Embed Size (px)
Citation preview

UMBCUMBCan Honors University in an Honors University in
MarylandMaryland 1
Adding Semantics to
Social Websites for Citizen Science Pranam Kolari
University of Maryland,Baltimore County
Joint work with Andriy Parafiynyk, Tim Finin, Cynthia Parr, Joel Sachs, and Lushan Han
http://ebiquity.umbc.edu/paper/html/id/365
http://creativecommons.org/licenses/by-nc-sa/2.0/ This work was partially supported by DARPA contract F30602-97-1-0215, NSF grants CCR007080 and IIS9875433

2
This talk
• Motivation• Swoogle Semantic Web
search engine• Social Semantic Web
• Conclusions

3
Social media describes the online technologies and practices that people use to share opinions, insights, experiences, and perspectives and engage with each other.
Wikipedia 07
SOCIAL MEDIA

4
Social Media for agents
• Today social media supports information sharing among communities of people - enables Citizen Journalism
• An infrastructure based on pings, feeds, content aggregators, and filters (e.g. pipes) aids scalability
• Social media now accounts for ~1/3 of new Web content!
• We need to explore how networks of agents can use the same strategies to share data and knowledge

5
This talk
• Motivation• Swoogle Semantic Web
search engine• Social Semantic Web
• Conclusions

6
Google has made us smarter

7
But what about our agents?
tell
register
Agents still have a very minimal understanding of text and images.

8
But what about our agents?
A Google for knowledge on the Semantic Web is needed by software agents and programs
SwoogleSwoogle
Swoogle
Swoogle
SwoogleSwoogle
SwoogleSwoogle
Swoogle SwoogleSwoogle
SwoogleSwoogle
SwoogleSwoogle
tell
register
9
•http://swoogle.umbc.edu/•Running since summer 2004•2.2M RDF docs, 434M triples, 10K
ontologies,15K namespaces, 1.5M classes, 185K properties, 49M instances, 800 registered users
•http://swoogle.umbc.edu/•Running since summer 2004•2.2M RDF docs, 434M triples, 10K
ontologies,15K namespaces, 1.5M classes, 185K properties, 49M instances, 800 registered users
10
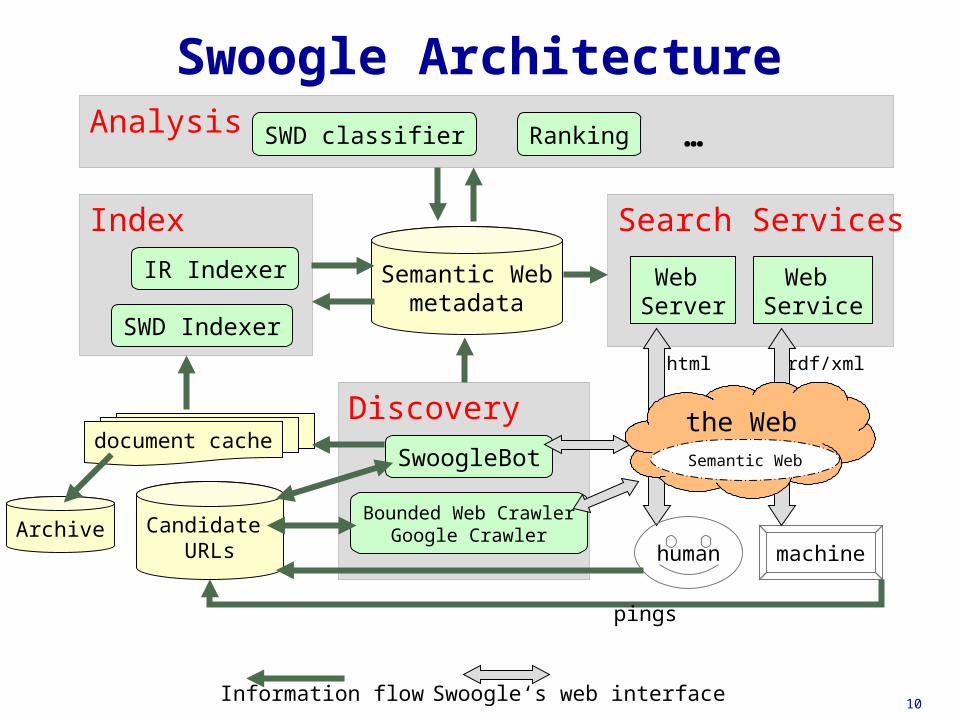
Analysis
Index
Discovery
IR Indexer
Search Services
Semantic Webmetadata
Web Service
Web Server
Candidate URLs
Bounded Web CrawlerGoogle Crawler
SwoogleBot
SWD Indexer
Ranking
document cache
SWD classifier
human machine
html rdf/xml
…
the WebSemantic Web
Information flow Swoogle‘s web interface
Swoogle Architecture
pings
Archive

11
Applications and use cases
Supporting Semantic Web developers– Ontology designers, vocabulary discovery, who’s using
my ontologies or data?, use analysis, errors, statistics, etc.
Searching specialized collections– Spire: aggregating observations and data from biologists
– InferenceWeb: searching over and enhancing proofs
– SemNews: Text Meaning of news stories
Supporting SW tools– Triple shop: finding data for SPARQL queries
1
2
3
12
2
An NSF ITR collaborative project with•University of Maryland, Baltimore County •University of Maryland, College Park•U. Of California, Davis•Rocky Mountain Biological Laboratory
An NSF ITR collaborative project with•University of Maryland, Baltimore County •University of Maryland, College Park•U. Of California, Davis•Rocky Mountain Biological Laboratory

13
An invasive species scenario• Nile Tilapia fish have been found in a California lake.
• Can this invasive species thrive in this environment?• If so, what will be the likely
consequences for theecology?
• So…we need to understandthe effects of introducingthis fish into the food webof a typical California lake

