Embed Size (px)
Citation preview

User-Space Process Virtualization in the Context of
Checkpoint-Restart and Virtual Machines
A dissertation presented
by
Kapil Arya
to the Faculty of the Graduate School
of the College of Computer and Information Science
in partial fulfillment of the requirements for the degree of
Doctor of Philosophy
Northeastern University
Boston, Massachusetts
August 2014
Copyright c© August 2014 by Kapil Arya


NORTHEASTERN UNIVERSITYGRADUATE SCHOOL OF COMPUTER SCIENCE
Ph.D. THESIS APPROVAL FORM
THESIS TITLE: User-Space Process Virtualization in the Context ofCheckpoint-Restart and Virtual Machines
AUTHOR: Kapil Arya
Ph.D. Thesis approved to complete all degree requirements for the Ph.D. degreein Computer Science
Distribution: Once completed, this form should be scanned and attached to the frontof the electronic dissertation document (page 1). An electronic version of the documentcan then be uploaded to the Northeastern University-UMI website.


Abstract
Checkpoint-Restart is the ability to save a set of running processes to a check-point image on disk, and to later restart them from the disk. In addition toits traditional use in fault tolerance, recovering from a system failure, it hasnumerous other uses, such as for application debugging and save/restore ofthe workspace of an interactive problem-solving environment. Transparentcheckpointing operates without modifying the underlying application pro-gram, but it implicitly relies on a “Closed World Assumption” — the world(including file system, network, etc.) will look the same upon restart as itdid at the time of checkpoint. This is not valid for more complex programs.Until now, checkpoint-restart packages have adopted ad hoc solutions foreach case where the environment changes upon restart.
This dissertation presents user-space process virtualization to decouple ap-plication processes from the external subsystems. A thin virtualization layeris introduced between the application and each external subsystem. It pro-vides the application with a consistent view of the external world and allowsfor checkpoint-restart to succeed. The ever growing number of external sub-systems make it harder to deploy and maintain virtualization layers in amonolithic checkpoint-restart system. To address this, an adaptive pluginbased approach is used to implement the virtualization layers that allow thecheckpoint-restart system to grow organically.
The principle of decoupling the external subsystem through process vir-tualization is also applied in the context of virtual machines for providinga solution to the long standing double-paging problem. Double-paging oc-curs when the guest attempts to page out memory that has previously beenswapped out by the hypervisor and leads to long delays for the guest as thecontents are read back into machine memory only to be written out again.The performance rapidly drops as a result of significant lengthening of thetime to complete the guest I/O request.


Acknowledgments
No dissertation is accomplished without the support of many people and I
can only begin to thank all those who have helped me in completing it.
I am indebted to my advisor, Gene Cooperman, for his patience, encour-
agement, support, and guidance over the years. It is because of Gene that
I decided to go for a Ph.D., while I was a Master’s student at Northeastern.
Gene taught me about how to do research and to distinguish the ideas that
only I would find interesting, from the ideas that are important. I could not
have asked for a better teacher and without him, this document would not
exist.
I am thankful to Panagiotis (Pete) Manolios, Alan Mislove and William
Robertson for serving on my committee and for providing their insightful
input and constructive criticism. I resoundingly thank Peter Desnoyers for
always being available to discuss ideas and for providing constructive feed-
back on several occasions.
I also want to thank the International Student and Scholar Institute (ISSI)
team and Bryan Lackaye for helping with the administrative matters during
my stay at Northeastern.
I was fortunate to be mentored by Alex Garthwaite during the summer
internships at VMware. His guidance and encouragement is always there
and never seems to fade away. Alex agreed to be the external member in
my committee and I am thankful for his feedback and thoughtful comments
that have not only improved the quality of this dissertation, but also pro-

vided ideas for future directions. His dictum that a good dissertation is a
completed one, became my mantra during the last two years.
I also want to thank Yury Baskakov for all the help that I received while
working on the Tesseract project. He never got tired of my random specula-
tions and was always there to provide further insights and also to cover my
blind spots. A special thanks goes to Jerri-Ann Meyer and Joyce Spencer for
their continued support of the project. Finally, I want to thank Ron Mann
for his continued advise and guidance that has helped me become a better
engineer.
I am grateful to Alok Singh Gehlot for his friendship, all the advice he
provided me over the years, and for his constant reminder that it’s not done
until it’s done. He was always available for me and without his guidance, I
would not have been at Northeastern for my Master’s and later, Ph.D.
I want to thank Rohan Garg and Jaideep Ramachandran for going through
the thesis drafts and sitting through my practice talks and for providing valu-
able feedback. Over the years, I have had the support of a lot of friends and
I want to thank Jaijun Cao, Harsh Raju Chamarthi, Tyler Denniston, Anand
Gehlot, Gregory Kerr, Samaneh Kazemi Nafchi, Artem Polyakov, Sumit Puro-
hit, Praveen Singh Solanki, Ana-Maria Visan, Vishal Vyas, any others I regret-
tably failed to name. I am enormously thankful to Surbhi for her enduring
friendship and companionship through all these years.
Finally, I owe much to my family. I want to express my deepest gratitude
for my grandparents, Smt. Mohini Devi and Sh. Omdutt Ji, my parents, Smt.
Jamana Devi and Sh. Nem Singh Ji, my aunt and uncle, Smt. Sangeeta Devi
and Sh. Hari Singh Ji, my uncles Sh. Kamlesh Ji and Sh. Dilip Ji, and my
siblings and cousins, Kavita, Lalita, Shilpa, and Anil, for their never ending
love, dedication and support. I am forever indebted to them.

To my grandfather
Shri Omdutt Ji Solanki
And my school teacher
Shri Devi Singh Ji Kachhwaha


Contents
Contents
List of Figures
List of Tables
1 Overview 1
1.1 Closed-World Assumption . . . . . . . . . . . . . . . . . . . 2
1.2 Double-Paging Anomaly . . . . . . . . . . . . . . . . . . . . 4
1.3 Process Virtualization . . . . . . . . . . . . . . . . . . . . . . 4
1.4 Thesis Statement . . . . . . . . . . . . . . . . . . . . . . . . 6
1.5 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.5.1 Process Virtualization through Plugins . . . . . . . . 7
1.5.2 Application-Specific Plugins . . . . . . . . . . . . . . 8
1.5.3 Third-Party Plugins . . . . . . . . . . . . . . . . . . . 9
1.5.4 Solving the Double-Paging Problem . . . . . . . . . . 9
1.6 Organization . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2 Concepts Related to Checkpoint-Restart and Virtualization 13
2.1 Checkpoint-Restart . . . . . . . . . . . . . . . . . . . . . . . 13
2.1.1 Kernel-Level Transparent Checkpoint-Restart . . . . . 15
2.1.2 User-Level Transparent Checkpoint-Restart . . . . . . 18
2.1.3 Fault Tolerance . . . . . . . . . . . . . . . . . . . . . 21
2.2 System Call Interpositioning . . . . . . . . . . . . . . . . . . 21

CONTENTS
2.3 Virtualization . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.3.1 Language-Specific Virtual Machines . . . . . . . . . . 22
2.3.2 Process Virtualization . . . . . . . . . . . . . . . . . . 22
2.3.3 Lightweight O/S-based Virtual Machines . . . . . . . 23
2.3.4 Virtual Machines . . . . . . . . . . . . . . . . . . . . 24
2.4 DMTCP Version 1 . . . . . . . . . . . . . . . . . . . . . . . . 25
2.4.1 Library Call Wrappers . . . . . . . . . . . . . . . . . 27
2.4.2 DMTCP Coordinator . . . . . . . . . . . . . . . . . . 27
2.4.3 Checkpoint Thread . . . . . . . . . . . . . . . . . . . 27
2.4.4 Checkpoint . . . . . . . . . . . . . . . . . . . . . . . 28
2.4.5 Restart . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.4.6 Checkpoint Consistency for Distributed Processes . . 29
3 Adaptive Plugins as a Mechanism for Virtualization 31
3.1 The Ever Changing Execution Environment . . . . . . . . . . 31
3.1.1 PID: Virtualizing Kernel Resource Identifiers . . . . . 32
3.1.2 SSH Connection: Virtualizing a Protocol . . . . . . . 33
3.1.3 InfiniBand: Virtualizing a Device Driver . . . . . . . . 35
3.1.4 OpenGL: A Record/Replay Approach to Virtualizing a
Device Driver . . . . . . . . . . . . . . . . . . . . . . 36
3.1.5 POSIX Timers: Adapting to Application Requirements 36
3.2 Virtualizing the Execution Environment . . . . . . . . . . . . 37
3.2.1 Virtualize Access to External Resources . . . . . . . . 37
3.2.2 Capture/Restore the State of External Resources . . . 38
3.3 Adaptive Plugins as a Synthesis of System-Level and Application-
Level Checkpointing . . . . . . . . . . . . . . . . . . . . . . 39
4 The Design of Plugins 41
4.1 Plugin Architecture . . . . . . . . . . . . . . . . . . . . . . . 42
4.1.1 Virtualization through Function Wrappers . . . . . . 43
4.1.2 Event Notifications . . . . . . . . . . . . . . . . . . . 46

CONTENTS
4.1.3 Publish/Subscribe Service . . . . . . . . . . . . . . . 49
4.2 Design Recipe for Virtualization through Plugins . . . . . . . 50
4.3 Plugin Dependencies . . . . . . . . . . . . . . . . . . . . . . 52
4.3.1 Dependency Resolution . . . . . . . . . . . . . . . . . 52
4.3.2 External Resources Virtualized by Other Plugins . . . 54
4.3.3 Multiple Plugins Wrapping the Same Function . . . . 55
4.4 Extending to Multiple Processes . . . . . . . . . . . . . . . . 56
4.4.1 Unique Resource-id for Shared Resources . . . . . . . 57
4.4.2 Checkpointing Shared Resources . . . . . . . . . . . 58
4.4.3 Restoring Shared Resources . . . . . . . . . . . . . . 61
4.5 Three Base Plugins . . . . . . . . . . . . . . . . . . . . . . . 62
4.5.1 Coordinator Interface Plugin . . . . . . . . . . . . . . 62
4.5.2 Thread Plugin . . . . . . . . . . . . . . . . . . . . . . 62
4.5.3 Memory Plugins . . . . . . . . . . . . . . . . . . . . . 63
4.6 Implementation Challenges . . . . . . . . . . . . . . . . . . 65
4.6.1 Wrapper Functions . . . . . . . . . . . . . . . . . . . 65
4.6.2 New Process/Program Creation . . . . . . . . . . . . 67
4.6.3 Checkpoint Deadlock on a Runtime Library Resource 68
4.6.4 Blocking Library Functions and Checkpoint Starvation 69
5 Expressivity of Plugins 71
5.1 File Descriptor Related Plugins . . . . . . . . . . . . . . . . . 73
5.2 Pid, System V IPC, and Timer Plugins . . . . . . . . . . . . . 77
5.3 Application-Specific Plugins . . . . . . . . . . . . . . . . . . 77
5.4 SSH Connection . . . . . . . . . . . . . . . . . . . . . . . . . 78
5.5 Batch-Queue Plugin for Resource Managers . . . . . . . . . 81
5.6 Ptrace Plugin . . . . . . . . . . . . . . . . . . . . . . . . . . 84
5.7 Deterministic Record-Replay . . . . . . . . . . . . . . . . . . 85
5.8 Checkpointing Networks of Virtual Machines . . . . . . . . . 87

CONTENTS
5.9 3-D Graphic: Support for Programmable GPUs in OpenGL 2.0
and Higher . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
5.10 Transparent Checkpointing of InfiniBand . . . . . . . . . . . 89
5.11 IB2TCP: Migrating from InfiniBand to TCP Sockets . . . . . 89
6 Tesseract: Reconciling Guest I/O and Hypervisor Swapping in
a VM 91
6.1 Redundant I/O . . . . . . . . . . . . . . . . . . . . . . . . . 93
6.2 Motivation: The Double-Paging Anomaly . . . . . . . . . . . 94
6.3 Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
6.3.1 Extending The Hosted Platform To Be Like ESX . . . 97
6.3.2 Reconciling Redundant I/Os . . . . . . . . . . . . . . 99
6.3.3 Tesseract’s Virtual Disk and Swap Subsystems . . . . 102
6.4 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . 105
6.4.1 Explicit Management of Hypervisor Swapping . . . . 105
6.4.2 Tracking Memory Pages and Disk Blocks . . . . . . . 106
6.4.3 I/O Paths . . . . . . . . . . . . . . . . . . . . . . . . 107
6.4.4 Managing Block Indirection Metadata . . . . . . . . . 111
6.5 Guest Disk Fragmentation . . . . . . . . . . . . . . . . . . . 112
6.5.1 BSST Defragmentation . . . . . . . . . . . . . . . . . 113
6.5.2 Guest VMDK Defragmentation . . . . . . . . . . . . . 115
6.6 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
6.6.1 Inducing Double-Paging Activity . . . . . . . . . . . . 116
6.6.2 Application Performance . . . . . . . . . . . . . . . . 117
6.6.3 Double-Paging and Guest Write I/O Requests . . . . . 121
6.6.4 Fragmentation in Guest Read I/O Requests . . . . . . 122
6.6.5 Evaluating Defragmentation Schemes . . . . . . . . . 123
6.6.6 Using SSD For Storing BSST VMDK . . . . . . . . . . 126
6.6.7 Overheads . . . . . . . . . . . . . . . . . . . . . . . . 127
6.7 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . 128

CONTENTS
6.7.1 Hypervisor Swapping and Double Paging . . . . . . . 128
6.7.2 Associations Between Memory and Disk State . . . . 130
6.7.3 I/O and Memory Deduplication . . . . . . . . . . . . 131
6.8 Observations . . . . . . . . . . . . . . . . . . . . . . . . . . 131
7 Impact for the Future 133
7.1 Compiled Code In Scripting Languages: Fast-Slow Paradigm 133
7.2 Support for Hadoop-style Big Data . . . . . . . . . . . . . . 134
7.3 Cybersecurity . . . . . . . . . . . . . . . . . . . . . . . . . . 135
7.4 Algorithmic debugging . . . . . . . . . . . . . . . . . . . . . 135
7.5 Reversible Debugging . . . . . . . . . . . . . . . . . . . . . . 136
7.6 Android-Based Mobile Computing . . . . . . . . . . . . . . . 136
7.7 Cloud Computing . . . . . . . . . . . . . . . . . . . . . . . . 136
8 Conclusion 137
A Plugin Tutorial 139
A.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
A.2 Anatomy of a plugin . . . . . . . . . . . . . . . . . . . . . . 140
A.3 Writing Plugins . . . . . . . . . . . . . . . . . . . . . . . . . 141
A.3.1 Invoking a plugin . . . . . . . . . . . . . . . . . . . . 141
A.3.2 The plugin mechanisms . . . . . . . . . . . . . . . . 141
A.4 Application-Initiated Checkpoints . . . . . . . . . . . . . . . 145
A.5 Plugin Manual . . . . . . . . . . . . . . . . . . . . . . . . . . 146
A.5.1 Plugin events . . . . . . . . . . . . . . . . . . . . . . 146
A.5.2 Publish/Subscribe . . . . . . . . . . . . . . . . . . . . 151
A.5.3 Wrapper functions . . . . . . . . . . . . . . . . . . . 152
A.5.4 Miscellaneous utility functions . . . . . . . . . . . . . 152
Bibliography 155


List of Figures
1.1 Application surface of a running process . . . . . . . . . . . . . 5
2.1 Architecture of DMTCP . . . . . . . . . . . . . . . . . . . . . . . 26
3.1 Virtualization of Process Id . . . . . . . . . . . . . . . . . . . . . 33
3.2 Two processes communicating over SSH . . . . . . . . . . . . . 33
3.3 Virtualizing an SSH connection . . . . . . . . . . . . . . . . . . 34
4.2 Event notifications for write-ckpt and restart events . . . . . . . 47
4.4 Nested wrappers . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.5 Plugin dependency for distributed processes . . . . . . . . . . . 61
5.1 Restoring an SSH connection . . . . . . . . . . . . . . . . . . . 80
6.1 Some cases of redundant I/O in a virtual machine. . . . . . . . 93
6.2 An example of double-paging. . . . . . . . . . . . . . . . . . . . 96
6.3 Double-paging with Tesseract. . . . . . . . . . . . . . . . . . . . 102
6.4 Write I/O and hypervisor swapping. . . . . . . . . . . . . . . . 103
6.5 Examples of reference count with Tesseract and with defragmen-
tation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
6.6 VMware Workstation I/O Stack . . . . . . . . . . . . . . . . . . 108
6.7 Modified scatter-gather list to avoid double-paging . . . . . . . 109
6.8 Splitting scatter-gather list during read . . . . . . . . . . . . . . 110
6.9 Defragmenting the BSST. . . . . . . . . . . . . . . . . . . . . . 114

LIST OF FIGURES
6.10 Defragmenting the guest VMDK. . . . . . . . . . . . . . . . . . 115
6.11 Trends for scores and pauses in SPECjbb runs with varying guest
memory pressure and 10% host overcommitment. . . . . . . . . 118
6.12 Maximum single pauses observed in SPECjbb instantaneous scor-
ing with varying guest memory pressure and 10% host memory
overcommitment. . . . . . . . . . . . . . . . . . . . . . . . . . . 119
6.13 Scores and total pause times for SPECjbb runs with varying host
overcommitment and 60 MB memhog. . . . . . . . . . . . . . . 120
6.14 Comparing maximum single pauses for SPECjbb under various
defragmentation schemes with varying host memory overcom-
mitment and 60 MB memhog . . . . . . . . . . . . . . . . . . . 121
6.15 Scores and pauses in SPECjbb runs under various defragmenta-
tion schemes with 10% host overcommitment. . . . . . . . . . . 123
6.16 Score and pauses in SPECjbb under various defragmentation schemes
with varying host overcommitment and 60 MB memhog. . . . . 124
6.17 Comparing maximum single pauses for SPECjbb under various
defragmentation schemes with 10% host memory overcommit-
ment. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
6.18 Tesseract performances with BSST placed on an SSD disk. . . . 126

List of Tables
2.1 Comparison of various checkpointing systems. . . . . . . . . . . 21
5.1 Comparison of process virtualization based checkpoint-restart with
prior art . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
5.2 Statistics for various plugins. . . . . . . . . . . . . . . . . . . . 74
6.1 Holes in write I/O requests for varying host overcommitment and
60 MB memhog inside the guest. . . . . . . . . . . . . . . . . . 122
6.2 Holes in read I/O requests for Tesseract without defragmentation
for varying levels of host overcommitment and 60 MB memhog
inside the guest. . . . . . . . . . . . . . . . . . . . . . . . . . . 122
6.3 Total I/Os with BSST and guest defragmentation. . . . . . . . . 125
6.4 Average read and write prepare/completion times in microsec-
onds for baseline and Tesseract with and without defragmenta-
tion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127


CHAPTER 1
Overview
Checkpoint-restart is a powerful mechanism to save the state of one or more
running processes to disk and later restore it. In addition to the tradi-
tional use case of fault tolerance in long-running jobs, other use cases of
checkpoint-restart include process migration, debugging, and save/restore
of workspace.
At a high-level, checkpointing a process can be viewed as writing all of
process memory, including shared libraries, text and data, to a checkpoint
image. Accordingly, restarting involves recreating the process memory by
reading the checkpoint image from the disk. This works for simple programs,
but for complex programs, one also needs to save and restore information
about threads, open files, etc. In more sophisticated applications, it involves
saving the network state (in-flight data, etc.), and information about the
external environment such as the terminal, the standard input/output/error,
and so on.
Current checkpointing techniques fall into two categories: application-
level and system-level. Application-level checkpointing requires modifica-
tions to the target program to insert checkpoint-restart code. The developer
identifies the relevant state and data to be checkpointed and implements the
mechanism for checkpointing and restoring them. While it is flexible and
allows the programmer to optimize and have greater control over the check-
1

2 CHAPTER 1. OVERVIEW
pointing process, there is a high cost paid by the developer for implementing
and maintaining it. Further, the timing and frequency of checkpoints may
not be specified in a flexible manner and could be limited to certain “safe”
points in the program. System-level (or transparent) checkpointing on the
other hand works without modifying the target application program. How-
ever, a simple implementation is less flexible in that it requires the same
environment on restart (the case of homogeneous computer hosts).
1.1 Closed-World Assumption
Traditionally checkpoint-restart packages have made a closed-world assump-
tion:
The execution environment (file system, network, etc.) does not
change between checkpoint and restart. Thus to save and restore
the state of the processes of a computation, it suffices to save the
state of the CPU registers, the process’s virtual memory, and kernel
state.
While the closed world assumption holds for simple programs, it is not
valid for more complex programs (such as distributed processes), and can
cause checkpoint-restart to fail in remarkable ways. For example a process
with open files will fail to restart if the underlying filesystem mount-point
has changed, or if the host has a new IP address while the process remembers
the old one. At a more basic level, the restarted process will have a new
process id (pid) provided by the kernel. Thus, any attempt by the target
application to re-use a previously cached old pid will result in a failure.
One way to overcome the closed-world assumption is application-level
checkpointing — modifying the application program to account for the chang-
ing environment. As mentioned earlier, this approach is costly and hard to
maintain.

1.1. CLOSED-WORLD ASSUMPTION 3
For these reasons, the existing systems have been used mostly for applica-
tions that obey the closed-world assumption such as isolated batch jobs run-
ning solely on traditional multi-core computer nodes within a cluster. The
closed world assumption is enforced by posing several restrictions on the fea-
tures that an application can use or by creating special-purpose workarounds
to handle exceptions to the closed-world assumption.
For example, Condor [110] restricts applications from using multi-process
jobs, interprocess communication, multi-threading, timers, and file locks,
etc. [109]. BLCR [52] is implemented through a Linux kernel module, which
restores the original pid when it is still unused and fails if it is unavailable.
CRIU [111] places all target processes in a Linux container (lightweight vir-
tual machine), which has private namespaces for kernel objects, but is iso-
lated from other processes within the same host.
The closed world assumption breaks down as users ask to checkpoint
more general types of software that communicate with the external world.
Examples include communication with system daemons (e.g., NSCD, LDAP
authentication servers), 3-D graphics libraries (e.g., OpenGL), connections
with database servers, networks of virtual machines, hybrid computations
using CPU accelerators (e.g., GPU and Xeon Phi), Hadoop-style computa-
tions, a broader variety of network models (TCP sockets, InfiniBand, the
SCIF network for the Intel Xeon Phi), competing implementations of Infini-
Band libraries (QLogic/PSM versus InfiniBand OpenIB verbs), and so on.
These complex applications have created a dilemma. A system for pure
transparent checkpointing has no knowledge of the application’s external
world, and an application-level checkpointing system would require the
writer of the target application to insert code that adapts to the modified
external environment after restart. This conflict is the core problem being
solved.

4 CHAPTER 1. OVERVIEW
1.2 Double-Paging Anomaly
Hypervisors often overcommit memory to achieve higher VM consolidation
on the physical host. When overcommitting host physical memory, guest
memory is paged in and out from a hypervisor-level swap file to reclaim
host memory. Further, guests running in the virtual machines manage their
own physical address space and may overcommit memory as needed.
Double-paging is an often-cited problem in multi-level scheduling of mem-
ory between virtual machines (VMs) and the hypervisor. This problem oc-
curs when both a virtualized guest and the hypervisor overcommit their re-
spective physical address-spaces. When the guest pages out memory previ-
ously swapped out by the hypervisor, it initiates an expensive sequence of
steps causing the contents to be read in from the hypervisor-level swapfile
only to be written out again, significantly lengthening the time to complete
the guest I/O request. As a result, performance rapidly drops.
1.3 Process Virtualization
Often, application processes violate the closed-world assumption. When
restarting from a checkpoint image, the recreated objects derived from ex-
ternal systems/services may not be the same as their pre-checkpoint version.
This is due to the changing execution environment across a checkpoint-
restart boundary. In order to successfully restart an application process, we
need to virtualize these objects in such a way that the application view of
the objects does not change across checkpoint and restart.
Definition: The application surface of a running application is a set of code
and associated data that includes all application-specific objects (code+data)
and excludes all opaque objects derived from any outside systems/services.
(An opaque object is an object for which the application knows nothing
about the internal structure. The opaque object is only accessible through

1.3. PROCESS VIRTUALIZATION 5
Process
Application
ApplicationSurface
ExternalResource
real names
virtual names
Translation layer
Figure 1.1: Application surface of a running process. The virtual names lieinside the application surface, whereas the real names lie outside the surface.
an identifying handle)
Definition: User-space process virtualization finds a surface that is at least as
large as the application surface, such that any virtualized view of an object
lies inside this surface and any real view lies outside this surface (see Fig-
ure 1.1). On restart, the opaque objects are recreated to provide semanti-
cally equivalent functionality to their pre-checkpoint version. Process virtu-
alization then links these opaque objects with their virtualized view inside
the application surface (through the identifying handles).
There can be more than one possible application surface. Typically one
chooses an application surface close to a well known API for the sake of
stability and maintainability. A wrapper around any call to the API will
update both the virtual and the real view in a consistent manner.
Remarks:
1. In virtualizing a pid, we will see that libc will retain the real pid known
to the kernel. Thus libc is outside the application surface. But the ap-
plication knows only the virtual pid that resides inside the application
surface.

6 CHAPTER 1. OVERVIEW
2. In the case of a shadow device driver, the user-space memory of the
application may contain both some opaque objects (e.g., InfiniBand
queues) and their virtualized views. In this case the application surface
excludes parts of the user-space memory of the application process.
3. Because daemons and the kernel are opaque to the application, they
always lie outside the application surface.
4. An application may create an auxiliary child process (or even dis-
tributed processes in the case of MPI). In this case, the application
surface includes these auxiliary processes.
The goal of user-space process virtualization is to break the tight coupling
between the application process and an external subsystem not under the
control of the application process. In effect, each API is designed to provide
a stable interface to a single system service under the lifetime of a process.
This thesis will demonstrate the ability to find an application surface and
a corresponding API, for which a software translation layer can be built,
enabling the application process to continue to receive the corresponding
system service from an alternative external subsystem. This decouples the
application process from the external subsystem.
1.4 Thesis Statement
User-space process virtualization can be used to decouple application pro-
cesses from external subsystems to allow checkpoint-restart without enforc-
ing a strict “closed-world assumption”. The method of decoupling subsys-
tems applies beyond checkpointing as seen in a solution to the long standing
double-paging problem.

1.5. CONTRIBUTIONS 7
1.5 Contributions
This dissertation shows that a checkpointing system can “adapt” to the ex-
ternal environment, one subsystem at a time, by using the user-space process
virtualization technique. To that end, this work introduces a plugin archi-
tecture based on adaptive plugins to virtualize these external subsystems. A
plugin is responsible for virtualizing and checkpointing exactly one external
subsystem to allow the application to adapt to the modified external subsys-
tem.
The plugin architecture allows us to do selective (or partial) virtualiza-
tion of the underlying resources for efficiency purposes. Plugins can be load-
ed/unloaded to suit application requirements. Further, it allows the check-
pointing system to be extended organically, in a non-monolithic manner.
1.5.1 Process Virtualization through Plugins
To demonstrate the strength of the plugin architecture for user-space pro-
cess virtualization, this work presents principled techniques for the follow-
ing problems, which have resisted successful checkpoint-restart solutions for
at least a decade (these plugins are original with this dissertation):
• The PID plugin (§5.2) virtualizes the process and thread identifiers
assigned by the kernel.
• The System V IPC plugin (§5.2) virtualizes the shared memory, semaphore,
and message queue identifiers assigned by the kernel.
• The Timer plugin (§5.2) virtualizes posix timers as well as as clock
identifiers assigned by the kernel.
• The SSH plugin (§5.4) virtualizes the underlying SSH connection be-
tween two processes to allow recreation on restart.

8 CHAPTER 1. OVERVIEW
• The IB2TCP plugin (§5.11) virtualizes the InfiniBand device driver to
allow a computation to be checkpointed on the InfiniBand hardware
and restarted on the TCP hardware.
Notice that the Zap [86] system virtualized the kernel resource identi-
fiers such as pids and System V IPC ids in kernel space. However, the work
of this dissertation virtualizes entirely in user space without any applica-
tion or kernel modifications or kernel modules. Further, this work extends
the notion of user-space virtualization to processes/services outside the ker-
nel such as SSH connections, network daemons and device drivers. This
is achieved either through interposing library calls or by creating shadow
agents/processes for the external resources.
1.5.2 Application-Specific Plugins
Next, we show that plugins can be used for application-specific adapta-
tions, providing the benefits of application-level checkpointing without hav-
ing to modify the base application. The following application-specific plug-
ins (§5.3) are original with this dissertation:
• Malloc plugin virtualizes access to the underlying memory allocation
library (e.g., libc malloc, tcmalloc, etc.).
• DL plugin is used to ensure atomicity for dlopen/dlsym functions with
respect to checkpoint-restart.
• CkptFile plugin provides heuristics for checkpointing open files. It also
helps the file plugin to locate files on restart.
• Uniq-Ckpt plugin is used to control the checkpoint file names, loca-
tions, etc.

1.5. CONTRIBUTIONS 9
1.5.3 Third-Party Plugins
Finally, the success of the plugin architecture can also be seen in third party
plugins. We show that third parties can write orthogonal customized plugins
to fit their needs. The following demonstrates original work due to plugins
created by third party contributors (this dissertation is not claiming these
results):
• Ptrace plugin [127] virtualizes the ptrace system call to allow check-
pointing of an entire gdb session for reversible debugging.
• Record-replay plugin [126] provides a light-weight deterministic re-
play mechanism by recording library calls for reversible debugging.
• KVM plugin [44] is used for checkpointing the KVM/Qemu virtual ma-
chine.
• Tun plugin [44] is used for checkpointing the Tun/Tap network inter-
face for checkpointing a network of virtual machines.
• RM plugin [93] is used for checkpointing in a batch-queue environ-
ment and can handle multiple batch-queue systems.
• InfiniBand plugin [27] provides the first non MPI-specific transparent
checkpoint-restart of InfiniBand network.
• OpenGL plugin [62] uses a record-prune-replay technique for check-
pointing 3D graphics (OpenGL 2.0 and beyond).
1.5.4 Solving the Double-Paging Problem
The process virtualization principles are also applied in the context of vir-
tual machines. The double-paging problem is directly and transparently ad-
dressed by applying the decoupling principle [11]. The guest and hyper-
visor I/O operations are tracked to detect redundancy and are modified to

10 CHAPTER 1. OVERVIEW
create indirections to existing disk blocks containing the page contents. The
indirection is created by introducing a thin virtualization layer to virtualize
access to the guest disk blocks. Further, the virtualization is done completely
in user space.
1.6 Organization
The remainder of this dissertation is organized as follows.
A literature review is presented in Chapter 2 and various checkpoint-
restart mechanisms are discussed. The review also includes various virtual-
ization schemes in the context of checkpointing. (Literature for the double-
paging problem is reviewed in Chapter 6)
Chapter 3 provides several examples to motivate the need for virtualiz-
ing the execution environment. This chapter then uses this motivation to
outline two basic requirements for virtualizing the execution environment.
It is argued there that an adaptive plugin based approach is well suited for
process virtualization.
Chapter 4 describes the design of adaptive plugins and presents the plu-
gin architecture. The proposed plugin architecture is shown to meet the vir-
tualization requirements laid out in Chapter 3. This is followed by a design
recipe for developing new plugins. Dependencies among multiple plugins
are also discussed and an approach to dependency resolution is provided.
Finally, some implementation challenges involved in designing plugins are
presented.
Chapter 5 provides some case studies involving various plugins. In-
cluded there are seven plugins that provide novel checkpointing solutions
of their corresponding subsystems. Some application-specific plugins are
also demonstrated along with several plugins that provide virtualization of
kernel resource identifies in the user space.
Chapter 6 then turns to the double-paging problem. Like the core issue

1.6. ORGANIZATION 11
in checkpoint-restart, here also one is presented by distinct subsystems that
must be combined in a unified virtualization scheme. The core problem is
described and motivated, and a design and implementation of a solution is
presented. We also discuss some of the side-effects of the proposed solution
and finally present evaluation.
Chapter 7 provides some new directions and applications of checkpoint-
restart to non-traditional use-cases that can be pursued based on this disser-
tation, with a conclusion presented in Chapter 8.
Finally, a plugin tutorial is presented in Appendix A, thus providing a
concrete view of the plugin API.


CHAPTER 2
Concepts Related to
Checkpoint-Restart and
Virtualization
This dissertation intersects with four broad areas. The first is that of checkpoint-
restart at the process level. The second concerns system/library call inter-
positioning for modifying process behavior. The third concerns process level
virtualization. The fourth concerns the double-paging problem in the con-
text of virtual machines. The literature for the first three areas is reviewed
here, whereas the related work for the double-paging problem is discussed
in Chapter 6. Since this work builds on the DMTCP software package, a brief
overview of the legacy DMTCP software (DMTCP version 1) is also provided.
2.1 Checkpoint-Restart
Checkpoint-restart has a long history with several mechanisms proposed
over the years [90, 97, 98, 35]. It is often used for process migration,
for load balancing, for fault tolerance, and so on [34]. The work of Milo-
jicic et al. [81] provides a review of the field of process migration. Egwu-
tuoha et al. [35] provides a survey of various checkpoint/restart implemen-
13

14 CHAPTER 2. CONCEPTS RELATED TO CHECKPOINT-RESTART AND VIRTUALIZATION
tations in high performance computing. The website checkpointing.org
also lists several checkpoint-restart systems. There are three primary ap-
proaches to checkpointing: virtual machine snapshotting, application-level
checkpointing, and transparent checkpointing.
Virtual machine snapshotting
Virtual machine (VM) snapshotting is a form of checkpointing for virtual
machines and is often used for virtual machine migration. A complex appli-
cation is treated as a black box, and its application surface is expanded to
include the entire guest physical memory, operating system state, devices,
etc. Checkpointing an application involves involves saving everything inside
the application surface (i.e. the entire virtual machine). While this tech-
nique is general and has been discussed quite extensively [80], it is also
slower and produces larger checkpoint images because the checkpoint mod-
ule is unable to exclude unnecessary parts of guest physical memory from
the application surface. Hence, it is not commonly used for mechanisms of
checkpoint-restart.
Application-level checkpointing
Application-level checkpointing is the simplest form of checkpointing. The
developer of the application inserts checkpointing code directly inside the
application to save the process state, such as data structures, to a file on disk
that is later used to resume the computation. This is application-specific and
requires extensive knowledge of the application. The knowledge of the ap-
plication internals provides complete flexibility, but places a larger burden
on the end user. There are several techniques [129] and frameworks that
provide tools to assist in application-level checkpointing. Examples include
pickling for Python [120] and Boost serialization [108] for C++. A some-
what lighter mode of application-level checkpointing is the save/restore

2.1. CHECKPOINT-RESTART 15
workspace feature for interactive sessions. Notably, Bronevetsky et al. have
applied this to shared memory parallelism in the context of OpenMP [24, 25]
and distributed parallelism in the context of MPI [100, 23], where they pro-
vide tools to lighten the end-user burden for writing checkpointing code.
The rest of this section focuses on several varieties of transparent check-
pointing, in which the end-user does not need to make any changes to the
target application.
Transparent checkpointing
This is sometimes called system-level or system-initiated checkpointing. It
is the ability to checkpoint an application without making any changes to
the application source or binary. The history of transparent checkpointing
extends back at least to 1990 [73]. While, there are many systems that
perform single-process checkpointing [91, 33, 89, 92, 73, 74, 29, 1, 3, 76],
we will focus on systems that support multiple processes and/or distributed
processes. Transparent system-level checkpointing technique can be further
broken down into Kernel-level and user-level checkpointing. The two tech-
niques are further discussed in Sections 2.1.1 and 2.1.2 respectively.
2.1.1 Kernel-Level Transparent Checkpoint-Restart
In kernel-level checkpointing, the operating system is modified to support
checkpointing for applications. This approach leads to checkpoints being
more tightly coupled to kernel versions. While there have been several such
kernel-level packages, the difficulty of supporting multiple kernel versions
makes it more difficult. It also makes future ports to other operating systems
more difficult.

