Embed Size (px)
Citation preview

What is new in the cloud?
Donald KossmannETH Zurich
http://systems.ethz.ch

Acknowledgments

Questions?

Agenda
• Why?
• How?
• What?

Simple Truths• „Power of data“
– the more data the merrier (GB -> TB -> PB)– data comes from everywhere in all shapes– value of data often discovered later– data has no owner within an organization (no silos!)
• Services turn data into $– the more services the merrier (10s -> 1000s -> Ms)– need to adapt quickly
• Examples: Google, FB, Amadeus, Walmart, BMW, ...• Platforms: Oracle, MS, SAP, Google, ..., 28msec

Promises of cloud computing?• Cost
– „pay as you go“ for HW and SW• no upfront cost / investment: CapEx vs. OpEx• scale down if service becomes less popular
– utilization: statistical allocation of resources – out-source and commoditize computing
• HW automatically gets cheaper and faster• economy of scale for admin: patches, backups, etc.
– failures: cost of preventing and having failures
• Time to market– avoid unnecessary steps
• HW provisioning, puchasing, test

What to optimize? Feature Traditional Cloud
Cost [$] fixed optimize
Performance [tps, secs] optimize fixed
Scale-out [#cores] optimize fixed
Predictability [($)] - fixed
Consistency [%] fixed ???
Flexibility [#variants] - optimize
[Florescu & Kossmann, SIGMOD Record 2009]
Put $ on the y-axis of your graphs!!!

Misconceptions• Variable Cost -> Unpredictable Cost
– pay-as-you-go and predictability can be combined– IT department needs to rethink „budget models“
• Performance is more fundamental than $– at that scale, prices must be honest– how relevant are your perf. numbers of 1992 today?– technology follows business; business follows technol.
• Time is money („secs“ ~ „$“ in my graphs)– often true; often enough not true:
• Put computing where the energy is (ocean, desert, ...)• Writing inner track of disk consumes 2x energy
[Source: SIGMOD, VLDB, ICDE Reviews]

Problem: Vendor Lock-In• Hardware
– no standard APIs for IaaS– expensive to move TBs of data between clouds– this was actually a solved problem before the cloud
• Platform– PaaS makes it neither better nor worse– (situation is very bad as is)
• Apps and Devices– iTunes, Google Docs, Amazon Kindle, iPhone Apps, ...– they own your data; you don´t own their (paid for) data

Agenda
• Why?
• How?
• What?

Teach your DBMS to swim
+
Industry: Add a layer to your favorite DBMS

Research Perspective ...
It is time to start from scratch!

Scope of this talk• Workloads: Focus on OLTP
– OLAP under heavy debate by others– streaming not addressed yet (~ OLTP)– testing, archiving, etc. is boring
• Types of clouds: Any type– both private, public, hybrid
• only difference: private clouds have planned downtime
– cloud on the chip– swarms: ad-hoc private clouds
• IaaS vs. PaaS vs. SaaS: Focus on PaaS

