Embed Size (px)
Citation preview

Twister4Azure
Iterative MapReduce for Windows Azure Cloud
Thilina Gunarathne ([email protected])Indiana University
Iterative MapReduce for Azure Cloud
http://salsahpc.indiana.edu/twister4azure

Twister4Azure – Iterative MapReduce
• Decentralized iterative MR architecture for clouds– Utilize highly available and scalable Cloud services
• Extends the MR programming model • Multi-level data caching – Cache aware hybrid scheduling
• Multiple MR applications per job• Collective communication primitives• Outperforms Hadoop in local cluster by 2 to 4 times• Dynamic scheduling, load balancing, fault tolerance,
monitoring, local testing/debugging
http://salsahpc.indiana.edu/twister4azure/
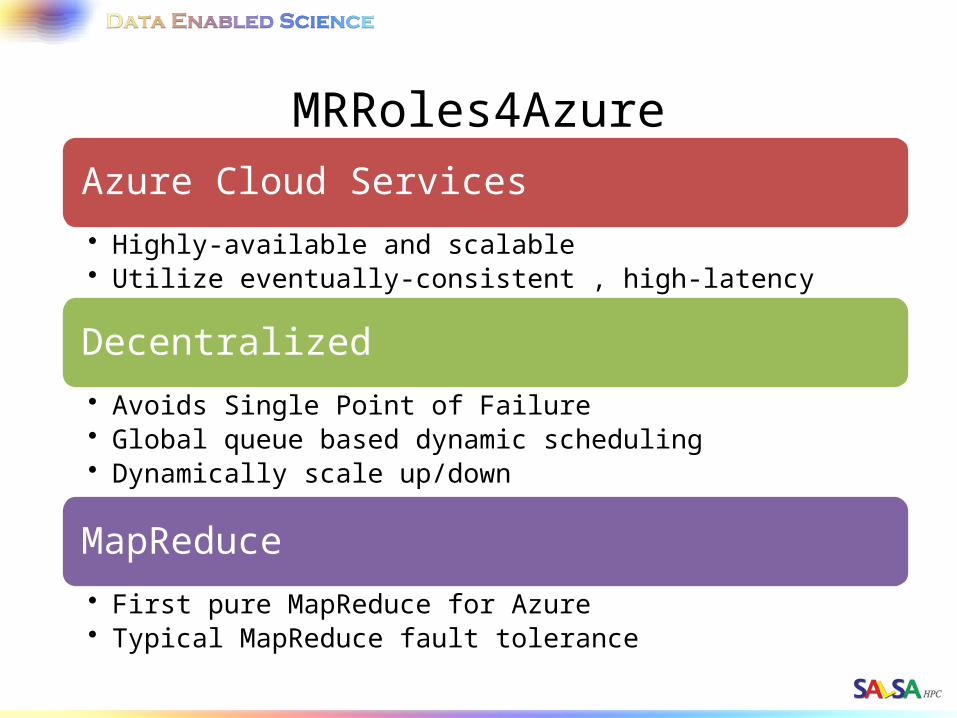
MRRoles4AzureAzure Cloud Services• Highly-available and scalable• Utilize eventually-consistent , high-latency cloud services effectively• Minimal maintenance and management overhead