14
Food Webs• A food web models the trophic (feeding)
relationships between organisms in an ecology– Food web simulators explore consequences of ecological
changes, i.e., species introduction or removal
– Food web are constructed from studies of a location’s species inventory and the known trophic relations.
• Goal: automatically construct a food web for a new species using existing data and knowledge
• ELVIS: Ecosystem Location Visualization and Information System
15
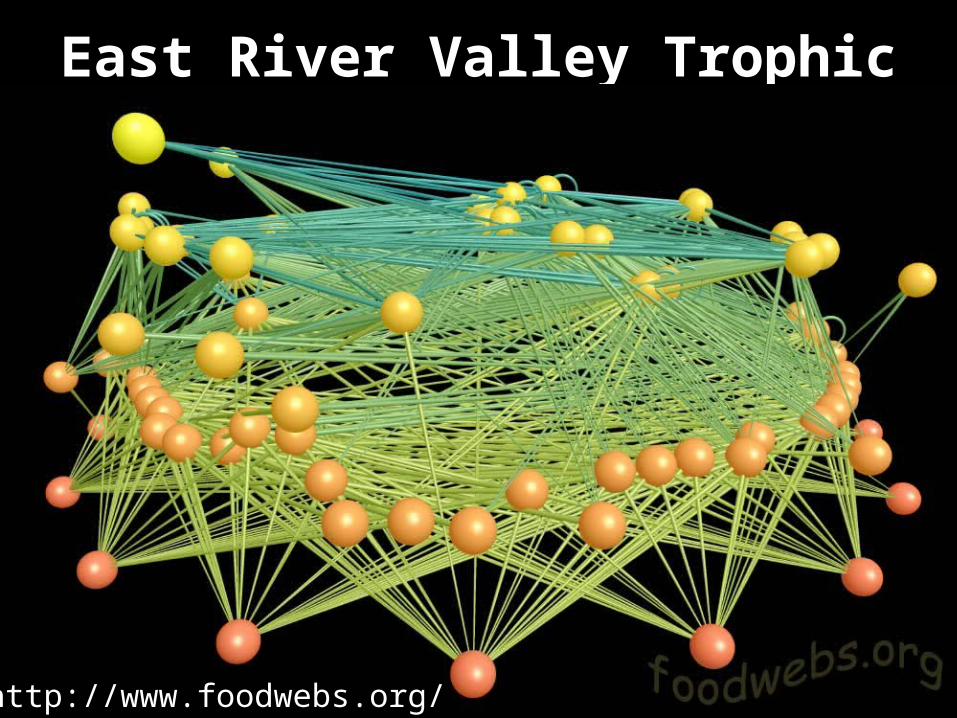
East River Valley Trophic Web
http://www.foodwebs.org/

16
The problem
• We have data on what species are known to be in the location and can further restrict and fill in with other ecological models=> Maybe we can mine social media for species
observations data?
• But we don’t know which of these the Nile Tilapia eats of who might eat it.
• We can reason from taxonomic data (similar species) and known natural history data (size, mass, habitat, etc.) to fill in the gaps.
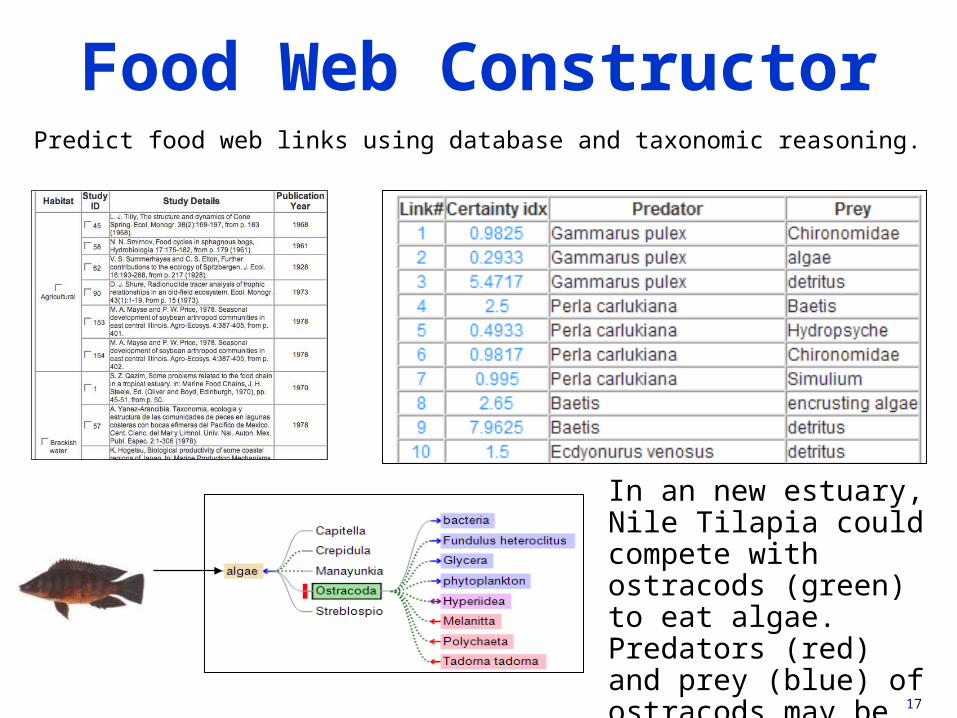
17
Food Web ConstructorPredict food web links using database and taxonomic reasoning.
In an new estuary, Nile Tilapia could compete with ostracods (green) to eat algae. Predators (red) and prey (blue) of ostracods may be affected

18
Status• ELVIS (Ecosystem Location Visualization and
Information System) as an integrated set of web services for constructing food webs for a given location.
• Background ontologies– SpireEcoConcepts: concepts and properties to
represent food webs, and ELVIS related tasks, inputs and outputs
– ETHAN (Evolutionary Trees and Natural History) Concepts and properties for ‘natural history’ information on species derived from data in the Animal diversity web and other taxonomic sources. 250K classes on plants and animals