Game Changers
• OLTP: „Key-value Store“ vs. „DBMS“ [No-SQL]
– virtually infinite scale-out– fault-tolerance
• Virtualization– transparent use of resources (computers + humans)
• hide heterogeneity of resources
• 100Ks machines are a reality– problems that need 100Ks machines are a reality
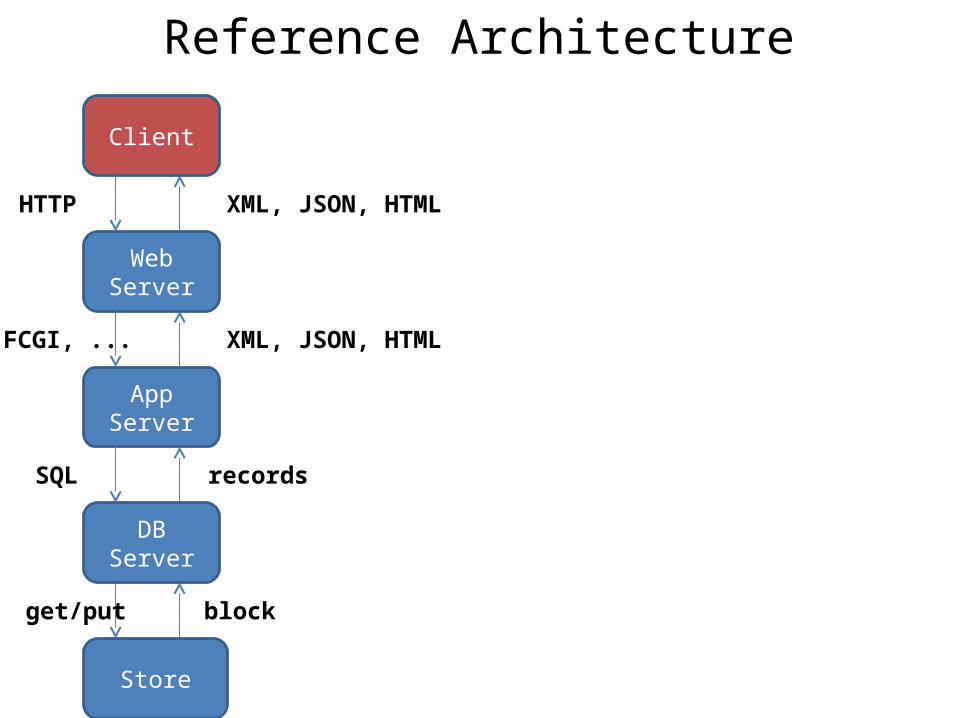
Reference Architecture
Client
Store
HTTP
Web Server
App Server
DB Server
FCGI, ...
SQL
get/put block
records
XML, JSON, HTML
XML, JSON, HTML
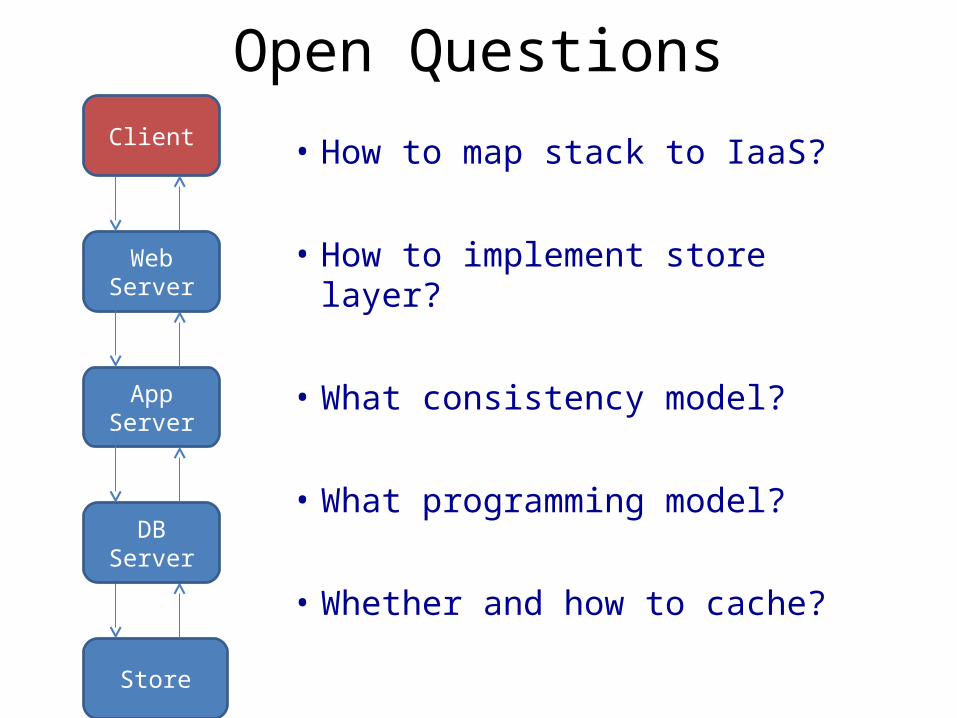
Open QuestionsClient
Store
Web Server
App Server
DB Server
• How to map stack to IaaS?
• How to implement store layer?
• What consistency model?
• What programming model?
• Whether and how to cache?
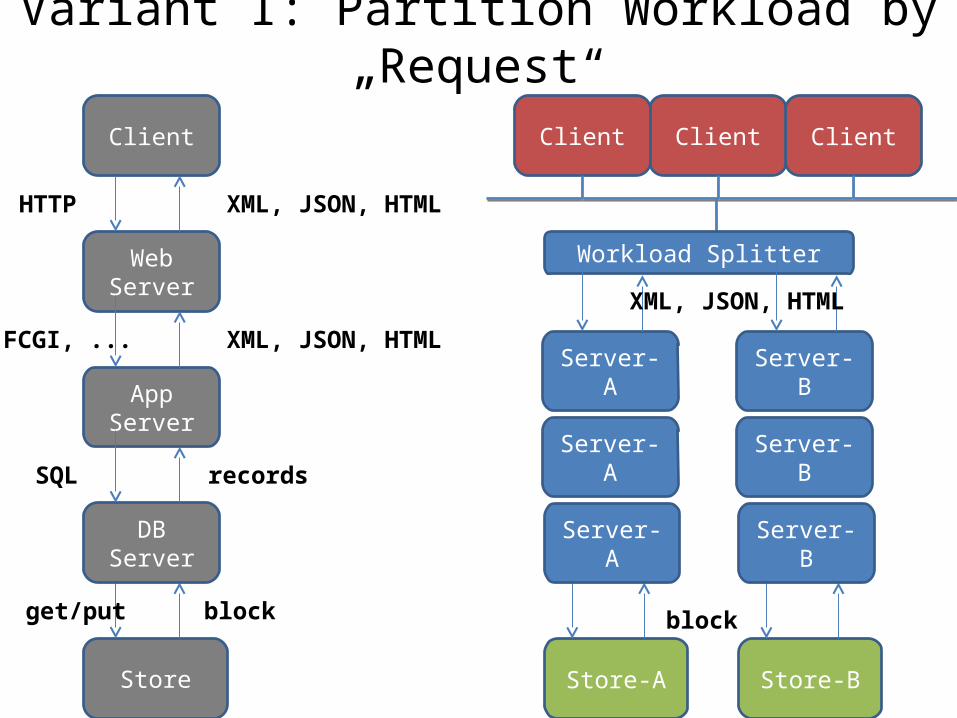
Variant I: Partition Workload by „Request“
Client
Store
HTTP
Web Server
App Server
DB Server
FCGI, ...
SQL
get/put block
records
XML, JSON, HTML
XML, JSON, HTML
Client ClientClient
Workload Splitter
Store-A
Server-A
Server-A
Server-A
Store-B
Server-B
Server-B
Server-B
XML, JSON, HTML
block

