Embed Size (px)
Citation preview

Using Machine Learning to Discover and Understand Structured Data
William W. Cohen
Machine Learning Dept. and Language Technologies Inst.School of Computer ScienceCarnegie Mellon University

Outline
• Information integration: – Some history– The problem, the economics, and the
economic problem
• “Soft” information integration• Concrete uses of “soft” integration
– Classification– Collaborative filtering– Set expansion










When are two entities the same?
• Bell Labs• Bell Telephone Labs• AT&T Bell Labs• A&T Labs• AT&T Labs—Research• AT&T Labs Research,
Shannon Laboratory• Shannon Labs• Bell Labs Innovations• Lucent Technologies/Bell
Labs Innovations
History of Innovation: From 1925 to today, AT&T has attracted some of the world's greatest scientists, engineers and developers…. [www.research.att.com]
Bell Labs Facts: Bell Laboratories, the research and development arm of Lucent Technologies, has been operating continuously since 1925… [bell-labs.com]
[1925]

In the once upon a time days of the First Age of Magic, the prudent sorcerer regarded his own true name as his most valued possession but also the greatest threat to his continued good health, for--the stories go--once an enemy, even a weak unskilled enemy, learned the sorcerer's true name, then routine and widely known spells could destroy or enslave even the most powerful. As times passed, and we graduated to the Age of Reason and thence to the first and second industrial revolutions, such notions were discredited. Now it seems that the Wheel has turned full circle (even if there never really was a First Age) and we are back to worrying about true names again:
The first hint Mr. Slippery had that his own True Name might be known--and, for that matter, known to the Great Enemy--came with the appearance of two black Lincolns humming up the long dirt driveway ... Roger Pollack was in his garden weeding, had been there nearly the whole morning.... Four heavy-set men and a hard-looking female piled out, started purposefully across his well-tended cabbage patch.…
This had been, of course, Roger Pollack's great fear. They had discovered Mr. Slippery's True Name and it was Roger Andrew Pollack TIN/SSAN 0959-34-2861.


Deduction via co-operation
Site1Site2
Site3
KB1KB2
KB3
Standard Terminology
Integrated KB
UserEconomic issues:
• Who pays for integration? Who tracks errors & inconsistencies? Who fixes bugs? Who pushes for clarity in underlying concepts and object identifiers?
• Standards approach publishers are responsible publishers pay
• Mediator approach: 3rd party does the work, agnostic as to cost

LinkageQueries
Traditional approach:
Uncertainty about what to linkmust be decided by the integration
system, not the end user

Link items asneeded by Q
Query Q
SELECT R.a,S.a,S.b,T.b FROM R,S,T
WHERE R.a=S.a and S.b=T.b
R.a S.a S.b T.b
Anhai Anhai Doan Doan
Dan Dan Weld Weld
Strongest links: those agreeable to most users
William Will Cohen Cohn
Steve Steven Minton Mitton
Weaker links: those agreeable to some users
William David Cohen Cohneven weaker links…
WHIRL approach:

Link items asneeded by Q
WHIRL approach:
Query Q
SELECT R.a,S.a,S.b,T.b FROM R,S,T
WHERE R.a~S.a and S.b~T.b (~ TFIDF-similar)
R.a S.a S.b T.b
Anhai Anhai Doan Doan
Dan Dan Weld Weld
Incrementally produce a ranked list of possible links,
with “best matches” first. User (or downstream process)
decides how much of the list to generate and examine.
William Will Cohen Cohn
Steve Steven Minton Mitton
William David Cohen Cohn

WHIRL queries• Assume two relations:
review(movieTitle,reviewText): archive of reviews
listing(theatre, movieTitle, showTimes, …): now showing
The Hitchhiker’s Guide to the Galaxy, 2005
This is a faithful re-creation of the original radio series – not surprisingly, as Adams wrote the screenplay ….
Men in Black, 1997
Will Smith does an excellent job in this …
Space Balls, 1987
Only a die-hard Mel Brooks fan could claim to enjoy …
… …
Star Wars Episode III
The Senator Theater
1:00, 4:15, & 7:30pm.
Cinderella Man
The Rotunda Cinema
1:00, 4:30, & 7:30pm.
… … …

