Embed Size (px)
Citation preview

Transformational Changes Facing Global Simulation Science
James J. Hack, Director National Center for Computational Sciences Oak Ridge National Laboratory Buddy Bland, Project Director Oak Ridge Leadership Computing Facility
2 Managed by UT-Battelle for the U.S. Department of Energy
Science will be enabled by advanced computational facilities
3 Managed by UT-Battelle for the U.S. Department of Energy Data from http://www.Top500.org
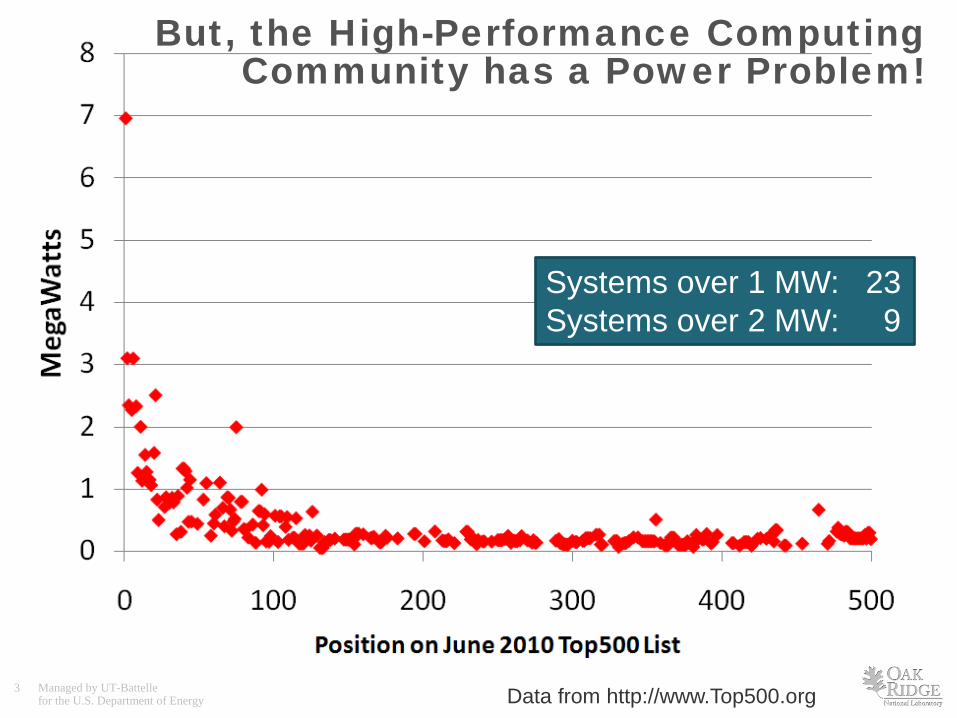
But, the High-Performance Computing Community has a Power Problem!
Systems over 1 MW: 23 Systems over 2 MW: 9
4 Managed by UT-Battelle for the U.S. Department of Energy
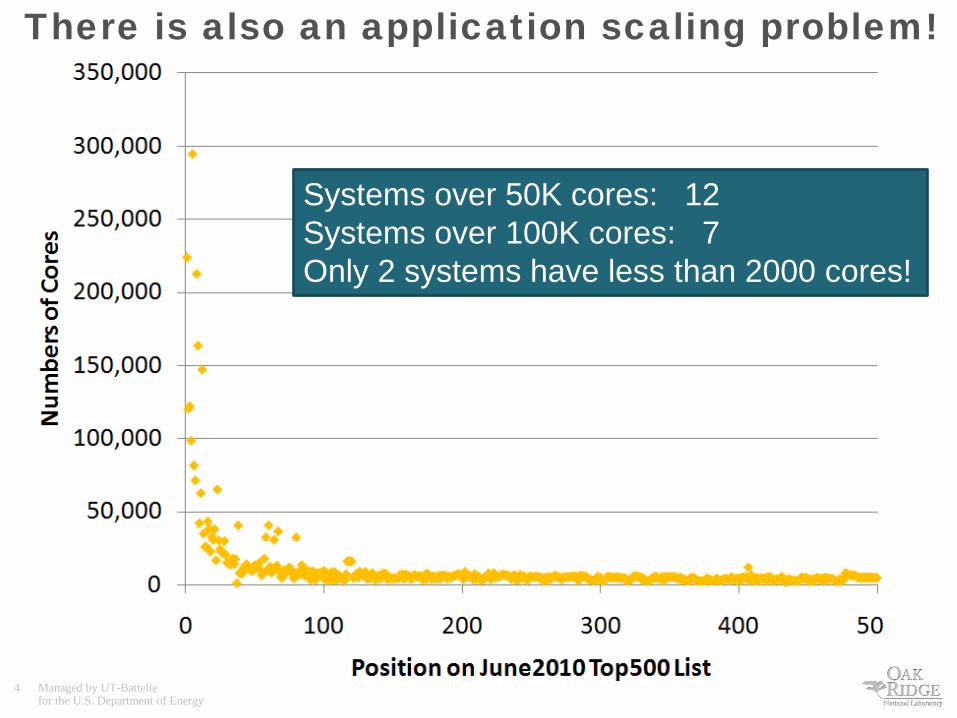
There is also an application scaling problem!
