Embed Size (px)
Citation preview

Using Percolated Dependencies in PBSMTUsing Percolated Dependencies in PBSMT
Ankit K. Srivastava and Andy Way
Dublin City University
CLUKI XII: April 24, 2009

About
PARSING PBSMT SYSTEM
Using Percolated Dependencies in Phrase Based Statistical Machine Translation
ENDNOTE ANALYSIS NUMBERS

Syntactic Parsing and Head Percolation
PARSING PBSMT SYSTEM
Using Percolated Dependencies in Phrase Based Statistical Machine Translation
ENDNOTE ANALYSIS NUMBERS
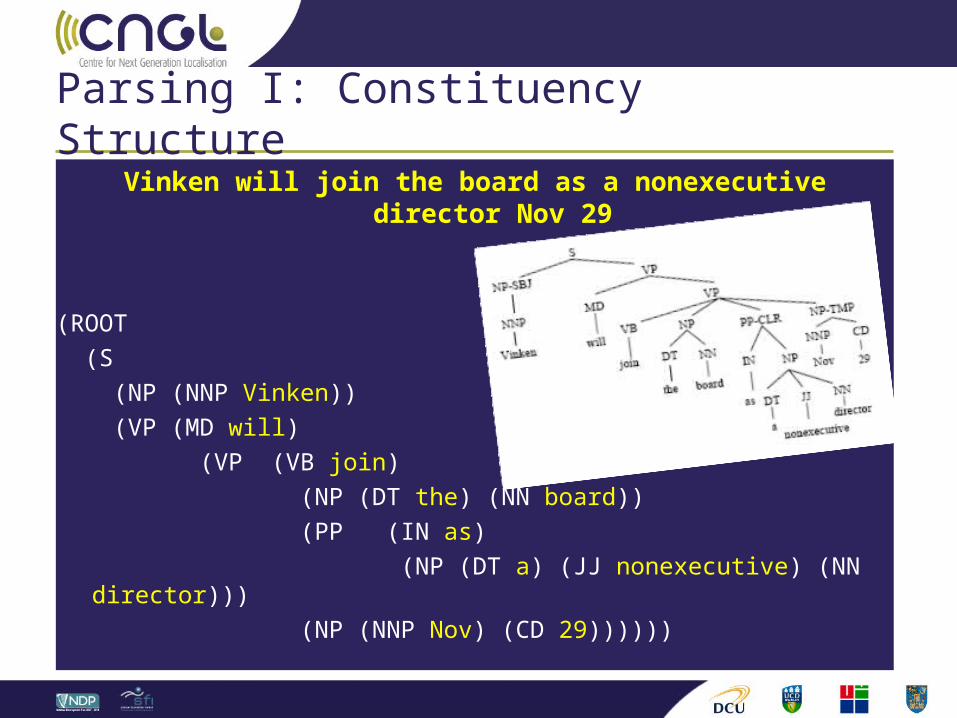
Parsing I: Constituency Structure
Vinken will join the board as a nonexecutive director Nov 29
(ROOT (S (NP (NNP Vinken)) (VP (MD will) (VP (VB join) (NP (DT the) (NN board)) (PP (IN as) (NP (DT a) (JJ nonexecutive) (NN director))) (NP (NNP Nov) (CD 29))))))
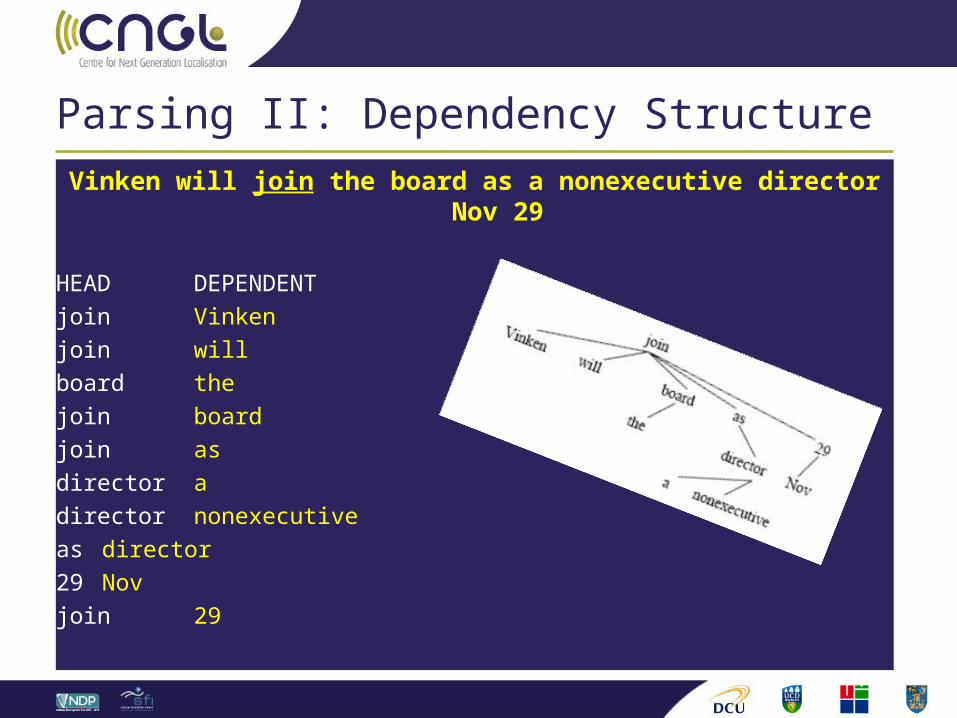
Vinken will join the board as a nonexecutive director Nov 29
HEAD DEPENDENTjoin Vinkenjoin willboard thejoin boardjoin asdirector adirector nonexecutiveas director29 Novjoin 29
Parsing II: Dependency Structure

