Embed Size (px)
Citation preview

CENTRO DE INVESTIGACIÓN Y DOCENCIA ECONÓMICAS, A.C.
UNA ESTRATEGIA DE PRONÓSTICO PARA EL PIB
TESINA
QUE PARA OBTENER EL TÍTULO DE
LICENCIADO EN POLÍTICAS PÚBLICAS
PRESENTA
JOSÉ SANTIAGO CASTILLO VARGAS
DIRECTOR DE LA TESINA: DRA. DANIELA MOCTEZUMA Y DR. DANIEL VENTOSA
AGUASCALIENTES, AGS. SEPTIEMBRE, 2017

ParaDoña Lucia Bravo Pulido y
Don José Santiago Castillo Peña.

Resumen
En este trabajo se presenta una comparación de pronósticos del PIB con Modelos Autoregre-sivos de Media Móviles (ARMA) y Métodos de aprendizaje computacional. Para el pronósticodel PIB se propone una estrategia: realizar una trasformación Box-Cox de los datos, una de-sestacionalización con filtro X-12 ARIMA, pruebas de raíz unitaria y quiebre estructural. Laestrategia de pronóstico presentada en esta tesina mejora los modelos ARMA y proporciona elmejor pronóstico para el PIB. Sin embargo, no mejora los pronósticos de los modelos SVR.
Palabras clave: Modelos Autoregresivos de Media Móviles, Máquinas de Soporte Vectorial,filtro X-12, transformación Box-Cox, Pruebas de raíz unitaria, Quiebre estructural.Clasificación JEL:C52

Contenido
1 Introducción 1
2 Revisión de Literatura 4
2.1 Teorías sobre la estabilización . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2 Teorías alternativas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.3 Competencias de pronósticos y funciones de perdida . . . . . . . . . . . . . . 6
3 El caso mexicano 8
3.1 Importancia de las proyecciones en México . . . . . . . . . . . . . . . . . . . 8
3.2 Características de los datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
3.3 Variables habituales en los modelos predictivos del PIB . . . . . . . . . . . . . 9
3.4 Estimación a la mexicana . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
4 Los datos 12
5 Metodología 17
5.1 Transformación de variables . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
5.2 Desestacionalidad de las series . . . . . . . . . . . . . . . . . . . . . . . . . . 19
5.3 Estimación del quiebre estructural . . . . . . . . . . . . . . . . . . . . . . . . 20
5.4 Pruebas de estacionariedad . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
5.5 Estimación del modelo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
5.5.1 Modelos Autoregresivos con Medias Móviles . . . . . . . . . . . . . . 22
i

5.5.2 Support Vector Regression (SVR) y Kernel Ridge Regression (KRR) . 23
6 Resultados 25
6.1 Modelos Autoregresivos con Medias Móviles . . . . . . . . . . . . . . . . . . 25
6.1.1 Aproximación con modelos ARMA . . . . . . . . . . . . . . . . . . . 26
6.1.2 Aproximación con modelos ARMAX . . . . . . . . . . . . . . . . . . 27
6.1.3 Aproximación con modelos que utilizan la trasformación Box-Cox, el
filtro X − 12 y el ajuste de quiebre estructural de Bai y Perron . . . . . 27
6.2 Métodos de aprendizaje computacional . . . . . . . . . . . . . . . . . . . . . . 29
6.2.1 Aproximación con SVR radiales . . . . . . . . . . . . . . . . . . . . . 29
6.2.2 Aproximación con modelos KRR . . . . . . . . . . . . . . . . . . . . 31
6.3 Comparación de pronósticos intramuestrales y extramuestrales . . . . . . . . . 33
7 Implicaciones de Política Pública 40
8 Conclusiones 42
Referencias 44
ii

Lista de figuras
4.1 Gráficas temporales del PIB-IGAE . . . . . . . . . . . . . . . . . . . . . . . . 14
4.2 Gráficas temporales del PIB-INPC subyacente . . . . . . . . . . . . . . . . . . 14
4.3 Gráficas temporales del PIB-IPC . . . . . . . . . . . . . . . . . . . . . . . . . 15
4.4 Gráficas de las primeras diferencias del PIB-Precio del petróleo . . . . . . . . . 16
4.5 Gráficas de las primeras diferencias del PIB-Tipo de cambio . . . . . . . . . . 16
5.1 Optimización de la trasformación Box-Cox . . . . . . . . . . . . . . . . . . . 18
5.2 Filtro X-12 ARIMA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.3 Quiebre estructural . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
5.4 Muestreo y trasformación de los datos de los métodos de aprendizaje computa-
cional . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
5.5 Support Vector Regression y Kernel Ridge Regression . . . . . . . . . . . . . 24
6.1 Estimación intramuestral del PIB . . . . . . . . . . . . . . . . . . . . . . . . . 28
6.2 Curva de aprendizaje de los modelos que usan datos originales . . . . . . . . . 30
6.3 Curva de aprendizaje de los modelos que usan datos tratados . . . . . . . . . . 30
6.4 Curva de aprendizaje de los modelos que usan primeras diferencias . . . . . . . 31
6.5 Curva de aprendizaje de los mejores tres modelos . . . . . . . . . . . . . . . . 32
6.6 Estimación intramuestral del PIB con modelos KRR . . . . . . . . . . . . . . . 32
6.7 Pronóstico ARMAX intra y extra-muestral . . . . . . . . . . . . . . . . . . . . 33
6.8 PIB original con respecto al pronóstico intramuestral de KRR . . . . . . . . . . 34
6.9 PIB con respecto al pronóstico intramuestral ARMAX con datos tratados . . . 35
iii

6.10 Pronóstico ARMAX extramuestral . . . . . . . . . . . . . . . . . . . . . . . . 36
6.11 Pronóstico KRR extramuestral . . . . . . . . . . . . . . . . . . . . . . . . . . 37
6.12 PIB con respecto al pronóstico extramuestral ARMAX con datos tratados . . . 37
6.13 PIB con respecto al pronóstico extramuestral KRR con datos originales . . . . 38
iv

Lista de tablas
4.1 Resumen de los Datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
6.1 Resumen de modelos ARMA . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
6.2 Resumen de modelos ARMAX . . . . . . . . . . . . . . . . . . . . . . . . . . 27
6.3 Modelo ARMAX con tratamiento de cambio estructural . . . . . . . . . . . . . 28
6.4 Ajuste Mínimo Cuadrático de los pronósticos intramuestrales . . . . . . . . . 35
6.5 Ajuste Mínimo Cuadrático de los pronósticos extramuestrales . . . . . . . . . 38
v

Capítulo 1
Introducción
Las predicciones del comportamiento del PIB o Ingreso Nacional 1 se han realizado con mode-
los comúnmente utilizados en macroeconomía, Elguézabal (2004b). Estos modelos se centran
en la relación causal de Ingreso-Gasto sin tomar en cuenta los cambios estructurales del com-
portamiento del PIB, Singh y Sahni (1984). De tal forma, las predicciones sobre el PIB tienen
que modificarse constantemente.
Por citar un ejemplo, considerando la previsión del Banco de México (Banxico) del 19 de
noviembre de 2014 hasta el primer trimestre del 2017, ya se han realizado cuatro ajustes. El
pronóstico original consideraba un rango de crecimiento de 3.2 a 4.2 por ciento. Durante el año
2015 se realizaron los primeros dos ajustes: el primero fue el 18 de febrero donde el rango de
crecimiento disminuyo quedando en 2.9 a 3.9 por ciento y el segundo se realizó el 19 de mayo
quedando en 2.5 a 3.5 por ciento. Durante el 2016 se realizó una modificación el 3 de marzo,
el nuevo ajuste dejo el pronóstico de crecimiento en 2 a 3 puntos porcentuales. Por último, el
primero de marzo del 2017 Banxico redujo su expectativa de crecimiento a un rango de 1.3 a
2.3 por ciento, Capistrán y López-Moctezuma (2010).
Los estudios sobre la estimación del ingreso nacional muestran diversas estrategias respecto
a la forma de predicción. Para fines prácticos de esta tesis, estos estudios son clasificados en dos
categorías: i) las teorías que intentan estabilizar los movimientos estocásticos y ii) las teorías
1Sin distinción para efectos de esta tesina
1

que proveen alternativas al modelo de los movimientos estocásticos. En la primera categoría
se encuentran los modelos de estimación que se concentran en la reducción de incertidumbre
provocada por el quiebre estructural y raíz unitaria. En la segunda categoría se encuentran
los modelos que parten de la estandarización del error estocástico para aumentar la capacidad
predictiva. Mejor dicho, los modelos que transforman los datos en múltiples dimensiones con el
objetivo de encontrar una solución global que minimice el error en la predicción.
El objetivo de esta tesina es evaluar los modelos de predicción del PIB a través de las nuevas
aportaciones en macro-econometría y aprendizaje computacional sobre el estudio del compor-
tamiento estocástico. La pregunta que guía esta tesis es ¿la estandarización del error estocástico
mejorará la predicción del PIB? Para responder a la pregunta anterior se realiza una compara-
ción de dos tipos de modelos: 1) los modelos que se concentran en el tratamiento de quiebre
estructural y raíz unitaria y 2) los modelos que estandarizan el error estocástico a través de la
trasformación de los datos en hiperplanos. En concreto, se modelará el comportamiento del PIB
de México con datos comprendidos de 1994 hasta 2016. Para esto, se utilizan tres modelos de
series de tiempo y dos modelos de máquinas de soporte vectorial (SVM por sus siglas en ingles)
para predecir el comportamiento del PIB. Posteriormente se utilizan funciones de pérdida para
evaluar la capacidad predictiva de los modelos.
Este trabajo es relevante en el ámbito público y privado. En lo que concierne a la relevancia
del sector público destacan tres ejemplos: primero, el presupuesto de egresos de la federación,
segundo, la ley de ingresos y tercero, la oferta de dinero del Banxico.
Primero, los pronósticos son relevantes en la Ley de Ingresos de la Federación porque me-
diante la diferencia entre la estimación del PIB y el presupuesto de Egresos aprobado por la Cá-
mara de Diputados se determina el monto de deuda pública, Amparán y Palacio (2003). Tener
estimaciones más precisas permitirá reducir los costos financieros sobre la deuda. Según la
SHCP en Hernández Veleros (2011), el costo financiero por un sobreendeudamiento constituye
hasta un 0.9 porciento del PIB (aproximadamente 120 mil millones de pesos).
Segundo, los pronósticos son relevantes para el presupuesto de Egresos principalmente por
2

