Embed Size (px)
Citation preview

Two Approaches to MorphologicalComplexity3rd Lecture
Anna Maria Di SciulloUQAM
Morphology FestSymposium on Morphological Complexity
Bloomington June 16-20, 2014
This work is supported in part by funding from the SSHRC of Canada to the Major CollaborativeResearch Initiative on Interface Asymmetries 214-2003-1003, www.interfaceasymmetry.uqam.ca,and by a grant from the FQRSC to the Dynamic Interfaces research project grant no 103690.

Sources of complexity in morphology
Irregularity (non canonical morphology)
o One source of morphological complexity is the non systematic one-to-onecorrespondence between meaning and form.
Irregular (non canonical) pattern: In English, we have word form pairs likeox/oxen, goose/geese, and sheep/sheep, where the difference betweenthe singular and the plural is signaled in a way that departs from theregular pattern, or is not signaled at all.
Allomorphy: Even cases considered "regular", with the final -s, are not sosimple; the -s in dogs is not pronounced the same way as the -s in cats,and in a plural like dishes, an "extra" vowel appears before the -s. In thesecases, the same distinction is effected by alternative forms of a "word".
o ……..

Sources of complexity in morphology Recursive overt affixation
o Another source of complexity is multiple affixation, either prefixation orsuffixation.
o Iterative affixation may give rise to complex grammatical words, such asantidisestablishmentarianism.
o Recursive affixation may also give rise to complex grammatical words
anti-missile missile 'directed against enemy missiles' anti-anti-missile missile 'opposed to that which is directed against enemy missiles' anti-missile missile missile 'missile designed to intercept and destroy an antimissile
missile in flight' (Bar-Hillel and Shamir 1960)
o Recursive affixation may give rise to center-embedded morphologicalstructures, such as un-diagonal-iz-able.
….

Sources of complexity in morphology
Substance-free morphological complexity
o Complexity brought about by the recursive application of the operationcombining the parts of a morphological object that is not spelled out byovert material at the sensori-motor interface.
o Recursive affixation, where the affixes are part of different kinds ofstructural projections, for example sequential and directional affixes, asin re-close and en-close, dis-trust and en-trust.
o Compound formation, where the non-head is a complement or a non-complement of the verbal projection, for example glass-painting andhand-painting.

OutlineFirst, I formulate the logical problem of morphological complexity, andconsider the information theoretical notion of complexity and thenotion of E-complexity.
Second, I define the notion of substance-free morphologicalcomplexity, or I-complexity, and point to neuro- and psycholinguisticevidence that supports its processing by the brain.
Third, I discuss evidence from computational experiments that showthat parsing complexity can be reduced by linearization.
Finally, I draw some consequences for separating internal andexternal complexity.
See Di Sciullo (2012) for discussion.

1. The logical problem of morphological complexityThere is a close relation between the logical problem of morphologicalcomplexity and the logical problem of language acquisition:
The logical problem of language acquisition: How can a child develop a language on the basis of
scarce evidence? Given the poverty of the stimulus, the child relies on
internal knowledge of language, which is structuredependent.
The logical problem of morphological complexity:How can a child develop morphology on the basis of complex evidence?
anti-dis-establish-ment-arian-ism (28 characters) anti-missile-missile, redd-ish-ish-ish (recursion)
un-diagonal-iz-able (center-embedding)
Given the complexity of the stimulus, the child relies oninternal knowledge of language, which is structuredependent.

Complexity, complex systems, Information Theory
Complexity arises with complex systems such as biologicaland technological systems.
Complex systems tend to be high-dimensional, non-linearand hard to model.
What Kolmogorov complexity (Solomonoff 1964, Kolmogorov1965, Chaitin 1987) aims to formalize is that one object ismore complex than another insofar as it takes longer todescribe as a property of strings.
Information Theory is concerned with the complexity ofstrings of data.

The Kolmogorov complexity of an object
In algorithmic information theory, the Kolmogorov complexity of an object,such as a piece of text, is a measure of the computational resourcesneeded to specify the object.
Kolmogorov complexity is also known as descriptive complexity, Kolmogorov-Chaitin complexity, stochastic complexity, algorithmic entropy, or program-size complexity.
The theoretical treatment of Kolmogorov (1965) complexity of a string isobtained by identifying the length of the shortest binary program which canoutput that string.
The length of the shortest descriptionAn object is more complex if it takes longer to describe.

The Kolmogorov complexity of an object
For example, the following two strings of length 64, each containing onlylowercase letters, numbers, and spaces:
abababababababababababababababababababababababababababababababab
4c1j5b2p0cv4w1x8rx2y39umgw5q85s7uraqbjfdppa0q7nieieqe9noc4cvafzf
The first string has a short English-language description, namely "ab 32times", which consists of 11 characters. The second one has no obvioussimple description (using the same character set) other than writingdown the string itself, which has 64 characters.
The length of the shortest descriptionAn object is more complex if it takes longer to describe.

Linguistica
Linguistica (Goldsmith 2001, 2006) is a morphological analyzerthat accepts raw linguistic data as input, and produces as itsoutput an analysis of the data, or a grammar.
The primary goal is the determination of the location of the breaksbetween morphemes inside a word.
The algorithm is developed for the purposes of learningmorphology on the basis of essentially no prior knowledgeof the data.
It attempts to construct as small a model of the data as possible,that simultaneously predicts the data as well as possible.

LinguisticaLinguistica reads in a corpus of text in the target language and iteratively
applies a series of heuristics to find the simplest model (i.e., lexicon asbelow) that best describes the corpus. Linguistica applies to a text andinduces a morphological lexicon of stems, prefixes, suffixes, and signaturesdescribing their possible combinations.
Stem Suffixal Signature a. accompli ∅.e.t.r.s.ssent.ssez
b. academi cien.e.es.quec. academicien ∅.s
That is, for each stem, affix, and signature, a description length is calculatedand tracked, and the simplest model in this case is that with the smallesttotal description length over all stems, affixes, and signatures. Thesedescription lengths are approximations, or indices, of complexity (in theKolmogorov sense), so that a lexicon’s total description length is anapproximation of its complexity.