Systems over 50K cores: 12 Systems over 100K cores: 7 Only 2 systems have less than 2000 cores!

5 Managed by UT-Battelle for the U.S. Department of Energy
What is behind architectural evolution?
• Power – Power per chip increases with the square of the clock rate
and proportional to the voltage – Voltages are about as low as they can go
• To get increases in performance, commodity vendors adding more parallelism – More cores per chip – More chips per system – More power!
• Moving data across a wire takes a lot of energy
6 Managed by UT-Battelle for the U.S. Department of Energy
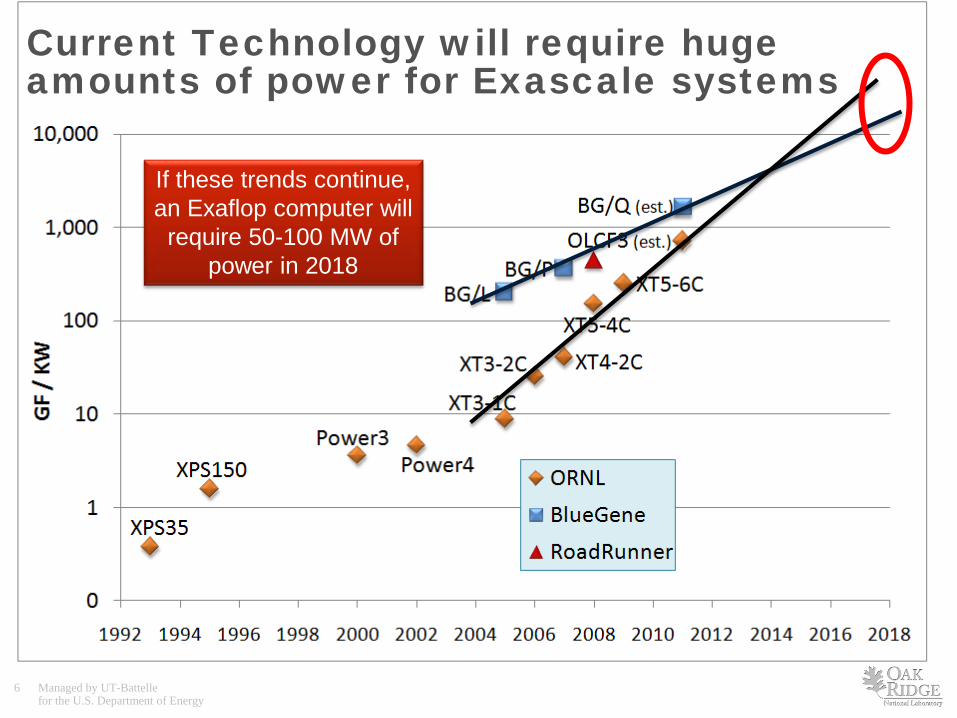
Current Technology will require huge amounts of power for Exascale systems
If these trends continue, an Exaflop computer will
require 50-100 MW of power in 2018
