Embed Size (px)
Citation preview

Week 3: Model-free Prediction and Control
Bolei Zhou
The Chinese University of Hong Kong
September 19, 2021
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 1 / 54

Announcement
1 Project proposal due by the end of next week1 2-page proposal in Latex Template: https://github.com/
cuhkrlcourse/RLexample/tree/master/project_template2 Submit through Blackboard, with title: 2021fall-IERG5350-proposal3 Please list each team member’s name and student ID in the proposal
2 Assignment 1 dues on 23:59 October 3 (Sunday), 2021.1 https://github.com/cuhkrlcourse/ierg5350-assignment-20212 Please start early!
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 2 / 54

This Week’s Plan
1 Last week1 MDP, policy evaluation, policy iteration and value iteration for solving
a known MDP
2 This week1 Model-free prediction: Estimate value function of an unknown MDP2 Model-free control: Optimize value function of an unknown MDP
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 3 / 54

Review on the control in MDP
1 When the MDP is known?1 Both R and P are exposed to the agent2 Therefore we can run policy iteration and value iteration
2 Policy iteration: Given a known MDP, compute the optimal policyand the optimal value function
1 Policy evaluation: iteration on the Bellman expectation backup
vi (s) =∑a∈A
π(a|s)(R(s, a) + γ∑s′∈S
P(s ′|s, a)vi−1(s ′))
2 Policy improvement: greedy on action-value function q
qπi (s, a) =R(s, a) + γ∑s′∈S
P(s ′|s, a)vπi (s′)
πi+1(s) = arg maxa
qπi (s, a)
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 4 / 54

Review on the control in MDP
1 Value iteration: Given a known MDP, compute the optimal valuefunction
2 Iteration on the Bellman optimality backup
vi+1(s)← maxa∈A
R(s, a) + γ∑s′∈S
P(s ′|s, a)vi (s′)
3 To retrieve the optimal policy after the value iteration:
π∗(s)← arg maxa
R(s, a) + γ∑s′∈S
P(s ′|s, a)vend(s ′) (1)
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 5 / 54

RL when knowing how the world works
1 Both of the policy iteration and value iteration assume the directaccess to the dynamics and rewards of the environment
2 In a lot of real-world problems, MDP model is either unknown orknown by too big or too complex to use
1 Atari Game, Game of Go, Helicopter, Portfolio management, etc
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 6 / 54

Model-free RL: Learning through interactions
1 Model-free RL can solve the problems through the interaction withthe environment
2 No more direct access to the known transition dynamics and rewardfunction
3 Trajectories/episodes are collected by the agent’s interaction with theenvironment
4 Each trajectory/episode contains {S1,A1,R2,S2,A2,R3, ...,ST}
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 7 / 54

Model-free prediction: policy evaluation without the accessto the model
1 Estimating the expected return of a particular policy if we don’t haveaccess to the MDP models
1 Monte Carlo policy evaluation2 Temporal Difference (TD) learning
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 8 / 54

Monte-Carlo Policy Evaluation
1 Return: Gt = Rt+1 + γRt+2 + γ2Rt+3 + ... under policy π
2 vπ(s) = Eτ∼π[Gt |st = s], thus expectation over trajectories τgenerated by following π
3 MC simulation: we can simply sample a lot of trajectories, computethe actual returns for all the trajectories, then average them
4 MC policy evaluation uses empirical mean return instead of expectedreturn
5 MC does not require MDP dynamics/rewards, no bootstrapping, anddoes not assume state is Markov.
6 Only applied to episodic MDPs (each episode terminates)
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 9 / 54

Monte-Carlo Policy Evaluation
1 To evaluate state v(s)1 Every time-step t that state s is visited in an episode,2 Increment counter N(s)← N(s) + 13 Increment total return S(s)← S(s) + Gt
4 Value is estimated by mean return v(s) = S(s)/N(s)
2 By law of large numbers, v(s)→ vπ(s) as N(s)→∞
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 10 / 54

Monte-Carlo Policy Evaluation
1 How to calculate G (s): compute backward
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 11 / 54