19
This talk
• Motivation• Swoogle Semantic Web
search engine• Social Semantic Web
• Conclusions
20
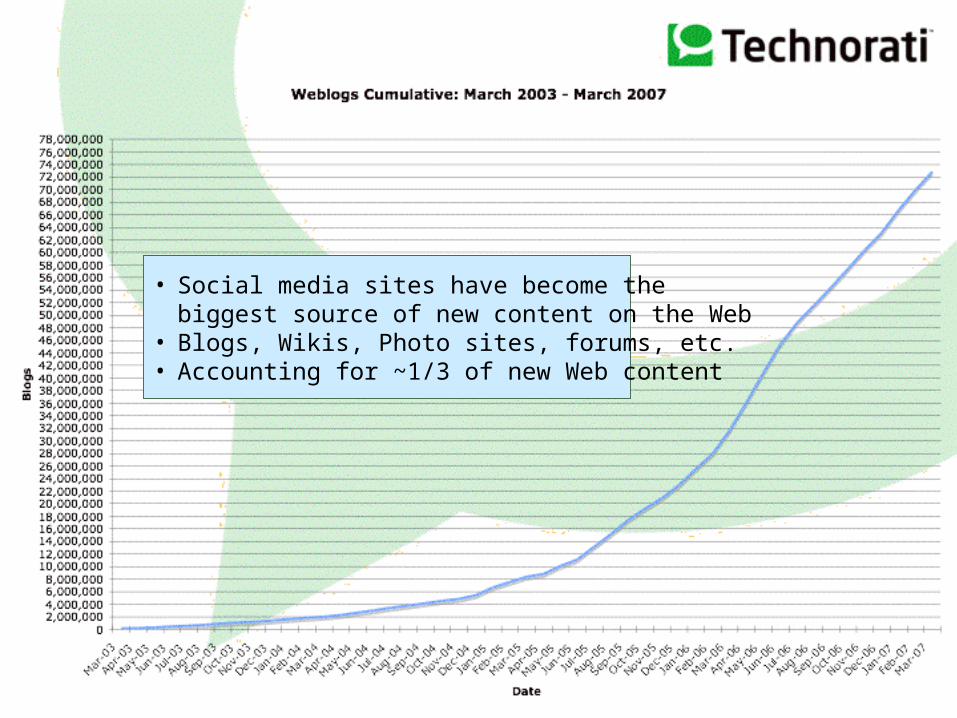
• Social media sites have become thebiggest source of new content on the Web
• Blogs, Wikis, Photo sites, forums, etc.• Accounting for ~1/3 of new Web content
21
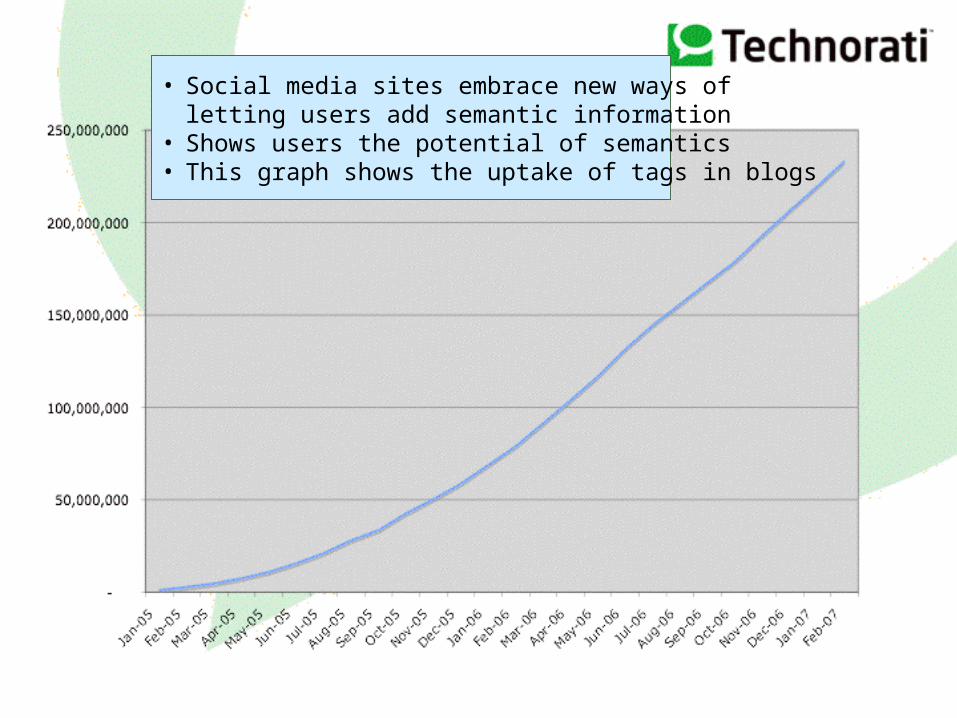
• Social media sites embrace new ways of letting users add semantic information
• Shows users the potential of semantics• This graph shows the uptake of tags in blogs

