Embed Size (px)
Citation preview

SEOUL | Oct.7, 2016
Tran Minh Quan and Won-Ki Jeong
High-performance Visual Computing Laboratory, NVIDIA GPU Research Center
http://hvcl.unist.ac.kr
VARIOUS OPTIMIZATION STRATEGIES FOR IMPLEMENTING FAST DISCRETE WAVELET TRANSFORMS ON GPUS

2
AGENDA
Introduction
Related work
Background
GPU Optimization Strategies
Results and Discussions
Conclusions

3
INTRODUCTION
4
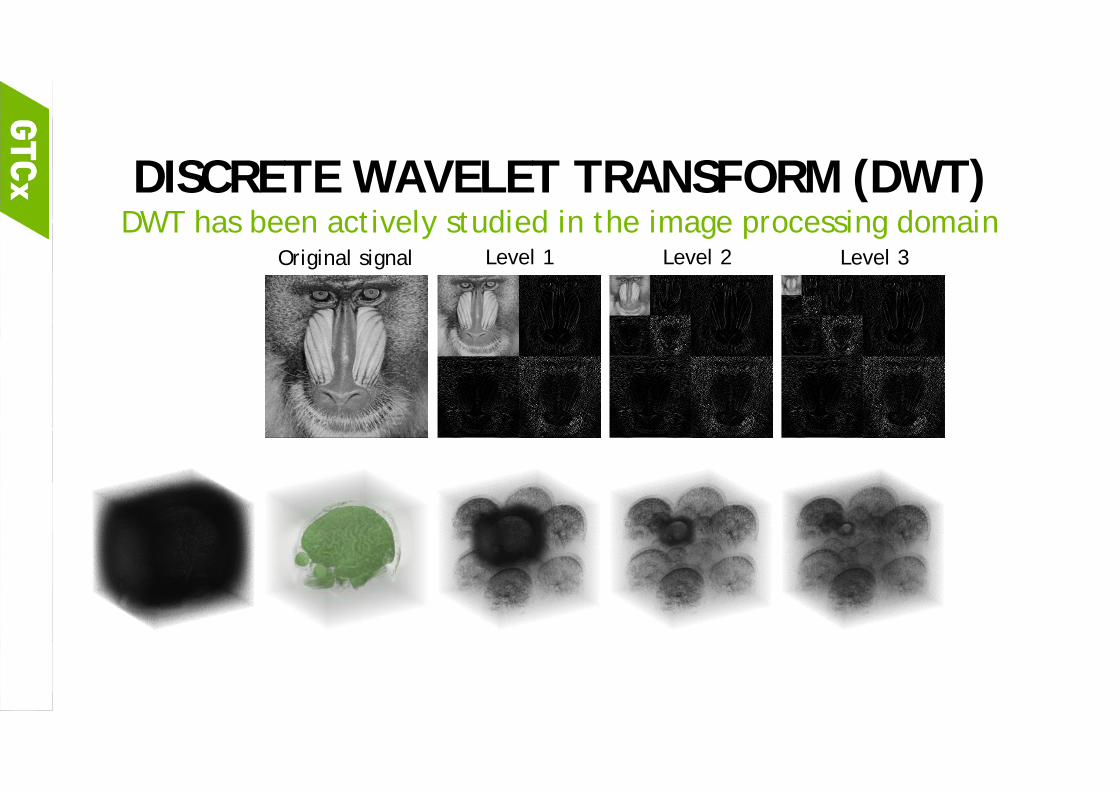
DISCRETE WAVELET TRANSFORM (DWT)DWT has been actively studied in the image processing domain
Original signal Level 1 Level 2 Level 3

5
DISCRETE WAVELET TRANSFORM (DWT)DWT can be accelerated by using special hardware (FPGAs, MIC, GPUs)
NVIDIA CUDA and OpenCL

6
RELATED WORK
7
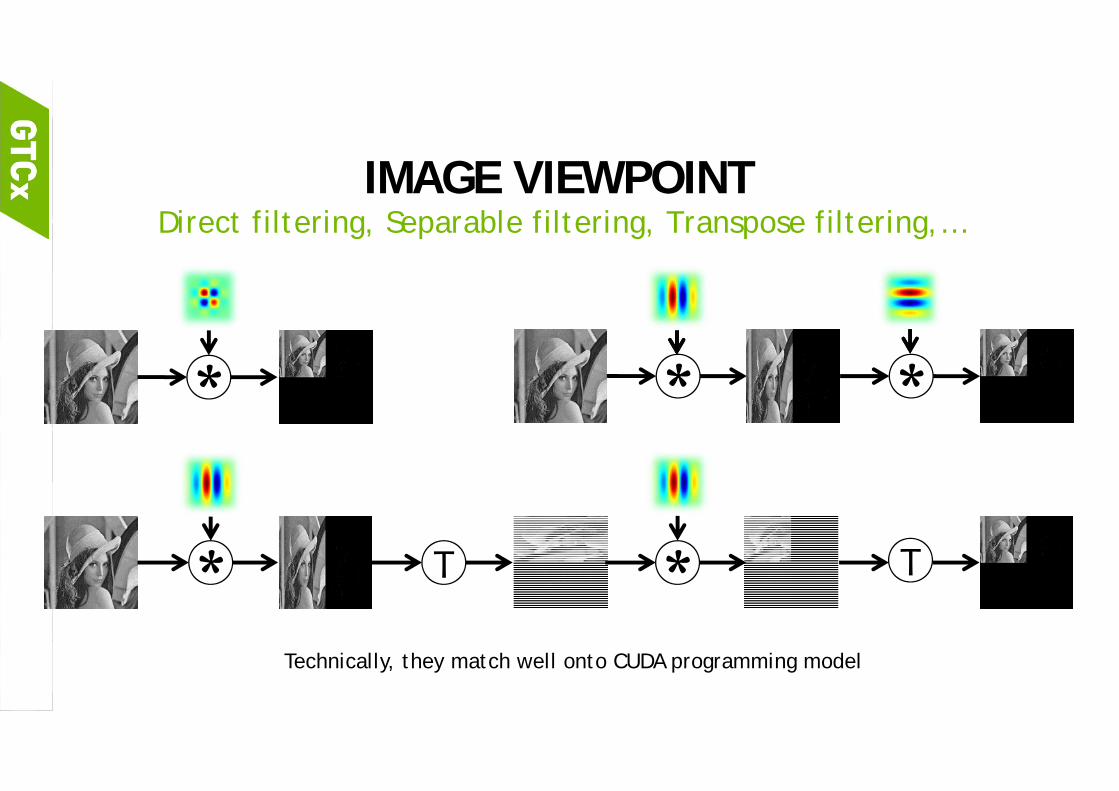
IMAGE VIEWPOINTDirect filtering, Separable filtering, Transpose filtering,…
* **
* T * T
Technically, they match well onto CUDA programming model

8
LITURATURE SUMMARY Recent GPU-based Discrete Wavelet Transform
[2009] J. Matela, “GPU–Based DWT acceleration for JPEG2000,” 2D filtered + shared memory[2009] J. Franco, G. Bernabe, J. Fernandez, and M. Acacio, “A parallel implementation of the 2D wavelettransform using CUDA,”[2010] J. Franco, G. Bernab, J. Fernndez, and M. Ujaldn, “Parallel 3D fast wavelet transform on many-coreGPUs and multicore CPUs,” 1D filtering + 2D transpose[2009] W. van der Laan, J. B. T. M. Roerdink, and A. Jalba, “Accelerating wavelet-based video coding ongraphics hardware using CUDA,” 1D lifting scheme + shared memory[2011] W. van der Laan, A. Jalba, and J. B. T. M. Roerdink, “Accelerating wavelet lifting on graphicshardware using CUDA,” 1D lifting scheme + shared memory + sliding windows[2011] C. Song, Y. Li, and B. Huang, “A GPU-accelerated wavelet decompression system with SPIHT andreed-solomon decoding for satellite images,” 1D lifting scheme + shared memory[2014] C. Song, Y. Li, J. Guo, and J. Lei, “Block-based two-dimensional wavelet transform running ongraphics processing unit,” 2D lifting scheme + shared memory[2015] P. Enfedaque, F. Auli-Llinas, and J. Moure, “Implementation of the DWT in a GPU through a register-based strategy,” 2D lifting scheme + register-based + warp shuffles

9
BACKGROUND: DISCRETE WAVELET TRANSFORM

10
WAVELET LIFTING SCHEMESHaar wavelet family
Haar CDF 5/3 CDF 9/7
α 1.0 0.50 1.58613434
β 0.5 0.25 0.05298012
γ N/A N/A 0.88291108
δ N/A N/A 0.44350685

11
WAVELET LIFTING SCHEMESCDF 5/3 wavelet family
Haar CDF 5/3 CDF 9/7
α 1.0 0.50 1.58613434
β 0.5 0.25 0.05298012
γ N/A N/A 0.88291108
δ N/A N/A 0.44350685

