Embed Size (px)
Citation preview

UU PP CC
Reducing Misspeculation Penalty in Trace-Level Speculative
Multithreaded Architectures
Reducing Misspeculation Penalty in Trace-Level Speculative
Multithreaded Architectures
Carlos Molina ψ, ф
Jordi Tubella ф
Antonio González λ,ф
ISHPC-VI, Nara City (Japan) - September 7-9, 2005
λ Intel Barcelona Research Center
Intel Labs - UPC
Barcelona, Spain
ф Dept. Arquitectura de Computadors
Universitat Politècnica de Catalunya
Barcelona, Spain
{antonio,cmolina,jordit}@ac.upc.edu
ψ Dept. Enginyeria Informàtica
Universitat Rovira i Virgili
Tarragona, Spain

Techniques to Boost I ExecutionTechniques to Boost I Execution
Data Value ReuseData Value Reuse Data Value SpeculationData Value Speculation
Avoid serialization caused by data dependences
Determine results of instructions without executing them
Target is to boost the execution of programs
Avoid serialization caused by data dependences
Determine results of instructions without executing them
Target is to boost the execution of programs
Computation RepetitionComputation Repetition

NON SPECULATIVE !!!
Buffers previous inputs and their corresponding outputs
Only possible if a computation has been done in the past
Inputs have to be ready at reuse test time
NON SPECULATIVE !!!
Buffers previous inputs and their corresponding outputs
Only possible if a computation has been done in the past
Inputs have to be ready at reuse test time
Techniques to Boost I ExecutionTechniques to Boost I Execution
Computation RepetitionComputation Repetition
Data Value ReuseData Value Reuse Data Value SpeculationData Value Speculation

SPECULATIVE !!!
Predicts values as a function of the past history
Needs to confirm speculation at a later point
Solves reuse test but introduces misspeculation penalty
SPECULATIVE !!!
Predicts values as a function of the past history
Needs to confirm speculation at a later point
Solves reuse test but introduces misspeculation penalty
Techniques to Boost I ExecutionTechniques to Boost I Execution
Computation RepetitionComputation Repetition
Data Value ReuseData Value Reuse Data Value SpeculationData Value Speculation

Trace Level SpeculationTrace Level Speculation
Avoids serialization caused by data dependences
Skips in a row multiple instructions
Predicts values based on the past
Introduces penalties due to misspeculations
With Live Output TestWith Live Output Test
Trace Level SpeculationTrace Level Speculation
With Live Input TestWith Live Input Test

BUFFERBUFFER
Trace Level Speculation with Live Output Test
Trace Level Speculation with Live Output Test
Live Output Update & Trace Speculation
NST
ST
Trace Miss Speculation Detection & Recovery Actions
INSTRUCTION EXECUTION
NOT EXECUTED
LIVE OUTPUT VALIDATION

MotivationMotivation
Two orthogonal issues microarchitecture support for trace speculation control and data speculation techniques
– prediction of initial and final points– prediction of live output values
This work focuses on microarchitecture support (TSMA)
concretely, on reducing penalties due to misspeculations
Molina, González, Tubella, “Trace-Level Speculative Multithreaded Architecture (TSMA)”, ICCD’02
Molina, González, Tubella “Compiler Analysis for TSMA”, INTERACT’05

OutlineOutline
TSMA (Trace-level Speculative Multithreaded Architecture)
Verification Engine
Enhanced Verification Engine
Experimental Framework
Simulation Results
Conclusions