16 CHAPTER 2. CONCEPTS RELATED TO CHECKPOINT-RESTART AND VIRTUALIZATION
The Zap system and its derivatives
As an extension of CRAK (Checkpoint and Restart as a Kernel Module) [139],
Zap [86, 67] implements checkpoint-restart using a kernel module. Zap can
be considered a precursor to the Linux Containers (LXC) [117] as it also
provides a virtualized view of the kernel resources. Zap uses a pod (process
domain) abstraction, that provides a group of processes with a consistent vir-
tualized view. The pods abstraction virtualizes kernel resource identifiers to
present a pod-specific view. This isolates the process from the external world
and provides a conflict free environment when migrating processes to other
nodes. The downside of this implementation is the inability of processes in-
side a pod to communicate with processes outside the pod. It intercepts all
systems calls operating on the virtualized kernel resource identifiers, trans-
lating their arguments and return values as needed. System call interception
is also required for all processes in the system and poses runtime overhead
for processes outside the pods.
Zap was later extended to support distributed network applications by
Laadan et al. [68] to create ZapC and by Janakiraman et al. [59] to create
CRUZ. The key enhancement was the support for virtualization of the net-
work layer to decouple the processes from the node they are running on.
This allowed these systems to checkpoint-restart distributed computations
over a cluster. For ZapC network virtualization was achieved by inserting
hooks into the network stack using netfilter. The source and destination
addresses were translated between virtual and real addresses for both in-
coming and outgoing network packets.
The work of this dissertation is based entirely in the user space and
doesn’t require any kernel modification or kernel modules. As explained
by Laadan [66], the kernel module based approach incurs a burden both on
users because it is cumbersome to install, and on developers because main-
taining it on top of quickly changing upstream kernels is a sisyphean task and

2.1. CHECKPOINT-RESTART 17
development quickly falls behind. Further, user-space virtualization poses no
runtime overhead for processes that are not part of the computation being
checkpointed. Finally, this work can be used to virtualize agents/process-
es/services outside the kernel. Examples include SSH connection, network
daemons and device drivers.
Berkeley Lab Checkpoint Restart (BLCR)
BLCR [52] is another widely used checkpointing system that is implemented
as a kernel module. It is used primarily in high performance computing.
BLCR is often used along with MPI libraries to checkpoint a distributed com-
putation. The BLCR does not have any support for virtualization and may
fail if a kernel resource identifier (such as a pid) is not available at the time of
restart. It also relies on MPI daemons to handle changed network addresses,
mount points, etc. However, if the application has cached a directory name
from before checkpoint and tries to open it after restart, it may fail.
Another notable kernel based system was Chpox by Sudakov et al. [105].
Initially, Chpox was implemented as a kernel module for Linux 2.4, whereas
a later version for Linux 2.6 required base kernel modifications as well.
Pure kernel-level approaches
A more recent attempt by Laadan et al. [68] also implemented a single-host
in-kernel solution. It consisted of some user-space utilities and a series of
patches to the Linux 2.6 kernel to add checkpoint support in the mainline
kernel itself. This was proposed for inclusion in the Linux kernel, but ulti-
mately not accepted due to its invasive approach that touched/modified a
large number of kernel subsystems [8].

18 CHAPTER 2. CONCEPTS RELATED TO CHECKPOINT-RESTART AND VIRTUALIZATION
2.1.2 User-Level Transparent Checkpoint-Restart
User level checkpointing works without any changes to the operating system
kernel. The use of published APIs (e.g., POSIX and the Linux proc filesystem)
to communicate with the kernel and to perform checkpoint-restart makes it
highly stable.
Checkpointing library
The ground-breaking work of Plank et al. [92] on Libckpt uses a library to
do the checkpointing and the application program is linked to this user-level
library. Similar techniques are used by Condor [76]. These techniques are
not completely transparent to the user as the application code is modified,
recompiled, and relinked with the dynamic library. However, the amount of
code changes is often fairly small (e.g., for Libckpt, the application program-
mer needs to rename the main() to ckpt_target()). The main disadvantage
of using such systems is the restrictions imposed on the operating system
features such as interprocess communication, that the application program
can use [109]. Further, these systems do not support process trees or dis-
tributed computations.
Distributed checkpointing with MPI
Although application-level checkpointing for distributed programs dates back
at least to 1997 [17], most practical systems were built around MPI-based
distributed computations for supporting high performance computing. They
use hooks or callback functions for specific MPI implementations [31, 54,
137, 138, 104, 21, 133, 49, 52, 99]. (MPI, Message Passing Interface, is
a standard for message-based distributed high performance computation.)
Most MPI implementors chose to build a custom checkpoint-restart service.
This came about when InfiniBand became the preferred network for high
performance computing, and there was still no package for transparent check-

2.1. CHECKPOINT-RESTART 19
pointing over InfiniBand. Examples of checkpoint-restart services can be
found in Open MPI [54, 55], LAM/MPI [99] (now incorporated into MVA-
PICH2 [77, 41]), MPICH-V [22], and MVAPICH2 [41], as well as a fault-
tolerant “backplane”, CIFTS [51]. Each checkpoint-restart service would dis-
connect from the network prior to checkpoint, and re-connect after restart.
Hence, while the network was disconnected, the MPI checkpoint-restart ser-
vice was then able to delegate single-host checkpointing to the BLCR [52]
kernel module. This created an extra layer of complication, but it was un-
avoidable at that time, due to the lack of support for transparent checkpoint-
ing over InfiniBand. On restart, the network connections are restored and
the checkpointer is called upon to restore the user processes. Since it’s work-
ing at the MPI level, the ability to adapt to the environment outside of MPI
is limited, and generally proves difficult to maintain.
Bronevetsky et al. produced a novel application-level checkpointing de-
sign for the special case of MPI [23]. In this approach, a pre-compiler in-
struments the application MPI code with additional information needed for
checkpointing, thus coming close to the ideal of transparent checkpointing.
The application programmer then adds code indicating valid points in the
program for a potential checkpoint. The use of a pre-compiler relieved much
of the burden of adding application-specific code to support checkpointing.
Cryopid
Cryopid [18] and Cryopid2 [85] use the ptrace system call to attach to
a running process and create a core dump of the application process that is
later used to restart the computation. The checkpointable features supported
are quite limited as compared to other checkpointing packages, and adding
a new feature is often harder.

20 CHAPTER 2. CONCEPTS RELATED TO CHECKPOINT-RESTART AND VIRTUALIZATION
Checkpoint Restart In Userspace (CRIU)
CRIU [111] is a more recent checkpointing package based on Linux con-
tainers (LXC) [117]. The support is restricted to process trees and contain-
ers. The Linux kernel API was extended for new kernel features to sup-
port the user space tool. Like Cryopid, it also uses the ptrace system call
to inject checkpointing code inside the user processes. The checkpointing
code executes in the context of a process to gather all the relevant informa-
tion using the extended kernel API. Due to security issues, the checkpoint-
ing capability is only available for users with CAP_SYS_ADMIN capability.
(CAP_SYS_ADMIN capability is a successor to the Linux setuid-root feature
that is used to grant admin privileges to select applications/processes.)
Distributed MultiThreaded Checkpointing (DMTCP)
DMTCP version 1 [7] is implemented using user space shared libraries. The
original DMTCP supported TCP sockets, but was limited in that it did not
support distributed computations communicating over ssh or InfiniBand.
Further, even in the single-host case, it did not support virtualization of
such kernel resources as pids, System V IPC, POSIX and System V shared
memory, and POSIX timers. Section 2.4 provides a brief background on the
architecture and the working of DMTCP version 1.
This work represents a rewrite of the original DMTCP [7], in order to
introduce user-space process virtualization for checkpointing the external
environment. This enables us to checkpoint a wide variety of applications.
The virtualization layer is implemented completely in user space with mini-
mal overhead. Process virtualization goes beyond virtualizing the kernel re-
source identifiers and can be used to virtualize even higher level constructs
and abstractions such as the SSH protocol, as discussed in Chapter 3. Ta-
ble 2.1 summarizes the difference between this work and the prominent
transparent checkpointing packages.

2.2. SYSTEM CALL INTERPOSITIONING 21
Ckpt Multi-host Resource Virtualization Applic- Third-
System computations kernel other specific party
resources resources tuning plugins
BLCR 7 7 7 7 7
Zap 7 3 7 7 7
CRIU 7 3 7 7 7
Cryopid2 7 7 7 7 7
DMTCP (v1) 3 7 7 7 7
Extensible 3 3 3 3 3
CKPT
Table 2.1: Comparison of various checkpointing systems. The other resourcevirtualization refers to the ability to virtualize protocols, device drivers, etc.
2.1.3 Fault Tolerance
Fault tolerance [70, 58] is a broader concept not discussed here. It enables
a system to continue operating properly in the event of a failure of one
of its components. Several strategies can be deployed to make a system
fault tolerant such as: redundancy, partial re-execution, atomic transactions,
instrumentation of data, and so on.
2.2 System Call Interpositioning
The concept of wrappers, as implemented in DMTCP, have a long and inde-
pendent history under the more general heading of interposition. Interpo-
sition techniques have been used for a wide variety of purposes [123, 136,
65]. See especially [123] for a survey of a wide variety of interposition tech-
niques. The work of Garfinkel [42] discusses practical problems associated
with system call interpositioning. The packages PIN [88] and DynInst [124]
are two examples of software packages that provide interposition techniques
at the level of binary instrumentation.

22 CHAPTER 2. CONCEPTS RELATED TO CHECKPOINT-RESTART AND VIRTUALIZATION
2.3 Virtualization
Virtualization is the process of allowing unmodified source code or an un-
modified binary to transparently run under varied external environments
(different CPU, different network, different graphics server (e.g., X11-server),
etc.). Most of the original checkpointing packages [73, 74, 26, 31, 71] ig-
nored these issues and concentrated on homogeneous checkpointing.
Virtualization techniques have been developed since the 1960s. Since
then, systems have implemented different flavors of virtualization. In this
section, we discuss the four types of virtualization techniques in common
use today that are closest in spirit to this work.
2.3.1 Language-Specific Virtual Machines
A language-specific virtual machine, sometimes also known as an applica-
tion virtual machine, a runtime environment, or a process virtual machine,
allows an application to execute on any platform without having to write any
platform-specific code. This is achieved by creating a platform-independent
programming environment that abstracts the details of the underlying hard-
ware or operating system. This abstraction is provided at the level of a
high-level programming language. Notable examples include Java Virtual
Machine (JVM) [75], .NET framework [122], and Android virtual machines
(Dalvik) [20, 36].
Language-specific virtual machines are often implemented using an in-
terpreter, with an option of using just-in-time compilation for performance
close to that of a compiled language [32].
2.3.2 Process Virtualization
Process virtualization allows a process to be migrated or restarted in a new
external environment, while preserving the process’s view of the external
world. For example, a kernel may assign to a restarted process a different

2.3. VIRTUALIZATION 23
pid than the original pid at the time of checkpoint. The earliest checkpoint-
ing packages had assumed that the targeted user process would not save
the value of the pid of a peer process, but rather would re-discover that
pid on each use. As software complexity grew, this assumption became
unreliable. More recent packages either modified the Linux kernel (e.g.,
BLCR [52]), or ran inside a Linux Container, a lightweight virtual machine
(e.g., CRIU [111]).
Process virtualization (as exemplified by this work) has been considered
intensively in the context of checkpointing only recently. Nevertheless, it has
important forerunners in process hijacking [136] and in the checkpointing
packages [76, 135] used in Condor’s Standard Universe. Similarly, there are
connections of process virtualization with dynamic instrumentation (e.g.,
Paradyn/DynInst [124], PIN [88]).
2.3.3 Lightweight O/S-based Virtual Machines
O/S virtualization allows several isolated execution environments to run
within a single operating system kernel. This technique exhibits better per-
formance and density compared to virtual machines. On the downside, it
cannot host a guest operating system different from the host operating sys-
tem, or a different guest kernel (different Linux distributions is fine). Some
examples include FreeBSD Jail [61], Solaris Zones [96], Linux Containers
(LXC) [117], Linux-VServer [116], OpenVZ [118] and Virtuozzo [119].
Linux Containers are a kernel-level tool for providing a type of virtual-
ization in the form of namespaces for process spaces and network spaces.
This provides an alternative approach for such tasks as that of pid virtu-
alization. The CRIU [111] checkpointing system uses LXC namespaces to
virtualize kernel resource identifiers within the container. The namespaces
avoid the problem of name conflicts for kernel resource identifiers during
process migration.

24 CHAPTER 2. CONCEPTS RELATED TO CHECKPOINT-RESTART AND VIRTUALIZATION
Although process-level virtualization and Library OS [6, 95, 107] both
operate in user space without special privileges, the goal of Library OS
is quite different. A Library OS modifies or extends the system services
provided by the operating system kernel. For example, Drawbridge [95]
presents a Windows 7 personality, so as to run Windows 7 applications un-
der newer versions of Windows. Similarly, the original exokernel operating
system [37] provided additional operating system services beyond those of
a small underlying operating system kernel, and this was argued to often be
more efficient that a larger kernel directly providing those services.
2.3.4 Virtual Machines
Hardware virtualization uses an abstract computing platform. Thus, it hides
the hardware platform (the host software). On top of the host software, a
virtual machine (guest software) is running. The guest software executes as
if it were running directly on the physical hardware, with a few restrictions,
such as the network access, display, keyboard, and disk storage. Examples
of virtual machines include VMware, Qemu/KVM [114], Xen [15], Virtu-
alBox [130], and Lguest [115]. The virtual machines often run a set of
tools inside the guest operating system to inspect and control its behavior.
Further, in some cases the guest operating system is modified to provide
additional support/features and the technique is referred to as paravirtu-
alization. Some notable examples of paravirtualization are Xen [15] and
Microsoft Hyper-V [125].
One could also include binary instrumentation techniques such PIN [88]
and DynInst [124] in a discussion of virtualization, but this tends not to be
used much with checkpointing.
The work of this thesis introduces process virtualization for abstractions
beyond the traditional kernel resource identifiers in order to virtualize nu-
merous external subsystems such as SSH connections, InfiniBand network,

2.4. DMTCP VERSION 1 25
KVM and Tun/Tap interfaces, SLURM and Torque batch queues, and GPU
drivers. The modular approach to virtualize these external subsystems al-
lows the checkpointing system to grow organically (see Chapter 4). By vir-
tualizing these external environments, this work enabled some projects to
be the “first” to support checkpointing.
2.4 DMTCP Version 1
DMTCP (Distributed MultiThreaded CheckPointing) is free, open source soft-
ware (http://dmtcp.sourceforge.net, LGPL license) and traces its
roots to early 2005 [30]. The DMTCP approach has always insisted on not
making modifications to the kernel, and not requiring any root (administra-
tive) privileges. While this was sometimes more difficult than an approach
with full privileges inside the kernel, it integrates better with complex cyber
infrastructures. DMTCP’s lack of administrative privilege provides a level of
security assurance.
As a side effect of working completely in the user-space, DMTCP relies
only on the published APIs (e.g., POSIX and the Linux proc filesystem) to
perform checkpoint-restart. Thanks to the highly stable kernel API, the same
DMTCP software can be used on Linux kernel ranging from the latest bleed-
ing edge release to Linux 2.6.5 (released in April, 2004). In this section,
we provide a only brief overview of the checkpoint-restart mechanisms of
DMTCP. More Details can be found in Ansel et al. [7].
Using DMTCP with an application is as simple as:
dmtcp_launch ./myapp arg1 ...
# From a second terminal window:
dmtcp_command --checkpoint
dmtcp_restart ckpt_myapp_*.dmtcp
This checkpoint image contains a complete standalone image of the ap-

26 CHAPTER 2. CONCEPTS RELATED TO CHECKPOINT-RESTART AND VIRTUALIZATION
plication with all the relevant information required to restart it later. It can
be replicated and migrated as needed. DMTCP also creates a restart script
to help automate restart of distributed computation.
DMTCP
COORDINATOR
CKPT MSG
CKPT THREAD
USER PROCESS 1
SIG
US
R2
SIG
US
R2
USER THREAD B
USER THREAD A
CKPT MSG
SIG
US
R2
connectionsocket
USER THREAD C
CKPT THREAD
USER PROCESS 2
Figure 2.1: Architecture of DMTCP
As seen in Figure 2.1, a computation running under DMTCP consists of
a centralized coordinator process and several user processes. The user pro-
cesses may be local or distributed. User processes may communicate with
each other using sockets, shared-memory, pseudo-terminals, etc. Further,
each user process has a checkpoint thread which communicates with the co-
ordinator. The checkpoint thread is created by the DMTCP library dmtcphi-
jack.so, that is loaded into each of the application processes at startup (be-
fore calling application’s main() function) by using the LD_PRELOAD fea-
ture of the loader. The DMTCP library install signal handler for the check-
point signal that is later used to quiesce user threads. The checkpoint thread
is responsible for creating checkpoint images as and when requested by the
coordinator.

2.4. DMTCP VERSION 1 27
2.4.1 Library Call Wrappers
The DMTCP library adds wrappers around a small number of libc func-
tions. For efficiency reasons, it avoids wrapping any frequently invoked sys-
tem calls such as read and write. The wrappers are used to gather infor-
mation about the current process and to track all forked child processes as
well as remote processes created via SSH and to automatically put them un-
der checkpoint control. The local child processes inherit the LD_PRELOAD
environment variable, whereas for the remote child processes, the comman-
dline is modified to launch them under DMTCP control. In the case of sock-
ets, DMTCP needs to know whether the sockets are TCP/IP sockets (and
whether they are listener or non-listener sockets), UNIX domain sockets, or
pseudo-terminals. Again, it uses wrappers around socket, connect, accept,
open, close, etc., to do that.
2.4.2 DMTCP Coordinator
DMTCP uses a stateless centralized process, the DMTCP coordinator, to syn-
chronize the separate phases at the time of checkpoint and restart. The
checkpoint threads communicates with the DMTCP coordinator through a
socket connection. Checkpoint procedure can be initiated by the coordi-
nator on an explicit request from the user through its interactive interface,
through the dmtcp_command utility, or on expiration of a predefined check-
point interval. It should be noted that the coordinator is a single point of
failure since the entire computation relies on it.
2.4.3 Checkpoint Thread
The checkpoint thread waits for a checkpoint request from the coordinator.
On receiving a checkpoint request, the checkpoint thread quiesces the user
threads (by sending a checkpoint signal) and takes the process through the
phases of creating a checkpoint image. Similarly, during restart, it takes the

28 CHAPTER 2. CONCEPTS RELATED TO CHECKPOINT-RESTART AND VIRTUALIZATION
process through the restart phases and finally un-quiesces the user threads.
The checkpoint thread is dormant during the normal execution of the pro-
cess and is only active during the checkpoint/restart procedures.
2.4.4 Checkpoint
On receiving the checkpoint request from the coordinator, the checkpoint
thread sends the checkpoint signal to all the user threads in the process.
This quiesces the user threads by forcing them to block inside a signal han-
dler previously installed by DMTCP. The checkpoint image is created by writ-
ing all of user-space memory to a checkpoint image file. Each process has its
own checkpoint image. Prior to creating the checkpoint image, the check-
point thread also copies into the user-space memory, any kernel state that is
required to restart the process such as the state of associated with network
sockets, files, and pseudo-terminals.
At the time of checkpoint, all of user-space memory is written to a check-
point image file. The user threads are then allowed to resume executing
application code. Note that user-space memory includes all of the run-time
libraries (libc, libpthread, etc.), which are also saved in the checkpoint im-
age.
DMTCP doesn’t directly handle asynchronous DMA operations that may
be pending or ongoing at the time of checkpoint. This could result in a
inconsistent checkpoint state as the “quiesce” property has been violated.
2.4.5 Restart
As the first step of restart phase, DMTCP group all restart images from a
single node under a single dmtcp_restart process. The dmtcp_restart process
recreates all file descriptors. It then uses a discovery service to discover the
new addresses for processes migrated to new hosts and restores network
connections. It then forks a child process for each checkpoint image. These

2.4. DMTCP VERSION 1 29
individual processes then restore their memory areas. Next, the user threads
are recreated using the original thread stacks. All user threads restore their
pre-checkpoint context using the longjmp system call and are forced to
wait in the signal handler. The checkpoint thread then restoring the kernel
state that was saved during the checkpoint phase. Finally, the checkpoint
thread un-quiesces the user threads and the user threads resume executing
application code.
2.4.6 Checkpoint Consistency for Distributed Processes
In case of distributed processes, one needs to determine a consistent global
state of the asynchronous system at the time of checkpoint. The notion of
the global state of the system was formalized by Chandy and Lamport [28].
The central idea is to use marker (snapshot) messages. A process that wants
to initiate a checkpoint, records its local state and sends a marker message
on each of its outgoing channels. All other processes save their local state
on receiving the first marker message on some incoming channel. For every
other channel, any messages received before the marker message were ob-
viously sent before the snapshot “cut off”. Hence they are included in the
local snapshot.
Chandy and Lamport were primarily concerned with “uncoordinated snap-
shots” (no centralized coordinator). DMTCP employs a strategy of “coordi-
nated snapshots” using a global barrier. This makes the implementation of
Chandy-Lamport consistency particularly easy, since messages can be sent
only prior to the global barrier. Processes are “quiesced” (frozen) at the bar-
rier. Next, the checkpoint thread of each process receives all pending data in
the network, after which a globally consistent snapshot is taken. The details
of the DMTCP implementation follow.
To initiate a checkpoint, the coordinator broadcasts a quiesce message
to each process in the computation. On receiving the message, the check-

30 CHAPTER 2. CONCEPTS RELATED TO CHECKPOINT-RESTART AND VIRTUALIZATION
point manager thread in each process quiesces the user threads, sends an
acknowledgement to the coordinator, and waits for the drain message. Af-
ter receiving acknowledgements from all processes, the coordinator lifts the
global barrier and broadcasts the drain message. On receiving the drain
message, the checkpoint manager thread sends a special cookie (marker mes-
sage) through the “send” end of each socket. Next, it reads data from the
“receive” end of each socket until the special cookie is received. Since user
threads in all the processes have already been quiesced, there can be no
more in-flight data. The received in-flight data has now been copied into
user-space memory, and will be included in the checkpoint image.
On restart, once the socket connections have been restored, the check-
point manager thread sends the saved in-flight data (previously read from
the “receive” end of the socket) back to its peer processes. The peer processes
then refill the network buffers, by pushing the data back into the network
through the “send” end of each restored socket connection. The checkpoint
manager thread then sends a message to the coordinator to indicate the end
of the refill phase and waits for the resume message. Once the coordina-
tor has received messages indicating end of refill phase from all involved
processes, it lifts the global barrier and broadcasts the resume message. On
receiving the resume message, the checkpoint manager un-quiesces the user
threads and they resume executing user code.

CHAPTER 3
Adaptive Plugins as a Mechanism
for Virtualization
This chapter introduces several important examples of the need to integrate
checkpointing with an external subsystem: Pid virtualization, SSH virtual-
ization, virtualization of the InfiniBand network, virtualization of OpenGL,
and virtualization of POSIX timers. The concept of process virtualization is
introduced in concrete examples.
Virtualization of InfiniBand [27] and OpenGL [62] were extensive projects
requiring much domain knowledge. The specific results represent long-
standing open problems and are not part of this dissertation. We use those
examples to motivate the need for process virtualization, and we use those
examples to argue for the expressivity of process virtualization in Chapter 5.
3.1 The Ever Changing Execution Environment
In the next subsections, five examples of strategies for process virtualization
are described, in order to make clear the rich design space available for
process virtualization. In each of these cases, the nature of its virtualization
requirement is unique. The five examples are:
31

32 CHAPTER 3. ADAPTIVE PLUGINS AS A MECHANISM FOR VIRTUALIZATION
1. virtualization of kernel resource identifiers, using the example of process
id (pid) (Section 3.1.1);
2. virtualization of protocols, using the SSH protocol as its example (Sec-
tion 3.1.2);
3. a shadow device driver approach for transparent checkpointing over In-
finiBand (Section 3.1.3);
4. a record-replay approach, using transparent checkpointing of OpenGL
3D-graphics as an example (Section 3.1.4); and
5. adapting to application requirements for more control over checkpoint-
ing (Section 3.1.5).
3.1.1 PID: Virtualizing Kernel Resource Identifiers
Pid is one of the simplest examples of the kernel resource identifiers that
needs virtualization. The operating system kernel is unlikely to assign the
same pid on restart as existed at the time of checkpoint. Even if the kernel
were to allow a mechanism to request a particular pid, the requested pid
might be in use (assigned to a different process).
If the target application has saved the pre-checkpoint pid and tries to use
it after restart, it could have undesired effects. For example, if the process
uses the saved pid to send a signal after restart, in the best case, the process
will fail because the saved pid is invalid. In the worst case, the saved pid
might correspond to some other process and signal will be sent to that other
process.
To avoid these situations, we must provide a mechanism such that the
processes can continue to use the saved pid after restart without any un-
desired side effects. This can be done by providing the application process
with a virtual pid that never changes for the duration of the process lifetime.
When communicating with the kernel, the corresponding real pid that the

3.1. THE EVER CHANGING EXECUTION ENVIRONMENT 33
User Process
PID: 4000
User Process
PID: 4001
Virt. PID Real PID
4000 26524001 3120
Translation Table
getpid()26524000
kill(4001, 9) KERNEL
4001Sending signal 9to pid 31203120
Figure 3.1: Virtualization of kernel resource identifiers (example shown forprocess id)
kernel knows about is looked up in the translation table and passed on to
the kernel. Figure 3.1 shows a simple schematic of a translation layer be-
tween the user processes and the operating system kernel along with a pid
translation table to convert between virtual and real pids. At each restart,
the translation table is refreshed to update the real pids.
3.1.2 SSH Connection: Virtualizing a Protocol
Pid virtualization is a classic example of virtualizing low level kernel re-
source identifiers using a translation layer. However, the same solution
doesn’t suffice for higher level abstractions, such as an SSH connection.
app1 app2
std
io
Node1 Node2
socketSSH client
(ssh) (sshd)SSH server
std
io
Figure 3.2: SSH connection: ssh Node2 app2The user process, app1, forks a child SSH client process (ssh) to call the SSHserver (sshd) on the remote node to create a remote peer process, app2.

34 CHAPTER 3. ADAPTIVE PLUGINS AS A MECHANISM FOR VIRTUALIZATION
Recall that the ssh command operates by connecting across the net-
work to a remote SSH daemon, sshd, as shown in Figure 3.2. Since the
SSH daemon is privileged, it is not possible for the unprivileged user-space
checkpointing system to start a new SSH daemon during restart. The issue
becomes even more complicated when the client and server processes are
restarted at entirely different network addresses on different hosts.
For virtualizing an SSH connection, it doesn’t suffice to virtualize just the
network address. Instead, it must virtualize the entire SSH client-server con-
nection. In essence, the SSH daemon represents a privileged process running
a certain protocol. Regardless of whether the protocol is an explicit standard
or a de facto standard internal to the subsystem, process virtualization must
virtualize that protocol. Checkpointing and restarting the privileged SSH
daemon is not an option.
app1 app2
std
io
Node1 Node2
SSH serverSSH client
(ssh) socket
virt_ssh virt_sshd
(sshd)
std
io
std
io
std
io
Figure 3.3: Virtualizing an SSH connection: ssh Node2 app2The call to launch an SSH client process is intercepted to launch virtualssh client (virt_ssh) and server (virt_sshd) processes. virt_ssh andvirt_sshd are unprivileged processes.
Process virtualization provides a principled and robust algorithm for trans-
parently checkpointing an SSH connections. As shown in Figure 3.3, the SSH

3.1. THE EVER CHANGING EXECUTION ENVIRONMENT 35
connection is virtualized by creating virt_ssh and virt_sshd helper pro-
cesses that shadow the SSH client and server processes respectively. The
virt_ssh and virt_sshd processes are owned by the user and are placed
under checkpoint control. The ssh and sshd processes are not check-
pointed.
On restart, the user processes are restored along with virt_ssh and
virt_sshd processes (without the underlying SSH connection) on new
hosts. The virt_ssh process then recreates a new SSH connection (see Sec-
tion 5.4).
3.1.3 InfiniBand: Virtualizing a Device Driver
Both ssh for a traditional TCP network and the new InfiniBand network
are intimately connected with high performance implementations of MPI
(Message Passing Interface). An implementation usually retains ssh and
TCP in addition to InfiniBand support, since typical MPI implementations
bootstrap their operation through ssh in order to create additional MPI
processes (MPI ranks), and to exchange InfiniBand addresses among peers.
InfiniBand virtualization has been a particular challenge both due to its
complexity [134, 63, 16] and due to the fact that much of the state is hid-
den either within a proprietary device driver or within the hardware itself.
The solution here is to use a shadow device driver approach [106]. The
InfiniBand plugin (§5.10) maintains a replica of the device driver and hard-
ware state by intercepting and recording the InfiniBand library calls. On
restart, this replica is used to recreate and restore the state of the InfiniBand
connection.

36 CHAPTER 3. ADAPTIVE PLUGINS AS A MECHANISM FOR VIRTUALIZATION
3.1.4 OpenGL: A Record/Replay Approach to Virtualizing
a Device Driver
Scientific visualization is yet another example that requires a different kind
of virtualization solution. Some graphics computations are extremely GPU-
intensive. Further, most scientific visualizations today use OpenGL for 3D-
graphics. If a scientist walks away from a visualization and needs to restart
it the next day, there will be wasted time to reproduce it. Further, switch-
ing between multiple scientific visualizations becomes extremely inefficient.
Hence, checkpoint-restart is a critical technology. However, it is difficult
to checkpoint, because much of the graphics state is encapsulated into a
vendor-proprietary hardware GPU chip.
The OpenGL plugin (§5.9) achieves checkpoint-restart of 3-D graphics
by using a process virtualization strategy of record (record all OpenGL calls),
prune (prune any calls not needed to reproduce the most recent graphics state),
and replay (replay the calls during restart in order to place the GPU into a
semantically equivalent state to the state that existed prior to checkpoint).
3.1.5 POSIX Timers: Adapting to Application
Requirements
A posix timer is an external resource maintained within the kernel and has
an associated kernel resource identifier known as timer id. As with pid virtu-
alization, the timer-id needs to be virtualized as well and can use the same
strategy.
Consider a process that is checkpointed while a timer is still armed, i.e.
the timeout specified with the timer has not expired yet. On restart, what
is the desired behavior? Should the timer expire immediately or should it
expire after exhausting the remaining timeout period? There is no single
correct answer as the desired result is application dependent. For an appli-
cation that is waiting for a response from a web server, it is desired to expire

3.2. VIRTUALIZING THE EXECUTION ENVIRONMENT 37
the timer on restart. However, for an application process that is monitor-
ing a peer process for potential deadlocks, the time should continue for the
remaining time period.
3.2 Virtualizing the Execution Environment
As seen in the previous section, it is imperative to virtualize the external
resources in order to fully support checkpoint restart for any application. In
order to be successful, virtualization should be done transparently to the ap-
plication. This assumes that the application is interacting with the external
resource through a fixed set of API. Two basic requirements for virtualizing
an external resource for checkpointing are:
1. Virtualize external subsystems.
2. Capture/restore the state of external resources.
Next, we talk about each of these requirements and elaborate on their im-
portance and discuss what additional features are required for a complete
virtualization solution.
3.2.1 Virtualize Access to External Resources
Since external resources may change between checkpoint and restart, we
need to virtualize them. This can be achieved through a translation layer
between the application process and the resource. Virtualizing a resource
may be as simple as translating between virtual and real identifiers such
as pid-virtualization (Section 3.1.1) or it may involve more sophisticated
mechanisms like shadow device drivers (Section 3.1.3). Depending upon the
external resource, the translation may be active throughout the computation
(e.g., for pids) or only during the restart procedure (for SSH).
Further, the translation layer should ensure that the access to a resource
is atomic with respect to checkpoint-restart i.e. a checkpoint shouldn’t be

38 CHAPTER 3. ADAPTIVE PLUGINS AS A MECHANISM FOR VIRTUALIZATION
allowed while the process is in the middle of manipulating/accessing the re-
source. Not doing this may result in an inconsistent state at restart. Consider
pid virtualization where a thread tries to send a signal to another thread us-
ing the virtual tid (thread id). The pid virtualization layer translates the
virtual tid to the real tid and sends the signal using real tid. Further con-
sider that the process is checkpointed after the translation from virtual to
real, but before the signal is actually sent. On restart, the process will re-
sume and will try to send the signal with the old real tid, which of course is
not valid now.
Share the virtualized view with peers
Virtualizing access to external resources gets complicated in a distributed
environment. Processes communicate with their peers. This demands a
consistent virtualization layer across all involved parties. It becomes more
evident after restart, when the translation table is updated to reflect the
current view of the external resource. These updates must be shared with all
the peer processes to allow them to update their own translation tables. For
example, in case of network address virtualization, each process must inform
its peers of its new network address on restart to allow them to restore socket
connections.
3.2.2 Capture/Restore the State of External Resources
When restarting a process from a previous checkpoint, we need to restore
the process view of the external resource. We need to identify the relevant
information that would be required to restore/recreate the external resource
during restart. This information should be gathered at the time of check-
point and should be saved as part of the checkpoint image. This information
can then be read from the ckpt image on restart.