12
WAVELET LIFTING SCHEMESCDF 9/7 wavelet family
Haar CDF 5/3 CDF 9/7
α 1.0 0.50 1.58613434
β 0.5 0.25 0.05298012
γ N/A N/A 0.88291108
δ N/A N/A 0.44350685
halo halo
13
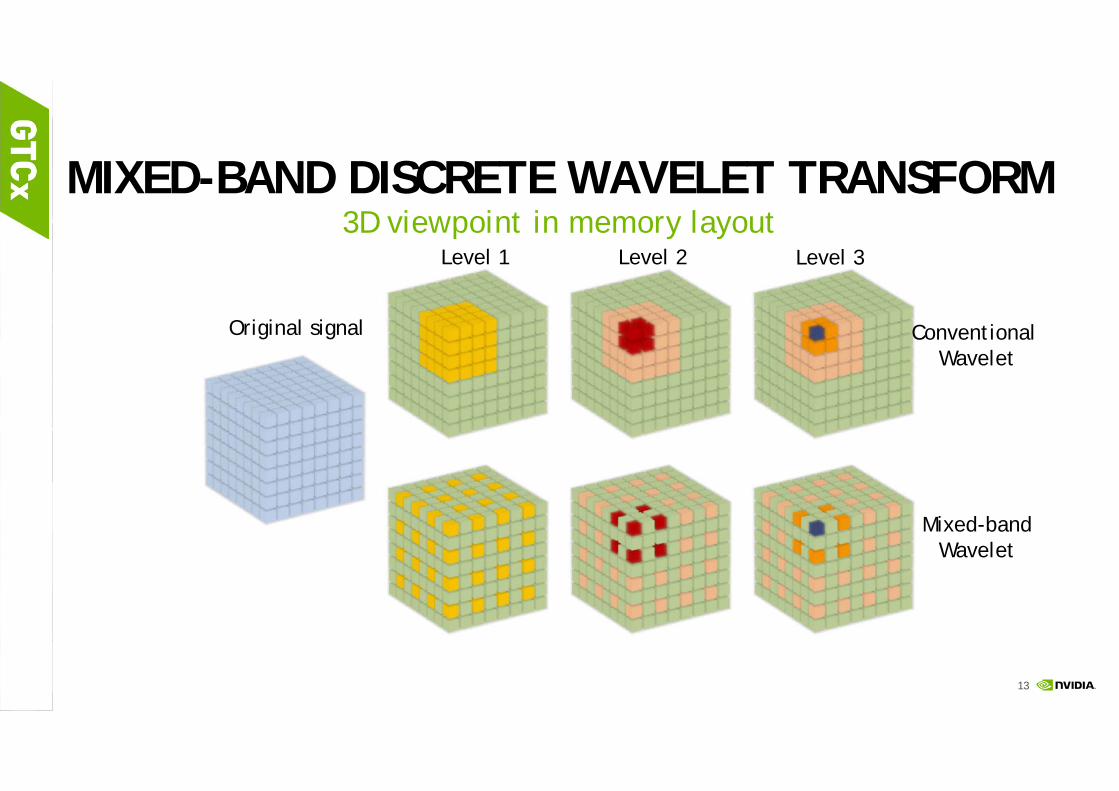
MIXED-BAND DISCRETE WAVELET TRANSFORM3D viewpoint in memory layout
Original signal
Level 1 Level 2
Mixed-bandWavelet
Conventional Wavelet
Level 3
14
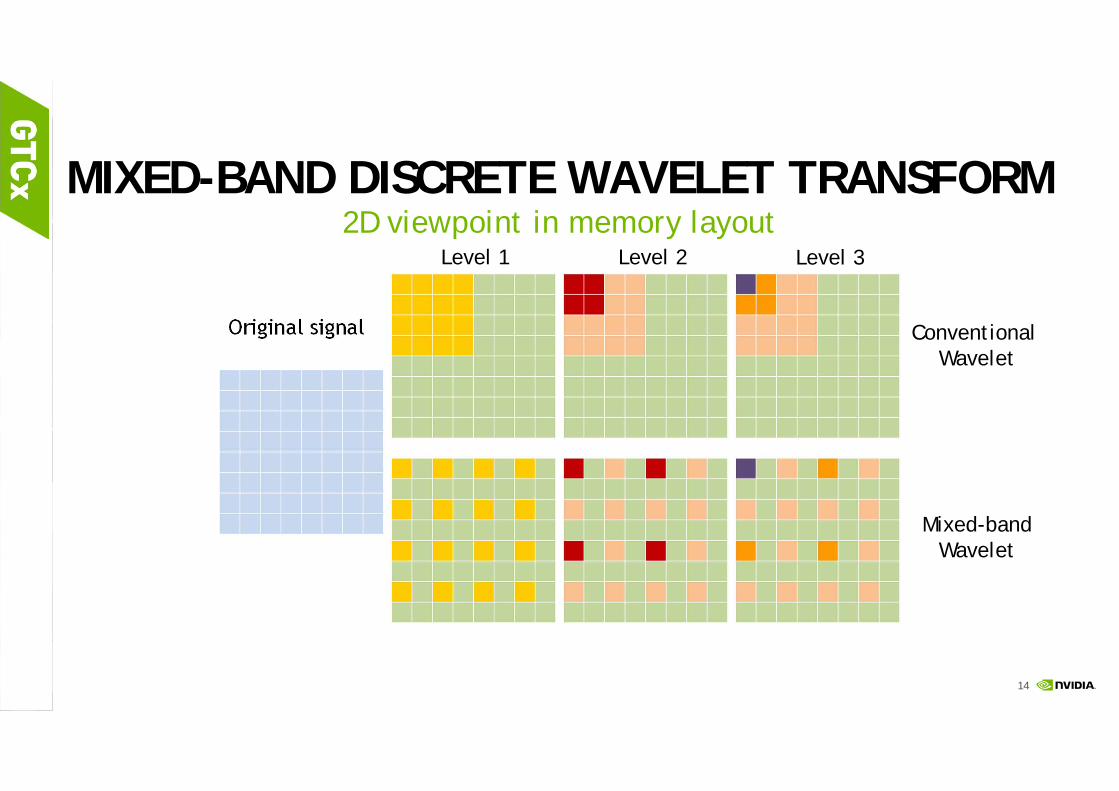
MIXED-BAND DISCRETE WAVELET TRANSFORM2D viewpoint in memory layout
Original signal
Level 1 Level 2
Mixed-bandWavelet
Conventional Wavelet
Level 3
15
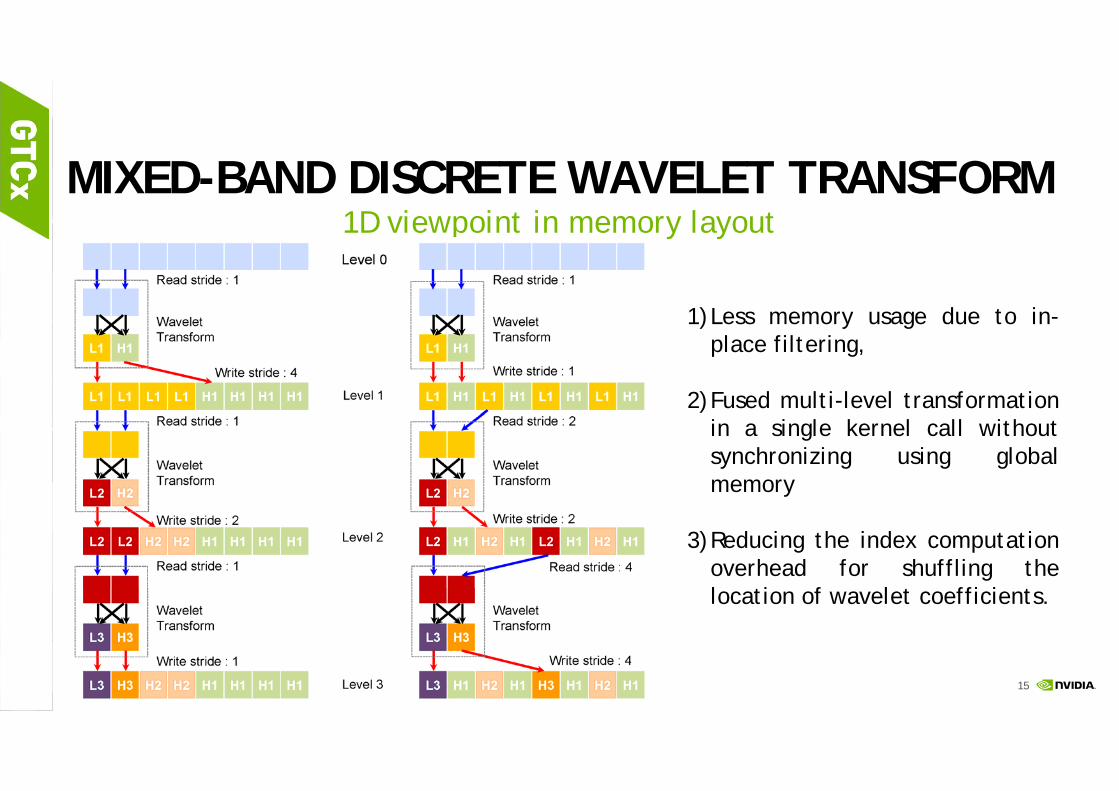
MIXED-BAND DISCRETE WAVELET TRANSFORM1D viewpoint in memory layout
1)Less memory usage due to in-place filtering,
2)Fused multi-level transformationin a single kernel call withoutsynchronizing using globalmemory
3)Reducing the index computationoverhead for shuffling thelocation of wavelet coefficients.
16
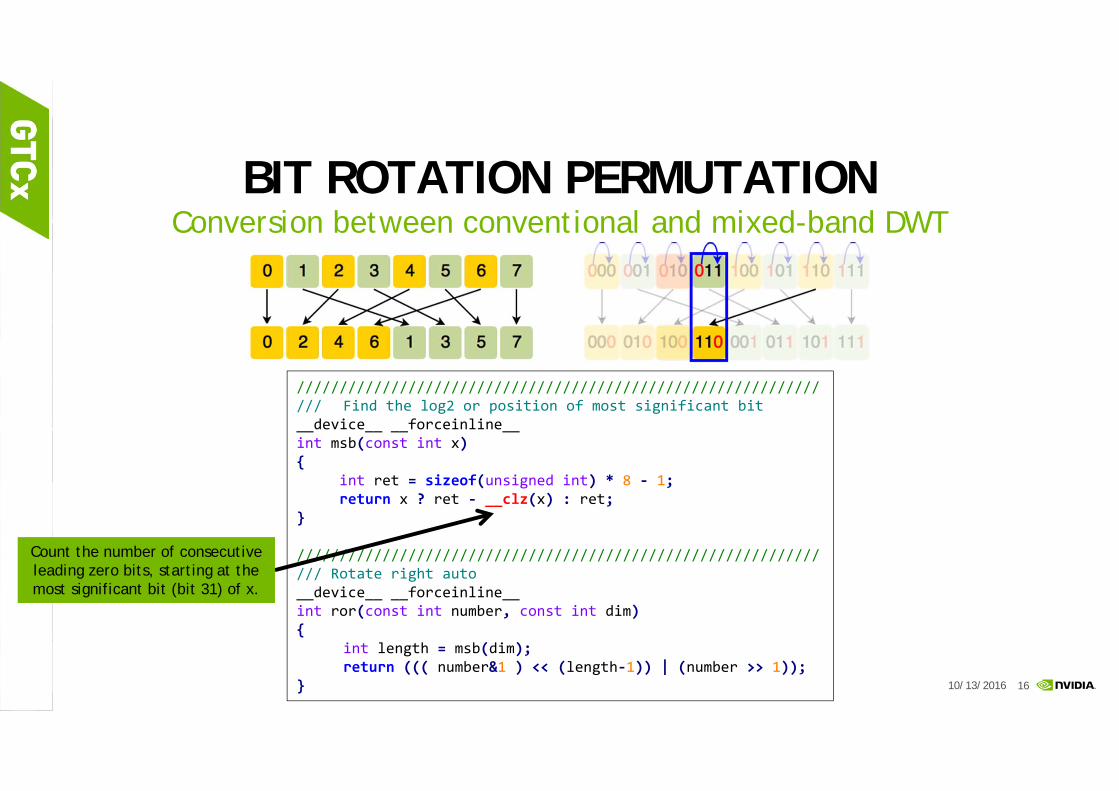
BIT ROTATION PERMUTATIONConversion between conventional and mixed-band DWT
10/13/2016
//////////////////////////////////////////////////////////////// Find the log2 or position of most significant bit __device__ __forceinline__ int msb(const int x){
int ret = sizeof(unsigned int) * 8 ‐ 1;return x ? ret ‐ __clz(x) : ret;
}
//////////////////////////////////////////////////////////////// Rotate right auto __device__ __forceinline__int ror(const int number, const int dim){
int length = msb(dim);return ((( number&1 ) << (length‐1)) | (number >> 1));
}
Count the number of consecutive leading zero bits, starting at the most significant bit (bit 31) of x.