WHIRL queries
• “Find reviews of sci-fi comedies [movie domain]
FROM review SELECT * WHERE r.text~’sci fi comedy’
(like standard ranked retrieval of “sci-fi comedy”)
• “ “Where is [that sci-fi comedy] playing?”FROM review as r, LISTING as s, SELECT *
WHERE r.title~s.title and r.text~’sci fi comedy’
(best answers: titles are similar to each other – e.g., “Hitchhiker’s Guide to the Galaxy” and “The Hitchhiker’s Guide to the Galaxy, 2005” and the review text is similar to “sci-fi comedy”)

WHIRL queries• Similarity is based on TFIDF rare words are most important.
• Search for high-ranking answers uses inverted indices….
The Hitchhiker’s Guide to the Galaxy, 2005
Men in Black, 1997
Space Balls, 1987
…
Star Wars Episode III
Hitchhiker’s Guide to the Galaxy
Cinderella Man
…
Years are common in the review archive, so have low weight
hitchhiker movie00137
the movie001,movie003,movie007,movie008, movie013,movie018,movie023,movie0031,
…..
- It is easy to find the (few) items that match on “important” terms
- Search for strong matches can prune “unimportant terms”





Outline
• Information integration: – Some history– The problem, the economics, and the
economic problem
• “Soft” information integration• Concrete uses of “soft” integration
– Classification– Collaborative filtering– Set expansion











Outline
• Information integration: – Some history– The problem, the economics, and the
economic problem
• “Soft” information integration• Concrete uses of “soft” integration
– Classification– Collaborative filtering– Set expansion





Outline
• Information integration: – Some history– The problem, the economics, and the economic
problem
• “Soft” information integration• Concrete uses of “soft” integration
– Classification– Collaborative filtering– Set expansion: using generalized notion of
similarity

Recent work: non-textual similarity
“William W. Cohen, CMU”
“Dr. W. W. Cohen”
cohenwilliam w
drcmu
“George W. Bush”
“George H. W. Bush”
“Christos Faloutsos, CMU”

Recent work
• Personalized PageRank aka Random Walk with Restart:– Similarity measure for nodes in a graph, analogous
to TFIDF for text in a WHIRL database– natural extension to PageRank– amenable to learning parameters of the walk
(gradient search, w/ various optimization metrics):
• Toutanova, Manning & NG, ICML2004; Nie et al, WWW2005; Xi et al, SIGIR 2005
– various speedup techniques exist– queries:
Given type t* and node x, find y:T(y)=t* and y~x

proposal
CMU
CALO
graph
William
6/18/07
6/17/07
Sent To
Term In Subject
Learning to Search Email
[SIGIR 2006, CEAS 2006, WebKDD/SNA 2007]
Einat Minkov, CMU; Andrew Ng, Stanford

Tasks that are like similarity queries
Person namePerson namedisambiguationdisambiguation
ThreadingThreading
Alias findingAlias finding
[ term “andy” file msgId ]
“person”
[ file msgId ]
“file”
What are the adjacent messages in this thread?
A proxy for finding “more messages like this one”
What are the email-addresses of Jason ?...
[ term Jason ]
“email-address”
Meeting Meeting attendees finderattendees finder
Which email-addresses (persons) should I notify about this meeting? [ meeting mtgId ]
“email-address”

Learning to search better
Query a
node rank 1
node rank 2
node rank 3
node rank 4
…
node rank 10
node rank 11
node rank 12
…
node rank 50
Query b Query q
node rank 1
node rank 2
node rank 3
node rank 4
…
node rank 10
node rank 11
node rank 12
…
node rank 50
node rank 1
node rank 2
node rank 3
node rank 4
…
node rank 10
node rank 11
node rank 12
…
node rank 50
…
GRAPH WALK
+ Rel. answers a + Rel. answers b + Rel. answers q
Task T (query class)