3.3. ADAPTIVE PLUGINS 39
Quiesce the external resource
During checkpoint, the external resources should be quiesced to ensure a
consistent state. For example, an asynchronous disk read operation must be
allowed to finish before writing the process memory to the checkpoint image
to avoid data transformation due to on going memory updates (DMA).
Consistency of the computation state
As discussed above, a virtualization scheme should be transparent to the
user application. Thus, the application view of the external resource should
be consistent before and after checkpoint. Similarly, the application process
should not observe any change in its own state before and after checkpoint.
This involves preserving the state of the running process (e.g., threads, mem-
ory layout, and file descriptors) between checkpoint and restart.
Note that it is acceptable to alter the process state and/or the state of
external resource while perform checkpoint-restart. However, such changes
should be reverted and the pre-checkpoint view of the application should
be restored before the application process is allowed to resume executing
application code.
3.3 Adaptive Plugins as a Synthesis of
System-Level and Application-Level
Checkpointing
So far we have discussed the motivation for virtualizing the execution envi-
ronment along with the basic requirements for achieving the same. In this
section we will discuss possible design choices.
There are two basic approaches for achieving the goals discussed in Sec-
tion 3.2. One is to use application-specific checkpointing by having the ap-

40 CHAPTER 3. ADAPTIVE PLUGINS AS A MECHANISM FOR VIRTUALIZATION
plication developer write extra code for supporting checkpointing. However,
as discussed in Section 2.1, this is not an ideal solution as it requires knowl-
edge of the internals of the applications and puts a burden on the developer.
The second approach is to use an existing monolithic checkpointing system
such as DMTCP version 1 and insert the virtualization code in it along with
a large number of heuristics to satisfy a variety of application needs (e.g.,
heuristics for posix timers as discussed in Section 3.1.5). However, there is
no universal set of heuristics that can be used with all applications as each
application requires specific heuristics to cater its needs.
In this work, we present adaptive plugins as an ideal compromise be-
tween these two extreme approaches to meet the virtualization require-
ments. An adaptive plugin is responsible for virtualizing a single external
resource. By basing plugins on top of a transparent checkpointing package
such as DMTCP, the simplicity of transparent checkpointing is maintained.
With plugins, no target application code is ever modified, yet they enable
application-specific fine tuning for checkpoint-restart. We have already seen
examples where the external resource needs to be virtualized in previous
sections. The posix timer plugin is an example of application-specific heuris-
tic plugin. A memory cutout plugin to reduce the memory footprint of the
process for reducing checkpoint image size would be yet another example of
an application-specific plugin.

CHAPTER 4
The Design of Plugins
In the previous chapter, we discussed several use cases that require virtual-
ization of external resources in order to support checkpoint-restart. External
resources may include, but are not limited to kernel resource identifiers,
protocols, and hardware device drivers. We further listed the two basic re-
quirements for virtualizing an external resource and discussed how a design
based on adaptive plugins is well suited for such tasks.
Section 4.1 introduces a basic framework of a plugin architecture that pro-
vides the same set of services for virtualizing external resources that were
introduced informally in Chapter 3. A plugin is an implementation of the
process virtualization abstraction. In process virtualization, an external sub-
system is virtualized by a plugin. All software layers above the layer of that
plugin see a modified subsystem.
Section 4.2 then uses these requirements to provide a design recipe for
virtualization through plugins. Section 4.3 then takes into account the is-
sue of dependencies among multiple plugins within the same application
process. Section 4.4 extends that design recipe to multiple processes, in-
cluding distributed processes on multiple hosts. Section 4.5 describes three
special-purpose plugins that are required for checkpointing all processes.
This chapter concludes with Section 4.6, containing some implementation
challenges.
41

42 CHAPTER 4. THE DESIGN OF PLUGINS
Operating System Kernel
Memory Plugin
Plugin EngineRuntime Libraries(libc, etc.)
Ap
pli
cati
on
Ta
rget
Target Application (program+data)
Thread Plugin
Coordinator Interface Plugin
Lib
rari
es
Ru
nti
me
Lib
rari
es
Ba
se P
lug
inIn
tern
al
an
d T
hir
d−
Pa
rty
Plu
gin
Lib
sCapture/Restore State
Virtualize ResourceLibrary Wrappers
Library Wrappers Virtualize Resource
Capture/Restore State
Figure 4.1: Plugin Architecture.
4.1 Plugin Architecture
An application consists of program and data. It interacts with the execution
environment through various libraries. For example, the libc runtime library
provides access to the kernel resources, a device driver library may provide
access to the underlying device hardware, and so on. Thus one can imagine
virtualizing the execution environment by intercepting the relevant library
calls. This allows us to inspect and modify the behavior of the underlying
subsystem as seen by the application.
Figure 4.1 shows a high level view of the plugin architecture. It has

4.1. PLUGIN ARCHITECTURE 43
two main components: (1) plugins, and (2) the plugin engine. Plugins
and the plugin engine are implemented as separate dynamic libraries. They
are loaded into the application using the LD_PRELOAD feature of the Linux
loader.
Plugin
A plugin is a checkpoint subsystem that virtualizes a single external resource
or subsystem with the help of function wrappers (§4.1.1). It save/restores
the state of the external subsystem. Examples of external subsystems are:
process-id, network sockets, InfiniBand, etc. Application processes are con-
sidered as if they are independent and inter process communication through
pids, sockets, etc. is handled through plugins. Further, a plugin is transpar-
ent to the target application and can be enabled/disabled for the application
as needed. Finally, third parties can write orthogonal customized plugins to
fit their needs.
Plugin Engine
The plugin engine provides event notification services (§4.1.2) to assist plug-
ins to capture/restore the state of their specific external resources. It further
interacts with a coordinator interface plugin to provide publish/subscribe
services (§4.1.3) to enable plugins to interact with each other and share the
translation tables for resource virtualization.
4.1.1 Virtualization through Function Wrappers
Since the underlying resources provided by the operating system may change
between checkpoint and restart, there is a need to virtualize them. The plu-
gin virtualizes the external resources by putting wrappers around interesting
library calls, which interpose when the target application makes such a call.
In case of pids, the virtualization can be done using a simple table translat-

44 CHAPTER 4. THE DESIGN OF PLUGINS
ing between virtual and real pids as shown in Listing 4.1. The arguments
passed to the library call are modified to replace the virtual pid with the real
pid. Similarly, the return value can also be modified as required. The virtual
pid column of this table is saved as part of checkpoint image and at restart
time the real pid column is populated as processes/threads are recreated.
int kill(pid_t pid, int sig) {
disable_checkpoint();
real_pid = virt_to_real(pid);
int ret = REAL_kill(real_pid, sig);
enable_checkpoint();
return ret;
} �Listing 4.1: A simple wrapper for kill
As seen in the above listing, a function wrapper is implemented by defin-
ing a function of the same name as the call it is going to wrap. Real function
here refers to the function by the same signature, in a later plugin or a run-
time library. It is possible for multiple plugins to create wrappers around a
single library function. The order of execution of wrappers is determined
by a plugin hierarchy corresponding to the order in which the plugins are
invoked (Section 4.3).
Capture/Restore state of external resource
Wrappers are also used to “spy” on the parameters used by an application to
create a system resource, in order to assist in creating a semantically equiv-
alent copy on restart. At the time of checkpoint, a plugin saves the current
state of its underlying resources into the process memory. The state can be
obtained from a number of places such as the process environment and the

4.1. PLUGIN ARCHITECTURE 45
operating system kernel. In some cases, the function wrappers can also be
used to gather the information about the external resources. For example, in
the “socket” wrapper (Listing 4.2), the socket plugin will save the associated
domain and protocol information along with the socket identifier.
int socket(int domain, int type, int protocol) {
disable_checkpoint();
int ret = REAL_socket(domain, type, protocol);
if (ret != -1) {
register_new_socket(ret, domain, type, protocol);
}
enable_checkpoint();
return ret;
} �Listing 4.2: Wrapper for socket() to record socket state
Atomic transactions
Plugins may have to perform atomic operations that must not be interrupted
by a checkpoint. For example, the translation and call to real function should
be done atomically with respect to checkpoint-restart. Otherwise, there is a
possibility of checkpointing after the translation but before the real function
is called. In that case, on restart, the translated value is no longer valid
and can impact the correctness of the program. The plugin engine provides
disable_checkpoint and enable_checkpoint services for enclosing the critical
section as seen in Listing 4.1.
The disable_checkpoint and enable_checkpoint services are implemented
using a modified write-biased reader-writer lock. The modification allows a
recursive reader lock even if the writer is queued and waiting for the lock.
The checkpoint thread must acquire the writer lock before it can quiesce the

46 CHAPTER 4. THE DESIGN OF PLUGINS
user threads. On the other hand, the user threads acquire and release the
reader lock as part of a call to disable_checkpoint and enable_checkpoint
respectively. If a checkpoint request arrives while a user thread is in the
middle of a critical section, the checkpoint thread will wait until the user
thread comes out of the critical section and releases the reader lock. A user
thread is not allowed to acquire a reader lock if the checkpoint thread is
already waiting for the writer lock to prevent checkpoint starvation.
Atomicity is especially important for wrappers that create or destroy a
resource instance. For example, when creating a network socket, if the
checkpoint is taken right after the socket is created but before the socket
plugin has a chance to register it, the socket may not be create at restart as
no record exists of the socket. Thus one must atomically create and record
socket state as shown in Listing 4.2.
Wrappers can be considered the most basic of all virtualization tools. A
flexible, robust implementation of wrapper functions turns out to be surpris-
ingly subtle and is discussed in more detail in Section 4.6.1.
4.1.2 Event Notifications
Event notifications are used to inform other plugins (within the same pro-
cess) of interesting events. Any plugin can generate notifications. Plugin
engine then delivers these notification to all available plugin in a sequential
fashion. The order of delivery of notification depends on the plugin hier-
archy as discussed in Section 4.3. Plugins must declare an event hook in
order to receive event notifications. A plugin may decide to ignore any or all
notifications.
Figure 4.2 shows the “write-ckpt” and “restart” events generated by the
coordinator interface plugin which are then delivered to all other plugins by
the plugin engine.

4.1. PLUGIN ARCHITECTURE 47
Plugin Engine
Target Application
Socket Plugin
Fork/Exec Plugin
Pid Plugin
Coordinator Interface Plugin
Memory Plugin
write−ckpt
wri
te−
ckp
t
(1)
(2)
(3)
(4)
(5)
(6)
(a) Event notification for write-ckpt
Plugin Engine
Target Application
Socket Plugin
Fork/Exec Plugin
Pid Plugin
Coordinator Interface Plugin
Memory Pluginresta
rt
rest
art
(1)
(6)
(5)
(4)
(3)
(2)
(b) Event notification for restart
Figure 4.2: Event notifications for write-ckpt and restart events. The numbersin the parenthesis indicate the order in which messages are sent. Notice that therestart event notification is delivered in the opposite order of write-ckpt event.
Some of the interesting notifications are:
• Initialize: generated during the process initialization phase (even be-
fore main() is called). The plugins can initialize data structures, etc. A
plugin may choose to register an exit-handler using atexit() which will
be called when the process is terminating.
• Write-Ckpt: each plugin saves the state of the external resources into
process’s memory. The memory plugin(s) then create the checkpoint
image.)
• Resume: generated during the checkpoint cycle.
• Restart: generated during restart phase.
• AtFork: generated during a fork and works similar to the libc function,
pthread_atfork.

48 CHAPTER 4. THE DESIGN OF PLUGINS
dmtcp_event_hook(is_pre_process, type, data) {
if (is_pre_process) {
switch (type) {
case Initialize:
myInit(); break;
case Write_Ckpt:
myWriteCkpt(); break;
...
}
}
if (!is_pre_process) {
switch (type) {
case Resume:
myResume(); break;
case Restart:
myRestart(); break;
...
}
}
} �Listing 4.3: An event hook inside a plugin
The Resume and Restart notifications are sent to plugins in the oppo-
site order from the Write-Checkpoint notification (see Listing 4.3 and Fig-
ure 4.2b). This is to ensure that any dependencies of a plugin are restored
before the plugin itself is restored. For example, the memory plugin (re-
sponsible for writing out or reading back the checkpoint image) is always
the lowest layer (see Figure 4.1). This is so that other plugins may save data
in the process’s memory during checkpoint, and find it again at the same
address during restart.

4.1. PLUGIN ARCHITECTURE 49
Target Application
Coordinator Interface Plugin
Plugin Engine
Socket Plugin
Coordinator Interface Plugin
Plugin Engine
Target Application
Socket Plugin
Coordinator
current local addr
current remote addr
curren
t loc
al a
ddr
curren
t rem
ote
addr
Node 1 Node 2
Figure 4.3: Publish/Subscribe example for sockets.
4.1.3 Publish/Subscribe Service
In a distributed environment, a publish/subscribe service is needed so that a
given type of plugin may communicate with its peers in different processes.
Typically, on restart, once the process resources have been recreated, the
plugins publish their virtual ids along with the corresponding real ids using
the publish/subscribe service. Next they subscribe for updates from other
processes and update their translation tables accordingly. This was seen
for the pid virtualization plugin (Section 3.1.1). Similarly, when a parallel
computation is restarted on a new cluster, the socket plugin must exchange
socket addresses among peers.
At the heart of the publish/subscribe services is a key-value database
whose key corresponds to the virtual name and whose value corresponds to
the real name of the underlying resource. The database is populated when
plugins publish the key-value pairs. Once the plugin has published all of
the relevant key-value pairs, it may now subscribe by sending queries to the
database. The plugins are notified as soon as a match for the queried key is
available. Typically, the key-value database is used only at restart time, as
doesn’t need to be preserved across checkpoint-restart.

50 CHAPTER 4. THE DESIGN OF PLUGINS
Figure 4.3 shows an example of the socket plugins exchanging their cur-
rent network address with their peers. During the Write-Checkpoint phase,
the socket peers agree on using a unique key (see Section 4.4.1) to iden-
tify the connection. While restarting, this unique key is used to publish the
current network address.
It is possible to have multiple publish/subscribe APIs that differ accord-
ing to scope. It is left to the plugins to choose the scope best suited for their
needs. Two trivial scopes are node-private and cluster-wide. Node-private
publish/subscribe API is sufficient for plugins dealing with resources limited
to a single node, such as pseudo-terminals, shared-memory, and message-
queues. Whereas plugins dealing with resources that may span over multiple
nodes, such as sockets and InfiniBand, should use the cluster-wide publish/-
subscribe API.
The node-private publish/subscribe service may be implemented using
shared-memory while the cluster-wide publish/subscribe service must be
provided by some centralized resource such as the DMTCP coordinator.
4.2 Design Recipe for Virtualization through
Plugins
So far we have seen the plugin architecture and the services provided by
it. We have also seen how these services suffice to meet the virtualization
requirements. We use this information to create a typical recipe for writing a
new plugin to virtualize an “external resource”. One is usually given a name
or id (identifier) to provide a link to the external resource. The id may be for
an InfiniBand queue pair, for a graphics window, for a database connection,
for a connection from a guest virtual machine to its host/hypervisor, and so
on.

4.2. DESIGN RECIPE FOR VIRTUALIZATION THROUGH PLUGINS 51
In all of these cases, the recipe is:
1. Intercept communication to the external resource (usually by inter-
posing between library calls), and translate between any real ids from
the external resource and virtual ids that are passed to the application
software. A plugin maintains this translation table of virtual/real ids.
2. Quiesce the external resource (or wait until the external resource has
itself reached a quiescent state);
3. Interrogate the state of the external resource sufficiently to be able to
reconstruct a semantically equivalent resource at restart time.
4. Checkpoint the application. The checkpoint will include state infor-
mation about the external resource, as well as a translation table of
virtual/real ids.
5. At restart time, the state information for the external resource is used
to create a semantically equivalent copy of the external resource. The
translation table is then updated to maintain the same virtual ids,
while replacing the real ids of the original external resource with the
real ids of the newly created copy of the external resource.
It is not always efficient to quiesce and save the state of an external
resource. The many disks used by Hadoop are a good example of this. The
data in an external database server is another example. It is not practical to
drain and save all of the external data in secondary storage.
There are two potential approaches. The first approach is to delay the
checkpoint during a critical phase. In the case of Hadoop, one would delay
the checkpoint until the Hadoop computation has executed a reduce oper-
ation, in order to not overly burden the resources of the Hadoop back end.
A similar approach can be taken for NVIDIA GPUs. In many cases, there
are also strategies for plugins to transparently detect this critical phase and
delay the checkpoint until that time.

52 CHAPTER 4. THE DESIGN OF PLUGINS
The second approach is to allow for a partial closed-world assumption
in which some state (data/contents) is assumed to be compatible across
checkpoint and restart. In case of the external database server, the external
data already lies in fault tolerant storage and is compatible across checkpoint
and restart. Thus the solution is to maintain a virtual id that identifies the
external storage of the server. That virtual id is used at restart time to restore
the connection to the database server.
4.3 Plugin Dependencies
Some plugins may have dependencies on other plugins. For example, the
File plugin depends on the Pid plugin to restore file descriptors pointing to
“/proc/PID/maps” and so on. Each plugin provides the list of dependencies
which must be satisfied to successfully load the given plugin. The depen-
dency declaration also affects the level of parallelism that can be achieved
when performing phases such as Checkpoint, Resume and Restart.
Subject to the dependencies among plugins, this design provides end
users with the possibility of selective virtualization. Selectively including only
some plugins is advantageous for three reasons: (i) performance reasons
(some end-user plugins might have high overhead); (ii) software mainte-
nance (other plugins can be removed while debugging a particular plugin);
and (iii) platform-specific plugins.
4.3.1 Dependency Resolution
Similar in spirit to modern software package formats such as RPM and deb,
a plugin provides a list of features/services that it provides, depends on,
or conflicts with. For example, the socket plugin may provide services for
“TCP”, “UDS” (Unix Domain Sockets), and “Netlink” socket types and de-
pends on the “File” plugin (to restore file system based unix domain sock-
ets).

4.3. PLUGIN DEPENDENCIES 53
The dmtcp_launch program, that is used to launch an application un-
der checkpoint control, compiles list of all available plugins by looking at
various environment variables, such as LD_LIBRARY_PATH. A user-defined
list of plugins can also be specified to be loaded into the application. The
dmtcp_launch program examines this plugin list and creates a partial or-
der of dependencies among the plugins. The list of available plugins is
searched to fulfill any missing dependencies for the user-defined plugins.
If a match is found, plugins are loaded automatically. Otherwise an error is
reported. If two or more plugins provide the same feature/service, a conflict
is recorded and the user is provided with the conflicting plugins.
void dmtcp_plugin_dependencies(const char ***provides,
const char ***requires,
const char ***conflicts) {
static const char *_provides[] = { "TCP ", "UDS", " Ne t l ink ",
NULL};
static const char *_requires[] = { " F i l e ", NULL};
static const char *_conflicts[] = {NULL};
*provides = _provides;
*requires = _requires;
*conflicts = _conflicts;
} �Listing 4.4: Dependencies declared by a plugin. The dmtcp_launch utility
uses these fields to generate a partial order among the given plugins and to
report any missing dependencies or any conflicts.
Listing 4.4 provides an example of dependency information as exported
by the socket plugin. Since the plugins are implemented as shared libraries,
the dmtcp_launch program can perform dlopen/dlsym to find and call
the dmtcp_plugin_dependencies function to learn about the dependencies.

54 CHAPTER 4. THE DESIGN OF PLUGINS
Further, this approach assumes a common naming scheme to resolve
matches/dependencies across plugins. This could be automated by scan-
ning symbols in the object files, for example, for both definitions and uses.
If a symbol is defined in more than one plugin, it can be listed as a potential
source of conflict to help the plugin writer in debugging plugins.
Parallel event handling
In Section 4.1.2, we discussed how the plugin engine assumed serial delivery
of event notifications due to plugin dependencies expressed in a linear order
(Figure 4.2). However, for non-linear plugin dependencies, a dependency
graph can be created to relax the order of notification delivery. The event
notifications can be processed by multiple plugins in parallel as long as there
is no dependency between them. This is useful in modern multi-core systems
to allow idle CPU cores to process the event notifications for the plugins. It is
also useful for plugins that need to perform asynchronous operations during
event handling. In such cases, rather than blocking on a single plugin, the
event notification can be carried out in parallel in other plugins.
4.3.2 External Resources Virtualized by Other Plugins
Plugins may use resources that are virtualized by an earlier plugin. For ex-
ample, plugins are allowed to create threads, open sockets, use files etc.
However, if the resource is created/used in a way that bypasses the wrap-
pers created by the earlier plugin, the resources may not be virtualize/save-
restored. In situations where this is not true, only the plugin using the
resources can save-restore its state. This is done to avoid circular depen-
dencies. If the save-restore/virtualization is absolutely required, the plugin
should be broken into two or more smaller plugins and the newer plugin
should be moved higher in the plugin-hierarchy.

4.3. PLUGIN DEPENDENCIES 55
4.3.3 Multiple Plugins Wrapping the Same Function
Multiple plugins are allowed to place wrappers around the same library
call. For example, the open("/proc/PID/maps", ...) function is
wrapped by the file plugin as well as the pid plugin. The file plugin needs
to be able to save/restore the file descriptor, whereas the pid plugin has to
convert the virtual PID to a real one. Figure 4.4 shows nested-wrappers
provided by the pid plugin and the file plugin.
func1(...) {
p="/proc/1234/maps" ...
...
fd = open(p, ...) ...
close(fd) ...}
REAL_open(...)
open(...) { ...
} ...
Target Application File Plugin PID Plugin Libc
REAL_open(...)
open(...) { ...
...}
close(...) {
REAL_close(...)
} ...
... ...
...}
close(...) {
...
...}
getpid() {
sys_close(...)
sys_getpid()
open(...) { ...
...}
sys_open(...)
}
REAL_getpid()
getpid() {
...
...
Figure 4.4: Nested wrappers: open function is wrapped both by the File pluginand by the Pid plugin.
Once a plugin has performed all the required pre-processing actions, it
calls the function wrapper in the next plugin library. This is done by using the
RTLD_NEXT feature of dlsym function call. The RTLD_NEXT service will find
the next occurrence of the given function in the library search order after
the current library. For example, in case of open wrapper in the File plugin
from Figure 4.4, dlsym(RTLD_NEXT, “open”) would return the address of
the open function defined in the Pid plugin. However, dlsym(RTLD_NEXT,
“close”) would return the address of the close function defined in Libc as
the close wrapper is not defined in the Pid plugin.
Since the wrappers execute both before and after the library call, a plugin
that was loaded earlier can place a wrapper around the wrapper created by
a later plugin. Thus the pre-processing takes place in the order of plugin
load sequence, whereas the post-processing takes place in the reverse order.

56 CHAPTER 4. THE DESIGN OF PLUGINS
4.4 Extending to Multiple Processes
Until this point, plugins have been described in the context of a single pro-
cess. For distributed computations, the interaction among distributed pro-
cesses is critical to making the plugin model practical. As we have seen,
the plugins virtualize the resources for several reasons. However, in case
of multiple processes, several processes may be using a common resource.
For example, several processes may share a file descriptor open to the same
file. A mapped memory region may be shared. A socket may be shared
among multiple processes. Several processes may have duplicate pointers
to the same underlying resource. These duplicate pointers may be created
explicitly (e.g., the dup() system call creates a duplicate file descriptor), or
implicitly (by creating a child process; the child process automatically gets a
copy of all the file-descriptors, shared memory, etc.).
How does one ensure correctness if multiple processes are using the same
resource and hence virtualizing it independently of each other? Should all
processes save/restore the common resource or only one of them?
The correct answer is that only a single process should be allowed to
save/restore the state of the underlying resource. This is required for two
reasons: (i) for some resources, part of the state to be checkpointed can
be read only once. This is the case with data in kernel buffers or network
data; and (ii) if multiple processes recreate the resource during restart, it
may no longer be shared. In some situations, it is impossible to recreate the
resource (e.g. sockets) by multiple processes, while in other case, recreating
the resource multiple times is permitted but results in incorrect behavior
(e.g. same file can be opened by multiple processes resulting in loss of
semantics).

4.4. EXTENDING TO MULTIPLE PROCESSES 57
Single process
It is possible to have duplicate pointers within a single process. Thus the
plugins must ensure that only one copy is checkpointed and the duplication
is restored during restart. This requires the ability of the plugins to identify
duplicate resources during the checkpoint phase. For some resources, the
operating system kernel (or the execution environment) assigns a unique
id at the time of creation. Examples include sockets, pid, System V shared
memory objects, semaphores, etc. When these resources are duplicated, the
duplicates may be detected easily by querying the kernel for the resource id.
Multiple processes
The two key issues in dealing with multiple processes are: (i) checkpoint-
restart of shared resources; and (ii) finding the current location of peer pro-
cesses. We employ the publish/subscribe service to assist us in dealing with
these issues. While it allows a central coordinator to mediate among multi-
ple processes, it also implicitly produces a barrier. Hence, it is important to
use that facility sparingly for the sake of efficiency.
4.4.1 Unique Resource-id for Shared Resources
Duplicate detection for the remaining resources must be done by keeping
track of when the duplicates are created — explicitly or implicitly. This
is done by assigning a unique resource-id to each resource when it is cre-
ated. The resources duplication is tracked by putting wrappers around cor-
responding library calls (such as dup or fork). Once detected, the duplicates
are assigned the same resource-id as the original resource.
A globally unique resource-id can be created in several ways. One possi-
ble solution is to use a mixture of hostname, virtual/real pid of the process
creating the resource, creation timestamp, etc.

58 CHAPTER 4. THE DESIGN OF PLUGINS
4.4.2 Checkpointing Shared Resources
Since only one process should be allowed to save the state of the shared
resources and the original resource creator might not be present, we must
select a checkpoint-leader process for each resource. The checkpoint-leader
is responsible for saving and restoring the state of the underlying resource.
Checkpoint-leader election — consensus across processes
The processes sharing the underlying resource may elect a checkpoint-leader
using several mechanisms. The basic idea is to have consensus across par-
ticipating processes. Ansel et al. [7] used the fcntl system call to set own-
ership of the file descriptors. Each process tries to set itself as the owner of
the given file descriptor. The centralized coordinator process was used to
create a global barrier to signal the end of election after each process had a
chance to make the system call. The last process to perform the system call
is considered the checkpoint-leader. An example is shown in Listing 4.5.
checkpoint_file(int fd) {
// Participate in checkpoint-leader election;
// publish ourself as the owner of the resource
fcntl(fd, F_SETOWN);
// Now wait for the election to be over
wait_for_global_barrier(LEADER_ELECTION);
// If we are the owner, we are ckpt-leader
if (fcntl(fd, F_GETOWN) == getpid()) {
// capture the state of the file descriptor
capture_state(fd);
}
} �Listing 4.5: An example of leader election using the fcntl system call.

4.4. EXTENDING TO MULTIPLE PROCESSES 59
While this approach works for shared file descriptors, it doesn’t work for
other resources, such as files. There can be multiple unique file descriptors
that are opened on the same file. In this case, each unique file descriptor
gets a checkpoint leader. This results in checkpointing of multiple copies
of the file. The publish/subscribe service can be used to provide a better
solution. Each process publishes itself as the checkpoint-leader using the
unique resource-id of the resource. The last process to publish is elected the
checkpoint-leader. Since files can have multiple unique file descriptors (and
hence multiple unique resource-ids) associated with them, we can publish
using the absolute file path or the inode number for leader election.
Global barriers
As mentioned above, a global barrier allows plugins in different processes to
synchronize during checkpoint and restart. A simple implementation of the
global barrier requires a centralized coordinator that keeps the count of all
processes that have reached the barrier. Once all processes reach the barrier,
it lifts the barrier and allows them to proceed as shown in Listing 4.6.
void wait_for_global_barrier(BarrierId id) {
MessageType msg, rmsg;
msg.type = GLOBAL_BARRIER;
msg.barrierId = id;
// Tell the coordinator that we have reached the barrier
send_msg_to_coordinator(msg);
// Wait until all other peers reach the barrier
recv_msg_from_coordinator(&rmsg);
assert(rmsg.type = GLOBAL_BARRIER_LIFTED);
// barrier has been lifted
} �Listing 4.6: Global barrier.

60 CHAPTER 4. THE DESIGN OF PLUGINS
Global barriers are costly as each process has to communicate with the
centralized coordinator process. If each plugin implements several global
barriers, the performance impact can be significant in terms of checkpoint
and restart times. The total number of global barriers can be reduced signif-
icantly by using process level anonymous global barriers that can be imple-
mented in the coordinator interface plugin as show in Listing 4.7.
void implement_global_barriers() {
// Create an anonymous global barrier
wait_for_global_barrier(BARRIER_ANON_1);
// generate event notification indicating
// lifting of anonymous barrier 1
generate_event(ANON_GLOBAL_BARRIER_1);
wait_for_global_barrier(BARRIER_ANON_2);
generate_event(ANON_GLOBAL_BARRIER_2);
wait_for_global_barrier(BARRIER_ANON_3);
generate_event(ANON_GLOBAL_BARRIER_3);
...
} �Listing 4.7: Global barrier.
Consider the example of leader election. On receiving the event notifica-
tion for ANON_GLOBAL_BARRIER_1 event, each plugin will participate in
leader election for its resources by publishing itself as the checkpoint leader.
On receiving the event notification for ANON_GLOBAL_BARRIER_2, each
plugin can check to see if it is the checkpoint-leader by subscribing to the
checkpoint leader information for the unique resource id.

4.4. EXTENDING TO MULTIPLE PROCESSES 61
File Plugin
Socket Plugin
Memory Plugin(s)
Fork/Exec Plugin
Pid Plugin
Coord Interface Plugin
Thread Plugin
Res
um
e/R
esta
rt
Wri
teC
hec
kp
oin
t
Figure 4.5: Plugin dependency for distributed processes
4.4.3 Restoring Shared Resources
Note that memory regions are restored before plugins can restore the state of
their corresponding resources. In case of shared resources, the checkpoint-
leader recreates the underlying resources and then shares them with other
processes using publish/subscribe service. The checkpoint leader publishes
while the remaining processes subscribe to the resource-id.
Remark: Resources involving file-descriptors can be shared by passing them
over the Unix Domain Sockets.
Note that sharing of resources forces a certain dependency among plu-
gins that is summarized in Figure 4.5. The required dependency can be
observed by noting the required actions of a plugin at the time of restart.
The pid-plugin is responsible for virtualizing the pids which is required for
fork/exec plugin to restore the process-trees. Once the process-trees have
been created, the file, socket, System V shared memory, etc. plugins may
recreate/restore the resources and share them with other processes.

62 CHAPTER 4. THE DESIGN OF PLUGINS
4.5 Three Base Plugins
In this section we discuss three special-purpose plugins: the coordinator
interface plugin, the thread plugin, and the memory plugins.
4.5.1 Coordinator Interface Plugin
A centralized coordinator process is used to synchronize checkpoint-restart
between multiple processes on the same or different hosts. A coordinator
interface plugin communicates with the coordinator process and generates
events related to checkpointing when requested by the coordinator. It cre-
ates a checkpoint-manager thread, which listens to the coordinator process
for a checkpoint message while the user threads are executing application
code. On receiving a coordinator message, the checkpoint-manager thread
generates the checkpoint, resume, or restart event which are then delivered
to all other plugins.
The coordinator interface plugin and the coordinator process can best be
thought of as a single programming unit. It is this programming unit that
implements global barriers at the time of checkpoint or restart.
The special case of a single standalone target process can be supported by
a minimal coordinator interface plugin, which directly generates the three
basic event notifications: checkpoint, resume, and restart. In this case, one
does not need any external coordinator process.
At the other extreme, a coordinator interface plugin can be written to
support a set of redundant coordinators. This alternative eliminates the
possibility of a single point of failure.
4.5.2 Thread Plugin
The thread plugin is responsible for saving and restoring the state of all user
threads during checkpointing. The plugin engine invokes the checkpoint-
manager thread through the write-ckpt event hook. The checkpoint manager

4.5. THREE BASE PLUGINS 63
then sends a POSIX signal to all user threads. This forces the user threads
into a checkpoint-specific signal handler (which was defined earlier within
the thread plugin). The handler causes each user thread to save its context
(register values, etc.) into the process memory and to then wait on a lock.
When the checkpoint completes, the thread plugin releases all user threads
from their locks, and user execution resumes.
On restarting, the memory plugin restores user-space memory from a
checkpoint image, and control is then passed to a restart event hook of the
thread plugin. Only the primary thread of the restarted process exists at this
time. That thread recreates the other threads, restores their context, and re-
leases the user threads from the locks that were entered prior to checkpoint.
(The state of a lock depends only on user-space memory.)
4.5.3 Memory Plugins
Compression
Encryption
Write to network socket
Zero−page detection
Prepare list of memory areas
Runtime Libraries, Plugin Engine
Other Plugin Libraries
Var
ious
Mem
ory
Plu
gin
s
Figure 4.6: Various memory plugins stacked together
Memory plugins are responsible for writing the contents of a process’s
memory into the checkpoint image. The checkpoint image is read during

64 CHAPTER 4. THE DESIGN OF PLUGINS
restart process to recreate the process memory. Memory plugins are the last
in the plugin loading sequence as every other plugin necessarily depends on
the memory resource. Figure 4.6 shows an example of sequence of memory
plugins that perform zero-page optimizations followed by compression and
encryption before writing the checkpoint data to a network socket. A pro-
cess on the other end of the socket may then save the data onto persistent
storage.
At restart time, a special application, dmtcp_restart, is needed to boot-
strap the restart procedure to load the restoration code corresponding to
all the memory plugins involved. Control is then passed to memory plug-
ins which then perform restoration of rest of process memory. After restor-
ing memory, the rest of the plugins recreate/restore their corresponding re-
sources. User threads are then recreated and the process resumes executing
application code.
Here we list some characteristics of the memory plugins:
1. Since writing the checkpoint image is the last step in checkpoint pro-
cess, the memory plugins must appear last in the plugin sequence.
2. If it is possible for memory plugins to alter the memory maps of the
current process, the first memory plugin must create a list of memory
areas to be written to the checkpoint image. The memory plugins can
then map new memory area for checkpoint purposes only and these
areas will not be checkpointed.
3. The memory plugins pass information to the next memory plugin using
a pipe mechanism i.e. each plugin may process the incoming data and
send the processed (and potentially modified) data to the next plugin.
Data piping can be implemented by creating hooks for writing and
reading memory.

4.6. IMPLEMENTATION CHALLENGES 65
4. The plugins agree on some notion of end-of-data to finish writing the
checkpoint image.
5. Last memory plugin disposes the data onto persistent storage (file) or
writes to a pipe/socket. There can be a different process on the other
end of the pipe/socket which then saves it to a persistent device, or
it restarts the process on the fly. The last memory plugin here means
the final or lowest memory plugin (e.g., the “write to network socket”
plugin in Figure 4.6).
6. Last memory plugin is responsible for reading from the checkpoint im-
age.
7. During restart, memory plugins are responsible for restoring other run-
time libraries, thus these plugin libraries must be self contained.
Remark: Note that the state managed by the memory plugins will not be
compressed or encrypted in our running example of memory plugins. This
is necessary to solve the problem of bootstrapping on restart. If the boot-
strapping code were also encrypted, it would be impossible to bootstrap.
4.6 Implementation Challenges
In this section we describe some of the implementation challenges that we
faced in implementing the plugin based virtualization in DMTCP version 2.
4.6.1 Wrapper Functions
We discuss three different implementation techniques that were tried in suc-
cession, before settling on a fourth choice: a hybrid of the second and third
options:
1. dlopen/dlsym: This is a naive approach, well-known in the literature. It
allows the plugin to define a system call of the same name, whose body

66 CHAPTER 4. THE DESIGN OF PLUGINS
uses dlopen/dlsym to open the run-time library (e.g. libc, libpthread,
etc.), and then call the system call in the run-time library. However,
this fails when creating a wrapper for the GNU implementation of
calloc. The GNU implementations of dlopen and dlsym would call
calloc, thus creating a circular dependency. Wrapping occurrence of
dlopen/dlsym from a user’s application creates a similar circular de-
pendency. However, a still more severe criticism is that if the wrapper
function directly calls the run-time library, then nested wrappers be-
come impossible. In our implementation, multiple plugins frequently
wish to wrap the same system call.
2. offsets within a run-time library: This was implemented in order to
avoid the use of dlopen/dlsym. A base address is chosen within
the run-time library. (It may be the start address of the library or an
unusual system call unlikely to be needed by wrappers.) For all sys-
tem calls to be wrapped, the offset from that system call to the base
address is calculated before launching the end-user application. The
end-user application is then launched and the base address is recalcu-
lated. Next, the base address is used along with offsets to determine
the addresses of the functions in the run-time library. At this point, the
functions in the run-time library can be called using the corresponding
addresses. This solves the issues caused by circular dependencies (e.g.
dlopen, dlsym, calloc). However, nested wrappers still cannot
be implemented.
3. dlsym/RTLD_NEXT: The POSIX option RTLD_NEXT for dlsym is de-
signed in part to implement wrapper functions. This option causes
dlsym to search the sequence of currently open libraries for the next
matching symbol beyond the current library. This fixes the problem of
implementing nested wrappers, but it does not solve the problem of
circular dependencies.