dos razones. Por un lado, los pronósticos del PIB ayudan a realizar escenarios sobre las prin-
cipales variables macroeconómicas del año siguiente como la inflación, la tasa de interés, el
crecimiento económico y el precio del petróleo, Elguézabal (2004b). Por otro lado, se realiza
una jerarquía de las políticas públicas y el mondo a designar con base en las estimaciones del
PIB. Inclusive, pronósticos del PIB son utilizados para ajustar el monto correspondiente a los
programas y proyectos vigentes, de La Federación y del presupuesto de las asignaciones (2015).
Tercero, mejorar las predicciones del PIB tiene implicaciones en la evaluación de reformas
estructurales en materia económica y en la efectividad de las políticas públicas. Mas especí-
ficamente, la capacidad de predecir el PIB tiene implicaciones directas en política monetaria,
Gutiérrez Lara (2015). Las variaciones en el PIB determinan la oferta de dinero en la economía.
Por lo tanto, una predicción más precisa sobre las variaciones del PIB podría aumentar la efec-
tividad de la política monetaria, y consecuentemente, ayudar a mantener un mejor control sobre
la estabilidad económica del país.
Los resultados de este trabajo son dos: 1) la estrategia de pronóstico que se propone en esta
tesis mejora las estimaciones de los modelos autoregresivos de medias móviles y 2) los modelos
que utilizan la estandarización del error estocástico, SVR, funcionan mejor con la variación
entre las observaciones.
Esta tesina se divide en seis secciones: la primera sección es una introducción al problema;
la segunda sección realiza una revisión de la literatura sobre los modelos para predecir el ingreso
nacional; en la tercera sección se describen los modelos utilizados en México; la cuarta sección
explica las variables utilizadas; en la quinta sección se describe la metodología de predicción
utilizada; en la sexta sección se evalúan los modelos utilizados para la predicción del PIB; en la
séptima y octava sección se describen las implicaciones sobre política pública y conclusiones,
respectivamente.
3

Capítulo 2
Revisión de Literatura
Los estudios sobre la estimación de series de tiempo son muy diversos respecto a la forma de
predecir. En esta tesis, los estudios que proponen distintas formas de estimación son clasificados
en dos grandes categorías: i) las teorías que intentan estabilizar los movimientos estocásticos, y
ii) las teorías que proveen alternativas al modelo de los movimientos estocásticos.
2.1 Teorías sobre la estabilización
Las teorías que estabilizan los movimientos estocásticos primordialmente están documentadas
en los estudios de Singh y Sahni (1984), Enders (2004) y Hamilton (1994). En estos estudios,
los modelos de estimación se concentran en la reducción de incertidumbre provocada por el
quiebre estructural y la raíz unitaria, conocen los cambios estructurales y analizan las raíces de
la serie.
En concreto, las estimaciones de los modelos resuelven problemas como estacionariedad y
ergodicidad de la serie, Box y Jenkins (1976). No obstante, es difícil modelar cuando la serie
tiene combinaciones de cambios estructurales. El problema de estos modelos es que la capacidad
predictiva se limita a un periodo de tiempo limitado, Cowpertwait y Metcalfe (2009). Además,
la modelación de la volatilidad ocasiona sesgos en las predicciones o aumenta el intervalo de
confianza, Sargan y Bhargava (1983). En suma, los modelos utilizados en esta categoría suelen
4

tener deficiencias con los cambios estructurales de las series de tiempo.
2.2 Teorías alternativas
Entre las teorías que proveen alternativas al modelo de movimientos estocásticos, principal-
mente, se encuentran los estudios que matematizan la parte estocástica de los modelos y los
modelos que aumentan la dimensión de los datos en búsqueda de una solución global que min-
imice el error.
Por un lado, los estudios de Revuz y Yor (1999) y Kleinert (2004) proponen la matemati-
zación del error estocástico para reducir la parte estocástica de los modelos. En otras palabras,
buscan una función matemática como unidad de medida de los errores estocásticos. Este tipo de
modelos se concentra en la series con alta volatilidad y choques estocásticos. Estos modelos le
dan mayor preponderancia al estudio de la parte estocástica cuando no hay variables conocidas
que puedan ser utilizadas en el modelo.
Sin embargo, la metodología que emana de estos modelos es complicada. El número de ob-
servaciones necesario para implementar estos modelos suele ser mayor a los modelos comunes,
Cowpertwait y Metcalfe (2009). En suma, los costos por aprender estas técnicas son altos y no
hay incentivos para su utilización.
Por otro lado, estudios de Cao (2003), Qiu, Suganthan, y Amaratunga (2017), Rüping (2001),
Thissen, Van Brakel, De Weijer, Melssen, y Buydens (2003) proponen las máquinas de soporte
vectorial (SVM por sus siglas en inglés) para analizar datos de serie temporal. Las máquinas de
soporte vectorial están basados en el trabajo de Vapnik y Vapnik (1998) sobre la teoría del apren-
dizaje estadístico. Estos modelos transforman los datos en múltiples dimensiones en búsqueda
de una representación más simple de ellos. Después, proponen distintos modelos que minimizan
una función de pérdida. En general, solamente hay una solución global que minimiza la fun-
ción de pérdida y las máquinas de soporte vectorial encuentran la solución que minimiza dicha
función.
5

Los Support Vector Regresion (SVR) pueden encontrar relaciones no lineales entre los datos
y estabilizan los comportamientos erráticos de las series no ergódicas, Welling (2013). Específi-
camente, este tipo de modelos pueden ofrecer una alternativa a los problemas de no estacionar-
iedad y volatilidad de la serie. No obstante, es común el problema de sobreajuste del modelo,
Cao (2003). Esto pasa cuando el modelo parece ajustarse demasiado bien a los pronósticos
dentro de la muestra pero no pasa lo mismo con los pronósticos fuera de la muestra.
2.3 Competencias de pronósticos y funciones de perdida
En otro orden de ideas, la elección de ciertos modelos para pronosticar una serie suele ser com-
plementaria. Los modelos de predicción pueden integrar varias estrategias de predicción con
el único fin de reducir la incertidumbre en sus pronósticos. Con este objetivo, los expertos
en competencias de pronósticos como Makridakis et al. (1982) frecuentemente combinan las
ventajas comparativas de los modelos, aumentando la capacidad predictiva y evaluando el com-
portamiento con series particulares.
Las competencias de pronósticos contribuyen con formas innovadoras para comparar la pre-
cisión en la extrapolación, Neter, Kutner, Nachtsheim, y Wasserman (1996). Tales competencias
incentivan la investigación y nuevas formas de estudiar el comportamiento de los modelos. Las
formas más usuales para comparar son las funciones de pérdida.
La contribución particular de este trabajo se concentra en la utilización de ambas categorías
para desarrollar un modelo de predicción de PIB. El desarrollo de un modelo de predicción que
combine las dos categorías es innovador en dos sentidos. Primero, hay un ahorro de tiempo
considerable desde el desarrollo del modelo hasta la predicción. Segundo, los modelos pueden
realizarse de forma independiente y combinarse en el momento de predecir. La contribución
general de esta tesina se enfoca en la explicación de ciertos procesos y conceptos para influen-
ciar la utilización de los modelos alternativos del movimiento estocástico. Incluso, analizar el
comportamiento de los nuevos modelos en la predicción de series reales.
6

La evaluación de los modelos se realizará tomando en cuenta los métodos de comparación
utilizados en las competencias de pronósticos. El estudio empírico del comportamiento de los
modelos propicia a una mejor utilización de las ventajas comparativas. En conclusión, la hipóte-
sis que guía este trabajo es que los modelos combinados que utilizan diversas estrategias para el
tratamiento del error estocástico tienden a tener mayor capacidad de predicción, comparado con
los modelos que no lo utilizan.
7