22
Social Media and the Semantic Web• Many are exploring how Semantic Web technology
can work with social media
• Social media like blogs are typically temporally organized– valued for their timely and dynamic information!
• If static pages form the Web’s long term memory, then the Blogosphere is its stream of consciousness
• Maybe we can (1) help people publish data in RDF on their blogs, (2) mine social media sites for useful information, (3) exploit new infrastructure ideas for sharing Semantic Web data.
23
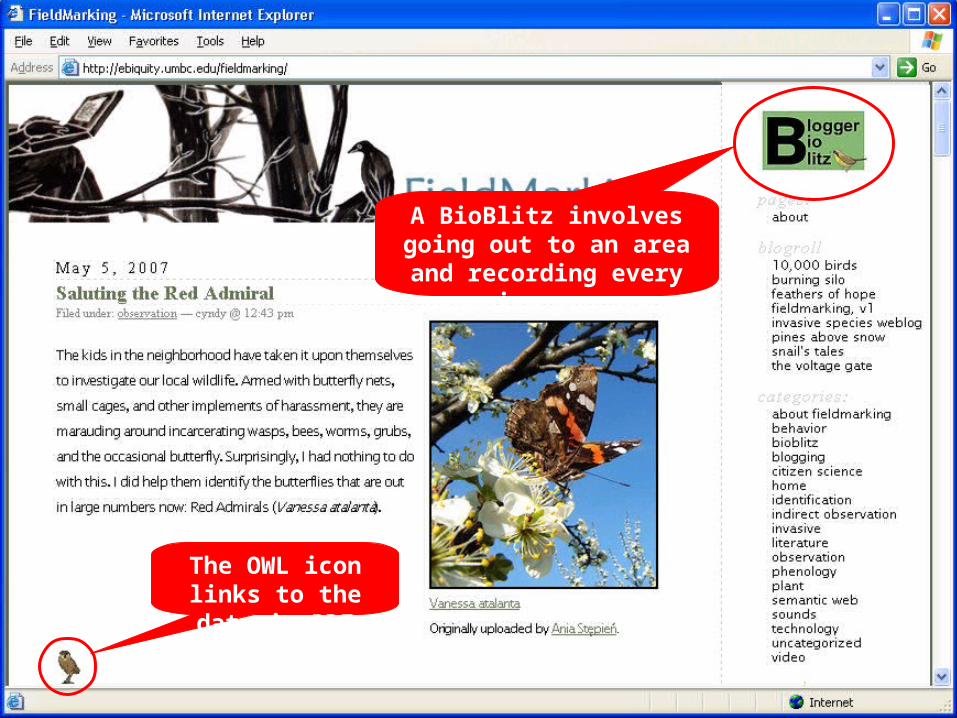
The OWL icon links to the data in RDF
A BioBlitz involves going out to an area and recording every organism you see
24
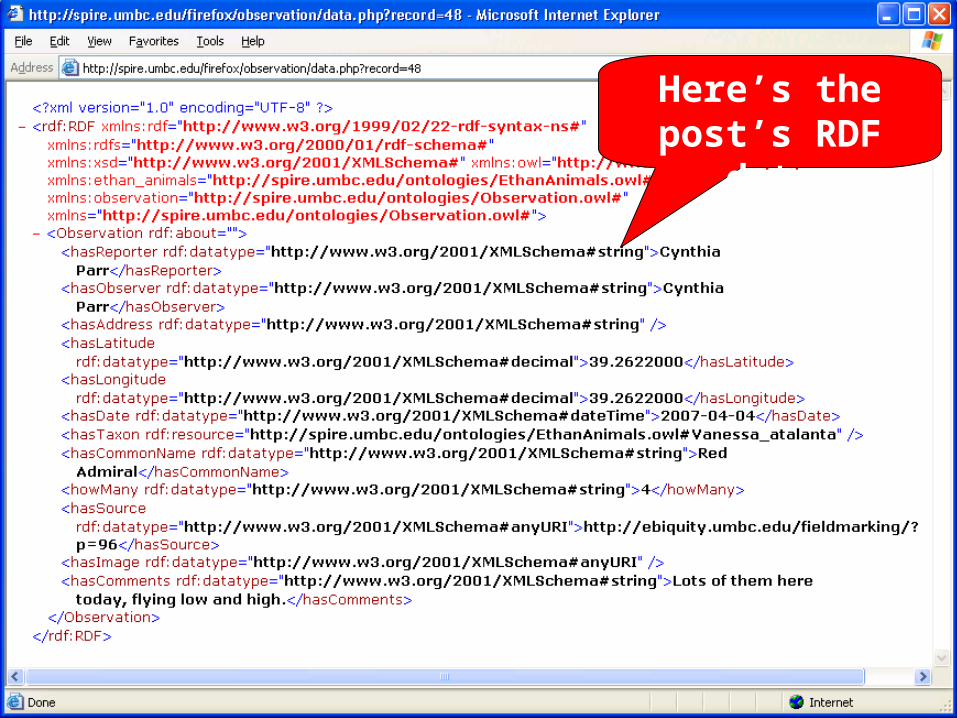
Here’s the post’s RDF
data

25
A good Semantic Web opportunity• We want to make it easy for scientists to enter
and collect information from social media –Professionals, students and amateurs!
• Some early examples–SPOTter – a tool to add Semantic Web data
to blogs–Splickr – a system to mine Flickr for images
of organisms–RDF123 – an application and Web service to
render spreadsheets as RDF data

26
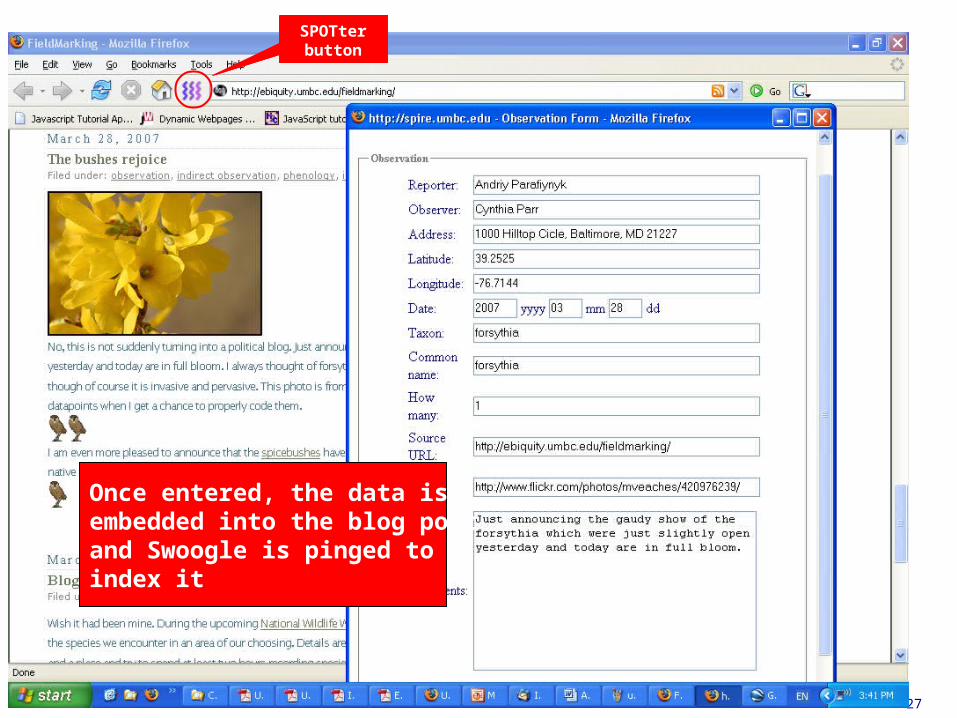
SPOTter: SPire Observation Tool
• We’ve developed some simple components to help people add RDF data to blogs and ping Swoogle to get it indexed.
• SPOTter is an initial prototype that uses the ETHAN ontology and is being used in some BioBlitz activities with students.
• We’re working toward a version that uses Twitter so that people can make the blog entries from the cell phones via SMS– The SPOTter agent will get the entries (via RSS)
and index the data
27
SPOTter button
Once entered, the data isembedded into the blog postand Swoogle is pinged toindex it
28
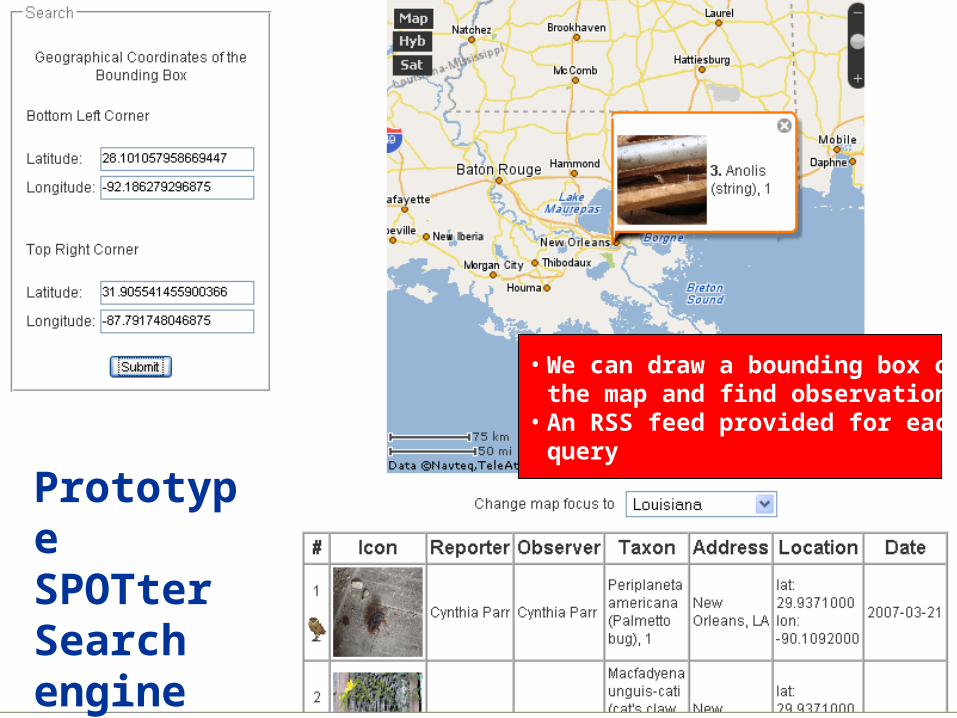
Prototype SPOTterSearch engine
• We can draw a bounding box onthe map and find observations
• An RSS feed provided for eachquery