Decentralized• Avoids Single Point of Failure• Global queue based dynamic scheduling• Dynamically scale up/down
MapReduce• First pure MapReduce for Azure• Typical MapReduce fault tolerance
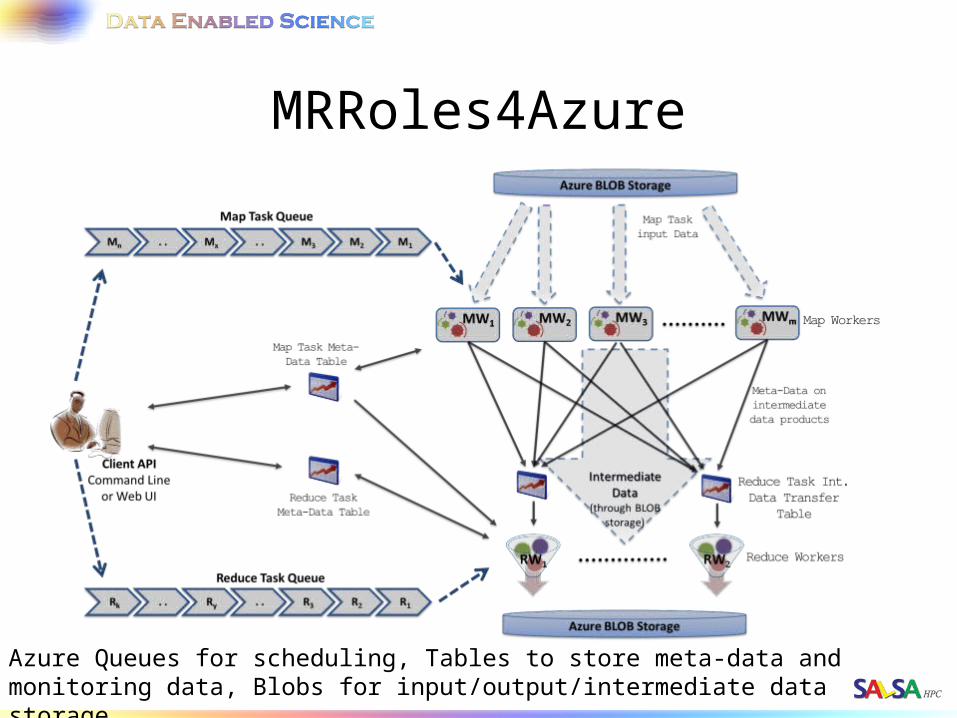
MRRoles4Azure
Azure Queues for scheduling, Tables to store meta-data and monitoring data, Blobs for input/output/intermediate data storage.

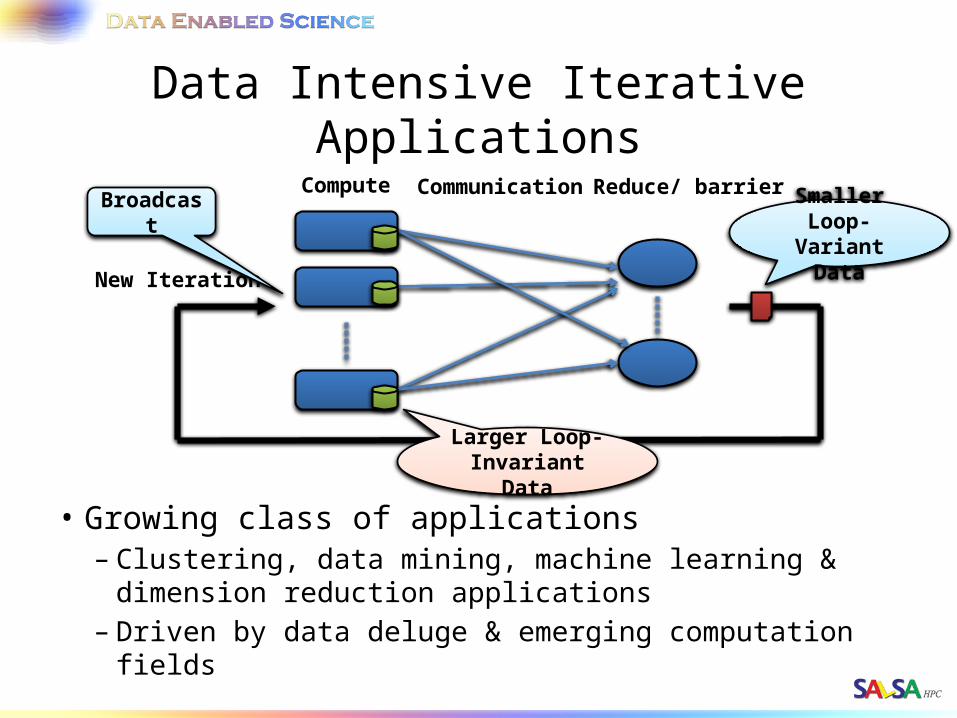
Data Intensive Iterative Applications• Growing class of applications
– Clustering, data mining, machine learning & dimension reduction applications
– Driven by data deluge & emerging computation fields– Lots of scientific applications
k ← 0;MAX ← maximum iterationsδ[0] ← initial delta valuewhile ( k< MAX_ITER || f(δ[k], δ[k-1]) ) foreach datum in data β[datum] ← process (datum, δ[k]) end foreach
δ[k+1] ← combine(β[]) k ← k+1end while
Data Intensive Iterative Applications
• Growing class of applications– Clustering, data mining, machine learning & dimension