Capítulo 3
El caso mexicano
3.1 Importancia de las proyecciones en México
La medición del ingreso nacional es esencial para el análisis macroeconómico y la toma de
decisiones, Elizondo (2012). En concreto, el Producto Interno Bruto es uno de los indicadores
económicos más importantes de las cuentas nacionales y de la economía, debido a que representa
una medida amplia de la actividad económica y proporciona señales de la dirección general de
la actividad económica agregada, Elguezabal (1995).
3.2 Características de los datos
El PIB es influenciado por múltiples factores económicos y exógenos a la economía, Ize y Salas
(1983). Por un lado, entre los factores económicos se encuentran las reestructuras fiscales,
reformas políticas, políticas públicas y política monetaria. Por otro lado, entre los factores
exógenos se encuentran los desastres naturales, enfermedades epidémicas, amenazas de guerra,
entre otros.
Los datos del PIB son publicados cada trimestre. Sin embargo, la frecuencia de los datos
trae problemas en la estimación, Elguezabal (1995). Por un lado, la frecuencia de los datos no
permite conocer el estado de la economía entre los periodos trimestrales. Por otro lado, la fre-
8

cuencia del PIB limita los modelos econométricos que pueden ser utilizados para la predicción.
No obstante, en búsqueda de solucionar el problema se realizan algunas estrategias de carác-
ter metodológico. Una muy obvia consiste en modificar la frecuencia2 de las variables que
pueden explicar el PIB, Elguézabal (2004a). También, la utilización de otras variables para pre-
decir los periodos entre cada trimestre, Elguézabal (2004b). Incluso, cambiar la frecuencia del
PIB (trimestral a mensual) mediante distintos métodos, Elizondo (2012).
3.3 Variables habituales en los modelos predictivos del PIB
Los modelos utilizados por los responsables de la política económica (Banxico) consideran fre-
cuentemente dos variables para la aproximación del PIB, Elizondo (2012). La primera variable a
considerar es el Indicador Global de la Actividad Económica (IGAE) . El IGAE es información
preliminar sujeta a datos auto reportados de empresas y organismos públicos. Este indicador
permite conocer y dar seguimiento a la evolución del sector real de la economía, en el corto
plazo. Aunque no incluye toda la información de las actividades económicas contenidas en el
PIB, la utilidad del IGAE es determinar la tendencia de la actividad económica a corto plazo.
La segunda variable a considerar es el Índice Nacional de Precios al Consumidor (INPC).
Hay evidencia del impacto del INPC sobre variables económicas reales, Elguézabal (2004a).
Específicamente, el índice permite conocer ciertos impactos temporales en la economía nacional.
Por ejemplo, la inflación puede generar expectativa sobre el cambio de tendencia de la economía.
En consecuencia, el INPC es una variable determinante en la estimación del PIB.
3.4 Estimación a la mexicana
Actualmente, en México, se utilizan diversas metodologías para el tratamiento del PIB, los méto-
dos comúnmente utilizados pueden enmarcarse en tres categorías 3: 1) Los modelos derivados
2La estimación determinística y el método de Denton son los métodos para cambiar la frecuencia de los datos.Más adelante se explica la intuición de estos métodos.
3Véase en Elizondo (2012)
9

del método de Denton, 2) los modelos derivados del filtro de Kalman y 3) la especificación de
cambios estructurales múltiples. A continuación se explica cada categoría.
Primero, el método de Denton construye el PIB a partir de otra variable relacionada. Este
método constituye una alternativa formal para la proyección de datos de baja frecuencia uti-
lizando una serie de alta frecuencia. Es decir, se obtiene un algoritmo a través de los datos
mensuales de una variable relacionada con el PIB (puede ser IGAE o precio del petróleo, entre
otras) y a partir de ahí, se realizan las estimaciones trimestrales subsecuentes del PIB.
Metodológicamente, el método de Denton combina las series de alta frecuencia relacionadas
con el PIB y una serie que minimiza el residual (la diferencia entre la observación real y la
predicción). No obstante, esta aproximación es solo intuitiva pues sirve para marcar una tenden-
cia a corto plazo sin importar que los estimadores cumplan algún supuesto.
Segundo, los modelos que se derivan del filtro de Kalman utilizan la misma variable a estimar
y un conjunto de variables relacionadas con la ella. Elaboran un estimador recursivo basado en
la estimación de un sistema estocástico con las variables relacionadas y observables. El filtro de
Kalman combina toda la información observada en un periodo determinado y el conocimiento
previo del sistema. En otras palabras, utiliza la información histórica de la serie del PIB y la
información histórica de otras variables relacionadas con el PIB (puede ser IGAE, inflación o
precio del petróleo) para predecir una observación contemporánea o futura.
Tercero, la especificación de cambios estructurales múltiples fragmenta la serie histórica del
PIB para darle un tratamiento específico. Mejor dicho, divide la serie de tiempo en periodos
que aproximadamente tienen las mismas propiedades estadísticas para crear un modelo local
adecuado. Este tipo de modelos contempla los choques exógenos y su utilización es la más
frecuente para predecir variables como el PIB.
A partir de la descripción anterior, se destacan dos problemas. El primer problema proviene
de los modelos derivados del método de Denton, mientras que el segundo problema es resul-
tado de los modelos derivados del filtro de Kalman y la especificación de cambios estructurales
múltiples, Ize y Salas (1983).
10

El principal problema de los modelos que se derivan del método de Denton es que la fre-
cuencia de los datos suele aumentar el ruido en la serie de nuestra variable de interés, Elguézabal
(2004a). Mejor dicho, los intervalos de confianza de este tipo de modelos suele ser más amplios
y la predicción es menos precisa que los modelos de las otras dos categorías.
El problema de los otros dos modelos reside en la capacidad explicativa de las variables uti-
lizadas. Los modelos econométricos suelen utilizar otras variables para extrapolar el valor del
PIB, sin embargo, la información de las variables explicativas no es suficiente para poder ex-
plicar totalmente el comportamiento del PIB, Elguézabal (2004b). En otras palabras, tendríamos
que incluir una gran cantidad de variables que explican relativamente poco sobre PIB pero son
necesarias para aumentar la precisión de la estimación. En otros términos, los modelos no son
parsimoniosos y suele ser complicado tener actualizadas todas las variables explicativas. De tal
forma, la elaboración de estos modelos suele ser compleja y costosa en términos de tiempo.
En este sentido, este trabajo plantea una nueva metodología basada en la combinación de
diversos modelos econométricos. En concreto, la propuesta de este trabajo es demostrar la
combinación de estimadores que modelan los cambios estructurales, estrategias que optimizan
la correlación entre las variables y métodos para estimar y limpiar el error estocástico, suele
comportarse mejor que los modelos descritos con anterioridad.
11

Capítulo 4
Los datos
Se utilizaron siete series de tiempo para las estimaciones del PIB a precios constantes. Las series
de tiempo utilizadas tienen una frecuencia trimestral o mensual. Para empezar, los datos longi-
tudinales del PIB son los únicos que tienen una frecuencia trimestral y son desestacionalizados4
para el periodo de marzo de 1993 a enero 2017. Estos datos, con el año base en el 2003, están
conformados por 97 observaciones y fueron obtenidos del INEGI.
Entre las series de tiempo que tienen datos mensuales se encuentran: 1) Índice Nacional
de Precios al Consumidor (INPC), 2) Indicador Global de la Actividad Económica (IGAE), 3)
Tipo de cambio (peso-dólar), 4) Precio del petróleo y 5) el Índice de Precios y Cotizaciones. A
continuación se detallará los pormenores de cada una de ellas.
Se utilizaron dos series de INPC: datos originales y subyacentes5 . Los datos del INPC
registran el precio de la canasta básica a través del tiempo, es decir, miden la inflación. Estos
datos tienen una frecuencia mensual para el periodo 1993 a 2017, lo que corresponde a 312
observaciones para cada serie. El año base para ambas series es el año 2003 y los datos fueron
obtenidos del INEGI.
El IGAE provee información básica sobre la actividad económica y no incluye todas las
actividades como lo hace el PIB. Sin embargo, provee información preliminar para indicar la
4En las series desestacionalizadas se remueve a influencia de los factores estacionales y periódicos. La influenciade los factores estacionales suele dificultar el pronóstico de una serie económica.
5Los datos del INPC subyacente no incluyen los bienes temporales.
12

dirección de la actividad económica del país. Los datos del IGAE tienen una frecuencia mensual
desde 1994 hasta 2016. Las 279 observaciones fueron obtenidas del INEGI.
El tipo de cambio y el precio del petróleo representan la influencia del comercio internacional
en la economía nacional. Ambas series tienen una frecuencia mensual desde el año 2003 al 2017,
con 322 y 319 observaciones, respectivamente. Los datos de ambas series fueron obtenidos del
banco de datos del Banco de México.
Por último, el IPC representa la valoración del mercado de las principales empresas en el
país. Tal indicador provee información acerca de las expectativas sobre el mercado mexicano
y las oportunidades de inversión. Este índice tiene una frecuencia mensual y se utilizan en la
estimación de datos desde 1993 hasta 2017, correspondiente a 321 observaciones. Los datos
sobre el IPC fueron obtenidos del Banco de México. La tabla 4.1 resume las características
importantes sobre los datos a utilizados:
Datos Frecuencia Numero de FuenteObservaciones
PIB* Trimestral 97 INEGIINPC(subyacente) Mensual 312 INEGIINPC Mensual 312 INEGIIGAE Mensual 279 INEGITipo de cambio Mensual 322 BanxicoPrecio del Petróleo Mensual 319 BanxicoIPC Mensual 321 Banxico
Tabla 4.1: Resumen de los Datos
Para ver la relación entre las variables, se presenta las Figuras 4.1, 4.2 y 4.3 en donde se
observa el comportamiento del PIB desestacionalizado comparado con el IGAE, el IPC y con
el INPC subyacente. La figura superior muestra que el IGAE es un buen pronosticador; es fácil
identificar que el IGAE tiene la misma dirección que los movimientos del PIB. La Figura 4.2
muestra que el INPC subyacente tiene la misma tendencia que el PIB. Asi mismo, la Figura 4.3
muestra que el IPC converge en la misma dirección que el producto interno bruto. La relación
gráfica entre las variables que se representa en la figuras es un indicio de que las variables IGAE
13

e INPC pueden ser utilizadas para el pronostico del PIB.
Figura 4.1: Gráficas temporales del PIB-IGAE
7
8
9
10
11
12
13
14
15
1995 2000 2005 2010 2015 0.6
0.7
0.8
0.9
1
1.1
1.2
Mill
ones
de
peso
s
Mill
ones
de
peso
s
Años
PIB (izquierda)IGAE (derecha)
Figura 4.2: Gráficas temporales del PIB-INPC subyacente
7
8
9
10
11
12
13
14
15
1990 1995 2000 2005 2010 2015 0
0.2
0.4
0.6
0.8
1
1.2
Mill
ones
de
pes
os
Mill
ones
de
pes
os
Años
PIB (izquierda)INPC subyacente (derecha)
14

