Embed Size (px)
Citation preview

1
XXXI CONFERENZA ITALIANA DI SCIENZE REGIONALI UNA NUOVA STRATEGIA PER IL CENSIMENTO DELLA POPOLAZIONE E DELLE ABITAZIONI DEL 2011: CONFRONTO TRA TECNICHE PER LA PRODUZIONE DI INFORMAZIONE TERRITORIALE DI QUALITÀ
Francesco BORRELLI1, Giancarlo CARBONETTI2, Silvia DARDANELLI3 e
Luana DE FELICI4
SOMMARIO
La strategia decisa per l’esecuzione del prossimo censimento sarà caratterizzata
dall’introduzione di tecniche di campionamento. In particolare nei comuni di maggiori
dimensioni si procederà a somministrare un questionario di tipo long, contenente tutte le
variabili tradizionalmente rilevate con il censimento, solo ad un campione di famiglie e un
questionario in forma ridotta (short form) comprendente solo le variabili demografiche (sesso,
età, cittadinanza, stato civile, …) a tutte le famiglie non incluse nel campione. Si sta
valutando la possibilità di adottare, in alternativa alla versione short form, un questionario
medium form in cui siano inserite anche alcune domande relative al titolo di studio, alla
condizione professionale e agli spostamenti quotidiani, con livelli di classificazione di
minimo dettaglio.
L’obiettivo del presente lavoro è di valutare l’effetto sull’efficienza delle stime che si avrebbe
adottando una strategia campionaria basata su medium/long rispetto a quella basata su
short/long. A tale scopo i due scenari sono stati sottoposti a sperimentazione, utilizzando i
dati del censimento del 2001, per misurare e confrontare i livelli di accuratezza delle stime
riferite alle variabili che verranno rilevate tramite campione.
1 Istituto Nazionale di Statistica, Via Adolfo Ravà 150, 00142, Roma, e-mail: [email protected] 2 Istituto Nazionale di Statistica, Via Adolfo Ravà 150, 00142, Roma, e-mail: [email protected] 3 Istituto Nazionale di Statistica, Via Adolfo Ravà 150, 00142, Roma, e-mail: [email protected] 4 Istituto Nazionale di Statistica, Via Adolfo Ravà 150, 00142, Roma, e-mail: [email protected]

2
1 ITRODUZIOE5
Il censimento della popolazione, riguardando la totalità dei residenti sul territorio nazionale, è
l’operazione statistica più impegnativa in termini di risorse economiche, di organizzazione e
di lavoro sul campo (Fortini et al., 2007). L’analisi sulla conduzione del censimento del 2001
ha fatto emergere alcune criticità che, unitamente ai vincoli6 sui tempi di consegna dei dati ad
Eurostat (trasmissione entro il 1° Aprile 2014), sulle variabili obbligatorie (core topics), sulle
classificazioni (breakdowns) e sulle tavole statistiche (hypercubes), hanno portato alla
necessità di ristrutturare l’intero processo della rilevazione censuaria, in termini di
organizzazione, di strumenti e di metodologie.
Al fine quindi di migliorare l’efficienza delle operazioni di censimento sul campo e di
rispettare gli obblighi internazionali, sono state formalizzate diverse proposte di innovazione:
- diversificazione di metodi e organizzazione tra comuni di diversa ampiezza demografica;
- formazione di aree di censimento sub-comunali (Astorri et al., 2007) per la diffusione dei
risultati;
- realizzazione di archivi comunali di numeri civici geocodificati alle sezioni di censimento;
- impiego di liste pre-censuarie desunte dalle anagrafi comunali per la spedizione postale dei
questionari;
- uso congiunto di questionari ridotti e questionari completi;
- consegna postale dei questionari;
- multicanalità per la raccolta dei questionari (postale, web, centri di raccolta comunali).
Gli obiettivi di queste azioni sono quelli di ottenere un’organizzazione più flessibile sul
territorio, di aumentare il grado di specializzazione degli organi coinvolti, di diminuire i
rilevatori impiegati nelle operazioni e di ridurre il “fastidio statistico” sui rispondenti. Per
quest’ultimo scopo, la strategia censuaria progettata per il 2011 prevede, nei comuni più
grandi, l’adozione di tecniche di campionamento al fine di rilevare parte dell’informazione
socio-economica solo su campioni di famiglie.
La scelta di introdurre il campionamento nel censimento italiano è avvalorata anche
dall’analisi delle esperienze estere (Abbatini et al., 2007) dalla quale emergono realtà di Paesi
(Canada, Usa, Francia, Germania, Israele, Olanda) nei quali, adottando approcci non
tradizionali per il censimento, si producono stime per le variabili non strettamente
demografiche.
5 Ai fini dell’attribuzione delle singole parti del lavoro si fa presente che: i paragrafi 1, 2, 3.1, 3.2 e 6.1 sono interamente redatti da Giancarlo Carbonetti, il paragrafo 3.3, 5.1, 5.1.1, 5.1.2 e 7 da Luana De Felici, il paragrafo 4 da Silvia Dardanelli, il paragrafo 5.2 e 6.2 da Francesco Borrelli. 6 Tali vincoli sono stabiliti nel “CES Recommendations for the 2010 Censuses of Population and Housing”, preparato dall’UNECE (United %ations Economic Commission for Europe) in collaborazione con Eurostat (Statistical Office of European Communities) formalmente adottato a giugno 2006, in occasione della Conferenza degli Statistici Europei.

3
Alle famiglie estratte per il campione verrà somministrato un questionario completo
contenente tutte le variabili tradizionalmente osservate al censimento e al massimo livello
classificatorio; invece, alle famiglie escluse dal campione, si sta decidendo se somministrare
un questionario in versione molto ridotta (short form) contenente solo le domande relative alle
caratteristiche demografiche familiari e individuali, o uno in versione più ampia (medium form) comprendente anche alcune variabili socio-economiche classificate secondo un ridotto
numero di modalità.
Dal momento che l’adozione delle tecniche campionarie comporta l’errore di campionamento,
sono stati condotti alcuni studi rivolti a valutare i livelli di accuratezza attesa delle stime
prodotte nel contesto censuario. In particolare, la strategia basata sull’utilizzo di un disegno
casuale semplice di famiglie da lista anagrafica e sull’uso di stimatori di ponderazione
vincolata è stata ritenuta la migliore soluzione per produrre stime affidabili a livelli territoriali
comunali e sub-comunali.
Questo lavoro ha lo scopo di completare gli studi fino ad ora effettuati cercando di
confrontare, a partire dalla strategia individuata come la migliore, i livelli di efficienza delle
stime ottenibili tramite i questionari short/long rispetto ai questionari medium/long, anche per
differenti tassi di campionamento.
Dopo una descrizione della strategia campionaria proposta per il censimento del 2011
(paragrafo 2), si passa alla trattazione dei pesi di riporto all’universo e del procedimento di
calibrazione (paragrafo 3). In seguito vengono illustrati i contenuti informativi dei diversi tipi
di questionario proposti per la rilevazione censuaria del 2011 (paragrafo 4). Nella parte
seguente del lavoro si descrive prima la fase di sperimentazione (paragrafo 5) e
successivamente quella di analisi dei risultati (paragrafo 6). Sono infine riportate alcune
considerazioni connesse ai risultati ottenuti (paragrafo 7).
2 LA STRATEGIA CAMPIOARIA PER IL CESIMETO DELLA
POPOLAZIOE DEL 2011
Il campionamento, che interesserà solo i comuni di maggiori di dimensioni, prevede l’utilizzo
contemporaneo di un questionario breve, in una forma contenente solo quesiti relativi alle
abitazioni e alle caratteristiche familiari e demografiche (short form) o, in alternativa, in una
forma contenente anche alcune domande su “titolo di studio”, “condizione professionale” e
“non professionale” e “pendolarismo” (medium form), e di un questionario esteso (long form),
contenente tutte le variabili tradizionalmente rilevate in occasione del censimento.
Il questionario in versione long sarà somministrato, nei comuni sopra i 20mila abitanti7, solo a
campioni rappresentativi di famiglie, mentre il questionario breve sarà sottoposto alle
7 È in corso di valutazione la possibilità di estendere questa strategia anche ai comuni tra 5mila e 20mila abitanti.

4
rimanenti famiglie non incluse nel campione. Nei comuni più piccoli, invece, l’indicazione è
quella di utilizzare il questionario in versione estesa per tutte le famiglie residenti.
In base a tale approccio, i dati demografici e familiari deriverebbero da un conteggio
esaustivo, mentre, relativamente ai comuni sottoposti a campionamento, tutte o quasi (a
seconda che si utilizzi il questionario breve nella versione short o in quella medium) le
informazioni di tipo socio-economico e il loro incrocio con le variabili demografiche
sarebbero desunte da stime campionarie.
In generale, l’adozione di una strategia campionaria richiede scelte metodologiche connesse al
disegno di campionamento, ai domini per i quali produrre le stime8, alle variabili oggetto di
rilevazione campionaria, ai parametri da stimare e allo stimatore da utilizzare.
L’impostazione di base è comunque quella di adottare uno schema semplice di selezione del
campione di famiglie ed eventualmente diversificare la scelta dello stimatore per ottenere
elevati livelli di precisione delle stime campionarie. In merito sono state svolte delle
sperimentazioni per testare quali fossero, tra le possibili soluzioni metodologiche, quelle più
facilmente praticabili da un punto di vista organizzativo e più rispondenti alle esigenze di
precisione e qualità. In particolare, sono state condotte simulazioni sui dati del censimento
della popolazione del 2001 (Carbonetti et al., 2008b) al fine di valutare l’accuratezza delle
stime inerenti le frequenze relative e assolute per le modalità delle variabili di long form
singole o di incrocio (con le modalità delle variabili demografiche).
I risultati sperimentali hanno messo in evidenza che la strategia campionaria più efficiente è
quella che prevede l’adozione di uno schema di campionamento secondo un disegno casuale
semplice di famiglie da lista e l’uso di stimatori calibrati (Deville e Särndal, 1992), che hanno
il pregio di favorire una elevata rappresentatività del campione di famiglie.
Riguardo gli effetti sulla produzione del dato, dalle sperimentazioni è emerso che:
- le stime comportano un errore che, espresso in termini percentuali, diminuisce al crescere
della frequenza assoluta della variabile cui fa riferimento;
- errori più grandi sono prevedibili per frequenze assolute più piccole; a riguardo si sono
valutati metodi indiretti (Borrelli et al., 2008) per aumentare la precisione e quindi
l’affidabilità.
Infine, la scelta dell’adozione della strategia campionaria comporterà, per i comuni coinvolti,
una riduzione della mole dei dati da acquisire ed elaborare e favorirà l’esecuzione di maggiori
controlli sui dati raccolti a vantaggio della diminuzione degli errori di misura sempre presenti
al censimento (Cocchi, 2007).
8 A tal riguardo, per i comuni sopra i 20mila abitanti, si intende produrre stime relative al livello di massimo dettaglio territoriale coincidente con le aree di censimento, domini sub-comunali di dimensioni intorno alle 15mila unità, dati da aggregazioni di sezioni di censimento di tipo “centro” con il vincolo della contiguità.