reduction applications– Driven by data deluge & emerging computation fields
Compute Communication Reduce/ barrier
New Iteration
Larger Loop-Invariant Data
Smaller Loop-Variant Data
Broadcast
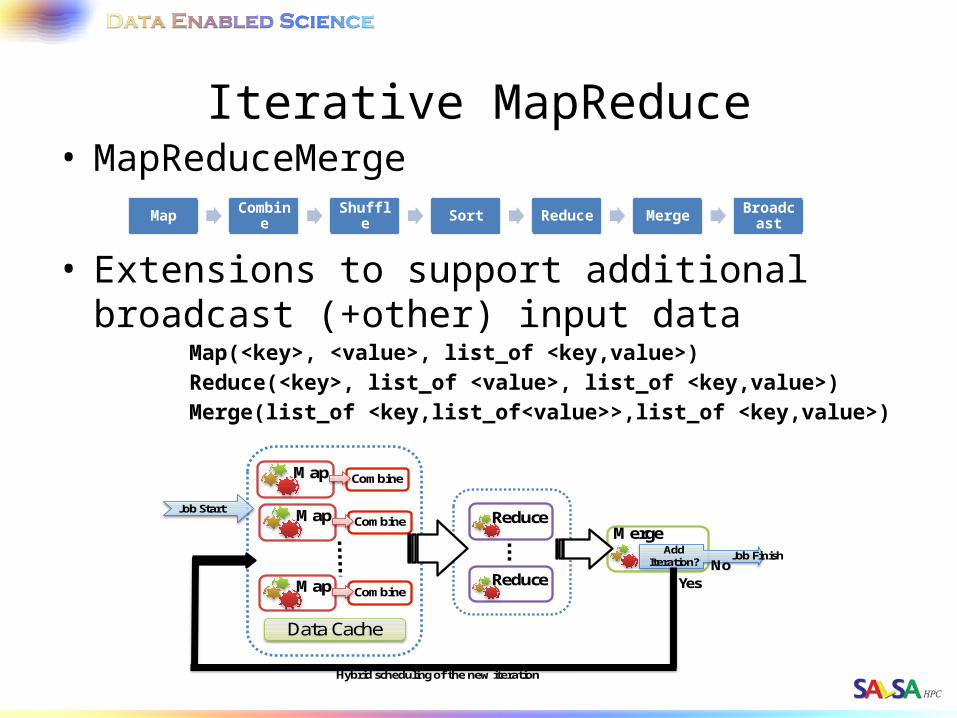
Iterative MapReduce• MapReduceMerge
• Extensions to support additional broadcast (+other) input data
Map(<key>, <value>, list_of <key,value>)Reduce(<key>, list_of <value>, list_of <key,value>)Merge(list_of <key,list_of<value>>,list_of <key,value>)
Reduce
Reduce
MergeAdd
Iteration? No
Map Combine
Map Combine
Map Combine
Data Cache
Yes
Hybrid scheduling of the new iteration
Job Start
Job Finish
Map Combine Shuffle Sort Reduce Merge Broadcast

Merge Step• Extension to the MapReduce programming model to support
iterative applications– Map -> Combine -> Shuffle -> Sort -> Reduce -> Merge
• Receives all the Reduce outputs and the broadcast data for the current iteration