Figura 4.3: Gráficas temporales del PIB-IPC
0
5000
10000
15000
20000
25000
30000
35000
40000
45000
50000
1990 1995 2000 2005 2010 2015 7
8
9
10
11
12
13
14
15
Mill
ones
de
pes
os
Años
IPC (izquierda)PIB (derecha)
En la Figura 4.4 y 4.5 se realizaron primeras diferencias6 en las series para mostrar mejor
las relaciones entre variables PIB con el precio del petróleo y PIB con el tipo de cambio. La
gráfica superior muestra que la primera diferencia del precio del petróleo está relacionada con
la primera diferencia del PIB. Lo mismo pasa con la primera diferencia del tipo de cambio con
la primera diferencia del PIB. En suma, la relación del PIB con el petróleo y el tipo de cambio
es menos identificable que la relación del PIB con el IGAE y el INPC.
En resumen, se tendrán siete series temporales para realizar modelos de estimación del PIB.
Seis series tienen frecuencia mensual: 1) Índice Nacional de Precios al Consumidor (INPC), 2)
INPC subyacente, 3) Indicador Global de la Actividad Económica (IGAE), 4) Tipo de cambio
(peso-dólar), 5) Precio del petróleo y 6) el Índice de Precios y Cotizaciones. Además, una serie
con frecuencia trimestral: PIB. Los datos históricos del PIB son utilizados para predecir su
comportamiento en el futuro mediante una especificación autoregresiva7.
6La primera diferencia de una serie es necesaria para quitar la tendencia. La diferencia es el resultado del valorpresente menos el valor pasado. Es decir, ∆PIB = PIBt − PIBt−1.
7La función de autocorrelación encuentra patrones repetitivos dentro de una serie para proyectar los patrones enel futuro.
15
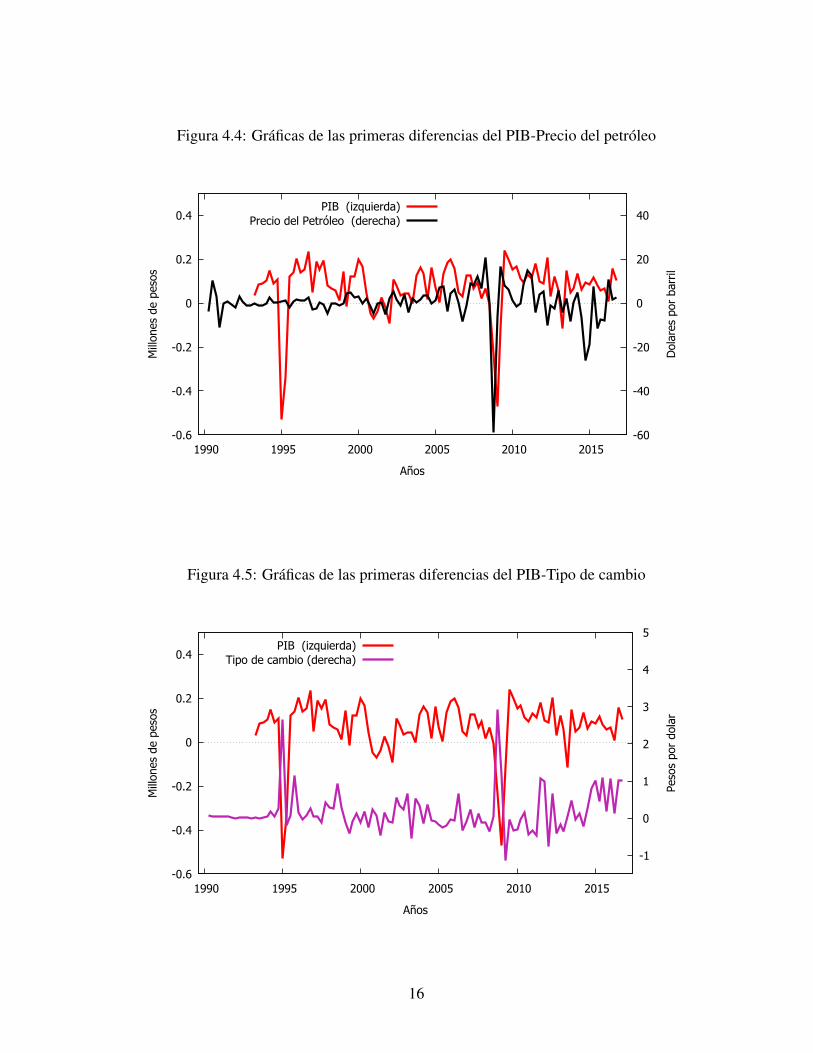
Figura 4.4: Gráficas de las primeras diferencias del PIB-Precio del petróleo
-0.6
-0.4
-0.2
0
0.2
0.4
1990 1995 2000 2005 2010 2015-60
-40
-20
0
20
40
Mill
ones
de
peso
s
Dol
ares
por
bar
ril
Años
PIB (izquierda)Precio del Petróleo (derecha)
Figura 4.5: Gráficas de las primeras diferencias del PIB-Tipo de cambio
-0.6
-0.4
-0.2
0
0.2
0.4
1990 1995 2000 2005 2010 2015
-1
0
1
2
3
4
5
Mill
ones
de
peso
s
Peso
s po
r do
lar
Años
PIB (izquierda)Tipo de cambio (derecha)
16

Capítulo 5
Metodología
En esta sección, se describe el procedimiento econométrico utilizado para la predicción del PIB.
Para predecir el PIB trimestral se utilizó una combinación de estrategias para pronósticos: 1)
Trasformaciones de variables Box y Cox (1964); 2) Desestacionalización de las series con un
filtro X12 ARIMA de Bureau (2002); 3) Tratamiento de cambios estructurales con la prueba
Bai y Perron (1998) y 4) Pruebas de estacionariedad de la serie.
Posteriormente, se utilizaron dos tipos de modelos: 1) Modelos econométrico auto regresivo
con medias móviles y con variables exógenas (ARMAX por sus siglas en ingles) y 2) Modelos de
aprendizaje computacional. A continuación se explica cada estrategia y cada modelo utilizado.
Para comenzar la explicación, es importante destacar que para cada una de las series, de-
scritas en la sección anterior, se realizaron las cuatro estrategias de pronósticos. Sin embargo,
se ejemplifica cada estrategia únicamente con el tratamiento de la variable dependiente PIB. La
finalidad de las cuatro estrategias es optimizar el modelo ARMAX e incrementar la capacidad
predictiva del modelo.
5.1 Transformación de variables
En primer lugar, se realizó una trasformación Box y Cox (1964) de cada variable explicativa.
Esta trasformación tiene el objetivo de mejorar la correlación entre las variables al garantizar el
17

cumplimiento de todos los supuestos del modelo lineal. Es decir, que las variables explicativas
tengan una varianza homogénea y su distribución de probabilidad se parezca a una distribución
normal.
Figura 5.1: Optimización de la trasformación Box-Cox
Las trasformaciones Box-Cox están dadas por:
Y (λ) =
(Y λ−1)
(λ×GMλ−1) cuando λ 6= 0
GM(ln(Y )) cuando λ = 0
Donde: GM = (Y1Y2Y3 . . . Yn)1/n
Donde se elige una lambda que minimice la diferencia de la distribución de los datos al
18

compararla con una distribución normal. Esta lambda se estima con un modelo de máxima
verosimilitud y se selecciona la lambda que acerque la distribución de los datos a una normal.
La Figura 5.1 muestra la elección de la lambda óptima para la variable PIB, donde se mini-
miza la varianza de la distribución de la variable exógena en comparación con una distribución
normal. Esta transformación mejora la correlación entre el PIB y las otras variables. En conse-
cuencia, mejora la predicción del PIB.
5.2 Desestacionalidad de las series
El filtro X-12 ARIMA desarrollado por Yule’s y Yule’s (n.d.) para efectuar la desestacional-
ización de la serie, supone que está compuesta por:
Xt = TCt + Et+ It
Dónde:
Xt = serie original
TCt = componente tendencia-ciclo
Et = componente estacional
It = componente irregular
Los métodos de promedios móviles presuponen que tanto la tendencia como la estacionali-
dad tienen comportamientos dinámicos con el paso del tiempo. En consecuencia, la tendencia y
el componente estacional, en un punto determinado del tiempo, se estima como promedio de las
observaciones previas y futuras.
La desestacionalización elimina el componente estacional y el componente de tendencia-
ciclo con el objetivo de eliminar la influencia de factores exógenos como: variaciones climáticas
estacionales, convenciones sociales o reglas administrativas (como las vacaciones). La deses-
tacionalidad elimina la irregularidad de la variable para dejar limpio el efecto de la variable
PIB.
19