5
3 LA DETERMIAZIOE DEI PESI DI RIPORTO ALL’UIVERSO
3.1 I pesi di riporto all’universo
I pesi di riporto all’universo sono utilizzati nel procedimento di stima e sono applicati agli
individui e alle famiglie selezionati dal disegno campionario, su cui si è proceduto alla
rilevazione con il questionario long. Ad ogni unità campionaria è quindi associato un peso base (peso diretto o da disegno) che esprime quante unità della popolazione sono
rappresentate dall’unità in questione. Una volta stabilito il disegno campionario si determina
il peso di ciascuna unità definito dall’inverso della probabilità di inclusione nel campione
della generica unità.
3.2 La fase di calibrazione
Al fine di aumentare la rappresentatività del campione e la coerenza dei dati osservati con
alcune informazioni note sulla popolazione di riferimento, si ricorre alla calibrazione. Tale
procedura permette di determinare i pesi di riporto all’universo in modo tale che essi risultino
il più vicino possibile ai pesi base secondo una prefissata misura di distanza, e allo stesso
tempo soddisfino il seguente criterio di calibrazione: le stime dei totali delle variabili
ausiliarie ottenute con questi pesi devono essere uguali ai corrispondenti totali di popolazione.
La determinazione, quindi, dei pesi finali delle unità campionarie procede dal calcolo dei pesi
iniziali (pesi diretti) e prosegue, tramite il procedimento di riponderazione, nella
determinazione dei pesi finali (pesi calibrati); è proprio l’operazione di calibrazione che
consente di migliorare la rappresentatività del campione e aumentare la precisione delle stime
finali.
Per la definizione della strategia campionaria, è stato deciso di utilizzare gli stimatori di ponderazione vincolata mediante l’introduzione di vincoli a totali noti di popolazione; la
costruzione dei pesi di riporto all’universo si è basata sulla risoluzione di un problema di
minimo vincolato, che impone l’uguaglianza tra un prefissato insieme di totali riferiti a tutte
le unità dell’area di censimento di centro abitato e relativi ad alcune variabili rilevate
esaustivamente (totali noti), e le corrispondenti stime campionarie determinate a livello di
area di censimento e derivanti dal questionario long form.
È stato condotto uno specifico studio per determinare l’insieme delle variabili di calibrazione,
tra quelle rilevate esaustivamente, i cui totali noti, risolvendo in maniera ottimale i problemi
di convergenza dell’algoritmo sottostante al software utilizzato9, rendono praticabile il
9 Per la procedura di calibrazione si è fatto uso della funzione di calibrazione del software Genesees v3.0 sviluppato in Istat (Pagliuca, 2005).

6
procedimento di calibrazione utilizzando un numero elevato di vincoli (i risultati sono
presentati in maniera dettagliata nel paragrafo 5.1).
3.3 Revisioni della procedura di calibrazione
A causa della convergenza non perfetta dell’algoritmo di ponderazione, riscontrata nelle
precedenti sperimentazioni in alcuni domini di stima, si è deciso di apportare delle modifiche
alla procedura di calibrazione. Dai lavori passati è emerso che le criticità venivano riscontrate
generalmente in caso di frequenze campionarie piccole delle variabili di calibrazione (0, 1, 2 o
3 unità). In questi casi, la mancata convergenza osservata come differenza tra stime finali e
totali noti riferiti alle variabili di calibrazione, può essere imputata all’elevata varianza
campionaria delle stime dirette che sono basate su poche unità campionate. Nelle precedenti
sperimentazioni la scelta risolutiva è stata quella di rivedere la struttura del sistema di vincoli
aggregando i totali noti con meno unità campionate al fine di giungere alla completa
convergenza dell’algoritmo. In questo lavoro invece si è deciso di introdurre delle modifiche
che si possono suddividere in due tipi:
� “interna”: cambiamento dei valori di alcuni parametri previsti dalla procedura di
calibrazione;
� “esterna” (da eseguire prima della procedura di calibrazione): operazioni sul dataset dei dati campionari10, utilizzato come input nella procedura, tramite l’introduzione di
unità campionarie supplementari o la variazione dei pesi diretti relativi ad alcune
famiglie.
La modifica del primo tipo ha riguardato l’allargamento dell’intervallo di variazione del peso
finale cambiando i valori dei moltiplicatori che sono fissati nella procedura per default. In
particolare, si è modificato il valore massimo del moltiplicatore così da far ricadere l’intero
insieme dei pesi finali nell’intervallo definito dai limiti allargati11.
Un altro problema che causa la non perfetta convergenza dell’algoritmo è la presenza di zeri campionari non strutturali in alcuni domini, ossia di valori che nel campione sono pari a zero
mentre nella popolazione sono diversi da zero. Tale situazione è stata risolta tramite la
costituzione, per ogni totale noto, di opportuni serbatoi di donatori formati dalle famiglie
campione. Nel caso in cui per dei totali noti in alcuni domini non venga estratta alcuna unità
10 La procedura di calibrazione prevede preliminarmente la definizione di due dataset di input: “Totali noti” e “Dati campionari”. Il primo contiene i totali, a livello di dominio pianificato, delle variabili ausiliarie utilizzate nello stimatore di calibrazione e ha tante righe quanti sono i domini pianificati. Il secondo dataset contiene le informazioni riferite alle unità campionarie che in questo studio sono le famiglie. Questo dataset contiene i valori delle varabili ausiliarie assunti da ciascuna unità . 11 La funzione di distanza utilizzata nel processo di calibrazione è la logaritmica troncata, sulla base della quale si individua l’insieme dei pesi finali che da un lato soddisfa il sistema dei vincoli, e dall’altro modifica il meno possibile l’insieme dei pesi diretti. L’adozione di tale funzione fornisce un’insieme di pesi finali compresi in un intervallo definito sulla base dei valori dei coefficienti moltiplicativi nel caso in cui l’algoritmo ammetta soluzione.

7
campionaria, si sceglie in modo casuale dai serbatoi suddetti un numero di famiglie
supplementari uguale al valore del totale noto moltiplicato per la frazione campionaria. A
queste famiglie si attribuisce un codice identificativo fittizio e l’appartenenza al dominio in
cui si verificano gli zeri campionari. Tali famiglie vengono aggiunte al dataset delle
osservazioni campionarie così da risolvere il problema dell’assenza di qualche modalità in
alcuni domini.
Un’ulteriore correzione è stata quella di cambiare il peso diretto nel dataset dei dati
campionari per le variabili di calibrazione che presentano poche unità nel campione.
Dapprima sono stati identificati i domini pianificati nei quali fossero presenti totali noti
campionari pari a 1, 2 o 3 unità; in seguito, alle famiglie che contribuiscono a fornire tali
valori campionari è stato riattribuito un peso iniziale pari al rapporto tra il totale noto del
dominio e il totale campionario relativo a quella variabile nel medesimo dominio.
Nel caso in cui ad una famiglia fosse attribuito più di un peso diretto relativo a più di un
valore campionario piccolo (1, 2 o 3) delle variabili di calibrazione (famiglia “critica”) è stata
adottata la seguente soluzione:
a) estrazione, in modo casuale dai serbatoi dei donatori relativi alle variabili di calibrazione
con valori campionari piccoli della famiglia critica, di una sola famiglia che viene
aggiunta al campione di famiglie riferite al dominio della famiglia critica e con codice
identificativo fittizio;
b) assegnazione alla famiglia critica di un peso iniziale pari all’inverso della frazione di
campionamento.
Attraverso tali modifiche si è raggiunta la convergenza dell’algoritmo di calibrazione per gli
insiemi di variabili scelte.
4 IL COTEUTO IFORMATIVO DEI QUESTIOARI SHORT, MEDIUM E
LOG
La definizione dei contenuti informativi del questionario per il prossimo censimento è stata
influenzata da un lato dai vincoli internazionali, suggeriti dalle Raccomandazioni e imposti
dal Regolamento Quadro e dai Regolamenti di attuazione e dall’altro dall’analisi della
esperienza italiana, come anche dall’introduzione della nuova strategia censuaria. Le
variazioni introdotte nel nuovo modello di rilevazione, rispetto al questionario del 2001,
risentono delle innovazioni previste sia in ambito europeo che in ambito italiano.
In vista della prossima tornata censuaria, e come accaduto anche per i censimenti 2000-01, la
Commissione Economica per l’Europa delle Nazioni Unite (UNECE) in cooperazione con
l’Ufficio Statistico della Comunità Europea (Eurostat) ha redatto le Recommendations for the 2010 Censuses of Population and Housing. Queste, al fine di garantire la comparabilità degli
output nei diversi paesi, contengono indicazioni per una definizione chiara dei concetti, per

8
una sincronizzazione delle operazioni di rilevazione e di quelle per la produzione dei dati
censuari.
Un’ampia parte delle Raccomandazioni internazionali è dedicata ai contenuti informativi, cioè
alla definizione degli argomenti e delle variabili da rilevare e alle relative classificazioni.
Accanto ai core topics (da inserire nel piano di rilevazione e/o diffusione obbligatoriamente)
nelle Raccomandazioni sono presentati i non core topics, ovvero variabili opzionali: ad ogni
singolo Stato viene lasciata la libertà di inserirle sulla base delle necessità e delle esigenze
informative proprie del Paese.
Inoltre, la Commissione Europea ha stabilito, per la tornata censuaria del 2010-11, di redarre
un Framework Regulation, Regolamento Quadro del Parlamento Europeo e del Consiglio
relativo ai censimenti della popolazione e delle abitazioni12. Il Regolamento Quadro nasce
dall’esigenza di garantire la conformità con le Raccomandazioni internazionali, armonizzare i
contenuti, sincronizzare i tempi e assicurare maggiore qualità e comparabilità dei dati prodotti
dai diversi paesi. Esso è contraddistinto da un approccio volto a garantire l’uniformità
dell’output delle rilevazioni censuarie, indipendentemente dalle tecniche e dai metodi
utilizzati. Il Framework Regulation pone le basi per la definizione di un programma
armonizzato di diffusione dei dati censuari a livello europeo, elencando in allegato le variabili
che dovranno essere obbligatoriamente diffuse in ambito censuario. Si tratta dei topics
identificati come core nell’ambito delle Recommendations 2010 e riguardano caratteristiche
demografiche, sociali ed economiche delle persone, ma anche aspetti legati alle famiglie, ai
nuclei familiari ed agli alloggi. Il Regolamento specifica, inoltre, quali di questi topics sono
obbligatori fino al livello di dettaglio geografico LAU2 (comunale per l’Italia) e quali solo
fino al livello NUTS2 (regionale). In aggiunta al Regolamento sono stati predisposti anche
alcuni Implementing Regulations (Regolamenti di attuazione), che riguardano le
classificazioni e specifiche tecniche (Implementing Regulation on population and housing censuses as regards the technical specifications of the topics and their breakdowns) e gli
ipercubi (Programme of the statistical data and of the metadata for population and housing censuses)13.
Nella progettazione dei contenuti informativi dei questionari di rilevazione italiani è stato
necessario garantire la conformità con i Regolamenti dell’Unione Europea ed il rispetto delle
definizioni e delle classificazioni imposte dalla normativa nazionale e internazionale; si è
inoltre tenuto conto della necessità di garantire la continuità con le passate rilevazioni
censuarie e di soddisfare specifiche esigenze informative degli utilizzatori italiani.
La nuova strategia di rilevazione, che prevede l’introduzione di tecniche di campionamento
per l’acquisizione di una parte delle informazioni censuarie, ha portato alla definizione di due
12 Il Regolamento è stato adottato a maggioranza dal Parlamento Europeo a febbraio, approvato a luglio e pubblicato nella Gazzetta Ufficiale dell’Unione europea ad agosto 2008. 13 Il terzo Regolamento di attuazione, in fase di stesura, riguarda la qualità dei dati (Implementing Regulation as regards the report on the quality of the transmitted data and the technical format for the data transmission).

