Embed Size (px)
Citation preview

UNIVERSITE DE NICE SOPHIA ANTIPOLIS
Clustering des News
Clustering sous le projet Zone
EL FOUZI Ilhame
06/03/2013
Encadré par :
� Mr.Christophe DESCLAUX : Développeur de l’application ZONE.
� Mme.Elena Cabrio : Post-Doctorante dans équipe Wimmics. � Mme.Catherine Faron Zucker : Responsable de la formation
Knowledge and Information Systems.

Remerciement Tout d’abord, je tiens à remercier mon encadrant principale Mr.Christophe DESCLAUX pour son soutien, ses conseils pertinents le temps qu’il m’a consacré tout au long de cette période, sachant répondre à toutes mes interrogations.
De même, j’aimerais exprimer ma gratitude à ma deuxième encadrante Mme.Elena Cabrio , de ces orientation et ses conseils pertinentes, ainsi de ses encouragement tout au long du projet, ses motivations et les ressources documentaires.
Ainsi qu’un grand merci à Mme.Catherine Faron Zucker , pour sa confiance qu’il m’a accordé dès le début en me confiant ce projet, et en me faisant découvrir le monde de la fouille de données.
Je remercie également, Mme .Celia Pereira ainsi que Mr.Frederic PRECIOSO pour leur réponse à mes questions et de m’avoir confirmé les bon outils pour la réalisation de ce projet dans les meilleures conditions.
Enfin, je tiens à remercier mes parents et ma famille qui m’ont offert le soutien moral et financier tout au long de mes années d’études au Maroc comme en France et pour lesquels je dédie ce travail.

Table des figures Figure 1 : Processus de fouille de données [9] ........................................................................... 8
Figure 2: Iris_Flowers_Clustering_kMeans.svg [1]................................................................... 11
Figure 3 : L'algorithme K-Means .............................................................................................. 12
Figure 4 :sélection des centres [5] ........................................................................................... 13
Figure 5 :Affectation des objets [5] .......................................................................................... 13
Figure 6: Recalcule des centres des clusters [5] ....................................................................... 13
Figure 7 : Lemmatisation du Corpus ........................................................................................ 16
Figure 8 : Les documents nettoyés .......................................................................................... 17
Figure 9 :Formule TF-IDF [17] .................................................................................................. 17
Figure 10 : Fichiers contenant les vecteurs .............................................................................. 18
Figure 11 : Clusters ................................................................................................................... 18
Figure 12 : Importantes classes de la phases preprocessing ................................................... 20
Figure 13 : Importantes Classes dans la phase clustering ........................................................ 20
Figure 14 : Structuration de la JVM .......................................................................................... 21

Sommaire Table des figures .................................................................................................................................. 3
Introduction Général ............................................................................................................................. 5
Présentation du projet .......................................................................................................................... 6
1. Objectifs du projet ........................................................................................................................ 6
2. Contexte du projet ........................................................................................................................ 6
3 Acteurs ............................................................................................................................................ 6
Etat de l'art ............................................................................................................................................. 7
I- Fouille de texte .............................................................................................................................. 7
1. Introduction ................................................................................................................................ 7
2. Processus de la fouille de texte ............................................................................................. 7
II- Apprentissage statistique ............................................................................................................ 9
1. Apprentissage non supervisé ............................................................................................... 10
3. Algorithme K-Means .............................................................................................................. 11
Expérimentation .................................................................................................................................. 15
1. Le mode Prétraitement .......................................................................................................... 15
Spécification logiciels ......................................................................................................................... 19
1. Langage de développement ..................................................................................................... 19
2. outils de développement ........................................................................................................... 19
Problème rencontrés .......................................................................................................................... 21
Perspectives ........................................................................................................................................ 22
Conclusion ........................................................................................................................................... 22
Références .......................................................................................................................................... 23

Introduction Général
Durant ces dernières années, on assiste à une forte augmentation tant dans le nombre que dans le volume des informations mémorisées par des bases de données scientifiques, économiques, financières, administratives, médicales etc.
Trouver des relations entre les éléments stockés dans ces bases, et l'interprétation est un besoin recommandé. Les chercheurs ont focalisé leurs intérêts dans les nouvelles techniques informatiques afin de répondre à cette problèmatique. Le "Knowledge Discovery in Databases " (KDD) et le "Data Mining " se sont deux domaines émergeant répondant à ces objectifs.
Extraction de Connaissance à partir de Données ( Knowledge Discovery in Databases ) est l'extraction d'information potentiellement utile et non connue, qui est stockée dans des bases volumineuses. Ils permettent, grâce à plusieurs techniques spécifiques, de faire apparaître des connaissances. Dans la littérature, KDD a plusieurs objectifs, à savoir la classification, le regroupement, la régression, la découverte de règles associatives, etc.
L'information extraite peut être exprimée sous forme d'un ensemble de règles associatives, qui permettent de définir des liens entre les données, et par la suite, prédire la conduite d'autres données différentes de celles stockées dans la base.
Le Data Mining ou Fouille de données est souvent vu comme un processus équivalent au KDD, bien que la plupart des chercheurs voient en lui une étape essentielle de la découverte de connaissance. C’est en effet une étape non triviale du processus d’extraction de connaissance qui consiste à identifier des motifs (patterns) valides, nouveaux, potentiellement utiles et compréhensibles à partir d’une grande collection de données.