Figura 5.2: Filtro X-12 ARIMA
7
8
9
10
11
12
13
14
15
16
1995 2000 2005 2010 2015
Mill
ones
de
peso
s
Años
PIBPIB despues del filtro(X-12 ARIMA)
La Figura numero 5.2 muestra la desestacionalización del PIB trimestral. En la gráfica supe-
rior se muestra la gráfica del PIB antes del proceso de desestacionalización y en la línea azul se
muestra la misma gráfica del PIB después del tratamiento de desestacionalización con el filtro
X-12 ARIMA.
5.3 Estimación del quiebre estructural
Un cambio estructural existe cuando hay un cambio inesperado en una serie de tiempo. Los
cambios estructurales pueden ser un cambio en la constante o un cambio en la tendencia. La es-
timación de quiebres estructurales de Bai y Perron (1998) recolecta varias muestras de la serie,
introduce un cambio estructural y estima un modelo lineal de mínimos cuadrados. Posterior-
mente, la prueba indica el punto en el tiempo donde la suma de los residuales al cuadrado es
mínima.
La Figura 5.3 muestra el tratamiento de quiebre estructural de la variable PIB. Como puede
observarse, la línea azul representa las distintas tendencias a lo largo de la serie. Los saltos
20

de la línea azul representan los quiebres estructurales de la serie. Mediante esta estimación
de cambios de constante y tendencia podemos definir mejor los cambios abruptos del PIB. Se
encontró que la variable PIB tiene tres quiebres estructurales. Las fechas son: 1995:1, 2007:4 y
2009:1.
Figura 5.3: Quiebre estructural
150
200
250
300
350
400
450
500
1995 2000 2005 2010 2015
Mile
s de
mill
ones
de
peso
s
Años
PIBLinea de tendencia
1995/1
2007/4
2009/11°quiebre:
2° quiebre:
3° quiebre:
5.4 Pruebas de estacionariedad
Al correr una regresión es importante la estacionariedad8 de la variable dependiente y la vari-
able independiente. La estacionariedad de la serie afecta las propiedades estadísticas de los esti-
madores. De tal forma, que una regresión con una que emplea variables no estacionarias puede
generar inferencia sin sentido (lo que se conoce habitualmente como regresión espuria), Granger
y Newbold (1974). Por lo consiguiente, antes de incluir las variables en el modelo econométrico
es necesario investigar individualmente la estacionariedad de cada serie de tiempo. En este8Estacionariedad en covarianzas se define como: sea {Y }∞t=−∞ un proceso aleatorio. Si ni sus medias ni
sus auto covarianzas (µt ni γjt∀j = 1, 2, . . . ) dependen del instante t entonces el proceso es estacionario encovarianzas.
21

proceso se hicieron cuatro pruebas de estacionalidad: 1) prueba de Dickey y Fuller (1979), 2)
prueba Dickey-Fuller GLS , 3) prueba Phillips y Perron (1988) y 4) coeficiente de integración
fraccional de Whittle (1951).
5.5 Estimación del modelo
Después de realizar las cuatro estrategias, se utilizaron dos tipos de modelos para la predicción
de la variable dependiente: Modelos autoregresivos con medias móviles y máquinas de soporte
vectorial.
La variable dependiente es el PIB trimestral. Mientras que las variables independientes son:
1) Índice Nacional de Precios al Consumidor (INPC), 2) INPC subyacente, 3) Indicador Global
de la Actividad Económica (IGAE), 4) Tipo de cambio (peso-dólar), 5) Precio del petróleo y
6) el Índice de Precios y Cotizaciones. A continuación se explican las características de cada
modelo en cuestión.
5.5.1 Modelos Autoregresivos con Medias Móviles
El modelo ARMAX (p, q, b) se refiere al modelo con p términos autoregresivos, q medias
móviles y b variables exógenas. El modelo ARMAX tiene los mismos principios del modelo
ARMA: se ponderan los rezagos que se correlacionan con la observación contemporánea AR
(p) y también se ponderan los residuales que se correlacionan con el error contemporáneo MA
(q). Adicionalmente, se incluye la correlación lineal de la combinación de variables exógenas
(d).
Xt = εt +
p∑i=1
φiXt−i +
q∑i=1
θiεt−i +b∑i=1
ηidt−i
Donde: η1 . . . ηb son los parámetros de las variables exógenas (dt).
22

5.5.2 Support Vector Regression (SVR) y Kernel Ridge Regression (KRR)
Los SVR y KRR se refieren a algoritmos computacionales basados en la teoría de aprendizaje.
Estos modelos realizan tres procedimientos para encontrar un modelo de clasificación parsi-
monioso: Primero, realizan una partición de los datos en regiones disconjuntas. Mediante un
algoritmo determinan el número de muestras en los datos. Segundo, el modelo realiza repre-
sentaciones de múltiples dimensiones de los datos. El objetivo es encontrar la representación
más simple de los datos para disminuir la complejidad del modelo. Tercero, el algoritmo pro-
pone una función que minimice el error entre el valor real y el valor predicho.
Figura 5.4: Muestreo y trasformación de los datos de los métodos de aprendizaje computacional
La Figura 5.4 muestra las dos primeras etapas del procedimiento de los SVR y KRR: En el
panel izquierdo se ejemplifica el muestreo de los datos y la partición de los datos en regiones
disconjuntas, mientras, el panel derecho muestra la segunda etapa donde se aumenta la dimen-
sión de los datos para encontrar un relación más simple de ellos. Finalmente, en la Figura 5.5
se muestra el ajuste de los diferentes modelos: en el panel izquierdo se muestra el ajuste de un
SVR y en el panel derecho se muestra el ajuste de un KRR.
23

Figura 5.5: Support Vector Regression y Kernel Ridge Regression
Existen múltiples tipos de SVR, o mejor dicho, existen SVR especializados en encontrar
distintas funciones en los datos: lineales, radiales, logarítmicas, exponenciales, entre otras. En
esta tesina se evalúa el comportamiento de los modelos SVR lineales, radiales y modelos no
lineales, llamados Kernel Ridge Regression (KRR), Welling (2013).
La técnica KRR propone una solución no lineal. Esta técnica parte de un espacio de entrada
no lineal y propone una solución no lineal para moverse a un espacio de características lineales.
La idea del KRR es semejante al SVR al hacer un muestreo de los datos de entrada y aumentar
la dimensión de los datos hasta encontrar un modelo idóneo. La principal diferencia entre los
modelos SVR y KRR es que los modelos SVR buscan dar ajuste a una regresión lineal mientras
que los modelos KRR amplían el catalogo de funciones a las funciones no lineales.
24

Capítulo 6
Resultados
En esta sección se describen y evalúan los resultados provenientes de dos tipos de modelos. Por
un lado están los resultados de los modelos Autoregresivos con medias móviles: 1) los modelos
que utilizan solamente el modelo ARIMA, 2) los modelos que utilizan el modelo ARMAX y 3)
los modelos que utilizan la trasformación Box-Cox, el filtroX−12 y el ajuste de quiebre estruc-
tural de Bai y Perron (2017). Por otro lado, están los resultados de los métodos de aprendizaje
computacional: 1) SVR radiales y 2) KRR.
6.1 Modelos Autoregresivos con Medias Móviles
La evaluación de los modelos de predicción se realiza tomando en cuenta dos aspectos. En
primer lugar, el tamaño del periodo9 . Se parte de la idea generalizada que los modelos a corto
plazo tienen más oportunidades de predicción que los de largo plazo. No obstante, la capacidad
para extrapolar el modelo es mejor en los modelos de largo plazo que en los modelos de corto
plazo. Por tal motivo, todos los modelos utilizan la muestra completa de los datos, Makridakis
et al. (1982).9El tamaño del periodo puede ser corto o largo plazo. Aunque son términos comparativos, se considera un
largo plazo cuando se utilizan todas las observaciones para predecir y en correspondencia, se considera corto plazocuando se utiliza solamente una muestra para la predicción. Por ejemplo: si nuestra base de datos es de 1993 hasta2016, un modelo de largo plazo utilizará este mismo periodo para predecir el año 2017. Mientras tanto, un modelode corto plazo puede utilizar solamente el año 2016 para predecir el 2017.
25

En segundo lugar, se toma en cuenta el porcentaje de error absoluto medio10 (MAPE por
sus siglas en inglés). Este porcentaje puede ser utilizado para comparar los ajustes obtenidos de
diferentes modelos. Los valores más pequeños indican un modelo de ajuste más adecuado.
6.1.1 Aproximación con modelos ARMA
Para el primer tipo de modelos se considera la representación más sencilla de un modelo ARMA
y se utiliza la misma variable del PIB rezagada para la predicción. El modelo ARMA utiliza
la serie del PIB trimestral diferenciada para eliminar la tendencia de la serie y los quiebres
estructurales. En el cuadro 6.1 se muestra un resumen de los resultados de los mejores modelos
estimados a partir de los modelos ARIMA:
Número Porcentaje Porcentaje deModelos de de error error absoluto
Observaciones medio medio
Datos tratados1) α + θ1 95 -0.098 1.11
Datos originales2) α + φ1 + φ3 + φ4 + φ6 + φ11 78 -103.35 210.19
Tabla 6.1: Resumen de modelos ARMA
El cuadro 6.1 muestra que el modelo con mejor ajuste es el modelo que usa los datos con el
tratamiento de la función Box Cox y el filtro X-12 ARIMA. Con base en el criterio del mínimo
porcentaje de error absoluto medio y el porcentaje de error medio podemos observar que la
utilización de datos tratados mejora la estimación de la serie dentro de la muestra.
10El error porcentual absoluto medio es un indicador del desempeño del pronóstico. El MAPE mide el tamañodel error absoluto en términos porcentuales. La fórmula del MAPE es: [(
∑| (Yt − yt)Yt |) /n]× 100 donde Yt es
igual al valor real, es igual al valor ajustado y n es igual al número de observaciones.
26