Partition Workload by „Request“• Principle
– partition data by „tenant“– route request to DB of that tenant
• Advantages– reuse existing database stack (RDBMS)
• Disadvantages– multi-tenant problem [Salesforce], [Jacobs]
• optimization, migration, load balancing, fix cost
– need DB federator for inter-tenant requests– expensive HW and SW for high availabilty
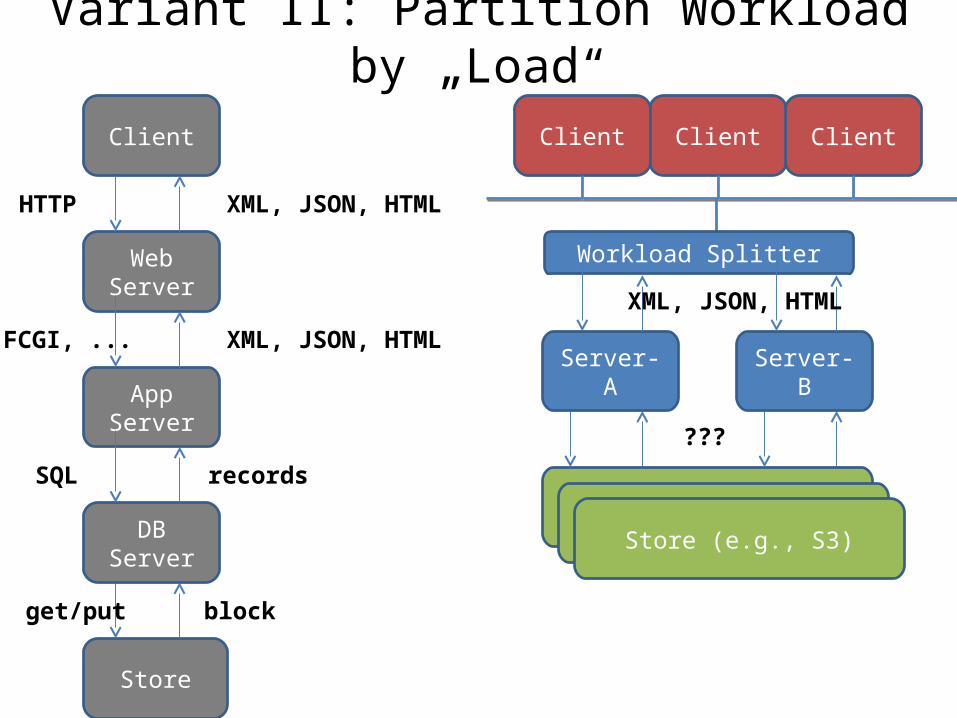
Variant II: Partition Workload by „Load“
Client
Store
HTTP
Web Server
App Server
DB Server
FCGI, ...
SQL
get/put block
records
XML, JSON, HTML
XML, JSON, HTML
Client ClientClient
Workload Splitter
Store (e.g., S3)
Server-A Server-B
XML, JSON, HTML
???
Store (e.g., S3)Store (e.g., S3)

