Embed Size (px)
Citation preview

TrainingNeuralNetworksRegularization
M.SoleymaniSharifUniversityofTechnology
Spring2019
MostslideshavebeenadaptedfromBhiksha Raj,11-785,CMU2019andsomefromFei Fei Liet.al,cs231n,Stanford2017

Outline
• Regularization• Early stopping• Model ensembles• Drop-out• Data Augmentation• Hyper-parameter selection

• We attempt to learn an entire function from just a fewsnapshots of it
3
Learningthenetwork

• Problem: Network may just learn the values at the inputs– Learn the red curve instead of the dotted blue one
• Given only the red vertical bars as inputs
4
Overfitting

BeyondTrainingError

BeyondTrainingError

WhyL2regularizationcalledweightdecay
𝐽 𝑊 = 𝐿 𝑊 + 𝜆𝑅 𝑊
𝐽 𝑊 = 𝐿 𝑊 + 𝜆( 𝑊 ) *+
),-
𝑊[)] ← 𝑊[)] − 𝛼𝛻4[5]𝐿 𝑊 − 2𝜆𝑊[)]
𝑊[)] ← 𝑊[)] 1 − 2𝜆 − 𝛼𝛻4[5]𝐿 𝑊
With regularization, smoother cost vs. #epoch curve is obtained.
Weightdecay

Regularizationparameter
• 𝜆 is the regularization parameter whose value depends on howimportant it is for us to want to minimize the weights
• Increasing 𝜆 assigns greater importance to shrinking the weights– Make greater error on training data, to obtain a more acceptable network

Regularizationcanpreventoverfitting
• Small𝑊 linear regime of sigmoid or tanh• A deep network with small𝑊can also act as a near linear function

• Using a sigmoid activation– As |𝑤| increases, the response becomes steeper
10
Theindividualneuron

x
y
• Steep changes that enable overfitted responses are facilitated byneurons with large𝑤
• Constraining the weights 𝑤 to be low will force slower perceptrons andsmoother output response
11
Smoothnessthroughweightmanipulation

x
y
• Steep changes that enable overfitted responses are facilitated by neuronswith large 𝑤
• Constraining the weights 𝑤 to be low will force slower neurons andsmoother output response
12
Smoothnessthroughweightmanipulation

Regularization..
• Other techniques have been proposed to improve the smoothness ofthe learned function– L1 regularization of network activations– Regularizing with added noise..
• Possibly the most influential method has been “dropout”
13

Regularization:Addtermtoloss
𝐽 𝑊 =1𝑁(𝐿 < (𝑊)
?
<,-
+ 𝜆𝑅 𝑊

• Data underspecification can result in overfitted models and must behandled by regularization and more constrained (generally deeper)network architectures
15
Storysofar

Regularization:Dropout
• In each forward pass, randomly set some neurons to zero– Probability of dropping is a hyperparameter; 0.5 is common
• Thus, a smaller network is trained for each sample– Smaller network provides a regularization effect
Srivastavaetal,“Dropout:Asimplewaytopreventneuralnetworksfromoverfitting”,JMLR2014

Dropout
• During training: For each input, at each iteration,“turn off” each neuron with a probability 1-a
• a shows keep probability
Input
Output
17

Dropout
• During training: For each input, at each iteration,“turn off” each neuron with a probability 1-a– Also turn off inputs similarly
Input
Output
18

Dropout
• During training: For each input, at each iteration, “turn off” each neuron(including inputs) with a probability 1-a– In practice, set them to 0 according to the success of a Bernoulli random numbergenerator with success probability 1-a
Input
Output
19

Implementingdropout(Inverteddropout)
• for l=1,…L–𝑚[)] ← 𝐼 𝑟𝑎𝑛𝑑(#𝑛𝑒𝑢𝑟𝑜𝑛𝑠 ) , 1) < 𝑘𝑒𝑒𝑝_𝑝𝑟𝑜𝑏–𝑎[)] ← 𝑎 ) .∗ 𝑚 )

Whydoesdrop-outwork?
• Intuition: cannot rely on any one feature, so have to spread outweights
• Thus, shrinking the weights (𝑊Y𝑊) and shows similar effect to the 𝐿*regularization
[Andrew Ng, Deep Learning Specialization, 2017]© 2017 Coursera Inc.