Présentation du projet
1. Objectifs du projet L’objectif de ce PFE est le développement d’un outil permettant le Clustering d'un ensemble de News en appliquant l'algorithme K-Means tout en essayant de diminuer les erreurs de Clustering.
Le but du développement de cet outil est de pouvoir appliquer le Clustering sur le projet ZONE, ce dernier est un outil qui permet d'extraire les nouvelles en provenance du Web. Le projet ZONE est un outil qui permet d'extraire les nouvelles en provenance du Web. L'extraction se base sur une agrégation des flux RSS puis un enrichissement de ces nouvelles en utilisant des annotations sémantiques.
La base de connaissances "DBpedia" enrichi le projet Zone par les nouvelles. Il s'agit d'une base de connaissance utilisant des données en provenance du service d'annotations "WikiMeta", DBpedia enrichit sémantiquement ces données à l'aide de liens vers d'autres ressources liées à l'élément.
Afin d'avoir une vue claire sur les données, l'organisation des nouvelles extraites est recommandé. Il existe plusieurs outils permettant de classer des informations. Il existe deux grandes catégories, l'apprentissage supervisé et l'apprentissage non supervisé.
Le projet de fin d'étude consiste à classer des nouvelles en utilisant un algorithme de clustering basé sur l'apprentissage non supervisé. Cet algorithme regroupe les informations ayant une grosse similarité entre elles, ceci sans spécifier a priori des catégories.
2. Contexte du projet La phase la plus importante dans ce projet et l'application de l'algorithme K-Means sur une banque de News importante tout en garantissant un niveau de Clustering intéressant.
Afin d'arriver au but de ce projet, son implémentation a respecté les phases de la fouille de données et a subit des transformations au fur et à mesure afin d'améliorer le résultat du Clustering.
3 Acteurs Maitrise d’ouvrage :
� Mr.Christophe DESCLAUX : Développeur de l’application ZONE. � Mme.Elena Cabrio : Post-Doctorante dans équipe Wimmics. � Mme.Catherine Faron Zucker : Responsable de la formation Knowledge and
Information Systems.
Maitrise d’œuvre :

� Ilhame EL FOUZI : Etudiante à l'Université de Nie Sophia Antipolis - Master 2 Knowledge and Information Systems.
Etat de l'art
I- Fouille de texte
1. Introduction
La Fouille de Texte (FT) est introduite, par Feldman and Degan en 1995 sous le terme Knowledge Discovery in Textual Databases (KDT) [Feldman, 1995], ou Text Data Mining (TDM) par Marti A. Hearst en 1999 [Hearst, 1999], et traduit en français par [Kodratoff, 1999] en Extraction des Connaissances à partir de Textes (ECT). [7]
Feldman et Degan, décrivent la Fouille de Texte comme un processus d’analyse exploratoire qui permet de révéler des informations exploitables du texte. Ainsi la FT peut être aussi définie comme un processus de découverte de connaissances qui consiste à extraire des informations utiles à partir des données textuelles par des outils d’analyses [Feldman, 2007]. Le but d’un processus de FT est de trouver des relations intéressantes impossibles ou difficiles à détecter par une analyse séquentielle de l’information [Kodratoff, 1999]. [7]
Nous considérons l’ECT comme un paradigme de l’ECBD au sens où le processus d’ECT prend modèle sur celui de l’ECBD, c’est-à-dire que c’est une instance de l’ECBD appliquée aux textes [Cherfi, 2004]. Et la fouille de texte ne représente qu’une étape du processus d’ECT.
Comparée à la Fouille de Données (FD), qui permet l’extraction automatique de connaissances à partir de données structurées, l’objectif de la FT est d’extraire de l’information élaborée à partir d’informations textuelles peu ou mal structurées. [Feldman, 2007] indiquent que les résultats de la FT représentent généralement les caractéristiques des documents plutôt que les documents eux-mêmes. [7]
L’ECT est à l’intersection de deux disciplines à savoir la statistique et la linguistique. Ces deux disciplines sont fondamentalement différentes dans leurs principes et dans leur histoire [Lebart, 1998], [Mothe, 2000], la linguistique ne s’intéressant qu’au langage utilisé pour constituer les textes. Dans l’analyse de texte les différents niveaux suivants sont considérés [Lebart, 1998], [Pazienza, 1997].[7]
2. Processus de la fouille de texte
L’information représente une valeur économique certaine, tout simplement parce que celui qui la détient dispose d’une richesse par rapport à celui qui ne l’a pas. Le data mining offre cette possibilité de trouver des informations cachées dans un ensemble de données et s’inscrit dans le courant, « aujourd’hui irréversible » de la gestion des connaissances. Mais il n’est en soi qu’un élément du processus de transformation des données en connaissance. En effet, plusieurs étapes le composent

