Embed Size (px)
Citation preview

甲南大学大学院自然科学研究科知能情報学専攻修士論文 No. 175
Twitterにおける見落とし情報の話題構造抽出手法
A Method for Extracting Topic Structure of Missing Tweet
2016年 3月
大原 啓詳
甲南大学大学院 自然科学研究科

要旨
近年,情報を手軽に送受信するツールとしてTwitterが広く普及している.Twitterでは閲覧者が,興味を持ったユーザをフォローすることで,そのユーザの投稿したツイートを閲覧者自身のタイムラインに集約することが可能となる.しかしながら多くのユーザをフォローしている場合,タイムライン上のツイート量が増加し,有益な情報の見落としが発生する.本研究では,閲覧者が見落とした期間の時間情報と,話題の粒度を考慮し,見落とした情報の抽出を行う.そしてトピックグラフを用いて見落とし情報の話題構造を提示することにより,閲覧者にわかりやすく提示する手法を提案する.
Summary
Nowadays, Twitter is becoming popular. People use twitter for getting some information
which they interested in. In Twitter, viewing users who browse tweets can follow other users in
whom they are interested. They can obtain interesting information from another user’s tweets
on their timeline easily. However, when the viewing user follow so many people, they can not
read all tweets on their timeline because that contain large amount of information. In this
case they can lose important information. We propose a method to extract lost information
automatically based on the browsing time interval and the user’s topic structure. After we
extract lost information, we propose topic structure of lost information on network-graph.

目 次
1 はじめに 1
2 関連研究 2
3 見落とし情報のタイプと話題の粒度 4
3.1 閲覧期間に基づく見落とし情報 . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
3.2 話題の粒度 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
4 見落とし情報の抽出手法 5
4.1 見落とし情報の抽出手法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
4.1.1 ツイートのクラスタリング . . . . . . . . . . . . . . . . . . . . . . . . . . 6
4.1.2 話題クラスタの粒度構造 . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
4.2 閲覧期間に基づく見落とし情報の分類 . . . . . . . . . . . . . . . . . . . . . . . . 10
5 見落とし情報の提示手法 11
5.1 見落とし情報提示システム . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
5.2 トピックグラフの結合と見落とし情報の分類 . . . . . . . . . . . . . . . . . . . . 12
6 実験 20
6.1 ツイートのクラスタリングの実験 . . . . . . . . . . . . . . . . . . . . . . . . . . 20
6.2 概念構造と話題の粒度についての実験 . . . . . . . . . . . . . . . . . . . . . . . . 23
6.3 トピックグラフの結合に関する実験 . . . . . . . . . . . . . . . . . . . . . . . . . 32
7 まとめと今後の課題 34

図 目 次
1 閲覧期間に基づく見落とし情報の分類 . . . . . . . . . . . . . . . . . . . . . . . . 4
2 話題の粒度構造 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
3 提案手法のシステムフロー . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
4 話題の粒度抽出のフロー . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
5 最小のトピックグラフ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
6 共通する概念ノードによる結合 . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
7 トピックノードが他のトピックノードの上位概念となる結合 . . . . . . . . . . . 11
8 閲覧期間に基づく話題分類のフロー . . . . . . . . . . . . . . . . . . . . . . . . . 12
9 ツイートの投稿時間と分類 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
10 トピックグラフ結合の具体例 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
11 プロトタイプシステムの出力例 1 . . . . . . . . . . . . . . . . . . . . . . . . . . 14
12 プロトタイプシステムの出力例 2 . . . . . . . . . . . . . . . . . . . . . . . . . . 15
13 プロトタイプシステムの出力例 3 . . . . . . . . . . . . . . . . . . . . . . . . . . 16
14 結合の基となる最小のトピックグラフ組 . . . . . . . . . . . . . . . . . . . . . . 16
15 トピックグラフの結合が行われないパターン . . . . . . . . . . . . . . . . . . . . 17
16 共通の概念ノードによりトピックグラフが結合するパターン 1 . . . . . . . . . . 17
17 共通の概念ノードによりトピックグラフが結合するパターン 2 . . . . . . . . . . 18
18 片方のトピックノードが他方の概念ノードと結合するパターン 1 . . . . . . . . . 18
19 片方のトピックノードが他方の概念ノードと結合するパターン 2 . . . . . . . . . 19

表 目 次
1 クラスタリングの結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2 各ユーザの話題クラスタの特徴語 . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3 評価対象データの例 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4 各カテゴリの被験者数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
5 話題の粒度と概念構造のマッピングに関する実験結果 . . . . . . . . . . . . . . . 25
6 カテゴリ「政治」の実験結果の例 . . . . . . . . . . . . . . . . . . . . . . . . . . 26
7 カテゴリ「音楽,芸能」の実験結果の例 . . . . . . . . . . . . . . . . . . . . . . 28
8 カテゴリ「コンピュータ」の実験結果の例 . . . . . . . . . . . . . . . . . . . . . 29
9 カテゴリ「スポーツ」の実験結果の例 . . . . . . . . . . . . . . . . . . . . . . . . 30
10 カテゴリ「アニメ,ゲーム」の実験結果の例 . . . . . . . . . . . . . . . . . . . . 31
11 トピックの結合に関する実験の結果の一例 . . . . . . . . . . . . . . . . . . . . . 33
12 概念語の下位カテゴリ数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33

1 はじめに
近年,スマートフォンなどの携帯端末などの普及により,人々は様々な場面で,手軽に情報の送受信を行うことが可能となった.これに伴い,情報を手軽に共有する手段として,マイクロブログが広く普及している.特に代表的なマイクロブログサービスの一つであるTwitter1は,2015年現在では全世界に 3億 2千万人のアクティブユーザ 2が存在し,世界中から膨大な量の情報が投稿されている.Twitterでは,ツイートと呼ばれる 140文字以内の短文を投稿することで情報の送信が行わ
れる.また Twitterでは,ある閲覧者が自分の興味のある情報の発信者に対してフォローを行うことで,フォローした情報の発信者が投稿したツイートを,閲覧者自身のタイムライン上で閲覧することができる.この機能により,閲覧者は膨大なツイートの中から,興味のある情報の発信者が投稿したツイートを自身のタイムライン上に集約することができる.本研究では閲覧者がフォローしている情報の発信者をフォロイーと呼ぶ.閲覧者はより多くのフォロイーをフォローするほど,多くのツイートを自身のタイムライン上で閲覧することが可能となる.一方で日常生活においては閲覧者がタイムラインを常に閲覧しているということは困難であ
る.特にフォロイーの多いユーザは,タイムラインを見落とした期間が存在した場合に,見落とされるツイートの量も多いと考えられる.このとき見落としたタイムラインのツイートを遡り,閲覧者自身にとって重要な情報を発見することは,見落とされたツイートの量が膨大であることや,見落とした期間における話題の多様性などから困難であると考えられる.このことからフォロイー数の増加は,閲覧者にとって重要な情報の見落としの原因となると考えられる.本研究では,閲覧者がタイムラインを閲覧していなかった期間を見落とし期間,見落とし期間中に投稿されたツイートを見落とし情報と呼ぶ.見落とし情報には,閲覧者にとって興味のある情報と,不要な情報が混在している.そこで本
研究では,まず見落とし期間中に投稿されたツイートが,どのような話題について述べたものであるかを抽出し提示する.これにより閲覧者は,見落とし期間中に投稿された全てのツイートの内容を確認せずとも,見落とし期間中から興味のある話題を発見することが可能となる.しかし単純にツイートの話題を提示するだけでは閲覧者が,ある話題全体を見落としているのか,話題の一部のみを見落としているかが分からない.そこで本研究では,話題を粒度に基づき構造化し提示する手法を提案する.本研究における話題の粒度とは話題の詳細さのことである.しかしもともとのツイートの話題は,構造をもつものではない.そこで本研究では,ツイートの話題を概念構造に当てはめることで,話題に粒度を持たせる手法を提案する.本研究では見落としたツイートの話題の粒度と,見落とし期間の時間情報の 2点に着目し,話
題の粒度を考慮した見落とし情報の抽出と提示を試みている.また得られた見落とし情報について,閲覧者が直感的に理解可能な提示手法として,話題の粒度に基づくネットワークグラフを用いて見落とし情報を閲覧者に提示する手法について述べる.以下,本論文の構成として,第 2章では先行研究について述べ,第 3章では本研究における
見落とし情報と話題の粒度の定義を述べ,第 4章では本研究における閲覧期間と話題の粒度に基づく見落とし情報の抽出手法について述べ,第 5章で見落とし情報の提示手法について述べ,第 6章で話題の粒度ついての実験について述べ,第 7章に結論と今後の課題について記す.
1https://twitter.com2https://about.twitter.com/ja/company
1