4.6. IMPLEMENTATION CHALLENGES 67
The ultimate solution requires an additional observation: The run-time
library sometimes internally calls a system call (as with dlopen/dlsym
calling calloc). It is a mistake for the plugin to execute the wrapper function
around this internal call. Yet, when dlsym internally calls calloc, the ELF
loader will call the first definition of calloc that it finds. The first library to
be loaded was libdmtcp.so, as part of the design of DMTCP. So, the calloc
wrapper in libdmtcp.so is called.
A standard wrapper for callocwithin libdmtcp.so would then call dlsym
to determine the address of calloc within libc.so. But this would create the
circularity. Instead, the wrapper detects that this is a circular call originating
from the run-time library (libc.so). Upon detecting this, the calloc wrap-
per reverts to second method above (offsets within a run-time library) in
order to directly call the implementation of calloc within libc. Thus the
circularity is broken.
4.6.2 New Process/Program Creation
When a process forks to create a new child process, the thread that calls
fork() is the only thread in the new process. This poses certain challenges
for plugins especially when dealing with locks. If at the time of fork(), some
other thread is holding a lock, the threads in the new process may deadlock
on this lock. The solution is to install atfork() handles in all plugins that
use locks or similar artifacts and whenever a child process is created, it re-
initialized the locks before doing anything. An alternate is to use the AtFork
event generated by the fork/exec plugin. Glibc and firefox are two real
world examples which install atfork handles to re-initialize the locks for their
respective malloc-arenas.
New programs created by calling execve() have a different set of prob-
lems. Since the new program gets completely new address space, all infor-
mation that was gathered by the plugin prior to exec is lost. Plugins that

68 CHAPTER 4. THE DESIGN OF PLUGINS
need to preserve information across exec need a lifeboat where they can
put the information for later use. A typical example of lifeboat would be a
temporary file created on disk. The plugins serialize the previously captured
information to the lifeboat. Since the plugins are independent of each other,
there can be multiple lifeboats per process.
Remark: As an optimization, it is possible to provide a single lifeboat that
can be used by all the plugins.
4.6.3 Checkpoint Deadlock on a Runtime Library
Resource
Atomic wrapper operations are also desired when dealing with resources
that use locks for atomicity. Suppose a user thread is quiesced while holding
the resource lock. Later on, if the resource is needed to complete check-
point, it can cause a deadlock within the process. For example, in one of
the most frequent scenario, a user thread is quiesced while performing mal-
loc/free inside glibc. The checkpoint thread is blocked when it calls any
of these functions during the checkpoint process. There are two possible
solutions: (i) modify checkpointing logic to never call these functions, and
(ii) create wrappers around these function which call disable_checkpoint,
enable_checkpoint around the call to the real library functions as shown in
Listing 4.8
malloc(size) {
disable_checkpoint()
ret_val = real_malloc(size)
enable_checkpoint()
return ret_val
} �Listing 4.8: Malloc wrapper to avoid deadlock during checkpointing

4.6. IMPLEMENTATION CHALLENGES 69
4.6.4 Blocking Library Functions and Checkpoint
Starvation
There are certain wrappers around blocking library functions that need to
virtualize the underlying system resource. As discussed in Section 4.1.1,
the call to library function and translation between real and virtual names
should be atomic with respect to checkpointing. However, if a function call
is blocking, the checkpoint may never succeed. Examples of such function
are waitpid and pthread_join, etc.
pid_t waitpid(pid, <args>) {
while (true) {
disable_checkpoint()
real_pid = virtual_to_real(pid)
// WNOHANG flag tells waitpid to return
// immediately if the operation would block.
ret_val = real_waitpid(real_pid, WNOHANG | <args>)
virt_pid = real_to_virtual(ret_val)
enable_checkpoint()
if (ret_val != -1) // Success
return virt_pid
// If error other than timeout, the function failed.
if (errno != ETIMEDOUT)
break
// Yield CPU to avoid spinning
yield()
}
return -1;
} �Listing 4.9: Wrapper for waitpid with non-blocking calls to the real waitpid
function

70 CHAPTER 4. THE DESIGN OF PLUGINS
In these situations, one can modify the wrapper as seen in Listing 4.9 to
call the non-blocking version of the function in a loop until it succeeds or
returns an error other than timeout. The timed version waits for the given
time period before returning instead of blocking indefinitely.
In some situations, the blocking call may not provide a non-blocking
version. In those cases a potential solution is to use signalling mechanism
to force the call to return with an error. At this point, the checkpoint can
take place. However, the wrapper must be re-executed from the beginning
to avoid any stale state.

CHAPTER 5
Expressivity of Plugins
This chapter presents a large variety of examples of adaptive plugins, to
demonstrate the expressivity of the plugin framework. They fall into sev-
eral categories, each of which represents a unique type of contribution, in
generalizing the traditional functionality of checkpoint-restart.
Some of the plugins represent long-standing challenges. Not only do
these plugins provide additional functionality for checkpoint-restart, but
they do so with far fewer lines of code than the previously available less func-
tional approaches.These include transparent checkpointing of: InfiniBand
networks by Cao et al. [27]; hardware accelerated 3-D graphics (OpenGL
2.0 and beyond) by Kazemi Nafchi et al. [62]; a network of virtual machines
by Garg et al. [44]; and GDB sessions by Visan et al. [127]. Each of these
efforts was led by a different author. Thus they represent trials of the new
plugin feature by independent users. The full details of each plugin can be
found in the publications and technical reports of those authors.
While I believe any of these could have been done by adding support
in any of the existing checkpointing package, the amount of effort (both
in terms of person-hours and lines of code) would have been enormous.
Instead, by using the adaptive plugins to implement a process virtualization
approach, the job was made much easier. In all cases, the plugin writers
71

72 CHAPTER 5. EXPRESSIVITY OF PLUGINS
didn’t need to learn the details of DMTCP internals, allowing them to focus
only on the plugin.
Plugin Lines Novelty Prior Art Lines
of code of code
SSH session 1,021 The only solution — —
GDB session 938 The only solution — —
Batch-Queue 1,715 The only solution — —
KVM/Tun 1,100 Full snapshots of net-work of VMs
Single VMsnapshots
??
OpenGL 4,500 Supports programmableGPUs (OpenGL 2.0 andbeyond)
VMGL [69] 78,000
InfiniBand 2,500 Native InfiniBand check-point for both MPI andnon-MPI jobs
MPI-specific [55]
17,000
IB2TCP 1,000 InfiniBand to TCP mi-gration for both MPI andnon-MPI jobs
MPI-specific [55]
??
Table 5.1: Process virtualization based checkpoint-restart is both more generaland typically an order of magnitude less in implementation size
The expressivity is measured along two dimensions (see Table 5.1). The
first dimension is a measurement of lines of code for the plugins. Since
each example was a “first” for that functionality, we compare with lines of
code for a pevious published implementation with lesser functionality where
possible.
In the second dimension, we compare functionality with that application
identified as having the most previous functionality in the corresponding
domain. Thus a two-fold argument is presented. The process virtualization
approach permits implementations with much larger functionality than had
previously been practical with moderate resources. Second, the process vir-
tualization approach results in an implementation with many fewer lines of
code than would have been practical by other approaches. (Of course, the

5.1. FILE DESCRIPTOR RELATED PLUGINS 73
fewer lines of code in the plugin is made possible by using the base support
for plugins in DMTCP version 2.)
Note that some of the plugins discussed in this chapter were not created
as part of this thesis. Instead, they were created by different authors using
the plugin API. Further details of each plugin can be found in the publica-
tions and technical reports of those authors.
Statistics for various plugins
Table 5.2 provides several statistics including the source lines of code, the
number of library call wrappers and various services used by the plugins.
The lines of code were obtained by using SLOCCount [132].
Section 5.1 provides a brief overview of the plugins related to file descrip-
tor handling. Section 5.2 provides an overview of the working of the plugin
handling System V IPC mechanism. A few application-specific plugins are
discussed in Section 5.3. The remaining sections provide various case stud-
ies where new functionality was implemented, whereas previously in other
checkpoint-restart packages, the added functionality was implemented only
through independent, auxiliary applications.
5.1 File Descriptor Related Plugins
Since file descriptors may be used for file objects, socket connections, or
event notifications, the corresponding plugins share some code for handling
generic file descriptors. This results in a cleaner design and smaller code
footprint. The shared code provides services for generating unique file de-
scriptor ids, detecting/managing duplicate file descriptors, leader election,
and re-sharing of file descriptors on restart.
Note that DMTCP version 1 provided support for checkpointing TCP and
Unix domain sockets for checkpointing distributed applications. It also pro-
vided limited support for handling files and pseudo-terminals. For this work,

74 CHAPTER 5. EXPRESSIVITY OF PLUGINS
Plugin Language Lines of Code Wrappers Services usedInternal Plugins
File C/C++ 2,276∗ 48 a,b,c,d,eSocket C/C++ 1,356∗ 17 a,b,c,dEvent C/C++ 909∗ 12 a,b,c,d,ePid C/C++ 1,644 47 c,d,eSysVIPC C/C++ 1,154 14 a,b,c,d,eTimer C/C++ 419 14 a,c,d,eSSH C/C++ 1,021 3 a,b,c,d,e
Contrib PluginsBatch-Queue C/C++ 1,715 13 e†
Ptrace C/C++ 938 7 a,b,cRecord-replay C/C++ 8,071 164 a,b,c,eKVM C 749 2 a,b,c,eTun C 351 3 a,b,c,eOpenGL C/C++ 4,500 119 a,b,c,e,fInfiniBand C 2,788 34 a,b,c,d,eIB2TCP C/C++ 804 31 c,d,e
Application-Specific PluginsMalloc C/C++ 116 10 fDlopen C/C++ 28 3 fModify-env C 134 0 c,eCkptFile C/C++ 37 0 a,cUniq-Ckpt C/C++ 39 0 a,c
∗: Uses additional 899 lines of shared common code.†: Uses specialized utilities to detect restart.
Plugins Services:(a) Write checkpoint hook(b) Resume hook(c) Restart hook(d) Publish/Subscribe(e) Virtualization(f) Protect critical sections of code
Table 5.2: Statistics for various plugins.

5.1. FILE DESCRIPTOR RELATED PLUGINS 75
the plugins were created by rewriting the existing solution from DMTCP ver-
sion 1. This greatly enhanced the available features and provided an easier
way for the user to fine tune checkpointing. This section provides a brief
overview of the three plugins.
File plugin
The File plugin is responsible for handling file descriptors pointing to regular
files and directories. For implementation purposes, it also handles pseudo-
terminals (ptys) and FIFO (first in first out) objects, since they have similar
semantics as file objects. Apart from restore the relevant file descriptors,
the File plugin also needs to translate the file paths if the computation is
restarted on a system with different mount points or by a different user.
There are several ways to provide file path translation. A simple mecha-
nism involves recording the relative file paths on checkpoint and using the
relative path information on restart to find the file. Another approach may
involve wild card substitution, where a certain component of the file path is
transparently replaced with a different one. For example, if a mount point
has changed from /mnt/foo to /bar, the plugin would replace /mnt/foo/baz
with /bar/baz.
The file plugin also deploys some heuristics to determine if it also needs
to save and restore the associated file data. In some cases, the file data must
always be checkpointed. Examples include unlinked files (Linux allows a file
to be unlinked while a process still has a valid file descriptor) and temporary
files created by programs like vim and emacs.
For a simpler design, the heuristics part of the File plugin is now im-
plemented as a separate plugin (Ckpt-File). This way the user can tweak
this relatively simple newer plugin according to their wishes. Similarly, the
file path translation mechanism can also be moved into its own plugin. As
obvious, the original File plugin will depend on these two plugins for their
services.

76 CHAPTER 5. EXPRESSIVITY OF PLUGINS
Socket plugin
The Socket plugin is responsible for checkpointing and restoring the TCP/IP
sockets, Unix domain sockets, and netlink sockets. Potentially, this plugin
can also be split into three different plugins, but for implementation pur-
poses it is kept as a single unit. Further, since the Unix domain sockets may
be backed by a file on the disk, it also depends on the File plugin for file path
translation. The Socket plugin assigns a unique id to each end of a socket
connection. In our implementation, the unique id comprises of the unique-
id of the process that originally created the socket file descriptor and a per-
process monotonously incrementing counter. At the time of checkpoint, the
processes on each end of a socket connection perform a handshake to ex-
change the unique socket id. On restart, this unique socket id is used to find
the current location of the peer process using the publish-subscribe service.
Event plugin
The Event plugin is responsible for checkpointing and restoring the file de-
scriptors used for event notifications. Apart from supporting the older poll
system call (used for monitoring file descriptors), this plugin provides sup-
port for epoll (similar to poll), eventfd (used for event wait/notify mech-
anism from user space), signalfd (used for accepting signals targeted at
the caller), and inotify (used for monitoring file system events) system
calls. Inotify is the most difficult to checkpoint and restart. The desired be-
havior on restart is not well-defined and may be application dependent. For
example, inotify can be used to get notification if a file has been renamed.
Suppose that the file is renamed after checkpoint. On restart, the file will be
present with a new name and thus won’t be renamed. In this case, it is not
clear if an event notification should be generated or not. The plugin can be
modified to allow the user to specify the default behavior for use with the
application.

5.2. PID, SYSTEM V IPC, AND TIMER PLUGINS 77
5.2 Pid, System V IPC, and Timer Plugins
We have already discussed the Pid plugin as an example of virtualizing the
kernel resource identifiers in Section 3.1.1.
The System V IPC (SysVIPC) plugin support checkpointing of System V
shared memory, semaphores, and message queues. The operating system
kernel generates an identifier for each System V IPC object. The identifier
may change on restart and thus we need to virtualize it. The SysVIPC plugin
virtualizes these identifiers in a similar manner to the Pid plugin. A virtual
id is generated for each System V IPC object and a translation is kept for
translating between virtual and real ids. In addition to virtualizing the re-
source ids, the SysVIPC plugin also needs to checkpoint the associated state
of the System V IPC object. For example, the memory contents of the shared
memory region need to be checkpointed, the semaphore value needs to be
restored, and the message queue needs to be drained on checkpoint and re-
filled on restart. Since these objects are potentially shared between multiple
processes, the plugin performs leader election using the publish-subscribe
mechanism.
Lastly, we discussed the virtualization of clock and timer ids in Sec-
tion 3.1.5. As described there, in addition to virtualizing the resource ids,
application-specific fine tuning is required to control the behavior of timers
on restart.
5.3 Application-Specific Plugins
The CkptFile plugin is used to provide heuristics for saving the contents of
open files during checkpoint. The plugin can be used to read wildcard pat-
terns from a configuration file for dynamically updating the heuristics. The
File plugin consults the CkptFile plugin for each open file. The CkptFile
plugin may respond whether to checkpoint the data of the given file or not.

78 CHAPTER 5. EXPRESSIVITY OF PLUGINS
The Environ plugin provides heuristics for restoring/updating the process
environment variables after a restart. This is useful for processes that use
environment variables to find addresses, etc. of system services, daemons,
etc. The Environ plugin reads patterns from a configuration file to selectively
update the restarting process’s environment.
The Uniq-Ckpt plugin is responsible for keeping a rolling set of checkpoint
images as configured by the user. It can automatically delete or rename the
older checkpoint images to save disk space.
The Malloc plugin puts wrappers around malloc, free, etc. to avoid dead-
lock inside malloc library as explained in Section 4.6.3. The plugin can be
further used to switch to a different malloc implementation for debugging.
The Dlopen plugin provides wrappers for dlopen, dlsym, and dlclose li-
brary calls. The dlopen wrapper is used to ensure atomicity with respect to
checkpointing so that the process doesn’t get checkpointed while the library
is still being initialized. The dlsym wrapper is used to create wrappers for
function that are present in the library being loaded. The dlsym wrapper can
return the address of the wrapper function (defined in the plugin) instead
of the library function. The wrapper function then may call the real function
in the newly loaded library.
5.4 SSH Connection
The issues involved with checkpointing an SSH session as discussed in Sec-
tion 3.1.2 are reviewed followed by a description of the solution based on
our virtualization scheme. Previous support for distributed checkpointing
covered the common uses of ssh where it is used to launch remote jobs
but not used for active communication. In some HPC environments (e.g.,
Open MPI), this is the default behavior. Remote processes are launched over
SSH, and later establish a simple TCP socket for efficient communication.
This work provides support for active communications over SSH.

5.4. SSH CONNECTION 79
Recall that SSH allows two processes to securely communicate over an
insecure network. A user process uses an SSH client process to connect to a
remote SSH server (daemon) process. On creating a secure connection, the
SSH server process (sshd) launches the child process (app2), as shown in
Figure 3.2. The process app1 appears to read and write locally through a
pipe to app2.
The SSH daemon is a privileged process running a certain protocol. In
the process virtualization approach, the plugin must virtualize that protocol.
Further, checkpointing and restarting the privileged SSH daemon by an un-
privileged user is not possible, since the user cannot recreate the privileged
ssh daemon (sshd) on restart.
Launching remote process under checkpoint control
Recall that a process on Node1 launches a remote process on Node2 by
running the SSH client program as ssh Node2 app2. The earlier DMTCP
used a strategy of detecting an codeexec that calls ssh Node2 app2 and
replacing it by ssh Node2 dmtcp_launch app2. Ad hoc code was used
that allowed ssh to create a remote process under checkpoint control, but
it was assumed that the application would then close the SSH connection.
The solution for supporting long-lived SSH connections is shown in Fig-
ure 3.3. In essence, following a process virtualization approach, the SSH
plugin defines a wrapper function around the exec family of system calls.
It then replaces a call by exec to ssh Node2 app2 with a call to:
ssh Node2 dmtcp_launch virt_sshd app2
For technical reasons, the plugin actually creates two auxiliary processes,
virt_ssh and virt_sshd. (The code for these processes is part of the
SSH plugin, which arranges for them to run as separate processes.) These
processes also allow us to recreate the SSH connection on restart — even
in the less common situations where the app1 process has exited, leaving a
child of app1 to continue to employ the SSH connection from Node1.

80 CHAPTER 5. EXPRESSIVITY OF PLUGINS
Checkpoint
At the time of checkpoint, only processes app1, app2, virt_ssh, and
virt_sshd are checkpointed. The ssh and sshd process are not under
checkpoint control and are not checkpointed. Further, the virt_ssh and
virt_sshd can directly “drain” any in-flight network data that has not yet
reached its destination at the time of checkpoint. Thus, they act as buffers
to hold network data prior to resume or restart. During resume, the drained
data is written directly to the corresponding pipes between the user pro-
cesses and the dmtcp helper processes.
app1 app2st
dio
Node1 Node2
SSH server
socket
virt_ssh virt_sshd
(sshd)(ssh)
SSH client
std
io sshd helper
stdio
stdio
std
io
Figure 5.1: Restoring an SSH connection. The virt_ssh process launchedsshd_helper on Node2 that relays stdio between ssh and virt_sshd.
Restart
Figure 5.1 illustrates how the four checkpointed processes are restored dur-
ing restart. The four processes on Node1 and Node2 are restarted via:
ssh Node1 dmtcp_restart <virt_ssh.ckpt> <app1.ckpt>ssh Node2 dmtcp_restart <virt_sshd.ckpt> <app2.ckpt>

5.5. BATCH-QUEUE PLUGIN FOR RESOURCE MANAGERS 81
Note that in the general case, Node1 and Node2 may both have been remote
nodes. Next, an SSH connection must be created between the two processes,
virt_ssh and virt_sshd. To accomplish this, the virt_ssh will use
publish/subscribe to discover the address of the virt_sshd process. Next,
virt_ssh will fork a child process, which “execs” into the following pro-
gram:
ssh Node2 sshd_helper <virt_sshd address>
Finally, the sshd_helper process will relay the data of its stdio pipes
from the SSH server process through stdio pipes to the virt_sshd pro-
cess. The sshd_helper process exits when the virt_sshd process exits.
The sshd_helper process is never part of any subsequent checkpoint.
5.5 Batch-Queue Plugin for Resource Managers
One of the long-standing functionality requirements for batch-queue man-
agers at various HPC centers is the ability to suspend a low priority job
to allow execution of a high priority job as soon as it arrives. While there
have been MPI-specific solutions to support this use-case (see Section 2.1.2),
they have not been integrated into the batch-queue systems for the lack of
complete functionality. The batch-queue plugin by Polyakov [93] solves this
problem by providing a native checkpoint-restart facility that can be embed-
ded in the batch-queue itself.
The goal of the batch-queue plugin is to recreate the original parallel
computation in a transparent manner. This mechanism is invisible both to
any resource manager and to the MPI libraries themselves. During restart,
the batch-queue plugin must adapt to a new execution environment created
by the resource manager at that time. The plugin must detect the newly
available nodes during restart, and arrange for launching the restarted user
processes onto appropriate nodes. Issues specific to a resource manager may

82 CHAPTER 5. EXPRESSIVITY OF PLUGINS
arise during this process, such as the creation by the resource manager of a
new read-only nodefile that is inconsistent with the pre-checkpoint version
(see below).
Recall that modern resource management (RM) systems allocate resources
for jobs, which are then launched in background in a non-interactive mode.
Although the RM systems don’t intervene much in a program’s execution
(except for PMI, see an example blow), they do modify part of its execution
environment. For example, some of them redirect a program’s standard in-
put, output and error to special files, and later move those files to the user’s
working directory once the program is finished or killed. They also provide
services for remote launch of programs such as tm_spawn for TORQUE PBS,
lsb_launch() for Load Sharing Facility (LSF), and even standalone commands
such as srun for SLURM.
The batch-queue plugin can handle the new execution environment dur-
ing restart. It detects the available nodes, and launches the restarting pro-
cesses onto the nodes as required. The new program may not have per-
missions to overwrite some environment files (e.g., nodefile) and may need
to update these file descriptors to point to the copy of files saved during
checkpoint.
We next discuss some of the virtualization strategies provided by the
batch-queue plugin.
Support for batch system remote launch mechanism
To fully support parallel programs in modern RM systems, the remote child
processes should be automatically placed under checkpoint control. For all
supported batch systems this plugin uses the same technique to provide this
service: it patches the command line passed to the remote launch mecha-
nism by adding a prefix, dmtcp_launch < options >. For example, in the case
of TORQUE PBS, a wrapper for tm_spawn updates the passed arguments to
insert the dmtcp_launch command.

5.5. BATCH-QUEUE PLUGIN FOR RESOURCE MANAGERS 83
Communication between Batch Systems and the Application
A common issue for any resource manager is the binding of stdin/out/err
to files. Those files must be saved in the checkpoint image, for the sake of
consistency and transparency. At restart time, the plugin must discover the
bindings of stdin/out/err to the new files created by the resource manager.
Any saved content from prior to checkpoint must be written into those files.
Batch systems usually communicate with applications using special en-
vironment variables. Some batch systems use auxiliary files in addition to
the environment variables. For example, TORQUE saves a list of its allocated
nodes into a read-only nodefile, which can be cached by the application. But
at restart time, a new read-only nodefile will be generated, different from
the one cached by the application. To address this situation, the batch-queue
plugin creates a temporary file containing the original nodefile contents and
modifies the file descriptor of the restarted application to point to this alter-
nate nodefile.
Communication between MPI Application and External PMI Interface
Most modern MPI implementations use or support the Process Management
Interface (PMI) [14]. The PMI model comprises three entities: the MPI li-
brary, PMI library and the process manager. Currently there are several im-
plementations of process manager entities, including the standalone Hydra
package, and the PMI server of the SLURM resource manager.
While the multi-host capable Socket plugin transparently supports the
Hydra implementation, additional plugin support is needed to integrate the
SLURM PMI implementation. SLURM requires an MPI process to commu-
nicate with the SLURM job step daemon, which is not under checkpoint
control. In this case, an batch-queue plugin finalizes PMI session before
checkpointing and recreates it afterward.

84 CHAPTER 5. EXPRESSIVITY OF PLUGINS
Specialized peer-discovery and remote launch service
The processes may be restarted on different nodes. The number of slots
(number of processes per node) may be different for the new nodes. The
batch-queue plugin employs a node discovery tool to find the new nodes
and to map old resources to the newly allocated node set. For TORQUE
RM, the plugin analyzes the new nodefile and for SLURM it parses the
SLURM_JOB_NODELIST and SLURM_TASKS_PER_NODE environment vari-
ables. After this step resource allocation is available in RM-independent for-
mat. Next, the old resources are mapped onto new ones. Once the resources
have been mapped, the application is launched using the appropriate RM
system mechanism. The mapping algorithm should consider the slots when
matching resources between the old and new sets. It should be noted that
the processes that were launched on the head node of a cluster usually have
a special environment (special stdin/out/err connections and access to the
nodefile) and may need special treatment.
5.6 Ptrace Plugin
The ptrace system call is used by a superior process (e.g., gdb, strace,
etc.) to attach to an inferior process (e.g., a.out) in order to trace it. The
ptrace system call uses CPU hardware support, making it harder to check-
point. The inferior process can’t perform a checkpoint until it is detached or
allowed to run freely during the checkpoint phase. A ptrace plugin is used
to solve these problems [127]. The ptrace plugin in the superior process de-
taches the inferior process before checkpointing and re-attaches right after
restart.
The ptrace plugin in the inferior process has an added responsibility. It
is often the case that the inferior threads are quiesced while they are in
possession of a system resource, or while executing a critical section in the
code. This can result in a deadlock. To fix this, the ptrace plugin forces the

5.7. DETERMINISTIC RECORD-REPLAY 85
user threads to release resources before entering a quiescent state. This is
done by using Pre/Post-Quiesce event notifications. Pre-Quiesce is generated
by the user thread just before entering the quiesce state. While processing
this hook, each thread ensures that it is not holding any system resources,
locks, etc. that can result in a deadlock. The Post-Quiesce phase forces the
inferior thread to wait until the superior can attach to it after restart.
5.7 Deterministic Record-Replay
The record-replay plugin is needed by any reversible debugger that uses
checkpoint, restart and re-execute. FReD (Fast Reversible Debugger) [112]
can add reversibility to any debugger by using checkpoint, restart and re-
execute strategy. FReD uses DMTCP for checkpointing. Deterministic record-
replay for FReD was achieved by creating a record-replay plugin to be used
with DMTCP. This plugin is generally placed before any other plugin in the
plugin hierarchy, to allow it to “hijack” library calls. Due to its complex-
ity, the record-replay plugin is the largest plugin in terms of lines of code
(see Table 5.2).
There are several potential sources of nondeterminism in program ex-
ecution, and record-replay must address all of them: thread interleaving,
external events (I/O, etc.), and memory allocation. While correct replay of
external events is required for all kind of programs, memory accuracy is of-
ten not an issue for higher-level languages like Python and Perl, which do
not expose the underlying heap to the user’s program.
FReD handles all these aspects by wrapping various system calls. Rele-
vant events are captured by interposing on library calls using dlopen/dlsym
for creating function wrappers for interesting library functions. The wrap-
pers record events into the log on the first execution and then return the
appropriate values (or block threads as required) on replay.
We start recording when directed by FReD (often after the first check-

86 CHAPTER 5. EXPRESSIVITY OF PLUGINS
point). The system records the events related to thread-interleaving, exter-
nal events, and memory allocation into a log. On replay, it ensures that the
events are replayed in the same order as they were recorded. The plugin
guarantees deterministic replay — even when executing on multiple cores
— so long as the program is free of data races.
Thread interleaving
FReD uses wrappers around library calls such as
pthread_mutex_lock and pthread_mutex_unlock, to enforce the cor-
rect thread interleaving during replay. Apart from the usual pthread_xxx
functions, some other functions that can enforce a certain interleaving are
blocking functions like read. For example, a thread can signal another
thread by writing into the write-end of a pipe when the other thread is do-
ing a blocking read on the read-end of the pipe.
Replay of external events
Applications typically interact with the outside world as part of their execu-
tion. They also interact with the debugger and the user, as part of the debug-
ging process. Composite debugging requires separating these streams. For
debuggers that trace a program in a separate process, the I/O by the process
being debugged is recorded and replayed whereas the I/O by the debugger
process is ignored.
For interpreted languages, the situation becomes trickier as the record-
replay plugin cannot differentiate between the debugger I/O and the appli-
cation I/O. FReD handles this situation heuristically. It designates the stan-
dard input/output/error file descriptors as pass-through devices. Activity on
the pass-through devices is ignored by the record-replay component.

5.8. CHECKPOINTING NETWORKS OF VIRTUAL MACHINES 87
Memory accuracy
One important feature of FReD is memory-accuracy: the addresses of ob-
jects on the heap do not change between original execution and replay. This
is important because it means that developers can use address literals in
expression watchpoints (assuming they are supported by the underlying de-
bugger).
With true replay of application program, one would expect the memory
layout to match the record phase, but the DMTCP libraries have to perform
different actions during normal run and on restart. This results in some
memory allocation/deallocations originating from DMTCP libraries that can
alter the memory layout. Another cause for the change in memory layout
is the memory allocated by the operating system kernel when the process
doesn’t specify a fixed address. An example is the mmap system call without
any address hint. In this case, the kernel is free to choose any address for
the memory region.
Memory-accuracy is accomplished by logging the arguments, as well as
the return values of mmap, munmap, etc. on record. On replay, the real
functions or system calls are re-executed in the exact same order. However,
the record-replay plugin provides a hint to the kernel to obtain the same
memory address as was received at record-time. FReD handles any conflicts
caused by memory allocation/deallocation originating from DMTCP itself by
forcing use of a separate allocation arena for DMTCP requests.
5.8 Checkpointing Networks of Virtual
Machines
Garg et al. [43] used DMTCP and plugins to provide a generic checkpoint-
restart mechanism for three cases of virtual machines: user-space (stan-
dalone) QEMU [121], KVM/QEMU [114], and Lguest [115]. In all three

88 CHAPTER 5. EXPRESSIVITY OF PLUGINS
cases, the hypervisor (VMM — virtual machine monitor) was based on Linux
as the host operating system. These examples covers three distinct virtual-
ization scenarios: entirely user-space virtualization (QEMU), full virtualiza-
tion using a Linux kernel driver (KVM/QEMU), and paravirtualization using
a Linux kernel driver [115].
The user-space QEMU virtual machine did not require any specific plugin.
The KVM/QEMU and Lguest virtual machines required a new plugin consist-
ing of approximately 200 lines of code. In addition, the kernel driver from
Lguest required an additional 40 lines of new code to support checkpoint-
restart capability. The authors estimated the implementation time at approx-
imately five to ten person days. This is in contrast with the number of lines
of code required for libvirt.
Garg et al. [44] further implemented the first system to checkpoint a
network of virtual machines by virtualizing the tun/tap interface using a
plugin. The tun plugin consisted of approximately 350 lines of code.
5.9 3-D Graphic: Support for Programmable
GPUs in OpenGL 2.0 and Higher
Kazemi Nafchi et al. [62] describe a mechanism for transparently check-
pointing hardware-accelerated 3D graphics. The approach is based on DMTCP
with a plugin to record-prune-replay of OpenGL library calls. The calls not
relevant to the last graphics frame prior to checkpointing is discarded. The
remaining OpenGL calls are replayed on restart. The plugin uses approxi-
mately 4,500 lines of code.
Previously, Lagar-Cavillaet al. [69] presented VMGL for vector-independent
checkpoint restart. VMGL used a shadow device driver for OpenGL, which
shadows most OpenGL calls to model OpenGL state, and restores it when
restarting form a checkpoint. The code to maintain OpenGL state was ap-

5.10. TRANSPARENT CHECKPOINTING OF INFINIBAND 89
proximately 78,000 lines of code.
Further, the new plugin has added functionality. Lagar-Cavillaet al. sup-
ported only OpenGL 1.5 (fixed pipeline functionality). The approach of the
new plugin was demonstrated to apply to programmable GPUs (OpenGL 2.0
and beyond).
5.10 Transparent Checkpointing of InfiniBand
The InfiniBand plugin by Cao et al. [27] is the first to support checkpoint-
restart of native InfiniBand network. Previous checkpoint-restart systems [55]
were MPI-specific. This plugin provides support for checkpointing UPC, an
example of a PGAS language, which runs more efficiently when it runs na-
tively over the InfiniBand fabric (instead of on top of an MPI layer). For
applications such as these, there is no alternate solution.
Compared to approximately 3,000 lines of code for the InfiniBand plugin,
the checkpoint-restart functionality in Open MPI uses approximately 17,000
lines of code (without counting the InfiniBand-specific code). This is in ad-
dition to the single process checkpointer, BLCR, that is used by OpenMPI.
5.11 IB2TCP: Migrating from InfiniBand to TCP
Sockets
Some traditional checkpoint-restart services, such as that for Open MPI [55],
offer the ability to checkpoint over one network, and restart on a second net-
work. This is especially useful for interactive debugging. A set of checkpoint
images from an InfiniBand-based production cluster can be copied to an
Ethernet/TCP-based debug cluster. Thus if a bug is encountered after run-
ning for hours on the production cluster, the most recent checkpoints can
be used to restart on the debug cluster under a symbolic debugger, such as
GDB.

90 CHAPTER 5. EXPRESSIVITY OF PLUGINS
The IB2TCP plugin enables checkpointing over InfiniBand and restart-
ing over Ethernet in the similar fashion. An important contribution of the
IB2TCP plugin [27], is that unlike the BLCR kernel-based approach, the
DMTCP/IB2TCP approach supports using an Ethernet-based cluster that uses
a different Linux kernel, something that occurs frequently in practice. Fur-
ther, the IB2TCP plugin can be used with the InfiniBand plugin or without
InfiniBand plugin (but with limited support for checkpointing).

