Embed Size (px)
Citation preview

Entfernung von Duplikaten in Data
WarehousesDaniel Martens
11.09.2015, Informationsintegration, Seminar
1/41

Gliederung
● Problem & Motivation
● Domänen-unabhängige Verfahren
● Domänen-abhängige Verfahren
● DELPHI
2/41

Problem
Wie viele Jane Does gibt es wirklich?
Jane Does
3/41

Problem
Wie viele Jane Does gibt es wirklich?
Jane Does
Jane Doe #1
4/41
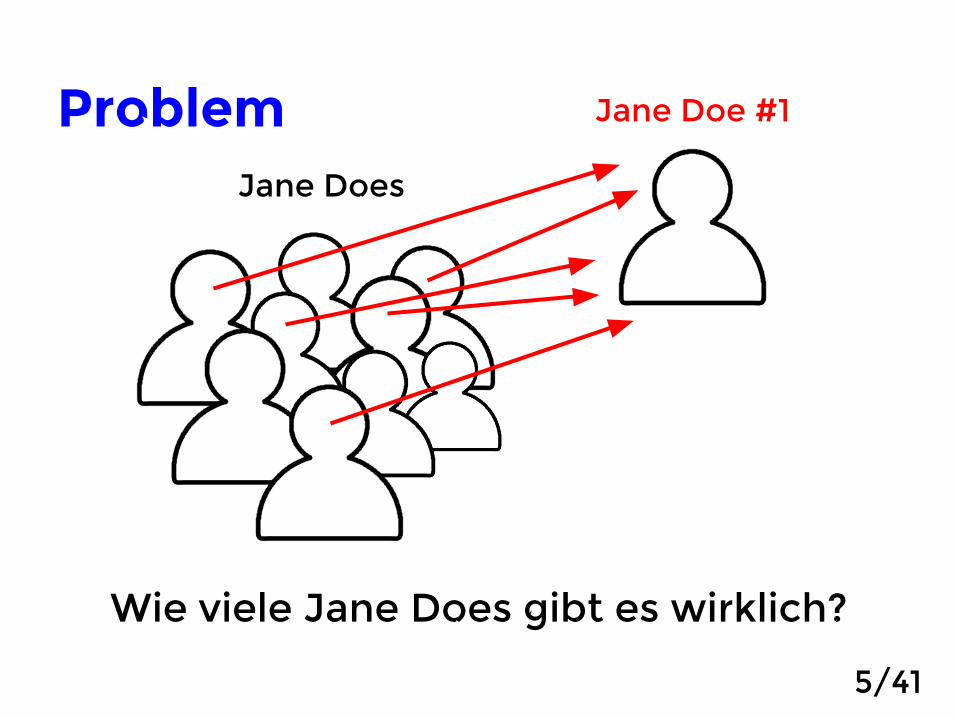
Problem
Wie viele Jane Does gibt es wirklich?
Jane Does
Jane Doe #1
5/41
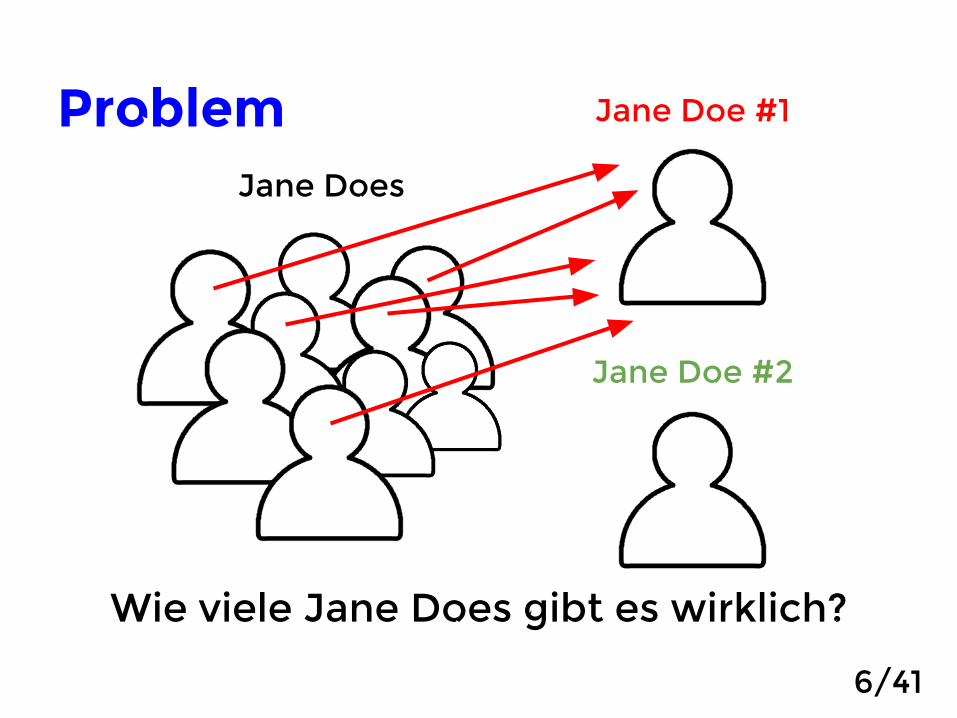
Problem
Wie viele Jane Does gibt es wirklich?
Jane Does
Jane Doe #1
Jane Doe #2
6/41