Parsing III: Head Percolation It is straightforward to convert constituency tree to an unlabeled
dependency tree (Gaifman 1965) Use head percolation tables to identify head child in a constituency
representation (Magerman 1995) Dependency tree is obtained by recursively applying head child and
non-head child heuristics (Xia & Palmer 2001)
(NP (DT the) (NN board))
NP right NN/NNP/CD/JJ
(NP-board (DT the) (NN board))
the is dependent on board
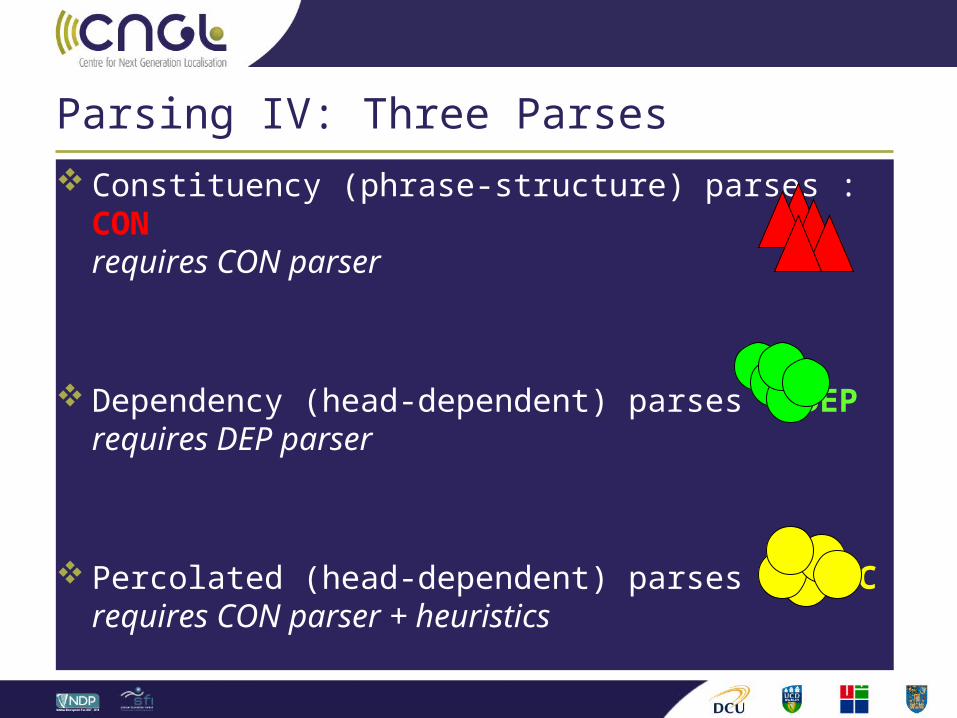
Parsing IV: Three Parses
Constituency (phrase-structure) parses : CONrequires CON parser
Dependency (head-dependent) parses : DEPrequires DEP parser
Percolated (head-dependent) parses : PERCrequires CON parser + heuristics