6.1.2 Aproximación con modelos ARMAX
Para el segundo tipo de modelos se considera la representación más sencilla de los modelos
ARMAX. Para predecir el PIB trimestral los modelos ARMAX utilizan cinco series de tiempo
adicionales: 1) Índice Nacional de Precios al Consumidor (INPC), 2) Indicador Global de la
Actividad Económica (IGAE), 3) Tipo de cambio (peso-dólar), 4) Precio del petróleo y 5) el
Índice de Precios y Cotizaciones. En el cuadro 6.2 se muestra un resumen de los tres modelos
ARMAX con el mejor ajuste.
Número Porcentaje Porcentaje deModelos de de error error absoluto
Observaciones medio medio
Datos tratados3) α + θ1 + θ2 94 0.054962 0.67042+∆Tipodecambio+ ∆IPC + ∆IGAE
Datos originales4) α + θ1 + θ2 94 -4.1821 133.73+∆Tipodecambio+ ∆IPC + ∆IGAE
Tabla 6.2: Resumen de modelos ARMAX
El cuadro 6.2 muestra que el modelo con mejor ajuste ocurre cuando se utilizan los datos
tratados. Según el mínimo porcentaje de error absoluto y el porcentaje de error medio, los mod-
elos ARMAX con datos tratos son mejores para la estimación del PIB. Es importante destacar
que todos los modelos estimados con el modelo ARMAX utilizan más datos y en general tienen
un mejor ajuste que los modelos de largo plazo ARMA.
6.1.3 Aproximación con modelos que utilizan la trasformación Box-Cox,
el filtro X − 12 y el ajuste de quiebre estructural de Bai y Perron
Para el tercer tipo de modelos se considera el modelo ARMAX y el ajuste de quiebre estructural
del PIB. Es importante destacar que tiene la misma especificación que el modelo ARMAX con
los datos tratados de la clasificación anterior con la única diferencia que se estima los quiebres
27

estructurales. En el cuadro 6.3 se muestra que mejora la estimación del PIB. Según los criterios
de Porcentaje de error Medio y el porcentaje de error absoluto medio podemos decir que este
modelo es el mejor de los modelos presentados en este trabajo. La Figura 6.1.3 muestra el
pronóstico dentro de la muestra realizado con el modelo. Se puede observar que la línea de
predicción se asemeja a la variable observada.
Número Porcentaje Porcentaje deModelo de de error error absoluto
Observaciones medio medio
Datos tratados5) α + θ1 + θ2 + ∆Tipodecambio 94 0.015425 0.6519+∆IPC + ∆IGAE + SB∗
Tabla 6.3: Modelo ARMAX con tratamiento de cambio estructural
Figura 6.1: Estimación intramuestral del PIB
40
60
80
100
120
140
160
180
200
1995 2000 2005 2010 2015
Billo
nes
de p
esos
Años
PIB observadoPIB estimado (intramuestral)
28

6.2 Métodos de aprendizaje computacional
La evaluación de este tipo de modelos se realiza utilizando las curvas de aprendizaje. Las curvas
de aprendizaje relacionan el tamaño de la muestra que el modelo utiliza para el entrenamiento y
el error absoluto medio del modelo.
Se parte de la idea que entre mayor sea el tamaño de la muestra mayor será la capacidad de
predicción. No obstante, es conveniente usar las curvas de aprendizaje porque pueden mostrar
el problema de ajuste en el modelo. Es decir, que el modelo no mejora la predicción aunque
aumente la muestra para entrenamiento, por el contrario, la predicción empeora. Además, las
curvas de aprendizaje puede mostrar gráficamente cuan mejor es un modelo respecto a otro. Por
este motivo, estos gráficos brindan la mejor alternativa en el momento de comparar distintos
modelos SVR y KRR.
6.2.1 Aproximación con SVR radiales
Debido a las características cíclicas del PIB, el modelo radial es quien mejor predice el compor-
tamiento del PIB comparado con el modelo lineal y polinomial. Los SVR radiales funcionan
mejor con los datos originales. Los datos originales son los que tiene mayor varianza y es
evidente el componente cíclico porque los datos no han sido desestacionalizados.
Con base en la curva de aprendizaje 6.2 y 6.3 podemos apreciar que no hay diferencia entre
mayor sea el porcentaje de los datos que el modelo utiliza para el entrenamiento. Es decir, que
el modelo SVR radial suele comportarme mejor que los modelos KRR cuando la muestra de
entrenamiento es pequeña (menos del 15 porciento de los datos).
Además, el modelo SVR radial funciona mejor cuidando los principios de ergodicidad y
estacionariedad de las series. Al utilizar las primeras diferencias de los datos se eliminó la
tendencia y la sospecha de caminata aleatoria de la serie. Es importante destacar que las pruebas
de estacionariedad dan prueba de la utilización de las primeras diferencias. Inclusive, la Figura
6.1 es evidencia que el modelo SVR radial funciona mejor con la primera diferencia de los datos
29

Figura 6.2: Curva de aprendizaje de los modelos que usan datos originales
Figura 6.3: Curva de aprendizaje de los modelos que usan datos tratados
originales.
30

6.2.2 Aproximación con modelos KRR
Los modelos KRR resultaron ser los mejores con los datos originales, los tratados y las primeras
diferencias. Este tipo de modelos amplia el catálogo de funciones lineales y no lineales que los
modelos SVR, por tal motivo, resulta esperado que mejoren los pronósticos al encontrar más
relaciones entre las variables.
Figura 6.4: Curva de aprendizaje de los modelos que usan primeras diferencias
Los modelos KRR mejoran con el aumento de la muestra de datos para entrenamiento. El
aumento en el ajuste del modelo aumenta exponencialmente después del 10 porciento del por-
centaje de datos para el entrenamiento. Esto nos puede dar una idea del funcionamiento y de
la utilización de estos modelos para predecir. En otras palabras, los modelos KRR son ideales
cuando tenemos un mayor número de observaciones.
Al igual que los modelos SVR radiales, el modelo KRR funciona mejor cuidando los princi-
pios de ergodicidad y estacionaridad de la serie. La Figura 6.5 da evidencia del sobreajuste del
modelo KRR con los datos originales (línea amarilla).
No obstante, el modelo KRR con los datos originales es el mejor modelo para pronóstico
31
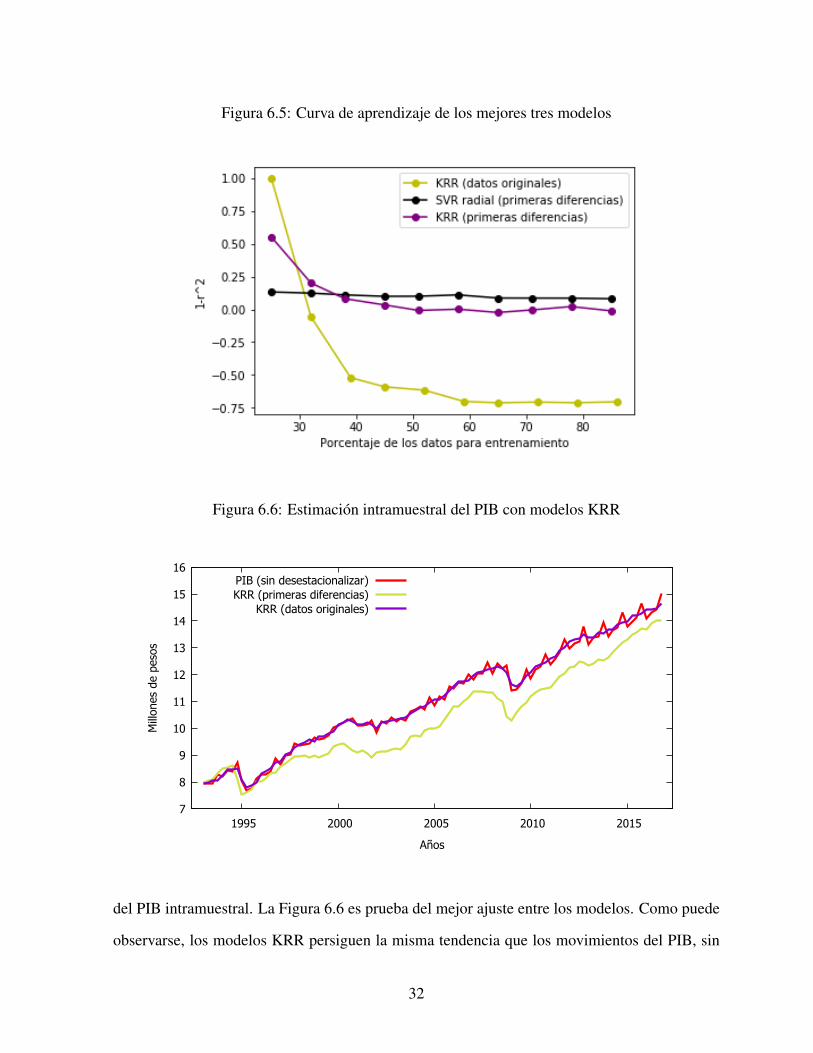
Figura 6.5: Curva de aprendizaje de los mejores tres modelos
Figura 6.6: Estimación intramuestral del PIB con modelos KRR
7
8
9
10
11
12
13
14
15
16
1995 2000 2005 2010 2015
Mill
ones
de
peso
s
Años
PIB (sin desestacionalizar)KRR (primeras diferencias)
KRR (datos originales)
del PIB intramuestral. La Figura 6.6 es prueba del mejor ajuste entre los modelos. Como puede
observarse, los modelos KRR persiguen la misma tendencia que los movimientos del PIB, sin
32