Partition Workload by „Load“• Principle
– fine-grained data partitioning by page or object– any server can handle any request– implement DBMS as a library (not server)
• Advantages– avoids disadvantages of Variant I
• Disadvantages– new synchronization problem (CAP theorem)– whole new breed of systems – caching not effective (see later)

Experiments [Loesing et al. 2010]
• TPC-W Benchmark– throuphput: WIPS– latency: fixed depending on request type– cost: cost / WIPS, total cost, predictability
• Players– Amazon RDS, SimpleDB– 28msec [Brantner et al. 2008]
– Google AppEngine– Microsoft Azure

Scale-up Experiments
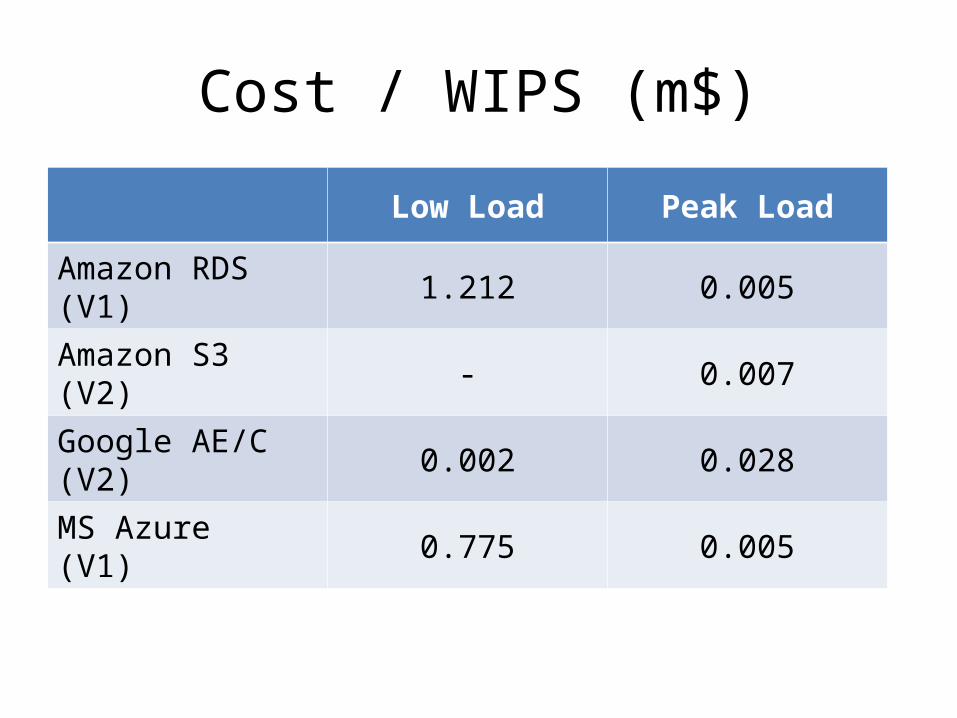
Cost / WIPS (m$)
Low Load Peak Load
Amazon RDS (V1) 1.212 0.005
Amazon S3 (V2) - 0.007
Google AE/C (V2) 0.002 0.028
MS Azure (V1) 0.775 0.005

Open Questions
• How to map traditional DB stack to IaaS?• How to implement the storage layer?• What is the right consistency model?• What is the right programming model?• Whether and how to make use of caching?