Phrase-Based Statistical Machine Translation
PARSING PBSMT SYSTEM
Using Percolated Dependencies in Phrase Based Statistical Machine Translation
ENDNOTE ANALYSIS NUMBERS

PBSMT I: Framework
argmaxe p(e|f) = argmaxe p(f|e) p(e)
Decoder, Translation Model, Language Model PBSMT framework in Moses (Koehn et al., 2007)
Phrase Table in Translation Model := Align words + extract phrases + score phrases
Different methods to extract phrases Moses phrase extraction as baseline system…
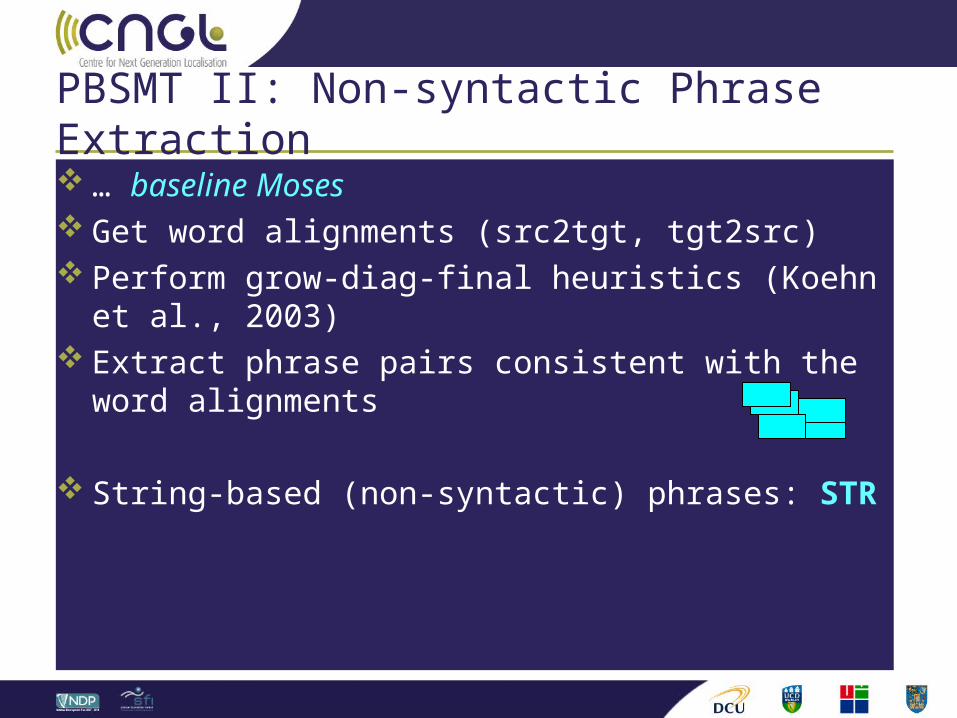
PBSMT II: Non-syntactic Phrase Extraction
… baseline Moses Get word alignments (src2tgt, tgt2src) Perform grow-diag-final heuristics (Koehn et al., 2003) Extract phrase pairs consistent with the word alignments
String-based (non-syntactic) phrases: STR
PBSMT III: Syntactic Phrase Extraction
Get word alignments (src2tgt, tgt2src) Parse src sentences Parse tgt sentences Use Tree Aligner to align subtree nodes (Zhechev 2009) Extract surface-level chunks from parallel treebanks Previously, Tinsley et al., 2007 & Hearne et al., 2008 Syntactic phrases:
CON DEP PERC