17
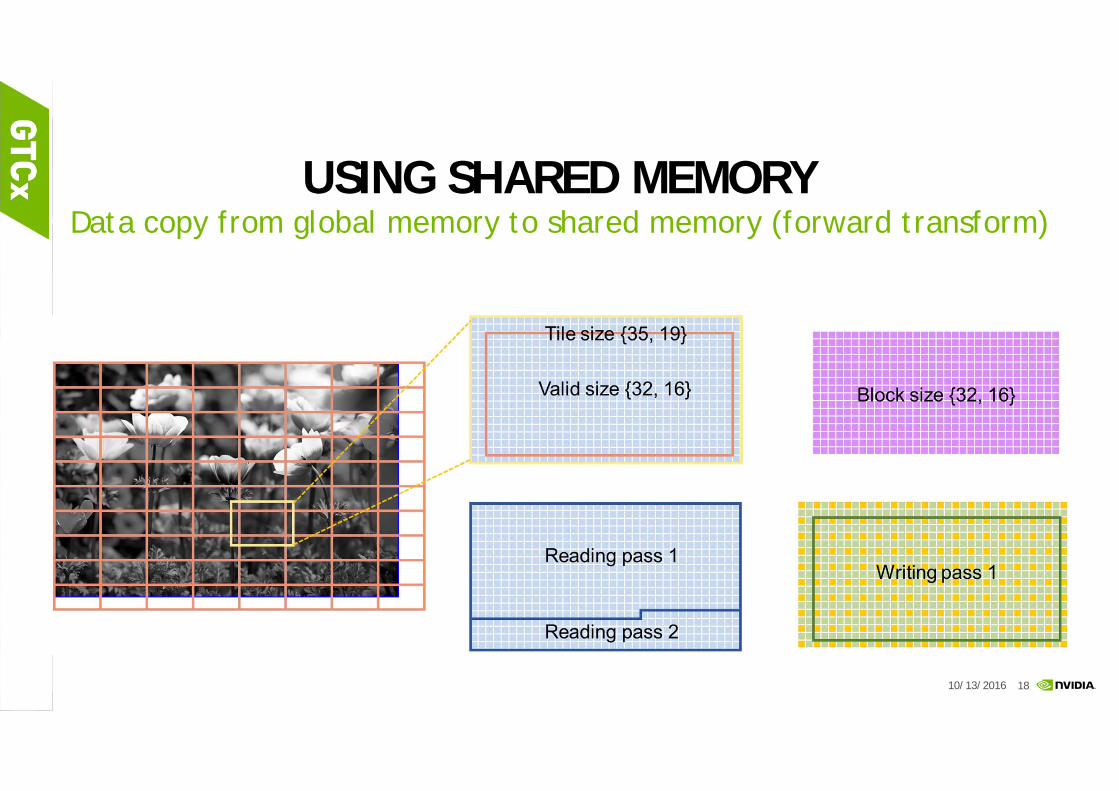
GPU OPTIMIZATION STRATEGIESUSING SHARED MEMORY
18
USING SHARED MEMORYData copy from global memory to shared memory (forward transform)
10/13/2016
19
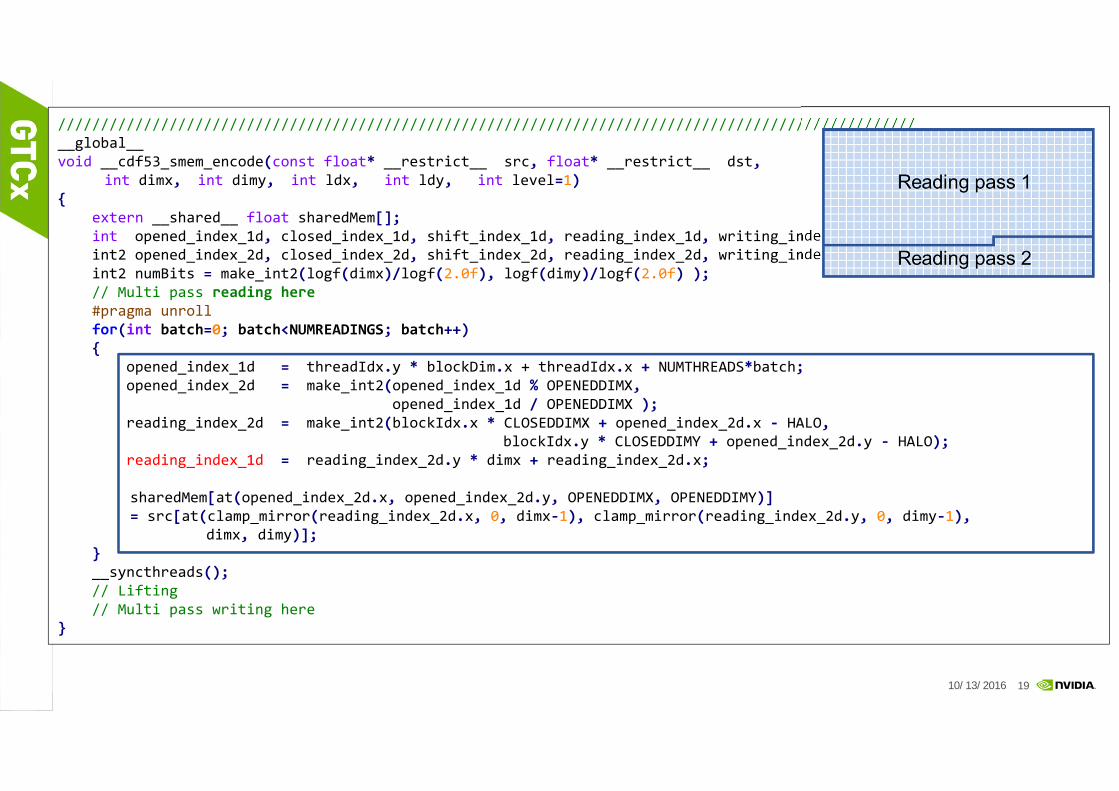
USING SHARED MEMORYData copy from global memory to shared memory
10/13/2016
////////////////////////////////////////////////////////////////////////////////////////////////////__global__void __cdf53_smem_encode(const float* __restrict__ src, float* __restrict__ dst,
int dimx, int dimy, int ldx, int ldy, int level=1){
extern __shared__ float sharedMem[];int opened_index_1d, closed_index_1d, shift_index_1d, reading_index_1d, writing_index_1d;int2 opened_index_2d, closed_index_2d, shift_index_2d, reading_index_2d, writing_index_2d;int2 numBits = make_int2(logf(dimx)/logf(2.0f), logf(dimy)/logf(2.0f) );// Multi pass reading here#pragma unrollfor(int batch=0; batch<NUMREADINGS; batch++){
opened_index_1d = threadIdx.y * blockDim.x + threadIdx.x + NUMTHREADS*batch;opened_index_2d = make_int2(opened_index_1d % OPENEDDIMX,
opened_index_1d / OPENEDDIMX );reading_index_2d = make_int2(blockIdx.x * CLOSEDDIMX + opened_index_2d.x ‐ HALO,
blockIdx.y * CLOSEDDIMY + opened_index_2d.y ‐ HALO);reading_index_1d = reading_index_2d.y * dimx + reading_index_2d.x;
sharedMem[at(opened_index_2d.x, opened_index_2d.y, OPENEDDIMX, OPENEDDIMY)]= src[at(clamp_mirror(reading_index_2d.x, 0, dimx‐1), clamp_mirror(reading_index_2d.y, 0, dimy‐1),
dimx, dimy)];}__syncthreads();// Lifting// Multi pass writing here
}

20
USING SHARED MEMORY (CON’T)Lifting in the shared memory
10/13/2016
// Lifting along xif((threadIdx.x&1)==0) //lifting with alpha{
sharedMem[at(opened_index_2d.x + 1, opened_index_2d.y, ...)]+= a*(sharedMem[at(opened_index_2d.x + 0, opened_index_2d.y, ...)]
+sharedMem[at(opened_index_2d.x + 2, opened_index_2d.y, ...)]);}__syncthreads();
if((threadIdx.x&1)==0) //lifting with beta{
sharedMem[at(opened_index_2d.x + 0, opened_index_2d.y, ...)]+= b*(sharedMem[at(opened_index_2d.x ‐ 1, opened_index_2d.y, ...)]
+sharedMem[at(opened_index_2d.x + 1, opened_index_2d.y, ...)]);}__syncthreads();
// Lifting along y...

21
////////////////////////////////////////////////////////////////////////////////////////////////////__global__void __cdf53_smem_encode(const float* __restrict__ src, float* __restrict__ dst,
int dimx, int dimy, int ldx, int ldy, int level=1){
// Multi pass reading here// Lifting// Multi pass writing here#pragma unrollfor(int batch=0; batch<NUMWRITINGS; batch++){
closed_index_1d = threadIdx.y * blockDim.x + threadIdx.x + NUMTHREADS*batch;closed_index_2d = make_int2(closed_index_1d % CLOSEDDIMX ,
closed_index_1d / CLOSEDDIMX );writing_index_2d = make_int2(blockIdx.x * CLOSEDDIMX + closed_index_2d.x, //block stride
blockIdx.y * CLOSEDDIMY + closed_index_2d.y); //block stridewriting_index_1d = writing_index_2d.y * dimx + writing_index_2d.x;
if ((writing_index_2d.y < dimy) && (writing_index_2d.x < dimx)&& (writing_index_2d.y >= 0) && (writing_index_2d.x >= 0)&& (closed_index_2d.y < CLOSEDDIMY) && (closed_index_2d.x < CLOSEDDIMX) ){
float result = sharedMem[at(closed_index_2d.x + HALO, closed_index_2d.y + HALO, OPENEDDIMX, OPENEDDIMY)];dst[at(ror(clamp_mirror(writing_index_2d.x, 0, dimx‐1), dimx),
ror(clamp_mirror(writing_index_2d.y, 0, dimy‐1), dimy), dimx, dimy)]= result;
}}
}
22
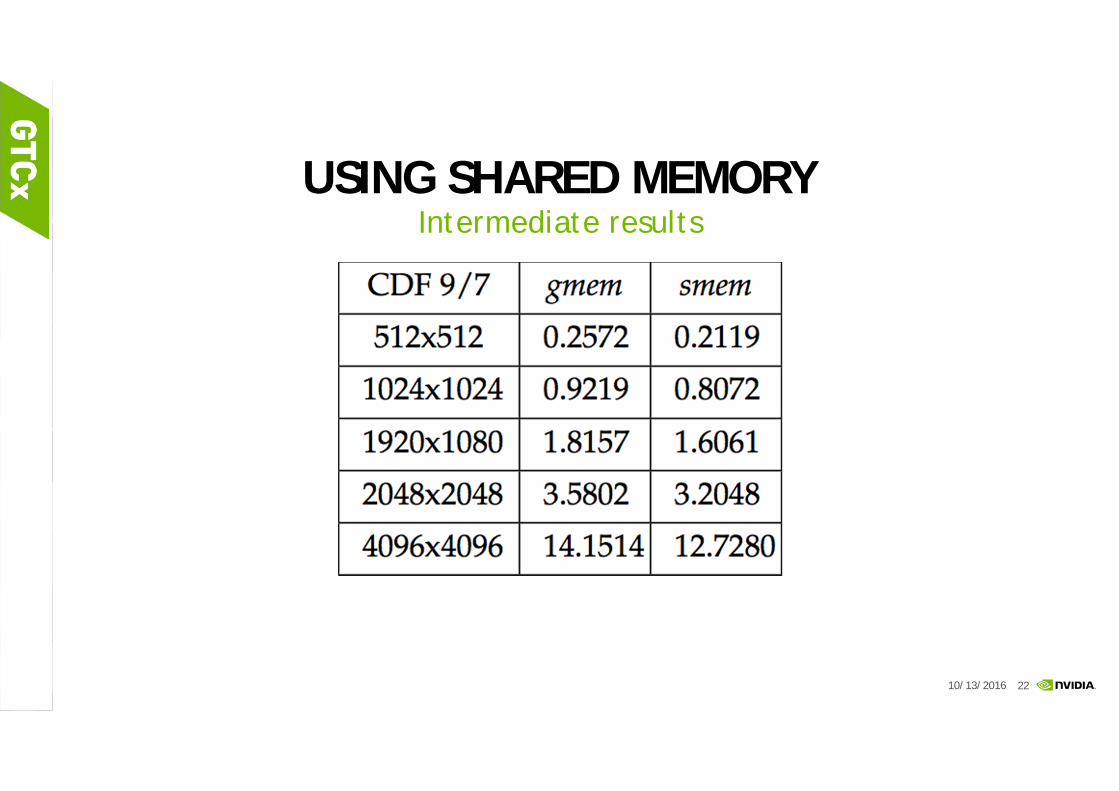
USING SHARED MEMORYIntermediate results
10/13/2016