Store Variants• Traditional (e.g., Amazon EBS)
– local disks with physically exclusive access – put/get interface; no synchronization– only works for V1
• Key-value stores (e.g., Amazon S3)– DHTs with concurrent access– put/get interface; no synchronization– works for V1 and V2; makes more sense for V2

Open Questions
• How to map traditional DB stack to IaaS?• How to implement the storage layer?• What is the right consistency model?• What is the right programming model?• Whether and how to make use of caching?

CAP Theorem• Three properties of distributed systems
– Consistency (ACID transactions w. serializability)– Availability (nobody is ever blocked)– resilience to network Partitioning
• Result– it is trivial to achieve 2 out of 3– it is impossible to have all three
• Two schools– Databases: sacrifice availability– Distributed systems: sacrifice consistency

Why sacrifice Consistency? • It is a simple solution
– nobody understands what sacrificing „P“ means– sacrificing „A“ is unacceptable in the Web– possible to push the problem to app developer
• „C“ not needed in many applications– Banks do not implement ACID (classic example wrong)– Airline reservation only transacts reads (Huh?)– MySQL et al. ship by default in lower isolation level
• Data is noisy and inconsistent anyway– making it, say, 1% worse does not matter
[Vogels, VLDB 2007]

What have people done?• Client-side Consistency Models [Tannenbaum],[PNUTS08]
• New DB transaction models– Escrow, Reservation Pattern [O‘Neil 86], [Gawlick 09]
– SAGAs and compensation; e.g., in BPEL [G.-Molina,Salem]
– SAP, Amadeus et al. [Buck-Emden], [Kemper et al. 98]
• Limit the size of transacted data– E.g., Microsoft Azure
• Levels of Consistency, Consistency-Cost Tradeoffs– read/write monotonicy + „A“ + „P“ [Brantner08]
– economic models for consistency [Amadeus], [Kraska09]
• Educate Application Developers [Helland 2009]

Open Questions
• How to map traditional DB stack to IaaS?• How to implement the storage layer?• What is the right consistency model?• What is the right programming model?• Whether and how to make use of caching?

Programming Model• Properties of a programming lang. for the cloud
– support DB-style + OO-style– avoid keeping state at servers for V2 architecture
• Many languages will work in the cloud– SQL, XQuery, Ruby, ...; we have shown it for XQuery– J2EE will not work
• Open (research) questions– do OLAP on the OLTP data: My guess is yes!– rewrite your apps: My guess is yes!

Caching• Many Variants Possible
– this is just one– V1 caching mandatory– V2 caching prohibitive
• TPC-W Experiments– marginal improvements
for Google AppEngine
• No low hanging fruit

Agenda
• Why?
• How?
• What?