Graph walk
Feature generatio
n
Learnre-ranker
Re-rankingfunction
Learning
Node re-ordering:
train task

Learning Approach
train task Graph walk
Feature generatio
n
Learnre-ranker
Re-rankingfunction
Graph walk
Feature generatio
n
Score byre-
ranking function
Node re-ordering:
Boosting
test task
[Collins & Koo, CL 2005; Collins, ACL 2002]
Voted Perceptron;RankSVM;
PerceptronCommittees;…
[Joacchim KDD 2002,Elsas et al WSDM 2008]

Graph walk
Weightupdate
Theta*
Learning approaches
Edge weight tuning:

Graph walk
Weightupdate
Graph walk
Learning approaches
Edge weight tuning:
Theta*
task
Graph walk
Feature generatio
n
Learnre-ranker
Re-rankingfunction
Graph walk
Feature generatio
n
Score byre-
ranking function
Node re-ordering:
Boosting;Voted Perceptron
Question: which is better?
[Diligenti et al, IJCAI 2005; Toutanova & Ng, ICML 2005; … ]

Results on one task
0%
20%
40%
60%
80%
100%
1 2 3 4 5 6 7 8 9 10
Rank
Rec
all
Mgmt. game
PER
SO
N
NA
ME
DIS
AM
BIG
UA
TIO
N

Results on several tasks (MAP)
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
M.game sager Shapiro
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
M.game Farmer Germany
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
Meetings
Namedisambiguation
Threading
Alias finding
*
*
*
*
*
*
*
*
** *
+
+
+
+ +
*

Set Expansion using the Web
• Fetcher: download web pages from the Web• Extractor: learn wrappers from web pages• Ranker: rank entities extracted by wrappers
1. Canon2. Nikon3. Olympus
4. Pentax5. Sony6. Kodak7. Minolta8. Panasonic9. Casio10. Leica11. Fuji12. Samsung13. …
Richard Wang, CMU

The Extractor
• Learn wrappers from web documents and seeds on the fly– Utilize semi-structured documents– Wrappers defined at character level
• No tokenization required; thus language independent
• However, very specific; thus page-dependent– Wrappers derived from document d is applied to d only