2 関連研究
見落としの解消を目的とする研究本研究と同様に,閲覧者の有益な情報の見落としの解消を目的とした研究は行われている.辻ら [1]は,閲覧者のタイムライン上の頻出語から興味を推定し,新着ツイート中に含まれる閲覧者にとって興味のありそうな話題のツイートの抽出を行っている.辻らは,フォローしているユーザ全体を対象として興味分析とツイートの部類を行っているが,本研究ではより詳細な情報を取得するためにフォロイーのみを対象として有益な情報の抽出を試みている点が異なる.Renら [2]は,時系列変化とユーザ間のつながりに基づくトピックモデルを提案しトピック抽出を行い,有益と判断されたツイートに対しWikipediaの概要部分を利用し要約と説明を行っている.本研究ではツイート群の文章による要約ではなく話題をトピックグラフとして提示することで,ユーザが話題の構造などを理解しやすくすることを目的としている点が異なる.ツイートのクラスタリングに関する研究本研究ではツイートのクラスタリングを行っている.ツイートのクラスタリングに関する研究として,Rosaら [26]は,教師なしクラスタリング手法と教師ありクラスタリング手法をツイートに対し適応した結果について,一般文書にしばしば用いられる代表的な教師なしクラスタリング手法である,潜在的ディリクレ配分法 (LDA)[24]や K-means法 [21]のツイートへの応用は,ツイートの短さや内容の煩雑さから困難であるとの実験結果を示している.本研究では短文にも比較的対応可能な K-means法の応用手法である Repeated-Bisection法を用いる.またSriramら [27]は,投稿者のツイート傾向などの特徴に基づき,ツイートを「ニュース」「イベント」「意見」といったいくつかのカテゴリにクラスタリングしている.しかしながら Sriamらの手法では,ツイートを多様なトピックへとクラスタリングすることは困難である.また西田ら [4]は,閲覧者が着目している話題に関するツイートを,情報圧縮を行った際に着目している話題と,その他の話題のどちらに分類されやすいかという点に着目し,単語や文章に依存しないツイートの特定の話題への分類を行っている.西田らの手法は閲覧者が着目している話題が明確に定まっている場合に,着目している話題に関する有益なツイートを集約する際には有効である.一方,本研究ではフォロイーの話題の多様さにも着目し,フォロイーのツイート全体に含まれる複数の話題へと分類することを試みている.これにより本研究では,閲覧者の興味が明確ではない場合などでも,閲覧者が有益な情報を容易に発見できる仕組みが実現できると考える.ツイートのトピック抽出に関する研究本研究ではツイートの話題に着目し,ツイートからのトピック抽出を行っている.Twitterを対象としたトピック抽出に関する研究として,Mathioudakisら [23]はある時点において盛り上がりを見せている話題を,ツイート中でバーストしているキーワードを用いることで抽出を試みている.Beckerら [15]は,現実世界におけるイベントとの関連付けにより,ある時点におけるツイートの主なトピックの抽出を行っている.また Leeら [20]はツイートの文に基づくテキストベースの分類手法と,Twitterにおけるフォロー関係に基づくネットワークベースの分類手法の 2つのアプローチにより,ツイートからのトピック抽出を行っている.これらの研究はいずれも Twitter全体におけるトレンドや,複数のユーザのネットワークにおける話題に着目した研究である.より詳細度の高い,個人のツイートに関する研究として,Hongら [18]は LDAと,
投稿者毎のトピックの確率分布を考慮したAuthor-Topic Model[25]を用いてツイートのトピックモデリングを行っている.Xuら [28]はWikipediaの記事と記事間リンク履歴の情報をもと
2

に,ツイートのトピック抽出を試みている.またKasiviswanathanら [19]は辞書学習を用いることで,ツイートからのトピック抽出を試みている.Bernsteinら [16]はWeb検索エンジンの検索結果を用いることで,ツイートから適切なトピックの抽出を試みている.本研究では,これらの研究におけるトピック抽出に加えて,さらに話題の粒度を考慮することで,情報の詳細度を提示することが可能なトピック抽出を試みている.また,Michelsonら [6]は 1アカウントが発するツイートのトピック抽出のため,ツイート中の語に対するWikipediaのカテゴリ構造を用いている.Michelsonらの研究は本研究に同様に,話題の粒度をある程度考慮しているといえる.しかしながらMichelsonらの研究では時系列的な話題の変化等には着目していない点が我々の研究とは異なる.トピック抽出と時間情報の双方を用いた研究本研究同様に,ツイートの話題と時間の両方を考慮している研究として,糸川ら [9]は特定のトピックに対する特徴語の時間経過による変化などから,話題追跡を行っている.糸川らの提案手法では時間ごとに出現する話題を提示しているが,本研究は話題の粒度に基づき,話題間の関連性を考慮している点で異なる.Cataldiら [17]は,投稿者のツイート内容に関する情報と,トピックのライフサイクルを考慮したモデルにより,Twitterにおける時間経過を考慮したトピック抽出を試みている.Cataldiらの研究と本研究との違いは,Cataldiらが Twitter全体の時間の流れを考慮しているのに対して,本研究では閲覧者の見落とし期間という限定的な時間に限定して情報の抽出を試みている点である.これにより,本研究では,より詳細かつ閲覧者の興味と近いトピックを抽出できると考える.藤野ら [3]はダイナミックトピックモデル [7]によるツイートのトピック抽出と,投稿内容の時系列変化に着目しユーザの相関関係の発見を行っている.藤野らの研究ではツイートから得られたユーザの特徴をもとに,ユーザのタイプ分類とユーザ間の相関関係を発見することを目的としている.時間情報とトピックを用いている点が共通しているが,本研究の目的はユーザの分類ではなく,話題そのものが持つ概念構造を抽出することを目的としている点が,藤野らの研究とは異なる.Magdyら [22]はツイートの投稿時間と現実世界のイベントとの関連付けにより,ツイートの適切な要約を試みている.Magdyらの研究では話題と時間情報の双方を用いているが話題の粒度については考慮されていない.また,時系列を考慮したトピックモデルに関する研究として佐々木ら [5]は Twitter-LDA[8]を話題の時間発展を考慮することで拡張した手法により,ツイートのトピックモデル化を試みている.本研究では,時間,ツイートのトピックモデル抽出のみならず,トピック間の概念構造に対しても着目している点が佐々木らの研究とは異なる.ネットワークグラフによる情報の可視化に関する研究本研究ではタイムライン上の話題について,ネットワークグラフによる可視化を行っている.本研究同様,時間と話題の両方を考慮したネットワークグラフの提示に関する研究として,内田ら [13]は,ウェブログを対象として,話題のクラスタをネットワークグラフにより提示し,時間的な話題の変化の分析を行っている.内田らの提案する手法では,ウェブログの trackbackに基づきネットワークを構成しているため,本研究で対象としている twitterには直接用いることができない.そこで我々の研究では,話題の概念構造へのマッピングからグラフの構成を試みているという点が異なる.松尾ら [14]は,ツイートの話題と共起頻度,および話題の時系列変化に着目したグラフの生成と分析を行っている.松尾らの研究では,時間経過による話題の出現回数や話題間の共起の変化などを読み取る際には有効な手法である.一方で我々の提案手法では話題の粒度を考慮することにより,話題の詳細度や共起頻度は低いが関連性の強い話題の分析などが可能になると考えている.
3

図 1: 閲覧期間に基づく見落とし情報の分類
3 見落とし情報のタイプと話題の粒度
3.1 閲覧期間に基づく見落とし情報
本研究では見落とし情報を “未知の話題”と “既知の話題”という 2種類のタイプに分類する.以下にそれぞれのタイプの定義を示す.
• 既知の話題見落とし期間中に存在する話題のうち,閲覧者が閲覧していた期間中にもその話題のツイートが存在しており,その話題について閲覧者が部分的に閲覧したことのある話題.
• 未知の話題見落とし期間中に存在する話題のうち,見落し期間にのみ出現する話題であり,閲覧者が閲覧したことのない話題.
既知の話題,未知の話題の分類について図 1に示す.図 1では,“野球”,“研究”という話題は閲覧していた期間と見落とした期間の両方に含まれる話題であるため,既知の話題となる.一方で “サッカー”に関する話題は見落とした期間にのみ含まれる話題である.この時,話題 “サッカー”は未知の話題となる.
3.2 話題の粒度
本研究における話題の粒度とは,話題の細かさのことである.話題の粒度は見落とし期間中に投稿されたツイートの話題構造の把握と,閲覧期間に基づく話題の分類において重要な要素の一つである.例えば図 2では,図 2の話題の中では最も小さな粒度の話題である「イチロー」「田中将大」
といった 2つの話題に着目した場合,これらの話題はいずれも「MLBの日本人選手」に関する話題であると考えることができる.さらに「日本野球リーグの野球選手」の話題なども合わせて考えると,これらはいずれも「野球選手」に関する話題であり,さらにほかの野球に関する
4

図 2: 話題の粒度構造
話題も含めて「野球」に関する話題であるととらえることもできる.このような話題の細かさを話題の粒度として本研究では取り扱う.また,本研究では見落とし期間の時間情報を考慮した既知の話題,未知の話題への分類を考え
る際にも,話題の粒度構造に着目する必要があると考える.例えば上記の例において閲覧者にとっての未知の話題が “イチロー”,“田中将大”だけであった場合,閲覧者にとって “日本人メジャーリーガー”の話題全体が未知の話題であるといえる.一方,“野球選手”や “野球”といった粒度の話題については,“坂本勇人”,“鳥谷敬”といった既知の話題が含まれるため,これらも既知の話題であると判断できる.
4 見落とし情報の抽出手法
本研究において我々は,見落としたツイートの話題の粒度,閲覧期間と非閲覧期間の時間情報の 2点に着目し見落とし情報の抽出を行う.図 3に本研究の提案システムのシステムフローを示す.図 3では,手順 3までの内容が見落とし情報の抽出に関する部分である.そして,手順 4にて閲覧者への見落とし情報の提示を行う.
5
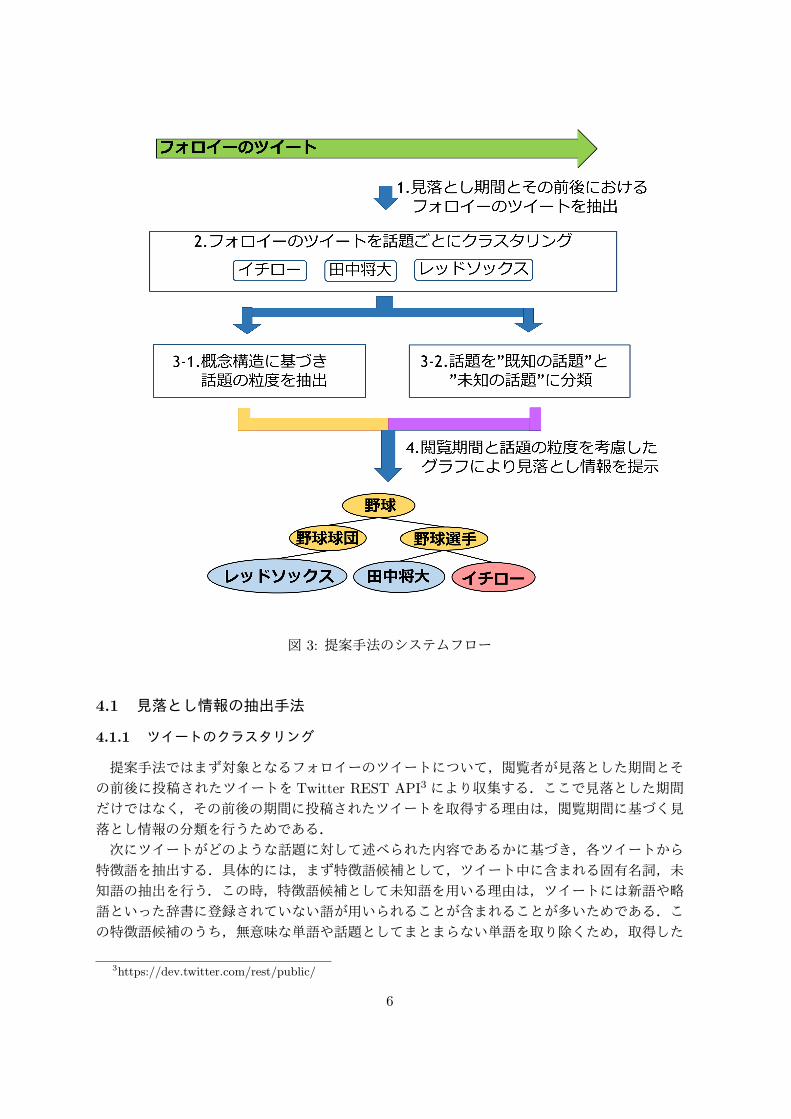
図 3: 提案手法のシステムフロー
4.1 見落とし情報の抽出手法
4.1.1 ツイートのクラスタリング
提案手法ではまず対象となるフォロイーのツイートについて,閲覧者が見落とした期間とその前後に投稿されたツイートを Twitter REST API3により収集する.ここで見落とした期間だけではなく,その前後の期間に投稿されたツイートを取得する理由は,閲覧期間に基づく見落とし情報の分類を行うためである.次にツイートがどのような話題に対して述べられた内容であるかに基づき,各ツイートから
特徴語を抽出する.具体的には,まず特徴語候補として,ツイート中に含まれる固有名詞,未知語の抽出を行う.この時,特徴語候補として未知語を用いる理由は,ツイートには新語や略語といった辞書に登録されていない語が用いられることが含まれることが多いためである.この特徴語候補のうち,無意味な単語や話題としてまとまらない単語を取り除くため,取得した
3https://dev.twitter.com/rest/public/
6