What is Sausalito?• Application Server + Web Server + Database
– keeps any kind of data – runs services
• Fully cloud-enabled– full elasticity (cost and throughput)– full fault-tolerance– runs on cheap hardware (private and public clouds)
• Fully Web Standard compliant– Web Services, REST– XML, JSON, CSV, ...– XML Schema, XQuery, XPath
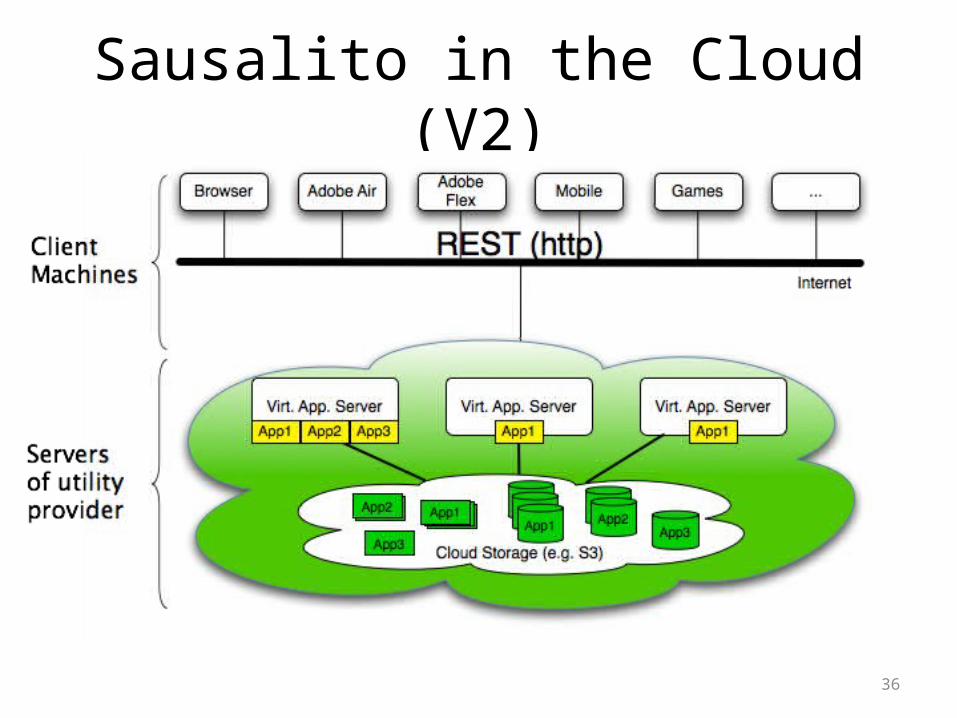
Sausalito in the Cloud (V2)
36
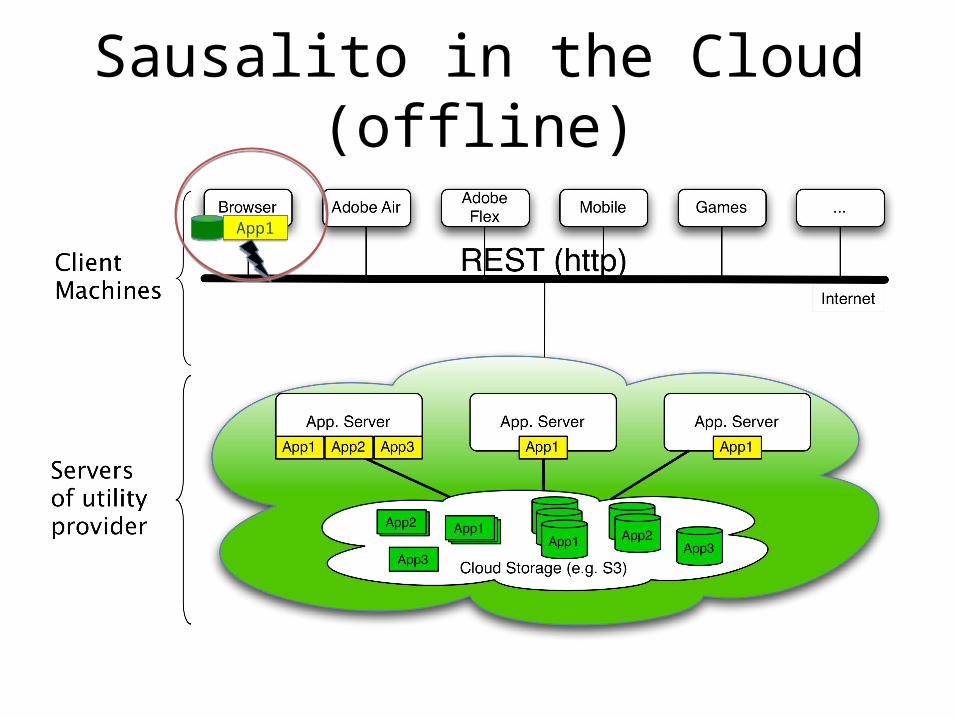
Sausalito in the Cloud (offline)
App1App1

Bets Made• How to map traditional DB stack to IaaS?
– implemented both architectures (V1 + V2)– V1 only in a single server variant for low end
• How to implement the storage layer?– EBS for V1; KVS for V2
• What is the right consistency model?– ACID for V1; configurable for V2
• What is the right data + programming model?– XML & XQuery
• Whether and how to make use of caching?– No! (Only for code / precompiled query plans)

Cloud: Fans and Skeptics• Fans
– VCs: low CapEx, Gartner hype– USA Government: lack of alternative– Departments: time-to-market, by-pass IT dept.– USA Researchers: next big thing– IT start-ups: levels the field
• Skeptics– EU Government: next big USA thing– EU Researchers: burnt by Grid Computing– IT department: lock-in, become irrelevant – Big enterprise IT vendors: low margins, forced to adapt

Conclusion
• Researchers study tradeoffs– Key-values stores are game changers– Measuring $ is a game changer– MMDBs (ClockScan) could be a game changer
• Entrepreneurs make bets– Pay per use is a game changer– XML & XQuery could be game changers
• Personal experience: You cannot do both!– You cannot play and observe at the same time
[Heisenberg]





