29
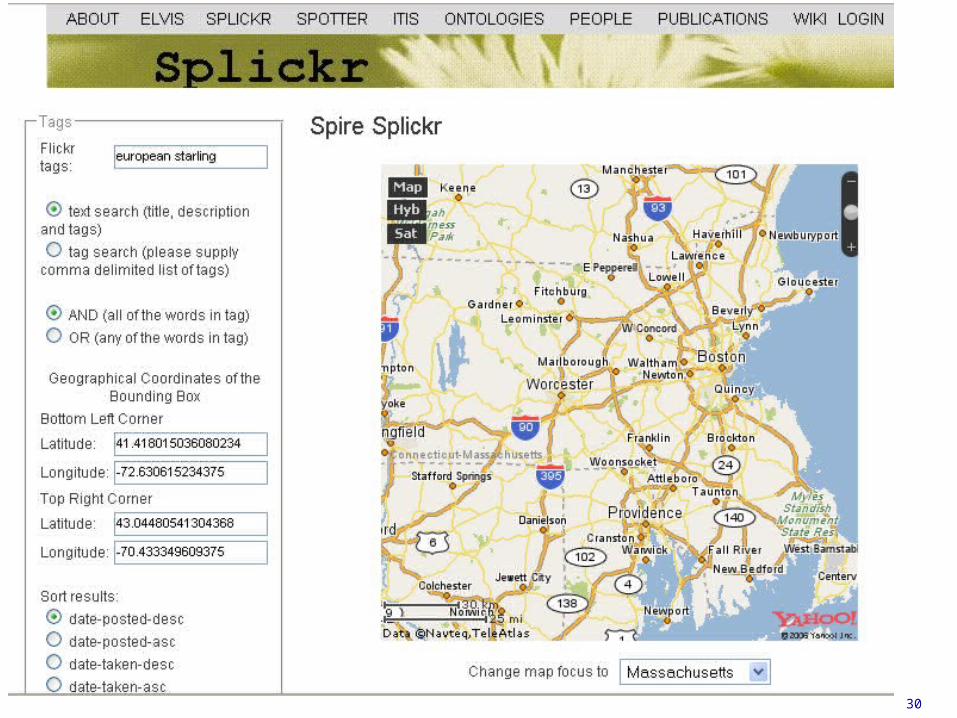
Flickr • The Flickr “photo sharing” site has millions of
photographs– Many of plants and animals
• Most of them have descriptions, timestamps, tags and even geo-tags– Flickr has even introduced “machine tags” that can
be mapped into RDF• Any Flickr users (humans or bots) can add comments
and annotations• There’s a good API• It could be a good source of ecological information
30
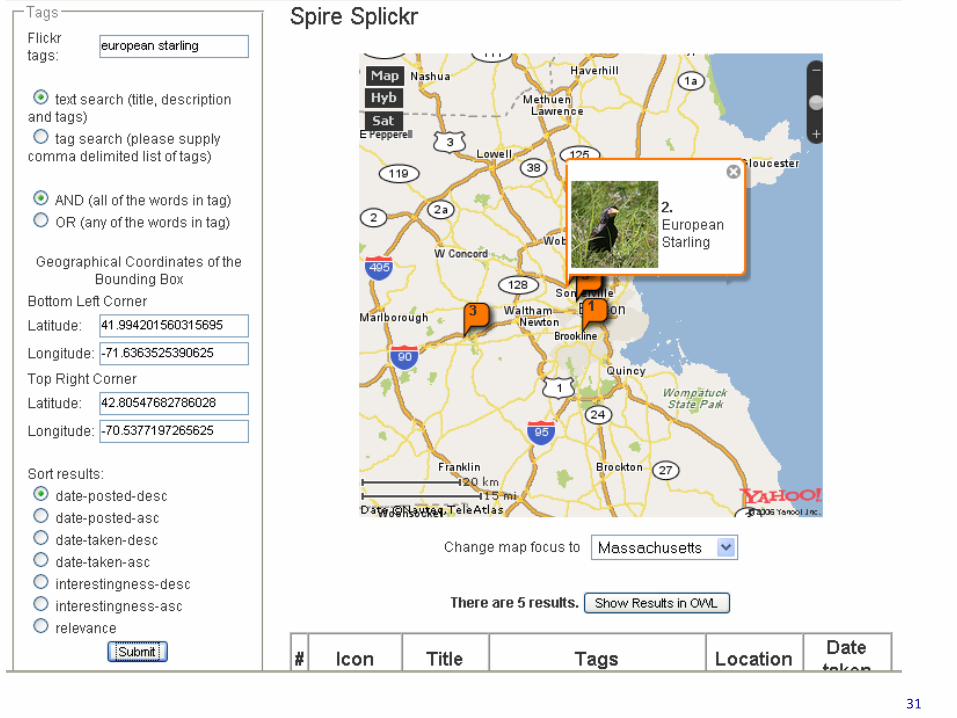
31