Problem
Wie viele Jane Does gibt es wirklich?
Jane Does
Jane Doe #1
Jane Doe #2
7/41

Motivation (1/2)
8/41[1]

Motivation (1/2)
9/41
Reduzierung der Duplikate um 5 % in einer Patienten-Datenbank mit 200.000 Einträgen kann zu einer Ersparnis von
3 Millionen Dollar führen.

Motivation (2/2)
10/41[2]

Motivation (2/2)
11/41

Motivation (2/2)
● Kosten
13/41
$ 50 Grundkosten je doppelte Patientenakte
60+ h Zusammenführung nicht digitaler Patientenakten
240+ h Zusammenführung digitaler Patientenakten
$ 1100 Kosten für wiederholte Tests

Gliederung
● Problem & Motivation
● Domänen-unabhängige Verfahren
○ Probleme
○ Optimierungen
● Domänen-abhängige Verfahren
● DELPHI
14/41

Domänen-unabhängige Verfahren
● Vorgehen: Vergleich inhaltlicher
Ähnlichkeiten mehrere Datensätze
● Verfahren
○ Edit-Distanz
○ Kosinus-Ähnlichkeit
● Problem: Hoher Anteil an False
Positives
15/41

Domänen-unabhängige Verfahren
● Beispiel
○ 1) v = “US”, v’ = “United States”
○ 2) v = “USSR”, v’ = “United States”
● Edit-Distanz
○ Wird 1) als Duplikat erkannt, dann wird 2)
inkorrekterweise ebenfalls als Duplikat
erkannt
16/41

Domänen-unabhängige Verfahren
● Optimierungen
○ Automatische Anpassung des Schwellwert
○ Relationen der Daten einbeziehen
17/41

Gliederung
● Problem & Motivation
● Domänen-unabhängige Verfahren
● Domänen-abhängige Verfahren
○ Allgemein
○ Dimensionale Hierarchien
○ Inverse Document Frequency
○ Token Containment Metric (tcm)
○ Foreign Key Containment Metric (fkcm)
● DELPHI
18/41

Domänen-abhängige Verfahren
● Allgemein
○ Binäre Funktion
■ Vergleicht Paare von Tupeln
r = [r1, …, rm]
s = [s1, …, sm]
○ Ergebnis
■ “1”: Paare sind Duplikate
■ “-1”: Paare sind keine Duplikate19/41

Domänen-abhängige Verfahren
● Allgemein
○ Beispiel
■ r = [“Compuware, #20 Main Street”, “Jopin”, “MO”, “United States”]
■ s = [“Compuwar, #20 Main Street”, “Joplin”, “Missouri”, “USA”]
○ Ergebnis
20/41
r Compuware, #20 Main Street
Jopin MO United States
s Compuwar, #20 Main Street
Joplin Missouri USA
fi-Berechnung -1 -1 -1 -1

Domänen-abhängige Verfahren
● Dimensionale Hierarchien
○ [S1, MO, 1] ist Kind von [1, United States ...]
○ IDs werden aus dem Vergleich
ausgeschlossen
■ Meist künstlich generiert
■ Keine sinnliche Übereinstimmung mit Obj.
21/41