Incremental Mean
Mean from the average of samples x1, x2, ...
µt =1
t
t∑j=1
xj
=1
t
(xt +
t−1∑j=1
xj
)=
1
t(xt + (t − 1)µt−1)
=µt−1 +1
t(xt − µt−1)
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 12 / 54

Incremental MC Updates
1 Collect one episode (S1,A1,R2, ...,St)
2 For each state st with computed return Gt
N(St)←N(St) + 1
v(St)←v(St) +1
N(St)(Gt − v(St))
3 Or use a running mean (old episodes are forgotten). Good fornon-stationary problems.
v(St)← v(St) + α(Gt − v(St))
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 13 / 54

Difference between DP and MC for policy evaluation
1 Dynamic Programming (DP) computes vi by bootstrapping the restof the expected return by the value estimate vi−1
2 Iteration on Bellman expectation backup:
vi (s)←∑a∈A
π(a|s)(R(s, a) + γ
∑s′∈S
P(s ′|s, a)vi−1(s ′))
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 14 / 54

Difference between DP and MC for policy evaluation
1 MC updates the empirical mean return with one sampled episode
v(St)← v(St) + α(Gi ,t − v(St))
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 15 / 54

Advantages of MC over DP
1 MC works when the environment is unknown
2 Working with sample episodes has a huge advantage, even when onehas complete knowledge of the environment’s dynamics, for example,transition probability is complex to compute
3 Cost of estimating a single state’s value is independent of the totalnumber of states. So you can sample episodes starting from thestates of interest then average returns
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 16 / 54

Temporal-Difference (TD) Learning
1 TD methods learn directly from episodes of experience
2 TD is model-free: no knowledge of MDP transitions/rewards
3 TD learns from incomplete episodes, by bootstrapping
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 17 / 54

Temporal-Difference (TD) Learning
1 Objective: learn vπ online from experience under policy π2 Simplest TD algorithm: TD(0)
1 Update v(St) toward estimated return Rt+1 + γv(St+1)
v(St)← v(St) + α(Rt+1 + γv(St+1)− v(St))
3 Rt+1 + γv(St+1) is called TD target
4 δt = Rt+1 + γv(St+1)− v(St) is called the TD error5 Comparison: Incremental Monte-Carlo
1 Update v(St) toward actual return Gt given an episode i
v(St)← v(St) + α(Gi,t − v(St))
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 18 / 54

Advantages of TD over MC
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 19 / 54

Comparison of TD and MC
1 TD can learn online after every step
2 MC must wait until end of episode before return is known
3 TD can learn from incomplete sequences
4 MC can only learn from complete sequences
5 TD works in continuing (non-terminating) environments
6 MC only works for episodic (terminating) environments
7 TD exploits Markov property, more efficient in Markov environments
8 MC does not exploit Markov property, more effective in non-Markovenvironments
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 20 / 54

n-step TD
1 n-step TD methods that generalize both one-step TD and MC.
2 We can shift from one to the other smoothly as needed to meet thedemands of a particular task.
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 21 / 54

n-step TD prediction
1 Consider the following n-step returns for n = 1, 2,∞
n = 1(TD) G(1)t =Rt+1 + γv(St+1)
n = 2 G(2)t =Rt+1 + γRt+2 + γ2v(St+2)
...
n =∞(MC ) G∞t =Rt+1 + γRt+2 + ...+ γT−t−1RT
2 Thus the n-step return is defined as
Gnt = Rt+1 + γRt+2 + ...+ γn−1Rt+n + γnv(St+n)
3 n-step TD: v(St)← v(St) + α(Gnt − v(St)
)Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 22 / 54