Figure 1 : Processus de fouille de données [9]
2.1. Consolidation
La première chose à faire dans le processus de dataMining est d'identifier le domaine d'étude, cette étape est très important puisqu'elle vas servir à l'extraction des connaissance par l'outil de DataMining. Il est primordiale donc de sélectionner avec un grand soin les données qui décrivent au mieux la problématique . Les données sont ensuite stocké dans des entrepôts de données. [10]
2.2.Sélection L'étapes de la sélection des données consiste à sélectionner, dans l’entrepôt les données qui seront retenues pour construire le modèle.
2.3. Preprocessing
L'étape de preprocessing a deux objectifs principaux :
� Nettoyage.
� Transformations des données.
Le nettoyage des données consiste à augmenter la qualité des données, à l'évidence une mauvaise qualité entrainera une mauvaise qualité d'informations. Cette étape se déroule en sous autres étapes, en premier lieu, il est important de supprimer les valeurs aberrantes, qui sont éparpiller dans à peu près tout les documents.
En second lieu, on gère les valeurs manquantes puisque l'absence de certaine données n'est pas compatible avec l'ensemble des outils de dataMining. La gestion des valeurs manquantes se fait soit par une suppression de l'enregistrement

incomplet ce qui n'est pas toujours fiable puisque cet enregistrement peut contenir une information importante, soit en corrigeant les données manquantes.
la transformation consiste à structurer les données dans le formalisme attendu par les algorithmes qui seront appliqués par la suite.[10]
2.4. DataMining
L'étape de dataMining est le cœur du processus du processus d'extraction de connaissance. C’est ici que l’on procède à la recherche de lois ou de dépendances dans les données. A cette étape, différents types d’algorithmes peuvent être appliqués pour extraire des règles d’association. [10]
2.5 Evaluation du résultat
L'étape d'évaluation ou d'interprétation des résultat consiste en l'analyse des résultats de l'étape précédentes par un expert, dans le but d'estimer la qualité du modèle, autrement dit sa capacité à déterminer correctement les données.
2.5. Connaissances
Cette étape consiste en l'intégration de la connaissance, en principe la connaissance doit être convertie en décision puis en action.
Il est important de noter que l’enchaînement des différentes étapes du processus ECD, tel que décrit précédemment, conduit à la construction d’un modèle de description des données et par conséquent du système cible.
II- Apprentissage statistique L'apprentissage statistique est un paradigme qui regroupe une collection d'algorithmes et de méthodes permettant d'extraire l'information pertinente des données, ou d'apprendre des comportements à partir des exemples.
On distingue deux grands axes en apprentissage statistique :
� l'apprentissage supervisé � l'apprentissage non supervisé
1. Apprentissage supervisé
L'apprentissage supervisé a pour but d'établir des règles de comportement à partir d'une base de données contenant des exemples de cas déjà étiquetés. La base de données est en principe un ensemble de couples entrées sorties {(X,Y)}. Le but est d'apprendre à prédire pour toute nouvelle entrée X, la sortie Y.