• User can add a new iteration or schedule a new MR job from the Merge task.– Serve as the “loop-test” in the decentralized architecture
• Number of iterations • Comparison of result from previous iteration and current iteration
– Possible to make the output of merge the broadcast data of the next iteration
Reduce
Reduce
MergeAdd
Iteration? No
Map Combine
Map Combine
Map Combine
Data Cache
Yes
Hybrid scheduling of the new iteration
Job Start
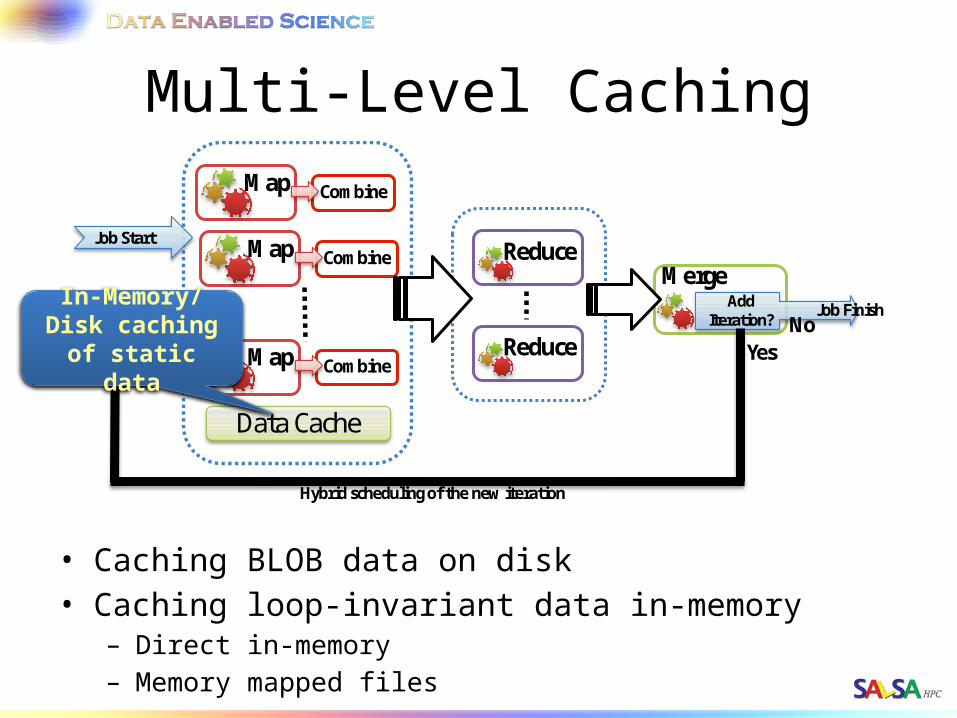
Job FinishIn-Memory/Disk caching of static
data
Multi-Level Caching
• Caching BLOB data on disk• Caching loop-invariant data in-memory
– Direct in-memory– Memory mapped files
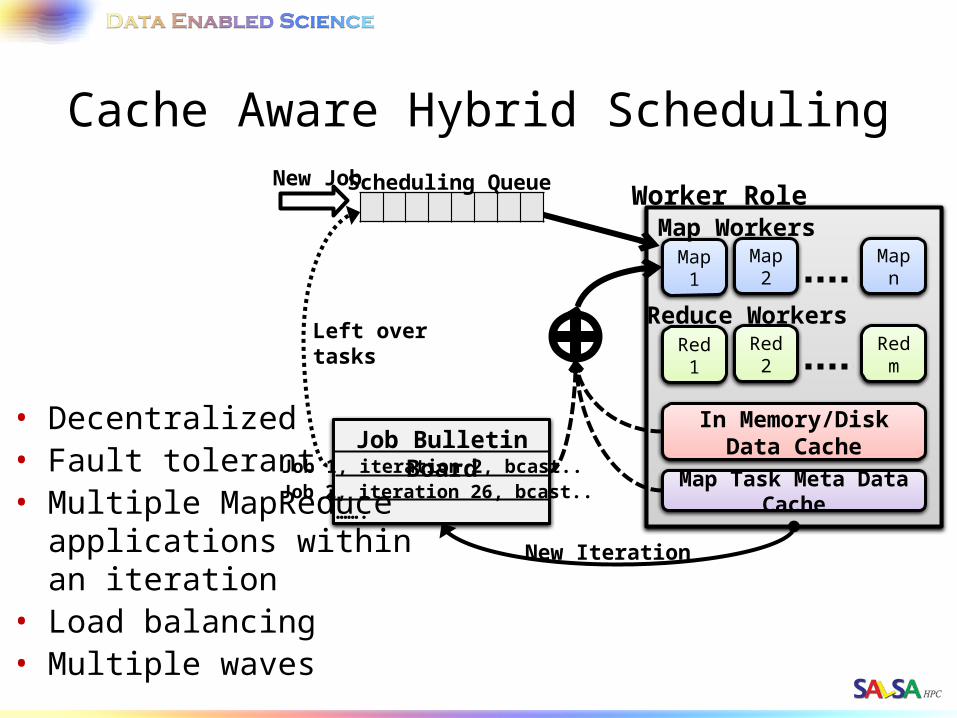
Cache Aware Hybrid Scheduling
Map 1
Map 2
Map n
Map Workers
Red 1
Red 2
Red m
Reduce Workers
In Memory/Disk Data Cache
Map Task Meta Data Cache
Worker Role
New Iteration
Left over tasks
New Job
Job Bulletin BoardJob 1, iteration 2, bcast..Job 2, iteration 26, bcast..…….