CHAPTER 6
Tesseract: Reconciling Guest I/O
and Hypervisor Swapping in a VM
The previous chapters were concerned with adaptive plugins, a virtualiza-
tion mechanism that decoupled the application process from the execution
environment to facilitate transparent checkpoint-restart. In this chapter, I
will present a virtualization mechanism that decouples the guest virtual disk
from the guest operating system to prevent redundant I/O operations be-
tween the guest and the hypervisor.
Guests running in virtual machines read and write state between their
memory and virtualized disks. Hypervisors such as VMware ESXi [57] like-
wise may page guest memory to and from a hypervisor-level swap file to
reclaim memory. To distinguish these two cases, we refer to the activity
within the guest OS as paging and that within the hypervisor as swapping.
In overcommitted situations, these two sets of operations can result in a
two-level scheduling anomaly known as “double paging”. Double-paging
occurs when the guest attempts to page out memory that has previously
been swapped out by the hypervisor and leads to long delays for the guest
as the contents are read back into machine memory only to be written out
again (see Sections 6.1 and 6.2). While the double-paging anomaly is well
known [46, 48, 47, 128, 82], its impact on real workloads is not established.
91

92 CHAPTER 6. TESSERACT: RECONCILING GUEST I/O AND HYPERVISOR SWAPPING
Our approach addresses the double-paging problem directly in a man-
ner transparent to the guest(see Section 6.3). First, the virtual machine is
extended to track associations between guest memory and either blocks in
guest virtual disks or in the hypervisor swap file. Second, the virtual disks
are extended to support a mechanism to redirect virtual block requests to
blocks in other virtual disks or the hypervisor swap file. Third, the hyper-
visor swap file is extended to track references to its blocks. Using these
components to restructure guest I/O requests, we eliminate the main effects
of double-paging by replacing the original guest operations with indirections
between the guest and swap stores. An important benefit of this approach
is that where hypervisors typically attempt to avoid swapping pages likely
to be paged out by the guest, the two levels may now cooperate in selecting
pages since the work is complementary.
We have prototyped our approach on the VMware Workstation [56] plat-
form enhanced to explicitly swap memory in and out. While the current
implementation focuses on deduplicating guest I/Os for contents stored in
the hypervisor swap file, it is general enough to also deduplicate redundant
contents between guest I/Os themselves or between the hypervisor swap file
and guest disks (see Section 6.4).
In Section 6.5, we also show the impact of an unexpected side-effect of
our solution: loss of locality caused by indirections to the hypervisor swap
file which can substantially slow down subsequent guest I/Os. Finally, we
describe techniques to detect this loss of locality and to recover it. These
techniques isolate the expensive costs of the double-paging effect and mak-
ing them asynchronous with respect to the guest.
In Section 6.6, we present results using a synthetic benchmark that show,
for the first time, the cost of the double-paging problem. Finally, in Sec-
tion 6.7, we discuss related work.

6.1. REDUNDANT I/O 93
Host
DevicePaging
Guest
DiskVirtual
Guest Physical Memory
PPN
(2) (1)
(a) Host swap out followed by guestdisk read
Host
DevicePaging
Guest
DiskVirtual
Guest Physical Memory
(2)
(1)
PPN vCPU
(b) Host swap out followed by guestoverwriting the entire page
Host
DevicePaging
Guest
DiskVirtual
Guest Physical Memory
PPN
(1) (2)
notdirty
(c) Host swap out of an unmodifiedguest page
Host
DevicePaging
Guest
DiskVirtual
Guest Physical Memory
PPN
(2) (1)
(d) Host swap out followed by guestdisk write (Double-Paging)
Figure 6.1: Some cases of redundant I/O in a virtual machine.
6.1 Redundant I/O
Figure 6.1 shows some examples of redundant I/O resulting from bad in-
teraction between hypervisor swapping and guest I/O. In Figure 6.1a, the
hypervisor swap out is followed by guest overwriting the entire page by
doing a disk read. From the hypervisor’s point of view, the guest has ac-
cessed the page, and so it unnecessarily swaps in the guest page. Similarly,
in Figure 6.1b, the host swap out is followed by the guest zeroing out the
entire page. Here again, the hypervisor swap in is wasteful. In Figure 6.1c,
the guest reads a page from the disk into its physical memory. The page
is “clean” i.e. the contents have not been modified by the guest. However,
when under memory pressure, the hypervisor tries to swap out this page
as well. Ideally, the hypervisor could have discarded the page contents and

94 CHAPTER 6. TESSERACT: RECONCILING GUEST I/O AND HYPERVISOR SWAPPING
later restore them from guest disk if needed. Finally, in Figure 6.1d, the
guest tries to page out a page that is already swapped out by the host. This
is the case of double-paging.
The first two cases, (Figures 6.1a and 6.1b) have already been addressed
in some commercial products such as the VMware ESX hypervisor. Further,
concurrent work of Amit et al. [5] implements solutions for the first three
cases (using mmap structures as the remapping mechanism or boundary in
Linux) but ignore the fourth. Tesseract has a system that addresses solutions
for the first two cases (Figures 6.1a and 6.1b) along with a solution to the
double-paging case(Figure 6.1d). In addition, it can serve as a basis for a
third case (Figure 6.1c) and a fifth case – guest write followed by another
guest write.
6.2 Motivation: The Double-Paging Anomaly
Tesseract has four objectives. First, to extend VMware’s hosted platforms,
WorkStation and Fusion, to explicitly manage how the hypervisor pages out
memory so that its swap subsystem can employ many of the optimizations
used by the ESX platform. Second, to prototype the mechanisms needed
to identify redundant I/Os originating from the guest and virtual machine
monitor (VMM) and eliminate these. Third, to use this prototype to justify
restructuring the underlying virtual disks of VMs to support this optimiza-
tion. Finally, to simplify the hypervisor’s memory scheduler so that it need
not avoid paging out memory that guest may decide to page. To address
these, the project initially focused on the double-paging anomaly.
One of the tasks of the hypervisor is to allocate and map host (or ma-
chine) memory to the VMs it is managing. Likewise, one of the tasks of
the guest operating system in a VM is to manage the guest physical address
space, allocating and mapping it to the processes running in the guest. In
both cases, either the set of machine memory pages or the set of guest phys-

6.2. MOTIVATION: THE DOUBLE-PAGING ANOMALY 95
ical pages may be oversubscribed.
In overcommitted situations, the appropriate memory scheduler must
repurpose some memory pages. For example, the hypervisor may reclaim
memory from a VM by swapping out guest pages to the hypervisor-level
swap file. Having preserved the contents of those pages, the underlying ma-
chine memory may be used for a new purpose. The guest OS may reclaim
memory within a VM too to allow a guest physical page to be used by a new
virtual mapping.
As hypervisor-level memory reclamation is transparent to the guest OS,
the latter may choose to page out to a virtualized disk pages that were
already swapped by the hypervisor. In such cases, hypervisor must syn-
chronously allocate machine pages to hold the contents and read the already
swapped contents back into that memory so they can be saved, in turn, to
the guest OS’s swap device. This multi-level scheduling conflict is called
double-paging.
Figure 6.2 illustrates the double-paging problem. Suppose the hypervisor
decides to reclaim a machine page (MPN) that is backing a guest physical
page (PPN). In step 1, the mapping between the PPN and MPN is invalidated
and, in step 2, the contents of MPN is saved to the hypervisor’s swap file.
Suppose the guest OS later decides to reallocate PPN for a new guest virtual
mapping. It, in turn, in step 3a invalidates the guest-level mappings to that
PPN and initiates an I/O to preserve its contents in a guest virtual disk (or
guest VMDK). In handling the guest I/O request, the hypervisor must ensure
that the contents to be written are available in memory. So, in step 4, the
hypervisor faults the contents into a newly allocated page (MPN2) and, in
step 5, establishes a mapping from PPN to MPN2. This sequence puts extra
pressure on the hypervisor memory system and may further cause additional
hypervisor-level swapping as a result of allocating MPN2. In step 6, the guest
OS completes the I/O by writing the contents of MPN2 to the guest VMDK.
Finally, the guest OS is able to zero the contents of the new MPN so that the

96 CHAPTER 6. TESSERACT: RECONCILING GUEST I/O AND HYPERVISOR SWAPPING
Host
Paging
Device
Guest
Disk
hypervisor view
guest view
Guest
MemoryHost
LP1
(3a)(3b)
(6)
(5)
(1)
(4)
(2)
Phys Mem.PPN
MPN MPN2
(1), (2) : Swap out(3a,3b) : Guest block write request
(4) : Memory allocation and swap in(5) : Establish PPN to MPN mapping(6) : Write block to guest disk(7) : Zero the new MPN for reuse
Figure 6.2: An example of double-paging.
PPN that now maps to it can be used for a new virtual mapping in step 7.
A hypervisor has no control over when a virtualized guest may page
memory out to disk, and may even employ reclamation techniques like bal-
looning [128] in addition to hypervisor-level swapping. Ballooning is a tech-
nique that co-opts the guest into choosing pages to release back to the plat-
form. It employs a guest driver or agent to allocate, and often pin, pages
in the guest’s physical address-space. Ballooning is not a reliable solution in
overcommitted situations since it requires guest execution to choose pages
and release memory and the guest is unaware of which pages are backed
by MPNs. Hypervisors that do not also page risk running out of memory.
While preferring ballooning, VMware uses hypervisor swapping to guaran-
tee progress. Because levels of overcommitment vary over time, hypervisor
swapping may interleave with the guest, under pressure from ballooning,

6.3. DESIGN 97
also paging. This can lead to double paging.
The double-paging problem also impacts hypervisor design. Citing the
potential effects of double-paging, some [82] have advocated avoiding the
use of hypervisor-level swapping completely. Others have attempted to mit-
igate the likelihood through techniques such as employing random page
selection for hypervisor-level swapping [128] or employing some form of
paging-aware paravirtualized interface [48, 47]. For example, VMware’s
scheduler uses heuristics to find “warm” pages to avoid paging out what
the guest may also choose to page out. These heuristics have extended ef-
fects, for example, on the ability to provide large (2MB) mappings to the
guest. Our goals are to address the double-paging problem in a manner
that is transparent to the guest running in the VM and identifies and elides
the unnecessary intermediate steps such as steps 4, 5 and 6 in Figure 6.2
and to simplify hypervisor scheduling policies. Although we do not demon-
strate that double-paging is a problem in real workloads, we do show how
its effects can be mitigated.
6.3 Design
We now describe our prototype’s design. First, we describe how we extended
the hosted platform to behave more like VMware’s server platform, ESX.
Next, we outline how we identify and eliminate redundant I/Os. Finally, we
describe the design of the hypervisor swap subsystem and the extensions to
the virtual disks to support indirections.
6.3.1 Extending The Hosted Platform To Be Like ESX
VMware supports two kinds of hypervisors: the hosted platform in which
the hypervisor cooperatively runs on top of an unmodified host operating
system such as Windows or Linux, and ESX where the hypervisor runs as
the platform kernel, the vmkernel. Two key differences between these two

98 CHAPTER 6. TESSERACT: RECONCILING GUEST I/O AND HYPERVISOR SWAPPING
platforms are how memory is allocated and mapped to a VM, and where the
network and storage stacks execute.
In the existing hosted platform, each VM’s device support is managed in
the vmx, a user-level process running on the host operating system. Privi-
leged services are mediated by the vmmon device driver loaded into the host
kernel, and control is passed between the vmx and the VMM and its guest
via vmmon. An advantage of the hosted approach is that the virtualization
of I/O devices is handled by libraries in the vmx and these benefit from the
device support of the underlying host OS. Guest memory is mmapped into
the address space of the vmx. Memory pages exposed to the VMM and guest
by using the vmmon device driver to pin the pages in the host kernel and
return the MPNs to the VMM. By backing the mmapped region for guest
memory with a file, hypervisor swapping is a simple matter of invalidating
all mappings for the pages to be released in the VMM, marking, if necessary,
those pages as dirty in the vmx’s address space, and unpinning the pages on
the host.
In ESX, network and storage virtual devices are managed in the vmker-
nel. Likewise, the hypervisor manages per-VM pools of memory for backing
guest memory. To page memory out to the VM’s swap file, the VMM and
vmkernel simply invalidate any guest mappings and schedule the pages’ con-
tents to be written out. Because ESX explicitly manages the swap state for
a VM including its swap file, it is able to employ a number of optimizations
unavailable on the current hosted platform. These optimizations include the
capturing of writes to entire pages of memory [4], and the cancellation of
swap-ins for swapped-out guest PPNs that are targets for disk read requests.
The first optimization is triggered when the guest accesses an unmapped
or write-protected page and faults into the VMM. At this point, the guest’s
instruction stream is analyzed. If the page is shared [128] and the effect
of the write does not change the content of the page, page-sharing is not
broken. Instead, the guest’s program counter is advanced past the write and

6.3. DESIGN 99
it is allowed to continue execution. If the guest’s write is overwriting an
entire page, one or both of two actions are taken. If the written pattern is
a known value, such as repeated 0x00, the guest may be mapped a shared
page. This technique is used, for example, on Windows guests because Win-
dows zeroes physical pages as they are placed on the freelist. Linux, which
zeroes on allocation of a physical page, is simply mapped a writeable zeroed
MPN. Separately, any pending swap-in for that PPN is cancelled. Since the
most common case is the mapping of a shared zeroed-page to the guest, this
optimization is referred to as the PShareZero optimization.
The second optimization is triggered by interposition on guest disk read
requests. If a read request will overwrite whole PPNs, any pending swap-ins
associated with those PPNs are deferred during write-preparation, the pages
are pinned for the I/O, and the swap-ins are cancelled on successful I/O
completion.
We have extended Tesseract so that its guest-memory and swap mecha-
nisms behave more like those of ESX. Instead of mmapping a pagefile to pro-
vide memory for the guest, Tesseract’s vmx process mmaps an anonymously-
backed region of its address space, uses madvise to mark the range as NOT-
NEEDED, and explicitly pins pages as they are accessed by either the vmx or
by the VMM. Paging by the hypervisor becomes an explicit operation, read-
ing from or writing to an explicit swap file. In this way, we are able to also
employ the above optimizations on the hosted platform. We consider these
as part of our baseline implementation.
6.3.2 Reconciling Redundant I/Os
Tesseract addresses the double-paging problem transparently to the guest al-
lowing our solution to be applied to unmodified guests. To achieve this goal,
we employ two forms of interposition. The first tracks writes to PPNs by the
guest and is extended to include a mechanism to track valid relationships

100 CHAPTER 6. TESSERACT: RECONCILING GUEST I/O AND HYPERVISOR SWAPPING
between guest memory pages and disk blocks that contain the same state.
The second exploits the fact that the hypervisor interposes on guest I/O re-
quests in order to transform the requests’ scatter-gather lists. In addition,
we modify the structure of the guest VMDKs and the hypervisor swap file,
extending the former to support indirections from the VMDKs into the hy-
pervisor swap disk. Finally, when the guest reallocates the PPN and zeroes
its contents, we apply the PShareZero optimization in step 7 in Figure 6.2.
In order to track which pages have writable mappings in the guest, MPNs
are initially mapped into the guest read-only. When written by the guest, the
resulting page-fault allows the hypervisor to track that the guest page has
been modified. We extend this same tracking mechanism to also track when
guest writes invalidate associations between guest pages in memory and
blocks on disk. The task is simpler when the hypervisor, itself, modifies guest
memory since it can remove any associations for the modified guest pages.
Likewise, virtual device operations into guest pages can create associations
between the source blocks and pages. In addition, the device operations may
remove prior associations when the underlying disk blocks are written. This
approach, employed for example to speed the live migration of VMs from
one host to another [87], can efficiently track which guest pages in memory
have corresponding valid copies of their contents on disks.
The second form of interposition occurs in the handling of virtualized
guest I/O operations. The basic I/O path can be broken down into three
stages. The basic data structure describing an I/O request is the scatter-
gather list, a structure that maps one or more possibly discontiguous mem-
ory extents to a contiguous range of disk sectors. In the preparation stage,
the guest’s scatter-gather list is examined and a new request is constructed
that will be sent to the underlying physical device. It is here that the unmod-
ified hypervisor handles the faulting in of swapped out pages as shown in
steps 4 and 5 of Figure 6.2. Once the new request has been constructed, it is
issued asynchronously and some time later there is an I/O completion event.

6.3. DESIGN 101
To support the elimination of I/Os to and from virtual disks and the hy-
pervisor block-swap store (or BSST), each guest VMDK has been extended
to maintain a mapping structure allowing its virtual block identifiers to refer
to blocks in other VMDKs. Likewise, the hypervisor BSST has been extended
with per-block reference counts to track whether blocks in the swap file are
accessible from other VMDKs or from guest memory.
The tracking of associations and interposition on guest I/Os allows four
kinds of I/O elisions:
swap - guest-I/O a guest I/O follows the hypervisor swapping out a page’s
contents (Figures 6.1a and 6.1d)
swap - swap a page is repeatedly swapped out to the BSST with no inter-
vening modification
guest-I/O - swap the case in which the hypervisor can take advantage of
prior guest reads or writes to avoid writing redundant contents to the
BSST (Figure 6.1c)
guest-I/O - guest-I/O the case in which guest I/Os can avoid redundant
operations based on prior guest operations where the results known
reside in memory (for reads) or in a guest VMDK (for writes)
For simplicity, Tesseract focuses on the first two cases since these capture the
case of double-paging. Because Tesseract does not introspect on the guest,
it cannot distinguish guest I/Os related to memory paging from other kinds
of guest I/O. But the technique is general enough to support a wider set
of optimizations such as disk deduplication for content streamed through a
guest. It also complements techniques that eliminate redundant read I/Os
across VMs [82].

102 CHAPTER 6. TESSERACT: RECONCILING GUEST I/O AND HYPERVISOR SWAPPING
Guest
Disk
BSST
Blo
ck I
ndir
ecti
on L
ayer
LP1
Guest Physical Memory
Host Memory
PPN
MPN
hypervisor view
guest view
Figure 6.3: Double-paging with Tesseract.
6.3.3 Tesseract’s Virtual Disk and Swap Subsystems
Figure 6.3 shows our approach embodied in Tesseract. The hypervisor swaps
guest memory to a block-swap store (BSST) VMDK, which manages a map
from guest PPNs to blocks in the BSST, a per-block reference-counting mech-
anism to track indirections from guest virtual disks, and a pool of 4KB disk
blocks. When the guest OS writes out a memory page that happens to be
swapped out by the hypervisor, the disk subsystem detects this condition
while preparing to issue the write request. Rather than bringing memory
contents for the swapped out page back to memory, the hypervisor updates
the appropriate reference counts in the BSST, issues the I/O, and updates
metadata in guest VMDK and adds a reference to the corresponding disk
block in BSST.
Figure 6.4 shows timelines for the scenario when guest OS is paging out
an already swapped page with and without Tesseract. With Tesseract we are
able to eliminate the overheads of a new page allocation and a disk read.
To achieve this, Tesseract modifies the I/O preparation and I/O comple-
tion steps. For write requests, the memory pages in the scatter-gather list are

6.3. DESIGN 103
VMM SwapOut Allocate Memory
Synchronous SwapIn Guest
Write I/OZeroWrite
UpdatePTE...
(a) Baseline (without Tesseract)
VMM SwapOutGuestWrite
WriteMetadata
PShareZero
UpdatePTE...
(b) With Tesseract
Figure 6.4: Write I/O and hypervisor swapping.
checked for valid associations to blocks in the BSST. If these are found, the
target VMDK’s mapping structure is updated for those pages’ corresponding
virtual disk blocks to reference the appropriate blocks in the BSST and the
reference counts of these referenced blocks in the BSST are incremented. For
read requests, the guest I/O request may be split into multiple I/O requests
depending on where the source disk blocks reside.
Consider the state of a guest VMDK and the BSST as shown in Fig-
ure 6.5a. Here, a guest write operation wrote five disk blocks in which
two were previously swapped to the BSST. In this example, block 2 still con-
tains the swapped contents of some PPN and has a reference count reflecting
this fact and the guest write. Hence, its state has “swapped” as true and a
reference count of 2. Similarly, block 4 only has a nonzero reference count
because the PPN whose swapped contents originally created the disk block
has since been accessed and its contents paged back in. Hence, its state has
“swapped” as false and a reference count of 1. To read these blocks from
the guest VMDK now requires three read operations: one against the guest
VMDK and two against the BSST. The results of these read operations must
then be coalesced in the read completion path.
One can view the primary cost of double-paging in an unmodified hy-
pervisor as impacting the write-preparation time for guest I/Os. Likewise,
one can view the primary cost of these cases in Tesseract as impacting the
read-completion time. To mitigate these effects, we consider two forms of
defragmentation. Both strategies make two assumptions:

104 CHAPTER 6. TESSERACT: RECONCILING GUEST I/O AND HYPERVISOR SWAPPING
1
D
3
D
5
Guest VMDK
2
Block-Swap Store (BSST)
swapped: true
swapped: false
refcnt: 2
refcnt: 1
(a) With Tesseract
1
D
3
D
5
Guest VMDK
2
Block-Swap Store (BSST)
swapped: false
swapped: false
refcnt: 0
swapped: truerefcnt: 2
refcnt: 0
swapped: falserefcnt: 1
2
(b) With Tesseract and BSST defragmentation
1
2
3
4
5
Guest VMDK
S
Block-Swap Store (BSST)
swapped: true
swapped: false
refcnt: 1
refcnt: 0
(c) With Tesseract and guest VMDK defragmentation
Figure 6.5: Examples of reference count with Tesseract and with defragmenta-tion.
• the original guest write I/O request (represented in blue) captures the
guest’s notion of expected locality, and
• the guest is unlikely to immediately read the same disk blocks back
into memory

6.4. IMPLEMENTATION 105
Based on these assumptions, we extended Tesseract to asynchronously reor-
ganize the referenced state in the BSST. In Figure 6.5b, we copy the refer-
enced blocks into a contiguous sequence in the BSST and update the guest
VMDK indirections to refer to the new sequence. This approach reduces
the number of split read operations. In Figure 6.5c, we copy the references
blocks back to the locations in the original guest VMDK where the guest
expects them. With this approach, the typical read operation need not be
split. In effect, Tesseract asynchronously performs the expensive work that
occurred in steps 4, 5, and 6 of Figure 6.2 eliminating its cost to the guest.
6.4 Implementation
Our prototype extends VMware Workstation as described in Section 6.3.1.
Here, we provide more detail.
6.4.1 Explicit Management of Hypervisor Swapping
VMware Workstation relies on the host OS to handle much of the work as-
sociated with swapping guest memory. A pagefile is mapped into the vmx’s
address space and calls to the vmmon driver are used to lock MPNs backing
this memory as needed by the guest. When memory is released through hy-
pervisor swapping, the pages are dirtied, if necessary, in the vmx’s address
space and unlocked by vmmon. Should the host OS need to reclaim the
backing memory, it does so as if the vmx were any other process: it writes
out the state to the backing pagefiles and repurposes the MPN.
For Tesseract, we modified Workstation to support explicit swapping of
guest memory. First, we eliminated the pagefile and replaced it with a spe-
cial VMDK, the block swap store (BSST) into which swapped-out contents
are written. The BSST maintains a partial mapping from PPNs to disk blocks
tracking the contents of currently swapped-out PPNs. In addition, BSST

106 CHAPTER 6. TESSERACT: RECONCILING GUEST I/O AND HYPERVISOR SWAPPING
maintains a table of reference counts on the blocks in the BSST referenced
by other guest VDMKs.
Second, we split the process for selecting pages for swapping from the
process for actually writing out contents to the BSST and unlocking the back-
ing memory. This split is motivated by the fact that having eliminated dupli-
cate I/Os between hypervisor swapping and guest paging, the system should
benefit by both levels of scheduling choosing the same set of pages. The se-
lected swap candidates are placed in a victim cache to “cool down”. Only
the coldest pages are eventually written out to disk. This victim cache is
maintained as a percentage of locked memory by the guest—for our study,
10%. Should the guest access a page in the pool, it is removed from the pool
without being unlocked.
When the guest pages out memory, it does so to repurpose a given guest
physical page for a new linear mapping. Since this new use will access that
guest physical page, one may be concerned that this access will force the
page to be swapped in from the BSST first. However, because the guest will
either zero the contents of that page or read into it from disk and because the
VMM can detect that the whole page will be overwritten before it is visible
to the guest, the vmx is able to cancel the swap-in and complete the page
locking operation.
6.4.2 Tracking Memory Pages and Disk Blocks
There are two steps to maintaining a mapping between disk blocks and pages
in memory. The first is recognizing the pages read and written in guest and
hypervisor I/O operations. By examining scatter-gather lists of each I/O,
one can identify when the contents in memory and on disk match. While
we plan to maintain this mapping for all associations between guest disks
and guest memory, we currently only track the associations between blocks
in the BSST and main memory.

6.4. IMPLEMENTATION 107
The second step is to track when these associations are broken. For guest
memory, this event happens when the guest modifies a page of memory. The
VMM tracks when this happens by trapping the fact that a writable mapping
is required and this information is communicated to the vmx. For device
accesses, on the other hand, this event is tracked either through explicit
checks in the module which provides devices the access to guest memory, or
by examining page-lists for I/O operations that read contents into memory
pages.
6.4.3 I/O Paths
When the guest OS is running inside a virtual machine, guest I/O requests
are intercepted by the VMM, which is responsible for storage adaptor virtu-
alization, and then passed to the hypervisor, where further I/O virtualization
occurs.
Figure 6.6 identifies the primary modules in VMware Workstation’s I/O
stack. Guest operating system generates scatter-gather lists for I/O (1).
Tesseract inspects scatter-gather lists of incoming guest I/O requests in the
SCSI Disk Device layer, where a request to the guest VMDK may be updated
(2). Any extra I/O requests to the BSST may be issued (3) as shown in
Table 6.2. The Asynchronous I/O manager issues sends to I/O requests to
the host file system (4). On completion, the asynchronous I/O manager
generates completion events (5). Waiting for the completion of all the I/O
requests needed to service the original guest I/O request is isolated to the
SCSI Disk Device layer as well (6). When running with defragmentation
enabled (see Section 6.5), Tesseract allocates a pool of worker threads for
handling defragmentation requests.
Guest Write I/Os
Guest I/O requests have PPNs in scatter-gather lists. The vmx rewrites the
scatter-gather list, replacing guest PPNs with virtual pages from its address

108 CHAPTER 6. TESSERACT: RECONCILING GUEST I/O AND HYPERVISOR SWAPPING
Asynchronous I/O Manager
Host File Layer
VMX
Virtual Machine Monitor (VMM)
Guest Operating System
(1)
(3)
(4)
SCSI Disk Device
(5)
I/O completionI/O dispatch
Block Indirection Layer(2) (6)
Guest I/O requests(1) : S/G list received from guest(2) : Tesseract updates S/G list
: (write): swapped pages are removed: (read) : guest VMDK indirections are looked up
(3) : dispatch I/O request: (write): a single request with holes: (read) : one request to guest VMDK;
one or more requests to BSST(4) : asynchronous I/O scheduled
. . .I/O takes place asynchronously. . .
(5) : completion events generate for each dispatched I/O(6) : notify guest of completion:
: (write): create guest to BSST indirections: (read) : wait for all requests; merge results
Figure 6.6: VMware Workstation I/O Stack
space before passing it further to the physical device. Normally, for write
I/O requests, if a page was previously swapped, so that PPN does not have
a backing MPN, the hypervisor allocates a new MPN and brings page’s con-
tents from disk.
With Tesseract, we check if the PPNs are already swapped out to BSST
blocks by querying the PPN BSST-block mapping. We then use a virtual

6.4. IMPLEMENTATION 109
address of a special dummy page in the scatter-gather list for each page that
resides in the BSST. On completion of the I/O, metadata associated with the
guest VMDK is updated to reflect the fact that the contents of guest disk
blocks for BSST-resident pages are in the BSST. This sequence allows the
guest to page out memory without inducing double-paging.
1 2 3 4 5 6 7 8
(a) Scatter-gather prepared by the guest OS for disk write.
���������
���������
������
������
���������
���������
������
������
1 3 5 8
(b) Modified scatter-gather to avoid double-paging
��������
pages swapped out to BSSTpages in host memory dummy page
Figure 6.7: The pages swapped out to BSST are replaced with a dummy pageto avoid double-paging. Indirections are created for the corresponding guestdisk blocks.
Figure 6.7 illustrates how write I/O requests to the guest VMDK are han-
dled by Tesseract. Tesseract recognizes that contents for pages 2, 4, 6 and 7
in the scatter-gather list provided by the guest OS reside in the BSST (Fig-
ure 6.7a). When a new scatter-gather list to be passed to the physical device
is formed, a dummy page is used for each BSST resident (Figure 6.7b).
Guest Read I/Os and Guest Disk Fragmentation
Recognizing that data may reside in both the guest VMDK and the BSST is a
double-edged sword. On the guest write path it allows us to dismiss pages
that are already present in the BSST and thus avoid swapping them in just to
be written out to the guest VMDK. However, when it comes to guest reads,
the otherwise single I/O request might have to be split into multiple I/Os.
This happens when some of the data needed by the I/O is located in the
BSST.
Since data that has to be read from the BSST may not be contiguous on
disk, the number of extra I/O requests to the BSST may be as high as the
number of data pages in the original I/O request that reside in the BSST. We

110 CHAPTER 6. TESSERACT: RECONCILING GUEST I/O AND HYPERVISOR SWAPPING
refer to a collection of pages in the original I/O request for which a separate
I/O request to the BSST must be issued as a hole. Read I/O requests to the
guest VMDK which have holes are called fragmented.
We modify a fragmented request so that all pages that should be filled
in with the data from the BSST are replaced with a dummy page which will
serve as a placeholder and will get random data read from the guest VMDK.
So in the end for each fragmented read request we issue one modified I/O
request to the guest VMDK and N requests to the BSST, where N is the
number of holes. After all the issued I/Os are completed, we signal the
completion of the originally issued guest read I/O request.
������
������
���������
���������
���������
���������
���������
���������
����������������������������
����������������������������
�������������������������������������������������
�������������������������������������������������
���������������������
���������������������
�����������������������������������
�����������������������������������
����������������������������
����������������������������
������������������������������������������
������������������������������������������
�����������������������������������
�����������������������������������
����������������������������
����������������������������
1 3 5 8 2 4 6 7
1 2 3 4 5 6 7 8
��������
pages swapped out to BSSTpages in host memory dummy page
Figure 6.8: Original guest read request split into multiple reads requests dueto holes in the guest VMDK.
In Figure 6.8, the guest read I/O request finds disk blocks for pages 2, 4,
6 and 7 located on the BSST, where they are taking non-contiguous space.
Tesseract issues one read request to the guest VMDK to get data for pages 1,
3, 5 and 8. In the scatter-gather list sent to the physical device, a dummy
page is used as a read target for pages 2, 4, 6 and 7. Together with that one
read I/O request to the guest VMDK, four read I/O requests are issued to
the BSST. Each of those four requests reads data from one of the four disk
blocks in the BSST.
Optimization of Repeated Swaps
In addition to addressing the double-paging anomaly by tracking guest I/Os
whose contents exist in the BSST, we also implemented an optimization for
back-to-back swap-out requests for a memory page whose contents remain

6.4. IMPLEMENTATION 111
clean. If a page’s contents are written out to the BSST, and later swapped
back in, we continue to track the old block in the BSST as a form of victim
cache. If the same page is chosen to be swapped out again and there has
been no intervening modification of the contents of the page in memory, we
simply adjust the reference count (see Section 6.4.4) for the block copy that
is already in the BSST.
6.4.4 Managing Block Indirection Metadata
Tesseract keeps in-memory metadata for tracking PPN-to-BSST block map-
pings and for recording block indirections between guest and BSST VMDKs.
The PPN-to-BSST block mapping is stored as key-value pair using a hash
table. Indirection between guest and BSST VMDKs are tracked in a similar
manner.
Tesseract also keeps reference counts for the BSST blocks. When a new
PPN-to-BSST mapping is created, the reference count for the corresponding
BSST block is set to 1. The reference count is incremented in the write
prepare stage for PPNs found to have PPN-to-BSST block mappings. This
ensures that such BSST blocks are not repurposed while the guest write
is still in progress. Later, on the write completion path, the guest-VMDK-
to-BSST indirection is created. The reference count of the BSST blocks is
decremented during hypervisor swap in operation. It is also decremented
when the guest VMDK block is overwritten by new contents and the previous
guest block indirection is invalidated. Blocks with zero reference counts are
considered free and reclaimable.
Metadata Consistency
While updating metadata in memory is faster than updating it on the disk,
it poses consistency issues. What if the system crashes before the metadata
is synced back to persistent storage? To reduce the likelihood of such prob-
lems, Tesseract periodically synchronizes the metadata to disk on the same

112 CHAPTER 6. TESSERACT: RECONCILING GUEST I/O AND HYPERVISOR SWAPPING
schedule used by the VMDK management library for virtual disk state. How-
ever, because reference counts in the BSST and block-indirections in VMDKs
are written at different stages in an I/O request, crashes must be detected
and a fsck-like repair process run.
Entanglement of guest VMDKs and BSST
Once indirections are created between guest and BSST VMDK, it becomes
impossible to move just the guest VMDK. To disentangle the guest VMDK,
we must copy each block from the BSST to its guest VMDK for which there
is an indirection. This can be done both online and offline. More details
about the online process are in Section 6.5.2.
6.5 Guest Disk Fragmentation
As mentioned in Section 6.4.3, when running with Tesseract, guest read I/O
requests might be fragmented in the sense that some of the data the guest
is asking for in a single request may reside in both the BSST and the guest
VMDK.
The fragmentation level depends on the nature of the workload, the
guest OS, and swap activity at the guest and the hypervisor level. Our ex-
periments with SPECjbb2005 [103] showed that even for moderate level of
memory pressure as much as 48% of all read I/O requests had at least one
hole.
By solving double-paging problem Tesseract significantly reduced write-
prepare time of the guest I/O requests since synchronous swap-in requests
no longer cause delays. However, a non-trivial overhead was added to read-
completion. Indeed, instead of waiting for a single read I/O request to the
guest VMDK, the hypervisor may now have to wait for several extra read
I/O requests to the BSST to complete before reporting the completion to the
guest.