ツイート群のうち,2ツイート以上に出現する単語のみを特徴語として用いる.また,多数のツイート中にて一般的に用いられる語などの影響を小さくするため,特徴語の重みは,1ツイートを 1ドキュメントとした際の逆文書頻度 idfにより重みづけを行う.idf算出には式 1を用いる.
idf = logN
dft(1)
式 1において,N はクラスタリング対象の全ツイート数,dftは特徴語 tが出現するツイート数である.クラスタリング手法にはCLUTO[11]やBayon4といったクラスタリングツールで用いられて
いるクラスタリング手法である Repeated Bisection法 [12]を用いる.この手法は K-means法の拡張手法の一つであり,短文に対してもある程度の対応が可能である [10].Repeated Bisection法はハードクラスタリングの手法であるため,本来いずれのクラスタに
も属さないようなツイートが不適切なクラスタに分類されることや,内容が極端に疎なクラスタが生成される場合がある.そこで,本研究ではクラスタの中心ベクトルと,ツイートの特徴ベクトルのコサイン類似度の値が小さいツイートについては,所属度の低いツイートとしてクラスタリング結果から削除する処理を行う.本論文ではクラスタリングの結果として得られた各クラスタを話題クラスタと定義する.また,この時クラスタの中心ベクトルを生成する特徴語のうち,最も成分の大きい語を,話題クラスタのトピックとする.
4.1.2 話題クラスタの粒度構造
4.1.1節のクラスタリング手法では,特徴語ごとにツイートをクラスタリングしたのみであり,話題の粒度が考慮されていない.そこで,各話題クラスタのトピックを概念構造にマッピングすることにより話題の粒度の抽出を行う.話題の粒度抽出手法のフローを図 4に示す.本研究では更新頻度が高く,Twitter上で用いられている新語にも比較的対応可能な日本語版
Wikipediaのカテゴリ構造をマッピング先の概念構造として用いる.まず各話題クラスタの中心ベクトルを構成する特徴語の中で最も,要素の値が大きい語を話題クラスタのトピック ciとする.次に全話題クラスタのトピック集合C = {c1, c2, . . . , cn}の要素 cxにおいて,Wikipediaの cxをタイトルとする記事に付与されたカテゴリをWikipediaのカテゴリリンクデータベースより取得し,cxの上位概念 Sx = {sx1 , sx2 , . . . , sxi , . . . , sxm}とする.この時,「Wiki」や「~のスタブ」,「~であるユーザ」といったWikipediaの内容編集に関するカテゴリについては上位概念になりえないため削除する.また「存命人物」や「~語圏の人名」といった,重要な意味を持たないカテゴリについても削除する.また,各カテゴリ sxiの上位カテゴリ集合 Sxi = {sxi1
, sxi2, . . . , sxij
}をWikipediaのカテゴリ構造から取得し,これを cxの 2段階上位の上位概念語として付与する.この手法により,n階層上位までのカテゴリを各トピックに対して付与することで,トピックの粒度を抽出する.例えば,「イチロー」というトピックの話題クラスタが存在した場合,まずWipkipedia上の「イ
チロー」の記事に付与されたカテゴリを取得する.そして,記事から取得した「盗塁王 (MLB)」や「日本人メジャーリーガー」といったカテゴリを,トピック「イチロー」の上位概念として付与する.さらに「盗塁王 (MLB)」,「日本人メジャーリーガー」といった語についても同様に記事に付与されているカテゴリを上位概念として付与する.この手順を n回繰り返すことにより,トピック「イチロー」に対して n階層上位までの上位概念を付与する.
4https://code.google.com/p/bayon/
7

図 4: 話題の粒度抽出のフロー
次に話題クラスタとその上位概念からトピックグラフの生成を行う.まずグラフ生成のために,以下の 2種類のノードを定義する.
トピックノードツイート群から提案手法により抽出したトピックをラベルに持ち,ツイートを含むノード
概念ノードクラスタのトピックの上位概念語をラベルに持ち,ツイートを含まないノード
これらの 2種類のノードを用いて,各クラスタについて最小のトピックグラフを生成する.最小のトピックノードのイメージを図 5に示す.次に最小のトピックグラフ同士を共通するラベルにより結合する.この時,本研究における
最小のトピックグラフの結合手法には以下の 2つのパターンが存在する.
1. 共通する概念ノードによる結合
2. トピックノードが他のトピックノードの上位概念となる結合
結合パターン 1の場合は,それぞれの最小のトピックグラフに含まれる概念ノードのラベルが共通した場合に 2つのグラフを結合する.そのため,結合を行った上位概念ノードはツイートを含まない,ラベルのみのノードとなる.結合パターン 1の例を図 6に示す.例えば,図 6で
8

図 5: 最小のトピックグラフ
は,「イチロー」と「田中将大」という 2つの話題クラスタからの最小のトピックグラフをまず生成している.そして,これら 2つの最小のトピックグラフについて,共通する概念ノードである日本人メジャーリーガーにより 2つの最小のトピックグラフを結合している.ここで,「イチロー」「田中将大」のトピックノードにはツイートが含まれているが,「日本人メジャーリーガー」というノードは,いずれの最小のトピックノードにおいても概念ノードであったため,ツイートを含まない.一方で結合パターン 2の場合はあるトピックノードのラベルが,別の最小のトピックグラフ
における概念ノードと共通するラベルを持つ場合の結合である.そのため,結合を行ったノードは,概念ノードでありながら,ツイートを含むノードとなる.結合パターン 2の例を図 7に示す.この結合手順を繰り返すことにより,粒度を考慮したトピックグラフの生成を行う.次に,結合後のトピックグラフ上のトピックノードを話題の粒度に基づき,2種類に分類する.
概念トピックノード他のトピックノードの上位概念であるトピックノード
末端トピックノード下位概念を持たないトピックノード
これによりノードを概念ノード,概念トピックノード,末端トピックノードの 3種類に分類する.図 6の例におけるトピックノード「イチロー」「田中将大」や図 7のトピックノード「プロ野球選手」は末端トピックノードである.一方,図 7のトピックノード「プロ野球」は末端トピックノード「プロ野球選手」の上位概念であるため,概念トピックノードとなる.この分類により全てのノードに対して概念ノード,概念トピックノード,末端トピックノードの 3種類の属性を付与する.上記の手順により,フォロイーのツイートからトピックグラフの生成,そしてグラフ上のノー
ドの属性を決定する.
9

図 6: 共通する概念ノードによる結合
4.2 閲覧期間に基づく見落とし情報の分類
本研究では話題の粒度構造と合わせて,閲覧期間に基づいた話題の分類を考慮することにより,閲覧者にどの話題を見落としているかをわかりやすく提示する.話題の粒度抽出手法のフローを図 8に示す.まず閲覧者の見落とし期間を示す時間情報と,見落とし情報の抽出対象であるツイート群に
含まれるツイートの投稿時間を取得する.次に,それぞれのツイートが,見落とし期間中に投稿されたツイートであるか,閲覧していた期間中に投稿されたツイートであるかを分類する.そして,この結果より,それぞれの話題クラスタについて,クラスタ中の全てのツイートが見落とし期間中に投稿されたツイートであるような話題クラスタを,見落とした話題とする.一方,ある話題クラスタ中のツイートについて,閲覧済みのツイートと見落とし期間中に投稿されたツイートの両方を含むような話題クラスタを既知の話題とする.閲覧期間に基づく見落とし情報の分類の例を図 9に示す.図 9の例では,話題クラスタ「田
中将大」は,含まれるツイートがすべて,見落とした期間に投稿されたものである.そのため「田中将大」は未知の話題となる.一方で話題クラスタ「イチロー」は見落とした期間に投稿されたツイートと,閲覧していた期間に投稿されたツイートの両方を含んでいる.そのため「イチロー」は既知の話題となる.
10

図 7: トピックノードが他のトピックノードの上位概念となる結合
5 見落とし情報の提示手法
本論文では 4章にて抽出した見落とし情報の話題の粒度と,閲覧期間に基づく見落とし情報の分類を用いて,見落とし情報の提示を行う.本論文では提示手法実装の初めの一歩として,各クラスタに対して 1階層上位の上位概念語のみを用いてグラフを生成し提示する.
5.1 見落とし情報提示システム
本論文では,抽出と分類を行った見落とし情報を提示するにあたり,効果的な見落とし情報提示システム開発の第一歩として,閲覧期間を考慮した見落とし情報の話題構造をネットワークグラフにより提示するプロトタイプシステムを開発した.まず,抽出した概念構造を提示するネットワークグラフの例を図 10に示す.図 10の例では,「ヤクルト」「ソフトバンク」の 2つのトピックノードが概念ノード「福岡県発
祥の企業」により結合されている.しかしながら,このインタフェースでは閲覧者が話題の粒度について,接続された 2つのノードのうち,どちらがより大きい粒度であるかを認識することが困難である.そこで本研究ではグラフ上のノードについて,話題の粒度に基づきフィルタリングを行う機能を実装している.本研究におけるプロトタイプシステムの出力例を図 11,図12に示す.
11

