Embed Size (px)
Citation preview
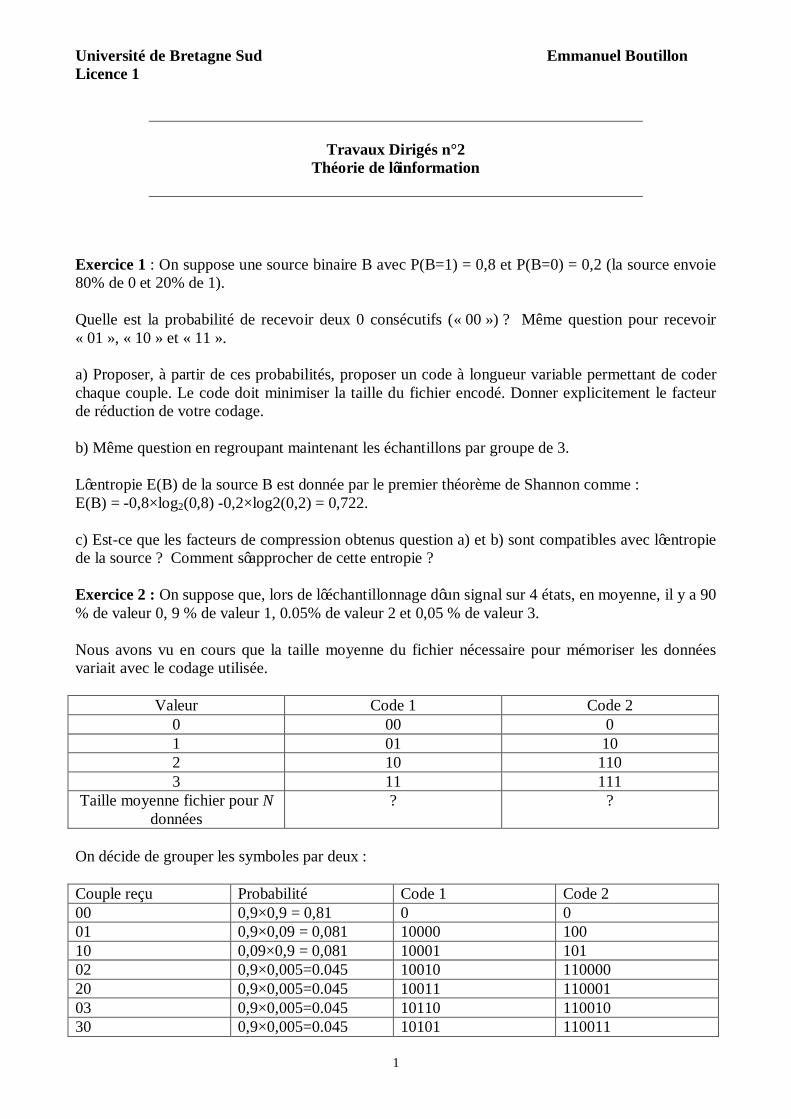
Université de Bretagne Sud Emmanuel Boutillon Licence 1
1
Travaux Dirigés n°2
Théorie de l’information
Exercice 1 : On suppose une source binaire B avec P(B=1) = 0,8 et P(B=0) = 0,2 (la source envoie 80% de 0 et 20% de 1). Quelle est la probabilité de recevoir deux 0 consécutifs (« 00 ») ? Même question pour recevoir « 01 », « 10 » et « 11 ». a) Proposer, à partir de ces probabilités, proposer un code à longueur variable permettant de coder chaque couple. Le code doit minimiser la taille du fichier encodé. Donner explicitement le facteur de réduction de votre codage. b) Même question en regroupant maintenant les échantillons par groupe de 3. L’entropie E(B) de la source B est donnée par le premier théorème de Shannon comme : E(B) = -0,8×log2(0,8) -0,2×log2(0,2) = 0,722. c) Est-ce que les facteurs de compression obtenus question a) et b) sont compatibles avec l’entropie de la source ? Comment s’approcher de cette entropie ? Exercice 2 : On suppose que, lors de l’échantillonnage d’un signal sur 4 états, en moyenne, il y a 90 % de valeur 0, 9 % de valeur 1, 0.05% de valeur 2 et 0,05 % de valeur 3. Nous avons vu en cours que la taille moyenne du fichier nécessaire pour mémoriser les données variait avec le codage utilisée.
Valeur Code 1 Code 2 0 00 0 1 01 10 2 10 110 3 11 111
Taille moyenne fichier pour N données
? ?
On décide de grouper les symboles par deux : Couple reçu Probabilité Code 1 Code 2 00 0,9×0,9 = 0,81 0 0 01 0,9×0,09 = 0,081 10000 100 10 0,09×0,9 = 0,081 10001 101 02 0,9×0,005=0.045 10010 110000 20 0,9×0,005=0.045 10011 110001 03 0,9×0,005=0.045 10110 110010 30 0,9×0,005=0.045 10101 110011

Université de Bretagne Sud Emmanuel Boutillon Licence 1
2
11 0,09×0,09=0.0081 10110 110110 12 0,09×0,005=0.0045 10111 110101 13 0,09×0,005=0.0045 11000 110110 21 0,09×0,005=0.0045 11001 110111 31 0,09×0,005=0.0045 11010 111000 22 0,005×0,005=0,00025 11011 111001 23 0,005×0,005=0,00025 11100 111010 32 0,005×0,005=0,00025 11101 111011 33 0,005×0,005=0,00025 11111 111100 Décoder la séquence : « 01000100101100101010100100 » avec le code 1 puis le code 2. Quelle est la taille moyenne d’un message de taille N comprimé avec le code n°1 et avec le code n°2 ? Pourquoi le code n°2 est-t-il plus efficace que le code n°1 ? Remarque : en regroupant les échantillons dans des paquets de plus en plus grands, on diminue la taille moyenne du fichier compressé. La limite ultime, donnée par la théorie de l’information (premier théorème de Shannon) est l’entropie E de la source avec E en bit/échantillon égal à E = − ∑ ������(��)�
��� E = = -0,9×log2(0,9) - 0,09×log2(0 ,09) - 0,005×log2(0,005) - 0,005×log2(0,005)= 0,626 (bit/éch.) Exercice 3 : On considère le code correcteur d’erreur qui a 4 données (a0,a1,a2,a3) associe un mot de code C = (a0, a1, a2, a3, r0, r1, r2), avec r0, r1 et r2 définis par : r0 tel que le nombre de 1 dans (r0, a1, a2, a3) soit pair. r1 tel que le nombre de 1 dans (a0, r1, a2, a3) soit pair. r2 tel que le nombre de 1 dans (a0, a1, r2, a3) soit pair. a) Coder (0000), (0110) et (1100) avec ce code. b) Le récepteur reçoit (0001111). Est-ce un mot de code ? c) Le récepteur reçoit (1100000), est-ce un mot de code ? d) Selon vous, quel sera le mot corrigé donné par le décodeur ? On admettra que ce code (appelé code de Hamming(7, 4, 3) (7 = longueur du code, 4 = nombre de bits d’information, 3 = nombre minimal de différences entre deux mots du code) permet de corriger une erreur de transmission. e) Sachant que dans le canal, la probabilité d’erreur est de 10-6, quelle est la probabilité de transmettre un mot de 4 bits sans erreur ? Même question si le code Hamming(7,4,3) est utilisé ?