Language’s morphological complexity
.

Statistical ranking of languages wrt their rate ofmorphological complexity
A corpus-based analysis using Linguistica provides the followingranking:
(1) Rates of morphologica l com plex ity
Latin 35.51 % F r ench 23 .05 % E ng l is h 16.88% B islam a* 5.38%
Hungarian 33.98% Danish 22.86% Maori 13.62% K i tuba * 3.40%
Italian 28.34% S we dis h 21.85% P a p iamentu* 10.16% Solomon Pij in* 2.91%
Spanish 27.50% Ge r m a n 20.40% N iger i an Pidgin * 9.80 % Hai tian Cre ole* 2.58%
Icel andi c 26.54% Dutch 19 .58 % Tok P isin* 8.93 % V i etnames e 0.05 %

Different perspectives on complexity
Morphological complexity can be evaluated on the basis of statisticalcalculi on the occurrences of affixes in a corpus (Bane 2007).
In the statistical approach, one criterion of morphological complexity isthe actual number of affixes available in a given language, and thenumber of possible combinations of these affixes with respect toroots/stems.

Different perspectives on complexity I-complexityand E-complexity
On the one hand, Information theory is concerned with the complexity ofstrings.
On the other hand, linguistic theory is concerned with the complexity ofstructured data.
The theoretical treatment of Fodor, Bever and Garret’s (1994) complexityof a sentence is obtained by identifying the length of the derivation, viz.,the number of operations which can output that sentence.

2. I-complexity
Given the Internalist approach morphological complexity cannotbe calculated via statistical corpus-based analyses, because I-language (the mentally represented linguistic knowledge, themental object) is not occurrence dependent.

E-complexity and I-complexity
I show that languages that differ with respect to E-complexityshare the same I-complexity.

Linguistic theory, complexity metrics, and limits oncomplexity
Linguistic theory is concerned with the complexity of structureddata. The theoretical treatment of Fodor, Bever and Garrett’s(1974) complexity of a sentence is obtained by measuring thenumber of applications of the rules required to derive it.
I-complexity can be brought about by the recursiveapplication of the combinatorial operation
Principles external to the language faculty reduce thecomplexity Units of computation/storage limitations (Chomsky and Miller
1963) Short-term memory limitations (Bever 1970)

Measuring I-complexity
I posit that substance-free morphological complexity is brought about by I-language computation. It is based on the derivation of structures which arenot spelled out by substantive morphological forms.
I-language complexity can be measured by neuro- and psycholinguisticexperimentations as well as by experiments using as brain-imagingtechniques.
Interestingly, this kind of complexity is shared by languages which areapparently dissimilar with respect to the corpus-based statistical approach.

In terms of E-complexity, French has a higher percentage of morphologicalcomplexity than English, according to Brame (2007).
Rates of morphological complexity: French : 23.51% English : 16.88%
However, these languages have the same I-complexity.
I discuss the case of the processing of French prefixed verbs and Englishverbal-based compounds.
E-complexity and I-complexity

Measuring I-complexity: prefixed verbs
Di Sciullo (1997, 2005) showed that prefixed verbs in Frenchand Italian, such as French verbs re-fermer and en-fermerwhich have the same string-linear properties, differ withrespect to their hierarchical structure.
They include material that is not part of their string-linearsubstantive morphological shape.
re- F2
en- F1 V
Empirical evidence
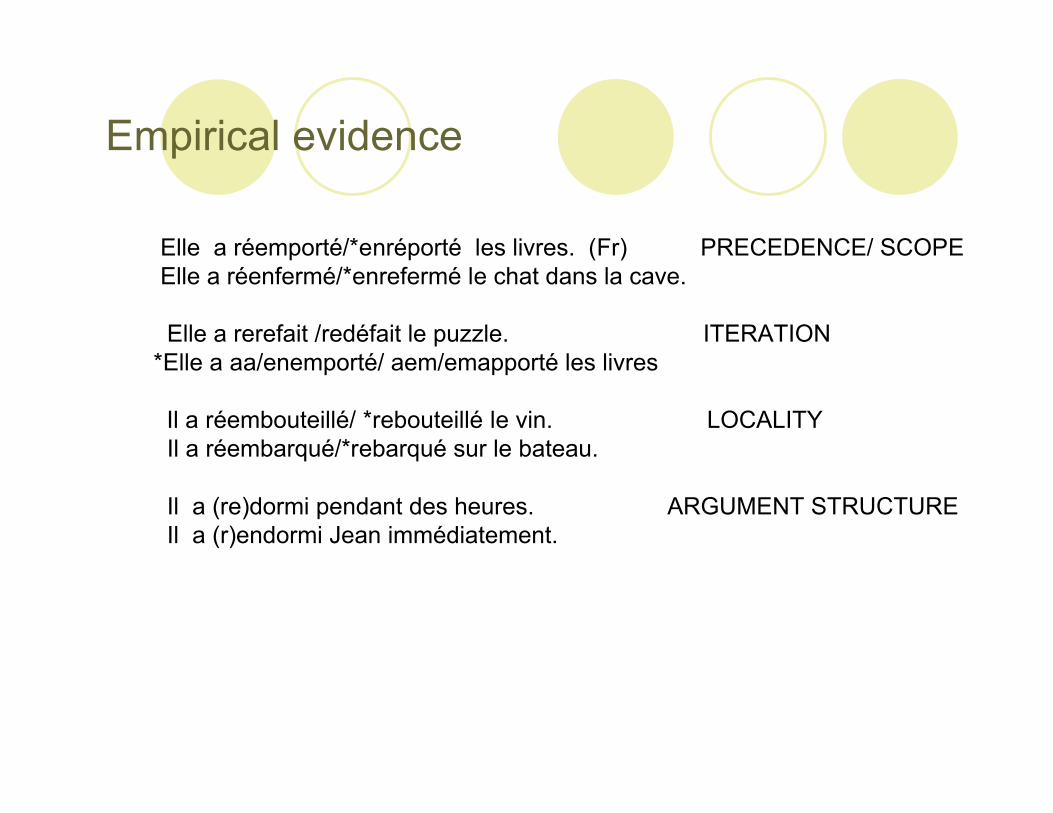
Elle a réemporté/*enréporté les livres. (Fr) PRECEDENCE/ SCOPE Elle a réenfermé/*enrefermé le chat dans la cave.
Elle a rerefait /redéfait le puzzle. ITERATION*Elle a aa/enemporté/ aem/emapporté les livres
Il a réembouteillé/ *rebouteillé le vin. LOCALITY Il a réembarqué/*rebarqué sur le bateau.
Il a (re)dormi pendant des heures. ARGUMENT STRUCTURE Il a (r)endormi Jean immédiatement.