6.5. GUEST DISK FRAGMENTATION 113
To address these overheads, Tesseract was extended with a defragmen-
tation mechanism that improves read I/O access locality and thus reduces
read-completion time. We investigated two approaches to implementing
defragmentation - BSST defragmentation and guest VMDK defragmentation.
While defragmentation is intended to help reduce read-completion time, it
has its own cost. Defragmentation requests are asynchronous and reduce
time to complete affected guest I/Os, but, at the same time, they contribute
to a higher disk load and in the extreme cases may have an impact on read-
prepare times. The defragmentation activity can be throttled on detecting
performance bottlenecks due to higher disk load. ESX, for example, pro-
vides a mechanism, SIOC, that measures latencies to detect overload and
enforce proportional-share fairness [50]. The defragmentation mechanism
could participate in this protocol.
6.5.1 BSST Defragmentation
BSST defragmentation uses guest write I/O requests as a hint of which BSST
blocks might be accessed together in a single I/O read request in the future.
Given that information we then group together the identified blocks in the
BSST.
Figure 6.9 shows a scatter-gather list of the write I/O request that goes
to the guest VMDK. In that request, the contents of pages 2, 4, 6 and 7 is
already present in the BSST. As soon as these blocks are identified, a worker
thread picks up a reallocation job that will allocate a new set of contiguous
blocks in BSST and will copy the contents of BSST blocks for pages 2, 4,
6 and 7 into that new set of block. This copying allows those blocks to be
read later as a single I/O request issued by the guest and reflects its own
expectation of the locality of these blocks.
BSST defragmentation is not perfect. If multiple guest VMDK writes cre-
ate indirections to the same BSST blocks, multiple copies of those blocks

114 CHAPTER 6. TESSERACT: RECONCILING GUEST I/O AND HYPERVISOR SWAPPING
���������
���������
������
������
���������
���������
������
������
4
7 6
7642
2
1 3 5 8
BSST DiskGuest Disk
Figure 6.9: Defragmenting the BSST.
may be made in the BSST. Further, since blocks are still present in both the
guest VMDK and the BSST, extra I/O requests to the BSST cannot be en-
tirely eliminated. In addition, BSST defragmentation tries to predict read
access locality from write access locality and obviously the boundaries of
read requests will not match with the boundaries of the write requests. So
each read I/O request that without defragmentation would have required
reads from both the guest VMDK and the BSST will still be split into the one
which goes to the guest VMDK and one or more requests to the BSST. All
this contributes to longer read completion times as shown in Table 6.4.
However, it is relatively easy to implement BSST defragmentation with-
out worriying too much about data races with the I/O going to the guest
VMDK. It can significantly reduce the number of extra I/Os that have to be
issued to the BSST to service the guest I/O request as shown in Table 6.3.
If a guest read I/O request preserves the locality observed at the time
of guest writes, we need more than one read I/O request from the BSST
only when it hits more than one group of blocks created during BSST de-
fragmentation. Although this is entirely dependent on a workload, one can
expect read requests to typically be smaller than write requests, and, so, the
number of extra I/O requests to BSST being reduced to one (fits into one de-
fragmented area) or two (crosses the boundary of two defragmented areas)
in many cases.

6.5. GUEST DISK FRAGMENTATION 115
4
7 6
2
2 4 761 3 5 8
BSST DiskGuest Disk
Figure 6.10: Defragmenting the guest VMDK.
6.5.2 Guest VMDK Defragmentation
Like BSST defragmentation, guest VMDK defragmentation uses the scatter-
gather lists of write I/O requests to identify BSST blocks that must be copied.
But unlike BSST defragmentation, these blocks are copied to the guest VMDK.
The goal is to restore the guest VMDK to the state it would have had with-
out Tesseract. Tesseract with guest VMDK defragmentation replaces swap-in
operations with asynchronous copying from the BSST to the guest VMDK.
For example, in Figure 6.10, blocks 2, 4, 6 and 7 are copied to the relevant
locations on the guest VMDK by a worker thread.
We enqueue a defragmentation request as soon as the scatter-gather list
of the guest write I/O request is processed and blocks to be asynchronously
fetched to the guest VMDK are identified. The defragmentation requests are
organized as a priority queue. If a guest read I/O request needs to read
data from the block that has not been copied from the BSST, the priority of
the defragmentation request that refers to the block is raised to highest and
the guest read I/O request is blocked until copying of all the missing blocks
finishes.
While Tesseract with guest defragmentation can have an edge over Tesser-
act without defragmentation, it is not always a win. With guest defragmen-
tation, before a guest I/O read request has a chance to be issued to the
guest VMDK, it may become blocked waiting for a defragmentation request
to complete. This may end up being slower than issuing requests to the
BSST and the guest VMDK in parallel.

116 CHAPTER 6. TESSERACT: RECONCILING GUEST I/O AND HYPERVISOR SWAPPING
Disentanglement of Guest and BSST VMDKs.
Guest defragmentation has an added benefit of removing the entanglement
between guest and BSST VMDK. Once there are no block indirections be-
tween guest and BSST VMDK, the guest VMDK can be moved easily. This
also allows us to disable Tesseract’s double-paging optimization on-the-fly.
6.6 Evaluation
We ran our experiments on an AMD Opteron 6168 (Magny-Cours) with 12
1.9 GHz cores, 1.5 GB of memory and a 1 TB 7200rpm Seagate SATA drive, a
1 TB 7200rpm Western Digital SATA drive, and a 128 GB Samsung SSD drive.
We used OpenSUSE 11.4 as the host OS and a 6 VCPU 700 MB VM running
Ubuntu 11.04. We used Jenkins [113] to monitor and manage execution of
the test cases.
To ensure same test conditions for all test runs, we created a fresh copy
of the guest virtual disk from backup before each run. For the evaluation
we ran SPECjbb2005 [103] that was modified to emit instantaneous scores
every second. It was run with 6 warehouses for 120 seconds. The heap size
was set to 450 MB. The SPECjbb benchmark creates several warehouses and
processes transactions for each of them.
We induced hypervisor-level swapping by setting a maximum limit on
the pages the VM can lock. The BSST VMDK was preallocated. Swap-out
victim cache size was chosen to be 10% of the VM’s memory size.
All experiments except the one with SSD represent results from five trial
runs. The SSD experiment represents results from three trial runs.
6.6.1 Inducing Double-Paging Activity
To control hypervisor swapping, we set a hypervisor-imposed limit on the
machine memory available for the VM. Guest paging was induced by running

6.6. EVALUATION 117
the SPECjbb benchmark with a working set larger than the available guest
memory.
To induce double-paging, the guest must page out the pages that were
already swapped by the hypervisor. Since, the hypervisor would choose only
the cold pages from the guest memory, we employed a custom memhog that
would lock some pages in the guest memory for a predetermined amount
of time inside the guest. While the pages were locked by this memhog, a
different memhog would repeatedly touch the rest of available guest pages
making them “hot”. At this point the pages locked by the first memhog are
considered “cold” and swapped out by the hypervisor.
Next, memhog unlocks all its memory and the SPECjbb benchmark is
started inside the guest. Once the warehouses have been created by SPECjbb,
the memory pressure increases inside the guest. The guest is forced to find
and page out “cold pages”. The pages unlocked by memhog are good candi-
dates as they have not been touched in the recent past.
We used memhog and memory locking in our setup to make the exper-
iments more repeatable. In real world the conditions we were simulating
could have been observed, for example, when execution phase shift of an
application occurs, or when an application that caches a lot of data in mem-
ory and not actively uses is descheduled and another memory intensive ap-
plication is woken up by the guest.
As a baseline we ran with Tesseract disabled. This effectively disabled
analysis and rewriting of guest I/O commands so that all pages affected by
an I/O command that happened to be swapped out by the hypervisor had to
be swapped back in before the command could be issued to disk.
6.6.2 Application Performance
While it is hard to control and measure the direct impact of individual
double-paging events, we use the pauses or gaps observed in the logged

118 CHAPTER 6. TESSERACT: RECONCILING GUEST I/O AND HYPERVISOR SWAPPING
instantaneous scores of each SPECjbb run to characterize the application be-
havior. Depending upon the amount of double-paging activity, the pauses
can be as big as 60 seconds in a 120 second run and negatively affect the
final score. Often the pauses are associated with garbage collection activity.
0 5 10 15 20 25 30 35 40Total SPECjbb blockage time (seconds)
4500
5000
5500
6000
6500
7000
7500
SPECjbb sco
re
baseline
tesseract
(a) No memhog
0 5 10 15 20 25 30 35 40Total SPECjbb blockage time (seconds)
4500
5000
5500
6000
6500
7000
7500
SPECjbb sco
re
baseline
tesseract
(b) 30 MB memhog
0 5 10 15 20 25 30 35 40Total SPECjbb blockage time (seconds)
4500
5000
5500
6000
6500
7000
7500
SPECjbb sco
re
baseline
tesseract
(c) 60 MB memhog
0 5 10 15 20 25 30 35 40Total SPECjbb blockage time (seconds)
4500
5000
5500
6000
6500
7000
7500
SPECjbb sco
re
baseline
tesseract
(d) 90 MB memhog
0 5 10 15 20 25 30 35 40Total SPECjbb blockage time (seconds)
4500
5000
5500
6000
6500
7000
7500
SPECjbb sco
re
baseline
tesseract
(e) 120 MB memhog
0 5 10 15 20 25 30 35 40Total SPECjbb blockage time (seconds)
4500
5000
5500
6000
6500
7000
7500
SPECjbb sco
re
baseline
tesseract
(f) 150 MB memhog
Figure 6.11: Trends for scores and pauses in SPECjbb runs with varying guestmemory pressure and 10% host overcommitment.

6.6. EVALUATION 119
Varying Levels of Guest Memory Pressure
Figure 6.11 shows scores and pause times for different sizes of memhog in-
side the guest with 10% host overcommitment. When the guest is trying
to page out pages which are swapped by the hypervisor, the latter is swap-
ping them back in and is forced to swap out some other pages. This cascade
effect is responsible for increased pause period for the baseline. With Tesser-
act, however, the pause periods grow at a lower rate. This growth can be
explained by longer wait times due to increased disk activity. Although the
scores are about the same for higher guest memory pressure, the total pauses
for Tesseract are less than that for the baseline.
0 30 60 90 120 150 180 240
Memhog Sizes (MB)
0
5
10
15
20
25
30
Max p
ause
/blo
ckage tim
e (se
conds)
tesseract
baseline
Figure 6.12: Maximum single pauses observed in SPECjbb instantaneous scor-ing with varying guest memory pressure and 10% host memory overcommit-ment.
Figure 6.12 shows the effect of increased memory pressure on the length
of the biggest application pause. The bars represent the range of maximum
pauses for individual sets of runs. There are five runs in each set. Notice that
Tesseract clearly outperforms the baseline. The highest maximum pause
time with Tesseract is 7 seconds, compared to 30 seconds for the baseline.
This shows that the application is more responsive with Tesseract.

120 CHAPTER 6. TESSERACT: RECONCILING GUEST I/O AND HYPERVISOR SWAPPING
0 10 20 30 40 50 60Total SPECjbb blockage time (seconds)
1000
2000
3000
4000
5000
6000
7000
SPECjbb sco
re
baseline
tesseract
(a) 0% host overcommitment
0 10 20 30 40 50 60Total SPECjbb blockage time (seconds)
1000
2000
3000
4000
5000
6000
7000
SPECjbb sco
re
baseline
tesseract
(b) 5% host overcommitment
0 10 20 30 40 50 60Total SPECjbb blockage time (seconds)
1000
2000
3000
4000
5000
6000
7000
SPECjbb sco
re
baseline
tesseract
(c) 15% host overcommitment
0 20 40 60 80 100Total SPECjbb blockage time (seconds)
1000
2000
3000
4000
5000
6000
7000
SPECjb
b s
core
baseline
tesseract
(d) 20% host overcommitment
Figure 6.13: Scores and total pause times for SPECjbb runs with varying hostovercommitment and 60 MB memhog.
Varying Levels of Host Memory Pressure
To study the effect of increasing memory pressure by the hypervisor, we
ran the application with various levels of host overcommitment with 60 MB
memhog inside the guest.
Figure 6.13 shows the effect of increasing host memory pressure on the
application scores and total pause times. For lower host pressure (0% and
5%), the score and pause times for the baseline and Tesseract are about the
same. However, for higher memory pressure there is a significant difference
in the performance. For example, in the 20% case, the baseline observes
total pauses in the range of 80–110 seconds. Tesseract, on the other hand,
observes total pauses in a much lower range of 30–60 seconds.

6.6. EVALUATION 121
0 5 15 20
Host Memory Overcommitment (%)
0
10
20
30
40
50
60
70
80
Max p
ause
/blo
ckage tim
e (se
conds)
no-defrag
guest-defrag
bsst-defrag
baseline
Figure 6.14: Comparing maximum single pauses for SPECjbb under vari-ous defragmentation schemes with varying host memory overcommitment and60 MB memhog
Figure 6.14 focuses on the maximum pauses seen by the application as
host memory pressure grows. While the maximum pauses are insignificant
at lower memory pressure, with a higher pressure Tesseract clearly outper-
forms the baseline.
6.6.3 Double-Paging and Guest Write I/O Requests
Table 6.1 shows why double-paging is affecting guest write I/O performance.
As expected, if the host is not experiencing memory pressure, none of the
1,030 guest write I/O requests refer to pages swapped by the hypervisor.
As memory pressure builds up, more and more guest write I/O requests
require one or more pages to be swapped in before a write can be issued to
the physical disk. All of this contributes to a longer write-prepare time for
such a requests.
Consider a setup with 20% host memory is overcommitment. Of 1,366
guest write I/O requests 981 had at least one page that had to be swapped
in. Then, 524 guest write I/O requests needed between 1 and 20 swap-
in requests completed by the hypervisor in order to proceed, 177 needed

122 CHAPTER 6. TESSERACT: RECONCILING GUEST I/O AND HYPERVISOR SWAPPING
Host Guest I/Os I/Os I/Os I/Os Double-(%) I/Os with 1 – 20 21 – 50 > 50 paging
Issued holes holes holes holes cases0 1,030 0 0 0 0 05 981 537 343 106 88 11,254
10 1,042 661 358 132 171 19,38115 1,292 766 377 237 152 22,58420 1,366 981 524 177 280 32,547
Table 6.1: Holes in write I/O requests for varying host overcommitment and60 MB memhog inside the guest.
between 21 and 50 swap-in requests completed, and, finally, 280 guest write
I/O requests needed more than 50 swap-in requests.
6.6.4 Fragmentation in Guest Read I/O Requests
Table 6.2 quantifies the number of extra read I/O requests that have to be
issued to the BSST if defragmentation is not used.
Host Guest I/Os I/Os w/ Total Total I/Os Score(%) Issued Holes Holes Issued
0 5,152 0 0 5,152 7,0105 5,230 708 1,675 6,197 6,801
10 5,206 2,161 5,820 8,865 6,27115 4,517 2,084 6,990 9,423 6,04820 5,698 2,739 11,854 14,813 2,841
Table 6.2: Holes in read I/O requests for Tesseract without defragmentationfor varying levels of host overcommitment and 60 MB memhog inside the guest.
Without host memory pressure there is no hypervisor level swapping and
all 5,152 guest read I/O requests can be satisfied without going to the BSST.
At higher levels of memory pressure, the hypervisor starts swapping pages
to disk. Tesseract detects pages in guest write I/O requests that are already
in the BSST to avoid swap-in requests for such pages. The amount of work
saved by Tesseract on the write I/O path is quantified in the final column of
Table 6.1.

6.6. EVALUATION 123
0 5 10 15 20 25 30 35 40Total SPECjbb blockage time (seconds)
4500
5000
5500
6000
6500
7000
7500
SPECjbb sco
re
baseline
no-defrag
bsst-defrag
guest-defrag
(a) 60 MB memhog
0 5 10 15 20 25 30 35 40Total SPECjbb blockage time (seconds)
4500
5000
5500
6000
6500
7000
7500
SPECjbb sco
re
baseline
no-defrag
bsst-defrag
guest-defrag
(b) 120 MB memhog
0 5 10 15 20 25 30 35 40Total SPECjbb blockage time (seconds)
4500
5000
5500
6000
6500
7000
7500
SPECjbb sco
re
baseline
no-defrag
bsst-defrag
guest-defrag
(c) 180 MB memhog
0 5 10 15 20 25 30 35 40Total SPECjbb blockage time (seconds)
4500
5000
5500
6000
6500
7000
7500
SPECjbb sco
re
baseline
no-defrag
bsst-defrag
guest-defrag
(d) 240 MB memhog
Figure 6.15: Scores and pauses in SPECjbb runs under various defragmenta-tion schemes with 10% host overcommitment.
When host memory is 20% overcommitted we can see that out of 5,698
guest read I/O requests 2,739 will require extra read I/Os to be issued to
read data from the BSST. The total number of such an extra I/Os to the
BSST was 11,854, which made the total number of read I/O requests issued
to both the guest VMDK and the BSST equal 14,813.
6.6.5 Evaluating Defragmentation Schemes
Figures 6.15 and 6.16 show the impact of using BSST and guest VMDK de-
fragmentation on SPECjbb throughput, while Figures 6.14 and 6.17 give
insight into SPECjbb responsiveness.
Guest defragmentation performs better than the baseline in all situations

124 CHAPTER 6. TESSERACT: RECONCILING GUEST I/O AND HYPERVISOR SWAPPING
0 10 20 30 40 50 60Total SPECjbb blockage time (seconds)
1000
2000
3000
4000
5000
6000
7000
SPECjbb sco
re
baseline
no-defrag
bsst-defrag
guest-defrag
(a) 0% host overcommitment
0 10 20 30 40 50 60Total SPECjbb blockage time (seconds)
1000
2000
3000
4000
5000
6000
7000
SPECjbb sco
re
baseline
no-defrag
bsst-defrag
guest-defrag
(b) 5% host overcommitment
0 10 20 30 40 50 60Total SPECjbb blockage time (seconds)
1000
2000
3000
4000
5000
6000
7000
SPECjbb sco
re
baseline
no-defrag
bsst-defrag
guest-defrag
(c) 15% host overcommitment
0 20 40 60 80 100Total SPECjbb blockage time (seconds)
1000
2000
3000
4000
5000
6000
7000
SPECjb
b s
core
baseline
no-defrag
bsst-defrag
guest-defrag
(d) 20% host overcommitment
Figure 6.16: Score and pauses in SPECjbb under various defragmentationschemes with varying host overcommitment and 60 MB memhog.
and is as good or better than BSST defragmentation. With low levels of
host memory overcommitment Tesseract with guest VMDK defragmentation
secures better SPECjbb scores than Tesseract without defragmentation and
performs on par in responsiveness metrics.
With increasing host memory overcommitment, Tesseract without de-
fragmentation starts outperforming Tesseract with either of the defragmen-
tation schemes in both the application throughput and responsiveness as
the total and maximum pause times grow slower for the no-defragmentation
case. This is due to the fact that at higher levels of hypervisor level swapping,
guest read I/O becomes more and more fragmented and pending defrag-
mentation requests become a bottleneck leading to longer read completion
times.
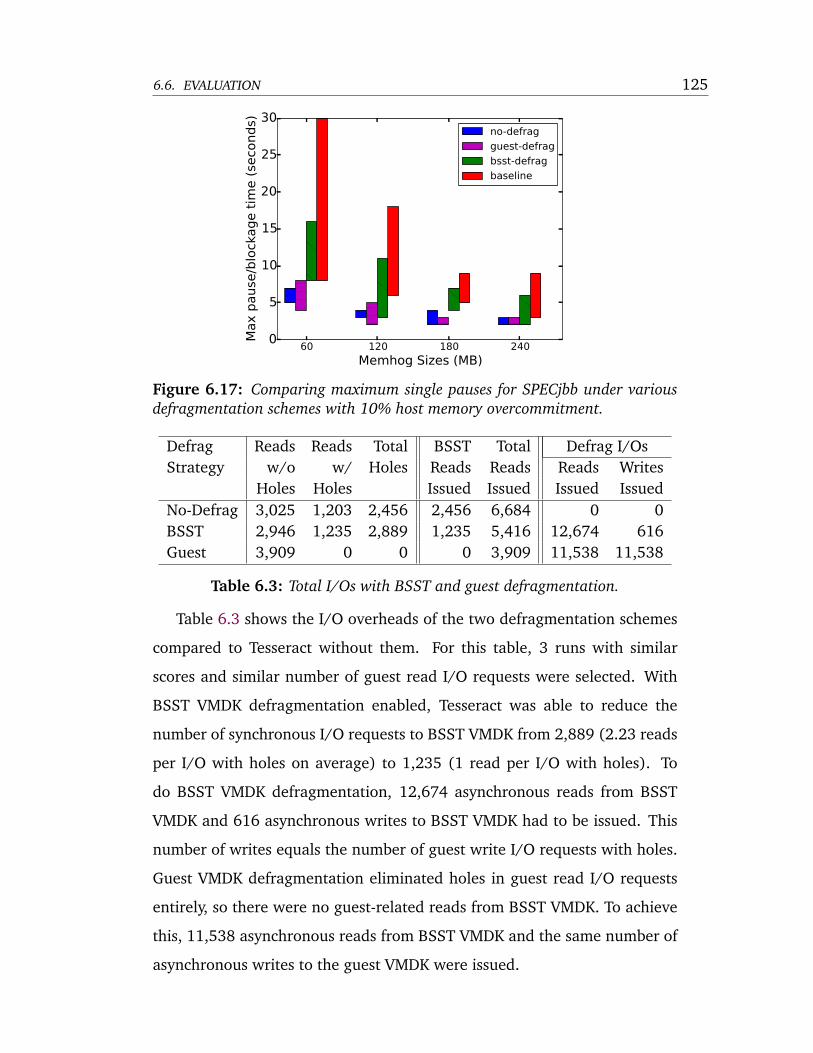
6.6. EVALUATION 125
60 120 180 240
Memhog Sizes (MB)
0
5
10
15
20
25
30
Max pause
/block
age tim
e (se
conds)
no-defrag
guest-defrag
bsst-defrag
baseline
Figure 6.17: Comparing maximum single pauses for SPECjbb under variousdefragmentation schemes with 10% host memory overcommitment.
Defrag Reads Reads Total BSST Total Defrag I/OsStrategy w/o w/ Holes Reads Reads Reads Writes
Holes Holes Issued Issued Issued IssuedNo-Defrag 3,025 1,203 2,456 2,456 6,684 0 0BSST 2,946 1,235 2,889 1,235 5,416 12,674 616Guest 3,909 0 0 0 3,909 11,538 11,538
Table 6.3: Total I/Os with BSST and guest defragmentation.
Table 6.3 shows the I/O overheads of the two defragmentation schemes
compared to Tesseract without them. For this table, 3 runs with similar
scores and similar number of guest read I/O requests were selected. With
BSST VMDK defragmentation enabled, Tesseract was able to reduce the
number of synchronous I/O requests to BSST VMDK from 2,889 (2.23 reads
per I/O with holes on average) to 1,235 (1 read per I/O with holes). To
do BSST VMDK defragmentation, 12,674 asynchronous reads from BSST
VMDK and 616 asynchronous writes to BSST VMDK had to be issued. This
number of writes equals the number of guest write I/O requests with holes.
Guest VMDK defragmentation eliminated holes in guest read I/O requests
entirely, so there were no guest-related reads from BSST VMDK. To achieve
this, 11,538 asynchronous reads from BSST VMDK and the same number of
asynchronous writes to the guest VMDK were issued.

126 CHAPTER 6. TESSERACT: RECONCILING GUEST I/O AND HYPERVISOR SWAPPING
0 10 20 30 40 50Total SPECjbb blockage time (seconds)
1000
2000
3000
4000
5000
6000
7000
SPECjbb sco
re
baseline
tesseract
(a) 15% host overcommitment
0 10 20 30 40 50Total SPECjbb blockage time (seconds)
1000
2000
3000
4000
5000
6000
7000
SPECjbb sco
re
baseline
tesseract
(b) 20% host overcommitment
0 10 20 30 40 50Total SPECjbb blockage time (seconds)
1000
2000
3000
4000
5000
6000
7000
SPECjbb sco
re
baseline
tesseract
(c) 25% host overcommitment
0 10 20 30 40 50Total SPECjbb blockage time (seconds)
1000
2000
3000
4000
5000
6000
7000
SPECjbb sco
re
baseline
tesseract
(d) 30% host overcommitment
Figure 6.18: Tesseract performances with BSST placed on an SSD disk.
6.6.6 Using SSD For Storing BSST VMDK
SSDs have dramatically better performance over magnetic disk in terms of
lower latencies for random reads. However, their relatively higher cost keeps
them from getting into mainstream server market. They are used in smaller
units for boosting performance. One potential application for SSDs in servers
is as a hypervisor swap device allowing for higher memory overcommitment
as the cost of swapping is reduced.
In our experiment, we placed the BSST VMDK on a SATA SSD. Fig-
ure 6.18 shows the performance of the baseline and Tesseract. At lower
memory pressure, there is no difference in the performance, but as the mem-
ory pressure increases, at both guest and hypervisor level, Tesseract starts to
show benefits over the baseline.

6.6. EVALUATION 127
I/O Path Baseline No-defrag BSST defrag Guest defragRead prepare 0 37 30 109Read completion 0 232 247 55Write prepare 24,262 220 256 265Write completion 0 49 91 101
Table 6.4: Average read and write prepare/completion times in microsecondsfor baseline and Tesseract with and without defragmentation. Host overcom-mitment was 10%; memhog size was 60 MB.
6.6.7 Overheads
I/O Path Overhead
Table 6.4 presents Tesseract overheads on I/O paths. The average overhead
per I/O is on the order of microseconds. Read prepare time for guest defrag-
mentation is higher than the others due to the contention on guest VMDK
during defragmentation. At the same time, the read completion time for
guest defragmentation case is much lower than the other two cases as there
are no extra reads going to the BSST. On the write I/O path, the defrag-
mentation schemes have larger overhead. This is due to the background
defragmentation of the disks which is kicked off as soon as the write I/O is
scheduled.
Memory Overhead
Per Section 6.4.4, Tesseract maintains in-memory metadata for three pur-
poses: tracking (a) associations between PPN and BSST blocks; (b) refer-
ence counts for BSST blocks; and (c) indirections between guest VMDK and
BSST VMDK. We use 64 bits to store a (4 KB) block number. To track asso-
ciations between PPN and BSST blocks we re-use MPN field in page frames
maintained by the hypervisor so there is no extra memory overhead here.
In general case where associations between PPN and blocks in guest VMDK
have to be tracked we will need a separate memory structure with a maxi-

128 CHAPTER 6. TESSERACT: RECONCILING GUEST I/O AND HYPERVISOR SWAPPING
mum overhead of 0.2% of VM’s memory size. Each BSST block’s reference
count requires 4 bytes per disk block. To optimize the lookup for free/avail-
able BSST blocks, a bitmap is also maintained with one bit for each block.
The guest VMDK to BSST VMDK indirection metadata requires 24 bytes for
each guest VMDK block for which there is a valid indirection to BSST. A
bitmap similar to that for BSST is maintained for guest VMDK blocks to de-
termine if an indirection to BSST exists for a given guest VMDK block.
6.7 Related Work
This work intersects three areas. The first is that of uncooperative hypervisor
swapping and the double-paging problem. The second concerns the tracking
of associations between guest memory and disk state. The third concerns
memory and I/O deduplication.
6.7.1 Hypervisor Swapping and Double Paging
Concurrent work by Amit et al. [5] systematically explores the behavior of
uncooperative hypervisor swapping and implement an improved swap sub-
system for KVM called VSwapper. The main components of their imple-
mentation are the Swap Mapper and the False Reader Preventer. The paper
identifies five primary causes for performance degradation, studies each, and
offers solutions to address them. The first, “silent swap writes”, corresponds
to our notion of guest-I/O–swap optimization which we do not yet support
because we do not support reference-counting on blocks in guest VMDKs.
The second and third, “stale swap reads” and “false swap reads”, and their
solutions are similar to the existing ESX optimizations that cancel swap-ins
for memory pages that are either overwritten by disk I/O or by the guest.
For “silent swap writes” and “stale swap reads”, the Swap Mapper uses the
same techniques Tesseract does to track valid associations between pages in
guest memory and blocks on disk. Their solution to “false swap reads”, the

6.7. RELATED WORK 129
False Reader Preventer, is more general, however, because it supports the
accumulation of successive guest writes in a temporary buffer to identify if
a page is entirely overwritten before next read. The last two, “decayed swap
sequentiality” and “false page anonymity”, are not issues we consider. In
their investigation, they did not observe double-paging to have much impact
on performance. This is likely due to the fact that they followed guidelines
from VMware and provisioned guests with enough VRAM that guest pag-
ing was uncommon and most of the experiments were run with a persistent
level of overcommitment. Tesseract allows for optimizing operations involv-
ing guest I/O followed by another guest I/O with either same pages or disk
blocks. This is not possible with VSwapper. Also, vswapper doesn’t allow for
defragmentation or disk deduplication.
The double-paging problem was first identified in the context of virtual
machines running on VM/370 [46, 101]. Goldberg and Hassinger [46] dis-
cuss the impact of increased paging when the virtual machine’s address ex-
ceeds that with which it is backed. Seawright and MacKinnon [101] mention
the use of handshaking between the VMM and operating system to address
the issue but do not offer details.
The Cellular Disco project at Stanford describes the problem of paging
in the guest and swapping in the hypervisor [48, 47]. They address this
double-paging or redundant paging problem by introducing a virtual paging
device in the guest. The paging device allows the hypervisor to track the
paging activity of the guest and reconcile it with its own. Like our approach,
the guest paging device identified already swapped-out blocks and creates
indirections to these blocks that are already persistent on disk. There is no
mention of the fact that these indirections destroy expected locality and may
impact subsequent guest read I/Os.
Subsequent papers on scheduling memory for virtual machines also refer
in passing to the general problem. Waldspurger [128], for example, men-
tions the impact of double-paging and advocates random selection of pages

130 CHAPTER 6. TESSERACT: RECONCILING GUEST I/O AND HYPERVISOR SWAPPING
by the hypervisor as a simple way to minimize overlap with page-selection
by the guest. Others projects, such as the Satori project [82], use double-
paging to advocate against any mechanism to swap guest pages from the
hypervisor.
Our approach differs from these efforts in several ways. First, we have
a system in which we can—for the first time—measure the extent to which
double-paging occurs. Second, we have an approach that directly addresses
the problem of double-paging in a manner transparent to the guest. Finally,
our techniques change the relationship between the two levels of scheduling:
by reconciling and eliding redundant I/Os, Tesseract encourages the two
schedulers to choose the same pages to be paged out.
6.7.2 Associations Between Memory and Disk State
Tracking the associations between guest memory and guest disks has been
used to improve memory management and working-set estimation for vir-
tual machines. The Geiger project [60], for example, uses paravirtualization
and intimate knowledge of the guest disks to implement a secondary cache
for guest buffer-cache pages. Lu et al. [78] implement a similar form of
victim cache for the Xen hypervisor.
Park et al. [87] describe a set of techniques to speed live-migration of
VMs. One of these techniques is to track associations between pages in
memory and blocks on disks whose contents are shared between the source
and destination machines. In cases where the contents are known to be
resident on disk, the block information is sent to the destination in place
of the memory contents. In the paper, the authors describe techniques for
maintaining this mapping both through paravirtualization and through the
use of read-only mappings for fully virtualized guests.

6.8. OBSERVATIONS 131
6.7.3 I/O and Memory Deduplication
The Satori project [82] also tracks the association between disk blocks and
pages in memory. It extends the Xen hypervisor to exploit these associations,
allowing it to elide repeated I/Os that read the same blocks from disk across
VMs immediately sharing these pages of memory across those guests.
Originally inspired by the Cellular Disco and Geiger projects, Tesseract
shares much in common with these approaches. Like many of them, it tracks
valid associations between memory pages and disk blocks that contain iden-
tical content. Like Park et al., it employs techniques that are fully transpar-
ent to the guest allowing it to be applied in a wider set of contexts. Unlike
the Satori projects which focused on eliminating redundant read operations
across VMs, Tesseract uses that mapping information to deduplicate I/Os
from a specific guest and its hypervisor. As such, our approach complements
and extends these others.
6.8 Observations
Our experience in this project has led us to question the existing interface
for issuing I/O requests with scatter-gather lists. Given that the underly-
ing physical organization of the disk blocks can differ significantly from the
virtual disk structure, it makes little sense for a scatter-gather list to require
that the target blocks on disk be contiguous. Having a more flexible structure
may allow I/Os to be expressed more succinctly and to be more effective at
communicating expected relationships or locality among those disk blocks.
Further, one can think of generalizing I/O scatter-gather lists and espe-
cially virtual disks to just be indirection tables into a large sea-of-blocks. This
allows for a natural application surface for block indirection.


CHAPTER 7
Impact for the Future
In this chapter, we discuss some of the future directions that can be pursued
based on this dissertation.
7.1 Compiled Code In Scripting Languages:
Fast-Slow Paradigm
For many scripting languages (Python, R, Matlab, etc.), the interpreted lan-
guage was developed first, and researchers developed an efficient compiler
after the fact. As a result, we often have fast compiled functions that run
inside the interpreted language. The compiled code makes assumptions to
generate efficient code. Unusual user applications may violate these assump-
tions, causing the compiled code to silently return an incorrect answer. So, a
user must choose between reliable, interpreted (slow) code, and unreliable
compiled (fast) code.
Checkpointing provides an interesting third alternative. One splits the
computation into segments. For concreteness, we will give an example with
ten segments, and we will assume that ten additional “checking” hosts (or
ten additional CPU cores) are available to run in parallel.
Initially, the compiled code is run. At the beginning of each of the ten
segments, one takes a checkpoint and copies it to a different “checking”
133

134 CHAPTER 7. IMPACT FOR THE FUTURE
computer. That computer runs the next segment in interpreted mode. At
the end of that segment, the data from the corresponding checkpoint of the
compiled segment is compared with the data at the end of the interpreted
segment for correctness.
At the end, either the ten “checking” hosts (or ten “checking” CPU cores)
report that the computation is correct, or else they report that the compu-
tation must switch to interpreted mode for correctness at the beginning of
a particular segment (after which, one can return to compiled operation as
described above).
Wester et al. [131] implemented a speculation mechanism in the operat-
ing system. It provided coordination across all applications and kernel state
while the speculation policy was left up to the applications. A scheme similar
to this was employed using DMTCP by Ghoshal et al. [45] in an application
to MPI [45] and by Arya and Cooperman [9] to support the Python scripting
language.
7.2 Support for Hadoop-style Big Data
Hadoop [39] and Spark [40] support a map-reduce paradigm in which the
size of intermediate data may increase during a “map” phase and may de-
crease during a “reduce” phase. Thus, the best place to checkpoint is at
the end of a “reduce” phase. With the right hooks added to Hadoop (or
Spark), Hadoop could be instructed by a plugin to move back-end data to
longer-term storage. On restart, the plugin would use those hooks to move
the longer-term storage back to active storage, and the front end would re-
connect.

7.3. CYBERSECURITY 135
7.3 Cybersecurity
Section 5.8 described the ability to checkpoint a network of virtual machines
using plugins [44]. This can be combined with DMTCP plugins to monitor
and modify the operation of a guest virtual machine. In particular, if mal-
ware uses any external services (from gettimeofday to calling back to a con-
troller on the Internet), this can be intercepted by a suitable DMTCP plugin,
and even replayed, in order to more closely examine the malware. See Visan
et al. [127] and Arya et al. [10] for examples of using record-replay through
DMTCP plugins. (While some malware tries to detect if it is running inside
a virtual machine, malware will often continue to run in this situation. Oth-
erwise, virtual machines would provide a good defense against malware.)
7.4 Algorithmic debugging
Algorithmic debugging [102, 13, 94, 83, 84, 79] is a well-developed tech-
nique that was especially explored in the 1990s. Roughly, the idea is that
an algorithmic debugger keeps a trace of the computation, and shows the
user the input and output of various subprocedures. Through a series of
questions and answers (similar to the game of 20 questions), the software
determines which low-level subprocedure caused the bug. This tended to
be used in functional languages and declarative languages such as Prolog,
because of the ease of capturing the input and output of a subprocedure.
The use of checkpoints allows one to apply this same technique to main-
stream languages including C/C++, Python, and others. Instead of en-
capsulating a small input and output, a traditional debugger (e.g., GDB,
Python pdb) would be used to allow the programmer to fully explore the
global state at the beginning and end of the subprocedure. In case of a
failed step, checkpoint-restart would allow us to restart from the last valid
step instead of rerunning the program from the beginning.