Regularization:Dropout
• How can dropout be a good idea?

Dropoutonlayers
• Different keep-prob can be used for different layers– However, more hyper-parameters are required

Regularization:Dropout
• How can this possibly be a good idea? (Another interpretation)– Dropout is training a large ensemble of models (that share parameters).– Each binary mask is one model
• An FC layer with 4096 units has 2Z[\]~10-*`` possible masks!• Only ~10a* atoms in the universe...

• Popular method proposed by Leo Breiman:– Sample training data and train several different classifiers– Classify test instance with entire ensemble of classifiers– Vote across classifiers for final decision– Empirically shown to improve significantly over training a singleclassifier from combined data
• Returning to our problem….25
Abriefdetour..Bagging
Trainingset1
Trainingset2
Trainingset3

Dropout
• During training: For each input, at each iteration,“turn off” each neuron (including inputs) with aprobability 1-a
The pattern of dropped nodeschanges for each inputi.e. in every pass through the net
Input
Output
x(1) y(1)
Input
Output
x(2) y(2)
Input
Output
x(3) y(3)
26
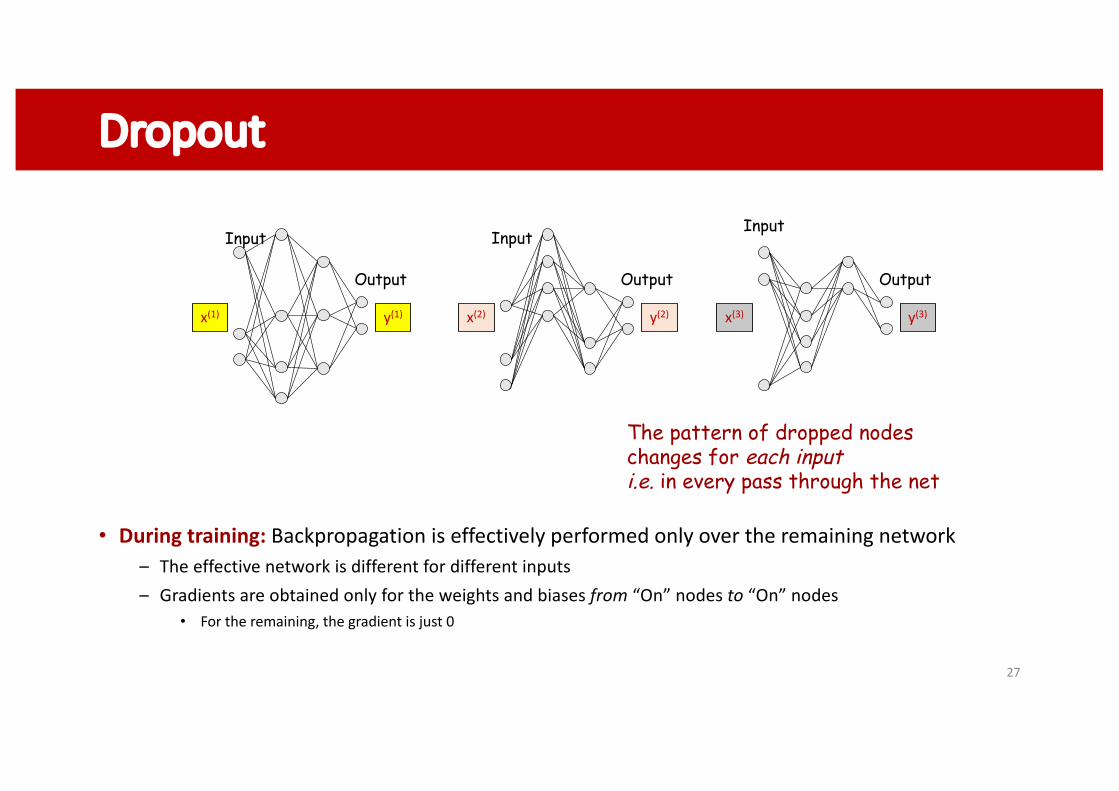
Dropout
• During training: Backpropagation is effectively performed only over the remaining network– The effective network is different for different inputs– Gradients are obtained only for the weights and biases from “On” nodes to “On” nodes
• For the remaining, the gradient is just 0
The pattern of dropped nodeschanges for each inputi.e. in every pass through the net
Input
Output
x(1) y(1)
Input
Output
x(2) y(2)
Output
x(3) y(3)
Input
27