図 8: 閲覧期間に基づく話題分類のフロー
提案システムの提示手法では,概念ノード,概念トピックノード,末端トピックノードの 3種類のノードについて表示,非表示を切り替えることにより,閲覧者は情報の粒度を把握しやすくなると考える.閲覧者は提案手法により提示したグラフについて,ラベルを参照することで,閲覧者自身が
興味を持った話題を発見する.この時,閲覧者が興味を持った話題については詳細な情報を提示する必要がある.提案手法では,閲覧者がトピックノードを指定した際には,そのノードに含まれるツイートを提示する.図 13にツイート提示の例を示す.また,概念トピックノードを指定した際には,ノードに含まれるツイートだけではなく,閲覧者に話題の粒度を示すために,そのノードの下位概念となるノードのラベルも提示する.そして概念ノードを選択した場合は,下位概念ノードのラベルを提示する.
5.2 トピックグラフの結合と見落とし情報の分類
本研究では,見落とし情報をよりわかりやすく提示するために,閲覧者に対してグラフの提示のみではなく,見落とし情報のサマリを提示する手法についても考慮している.ここで,本研究では,任意のフォロイーについて,閲覧者がそのフォロイーをフォローしているという状況から,閲覧者の興味から大きくかけ離れた話題についての投稿はあまり存在しないと考える.このとき,未知の話題についての投稿は,閲覧者が比較的興味のある内容かつ,閲覧者が内容に
12

図 9: ツイートの投稿時間と分類
図 10: トピックグラフ結合の具体例
ついて全く知らない情報であるため,詳細な内容を閲覧者に提示する必要があると考える.一方で既知の話題については,閲覧者がもともと知っているような情報についての投稿であるため,未知の話題のように詳細な情報を提示する必要はないと考える.これらの条件に基づき,見落とし情報の提示範囲を指定する際には,見落とし情報の粒度に
ついて考慮する必要がある.まず図 14に基本となる 2つの最小のトピックグラフについて示す.このトピックグラフの組
に対して,結合のパターンを考える.トピックグラフの結合が行われないパターンまず,それぞれの最小のトピックグラフが結合されない場合について,2つの提示範囲を図 15
に示す.
(a) トピックグラフの結合が行われず末端トピックノードが既知の話題図 15(a)のパターンでは閲覧者が既に知っている話題かつ,独立した話題についてのトピッ
13

図 11: プロトタイプシステムの出力例 1
クグラフであるため,多くの情報を提示する必要はない.そこで末端トピックノードのラベルのみを閲覧者に提示する.
(b) トピックグラフの結合が行われず末端トピックノードが未知の情報図 15(b)のパターンでは閲覧者が知らない話題かつ,独立した話題についてのトピックグラフであるため,末端トピックノードのトピック,概念ノードのトピック,および末端トピックノード中のツイートについて提示する.
共通の概念ノードによりトピックグラフの結合が行われるパターン次に,2つの最小のトピックグラフが,共通する概念ノードにより結合されるパターンのうち,既知の話題同士,未知の話題同士が結合されるパターンについて,図 16に示す.
(c). 結合するトピックグラフが,いずれも既知の話題の場合図 16(c)のパターンでは,2つのトピックノードの話題がいずれも閲覧者が既に知っている話題であるため,多くの情報を提示する必要はない.しかし,その話題の粒度の大きさを把握しやすくするためには,上位概念についても提示する必要があると考える.そこで末端トピックノードのラベルと,2つのトピックグラフを結合する概念ノードのラベルを閲覧者に提示する.
(d). 結合するトピックグラフが,いずれも未知の話題の場合図 16(d)のパターンでは,2つのトピックノードの話題がいずれも閲覧者が知らない話題であるため,より大きな粒度においても,閲覧者の全く知らない話題であると考えられる.そこで末端トピックノードのトピック,概念ノードのトピック,および末端トピックノード中のツイート全てを提示する.
次に,2つの最小のトピックグラフが,共通する概念ノードにより結合されるパターンのうち,既知の話題と未知の話題が結合されるパターンについて,図 17に示す.
14

図 12: プロトタイプシステムの出力例 2
(e). 結合するトピックグラフが,未知の話題と既知の話題の場合図 17(e)のパターンでは,結合したトピックノードに未知の話題と既知の話題が混在している.そこで既知の話題については末端トピックノードのラベルを提示し,既知のグラフについては,末端トピックノードのラベルとツイートを提示する.また,共通する概念ノードのラベルを提示する.
片方のトピックノードが他方の概念ノードと結合するパターン次に,片方のトピックノードが,他方の概念ノードと結合するパターンのうち,既知の話題が末端トピックノードとなるパターンについて,図 18に示す.
(f). 既知の話題が既知の話題の概念トピックノードとなる場合図 18(f)のパターンでは,2つのトピックノードの話題がいずれも閲覧者既に知っている話題であるため,多くの情報を提示する必要はない.また,上位概念となるトピックノードの内容についても閲覧者が知っているということから,2つのトピックノードのラベルのみを閲覧者に提示する.
(g). 未知の話題が既知の話題の概念トピックノードとなる場合図 18(g)のパターンでは,上位概念となるトピックノードが閲覧者の知らない話題であるため,下位概念となる末端トピックノードは,上位概念トピックノードの話題の一部であると考えられる.そこで結合が行われた概念ノードとトピックノード全てのラベル,および末端トピックノード中のツイート全てを提示する.
片方のトピックノードが他方の概念ノードと結合するパターン次に,片方のトピックノードが,他方の概念ノードと結合するパターンのうち,既知の話題が末端トピックノードとなるパターンについて,図 19に示す.
(h) 既知の話題が未知の話題の概念トピックノードとなる場合図 19(h)のパターンでは,上位概念となる概念トピックノードが閲覧者の既に知っている
15

図 13: プロトタイプシステムの出力例 3
図 14: 結合の基となる最小のトピックグラフ組
話題であるため,下位概念となる末端トピックノードは,上位概念トピックノードの話題の一部であると考えられる.そのため 2つのトピックノードのラベルのみを閲覧者に提示する.
(i) 未知の話題が未知の話題の概念トピックノードとなる場合図 19(i)のパターンでは,2つのトピックノードの話題がいずれも閲覧者の全く知らない話題である.そのため,結合後のトピックグラフ全体を未知の話題として,含まれる概念ノードとトピックノード全てのラベルと,トピックノード中のツイートを閲覧者に提示する.
16

図 15: トピックグラフの結合が行われないパターン
図 16: 共通の概念ノードによりトピックグラフが結合するパターン 1
17

図 17: 共通の概念ノードによりトピックグラフが結合するパターン 2
図 18: 片方のトピックノードが他方の概念ノードと結合するパターン 1
18

図 19: 片方のトピックノードが他方の概念ノードと結合するパターン 2
19

6 実験
本論文では見落とし情報の抽出に必要な,クラスタリング手法とトピックグラフの結合手法について,提案手法が適切であるかを確かめるために実験を行った.
6.1 ツイートのクラスタリングの実験
実験条件以下の条件にて実験を行った.
• データセット:対象アカウント数:5ユーザツイート件数:Twitter REST APIにより取得した,1ユーザあたり 1000件のツイート,計 5000件.
• 各ユーザの特徴:
ユーザA
主にアニメやゲームの話題について投稿.特定のタイトルではなく,多様なアニメやゲームについての投稿を行っている.他のユーザに比べて,短いツイートや重要な意味を持たないネタツイートなどが多い.
ユーザB
主にアニメやアイドルについての投稿.特に興味のある特定のアニメタイトルやアイドルグループ名を含むツイートの投稿が多い.
ユーザC
主にサッカーについて投稿.特に試合情報や選手情報に関する投稿が多い.またツイートの特徴として,他のユーザに比べて 1ツイートあたりの文字数や単語数が多い.
ユーザD
ゲームや野球,サッカーなどについて投稿.他のユーザに比べて,主な話題だけではなく,日常生活での実体験など雑多なツイートを多数投稿している.
ユーザE
音楽,ラジオについての投稿が比較的多い.地名や施設名などがツイート中に多く含まれる.
20