7 Managed by UT-Battelle for the U.S. Department of Energy
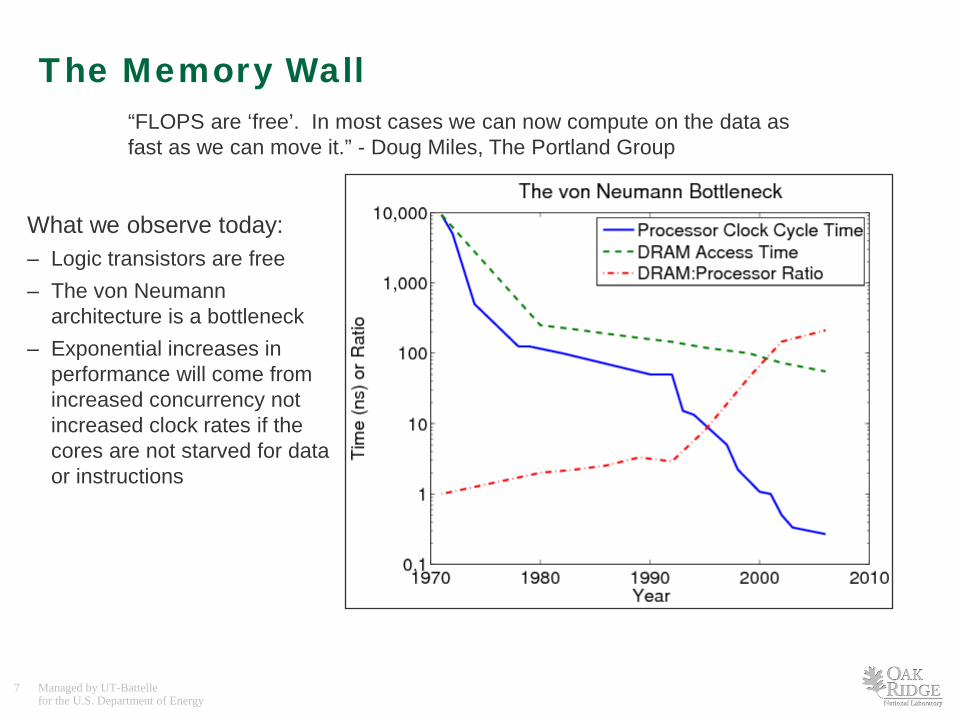
What we observe today: – Logic transistors are free – The von Neumann
architecture is a bottleneck – Exponential increases in
performance will come from increased concurrency not increased clock rates if the cores are not starved for data or instructions
The Memory Wall “FLOPS are ‘free’. In most cases we can now compute on the data as fast as we can move it.” - Doug Miles, The Portland Group

8 Managed by UT-Battelle for the U.S. Department of Energy
What’s required to go beyond Jaguar
• Weak scaling of apps has run its course
• Need more powerful nodes for strong scaling – Faster processors but using much less power per GFLOPS – More memory – Better interconnect