embargo, hay un sesgo en el modelo que utiliza las primeras diferencias. Esto puede deberse a
la perdida de la tendencia al momento de diferenciar la serie.
6.3 Comparación de pronósticos intramuestrales y extramues-
trales
Figura 6.7: Pronóstico ARMAX intra y extra-muestral
100
120
140
160
180
200
220
2000 2002 2004 2006 2008 2010 2012 2014 2016
Billo
nes
de p
esos
Años
PIBPredicción
Intervalo de 95 por ciento
Predicción intramuestral
Predicción extramuestral
En este apartado se muestran los resultados de los pronósticos intramuestrales y extramues-
trales del mejor modelo ARMAX y el mejor modelo SVR. Los modelos ARMAX se evaluaron
con el porcentaje de error medio y el porcentaje de error absoluto medio. Mientras, los modelos
SVR se evaluaron con el coeficiente de determinación (R2). Además, el modelo ARMAX utiliza
datos tratados con la trasformación Box-Cox y el filtro X-12 ARIMA, mientras, el modelo SVR
utiliza los datos originales. Por tal motivo, la comparación de los modelos se realizó utilizando
el gráfico XY (o línea de 45 grados) para observar la relación lineal entre las dos variables.
Mejor dicho, se utiliza la línea de 45 grados para observar el ajuste del PIB observada y el PIB
33

estimada.
Figura 6.8: PIB original con respecto al pronóstico intramuestral de KRR
7
8
9
10
11
12
13
14
15
16
8 9 10 11 12 13 14
PIB
orig
inal
(M
dp)
KRR con datos originales (Mdp)
PIB ObservadoPIB Estimado
La línea de 45 grados puede mostrar visualmente el ajuste del modelo a los datos. Mientras
más alineados estén los datos observados (cruces rojas) a los datos estimados (línea recta) indica
que el modelo es un buen estimador. Es más, se puede realizar una estimación de mínimos
cuadrados ordinarios entre los datos observados y los datos estimados para saber el coeficiente
de determinación del modelo. Todo esto con el objetivo de realizar la comparación entre dos
tipos de modelos que utilizan diferentes formas de medir el ajuste y diferentes datos.
Pronósticos intramuestrales
Los pronósticos intramuestrales se realizaron utilizando los datos de 1993 a 2015. Estos datos
corresponden al 95 por ciento de la muestra. Las Figuras 6.6 y 6.1 muestran el ajuste de los
modelos. Mientras, las Figuras 6.7 y 6.8 muestran de una manera más simple el ajuste de
los modelos KRR y el modelo ARMAX. Visualmente podemos comparar en la línea de 45
grados que el ajuste ARMAX es mejor que el ajuste del modelo KRR porque las observaciones
34

Figura 6.9: PIB con respecto al pronóstico intramuestral ARMAX con datos tratados
40
60
80
100
120
140
160
180
200
220
60 80 100 120 140 160 180 200
PIB
con
dato
s tr
atad
os (
Bdp)
ARMAX con datos tratados (Bdp)
PIB ObservadoPIB Estimado
se alinean mejor en el modelo ARMAX. En el cuadro 6.4 se muestra el ajuste de mínimos
cuadrados de la línea diagonal con las observaciones del PIB. En resumen, las gráficas y el
cuadro indican que el mejor ajuste es el del modelo ARMAX.
NúmeroModelos de Coeficiente R2
observaciones
Datos tratados5)α + θ1 + θ2 + ∆Tipodecambio 91 .999984*** .999627+∆IPC + ∆IGAE + SB∗
Datos originales6)KRR 91 1.0049*** .993341kernel = lineal, α = .1
Tabla 6.4: Ajuste Mínimo Cuadrático de los pronósticos intramuestrales
35

Figura 6.10: Pronóstico ARMAX extramuestral
140
150
160
170
180
190
200
210
220
2011 2012 2013 2014 2015 2016
Billo
nes
de p
esos
Años
PIB estimadaPIB obsevada
Pronósticos extramuestrales
Los pronósticos extramuestrales se realizaron utilizando el 70 por ciento de los datos para el
entrenamiento del modelo y se utilizó el resto para probar el ajuste. Como puede observarse
en la gráfica 6.9, la predicción extramuestral corresponde al primer trimestre del 2010 hasta el
cuarto trimestre del 2016. Las gráficas 6.10 y 6.11 muestran el pronóstico del PIB extramuestral
utilizando los modelos ARMAX y KRR, respectivamente.
Además, las figuras 6.12 y 6.13 muestran gráficamente el ajuste de ambos modelos de man-
era más simple. Podemos observar que visualmente el ajuste del modelo ARMAX es mejor
que el ajuste del modelo KRR. El cuadro 6.5 indica el mismo resultado, según el coeficiente de
determinación.
Ventajas y desventajas
La estrategia de pronóstico está adaptada para los modelos ARMA, la estrategia se encarga de
optimizar la correlación entre las variables, limpiar los movimientos estacionales y los compo-
36
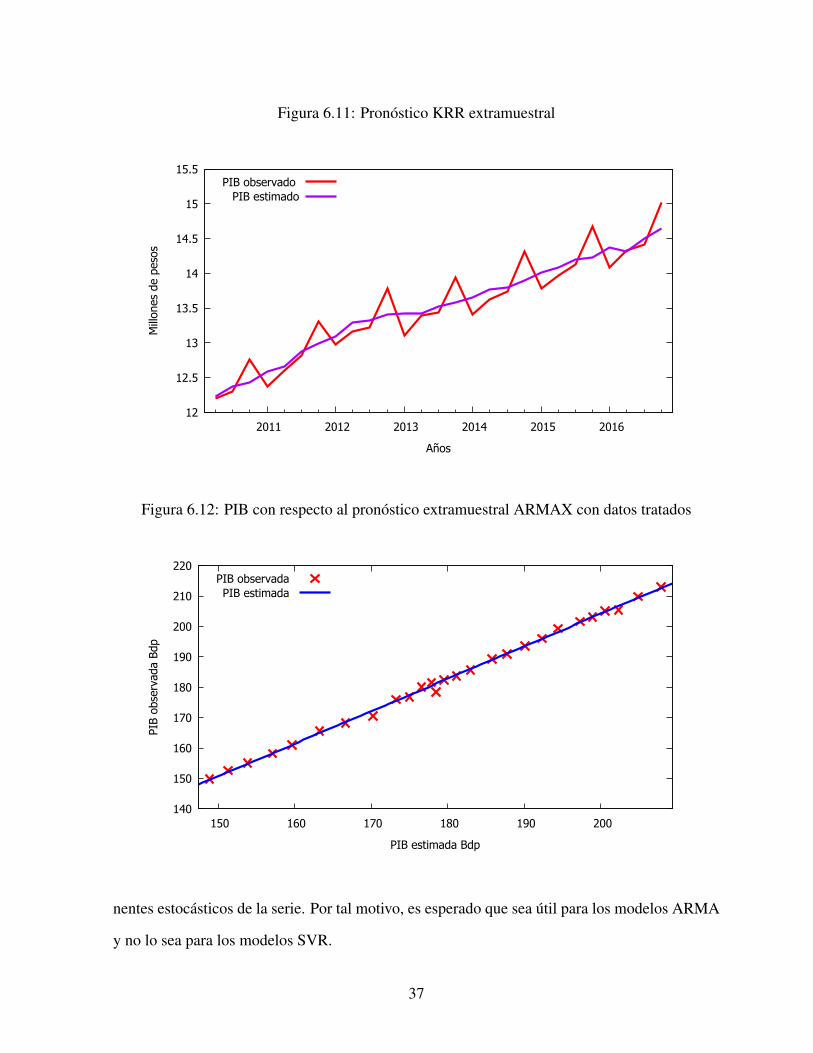
Figura 6.11: Pronóstico KRR extramuestral
12
12.5
13
13.5
14
14.5
15
15.5
2011 2012 2013 2014 2015 2016
Mill
ones
de
peso
s
Años
PIB observado PIB estimado
Figura 6.12: PIB con respecto al pronóstico extramuestral ARMAX con datos tratados
140
150
160
170
180
190
200
210
220
150 160 170 180 190 200
PIB
obse
rvad
a Bd
p
PIB estimada Bdp
PIB observada PIB estimada
nentes estocásticos de la serie. Por tal motivo, es esperado que sea útil para los modelos ARMA
y no lo sea para los modelos SVR.
37

Figura 6.13: PIB con respecto al pronóstico extramuestral KRR con datos originales
12
12.5
13
13.5
14
14.5
15
15.5
12.5 13 13.5 14 14.5
PIB
obse
rvad
a M
dp
PIB estimada Mdp
PIB observadaPIB estimada
NúmeroModelos de Coeficiente R2
observaciones
Datos tratados7)α + θ1 + IGAE + INPCsub 27 .93286*** .9979+∆IPC1 + SB∗
Datos originales8)KRR 27 1.02145*** .90017kernel = lineal, α = .1
Tabla 6.5: Ajuste Mínimo Cuadrático de los pronósticos extramuestrales
La construcción del mejor modelo presentado en esta tesis se realizó usando la metodología
Box-Jenkins y se realizaron aproximadamente 70 modelos para encontrar el modelo óptimo.
Este procedimiento tomo alrededor de 2 horas para cada modelo.
La construcción y el ajuste de los modelos ARMAX mejoran con el aumento de observa-
ciones. La estrategia de pronóstico tomo aproximadamente 8 horas para cada serie. El proceso
de construcción es artesanal. Es decir, es necesario tener práctica y conocimientos previos para
38

poder modelar.
La estrategia de pronóstico permite encontrar patrones en los movimientos de la serie que no
son esenciales para la construcción de un modelo ARMA. En este sentido, la estrategia divide
la serie en varios componentes que pueden ser tratados de una manera más especializada.
Los modelos SVR constituyen un buen pronóstico instantáneo de una serie de tiempo. En
particular los modelos KRR constituyen un mejor indicio que los modelos ARMA sin la es-
trategia de pronóstico. Estos modelos se nutren de la varianza de la serie y en consecuencia, la
estrategia de pronostico no mejora los resultados del pronóstico.
La construcción y ajuste de los modelos KRR toma alrededor de media hora. El modelo
se auto ajusta a partir de una línea de comando. En este caso el pronóstico del modelo KRR
solamente utilizo el 35 por ciento de los datos. En otra palabras, este tipo de modelos es útil en
muestras pequeñas.
39