9
di tipi di questionario: una versione “breve” ed una “estesa”. La prima include informazioni
che verranno rilevate in maniera esaustiva sull’intera popolazione italiana e comprendono
tutte le variabili demografiche necessarie per la produzione delle tavole statistiche
(hypercubes) che dovranno essere rese disponibili ad Eurostat a livello comunale. La versione
“estesa” (long form) contiene, oltre ai quesiti della forma “breve”, tutte le altre variabili
previste nel piano di rilevazione, che vengono dunque riservate ad un campione di famiglie
residenti.
In occasione della rilevazione pilota svolta ad ottobre del 2009, sono state predisposte due
forme “brevi” di questionario, le cosiddette short form e medium form, utilizzate
alternativamente in abbinamento con la long form. Di seguito si descrivono in maniera più
dettagliata i contenuti delle due proposte delineate.
4.1 La proposta short/long form
Tutti i questionari (short, medium e long) sono composti da: una Lista A contenente l’elenco
delle persone abitualmente dimoranti nell’alloggio (persone della famiglia), una Lista B
contenente l’elenco delle persone non abitualmente dimoranti nell’alloggio ma
temporaneamente o occasionalmente presenti nell’alloggio, una Sezione I con le notizie su
famiglia e alloggio e una Sezione II con le notizie sulle persone che hanno dimora abituale
nell’alloggio (notizie sui singoli componenti della famiglia). Le Liste A e B contengono le
stesse informazioni in tutte le versioni di questionario.
La versione short del modello di rilevazione include il minimo numero di quesiti, ovvero
esclusivamente le domande che permettono di produrre gli output da fornire
obbligatoriamente ad Eurostat a livello di dettaglio comunale. In particolare si tratta, per le
notizie su famiglia e alloggio, di informazioni sul tipo di alloggio, lo stato di occupazione, le
famiglie coabitanti e la superficie dell’abitazione; mentre per le notizie sulle persone che
hanno dimora abituale nell’alloggio si tratta solamente di caratteristiche demografiche
(relazione di parentela, sesso, età, luogo di nascita, stato civile, data di matrimonio, stato
civile prima dell’ultimo matrimonio, cittadinanza, dimora nell’anno precedente).
L’offerta informativa del modello di rilevazione di tipo long è notevolmente più ampia,
riguardando, oltre ai quesiti sopra citati, tutte le altre variabili di natura socio-economica
tradizionalmente acquisite in occasione del censimento, che sono relative all’istruzione e alla
formazione, alla condizione professionale, all’attività lavorativa ed al luogo di studio o di
lavoro. Per le notizie su famiglia e alloggio si aggiungono quesiti su l’acqua e l’impianto
igienico-sanitari, l’impianto di climatizzazione, l’auto e posto auto, il telefono e la
connessione ad internet.
I quesiti presenti esclusivamente nella versione long del modello rispondono ad esigenze
differenti: in alcuni casi rappresentano core topics imposti da Eurostat (ad esempio le variabili

10
sull’eventuale residenza all’estero e l’anno di arrivo nel Paese), in altri corrispondono a non core topics ritenuti particolarmente interessanti in ambito italiano (è il caso, ad esempio, del
Paese di nascita dei genitori che costituisce una novità per l’Italia e rende possibile una
valutazione del processo di integrazione degli immigrati e dei loro discendenti); vi sono poi
variabili che non vengono segnalate in ambito europeo ma rivestono esclusivamente interesse
nazionale (ad esempio, tra quelle relative al lavoro si può citare la frequenza di corsi di
formazione/aggiornamento professionale, il tipo di rapporto di lavoro e la tipologia dei
contratti di lavoro a tempo determinato). Nella long form sono inoltre inserite, al fine di
ampliare l’offerta dei dati sui flussi pendolari, le informazioni sul luogo di studio (degli
studenti) e di lavoro (degli occupati), sul mezzo di trasporto, sulla distanza percorsa e tempo
impiegato per recarsi al luogo di lavoro o di studio.
Secondo la proposta di tipo short/long form, comunque, la rilevazione esaustiva sarebbe
limitata alle caratteristiche demografiche degli individui, mentre le informazioni di natura
socio-economica rimarrebbero tutte oggetto di stima campionaria.
4.2 La proposta medium/long form
La proposta medium/long differisce dalla precedente in quanto la versione “breve” del
questionario di rilevazione è una medium form, caratterizzata, oltre che dalle variabili
strettamente demografiche, anche da poche informazioni di carattere socio-economico,
rimandando, anche qui, al questionario long form per una maggiore ricchezza informativa.
Il questionario di tipo medium contiene, oltre alle variabili della short form, anche un set di
quesiti relativi alla cittadinanza acquisita, al grado di istruzione, alle forze di lavoro e agli
spostamenti pendolari. In particolare, sono stati aggiunti 2 quesiti sulla acquisizione di
cittadinanza, 4 domande che riguardano il titolo di studio (con un minor numero di modalità
rispetto alla versione long), i corsi di formazione professionale regionale e i titoli di studio
post-laurea, 4 quesiti sulla condizione professionale che consentono di quantificare le forze di
lavoro e le non forze di lavoro, ed infine 4 quesiti relativi agli spostamenti quotidiani e al
luogo di lavoro. I contenuti informativi dei questionari short, medium e long sono riassunti,
per sezioni e sotto-sezioni nella Tabella 1.
Tutte le variabili rilevate con il questionario short (contenute anche nella versione long)
potranno essere diffuse a livello di sezione di censimento. Per le altre variabili contenute
esclusivamente nel modello long (quelle soggette a stima campionaria) sarà possibile
diffondere i dati non più per sezioni di censimento ma per aree di censimento. Naturalmente
questa distinzione varrà sicuramente per i comuni sopra i 20mila abitanti ma non per i comuni
sotto i 20mila (non sottoposti a campionamento) nei quali tutte le famiglie riceveranno il
questionario “esteso” e tutte le informazioni, rilevate esaustivamente, saranno disponibili
anche per sezione di censimento. La scelta di inserire nel questionario “breve” anche alcune

11
variabili di carattere socio-economico (proposta medium) permetterà di disporre di tali
informazioni a livello di sezione di censimento, seppur con un minor livello di dettaglio
classificatorio. Inoltre, con l’approccio medium/long form si avrebbe a disposizione una
maggiore informazione ausiliaria (rilevata esaustivamente sulla popolazione) utilizzabile in
fase di stima delle variabili inserite solo nei modelli long form e rilevate su un campione di
famiglie.
Tabella 1 - Distribuzione dei quesiti per sezioni nelle tre versioni di questionario.
Sezioni Sotto-sezioni
%umero quesiti
in LO%G
%umero quesiti rilevati esaustivamente
con SHORT
%umero quesiti rilevati esaustivamente con MEDIUM
Sezione I – Notizie su famiglia e alloggio
Tipo di alloggio e famiglia 4 3 4
Proprietà e struttura dell’abitazione 5 1 3
Acqua e impianto igienico-sanitari 6
Impianto di climatizzazione 4
Auto e posto auto 2
Telefono e connessione ad internet 2 Sezione II – Fogli individuali
Notizie anagrafiche 4 4 4
Stato civile e matrimonio 3 3 3
Cittadinanza 5 1 3
Dimora precedente 4 1 1
Istruzione e formazione 12 4
Condizione professionale 5 4
Attività lavorativa 8
Luogo di studio o di lavoro 7 4
Totale 71 13 30
5 LA SPERIMETAZIOE
L’obiettivo della sperimentazione è stato quello di misurare l’eventuale recupero di efficienza
ottenibile adottando una strategia campionaria basata su medium/long form rispetto a quella
basata su short/long form. A tale scopo si sono valutati i livelli di efficienza relativi alle stime
delle principali variabili rilevate in modo campionario tramite il questionario di tipo long form
nelle due strategie short/long e medium/long.

12
La sperimentazione è stata suddivisa in due fasi: la prima è relativa all’identificazione del set ottimale di vincoli di calibrazione per l’impiego dello stimatore di ponderazione vincolata
nell’ipotesi di adozione di una strategia basata su short/long form o su medium/long form. In
quest’ultimo caso, si potrà disporre di un più ampio insieme di variabili rilevate in modo
esaustivo, che potrebbero eventualmente essere utilizzate nella struttura di vincoli.
La seconda fase ha riguardato i confronti di efficienza del disegno casuale semplice da lista
per differenti frazioni di campionamento (ipotesi del 10%, 20% e 33%) per le due strategie
considerate.
Per ciascuna fase è stato condotto uno specifico blocco di sperimentazioni utilizzando i dati
relativi al censimento della popolazione e delle abitazioni del 2001.
5.1 Fase 1: la scelta dei vincoli di calibrazione
Lo stimatore calibrato richiede l’utilizzo di vincoli a totali noti di popolazione definiti in
funzione di specifici obiettivi. Con riferimento all’ambito censuario, è richiesto che le stime
di ponderazione vincolata riproducano il più possibile la struttura della popolazione rilevata in
modo esaustivo tramite i modelli short/long form o medium/long form.
Al fine di individuare l’insieme di vincoli di calibrazione, è stato condotto uno studio
sperimentale che accertasse la convergenza dell’algoritmo di ponderazione14 implementato
con le modifiche già descritte nel paragrafo 3.3. L’obiettivo è quello di definire i sistemi di
vincoli di massimo dettaglio che garantiscano da un lato la risoluzione esatta (convergenza
completa) del problema di minimo vincolato che sottintende l’algoritmo impiegato nella
calibrazione e dall’altro il rispetto delle distribuzioni marginali riferite alle variabili delle
tavole statistiche previste dal piano di diffusione del prossimo censimento.
La sperimentazione è partita considerando classificazioni a livello di massima
disaggregazione per passare poi, nei casi di non convergenza della procedura, a classificazioni
meno dettagliate tramite aggregazioni di modalità. Sono considerati ottimali gli insiemi di
variabili di calibrazione che, soddisfacendo la condizione di convergenza (sui domini
pianificati dal disegno di indagine: le aree di censimento di centro abitato), presentano
classificazioni con le disaggregazioni più fini.
La sperimentazione è stata eseguita separatamente per le strategie short/long e medium/long
per le diverse frazioni campionarie ipotizzate.
14 Le verifiche sono state eseguite su un numero limitato di simulazioni campionarie su dati riferiti al comune di Bologna.
13
5.1.1 La scelta dei vincoli di calibrazione per la strategia short/long
Per determinare l’insieme ottimale di totali noti nella strategia short/long sono state prese in
esame le due distribuzioni relative alla popolazione suddivisa per classi di età e sesso, per
stato civile e sesso (Tabelle 2 e 3).
Tabella 2 - Struttura della popolazione per età e sesso presa in esame per la calibrazione.
Struttura Descrizione dei vincoli di calibrazione: Età X Sesso Numero
di vincoli
16m16f (<6; 6-10; 11-14; 15-19; 20-24; 25-29; 30-34; 35-39; 40-44; 45-49; 50-54; 55-59; 60-64; 65-69; 70-74; >74) X (M ; F)
32
Tabella 3 - Strutture della popolazione per stato civile e sesso prese in esame per la
calibrazione.
Struttura Descrizione dei vincoli di calibrazione: Stato Civile X Sesso Numero
di vincoli
5cm5cf (celibi; coniugati e separati di fatto; separati legalmente; vedovi; divorziati) X (M ; F)
10
6cm6cf (celibi; coniugati; separati di fatto; separati legalmente; vedovi; divorziati) X (M ; F)
12
Tali strutture sono desunte dal piano di diffusione del censimento 2001 nell’ottica di vincolare
i totali noti alle distribuzioni marginali delle tavole dei risultati censuari definitivi.
Per la scelta dei vincoli di calibrazione le due classificazioni sono state considerate in modo
combinato tra loro: per esempio, con la notazione 16m16f6cm6cf si fa riferimento alla
classificazione della popolazione relativa a maschi e femmine in 16 classi di età (32 vincoli) e
alla suddivisione della stessa popolazione in maschi e femmine per 6 modalità di stato civile
(12 vincoli), per un totale di 44 vincoli.
Nella Tabella 4 sono riportati i risultati della verifica della convergenza dell’algoritmo di
calibrazione per gli insiemi di vincoli testati alle diverse frazioni campionarie. Come già detto
sono stati considerati gli insiemi che, soddisfacendo la condizione di convergenza (a livello di
area di censimento), presentano classificazioni con la massima disaggregazione:
• disegno casuale semplice da lista, frazione di campionamento del 33% e del 20% :
44 totali noti (16m16f6cm6cf);
• disegno casuale semplice da lista, frazione di campionamento del 10% :
42 totali (16m16f5cm5cf).