• Hierarchical programming model to expose more parallelism – Distributed memory among nodes 100K – 1M way parallelism – Threads within nodes 10s – 100s of threads per node – Vectors within the threads 10s – 100s of vector
elements/ thread
1 Billion way parallelism needed for exascale systems
9 Managed by UT-Battelle for the U.S. Department of Energy
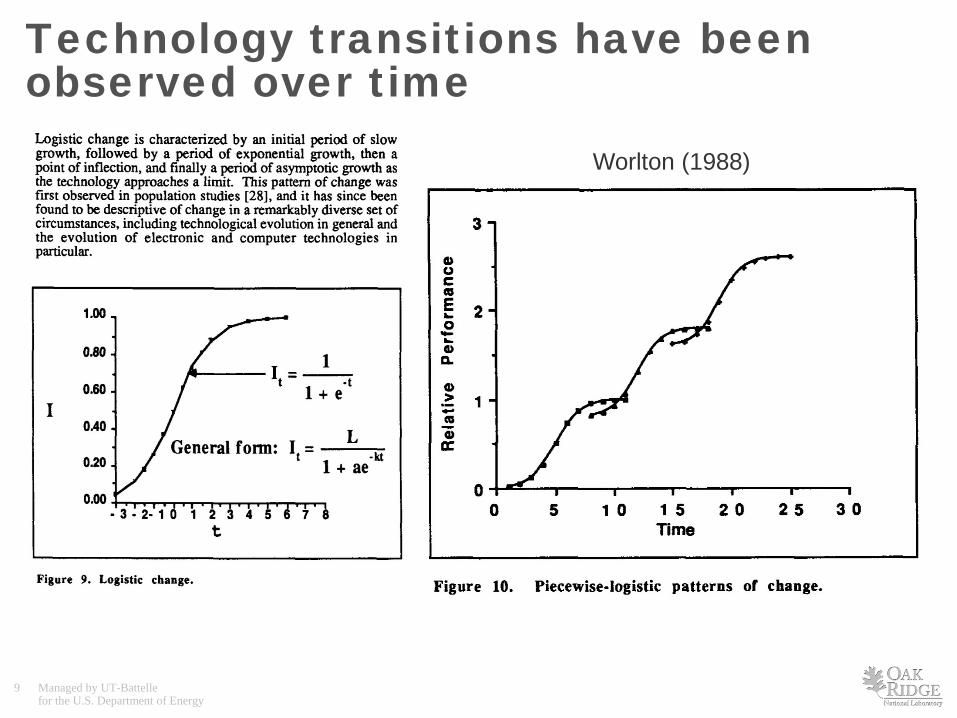
Technology transitions have been observed over time
Worlton (1988)
10 Managed by UT-Battelle for the U.S. Department of Energy
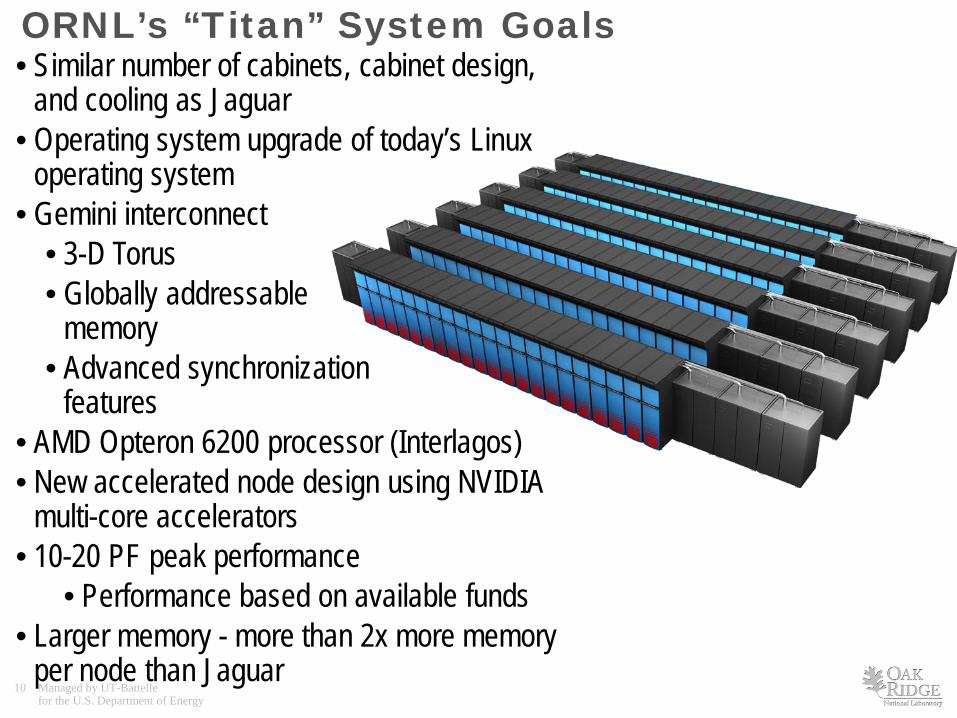
• Similar number of cabinets, cabinet design, and cooling as Jaguar
• Operating system upgrade of today’s Linux operating system
• Gemini interconnect • 3-D Torus • Globally addressable