Design:- 72 critical stimuli divided into 2 experimental lists- Each verb appears only once, either as a prefixed or base-form- Filler words: nouns, adjectives, and verbs (Density 75%)- Non-words were created by changing the first, middle,
or final consonant of randomly selected words matched for frequency.- The total 394 items in each list were randomized and dividedinto four blocks for each subject.- 30 training items were also used in the beginning of each session.
Participants :24 native French speakersuniversity students, normal-to-corrected vision, no reading disorders
Tsapkini, Jarema, and Di Sciullo (2004)
Lexical priming experiment
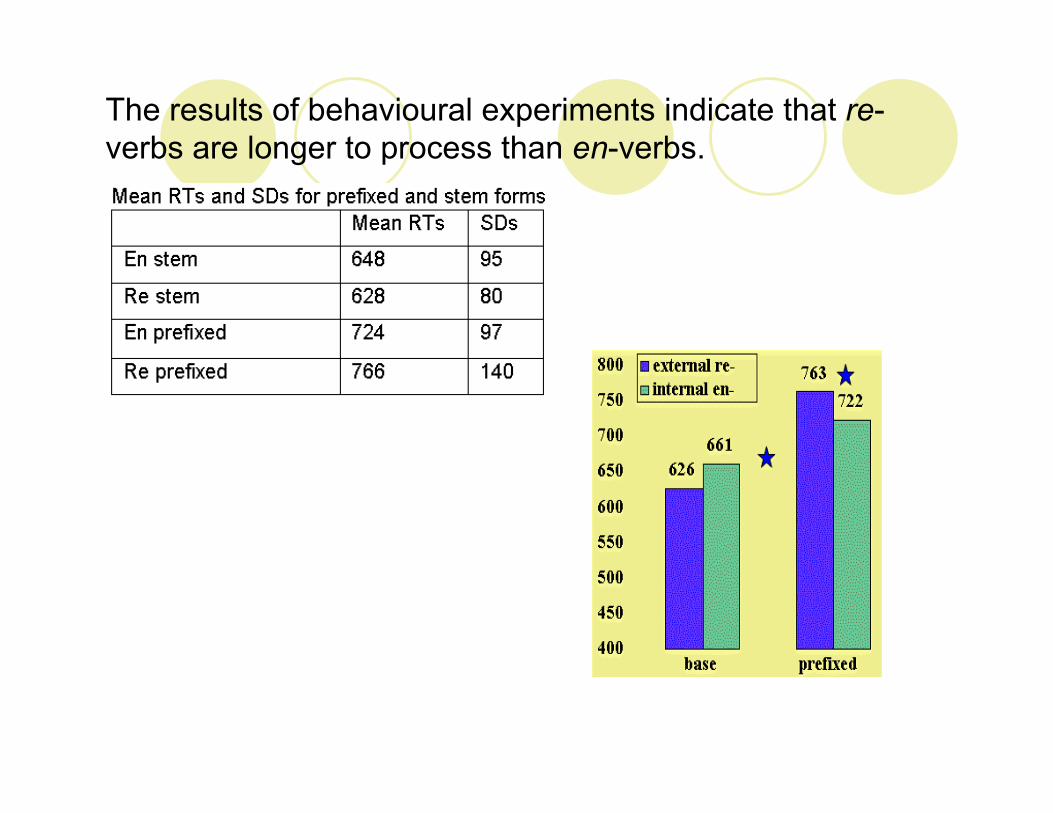
The results of behavioural experiments indicate that re-verbs are longer to process than en-verbs.
.

ERP experiment
Experimental paradigm: Evoked Related Potentials (ERPs)Is the F1/F2 asymmetry reflected in differential electrophysiological activity of the brain devoted to syntactic
processing?
Previous findings: Syntactic processing is correlated with two ERP components, namely an early left anterior negativity (ELAN) which is assumed to reflect automatic syntactic analysis
(Friederici et al., 1996).
Priming usually elicits a reduced N400 effect with respect to the unrelated controlcondition at the single word level (Dunay et al., 2001; Koivisto &
Revonsuo, 2001).

Design
Hypotheses:We expected to find an N400 effect when the related conditions for both verbcategories were compared to their unrelated ones and an early negativityand/or a late positivity difference between the two priming conditions involvingF1 vs. F2 prefixed verbs.
Category 1: fermer-enfermer (related)Category 2: fermer-refermer (related)Category 3: parler-enfermer (unrelated)Category 4: parler-refermer (unrelated)
Experimental paradigm:Visual lexical decision task with contiguous priming:Fixation point Prime Target ISI
* fermer refermer 250ms 250ms 2000ms I sec

Stimuli
54 verbs with external prefixesfermer-refermer 'to close again'
54 verbs with internal prefixesfermer-enfermer 'to enclose'
Control primes matched with the base verbs for - surface frequency-word-length- semantic transparency.

Design
Data acquisition parameters- 64-channel system- Instep system (version 3.3)- 4 electrodes (2 vertical and 2 horizontal) used for ocular movement correctionamplified 3,500 times- ERP recordings were amplified 10,000 times using a 0.O210OHz bandpassfilter- Electrode impedance reduced to <5kg2- Sampling rate set to 25OHz- Continuous recording was divided into 1970ms epochs including a -1 00 msbaseline prior to target onset.ERP components Time windows for the ERP components:
N100: 70-220 msN400:350-550 msP600: 550-800 ms
Participants11 native French speakers,20-35 years old, normal-to-corrected vision, no reading disorders

Results
N400 is reduced for the related condition as compared to the unrelated one for bothverb categories in line with the previous priming literature.
However, in the case of internally prefixed verbs, this difference is more pronounced in the anterior areas, whereas in the case of
externally prefixed verbs, it is more pronounced in the posterior areas.
The difference between internal and external prefixes is not observed at the electrophysiological level with an early negativity but rather with a late positivity having a left temporo-parietal distribution.
Configurational asymmetry between F1 and F2 prefixed verbs can be observed at the electrophysiological level.