14
Tabella 4 - Risultato della convergenza dell’algoritmo di calibrazione nel disegno causale
semplice da lista per differenti frazioni di campionamento. Strategia short/long.
Strategia short/long Disegno casuale semplice da lista
Struttura
Numero di vincoli
f.s.=10% f.s.=20% f.s.=33%
16m16f5cm5cf 42 OK OK OK
16m16f6cm6cf 44 NO OK OK
In caso di adozione della strategia short/long, scendendo dalla frazione sondata del 33% a
quella del 20%, la struttura ottimale di totali noti rimane identica (Tabella 4).
Per la frazione di campionamento del 10%, nonostante le modifiche apportate alla procedura
di calibrazione (paragrafo 3.3), la convergenza dell’algoritmo è raggiunta solo dopo aver
ridefinito il sistema di vincoli tramite l’aggregazione di alcune modalità di classificazione
della popolazione per sesso e stato civile; in particolare si è aggregata la classe dei “separati di
fatto” a quella dei “coniugati” per l’esiguo numero di casi osservati nei campioni relativi ad
alcuni domini pianificati.
5.1.2 La scelta dei vincoli di calibrazione per la strategia medium/long
Come già evidenziato, nel caso di una strategia medium/long si avrà a disposizione un
maggior numero di variabili ausiliarie, rilevate esaustivamente, da utilizzare come vincolo.
Tenendo conto del piano di diffusione del censimento passato, oltre alle due strutture di
popolazione esaminate per la strategia short/long (Tabelle 2 e 3), è stata considerata anche la
distribuzione per titolo di studio e sesso (Tabella 5), la distribuzione degli individui
appartenenti alle non forze lavoro per sesso e la distribuzione degli occupati per 4 classi di età
e per sesso (Tabella 6). In questa sperimentazione la distribuzione per sesso e stato civile ha
considerato quella riferita a 5 modalità di stato civile (5cm5cf).
Tabella 5 - Struttura della popolazione (≥ 6 anni) per titolo di studio e sesso presa in esame
per la calibrazione.
Struttura Descrizione dei vincoli di calibrazione: Età X Sesso Numero
di vincoli
5titm5titf
(Laurea, specializzazione, master, dottorato e diploma universitario; diploma secondario;licenza media; licenza elementare; privi di titolo di studio) X (M ; F)
10
15
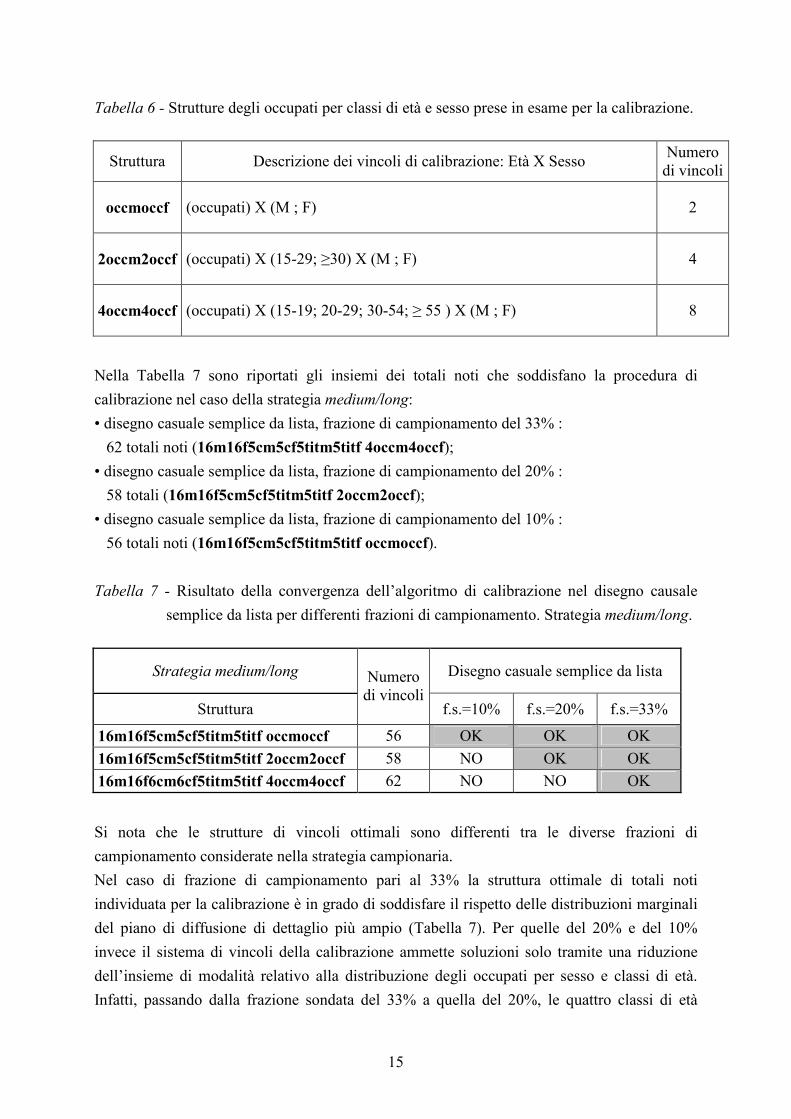
Tabella 6 - Strutture degli occupati per classi di età e sesso prese in esame per la calibrazione.
Struttura Descrizione dei vincoli di calibrazione: Età X Sesso Numero
di vincoli
occmoccf (occupati) X (M ; F) 2
2occm2occf (occupati) X (15-29; ≥30) X (M ; F) 4
4occm4occf (occupati) X (15-19; 20-29; 30-54; ≥ 55 ) X (M ; F) 8
Nella Tabella 7 sono riportati gli insiemi dei totali noti che soddisfano la procedura di
calibrazione nel caso della strategia medium/long:
• disegno casuale semplice da lista, frazione di campionamento del 33% :
62 totali noti (16m16f5cm5cf5titm5titf 4occm4occf);
• disegno casuale semplice da lista, frazione di campionamento del 20% :
58 totali (16m16f5cm5cf5titm5titf 2occm2occf);
• disegno casuale semplice da lista, frazione di campionamento del 10% :
56 totali noti (16m16f5cm5cf5titm5titf occmoccf).
Tabella 7 - Risultato della convergenza dell’algoritmo di calibrazione nel disegno causale
semplice da lista per differenti frazioni di campionamento. Strategia medium/long.
Strategia medium/long Disegno casuale semplice da lista
Struttura
Numero di vincoli
f.s.=10% f.s.=20% f.s.=33%
16m16f5cm5cf5titm5titf occmoccf 56 OK OK OK
16m16f5cm5cf5titm5titf 2occm2occf 58 NO OK OK
16m16f6cm6cf5titm5titf 4occm4occf 62 NO NO OK
Si nota che le strutture di vincoli ottimali sono differenti tra le diverse frazioni di
campionamento considerate nella strategia campionaria.
Nel caso di frazione di campionamento pari al 33% la struttura ottimale di totali noti
individuata per la calibrazione è in grado di soddisfare il rispetto delle distribuzioni marginali
del piano di diffusione di dettaglio più ampio (Tabella 7). Per quelle del 20% e del 10%
invece il sistema di vincoli della calibrazione ammette soluzioni solo tramite una riduzione
dell’insieme di modalità relativo alla distribuzione degli occupati per sesso e classi di età.
Infatti, passando dalla frazione sondata del 33% a quella del 20%, le quattro classi di età

16
vengono aggregate in due, mentre per la frazione del 10% si considera la suddivisione degli
occupati solo per sesso.
5.2 Fase 2: la determinazione dei livelli di errore campionario
L’ambito delle sperimentazioni ha richiesto la specificazione dei seguenti elementi:
a) il disegno campionario;
b) l’insieme delle variabili di studio;
c) i comuni da sottoporre a test;
d) i dati e le liste-universo;
e) l’implementazione della procedura di calcolo.
Relativamente al punto a) è stato considerato il disegno casuale semplice di famiglie che i
risultati di precedenti studi (Borrelli et al., 2007; Carbonetti e De Vitiis, 2007; Carbonetti e
Fortini, 2008a) hanno dimostrato essere la soluzione più efficiente per la produzione di stime
affidabili a livello comunale e sub-comunale.
Riguardo al punto b), la scelta delle variabili di studio è stata effettuata tramite un’analisi
preliminare sul questionario del censimento 2001 al fine di individuare le variabili che nel
2011 potrebbero essere rilevabili esclusivamente tramite il questionario long (paragrafo 4). Al
fine di una corretta confrontabilità degli errori campionari l’insieme di variabili sottoposto a
stima è stato definito in modo identico in entrambe le strategie.
Infatti, essendo più ridotto l’insieme di variabili da stimare nel caso medium/long rispetto al
caso short/long, le variazioni dei livelli di efficienza potrebbero essere condizionate dal
differente numero di variabili considerate e non da una reale maggiore o minore variabilità
delle stime.
Sono state quindi analizzate le frequenze relative p delle combinazioni (denominate incroci nel seguito) di modalità, per un totale pari a 71 (Tabella 8), delle variabili considerate:
- popolazione totale e popolazione maschile di età maggiore o uguale a 15 anni per
"condizione professionale" (6 modalità), per un totale di 11 incroci15;
- popolazione totale e popolazione maschile di età maggiore o uguale a 15 anni in condizione
di occupati per "settore di attività economica " (14 modalità), per un totale di 28 incroci;
- popolazione totale e popolazione maschile di età maggiore o uguale a 15 anni in condizione
di occupati per “posizione nella professione” (4 modalità), per un totale di 8 incroci;
- popolazione totale e popolazione maschile di età maggiore o uguale a 15 anni in condizione
di occupati per “posizione nella professione” (4 modalità) e per "settore di attività
economica" (3 modalità), per un totale di 24 incroci.
15 Il numero di incroci è pari a 11 perché la modalità casalinghe non viene prevista per il sesso maschile.

17
Tabella 8 - Descrizione delle modalità di classificazione delle variabili rilevabili
esclusivamente tramite questionario long e oggetto di stima campionaria.
Variabili rilevate con "long form" Modalità di classificazione
In cerca di occupazione In cerca di prima occupazione Casalinghe Studenti Ritirati dal lavoro
Condizione professionale (6 modalità)
In altra condizione Imprenditore e Libero professionista Lavoratore in proprio Coadiuvante familiare
Posizione nella professione (4 modalità)
Dipendente o in altra posizione subordinata Agricoltura Industria
Settore di attività economica (3 modalità)
Altre attività Agricoltura Totale Industria (Estrazione, Produzione energia) Industria (Manifatturiera) Industria (Costruzioni) Industria Totale Altre Attività (Commercio, riparazioni, Alberghi e Ristoranti) Altre Attività (Trasporti, Comunicazioni) Altre Attività (Intermediazione) Altre Attività (Immobiliari, Professionali, Imprenditoriali) Altre Attività (Pubblica Amm., Difesa, Ass. Sociale) Altre Attività (Istruzione) Altre Attività (Sanità, Servizi Sociali) Altre Attività (Servizi pubblici/domestici, Org. extraterritoriali)
Settore di attività economica (14 modalità)
Altre Attività Totale
Con riferimento al punto c), sono stati scelti 20 comuni (Tabella 9) tra i 40 considerati nei
precedenti studi; in particolare sono stati individuati quelli per i quali erano già stati calcolati i
livelli di efficienza del disegno casuale semplice da lista per le differenti frazioni di
campionamento (10 comuni per ciascuna delle 3 frazioni sondate sottoposte a
sperimentazione, di cui 5 in comune per ogni frazione di campionamento analizzata).