StatisticalInterpretation
• For a network with a total of M neurons, there are 2M possible sub-networks– Obtained by choosing different subsets of nodes– Dropout samples over all 2Mpossible networks– Effectively learns a network that averages over all possible networks
• Bagging
Input
Output
Input
Output Output
Input
Output
28

Dropoutasamechanismtoincreasepatterndensity
• Dropout forces the neurons to learn “rich”and redundant patterns
• E.g. without dropout, a non-compressivelayer may just “clone” its input to its output– Transferring the task of learning to the rest of thenetwork upstream
• Dropout forces the neurons to learn denserpatterns– With redundancy
29

Dropout:testtime
• Dropout makes our output random!
• Want to “average out” the randomness at test-time
• But this integral seems hard …

Dropout:testtime

Dropout:testtime

Dropout:testtime

Whateachneuroncomputes• Each neuron actually has the following activation:
𝑎b[)] = 𝐷𝜎 (𝑤eb
[)]𝑎e[)f-]
�
e
+ 𝑏b[)]
– Where 𝐷 is a Bernoulli variable that takes a value 1 with probability a
• 𝐷 may be switched on or off for individual sub networks, but over the ensemble, theexpected output of the neuron is
𝑎b[)] = a𝜎 (𝑤eb
[)]𝑎e[)f-]
�
e
+ 𝑏b[)]
• During test time, we will use the expected output of the neuron– Which corresponds to the bagged average output– Consists of simply scaling the output of each neuron by a
34

Dropoutsummary

Inverteddropout
• Since test-time performance is so critical, it is always preferable to useinverted dropout,– which performs the scaling at train time, leaving the forward pass at test timeuntouched.
– Just divide the activation of each layer by keep-prob

Implementingdropout(Inverteddropout)
• for l=1,…L–𝑚[)] ← 𝐼 𝑟𝑎𝑛𝑑(#𝑛𝑒𝑢𝑟𝑜𝑛𝑠 ) , 1) < 𝑘𝑒𝑒𝑝_𝑝𝑟𝑜𝑏–𝑎[)] ← 𝑎 ) .∗ 𝑚 )
• for l=1,…L–𝑚[)] ← 𝐼 𝑟𝑎𝑛𝑑(#𝑛𝑒𝑢𝑟𝑜𝑛𝑠 ) , 1) < 𝑘𝑒𝑒𝑝_𝑝𝑟𝑜𝑏–𝑎[)] ← 𝑎 ) .∗ 𝑚 )
–𝑎[)] ← 𝑎 ) /𝑘𝑒𝑒𝑝_𝑝𝑟𝑜𝑏

Inverteddropout

• Output layer (L) :–i)jkk(lm
[n],o)
ilm[n]
– i)jkk
ipm[n] = 𝑓+r 𝑧b
[+} i)jkk
ilm[n}
• For layer 𝑙 = 𝐿 − 1𝑑𝑜𝑤𝑛𝑡𝑜0– For 𝑖 = 1…𝑑[)]
• If (not dropout layer OR𝑚𝑎𝑠𝑘(𝑙, 𝑖))• i)jkk
ilm[5] = ∑ 𝑤be
[)y-]�e
i)jkk
ipz[5{|] 𝑚𝑎𝑠𝑘(𝑙 + 1, 𝑗)
• i)jkk
ipm[5] = 𝑓)r 𝑧b
[)] i)jkk
ilm[5]
• i~b�
i�mz[5{|] = 𝑎b
[)] i)jkk
ipz[5{|] 𝑚𝑎𝑠𝑘(𝑙 + 1, 𝑗) for 𝑗 = 1…𝑑[)y-]
• Else• i)jkk
ipm[5] = 0
39
BackwardPass

Dropoutissues
• If your NN is significantly overfitting, dropout usually help to preventoverfitting
• Training takes longer time but provides better generalization– Since in each iteration of weight update, only a subset of weights areupdated.
• If your NN is not overfitting, bigger NN with dropout can help
• The cost function is no longer well defined.• Gradcheck by turning off the dropout

• From Srivastava et al., 2013. Test error for differentarchitectures on MNIST with and without dropout– 2-4 hidden layers with 1024-2048 units 41
Dropout:Typicalresults

