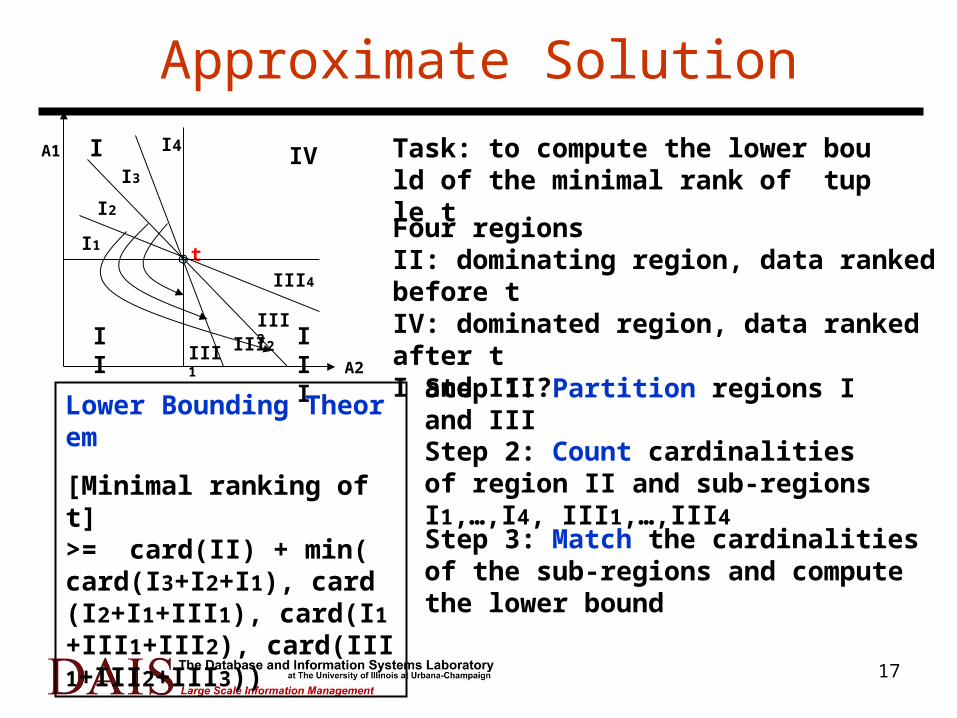
Approximate Solution
t
A1
A2
Task: to compute the lower bould of the minimal rank of tuple t
I
I1
I2
I3
I4
II III
IV
III1 III2III3
III4
Four regionsII: dominating region, data ranked before tIV: dominated region, data ranked after tI and III?
Step 1: Partition regions I and III
Step 2: Count cardinalities of region II and sub-regions I1,…,I4, III1,…,III4
Step 3: Match the cardinalities of the sub-regions and compute the lower bound
Lower Bounding Theorem
[Minimal ranking of t] >= card(II) + min(card(I3+I2+I1), card(I2+I1+III1), card(I1+III1+III2), card(III1+III2+III3))

18
Approximate Solution, Cont.
t
A1
A2
I
I1
I2
I3
I4
II III
IV
III1 III2III3
III4
Step 2: Count cardinalities of region II and sub-regions I1,…,I4, III1,…,III4
Count the cardinality of region II?1. All tuples in region II dominate t2. A reversed version of skyline problem3. Standard divide and conquer solution (details in the paper)
Count the cardinality of region I1?Suppose t: (a1,a2)Line L: A1 + 0.25A2=a1 + 0.25a2Tuples in region I1 satisfy-A1 <= -a1A1+0.25A2 <= a1 + 0.25 a2
Tid A1 A2
t 0.50 0.50
t1 0.15 0.80
t2 0.25 0.55
t3 0.40 0.35
Tid A1 A2
t -0.50 0.63
t1 -0.15 0.35
t2 -0.25 0.39
t3 -0.40 0.49A1=-A1
A2=A1+0.25A2
L

19
Quality of the Approximate Solution
• Complexity:– B: number of partitions in each subspace– n: number of tuples– d: number of dimensions
• Approximate quality:– Assume data forms a uniform distribution– Each subspace is partitioned evenly– Partitioning according to the data distribution i
s an important and interesting future topic