32
Results for people and machines
33
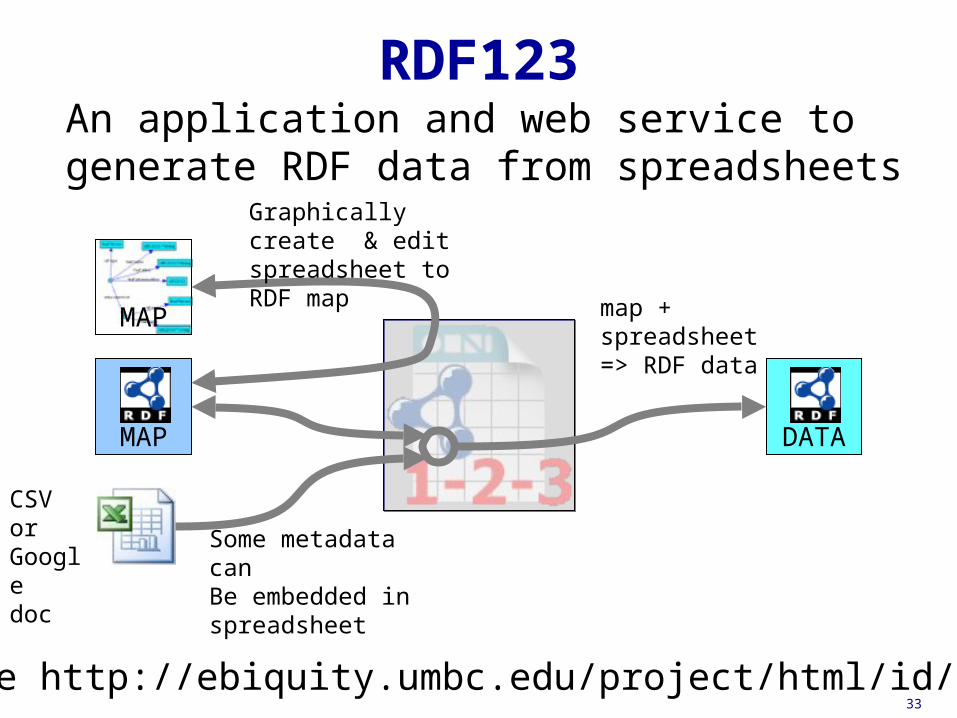
RDF123An application and web service to generate RDF data from spreadsheets
MAP
MAP
DATA
Graphically create & edit spreadsheet to RDF map
map + spreadsheet=> RDF data
Some metadata canBe embedded in spreadsheet
CSV or Googledoc
See http://ebiquity.umbc.edu/project/html/id/82/