136 CHAPTER 7. IMPACT FOR THE FUTURE
7.5 Reversible Debugging
Reversible debugging or time-travelling debuggers have a long history [19,
38, 64, 72]. Checkpointing provides an obvious approach in this area. Some
parts of this approach have already been developed within the context of
DMTCP (decomposing debugging histories for replay [127] and reverse ex-
pression watchpoints [10]).
7.6 Android-Based Mobile Computing
Huang and Cheng have already demonstrated the use of DMTCP to check-
point processes under Android [53]. This provides the potential for truly
pervasive mobile apps, which can checkpoint themselves and migrate them-
selves to other platforms. This can provide greater software sustainability
(software engineering) by saving the entire mobile app, instead of the cur-
rent practice of saving the state of an app and re-loading the state whenever
the app is re-launched.
7.7 Cloud Computing
Cloud computing provides on-demand self-service and rapid elasticity of re-
sources for applications. These characteristics are similar to that of the old-
style mainframes from the 1960s through 1980s. However, to make the
analogy complete, we need a scheduler for the Cloud. This scheduler must
support parallel applications in addition to single-process applications. A
scheduler for the Cloud can use DMTCP to suspend or migrate jobs. The ca-
pabilities of DMTCP contributing to this goal include providing checkpoint
support for: virtual machines [44], Intel Xeon Phi [12, 2], InfiniBand [27],
MPI, and 3D-graphics (for visualization) [62].

CHAPTER 8
Conclusion
Virtualization in the context of singular systems is well understood, but it
is more difficult in context of multiple systems. This dissertation presented
solutions to two long standing problems related to virtualization. A number
of future directions were presented to apply the results of this dissertation
both in context of checkpoint-restart and virtual machines.
Closed-World Assumption
This dissertation presented a framework for transparent checkpointing of
application processes that do not obey the closed world assumption. A pro-
cess virtualization approach was presented to decouple the application pro-
cesses from the external subsystems. This was achieved by introducing a
thin virtualization layer between the application and the external subsystem
that provided the application with a consistent view of the external subsys-
tem across checkpoint and restart. An adaptive plugin based architecture
was presented to allow the checkpointing system to grow organically with
each new external subsystem. The third-party plugins, developed to pro-
vide seven novel checkpointing solutions, demonstrated the success of the
plugin-based process virtualization approach.
137

138 CHAPTER 8. CONCLUSION
Double-Paging Problem
This work presented Tesseract, a system that directly and transparently (with-
out any modifications to the guest operating system) addressed the double-
paging problem. It reconciled and eliminated redundant I/O activity be-
tween the guest’s virtual disks and the hypervisor swap subsystem by track-
ing associations between the contents of the pages in guest memory and
those on disk.
Finding an Application Surface
In the first body of work, the application surface was always chosen close
to the application process. The concept of an application surface close to a
stable API served as a guide in discovering a virtualization strategy in situa-
tions where no previous virtualization strategy existed. The pid plugin is an
example of a minimal application surface at the POSIX API layer, whereas
the SSH plugin provided an application surface at the level of SSH protocol.
In the second body of the work, there were several possibilities of choos-
ing an application surface including the guest operating system, paravirtual-
ized guest devices, virtual devices in the hypervisor, virtual disk interface, or
the host kernel. We chose the application surface at the virtual disk device
interface as it provides a clear separation between the hypervisor and the
virtual disks. This application surface included the entire guest virtual ma-
chine including operating system, device, etc. However, being at the virtual
disk device layer, allowed us to provide block indirection without requiring
any knowledge of the guest internals (virtual address space, file system, etc.)
and without requiring any modifications to the host operating system.

APPENDIX A
Plugin Tutorial
A.1 Introduction
Plugins enable one to modify the behavior of DMTCP. Two of the most com-
mon uses of plugins are:
1. to execute an additional action at the time of checkpoint, resume, or
restart.
2. to add a wrapper function around a call to a library function (including
wrappers around system calls).
Plugins are used for a variety of purposes. The DMTCP_ROOT/contrib
directory contains packages that users and developers have contributed to
be optionally loaded into DMTCP.
Plugin code is expressive, while requiring only a modest number of lines
of code. The plugins in the contrib directory vary in size from 400 lines to
3000 lines of code.
Beginning with DMTCP version 2.0, much of DMTCP itself is also now a
plugin. In this new design, the core DMTCP code is responsible primarily for
copying all of user space memory to a checkpoint image file. The remaining
functions of DMTCP are handled by plugins, found in DMTCP_ROOT/plugin.
Each plugin abstracts the essentials of a different subsystem of the operating
139

140 APPENDIX A. PLUGIN TUTORIAL
system and modifies its behavior to accommodate checkpoint and restart.
Some of the subsystems for which plugins have been written are: virtualiza-
tion of process and thread ids; files(open, close, dup, fopen, fclose, mmap,
pty); events (eventfd, epoll, poll, inotify, signalfd); System V IPC constructs
(shmget, semget, msgget); TCP/IP sockets (socket, connect, bind, listen, ac-
cept); and timers (timer_create, clock_gettime). (The indicated system calls
are examples only and not all-inclusive.)
A.2 Anatomy of a plugin
A plugin modifies the behavior of either DMTCP or a target application,
through three primary mechanisms, plus virtualization of ids.
Wrapper functions: One declares a wrapper function with the same name
as an existing library function (including system calls in the run-time
library). The wrapper function can execute some prolog code, pass
control to the “real” function, and then execute some epilog code. Sev-
eral plugins can wrap the same function in a nested manner. One can
also omit passing control to the “real” function, in order to shadow
that function with an alternate behavior.
Events: It is frequently useful to execute additional code at the time of
checkpoint, or resume, or restart. Plugins provide hook functions to be
called during these three events and numerous other important events
in the life of a process.
Coordinated checkpoint of distributed processes: DMTCP transparently
checkpoints distributed computations across many nodes. At the time
of checkpoint or restart, it may be necessary to coordinate information
among the distributed processes. For example, at restart time, an inter-
nal plugin of DMTCP allows the newly re-created processes to “talk”
to their peers to discover the new network addresses of their peers.

A.3. WRITING PLUGINS 141
This is important since a distributed computation may be restarted on
a different cluster than its original one.
Virtualization of ids: Ids (process id, timer id, System V IPC id, etc.) are
assigned by the kernel, by a peer process, and by remote processes.
Upon restart, the external agent may wish to assign a different id than
the one assigned prior to checkpoint. Techniques for virtualization of
ids are described in Section Appendix A.3.2.
A.3 Writing Plugins
A.3.1 Invoking a plugin
Plugins are just dynamic run-time libraries (.so files).
gcc -shared -fPIC -IDMTCP_ROOT/include -o PLUGIN1.so
PLUGIN1.c
They are invoked at the beginning of a DMTCP computation as command-
line options:
dmtcp_launch -with-plugin PLUGIN1.so:PLUGIN2.so myapp
Note that one can invoke multiple plugins as a colon-separated list. One
should either specify a full path for each plugin (each .so library), or else to
define LD_LIBRARY_PATH to include your own plugin directory.
A.3.2 The plugin mechanisms
The mechanisms of plugins are most easily described through examples.
This tutorial will rely on the examples in DMTCP_ROOT/test/plugin. To
get a feeling for the plugins, one can “cd” into each of the subdirectories and
execute: “make check”.

142 APPENDIX A. PLUGIN TUTORIAL
Plugin events
For context, please scan the code of plugin/example/example.c. Exe-
cuting “make check” will demonstrate the intended behavior. Plugin events
are handled by including the function dmtcp_event_hook. When a DMTCP
plugin event occurs, DMTCP will call the function dmtcp_event_hook for
each plugin. This function is required only if the plugin will handle plugin
events. See Appendix A for further details.
void dmtcp_event_hook(DmtcpEvent_t event, DmtcpEventData_t *
data)
{
switch (event) {
case DMTCP_EVENT_WRITE_CKPT:
printf( " \n∗∗∗ The plugin i s being c a l l e d before
checkpoint ing . ∗∗∗\n ");
break;
case DMTCP_EVENT_RESUME:
printf( " ∗∗∗ Resume : the plug in has now been checkpointed
. ∗∗∗\n ");
break;
case DMTCP_EVENT_RESTART:
printf( " ∗∗∗ The plugin i s now being r e s t a r t e d . ∗∗∗\n ");
break;
...
default:
break;
}
DMTCP_NEXT_EVENT_HOOK(event, data);
} �

A.3. WRITING PLUGINS 143
Plugin wrapper functions
In its simplest form, a wrapper function can be written as follows:
unsigned int sleep(unsigned int seconds) {
static unsigned int (*next_fnc)() = NULL; /* Same type
signature as sleep */
struct timeval oldtv, tv;
gettimeofday(&oldtv, NULL);
time_t secs = val.tv_sec;
printf( " s leep1 : "); print_time(); printf( " . . . ");
unsigned int result = NEXT_FNC(sleep)(seconds);
gettimeofday(&tv, NULL);
printf( " Time elapsed : %f \n ",
(1e6*(val.tv_sec-oldval.tv_sec) + 1.0*(val.tv_usec
-oldval.tv_usec)) / 1e6);
print_time(); printf( " \n ");
return result;
} �In the above example, we could also shadow the standard “sleep” func-
tion by our own implementation, if we omit the call to “NEXT_FNC”.
To see a related example, try:
cd DMTCP_ROOT/test/plugin/sleep1; make check
Wrapper functions from distinct plugins can be nested. For a nesting of
plugin sleep2 around sleep1, do:
cd DMTCP_ROOT/test/plugin
make; cd sleep2; make check
If one adds a wrapper around a function from a library other than libc.so
(e.g., libglx.so), it is best to dynamically link to that additional library:

144 APPENDIX A. PLUGIN TUTORIAL
gcc ... -o PLUGIN1.so PLUGIN1.c -lglx.so
Plugin coordination among multiple or distributed processes
It is often the case that an external agent will assign a particular initial id
to your process, but later assign a different id on restart. Each process must
re-discover its peers at restart time, without knowing the pre-checkpoint ids.
DMTCP provides a “Publish/Subscribe” feature to enable communica-
tion among peer processes. Two plugin events allow user plugins to discover
peers and pass information among peers. The two events are: DMTCP_EVEN-
T_REGISTER_NAME_SERVICE_DATA and DMTCP_EVENT_SEND_QUERIES.
DMTCP guarantees to provide a global barrier between the two events.
An example of how to use the Publish/Subscribe feature is contained
in DMTCP_ROOT/test/plugin/example-db . The explanation below is
best understood in conjunction with reading that example.
A plugin processing DMTCP_EVENT_REGISTER_NAME_SERVICE_DATA
should invoke:
int dmtcp_send_key_val_pair_to_coordinator(const void *key, size_t key_len,
const void *val, size_t val_len).
A plugin processing DMTCP_EVENT_SEND_QUERIES should invoke:
int dmtcp_send_query_to_coordinator(const void *key, size_t key_len, void
*val, size_t *val_len).
Using plugins to virtualize ids and other names
Often an id or name will change between checkpoint and restart. For ex-
ample, on restart, the real pid of a process will change from its pid prior
to checkpoint. Some DMTCP internal plugins maintain a translation table
in order to translate between a virtualized id passed to the user code and a
real id maintained inside the kernel. The utility to maintain this translation
table can also be used within third-party plugins. For an example of adding
virtualization to a plugin, see the plugin in plugin/ipc/timer.

A.4. APPLICATION-INITIATED CHECKPOINTS 145
In some less common cases, it can happen that a virtualized id is passed
to a library function by the target application. Yet, that same library function
may be passed a real id by a second function from within the same library.
In these cases, it is the responsibility of the plugin implementor to choose a
scheme that allows the first library function to distinguish whether its argu-
ment is a virtual id (passed from the target application) or a real id (passed
from within the same library).
A.4 Application-Initiated Checkpoints
Application-initiated checkpoints are even simpler than full-featured plug-
ins. In the simplest form, the following code can be executed both with
dmtcp_launch and without.:
#include <stdio.h>
#include " dmtcp . h "
int main() {
if (dmtcpCheckpoint() == DMTCP_NOT_PRESENT) {
printf( " dmtcpcheckpoint : DMTCP not present . No
checkpoint i s taken . \ n ");
}
return 0;
} �For this program to be aware of DMTCP, it must be compiled with -fPIC
and -ldl :
gcc -fPIC -IDMTCP_ROOT/include -o myapp myapp.c -ldl
The most useful functions are:
int dmtcpIsEnabled() — returns 1 when running with DMTCP; 0

146 APPENDIX A. PLUGIN TUTORIAL
otherwise.
int dmtcpCheckpoint() — returns DMTCP_AFTER_CHECKPOINT,
DMTCP_AFTER_RESTART, or DMTCP_NOT_PRESENT.
int dmtcpDelayCheckpointsLock()— DMTCP will block any check-
point requests.
int dmtcpDelayCheckpointsUnlock() — DMTCP will execute any
blocked checkpoint requests, and will permit new checkpoint requests.
The last two functions follow the common pattern of returning 0 on suc-
cess and DMTCP_NOT_PRESENT if DMTCP is not present.
A.5 Plugin Manual
A.5.1 Plugin events
dmtcp_event_hook
In order to handle DMTCP plugin events, a plugin must define an entry
point, dmtcp_event_hook.
NAME
dmtcp_event_hook - Handle plugin events for this
plugin
SYNOPSIS
#include " dmtcp/ plug in . h "
void dmtcp_event_hook(DmtcpEvent_t event,
DmtcpEventData_t *data)
DESCRIPTION

A.5. PLUGIN MANUAL 147
When a plugin event occurs, DMTCP will look for the
symbol
dmtcp_event_hook in each plugin library. If the
symbol is found,
that function will be called for the given plugin
library. DMTCP
guarantees only to invoke the first such plugin
library found in
library search order. Occurrences of
dmtcp_event_hook in later
plugin libraries will be called only if each previous
function
had invoked DMTCP_NEXT_EVENT_HOOK. The argument, <
event>, will be
bound to the event being declared by DMTCP. The
argument, <data>,
is required only for certain events. See the
following section,
‘‘Plugin Events ’ ’ for a list of all events.
SEE ALSO
DMTCP_NEXT_EVENT_HOOK �DMTCP_NEXT_EVENT_HOOK
A typical definition of dmtcp_event_hook will invoke the hook in the next
plugin via DMTCP_NEXT_EVENT_HOOK.
NAME
DMTCP_NEXT_EVENT_HOOK - call dmtcp_event_hook in next
plugin library

148 APPENDIX A. PLUGIN TUTORIAL
SYNOPSIS
#include " dmtcp/ plug in . h "
void DMTCP_NEXT_EVENT_HOOK(event, data)
DESCRIPTION
This function must be invoked from within a plugin
function library
called dmtcp_event_hook. The arguments <event> and <
data> should
normally be the same arguments passed to
dmtcp_event_hook.
DMTCP_NEXT_EVENT_HOOK may be called zero or one times
. If invoked zero
times, no further plugin libraries will be called to
handle events.
The behavior is undefined if DMTCP_NEXT_EVENT_HOOK
is invoked more than
once. The typical usage of this function is to
create a wrapper around
the handling of the same event by later plugins.
SEE ALSO
dmtcp_event_hook �Event Names
The rest of this section defines plugin events. The complete list of plugin
events is always contained in DMTCP_ROOT/include/plugin.h .
DMTCP guarantees to call the dmtcp_event_hook function of the plugin
when the specified event occurs.

A.5. PLUGIN MANUAL 149
Plugins that pass significant data through the data parameter are marked
with an asterisk: ∗. Most plugin events do not pass data through the data
parameter.
Note that the events REGISTER_NAME_SERVICE_DATA, SEND_QUERIES,
RESTART, RESUME, and REFILL, should all be processed after the call to
DMTCP_NEXT_EVENT_HOOK() in order to guarantee that the internal DMTCP
plugins have first restored full functionality.
Checkpoint-Restart
DMTCP_EVENT_WRITE_CKPT — Invoked at final barrier before writing
checkpoint
DMTCP_EVENT_RESTART — Invoked at first barrier during restart of new
process
DMTCP_EVENT_RESUME — Invoked at first barrier during resume fol-
lowing checkpoint
Coordination of Multiple or Distributed Processes during Restart
(see Appendix A.5.2)
DMTCP_EVENT_REGISTER_NAME_SERVICE_DATA∗ restart/resume
DMTCP_EVENT_SEND_QUERIES∗ restart/resume
WARNING: EXPERTS ONLY FOR REMAINING EVENTS
Init/Fork/Exec/Exit
DMTCP_EVENT_INIT — Invoked before main (in both the original pro-
gram and any new program called via exec)
DMTCP_EVENT_EXIT — Invoked on call to exit/_exit/_Exit return from
main?;
DMTCP_EVENT_PRE_EXEC — Invoked prior to call to exec

150 APPENDIX A. PLUGIN TUTORIAL
DMTCP_EVENT_POST_EXEC — Invoked before DMTCP_EVENT_INIT in
new program
DMTCP_EVENT_ATFORK_PREPARE — Invoked before fork (see POSIX
pthread_atfork)
DMTCP_EVENT_ATFORK_PARENT — Invoked after fork by parent (see
POSIX pthread_atfork)
DMTCP_EVENT_ATFORK_CHILD — Invoked after fork by child (see POSIX
pthread_atfork)
Barriers (finer-grained control during checkpoint-restart)
DMTCP_EVENT_WAIT_FOR_SUSPEND_MSG — Invoked at barrier during
coordinated checkpoint
DMTCP_EVENT_SUSPENDED — Invoked at barrier during coordinated
checkpoint
DMTCP_EVENT_LEADER_ELECTION — Invoked at barrier during coordi-
nated checkpoint
DMTCP_EVENT_DRAIN — Invoked at barrier during coordinated check-
point
DMTCP_EVENT_REFILL — Invoked at first barrier during resume/restart
of new process
Threads
DMTCP_EVENT_THREADS_SUSPEND — Invoked within checkpoint thread
when all user threads have been suspended
DMTCP_EVENT_THREADS_RESUME — Invoked within checkpoint thread
before any user threads are resumed.

A.5. PLUGIN MANUAL 151
For debugging, consider calling the following code for this event:
static int x = 1; while(x);
DMTCP_EVENT_PRE_SUSPEND_USER_THREAD — Each user thread in-
vokes this prior to being suspended for a checkpoint
DMTCP_EVENT_RESUME_USER_THREAD — Each user thread invokes
this immediately after a resume or restart (isRestart() available
to plugin)
DMTCP_EVENT_THREAD_START — Invoked before start function given
by clone
DMTCP_EVENT_THREAD_CREATED — Invoked within parent thread when
clone call returns (like parent for fork)
DMTCP_EVENT_PTHREAD_START — Invoked before start function given
by pthread_created
DMTCP_EVENT_PTHREAD_EXIT — Invoked before call to pthread_exit
DMTCP_EVENT_PTHREAD_RETURN — Invoked in child thread when thread
start function of pthread_create returns
A.5.2 Publish/Subscribe
Section Appendix A.3.2 provides an explanation of the Publish/Subscribe
feature for coordination among peer processes at resume- or restart-time.
An example of how to use the Publish/Subscribe feature is contained in
DMTCP_ROOT/test/plugin/example-db .
The primary events and functions used in this feature are:
DMTCP_EVENT_REGISTER_NAME_SERVICE_DATA
int dmtcp_send_key_val_pair_to_coordinator(const void *key,

152 APPENDIX A. PLUGIN TUTORIAL
size_t key_len, const void *val, size_t val_len)
DMTCP_EVENT_SEND_QUERIES
int dmtcp_send_query_to_coordinator(const void *key, size_t key_len, void
*val, size_t *val_len)
A.5.3 Wrapper functions
For a description of including wrapper functions in a plugin, see Section Ap-
pendix A.3.2.
A.5.4 Miscellaneous utility functions
Numerous DMTCP utility functions are provided that can be called from
within dmtcp_event_hook(). The utility functions are still under active de-
velopment, and may change in small ways. Some of the more commonly
used utility functions follow. Functions that return “char *” will not allocate
memory, but instead will return a pointer to a canonical string, which should
not be changed.
void dmtcp_get_local_ip_addr(struct in_addr *in);
const char* dmtcp_get_tmpdir(); /* given by --tmpdir, or
DMTCP_TMPDIR, or TMPDIR */
const char* dmtcp_get_ckpt_dir();
/* given by --ckptdir, or DMTCP_CHECKPOINT_DIR, or curr
dir at ckpt time */
const char* dmtcp_get_ckpt_files_subdir();
int dmtcp_get_ckpt_signal(); /* given by --mtcp-checkpoint-
signal */
const char* dmtcp_get_uniquepid_str();
const char* dmtcp_get_computation_id_str();
uint64_t dmtcp_get_coordinator_timestamp();
uint32_t dmtcp_get_generation(); /* number of ckpt/restart

A.5. PLUGIN MANUAL 153
sequences encountered */
const char* dmtcp_get_executable_path();
int dmtcp_get_restart_env(char *name, char *value, int
maxvaluelen);
/* For ’name’ in environment, copy its value into ’value’
param, but with
* at most length ’maxvaluelen’.
* Return 0 for success, and return code for various
errors
* See contrib/modify-env for an example of its use.
*/ �


Bibliography
[1] Hazim Abdel-Shafi, Evan Speight, and John K. Bennett. Efficient user-
level thread migration and checkpointing on windows NT clusters.
In Proceedings of the 3rd Conference on USENIX Windows NT Sympo-
sium - Volume 3, WINSYM’99, page 1–1, Berkeley, CA, USA, 1999.
USENIX Association. URL http://dl.acm.org/citation.cfm?
id=1268427.1268428. (Cited on page 15.)
[2] David Abdurachmanov, Kapil Arya, Josh Bendavid, Tommaso Boc-
cali, Gene Cooperman, Andrea Dotti, Peter Elmer, Giulio Eu-
lisse, Francesco Giacomini, Christopher D. Jones, Matteo Man-
zali, and Shahzad Muzaffar. Explorations of the viability of ARM
and xeon phi for physics processing. Journal of Physics: Confer-
ence Series, 513(5):052008, June 2014. ISSN 1742-6596. doi:
10.1088/1742-6596/513/5/052008. URL http://iopscience.
iop.org/1742-6596/513/5/052008. (Cited on page 136.)
[3] Saurabh Agarwal, Rahul Garg, Meeta S. Gupta, and Jose E. Mor-
eira. Adaptive incremental checkpointing for massively parallel sys-
tems. In Proceedings of the 18th Annual International Conference on
Supercomputing, ICS ’04, page 277–286, New York, NY, USA, 2004.
ACM. ISBN 1-58113-839-3. doi: 10.1145/1006209.1006248. URL
http://doi.acm.org/10.1145/1006209.1006248. (Cited on
page 15.)
155

156 BIBLIOGRAPHY
[4] Ole Agesen. System and method for maintaining memory page shar-
ing in a virtual environment, February 2013. U.S. Classification
711/147, 711/152, 711/E12.102, 717/148; International Classifica-
tion G06F12/08, G06F9/455, G06F7/04; Cooperative Classification
G06F12/08, G06F9/544, G06F9/45537. (Cited on page 98.)
[5] Nadav Amit, Dan Tsafrir, and Assaf Schuster. VSwapper: a mem-
ory swapper for virtualized environments. In Proceedings of the 19th
International Conference on Architectural Support for Programming
Languages and Operating Systems, ASPLOS ’14, page 349–366, New
York, NY, USA, 2014. ACM. ISBN 978-1-4503-2305-5. doi: 10.
1145/2541940.2541969. URL http://doi.acm.org/10.1145/
2541940.2541969. (Cited on pages 94 and 128.)
[6] Glenn Ammons, Jonathan Appavoo, Maria Butrico, Dilma Da Silva,
David Grove, Kiyokuni Kawachiya, Orran Krieger, Bryan Rosenburg,
Eric Van Hensbergen, and Robert W. Wisniewski. Libra: A library
operating system for a jvm in a virtualized execution environment.
In Proceedings of the 3rd International Conference on Virtual Execution
Environments, VEE ’07, page 44–54, New York, NY, USA, 2007. ACM.
ISBN 978-1-59593-630-1. doi: 10.1145/1254810.1254817. URL
http://doi.acm.org/10.1145/1254810.1254817. (Cited on
page 24.)
[7] Jason Ansel, Kapil Arya, and Gene Cooperman. DMTCP: transparent
checkpointing for cluster computations and the desktop. In IEEE In-
ternational Symposium on Parallel Distributed Processing, 2009. IPDPS
2009, pages 1–12, May 2009. doi: 10.1109/IPDPS.2009.5161063.
(Cited on pages 20, 25, and 58.)
[8] Linux Kernel Mailing List (LKML) Archives. [LKML] checkpoint-
restart: naked patch serialization, March 2014. URL http://lkml.

BIBLIOGRAPHY 157
iu.edu/hypermail/linux/kernel/1011.0/00770.html.
(Cited on page 17.)
[9] Kapil Arya and Gene Cooperman. DMTCP: bringing checkpoint-
restart to python. In Proceedings of the 12th Python in Science Con-
ference, pages 2–7, 2013. URL http://conference.scipy.org/
proceedings/scipy2013/arya.html. (Cited on page 134.)
[10] Kapil Arya, Tyler Denniston, Ana-Maria Visan, and Gene Cooper-
man. Semi-automated debugging via binary search through a pro-
cess lifetime. In Proceedings of the Seventh Workshop on Program-
ming Languages and Operating Systems, PLOS ’13, page 9:1–9:7, New
York, NY, USA, 2013. ACM. ISBN 978-1-4503-2460-1. doi: 10.
1145/2525528.2525533. URL http://doi.acm.org/10.1145/
2525528.2525533. (Cited on pages 135 and 136.)
[11] Kapil Arya, Yury Baskakov, and Alex Garthwaite. Tesseract: Rec-
onciling guest I/O and hypervisor swapping in a VM. In Pro-
ceedings of the 10th ACM SIGPLAN/SIGOPS International Confer-
ence on Virtual Execution Environments, VEE ’14, page 15–28, New
York, NY, USA, 2014. ACM. ISBN 978-1-4503-2764-0. doi: 10.
1145/2576195.2576198. URL http://doi.acm.org/10.1145/
2576195.2576198. (Cited on page 9.)
[12] Kapil Arya, Gene Cooperman, Andrea Dotti, and Peter Elmer.
Use of checkpoint-restart for complex HEP software on tradi-
tional architectures and intel MIC. Journal of Physics: Confer-
ence Series, 523(1):012015, June 2014. ISSN 1742-6596. doi:
10.1088/1742-6596/523/1/012015. URL http://iopscience.
iop.org/1742-6596/523/1/012015. (Cited on page 136.)
[13] Evyatar Av-Ron. Top-Down Diagnosis of Prolog Programs. PhD thesis,
Weizmanm Institute, 1984. (Cited on page 135.)

158 BIBLIOGRAPHY
[14] Pavan Balaji, Darius Buntinas, David Goodell, William Gropp, Jayesh
Krishna, Ewing Lusk, and Rajeev Thakur. PMI: a scalable parallel
process-management interface for extreme-scale systems. In Proceed-
ings of the 17th European MPI Users’ Group Meeting Conference on
Recent Advances in the Message Passing Interface, EuroMPI’10, page
31–41, Berlin, Heidelberg, 2010. Springer-Verlag. ISBN 3-642-15645-
2, 978-3-642-15645-8. URL http://dl.acm.org/citation.
cfm?id=1894122.1894127. (Cited on page 83.)
[15] Paul Barham, Boris Dragovic, Keir Fraser, Steven Hand, Tim Har-
ris, Alex Ho, Rolf Neugebauer, Ian Pratt, and Andrew Warfield.
Xen and the art of virtualization. In Proceedings of the Nineteenth
ACM Symposium on Operating Systems Principles, SOSP ’03, page
164–177, New York, NY, USA, 2003. ACM. ISBN 1-58113-757-5. doi:
10.1145/945445.945462. URL http://doi.acm.org/10.1145/
945445.945462. (Cited on page 24.)
[16] Tarick Bedeir. Building an RDMA-Capable application with IB
verbs. Technical report, http://www.hpcadvisorycouncil.com/, Au-
gust 2010. http://www.hpcadvisorycouncil.com/pdf/building-an-
rdma-capable- application-with-ib-verbs.pdf. (Cited on page 35.)
[17] Adam Beguelin, Erik Seligman, and Peter Stephan. Applica-
tion level fault tolerance in heterogeneous networks of work-
stations. Journal of Parallel and Distributed Computing, 43(2):
147–155, June 1997. ISSN 0743-7315. doi: 10.1006/jpdc.
1997.1338. URL http://www.sciencedirect.com/science/
article/pii/S0743731597913381. (Cited on page 18.)
[18] Bernard Blackham. Cryopid, 2012. URL http://cryopid.
berlios.de/index.html. (Cited on page 19.)

BIBLIOGRAPHY 159
[19] Bob Boothe. Efficient algorithms for bidirectional debugging. In
Proceedings of the ACM SIGPLAN 2000 Conference on Programming
Language Design and Implementation, PLDI ’00, page 299–310, New
York, NY, USA, 2000. ACM. ISBN 1-58113-199-2. doi: 10.1145/
349299.349339. URL http://doi.acm.org/10.1145/349299.
349339. (Cited on page 136.)
[20] Dan Bornstein. Dalvik VM internals. In Google I/O Developer Confer-
ence, volume 23, page 17–30, 2008. (Cited on page 22.)
[21] George Bosilca, Aurelien Bouteiller, Franck Cappello, Samir Djilali,
Gilles Fedak, Cecile Germain, Thomas Herault, Pierre Lemarinier,
Oleg Lodygensky, Frederic Magniette, Vincent Neri, and Anton Se-
likhov. MPICH-V: toward a scalable fault tolerant MPI for volatile
nodes. In Proceedings of the 2002 ACM/IEEE Conference on Super-
computing, SC ’02, page 1–18, Los Alamitos, CA, USA, 2002. IEEE
Computer Society Press. URL http://dl.acm.org/citation.
cfm?id=762761.762815. (Cited on page 18.)
[22] Aurélien Bouteiller, Thomas Herault, Géraud Krawezik, Pierre
Lemarinier, and Franck Cappello. MPICH-V project: A multipro-
tocol automatic fault-tolerant MPI. International Journal of High
Performance Computing Applications, 20(3):319–333, 2006. doi:
10.1177/1094342006067469. URL http://hpc.sagepub.com/
content/20/3/319.abstract. (Cited on page 19.)
[23] Greg Bronevetsky, Daniel Marques, Keshav Pingali, and Paul
Stodghill. Automated application-level checkpointing of MPI pro-
grams. In Proceedings of the Ninth ACM SIGPLAN Symposium on
Principles and Practice of Parallel Programming, PPoPP ’03, page
84–94, New York, NY, USA, 2003. ACM. ISBN 1-58113-588-2. doi:

160 BIBLIOGRAPHY
10.1145/781498.781513. URL http://doi.acm.org/10.1145/
781498.781513. (Cited on pages 15 and 19.)
[24] Greg Bronevetsky, Daniel Marques, Keshav Pingali, Peter Szwed, and
Martin Schulz. Application-level checkpointing for shared mem-
ory programs. In Proceedings of the 11th International Conference
on Architectural Support for Programming Languages and Operating
Systems, ASPLOS XI, page 235–247, New York, NY, USA, 2004.
ACM. ISBN 1-58113-804-0. doi: 10.1145/1024393.1024421. URL
http://doi.acm.org/10.1145/1024393.1024421. (Cited on
page 15.)
[25] Greg Bronevetsky, Daniel Marques, Keshav Pingali, Radu Rugina, and
Sally A. McKee. Compiler-enhanced incremental checkpointing for
OpenMP applications. In Proc. of IEEE International Parallel and Dis-
tributed Processing Symposium (IPDPS), pages 1–12, May 2009. doi:
10.1109/IPDPS.2009.5160999. (Cited on page 15.)
[26] Guohong Cao and M. Singhal. On coordinated checkpointing in dis-
tributed systems. IEEE Transactions on Parallel and Distributed Sys-
tems, 9(12):1213–1225, December 1998. ISSN 1045-9219. doi:
10.1109/71.737697. (Cited on page 22.)
[27] Jiajun Cao, Gregory Kerr, Kapil Arya, and Gene Cooperman. Trans-
parent checkpoint-restart over InfiniBand. In ACM 23rd Int. Symp. on
High Performance Parallel and Distributed Computing (HPDC), 2014.
(to appear). (Cited on pages 9, 31, 71, 89, 90, and 136.)
[28] K. Mani Chandy and Leslie Lamport. Distributed snapshots: De-
termining global states of distributed systems. ACM Trans. Com-
put. Syst., 3(1):63–75, February 1985. ISSN 0734-2071. doi:
10.1145/214451.214456. URL http://doi.acm.org/10.1145/
214451.214456. (Cited on page 29.)

BIBLIOGRAPHY 161
[29] P. Emerald Chung, Woei-Jyh Lee, Yennun Huang, Deron Liang, and
Chung-Yih Wang. Winckp: A transparent checkpointing and rollback
recovery tool for windows NT applications. In Proc. of 29th Annual
International Symposium on Fault-Tolerant Computing, page 220–223,
1999. doi: 10.1109/FTCS.1999.781053. (Cited on page 15.)
[30] Gene Cooperman, Jason Ansel, and Xiaoqin Ma. Adaptive check-
pointing for master-worker style parallelism (extended abstract). In
Proc. of 2005 IEEE Computer Society International Conference on Clus-
ter Computing. IEEE Press, 2005. conference proceedings on CD.
(Cited on page 25.)
[31] Camille Coti, Thomas Herault, Pierre Lemarinier, Laurence Pilard,
Ala Rezmerita, Eric Rodriguez, and Franck Cappello. Blocking vs.
non-blocking coordinated checkpointing for large-scale fault tolerant
MPI. In Proceedings of the 2006 ACM/IEEE Conference on Supercom-
puting, SC ’06, New York, NY, USA, 2006. ACM. ISBN 0-7695-2700-0.
doi: 10.1145/1188455.1188587. URL http://doi.acm.org/10.
1145/1188455.1188587. (Cited on pages 18 and 22.)
[32] Timothy Cramer, Richard Friedman, Terrence Miller, David Seberger,
Robert Wilson, and Mario Wolczko. Compiling java just in time. IEEE
Micro, 17(3):36–43, May 1997. ISSN 0272-1732. doi: 10.1109/
40.591653. URL http://dx.doi.org/10.1109/40.591653.
(Cited on page 22.)
[33] William R. Dieter and James E. Lumpp,Jr. User-level checkpointing
for LinuxThreads programs. In Proceedings of the FREENIX Track:
2001 USENIX Annual Technical Conference, page 81–92, Berkeley, CA,
USA, 2001. USENIX Association. ISBN 1-880446-10-3. URL http:
//dl.acm.org/citation.cfm?id=647054.715766. (Cited on
page 15.)