18
Tabella 9 - Elenco dei 20 comuni sottoposti a sperimentazione.
Disegno casuale semplice Codice
Istat Nome Comune
f.s.=10% f.s.=20% f.s.=33%
037006 Bologna X X X 015146 Milano X 054039 Perugia X X X 004078 Cuneo X X X 086009 Enna X 049009 Livorno X 028060 Padova X 099014 Rimini X 075079 Squinzano X X X 081021 Trapani X X X 021008 Bolzano X 017029 Brescia X 092009 Cagliari X 028032 Cittadella X 048017 Firenze X 063049 Napoli X 050029 Pontedera X 065116 Salerno X 090064 Sassari X 102047 Vibo Valentia X
Riguardo al punto d), per ciascun comune, la lista universo è rappresentata dalla lista relativa
anagrafica. Non essendo questa al momento disponibile, per questo lavoro è stata utilizzata la
lista delle famiglie residenti censite nel 2001, nell’ipotesi di invarianza rispetto alla reale lista
anagrafica presente negli archivi amministrativi del relativo comune.
Le stime vengono prodotte con riferimento al dominio territoriale sub-comunale rappresentato
dalle aree di censimento.
Fissato il comune test, l’algoritmo calcola per tutte le 71 variabili di incrocio con riferimento
sia al comune intero (inteso come somma delle aree di centro esaminate) che per ciascuna area di censimento di centro, il valore medio campionario ( )xpE ˆ e lo scarto quadratico medio
campionario ( )xp̂σ che esprime la variabilità delle stime )(ˆ cp x di xp sullo spazio
campionario16. Successivamente, si passa al calcolo del coefficiente di variazione percentuale
16 In questa sperimentazione non sono state effettuate simulazioni come in precedenti lavori, ma si è utilizzata una procedura di calcolo opportunamente progettata. Questa, sfruttando la convergenza dello stimatore calibrato allo stimatore di regressione generalizzata, calcola un'approssimazione della varianza dello stimatore calibrato tramite la varianza dello stimatore di regressione generalizzata. Essendo questo uno stimatore non lineare, un'approssimazione della sua varianza si ottiene calcolando la varianza dell'approssimazione in serie di Taylor dello stimatore. Tale metodologia è nota in letteratura con il nome di linearizzazione, delta method (per esempio, Kalton, 1983) o propagation of variance (Kish, 1965).

19
(( )
100)ˆ(
ˆ⋅=
x
xx pE
pcv
σ), che quantifica la misura17 dell’errore che mediamente si commette con la
stima campionaria.
Sono stati infine costruiti alcuni indicatori di sintesi dei risultati per misurare il diverso
comportamento, nelle strategie short/long e medium/long, delle distribuzioni del coefficiente
di variazione. Le valutazioni sono state fatte tenendo conto sia del valore mediano che della
concentrazione dei valori campionari intorno ad esso (paragrafo 6.1); le analisi sono condotte
classificando preventivamente i valori dei cv attesi delle stime per classi di frequenze
relative18 osservate a livello di area di censimento.
6 RISULTATI
6.1 Criteri di valutazione della variazione dell’errore campionario
Per valutare quantitativamente l’effetto sull’errore di campionamento che si osserva passando
dalla strategia campionaria basata su short/long a quella basata su medium/long si calcola, per
ciascuna classe di frequenza percentuale presa in esame, la seguente misura relativa:
rid(cv) = 100×−
sh
medsh
cvcvcv
(1)
dove shcv e medcv sono i valori mediani del coefficiente di variazione delle stime delle
percentuali p appartenenti alla prefissata classe, calcolati rispettivamente per la strategia
short/long e medium/long.
L’espressione (1) permette di quantificare la variazione percentuale dell’errore campionario
atteso dovuta all’adozione del questionario in versione medium che, come detto, consente di
raccogliere in modo esaustivo maggiore informazione che può essere utilmente impiegata in
fase di stima.
Ulteriori valutazioni sulle variazioni dei livelli di efficienza dovute all’utilizzo della strategia
medium/long sono possibili procedendo all’analisi della distribuzione dei valori dei cv relativi
alle stime per ciascuna classe di p. A riguardo, l’attenzione è rivolta a studiare le variazioni
17 In base al valore di cv si determina la quantità 10096,1 cvpp ⋅⋅=∆ che rappresenta l’errore assoluto massimo
a cui è mediamente esposta la generica stima di p. In base alla teoria dei campioni, infatti, sotto valide ipotesi di normalità, il vero valore della percentuale p oggetto di stima sarà compreso tra )( pp ∆− e )( pp ∆+ con una
probabilità pari a 0,95 . Nel caso della stima dell’ammontare T, tramite il valore di cv si calcola l’errore assoluto
10096,1 cvTT ⋅⋅=∆ che permette di definire l’intervallo di confidenza )}ˆ();ˆ{( TT TT ∆+∆− che conterrà il vero
valore di T con prob.=0,95 . Esempio: per la stima di T=600, se il relativo cv=5,4% ne consegue che 641004,560096,1 ≅××=∆T . Quindi,
il 95% dei campioni produrrà una stima compresa tra 536 e 664 . 18 Le frequenze percentuali p oggetto di stima sono state classificate in 12 classi: p<0,05%; 0,05%≤p<0,1%; 0,1%≤p<0,25%; 0,25%≤p<0,5%; 0,5%≤p<1%; 1%≤p<2,5%; 2,5%≤p<5%; 5%≤p<10%;
10%≤p<15%; 15%≤p<20%; 20%≤p<30%; p≥30% .

20
della distribuzione campionaria dei cv delle stime in oggetto sia per la “forma” che per la
“posizione”, per ciascuna delle classi di p considerate.
I vantaggi derivanti dalla disponibilità di maggiori informazioni si dovrebbero tradurre in una
riduzione dell’errore di campionamento e in uno “spostamento” della distribuzione verso
valori del cv mediamente più bassi con un addensamento sulla coda di sinistra (aumento di
casi con cv più bassi) e una minore concentrazione sulla coda di destra (diminuzione di casi
con cv più alti).
Per le valutazioni si è proceduto al calcolo dei quartili19 e dei decili20 delle relative
distribuzioni.
6.2 Tavole e commenti
Nel presente paragrafo sono riportati i risultati ottenuti con la sperimentazione realizzata, atti
a valutare e comparare l’efficienza delle due strategie considerate. I confronti sono stati
effettuati in termini di coefficiente di variazione che, come detto, fornisce una misura
dell’errore che mediamente si commette con le stime campionarie.
Dai valori delle distribuzioni dei cv mediani emerge che, a parità di frazione di
campionamento, la strategia medium/long garantisce un errore inferiore a quello ottenibile nel
caso short/long per ogni classe di p (Tabelle 10, 11 e 12). Tale considerazione rimane valida
anche per quanto riguarda l’analisi dei valori massimi; per i valori minimi tale tendenza si
conferma per tutte le percentuali p superiori allo 0,5%.
19 I quartili sono le quantità che ripartiscono un insieme di valori, ordinati in modo non decrescente, in quattro parti con la stessa frequenza di casi (25%); generalmente sono denotati con Q1 (primo quartile), Q2 (secondo quartile, coincidente con la mediana) e Q3 (terzo quartile). Inoltre, la frequenza cumulata fino ai tre quartili è rispettivamente pari al 25%, 50% e 75%. 20 I decili sono le quantità che dividono un insieme di valori, precedentemente ordinati in modo non decrescente, in dieci parti uguali. Esempio: il primo 10% dei dati ordinato ha come limite superiore il primo decile, il 50% dei dati ordinati ha come limite il quinto decile (coincidente con la mediana).

21
Tabella 10 - Confronto tra i livelli di cv (minimo, mediano e massimo) osservati nelle
strategie short/long e medium/long per la frazione di campionamento del 33%.
Coefficiente di variazione
Strategia Short/Long f.s.=33%
Strategia Medium/Long f.s.=33%
Classi p min mediana max min mediana max
< 0,05% 0,42 94,19 468,31 1,06 93,27 467,86
0,05%├0,1% 1,56 49,98 127,04 0,49 49,85 126,92
0,1%├0,25% 1,17 33,58 145,84 0,51 33,15 97,95
0,25%├0,5% 0,45 22,90 62,69 0,72 22,39 67,00
0,5%├1% 8,52 16,26 56,20 3,94 15,53 40,95
1%├2,5% 4,00 10,65 33,01 2,76 10,06 34,10
2,5%├5% 3,25 6,84 15,04 2,06 6,46 14,70
5%├10% 1,99 4,55 10,08 1,07 4,32 8,98
10%├15% 1,37 2,94 4,95 0,72 2,62 4,53
15%├20% 1,26 2,20 3,65 0,64 1,82 3,24
20%├30% 1,23 1,94 3,50 0,93 1,58 2,90
≥ 30% 1,12 1,57 2,48 0,82 1,15 1,82
Tabella 11 - Confronto tra i livelli di cv (minimo, mediano e massimo) osservati nelle
strategie short/long e medium/long per la frazione di campionamento del 20%.
Coefficiente di variazione
Strategia Short/Long f.s.=20%
Strategia Medium/Long f.s.=20%
Classi p min mediana max min mediana max
< 0,05% 1,08 122,44 632,03 1,85 122,35 631,25
0,05%├0,1% 2,65 75,83 149,42 3,99 75,31 152,95
0,1%├0,25% 1,66 47,16 111,23 1,80 47,00 110,96
0,25%├0,5% 0,64 32,44 74,64 0,96 32,15 73,95
0,5%├1% 12,65 22,64 54,09 5,60 21,81 51,75
1%├2,5% 8,00 15,29 46,00 3,96 14,56 43,84
2,5%├5% 4,75 9,73 22,93 3,23 9,20 21,33
5%├10% 2,82 6,43 13,15 1,86 5,96 11,83
10%├15% 1,94 4,04 7,85 1,27 3,43 6,85
15%├20% 1,78 3,28 6,37 1,11 2,59 5,15
20%├30% 1,74 2,80 4,69 1,22 2,15 4,09
≥ 30% 1,58 2,23 3,37 1,12 1,63 2,39