Bootstrapping and Sampling for DP, MC, and TD
1 Bootstrapping: update involves an estimate1 MC does not bootstrap2 DP bootstraps3 TD bootstraps
2 Sampling: update samples an expectation1 MC samples2 DP does not sample3 TD samples
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 23 / 54
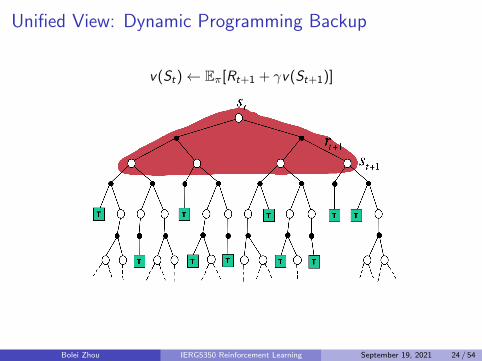
Unified View: Dynamic Programming Backup
v(St)← Eπ[Rt+1 + γv(St+1)]
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 24 / 54

Unified View: Monte-Carlo Backup
v(St)← v(St) + α(Gt − v(St))
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 25 / 54

Unified View: Temporal-Difference Backup
TD(0) : v(St)← v(St) + α(Rt+1 + γv(st+1)− v(St))
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 26 / 54

Unified View of Reinforcement Learning
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 27 / 54

Summary
1 Model-free prediction1 Evaluate the state value by only interacting with the environment2 Many algorithms can do it: Temporal Difference Learning and
Monte-Carlo method
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 28 / 54

Model-free Control for MDP
1 Model-free control:1 Optimize the value function of an unknown MDP2 Generate a optimal control policy
2 But is there model-based control? What is it? will come back to it
3 Generalized Policy Iteration (GPI) with MC or TD in the loop
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 29 / 54

Revisiting Policy Iteration
1 Iterate through the two steps:1 Evaluate the policy π (computing v given current π)2 Improve the policy by acting greedily with respect to vπ
π′ = greedy(vπ) (2)
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 30 / 54
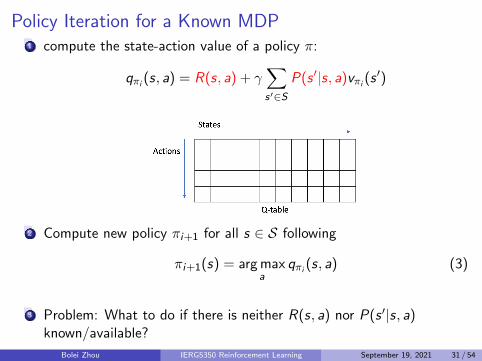
Policy Iteration for a Known MDP1 compute the state-action value of a policy π:
qπi (s, a) = R(s, a) + γ∑s′∈S
P(s ′|s, a)vπi (s′)
2 Compute new policy πi+1 for all s ∈ S following
πi+1(s) = arg maxa
qπi (s, a) (3)
3 Problem: What to do if there is neither R(s, a) nor P(s ′|s, a)known/available?
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 31 / 54
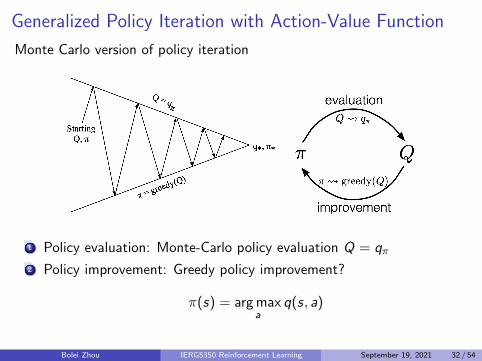
Generalized Policy Iteration with Action-Value Function
Monte Carlo version of policy iteration
1 Policy evaluation: Monte-Carlo policy evaluation Q = qπ2 Policy improvement: Greedy policy improvement?
π(s) = arg maxa
q(s, a)
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 32 / 54

Monte Carlo with Exploring Starts
1 One assumption to obtain the guarantee of convergence in PI:Episode has exploring starts
2 Exploring starts can ensure all actions are selected infinitely often
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 33 / 54

Monte Carlo with ε-Greedy Exploration
1 Trade-off between exploration and exploitation (we will talk aboutthis in later lecture)
2 ε-Greedy Exploration: Ensuring continual exploration1 All actions are tried with non-zero probability2 With probability 1− ε choose the greedy action3 With probability ε choose an action at random
π′(a|s) =
{ε/|A|+ 1− ε if a∗ = arg maxa∈AQ(s, a)
ε/|A| otherwise
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 34 / 54