Par contre, l'apprentissage non supervisé traite le cas ou on dispose seulement des entrées {X} sans avoir au préalable les sorties. Le traitement donc a pour but le partitionnement des données, cette opération s'appelle aussi le "Clustering". Il s'agit de regrouper les entrées en plusieurs groupes homogènes.
1. Apprentissage non supervisé
L'apprentissage non supervisée est un domaine important de l’analyse exploratoire des données. Les développements des méthodes de classification doivent beaucoup à l’évolution des capacités informatiques. L’objectif général de cette classification est de définir une partition des données de sorte que deux données sont soit regroupées, si elles sont très semblables, soit séparées si elles sont assez différentes. Dans l’approche non supervisée, l’interprétation dépend naturellement du domaine d’application, et ces domaines sont nombreux ( biologie, médecine, reconnaissance de formes )[6].
Les algorithmes d'apprentissage non supervisé (Clustering) diffèrent par la stratégie mise en place pour construire les clusters. La notion de mesure de similarité est utilisée par une part importante des approches.
Le résultat des algorithmes de Clustering peut se présenter sous différentes formes selon la possibilité ou non du chevauchement de deux clusters , autrement dit la possibilité qu'un objet appartient ou non à plusieurs clusters en même temps.
Le résultat le plus simple et le plus fréquent est le Clustering dur , cette forme de Clustering respecte le fait q'un élément appartient à un et un seul Cluster, autrement dit l'union des éléments de tout les Clusters forme l'ensemble des données de départ.
Le Clustering dur est le plus courant utilisé car facilement interprétable par l'expert. Néanmoins, il est nécessaire dans des cas de données une certaine flexibilité aux Clusters, admettant un Cluster, on peut trouver des éléments qui sont trop significatif et le fait d'affecter un autre objet qui a un degré d'importance minimale impact le processus de Clustering. Dans ce cas, un objet appartient à un ou aucun Cluster, c'est ce qu'on appel le Custering dur partiel.
Le Clustering flou, en effet est le Clustering permettant de classer un élément dans un ou plusieurs Cluster, ceci rend la tache d'interprétation pour l'expert très difficile car plus un élément vas appartenir à de nombreux Clusters plus le résultat perd sa précision.
La majorité des méthodes proposent un résultat sous forme d'une structure plate, autrement dit sans lien entre les Clusters. D'autres proposent une forme hiérarchique afin de données un vision globale sur les dépendances des Clusters.
Les premières méthodes de Clustering proposées se basent sur les distances, et sont toujours populaires. La mesure de similarité entre les éléments adoptés par ces
méthodes est la distance minimale. En effet, la distance minimale entre deus éléments affecte ces deux éléments dans le même Cluster.
Chaque Cluster est définie par un objet représentant, si celui-ci est calculé comme la moyenne des éléments du Cluster on l'appelle centroide , s'il est représenté par un élément particulier du Cluster celui-ci est appelé médoide. Les algorithmes les plus connus de cette famille d'algorithme sont les algorithme K-Means [Macqueen, 1967] et FUZZY C-Means[Dunn, 1974].
3. Algorithme K-Means
Le clustering est en mathématique, une méthode qui a comme objectif à partir un ensemble de données non étiqueté chercher une typologie ou partition des individus en cluster ou catégorie. Ceci est fait en optimisant un critère d'homogénéité des individu pour chaque classe. Un cluster est donc une collection d'objet similaires entre eux et dissimilaires aux autres collections. L'objectif de clustering est à distinguer aux autres procédure de classement pour lesquelles une typologie est a priori connu.[1]
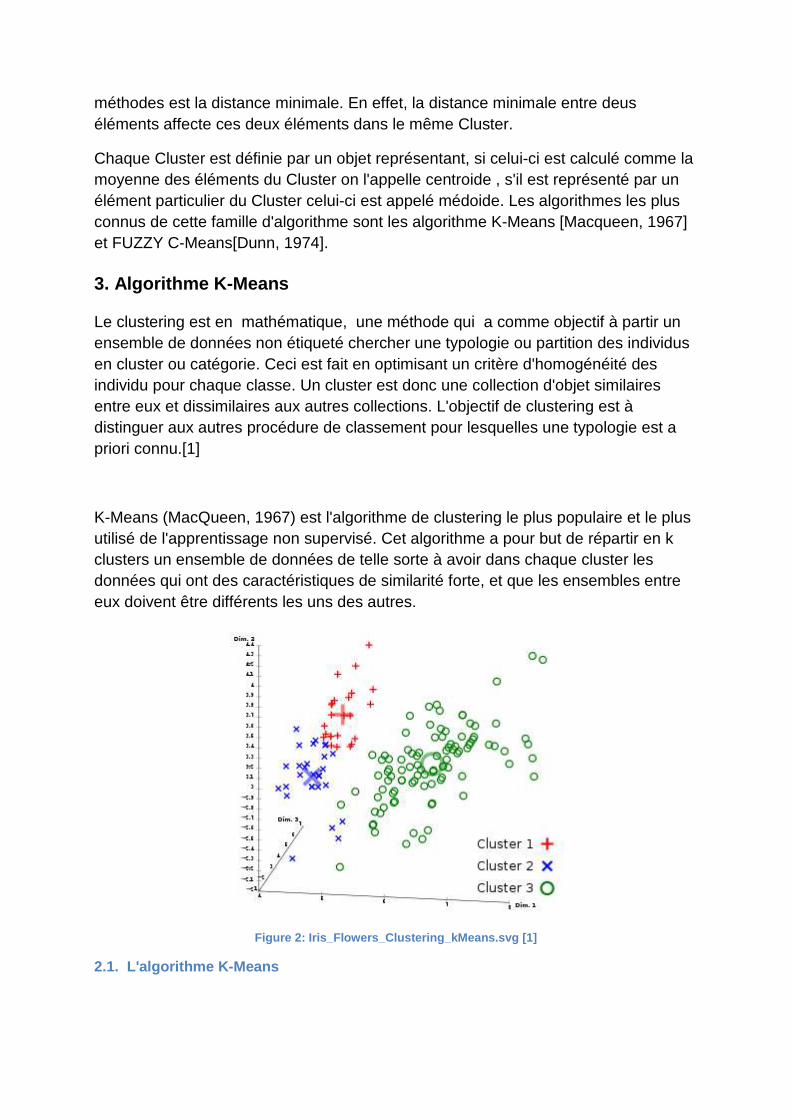
K-Means (MacQueen, 1967) est l'algorithme de clustering le plus populaire et le plus utilisé de l'apprentissage non supervisé. Cet algorithme a pour but de répartir en k clusters un ensemble de données de telle sorte à avoir dans chaque cluster les données qui ont des caractéristiques de similarité forte, et que les ensembles entre eux doivent être différents les uns des autres.
Figure 2: Iris_Flowers_Clustering_kMeans.svg [1]
2.1. L'algorithme K-Means