22
Tabella 12 - Confronto tra i livelli di cv (minimo, mediano e massimo) osservati nelle
strategie short/long e medium/long per la frazione di campionamento del 10%.
Coefficiente di variazione
Strategia Short/Long f.s.=10%
Strategia Medium/Long f.s.=10%
Classi p min mediana max min mediana max
< 0,05% 1,73 212,06 1234,95 2,54 211,83 1232,72
0,05%├0,1% 1,56 111,97 344,55 1,90 111,63 336,58
0,1%├0,25% 1,96 74,95 237,91 2,61 74,00 223,69
0,25%├0,5% 0,83 49,90 168,24 1,43 49,05 152,24
0,5%├1% 13,40 35,30 103,49 8,42 34,12 92,06
1%├2,5% 8,68 22,80 72,31 5,90 21,69 58,54
2,5%├5% 5,31 14,25 37,97 5,03 13,26 30,28
5%├10% 4,11 9,47 21,55 3,29 8,31 20,67
10%├15% 2,91 6,57 13,48 2,15 5,12 10,98
15%├20% 2,67 5,20 8,86 1,94 3,95 6,94
20%├30% 2,62 4,19 7,67 1,89 3,10 6,75
≥ 30% 2,43 3,26 5,48 1,75 2,40 4,03
Per cercare di valutare quantitativamente il guadagno di efficienza osservato con la strategia
medium/long è stata misurata la riduzione percentuale del cv tramite il calcolo
dell’espressione (1).
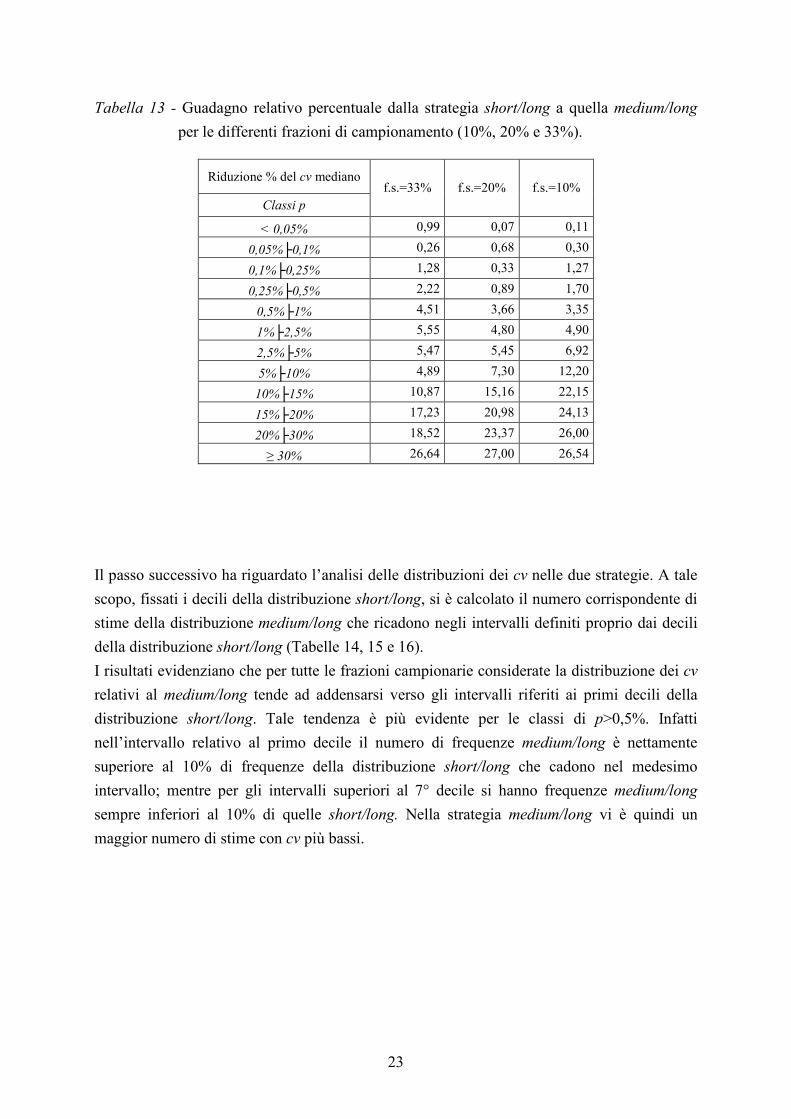
Dalla Tabella 13 risulta evidente che, a parità di frazione di campionamento, il guadagno di
efficienza aumenta al crescere di p, arrivando fino a valori intorno al 27% per tutte le frazioni
sondate considerate.
Per le p superiori al 2,5% il vantaggio che si ottiene dall’adozione della strategia medium/long
aumenta al decrescere della frazione campionaria. Per le p inferiori a tale soglia, la frazione
sondata pari al 33% è quella che fa registrare il guadagno relativo maggiore.
23
Tabella 13 - Guadagno relativo percentuale dalla strategia short/long a quella medium/long
per le differenti frazioni di campionamento (10%, 20% e 33%).
Riduzione % del cv mediano
Classi p f.s.=33% f.s.=20% f.s.=10%
< 0,05% 0,99 0,07 0,11
0,05%├0,1% 0,26 0,68 0,30
0,1%├0,25% 1,28 0,33 1,27
0,25%├0,5% 2,22 0,89 1,70
0,5%├1% 4,51 3,66 3,35
1%├2,5% 5,55 4,80 4,90
2,5%├5% 5,47 5,45 6,92
5%├10% 4,89 7,30 12,20
10%├15% 10,87 15,16 22,15
15%├20% 17,23 20,98 24,13
20%├30% 18,52 23,37 26,00
≥ 30% 26,64 27,00 26,54
Il passo successivo ha riguardato l’analisi delle distribuzioni dei cv nelle due strategie. A tale
scopo, fissati i decili della distribuzione short/long, si è calcolato il numero corrispondente di
stime della distribuzione medium/long che ricadono negli intervalli definiti proprio dai decili
della distribuzione short/long (Tabelle 14, 15 e 16).
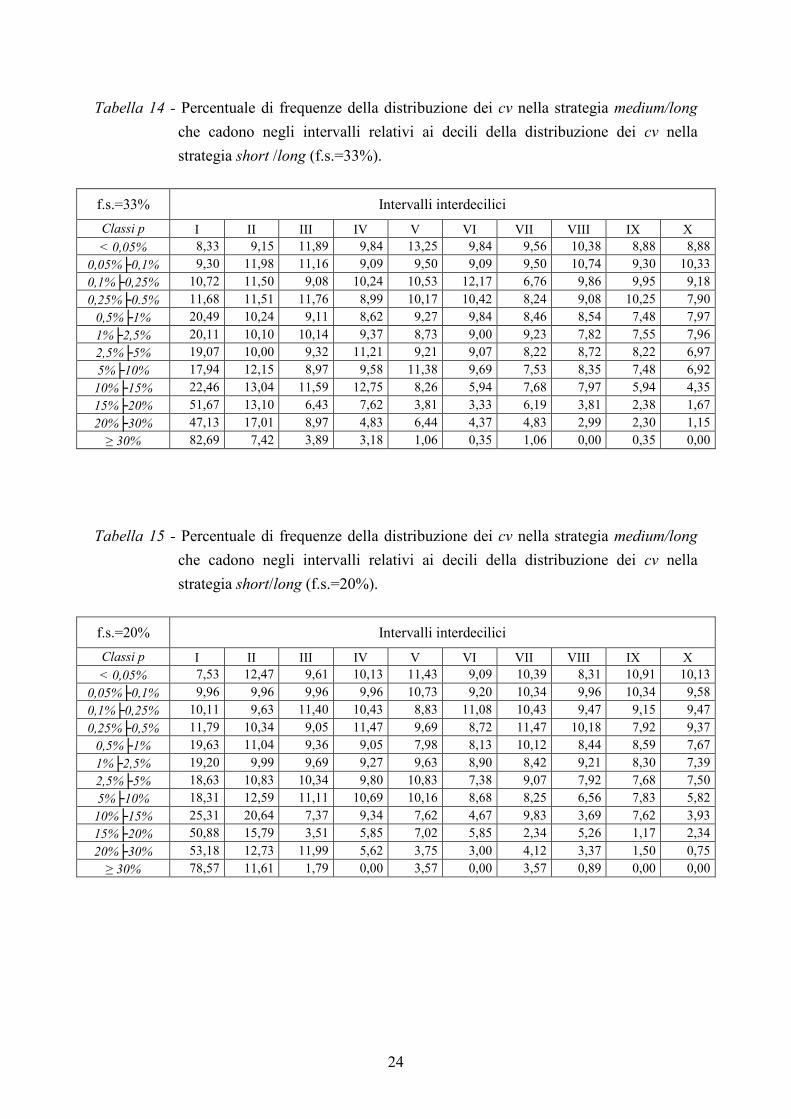
I risultati evidenziano che per tutte le frazioni campionarie considerate la distribuzione dei cv
relativi al medium/long tende ad addensarsi verso gli intervalli riferiti ai primi decili della
distribuzione short/long. Tale tendenza è più evidente per le classi di p>0,5%. Infatti
nell’intervallo relativo al primo decile il numero di frequenze medium/long è nettamente
superiore al 10% di frequenze della distribuzione short/long che cadono nel medesimo
intervallo; mentre per gli intervalli superiori al 7° decile si hanno frequenze medium/long
sempre inferiori al 10% di quelle short/long. Nella strategia medium/long vi è quindi un
maggior numero di stime con cv più bassi.
24
Tabella 14 - Percentuale di frequenze della distribuzione dei cv nella strategia medium/long
che cadono negli intervalli relativi ai decili della distribuzione dei cv nella
strategia short /long (f.s.=33%).
f.s.=33% Intervalli interdecilici
Classi p I II III IV V VI VII VIII IX X < 0,05% 8,33 9,15 11,89 9,84 13,25 9,84 9,56 10,38 8,88 8,88
0,05%├0,1% 9,30 11,98 11,16 9,09 9,50 9,09 9,50 10,74 9,30 10,33
0,1%├0,25% 10,72 11,50 9,08 10,24 10,53 12,17 6,76 9,86 9,95 9,18
0,25%├0.5% 11,68 11,51 11,76 8,99 10,17 10,42 8,24 9,08 10,25 7,90
0,5%├1% 20,49 10,24 9,11 8,62 9,27 9,84 8,46 8,54 7,48 7,97
1%├2,5% 20,11 10,10 10,14 9,37 8,73 9,00 9,23 7,82 7,55 7,96
2,5%├5% 19,07 10,00 9,32 11,21 9,21 9,07 8,22 8,72 8,22 6,97
5%├10% 17,94 12,15 8,97 9,58 11,38 9,69 7,53 8,35 7,48 6,92
10%├15% 22,46 13,04 11,59 12,75 8,26 5,94 7,68 7,97 5,94 4,35
15%├20% 51,67 13,10 6,43 7,62 3,81 3,33 6,19 3,81 2,38 1,67
20%├30% 47,13 17,01 8,97 4,83 6,44 4,37 4,83 2,99 2,30 1,15
≥ 30% 82,69 7,42 3,89 3,18 1,06 0,35 1,06 0,00 0,35 0,00
Tabella 15 - Percentuale di frequenze della distribuzione dei cv nella strategia medium/long
che cadono negli intervalli relativi ai decili della distribuzione dei cv nella
strategia short/long (f.s.=20%).
f.s.=20% Intervalli interdecilici
Classi p I II III IV V VI VII VIII IX X < 0,05% 7,53 12,47 9,61 10,13 11,43 9,09 10,39 8,31 10,91 10,13
0,05%├0,1% 9,96 9,96 9,96 9,96 10,73 9,20 10,34 9,96 10,34 9,58
0,1%├0,25% 10,11 9,63 11,40 10,43 8,83 11,08 10,43 9,47 9,15 9,47
0,25%├0,5% 11,79 10,34 9,05 11,47 9,69 8,72 11,47 10,18 7,92 9,37
0,5%├1% 19,63 11,04 9,36 9,05 7,98 8,13 10,12 8,44 8,59 7,67
1%├2,5% 19,20 9,99 9,69 9,27 9,63 8,90 8,42 9,21 8,30 7,39
2,5%├5% 18,63 10,83 10,34 9,80 10,83 7,38 9,07 7,92 7,68 7,50
5%├10% 18,31 12,59 11,11 10,69 10,16 8,68 8,25 6,56 7,83 5,82
10%├15% 25,31 20,64 7,37 9,34 7,62 4,67 9,83 3,69 7,62 3,93
15%├20% 50,88 15,79 3,51 5,85 7,02 5,85 2,34 5,26 1,17 2,34
20%├30% 53,18 12,73 11,99 5,62 3,75 3,00 4,12 3,37 1,50 0,75
≥ 30% 78,57 11,61 1,79 0,00 3,57 0,00 3,57 0,89 0,00 0,00
25
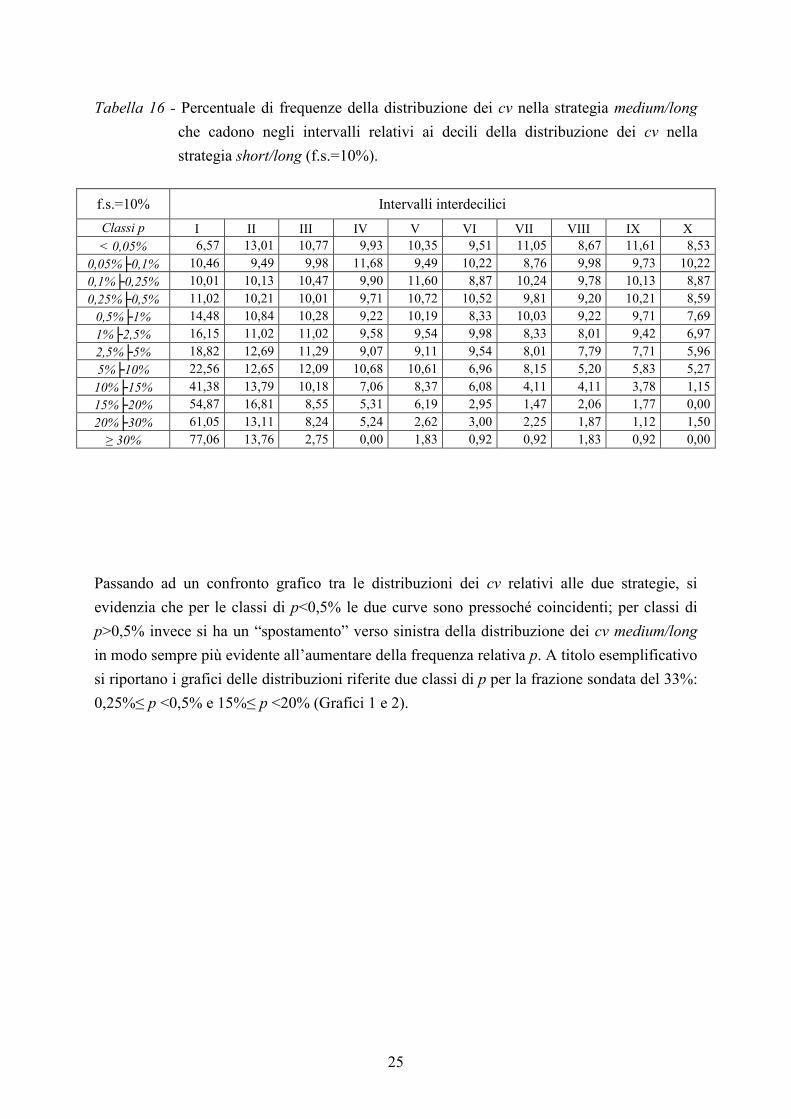
Tabella 16 - Percentuale di frequenze della distribuzione dei cv nella strategia medium/long
che cadono negli intervalli relativi ai decili della distribuzione dei cv nella
strategia short/long (f.s.=10%).
f.s.=10% Intervalli interdecilici
Classi p I II III IV V VI VII VIII IX X < 0,05% 6,57 13,01 10,77 9,93 10,35 9,51 11,05 8,67 11,61 8,53
0,05%├0,1% 10,46 9,49 9,98 11,68 9,49 10,22 8,76 9,98 9,73 10,22
0,1%├0,25% 10,01 10,13 10,47 9,90 11,60 8,87 10,24 9,78 10,13 8,87
0,25%├0,5% 11,02 10,21 10,01 9,71 10,72 10,52 9,81 9,20 10,21 8,59
0,5%├1% 14,48 10,84 10,28 9,22 10,19 8,33 10,03 9,22 9,71 7,69
1%├2,5% 16,15 11,02 11,02 9,58 9,54 9,98 8,33 8,01 9,42 6,97
2,5%├5% 18,82 12,69 11,29 9,07 9,11 9,54 8,01 7,79 7,71 5,96
5%├10% 22,56 12,65 12,09 10,68 10,61 6,96 8,15 5,20 5,83 5,27
10%├15% 41,38 13,79 10,18 7,06 8,37 6,08 4,11 4,11 3,78 1,15
15%├20% 54,87 16,81 8,55 5,31 6,19 2,95 1,47 2,06 1,77 0,00
20%├30% 61,05 13,11 8,24 5,24 2,62 3,00 2,25 1,87 1,12 1,50
≥ 30% 77,06 13,76 2,75 0,00 1,83 0,92 0,92 1,83 0,92 0,00
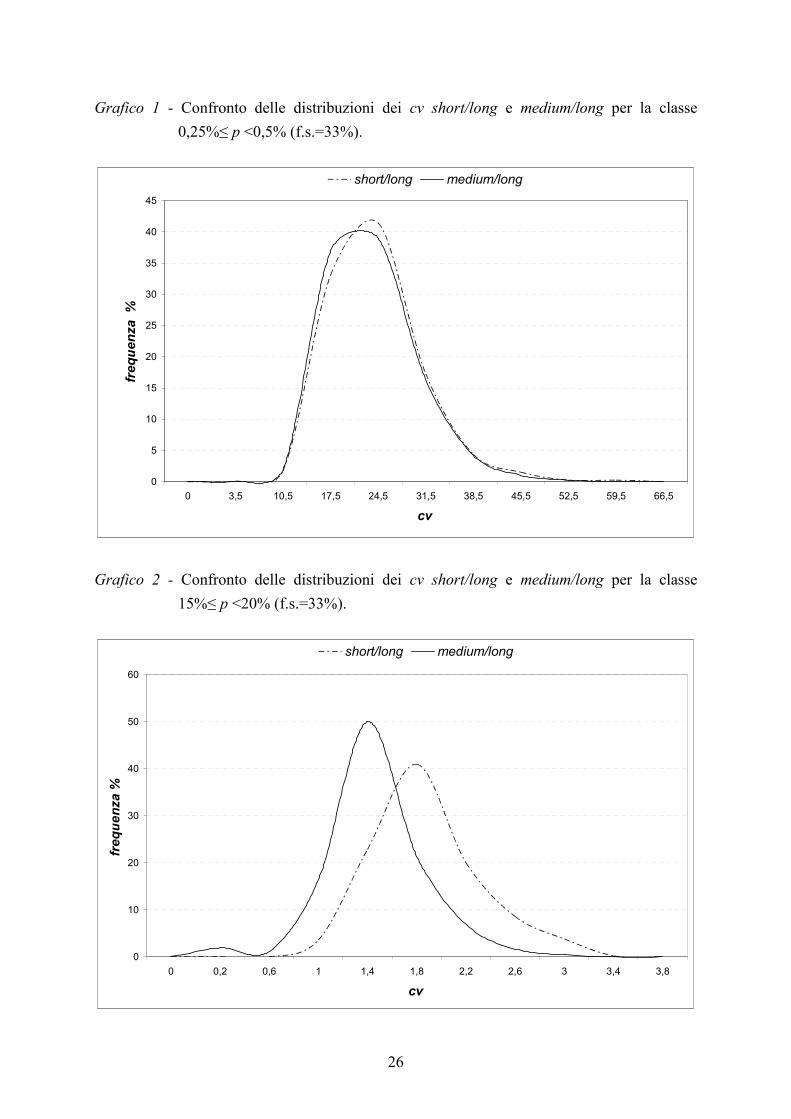
Passando ad un confronto grafico tra le distribuzioni dei cv relativi alle due strategie, si
evidenzia che per le classi di p<0,5% le due curve sono pressoché coincidenti; per classi di
p>0,5% invece si ha un “spostamento” verso sinistra della distribuzione dei cv medium/long
in modo sempre più evidente all’aumentare della frequenza relativa p. A titolo esemplificativo
si riportano i grafici delle distribuzioni riferite due classi di p per la frazione sondata del 33%:
0,25%≤ p <0,5% e 15%≤ p <20% (Grafici 1 e 2).
26
Grafico 1 - Confronto delle distribuzioni dei cv short/long e medium/long per la classe
0,25%≤ p <0,5% (f.s.=33%).
0
5
10
15
20
25
30
35
40
45
0 3,5 10,5 17,5 24,5 31,5 38,5 45,5 52,5 59,5 66,5
cv
frequenza %
short/long medium/long
Grafico 2 - Confronto delle distribuzioni dei cv short/long e medium/long per la classe
15%≤ p <20% (f.s.=33%).
0
10
20
30
40
50
60
0 0,2 0,6 1 1,4 1,8 2,2 2,6 3 3,4 3,8
cv
frequenza %
short/long medium/long
27
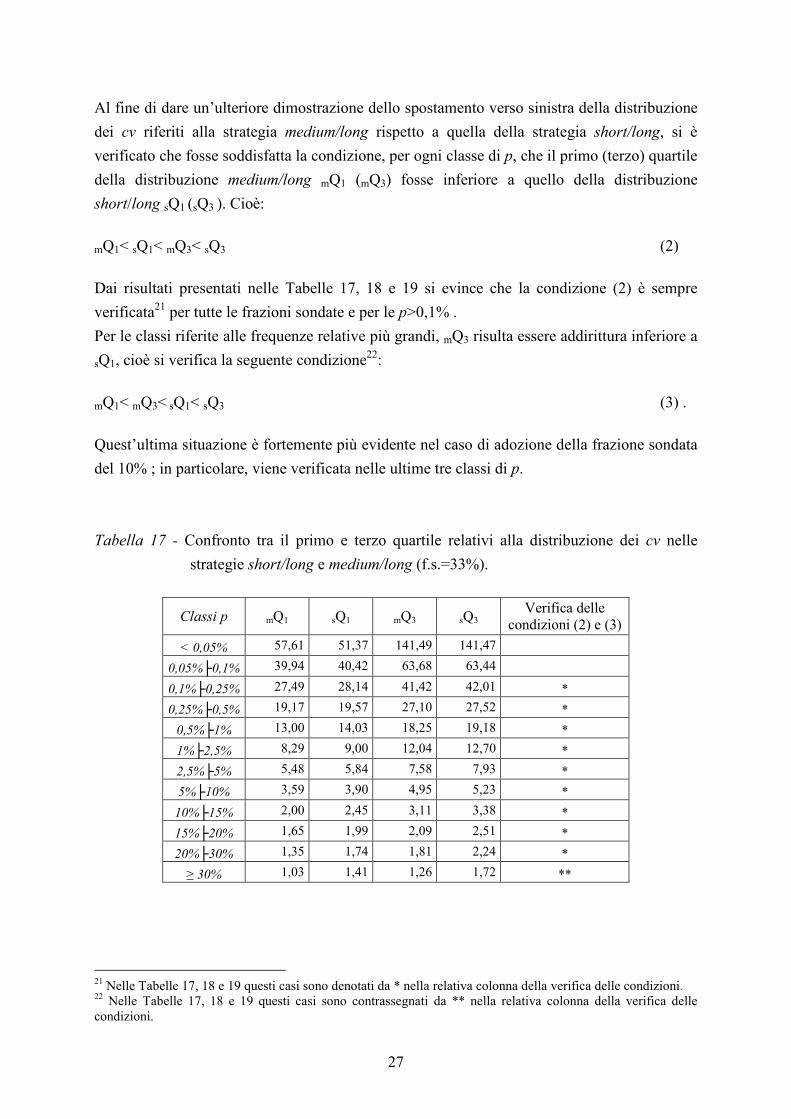
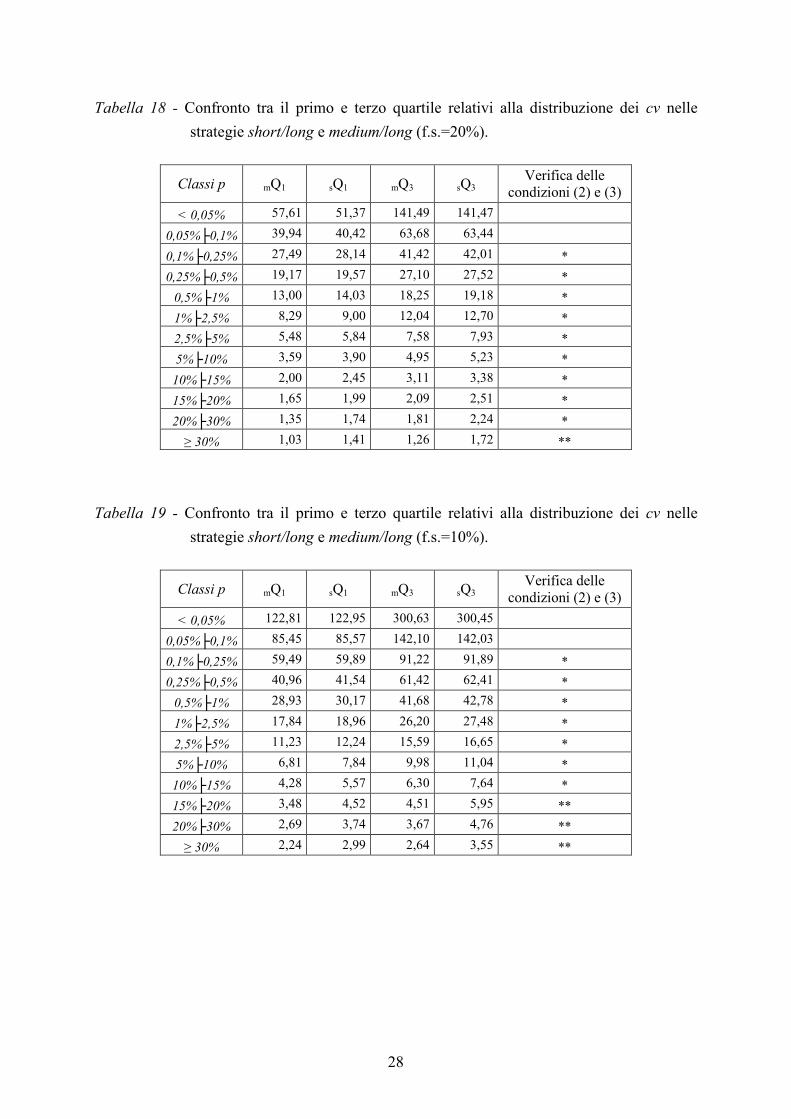
Al fine di dare un’ulteriore dimostrazione dello spostamento verso sinistra della distribuzione
dei cv riferiti alla strategia medium/long rispetto a quella della strategia short/long, si è
verificato che fosse soddisfatta la condizione, per ogni classe di p, che il primo (terzo) quartile
della distribuzione medium/long mQ1 (mQ3) fosse inferiore a quello della distribuzione
short/long sQ1 (sQ3 ). Cioè:
mQ1< sQ1< mQ3< sQ3 (2)
Dai risultati presentati nelle Tabelle 17, 18 e 19 si evince che la condizione (2) è sempre
verificata21 per tutte le frazioni sondate e per le p>0,1% .
Per le classi riferite alle frequenze relative più grandi, mQ3 risulta essere addirittura inferiore a
sQ1, cioè si verifica la seguente condizione22:
mQ1< mQ3< sQ1< sQ3 (3) .
Quest’ultima situazione è fortemente più evidente nel caso di adozione della frazione sondata
del 10% ; in particolare, viene verificata nelle ultime tre classi di p.
Tabella 17 - Confronto tra il primo e terzo quartile relativi alla distribuzione dei cv nelle
strategie short/long e medium/long (f.s.=33%).
Classi p mQ1 sQ1 mQ3 sQ3 Verifica delle
condizioni (2) e (3)
< 0,05% 57,61 51,37 141,49 141,47
0,05%├0,1% 39,94 40,42 63,68 63,44
0,1%├0,25% 27,49 28,14 41,42 42,01 *
0,25%├0,5% 19,17 19,57 27,10 27,52 *
0,5%├1% 13,00 14,03 18,25 19,18 *
1%├2,5% 8,29 9,00 12,04 12,70 *
2,5%├5% 5,48 5,84 7,58 7,93 *
5%├10% 3,59 3,90 4,95 5,23 *
10%├15% 2,00 2,45 3,11 3,38 *
15%├20% 1,65 1,99 2,09 2,51 *
20%├30% 1,35 1,74 1,81 2,24 *
≥ 30% 1,03 1,41 1,26 1,72 **
21 Nelle Tabelle 17, 18 e 19 questi casi sono denotati da * nella relativa colonna della verifica delle condizioni. 22 Nelle Tabelle 17, 18 e 19 questi casi sono contrassegnati da ** nella relativa colonna della verifica delle condizioni.
28
Tabella 18 - Confronto tra il primo e terzo quartile relativi alla distribuzione dei cv nelle
strategie short/long e medium/long (f.s.=20%).
Classi p mQ1 sQ1 mQ3 sQ3 Verifica delle
condizioni (2) e (3)
< 0,05% 57,61 51,37 141,49 141,47
0,05%├0,1% 39,94 40,42 63,68 63,44
0,1%├0,25% 27,49 28,14 41,42 42,01 *
0,25%├0,5% 19,17 19,57 27,10 27,52 *
0,5%├1% 13,00 14,03 18,25 19,18 *
1%├2,5% 8,29 9,00 12,04 12,70 *
2,5%├5% 5,48 5,84 7,58 7,93 *
5%├10% 3,59 3,90 4,95 5,23 *
10%├15% 2,00 2,45 3,11 3,38 *
15%├20% 1,65 1,99 2,09 2,51 *
20%├30% 1,35 1,74 1,81 2,24 *
≥ 30% 1,03 1,41 1,26 1,72 **
Tabella 19 - Confronto tra il primo e terzo quartile relativi alla distribuzione dei cv nelle
strategie short/long e medium/long (f.s.=10%).
Classi p mQ1 sQ1 mQ3 sQ3 Verifica delle
condizioni (2) e (3)
< 0,05% 122,81 122,95 300,63 300,45
0,05%├0,1% 85,45 85,57 142,10 142,03
0,1%├0,25% 59,49 59,89 91,22 91,89 *
0,25%├0,5% 40,96 41,54 61,42 62,41 *
0,5%├1% 28,93 30,17 41,68 42,78 *
1%├2,5% 17,84 18,96 26,20 27,48 *
2,5%├5% 11,23 12,24 15,59 16,65 *
5%├10% 6,81 7,84 9,98 11,04 *
10%├15% 4,28 5,57 6,30 7,64 *
15%├20% 3,48 4,52 4,51 5,95 **
20%├30% 2,69 3,74 3,67 4,76 **
≥ 30% 2,24 2,99 2,64 3,55 **