Measuring I-complexity: N V-af compounds
Complement vs. adjunct verb compounds, edge non-edgeasymmetry
Examples:the meat-cutting knifethe finger-painted portrait
In this experiment 10 English speakers saw 60 sentencescontaining two types of novel compounds noun object-verb, andnoun adjunct-verb.
All the verbs used in the compounds are mono-transitive andthe classification of the compound is evident from the sentence.
See Di Sciullo & Tomioka (2011) for discussion.

-ing /-ed We focused on the following difference between modifier-verb and
argument-verb compounds: Narg-V compounds take the participlemorpheme –ing, in contrast, Nmod-V compounds take the -edmorpheme.
In addition, we hypothesized that the effect of homophony isexpected between the participle morphology (ed and ing) and thetense/aspect suffix (-ed and -ing) on the acceptability of novelcompounds.
Thus, the presence of Narg-V compound, Nmod-V compoundrepresentation in the mental representation will form the basis forthe effect of homophony.
Results
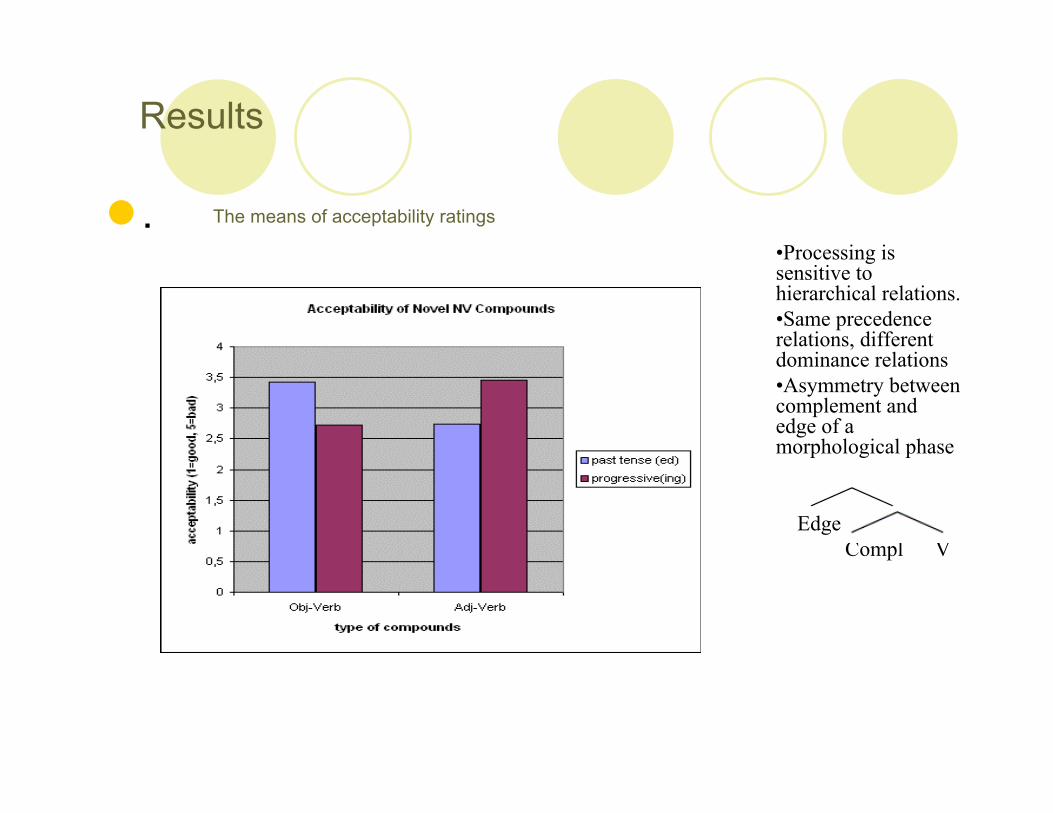
The means of acceptability ratings
•Processing issensitive tohierarchical relations.•Same precedencerelations, differentdominance relations•Asymmetry betweencomplement andedge of amorphological phase
Edge Compl V
.

Discussion The following pattern emerged from this experiment: With Narg-V
compounds, the subjects rated the –ing forms significantly more acceptablethan the –ed forms. With Nmod-V compounds, the subjects showedpreference for the –ed form over the –ing form.
What is interesting here is that the tendencies of these two types of novelcompounds go in opposing direction, which indicates that there is an effectof homophony.
Crucially, the observed pattern cannot be due to the nature of the suffixesalone as there is no relation between the choice of tense/aspectmorphemes and the semantics of the noun in the compound.
The effect of homophony/increased acceptability differentiates Narg-Vcompounds from Nmod-V compound categorically.
Object-V Adjunct-V
past tense (ed) 3,43 2,74
progressive (ing) 2,72 3,45

Behavioral and ERP experiments
I-Language complexity effects observed experimentally
Pre-verbsF2 > F1 lexical decision tests, and ERP
-longer RTS with F2V than with F1V-N400 F1V/ F2V (ERP)
• NV-{-ed, -ing}F1 > v acceptability judgments
-differences in acceptability betweennovel object-V and adjunct-V