memory • Advanced synchronization
features • AMD Opteron 6200 processor (Interlagos) • New accelerated node design using NVIDIA
multi-core accelerators • 10-20 PF peak performance
• Performance based on available funds • Larger memory - more than 2x more memory
per node than Jaguar
ORNL’s “Titan” System Goals
11 Fall Creek Falls Conference 2011, Buddy Bland
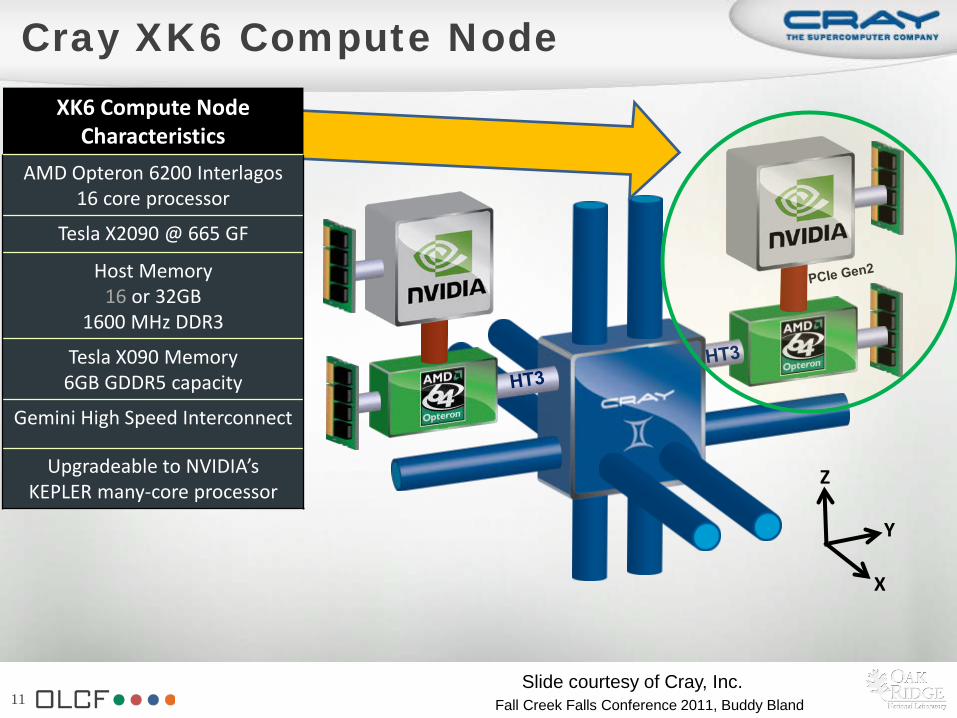
Cray XK6 Compute Node
Y
X
Z
XK6 Compute Node Characteristics
AMD Opteron 6200 Interlagos 16 core processor
Tesla X2090 @ 665 GF
Host Memory 16 or 32GB
1600 MHz DDR3
Tesla X090 Memory 6GB GDDR5 capacity
Gemini High Speed Interconnect
Upgradeable to NVIDIA’s KEPLER many-core processor
Slide courtesy of Cray, Inc.

12 Fall Creek Falls Conference 2011, Buddy Bland
File system details?