k-means est un algorithme itératif qui minimise la somme des distances entre chaque individu et le centroïde. Le choix initial des centroïdes conditionne le résultat final. Admettant un nuage d'un ensce nuage de points, k-Means change les points de chaque cluster jusqu'à ce que la somme ne puisse plus diminuer. Le résultat est un ensemble de clusters compacts et clairement séparés, sous réserve de c[2].
Explication
L'application de l'algorithme k
means est un algorithme itératif qui minimise la somme des distances entre chaque individu et le centroïde. Le choix initial des centroïdes conditionne le résultat final. Admettant un nuage d'un ensemble de points. Afin de construire des catégories de
Means change les points de chaque cluster jusqu'à ce que la somme ne puisse plus diminuer. Le résultat est un ensemble de clusters compacts et clairement séparés, sous réserve de choisir la bonne valeur k du nombre de clusters.
Figure 3 : L'algorithme K-Means
L'application de l'algorithme k-Means se fait en suivant les étapes suivante :
means est un algorithme itératif qui minimise la somme des distances entre chaque individu et le centroïde. Le choix initial des centroïdes conditionne le résultat final.
Afin de construire des catégories de Means change les points de chaque cluster jusqu'à ce que la
somme ne puisse plus diminuer. Le résultat est un ensemble de clusters compacts et hoisir la bonne valeur k du nombre de clusters.
Means se fait en suivant les étapes suivante :

1) Choix de k, le nombre de cluster à créer.
2) Choix des centres des clusters da manière aléatoire à partir des objets en entrée.
La procédure adopté pour le choix des centres des Clusters initiaux est extrêmement importante car elle a un impact direct sur le résultat final du Clustering. Il est donc très important de choisir des clusters bien séparées.[11]
L'algorithme K-Means basique se base sur une initialisation aléatoire, après plusieurs utilisation du résultat de l'algorithme K-Means, des chercheurs proposent des améliorations au niveau de cette étape puisqu'elle impact le résultat final.
Figure 4:sélection des centres [5]
1- Parcourir tous les objets afin de les affecter ou les réaffecter au cluster approprié en se basant sur la minimisation de la distance entre l'objet et le centre du cluster.
Figure 5 :Affectation des objets [5 ]
2- Calculer les centres de chaque cluster puisqu'ils peuvent changé après affectation des objets.
Figure 6: Recalcule des centr es des clusters [5]
3- Refaire les étapes (3) et (4) jusqu'aucun changement du calcul des centres des clusters ou un stabilité des objets.

3- Calcul de distance [8] ( En cours ) a-euclidienne b-Cosine Similarity 4-Existant a- Weka WEKA est un logiciel de Data Mining libre très populaire dans la communauté « Machine Learning ». Il intègre un grand nombre de méthodes, articulées essentiellement autour des approches supervisées et non supervisées.
WEKA peut importer différents formats de fichier. Mais il propose surtout un format propriétaire (*.ARFF) qui est un format texte, avec des spécifications ad hoc sur documenter les variables.
Importer un fichier ARFF ne pose donc pas de problèmes particuliers, dès lors que l’on sait appréhender un fichier texte.
De manière générale, le format texte présente l’avantage de la souplesse. Nous pouvons manipuler le fichier dans n’importe quel éditeur de texte, en dehors du logiciel, pour le visualiser, voire le corriger. En revanche, par rapport au format binaire, il est présente l’inconvénient de la lenteur. A chaque chargement dans le logiciel, il doit être décomposé, interprété. Il est difficile d’organiser une lecture par blocs efficace. Lorsque la base est d’une taille raisonnable, quelques milliers d’observations et des dizaines de variables, la différence de performances est peu perceptible. [13][14]
b-RApidMiner RapidMiner est un logiciel open source et gratuit dédié au data mining. Il contient de nombreux outils pour traiter des données: lecture de différents formats d'entrée, préparation et nettoyage des données, statistique, tous les algorithmes de data mining, évaluation des performances et visualisation diverses.
C'est un logiciel puissant, il n'est pas facile à manipuler au premier abord, mais avec un peu de pratique, il permet de mettre en place rapidement une chaine complète de traitement de données, de la saisie des données à leur classification.[20]
c- TANAGRA TANAGRA est une grande partie de la panoplie des méthodes de DATA MINING intégrées dans une seule structure. Le mode d'utilisation du logiciel est au standard logiciels du domaine, avec notamment la définition des opérations à réaliser sur les données à l'aide d'une représentation visuelle.[22]