23
GPU OPTIMIZATION STRATEGIESUSING REGISTERS
24
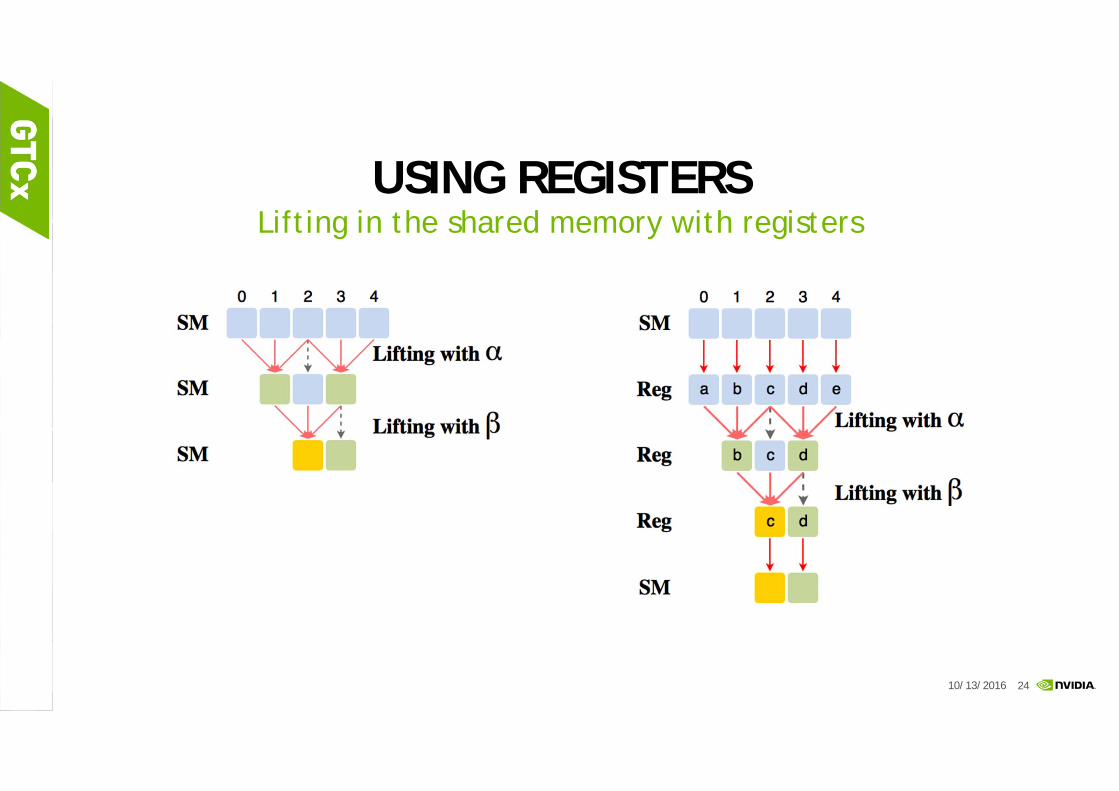
USING REGISTERSLifting in the shared memory with registers
10/13/2016

25
// Lifting along xfloat regs[6];regs[0] = sharedMem[at(opened_index_2d.x ‐ 2, opened_index_2d.y, OPENEDDIMX, OPENEDDIMY)];regs[1] = sharedMem[at(opened_index_2d.x ‐ 1, opened_index_2d.y, OPENEDDIMX, OPENEDDIMY)];regs[2] = sharedMem[at(opened_index_2d.x + 0, opened_index_2d.y, OPENEDDIMX, OPENEDDIMY)];regs[3] = sharedMem[at(opened_index_2d.x + 1, opened_index_2d.y, OPENEDDIMX, OPENEDDIMY)];regs[4] = sharedMem[at(opened_index_2d.x + 2, opened_index_2d.y, OPENEDDIMX, OPENEDDIMY)];// Lifting with alpharegs[1] += a*(regs[0]+regs[2]);regs[3] += a*(regs[2]+regs[4]);// Lifting with betaregs[2] += b*(regs[1]+regs[3]);__syncthreads();if((threadIdx.x&1)==0){
sharedMem[at(opened_index_2d.x + 0, opened_index_2d.y, OPENEDDIMX, OPENEDDIMY)] = regs[2];sharedMem[at(opened_index_2d.x + 1, opened_index_2d.y, OPENEDDIMX, OPENEDDIMY)] = regs[3];
}__syncthreads();
// Lifting along y...
USING REGISTERS (CON’T)Lifting in the shared memory with registers
10/13/2016
26
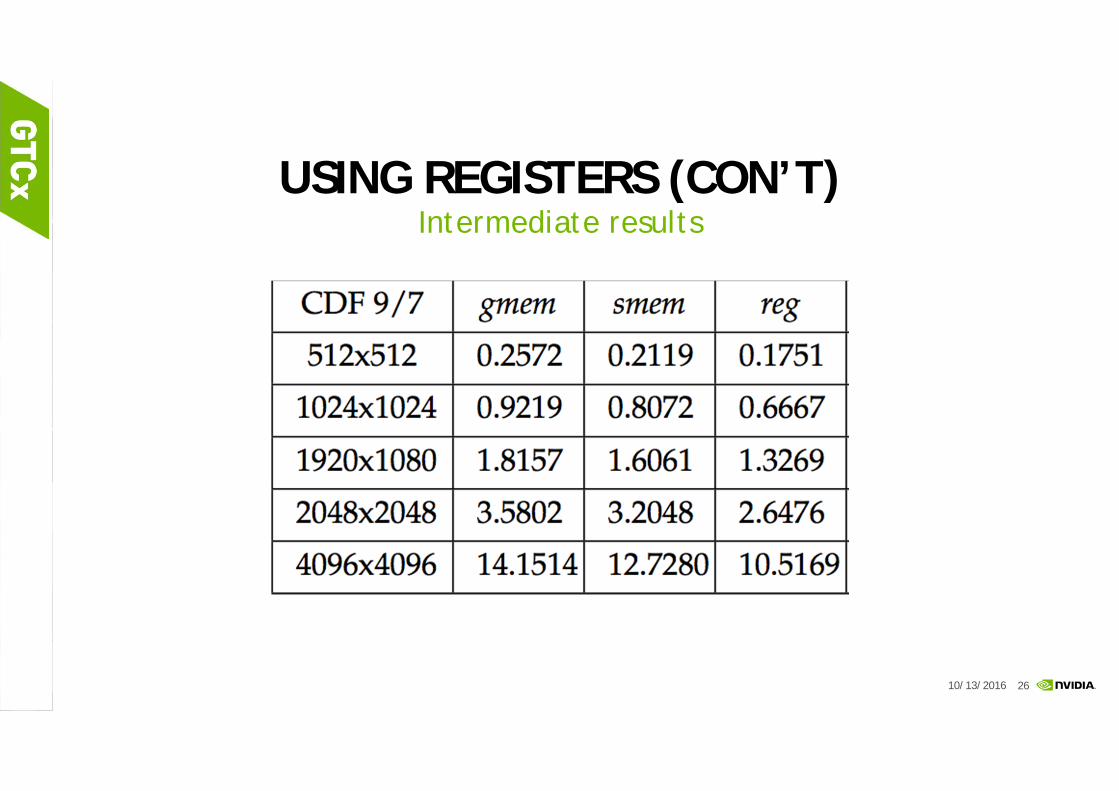
USING REGISTERS (CON’T)Intermediate results
10/13/2016

27
GPU OPTIMIZATION STRATEGIESEXPLOITING INSTRUCTION LEVEL
PARALLELISM (ILP)

28
EXPLOITING INSTRUCTION LEVEL PARALLELISM (ILP)
Data copy from global memory to shared memory (forward transform)
10/13/2016
29
USING SHARED MEMORYData copy from global memory to shared memory
10/13/2016
////////////////////////////////////////////////////////////////////////////////////////////////////__global__void __cdf53_smem_encode(const float* __restrict__ src, float* __restrict__ dst,
int dimx, int dimy, int ldx, int ldy, int level=1){
extern __shared__ float sharedMem[];int opened_index_1d, closed_index_1d, shift_index_1d, reading_index_1d, writing_index_1d;int2 opened_index_2d, closed_index_2d, shift_index_2d, reading_index_2d, writing_index_2d;int2 numBits = make_int2(logf(dimx)/logf(2.0f), logf(dimy)/logf(2.0f) );// Multi pass reading here#pragma unrollfor(int batch=0; batch<NUMREADINGS; batch++){
opened_index_1d = threadIdx.y * blockDim.x + threadIdx.x + NUMTHREADS*batch;opened_index_2d = make_int2(opened_index_1d % OPENEDDIMX,
opened_index_1d / OPENEDDIMX );reading_index_2d = make_int2(blockIdx.x * CLOSEDDIMX + opened_index_2d.x ‐ HALO,
blockIdx.y * CLOSEDDIMY + opened_index_2d.y ‐ HALO);reading_index_1d = reading_index_2d.y * dimx + reading_index_2d.x;
sharedMem[at(opened_index_2d.x, opened_index_2d.y, OPENEDDIMX, OPENEDDIMY)]= src[at(clamp_mirror(reading_index_2d.x, 0, dimx‐1), clamp_mirror(reading_index_2d.y, 0, dimy‐1),
dimx, dimy)];}__syncthreads();// Lifting// Multi pass writing here
}

30
////////////////////////////////////////////////////////////////////////////////////////////////////__global__void __cdf53_smem_encode(const float* __restrict__ src, float* __restrict__ dst,
int dimx, int dimy, int ldx, int ldy, int level=1){
// Multi pass reading here// Lifting// Multi pass writing here#pragma unrollfor(int batch=0; batch<NUMWRITINGS; batch++){
closed_index_1d = threadIdx.y * blockDim.x + threadIdx.x + NUMTHREADS*batch;closed_index_2d = make_int2(closed_index_1d % CLOSEDDIMX ,
closed_index_1d / CLOSEDDIMX );writing_index_2d = make_int2(blockIdx.x * CLOSEDDIMX + closed_index_2d.x, //block stride
blockIdx.y * CLOSEDDIMY + closed_index_2d.y); //block stridewriting_index_1d = writing_index_2d.y * dimx + writing_index_2d.x;
if ((writing_index_2d.y < dimy) && (writing_index_2d.x < dimx)&& (writing_index_2d.y >= 0) && (writing_index_2d.x >= 0)&& (closed_index_2d.y < CLOSEDDIMY) && (closed_index_2d.x < CLOSEDDIMX) ){
float result = sharedMem[at(closed_index_2d.x + HALO, closed_index_2d.y + HALO, OPENEDDIMX, OPENEDDIMY)];dst[at(ror(clamp_mirror(writing_index_2d.x, 0, dimx‐1), dimx),
ror(clamp_mirror(writing_index_2d.y, 0, dimy‐1), dimy), dimx, dimy)]= result;
}}
}