29
7 COSIDERAZIOI COCLUSIVE
Nel presente lavoro si è studiata la variazione dei livelli di efficienza attesi delle stime
campionarie nel caso di adozione di una strategia di campionamento basata su medium/long rispetto a quella basata su short/long.
A tale scopo i due scenari sono stati sottoposti a sperimentazione, utilizzando i dati del
censimento del 2001, per misurare e confrontare gli errori delle stime riferite alle variabili che
verrebbero rilevate tramite campione. Sono stati proposti diversi criteri per valutare la
variazione di efficienza dovuta all’adozione della strategia medium/long, confrontando le
distribuzioni campionarie dei cv relativi ai due scenari sia in termini di spostamento che di
concentrazione.
Dai risultati emerge che la strategia medium/long comporta in generale un miglioramento
delle stime per tutte le frazioni di campionamento considerate; tale guadagno aumenta al
crescere del livello della frequenza relativa p da stimare. Mentre per p>0,5% il vantaggio
relativo alla strategia medium/long è molto più evidente, per p inferiori a tale soglia le
distribuzioni degli errori risultano sostanzialmente simili nei due scenari.
Per tali classi di p si potrebbero comunque impiegare tecniche di stima per piccole aree che,
per quanto emerso da precedenti studi, consentono un recupero di efficienza, in termini di
riduzione dell’errore di campionamento, rispetto ai metodi diretti. Si ritiene che tale guadagno
sarebbe più consistente nel caso di adozione della strategia medium/long per la disponibilità di
un insieme più ampio di variabili ausiliarie.
La scelta finale della strategia da adottare per censimento della popolazione e delle abitazioni
del 2011 dovrà da un lato perseguire livelli più elevati di accuratezza delle stime campionarie,
dall’altro considerare il costo aggiuntivo necessario per la rilevazione di maggiori
informazioni in modo esaustivo. La valutazione inoltre dipenderà anche dalle ipotesi sui tassi
di risposta spontanei attesi per le differenti versioni del questionario (short, medium e long),
eventualmente condizionati dal numero dei quesiti.