4. Computational experiments
Computational experiments using a shift-reduce parsing model for thederivation of complex morphological expressions, such as form-al-iz-ableare described in Di Sciullo and Fong (2005).
The parser implements the X-bar selection of Di Sciullo (1995)incorporated in the Asymmetry Theory of Di Sciullo (2005). This theoryincludes two basic morpho-syntactic operations : Shift (a,b) and Link(a,b), as well as a PF reordering operation Flip (a).
The parser recovers the asymmetric structure by combining andorganizing constituents in a hierarchical structure. Il also recovers thelinking relations between constituents, including covert categories.
The computational experiments show that the FLIP operation, which ispart of the linearization of the hierarchical structure reducescomputational complexity of the morphological derivations.
Di Sciullo, A.M. 2005. Asymmetry in Morphology. Cambridge, Mass: The MIT Press. Di Sciullo, A. M. 1995. “X¢ selection”. In Phrase Structure and the Lexicon, J. Roorick and L. Zaring (eds),
Kluwer.
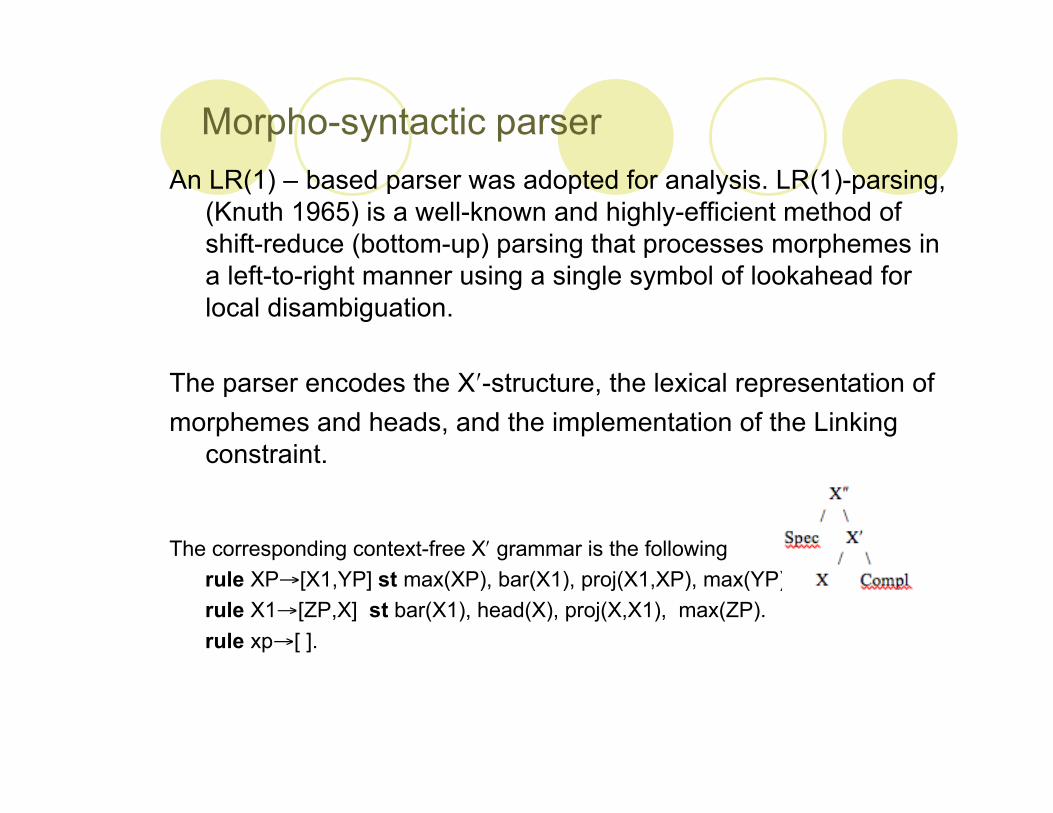
Morpho-syntactic parserAn LR(1) – based parser was adopted for analysis. LR(1)-parsing,
(Knuth 1965) is a well-known and highly-efficient method ofshift-reduce (bottom-up) parsing that processes morphemes ina left-to-right manner using a single symbol of lookahead forlocal disambiguation.
The parser encodes the X′-structure, the lexical representation ofmorphemes and heads, and the implementation of the Linking
constraint.
The corresponding context-free X′ grammar is the followingrule XP→[X1,YP] st max(XP), bar(X1), proj(X1,XP), max(YP).rule X1→[ZP,X] st bar(X1), head(X), proj(X,X1), max(ZP).rule xp→[ ].

LexiconThe lexicon uses a default feature system for lexical entries. The following
declaration expresses the lexical defaults for nouns, verbs, and adjectives:
default_features([n,v,a],[specR(f(a(-))),selR(f(a(-)))]). By default, computer hastwo A-bar-positions. Form and father, on the other hand, have one and twoA-positions, respectively.
lex(computer, n, []).lex(form, n, [selR(f(a(+)))]).lex(father, n, [specR(f(a(+))),selR(f(a(+)))]).
Affixes impose constraints on their Complement domain. For example, thenominal affix -er, e.g. as in employer, the Specifier of its complement mustbe an A-position. Similarly, -ee, e.g. as in employee, restricts both theSpecifier and Complement within its Complement to be A-positions.
lex(er,n,[link(spec), selR(spec(f(a(+))))]). lex(ee,n,[link(compl),selR([spec(f(a(+))),compl(f(a(+)))])])

Lexicon
The abstract causative morpheme, caus, differs from theinchoative inc in terms of selection in that it has an A-Specifier as well as restricting the Specifier of itsComplement to be an A-bar-position.
lex(caus,v,[specR(f(a(+))), selR(spec(f(a(−)))), caus]).lex(inc, v,[link(compl), selR(spec(f(a(−)))), inc]).
The –er, -ee, and inc morphemes have an additional featurelink(spec/compl), which specifies the target of A-bar-Specifier Linking in a complement domain.

LinkingThere is a single free-standing principle that encodes the following rule:Linking Rule: All Affix A-bar-positions must be linked to A-positions in
their Complement domain (if one exists).
This is implemented by the universally-quantified (over tree structure)condition linkR:linkR in_all_configuration CF where
linkConfig(CF,XP,Type,Dom) then findApos(YP,Type,Dom), coindex(XP,YP).
linkConfig (CF,XP,Type,Dom) :- maxProj(CF), CF has_feature link(Type)
XP specifier_of CF, \+ XP has_feature a(+),Dom complement_of CF.