31
EXPLOITING INSTRUCTION LEVEL PARALLELISM (ILP)
Each thread covers a {2, 2} region, which is 4× more memory transactions and 2× more lifting computations per thread.
10/13/2016
int2 eIndex = make_int2(threadIdx.x<<1, threadIdx.y<<1); //2*threadIdx.x
// Lifting along x#pragma unrollfor(p=0; p<2; p++){
sharedMem[at3(eIndex.x + 1, eIndex.y+p, OPENEDDIMX, OPENEDDIMY)]+= a*(sharedMem[at3(eIndex.x + 0, eIndex.y+p, OPENEDDIMX, OPENEDDIMY)]
+sharedMem[at2(eIndex.x + 2, eIndex.y+p, OPENEDDIMX, OPENEDDIMY)]);
sharedMem[at3(eIndex.x + 0, eIndex.y+p, OPENEDDIMX, OPENEDDIMY)]+= b*(sharedMem[at2(eIndex.x ‐ 1, eIndex.y+p, OPENEDDIMX, OPENEDDIMY)]
+sharedMem[at3(eIndex.x + 1, eIndex.y+p, OPENEDDIMX, OPENEDDIMY)]);}__syncthreads();// Lifting along y#pragma unrollfor(p=0; p<2; p++)
sharedMem[at3(eIndex.x+p, eIndex.y + 1, OPENEDDIMX, OPENEDDIMY)]+= a*(sharedMem[at3(eIndex.x+p, eIndex.y + 0, OPENEDDIMX, OPENEDDIMY)]
+sharedMem[at2(eIndex.x+p, eIndex.y + 2, OPENEDDIMX, OPENEDDIMY)]);__syncthreads();
#pragma unrollfor(p=0; p<2; p++)
sharedMem[at3(eIndex.x+p, eIndex.y + 0, OPENEDDIMX, OPENEDDIMY)]+= b*(sharedMem[at2(eIndex.x+p, eIndex.y ‐ 1, OPENEDDIMX, OPENEDDIMY)]
+sharedMem[at3(eIndex.x+p, eIndex.y + 1, OPENEDDIMX, OPENEDDIMY)]);__syncthreads();
32
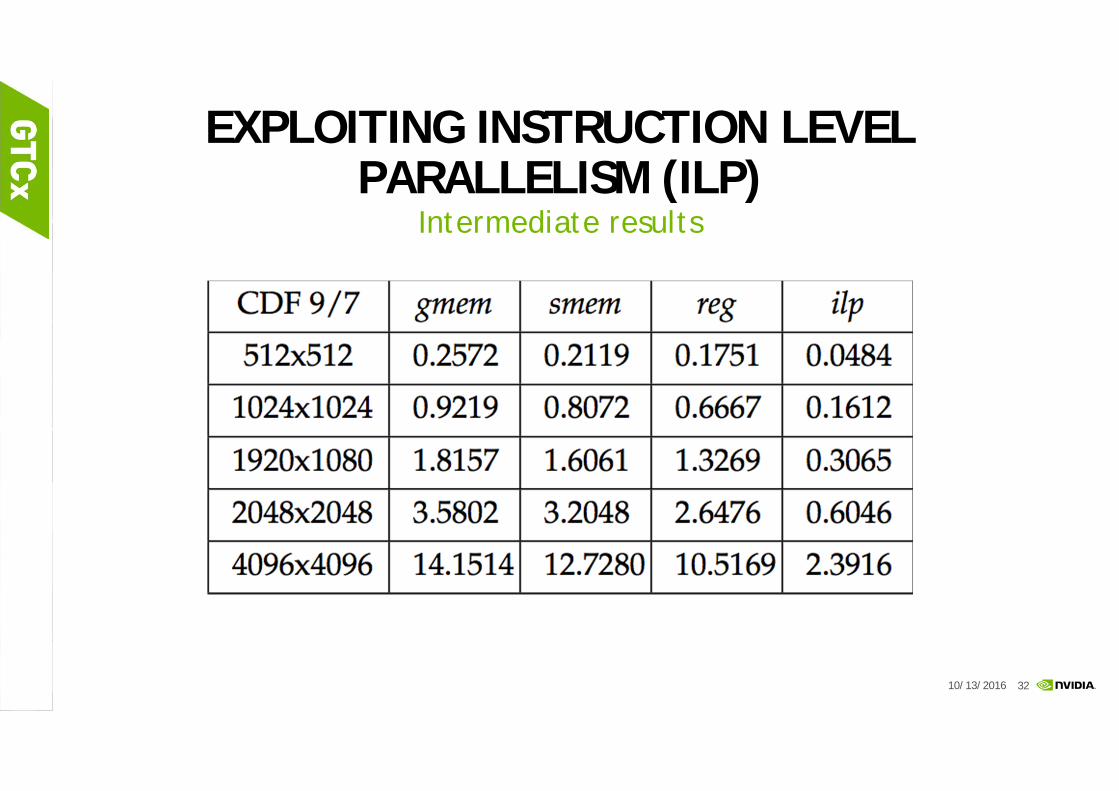
EXPLOITING INSTRUCTION LEVEL PARALLELISM (ILP)
Intermediate results
10/13/2016

33
GPU OPTIMIZATION STRATEGIESEXPLOITING WARP SHUFFLES ON KEPLER GPUS

34
EXPLOITING WARP SHUFFLESData copy from global memory (texture bound) to registers
10/13/2016
////////////////////////////////////////////////////////////////////////////////////////////////////__global__void __cdf53_smem_encode(const float* __restrict__ src, float* __restrict__ dst,
int dimx, int dimy, int ldx, int ldy, int level=1){
//...//==================================================================// Multi pass reading herexIndex = make_int2((thread1D&31)<<1, (thread1D>>5)<<0);yIndex = make_int2((thread1D>>4)<<0, (thread1D&15)<<1);index_2d = make_int2(__mul24(blockIdx.x,CLOSEDDIMX)+xIndex.x, __mul24(blockIdx.y,CLOSEDDIMY)+xIndex.y);//==================================================================
register float r[WORKPERTHREADSY][WORKPERTHREADSX];//Read from global memory to register#pragma unrollfor(y=0; y<1; y++){
#pragma unrollfor(x=0; x<2; x++){
xp = index_2d.x+x ‐ HALO;yp = index_2d.y+y ‐ HALO;xp = clamp_mirror(xp, 0, dimx‐1);yp = clamp_mirror(yp, 0, dimy‐1);r[y][x] = tex2D(texSrc, xp, yp);
}}// Lifting// Multi pass writing here
}
Binding read-only global memory to texture helps to read faster
35
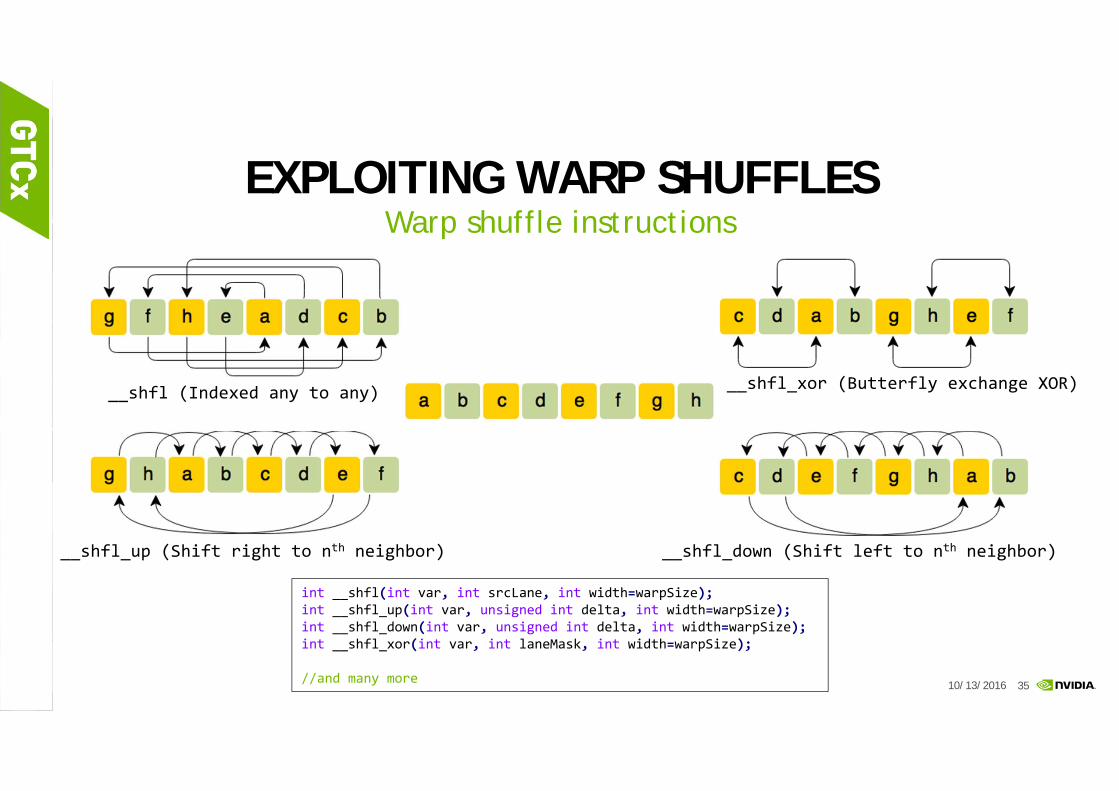
EXPLOITING WARP SHUFFLESWarp shuffle instructions
10/13/2016
int __shfl(int var, int srcLane, int width=warpSize);int __shfl_up(int var, unsigned int delta, int width=warpSize);int __shfl_down(int var, unsigned int delta, int width=warpSize);int __shfl_xor(int var, int laneMask, int width=warpSize);
//and many more
__shfl (Indexed any to any)
__shfl_up (Shift right to nth neighbor) __shfl_down (Shift left to nth neighbor)
__shfl_xor (Butterfly exchange XOR)
36
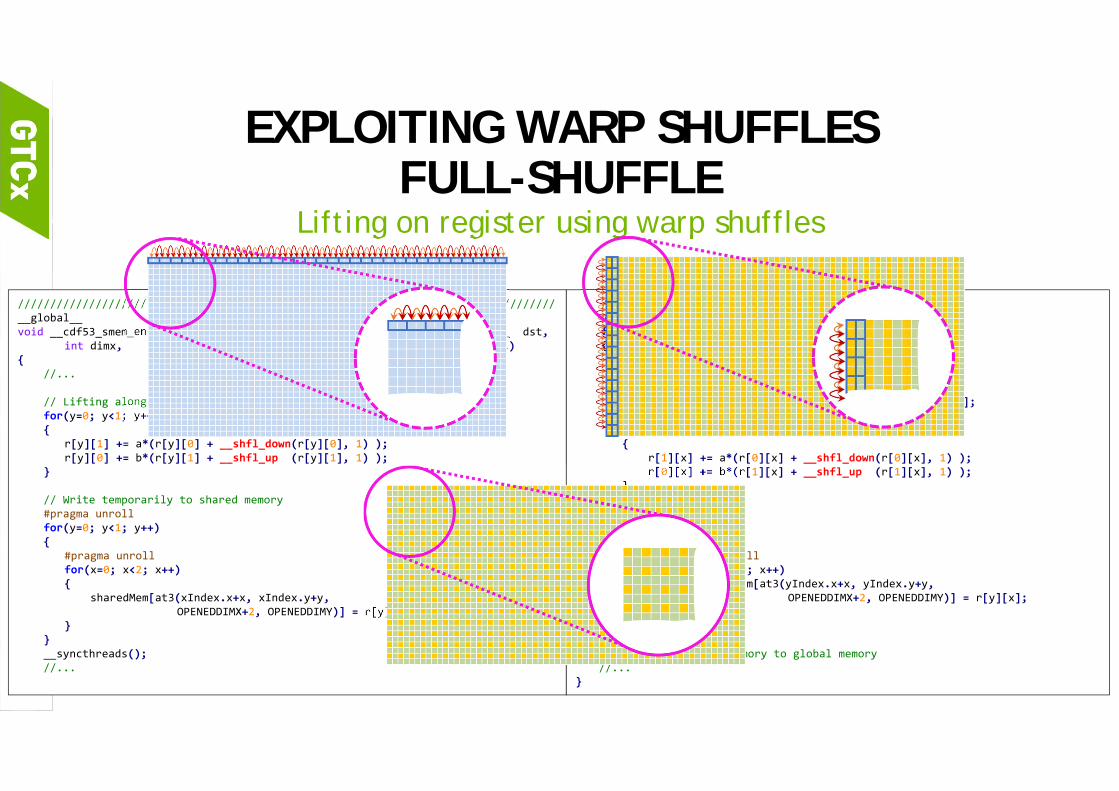
EXPLOITING WARP SHUFFLES FULL-SHUFFLE
Lifting on register using warp shuffles
10/13/2016
///////////////////////////////////////////////////////////////////////////////////__global__void __cdf53_smem_encode(const float* __restrict__ src, float* __restrict__ dst,
int dimx, int dimy, int ldx, int ldy, int level=1){
//...
// Lifting along xfor(y=0; y<1; y++){
r[y][1] += a*(r[y][0] + __shfl_down(r[y][0], 1) );r[y][0] += b*(r[y][1] + __shfl_up (r[y][1], 1) );
}
// Write temporarily to shared memory#pragma unrollfor(y=0; y<1; y++){
#pragma unrollfor(x=0; x<2; x++){
sharedMem[at3(xIndex.x+x, xIndex.y+y,OPENEDDIMX+2, OPENEDDIMY)] = r[y][x];
}}__syncthreads();//...
// Lifting along y#pragma unrollfor(y=0; y<2; y++){
#pragma unrollfor(x=0; x<1; x++)
r[y][x] = sharedMem[at3(yIndex.x+x, yIndex.y+y,OPENEDDIMX+2, OPENEDDIMY)];
#pragma unrollfor(x=0; x<1; x++){
r[1][x] += a*(r[0][x] + __shfl_down(r[0][x], 1) );r[0][x] += b*(r[1][x] + __shfl_up (r[1][x], 1) );
}__syncthreads();#pragma unrollfor(y=0; y<2; y++){
#pragma unrollfor(x=0; x<1; x++)
sharedMem[at3(yIndex.x+x, yIndex.y+y,OPENEDDIMX+2, OPENEDDIMY)] = r[y][x];
}__syncthreads();
}// Write from share memory to global memory//...
}
37
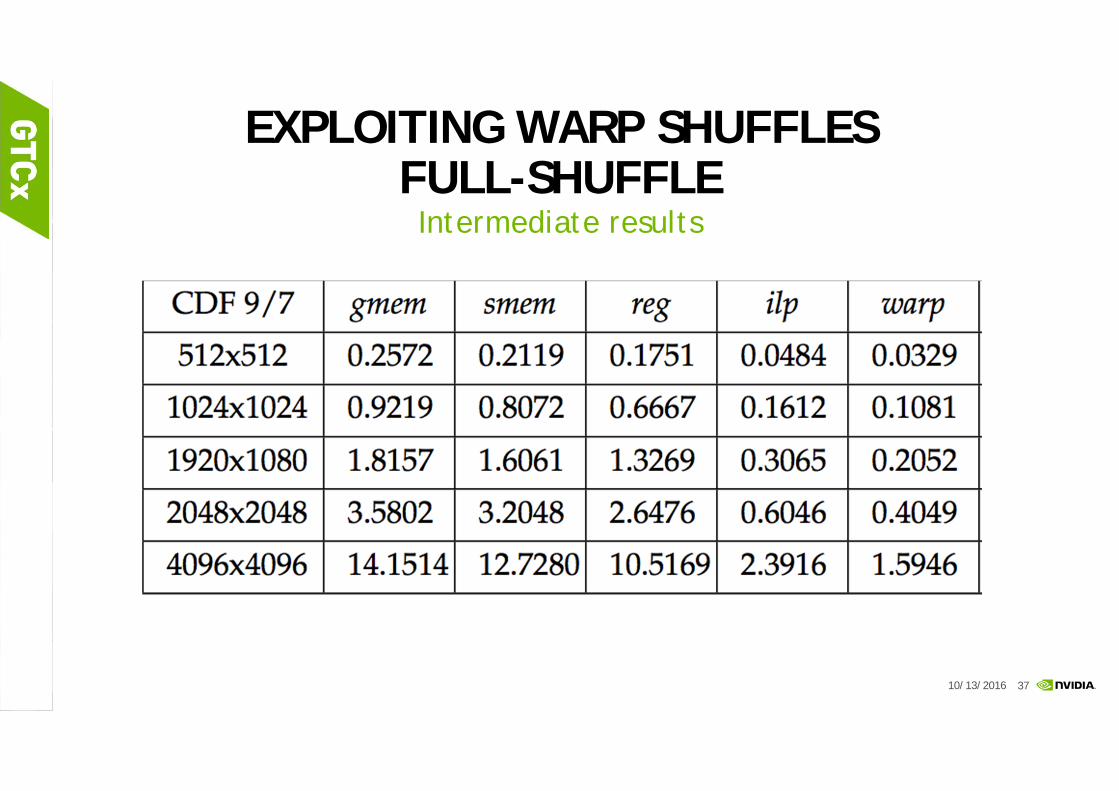
EXPLOITING WARP SHUFFLES FULL-SHUFFLE
Intermediate results
10/13/2016