d- R-project :
Un logiciel gratuit que l'on associe souvent aux statisticiens mais qui en réalité convient très bien pour la fouille de données. La bibliothèque des fonctions est impressionnante et s'enrichit chaque jour grâce au système des packages.[21]
Expérimentation Le processus de développement du projet est divisé en deux parties « Pré-traitement » et «Le Clustering »,chaque partie est constituée de plusieurs étapes, l’entrée de l’étape en cours représente la sortie de l’étape précédente ainsi de suite.
1. Le mode Prétraitement
Toute opération de fouille de texte a besoin en entrée d'un coprus, Un corpus est un ensemble de documents (textes, images, vidéos, etc.) regroupés dans une optique précise.
Un corpus n'est pas un objet simple, mais le fruit des choix des linguistes qui le rassemblent. L'objet corpus est censé représenter quelque chose, et ne doit pas être une simple collection de phrases ou un « sac de mots » (Rastier, 2005). L'ensemble qui forme un corpus est un assemblage de textes, il ne faut pas que la forêt cache l'arbre textuel. Cependant, cet ensemble peut couvrir des typologies de texte très divers, l'important est que le chercheur puisse justifier ces choix.[19]
La nature de la discipline et des corpus a été largement débattue (Williams, 2002 ; 2006), mais la discussion n'est pas close, puisque ce n'est qu'en créant et en explorant des corpus que nous pouvons commencer à comprendre la nature de ces vastes assemblages de textes. La définition la plus complète d'un corpus est celle de Sinclair (2005):
"A corpus is a collection of pieces of language text in electronic form, selected according to external criteria to represent, as far as possible, a language or language variety as a source of data for linguistic research"
Une définition qui est à la fois précise, et vague. « Pieces », des morceaux, est un choix délibéré afin d'éviter le mot « text » puisque ce dernier est toujours un sujet délicat en linguistique. [19]
L'entrée de notre projet sera une base de News, puisque le but est de regrouper des News. Pour cela nous utilisons le corpus Reuters[15], ce corpus inclus 12 902 document pour 90 classes, ceci est répartit entre les données d'apprentissage et les données de test.

La première étape à faire consiste à améliorer la qualité du corpus en le passant par une phase de prétraitement.
1. Suppression des StopWord Le nettoyage du corpus sert à retirer tout ce qui n’est pas utile pour une analyse syntaxique. En effet, un StopWord est un mot non significatif figurant dans un texte, ces mots sont très fréquent dans tout les document et donc il n'ont pas une valeur ajouté dans la catégorisation des documents.
Exemples de StopWord : { a, as, at, and, the, an, anyway}
2. Lemmatisation Après avoir supprimer les StopWord, on passe à la phase de lemmatisation. La lemmatisation est la technologie qui permet de retrouver la forme « canonique » des mots. Par exemple, le mot « animaux » est transformé dans sa forme canonique « animal ». Le service de lemmatisation est également en mesure d’identifier les traits dits « morphologiques » du mot : dans l’exemple précédent, le fait qu’il s’agisse de la forme plurielle. Optionnellement, le service peut désambiguïser les mots. Par exemple, dans la phrase « il juge un dessin » et « le juge s’est rendu en ville », le service est capable de comprendre que dans le premier cas il s’agit d’un verbe (-> « juger ») et dans le deuxième un nom (-> « juge »).
Figure 7 : Lemmatisation du Corpus
La première étape que nous avons fait, est la lemmatisation de notre Corpus, afin de mieux garantir cette étape nous avons utiliser le système StanFordNLP [16] existant permettant de lemmatiser un ensemble de texte.
Au fur et à mesure de la phase de lemmatisation on construit notre dictionnaire, celui-ci sert comme une référence de tout le corpus et donc il doit être construit à partir du corpus brut.
Le résultat de l'étape de nettoyage ( Suppression des StopWord, lemmatisation) , sera un fichier contenant pour chaque ligne un document du corpus nettoyé (Figure 8).

Figure 8 : Les documents nettoyés
3. La vectorisation
La vectorisation consiste à partir d’un texte, lui attribuer une représentation vectoriel, ce qui nous permet par la suite de comparer des textes entre eux et établir une relation de proximité.
Pour cela, nous récupérerons le fichier résultat du nettoyage et on donne pour chaque ligne de ce fichier (pour chaque document) une représentation vectorielle (Figure 10).
La vectorisation se fait en utilisant une formule (TF-IDF) nous permettant de représenter le document par un vecteur.
TF-IDF est une mesure statistique permet d'évaluer l'importance d'un mot par rapport à un document extrait d'une collection. Le poids augmente proportionnellement en fonction du nombre d'occurrences du mot dans le document. Il varie également en fonction de la fréquence du mot dans la collection.[18]
Figure 9 :Formule TF-IDF [17]
Dans la formule tfidf, tfi,j désigne le rapport de la fréquence du terme (i) dans le document (j) et de la taille du document, de ce fait plus le terme est important dans le document plus le tf est grand. La partie Idfi de la formue désigne le nombre de documents contenant le terme (i).