Specifier-Head-Complement Asymmetry
We considered the computational consequences of varying theSpecifier-Head linear order for the LR shift-reduce parsingframework .
It turns out there is a considerable difference both in terms of thenumber of LR actions performed and the stack depth required toprocess an example like formalize, analyzed as form-al-i(z)-e.
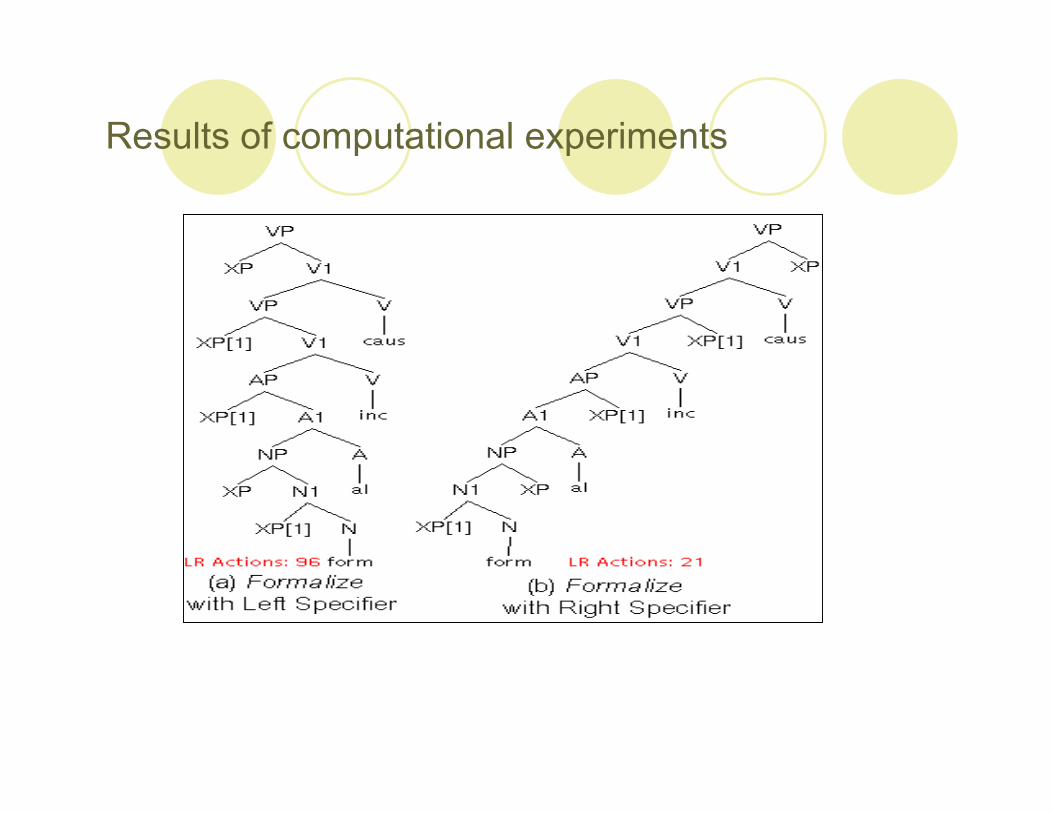
Results of computational experiments

Difference in the number of actions of the parser
The simple explanation is that the LR machine has to be ableto predict an arbitrary number of empty argument positionsbefore it can shift or "read" the first item, namely form, in(a). Contrast this with the situation in (b), where Specifiersare generated on the right side only.
Here, the LR machine needs only to generate a single emptyargument position before a shift can take place. Hence only21 actions and a stack depth of 2 are required in this case,compared to 96 and a stack depth of 5 in (b).
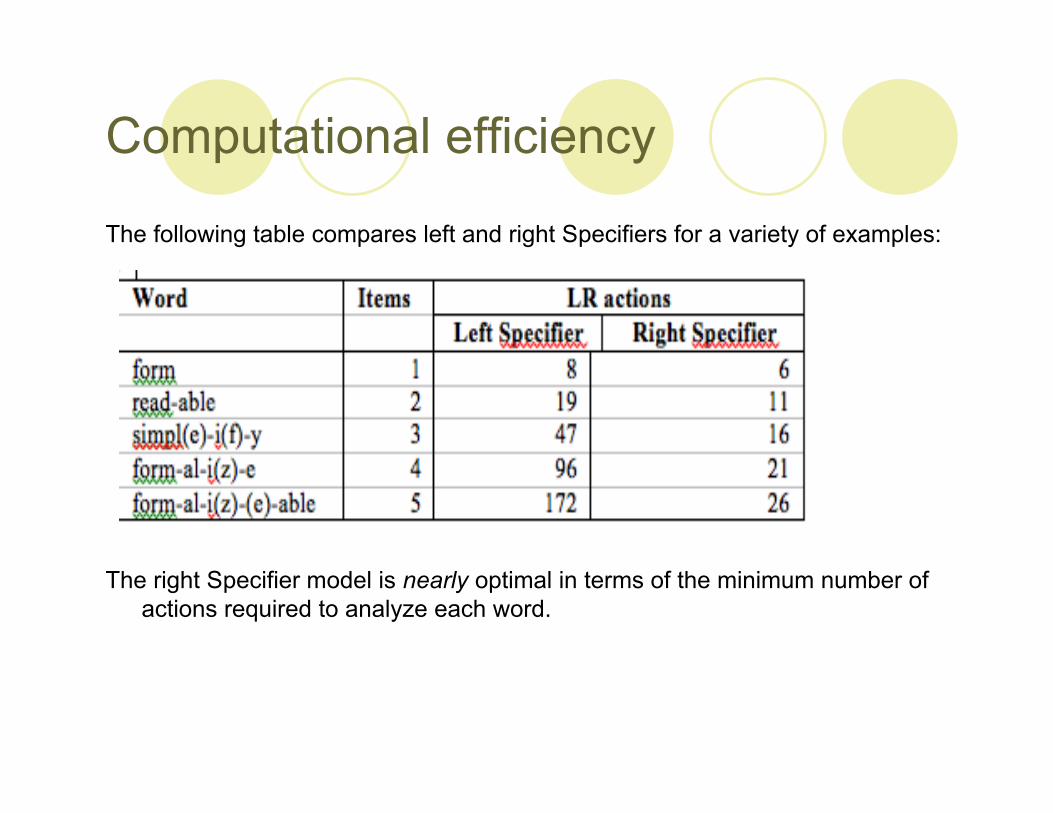
Computational efficiency
The following table compares left and right Specifiers for a variety of examples:
The right Specifier model is nearly optimal in terms of the minimum number ofactions required to analyze each word.