Scheduling Queue
• Decentralized• Fault tolerant• Multiple MapReduce
applications within an iteration
• Load balancing• Multiple waves
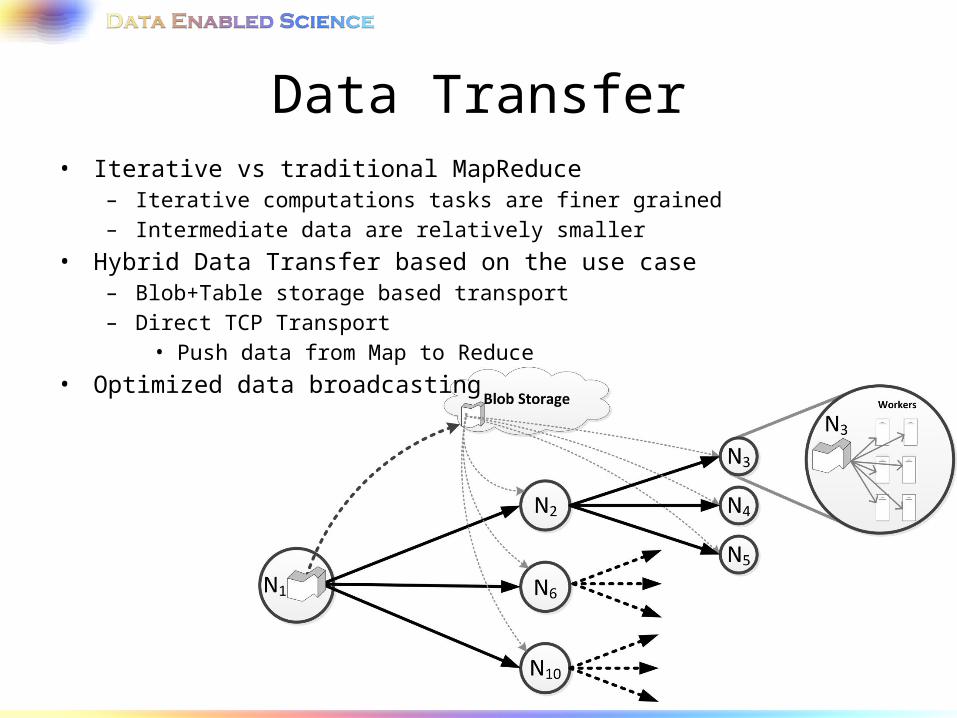
Data Transfer• Iterative vs traditional MapReduce
– Iterative computations tasks are finer grained – Intermediate data are relatively smaller
• Hybrid Data Transfer based on the use case– Blob+Table storage based transport– Direct TCP Transport
• Push data from Map to Reduce • Optimized data broadcasting

Fault Tolerance For Iterative MapReduce
• Iteration Level– Role back iterations
• Task Level– Re-execute the failed tasks
• Hybrid data communication utilizing a combination of faster non-persistent and slower persistent mediums– Direct TCP (non persistent), blob uploading in the
background.• Decentralized control avoiding single point of failures• Duplicate-execution of slow tasks

Collective Communication Primitives for Iterative MapReduce
• Supports common higher-level communication patterns• Performance