• Will continue to use Lustre™ – High-performance, scalable, center-wide accessibility – The only open-source solution – Strong community of users, developers, and integrators
• Expand our Spider file system infrastructure – Increase bandwidth, anticipate >1 TB/sec – Increase capacity by 10 – 30 Petabytes (disk technology dependent)
• Targeting Lustre 2.x – Enhanced metadata performance and resiliency under development
• NRE contract with Whamcloud – Leveraging OpenSFS activities
• Community engagement (requirements gathering, architecture, testing, etc.) • Next-generation feature development (accelerating the community roadmap)

13 Fall Creek Falls Conference 2011, Buddy Bland
Hybrid Architecture: Power vs. Single Thread Performance • Multi-core architectures are a good first response to power issues
• Performance through parallelism, not frequency • Exploit on-chip locality
• However, conventional processor architectures are optimized for single thread performance rather than energy efficiency • Fast clock rate with latency(performance)-optimized memory structures • Wide superscalar instruction issue with dynamic conflict detection • Heavy use of speculative execution and replay traps • Large structures supporting various types of predictions • Relatively little energy spent on actual ALU operations
• Could be much more energy efficient with multiple simple processors, exploiting vector/SIMD parallelism and a slower clock rate
• But serial thread performance is important (Amdahl’s Law): • If you get great parallel speedup, but hurt serial performance, then you end up with a
niche processor (less generally applicable, harder to program) http://computing.ornl.gov/workshops/scidac2010/presentations/s_scott.pdf
Courtesy of Steve Scott presented at SciDAC 2010 13 Copyright 2010 Cray Inc.

14 Fall Creek Falls Conference 2011, Buddy Bland
Exascale Conclusion: Heterogeneous Computing • To achieve scale and sustained performance per {$,watt}, must adopt: …a heterogeneous node architecture
• fast serial threads coupled to many efficient parallel threads …a deep, explicitly managed memory hierarchy
• to better exploit locality, improve predictability, and reduce overhead …a microarchitecture to exploit parallelism at all levels of a code
• distributed memory, shared memory, vector/SIMD, multithreaded • (related to the “concurrency” challenge—leave no parallelism untapped)
This sounds a lot like GPU accelerators… NVIDIA FermiTM has made GPUs feasible for HPC
Robust error protection and strong DP FP, plus programming enhancements
Expect GPUs to make continued and significant inroads into HPC Compelling technical reasons + high volume market
Programmability remains primary barrier to adoption Cray is focusing on compilers, tools and libraries to make GPUs easier to use There are also some structural issues that limit applicability of current designs…
Technical direction for Exascale: Unified node with “CPU” and “accelerator” on chip sharing common memory Very interesting processor roadmaps coming from Intel, AMD and NVIDIA….
Courtesy of Steve Scott presented at SciDAC 2010 14 Copyright 2010 Cray Inc.

15 Fall Creek Falls Conference 2011, Buddy Bland
A risky strategy?
• Hardware risk is low
• Applications are where there is risk
Component Risk
System Scale Same as Jaguar
Processor Opteron follow-on
Accelerator Fermi follow-on
Interconnect Deployed in Cielo & Franklin at scale
Operating System Incremental changes from Jaguar
Component Risk
Programmability Rewrite in CUDA or something else?
Tools Debuggers and development tools
Programmer reluctance to rewrite for GPUs
Fermi follow-on will provide a lot of capability

16 Managed by UT-Battelle for the U.S. Department of Energy
Evolution of the programming model?
• “The principal programming environment challenges will be on the node: concurrency, hierarchy and heterogeneity.”
• “. . . ultimately more than a billion-way parallelism to fully utilize an exascale system”
• “Portability will be a significant concern . . . In order to improve productivity a programming model that abstracts some of the architectural details from software developers is highly desirable.”