• 諸条件:クラスタリングツール:Bayon
クラスタ数:Bayonの分割ポイントにより自動で決定Bayonの分割ポイント:1.0
クラスタリング結果に対する cos類似度の閾値:0.5
形態素解析器:汎用日本語形態素解析エンジンMeCab5
辞書データ:IPA辞書を日本語版Wikipediaのページタイトルと,はてなキーワード 6の単語を固有名詞として追加した辞書
実験内容提案手法により,ユーザごとにクラスタリングを行い,クラスタリング結果の各クラスタに含まれるツイートに対して,適切なクラスタに分類されているかを人手で判断し適合率を求めた.結果と考察表 1に各ユーザについて,提案手法で分類可能であったツイート数,クラスタ数,含まれるツイート数が最大となったクラスタ中のツイート数,適合率を示す.また各ユーザのクラスタリング結果について,クラスタの中心ベクトルを構成する特徴語のポイントが特に大きい上位 5
クラスタについて,クラスタの ID,中心ベクトルを構成する特徴語 2件とそれぞれの特徴語のポイントを表 2に示す.なお,表中のクラスタ番号が最終結果のクラスタ数を上回っているものが存在するのは,cos類似度によるツイートのフィルタリングを行う前の数値を用いているためである.
表 1: クラスタリングの結果
特徴語を含むツイート数 クラスタ数 最大クラスタ中のツイート数 適合率
ユーザA 325 97 14 0.708
ユーザ B 353 47 23 0.912
ユーザ C 583 171 7 0.762
ユーザD 487 124 14 0.891
ユーザ E 469 121 12 0.938
平均 443.4 112 14 0.842
実験の結果,表 1からいずれのユーザについても 0.7以上の比較的高い適合率が得られていることがわかる.特にユーザB,D,Eについて高い適合率が得られることが確認された.表 2
から,これらのユーザはツイート中に人名や作品名,楽曲名,地名といった特徴的な固有名詞が多く含まれていたため,正確にクラスタリングを行うことができたと考えられる.しかしながらユーザAとCについては適合率が他の 3ユーザに比べて低くなった.これは,まずユーザAについてはツイートが短く,略語やスラングなどがツイート中で多用されていたことにより,クラスタリング適切な特徴語をツイート中から抽出することが困難であったことが原因として考えられる.またユーザCについてはツイートの分量は他のユーザより長いが,ツイートの話
5https://code.google.com/p/mecab/6http://d.hatena.ne.jp/keyword/
21
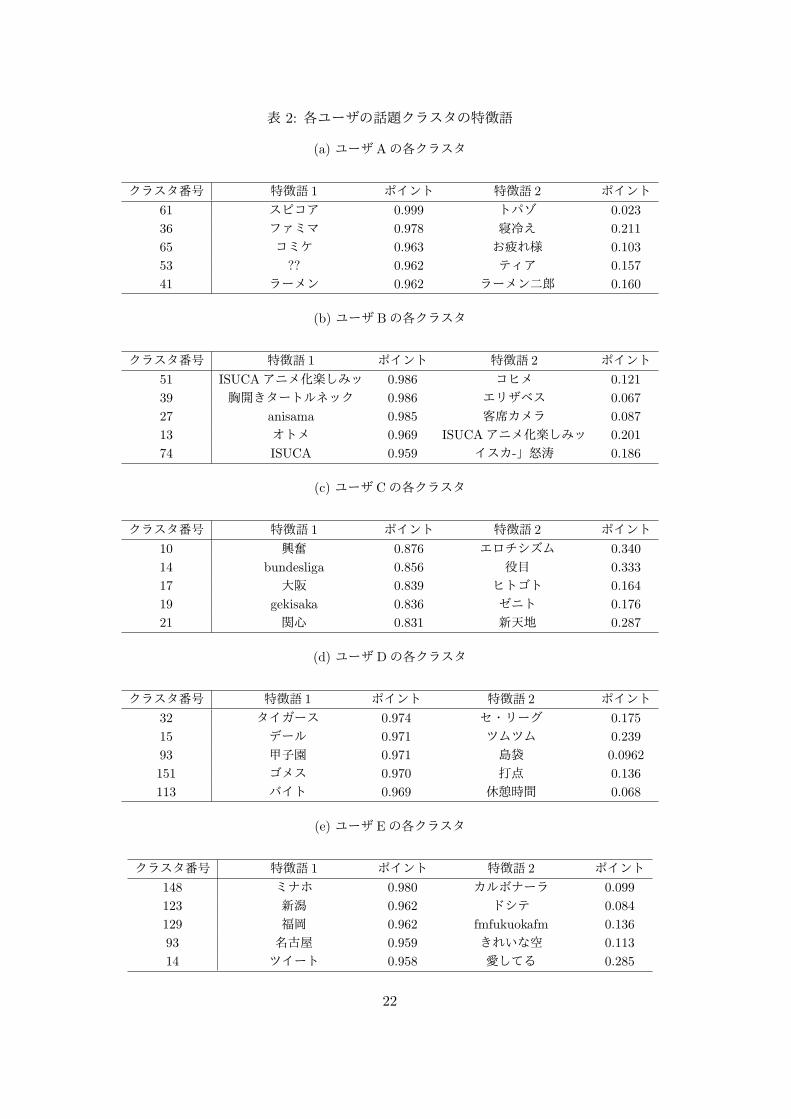
表 2: 各ユーザの話題クラスタの特徴語
(a) ユーザ Aの各クラスタ
クラスタ番号 特徴語 1 ポイント 特徴語 2 ポイント
61 スピコア 0.999 トパゾ 0.023
36 ファミマ 0.978 寝冷え 0.211
65 コミケ 0.963 お疲れ様 0.103
53 ?? 0.962 ティア 0.157
41 ラーメン 0.962 ラーメン二郎 0.160
(b) ユーザ Bの各クラスタ
クラスタ番号 特徴語 1 ポイント 特徴語 2 ポイント
51 ISUCAアニメ化楽しみッ 0.986 コヒメ 0.121
39 胸開きタートルネック 0.986 エリザベス 0.067
27 anisama 0.985 客席カメラ 0.087
13 オトメ 0.969 ISUCAアニメ化楽しみッ 0.201
74 ISUCA 0.959 イスカ-」怒涛 0.186
(c) ユーザ Cの各クラスタ
クラスタ番号 特徴語 1 ポイント 特徴語 2 ポイント
10 興奮 0.876 エロチシズム 0.340
14 bundesliga 0.856 役目 0.333
17 大阪 0.839 ヒトゴト 0.164
19 gekisaka 0.836 ゼニト 0.176
21 関心 0.831 新天地 0.287
(d) ユーザ Dの各クラスタ
クラスタ番号 特徴語 1 ポイント 特徴語 2 ポイント
32 タイガース 0.974 セ・リーグ 0.175
15 デール 0.971 ツムツム 0.239
93 甲子園 0.971 島袋 0.0962
151 ゴメス 0.970 打点 0.136
113 バイト 0.969 休憩時間 0.068
(e) ユーザ Eの各クラスタ
クラスタ番号 特徴語 1 ポイント 特徴語 2 ポイント
148 ミナホ 0.980 カルボナーラ 0.099
123 新潟 0.962 ドシテ 0.084
129 福岡 0.962 fmfukuokafm 0.136
93 名古屋 0.959 きれいな空 0.113
14 ツイート 0.958 愛してる 0.285
22

題が散漫であり,1ツイートの中心となる話題を 1つに特定できないツイートが存在したことが適合率低下の原因となったと考えられる.また “興奮”や “関心”のような一般的な名詞が,idf
値や出現回数の考慮では取り除くことができなかったことも原因の一つとして考えられる.これらの結果から,本論文で提案するツイート中の特徴語と,クラスタリング時に与えたパ
ラメータを用いる,Repeated Bisection法によるクラスタリングは,特徴語の選択などに改良が必要な点はあるが,ツイートを話題ごとにクラスタリングする際にはある程度有効であることが確認された.
6.2 概念構造と話題の粒度についての実験
本研究では話題の粒度を考慮するために,ツイートを話題の概念構造へとマッピングを行っている.しかしながら,もととなるツイートは,粒度構造になぞらえて投稿された情報ではない.そこで提案手法における話題構造へのマッピング手法が適切であるかを確かめるための実験を行った.本研究ではまず,少数のデータセットを用いて予備実験を行い,フォロイーのツイートに含
まれる話題のカテゴリに対して,以下の仮説を立てた.
1. 政治に関する話題について投稿するユーザのツイートは,話題の範囲が限定的であるため話題の粒度に概念構造を用いる手法が効果的である.
2. 音楽や芸能について投稿するユーザのツイートは,ツイート中にアーティスト名や番組名などを多く含むため,話題の粒度に概念構造を用いる手法が効果的である.
3. コンピュータについての投稿が多いユーザについては,マッピング先の概念構造に存在する専門用語がツイート中に多く含まれるため,話題の粒度に概念構造を用いる手法が効果的である.
4. スポーツについて投稿するユーザのツイートは,選手名や選手の略称,地名などの,多義語になりやすい語を多く含むため,話題の粒度に概念構造を用いることが困難である.
5. ゲームやアニメについて投稿するユーザのツイートは,ゲーム名やアニメ名など具体的なタイトルをあまり含まず,略称や登場人物名などが多用されるため,話題の粒度に概念構造を用いることが困難である.
これらの仮説について,各カテゴリの評価用データを作成し,評価実験により検証する.実験条件以下の条件にて実験を行った.
• データセット:各カテゴリ 50組の共通する上位概念を持つ 2つの話題クラスタに含まれるツイート本文とタグの組評価対象データの例を表 3に示す.
23

表 3: 評価対象データの例
ツイート 1 ツイート 2 タグ
1月9日の岡野原ニコニコ配信のお題は「ウェーブレット木」の予定です。ウェーブレット木はウェーブレット変換とはほぼまったく関係が無いそうですが、「万能のデータ構造」として注目を集めているもの。90分でぎゅっと圧縮した紹介をお願いする予定で ...;select の方はテーブルを rank のと共有しているので lognですね。定数用にするにはさらに補助データ構造必要です;既に出まわっていますが@tkngさんによる日本語入力の本が今日発売日です。日本語入力の歴史や現在の勢力図、それを支えるデータ構造、機械学習など内容が盛りだくさんです。’日本語入力を支える技術’;
メモリを4 G に増設したらすごぶる快調。;メモリ2倍、SSD化、Vista & 7、その他もろもろでスタンバイからの復帰時間が1分から2秒ぐらいになった。なぜいままでしなかったのか;今とこれからのメモリ事情がよくまとまっている;
コンピュータのデータ
• 被験者:各カテゴリについて,内容を理解できる被験者 3~10名.各カテゴリに対する被験者数を表 4に示す.
• 諸条件:話題クラスタ生成にはクラスタリング時の実験と同一条件を用いる.マッピング先の概念構造は日本語版Wikipediaのカテゴリ構造を用いる.略称などについては,Wikipediaのリダイレクト情報を用いて元の記事タイトルを引用できるもののみ対応する.
実験内容具体的な実験の手順について以下に示す.
1. 話題クラスタの中心クラスタを構成する特徴語の内,最も特徴量の大きい特徴語を,話題クラスタのトピックと決定する.
2. 話題クラスタのトピックの上位カテゴリを,Wikipediaのカテゴリデータベースより取得する.
24

表 4: 各カテゴリの被験者数
カテゴリ 被験者数
政治 7
音楽,芸能 10
コンピュータ 4
スポーツ 4
ゲーム,アニメ 3
3. 共通する上位カテゴリを持つ 2つの話題クラスタに対して,上位概念語をタグとして付与する.
4. 2つの話題カテゴリに含まれるツイートと,付与されたタグについて,付与されたタグが適切であるかを被験者が 5段階(1:不適切である,2:やや不適切である,3:どちらともいえない,4:やや適切である,5:適切である)で評価する.
5. 得られた評価値の平均を,ツイートとタグの組の評価値 vする.
結果と考察
まず実験結果について,各カテゴリの評価値の分布を表 5に示す.
表 5: 話題の粒度と概念構造のマッピングに関する実験結果
vの範囲 政治 音楽,芸能 コンピュータ スポーツ アニメ,ゲーム
1.0<=v<=2.0 9 19 17 25 9
2.0< v<=3.0 7 2 9 4 12
3.0< v<=4.0 24 10 12 10 13
4.0< v<=5.0 10 19 12 11 16
表 5カテゴリ「政治」については,50件のデータの内,評価値が 3.0より大きいものが 34件,評価値が 4.0より大きいものが 10件となった.この結果からデータ全体の 68%について,ある程度適切なタグが付与されていると判断されたと考えられる.特に評価値の大きい組と,小さい組の一例を表 6に示す.実験の結果,政治に関するツイートは,文中に「議員」や「政治」,「格差社会」など政治関係
の単語が多数出現する.これらの単語は,多義性が少なく,カテゴリ構造へのマッピングが比較的容易であるため,比較的適切なタグが付与されたデータが多かったと考えられる.よって仮説 1「政治に関する話題について投稿するユーザのツイートは,話題の範囲が限定的であるため話題の粒度に概念構造を用いる手法が効果的である.」は真であると判断する.
25