Capítulo 7
Implicaciones de Política Pública
La metodología propuesta en este trabajo establece guías de apoyo para mejorar los pronósticos.
También, mejora la interpretación y conocimiento de los movimientos que son complejos en la
series de tiempo. En esencia, reduce la incertidumbre y respalda las decisiones de los hacedores
de política pública.
Esta metodología es parte de un herramental para el diseño, construcción y evaluación de
políticas públicas. Proporciona un estimado cuantitativo de la importancia de los movimientos
estocásticos, los movimientos estacionales y los cambios en la tendencia natural de la serie. Ya
que, es posible establecer la proporción y la influencia de diversos efectos en el comportamiento
de las series. Esto es, se puede obtener un conocimiento más amplio de todos los efectos en
lugar de establecerlos como un ruido blanco.
Con base en los resultados obtenidos en este trabajo, las implicaciones directas que tiene la
metodología propuesta en este documento son cuatro. En primer lugar, la metodología puede
ser utilizada para otros datos de series de tiempo. Estas series pueden ser tan generales como
específicas. Por ejemplo, población, clima, temperatura, nivel del mar, flujos de efectivo, ventas,
entre otras.
En segundo lugar, es posible realizar estimaciones sobre el impacto de ciertas políticas públi-
cas. Es decir, mediante el estudio del quiebre estructural podemos saber el impacto de ciertas
40

reformas, cambios o creación de políticas públicas. En este sentido, el cambio estructural puede
mostrar cambios de una variable que representa un problema tratado con una política pública,
puede mostrar la evolución del problema y el efecto de diversas soluciones.
En tercer lugar, tener mejores mediciones puede mejorar el análisis de los problemas sociales
y contribuir al desarrollo de soluciones. Inclusive, puede mejorar la toma de decisiones por parte
de los hacedores de políticas y los diseñadores de programas sociales. Por ejemplo, se pueden
realizar estimaciones intramuestrales y extramuestrales para tomar decisiones sobre la viabilidad
de proyectos o sobre el comportamiento de variables con tendencia.
41

Capítulo 8
Conclusiones
En este documento se realizaron diferentes estimaciones del PIB trimestral dentro de la muestra
utilizando dos tipos de modelos. Primero, los Modelos Autorregresivos de medias móviles:
1) modelos ARMA, 2) modelos ARMAX y 3) modelos ARMAX con estimación de quiebres
estructurales. Segundo, Métodos de aprendizaje computacional: 1) SVR Radial y 2) KRR.
Además, para las estimaciones se utilizaron dos tipos de datos: datos trimestrales originales y
datos trimestrales tratados con la función de transformación Box Cox y el filtro X − − − 12
ARIMA.
Por un lado, el propósito de utilizar dos tipos de datos fue mostrar los beneficios de la es-
trategia de predicción que aquí se presenta. La utilización de la trasformación Box-Cox permite
optimizar la correlación entre las variables. Mientras tanto, el filtro X − 12 ARIMA permite
estimar el componente cíclico de las series y limpiar el error estocástico. Por otro lado, se uti-
lizaron datos trimestrales para no cambiar la frecuencia de los datos del PIB y aumentar el ruido
en la serie.
De las diferentes estimaciones del PIB dentro de la muestra, se encontró que la mejor aprox-
imación se obtuvo con modelos ARMAX que utiliza el ajuste de quiebre estructural de Bai y
Perron y los datos tratados con la trasformación Box-Cox y el filtro X − 12. La forma de eval-
uar los modelos fue comparando dos diferentes medidas de error: el porcentaje de error absoluto
42

medio, r2 y el error absoluto medio.
Cabe destacar que no fue posible evaluar la propuesta de estimación aquí presentada con la
metodología utilizada por el Banco de México para la predicción del PIB. La razón es que la
metodología del banco central está restringida al público.
43

Referencias
Amparán, J. P. G., y Palacio, Y. V. (2003). “Manual sobre la clasificación económica del gasto
público.” Programa de Presupuesto y Gasto Público. Centro de Investigación y Docencia
Económica. CIDE, AC.
Bai, J., y Perron, P. (1998). “Estimating and testing linear models with multiple structural
changes.” Econometrica, 47–78.
Box, G. E., y Cox, D. R. (1964). “An analysis of transformations.” Journal of the Royal
Statistical Society. Series B (Methodological), 211–252.
Box, G. E., y Jenkins, G. M. (1976). “Time series analysis, rev. ed.” Holden, Oakland.
Bureau, U. C. (2002). X12 arima reference manual (Tech. Rep.).
Cao, L. (2003). “Support vector machines experts for time series forecasting.” Neurocomputing,
51, 321–339.
Capistrán, C., y López-Moctezuma, G. (2010). “Las expectativas macroeconómicas de los
especialistas. una evaluación de pronósticos de corto plazo en méxico.” El trimestre
económico, 77(306), 275–312.
Cowpertwait, P. S., y Metcalfe, A. V. (2009). Introductory time series with r. Springer Science
& Business Media.
de La Federación, D. O., y del presupuesto de las asignaciones. (2015). “Presupuesto de egresos
de la federación para el ejercicio fiscal 2015.”
Dickey, D. A., y Fuller, W. A. (1979). “Distribution of the estimators for autoregressive time
series with a unit root.” Journal of the American statistical association, 74(366a), 427–
44

431.
Elguezabal, A. P.-L. (1995). Un modelo de cointegracion para pronosticar el pib de mexico.
Banco de Mexico.
Elguézabal, A. P. L. (2004a). An econometric forecast model of private investment in mexico
(Tech. Rep.). Banco de México.
Elguézabal, A. P. L. (2004b). “Un modelo de pronósticos de la formación bruta de capital
privada de méxico.”
Elizondo, R. (2012). Estimaciones del pib mensual basadas en el igae (Tech. Rep.). Working
Papers, Banco de México.
Enders, W. (2004). “Applied econometric time series, by walter.” Technometrics, 46(2), 264.
Granger, C. W., y Newbold, P. (1974). “Spurious regressions in econometrics.” Journal of
econometrics, 2(2), 111–120.
Gutiérrez Lara, A. A. (2015). “Gasto público y presupuesto base cero en méxico.” El Cotidi-
ano(192).
Hamilton, J. D. (1994). Time series analysis (Vol. 2). Princeton university press Princeton.
Hernández Veleros, Z. S. (2011). “Finanzas públicas y crecimiento económico en los años
2003-2010: endeudamiento estatal y crisis económica.”.
Ize, A., y Salas, J. (1983). El comportamiento macroeconómico de la economía mexicana entre
1961 y 1981: especificaciones, alternativas y pruebas de hipótesis (No. 53). Banco de
México, Subdirección de Investigación Económica.
Kleinert, H. (2004). “Option pricing for non-gaussian price fluctuations.” Physica A: Statistical
Mechanics and its Applications, 338(1), 151–159.
Makridakis, S., Andersen, A., Carbone, R., Fildes, R., Hibon, M., Lewandowski, R., . . . Win-
kler, R. (1982). “The accuracy of extrapolation (time series) methods: Results of a
forecasting competition.” Journal of forecasting, 1(2), 111–153.
Neter, J., Kutner, M. H., Nachtsheim, C. J., y Wasserman, W. (1996). Applied linear statistical
models (Vol. 4). Irwin Chicago.
45

Phillips, P. C., y Perron, P. (1988). “Testing for a unit root in time series regression.” Biometrika,
75(2), 335–346.
Qiu, X., Suganthan, P., y Amaratunga, G. A. (2017). “Short-term electricity price forecasting
with empirical mode decomposition based ensemble kernel machines.” Procedia Com-
puter Science, 108, 1308–1317.
Revuz, D., y Yor, M. (1999). Continuous martingales and brownian motion, vol. 293 of
grundlehren der mathematischen wissenschaften [fundamental principles of mathemat-
ical sciences]. Springer-Verlag, Berlin.
Rüping, S. (2001). Svm kernels for time series analysis (Tech. Rep.). Technical Report, SFB
475: Komplexitätsreduktion in Multivariaten Datenstrukturen, Universität Dortmund.
Sargan, J. D., y Bhargava, A. (1983). “Testing residuals from least squares regression for being
generated by the gaussian random walk.” Econometrica: Journal of the Econometric
Society, 153–174.
Singh, B., y Sahni, B. S. (1984). “Causality between public expenditure and national income.”
The Review of economics and Statistics, 630–644.
Thissen, U., Van Brakel, R., De Weijer, A., Melssen, W., y Buydens, L. (2003). “Using support
vector machines for time series prediction.” Chemometrics and intelligent laboratory
systems, 69(1), 35–49.
Vapnik, V. N., y Vapnik, V. (1998). Statistical learning theory (Vol. 1). Wiley New York.
Welling, M. (2013). “Kernel ridge regression.” Max Welling’s Classnotes in Machine Learning,
1–3.
Whittle, P. (1951). “Hypothesis testing in time series analysis-hafner.” New York, 1951.–136 p.
Yule’s, I., y Yule’s, K. (n.d.). “X-12-arima.”
46





