38
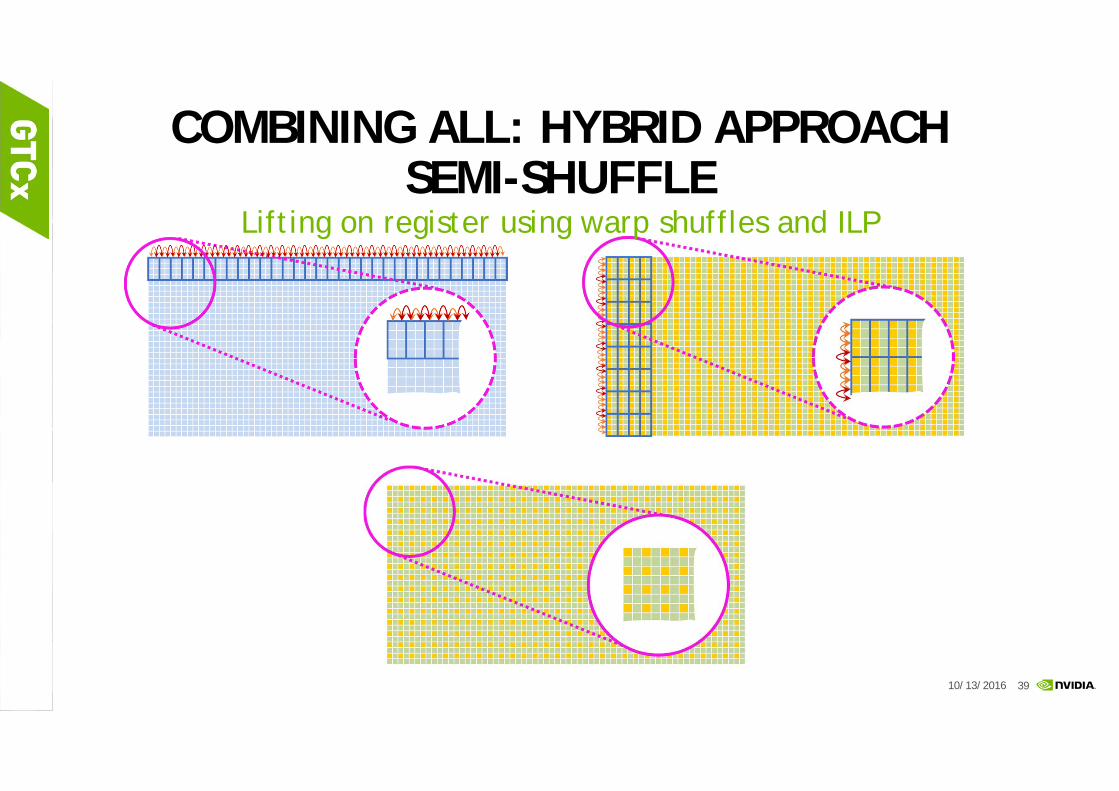
GPU OPTIMIZATION STRATEGIESCOMBINING ALL: HYBRID APPROACH
39
Lifting on register using warp shuffles and ILP
10/13/2016
COMBINING ALL: HYBRID APPROACHSEMI-SHUFFLE
40
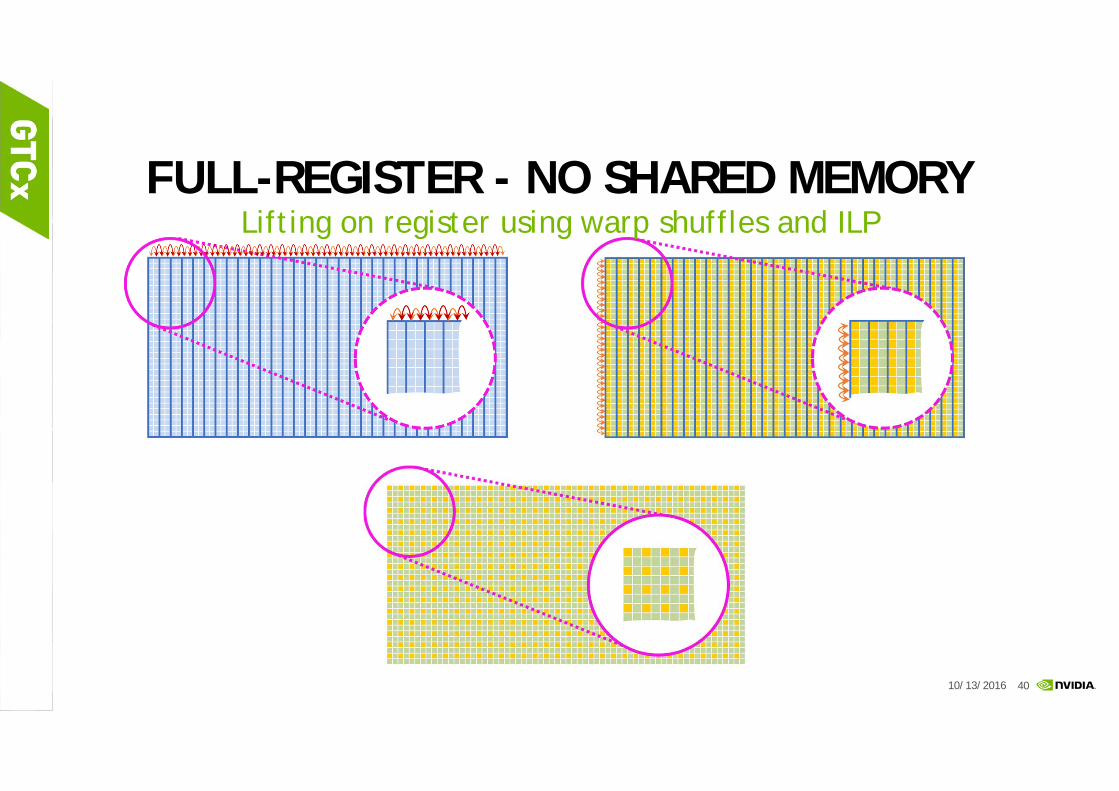
FULL-REGISTER - NO SHARED MEMORYLifting on register using warp shuffles and ILP
10/13/2016
41
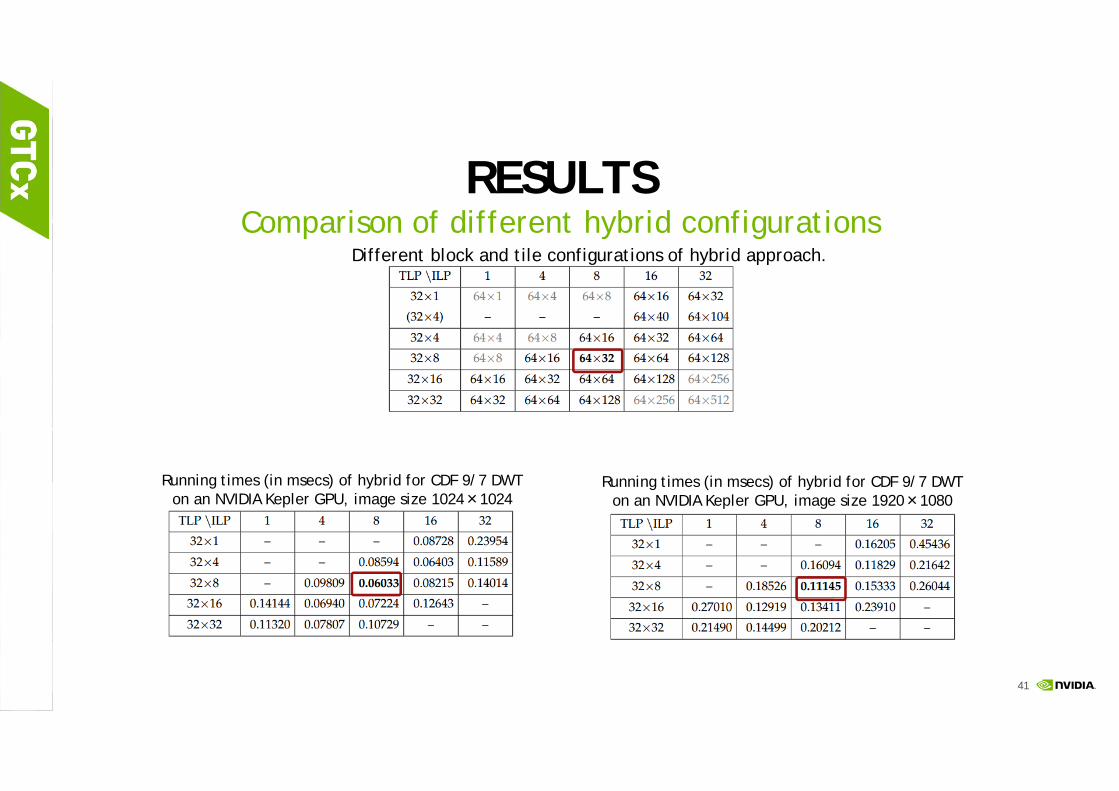
RESULTSComparison of different hybrid configurations
Different block and tile configurations of hybrid approach.
Running times (in msecs) of hybrid for CDF 9/7 DWT on an NVIDIA Kepler GPU, image size 1024×1024
Running times (in msecs) of hybrid for CDF 9/7 DWT on an NVIDIA Kepler GPU, image size 1920×1080
42
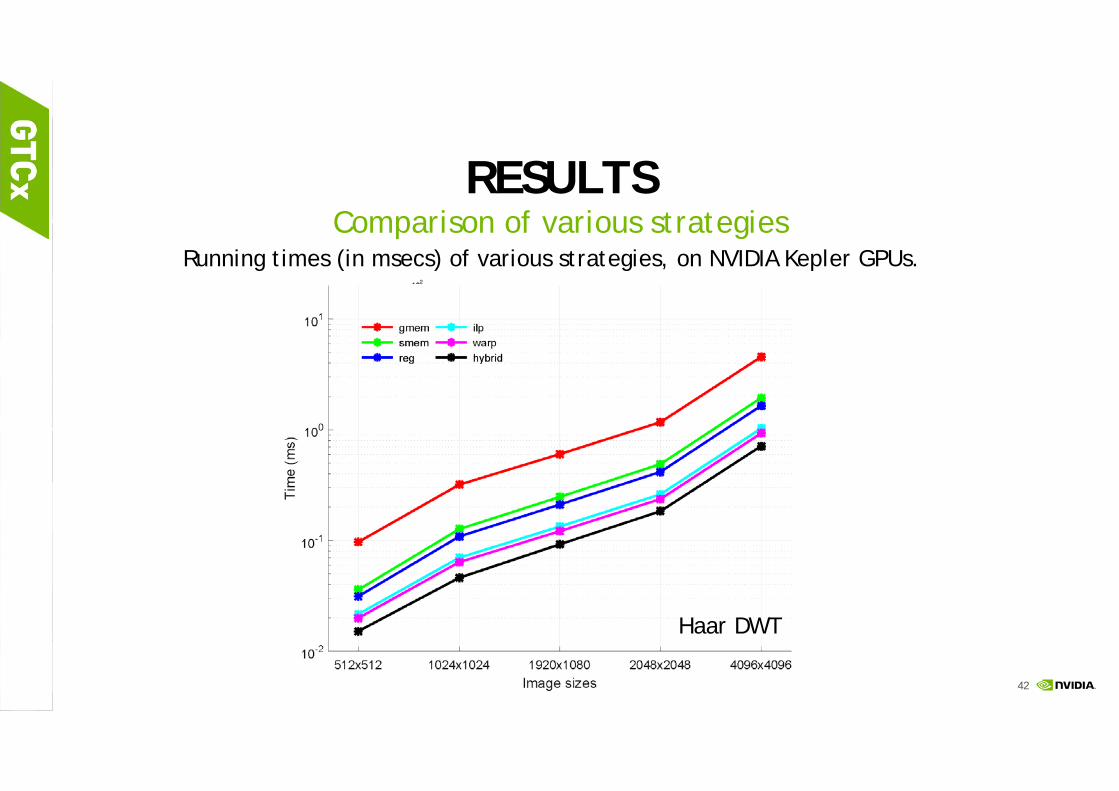
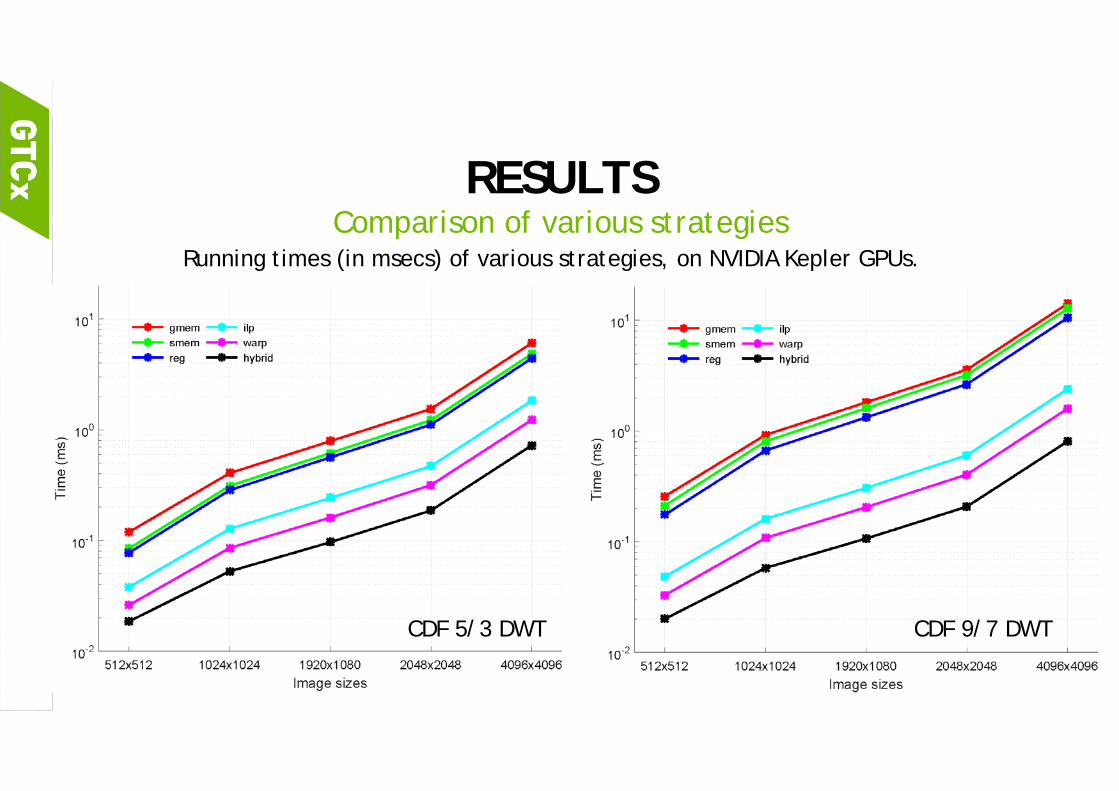
RESULTSComparison of various strategies
Running times (in msecs) of various strategies, on NVIDIA Kepler GPUs.
CDF 5/3 DWT
Haar DWT
43
RESULTSComparison of various strategies
Running times (in msecs) of various strategies, on NVIDIA Kepler GPUs.
CDF 5/3 DWT CDF 9/7 DWT