TSMA Block DiagramTSMA Block Diagram
CacheI
EngineFetch
RenameDecode &
UnitsFunctional
PredictorBranch
SpeculationTrace
NST Reorder BufferNST Reorder Buffer
ST Reorder BufferST Reorder Buffer
NST Ld/St QueueNST Ld/St Queue
ST Ld/St QueueST Ld/St Queue
NST I WindowNST I Window
ST I WindowST I Window
Look Ahead BufferLook Ahead Buffer
EngineVerification
L1NSDCL1NSDC L2NSDCL2NSDC
L1SDCL1SDC DataCache
Register FileNST Arch.
Register FileST Arch.
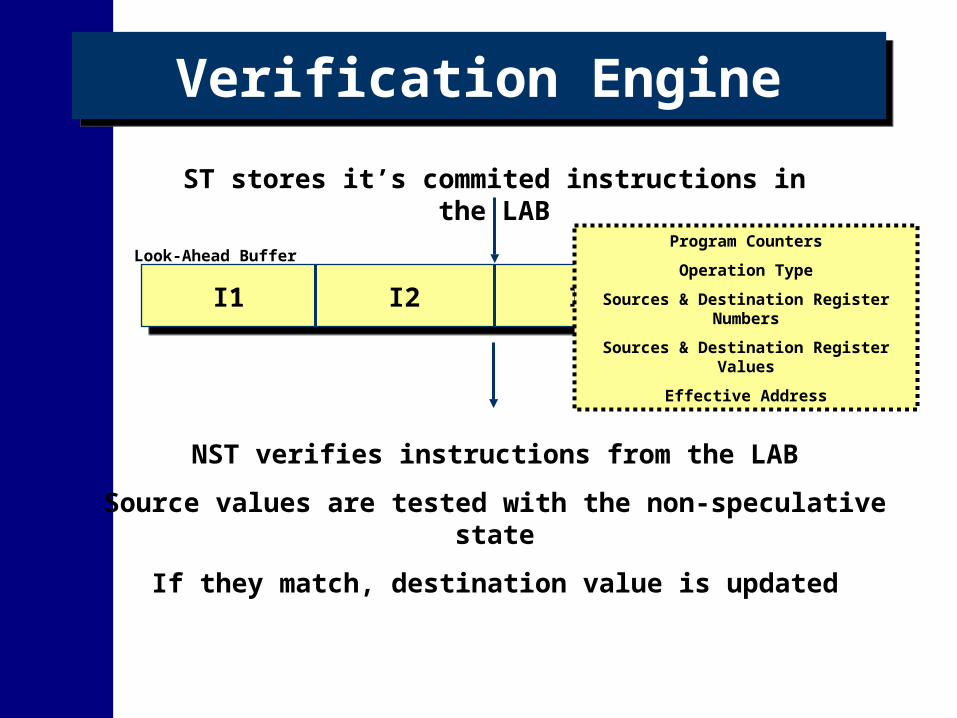
Verification EngineVerification Engine
ST stores it’s commited instructions in the LAB
Look-Ahead Buffer
I1 I2 I3 I4
Program Counters
Operation Type
Sources & Destination Register Numbers
Sources & Destination Register Values
Effective Address
NST verifies instructions from the LAB
Source values are tested with the non-speculative state
If they match, destination value is updated

BRANCHES: source value tested; program counter updatedBRANCHES: source value tested; program counter updated
Verification EngineVerification Engine
Look-Ahead Buffer
I1 I2 I3 I4
VERIFICATION
ENGINE
Non-Speculative
Memory Hierarchy
Non-Speculative
Register File
BRANCH Rsource1, Target
Non-Speculative
Register File

BRANCHES: source value tested; program counter updatedBRANCHES: source value tested; program counter updated
Verification EngineVerification Engine
Look-Ahead Buffer
I1 I2 I3 I4
VERIFICATION
ENGINE
ARITH IS: source values tested; destination register updatedARITH IS: source values tested; destination register updated
Non-Speculative
Memory Hierarchy
Non-Speculative
Register File
Non-Speculative
Register File
Rdest Rsource1 OP Rsource2
Non-Speculative
Register File

BRANCHES: source value tested; program counter updatedBRANCHES: source value tested; program counter updated
Verification EngineVerification Engine
Look-Ahead Buffer
I1 I2 I3 I4
VERIFICATION
ENGINE
ARITH IS: source values tested; destination register updatedARITH IS: source values tested; destination register updated
Non-Speculative
Memory Hierarchy
Non-Speculative
Register File
STORES: effective address verified; destination memory updatedSTORES: effective address verified; destination memory updated
M [ Rsource1 , literal ] Rsource2
Non-Speculative
Register File
Non-Speculative
Memory Hierarchy

BRANCHES: source value tested; program counter updatedBRANCHES: source value tested; program counter updated
Verification EngineVerification Engine
Look-Ahead Buffer
I1 I2 I3 I4
VERIFICATION
ENGINE
ARITH IS: source values tested; destination register updatedARITH IS: source values tested; destination register updated
Non-Speculative
Memory Hierarchy
Non-Speculative
Register File
STORES: effective address verified; destination memory updatedSTORES: effective address verified; destination memory updated
LOADS: effective address verified; memory value checked; register updatedLOADS: effective address verified; memory value checked; register updated
Rdest M [ Rsource1 , literal ]
Non-Speculative
Register File
Non-Speculative
Memory Hierarchy
Non-Speculative
Register File