20
Multiple Indices• Why?
– To relax the constraint– To decompose and strengthen
the constraints
• How? (e.g., for w1<=w2)– Linearly transform R to R’, and
build index on R’ (A1,A2) => (A1+A2, A2)– Rewrite query weights (w1,w2) => (w1,w2-w1)
Ranking function: F=w1A1+w2A2Where 0<=w1,w2<=1
Ranking function: F=w1A1+w2A2
Ranking function: F=w1A1+w2A2Where 0<=w1<=w2<=1, or 0<=w2<=w1<=1
Relax
Strengthen
Data are projected to a smaller subspace (e.g., A1’ >=A2’ in the transformed subspac
e)Tuples can be pushed deeper
since more domination can be found
21
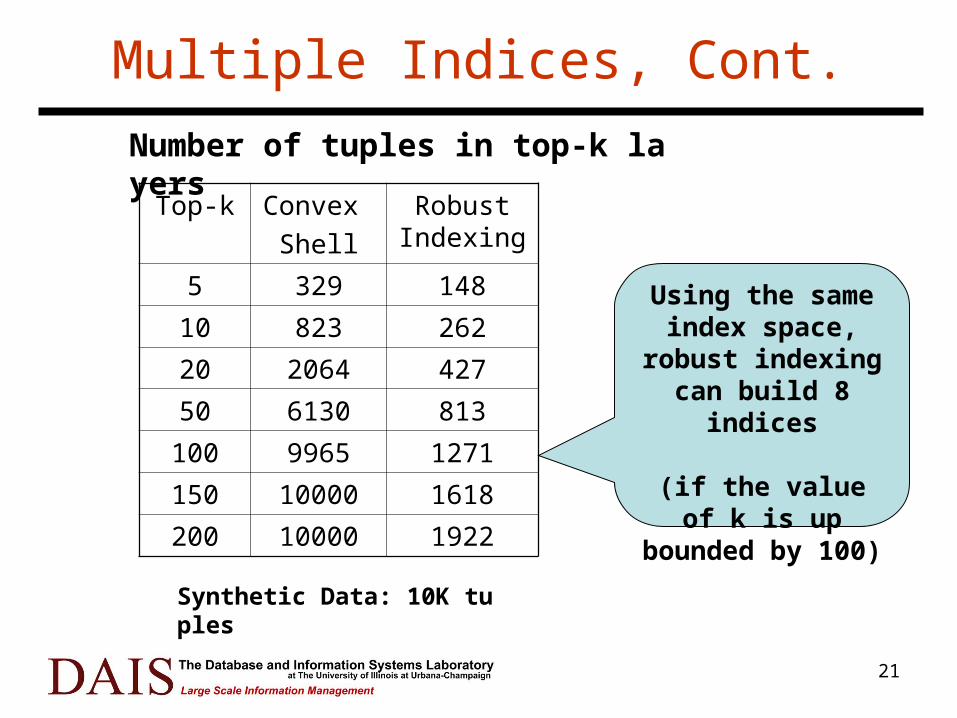
Multiple Indices, Cont.
Top-k Convex
Shell
Robust Indexing
5 329 148
10 823 262
20 2064 427
50 6130 813
100 9965 1271
150 10000 1618
200 10000 1922
Number of tuples in top-k layers
Synthetic Data: 10K tuples
Using the same index space, robust indexing can build
8 indices
(if the value of k is up bounded by 100)

22
Outline
• Introduction• Robust Index• Compute Robust Index
– Exact Solution– Approximate Solution– Multiple Indices
• Performance Study• Discussion and Conclusions