44
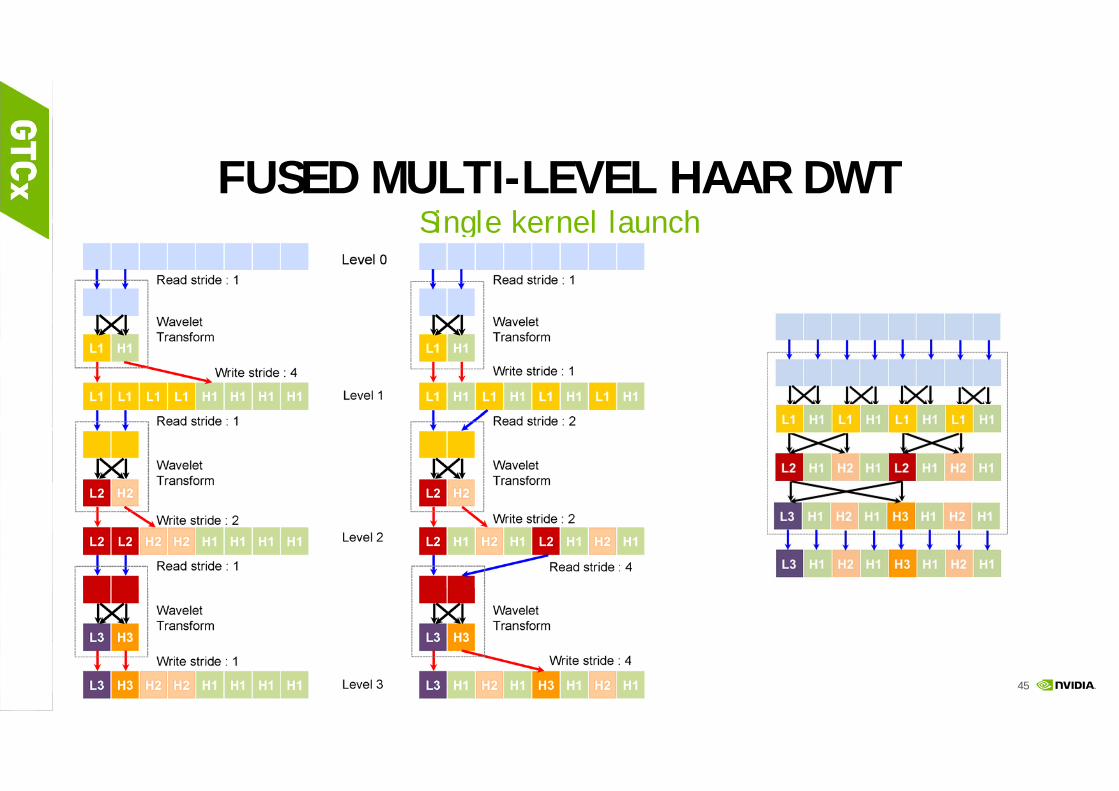
GPU OPTIMIZATION STRATEGIESFUSED MULTI-LEVEL HAAR DWT
45
FUSED MULTI-LEVEL HAAR DWTSingle kernel launch