System Design
PARSING PBSMT SYSTEM
Using Percolated Dependencies in Phrase Based Statistical Machine Translation
ENDNOTE ANALYSIS NUMBERS

System I: Tools and Resources English-French parallel corpora Phrase Structure Parsers (En, Fr) Dependency Structure Parsers (En, Fr) Head Percolation tables (En, Fr) Statistical Tree Aligner Giza++ Word Aligner SRILM (Language Modeling) Toolkit Moses Decoder
CORPORA TRAIN DEV TEST
JOC 7,723 400 599
EUROPARL 100,000 1,889 2,000
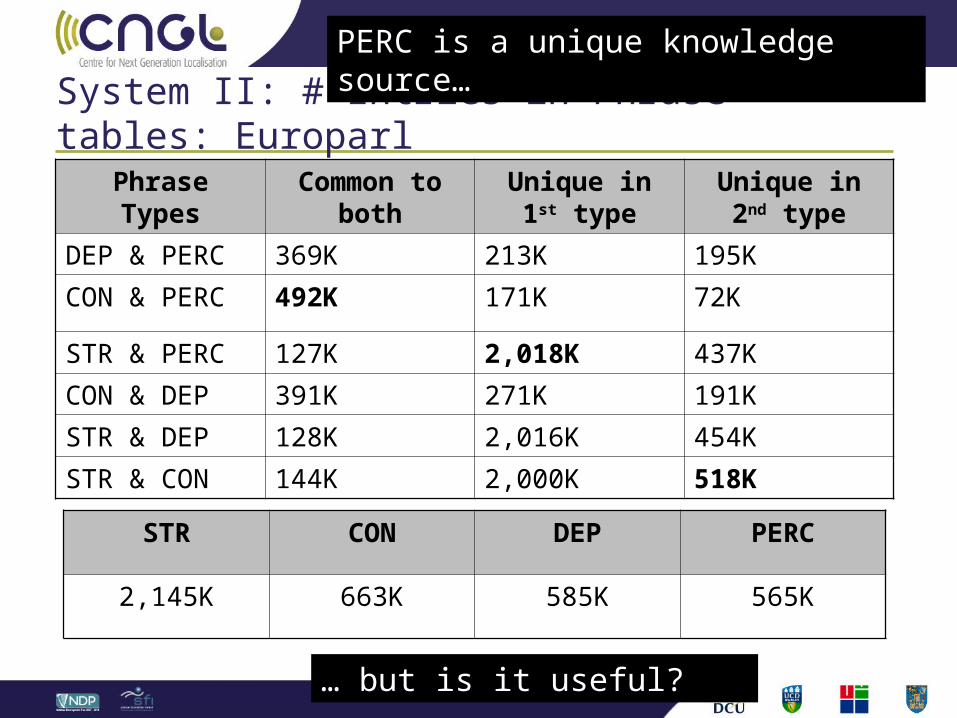
System II: # Entries in Phrase tables: Europarl
Phrase Types Common to both
Unique in 1st type
Unique in 2nd type
DEP & PERC 369K 213K 195K
CON & PERC 492K 171K 72K
STR & PERC 127K 2,018K 437K
CON & DEP 391K 271K 191K
STR & DEP 128K 2,016K 454K
STR & CON 144K 2,000K 518K
STR CON DEP PERC
2,145K 663K 585K 565K
PERC is a unique knowledge source…
… but is it useful?