– Framework can optimize these operations transparently to the users• Multi-algorithm
– Avoids unnecessary steps in traditional MR and iterative MR
• Ease of use– Users do not have to manually implement these logic (eg: Reduce and
Merge tasks)– Preserves the Map & Reduce API’s
• AllGather• We are working on several other primitives as well
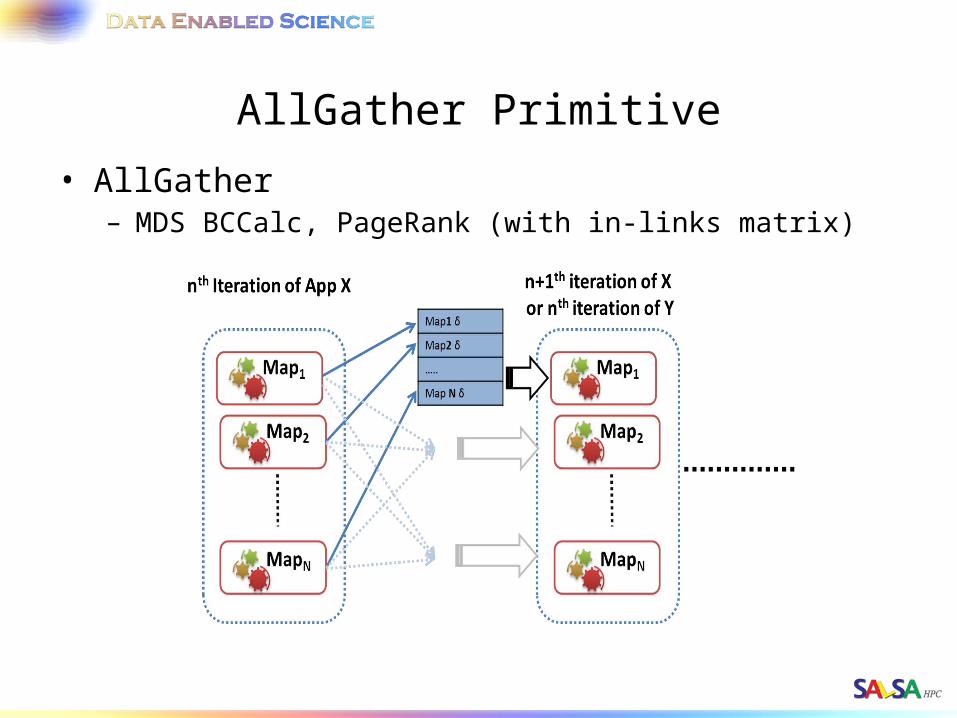
AllGather Primitive
• AllGather– MDS BCCalc, PageRank (with in-links matrix)
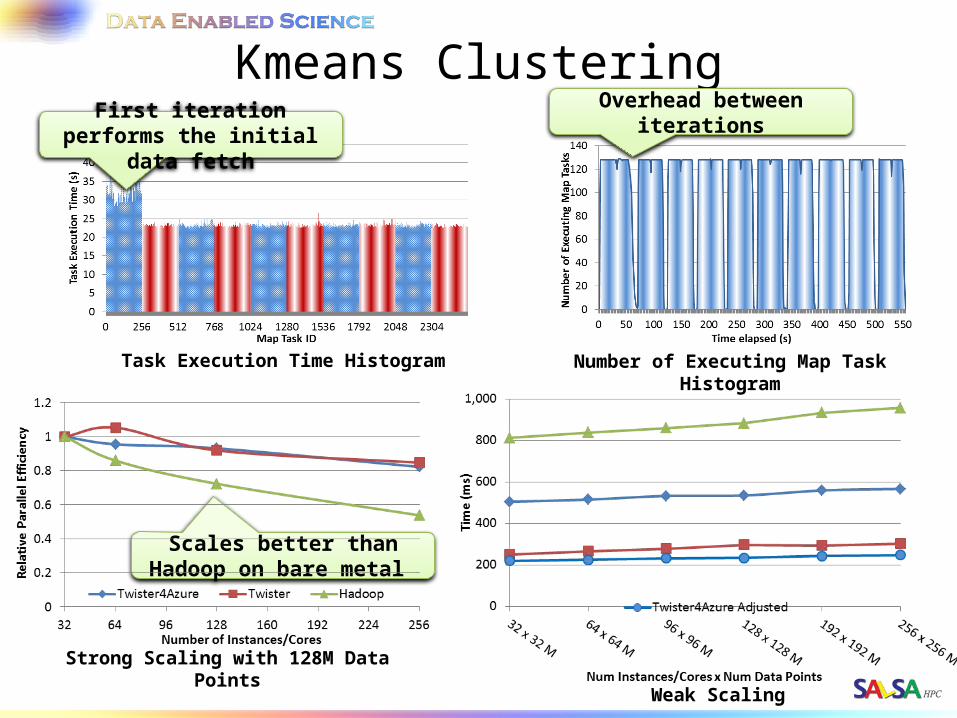
Kmeans Clustering
Number of Executing Map Task Histogram
Strong Scaling with 128M Data Points
Weak Scaling
Task Execution Time Histogram
First iteration performs the initial data fetch
Overhead between iterations
Scales better than Hadoop on bare metal
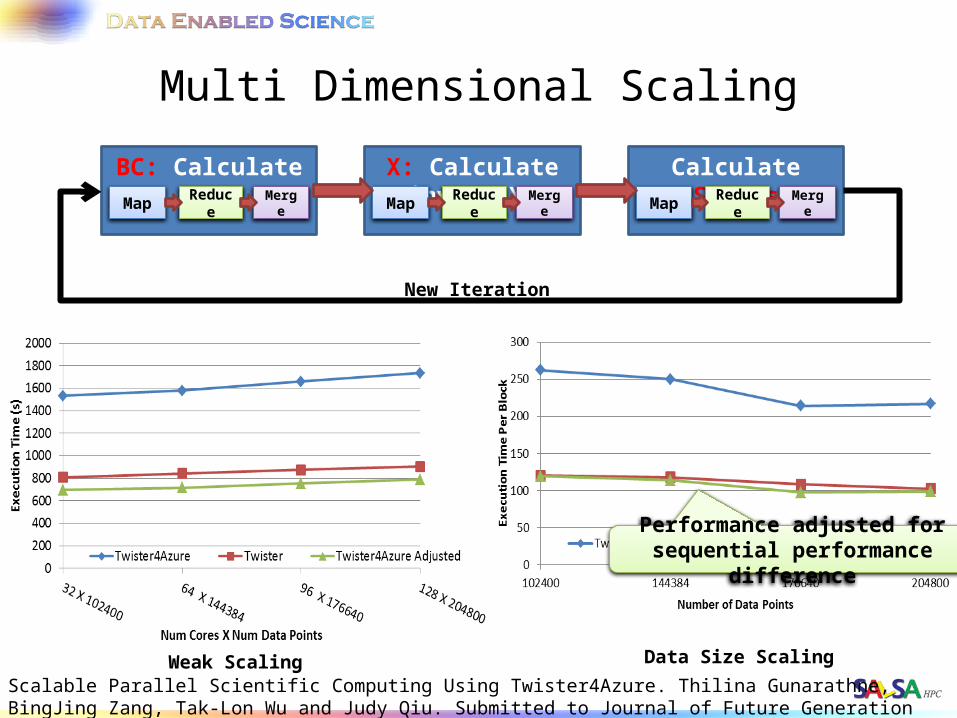
Multi Dimensional Scaling
Weak Scaling Data Size Scaling
Performance adjusted for sequential performance difference
X: Calculate invV (BX)Map Reduce Merge
BC: Calculate BX Map Reduce Merge