Figure 10 : Fichiers contenant les vecteurs
4. Application de l'algorithme K-Means
Cette étape consiste à l'application de l'algorithme k-Means sur les vecteurs que nous avons préparé dans l'étape précédente (Figure 10) . L'algorithme K-Means que nous avons mis en place se base sur la distance euclidienne pour mesurer la similarité entre les vecteurs . La première étape de l'algorithme consiste à lire tout les vecteurs du fichier, puis initialiser aléatoirement k cluster ensuite calculer la distance entre tout les vecteurs et les centres afin de définir la distance minimale pour pouvoir affecter un tel vecteur à un cluster. L'algorithme itère tant qu'il existe un vecteur qui n'est pas affecter ou bien la moyenne du cluster change toujours.
Après avoir affecter tout les vecteurs aux clusters les plus proches on génère les clusters résultat sauvegardé dans un fichiers (Figure 11).
Figure 11 : Clusters

Spécification logiciels
1. Langage de développement Ce projet est développé en java dans le but d'intégrer le projet Zone par la suite.
2. outils de développement Afin d'avoir un code source bien structuré, et afin d'optimiser le temps de maintenance du projet, j'ai opté pour la structuration du projet en utilisant Maven.
Maven est un outil open-source de build pour les projets Java très populaire, il est conçu pour supprimer les tâches difficiles du processus de build. Maven utilise une approche déclarative, où le contenu et la structure du projet sont décrits, plutôt qu'une approche par tâche utilisée par exemple par Ant. Cela aide à mettre en place des standards de développements au niveau d'une société et réduit le temps nécessaire pour écrire et maintenir les scripts de build.
Le coeur du projet est le modèle objet projet (appelé POM pour project object model-Pom.xml-). Il contient une description détaillée du projet, avec en particulier des informations concernant le versionnage et la gestion des configurations, les dépendances, les ressources de l'application, les tests, les membres de l'équipe, la structure et bien plus encore.
3. Diagramme de classes
les deux packages ci-dessous (Figure12, Figure13) représente les classes les plus importantes du système, dans un premier lieu, on trouve la classe Document va représenter la structure d'un fichier contenant son nom sa liste des mots lemmatisés et son vecteur TFIDF .
La classe StanfordLemmatiser servant à la lemmatisation des documents, cette classe utilise les librairies de l'outils StanFord pour trouver les lemmes.
La classe Metier, contenant l'implémentation des différents traitement nécessaire à accomplir la phase de preprocessing tel que une méthode pour l'algorithme TFIDF, méthode pour la lecture des fichier et la génération des vecteurs TFIDF.

Figure 12 : Importantes classes de la phases prepro cessing
Les classes les plus importantes dans la phase de Clustering est la Classe AlgoKMeans implémentant l'algorithme KMeans, contenant ainsi deux méthodes d'initialisation aléatoire des clusters (nous avons ajouté une méthode d'initialisation afin d'améliorer le résultat de l'algorithme) une méthode pour le calcul de distance.
La classe Cluster représente la structure d'un Cluster contenant une liste de vecteurs, la moyenne du cluster .
Vector, Classe représentant le vecteur en tant qu'un tableau de données.
Figure 13 : Importantes Classes dans la phase clust ering

Problème rencontrés Chaque projet, quelle que soit sa nature, a des moments pendant lesquels la rentabilité et la vitesse de développement ne sont pas constantes dans le temps, ce sont des moments où on rencontre des problèmes plus au moins difficiles, soit d’ordre conceptuel ou technique.
K-Means est sensible au bruit, donc j'avais un problème ou j'avais des vecteurs qui contenait beaucoup de "0", ce qui a impacter le résultat du Clustering. Pour palier à ce problème j'ai implémenté la suppression des stopWord.
Après avoir implémenter la suppression des stopWord, j'avais toujours le problème de mauvais clustering, en effet je n'ai pas géré la suppression de la ponctuation, ceci a posé problème au moment de calcul de TFIDF par exemple un mot (interest:) ne pourra pas être bien repéréau cas ou on a le même mot sans les ":".
Le problème majeur rencontré tout au long de l'implémentation du projet, est un problème de performance au moment de mettre en place tout le corpus contenant les 11413. La source de ce problème est la dimension des vecteurs qu'on prépare pour l'algorithme k-Means et qui doivent avoir la même dimension (dimension du dictionnaire qui a comme valeur à peu près 80 000). Dans la première version du projet j'utilisais des "List" pour sauvegarder une liste des objets documents, cette liste est nécessaire pour l'algorithme TFIDF, donc j'avais cette liste qui contient 11413 documents en mémoire ce qui a générer une exception OutOfMemory. Au début j'utiliser des HashMap pour calculer TFIDF, après avoir eu ce problème je me suis rendu compte que les HashMap alloue au début un espace figé en mémoire et si elles ont besoin après d'une taille grande elles redimensionne leur taille et c'est à ce moment la que ça plante.
Figure 14 : Structuration de la JVM
Dans un processus java On y trouve des zones techniques : JVM, OS. Des zones de stockage de données : Mémoire Heap et native. La zone d’échange entre la JVM et l’OS : Librairies.
Les paramètres de gestion les plus connus sont ms et mx qui régissent la taille de la Heap alors que nous venons de voir que ce n’est pas la seule zone mémoire d’une JVM.
Après avoir configurer les paramètres de la JVM pour l'augmenter afin de palier au problème de l'OutOfMemory, le problème existe toujours. L'étape suivante d'optimisation est d'utiliser des fichiers au lieu des liste pour sauvegarder tout ce qui a été sauvegarder comme temporaire en mémoire le sauvegarder en fichier. Cette solution n'as pas posé le problème d'outOfMemory mais prend du temps.

