Embed Size (px)
Citation preview

V. Clustering
2007.2.10.인공지능 연구실 이승희Text: Text mining
Page:82-93

Outline
V.1 Clustering tasks in text analysis
V.2 The general clustering problemV.3 Clustering algorithmV.4 Clustering of textual data

Clustering
Clustering• An unsupervised process through which
objects are classified into groups called cluster.
(cf. categorization is a supervised process.)• Data mining, document retrieval, image
segmentation, pattern classification.

V.1 Clustering tasks in text analysis(1/2)
Cluster hypothesis“Relevant documents tend to be more similar to each other than to nonrelevant ones.”
If cluster hypothesis holds for a particular document collection, then the clustering of documents may help to improve the search effectiveness.
• Improving search recall When a query matches a document its whole cluster can be retu
rn• Improving search precision
By grouping the document into a much smaller number of groups of related documents

V.1 Clustering tasks in text analysis(2/2)
• Scatter/gather browsing method Purpose: to enhance the efficiency of human browsing of a doc
ument collection when a specific search query cannot be a formulated.
Session1: a document collection is scattered into a set of clusters.
Sesson2: then the selected clusters are gathered into a new subcollection with which the process may be repeated.
참고사이트– http://www2.parc.com/istl/projects/ia/sg-backgroun
d.html
• Query-Specific clustering are also possible. - the hierarchical clustering is appealing

V.2 Clustering problem(1/2)
Cluster tasks• problem representation• definition proximity measures• actual clustering of objects• data abstraction• evalutation
Problem representation• Basically, optimization problem.• Goal: select the best among all possible groupings of objects• Similarity function: clustering quality function. • Feature extraction/ feature selection• In a vector space model,
objects: vectors in the high-dimensional feature space. the similarity function: the distance between the vectors in some metric

V.2 Clustering problem(2/2)
Similarity Measures• Euclidian distance
• Cosine similarity measure is the most common
k
jkikjiji xxxxxxSim )(),(
k
kjkj2
ii )y(x)y,D(x

V.3 Clustering algorithm (1/9)
• flat clustering: a single partition of a set of
objects into disjoint groups.• hierarchical clustering: a nested series of
partition.
• hard clustering: every objects may belongs to exactly one cluster.
• soft clustering: objects may belongs to several clusters with a fractional degree of membership in each.

V.3 Clustering algorithm (2/9)
• Agglomerative algorithm: begin with each
object in a separate cluster and successively merge cluster until a stopping criterion is satisfied.
• Divisive algorithm: begin with a single cluster containing all objects and perform splitting until stopping criterion satisfied.
• Shuffling algorithm: iteratively redistribute objects in clusters

V.3 Clustering algorithm (3/9)
k-means algorithm(1/2)• hard, flat, shuffling algorithm

V.3 Clustering algorithm (4/9)
•example of K-means algorithm

V.3 Clustering algorithm (5/9)
K-means algorithm(2/2)• Simple, efficient• Complexity O(kn)• bad initial selection of seeds.-> local optimal.• k-means suboptimality is also exist.-> Buckshot
algorithm. ISO-DATA algorithm• Maximizes the quality function Q:
)(),...,,Q( 21
i iC Cx
ik MxSimCCC

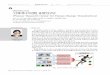
V.3 Clustering algorithm (6/9)
EM-based probabilistic clustering algorithm(1/2)• Soft, flat, probabilistic
V.3 Clustering algorithm (7/9)

V.3 Clustering algorithm (8/9)
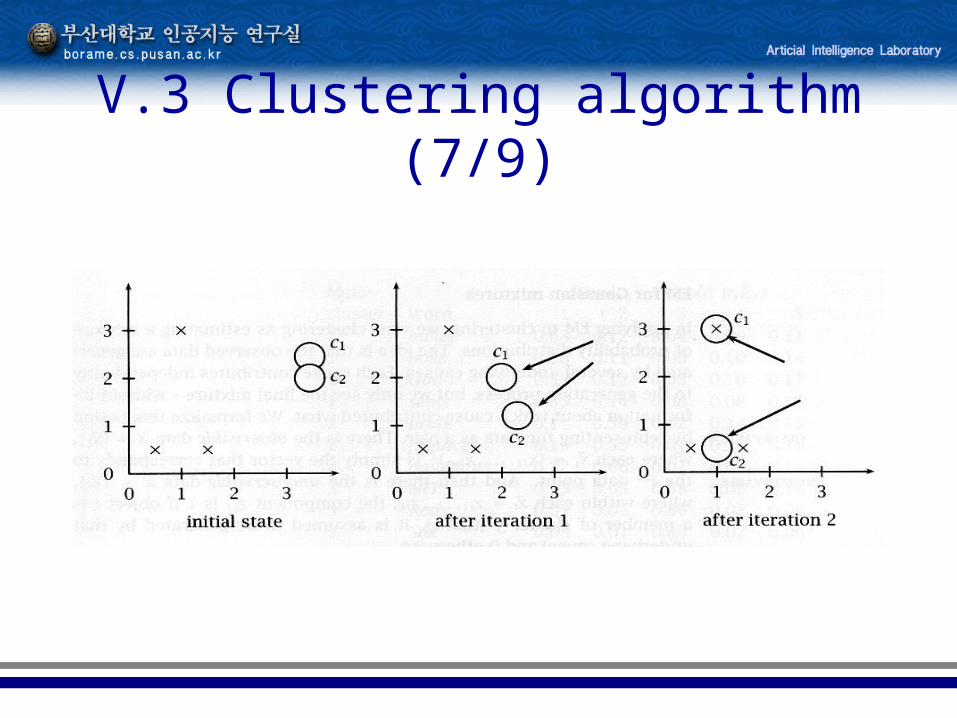
Hierarchical agglomerative Clustering
• single-link method• Complete-link method• Average-link method
V.3 Clustering algorithm (9/9)