表 6: カテゴリ「政治」の実験結果の例
ツイート 1 ツイート 2 タグ 評価値
福島みずほと女性の政治スクール 1回目は2月17日午後6時から、参議院議員会館101会議室で「ピケティから考える格差社会ニッポン」をテーマに和光大学の竹信三恵子さんに話をしてもらいます。詳細はまで。; 福島みずほと女性の政治スクール 1回目は2月17日(火)午後6時から、参議院議員会館 101会議室で「ピケティから考える格差社会ニッポン」をテーマに和光大学の竹信三恵子さんに話をしてもらいます。詳細はまで。;福島みずほと女性の政治スクール 1回目は2月17日午後6時から、参議院議員会館 101会議室で「ピケティから考える格差社会ニッポン」をテーマに和光大学の竹信三恵子さんに話をしてもらいます。資料代500円。詳細はまで。;
毎年 1月末に大逆事件を考える集会を開いています。今年は1月26日(月)16時から18時まで参議院議員会館講堂(予定)です。「大逆事件とヘイトスピーチ」というテーマで、ジャーナリストの安田浩一さんに話をしてもらいます。資料代500円。ぜひご参加を;今日 1月26日(月)16時から18時まで参議院議員会館講堂で、「大逆事件とヘイトスピーチ」というテーマで、ジャーナリストの安田浩一さんに話をしてもらいます。資料代500円。ぜひご参加を;毎年 1月末に大逆事件を考える集会を開いています。今年は 1月26日(月)16時から18時まで参議院議員会館講堂で、「大逆事件とヘイトスピーチ」というテーマで、ジャーナリストの安田浩一さんに話をしてもらいます。資料代500円。ぜひご参加を;
社会問題 4.7
札幌で、講演会をします。14
時半からです。自治労会館です。ぜひ来て下さい。;今日は、札幌. 2時半から、札幌市の自治労会館で、講演会をします。ぜひぜひきてください。;おはようございます。今日は、札幌です。自治労会館。1時半から始まりますが、わたしの講演は、2時半からです。よろしくお願いします。ぜひ来てください。;
堺市で食べたお昼ごはん。チラシ寿しが、本当においしい。ごちそうさま。; 昨日食べたチラシ寿し。みんなでわけて、食べました。;10月24日は、鳥取に行きます。講演会をします。ぜひぜひ来てください。;
日本の労働組合 1.3
26

一方で評価値が低いデータについては「労働組合」「日本の地名」のように,ツイート中の単語からの連想は可能であるが,内容を十分にあらわしていない語がタグとして付与された際に,評価値が小さくなっていることが確認された.次にカテゴリ「音楽,芸能」については,表 5より 50件のデータの内,評価値が 3.0より大
きいものが 29件,評価値が 4.0より大きいものが 19件であることが確認された.この結果からデータ全体の 58%について,ある程度適切なタグが付与されていると判断されたと考えられる.特に評価値の大きい組と,小さい組の一例を表 7に示す.実験の結果,カテゴリ「音楽,芸能」についての実験データの内,特に評価の高いものについ
ては楽曲名やアーティスト名などの上位概念によるタグ付けが行われていることが確認された.このことから仮説 2「音楽や芸能について投稿するユーザのツイートは,ツイート中にアーティスト名や番組名などを多く含むため,話題の粒度に概念構造を用いる手法が効果的である.」は真であると判断する.一方で評価値が低いデータについては「和製漢語」のような漠然とした上位概念や,「日本の
地名」といった上位概念が人名に誤って付与されているなどの問題が確認された.次にカテゴリ「コンピュータ」については,表 5より 50件のデータの内,評価値が 3.0より
大きいものが 24件,評価値が 4.0より大きいものが 12件であることが確認された.この結果からデータ全体の 48%について,ある程度適切なタグが付与されていると判断されたと考えられる.特に評価値の大きい組と,小さい組の一例を表 8に示す.実験の結果,カテゴリ「コンピュータ」について投稿しているユーザについては,ツイート
中にはコンピュータに関する専門用語なども多く確認されたが,得られる上位概念は「図書館学」や「研究」,「哲学の概念」といったタグが多くのデータに付与されていた.これらの問題の原因として,トピック抽出時に得られた専門用語が,Wikipediaの記事タイトルではなく,記事本文中に含まれる小見出しなど,詳細度が高い単語であったことが考えられる.この結果から仮説 3「コンピュータについての投稿が多いユーザについては,マッピング先の概念構造に存在する専門用語がツイート中に多く含まれるため,話題の粒度に概念構造を用いる手法が効果的である.」は偽であると判断する.次にカテゴリ「スポーツ」については,表 5より,50件のデータの内,評価値が 3.0より大
きいものが 21件,評価値が 4.0より大きいものが 11件存在した.この結果からデータ全体の42%について,ある程度適切なタグが付与されていると判断されたと考えられる.特に評価値の大きい組と,小さい組の一例を表 9に示す.実験の結果,カテゴリ「スポーツ」について投稿しているユーザについては,日本人選手の
名字などに対して「日本の地名」,競技場名などについて「日本の都市計画」といった,ツイートの内容を十分にあらわさないタグが多く付与されていることが確認された.この結果から仮説 4「スポーツについて投稿するユーザのツイートは,選手名や選手の略称,地名といった多義語を多く含むため,話題の粒度に概念構造を用いることが困難である.」は真であると判断する.一方で日本語版Wikipediaにおいては一意に記事タイトルへのマッピングが可能であった外
国人選手名などについては比較的適切なタグが付与されていることも確認された.最後にカテゴリ「アニメ,ゲーム」については,表 5より,50件のデータの内,評価値が 3.0
より大きいものが 29件,評価値が 4.0より大きいものが 16件存在することが確認された.この結果からデータ全体の 58%について,ある程度適切なタグが付与されていると判断されたと考えられる.特に評価値の大きい組と,小さい組の一例を表 10に示す.実験の結果,カテゴリ「アニメ,ゲーム」について投稿しているユーザについては,仮説のとお
27

表 7: カテゴリ「音楽,芸能」の実験結果の例
ツイート 1 ツイート 2 タグ 評価値
帰宅これから逃げ出したい現実に戻るけど頑張れる力を貰ったから頑張る; 家に寝るためだけに帰る生活始まりましたー現実つらああ;でも現実は引越しのために貯金;
そして関ジャニ∞デビュー 9
周年おめでとういつもほんとにありがとうしかないです。もっと早く好きになりたかったなーと後悔してるけど確実に大きくなってるからすごいなと;関ジャニ∞バンドできるんですよ面白いだけじゃなく引き出し多いんですよかっこいいんですよ;関ジャニ∞と中島美嘉さん最高にかっこいい;
関ジャニ∞ 4.7
【ジャニ勉 2/14】ハンバーグぬるいと言われてショックな渋谷さん。続けて米をかき込もうとする斗真に「その米は誤魔化しの米やろ美味しい米やないやろ」;【ジャニ勉2/14】進行しながら皆のハンバーグを覗く雛ちゃん。雛「マルお前それ…ケツやんけ」丸「ちがう脳っ」脳男にちなんだ丸ちゃん。ケツでも脳でも良いのですが、異質なハンバーグが多すぎる鉄板の上…カオス…;【ジャニ勉 2/14】明らかに異質な渋谷さんの棒状ハンバーグ…圧倒的な存在感…;
見るからに馬鹿そうな女子高生か女子大生の集団が電車の中で騒いでてドン引いた。隣に座ってた男の子たちの目線が汚いものを見る目で笑ったわ(^ O^ );かなって誰だよ男の集団うざい;MCは面白かったし仲みんな仲良すぎて愛しくなったじゃないのなんなのあの可愛いおじさん集団;
和製漢語 1.1
28

表 8: カテゴリ「コンピュータ」の実験結果の例
ツイート 1 ツイート 2 タグ 評価値
発表資料アップしました.;お疲れ様でした。資料についてはコピーして大丈夫です。よろしくお願いします。;発表資料は公開する予定です。ただ、当日口頭で話す内容もいろいろあると思いますので参加できるなら参加していただくのがいいですけどね;
lstmの構造を性能の観点から網羅的に調べた論文も参考になるかもしれません。ただ最近は単純な gruを使う場合が増えてきてるかなと。;私が引用した論文でも、最適化についてはそれが引用されていて、論文自体の貢献は双対問題の最適化と構造学習の argmax
の枠組みと結びつけたのと、np完全である問題も世の中の問題はほとんど単純で現実的な時間で解けたことを示したことですかね。; より一般の学習/モデルでの混ぜ方については未だに最適な戦略は発展途上です。ようやく等分割、SGD;
研究 5.0
思い立って、Regret最小化を中心に最新のオンライン学習アルゴリズムを解説する記事を書いていたが、今日は力尽きた。Regret による評価は学習機の理論的な評価によく使われる、VC次元による汎化誤差に比べてずっと実践的で、いろいろ情報にとんでいて面白いのだがまだ情報は少ない;Subsampled Random
Fourier Transform とか知らないのが多くて非常に勉強になる。実装は簡単。理論は奥深いというのがとても素敵;オンライン最適化とRegret最小化の記事をかきました。現時点でもっとも良いオンライン学習法の一つであるAdaGrad
も後半でちょっと解説します ;
非常に危険な状況; 聞こえてきた電話の会話が”今日はパイナップルで我慢してくれ”。どういう状況なのか;原発についても、未だ予断を許さない状況ですが私も情報を精査しながらいろいろ調べた感じでは現状の避難指示で大丈夫だと考えています。私も情報を常に収集して何かありましたら今後も twitter 経由でも連絡しますのでよろしくです;
哲学の概念 1
29