Linearization
Linearization operations might also be part of the factors thatreduce the derivational complexity. The followingcomputational experiment indicates that it might well be thecase.
Di Sciullo and Fong (2005) consider the computationalconsequences of varying the edge-head linear order in theLR shift-reduce parsing framework for morphologicalstructure.
Whether or not the edge of a morphological phase has legibleSM features is determinant in the linearization ofmorphological constituents, and the ordering of constituentscontributes to computational efficiency.
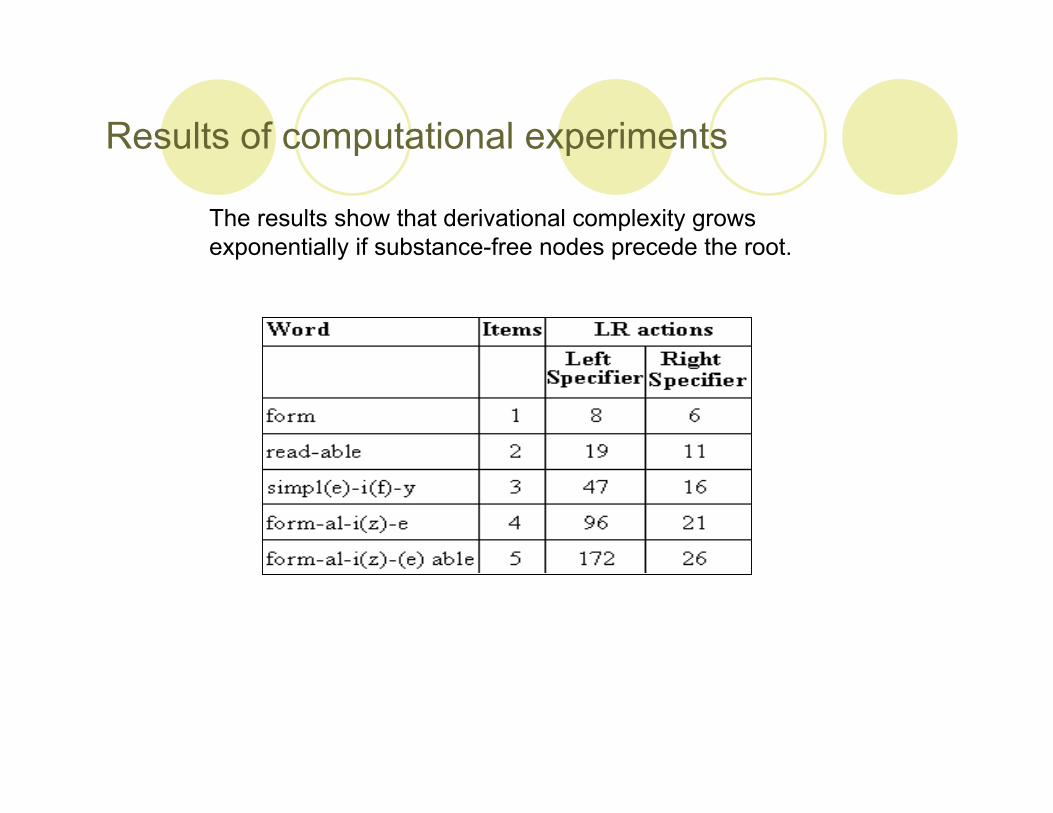
Results of computational experiments
The results show that derivational complexity growsexponentially if substance-free nodes precede the root.
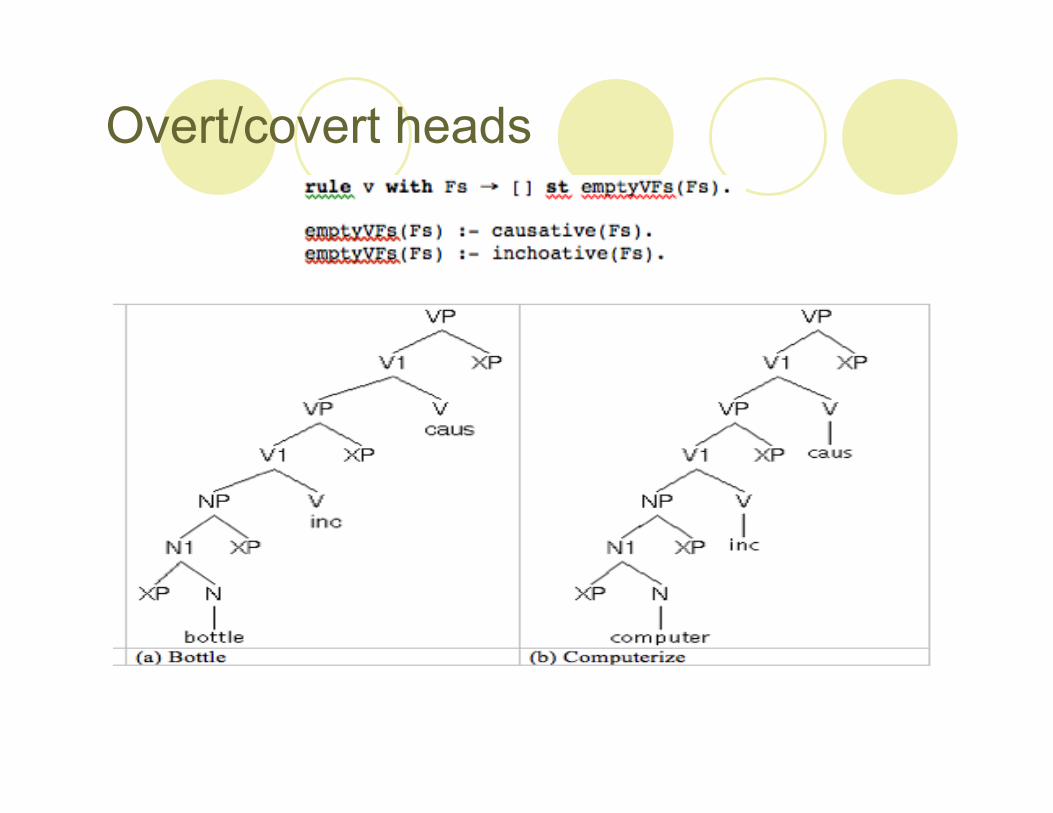
Overt/covert heads
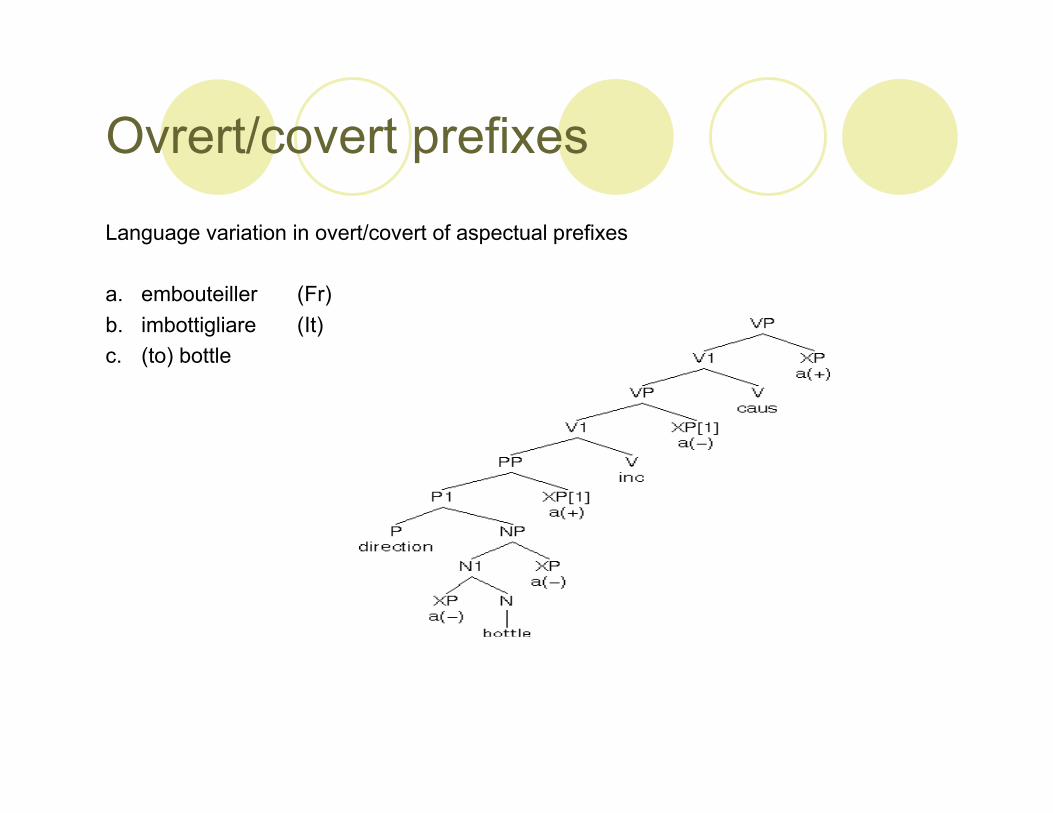
Ovrert/covert prefixes
Language variation in overt/covert of aspectual prefixes
a. embouteiller (Fr)b. imbottigliare (It)c. (to) bottle