Monte Carlo with ε-Greedy Exploration
1 ε-Greedy Policy improvement theorem: For any ε-greedy policy π, theε-greedy policy π′ with respect to qπ is an improvement,vπ′(s) ≥ vπ(s)
qπ(s, π′(s)) =∑a∈A
π′(a|s)qπ(s, a)
=ε
|A|∑a∈A
qπ(s, a) + (1− ε) maxa
qπ(s, a)
≥ ε
|A|∑a∈A
qπ(s, a) + (1− ε)∑a∈A
π(a|s)− ε|A|
1− εqπ(s, a)
=∑a∈A
π(a|s)qπ(s, a) = vπ(s)
Therefore from the policy improvement theorem vπ′(s) ≥ vπ(s)
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 35 / 54

Monte Carlo with ε-Greedy Exploration
Algorithm 1
1: Initialize Q(S ,A) = 0,N(S ,A) = 0, ε = 1, k = 12: πk = ε-greedy(Q)3: loop4: Sample k-th episode (S1,A1,R2, ...,ST ) ∼ πk5: for each state St and action At in the episode do6: N(St ,At)← N(St ,At) + 17: Q(St ,At)← Q(St ,At) + 1
N(St ,At)(Gt − Q(St ,At))
8: end for9: k ← k + 1, ε← 1/k
10: πk = ε-greedy(Q)11: end loop
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 36 / 54

MC vs. TD for Prediction and Control
1 Temporal-difference (TD) learning has several advantages overMonte-Carlo (MC)
1 Lower variance2 Online3 Incomplete sequences
2 So we can use TD instead of MC in our control loop1 Apply TD to Q(S ,A)2 Use ε-greedy policy improvement3 Update every time-step rather than at the end of one episode
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 37 / 54

Recall: TD Prediction
1 An episode consists of an alternating sequence of states andstate–action pairs:
2 TD(0) method for estimating the value function V (S)
At ← action given by π for S
Take action At , observe Rt+1 and St+1
V (St)← V (St) + α[Rt+1 + γV (St+1)− V (St)]
3 How about estimating action value function Q(S ,A)?
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 38 / 54

Sarsa: On-Policy TD Control
1 An episode consists of an alternating sequence of states andstate–action pairs:
2 ε-greedy policy for one step, then bootstrap the action value function:
Q(St ,At)← Q(St ,At) + α[Rt+1 + γQ(St+1,At+1)− Q(St ,At)
]
3 The update is done after every transition from a nonterminal state St4 TD target δt = Rt+1 + γQ(St+1,At+1)
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 39 / 54

Sarsa algorithm
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 40 / 54

n-step Sarsa
1 Consider the following n-step Q-returns for n = 1, 2,∞
n = 1(Sarsa)q(1)t =Rt+1 + γQ(St+1,At+1)
n = 2 q(2)t =Rt+1 + γRt+2 + γ2Q(St+2,At+2)
...
n =∞(MC ) q∞t =Rt+1 + γRt+2 + ...+ γT−t−1RT
2 Thus the n-step Q-return is defined as
q(n)t = Rt+1 + γRt+2 + ...+ γn−1Rt+n + γnQ(St+n,At+n)
3 n-step Sarsa updates Q(s,a) towards the n-step Q-return:
Q(St ,At)← Q(St ,At) + α(q(n)t − Q(St ,At)
)Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 41 / 54

On-policy Learning vs. Off-policy Learning
1 On-policy learning: Learn about policy π from the experiencecollected from π
1 Behave non-optimally in order to explore all actions, then reduce theexploration. e.g., ε-greedy
2 Another important approach is off-policy learning which essentiallyuses two different polices:
1 the one which is being learned about and becomes the optimal policy2 the other one which is more exploratory and is used to generate
trajectories
3 Off-policy learning: Learn about policy π from the experience sampledfrom another policy µ
1 π: target policy2 µ: behavior policy
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 42 / 54