Regularization:Acommonpattern
• Training: Add some kind of randomness Testing:𝑦� = 𝑓(𝑥, 𝑧;𝑊)
• Test: Average out randomness (sometimesapproximate)
𝑦� = 𝐸p 𝑓(𝑥, 𝑧;𝑊) = �𝑝 𝑧 𝑓 𝑥, 𝑧;𝑊 𝑑𝑧�
�

Regularization:Acommonpattern
• Training: Add some kind of randomness𝑦� = 𝑓(𝑥, 𝑧;𝑊)
• Testing: Average out randomness (sometimes approximate)
𝑦� = 𝐸p 𝑓(𝑥, 𝑧;𝑊) = �𝑝 𝑧 𝑓 𝑥, 𝑧;𝑊 𝑑𝑧�
�
Example:BatchNormalization
Training:Normalizeusingstatsfromrandommini-batches
Testing:Usefixedstatstonormalize
However,indrop-outvs.BachNorm,thereismorecontrolontheamountofregularizationbysetting𝛼

Dataaugmentation
• Getting more training data can be expensive
• But, sometimes we can generate more training examples from thedatasets

Additionalheuristics:DataAugmentation
• Available training data will often be small• “Extend” it by distorting examples in a variety of waysto generate synthetic labelled examples
46

Dataaugmentation
• Horizontal flip

Dataaugmentation
• Random crops and scales
• Training: sample random crops / scales– ResNet:
• 1. Pick random L in range [256, 480]• 2. Resize training image, short side = L• 3. Sample random 224 x 224 patch
• Testing: average a fixed set of crops– ResNet:
• 1. Resize image at 5 scales: {224, 256, 384, 480, 640}• 2. For each size, use 10 224 x 224 crops: 4 corners + center, + flips

Dataaugmentation
• Color Jitter

Dataaugmentation
• Random mix/combinations of :– Translation– Rotation– Stretching– Shearing– …

Regularization:Acommonpattern
• Training: Add random noise• Testing: Marginalize over the noise
• Examples:– Dropout– Batch Normalization– Data Augmentation

Regularization:Acommonpattern
• Training: Add random noise• Testing: Marginalize over the noise
• Examples:– Dropout– Batch Normalization– Data Augmentation– Dropconnect

Regularization:Acommonpattern
• Training: Add random noise• Testing: Marginalize over the noise
• Examples:– Dropout– Batch Normalization– Data Augmentation– Dropconnect– Stochastic depth

Otherheuristics:Earlystopping
• Continued training can result in over fitting to training data– Track performance on a held-out validation set– Apply one of several early-stopping criterion to terminate training whenperformance on validation set degrades significantly
error
epochs
training
validation
54

Otherheuristics:Earlystopping
L Thinks about approximation and generalization tasks separately• By stopping gradient descent early breaks whatever you are doing to optimize costfunction
J Advantage is that it needs running gradient descent process just once
#iterations
cost
𝐽�
𝐽��lb<

Modelensembles
1. Train multiple independent models
2. At test time average their results

Modelensembles
• Train multiple independent models, and at test time average theirpredictions.– improving the performance by a few percent
• Candidates– Same model, different initializations (after selecting the best hyperparameters)– Top models discovered during cross-validation– Different checkpoints of a single model (If training is very expensive)
• maybe limited success to form an ensemble.– Running average of parameters during training
• maintains an exponentially decaying sum of previous weights during training.

Modelensembles:Tipsandtricks
• Instead of training independent models, use multiple snapshots of asingle model during training!

Modelensembles:Tipsandtricks
• Instead of using actual parameter vector, keep a moving average ofthe parameter vector and use that at test time (Polyak averaging)
dwdww
w w w

Resources
• Deep Learning Book, Chapter 8.• Please see the following note:
– http://cs231n.github.io/neural-networks-3/





























![Chapter 2 Introduction to Neural networktomczak/PDF/[Grbic]Neural...Chapter 2 Introduction to Neural network 2.1 Introduction to Artiflcial Neural Net-work Artiflcial Neural Networks](https://img.pdfslide.net/doc/110x75/5f22a87bbf292e3b5d18b33c/chapter-2-introduction-to-neural-network-tomczakpdfgrbicneural-chapter-2.jpg)