System III: Combinations Concatenate phrase tables and re-estimate probabilities 15 different systems: ∑4Cr , 1≤r≤4
STR CON DEP PERC
UNI BI TRI QUAD
S SC, SD, SP SCD, SCP, SDP SCDP
C CD, CP CDP -
D DP - -
P - - -

MT Systems and Evaluation
PARSING PBSMT SYSTEM
Using Percolated Dependencies in Phrase Based Statistical Machine Translation
ENDNOTE ANALYSIS NUMBERS
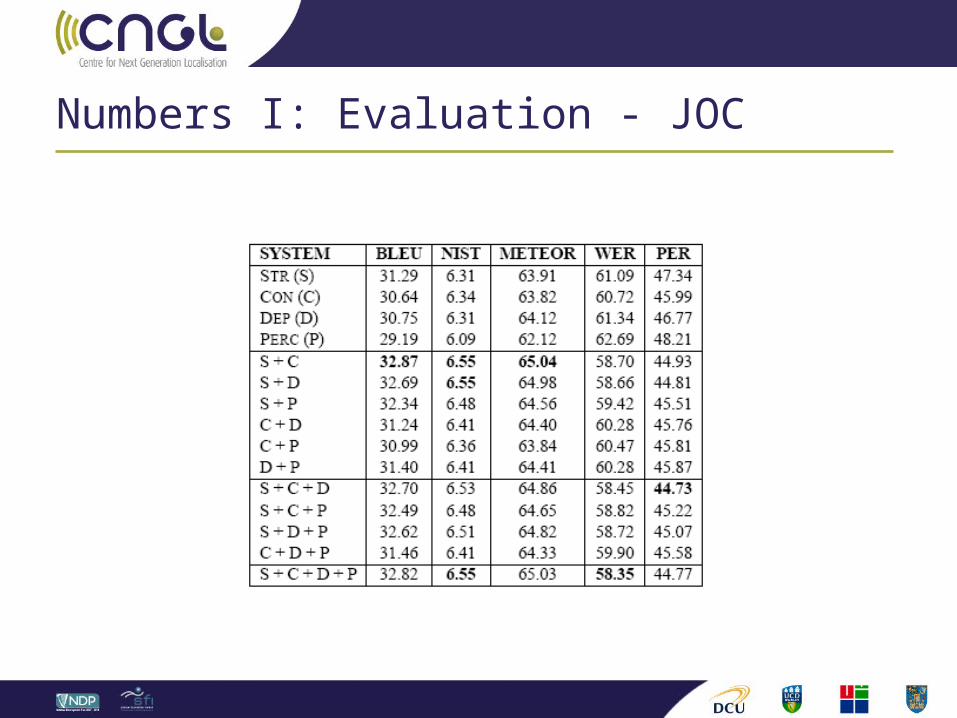
Numbers I: Evaluation - JOC