162 BIBLIOGRAPHY
[34] Fred Douglis and John Ousterhout. Transparent process migration:
Design alternatives and the sprite implementation. Software: Practice
and Experience, 21(8):757–785, August 1991. ISSN 1097-024X.
doi: 10.1002/spe.4380210802. URL http://onlinelibrary.
wiley.com/doi/10.1002/spe.4380210802/abstract.
(Cited on page 13.)
[35] Ifeanyi P. Egwutuoha, David Levy, Bran Selic, and Shiping
Chen. A survey of fault tolerance mechanisms and check-
point/restart implementations for high performance computing
systems. The Journal of Supercomputing, 65(3):1302–1326,
September 2013. ISSN 0920-8542, 1573-0484. doi: 10.
1007/s11227-013-0884-0. URL http://link.springer.com/
article/10.1007/s11227-013-0884-0. (Cited on page 13.)
[36] David Ehringer. The dalvik virtual machine architecture. Technical
report, 2010. (Cited on page 22.)
[37] Dawson R. Engler, M. Frans Kaashoek, and J.ames O’Toole,Jr. Ex-
okernel: An operating system architecture for application-level re-
source management. In Proceedings of the Fifteenth ACM Sympo-
sium on Operating Systems Principles, SOSP ’95, page 251–266, New
York, NY, USA, 1995. ACM. ISBN 0-89791-715-4. doi: 10.1145/
224056.224076. URL http://doi.acm.org/10.1145/224056.
224076. (Cited on page 24.)
[38] Stuart I. Feldman and Channing B. Brown. IGOR: a system for
program debugging via reversible execution. In Proceedings of the
1988 ACM SIGPLAN and SIGOPS Workshop on Parallel and Distributed
Debugging, PADD ’88, page 112–123, New York, NY, USA, 1988.
ACM. ISBN 0-89791-296-9. doi: 10.1145/68210.69226. URL http:
//doi.acm.org/10.1145/68210.69226. (Cited on page 136.)

BIBLIOGRAPHY 163
[39] Apache Software Foundation. Apache hadoop, March 2014. URL
http://hadoop.apache.org/. (Cited on page 134.)
[40] Apache Software Foundation. Apache spark — lightning-fast clus-
ter computing, March 2014. URL http://spark.incubator.
apache.org/. (Cited on page 134.)
[41] Qi Gao, Weikuan Yu, Wei Huang, and D.K. Panda. Application-
transparent Checkpoint/Restart for MPI programs over InfiniBand.
In International Conference on Parallel Processing, 2006. ICPP 2006,
pages 471–478, August 2006. doi: 10.1109/ICPP.2006.26. (Cited on
page 19.)
[42] Tal Garfinkel. Traps and pitfalls: Practical problems in system call
interposition based security tools. In In Proc. Network and Dis-
tributed Systems Security Symposium, page 163–176, 2003. (Cited
on page 21.)
[43] Rohan Garg, Komal Sodha, and Gene Cooperman. A generic
checkpoint-restart mechanism for virtual machines. Technical report,
arXiv tech. report, arXiv:1212.1787, December 2012. URL http:
//arxiv.org/abs/1212.1787. Published: arXiv:1212.1787
[cs.OS], http://arxiv.org/abs/1212.1787. (Cited on page 87.)
[44] Rohan Garg, Komal Sodha, Zhengping Jin, and Gene Cooperman.
Checkpoint-restart for a network of virtual machines. In Proc. of 2013
IEEE Computer Society International Conference on Cluster Computing,
pages 1–8. IEEE Press, 2013. doi: 10.1109/CLUSTER.2013.6702626.
(Cited on pages 9, 71, 88, 135, and 136.)
[45] Devarshi Ghoshal, Sreesudhan R. Ramkumar, and Arun Chauhan.
Distributed speculative parallelization using checkpoint restart. In
Proceedings of the International Conference on Computational Science,

164 BIBLIOGRAPHY
ICCS 2011, volume 4 of Proceedings of the International Conference on
Computational Science, ICCS 2011, pages 422–431, 2011. doi: 10.
1016/j.procs.2011.04.044. URL http://www.sciencedirect.
com/science/article/pii/S1877050911001025. (Cited on
page 134.)
[46] Robert P. Goldberg and Robert Hassinger. The double paging
anomaly. In Proceedings of the May 6-10, 1974, National Com-
puter Conference and Exposition, AFIPS ’74, page 195–199, New
York, NY, USA, 1974. ACM. doi: 10.1145/1500175.1500215. URL
http://doi.acm.org/10.1145/1500175.1500215. (Cited on
pages 91 and 129.)
[47] Kinshuk Govil. Virtual clusters: resource management on large shared-
memory multiprocessors. PhD thesis, Stanford University, Palo Alto,
CA, USA, 2001. AAI3000034. (Cited on pages 91, 97, and 129.)
[48] Kinshuk Govil, Dan Teodosiu, Yongqiang Huang, and Mendel Rosen-
blum. Cellular disco: Resource management using virtual clusters
on shared-memory multiprocessors. In Proceedings of the Seventeenth
ACM Symposium on Operating Systems Principles, SOSP ’99, page
154–169, New York, NY, USA, 1999. ACM. ISBN 1-58113-140-2. doi:
10.1145/319151.319162. URL http://doi.acm.org/10.1145/
319151.319162. (Cited on pages 91, 97, and 129.)
[49] Richard L. Graham, Sung-Eun Choi, David J. Daniel, Nehal N. De-
sai, Ronald G. Minnich, Craig E. Rasmussen, L. Dean Risinger, and
Mitchel W. Sukalski. A network-failure-tolerant message-passing sys-
tem for terascale clusters. In Proceedings of the 16th International Con-
ference on Supercomputing, ICS ’02, page 77–83, New York, NY, USA,
2002. ACM. ISBN 1-58113-483-5. doi: 10.1145/514191.514205.

BIBLIOGRAPHY 165
URL http://doi.acm.org/10.1145/514191.514205. (Cited
on page 18.)
[50] Ajay Gulati, Irfan Ahmad, and Carl A. Waldspurger. PARDA: pro-
portional allocation of resources for distributed storage access. In
Proccedings of the 7th Conference on File and Storage Technologies,
FAST ’09, page 85–98, Berkeley, CA, USA, 2009. USENIX Associa-
tion. URL http://dl.acm.org/citation.cfm?id=1525908.
1525915. (Cited on page 113.)
[51] Vishakha Gupta, Ada Gavrilovska, Karsten Schwan, Harshvard-
han Kharche, Niraj Tolia, Vanish Talwar, and Parthasarathy Ran-
ganathan. GViM: GPU-accelerated virtual machines. In Pro-
ceedings of the 3rd ACM Workshop on System-level Virtualization
for High Performance Computing, HPCVirt ’09, page 17–24, New
York, NY, USA, 2009. ACM. ISBN 978-1-60558-465-2. doi: 10.
1145/1519138.1519141. URL http://doi.acm.org/10.1145/
1519138.1519141. (Cited on page 19.)
[52] Paul H. Hargrove and Jason C. Duell. Berkeley lab checkpoint/restart
(BLCR) for linux clusters. Journal of Physics: Conference Series, 46(1):
494, September 2006. ISSN 1742-6596. doi: 10.1088/1742-6596/
46/1/067. URL http://iopscience.iop.org/1742-6596/
46/1/067. (Cited on pages 3, 17, 18, 19, and 23.)
[53] Jim Huang and Kito Cheng. Implement checkpointing for android
(slides). In Embedded Linux Conference Europe (ELCE2012). 0xlab,
November 2012. URL http://www.slideshare.net/jserv/
implement-checkpointing-for-android-elce2012. (Cited
on page 136.)
[54] J. Hursey, J.M. Squyres, T.I. Mattox, and A. Lumsdaine. The design
and implementation of Checkpoint/Restart process fault tolerance for

166 BIBLIOGRAPHY
open MPI. In Parallel and Distributed Processing Symposium, 2007.
IPDPS 2007. IEEE International, pages 1–8, March 2007. doi: 10.
1109/IPDPS.2007.370605. (Cited on pages 18 and 19.)
[55] Joshua Hursey, Timothy I. Mattox, and Andrew Lumsdaine. Intercon-
nect agnostic Checkpoint/Restart in open MPI. In Proceedings of the
18th ACM International Symposium on High Performance Distributed
Computing, HPDC ’09, page 49–58, New York, NY, USA, 2009. ACM.
ISBN 978-1-60558-587-1. doi: 10.1145/1551609.1551619. URL
http://doi.acm.org/10.1145/1551609.1551619. (Cited on
pages 19, 72, and 89.)
[56] VMware Inc. VMware workstation, March 2014. URL http://www.
vmware.com/products/workstation. (Cited on page 92.)
[57] VMware Inc. VMware vSphere hypervisor, March 2014. URL http:
//www.vmware.com/products/esxi-and-esx/overview.
(Cited on page 91.)
[58] Pankaj Jalote. Fault Tolerance in Distributed Systems. Prentice-Hall,
Inc., Upper Saddle River, NJ, USA, 1994. ISBN 0-13-301367-7. (Cited
on page 21.)
[59] G. (John) Janakiraman, Jose Renato Santos, Dinesh Subhraveti, and
Yoshio Turner. Cruz: Application-transparent distributed checkpoint-
restart on standard operating systems. In International Conference
on Dependable Systems and Networks, 2005. DSN 2005. Proceedings,
pages 260–269, June 2005. doi: 10.1109/DSN.2005.33. (Cited on
page 16.)
[60] Stephen T. Jones, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-
Dusseau. Geiger: Monitoring the buffer cache in a virtual ma-
chine environment. In Proceedings of the 12th International Confer-

BIBLIOGRAPHY 167
ence on Architectural Support for Programming Languages and Oper-
ating Systems, ASPLOS XII, page 14–24, New York, NY, USA, 2006.
ACM. ISBN 1-59593-451-0. doi: 10.1145/1168857.1168861. URL
http://doi.acm.org/10.1145/1168857.1168861. (Cited on
page 130.)
[61] Poul-henning Kamp and Robert N. M. Watson. Jails: Confining the
omnipotent root. In In Proc. 2nd Intl. SANE Conference, 2000. (Cited
on page 23.)
[62] Samaneh Kazemi Nafchi, Rohan Garg, and Gene Cooperman. Trans-
parent checkpoint-restart for hardware-accelerated 3D graphics.
Technical report, arXiv tech. report, arXiv:1312.6650, 2013. URL
http://arxiv.org/abs/1312.6650v2. (Cited on pages 9, 31,
71, 88, and 136.)
[63] Gregory Kerr, Alex Brick, Gene Cooperman, and Sergey Bra-
tus. Checkpoint-restart: Proprietary hardware and the ‘Spiderweb
API’. Technical report, Recon 2011, July 2011. talk: abstract
at http://recon.cx/2011/schedule/events/112.en.html; video at
https://archive.org/details/Recon_2011_Checkpoint_Restart. (Cited
on page 35.)
[64] Samuel T. King, George W. Dunlap, and Peter M. Chen. Debugging
operating systems with time-traveling virtual machines. In Proceed-
ings of the Annual Conference on USENIX Annual Technical Confer-
ence, ATEC ’05, page 1–1, Berkeley, CA, USA, 2005. USENIX Associa-
tion. URL http://dl.acm.org/citation.cfm?id=1247360.
1247361. (Cited on page 136.)
[65] Naveen Kumar and Ramesh Peri. Transparent debugging of dy-
namically instrumented programs. SIGARCH Comput. Archit. News,
33(5):57–62, December 2005. ISSN 0163-5964. doi: 10.

168 BIBLIOGRAPHY
1145/1127577.1127589. URL http://doi.acm.org/10.1145/
1127577.1127589. (Cited on page 21.)
[66] Oren Laadan. A Personal Virtual Computer Recorder. PhD the-
sis, Columbia University, 2011. URL http://academiccommons.
columbia.edu/catalog/ac:131552. (Cited on page 16.)
[67] Oren Laadan and Jason Nieh. Transparent checkpoint-restart of mul-
tiple processes on commodity operating systems. In 2007 USENIX An-
nual Technical Conference on Proceedings of the USENIX Annual Tech-
nical Conference, ATC’07, page 25:1–25:14, Berkeley, CA, USA, 2007.
USENIX Association. ISBN 999-8888-77-6. URL http://dl.acm.
org/citation.cfm?id=1364385.1364410. (Cited on page 16.)
[68] Oren Laadan, Nicolas Viennot, and Jason Nieh. Transparent,
lightweight application execution replay on commodity multiproces-
sor operating systems. In Proceedings of the ACM SIGMETRICS Interna-
tional Conference on Measurement and Modeling of Computer Systems,
SIGMETRICS ’10, page 155–166, New York, NY, USA, 2010. ACM.
ISBN 978-1-4503-0038-4. doi: 10.1145/1811039.1811057. URL
http://doi.acm.org/10.1145/1811039.1811057. (Cited on
pages 16 and 17.)
[69] H. Andres Lagar-Cavilla, Niraj Tolia, M. Satyanarayanan, and Eyal
de Lara. VMM-independent graphics acceleration. In Proceed-
ings of the 3rd International Conference on Virtual Execution Envi-
ronments, VEE ’07, page 33–43, New York, NY, USA, 2007. ACM.
ISBN 978-1-59593-630-1. doi: 10.1145/1254810.1254816. URL
http://doi.acm.org/10.1145/1254810.1254816. (Cited on
pages 72 and 88.)
[70] Peter Alan Lee and Thomas Anderson. Fault tolerance. In Fault Tol-
erance, number 3 in Dependable Computing and Fault-Tolerant Sys-

BIBLIOGRAPHY 169
tems, pages 51–77. Springer Vienna, January 1990. ISBN 978-3-
7091-8992-4, 978-3-7091-8990-0. URL http://link.springer.
com/chapter/10.1007/978-3-7091-8990-0_3. (Cited on
page 21.)
[71] Pierre Lemarinier, Aurélien Bouteiller, Thomas Herault, Géraud
Krawezik, and Franck Cappello. Improved message logging versus
improved coordinated checkpointing for fault tolerant MPI. In Pro-
ceedings of the 2004 IEEE International Conference on Cluster Comput-
ing, CLUSTER ’04, page 115–124, Washington, DC, USA, 2004. IEEE
Computer Society. ISBN 0-7803-8694-9. URL http://dl.acm.
org/citation.cfm?id=1111682.1111713. (Cited on page 22.)
[72] E. Christopher Lewis, Prashant Dhamdhere, and Eric Xiaojian Chen.
Virtual machine-based replay debugging, October 2008. Google Tech
Talks: http://www.youtube.com/watch?v=RvMlihjqlhY; further in-
formation at http://www.replaydebugging.com. (Cited on page 136.)
[73] Kai Li, Jeffrey F. Naughton, and James S. Plank. Real-time, con-
current checkpoint for parallel programs. In Proceedings of the Sec-
ond ACM SIGPLAN Symposium on Principles &Amp; Practice of Par-
allel Programming, PPOPP ’90, page 79–88, New York, NY, USA,
1990. ACM. ISBN 0-89791-350-7. doi: 10.1145/99163.99173.
URL http://doi.acm.org/10.1145/99163.99173. (Cited on
pages 15 and 22.)
[74] Kai Li, Jeffrey F. Naughton, and James S. Plank. Low-latency, con-
current checkpointing for parallel programs. IEEE Transactions on
Parallel and Distributed Systems, 5(8):874–879, August 1994. ISSN
1045-9219. doi: 10.1109/71.298215. (Cited on pages 15 and 22.)
[75] Tim Lindholm and Frank Yellin. Java Virtual Machine Specification.

170 BIBLIOGRAPHY
Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA, 2nd
edition, 1999. ISBN 0201432943. (Cited on page 22.)
[76] Michael Litzkow, Todd Tannenbaum, Jim Basney, and Miron Livny.
Checkpoint and migration of UNIX processes in the condor dis-
tributed processing system. Technical report 1346, University of Wis-
consin, Madison, Wisconsin, April 1997. (Cited on pages 15, 18,
and 23.)
[77] Jiuxing Liu, Jiesheng Wu, and Dhabaleswar K. Panda. High perfor-
mance RDMA-Based MPI implementation over InfiniBand. Interna-
tional Journal of Parallel Programming, 32(3):167–198, June 2004.
ISSN 0885-7458, 1573-7640. doi: 10.1023/B:IJPP.0000029272.
69895.c1. URL http://link.springer.com/article/10.
1023/B:IJPP.0000029272.69895.c1. (Cited on page 19.)
[78] Pin Lu and Kai Shen. Virtual machine memory access tracing with hy-
pervisor exclusive cache. In 2007 USENIX Annual Technical Conference
on Proceedings of the USENIX Annual Technical Conference, ATC’07,
page 3:1–3:15, Berkeley, CA, USA, 2007. USENIX Association. ISBN
999-8888-77-6. URL http://dl.acm.org/citation.cfm?id=
1364385.1364388. (Cited on page 130.)
[79] Machi Maeji and Tadashi Kanamori. Top-down zooming diagnosis of
logic programs. Technical report, Kyoto University, 1988. (Cited on
page 135.)
[80] Violeta Medina and Juan Manuel García. A survey of migration mech-
anisms of virtual machines. ACM Comput. Surv., 46(3):30:1–30:33,
January 2014. ISSN 0360-0300. doi: 10.1145/2492705. URL
http://doi.acm.org/10.1145/2492705. (Cited on page 14.)
[81] Dejan S. Milojicic, Fred Douglis, Yves Paindaveine, Richard Wheeler,
and Songnian Zhou. Process migration. ACM Computing Surveys,

BIBLIOGRAPHY 171
32(3):241–299, September 2000. ISSN 0360-0300. doi: 10.1145/
367701.367728. URL http://doi.acm.org/10.1145/367701.
367728. (Cited on page 13.)
[82] Grzegorz Miłós, Derek G. Murray, Steven Hand, and Michael A. Fet-
terman. Satori: Enlightened page sharing. In Proceedings of the
2009 Conference on USENIX Annual Technical Conference, USENIX’09,
page 1–1, Berkeley, CA, USA, 2009. USENIX Association. URL http:
//dl.acm.org/citation.cfm?id=1855807.1855808. (Cited
on pages 91, 97, 101, 130, and 131.)
[83] Henrik Nilsson. Declarative debugging for lazy functional languages.
Citeseer, 1998. (Cited on page 135.)
[84] Henrik Nilsson and Peter Fritzson. Algorithmic debugging for
lazy functional languages. In Maurice Bruynooghe and Martin
Wirsing, editors, Proceedings of the 4th International Symposium
on Programming Language Implementation and Logic Programming,
PLILP ’92, pages 385–399, London, UK, UK, 1992. Springer Berlin
Heidelberg. ISBN 3-540-55844-6. URL http://dl.acm.org/
citation.cfm?id=646448.692462. (Cited on page 135.)
[85] Mark O’Neill. Cryopid2, December 2013. URL http://
sourceforge.net/projects/cryopid2. (Cited on page 19.)
[86] Steven Osman, Dinesh Subhraveti, Gong Su, and Jason Nieh. The
design and implementation of zap: A system for migrating comput-
ing environments. In Proceedings of the 5th Symposium on Operating
Systems Design and implementation, OSDI ’02, page 361–376, New
York, NY, USA, 2002. ACM. ISBN 978-1-4503-0111-4. doi: 10.
1145/1060289.1060323. URL http://doi.acm.org/10.1145/
1060289.1060323. (Cited on pages 8 and 16.)

172 BIBLIOGRAPHY
[87] Eunbyung Park, Bernhard Egger, and Jaejin Lee. Fast and space-
efficient virtual machine checkpointing. In Proceedings of the 7th ACM
SIGPLAN/SIGOPS International Conference on Virtual Execution Envi-
ronments, VEE ’11, page 75–86, New York, NY, USA, 2011. ACM.
ISBN 978-1-4503-0687-4. doi: 10.1145/1952682.1952694. URL
http://doi.acm.org/10.1145/1952682.1952694. (Cited on
pages 100 and 130.)
[88] Harish Patil, Robert Cohn, Mark Charney, Rajiv Kapoor, Andrew Sun,
and Anand Karunanidhi. Pinpointing representative portions of large
intel® itanium® programs with dynamic instrumenta-
tion. In Proceedings of the 37th Annual IEEE/ACM International Sym-
posium on Microarchitecture, MICRO 37, page 81–92, Washington,
DC, USA, 2004. IEEE Computer Society. ISBN 0-7695-2126-6. doi:
10.1109/MICRO.2004.28. URL http://dx.doi.org/10.1109/
MICRO.2004.28. (Cited on pages 21, 23, and 24.)
[89] Eduardo Pinheiro. EPCKPT — a checkpoint utility for the linux ker-
nel, 2002. URL http://www.research.rutgers.edu/edpin/
epckpt/. (Cited on page 15.)
[90] James Plank. An overview of checkpointing in uniprocessor and
distributed systems, focusing on implementation and performance.
Technical report, University of Tennessee, Knoxville, TN, USA, 1997.
(Cited on page 13.)
[91] James S. Plank, Micah Beck, Gerry Kingsley, and Kai Li. Libckpt:
Transparent checkpointing under unix. In Proceedings of the USENIX
1995 Technical Conference Proceedings, TCON’95, page 18–18, Berke-
ley, CA, USA, 1995. USENIX Association. URL http://dl.acm.
org/citation.cfm?id=1267411.1267429. (Cited on page 15.)

BIBLIOGRAPHY 173
[92] James S. Plank, Jian Xu, and Robert H. B. Netzer. Compressed dif-
ferences: An algorithm for fast incremental checkpointing. Technical
Report CS-95-302, University of Tennessee, August 1995. (Cited on
pages 15 and 18.)
[93] Artem Y. Polyakov. Batch-queue plugin for DMTCP, March
2014. URL https://sourceforge.net/p/dmtcp/code/
HEAD/tree/trunk/plugin/batch-queue. (Cited on pages 9
and 81.)
[94] Bernard James Pope. A declarative debugger for Haskell. PhD thesis,
University of Melbourne, Department of Computer Science and Soft-
ware Engineering„ Victoria, Australia, 2007. (Cited on page 135.)
[95] Donald E. Porter, Silas Boyd-Wickizer, Jon Howell, Reuben Olinsky,
and Galen C. Hunt. Rethinking the library OS from the top down. In
Proceedings of the Sixteenth International Conference on Architectural
Support for Programming Languages and Operating Systems, ASPLOS
XVI, page 291–304, New York, NY, USA, 2011. ACM. ISBN 978-1-
4503-0266-1. doi: 10.1145/1950365.1950399. URL http://doi.
acm.org/10.1145/1950365.1950399. (Cited on page 24.)
[96] Daniel Price, Andrew Tucker, and Sun Microsystems. Solaris zones:
Operating system support for consolidating commercial workloads.
In In 18th Large Installation System Administration Conference, page
241–254, 2004. (Cited on page 23.)
[97] Eric Roman. A survey of Checkpoint/Restart implementations. Tech-
nical report, Lawrence Berkeley National Laboratory, Tech, 2002.
(Cited on page 13.)
[98] Jose Carlos Sancho, Fabrizio Petrini, Kei Davis, Roberto Gioiosa, and
Song Jiang. Current practice and a direction forward in check-
point/restart implementations for fault tolerance. In Parallel and

174 BIBLIOGRAPHY
Distributed Processing Symposium, 2005. Proceedings. 19th IEEE In-
ternational, pages 8 pp.–, April 2005. doi: 10.1109/IPDPS.2005.157.
(Cited on page 13.)
[99] Sriram Sankaran, Jeffrey M. Squyres, Brian Barrett, Vishal Sahay, An-
drew Lumsdaine, Jason Duell, Paul Hargrove, and Eric Roman. The
Lam/Mpi Checkpoint/Restart framework: System-initiated check-
pointing. International Journal of High Performance Computing Ap-
plications, 19(4):479–493, November 2005. ISSN 1094-3420, 1741-
2846. doi: 10.1177/1094342005056139. URL http://hpc.
sagepub.com/content/19/4/479. (Cited on pages 18 and 19.)
[100] Martin Schulz, Greg Bronevetsky, Rohit Fernandes, Daniel Marques,
Keshav Pingali, and Paul Stodghill. Implementation and evaluation of
a scalable application-level checkpoint-recovery scheme for MPI pro-
grams. In Proceedings of the 2004 ACM/IEEE Conference on Supercom-
puting, SC ’04, page 38–, Washington, DC, USA, 2004. IEEE Computer
Society. ISBN 0-7695-2153-3. doi: 10.1109/SC.2004.29. URL http:
//dx.doi.org/10.1109/SC.2004.29. (Cited on page 15.)
[101] Love H. Seawright and Richard A. MacKinnon. VM/370: a study
of multiplicity and usefulness. IBM Syst. J., 18(1):4–17, March 1979.
ISSN 0018-8670. doi: 10.1147/sj.181.0004. URL http://dx.doi.
org/10.1147/sj.181.0004. (Cited on page 129.)
[102] Josep Silva. A comparative study of algorithmic debugging strategies.
In Germán Puebla, editor, Logic-Based Program Synthesis and Trans-
formation, number 4407 in Lecture Notes in Computer Science, pages
143–159. Springer Berlin Heidelberg, January 2007. ISBN 978-3-
540-71409-5, 978-3-540-71410-1. URL http://link.springer.
com/chapter/10.1007/978-3-540-71410-1_11. (Cited on
page 135.)

BIBLIOGRAPHY 175
[103] Standard Performance Evaluation Corporation SPEC. SPECjbb2005,
March 2014. URL http://www.spec.org/jbb2005. (Cited on
pages 112 and 116.)
[104] G. Stellner. CoCheck: checkpointing and process migration for MPI.
In Parallel Processing Symposium, 1996., Proceedings of IPPS ’96, The
10th International, pages 526–531, April 1996. doi: 10.1109/IPPS.
1996.508106. (Cited on page 18.)
[105] O.O. Sudakov, I.S. Meshcheriakov, and Y.V. Boyko. CHPOX: transpar-
ent checkpointing system for linux clusters. In 4th IEEE Workshop on
Intelligent Data Acquisition and Advanced Computing Systems: Technol-
ogy and Applications, 2007. IDAACS 2007, pages 159–164, September
2007. doi: 10.1109/IDAACS.2007.4488396. (Cited on page 17.)
[106] Michael M. Swift, Muthukaruppan Annamalai, Brian N. Bershad, and
Henry M. Levy. Recovering device drivers. ACM Trans. Comput.
Syst., 24(4):333–360, November 2006. ISSN 0734-2071. doi: 10.
1145/1189256.1189257. URL http://doi.acm.org/10.1145/
1189256.1189257. (Cited on page 35.)
[107] Hajime Tazaki, Frédéric Urbani, Emilio Mancini, Mathieu Lacage,
Daniel Camara, Thierry Turletti, and Walid Dabbous. Direct code
execution: Revisiting library OS architecture for reproducible net-
work experiments. In The 9th International Conference on emerg-
ing Networking EXperiments and Technologies (CoNEXT), Santa Bar-
bara, États-Unis, December 2013. URL http://hal.inria.fr/
hal-00880870. (Cited on page 24.)
[108] Boost Team. Boost serialization, March 2014. URL www.boost.
org/libs/serialization. (Cited on page 14.)

176 BIBLIOGRAPHY
[109] Condor Team. Condor standard universe, 2013. URL
http://research.cs.wisc.edu/htcondor/manual/v7.
9/2_4Road_map_Running.html. (Cited on pages 3 and 18.)
[110] Condor Team. The condor project homepage, March 2014. URL
http://www.cs.wisc.edu/condor/. (Cited on page 3.)
[111] CRIU Team. CRIU, December 2013. URL http://criu.org/.
(Cited on pages 3, 20, and 23.)
[112] FReD Team. FReD software, 2011. URL https://github.com/
fred-dbg/fred. (Cited on page 85.)
[113] Jenkins Team. Jenkins, March 2014. URL http://jenkins-ci.
org. (Cited on page 116.)
[114] KVM Team. KVM/QEmu, March 2014. URL http://wiki.qemu.
org/KVM. (Cited on pages 24 and 87.)
[115] Lguest Team. Lguest: The simple x86 hypervisor, March 2014. URL
http://lguest.ozlabs.org. (Cited on pages 24, 87, and 88.)
[116] Linux-VServer Team. Linux-VServer, 2003. URL http://
linux-vserver.org. (Cited on page 23.)
[117] LXC Team. LXC linux containers, December 2013. URL https://
linuxcontainers.org/. (Cited on pages 16, 20, and 23.)
[118] OpenVZ Team. OpenVZ, 2006. URL http://openvz.org. (Cited
on page 23.)
[119] Parallels Virtuozzo Containers Team. Parallels virtuozzo contain-
ers, 2014. URL http://www.parallels.com/products/pvc/.
(Cited on page 23.)

BIBLIOGRAPHY 177
[120] Python Team. Pickle: Python object serialization, March 2014.
URL https://docs.python.org/2/library/pickle.html.
(Cited on page 14.)
[121] QEmu Team. QEmu, 1998. URL http://qemu.org. (Cited on
page 87.)
[122] Thuan L. Thai and Hoang Lam. .NET Framework Essentials.
O’Reilly & Associates, Inc., Sebastopol, CA, USA, 2001. ISBN
0596001657. (Cited on page 22.)
[123] Douglas Thain and Miron Livny. Multiple bypass: Interposition agents
for distributed computing. Cluster Computing, 4(1):39–47, March
2001. ISSN 1386-7857. doi: 10.1023/A:1011412209850. URL
http://dx.doi.org/10.1023/A:1011412209850. (Cited on
page 21.)
[124] Mustafa M. Tikir and Jeffrey K. Hollingsworth. Hardware monitors
for dynamic page migration. Journal of Parallel and Distributed Com-
puting, 68(9):1186–1200, September 2008. ISSN 0743-7315. doi:
10.1016/j.jpdc.2008.05.006. URL http://www.sciencedirect.
com/science/article/pii/S0743731508001020. (Cited on
pages 21, 23, and 24.)
[125] Anthony Velte and Toby Velte. Microsoft Virtualization with Hyper-
V. McGraw-Hill, Inc., New York, NY, USA, 1 edition, 2010. ISBN
0071614036, 9780071614030. (Cited on page 24.)
[126] Ana-Maria Visan. Temporal Meta-Programming: Treating Time as a
Spatial Dimension. PhD thesis, Northeastern University, 2012. (Cited
on page 9.)
[127] Ana-Maria Visan, Kapil Arya, Gene Cooperman, and Tyler Denniston.
URDB: a universal reversible debugger based on decomposing debug-

178 BIBLIOGRAPHY
ging histories. In Proc. of 6th Workshop on Programming Languages
and Operating Systems (PLOS) (part of Proc. of 23rd ACM Symp.
on Operating System Principles (SOSP)), 2011. electronic proceed-
ings at http://sigops.org/sosp/sosp11/workshops/plos/08-visan.pdf;
software for latest version, FReD (Fast Reversible Debugger), at
https://github.com/fred-dbg/fred. (Cited on pages 9, 71, 84, 135,
and 136.)
[128] Carl A. Waldspurger. Memory resource management in VMware
ESX server. In Proceedings of the 5th Symposium on Operating Sys-
tems Design and implementation, OSDI ’02, page 181–194, New
York, NY, USA, 2002. ACM. ISBN 978-1-4503-0111-4. doi: 10.
1145/1060289.1060307. URL http://doi.acm.org/10.1145/
1060289.1060307. (Cited on pages 91, 96, 97, 98, and 129.)
[129] John Paul Walters and Vipin Chaudhary. Application-level checkpoint-
ing techniques for parallel programs. In Sanjay K. Madria, Kajal T.
Claypool, Rajgopal Kannan, Prem Uppuluri, and Manoj Madhava
Gore, editors, Distributed Computing and Internet Technology, number
4317 in Lecture Notes in Computer Science, pages 221–234. Springer
Berlin Heidelberg, January 2006. ISBN 978-3-540-68379-7, 978-3-
540-68380-3. URL http://link.springer.com/chapter/10.
1007/11951957_21. (Cited on page 14.)
[130] Jon Watson. VirtualBox: bits and bytes masquerading as machines.
Linux J., 2008(166), February 2008. ISSN 1075-3583. URL http:
//dl.acm.org/citation.cfm?id=1344209.1344210. (Cited
on page 24.)
[131] Benjamin Wester, Peter M. Chen, and Jason Flinn. Operating sys-
tem support for application-specific speculation. In Proceedings of the
Sixth Conference on Computer Systems, EuroSys ’11, page 229–242,

BIBLIOGRAPHY 179
New York, NY, USA, 2011. ACM. ISBN 978-1-4503-0634-8. doi: 10.
1145/1966445.1966467. URL http://doi.acm.org/10.1145/
1966445.1966467. (Cited on page 134.)
[132] David A. Wheeler. SLOCCount: source lines of code counter, March
2014. URL http://www.dwheeler.com/sloccount. (Cited on
page 73.)
[133] Namyoon Woo, Soonho Choi, hyungsoo Jung, Jungwhan Moon,
Heon Y. Yeom, Taesoon Park, and Hyungwoo Park. MPICH-GF: pro-
viding fault tolerance on grid environments. In Proceedings of 3rd
IEEE/ACM International Symposium on Cluster Computing and the
Grid (CCGrid 2003), 2003. Published: The 3rd IEEE/ACM Interna-
tional Symposium on Cluster Computing and the Grid (CCGrid2003),
the poster and research demo session May, 2003, Tokyo, Japan.
(Cited on page 18.)
[134] Bob Woodruff, Sean Hefty, Roland Dreier, and Hal Rosenstock. In-
troduction to the InfiniBand core software. In Proceedings of the
Linux Symposium (Volume Two), page 271–282, Ottawa, Canada, July
2005. (Cited on page 35.)
[135] Victor C. Zandy. ckpt — a process checkpoint library, 2005. URL
http://cs.wisc.edu/~zandy/ckpt/. (Cited on page 23.)
[136] Victor C. Zandy, Barton P. Miller, and Miron Livny. Process hijack-
ing. In The Eighth International Symposium on High Performance Dis-
tributed Computing, 1999. Proceedings, pages 177–184, 1999. doi:
10.1109/HPDC.1999.805296. (Cited on pages 21 and 23.)
[137] Youhui Zhang, Dongsheng Wong, and Weimin Zheng. User-
level checkpoint and recovery for LAM/MPI. SIGOPS Oper. Syst.
Rev., 39(3):72–81, July 2005. ISSN 0163-5980. doi: 10.

180 BIBLIOGRAPHY
1145/1075395.1075402. URL http://doi.acm.org/10.1145/
1075395.1075402. (Cited on page 18.)
[138] Gengbin Zheng, Lixia Shi, and L.V. Kale. FTC-Charm++: an in-
memory checkpoint-based fault tolerant runtime for charm++ and
MPI. In 2004 IEEE International Conference on Cluster Comput-
ing, pages 93–103, September 2004. doi: 10.1109/CLUSTR.2004.
1392606. (Cited on page 18.)
[139] Hua Zhong and Jason Nieh. CRAK: linux Checkpoint/Restart as a
kernel module. Technical report CUCS-014-01, Dept. of Computer
Science, Columbia University, November 2001. (Cited on page 16.)





