Squashed Is from LABSquashed Is from LAB
020406080
100120140160180200
Amm
pApsi
Crafty Eon
Equake
Gcc Mcf
Mes
a
Mgrid
Sixtra
ck
Vortex
Vpr
A_Mean
On average, up to 85 instructions are squashed from
LAB in each thread synchronization
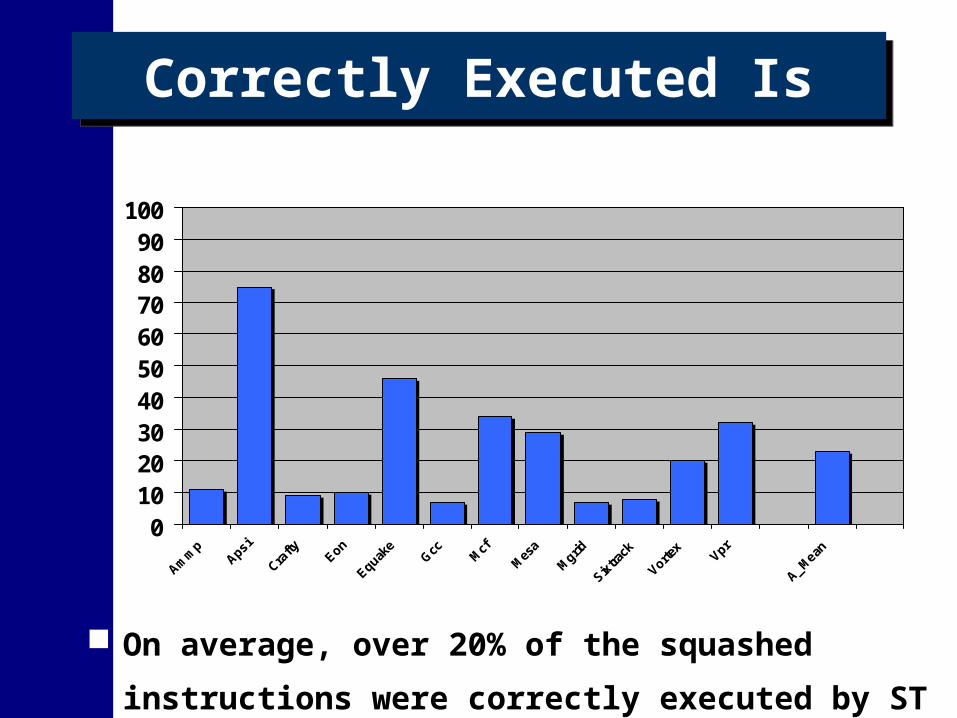
Correctly Executed IsCorrectly Executed Is
0102030405060708090
100
Amm
pApsi
Crafty Eon
Equake
Gcc Mcf
Mes
a
Mgrid
Sixtra
ck
Vortex
Vpr
A_Mean
On average, over 20% of the squashed instructions
were correctly executed by ST

Our ProposalOur Proposal
Enhanced Verification Engine does not throw away execution results of instructions
that are independent of the mispredicted point reduce the number of Is fetched and executed
thread synchronizations can be delayed or even aborted
verification of branches, loads, stores and single-cycle instructions is reconsidered.

Related WorkRelated Work
Instruction reissue [Lipasti 1997, González &
González 1997, Sato 1998]
Squash reuse [Sodani & Sohi 1997]
Control independence in trace processors
[Rotenberg et al, 1997]
Dynamic control independence [Chou et al 1999]
Register integration [Roth & Sohi 2000]

BRANCHES: branch target is validated instead of source values. BRANCHES: branch target is validated instead of source values.
Enhanced Verification EngineEnhanced Verification Engine
Look-Ahead Buffer
I1 I2 I3 I4
ENHANCED
VERIFICATION
ENGINE
Non-Speculative
Memory Hierarchy
Non-Speculative
Register File
BRANCH Rsource1, Target

BRANCHES: branch target is validated instead of source values. BRANCHES: branch target is validated instead of source values.
Enhanced Verification EngineEnhanced Verification Engine
Look-Ahead Buffer
I1 I2 I3 I4
ENHANCED
VERIFICATION
ENGINE
ARITH IS: if source values do not match, instruction is re-executed.ARITH IS: if source values do not match, instruction is re-executed.
Non-Speculative
Memory Hierarchy
Non-Speculative
Register File
Rdest Rsource1 OP Rsource2
Non-Speculative
Register File
Non-Speculative
Register File
F.U