Domänen-abhängige Verfahren
● Gewichtetes Voting zwischen
○ Textual Similarity Function (tcm)
○ Co-occurrence Function (fkcm)
● Gewichtung durch IDF-Faktoren
○ IDF = log( |G| / fG(o) )
22/41
Sammlung von Sätzen von Objekten
Objekt
Vorkommnisse von o in G

Domänen-abhängige Verfahren
● Token Containment Metric (tcm)
○ Beispiel
■ v = [“MO”, “United States”]
■ v’ = [“MO”, “United States of America”]
○ Ergebnis
■ tcm(v, v’) = cm(TS(v), TS(v’)) = 1.0
■ tcm(v’, v) = cm(TS(v’), TS(v)) = 0.6
○ Token mit geringer Bearbeitungsdistanz
werden als Synonyme behandelt 23/41

Domänen-abhängige Verfahren
● Foreign Key Containment Metric (fkcm)
○ Beispiel
■ v = [C3, Joplin, S4] (- [S3, Missouri, 3])
■ v‘ = [C4, Joplin, S3] (- [S3, MO, 3])
○ fkcm(v, v’) = cm(CS(v), CS(v’)) = 1.0
■ Child-Set von “Missouri” und “MO” ist
identisch: “Joplin”
■ Es ist anzunehmen, dass “Missouri” und “MO”
Duplikate sind24/41

Domänen-abhängige Verfahren
● Kombination von tcm und fkcm
○ pos: R -> {1, -1}
■ pos(x) = 1, wenn x > 0, sonst -1
● Berechnung
○ pos(
wt + pos( tcm(v, v’) - tcmthreshold) +
wc + pos( fkcm(v, v’) - fkcmthreshold)
) 25/41

Gliederung
● Problem & Motivation
● Domänen-unabhängige Verfahren
● Domänen-abhängige Verfahren
● DELPHI○ Allgemein
○ Duplicate Identification Filter
○ Token Table
○ Child Table
○ Translation Table 26/41

DELPHI
● Duplicate Elimination in the Presence
of HIerarchies
27/41[3]

DELPHI
28/41
Duplikate durch den Grad der Überlappung erkennen.

DELPHI
29/41
StateId State CityId
S1 MO 1
S2 MO 2
S3 MO 3
S4 Missouri 3
S5 BC 4
S6 Britisch Columbia 4
S7 Aberdeen shire 5
S8 Aberdeen 5
CityId Country
1 United States of America
2 United States
3 USA
4 Canada
5 UK
● Weise jeder CityId c eine Menge StateIds s(c) zu
● Jede größer die Schnittmenge von s(c1), s(c2) desto höher
die Wahrscheinlichkeit, dass c1, c2 Duplikate sind

DELPHI
30/41
StateId State CityId
S1 MO 1
S2 MO 2
S3 MO 3
S4 Missouri 3
S5 BC 4
S6 Britisch Columbia 4
S7 Aberdeen shire 5
S8 Aberdeen 5
CityId Country
1 United States of America
2 United States
3 USA
4 Canada
5 UK
● c1 = [3, USA], s(c1) = {S3, S4}
● c2 = [5, UK], s(c2) = {S7, S8}
○ Keine Duplikate
Leere Schnittmenge
von s(c1) und s(c2)

DELPHI
● Anzahl der Vergleiche minimieren
○ Gruppierungsstrategie
● Vorgehen
○ Paareweise Vergleiche nur innerhalb einer Relation
○ Tupel aus State nur miteinander vergleichen, wenn:
■ Gleiches Tupel in Country Relation referenziert
wird,
■ Zwei Tupel in Country referenziert werden, die
bereits als Duplikate erkannt sind.
31/41

DELPHI
● Anzahl der Vergleiche minimieren
○ Gruppierungsstrategie
● Vorgehen
○ Paareweise Vergleiche nur innerhalb einer Relation
○ Tupel aus State nur miteinander vergleichen, wenn:
■ Gleiches Tupel in Country Relation referenziert
wird,
■ Zwei Tupel in Country referenziert werden, die
bereits als Duplikate erkannt sind.
32/41