34
RDF123• The Bioblitz project needed a way to
collect and share observational data from students
• Spreadsheets selected as a common data format and templates developed
• RDF123 application and web service developed to ease exporting the data as RDF for a Maryland BioBlitz group– Supports a web service to generate RDF given
URLs for the sheet and map– Works on CSV files and also Google spreadsheets
UMBCUMBCan Honors University in an Honors University in
MarylandMaryland 35
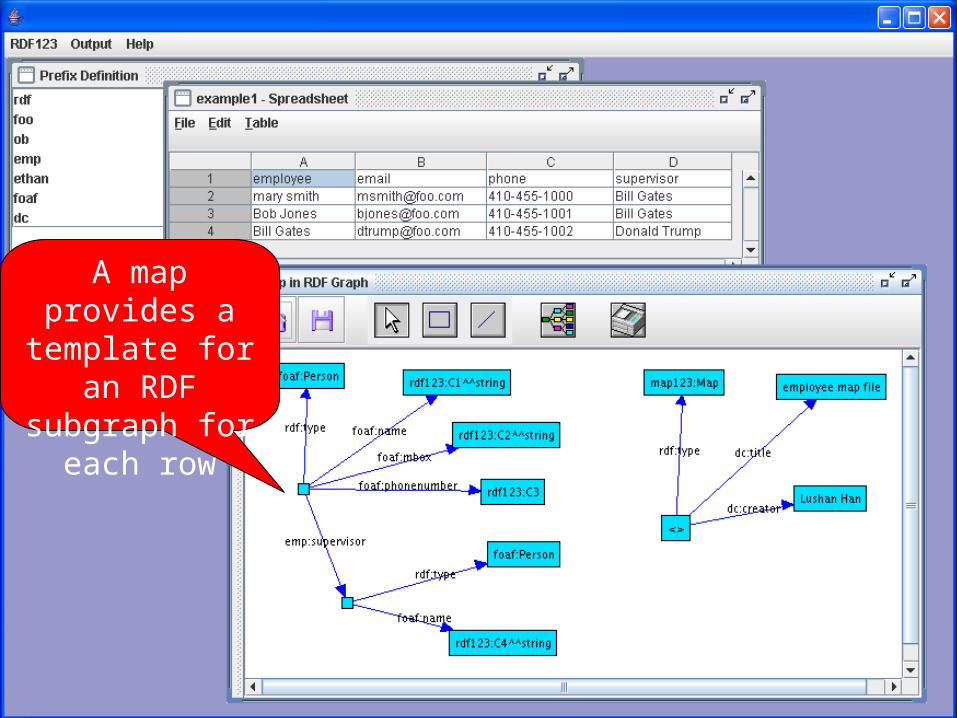
A map provides a template for
an RDF subgraph for
each row
36
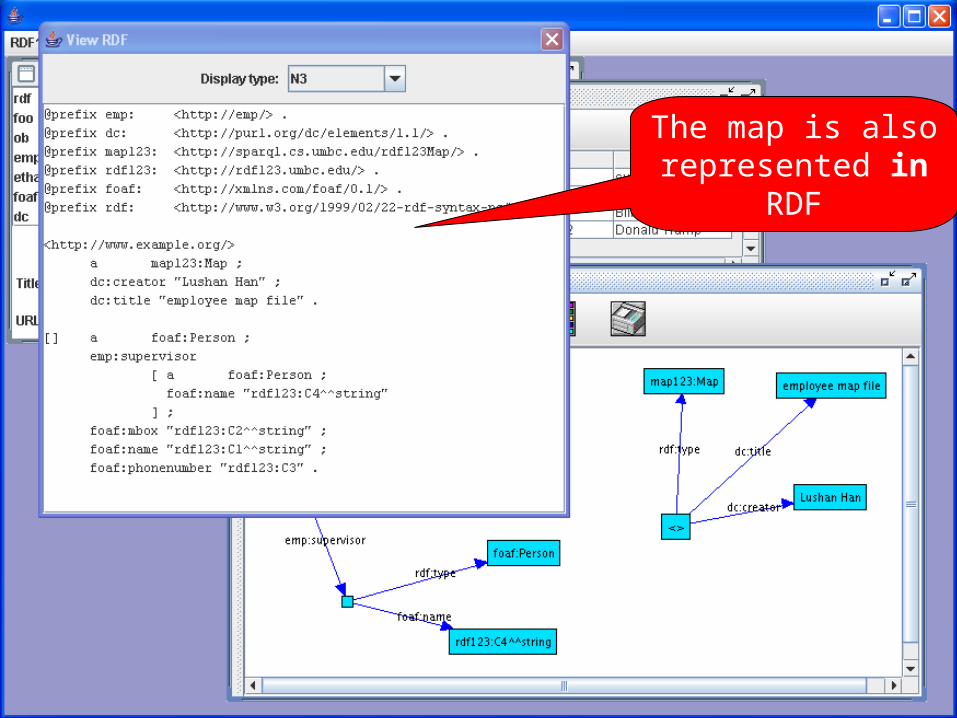
The map is also represented in
RDF
37
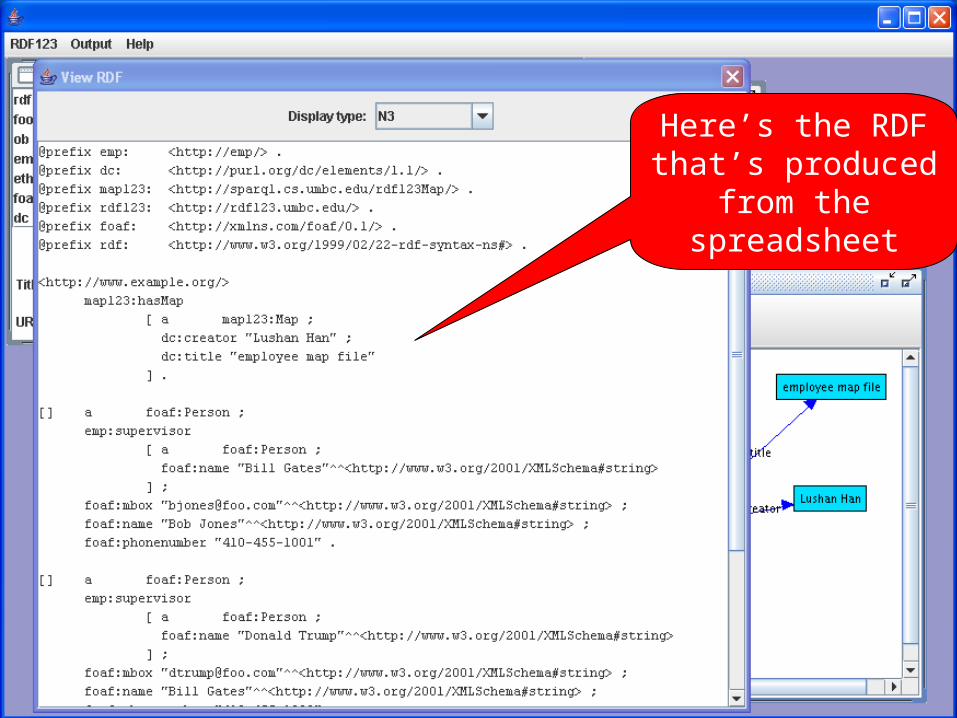
Here’s the RDF that’s produced
from the spreadsheet
38
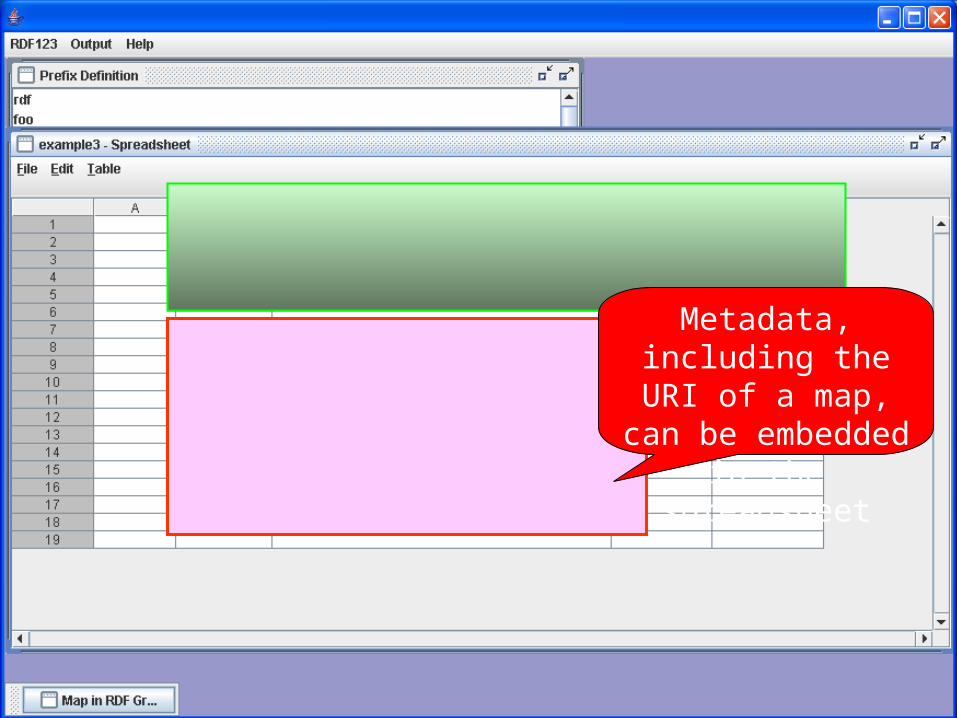
Metadata, including the URI of a map, can be embedded in the
spreadsheet