La difficulté principale de ce projet pour quelqu'un qui n'a jamais fait de la fouille de données est le non respect de l'enchainement des phases de la fouille de données ce qui impact le résultat, et donc le développeur retourne à une étape précédente pour bien la respecter.
Perspectives Vu les problèmes de performances que nous avons rencontrés tout au long de ce projet, je n'ai pas pu intégré le projet au projet Zone comme prévu.
Comme perspective, et pour avoir une meilleur performance après l'intégration à zone il est d'appliquer un algorithme MapReduce, permettant de faire des calculs parallèles .
Conclusion
Ce projet de fin d’études, intitulé« Clustering des News »s’inscrit dans le domaine de fouille de données, il traite comme problématique la catégorisation des News. Le système accomplit la phase de prétraitement, et après applique un algorithme de fouille de données (K-Means) pour le Clustering
La réalisation d’un tel projet, qui couvre à la fois, le domaine de la recherche et la technique, m’a permis d’améliorer mes capacités et mes réflexions au niveau de la conception comme au niveau de la programmation, d’autant plus qu’il s’agit d’un système qui implémente des méthodes et des approches de fouille de données, j'ai bien acquis par cette réalisation les fondements de la fouille de onnées.
En fin, ce projet était une expérience très intéressante d’autant plus qu’il ne s’agit pas de la réalisation d’une partie d’un programme ou la participation dans un projet collectif dans lequel on se contente d’exécuter les tâches confiées, mais sa particularité réside dans la prise de responsabilité de toutes les phases quelle soit l’état d’art, la conception, et cela n’était pas le fruit d’un travail individuel, mais aussi grâce à la supervision, les idées et les consignes de mon encadrant.

Références [1] http://en.wikipedia.org/wiki/K-means_clustering [2] D’Hondt Frédéric, El Khayati Brahim ,Etude de méthodes de Clustering pour la segmentation d’images en couleurs, Faculté Polytechnique de Mons, 5ème Electricité, Certificat Applicatifs Multimédia. [3] http://en.wikibooks.org/wiki/Data_Mining_Algorithms_In_R/Clustering/K-Means [4] http://eric.univ-lyon2.fr/publications/files/ONY_FDC_2007_WORKSHOP.pdf [5] http://www.codeproject.com/Articles/439890/Text-Documents-Clustering-using-K-Means-Algorithm [6] Frédéric BLANCHARD, Michel HERBIN, Philippe VAUTROT, Vers une classification non supervisée basée sur un nouvel indice de connectivité
[7] Ilhème GHALAMALLAH, Proposition d'un modèle d'analyse exploratoire multidimensionnelle dans un contexte d'Intelligence Economique. Université Toulouse III - Paul Sabatier, 2009
[8] Anna Huang, Similarity Measures for Text Document Clustering, The University of Waikato, Hamilton, New Zealand.
[9] Knowledge Discovery Annecy, http://kdacy-consulting.com/main/le-processus-ecd
[10] IBEKWE-SANJUAN Fidelia, SANJUAN Eric, Ingénierie linguistique et Fouille de texte
[11] M. Emre Celebi, Hassan A.Kingravi, Patricio A.Vela, A Comparative Study of E�cient Initialization Methods for the K-Means Clustering Algorithm, September 2012
[12] Z.Guellil, L.Zaoui, Proposition d'une solution au problème d’initialisation cas du K-means
[13] http://fr.wikipedia.org/wiki/Weka_(apprentissage_automatique)
[14] Sapna Jain, M Afshar Aalam, M. N DojaK-MEANS CLUSTERING USING WEKA INTERFACE
[15] http://disi.unitn.it/moschitti/corpora.htm
[16] http://www-nlp.stanford.edu/index.shtml
[17] http://fr.wikipedia.org/wiki/TF-IDF
[18] http://thibault.vanessa.free.fr/Th%E8se%20Thibault%20ROY/Redaction/Manuscrit%20final/parts/logiciel/doc/TFIDF%20-%3E%20Algo.pdf
[19] Geoffrey Williams, TEXTE ET CORPUS, N°3, Actes des cinquièmes journées de la Linguistique de Corpus
[20] http://rapid-i.com/content/view/181/190/
[21] http://pbil.univ-lyon1.fr/R_svn/pdf/tdr11.pdf
[22] http://eric.univ-lyon2.fr/~ricco/tanagra/fr/tanagra.html





