Architectures and Technology for Extreme Scale Computing, Workshop Report, 2009; http://www.er.doe.gov/ascr/ProgramDocuments/Docs/Arch-TechGrandChallengesReport.pdf
We are implementing this programming model on Titan, but the model works on current and future systems

17 Fall Creek Falls Conference 2011, Buddy Bland
Risk mitigation
• For code portability among various architectures, we ruled out CUDA as the primary programming model
• We are working with several vendors on programming environment tools for Titan – Allinea DDT debugger scales to full system size and with
ORNL support will be able to debug heterogeneous (x86/GPU) apps
– CAPS HMPP compiler supports both C and Fortran compilation for heterogeneous nodes. ORNL is supporting C++ development
– ORNL has worked with the Vampir team at TUD to add support for profiling codes on heterogeneous nodes
– PGI has a compiler that generates code for the accelerators
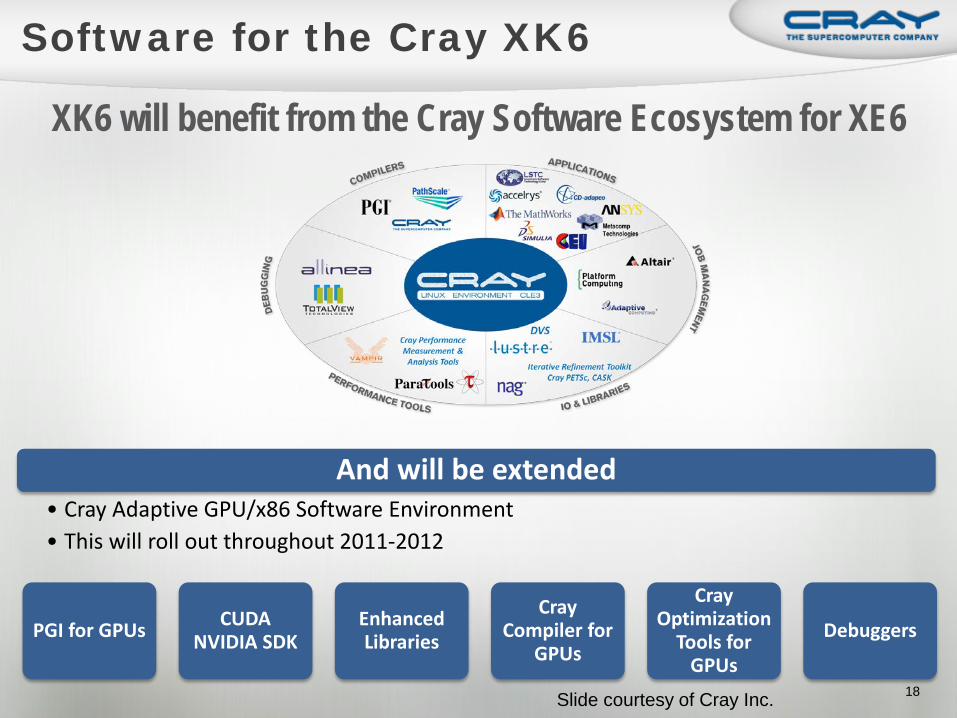
18 Fall Creek Falls Conference 2011, Buddy Bland
And will be extended • Cray Adaptive GPU/x86 Software Environment • This will roll out throughout 2011-2012
Software for the Cray XK6
18
XK6 will benefit from the Cray Software Ecosystem for XE6
PGI for GPUs CUDA NVIDIA SDK
Enhanced Libraries
Cray Compiler for
GPUs
Cray Optimization
Tools for GPUs
Debuggers
Slide courtesy of Cray Inc.
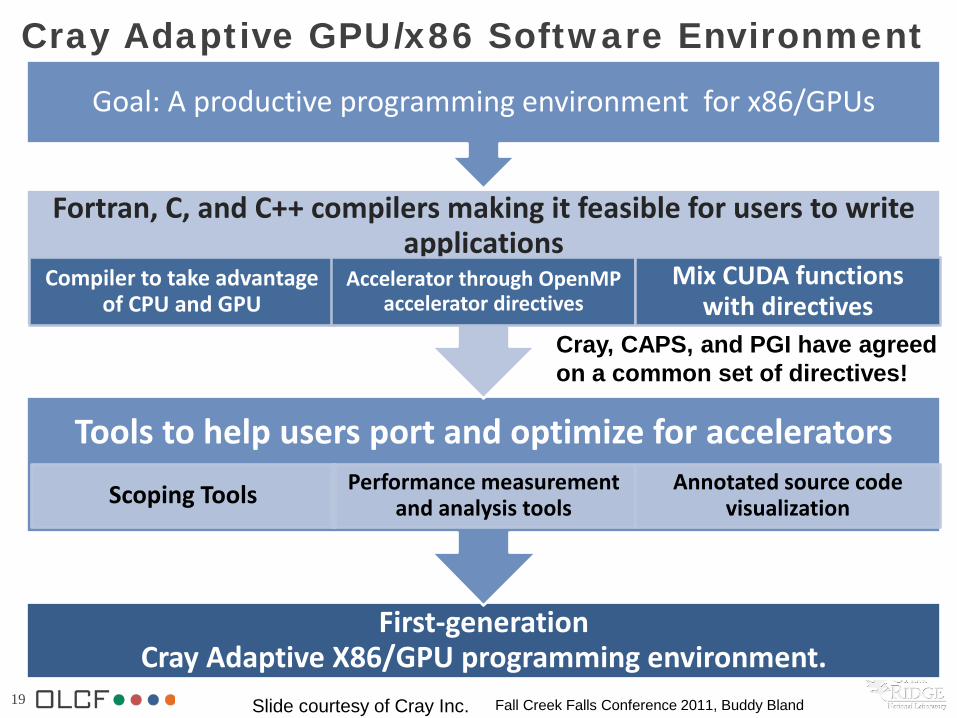
19 Fall Creek Falls Conference 2011, Buddy Bland
Cray Adaptive GPU/x86 Software Environment
First-generation Cray Adaptive X86/GPU programming environment.