23
Performance Study
• Data– Synthetic data– Real dataset (abalone3D, cover3D)
• Measure– Number of tuples retrieved– Execution time not reported, but the robust indexing is
expected to be even better
• Approaches for comparison– Onion (convex shell)– PREFER– Approximate Robust Indexing (AppRI), #partition=10
24
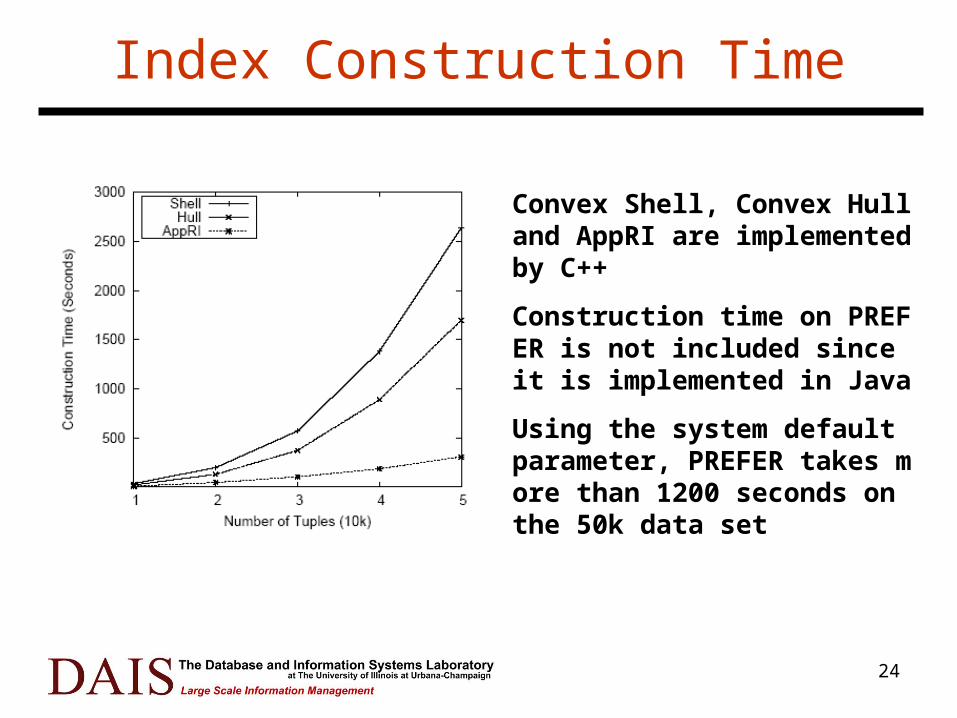
Index Construction Time
Convex Shell, Convex Hull and AppRI are implemented by C++
Construction time on PREFER is not included since it is implemented in Java
Using the system default parameter, PREFER takes more than 1200 seconds on the 50k data set
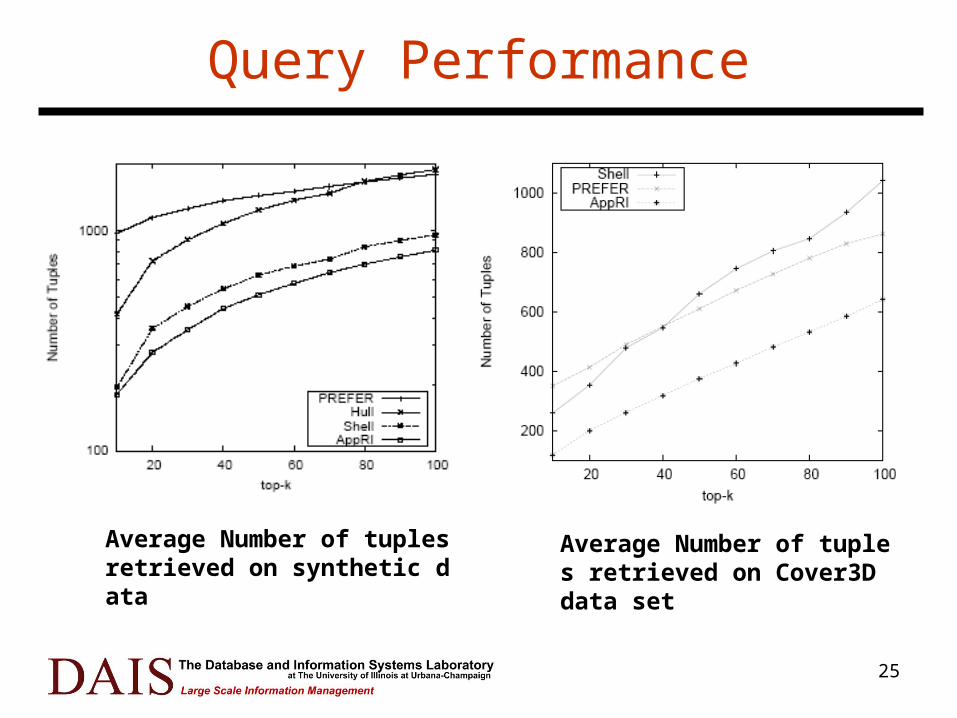
25
Query Performance
Average Number of tuples retrieved on synthetic data
Average Number of tuples retrieved on Cover3D data set

26
Multiple Indices (Views)
Synthetic Data, 3 dimensions
Build 3 robust indices by decompose the weighting parameters:
w1=max(w1,w2,w3)
w2=max(w1,w2,w3)
w2=max(w1,w2,w3)

27
Discussion and Conclusions
• Strength– Easy to integrate with current DBMS– Good query performance– Practical construction complexity
• Limitation– Online index maintenance is expensive (some
weaker maintaining strategies available)– Indexing high dimensional data remains a
challenging problem
![Meta Paths and Meta Structures: Analysing Large ...oDefinition [Sun et al. VLDB 2011] 20 Yizhou Sun, Jiawei Han, Xifeng Yan, Philip S. Yu, Tianyi Wu. PathSim: Meta Path-Based Top-K](https://img.pdfslide.net/doc/110x75/5f21d1f2d92bbf02be393064/meta-paths-and-meta-structures-analysing-large-odefinition-sun-et-al-vldb.jpg)




