BRANCHES: branch target is validated instead of source values. BRANCHES: branch target is validated instead of source values.
Enhanced Verification EngineEnhanced Verification Engine
Look-Ahead Buffer
I1 I2 I3 I4
ENHANCED
VERIFICATION
ENGINE
ARITH IS: if source values do not match, instruction is re-executed.ARITH IS: if source values do not match, instruction is re-executed.
Non-Speculative
Memory Hierarchy
Non-Speculative
Register File
STORES: effective address is re-computed if fails and memory is updated with value obtained from the non-speculative architectural state.
STORES: effective address is re-computed if fails and memory is updated with value obtained from the non-speculative architectural state.
M [ Rsource1 , literal ] Rsource2
Non-Speculative
Register File
Non-Speculative
Memory Hierarchy

BRANCHES: branch target is validated instead of source values. BRANCHES: branch target is validated instead of source values.
Enhanced Verification EngineEnhanced Verification Engine
Look-Ahead Buffer
I1 I2 I3 I4
ENHANCED
VERIFICATION
ENGINE
ARITH IS: if source values do not match, instruction is re-executed.ARITH IS: if source values do not match, instruction is re-executed.
Non-Speculative
Memory Hierarchy
Non-Speculative
Register File
STORES: effective address is re-computed if fails and memory is updated with value obtained from the non-speculative architectural state.
STORES: effective address is re-computed if fails and memory is updated with value obtained from the non-speculative architectural state.
Non-Speculative
Register File
LOADS: effective address is re-computed if fails and destination value obtained from memory is commited to register file.
LOADS: effective address is re-computed if fails and destination value obtained from memory is commited to register file.
Rdest M [ Rsource1 , literal ]
Non-Speculative
Memory Hierarchy
Non-Speculative
Register File

Incorrect Speculated IsIncorrect Speculated Is
0%10%20%30%40%50%60%70%80%90%
100%
Amm
pApsi
Crafty Eon
Equake
Gcc Mcf
Mes
a
Mgrid
Sixtra
ck
Vortex
Vpr
A_Mean
RestStoresLoadsBranches Simple Is
On average, close to 90% of the instructions are branches, loads, stores and single-cycle instructions
Only 1% Is inserted in LAB are incorrectly predicted

Experimental FrameworkExperimental Framework
Simulator Alpha version of the SimpleScalar Toolset
Benchmarks Spec2000, ref input
Maximum Optimization Level DEC C & F77 compilers with -non_shared -O5
Statistics Collected for 250 million instructions Skipping an initial part of 500 million instructions

Simulation ParametersSimulation Parameters
Base microarchitecture out of order machine, 4 instructions per cycle I cache: 16KB, D cache: 16KB, L2 shared: 256KB bimodal predictor
TSMA additional structures each thread: I window, reorder buffer, register file speculative data cache: 1KB trace table: 128 entries, 4-way set associative look ahead buffer: 128 entries verification engine: up to 8 instructions per cycle only one I reexecuted per cycle

Thread SynchronizationsThread Synchronizations
0102030405060708090
100
Amm
pApsi
Crafty Eon
Equake
Gcc Mcf
Mes
a
Mgrid
Sixtra
ck
Vortex
Vpr
A_Mean
Conventional VE Enhanced VE
On average, the number of thread synchronizations
is about 10% lower (from 30% to 20%)

SpeedupSpeedup
Amm
pApsi
Crafty Eon
Equake
Gcc Mcf
Mes
a
Mgrid
Sixtra
ck
Vortex
Vpr
A_Mean
1.35
1.30
1.25
1.20
1.15
1.10
1.05
1.00
1.40
1.45
Conventional VE Enhanced VE
On average, the average performance improvement
is around 9%

Executed Is ReducedExecuted Is Reduced
0102030405060708090
100
Amm
pApsi
Crafty Eon
Equake
Gcc Mcf
Mes
a
Mgrid
Sixtra
ck
Vortex
Vpr
A_Mean
On average, almost 8% of the instructions are
reduced in execution with the enhanced VE

ConclusionsConclusions
TSMA significant number of Is are correctly executed, but
discarded when synchronizing novel hardware technique to enhance TSMA
Enhanced Verification Engine thread synchros are delayed or even aborted
branches, loads, stores and single-cycle Is are reconsidered
Results show speedup of 38% (9% improvement) misprediction rate of 20% (10% reduction)

Future WorkFuture Work
Aggressive trace level predictors
Generalization to multiple threads

UU PP CC
Questions & AnswersQuestions & Answers
ISHPC-VI, Nara City (Japan) - September 7-9, 2005





