Tools to help users port and optimize for accelerators
Scoping Tools Performance measurement and analysis tools
Annotated source code visualization
Fortran, C, and C++ compilers making it feasible for users to write applications
Compiler to take advantage of CPU and GPU
Accelerator through OpenMP accelerator directives
Mix CUDA functions with directives
Goal: A productive programming environment for x86/GPUs
Slide courtesy of Cray Inc.
Cray, CAPS, and PGI have agreed on a common set of directives!

20 Managed by UT-Battelle for the U.S. Department of Energy
Early Science Applications
WL-LSMS Role of material disorder, statistics, and fluctuations in nanoscale materials and systems.
S3D How are going to efficiently burn next generation diesel/bio fuels? .
PFLOTRAN Stability and viability of large scale CO2 sequestration; predictive containment groundwater transport
LAMMPS Biofuels: An atomistic model of cellulose (blue) surrounded by lignin molecules comprising a total of 3.3 million atoms. Water not shown.
CAM / HOMME Answer questions about specific climate change adaptation and mitigation scenarios; realistically represent features like precipitation patterns/statistics and tropical storms
Denovo Unprecedented high-fidelity radiation transport calculations that can be used in a variety of nuclear energy and technology applications.

21 Managed by UT-Battelle for the U.S. Department of Energy
Titan Project: Application Strategy • Code team for each project
Science team, performance engineer, applied mathematician, library specialist
• Working with vendors on tools CAPS (HMPP) – Compiler mods for accelerators, C++ Allinea – Scale DDT to 250K cores; support for accelerators Vampir – Support for profiling accelerator code Cray – Compilers, Performance tools, unified tool set
• Application Readiness Review of our preparation Spent 6 months analyzing and porting 6 applications to a hybrid CPU/GPU
platform Review panel was asked to assess our analysis of the challenges, level of
effort, and potential for performance gains of science applications on a hybrid architecture

22 Fall Creek Falls Conference 2011, Buddy Bland
Deployment Timeline
• 4Q 2011: – Replace all of Jaguar’s XT5 node boards with new XK6 nodes
• 16 core processors • Double Jaguar’s memory • Gemini interconnect
– Two step upgrade, keeping at lease 1 PF of capability available throughout the process
– Deploy some Fermi GPUs to continue porting applications
• 2H 2012: – Add NVIDIA Kepler GPUs to the system
• 10-20 PF peak performance • Dependent on budget availability

23 Managed by UT-Battelle for the U.S. Department of Energy
Summary
• At a major inflection point in computer architectures – can’t continue to scale applications of millions of execution
threads to grow the performance of applications
• Surviving the transition? – “business as usual” will not get us to where we need to go – investments in scalable computational algorithms
• development of new programming models to express hierarchical concurrency, and portable tools to implement it on multiple architectures is essential
• data locality will rule the day – investments in software development environments – creation of multi-disciplinary project-like teams





