Off-policy Learning
1 Following behaviour policy µ(a|s) to collect data
S1,A1,R2, ...,ST ∼ µUpdate π using S1,A1,R2, ...,ST
2 It leads to many benefits:1 Learn about optimal policy while following exploratory policy2 Learn from observing humans or other agents3 Re-use experience generated from old policies π1, π2, ..., πt−1
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 43 / 54

Off-Policy Control with Q Learning
1 Off-policy learning of action values Q(s, a)
2 No importance sampling is needed
3 Next action in TD target is selected from the alternative actionA′ ∼ π(.|St)
4 update Q(St ,At) towards value of alternative action
Q(St ,At)← Q(St ,At) + α(Rt+1 + γQ(St+1,A
′)− Q(St ,At))
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 44 / 54

Off-Policy Control with Q-Learning1 We allow both behavior and target policies to improve
2 The target policy π is greedy on Q(s, a)
π(St+1) = arg maxa′
Q(St+1, a′)
3 The behavior policy µ could be totally random, but we let it improvefollowing ε-greedy on Q(s, a)
4 Thus Q-learning target:
Rt+1 + γQ(St+1,A′) =Rt+1 + γQ(St+1, arg maxQ(St+1, a
′))
=Rt+1 + γmaxa′
Q(St+1, a′)
5 Thus the Q-Learning update
Q(St ,At)← Q(St ,At) + α[Rt+1 + γmax
aQ(St+1, a)− Q(St ,At)
]Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 45 / 54

Q-learning algorithm
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 46 / 54

Comparison of Sarsa and Q-Learning
1 Sarsa: On-Policy TD control
Choose action At from St using policy derived from Q with ε-greedy
Take action At , observe Rt+1 and St+1
Choose action At+1 from St+1 using policy derived from Q with ε-greedy
Q(St ,At)← Q(St ,At) + α[Rt+1 + γQ(St+1,At+1)− Q(St ,At)
]2 Q-Learning: Off-Policy TD control
Choose action At from St using policy derived from Q with ε-greedy
Take action At , observe Rt+1 and St+1
Then ‘imagine’ At+1 as arg maxQ(St+1, a′) in the update target
Q(St ,At)← Q(St ,At) + α[Rt+1 + γmax
aQ(St+1, a)− Q(St ,At)
]
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 47 / 54

Comparison of Sarsa and Q-Learning
1 Backup diagram for Sarsa and Q-learning
2 In Sarsa, A and A’ are sampled from the same policy so it is on-policy
3 In Q Learning, A and A’ are from different policies, with A beingmore exploratory and A’ determined directly by the max operator
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 48 / 54

Example on Cliff Walk (Example 6.6 from Textbook)https://github.com/cuhkrlcourse/RLexample/blob/master/modelfree/cliffwalk.py
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 49 / 54

Summary of DP and TD
Expected Update (DP) Sample Update (TD)Iterative Policy Evaluation TD LearningV (s)← E[R + γV (S ′)|s] V (S)←α R + γV (S ′)
Q-Policy Iteration SarsaQ(S ,A)← E[R + γQ(S ′,A′)|s, a] Q(S ,A)←α R + γQ(S ′,A′)
Q-Value Iteration Q-LearningQ(S ,A)← E[R + γmaxa′∈A Q(S ′,A′)|s, a] Q(S ,A)←α R + γmaxa′∈A Q(S ′, a′)
where x ←α y is defined as x ← x + α(y − x)
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 50 / 54

Unified View of Reinforcement Learning
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 51 / 54

Sarsa and Q-Learning Example
https:
//github.com/cuhkrlcourse/RLexample/tree/master/modelfree
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 52 / 54

Summary
1 Model-free prediction in MDP
2 Model-free control in MDP
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 53 / 54

End
1 Project proposal due by the end of next week
2 Homework 1 is out3 Next week:
1 Off-policy learning and importance sampling2 Reinforcement Learning and Optimal control
Bolei Zhou IERG5350 Reinforcement Learning September 19, 2021 54 / 54





