46
FUSED MULTI-LEVEL HAAR DWTSingle kernel launch
10/13/2016
Haar 2x2
Haar 8x8
encode_8Kernel
decode_8Kernel

47
RESULTS AND DISCUSSIONS
48
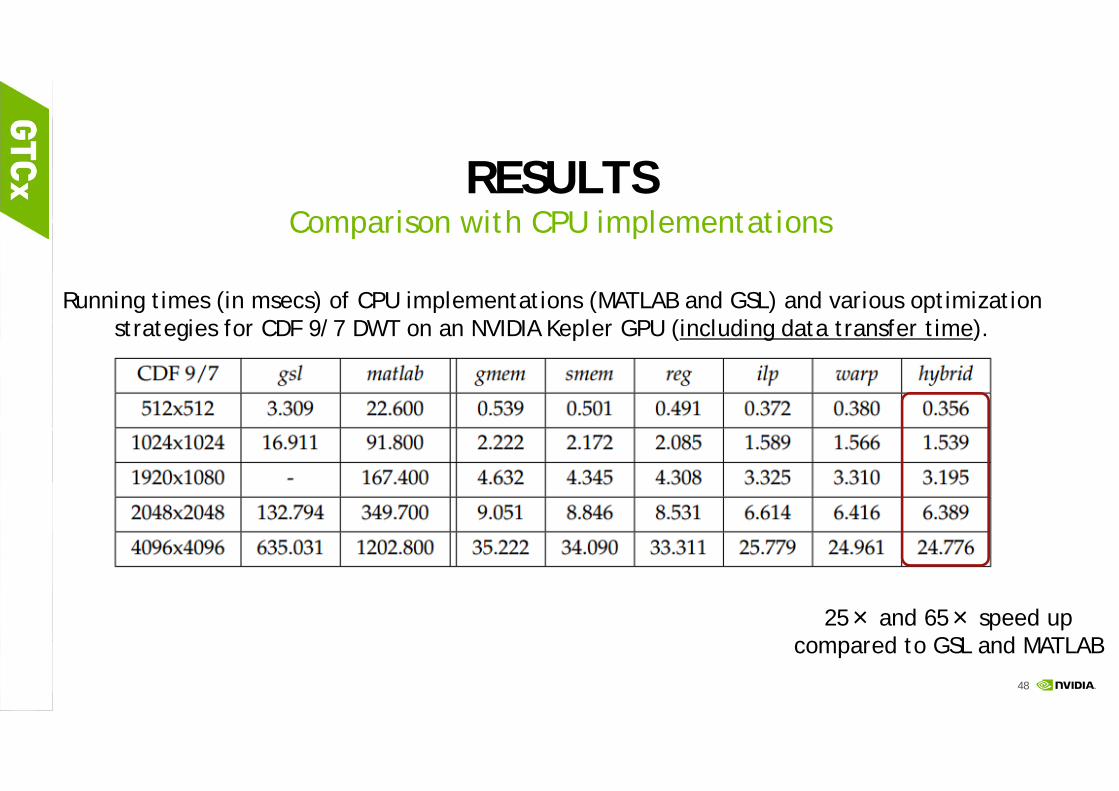
RESULTSComparison with CPU implementations
Running times (in msecs) of CPU implementations (MATLAB and GSL) and various optimization strategies for CDF 9/7 DWT on an NVIDIA Kepler GPU (including data transfer time).
25× and 65× speed up compared to GSL and MATLAB
49
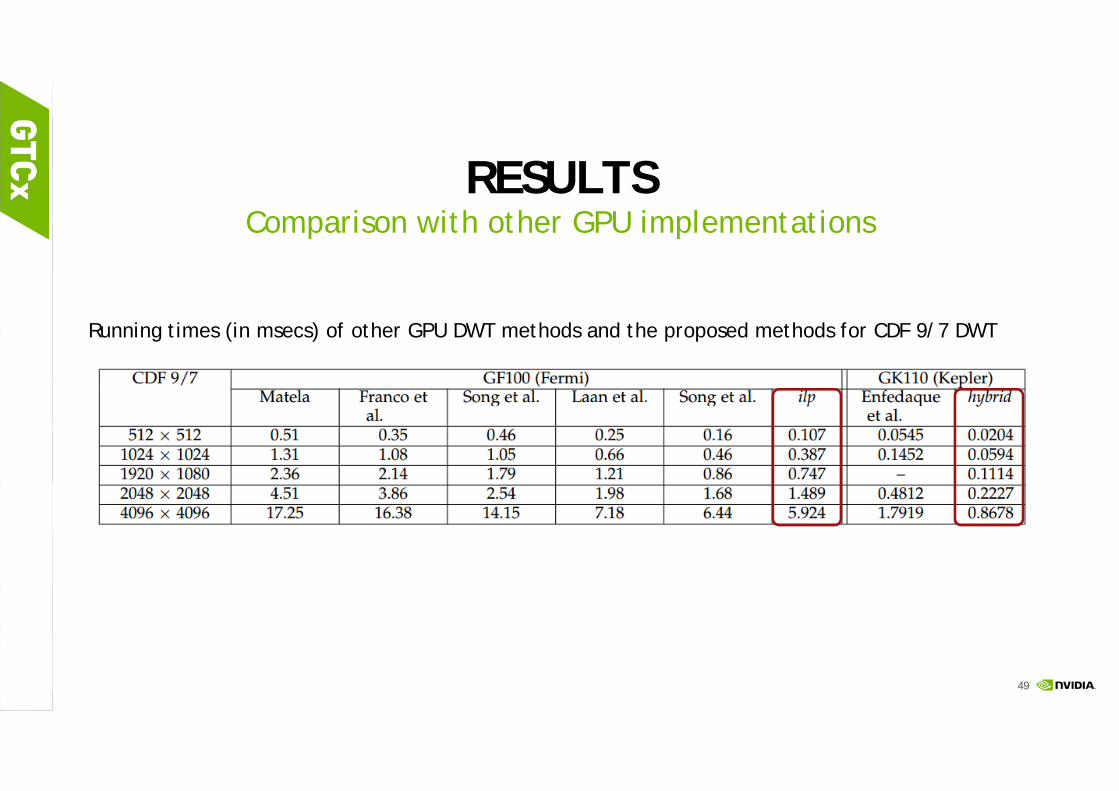
RESULTSComparison with other GPU implementations
Running times (in msecs) of other GPU DWT methods and the proposed methods for CDF 9/7 DWT
50
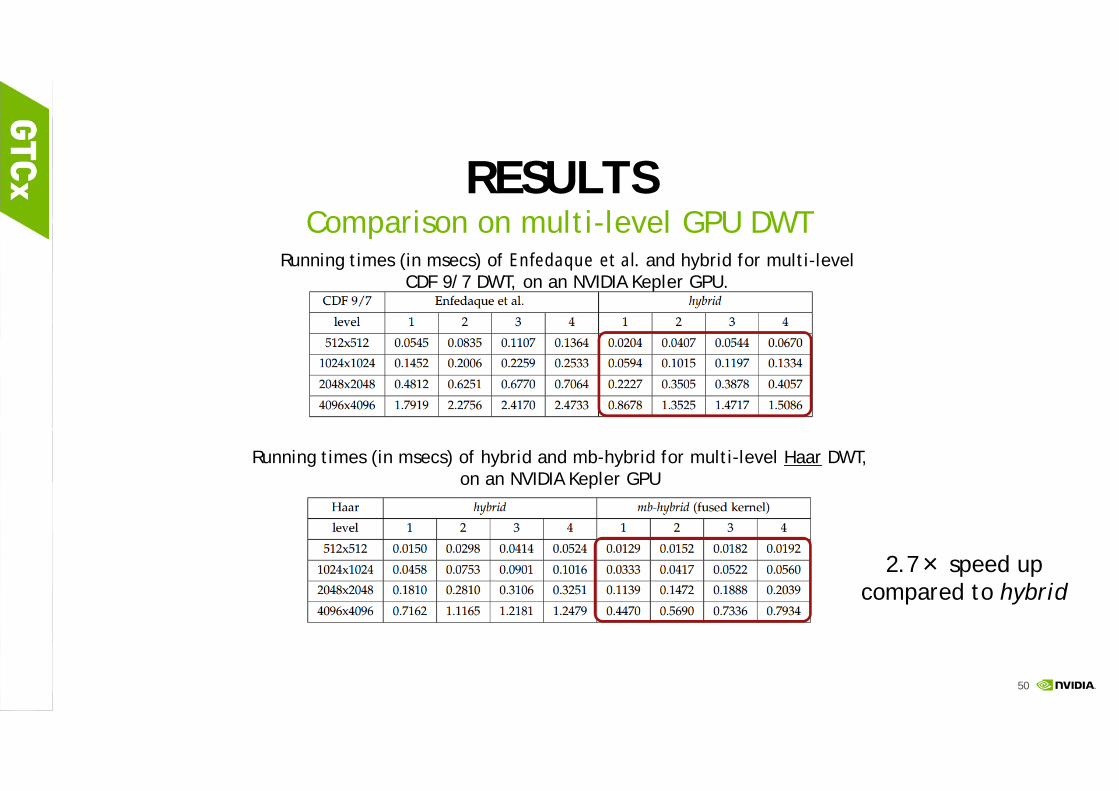
RESULTSComparison on multi-level GPU DWT
Running times (in msecs) of Enfedaque et al. and hybrid for multi-level CDF 9/7 DWT, on an NVIDIA Kepler GPU.
Running times (in msecs) of hybrid and mb-hybrid for multi-level Haar DWT, on an NVIDIA Kepler GPU
2.7× speed up compared to hybrid

51
CONCLUSION

52
CONCLUSION
• Various optimization strategies for 2D DWT on the GPUs have been introduced:
• leverage fast on-chip memories (shared memory and registers),
• warp shuffle instructions,
• thread- and instruction-level parallelism.
Unlike other state-of-the-art GPU DWTs, hybrid parallelism that exploits both ILPand TLP together results in the most optimal performance
• mixed-band layout of Haar DWT outperformed the conventional DWT, especiallyon multi-level transformation.
Contributions

53
RELATED PUBLICATIONS
T. M. Quan and W.-K. Jeong, “A fast Mixed-Band lifting wavelet transform on the GPU,”in IEEE International Conference on Image Processing, 2014, pp. 1238-1242.
T. M. Quan and W.-K Jeong, “A fast discrete wavelet transform using hybrid parallelismon GPUs,”IEEE Transactions on Parallel and Distributed Systems, published online.
10/13/2016

54
ACKNOWLEDGMENTS
• This work was partly supported by
• Institute for Information & communications Technology Promotion (IITP) grant funded by theKorea government (MSIP) (No. R0190-15-2012, High Performance Big Data Analytics PlatformPerformance Acceleration Technologies Development),
• the R&D program of MOTIE/KEIT (No. 10054548, Development of Suspended HeterogeneousNanostructure-based Hazardous Gas Microsensor System),
• Basic Science Research Program through the National Research Foundation of Korea (NRF)funded by the Ministry of Education (NRF- 2014R1A1A2058773).
• The authors would like to thank NVIDIA for their hardware support via NVIDIA GPUResearch Center Program

SEOUL | Oct.7, 2016
THANK YOU
Do you have any questions?





