<img src="/common/logos/honda/logo-horiz-rgb-lg-dkbg.gif" alt="4"></a> <ul><li><a href="http://www.curryhonda-ga.com/"> <span class="dName">Curry Honda Atlanta</span>...</li> <li><a href="http://www.curryhondamass.com/"> <span class="dName">Curry Honda</span>...</li> <li class="last"><a href="http://www.curryhondany.com/"> <span class="dName">Curry Honda Yorktown</span>...</li></ul> </li>
<li class="honda"><a href="http://www.curryauto.com/">
<li class="acura"><a href="http://www.curryauto.com/">
<li class="toyota"><a href="http://www.curryauto.com/">
<li class="nissan"><a href="http://www.curryauto.com/">
<li class="ford"><a href="http://www.curryauto.com/"> <img src="/common/logos/ford/logo-horiz-rgb-lg-dkbg.gif" alt="3"></a> <ul><li class="last"><a href="http://www.curryauto.com/"> <span class="dName">Curry Ford</span>...</li></ul> </li>
<img src="/curryautogroup/images/logo-horiz-rgb-lg-dkbg.gif" alt="5"></a> <ul><li class="last"><a href="http://www.curryacura.com/"> <span class="dName">Curry Acura</span>...</li></ul> </li>
<img src="/common/logos/toyota/logo-horiz-rgb-lg-dkbg.gif" alt="7"></a> <ul><li class="last"><a href="http://www.geisauto.com/toyota/"> <span class="dName">Curry Toyota</span>...</li></ul> </li>
<img src="/common/logos/nissan/logo-horiz-rgb-lg-dkbg.gif" alt="6"></a> <ul><li class="last"><a href="http://www.geisauto.com/"> <span class="dName">Curry Nissan</span>...</li></ul> </li>
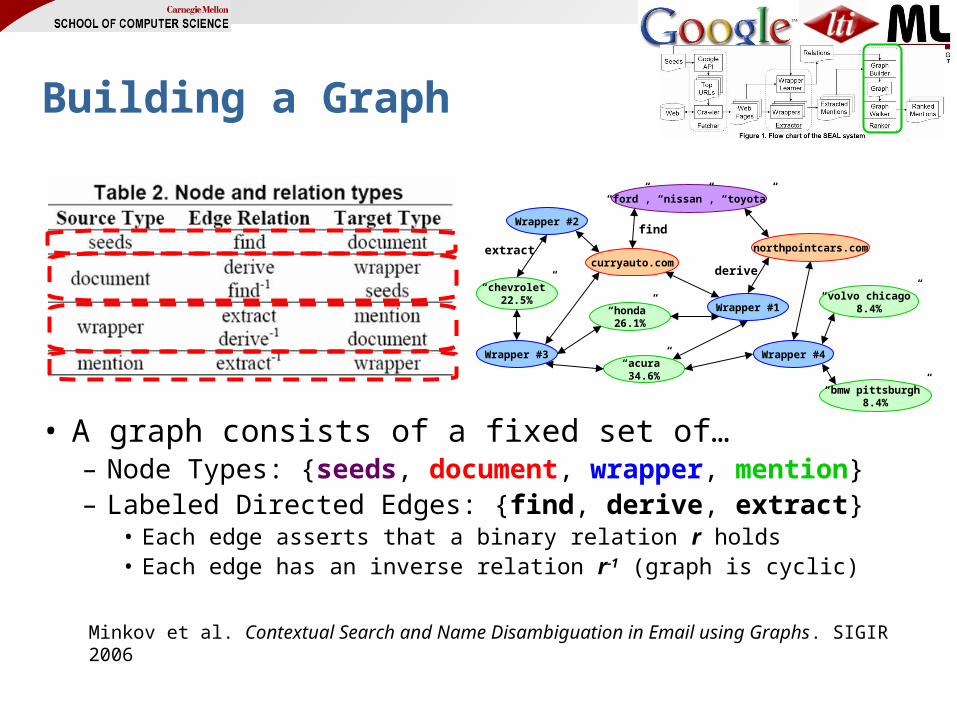
Building a Graph
• A graph consists of a fixed set of…– Node Types: {seeds, document, wrapper, mention}– Labeled Directed Edges: {find, derive, extract}
• Each edge asserts that a binary relation r holds• Each edge has an inverse relation r-1 (graph is cyclic)
“ford”, “nissan”, “toyota”
curryauto.com
Wrapper #3
Wrapper #2
Wrapper #1
Wrapper #4
“honda”26.1%
“acura”34.6%
“chevrolet”22.5%
“bmw pittsburgh”8.4%
“volvo chicago”8.4%
find
derive
extract northpointcars.com
Minkov et al. Contextual Search and Name Disambiguation in Email using Graphs. SIGIR 2006


Top three mentions are the seedsTry it out at http://rcwang.com/seal

Relational Set ExpansionSeeds

Additional relevant research
• Alon Halevey and friends:– “Pay as you go”, “on the fly”, data integration (e.g., SIGMOD 98):
integrate partially, then allow user to perform search to make up for inaccuracy of result
• Anhai Doan and friends:– “Best effort” information extraction (SIGMOD 98): write an approximate
program for extraction from web pages, then allow user to perform search to make up for inaccuracy of result
• Semi-structured extensions: – Kushmeric’s ELIXIR (SIGIR 2001); Bernstein’s iSPARQL (eg ESWC
2008)• Soft joins:
– Gravano et al WWW2003: Text Joints in an RDMS for Web Data Integration
– Bayardo et al, WWW2007: Scaling up all-pairs similarity search.– Koudas et al, SIGMOD 2006: Record linkage: similarity measures and
algorithms (survey)

Outline
• Information integration: – Some history– The problem, the economics, and the
economic problem
• “Soft” information integration• Concrete uses of “soft” integration
– Classification– Collaborative filtering– Set expansion– Questions?