Other clustering algorithms
minimal spanning treenearest neighbor clusteringBuckshot algorithm

V.4 clustering of textual data(1/6)
representation of text clustering problem• Objects are very complex and rich internal structur
e.• Documents must be converted into vectors in the f
eature space.• Bag-of-words document representation.• Reducing the dimensionality
Local method: delete unimportant components from individual document vectors.
Global method: latent semantic indexing(LSI)

V.4 clustering of textual data(2/6)
latent semantic indexing• map N-dimensional feature space F
onto a lower dimensional subspace V.• LSI is based upon applying the SVD to
the term-document matrix.

V.4 clustering of textual data(3/6)
Singular value decomposition (SVD)A = UDVT
U : column-orthonormal mxr matrixD: diagonal rxr matrix, matrix,digonal elements are the singular value
s of A
V: column-orthonormal nxrUUT = VTV = I
Dimension reduction
TTTTTT
T
VDDVVDUUDVAA
VDU A
V.4 clustering of textual data(4/6)
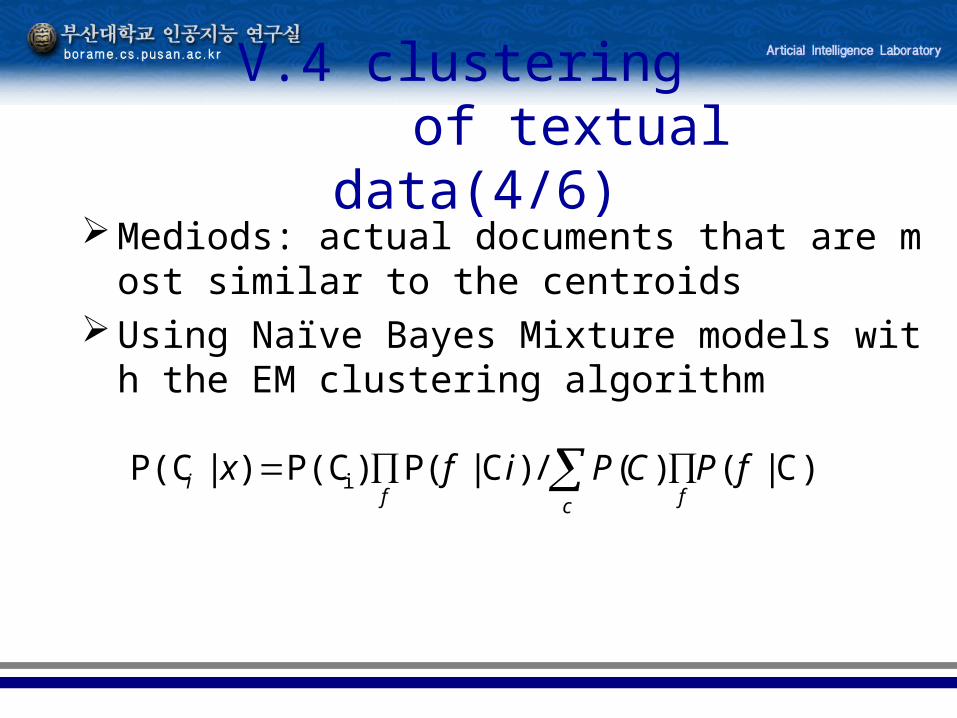
Mediods: actual documents that are most similar to the centroids
Using Naïve Bayes Mixture models with the EM clustering algorithm
)C|()(/)C|(P)P(C)|P(C i fPCPifxc ff
i

V.4 clustering of textual data(5/6)
Data abstraction in text clustering• generating meaningful and concise description of
the cluster.• method of generating the label automatically
a title of the medoid documentseveral words common to the cluster documents can b
e shown.a distinctive noun phrase.

V.4 clustering of textual data(6/6)
||/||max)( iijji CCLCPurity
Evaluation of text clustering - the quality of the result?• purity
assume {L1,L2,...,Ln} are the manually labeled classes of documents, {C1,C2,...,Cm} the clusters returned by the clustering process
• entropy, mutual information between classes and clusters