表 9: カテゴリ「スポーツ」の実験結果の例
ツイート 1 ツイート 2 タグ 評価値
クリスティアーノロナウドかっこよすぎ;いや、でもやっぱりクリスティアーノロナウドだ。;クリスティアーノロナウドだろ;
バルセロナもついにメッシにブーイングがとぶようになったか;メッシ笑;メッシも絶好調だし;
バロンドール受賞者 4.7
中西が失踪した件、記事を削除した件について、神戸新聞さんから電話ありました。「中西コーチが一度行方不明になったのは間違いないのですが、事件、事故の可能性が低くなったので記事を取り下げました」とのことです。; 中西失踪、その後、記事を削除。この件を神戸新聞に問い合わせた結果「見つかったから削除した」との解答。なお「詳しいことは記事を書いた担当者が席を外してるので、あとで本人から電話させます」とのこと。また詳細をツイートします。;中西失踪の件ですが、神戸新聞さんによると「未確認やけど淡路島で魚釣りをしてた」って情報もあるらしいです。以上で中西失踪関連のツイートは終了です。;
【春高速報】準々決勝金蘭 2-
1京都橘フルセット勝負は金蘭会今年もセンターコートへ。京都橘は今年も 3日目の壁…;
【春高バレー】大会 3日目は 3
回戦と準々決勝が行われます。センターコートに立つのは果たして?女子 3回戦 10:50 京都橘?国学院栃木解説:杉山祥子実況:廣岡俊光京都橘は大和南、旭川実と厳しい試合をものに。国学院栃木は久々の16強。2年生エースの打ち合いに注目;【春高全国きょう開幕】Dコート第 3試合女子 1
回戦京都橘 vs 大和南 解説:杉山祥子実況:廣岡俊光今年のインターハイ 1回戦と同じ対戦。勝った京都橘は勢いに乗り 3位になりました。大和南はリベンジなるか生放送はCSフジテレビ TWO、12時半試合開始予定です;
日本の計画都市 1
30

表 10: カテゴリ「アニメ,ゲーム」の実験結果の例
ツイート 1 ツイート 2 タグ 評価値
あけましておめでとうございます今年も宜しくお願い致します。スペハリ同人誌、楽しみにしております; まだ持ってないスペハリ全部集めて、いつか完全版の同人誌作りたい。;スペハリの本体が大枠が出来た後 6日で絶対に作りあげまーすノ;
スペハリ本、メチャメチャ楽しみにしてますよ HEDさんに会えることも;HEDさん、ありがとうございます私の方こそ、いつもスペハリ&マーク?
棚を楽しませてもらっていますよスペハリ最新移植作が遊べる龍が如くの新作たのしみですね;HEDさん、こんばんは今回のブログを拝見させて頂いて、スペハリのアイテムで思い出したことがあるので、後程DMしますね;
3Dシューティングゲーム 4.7
これで、残すコナミのスーパーファミコンタイトルは「ちびまる子ちゃん めざせ南のアイランド」のみとなりました 64タイトルの方も現在探索中です。;ブログを更新しました。コナミのスーパーファミコンタイトル;ブログを更新しました。コナミのスーパーファミコンタイトル揃いました、他。;
アマダのファミコンステッカーがステキ過ぎる件。; アマダのファミコンステッカー、私も大のお気に入りアイテムですプーヤン、ドアドア良いですね~;ポスターイイですねこのステッカー以外にもアマダ製のファミコングッズを集めたいです;
日経平均株価 1
31

り,ゲームのタイトルについて略称や愛称を多用していることが確認された.しかしWikipedia
のリダイレクト機能によりある程度の略称などについては適切な記事への関連付けが可能であり,その結果,比較的多くのタグが適切なタグと判断されたと考えられる.この結果から仮説5「ゲームやアニメについて投稿するユーザのツイートは,ゲーム名やアニメ名など具体的なタイトルをあまり含まず,略称や登場人物名などが多用されるため,話題の粒度に概念構造を用いることが困難である.」は偽であると判断する.以上の実験結果より,話題の粒度構造として概念構造,とくにWikipediaのカテゴリ構造を用
いる際にはカテゴリ「政治」や「音楽,芸能」のように話題の範囲が狭いユーザや,Wikipedia
の記事を一意に特定可能な人名や作品名,一般的に普及している略称,具体的なイベント名などをツイート中に多数含むユーザに対しては効果的であることが確認された.
6.3 トピックグラフの結合に関する実験
次にトピックグラフの結合について,どのような上位概念により結合される場合が適切であるかを確かめるための実験を行った.実験条件以下の条件で実験を行った.
• ツイート数:話題の判別が容易なツイート 2335件
• 話題クラスタ数:152クラスタ
• 評価を行う被験者:20代の男女 9名
• 諸条件:クラスタリング時のツールのパラメータなどは 6.1節の諸条件と同様のものを用いた.話題クラスタの中心ベクトルが複数の特徴語により構成される場合,特徴量が高い特徴語上位 2件を話題クラスタのトピックとして用いた.
実験内容具体的な実験の手順について以下に示す.
1. 各トピックについて 2階層上までのWikipediaカテゴリを検索し,最小トピックグラフを生成する.
2. 提案手法に基づき,最小トピックグラフ同士を結合する.今回の実験では 2つの最小トピックグラフを STGA,STGB と置き,2つずつ比較を行い,トピックグラフの結合を行う.
3. 結合した 2つのトピックグラフについて,それぞれのリーフノードのトピックと,2つの最小トピックグラフに共通する概念ノードやトピックノードのラベルとなっているトピッ
32

クを表示し,トピックグラフの結合が適切であるかを被験者 9名がそれぞれ 3段階(0,不適切である;1,少し適切である;2,適切である)で評価する
表 11: トピックの結合に関する実験の結果の一例
共通する概念語 STGAのリーフノードのトピック STGB のリーフノードのトピック 評価値の平均
Jリーグクラブ ベルマーレ,湘南 BMWスタジアム 浦和レッズ, urawareds 1.89
アニメ アニメ, NeversayNever 声優パラダイス, NeversayNever 1.78
マクロ経済学 プライマリバランス, セカンドレポート マクロ経済学 , 市政報告会 1.56
ヘルプ サッカー選手, 野球選手 Mamers, スケジュール 0.00
社会 テニス, コンディション エネルギー, 山雅メンバー 0.00
商標登録 ソフトバンク, 国道 1号線 キャンキャン, フラペチーノ 0.00
結果と考察今回の実験では 299件のトピックグラフの結合に対して評価を行った.実験結果のうち,評価の平均値が高かった結果と,評価の平均値が低かった結果について,それぞれの例を表 11 に示す.今回の実験では Jリーグクラブ,アニメ,マクロ経済学といった概念語により結合されたトピックグラフについて,比較的高い評価が得られた.一方でヘルプ,社会,商標登録といった概念語で結合されたトピックグラフについては非常に評価が低かった.また,表 12 に各概念語の下位カテゴリ数を示す.
表 12: 概念語の下位カテゴリ数
概念語 概念語の下位カテゴリ数
Jリーグクラブ 54
アニメ 95
マクロ経済学 79
ヘルプ 107
社会 149
商標登録 414
この結果から,Jリーグクラブやアニメ,マクロ経済学のように具体的な内容がわかる概念語かつ,Wikipediaのカテゴリ構造において下位概念となるカテゴリの少ない概念語については比較的高い評価が得られ,ヘルプや社会,商標登録のように内容が漠然としており,Wikipedia
のカテゴリ構造においても下位概念に多くのカテゴリを持つ概念語については,評価が低くなることが確認された.これらの特徴をもとに,今後は粒度構造を考慮する際に適切な上位概念となるような語がト
ピックグラフの生成時に用いられるように調節を行う予定である.
33

7 まとめと今後の課題
本研究では見落としたツイートの話題の粒度と,見落とし期間の時間情報の 2点に着目し,話題の粒度を考慮した見落とし情報の抽出と提示を試みた.そして抽出した見落とし情報について,閲覧者が直感的に理解可能な提示手法として,話題の粒度に基づくネットワークグラフを用いて見落とし情報を閲覧者に提示する手法を提案しプロトタイプシステムの開発を行った.さらに,効果的に情報を閲覧者に提示するための手法として,見落とし情報の分類と結合パターンに基づく,見落とし情報の提示範囲についての検討を行った.また,本研究では,ツイートのクラスタリング手法と,話題の粒度への概念構造のマッピング,そしてトピックグラフの生成と結合について,実際のツイートデータを用いた実験により評価を行った.そして提案手法が特に効果的に作用する条件を確認した.今後の課題としては,まずトピック抽出と上位概念付与については,ツイート中の特徴語を
より正確に抽出する手法の検討を行う必要がある.具体的には全文検索エンジンとWikipedia
の記事データや web文書,Twitter上の膨大なツイートデータなどを利用して,単語の多義性を解消する手法などが考えられる.本研究における見落とし情報の提示システムの改善としては,表示するノードの座標を考慮
し,トピックグラフ間の距離や概念構造を,より直感的に閲覧者に提示する工夫を行う必要がある.また,本論文にて提案した見落とし情報の提示範囲に関する提案は,プロトタイプシステムには実装されていない.そこで今後は閲覧者の興味とフォロイーのツイート内容などについても考慮したうえで,提示範囲の決定を行い実装する必要があると考えられる.本研究では,クラスタリング手法と話題の粒度の概念構造へのマッピング,そしてトピックグ
ラフの生成と結合についての実験を行った.しかしながら話題の粒度の概念構造へのマッピング手法について,本研究ではユーザの話題のみに着目し,実験を行った.今後はさらにフォロイーのツイートの投稿頻度や,フォロー数とフォロイー数,ツイートの分量など,フォロイーのツイート傾向に着目した実験や,フォロイー自身の投稿内容に含まれる,話題の粒度にも着目し,本手法が有効に作用するケースと,うまく作用しないケースについて検証を行う必要があると考えられる.
謝辞
本研究を進めるにあたり,たいへん多くの方々に御世話になりました.ここに深く感謝の意を表します.何よりもまず研究に際して,そして学生生活にて非常に多くの面において,3年半という長きにわたり心のこもったご指導を頂きました恩師,灘本明代先生に心より深く感謝を申し上げます.そして本論文をまとめるにあたり,有益な御助言と御教示を賜りました甲南大学 新田直也先生,甲南大学 永田亮先生に心より謝意を申し上げます.また,研究の内容や,学会発表,論文執筆の際に丁寧なご指導を頂いた奈良先端科学技術大学院大学 鈴木優先生に深く感謝を申し上げます.また,実験の際に被験者を快く引き受けてくださり,そして日頃の研究会において多くのご指摘を下さいました灘本研究室の,先輩,同期,後輩の皆様に深く感謝致します.最後になりましたが,大学院に進学するという決断に背中を押してくださり,ありとあらゆる場面で私を温かく見守り続けてくれた父 大原一文,母 大原里枝,祖母 栗原順子,そして私の成長を楽しみに見守ってくださった故大原エツコ氏,故栗原忠雄氏に深く感謝を致します.
34