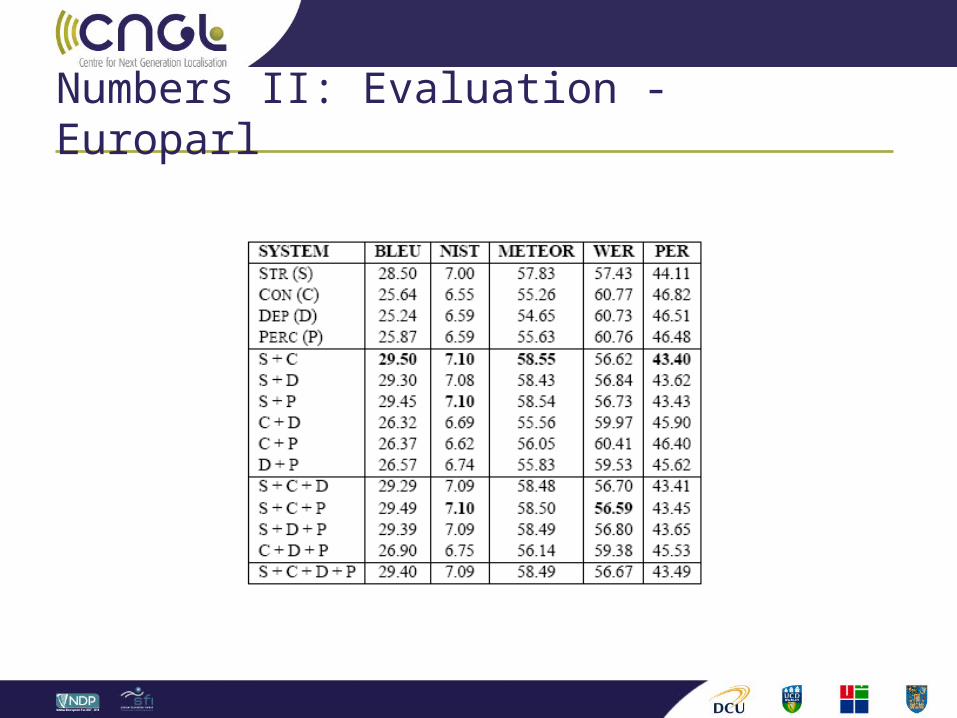
Numbers II: Evaluation - Europarl
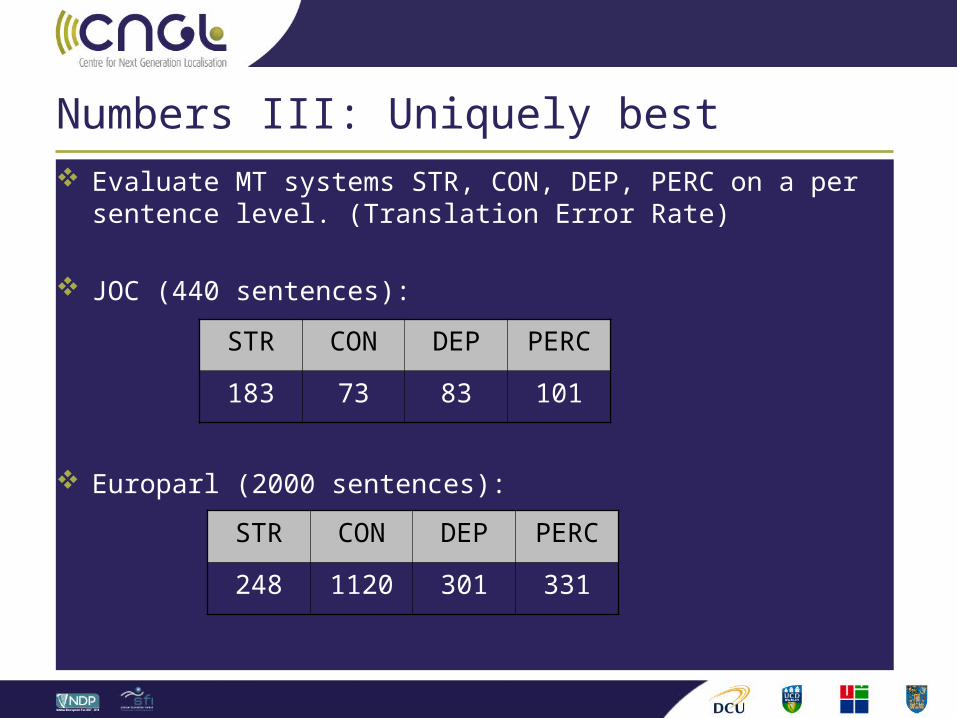
Numbers III: Uniquely best Evaluate MT systems STR, CON, DEP, PERC on a per sentence
level. (Translation Error Rate)
JOC (440 sentences):
Europarl (2000 sentences):
STR CON DEP PERC
183 73 83 101
STR CON DEP PERC
248 1120 301 331
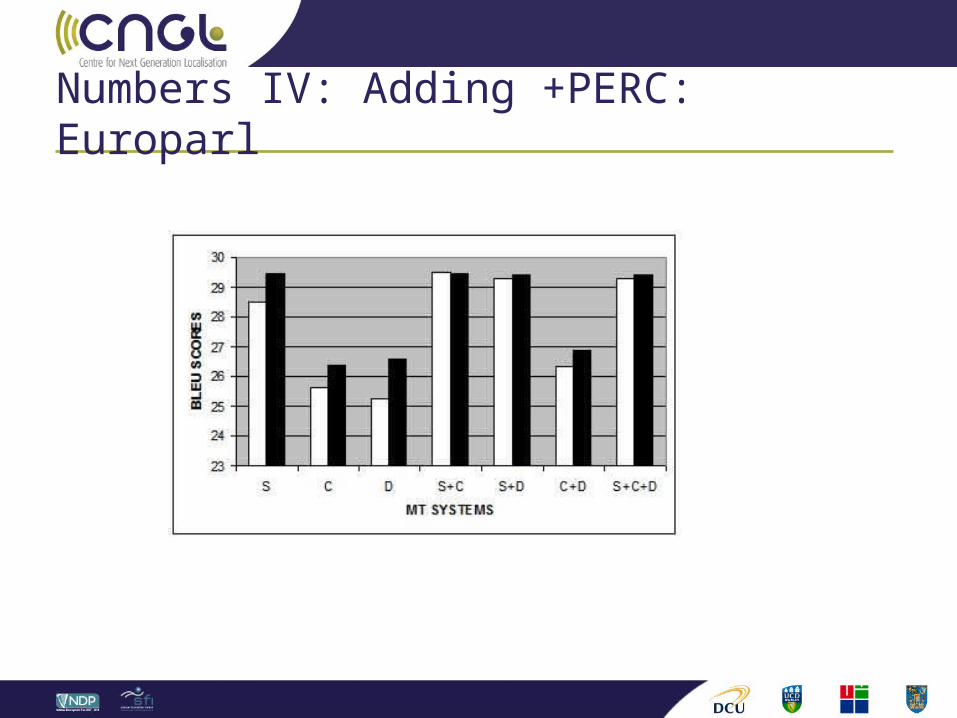
Numbers IV: Adding +PERC: Europarl