39
Ping and Feed Design Pattern
• The Web uses a ping and feed design pattern that is a variant of publish and subscribe
• It accounts for the scalable, smooth function of the Blogosphere and related social media systems
• Pings push and feeds pull
• We can use the same approach to managing volumes of Semantic Web data
40
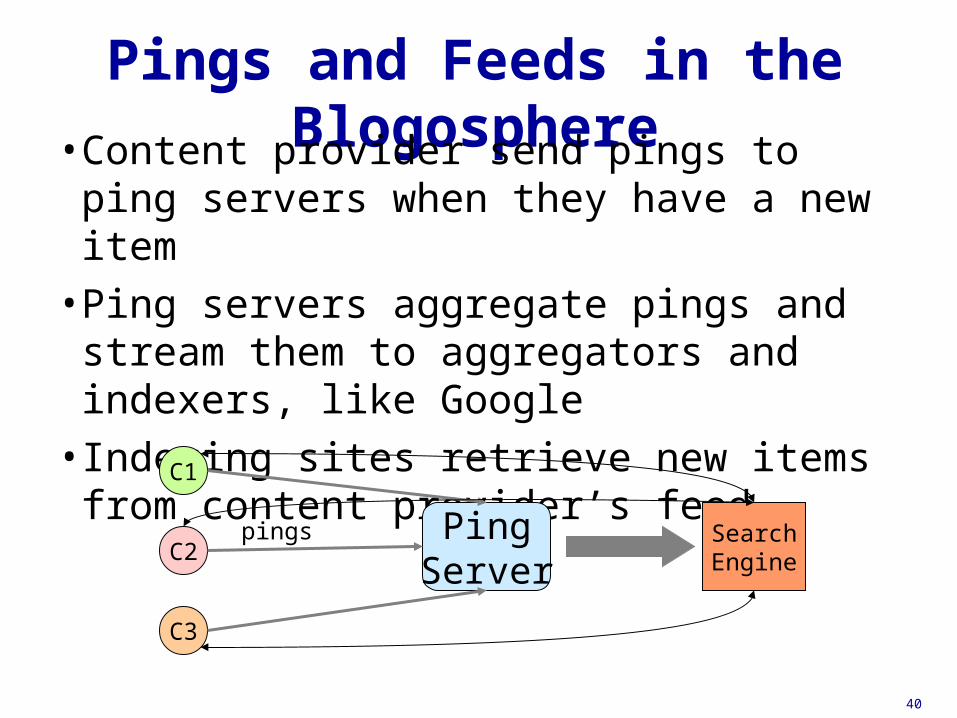
Pings and Feeds in the Blogosphere• Content provider send pings to ping servers when
they have a new item
• Ping servers aggregate pings and stream them to aggregators and indexers, like Google
• Indexing sites retrieve new items from content provider’s feed
PingServer
C1
C2
C3
pings SearchEngine
41
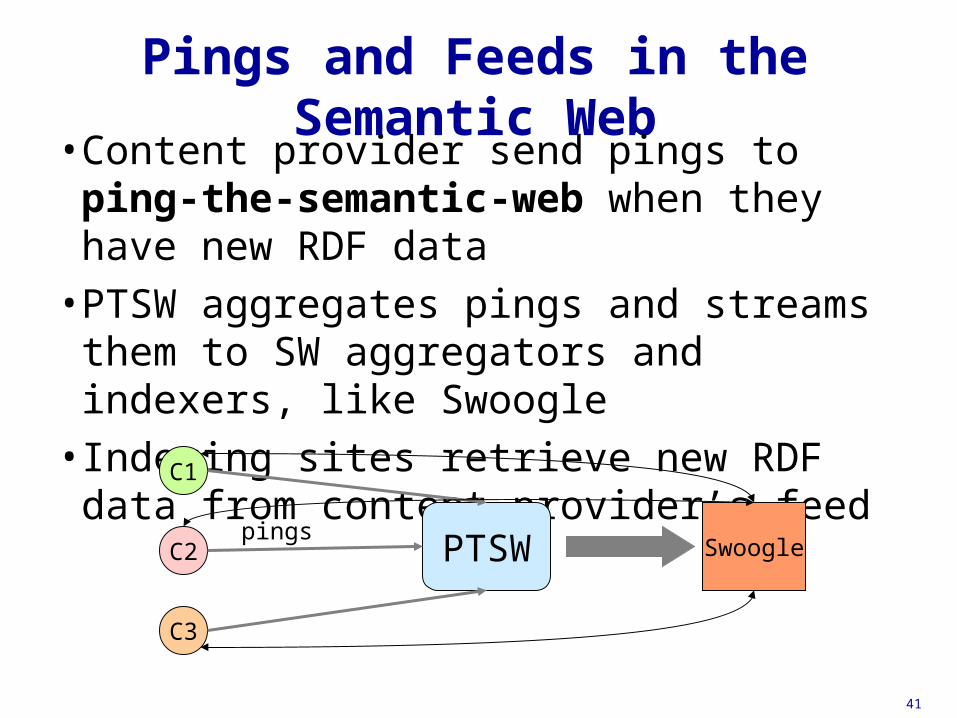
Pings and Feeds in the Semantic Web
• Content provider send pings to ping-the-semantic-web when they have new RDF data
• PTSW aggregates pings and streams them to SW aggregators and indexers, like Swoogle
• Indexing sites retrieve new RDF data from content provider’s feed
PTSW
C1
C2
C3
pingsSwoogle

42
Semantic Web Feeds drive Mashups• As in the regular web, sites and query engines use
feeds to capture queries
• Accessing a feed runs the query and produces a list of the first N results (usually 10 ≤ N ≤ 20)
• Such query feeds can drive mashups
• Systems like Yahoo pipes make it easy to compose feeds

43
This talk
• Motivation• Swoogle Semantic Web
search engine• Social Semantic Web
• Conclusions

44
Conclusion• The web will contain the world’s knowledge in
forms accessible to people and computers– We need better ways to discover, index, search and
reason over SW knowledge
• SW search engines address different tasks than html search engines– So they require different techniques and APIs
• Swoogle like systems can help create consensus ontologies and foster best practices
• Social media provide new challenges and opportunities for the Semantic Web

45
http://ebiquity.umbc.edu/
Annotatedin OWL
For more information





