DELPHI: Duplicate Identification Filter
● Jedes Tupel v aus G prüfen
● Fall 1: Kein Duplikat
○ tcm(v, G\{v}) < tcmthreshold
○ v ist kein Duplikat eines anderen v’ aus G
● Fall 2: Potentielles Duplikat
○ tcm(v, G\{v}) >= tcmthreshold
○ Füge v der Menge G’ an potentiellen
Duplikaten hinzu 33/41

● {[token = “MO”, frequency = 3, tupleList = <S1, S2, S3>]}
○ Hinzugefügt werden nur Elemente mit frequency > 1
● Ermitteln der Duplikate mit tcm
DELPHI: Token Table
34/41
CityId City StateId
C1 Joplin S1
C2 Jopin S2
C3 Joplin S4
C4 Joplin S3
C5 Victoria S5
C6 Victoria S6
C7 Vancouver S5
C8 Aberdeen S7
C9 Aberdeen S8
StateId State CtryId
S1 MO 1
S2 MO 2
S3 MO 3
S4 Missouri 3
S5 BC 4
S6 Britisch Columbia 4
S7 Aberdeen shire 5
S8 Aberdeen 5

● {[child = “Joplin”, frequency = 3, tupleList = <S1, S3, S4>]}
● Ermitteln der Duplikate mit fkcm
DELPHI: Child Table
35/41
CityId City StateId
C1 Joplin S1
C2 Jopin S2
C3 Joplin S4
C4 Joplin S3
C5 Victoria S5
C6 Victoria S6
C7 Vancouver S5
C8 Aberdeen S7
C9 Aberdeen S8
StateId State CtryId
S1 MO 1
S2 MO 2
S3 MO 3
S4 Missouri 3
S5 BC 4
S6 Britisch Columbia 4
S7 Aberdeen shire 5
S8 Aberdeen 5

DELPHI: Translation Table
● Beziehung zwischen kanonischem
Tupel und dazugehörigen Duplikaten
● Beispiel
○ [USA, MO]
○ [USA, Missouri]
● Bestimmen der Repräsentation
○ Verwendet wird Tupel mit höchstem IDF Wert
36/41

Diskussion
● Problem & Motivation
● Domänen-unabhängige Verfahren
● Domänen-abhängige Verfahren
● DELPHI
37/41

Quellen
● [1] http://www.nextgate.com/wp-
content/uploads/2015/06/
Duplicate-Record-Impact-NextGate.pdf
● [2] http://www.rightpatient.com/effect-of-duplicate-
medical-records-and-overlays-in-healthcare/
● [3] Rohit Ananthakrishna, Surajit Chaudhuri and Venkatesh
Ganti Eliminating fuzzy duplicates in data warehouses in:
Proceedings of the 28th international conference on Very
Large Data Bases (VLDB '02), 2002.
● [4] Andreas Bauer, Holger Günzel: Data-Warehouse-
Systeme: Architektur, Entwicklung, Anwendung. dpunkt,
2013, ISBN 3-89864-785-4
38/41

Quellen
● [5] Lehner; W.: Datenbanktechnologie für Data-
Warehouse-Systeme, Konzepte und Methoden, dpunkt,
2003, ISBN 3-89864-177-5
● [6] William H. Inmon: Building the Data Warehouse. John
Wiley & Sons, 1996, Seite 33
● [7] Navarro, Gonzalo (1 March 2001). "A guided tour to
approximate string matching" (PDF). ACM Computing
Surveys 33 (1): 31–88. doi:10.1145/375360.375365. Retrieved
19 March 2015.
39/41

Quellen
● [8] http://stackoverflow.com/questions/1746501/
can-someone-give-an-example-
of-cosine-similarity-in-very-simple-graphical-way
● [9] I. P. Felligi and A.B. Sunter. A theory for record linkage.
Journal of the American Statistical Society, 64:1183—1210,
1969.
● [10] B. Kilss and W. Avley. Record linkage techniques— 1985.
Statistics of income division. Internal revenue service
publication, 1985.
40/41

Quellen
● [11] A. Broder, S. Glassman, M. Manasse, and G. Zweig.
Syntactic Clustering of the Web. In Proc. Sixth Int’l. World
Wide Web Conference, World Wide Web Consortium,
Cambridge, pages 391-404, 1997.
● [12] Ricardo Baeza-Yates and Berthier Ribeiro-Neto.
Modern Information Retrieval. Addison Wesley Longman,
1999.
41/41





