Analysis of Results
PARSING PBSMT SYSTEM
Using Percolated Dependencies in Phrase Based Statistical Machine Translation
ENDNOTE ANALYSIS NUMBERS

Analysis I: STR
Using Moses baseline phrases (STR) is essential for coverage. SIZE matters!
However, adding any system to STR increases baseline score. Symbiotic!
Hence, do not replace STR, but augment it.
Analysis II: CON
Seems to be the best combination with STR (S+C seems to be the best performing system)
Has most common chunks with PERC
Does PERC harm a CON system – needs more analysis
Analysis III: DEP
PERC is different from DEP chunks, despite being formally equivalent
PERC can substitute DEP

Analysis IV: PERC
Is a unique knowledge source.
Sometimes, it helps.
Needs more work on finding connection with CON / DEP

Conclusion & Future Work
PARSING PBSMT SYSTEM
Using Percolated Dependencies in Phrase Based Statistical Machine Translation
ENDNOTE ANALYSIS NUMBERS

Conclusion & Future Work
Extended Hearne et al., 2008 by- scaling up data size from 7.7K to 100K- introducing percolated dependencies in PBSMT
Manual evaluation More analysis of results More combining strategies Seek to determine if each chunk type “owns” sentence
types
Thanks
<asrivastava @ computing.dcu.ie>





