研究業績
国内会議
• 大原 啓詳,鈴木 優,灘本 明代,“閲覧期間を考慮したTwitter上の意外な情報の抽出,”2014年度情報処理学会関西支部 支部大会, G-03, 2 pages, 2014.
• 大原 啓詳,鈴木 優,灘本 明代,“閲覧期間を考慮した Twitter上の見落とし情報抽出手法,” 第 7回データ工学と情報マネジメントに関するフォーラム (DEIM2015), A8-6, 7
pages, 2015.
• 大原 啓詳,鈴木 優,灘本 明代,“閲覧期間と話題構造に基づく Twitter上の見落とし情報の抽出,” 第 6回ソーシャルコンピューティングシンポジウム (SoC2015), 1-3, 6 pages,
2015.
• 大原 啓詳,鈴木 優,灘本 明代,“閲覧期間を考慮したトピックグラフに基づく Twitter
の見落とし情報抽出手法,” 第 162回データベースシステム研究発表会 (SIG-DBS),2015-
DBS-162(8), pp. 1-8, 2015.
• 大原 啓詳,鈴木 優,灘本 明代,“Twitterにおける閲覧期間を考慮した話題構造の抽出と提示手法,” 第 8回データ工学と情報マネジメントに関するフォーラム (DEIM2016),
2016.(to appear)
紀要
• 大原 啓詳,灘本 明代,鈴木優,“Twitter のある情報発信ユーザの意外なツイートの抽出手法の提案,” 甲南大学紀要知能情報学編, Vol. 7, No. 1, pp. 51-64, 2014.
ポスター発表
• 大原 啓詳,鈴木 優,灘本 明代,閲覧期間を考慮した Twitter上の見落とし情報抽出手法,” 第 7回データ工学と情報マネジメントに関するフォーラム (DEIM2015), 2015.
• 大原 啓詳,鈴木 優,灘本 明代,“トピック推定に基づくソーシャルメディアからの耳より情報抽出手法の提案,” 第 162回データベースシステム研究会 (2015), 2015.
• 大原 啓詳,鈴木 優,灘本 明代,“Twitterにおける閲覧期間を考慮した話題構造の抽出と提示手法,” 第 8回データ工学と情報マネジメントに関するフォーラム (DEIM2016),
2016. (to appear)
国際会議
• Hiromitsu Ohara, Yu Suzuki and Akiyo Nadamoto “Detection of Missing Tweets
based on Browsing Interval And Topic Granularity,” Proceedings of the 17th Interna-
tional Conference on Information Integration and Web-based Applications & Services
(iiWAS2015), pp. 206-214, 2015.
35

研究業績-表彰
学生奨励賞
• 大原 啓詳,鈴木 優,灘本 明代, “閲覧期間と話題構造に基づく Twitter上の見落とし情報の抽出,” 第 6回ソーシャルコンピューティングシンポジウム (SoC2015), 1-3, 6 pages,
2015.
• 大原 啓詳,鈴木 優,灘本 明代,“閲覧期間を考慮したトピックグラフに基づく Twitter
の見落とし情報抽出手法,” 第 162回データベースシステム研究発表会 (SIG-DBS), 2015-
DBS-162(8), pp. 1-8, 2015.
参考文献
[1] 辻 一明, 宝珍 輝尚, 野宮 浩揮, “新着ツイート群からの興味をひくツイートの抽出に関する考察,” 情報処理学会関西支部平成 23年度支部大会, C-7, 2011.
[2] Zhaochun Ren, Shangsong Liang, Edgar Meij and Maarten de Rijke, “Personalized Time-
Aware Tweets Summarization,” Proceedings of the 36th international ACM SIGIR con-
ference on Research and development in information retrieval, pp.513-522, 2013.
[3] 藤野 巖, 星野 祐子, “ダイナミックトピックモデルを用いたTwitterユーザーの時間相関特徴の発見手法について,” 第 7回Webとデータベースに関するフォーラム (WebDB Forum
2014),8 pages, 2014.
[4] 西田 京介, 坂野 遼平, 藤村 考, 星出 高秀. “データ圧縮による Twitter のツイート話題分類,” DEIM Forum 2011, A1-6, 2011.
[5] 佐々木謙太朗, 吉川大弘, 古橋武, “Twitterにおけるユーザの興味と話題の時間発展を考慮したオンライン学習可能なトピックモデルの提案,” 情報処理学会論文誌 数理モデル化と応用(TOM), Vol.7, No.1, pp.53-60, 2014.
[6] Matthew Michelson and Sofus A. Macskassy. “Discovering users’ topics of interest on
twitter: a first look,” Proceedings of the fourth workshop on Analytics for noisy unstruc-
tured text data, pp.73-80, 2010.
[7] D. M. Blei and J. D. Lafferty, “Dynamic topic models,” Proceedings of the 23rd interna-
tional conference on Machine learning, pp.113-120, 2006.
[8] W. X. Zhao, J. Jiang, J. Weng, J. He, E. Lim, H. Yan and X. Li, ”Comparing Twitter and
Traditional Media using Topic Models”, In Proceedings of the 33rd European Conference
on Information Retrieval, pp.338-349, 2011.
[9] 糸川翔太 , 白松俊 , 大囿忠親 , 新谷虎松, “時系列的話題追跡のためのツイートの特徴語を用いた探索的閲覧支援システムの開発,” 第 76回全国大会講演論文集 2014(1), pp. 107-108,
2014.
36

[10] 花井俊介, 灘本明代, “食材名をクエリとしたレシピ検索における酷似レシピクラスタリング,” 信学技報, vol. 114, no. 204, DE2014-31, pp. 47-52, 2014.
[11] G. Karypis, “CLUTO - A Clustering Toolkit,” Dept. of Computer Science, 2002.
[12] M. Steinbach and G. Karypis and V. Kumar, “A comparison of document clustering
techniques,” In 6th ACM SIGKDD,World Text Mining Conference, 2000.
[13] 内田誠 , 柴田尚樹, “ブログ記事ネットワークからの emerging topicの抽出と可視化,” 人工知能学会第 20回全国大会論文集 , 3D2-3, 4 pages, 2006.
[14] 松尾哉太, 新妻弘崇, 太田学, “Twitterタイムラインの話題の可視化の一手法,” 第 6回データ工学と情報マネジメントに関するフォーラム (DEIM2014), E1-5, 2014.
[15] H. Becker, M. Naaman and L. Gravano. Beyond, “trending topics: Real-world event
identification on twitter,” Proceedings of the Fifth International AAAI Conference on
Weblogs and Social Media (ICWSM ’11), pp. 2695-2697, 2011.
[16] M. S. Bernstein, B. Suh, L. Hong, J. Chen, S. Kairam and E. H. Chi, “Eddi: interac-
tive topic-based browsingof social status streams,” Proceedings of the 23rd annual ACM
symposium on User interface software and technology (UIST‘ 10), pp. 303-312, 2010.
[17] M. Cataldi, L. D. Caro, and C. Schifanella, “Emerging topic detection on twitter based on
temporal and social terms evaluation,” Proceedings of the Tenth International Workshop
on Multimedia Data Mining, pp. 1-10, 2010.
[18] L. Hong and B. D. Davison, “Empirical study of topic modeling in twitter,” Proceedings
of the First Workshop on Social Media Analytics (SOMA), pp. 80-88, 2010.
[19] S. P. Kasiviswanathan, P. Melville, A. Banerjee, and V. Sindhwani, “Emerging topic de-
tection using dictionary learning,” Proceedings of the 20th ACM international conference
on Information and knowledge management, 2011.
[20] K. Lee, D. Palsetia, R. Narayanan, M. M. A. Patwary, A. Agrawal and A. Choudhary,
“Twitter trending topic classification,” Proceedings of the 2011 IEEE 11th International
Conference on Data Mining Workshops, pp. 251-258, 2011.
[21] J. MacQueen, “Some methods for classification and analysis of multivariate observations,”
5th Berkeley Synap. Math. Statist,Vol. 1, pp. 281-297, 1967.
[22] W. Magdy, A. Ali and K. Darwish, “A summarization tool for time-sensitive social me-
dia,” Proceeding CIKM ’12 Proceedings of the 21st ACM international conference on
Information and knowledge management, pp. 2695-2697, 2012.
[23] M. Mathioudakis and N. Koudas, “Twittermonitor: trend detection over the twitter
stream,” SIGMOD’10 Proceedings of the 2010 ACM SIGMOD International Conference
on Management of data, pp. 1155-1158, 2010.
37

[24] D. M. Blei and A. Y. Ng and M. I. Jordan, “Latent dirichlet allocation,” The Journal of
Machine Learning Research, (3) , pp. 993-102, 2003.
[25] M. Rosen-Zvi, T. Griffiths, M. Steyvers and T. Smyth, “The author-topic model for
authors and documents,” Proceedings of the 20th conference on Uncertainty in artificial
intelligence. AUAI Press, pp. 487-494, 2004.
[26] K. D. Rosa, R. Shah, B. Lin, A. Gershman and R. Frederking, “Topical clustering of
tweets,” The 3rd Workshop on Social Web Search and Mining (SWSM), 2011.
[27] B. Sriram, D. Fuhry, E. Demir, H. Ferhatosmanoglu and M. Demirbas, “Short text classi-
fication in twitter to improve information filtering,” Proceedings of the 33rd international
ACM SIGIR conference on Research and development in information retrieval, 2010.
[28] T. Xu and D. W. Oard, “Wikipedia-based topic clustering for microblogs,” Proceedings
of the American Society for Information Science and Technology, pp. 1-10, 2011.
38