Calculate StressMap Reduce Merge
New Iteration
Scalable Parallel Scientific Computing Using Twister4Azure. Thilina Gunarathne, BingJing Zang, Tak-Lon Wu and Judy Qiu. Submitted to Journal of Future Generation Computer Systems. (Invited as one of the best 6 papers of UCC 2011)
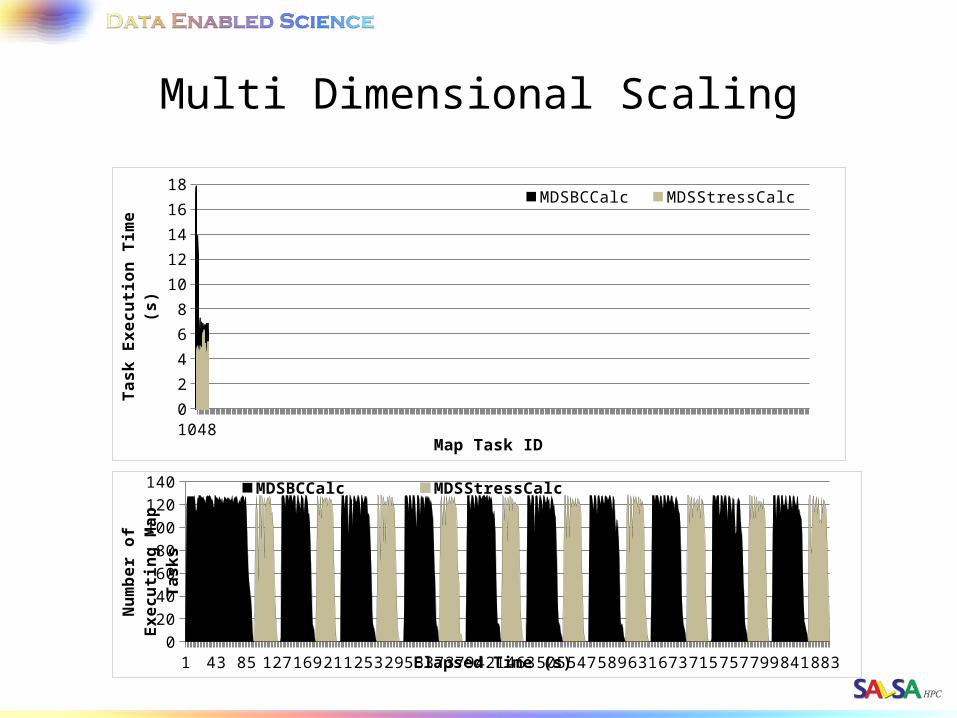
10480
2
4
6
8
10
12
14
16
18MDSBCCalc MDSStressCalc
Map Task ID
Task
Exe
cutio
n Ti
me
(s)
1 35 69 1031371712052392733073413754094434775115455796136476817157497838178518850
20406080
100120140 MDSBCCalc MDSStressCalc
Elapsed Time (s)
Num
ber
of E
xecu
ting
Map
Tas
ks
Multi Dimensional Scaling
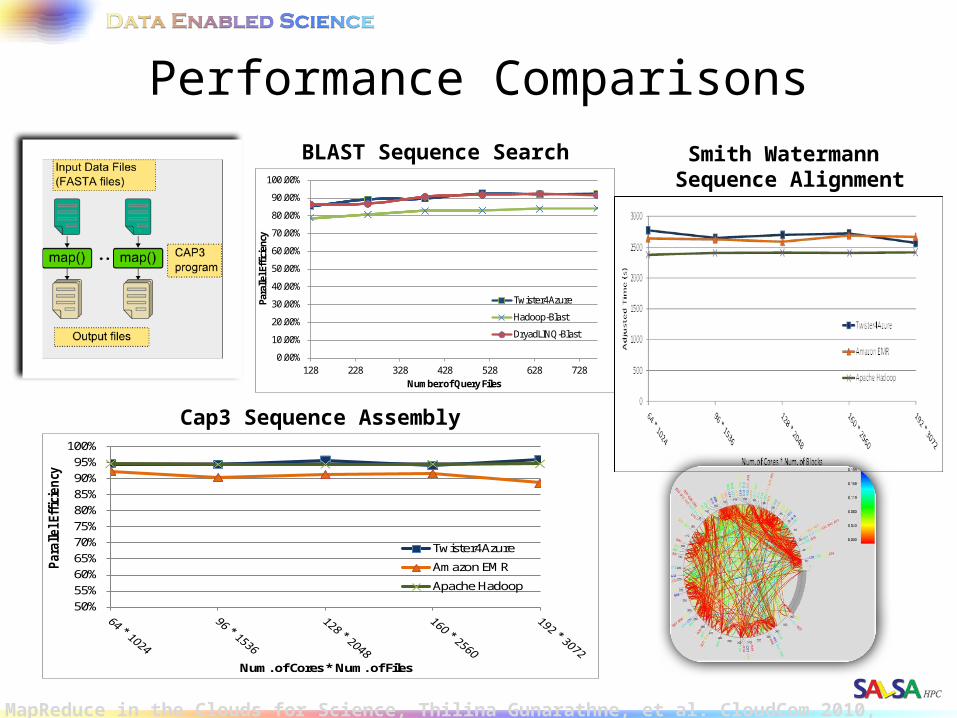
Performance Comparisons
0.00%
10.00%
20.00%
30.00%
40.00%
50.00%
60.00%
70.00%
80.00%
90.00%
100.00%
128 228 328 428 528 628 728
Para
llel E
ffici
ency
Number of Query Files
Twister4Azure
Hadoop-Blast
DryadLINQ-Blast
BLAST Sequence Search
50%55%60%65%70%75%80%85%90%95%
100%
Par
alle
l Effi
cie
ncy
Num. of Cores * Num. of Files
Twister4Azure
Amazon EMR
Apache Hadoop
Cap3 Sequence Assembly
Smith Watermann Sequence Alignment
MapReduce in the Clouds for Science, Thilina Gunarathne, et al. CloudCom 2010, Indianapolis, IN.

KMEANS CLUSTERING DEMO

Acknowledgement
• Microsoft Extreme Computing Group for the Azure Compute Grant
• Persistent Systems• IU Salsa Group
![Azure MapReduce - Indiana University Bloomingtonsalsahpc.indiana.edu/.../slides/0728/Azure_MapReduce.pdf · 2010-07-29 · Apache Hadoop [24] /(Google MR) Microsoft Dryad [25] Twister](https://img.pdfslide.net/doc/110x75/5ec9aa8362c48e455a33a399/azure-mapreduce-indiana-university-2010-07-29-apache-hadoop-24-google-mr.jpg)

















![The Performance Comparison of Hadoop and Spark · outperforms Hadoop MapReduce by 10x in iterative machine learning tasks [9] and is up to 20x faster for iterative applications [10]](https://img.pdfslide.net/doc/110x75/5f0e0fac7e708231d43d6ca9/the-performance-comparison-of-hadoop-and-spark-outperforms-hadoop-mapreduce-by-10x.jpg)