30
ABSTRACT
The Italian Institute of Statistics (ISTAT) is planning to use samples of households for the
next 2011 population and housing census, in order to produce estimates related to socio-
economic topics. The main aims are to improve the efficiency of the survey operations and
reduce the statistical burden for the people involved in the enumeration.
The strategy is to submit a long form containing all the topics to a sample of households,
while the demographic data will be observed on the whole of population by a short form.
ISTAT is evaluating the possibility to replace the short form with a medium form that contains
also some questions regarding educational level, occupational status and commuting with
reduced breakdowns.
The goal of this study is to evaluate the effect on the estimates accuracy that it is possible to
increase by adopting a medium/long form based strategy instead of a short/long one.
The two strategies have been tested in order to assess and to compare the accuracy levels of
the estimates referred to the variables that will be surveyed with a sampling technique.

31
8 Bibliografia
Abbatini D., Cassata L., Martire F., Reale A., Ruocco G., Zindato D. (2007) La progettazione
dei censimenti generali 2010-2011. Analisi comparativa di esperienze censuarie estere e
valutazione di applicabilità di metodi e tecniche ai censimenti italiani. ISTAT, Dati e
prodotti, Pubblicazioni scientifiche, Documenti n. 9/2007
http://www.istat.it/dati/pubbsci/documenti/Documenti/doc_2007/2007_9.pdf
Astorri P., Bianchi G., Di Pede F., Esposito N., Patruno E., Reale A., Ronchi I., Talice S.
(2007) Metodi di determinazione delle aree di censimento a livello sub comunale.
Relazione presentata alla XXVIII Conferenza Italiana di Scienze Regionali, Bolzano 26-28
Settembre 2007.
Borrelli F., Carbonetti G., De Felici L. (2007) Strategie campionarie per la stima di variabili
di censimento con long form, Atti della XXVIII Conferenza Italiana di Scienze Regionali, Bolzano 26-28 Settembre 2007.
Borrelli F., Carbonetti G., De Felici L., Solari F. (2008) Metodologie di stima per piccole aree
applicabili a variabili di censimento rilevabili tramite questionario long form, Relazione
presentata alla XXIX Conferenza Italiana di Scienze Regionali, Bari 24-26 Settembre 2008.
Carbonetti G., De Vitiis C., (2007) Efficienza di stime campionarie relative ad un
sottoinsieme di variabili di censimento: primi risultati delle sperimentazioni, “Censimenti
generali 2010-2011. Criticità e innovazioni”. CNR, Roma, Novembre 2007.
http://www.istat.it/istat/eventi/2007/interconferenza/interventi/Carbonetti_DeVitiis.pdf
Carbonetti G., Fortini M. (2008a) Sample results expected accuracy in the Italian population
and housing census. Joint UNECE/Eurostat Meeting on Population and Housing Censuses.
UN, Ginevra, Maggio 2008. ECE/CES/AC.6/2008/4
http://www.unece.org/stats/documents/ece/ces/ge.41/2008/4.e.pdf
Carbonetti G., Fortini M., Solari F. (2008b) Innovations on methods and survey process for
the 2011 Italian population census, Proceedings of the European Conference on Quality in Official Statistics, Roma 8-11 Luglio 2008.
Cocchi D. (2007) Uso dei campioni nelle rilevazioni censuarie, Conferenza Nazionale di
Statistica: “Censimenti generali 2010-2011. Criticità e innovazioni”. CNR, Roma,
Novembre 2007.
Deville J.C., Särndal, C.E. (1992) Calibration Estimators in Survey Sampling. Journal of the
American Statistical Association, vol. 87, pp. 367-382
Fortini M., Gallo G., Paluzzi E., Reale A., Silvestrini A. (2007) La progettazione dei
censimenti generali 2010-2011. Criticità di processo e di prodotto nel 14° Censimento
generale della popolazione e delle abitazioni: aspetti rilevanti per la progettazione del 15°
Censimento. ISTAT, Dati e prodotti, Pubblicazioni scientifiche, Documenti n. 10/2007
http://www.istat.it/dati/pubbsci/documenti/Documenti/doc_2007/2007_10.pdf

32
Kalton, G. (1983) Introduction to Survey Sampling, Sage, Newbury Park.
Kish, L. (1965) Survey Sampling, Wiley, New York.
Pagliuca D. (a cura di) (2005) Genesees v.3.0., Funzione Riponderazione. Manuale utente ed aspetti metodologici, Tecniche e Strumenti, ISTAT, n. 2





