Results of computational experiments
Namely, substance-free complexity in morphologicalderivation can be reduced if linearization proceeds byphases and is a function of the legibility of the edge ofthe phases.

5. Consequences for linguistic theory
These computational experiment results suggest thatmorphological I-complexity is not (only) based on statistics orprobability.
I-complexity is structure-dependent. It is an effect of theiterative/recursive property of the operations of the languagefaculty.
Results from behavioral and ERP experiments indicate thatthe human brain is sensitive to the complexity brought aboutby morphological computation.

Selected references Experimental studies in morphological complexity Di Sciullo, A.M. 2012. Perspectives on Morphological Complexity. Dans Ferenc Kiefer, Maria Ladanyi et Peter
Siptar (eds.), Morphology. (Ir)regularity, Frequency, Typology, 105-135. Amsterdam: John Benjamins.
Di Sciullo, AM and N, Tomioka, 2011. Compound Representation at the Interface. In Piotr Banski, Baetakukaszewicz, Monika Opalinska et Johanna Zaleska (eds.), Generative Investigations Syntax-Morphology andPhonology, 48-63. Cambridge Scholars Publishing.
Di Sciullo, A.M. and C. Aguero Bautista. 2008. The delay of Condition B Effect and its Absence in CertainLanguages. Language and Speech 51: 77-100.
Tsapkini, K., G. Jarema and A.M. Di Sciullo. 2004. The Role of Configurational Asymmetry in the Lexical Accessof Prefixed Verbs: Evidence from French. Brain and Language 90: 143-150.
Morpho-syntactic complexity and computational linguistics Di Sciullo, A.M., P. Gabrini, C. Batori and S. Somesfalean. 2010. Asymmetry, the Grammar, and the Parser. In
Giacomo Ferrari, Ruben Benatti and Monica Mosca (eds.), Linguistica e Modelli Tecnologici di Ricerca, 477-494.Rome: Bulzoni.
Di Sciullo, A.M. and S. Fong. 2005. Morpho-syntax Parsing. In Anna Maria Di Sciullo (ed.) UG and ExternalSystems. 247-248. Amsterdam: John Benjamins.
Di Sciullo, A.M. and S. Fong. 2002. Asymmetry, Zero Morphology and Tractability. In Language, Information andComputation. PACLIC 15. Language Information Sciences Research Center, 61-72. Hong Kong University.
Di Sciullo, A.M. and S, Fong. 2002. Efficient Parsing for Word Structure. In Natural Language Processing PacificRim Symposium, 741-748. Tokyo, Japan.
Di Sciullo, A.M. 2000. Parsing Asymmetries. In Dimitris Christodoulakis (ed), Natural LanguageProcessing: Proceedings of the Second International Conference, 24-39. Dordrecht: Springer.





























